
1. Introducción
Descripción general
En este lab, implementarás un agente del Kit de desarrollo de agentes (ADK) listo para producción con un backend de Gemma acelerado por GPU. El enfoque se centra en los patrones de implementación críticos: configurar servicios de Cloud Run habilitados para GPU, integrar backends de modelos con agentes de ADK y observar el comportamiento del ajuste de escala automático bajo carga.
Actividades
En este lab, te enfocarás en los aspectos críticos de la implementación de producción:
- Implementa Gemma en Cloud Run con GPU: Configura un backend de alto rendimiento para el modelo de Gemma
- Integra la implementación de Gemma con un agente del ADK: Conecta tu agente al modelo acelerado por GPU
- Prueba con la interfaz web del ADK: Valida que tu agente conversacional funcione correctamente.
- Realiza pruebas de elasticidad: Observa cómo ambas instancias de Cloud Run controlan la carga.
El énfasis está en los patrones de implementación de producción en lugar del desarrollo extenso de agentes.
Qué aprenderás
- Implementa modelos de Gemma acelerados por GPU en Cloud Run para usarlos en la producción
- Integra implementaciones de modelos externos con agentes del ADK
- Configura y prueba implementaciones de agentes de IA listos para producción
- Comprende el comportamiento de Cloud Run bajo carga
- Observa cómo se coordinan varias instancias de Cloud Run durante los picos de tráfico
- Aplica pruebas de elasticidad para validar el rendimiento
2. Configuración del proyecto
- Si aún no tienes una Cuenta de Google, debes crear una.
- Usar una cuenta personal en lugar de una cuenta laboral o educativa Es posible que las cuentas laborales y educativas tengan restricciones que te impidan habilitar las APIs necesarias para este lab.
- Accede a la consola de Google Cloud.
- Habilita la facturación en la consola de Cloud.
- Completar este lab debería costar menos de USD 1 en recursos de Cloud.
- Puedes seguir los pasos al final de este lab para borrar recursos y evitar cargos adicionales.
- Los usuarios nuevos pueden acceder a la prueba gratuita de USD 300.
- Crea un proyecto nuevo o elige reutilizar uno existente.
- Si ves un error sobre la cuota del proyecto, reutiliza un proyecto existente o bórralo para crear uno nuevo.
3. Abre el editor de Cloud Shell
- Haz clic en este vínculo para navegar directamente al editor de Cloud Shell.
- Si se te solicita autorización en algún momento, haz clic en Autorizar para continuar.
- Si la terminal no aparece en la parte inferior de la pantalla, ábrela:
- Haz clic en Ver.
- Haz clic en Terminal.
- En la terminal, configura tu proyecto con este comando:
- Formato:
gcloud config set project [PROJECT_ID] - Ejemplo:
gcloud config set project lab-project-id-example - Si no recuerdas el ID de tu proyecto, haz lo siguiente:
- Puedes enumerar todos los IDs de tus proyectos con el siguiente comando:
gcloud projects list | awk '/PROJECT_ID/{print $2}'
- Puedes enumerar todos los IDs de tus proyectos con el siguiente comando:
- Formato:
- Deberías ver el siguiente mensaje:
Updated property [core/project].
WARNINGy se te preguntaDo you want to continue (Y/n)?, es probable que hayas ingresado el ID del proyecto de forma incorrecta. Presionan, presionaEntery vuelve a intentar ejecutar el comandogcloud config set project.
4. Habilita las APIs y establece la región predeterminada
Antes de implementar servicios de Cloud Run con compatibilidad con GPU, debemos habilitar las APIs de Google Cloud necesarias y configurar los parámetros de configuración del proyecto.
- En la terminal, habilita las APIs:
gcloud services enable \
run.googleapis.com \
artifactregistry.googleapis.com \
cloudbuild.googleapis.com \
aiplatform.googleapis.com
Si se te solicita autorización, haz clic en Autorizar para continuar.
Este comando puede tardar unos minutos en completarse, pero, finalmente, debería producir un mensaje de éxito similar a este:
Operation "operations/acf.p2-73d90d00-47ee-447a-b600" finished successfully.
- Configura tu región predeterminada de Cloud Run.
gcloud config set run/region europe-west4
5. Prepara tu proyecto de Python
Configuraremos el código inicial que contiene la estructura básica de nuestros servicios de backend de Gemma y de agente del ADK.
- Clona el repositorio inicial:
cd ~ npx -y giget@latest gh+git:GoogleCloudPlatform/devrel-demos/agents/accelerate-ai-with-cloud-run/accelerate-ai-lab3-starter accelerate-ai-lab3-starter cd accelerate-ai-lab3-starter - Examina la estructura del proyecto:
ls -Raccelerate-ai-lab3-starter/ ├── README.md # Project overview ├── ollama-backend/ # Ollama backend (separate deployment) │ └── Dockerfile # Backend container (🚧 to implement) └── adk-agent/ # ADK agent (separate deployment) ├── pyproject.toml # Python dependencies (✅ completed) ├── server.py # FastAPI server (🚧 to implement) ├── Dockerfile # Container config (🚧 to implement) ├── elasticity_test.py # Elasticity testing (🚧 to implement) └── production_agent/ # Agent implementation ├── __init__.py # Package init (✅ completed) └── agent.py # Agent logic (🚧 to implement)
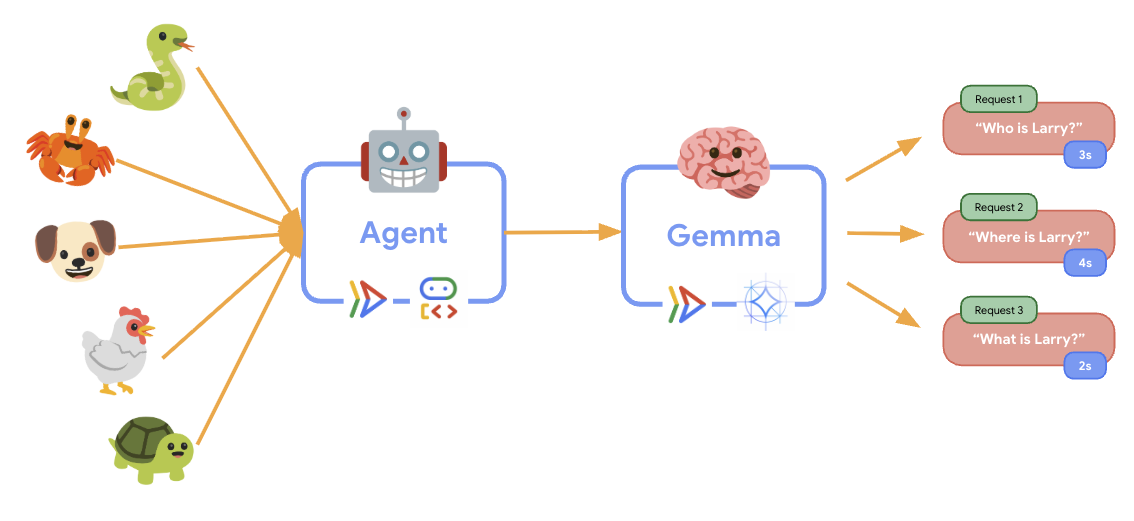
6. Descripción general de la arquitectura
Antes de la implementación, comprendamos la arquitectura de dos servicios:
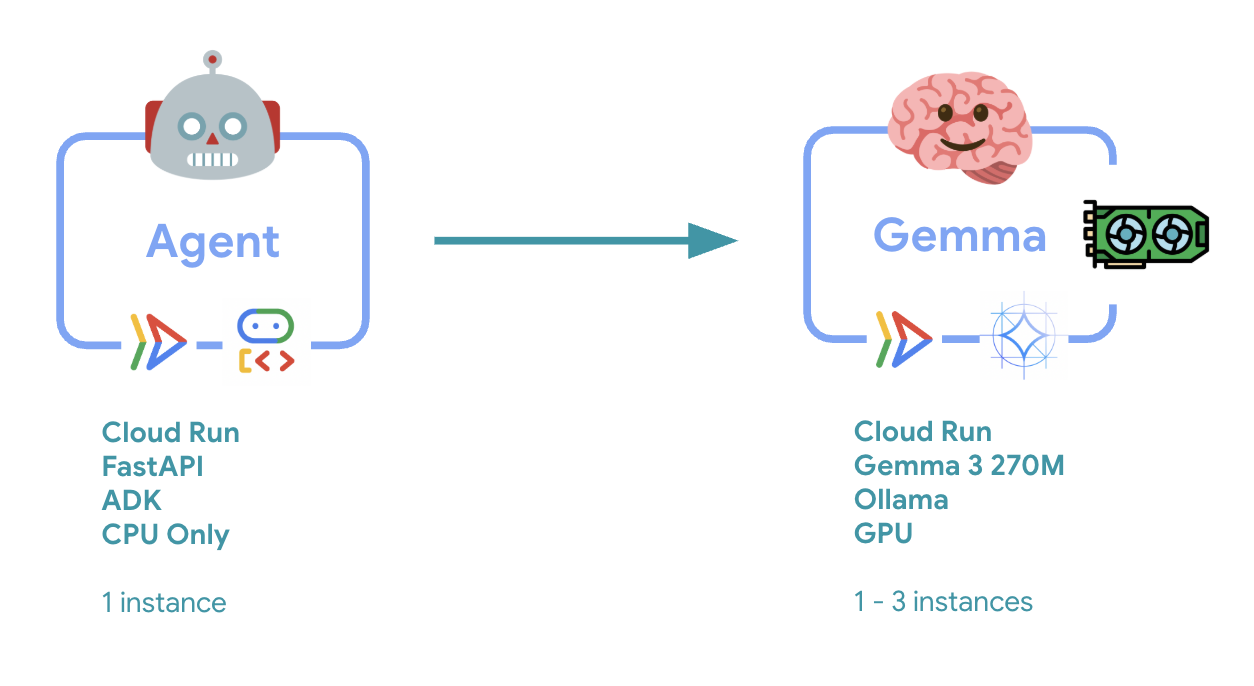
Estadística clave: Durante las pruebas de elasticidad, observarás que ambos servicios manejan la carga de trabajo de forma independiente: el backend de GPU (servicio de cuello de botella) usa su GPU para manejar la carga, mientras que el agente de ADK depende de su CPU para manejar las solicitudes que no requieren muchos recursos.
7. Implementa Gemma Backend en Cloud Run con GPU
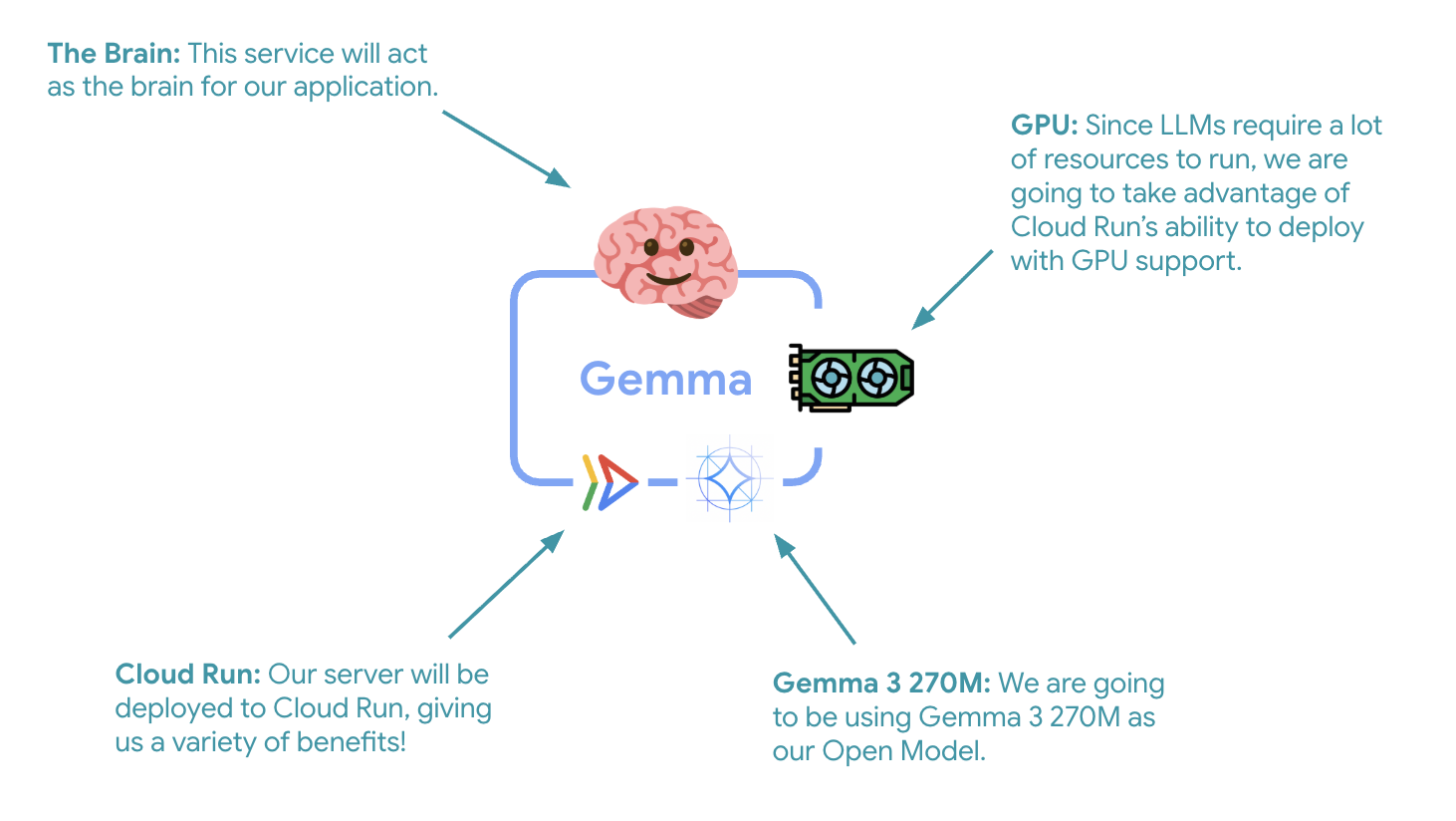
El primer paso fundamental es implementar un modelo de Gemma acelerado por GPU, que actuará como el cerebro de tu agente del ADK. Tener un LLM desacoplado e implementado puede ser favorable en arquitecturas en las que necesitas un modelo ajustado por separado o requieres un escalamiento aislado.
- Navega al directorio de backend de Ollama:
cd ollama-backend - Abre e implementa el Dockerfile de Ollama:
cloudshell edit DockerfileFROM ollama/ollama:latest # Listen on all interfaces, port 8080 ENV OLLAMA_HOST 0.0.0.0:8080 # Store model weight files in /models ENV OLLAMA_MODELS /models # Reduce logging verbosity ENV OLLAMA_DEBUG false # Never unload model weights from the GPU ENV OLLAMA_KEEP_ALIVE -1 # Store the model weights in the container image ENV MODEL gemma3:270m RUN ollama serve & sleep 5 && ollama pull $MODEL # Start Ollama ENTRYPOINT ["ollama", "serve"]- Usa la imagen oficial de Ollama como base
- Establece
OLLAMA_HOSTpara aceptar conexiones desde cualquier dirección IP - Expone el puerto 8080
- Implementa el backend de Gemma con compatibilidad con GPU:
gcloud run deploy ollama-gemma3-270m-gpu \
--source . \
--region europe-west4 \
--concurrency 7 \
--cpu 8 \
--set-env-vars OLLAMA_NUM_PARALLEL=4 \
--gpu 1 \
--gpu-type nvidia-l4 \
--max-instances 1 \
--memory 16Gi \
--allow-unauthenticated \
--no-cpu-throttling \
--no-gpu-zonal-redundancy \
--timeout 600 \
--labels dev-tutorial=codelab-agent-gpu
Si recibes el mensaje "La implementación desde el código fuente requiere un repositorio de Docker de Artifact Registry para almacenar los contenedores compilados. Se creará un repositorio llamado [cloud-run-source-deploy] en la región [europe-west4]", continúa.
⚙️ Explicación de la configuración clave:
- GPU: Se eligió la NVIDIA L4 por su excelente relación precio-rendimiento para las cargas de trabajo de inferencia. La L4 proporciona 24 GB de memoria de GPU y operaciones de tensor optimizadas, lo que la hace ideal para modelos de 270 millones de parámetros, como Gemma.
- Memoria: 16 GB de memoria del sistema para controlar la carga del modelo, las operaciones de CUDA y la administración de memoria de Ollama
- CPU: 8 núcleos para un manejo óptimo de las tareas de E/S y de preprocesamiento
- Simultaneidad: 7 solicitudes por instancia equilibran la capacidad de procesamiento con el uso de la memoria de la GPU
- Tiempo de espera: 600 segundos para la carga inicial del modelo y el inicio del contenedor
💰 Consideración de costos: Las instancias de GPU son significativamente más caras que las instancias solo de CPU (alrededor de USD 2 a 4 por hora en comparación con alrededor de USD 0.10 por hora). El parámetro de configuración --max-instances 1 ayuda a controlar los costos, ya que evita el ajuste innecesario de la escala de las instancias de GPU.
- Espera a que se complete la implementación y anota la URL del servicio:
export OLLAMA_URL=$(gcloud run services describe ollama-gemma3-270m-gpu \ --region=europe-west4 \ --format='value(status.url)') echo "🎉 Gemma backend deployed at: $OLLAMA_URL"
8. Implementa la integración del agente del ADK
Ahora, creemos un agente mínimo del ADK que se conecte a tu backend de Gemma implementado.
- Navega al directorio del agente del ADK:
cd ../adk-agent - Abre y aplica la configuración del agente:
cloudshell edit production_agent/agent.pyimport os from pathlib import Path from dotenv import load_dotenv from google.adk.agents import Agent from google.adk.models.lite_llm import LiteLlm import google.auth # Load environment variables root_dir = Path(__file__).parent.parent dotenv_path = root_dir / ".env" load_dotenv(dotenv_path=dotenv_path) # Configure Google Cloud try: _, project_id = google.auth.default() os.environ.setdefault("GOOGLE_CLOUD_PROJECT", project_id) except Exception: pass os.environ.setdefault("GOOGLE_CLOUD_LOCATION", "europe-west4") # Configure model connection gemma_model_name = os.getenv("GEMMA_MODEL_NAME", "gemma3:270m") api_base = os.getenv("OLLAMA_API_BASE", "localhost:10010") # Location of Ollama server # Production Gemma Agent - GPU-accelerated conversational assistant production_agent = Agent( model=LiteLlm(model=f"ollama_chat/{gemma_model_name}", api_base=api_base), name="production_agent", description="A production-ready conversational assistant powered by GPU-accelerated Gemma.", instruction="""You are 'Gem', a friendly, knowledgeable, and enthusiastic zoo tour guide. Your main goal is to make a zoo visit more fun and educational for guests by answering their questions. You can provide general information and interesting facts about different animal species, such as: - Their natural habitats and diet. 🌲🍓 - Typical lifespan and behaviors. - Conservation status and unique characteristics. IMPORTANT: You do NOT have access to any tools. This means you cannot look up real-time, specific information about THIS zoo. You cannot provide: - The names or ages of specific animals currently at the zoo. - The exact location or enclosure for an animal. - The daily schedule for feedings or shows. Always answer based on your general knowledge about the animal kingdom. Keep your tone cheerful, engaging, and welcoming for visitors of all ages. 🦁✨""", tools=[], # Gemma focuses on conversational capabilities ) # Set as root agent root_agent = production_agent- Se conecta a tu backend de Gemma implementado a través de LiteLLM
- Crea un agente conversacional simple
- Configura la integración de Google Cloud
- Abre e implementa el servidor de FastAPI:
cloudshell edit server.pyimport os from dotenv import load_dotenv from fastapi import FastAPI from google.adk.cli.fast_api import get_fast_api_app # Load environment variables load_dotenv() AGENT_DIR = os.path.dirname(os.path.abspath(__file__)) app_args = {"agents_dir": AGENT_DIR, "web": True} # Create FastAPI app with ADK integration app: FastAPI = get_fast_api_app(**app_args) # Update app metadata app.title = "Production ADK Agent - Lab 3" app.description = "Gemma agent with GPU-accelerated backend" app.version = "1.0.0" @app.get("/health") def health_check(): return {"status": "healthy", "service": "production-adk-agent"} @app.get("/") def root(): return { "service": "Production ADK Agent - Lab 3", "description": "GPU-accelerated Gemma agent", "docs": "/docs", "health": "/health" } if __name__ == "__main__": import uvicorn uvicorn.run(app, host="0.0.0.0", port=8080, log_level="info")- Crea un servidor de FastAPI con integración del ADK
- Habilita la interfaz web para las pruebas
- Proporciona extremos de verificación de estado
- Abre y, luego, implementa el Dockerfile:
cloudshell edit DockerfileFROM python:3.13-slim # Copy uv from the official image COPY --from=ghcr.io/astral-sh/uv:latest /uv /usr/local/bin/uv # Install system dependencies RUN apt-get update && apt-get install -y curl && rm -rf /var/lib/apt/lists/* # Set working directory WORKDIR /app # Copy all files COPY . . # Install Python dependencies RUN uv sync # Expose port EXPOSE 8080 # Run the application CMD ["uv", "run", "uvicorn", "server:app", "--host", "0.0.0.0", "--port", "8080"]- uv: Es un administrador de paquetes de Python moderno que es entre 10 y 100 veces más rápido que pip. Utiliza una caché global y descargas paralelas, lo que reduce significativamente los tiempos de compilación de contenedores.
- Python 3.13-slim: Es la versión más reciente de Python con dependencias mínimas del sistema, lo que reduce el tamaño del contenedor y la superficie de ataque.
- Compilación en varias etapas: Copiar uv de su imagen oficial garantiza que obtengamos el objeto binario optimizado más reciente.
9. Configura el entorno y el agente de implementación
Ahora configuraremos el agente del ADK para que se conecte a tu backend de Gemma implementado y lo implementaremos como un servicio de Cloud Run. Esto implica configurar variables de entorno y, luego, implementar el agente con la configuración correcta.
- Configura tu entorno:
cat << EOF > .env GOOGLE_CLOUD_PROJECT=$(gcloud config get-value project) GOOGLE_CLOUD_LOCATION=europe-west4 GEMMA_MODEL_NAME=gemma3:270m OLLAMA_API_BASE=$OLLAMA_URL EOF
Información sobre las variables de entorno en Cloud Run
Las variables de entorno son pares clave-valor que configuran tu aplicación en el tiempo de ejecución. Son particularmente útiles para lo siguiente:
- Extremos de API y URLs de servicio (como nuestro backend de Ollama)
- Configuración que cambia entre entornos (desarrollo, etapa de pruebas y producción)
- Datos sensibles que no se deben codificar
Implementa el agente del ADK:
export PROJECT_ID=$(gcloud config get-value project)
gcloud run deploy production-adk-agent \
--source . \
--region europe-west4 \
--allow-unauthenticated \
--memory 4Gi \
--cpu 2 \
--max-instances 1 \
--concurrency 50 \
--timeout 300 \
--set-env-vars GOOGLE_CLOUD_PROJECT=$PROJECT_ID \
--set-env-vars GOOGLE_CLOUD_LOCATION=europe-west4 \
--set-env-vars GEMMA_MODEL_NAME=gemma3:270m \
--set-env-vars OLLAMA_API_BASE=$OLLAMA_URL \
--labels dev-tutorial=codelab-agent-gpu
⚙️ Configuración clave:
- Ajuste de escala automático: Se fija en 1 instancia (control de solicitudes liviano)
- Simultaneidad: 50 solicitudes por instancia
- Memoria: 4 GB para el agente del ADK
- Environment: Se conecta a tu backend de Gemma.
🔒 Nota de seguridad: Este lab usa --allow-unauthenticated para simplificar. En producción, implementa la autenticación adecuada con lo siguiente:
- Autenticación de servicio a servicio de Cloud Run con cuentas de servicio
- Políticas de Identity and Access Management (IAM)
- Claves de API o OAuth para el acceso externo
- Considera usar
gcloud run services add-iam-policy-bindingpara controlar el acceso
Obtén la URL del servicio de tu agente:
export AGENT_URL=$(gcloud run services describe production-adk-agent \
--region=europe-west4 \
--format='value(status.url)')
echo "🎉 ADK Agent deployed at: $AGENT_URL"
✅ Prácticas recomendadas para las variables de entorno según la documentación de las variables de entorno de Cloud Run:
- Evita las variables reservadas: No establezcas
PORT(si necesitas cambiar la variable de entorno, usa la marca –port en su lugar) ni variables que comiencen conX_GOOGLE_. - Usa nombres descriptivos: Agrega un prefijo a tus variables para evitar conflictos (p. ej.,
GEMMA_MODEL_NAMEen lugar deMODEL). - Escape comas: Si tus valores contienen comas, usa un delimitador diferente:
--set-env-vars "^@^KEY1=value1,value2@KEY2=..." - Actualizar vs. Reemplazar: Usa
--update-env-varspara agregar o cambiar variables específicas sin afectar otras.
Cómo configurar variables en Cloud Run:
- From file:
gcloud run deploy SERVICE_NAME --env-vars-file .env --labels dev-tutorial codelab-adk(carga varias variables desde un archivo) - Varias marcas: Repite
--set-env-varspara valores complejos que no se pueden separar con comas.
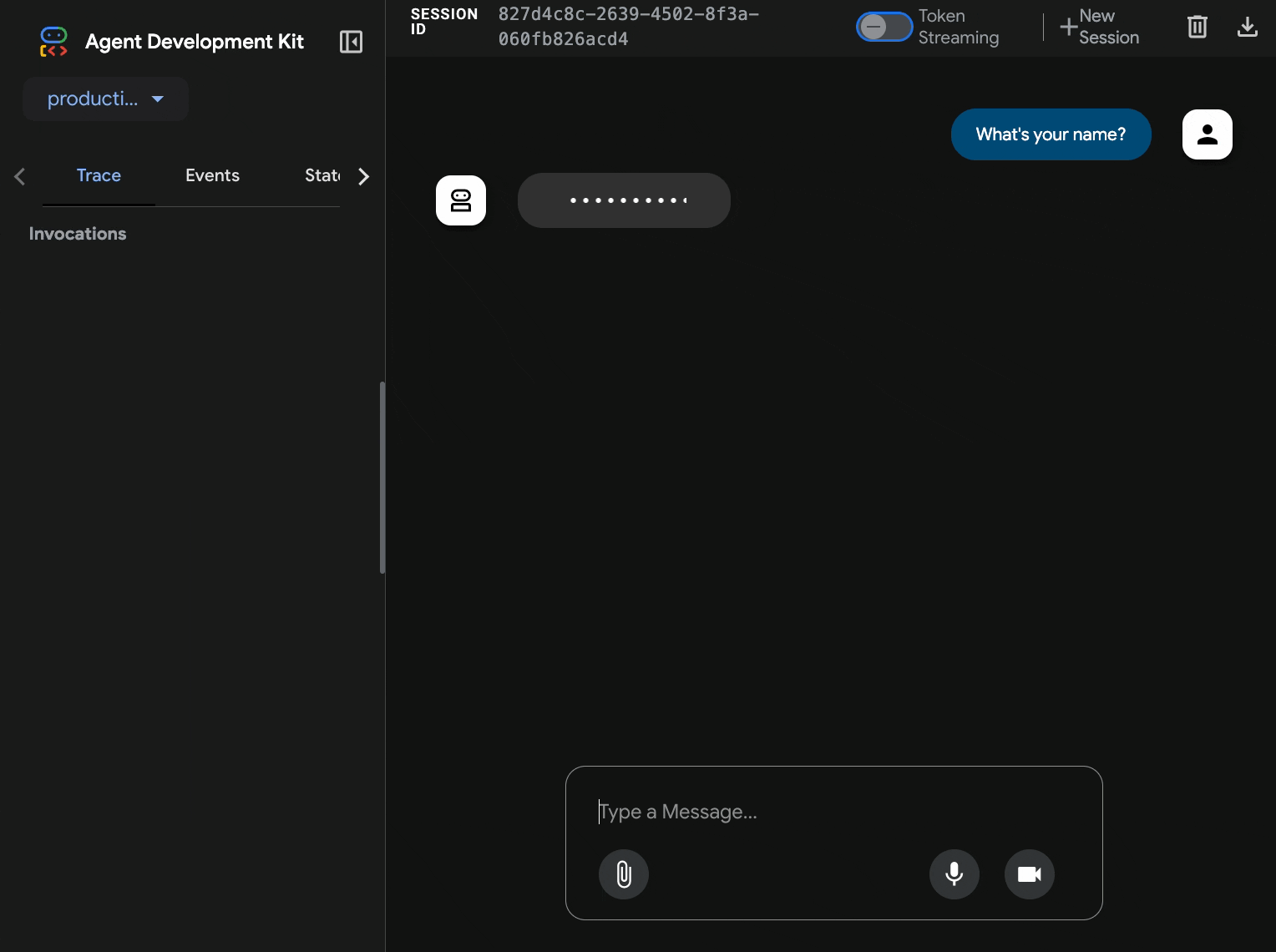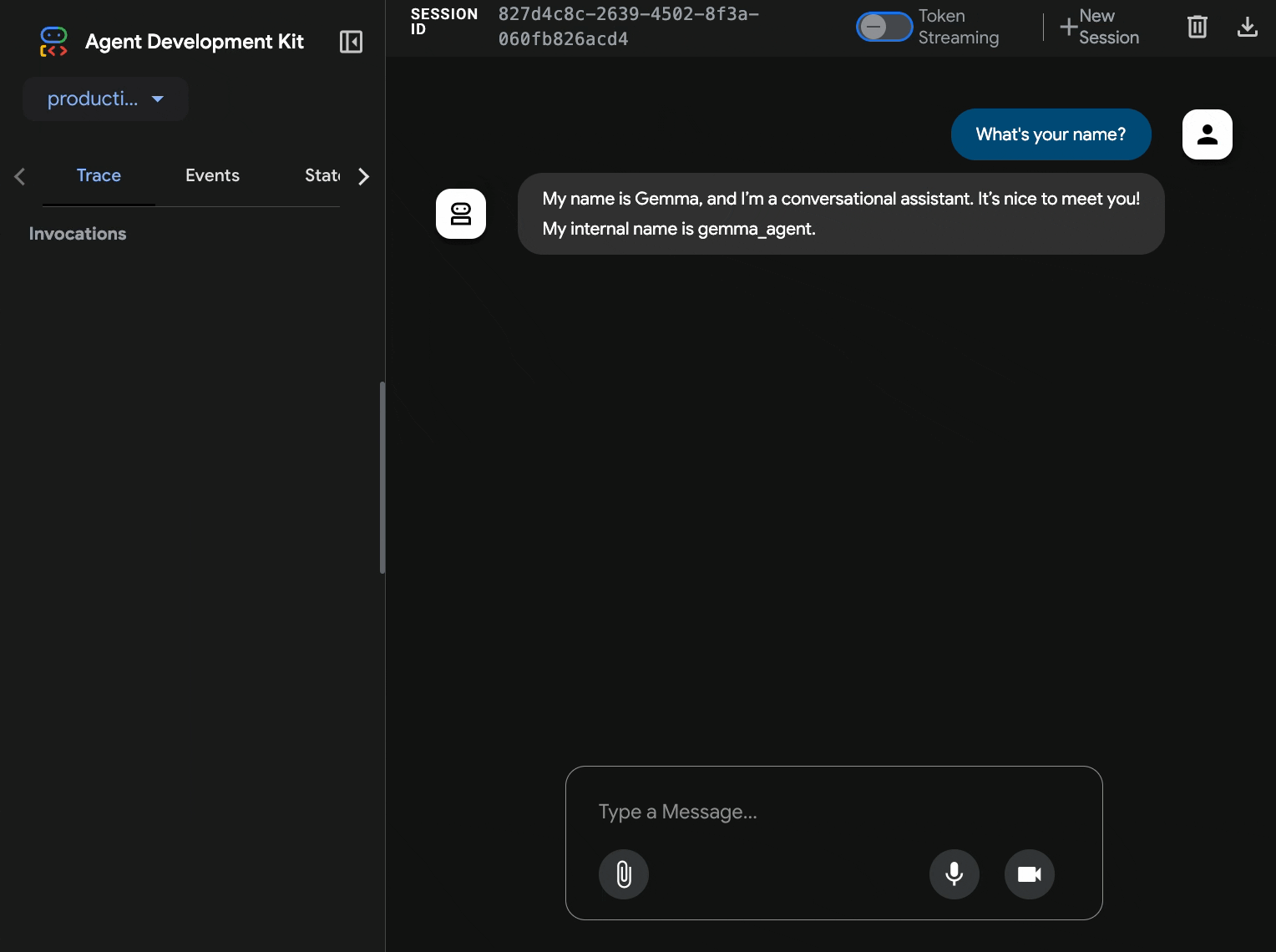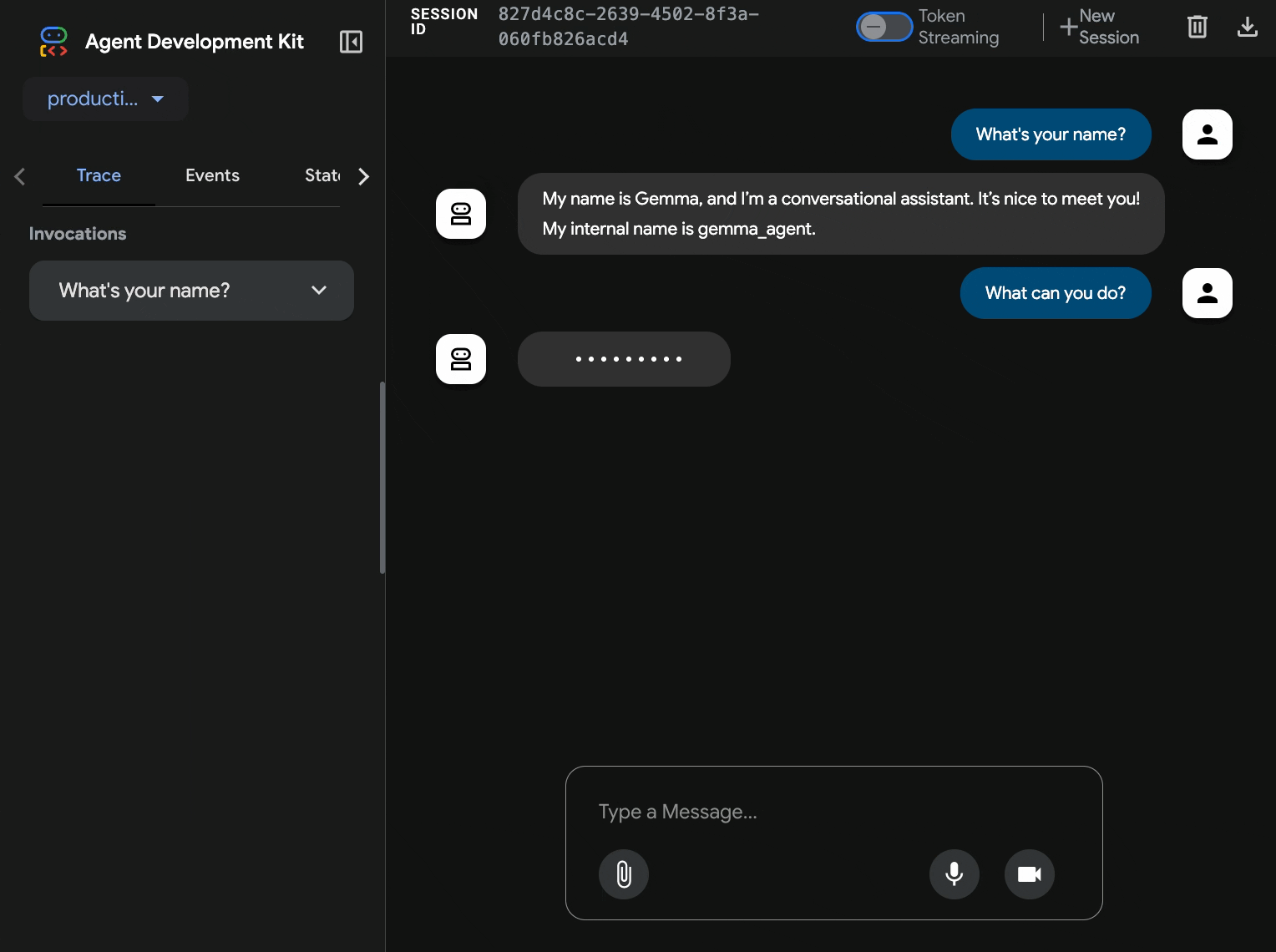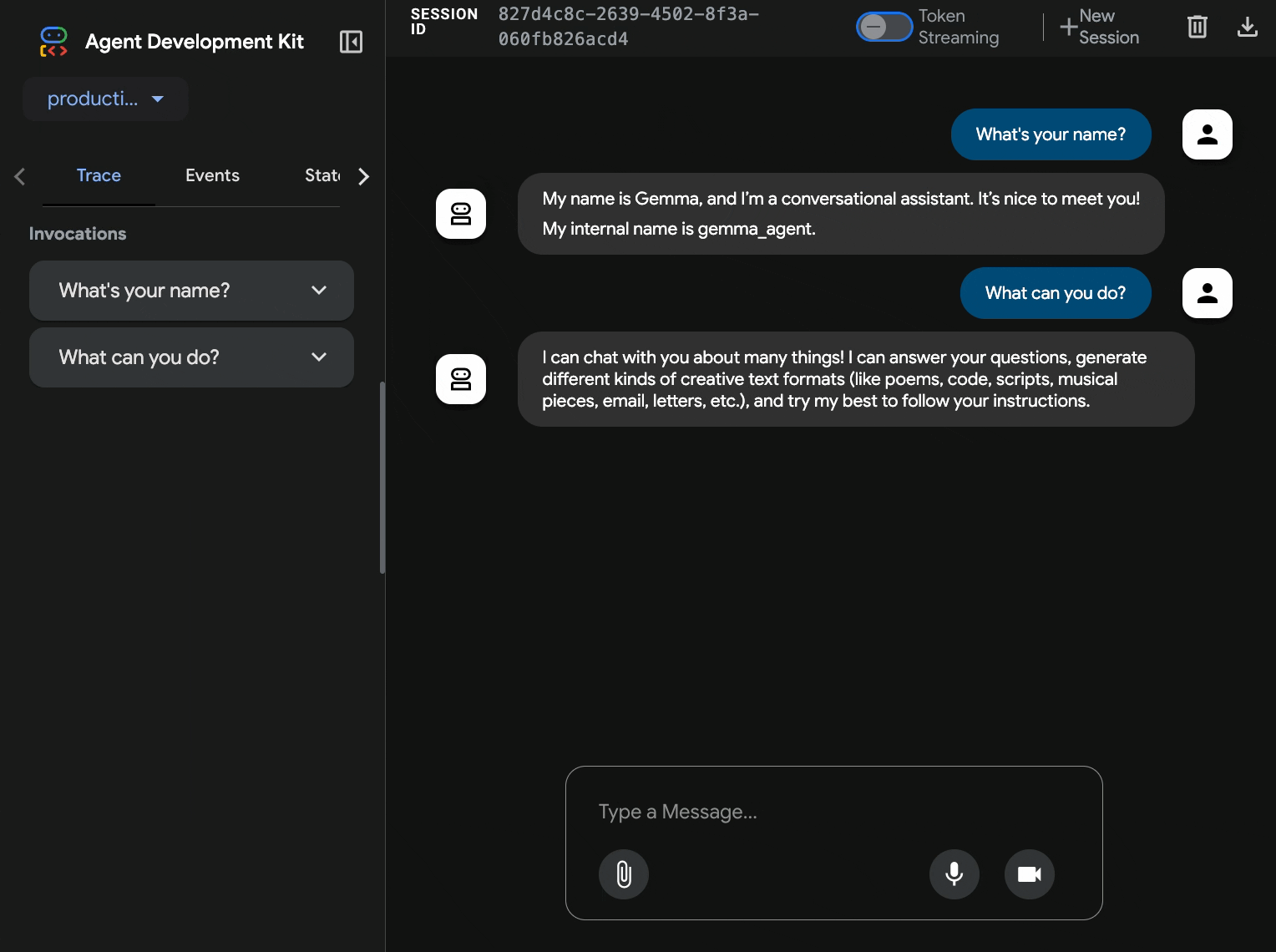
10. Prueba con la interfaz web del ADK
Con ambos servicios implementados, es hora de validar que tu agente del ADK pueda comunicarse correctamente con el backend de Gemma acelerado por GPU y responder a las consultas de los usuarios.
- Prueba el extremo de estado:
curl $AGENT_URL/health{ "status": "healthy", "service": "production-adk-agent" } - Para interactuar con tu agente, ingresa la URL de tu
production-adk-agenten una pestaña nueva del navegador. Deberías ver la interfaz web del ADK. - Prueba tu agente con estas conversaciones de ejemplo:
- "¿Qué suelen comer los pandas rojos en su hábitat natural?"
- "¿Puedes contarme un dato interesante sobre los leopardos de las nieves?"
- "¿Por qué las ranas dardo venenosas tienen colores tan brillantes?"
- "¿Dónde puedo encontrar al nuevo cangurito bebé en el zoológico?"
- El agente responde con el modelo de Gemma que implementaste. Para verificarlo, observa los registros de tu servicio de Gemma implementado. Lo haremos en la próxima sección.
- Las respuestas se generan con el backend acelerado por GPU
- La interfaz web proporciona una experiencia de chat limpia.
11. Implementa y ejecuta una prueba de elasticidad
Para comprender cómo tu implementación de producción controla el tráfico del mundo real, implementaremos una prueba de elasticidad que probará la capacidad del sistema para adaptarse a una carga de trabajo de producción "simulada" más alta.
- Abre y, luego, implementa la secuencia de comandos de prueba de elasticidad:
cloudshell edit elasticity_test.pyimport random import uuid from locust import HttpUser, task, between class ProductionAgentUser(HttpUser): """Elasticity test user for the Production ADK Agent.""" wait_time = between(1, 3) # Faster requests to trigger scaling def on_start(self): """Set up user session when starting.""" self.user_id = f"user_{uuid.uuid4()}" self.session_id = f"session_{uuid.uuid4()}" # Create session for the Gemma agent using proper ADK API format session_data = {"state": {"user_type": "elasticity_test_user"}} self.client.post( f"/apps/production_agent/users/{self.user_id}/sessions/{self.session_id}", headers={"Content-Type": "application/json"}, json=session_data, ) @task(4) def test_conversations(self): """Test conversational capabilities - high frequency.""" topics = [ "What do red pandas typically eat in the wild?", "Can you tell me an interesting fact about snow leopards?", "Why are poison dart frogs so brightly colored?", "Where can I find the new baby kangaroo in the zoo?", "What is the name of your oldest gorilla?", "What time is the penguin feeding today?" ] # Use proper ADK API format for sending messages message_data = { "app_name": "production_agent", "user_id": self.user_id, "session_id": self.session_id, "new_message": { "role": "user", "parts": [{ "text": random.choice(topics) }] } } self.client.post( "/run", headers={"Content-Type": "application/json"}, json=message_data, ) @task(1) def health_check(self): """Test the health endpoint.""" self.client.get("/health")- Creación de sesión: Usa el formato correcto de la API del ADK con POST a
/apps/production_agent/users/{user_id}/sessions/{session_id}. Después de crear unsession_idy unuser_id, se puede realizar una solicitud al agente. - Formato del mensaje: Sigue la especificación del ADK con
app_name,user_id,session_idy el objetonew_messageestructurado. - Extremo de conversación: Usa el extremo
/runpara recopilar todos los eventos a la vez (se recomienda para las pruebas de carga). - Carga realista: Crea una carga conversacional con tiempos de espera más cortos
- Creación de sesión: Usa el formato correcto de la API del ADK con POST a
- Instala las dependencias:
uv sync - Locust es una herramienta de prueba de carga de código abierto basada en Python y diseñada para probar el rendimiento y la carga de aplicaciones web y otros sistemas. Su característica principal es que los casos de prueba y el comportamiento del usuario se definen con código Python estándar, lo que ofrece una gran flexibilidad y expresividad en comparación con las herramientas que se basan en interfaces gráficas de usuario o lenguajes específicos del dominio. Usaremos Locust para simular el tráfico de usuarios a nuestros servicios.Ejecuta la prueba.
uv run locust -f elasticity_test.py \ -H $AGENT_URL \ --headless \ -t 60s \ -u 20 \ -r 5- Duración: 60 segundos
- Usuarios: 20 usuarios simultáneos
- Tasa de generación: 5 usuarios por segundo
- Objetivo: Activa el ajuste de escala automático en ambos servicios
12. Observa el comportamiento del ajuste de escala automático
A medida que se ejecute la prueba de elasticidad, podrás observar en acción la compatibilidad de Cloud Run con cargas de trabajo más altas. Aquí es donde verás los beneficios arquitectónicos clave de separar el agente del ADK del backend de la GPU.
Durante la prueba de elasticidad, supervisa cómo ambos servicios de Cloud Run controlan el tráfico en tu consola.
- En la consola de Cloud, navega a
- Cloud Run → production-adk-agent → Métricas
- Cloud Run → ollama-gemma3-270m-gpu → Métricas
👀 Qué debes observar:
🤖 Servicio de agente de ADK:
- Debe mantenerse estable en 1 instancia a medida que aumenta el tráfico.
- Aumento repentino del uso de CPU y memoria durante el tráfico alto
- Maneja la administración de sesiones y el enrutamiento de solicitudes de manera eficiente
🎮 Servicio de backend de Gemma (cuello de botella):
- Debe mantenerse estable en 1 instancia a medida que aumenta el tráfico.
- El uso de la GPU aumenta significativamente bajo carga
- Este servicio se convierte en el cuello de botella debido a la inferencia del modelo con uso intensivo de GPU.
- Los tiempos de inferencia del modelo siguen siendo coherentes gracias a la aceleración por GPU.
💡 Estadísticas clave:
- Ambos servicios se mantienen coherentes y no se escalan, ya que establecimos nuestras instancias máximas en
1. - Ambos servicios se escalan de forma independiente según sus características de carga individuales.
- La GPU ayuda a mantener el rendimiento en diferentes condiciones de carga.
13. Conclusión
¡Felicitaciones! Implementaste correctamente un agente del ADK listo para producción con un backend de Gemma acelerado por GPU, mientras probabas una carga de trabajo de producción simulada.
✅ Qué lograste
- ✅ Implementaste un backend del modelo de Gemma acelerado por GPU en Cloud Run
- ✅ Creaste e implementaste un agente de ADK que se integra con el backend de Gemma.
- ✅ Probaste el agente con la interfaz web del ADK
- ✅ Se observó el comportamiento del ajuste de escala automático en dos servicios coordinados de Cloud Run
💡 Estadísticas clave de este lab
- 🎮 Aceleración de GPU: La GPU NVIDIA L4 mejora significativamente el rendimiento de la inferencia del modelo.
- 🔗 Coordinación de servicios: Dos servicios de Cloud Run pueden trabajar juntos sin problemas
- 📈 Escalamiento independiente: Cada servicio se escala según sus características de carga individuales.
- 🚀 Preparación para la producción: La arquitectura controla los patrones de tráfico del mundo real de manera eficaz.
🔄 Próximos pasos
- Experimenta con diferentes patrones de carga y observa el comportamiento del ajuste de escala
- Prueba diferentes tamaños de modelos de Gemma (ajusta la memoria y la GPU según corresponda)
- Implementa la supervisión y las alertas para las implementaciones de producción
- Explora las implementaciones multirregionales para la disponibilidad global
🧹 Limpieza
Para evitar que se generen cargos, borra los recursos cuando termines:
gcloud run services delete production-adk-agent --region=europe-west4
gcloud run services delete ollama-gemma3-270m-gpu --region=europe-west4
📖 Recursos
- Repositorio de inicio
- Solución completa
- Documentación del ADK de Google
- Guía de pruebas del ADK: Referencia completa para los extremos de la API del ADK y los patrones de prueba
- Pruebas de carga en Cloud Run
- Documentación del Kit de desarrollo de agentes (ADK)
- Documentación de la GPU de Cloud Run
- Biblioteca de modelos de Ollama
- Documentación de Google Cloud Trace
- Prácticas recomendadas de seguridad de Cloud Run
- Administrador de paquetes de Python de UV
- Locust Load Testing Framework