
1. Introduction
Présentation
Dans cet atelier, vous allez déployer un agent Agent Development Kit (ADK) prêt pour la production avec un backend Gemma accéléré par GPU. L'accent est mis sur les modèles de déploiement critiques : configuration des services Cloud Run compatibles avec les GPU, intégration des backends de modèles aux agents ADK et observation du comportement d'autoscaling sous charge.
Objectifs de l'atelier
Dans cet atelier, vous vous concentrerez sur les aspects essentiels du déploiement en production :
- Déployer Gemma sur Cloud Run avec GPU : configurer un backend de modèle Gemma hautes performances
- Intégrer le déploiement Gemma à un agent ADK : connectez votre agent au modèle accéléré par GPU.
- Tester avec l'interface Web ADK : validez le bon fonctionnement de votre agent conversationnel.
- Effectuer des tests d'élasticité : observer comment les deux instances Cloud Run gèrent la charge
L'accent est mis sur les modèles de déploiement en production plutôt que sur le développement d'agents à grande échelle.
Points abordés
- Déployer des modèles Gemma accélérés par GPU sur Cloud Run pour une utilisation en production
- Intégrer des déploiements de modèles externes avec des agents ADK
- Configurer et tester des déploiements d'agents d'IA prêts pour la production
- Comprendre le comportement de Cloud Run sous charge
- Observer la coordination de plusieurs instances Cloud Run lors des pics de trafic
- Appliquer des tests d'élasticité pour valider les performances
2. Configuration du projet
- Si vous ne possédez pas encore de compte Google, vous devez en créer un.
- Utilisez un compte personnel au lieu d'un compte professionnel ou scolaire. Il est possible que des restrictions s'appliquent aux comptes professionnels et scolaires, ce qui vous empêche d'activer les API nécessaires pour cet atelier.
- Connectez-vous à la console Google Cloud.
- Activez la facturation dans la console Cloud.
- Cet atelier devrait vous coûter moins de 1 USD en ressources Cloud.
- Vous pouvez suivre les étapes à la fin de cet atelier pour supprimer les ressources et éviter ainsi des frais supplémentaires.
- Les nouveaux utilisateurs peuvent bénéficier d'un essai sans frais pour bénéficier d'un crédit de 300$.
- Créez un projet ou réutilisez-en un existant.
- Si vous voyez une erreur concernant le quota de projet, réutilisez un projet existant ou supprimez-en un pour en créer un.
3. Ouvrir l'éditeur Cloud Shell
- Cliquez sur ce lien pour accéder directement à l'éditeur Cloud Shell.
- Si vous êtes invité à autoriser l'accès à un moment donné aujourd'hui, cliquez sur Autoriser pour continuer.
- Si le terminal ne s'affiche pas en bas de l'écran, ouvrez-le :
- Cliquez sur Afficher.
- Cliquez sur Terminal
 .
.
- Dans le terminal, définissez votre projet à l'aide de la commande suivante :
- Format :
gcloud config set project [PROJECT_ID] - Exemple :
gcloud config set project lab-project-id-example - Si vous ne vous souvenez pas de l'ID de votre projet :
- Vous pouvez lister tous vos ID de projet avec la commande suivante :
gcloud projects list | awk '/PROJECT_ID/{print $2}'
- Vous pouvez lister tous vos ID de projet avec la commande suivante :
- Format :
- Le message suivant doit s'afficher :
Updated property [core/project].
WARNINGs'affiche et que vous êtes invité àDo you want to continue (Y/n)?, cela signifie probablement que vous avez saisi l'ID de projet de manière incorrecte. Appuyez surn, puis surEnter, et réessayez d'exécuter la commandegcloud config set project.
4. Activer les API et définir la région par défaut
Avant de pouvoir déployer des services Cloud Run compatibles avec les GPU, nous devons activer les API Google Cloud requises et configurer les paramètres de votre projet.
- Dans le terminal, activez les API :
gcloud services enable \
run.googleapis.com \
artifactregistry.googleapis.com \
cloudbuild.googleapis.com \
aiplatform.googleapis.com
Si vous êtes invité à autoriser l'accès, cliquez sur Autoriser pour continuer.
L'exécution de cette commande peut prendre quelques minutes, mais un message semblable à celui qui suit devrait s'afficher pour vous indiquer que l'opération s'est correctement déroulée :
Operation "operations/acf.p2-73d90d00-47ee-447a-b600" finished successfully.
- Définissez votre région Cloud Run par défaut.
gcloud config set run/region europe-west4
5. Préparer votre projet Python
Configurons le code de démarrage qui contient la structure de base pour nos services de backend Gemma et d'agent ADK.
- Clonez le dépôt de démarrage :
cd ~ npx -y giget@latest gh+git:GoogleCloudPlatform/devrel-demos/agents/accelerate-ai-with-cloud-run/accelerate-ai-lab3-starter accelerate-ai-lab3-starter cd accelerate-ai-lab3-starter - Examinez la structure du projet :
ls -Raccelerate-ai-lab3-starter/ ├── README.md # Project overview ├── ollama-backend/ # Ollama backend (separate deployment) │ └── Dockerfile # Backend container (🚧 to implement) └── adk-agent/ # ADK agent (separate deployment) ├── pyproject.toml # Python dependencies (✅ completed) ├── server.py # FastAPI server (🚧 to implement) ├── Dockerfile # Container config (🚧 to implement) ├── elasticity_test.py # Elasticity testing (🚧 to implement) └── production_agent/ # Agent implementation ├── __init__.py # Package init (✅ completed) └── agent.py # Agent logic (🚧 to implement)
6. Présentation de l'architecture
Avant d'implémenter l'architecture à deux services, examinons-la :
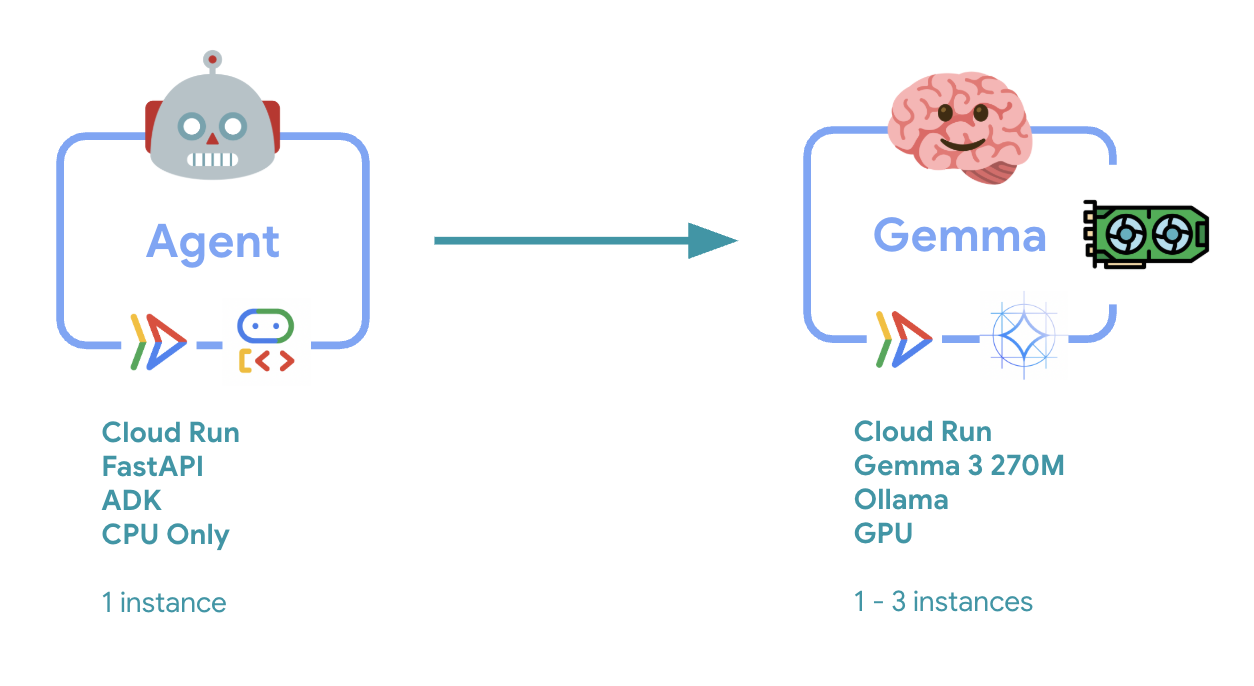
Insight clé : lors des tests d'élasticité, vous verrez les deux services gérer la charge de travail de manière indépendante. Le backend GPU (service de goulot d'étranglement) utilise son GPU pour gérer la charge, tandis que l'agent ADK s'appuie sur son CPU pour gérer les requêtes peu gourmandes en ressources.
7. Déployer le backend Gemma sur Cloud Run avec GPU
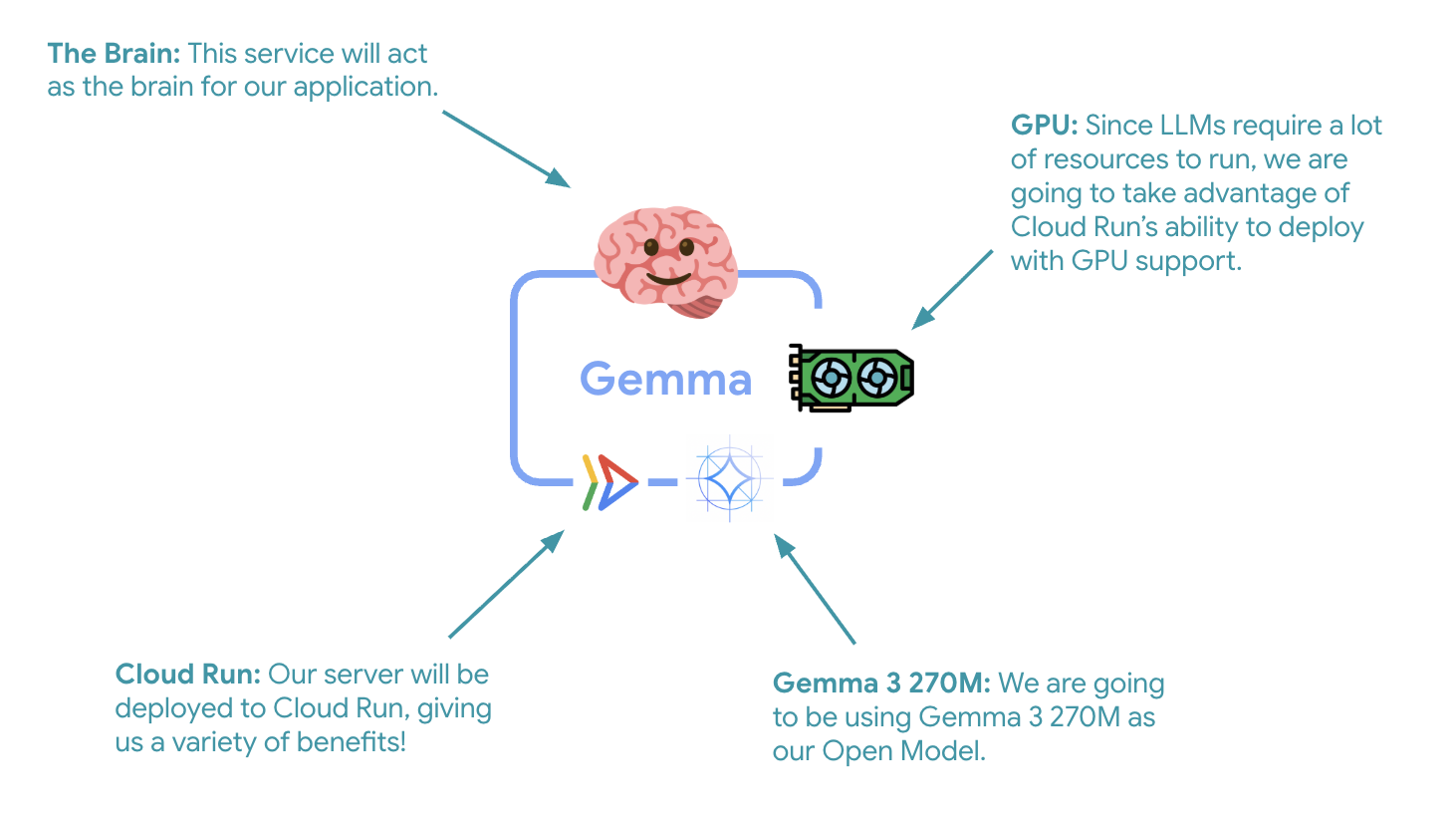
La première étape essentielle consiste à déployer un modèle Gemma accéléré par GPU, qui servira de cerveau à votre agent ADK. Il peut être préférable d'avoir un LLM déployé et découplé dans les architectures où vous avez besoin d'un modèle affiné distinct ou d'une mise à l'échelle isolée.
- Accédez au répertoire backend Ollama :
cd ollama-backend - Ouvrez et implémentez le Dockerfile Ollama :
cloudshell edit DockerfileFROM ollama/ollama:latest # Listen on all interfaces, port 8080 ENV OLLAMA_HOST 0.0.0.0:8080 # Store model weight files in /models ENV OLLAMA_MODELS /models # Reduce logging verbosity ENV OLLAMA_DEBUG false # Never unload model weights from the GPU ENV OLLAMA_KEEP_ALIVE -1 # Store the model weights in the container image ENV MODEL gemma3:270m RUN ollama serve & sleep 5 && ollama pull $MODEL # Start Ollama ENTRYPOINT ["ollama", "serve"]- Utilise l'image Ollama officielle comme base
- Définit
OLLAMA_HOSTpour accepter les connexions depuis n'importe quelle adresse IP - Expose le port 8080
- Déployez le backend Gemma avec prise en charge des GPU :
gcloud run deploy ollama-gemma3-270m-gpu \
--source . \
--region europe-west4 \
--concurrency 7 \
--cpu 8 \
--set-env-vars OLLAMA_NUM_PARALLEL=4 \
--gpu 1 \
--gpu-type nvidia-l4 \
--max-instances 1 \
--memory 16Gi \
--allow-unauthenticated \
--no-cpu-throttling \
--no-gpu-zonal-redundancy \
--timeout 600 \
--labels dev-tutorial=codelab-agent-gpu
Si vous recevez le message "Le déploiement à partir de la source nécessite un dépôt Docker Artifact Registry pour stocker les conteneurs créés. Si le message "Un dépôt nommé [cloud-run-source-deploy] dans la région [europe-west4] sera créé" s'affiche, cliquez sur "Continuer".
⚙️ Explication des configurations clés :
- GPU : NVIDIA L4 choisi pour son excellent rapport prix/performances pour les charges de travail d'inférence. Le L4 fournit 24 Go de mémoire GPU et des opérations de tenseur optimisées, ce qui le rend idéal pour les modèles à 270 millions de paramètres comme Gemma.
- Mémoire : 16 Go de mémoire système pour gérer le chargement des modèles, les opérations CUDA et la gestion de la mémoire d'Ollama
- Processeur : 8 cœurs pour une gestion optimale des E/S et des tâches de prétraitement
- Simultanéité : sept requêtes par instance permettent d'équilibrer le débit et l'utilisation de la mémoire GPU.
- Délai avant expiration : 600 secondes pour permettre le chargement initial du modèle et le démarrage du conteneur
💰 Considérations relatives aux coûts : les instances de GPU sont beaucoup plus chères que les instances de CPU uniquement (environ 2 à 4 $/heure contre environ 0,10 $/heure). Le paramètre --max-instances 1 permet de contrôler les coûts en évitant le scaling inutile des instances de GPU.
- Attendez la fin du déploiement et notez l'URL du service :
export OLLAMA_URL=$(gcloud run services describe ollama-gemma3-270m-gpu \ --region=europe-west4 \ --format='value(status.url)') echo "🎉 Gemma backend deployed at: $OLLAMA_URL"
8. Implémenter l'intégration de l'agent ADK
Nous allons maintenant créer un agent ADK minimal qui se connecte à votre backend Gemma déployé.
- Accédez au répertoire de l'agent ADK :
cd ../adk-agent - Ouvrez et implémentez la configuration de l'agent :
cloudshell edit production_agent/agent.pyimport os from pathlib import Path from dotenv import load_dotenv from google.adk.agents import Agent from google.adk.models.lite_llm import LiteLlm import google.auth # Load environment variables root_dir = Path(__file__).parent.parent dotenv_path = root_dir / ".env" load_dotenv(dotenv_path=dotenv_path) # Configure Google Cloud try: _, project_id = google.auth.default() os.environ.setdefault("GOOGLE_CLOUD_PROJECT", project_id) except Exception: pass os.environ.setdefault("GOOGLE_CLOUD_LOCATION", "europe-west4") # Configure model connection gemma_model_name = os.getenv("GEMMA_MODEL_NAME", "gemma3:270m") api_base = os.getenv("OLLAMA_API_BASE", "localhost:10010") # Location of Ollama server # Production Gemma Agent - GPU-accelerated conversational assistant production_agent = Agent( model=LiteLlm(model=f"ollama_chat/{gemma_model_name}", api_base=api_base), name="production_agent", description="A production-ready conversational assistant powered by GPU-accelerated Gemma.", instruction="""You are 'Gem', a friendly, knowledgeable, and enthusiastic zoo tour guide. Your main goal is to make a zoo visit more fun and educational for guests by answering their questions. You can provide general information and interesting facts about different animal species, such as: - Their natural habitats and diet. 🌲🍓 - Typical lifespan and behaviors. - Conservation status and unique characteristics. IMPORTANT: You do NOT have access to any tools. This means you cannot look up real-time, specific information about THIS zoo. You cannot provide: - The names or ages of specific animals currently at the zoo. - The exact location or enclosure for an animal. - The daily schedule for feedings or shows. Always answer based on your general knowledge about the animal kingdom. Keep your tone cheerful, engaging, and welcoming for visitors of all ages. 🦁✨""", tools=[], # Gemma focuses on conversational capabilities ) # Set as root agent root_agent = production_agent- Se connecte à votre backend Gemma déployé via LiteLlm
- Permet de créer un agent conversationnel simple
- Configure l'intégration à Google Cloud
- Ouvrez et implémentez le serveur FastAPI :
cloudshell edit server.pyimport os from dotenv import load_dotenv from fastapi import FastAPI from google.adk.cli.fast_api import get_fast_api_app # Load environment variables load_dotenv() AGENT_DIR = os.path.dirname(os.path.abspath(__file__)) app_args = {"agents_dir": AGENT_DIR, "web": True} # Create FastAPI app with ADK integration app: FastAPI = get_fast_api_app(**app_args) # Update app metadata app.title = "Production ADK Agent - Lab 3" app.description = "Gemma agent with GPU-accelerated backend" app.version = "1.0.0" @app.get("/health") def health_check(): return {"status": "healthy", "service": "production-adk-agent"} @app.get("/") def root(): return { "service": "Production ADK Agent - Lab 3", "description": "GPU-accelerated Gemma agent", "docs": "/docs", "health": "/health" } if __name__ == "__main__": import uvicorn uvicorn.run(app, host="0.0.0.0", port=8080, log_level="info")- Crée un serveur FastAPI avec l'intégration ADK
- Active l'interface Web pour les tests
- Fournit des points de terminaison de vérification de l'état
- Ouvrez et implémentez le fichier Dockerfile :
cloudshell edit DockerfileFROM python:3.13-slim # Copy uv from the official image COPY --from=ghcr.io/astral-sh/uv:latest /uv /usr/local/bin/uv # Install system dependencies RUN apt-get update && apt-get install -y curl && rm -rf /var/lib/apt/lists/* # Set working directory WORKDIR /app # Copy all files COPY . . # Install Python dependencies RUN uv sync # Expose port EXPOSE 8080 # Run the application CMD ["uv", "run", "uvicorn", "server:app", "--host", "0.0.0.0", "--port", "8080"]- uv : gestionnaire de paquets Python moderne 10 à 100 fois plus rapide que pip. Il utilise un cache global et des téléchargements parallèles, ce qui réduit considérablement les temps de compilation des conteneurs.
- Python 3.13-slim : dernière version de Python avec un minimum de dépendances système, ce qui réduit la taille du conteneur et la surface d'attaque
- Compilation en plusieurs étapes : la copie d'uv à partir de son image officielle garantit l'obtention du dernier binaire optimisé.
9. Configurer l'environnement et déployer l'agent
Nous allons maintenant configurer l'agent ADK pour qu'il se connecte à votre backend Gemma déployé et le déployer en tant que service Cloud Run. Cela implique de configurer des variables d'environnement et de déployer l'agent avec la configuration appropriée.
- Configurez votre environnement :
cat << EOF > .env GOOGLE_CLOUD_PROJECT=$(gcloud config get-value project) GOOGLE_CLOUD_LOCATION=europe-west4 GEMMA_MODEL_NAME=gemma3:270m OLLAMA_API_BASE=$OLLAMA_URL EOF
Comprendre les variables d'environnement dans Cloud Run
Les variables d'environnement sont des paires clé/valeur qui configurent votre application au moment de l'exécution. Ils sont particulièrement utiles pour :
- Points de terminaison d'API et URL de service (comme notre backend Ollama)
- Configuration qui change d'un environnement à l'autre (développement, préproduction, production)
- Données sensibles qui ne doivent pas être codées en dur
Déployez l'agent ADK :
export PROJECT_ID=$(gcloud config get-value project)
gcloud run deploy production-adk-agent \
--source . \
--region europe-west4 \
--allow-unauthenticated \
--memory 4Gi \
--cpu 2 \
--max-instances 1 \
--concurrency 50 \
--timeout 300 \
--set-env-vars GOOGLE_CLOUD_PROJECT=$PROJECT_ID \
--set-env-vars GOOGLE_CLOUD_LOCATION=europe-west4 \
--set-env-vars GEMMA_MODEL_NAME=gemma3:270m \
--set-env-vars OLLAMA_API_BASE=$OLLAMA_URL \
--labels dev-tutorial=codelab-agent-gpu
⚙️ Configuration clé :
- Autoscaling : fixé à une instance (traitement des requêtes léger)
- Simultanéité : 50 requêtes par instance
- Mémoire : 4 Go pour l'agent ADK
- Environnement : se connecte à votre backend Gemma
🔒 Remarque sur la sécurité : Cet atelier utilise --allow-unauthenticated pour plus de simplicité. En production, implémentez une authentification appropriée à l'aide des éléments suivants :
- Authentification de service à service Cloud Run avec des comptes de service
- Stratégies Identity and Access Management (IAM)
- Clés API ou OAuth pour l'accès externe
- Envisagez d'utiliser
gcloud run services add-iam-policy-bindingpour contrôler l'accès.
Obtenez l'URL de votre service d'agent :
export AGENT_URL=$(gcloud run services describe production-adk-agent \
--region=europe-west4 \
--format='value(status.url)')
echo "🎉 ADK Agent deployed at: $AGENT_URL"
✅ Bonnes pratiques concernant les variables d'environnement, basées sur la documentation sur les variables d'environnement Cloud Run :
- Évitez les variables réservées : ne définissez pas
PORT(si vous devez modifier la variable d'environnement, utilisez plutôt l'indicateur "–port") ni les variables commençant parX_GOOGLE_. - Utilisez des noms descriptifs : préfixez vos variables pour éviter les conflits (par exemple,
GEMMA_MODEL_NAMEau lieu deMODEL). - Échapper les virgules : si vos valeurs contiennent des virgules, utilisez un autre délimiteur :
--set-env-vars "^@^KEY1=value1,value2@KEY2=..." - Mettre à jour ou remplacer : utilisez
--update-env-varspour ajouter ou modifier des variables spécifiques sans affecter les autres.
Définir des variables dans Cloud Run :
- À partir d'un fichier :
gcloud run deploy SERVICE_NAME --env-vars-file .env --labels dev-tutorial codelab-adk(charge plusieurs variables à partir d'un fichier) - Plusieurs indicateurs : répétez
--set-env-varspour les valeurs complexes qui ne peuvent pas être séparées par une virgule.
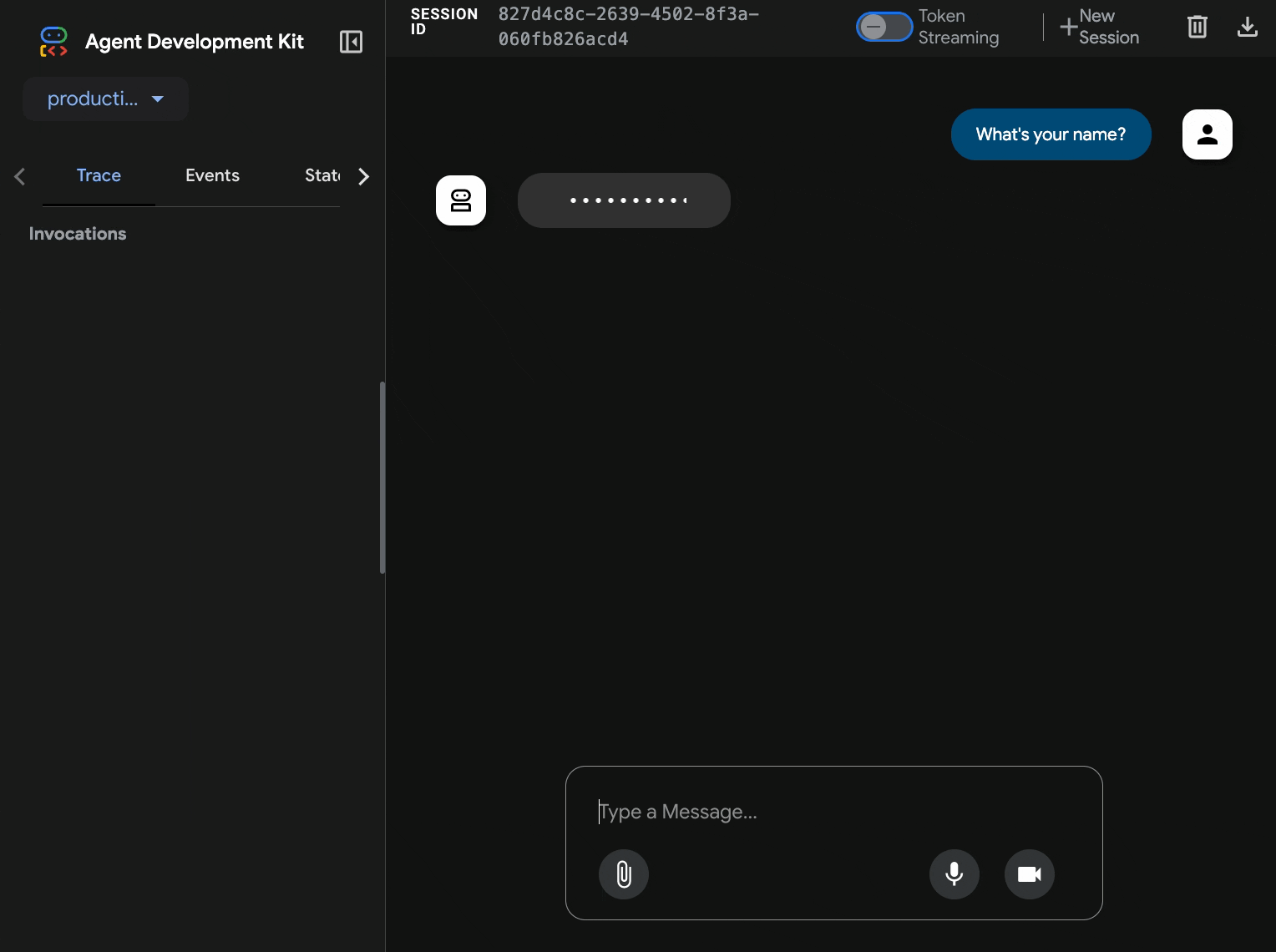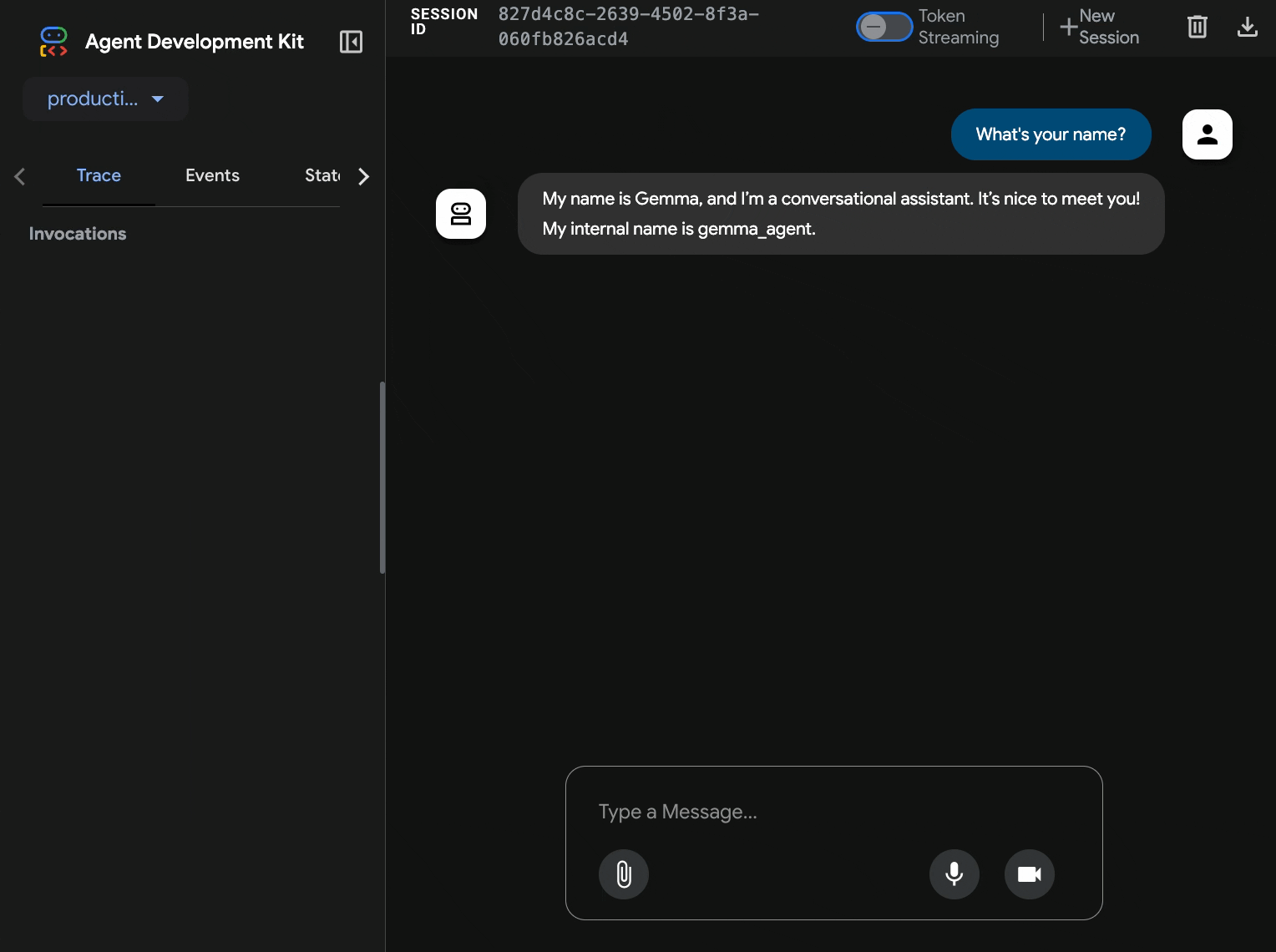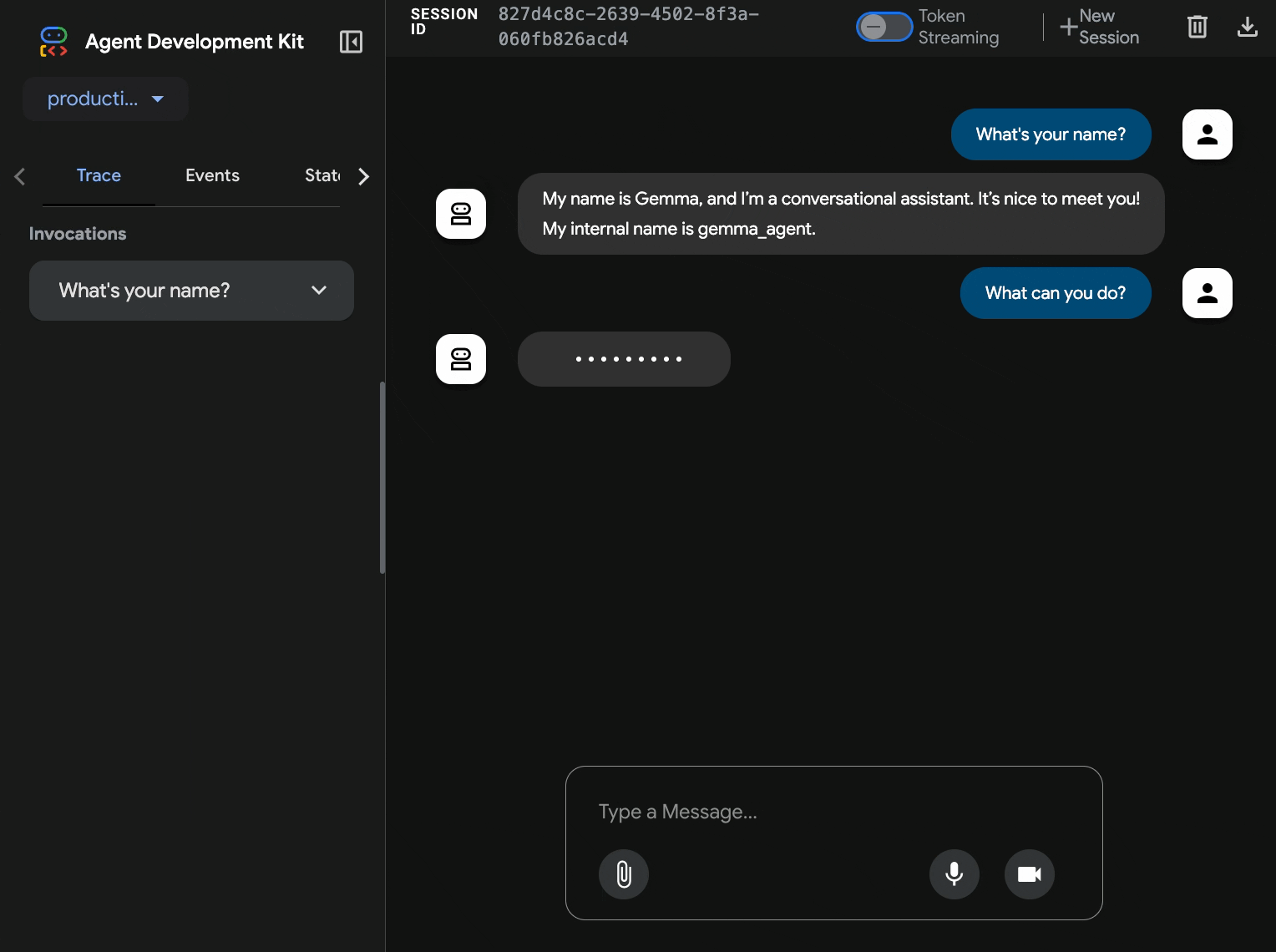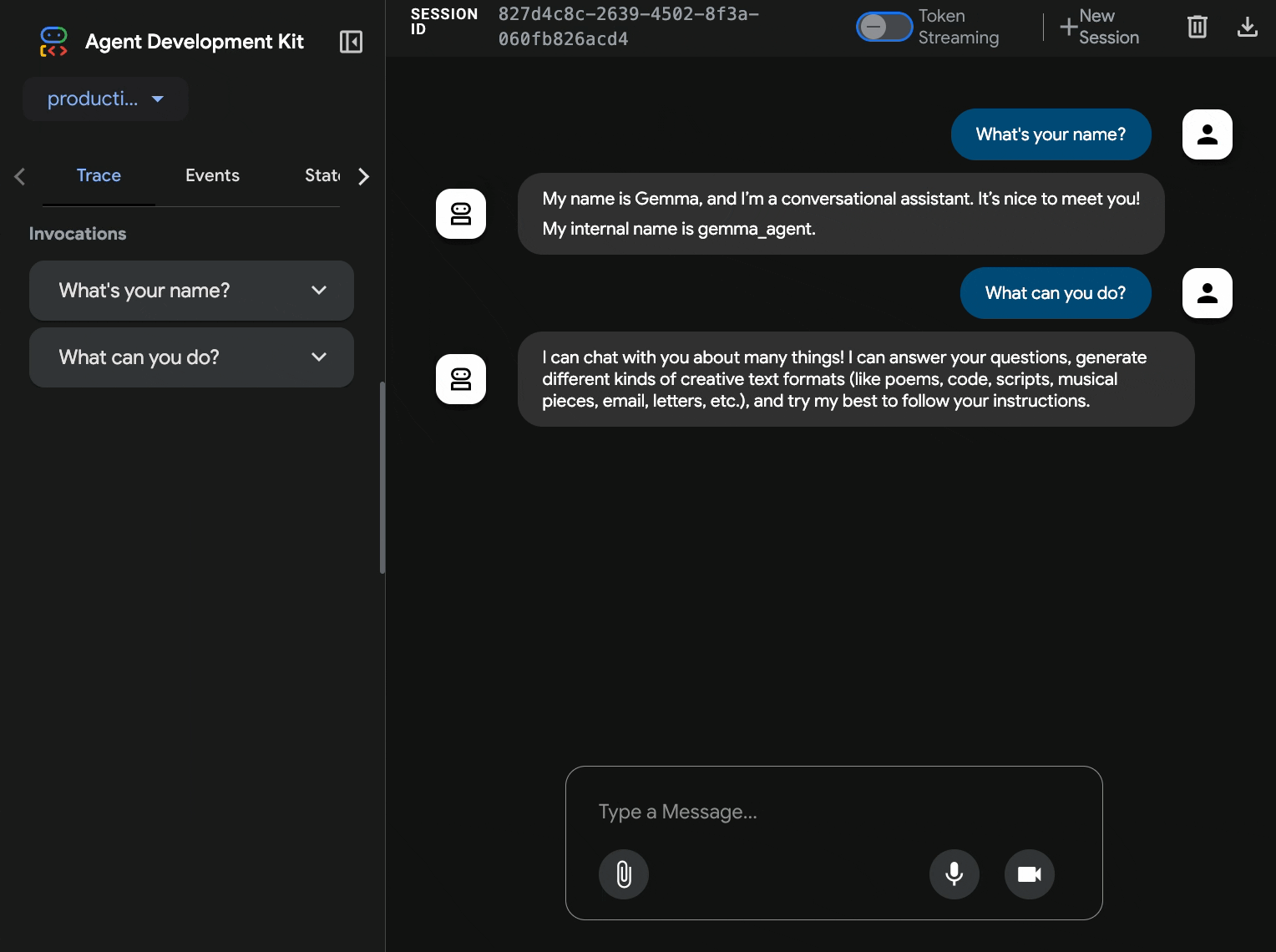
10. Tester avec l'interface Web ADK
Maintenant que les deux services sont déployés, il est temps de vérifier que votre agent ADK peut communiquer avec le backend Gemma accéléré par GPU et répondre aux requêtes des utilisateurs.
- Testez le point de terminaison d'état :
curl $AGENT_URL/health{ "status": "healthy", "service": "production-adk-agent" } - Interagissez avec votre agent en saisissant l'URL de votre
production-adk-agentdans un nouvel onglet de navigateur. L'interface Web de l'ADK devrait s'afficher. - Testez votre agent avec ces exemples de conversations :
- "Que mangent généralement les pandas roux à l'état sauvage ?"
- "Peux-tu me donner une information intéressante sur les panthères des neiges ?"
- "Pourquoi les dendrobates sont-elles si colorées ?"
- "Où puis-je trouver le nouveau bébé kangourou dans le zoo ?"
- L'agent répond à l'aide du modèle Gemma que vous avez déployé. Vous pouvez le vérifier en observant les journaux de votre service Gemma déployé. Nous le ferons dans la section suivante.
- Les réponses sont générées par le backend accéléré par GPU.
- L'interface Web offre une expérience de chat claire.
11. Implémenter et exécuter un test d'élasticité
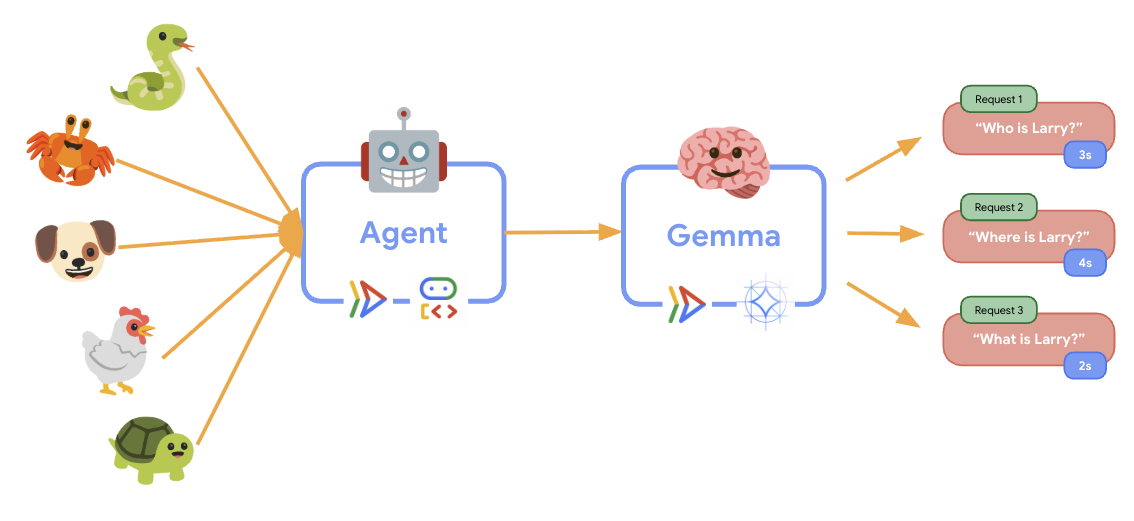
Pour comprendre comment votre déploiement en production gère le trafic réel, nous allons implémenter un test d'élasticité qui testera la capacité du système à s'adapter à une charge de travail de production "simulée" plus élevée.
- Ouvrez et implémentez le script de test d'élasticité :
cloudshell edit elasticity_test.pyimport random import uuid from locust import HttpUser, task, between class ProductionAgentUser(HttpUser): """Elasticity test user for the Production ADK Agent.""" wait_time = between(1, 3) # Faster requests to trigger scaling def on_start(self): """Set up user session when starting.""" self.user_id = f"user_{uuid.uuid4()}" self.session_id = f"session_{uuid.uuid4()}" # Create session for the Gemma agent using proper ADK API format session_data = {"state": {"user_type": "elasticity_test_user"}} self.client.post( f"/apps/production_agent/users/{self.user_id}/sessions/{self.session_id}", headers={"Content-Type": "application/json"}, json=session_data, ) @task(4) def test_conversations(self): """Test conversational capabilities - high frequency.""" topics = [ "What do red pandas typically eat in the wild?", "Can you tell me an interesting fact about snow leopards?", "Why are poison dart frogs so brightly colored?", "Where can I find the new baby kangaroo in the zoo?", "What is the name of your oldest gorilla?", "What time is the penguin feeding today?" ] # Use proper ADK API format for sending messages message_data = { "app_name": "production_agent", "user_id": self.user_id, "session_id": self.session_id, "new_message": { "role": "user", "parts": [{ "text": random.choice(topics) }] } } self.client.post( "/run", headers={"Content-Type": "application/json"}, json=message_data, ) @task(1) def health_check(self): """Test the health endpoint.""" self.client.get("/health")- Création de session : utilise le format d'API ADK approprié avec POST sur
/apps/production_agent/users/{user_id}/sessions/{session_id}. Une fois que vous avez créé unsession_idet unuser_id, vous pouvez envoyer une requête à l'agent. - Format du message : suit les spécifications ADK avec
app_name,user_id,session_idet l'objet structurénew_message. - Point de terminaison de conversation : utilise le point de terminaison
/runpour collecter tous les événements à la fois (recommandé pour les tests de charge) - Charge réaliste : crée une charge conversationnelle avec des temps d'attente plus courts.
- Création de session : utilise le format d'API ADK approprié avec POST sur
- Installez les dépendances :
uv sync - Locust est un outil de test de charge Open Source basé sur Python, conçu pour tester les performances et la charge des applications Web et d'autres systèmes. Sa principale caractéristique est que les scénarios de test et le comportement des utilisateurs sont définis à l'aide de code Python standard, ce qui offre une grande flexibilité et expressivité par rapport aux outils qui s'appuient sur des interfaces utilisateur graphiques ou des langages spécifiques à un domaine. Nous allons utiliser Locust pour simuler le trafic utilisateur vers nos services.Exécutez le test.
uv run locust -f elasticity_test.py \ -H $AGENT_URL \ --headless \ -t 60s \ -u 20 \ -r 5- Durée : 60 secondes
- Utilisateurs : 20 utilisateurs simultanés
- Taux de génération : 5 utilisateurs par seconde
- Cible : déclencher l'autoscaling sur les deux services
12. Observer le comportement de l'autoscaling
Lors de l'exécution du test d'élasticité, vous pourrez observer la prise en charge des charges de travail plus élevées par Cloud Run en action. C'est là que vous verrez les principaux avantages architecturaux de la séparation de l'agent ADK du backend GPU.
Pendant le test d'élasticité, surveillez la façon dont les deux services Cloud Run gèrent le trafic dans la console.
- Dans la console Cloud, accédez à :
- Cloud Run → production-adk-agent → Métriques
- Cloud Run → ollama-gemma3-270m-gpu → Métriques
👀 Ce que vous devez observer :
🤖 Service de l'agent ADK :
- Doit rester stable à une instance lorsque le trafic augmente
- Pic d'utilisation du processeur et de la mémoire en cas de trafic élevé
- Gère efficacement la gestion des sessions et le routage des requêtes
🎮 Service de backend Gemma (goulot d'étranglement) :
- Doit rester stable à une instance lorsque le trafic augmente
- L'utilisation du GPU augmente considérablement sous charge
- Ce service devient le goulot d'étranglement en raison de l'inférence de modèle nécessitant une utilisation intensive du GPU.
- Les temps d'inférence des modèles restent constants grâce à l'accélération par GPU.
💡 Insights clés :
- Les deux services restent cohérents et ne sont pas mis à l'échelle, car nous avons défini le nombre maximal d'instances sur
1. - Les deux services évoluent de manière indépendante en fonction de leurs caractéristiques de charge individuelles.
- Le GPU permet de maintenir les performances dans des conditions de charge variables.
13. Conclusion
Félicitations ! Vous avez déployé avec succès un agent ADK prêt pour la production avec un backend Gemma accéléré par GPU, tout en testant une charge de travail de production simulée.
✅ Ce que vous avez accompli
- ✅ Vous avez déployé un backend de modèle Gemma accéléré par GPU sur Cloud Run.
- ✅ Vous avez créé et déployé un agent ADK qui s'intègre au backend Gemma.
- ✅ Testé l'agent à l'aide de l'interface Web ADK
- ✅ Comportement d'autoscaling observé sur deux services Cloud Run coordonnés
💡 Points clés de cet atelier
- 🎮 Accélération GPU : le GPU NVIDIA L4 améliore considérablement les performances d'inférence du modèle.
- 🔗 Coordination des services : deux services Cloud Run peuvent fonctionner ensemble de manière fluide.
- 📈 Scaling indépendant : chaque service évolue en fonction de ses propres caractéristiques de charge.
- 🚀 Prêt pour la production : l'architecture gère efficacement les modèles de trafic réels.
🔄 Étapes suivantes
- Tester différents modèles de charge et observer le comportement de scaling
- Essayez différentes tailles de modèle Gemma (ajustez la mémoire et le GPU en conséquence).
- Implémenter la surveillance et les alertes pour les déploiements en production
- Explorer les déploiements multirégionaux pour une disponibilité mondiale
🧹 Nettoyer
Pour éviter que des frais ne vous soient facturés, supprimez les ressources une fois que vous avez terminé :
gcloud run services delete production-adk-agent --region=europe-west4
gcloud run services delete ollama-gemma3-270m-gpu --region=europe-west4
📖 Ressources
- Dépôt de démarrage
- Solution complète
- Documentation Google ADK
- Guide de test ADK : référence complète pour les points de terminaison de l'API ADK et les modèles de test
- Tests de charge sur Cloud Run
- Documentation Agent Development Kit (ADK)
- Documentation sur les GPU Cloud Run
- Bibliothèque de modèles Ollama
- Documentation Google Cloud Trace
- Bonnes pratiques de sécurité pour Cloud Run
- Gestionnaire de packages Python UV
- Framework de test de charge Locust