
۱. مقدمه
نمای کلی
در این آزمایش، شما یک عامل کیت توسعه عامل (ADK) آماده برای تولید را با بکاند Gemma شتابدهنده GPU مستقر خواهید کرد. تمرکز بر الگوهای استقرار حیاتی است: راهاندازی سرویسهای Cloud Run با قابلیت GPU، ادغام بکاندهای مدل با عاملهای ADK و مشاهده رفتار مقیاسپذیری خودکار تحت بار.
کاری که انجام خواهید داد
در این آزمایشگاه، شما بر جنبههای حیاتی استقرار تولید تمرکز خواهید کرد:
- استقرار Gemma در Cloud Run با GPU - راهاندازی یک backend مدل Gemma با کارایی بالا
- ادغام استقرار Gemma با یک عامل ADK - عامل خود را به مدل شتابیافته با GPU متصل کنید
- با رابط وب ADK تست کنید - تأیید کنید که عامل مکالمه شما به درستی کار میکند
- تست الاستیسیته انجام دهید - مشاهده کنید که هر دو نمونه Cloud Run چگونه بار را مدیریت میکنند
تأکید بر الگوهای استقرار تولید به جای توسعه گسترده عامل است.
آنچه یاد خواهید گرفت
- مدلهای Gemma شتابیافته با GPU را برای استفاده در محیط عملیاتی، در Cloud Run مستقر کنید.
- ادغام استقرارهای مدل خارجی با عوامل ADK
- پیکربندی و آزمایش استقرارهای عامل هوش مصنوعی آماده برای تولید
- رفتار Cloud Run را تحت بار درک کنید
- مشاهده کنید که چگونه چندین نمونه Cloud Run در طول افزایش ناگهانی ترافیک، هماهنگ میشوند.
- اعمال تست الاستیسیته برای اعتبارسنجی عملکرد
۲. راهاندازی پروژه
- اگر از قبل حساب گوگل ندارید، باید یک حساب گوگل ایجاد کنید .
- به جای حساب کاری یا تحصیلی از یک حساب شخصی استفاده کنید. حسابهای کاری و تحصیلی ممکن است محدودیتهایی داشته باشند که مانع از فعال کردن APIهای مورد نیاز برای این آزمایشگاه توسط شما شود.
- وارد کنسول ابری گوگل شوید.
- فعال کردن پرداخت در کنسول ابری
- تکمیل این آزمایشگاه باید کمتر از ۱ دلار آمریکا از طریق منابع ابری هزینه داشته باشد.
- شما میتوانید مراحل انتهای این آزمایش را برای حذف منابع دنبال کنید تا از هزینههای بیشتر جلوگیری شود.
- کاربران جدید واجد شرایط استفاده از دوره آزمایشی رایگان ۳۰۰ دلاری هستند.
- یک پروژه جدید ایجاد کنید یا از یک پروژه موجود دوباره استفاده کنید.
- اگر در مورد سهمیه پروژه خطایی مشاهده کردید، از یک پروژه موجود دوباره استفاده کنید یا یک پروژه موجود را حذف کنید تا یک پروژه جدید ایجاد شود.
۳. ویرایشگر Cloud Shell را باز کنید
- برای دسترسی مستقیم به ویرایشگر Cloud Shell ، روی این لینک کلیک کنید.
- اگر امروز در هر مرحلهای از شما خواسته شد که مجوز دهید، برای ادامه روی تأیید کلیک کنید.
- اگر ترمینال در پایین صفحه نمایش داده نشد، آن را باز کنید:
- روی مشاهده کلیک کنید
- روی ترمینال کلیک کنید
- در ترمینال، پروژه خود را با این دستور تنظیم کنید:
- قالب:
gcloud config set project [PROJECT_ID] - مثال:
gcloud config set project lab-project-id-example - اگر نمیتوانید شناسه پروژه خود را به خاطر بیاورید:
- شما میتوانید تمام شناسههای پروژه خود را با دستور زیر فهرست کنید:
gcloud projects list | awk '/PROJECT_ID/{print $2}'
- شما میتوانید تمام شناسههای پروژه خود را با دستور زیر فهرست کنید:
- قالب:
- شما باید این پیام را ببینید:
Updated property [core/project].
WARNINGمشاهده کردید و از شما پرسیده شدDo you want to continue (Y/n)?احتمالاً شناسه پروژه را اشتباه وارد کردهاید.nرا فشار دهید،Enterرا بزنید و دوباره سعی کنید دستورgcloud config set projectاجرا کنید.
۴. فعال کردن APIها و تنظیم منطقه پیشفرض
قبل از اینکه بتوانیم سرویسهای Cloud Run را با پشتیبانی از GPU مستقر کنیم، باید APIهای مورد نیاز Google Cloud را فعال کرده و تنظیمات پروژه شما را پیکربندی کنیم.
- در ترمینال، APIها را فعال کنید:
gcloud services enable \
run.googleapis.com \
artifactregistry.googleapis.com \
cloudbuild.googleapis.com \
aiplatform.googleapis.com
اگر از شما خواسته شد که مجوز دهید، برای ادامه روی تأیید کلیک کنید.
تکمیل این دستور ممکن است چند دقیقه طول بکشد، اما در نهایت باید پیامی مشابه این پیام موفقیتآمیز نمایش داده شود:
Operation "operations/acf.p2-73d90d00-47ee-447a-b600" finished successfully.
- منطقه پیشفرض Cloud Run خود را تنظیم کنید.
gcloud config set run/region europe-west4
۵. پروژه پایتون خود را آماده کنید
بیایید کد آغازین را که شامل ساختار اولیه برای سرویسهای بکاند Gemma و عامل ADK ما است، تنظیم کنیم.
- مخزن استارت را کلون کنید:
cd ~ npx -y giget@latest gh+git:GoogleCloudPlatform/devrel-demos/agents/accelerate-ai-with-cloud-run/accelerate-ai-lab3-starter accelerate-ai-lab3-starter cd accelerate-ai-lab3-starter - بررسی ساختار پروژه:
ls -Raccelerate-ai-lab3-starter/ ├── README.md # Project overview ├── ollama-backend/ # Ollama backend (separate deployment) │ └── Dockerfile # Backend container (🚧 to implement) └── adk-agent/ # ADK agent (separate deployment) ├── pyproject.toml # Python dependencies (✅ completed) ├── server.py # FastAPI server (🚧 to implement) ├── Dockerfile # Container config (🚧 to implement) ├── elasticity_test.py # Elasticity testing (🚧 to implement) └── production_agent/ # Agent implementation ├── __init__.py # Package init (✅ completed) └── agent.py # Agent logic (🚧 to implement)
۶. بررسی اجمالی معماری
قبل از پیادهسازی، بیایید معماری دو سرویسی را درک کنیم:
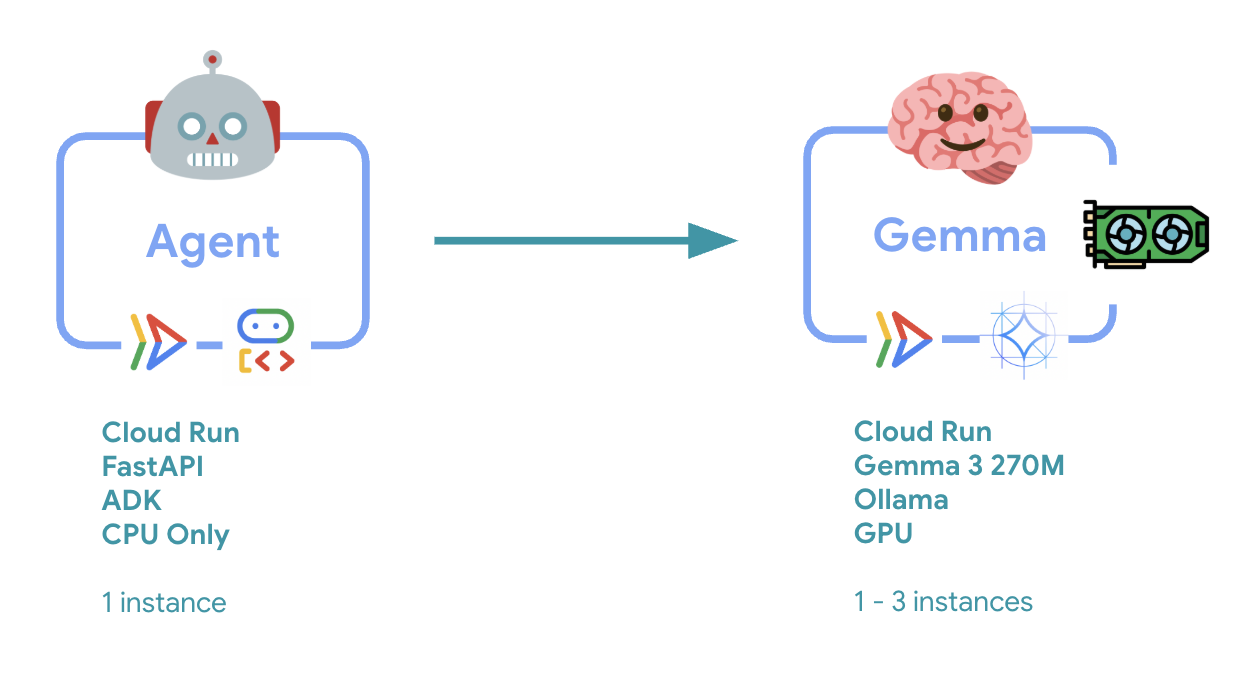
بینش کلیدی : در طول تست الاستیسیته، مشاهده خواهید کرد که هر دو سرویس به طور مستقل بار کاری را مدیریت میکنند - بخش پشتی GPU (سرویس گلوگاه) از GPU خود برای مدیریت بار استفاده میکند، در حالی که عامل ADK برای مدیریت درخواستهای غیرمنابعمحور به CPU خود متکی است.
۷. استقرار Gemma Backend در Cloud Run با GPU
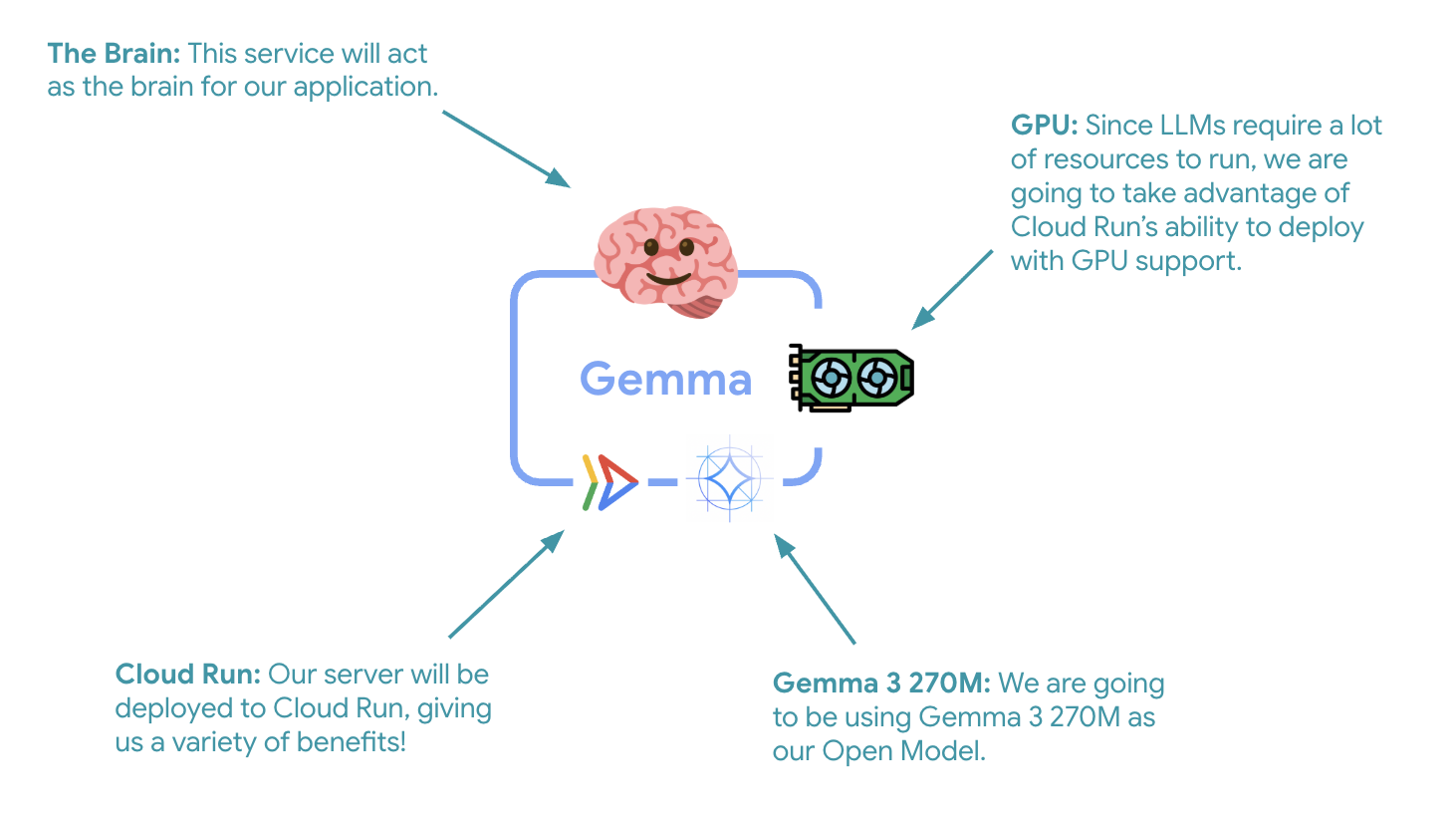
اولین گام حیاتی، استقرار یک مدل Gemma شتابیافته با GPU است که به عنوان مغز متفکر عامل ADK شما عمل خواهد کرد. داشتن یک LLM مستقر و جدا شده ممکن است در معماریهایی که به یک مدل تنظیمشده دقیق جداگانه یا مقیاسپذیری ایزوله نیاز دارید، مطلوب باشد.
- به دایرکتوری backend اولاما بروید:
cd ollama-backend - داکرفایل Ollama را باز و پیادهسازی کنید:
cloudshell edit DockerfileFROM ollama/ollama:latest # Listen on all interfaces, port 8080 ENV OLLAMA_HOST 0.0.0.0:8080 # Store model weight files in /models ENV OLLAMA_MODELS /models # Reduce logging verbosity ENV OLLAMA_DEBUG false # Never unload model weights from the GPU ENV OLLAMA_KEEP_ALIVE -1 # Store the model weights in the container image ENV MODEL gemma3:270m RUN ollama serve & sleep 5 && ollama pull $MODEL # Start Ollama ENTRYPOINT ["ollama", "serve"]- از تصویر رسمی اولاما به عنوان پایه استفاده میکند
-
OLLAMA_HOSTطوری تنظیم میکند که اتصالات را از هر آدرس IP بپذیرد. - پورت ۸۰۸۰ را در معرض دید قرار میدهد
- بکاند Gemma را با پشتیبانی از GPU مستقر کنید:
gcloud run deploy ollama-gemma3-270m-gpu \
--source . \
--region europe-west4 \
--concurrency 7 \
--cpu 8 \
--set-env-vars OLLAMA_NUM_PARALLEL=4 \
--gpu 1 \
--gpu-type nvidia-l4 \
--max-instances 1 \
--memory 16Gi \
--allow-unauthenticated \
--no-cpu-throttling \
--no-gpu-zonal-redundancy \
--timeout 600 \
--labels dev-tutorial=codelab-agent-gpu
اگر پیام «استقرار از منبع به یک مخزن Docker رجیستری مصنوعات برای ذخیره کانتینرهای ساخته شده نیاز دارد. یک مخزن با نام [cloud-run-source-deploy] در منطقه [europe-west4] ایجاد خواهد شد» دریافت کردید، ادامه دهید.
⚙️ توضیح پیکربندی کلید:
- پردازنده گرافیکی : NVIDIA L4 به دلیل نسبت عالی قیمت به عملکرد برای بارهای کاری استنتاج انتخاب شده است. L4 حافظه پردازنده گرافیکی 24 گیگابایتی و عملیات تانسور بهینه شده را فراهم میکند و آن را برای مدلهای پارامتری 270M مانند Gemma ایدهآل میسازد.
- حافظه : ۱۶ گیگابایت حافظه سیستم برای مدیریت بارگذاری مدل، عملیات CUDA و مدیریت حافظه Ollama
- پردازنده : ۸ هسته برای مدیریت بهینه ورودی/خروجی و وظایف پیشپردازش
- همزمانی : ۷ درخواست در هر نمونه، توان عملیاتی را با استفاده از حافظه GPU متعادل میکند.
- زمان انتظار : ۶۰۰ ثانیه برای بارگذاری اولیه مدل و راهاندازی کانتینر
💰 ملاحظات هزینه : نمونههای GPU به طور قابل توجهی گرانتر از نمونههای فقط CPU هستند (حدود ۲ تا ۴ دلار در ساعت در مقابل حدود ۰.۱۰ دلار در ساعت). تنظیم --max-instances 1 با جلوگیری از مقیاسبندی غیرضروری نمونه GPU به کنترل هزینهها کمک میکند.
- منتظر بمانید تا استقرار کامل شود و URL سرویس را یادداشت کنید:
export OLLAMA_URL=$(gcloud run services describe ollama-gemma3-270m-gpu \ --region=europe-west4 \ --format='value(status.url)') echo "🎉 Gemma backend deployed at: $OLLAMA_URL"
۸. پیادهسازی یکپارچهسازی عامل ADK
حالا بیایید یک عامل ADK مینیمال ایجاد کنیم که به بکاند Gemma مستقر شما متصل شود.
- به دایرکتوری عامل ADK بروید:
cd ../adk-agent - پیکربندی عامل را باز کرده و پیادهسازی کنید:
cloudshell edit production_agent/agent.pyimport os from pathlib import Path from dotenv import load_dotenv from google.adk.agents import Agent from google.adk.models.lite_llm import LiteLlm import google.auth # Load environment variables root_dir = Path(__file__).parent.parent dotenv_path = root_dir / ".env" load_dotenv(dotenv_path=dotenv_path) # Configure Google Cloud try: _, project_id = google.auth.default() os.environ.setdefault("GOOGLE_CLOUD_PROJECT", project_id) except Exception: pass os.environ.setdefault("GOOGLE_CLOUD_LOCATION", "europe-west4") # Configure model connection gemma_model_name = os.getenv("GEMMA_MODEL_NAME", "gemma3:270m") api_base = os.getenv("OLLAMA_API_BASE", "localhost:10010") # Location of Ollama server # Production Gemma Agent - GPU-accelerated conversational assistant production_agent = Agent( model=LiteLlm(model=f"ollama_chat/{gemma_model_name}", api_base=api_base), name="production_agent", description="A production-ready conversational assistant powered by GPU-accelerated Gemma.", instruction="""You are 'Gem', a friendly, knowledgeable, and enthusiastic zoo tour guide. Your main goal is to make a zoo visit more fun and educational for guests by answering their questions. You can provide general information and interesting facts about different animal species, such as: - Their natural habitats and diet. 🌲🍓 - Typical lifespan and behaviors. - Conservation status and unique characteristics. IMPORTANT: You do NOT have access to any tools. This means you cannot look up real-time, specific information about THIS zoo. You cannot provide: - The names or ages of specific animals currently at the zoo. - The exact location or enclosure for an animal. - The daily schedule for feedings or shows. Always answer based on your general knowledge about the animal kingdom. Keep your tone cheerful, engaging, and welcoming for visitors of all ages. 🦁✨""", tools=[], # Gemma focuses on conversational capabilities ) # Set as root agent root_agent = production_agent- از طریق LiteLlm به بکاند Gemma مستقر شده شما متصل میشود.
- یک عامل مکالمه ساده ایجاد میکند
- پیکربندی ادغام با گوگل کلود
- سرور FastAPI را باز و پیادهسازی کنید:
cloudshell edit server.pyimport os from dotenv import load_dotenv from fastapi import FastAPI from google.adk.cli.fast_api import get_fast_api_app # Load environment variables load_dotenv() AGENT_DIR = os.path.dirname(os.path.abspath(__file__)) app_args = {"agents_dir": AGENT_DIR, "web": True} # Create FastAPI app with ADK integration app: FastAPI = get_fast_api_app(**app_args) # Update app metadata app.title = "Production ADK Agent - Lab 3" app.description = "Gemma agent with GPU-accelerated backend" app.version = "1.0.0" @app.get("/health") def health_check(): return {"status": "healthy", "service": "production-adk-agent"} @app.get("/") def root(): return { "service": "Production ADK Agent - Lab 3", "description": "GPU-accelerated Gemma agent", "docs": "/docs", "health": "/health" } if __name__ == "__main__": import uvicorn uvicorn.run(app, host="0.0.0.0", port=8080, log_level="info")- یک سرور FastAPI با ادغام ADK ایجاد میکند.
- رابط وب را برای آزمایش فعال میکند
- نقاط پایانی بررسی سلامت را فراهم میکند
- داکرفایل را باز و پیادهسازی کنید:
cloudshell edit DockerfileFROM python:3.13-slim # Copy uv from the official image COPY --from=ghcr.io/astral-sh/uv:latest /uv /usr/local/bin/uv # Install system dependencies RUN apt-get update && apt-get install -y curl && rm -rf /var/lib/apt/lists/* # Set working directory WORKDIR /app # Copy all files COPY . . # Install Python dependencies RUN uv sync # Expose port EXPOSE 8080 # Run the application CMD ["uv", "run", "uvicorn", "server:app", "--host", "0.0.0.0", "--port", "8080"]- uv : مدیر بسته مدرن پایتون که ۱۰ تا ۱۰۰ برابر سریعتر از pip است. از یک حافظه پنهان سراسری و دانلودهای موازی استفاده میکند و زمان ساخت کانتینر را به میزان قابل توجهی کاهش میدهد.
- پایتون ۳.۱۳-slim : آخرین نسخه پایتون با حداقل وابستگیهای سیستمی، کاهش اندازه کانتینر و سطح حمله
- ساخت چند مرحلهای : کپی کردن uv از تصویر رسمی آن تضمین میکند که آخرین نسخه باینری بهینه شده را دریافت میکنیم
۹. پیکربندی محیط و استقرار عامل
اکنون عامل ADK را پیکربندی میکنیم تا به بکاند Gemma مستقر شما متصل شود و آن را به عنوان یک سرویس Cloud Run مستقر کند. این شامل تنظیم متغیرهای محیطی و استقرار عامل با پیکربندی مناسب است.
- پیکربندی محیط خود را تنظیم کنید:
cat << EOF > .env GOOGLE_CLOUD_PROJECT=$(gcloud config get-value project) GOOGLE_CLOUD_LOCATION=europe-west4 GEMMA_MODEL_NAME=gemma3:270m OLLAMA_API_BASE=$OLLAMA_URL EOF
درک متغیرهای محیطی در Cloud Run
متغیرهای محیطی جفتهای کلید-مقدار هستند که برنامه شما را در زمان اجرا پیکربندی میکنند. آنها بهویژه برای موارد زیر مفید هستند:
- نقاط پایانی API و URLهای سرویس (مانند backend اولامای ما)
- پیکربندی که بین محیطها تغییر میکند (توسعه، مرحلهبندی، تولید)
- دادههای حساسی که نباید کدگذاری شوند
عامل ADK را مستقر کنید:
export PROJECT_ID=$(gcloud config get-value project)
gcloud run deploy production-adk-agent \
--source . \
--region europe-west4 \
--allow-unauthenticated \
--memory 4Gi \
--cpu 2 \
--max-instances 1 \
--concurrency 50 \
--timeout 300 \
--set-env-vars GOOGLE_CLOUD_PROJECT=$PROJECT_ID \
--set-env-vars GOOGLE_CLOUD_LOCATION=europe-west4 \
--set-env-vars GEMMA_MODEL_NAME=gemma3:270m \
--set-env-vars OLLAMA_API_BASE=$OLLAMA_URL \
--labels dev-tutorial=codelab-agent-gpu
⚙️ پیکربندی کلید:
- مقیاسبندی خودکار : در ۱ نمونه رفع شد (مدیریت درخواست سبک)
- همزمانی : ۵۰ درخواست در هر نمونه
- حافظه : ۴ گیگابایت برای عامل ADK
- محیط : به بکاند Gemma شما متصل میشود
🔒 نکته امنیتی : این آزمایشگاه برای سادگی --allow-unauthenticated استفاده میکند. در محیط عملیاتی، احراز هویت مناسب را با استفاده از موارد زیر پیادهسازی کنید:
- احراز هویت سرویس به سرویس با حسابهای سرویس در Cloud Run
- سیاستهای مدیریت هویت و دسترسی (IAM)
- کلیدهای API یا OAuth برای دسترسی خارجی
- برای کنترل دسترسی، استفاده
gcloud run services add-iam-policy-bindingدر نظر بگیرید.
آدرس اینترنتی سرویس نماینده خود را دریافت کنید:
export AGENT_URL=$(gcloud run services describe production-adk-agent \
--region=europe-west4 \
--format='value(status.url)')
echo "🎉 ADK Agent deployed at: $AGENT_URL"
✅ بهترین شیوههای متغیرهای محیطی بر اساس مستندات متغیرهای محیطی Cloud Run :
- از متغیرهای رزرو شده اجتناب کنید :
PORT(اگر نیاز به تغییر متغیر env دارید، به جای آن از پرچم –port استفاده کنید) یا متغیرهایی که باX_GOOGLE_شروع میشوند را تنظیم نکنید. - از نامهای توصیفی استفاده کنید : برای جلوگیری از تداخل، متغیرهای خود را پیشوند قرار دهید (مثلاً به جای
MODEL،GEMMA_MODEL_NAME). - کاماهای Escape : اگر مقادیر شما حاوی کاما هستند، از جداکنندهی دیگری استفاده کنید:
--set-env-vars "^@^KEY1=value1,value2@KEY2=..." - Update در مقابل Replace :
--update-env-varsبرای اضافه کردن/تغییر متغیرهای خاص بدون تأثیر بر سایر متغیرها استفاده کنید.
نحوه تنظیم متغیرها در Cloud Run :
- از فایل :
gcloud run deploy SERVICE_NAME --env-vars-file .env --labels dev-tutorial codelab-adk(چندین متغیر را از یک فایل بارگذاری میکند) - چندین پرچم : برای مقادیر پیچیدهای که نمیتوان با کاما از هم جدا کرد،
--set-env-varsرا تکرار کنید.
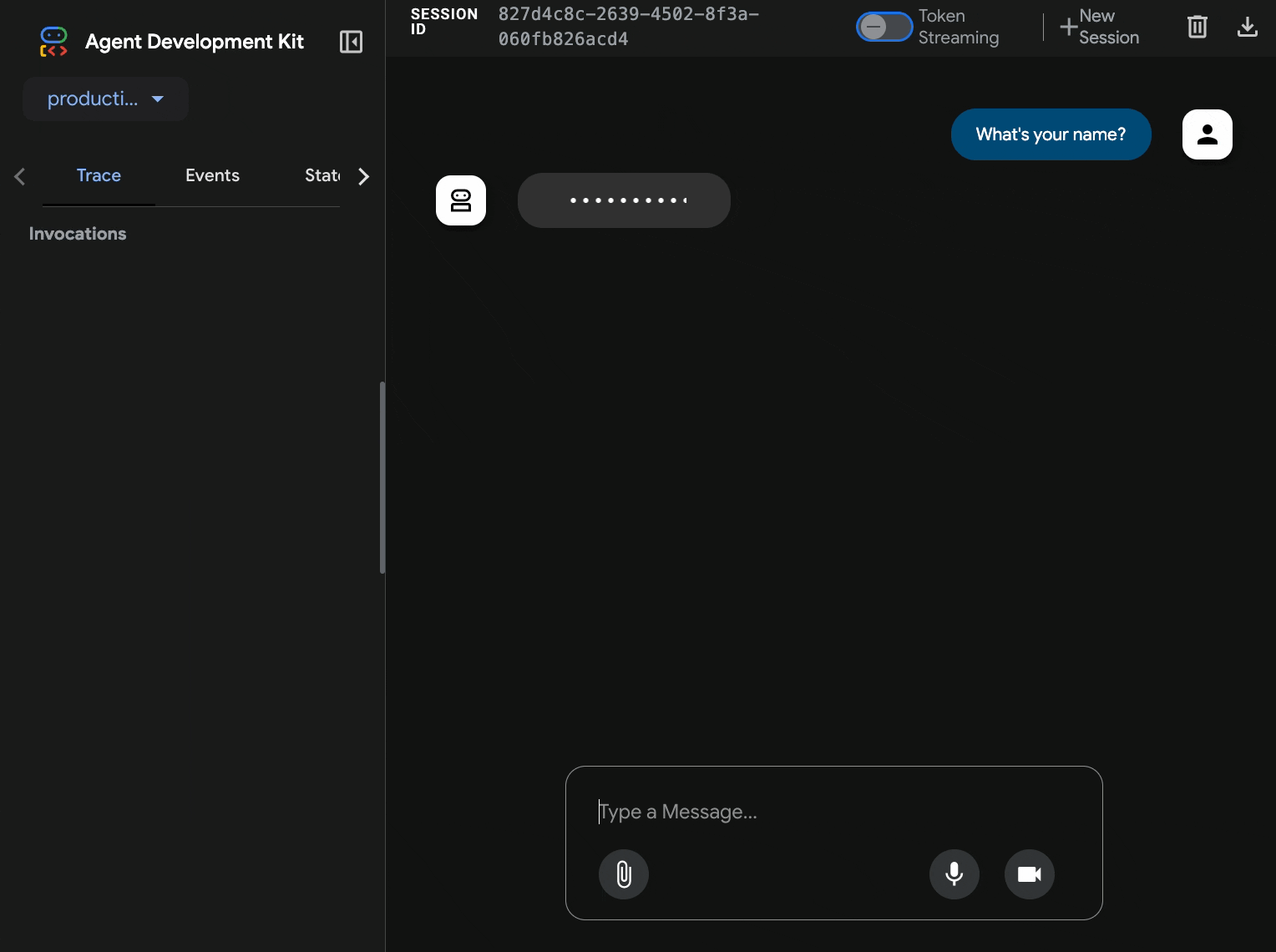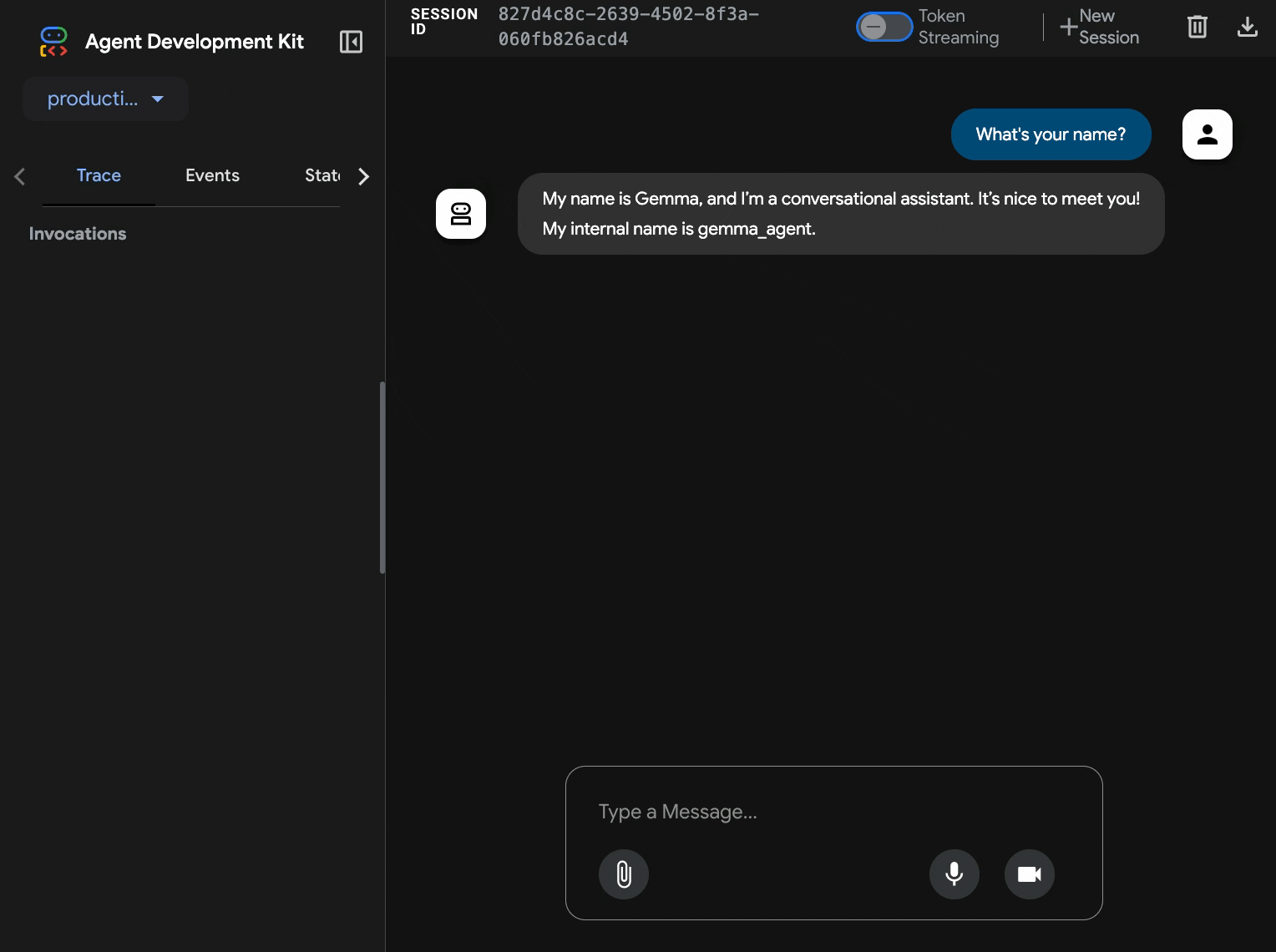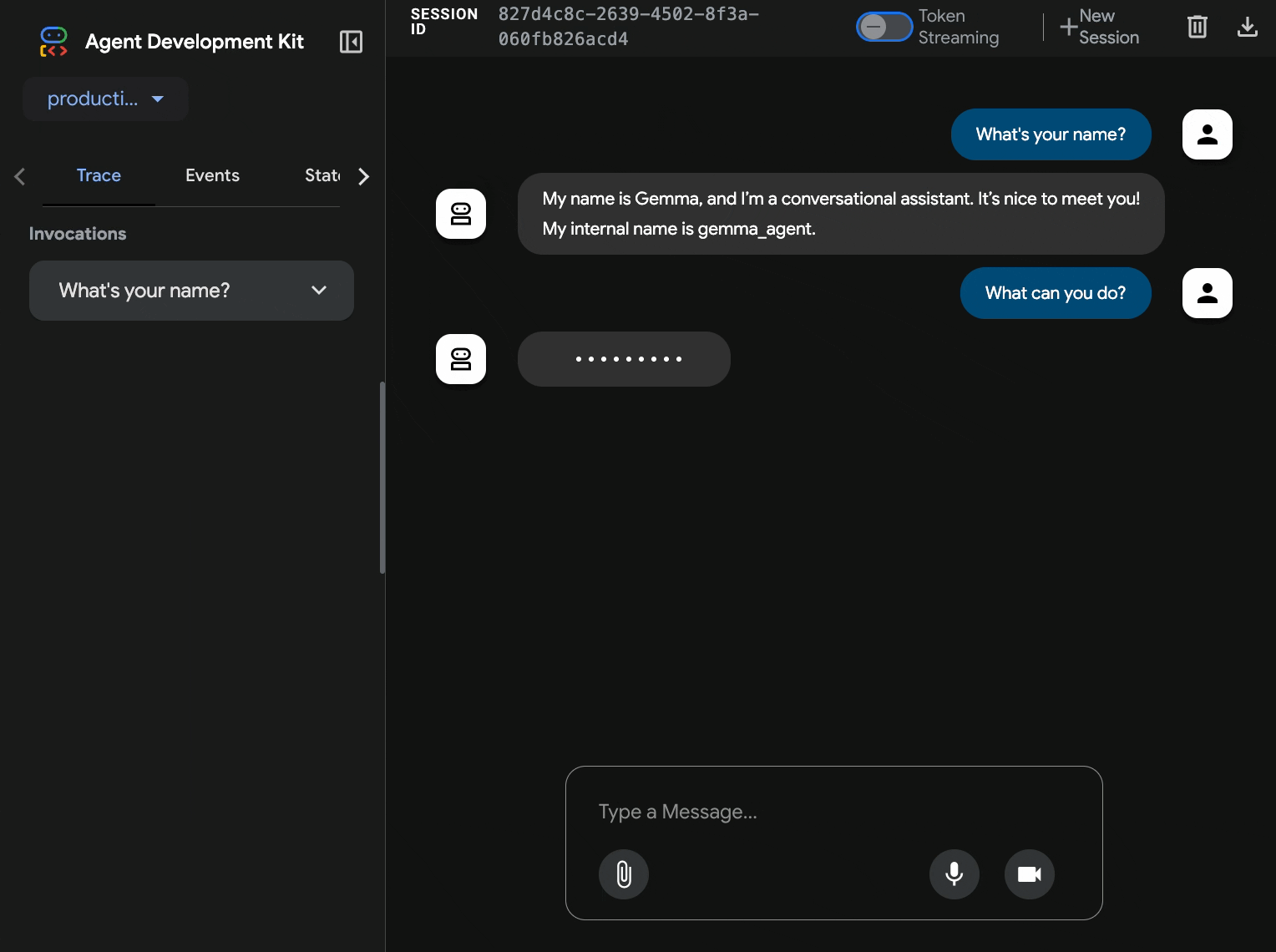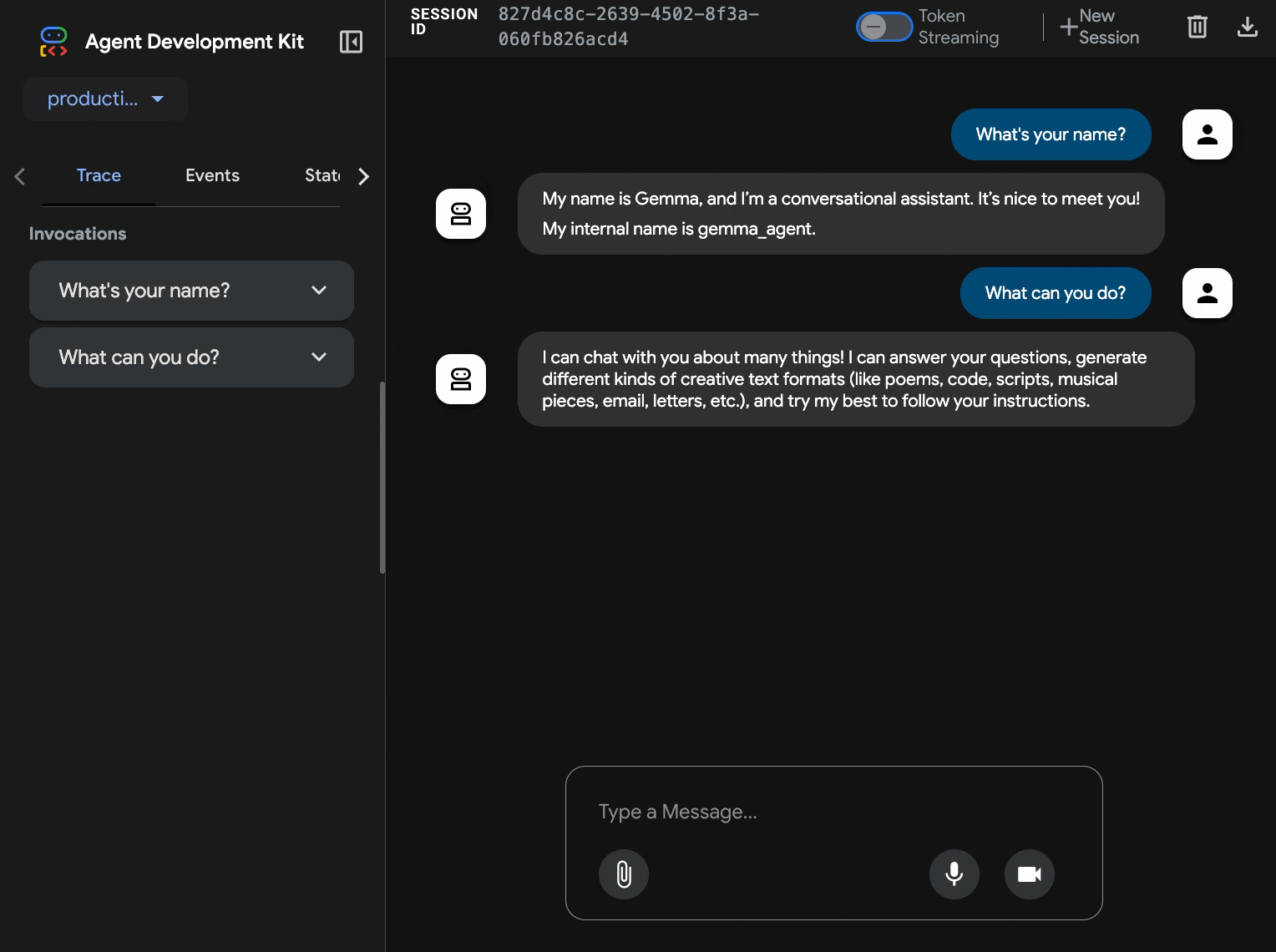
۱۰. تست با رابط وب ADK
با استقرار هر دو سرویس، زمان آن رسیده است که تأیید کنید عامل ADK شما میتواند با موفقیت با backend Gemma که توسط GPU شتاب داده شده است ارتباط برقرار کند و به درخواستهای کاربر پاسخ دهد.
- نقطه پایانی سلامت را آزمایش کنید:
curl $AGENT_URL/health{ "status": "healthy", "service": "production-adk-agent" } - با وارد کردن URL مربوط به
production-adk-agentخود در یک برگه مرورگر جدید، با عامل خود تعامل داشته باشید. باید رابط وب ADK را ببینید. - با این نمونه مکالمات، نماینده خود را محک بزنید:
- «پانداهای قرمز معمولاً در طبیعت چه میخورند؟»
- «میتوانید یک حقیقت جالب در مورد پلنگهای برفی به من بگویید؟»
- «چرا قورباغههای دارت سمی اینقدر رنگ روشنی دارند؟»
- «کجا میتوانم بچه کانگوروی جدید را در باغوحش پیدا کنم؟»
- عامل با استفاده از مدل Gemma مستقر شده شما پاسخ میدهد. میتوانید با مشاهده گزارشهای مربوط به سرویس Gemma مستقر شده خود، این موضوع را تأیید کنید. این کار را در بخش بعدی انجام خواهیم داد.
- پاسخها توسط backend شتابیافته با GPU تولید میشوند.
- رابط وب، یک تجربه چت تمیز را ارائه میدهد
۱۱. پیادهسازی و اجرای یک تست الاستیسیته
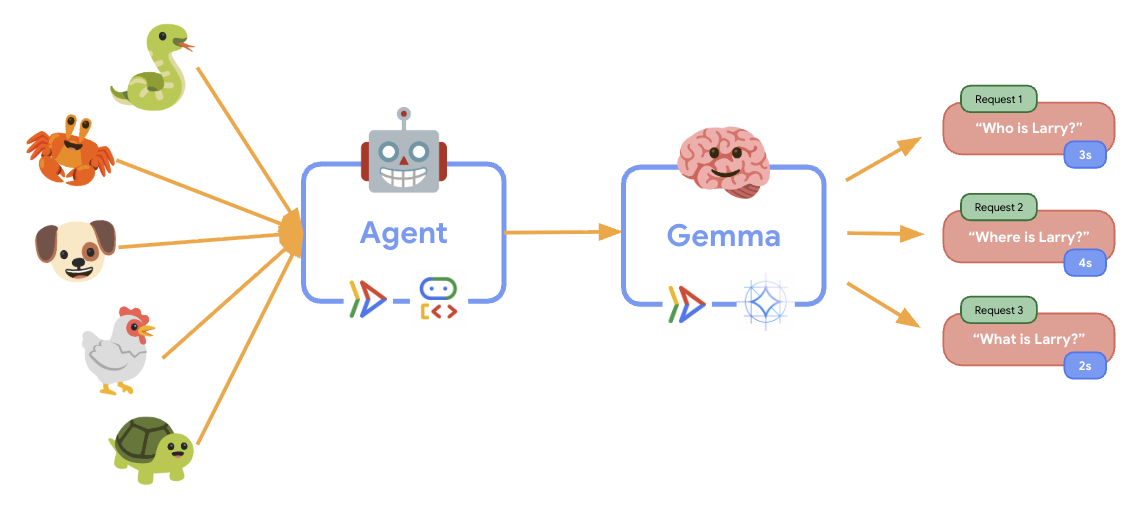
برای درک اینکه چگونه استقرار عملیاتی شما ترافیک دنیای واقعی را مدیریت میکند، ما یک تست الاستیسیته پیادهسازی خواهیم کرد که توانایی سیستم را برای سازگاری با حجم کاری عملیاتی «شبیهسازیشده» بالاتر میسنجد.
- اسکریپت تست الاستیسیته را باز کرده و پیادهسازی کنید:
cloudshell edit elasticity_test.pyimport random import uuid from locust import HttpUser, task, between class ProductionAgentUser(HttpUser): """Elasticity test user for the Production ADK Agent.""" wait_time = between(1, 3) # Faster requests to trigger scaling def on_start(self): """Set up user session when starting.""" self.user_id = f"user_{uuid.uuid4()}" self.session_id = f"session_{uuid.uuid4()}" # Create session for the Gemma agent using proper ADK API format session_data = {"state": {"user_type": "elasticity_test_user"}} self.client.post( f"/apps/production_agent/users/{self.user_id}/sessions/{self.session_id}", headers={"Content-Type": "application/json"}, json=session_data, ) @task(4) def test_conversations(self): """Test conversational capabilities - high frequency.""" topics = [ "What do red pandas typically eat in the wild?", "Can you tell me an interesting fact about snow leopards?", "Why are poison dart frogs so brightly colored?", "Where can I find the new baby kangaroo in the zoo?", "What is the name of your oldest gorilla?", "What time is the penguin feeding today?" ] # Use proper ADK API format for sending messages message_data = { "app_name": "production_agent", "user_id": self.user_id, "session_id": self.session_id, "new_message": { "role": "user", "parts": [{ "text": random.choice(topics) }] } } self.client.post( "/run", headers={"Content-Type": "application/json"}, json=message_data, ) @task(1) def health_check(self): """Test the health endpoint.""" self.client.get("/health")- ایجاد جلسه : از قالب مناسب ADK API با POST به
/apps/production_agent/users/{user_id}/sessions/{session_id}استفاده میکند. پس از ایجادsession_idوuser_id، میتوان درخواستی را به عامل ارسال کرد. - قالب پیام : از مشخصات ADK با
app_name،user_id،session_idو شیءnew_messageساختاریافته پیروی میکند. - نقطه پایانی مکالمه : از نقطه پایانی
/runبرای جمعآوری همزمان همه رویدادها استفاده میکند (برای تست بار توصیه میشود) - بارگذاری واقعگرایانه : بارگذاری مکالمه را با زمان انتظار کوتاهتر ایجاد میکند
- ایجاد جلسه : از قالب مناسب ADK API با POST به
- نصب وابستگیها:
uv sync - Locust یک ابزار تست بار مبتنی بر پایتون و متنباز است که برای تست عملکرد و بار برنامههای وب و سایر سیستمها طراحی شده است. ویژگی اصلی آن این است که سناریوهای تست و رفتار کاربر با استفاده از کد استاندارد پایتون تعریف میشوند و در مقایسه با ابزارهایی که به رابطهای کاربری گرافیکی یا زبانهای خاص دامنه متکی هستند، انعطافپذیری و بیان بالایی را ارائه میدهند. ما از Locust برای شبیهسازی ترافیک کاربر به سرویسهای خود استفاده خواهیم کرد. تست را اجرا کنید.
uv run locust -f elasticity_test.py \ -H $AGENT_URL \ --headless \ -t 60s \ -u 20 \ -r 5- مدت زمان : ۶۰ ثانیه
- تعداد کاربران : ۲۰ کاربر همزمان
- نرخ تولید مثل : ۵ کاربر در ثانیه
- هدف : فعالسازی مقیاسپذیری خودکار در هر دو سرویس
۱۲. رفتار مقیاسبندی خودکار را مشاهده کنید
همزمان با اجرای تست الاستیسیته، میتوانید پشتیبانی Cloud Run از حجم کاری بالاتر را در عمل مشاهده کنید. اینجاست که مزایای کلیدی معماری جداسازی عامل ADK از پردازنده گرافیکی (GPU) را مشاهده خواهید کرد.
در طول تست الاستیسیته، نحوه مدیریت ترافیک در کنسول خود توسط هر دو سرویس Cloud Run را بررسی کنید.
- در کنسول ابری ، به مسیر زیر بروید:
- اجرای ابری → production-adk-agent → معیارها
- اجرای ابری → ollama-gemma3-270m-gpu → معیارها
👀 مواردی که باید رعایت کنید:
🤖 خدمات نمایندگی ADK:
- باید در ۱ مورد ثابت بماند در حالی که ترافیک افزایش مییابد
- افزایش ناگهانی مصرف CPU و حافظه در زمان ترافیک بالا
- مدیریت نشستها و مسیریابی درخواستها را به طور کارآمد انجام میدهد
🎮 سرویس بکاند جما (گلوگاه):
- باید در ۱ مورد ثابت بماند در حالی که ترافیک افزایش مییابد
- استفاده از پردازنده گرافیکی (GPU) تحت بار کاری به طور قابل توجهی افزایش مییابد
- این سرویس به دلیل استنتاج مدل مبتنی بر GPU، به گلوگاه تبدیل میشود.
- زمان استنتاج مدل به دلیل شتابدهی GPU ثابت میماند
💡 نکات کلیدی:
- هر دو سرویس ثابت میمانند و مقیاسپذیری ندارند، زیرا حداکثر تعداد نمونهها را روی
1تنظیم کردهایم. - هر دو سرویس بر اساس ویژگیهای بار فردی خود، به طور مستقل مقیاسپذیر هستند
- پردازنده گرافیکی به حفظ عملکرد در شرایط بارگذاری متغیر کمک میکند
۱۳. نتیجهگیری
تبریک! شما با موفقیت یک ADK agent آماده برای تولید را با Gemma backend شتابدهی شده با GPU، در حین آزمایش یک بار کاری تولید شبیهسازی شده، مستقر کردید.
✅ کاری که انجام دادید
- ✅ یک بکاند مدل Gemma با شتابدهنده گرافیکی (GPU) روی Cloud Run مستقر شد.
- ✅ ایجاد و استقرار یک عامل ADK که با بکاند Gemma ادغام میشود
- ✅ عامل را با استفاده از رابط وب ADK آزمایش کرد
- ✅ رفتار مقیاسبندی خودکار مشاهدهشده در دو سرویس هماهنگ Cloud Run
💡 بینشهای کلیدی از این آزمایشگاه
- 🎮 شتابدهی پردازنده گرافیکی : پردازنده گرافیکی NVIDIA L4 به طور قابل توجهی عملکرد استنتاج مدل را بهبود میبخشد.
- 🔗 هماهنگی سرویس : دو سرویس Cloud Run میتوانند به طور یکپارچه با هم کار کنند
- 📈 مقیاسپذیری مستقل : هر سرویس بر اساس ویژگیهای بار منحصر به فرد خود، مقیاسپذیر میشود.
- 🚀 آمادگی برای تولید : معماری، الگوهای ترافیک دنیای واقعی را به طور مؤثر مدیریت میکند.
🔄 مراحل بعدی
- الگوهای بارگذاری مختلف را آزمایش کنید و رفتار مقیاسبندی را مشاهده کنید
- اندازههای مختلف مدل Gemma را امتحان کنید (حافظه و پردازنده گرافیکی را بر اساس آن تنظیم کنید)
- پیادهسازی نظارت و هشدار برای استقرارهای عملیاتی
- بررسی استقرارهای چند منطقهای برای دسترسی جهانی
🧹 تمیز کردن
برای جلوگیری از تحمیل هزینه، پس از اتمام کار، منابع را حذف کنید:
gcloud run services delete production-adk-agent --region=europe-west4
gcloud run services delete ollama-gemma3-270m-gpu --region=europe-west4
📖 منابع
- مخزن شروع کننده
- راه حل کامل
- مستندات گوگل ADK
- راهنمای تست ADK - مرجع کامل برای نقاط پایانی و الگوهای تست API ADK
- تست بار در Cloud Run
- مستندات کیت توسعه عامل (ADK)
- مستندات GPU در Cloud Run
- کتابخانه مدل اولاما
- مستندات ردیابی گوگل کلود
- بهترین شیوههای امنیتی Cloud Run
- مدیر بسته UV پایتون
- چارچوب تست بارگذاری ملخ