
1. מבוא
סקירה כללית
בשיעור ה-Lab הזה תפרסו סוכן של ערכה לפיתוח סוכנים (ADK) שמוכן לייצור עם Gemma backend מבוסס-GPU. הדגש הוא על דפוסי פריסה קריטיים: הגדרת שירותי Cloud Run עם תמיכה ב-GPU, שילוב של עורפי מודלים עם סוכני ADK ומעקב אחרי התנהגות של התאמה אוטומטית לעומס (autoscaling) בתנאי עומס.
הפעולות שתבצעו:
בשיעור ה-Lab הזה נתמקד בהיבטים הקריטיים של פריסת סביבת ייצור:
- פריסת Gemma ב-Cloud Run עם GPU – הגדרת קצה עורפי של מודל Gemma עם ביצועים גבוהים
- שילוב הפריסה של Gemma עם סוכן ADK – חיבור הסוכן למודל עם האצת GPU
- בדיקה באמצעות ממשק האינטרנט של ADK – אימות של הסוכן לשיחות
- ביצוע בדיקות גמישות – בדיקה של אופן הטיפול בעומס בשתי מכונות Cloud Run
הדגש הוא על דפוסי פריסה בסביבת ייצור ולא על פיתוח נרחב של נציגים.
מה תלמדו
- פריסת מודלים של Gemma עם האצת GPU ב-Cloud Run לשימוש בסביבת ייצור
- שילוב פריסות של מודלים חיצוניים עם סוכני ADK
- הגדרה ובדיקה של פריסות של סוכני AI שמוכנים לייצור
- הסבר על ההתנהגות של Cloud Run בעומס
- תצפית על תיאום בין כמה מופעים של Cloud Run במהלך עליות חדות בתעבורה
- איך משתמשים בבדיקת גמישות כדי לאמת את הביצועים
2. הגדרת הפרויקט
- אם עדיין אין לכם חשבון Google, אתם צריכים ליצור חשבון Google.
- משתמשים בחשבון לשימוש אישי במקום בחשבון לצורכי עבודה או בחשבון בית ספרי. יכול להיות שבחשבונות לצורכי עבודה או בחשבונות בית ספריים יש הגבלות שימנעו מכם להפעיל את ממשקי ה-API שנדרשים למעבדה הזו.
- נכנסים למסוף Google Cloud.
- מפעילים את החיוב במסוף Cloud.
- העלות של השלמת ה-Lab הזה במשאבי Cloud צריכה להיות פחות מ-1$.
- כדי למחוק משאבים ולמנוע חיובים נוספים, אפשר לבצע את השלבים בסוף ה-Lab הזה.
- משתמשים חדשים זכאים לתקופת ניסיון בחינם בשווי 300$.
- יוצרים פרויקט חדש או בוחרים להשתמש מחדש בפרויקט קיים.
- אם מופיעה שגיאה לגבי מכסת הפרויקט, צריך לעשות שימוש חוזר בפרויקט קיים או למחוק פרויקט קיים כדי ליצור פרויקט חדש.
3. פתיחת Cloud Shell Editor
- כדי לעבור ישירות אל Cloud Shell Editor, לוחצים על הקישור הזה.
- אם תתבקשו לאשר בשלב כלשהו היום, תצטרכו ללחוץ על אישור כדי להמשיך.
- אם הטרמינל לא מופיע בתחתית המסך, פותחים אותו:
- לוחצים על הצגה.
- לוחצים על Terminal (מסוף)
 .
.
- בטרמינל, מגדירים את הפרויקט באמצעות הפקודה הבאה:
- פורמט:
gcloud config set project [PROJECT_ID] - דוגמה:
gcloud config set project lab-project-id-example - אם אתם לא זוכרים את מזהה הפרויקט:
- כדי לראות את כל מזהי הפרויקטים, מריצים את הפקודה:
gcloud projects list | awk '/PROJECT_ID/{print $2}'
- כדי לראות את כל מזהי הפרויקטים, מריצים את הפקודה:
- פורמט:
- תוצג ההודעה הבאה:
Updated property [core/project].
WARNINGומוצגת השאלהDo you want to continue (Y/n)?, כנראה שהזנתם את מזהה הפרויקט בצורה שגויה. לוחצים עלn, לוחצים עלEnterומנסים להריץ שוב את הפקודהgcloud config set project.
4. הפעלת ממשקי API והגדרת אזור ברירת מחדל
כדי שנוכל לפרוס שירותי Cloud Run עם תמיכה ב-GPU, אנחנו צריכים להפעיל את ממשקי Google Cloud API הנדרשים ולהגדיר את הגדרות הפרויקט.
- בטרמינל, מפעילים את ממשקי ה-API:
gcloud services enable \
run.googleapis.com \
artifactregistry.googleapis.com \
cloudbuild.googleapis.com \
aiplatform.googleapis.com
אם מתבקשים לאשר, לוחצים על אישור כדי להמשיך.
הפקודה הזו עשויה להימשך כמה דקות, אבל בסופו של דבר היא אמורה להציג הודעה על הצלחה שדומה להודעה הזו:
Operation "operations/acf.p2-73d90d00-47ee-447a-b600" finished successfully.
- מגדירים את אזור ברירת המחדל של Cloud Run.
gcloud config set run/region europe-west4
5. הכנת פרויקט Python
נתחיל בהגדרת קוד לתחילת הדרך שמכיל את המבנה הבסיסי של שירותי ה-backend של Gemma ושל סוכן ה-ADK.
- משכפלים את מאגר המתחילים:
cd ~ npx -y giget@latest gh+git:GoogleCloudPlatform/devrel-demos/agents/accelerate-ai-with-cloud-run/accelerate-ai-lab3-starter accelerate-ai-lab3-starter cd accelerate-ai-lab3-starter - בדיקת מבנה הפרויקט:
ls -Raccelerate-ai-lab3-starter/ ├── README.md # Project overview ├── ollama-backend/ # Ollama backend (separate deployment) │ └── Dockerfile # Backend container (🚧 to implement) └── adk-agent/ # ADK agent (separate deployment) ├── pyproject.toml # Python dependencies (✅ completed) ├── server.py # FastAPI server (🚧 to implement) ├── Dockerfile # Container config (🚧 to implement) ├── elasticity_test.py # Elasticity testing (🚧 to implement) └── production_agent/ # Agent implementation ├── __init__.py # Package init (✅ completed) └── agent.py # Agent logic (🚧 to implement)
6. סקירה כללית של הארכיטקטורה
לפני שמיישמים, כדאי להבין את הארכיטקטורה של שני השירותים:
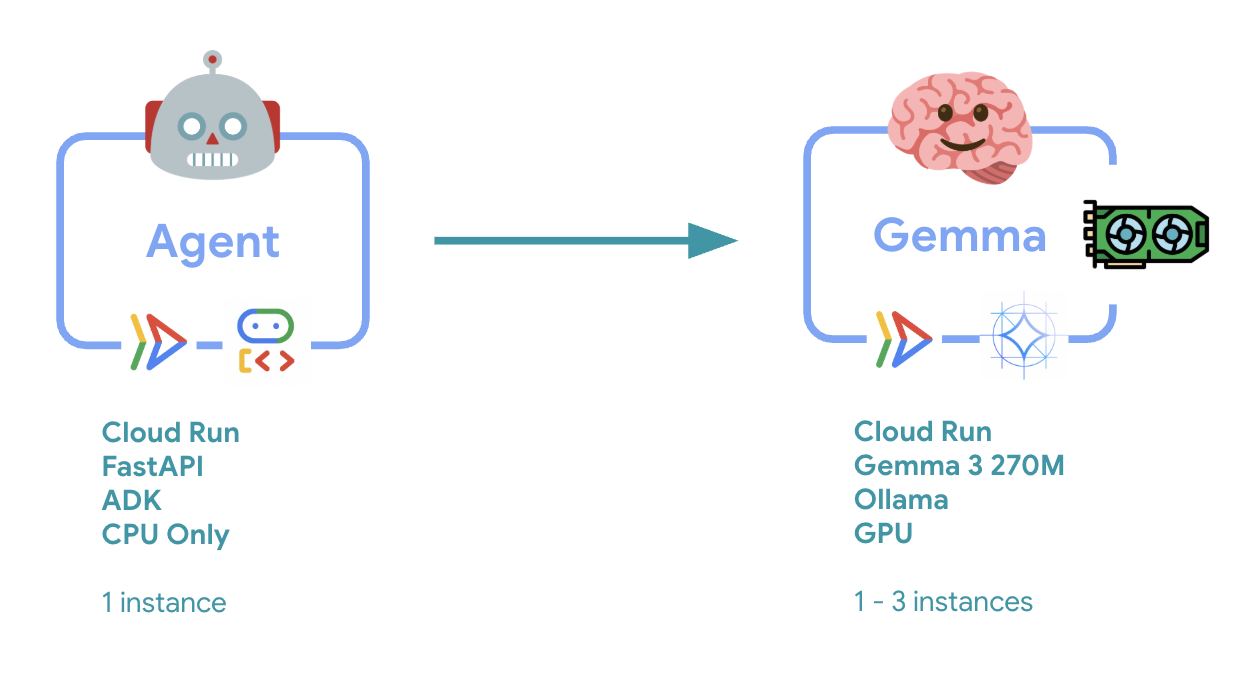
תובנה מרכזית: במהלך בדיקת הגמישות, תראו ששני השירותים מטפלים בעומס העבודה באופן עצמאי – קצה העורף של ה-GPU (שירות צוואר הבקבוק) משתמש ב-GPU שלו כדי לטפל בעומס, בעוד שאמצעי ה-ADK מסתמך על ה-CPU שלו כדי לטפל בבקשות שלא דורשות הרבה משאבים.
7. פריסת Gemma Backend ב-Cloud Run עם GPU
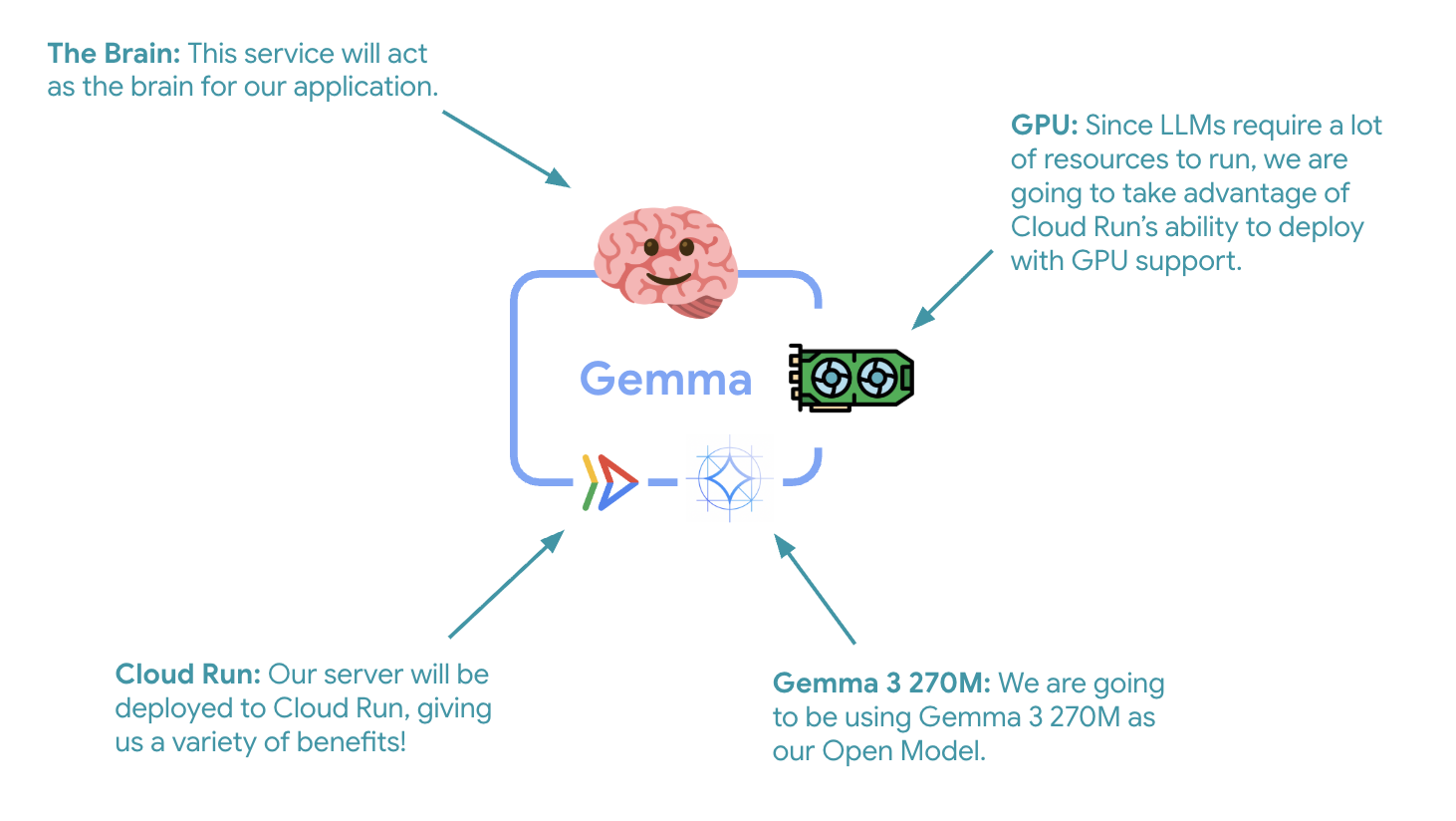
השלב הראשון והחשוב הוא פריסת מודל Gemma עם האצת GPU, שישמש כמוח של סוכן ה-ADK. יכול להיות שיהיה עדיף להשתמש ב-LLM מנותק ופרוס בארכיטקטורות שבהן נדרש מודל נפרד שעבר כוונון עדין, או שנדרש שינוי קנה מידה מבודד.
- עוברים לספריית ה-backend של Ollama:
cd ollama-backend - פותחים ומיישמים את Ollama Dockerfile:
cloudshell edit DockerfileFROM ollama/ollama:latest # Listen on all interfaces, port 8080 ENV OLLAMA_HOST 0.0.0.0:8080 # Store model weight files in /models ENV OLLAMA_MODELS /models # Reduce logging verbosity ENV OLLAMA_DEBUG false # Never unload model weights from the GPU ENV OLLAMA_KEEP_ALIVE -1 # Store the model weights in the container image ENV MODEL gemma3:270m RUN ollama serve & sleep 5 && ollama pull $MODEL # Start Ollama ENTRYPOINT ["ollama", "serve"]- הוא מבוסס על תמונת Ollama הרשמית
- הגדרה של
OLLAMA_HOSTלקבלת חיבורים מכל כתובת IP - חשיפת יציאה 8080
- פורסים את ה-backend של Gemma עם תמיכה ב-GPU:
gcloud run deploy ollama-gemma3-270m-gpu \
--source . \
--region europe-west4 \
--concurrency 7 \
--cpu 8 \
--set-env-vars OLLAMA_NUM_PARALLEL=4 \
--gpu 1 \
--gpu-type nvidia-l4 \
--max-instances 1 \
--memory 16Gi \
--allow-unauthenticated \
--no-cpu-throttling \
--no-gpu-zonal-redundancy \
--timeout 600 \
--labels dev-tutorial=codelab-agent-gpu
אם מופיעה ההודעה 'פריסה ממקור דורשת מאגר Docker ב-Artifact Registry לאחסון קונטיינרים שנבנו. הודעה 'ייווצר מאגר בשם [cloud-run-source-deploy] באזור [europe-west4]', ממשיכים.
⚙️ הסבר על הגדרות מרכזיות:
- GPU: נבחר NVIDIA L4 בגלל יחס המחיר-ביצועים המצוין שלו לעומסי עבודה של הסקת מסקנות. ה-L4 מספק זיכרון GPU של 24GB ופעולות טנסור מותאמות, ולכן הוא אידיאלי למודלים עם 270 מיליון פרמטרים כמו Gemma
- זיכרון: זיכרון מערכת בנפח 16GB לטיפול בטעינת המודל, בפעולות CUDA ובניהול הזיכרון של Ollama
- מעבד (CPU): 8 ליבות לטיפול אופטימלי בקלט/פלט ובמשימות עיבוד מקדים
- בו-זמניות (concurrency): 7 בקשות לכל מכונה מאזנות את התפוקה עם השימוש בזיכרון ה-GPU
- Timeout: 600 שניות כדי לאפשר טעינה ראשונית של המודל והפעלה של הקונטיינר
💰 שיקולי עלות: מכונות עם GPU יקרות משמעותית ממכונות עם CPU בלבד (כ-2-4$לשעה לעומת כ-0.10$לשעה). ההגדרה --max-instances 1 עוזרת לשלוט בעלויות על ידי מניעת שינוי גודל מיותר של מופעי GPU.
- ממתינים לסיום הפריסה ורושמים את כתובת ה-URL של השירות:
export OLLAMA_URL=$(gcloud run services describe ollama-gemma3-270m-gpu \ --region=europe-west4 \ --format='value(status.url)') echo "🎉 Gemma backend deployed at: $OLLAMA_URL"
8. הטמעה של שילוב סוכן ADK
עכשיו ניצור סוכן ADK מינימלי שמתחבר לחלק האחורי של Gemma שהופעל.
- מנווטים לספריית הסוכן ADK:
cd ../adk-agent - פותחים את הגדרות הסוכן ומטמיעים אותן:
cloudshell edit production_agent/agent.pyimport os from pathlib import Path from dotenv import load_dotenv from google.adk.agents import Agent from google.adk.models.lite_llm import LiteLlm import google.auth # Load environment variables root_dir = Path(__file__).parent.parent dotenv_path = root_dir / ".env" load_dotenv(dotenv_path=dotenv_path) # Configure Google Cloud try: _, project_id = google.auth.default() os.environ.setdefault("GOOGLE_CLOUD_PROJECT", project_id) except Exception: pass os.environ.setdefault("GOOGLE_CLOUD_LOCATION", "europe-west4") # Configure model connection gemma_model_name = os.getenv("GEMMA_MODEL_NAME", "gemma3:270m") api_base = os.getenv("OLLAMA_API_BASE", "localhost:10010") # Location of Ollama server # Production Gemma Agent - GPU-accelerated conversational assistant production_agent = Agent( model=LiteLlm(model=f"ollama_chat/{gemma_model_name}", api_base=api_base), name="production_agent", description="A production-ready conversational assistant powered by GPU-accelerated Gemma.", instruction="""You are 'Gem', a friendly, knowledgeable, and enthusiastic zoo tour guide. Your main goal is to make a zoo visit more fun and educational for guests by answering their questions. You can provide general information and interesting facts about different animal species, such as: - Their natural habitats and diet. 🌲🍓 - Typical lifespan and behaviors. - Conservation status and unique characteristics. IMPORTANT: You do NOT have access to any tools. This means you cannot look up real-time, specific information about THIS zoo. You cannot provide: - The names or ages of specific animals currently at the zoo. - The exact location or enclosure for an animal. - The daily schedule for feedings or shows. Always answer based on your general knowledge about the animal kingdom. Keep your tone cheerful, engaging, and welcoming for visitors of all ages. 🦁✨""", tools=[], # Gemma focuses on conversational capabilities ) # Set as root agent root_agent = production_agent- מתחבר ל-Gemma backend שהופעל באמצעות LiteLlm
- תבנית ליצירת צ'אט בוט פשוט
- הגדרה של שילוב עם Google Cloud
- פותחים את שרת FastAPI ומטמיעים אותו:
cloudshell edit server.pyimport os from dotenv import load_dotenv from fastapi import FastAPI from google.adk.cli.fast_api import get_fast_api_app # Load environment variables load_dotenv() AGENT_DIR = os.path.dirname(os.path.abspath(__file__)) app_args = {"agents_dir": AGENT_DIR, "web": True} # Create FastAPI app with ADK integration app: FastAPI = get_fast_api_app(**app_args) # Update app metadata app.title = "Production ADK Agent - Lab 3" app.description = "Gemma agent with GPU-accelerated backend" app.version = "1.0.0" @app.get("/health") def health_check(): return {"status": "healthy", "service": "production-adk-agent"} @app.get("/") def root(): return { "service": "Production ADK Agent - Lab 3", "description": "GPU-accelerated Gemma agent", "docs": "/docs", "health": "/health" } if __name__ == "__main__": import uvicorn uvicorn.run(app, host="0.0.0.0", port=8080, log_level="info")- יצירת שרת FastAPI עם שילוב ADK
- הפעלת ממשק האינטרנט לבדיקה
- מספק נקודות קצה לבדיקות תקינות
- פותחים את קובץ ה-Dockerfile ומטמיעים אותו:
cloudshell edit DockerfileFROM python:3.13-slim # Copy uv from the official image COPY --from=ghcr.io/astral-sh/uv:latest /uv /usr/local/bin/uv # Install system dependencies RUN apt-get update && apt-get install -y curl && rm -rf /var/lib/apt/lists/* # Set working directory WORKDIR /app # Copy all files COPY . . # Install Python dependencies RUN uv sync # Expose port EXPOSE 8080 # Run the application CMD ["uv", "run", "uvicorn", "server:app", "--host", "0.0.0.0", "--port", "8080"]- uv: מערכת מודרנית לניהול חבילות Python, שמהירה פי 10 עד פי 100 מ-pip. הוא משתמש במטמון גלובלי ובהורדות מקבילות, וכך מקצר משמעותית את הזמן שלוקח ליצור קונטיינרים
- Python 3.13-slim: הגרסה העדכנית ביותר של Python עם תלות מינימלית במערכת, שמקטינה את גודל הקונטיינר ואת שטח הפנים להתקפה
- Multi-stage build: Copying uv from its official image ensures we get the latest optimized binary
9. הגדרת הסביבה ופריסת הסוכן
עכשיו נגדיר את סוכן ה-ADK להתחבר לקצה העורפי של Gemma שפרסתם, ונפרוס אותו כשירות Cloud Run. התהליך כולל הגדרת משתני סביבה ופריסת הסוכן עם ההגדרה הנכונה.
- מגדירים את תצורת הסביבה:
cat << EOF > .env GOOGLE_CLOUD_PROJECT=$(gcloud config get-value project) GOOGLE_CLOUD_LOCATION=europe-west4 GEMMA_MODEL_NAME=gemma3:270m OLLAMA_API_BASE=$OLLAMA_URL EOF
הסבר על משתני סביבה ב-Cloud Run
משתני סביבה הם צמדי מפתח/ערך שמגדירים את האפליקציה בזמן הריצה. הם שימושיים במיוחד במקרים הבאים:
- נקודות קצה של API וכתובות URL של שירותים (כמו ה-Ollama backend שלנו)
- הגדרות שמשתנות בין סביבות (פיתוח, הכנה לייצור, ייצור)
- מידע אישי רגיש שאסור לכתוב בתוך הקוד
פורסים את סוכן ADK:
export PROJECT_ID=$(gcloud config get-value project)
gcloud run deploy production-adk-agent \
--source . \
--region europe-west4 \
--allow-unauthenticated \
--memory 4Gi \
--cpu 2 \
--max-instances 1 \
--concurrency 50 \
--timeout 300 \
--set-env-vars GOOGLE_CLOUD_PROJECT=$PROJECT_ID \
--set-env-vars GOOGLE_CLOUD_LOCATION=europe-west4 \
--set-env-vars GEMMA_MODEL_NAME=gemma3:270m \
--set-env-vars OLLAMA_API_BASE=$OLLAMA_URL \
--labels dev-tutorial=codelab-agent-gpu
⚙️ הגדרות מרכזיות:
- התאמה אוטומטית לעומס: קבוע על מופע אחד (טיפול קל בבקשות)
- בו-זמניות (concurrency): 50 בקשות לכל מופע
- זיכרון: 4GB לסוכן ADK
- סביבה: מתחבר לחלק האחורי של Gemma
🔒 הערה בנושא אבטחה: כדי לפשט את התרגיל הזה, נעשה שימוש ב---allow-unauthenticated. בסביבת ייצור, צריך להטמיע אימות מתאים באמצעות:
- אימות משירות לשירות ב-Cloud Run באמצעות חשבונות שירות
- כללי מדיניות של ניהול זהויות והרשאות גישה (IAM)
- מפתחות API או OAuth לגישה חיצונית
- כדאי להשתמש ב-
gcloud run services add-iam-policy-bindingכדי לשלוט בגישה
כדי לקבל את כתובת ה-URL של שירות הנציגים:
export AGENT_URL=$(gcloud run services describe production-adk-agent \
--region=europe-west4 \
--format='value(status.url)')
echo "🎉 ADK Agent deployed at: $AGENT_URL"
✅ שיטות מומלצות לשימוש במשתני סביבה על סמך התיעוד של משתני הסביבה ב-Cloud Run:
- לא להשתמש במשתנים שמורים: אל תגדירו את
PORT(אם אתם צריכים לשנות את משתנה הסביבה, השתמשו במקום זאת בדגל –port) או במשתנים שמתחילים ב-X_GOOGLE_ - שימוש בשמות תיאוריים: כדי למנוע התנגשויות, כדאי להוסיף קידומת למשתנים (למשל,
GEMMA_MODEL_NAMEבמקוםMODEL) - הוספת תו בריחה לפסיקים: אם הערכים מכילים פסיקים, צריך להשתמש בתו מפריד אחר:
--set-env-vars "^@^KEY1=value1,value2@KEY2=..." - עדכון לעומת החלפה: משתמשים ב-
--update-env-varsכדי להוסיף או לשנות משתנים ספציפיים בלי להשפיע על משתנים אחרים
איך מגדירים משתנים ב-Cloud Run
- מקובץ:
gcloud run deploy SERVICE_NAME --env-vars-file .env --labels dev-tutorial codelab-adk(טעינת כמה משתנים מקובץ) - כמה דגלים: חוזרים על
--set-env-varsעבור ערכים מורכבים שלא ניתן להפריד ביניהם באמצעות פסיקים
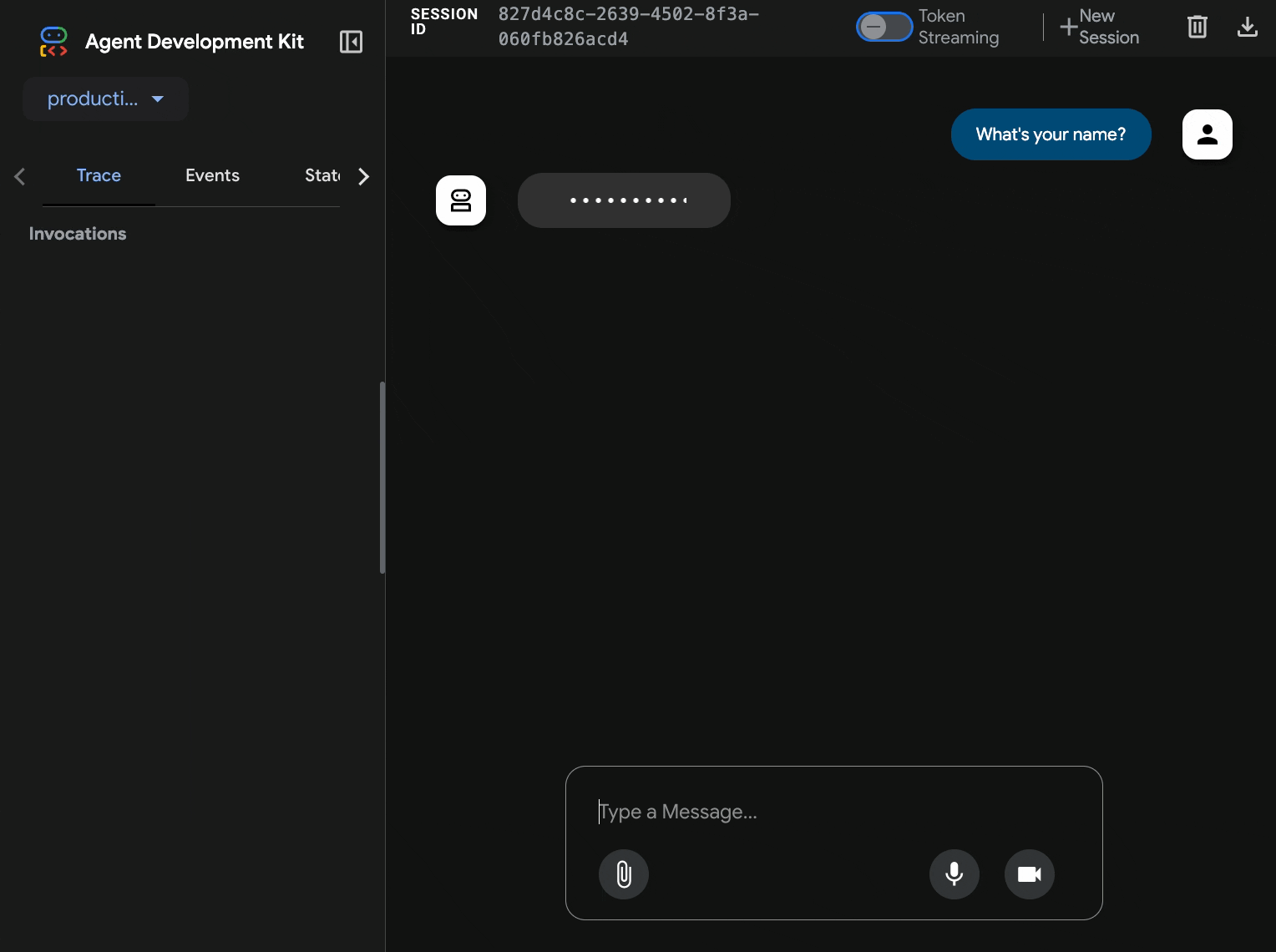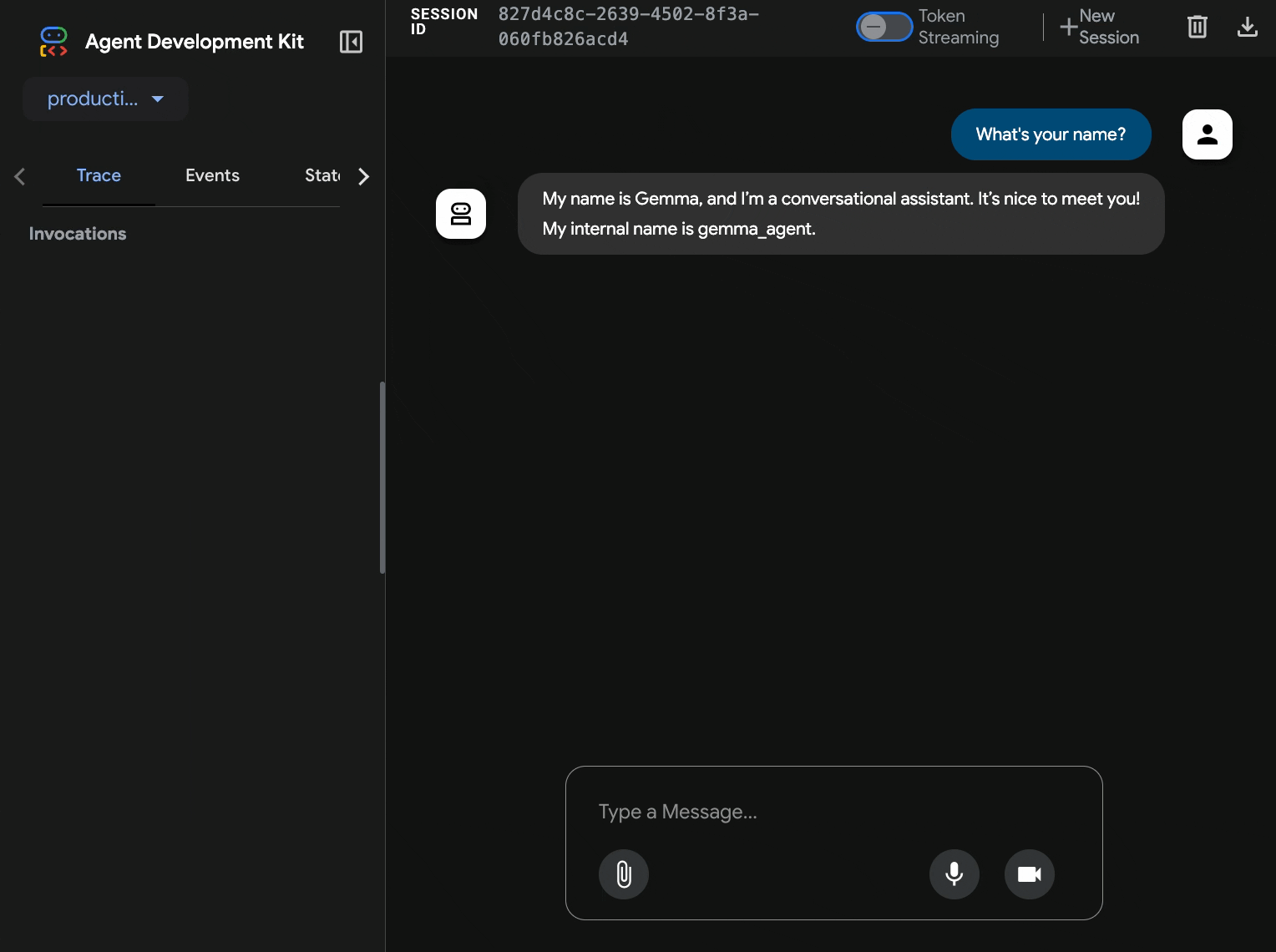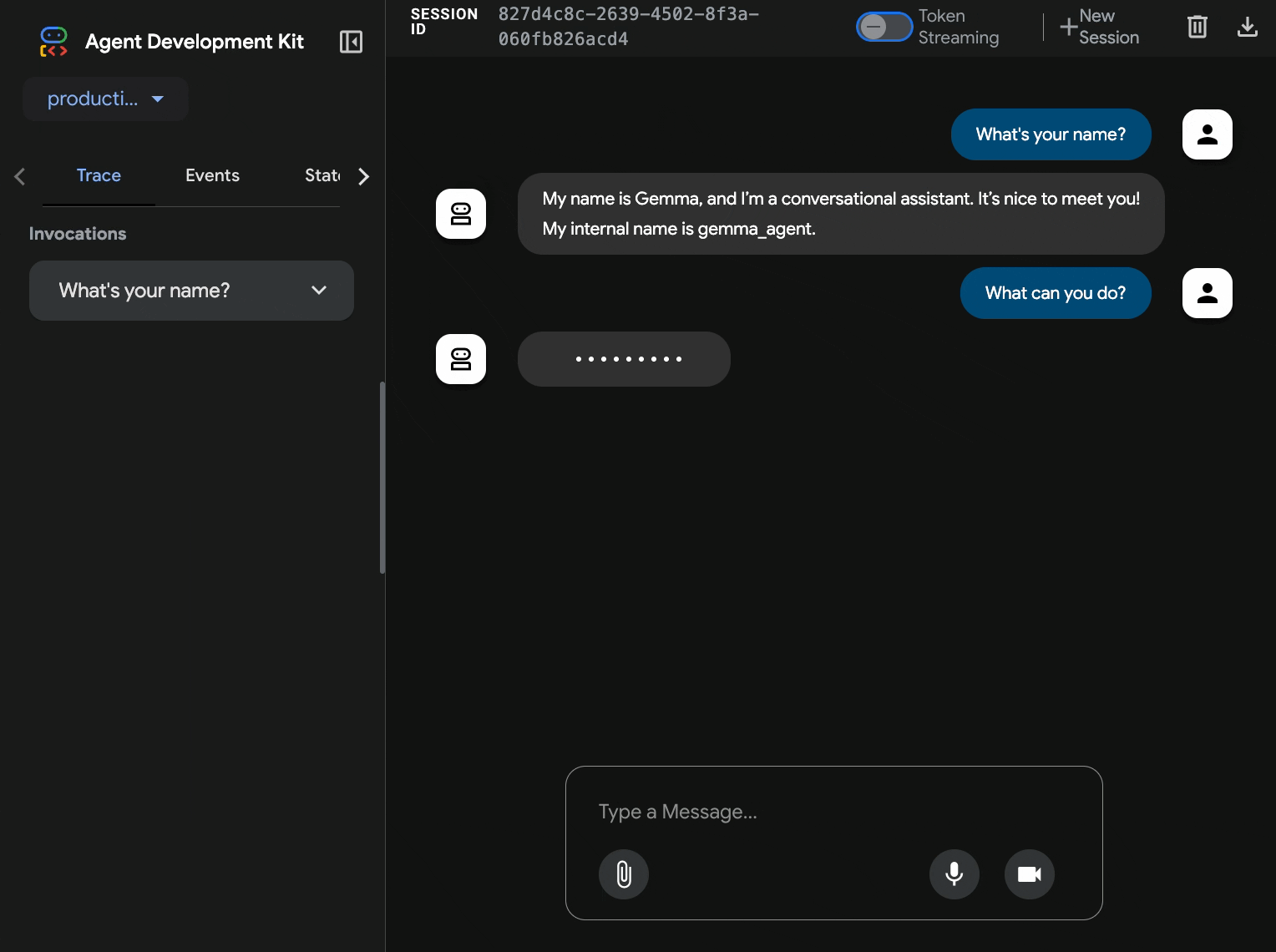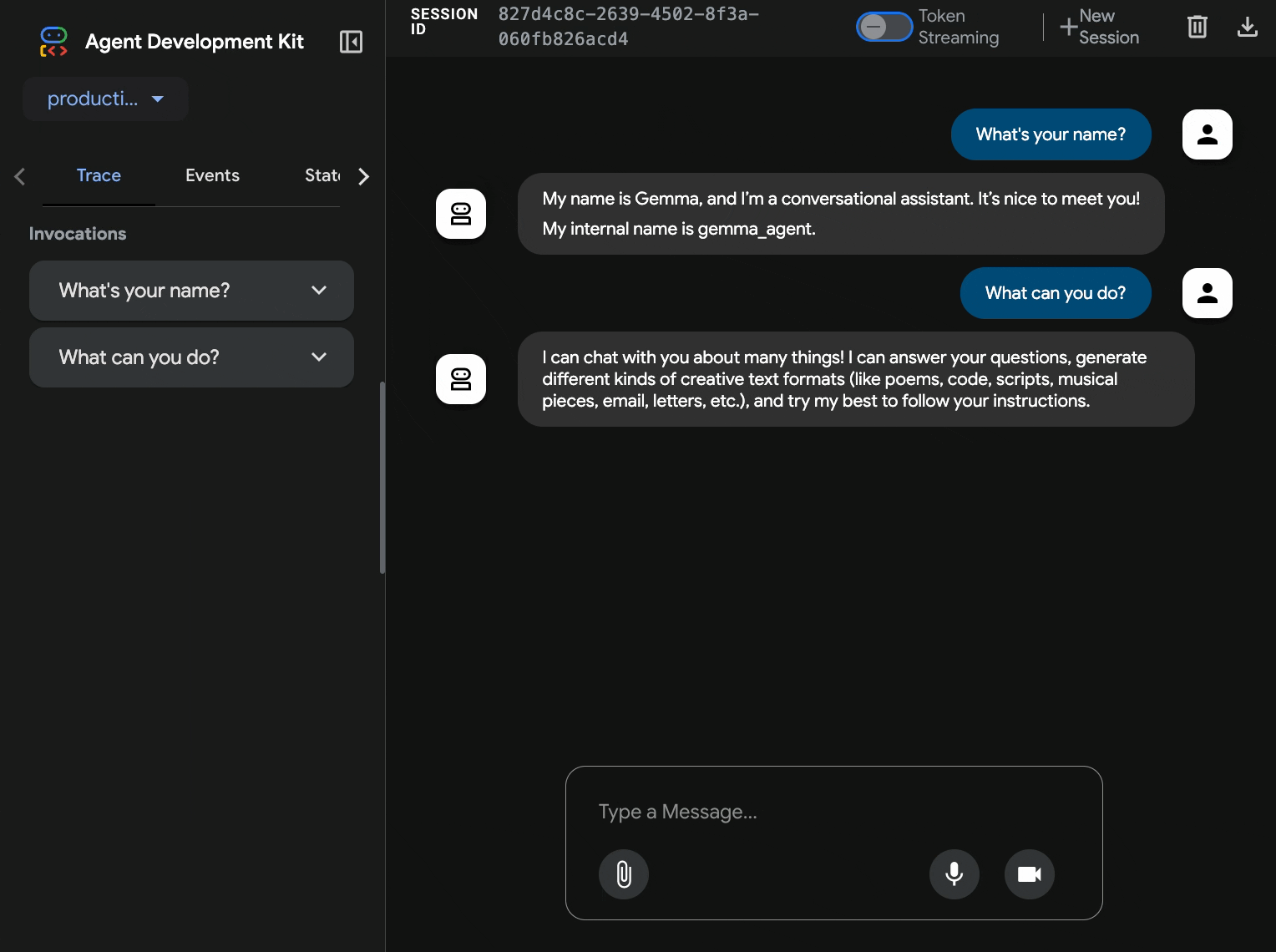
10. בדיקה באמצעות ממשק האינטרנט של ADK
אחרי שפורסים את שני השירותים, צריך לוודא שאפשר לתקשר עם הקצה העורפי של Gemma עם האצת GPU ולהגיב לשאילתות של משתמשים.
- בודקים את נקודת הסיום של בדיקת התקינות:
curl $AGENT_URL/health{ "status": "healthy", "service": "production-adk-agent" } - כדי ליצור אינטראקציה עם הסוכן, מזינים את כתובת ה-URL של
production-adk-agentבכרטיסייה חדשה בדפדפן. אמור להופיע ממשק האינטרנט של ADK. - כדאי לבדוק את הנציג באמצעות שיחות לדוגמה:
- "What do red pandas typically eat in the wild?"
- "Can you tell me an interesting fact about snow leopards?"
- "למה צפרדעים רעילות כל כך צבעוניות?"
- "איפה אפשר למצוא את גור הקנגורו החדש בגן החיות?"
- הנציג מגיב באמצעות מודל Gemma שפרסתם. כדי לוודא זאת, אפשר לעיין ביומנים של שירות Gemma שפרסתם. נעשה את זה בקטע הבא
- התשובות נוצרות על ידי קצה העורפי (backend) מבוסס-GPU
- ממשק האינטרנט מספק חוויית צ'אט נקייה
11. הטמעה והרצה של בדיקת גמישות
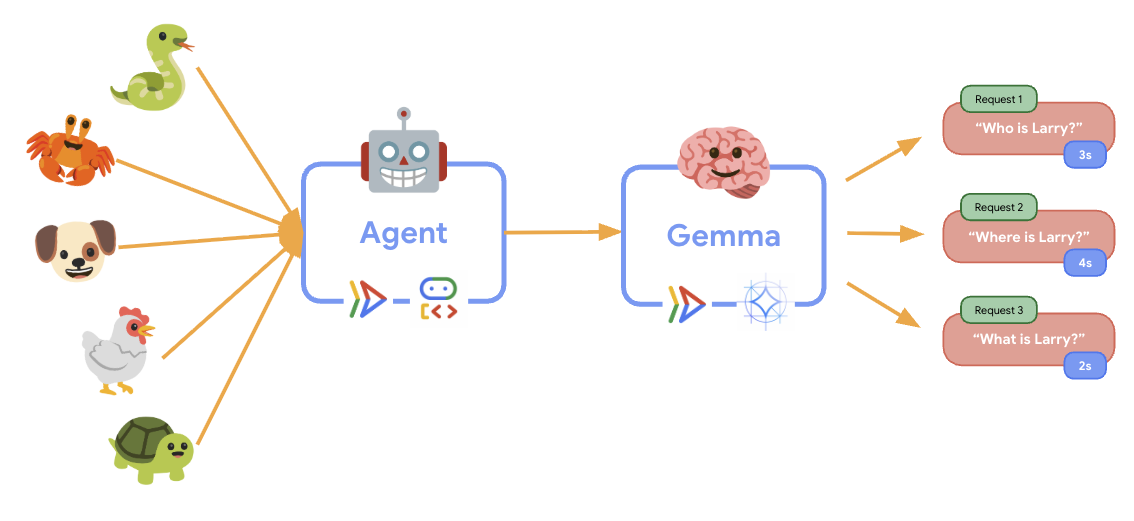
כדי להבין איך הפריסה בסביבת הייצור מתמודדת עם תנועה בעולם האמיתי, נטמיע בדיקת גמישות שתבדוק את היכולת של המערכת להסתגל לעומס עבודה גבוה יותר בסביבת הייצור 'המדומה'.
- פותחים את הסקריפט לבדיקת הגמישות ומטמיעים אותו:
cloudshell edit elasticity_test.pyimport random import uuid from locust import HttpUser, task, between class ProductionAgentUser(HttpUser): """Elasticity test user for the Production ADK Agent.""" wait_time = between(1, 3) # Faster requests to trigger scaling def on_start(self): """Set up user session when starting.""" self.user_id = f"user_{uuid.uuid4()}" self.session_id = f"session_{uuid.uuid4()}" # Create session for the Gemma agent using proper ADK API format session_data = {"state": {"user_type": "elasticity_test_user"}} self.client.post( f"/apps/production_agent/users/{self.user_id}/sessions/{self.session_id}", headers={"Content-Type": "application/json"}, json=session_data, ) @task(4) def test_conversations(self): """Test conversational capabilities - high frequency.""" topics = [ "What do red pandas typically eat in the wild?", "Can you tell me an interesting fact about snow leopards?", "Why are poison dart frogs so brightly colored?", "Where can I find the new baby kangaroo in the zoo?", "What is the name of your oldest gorilla?", "What time is the penguin feeding today?" ] # Use proper ADK API format for sending messages message_data = { "app_name": "production_agent", "user_id": self.user_id, "session_id": self.session_id, "new_message": { "role": "user", "parts": [{ "text": random.choice(topics) }] } } self.client.post( "/run", headers={"Content-Type": "application/json"}, json=message_data, ) @task(1) def health_check(self): """Test the health endpoint.""" self.client.get("/health")- יצירת סשן: נעשה שימוש בפורמט הנכון של ADK API עם POST ל-
/apps/production_agent/users/{user_id}/sessions/{session_id}. אחרי שיוצריםsession_idוuser_id, אפשר לשלוח בקשה לסוכן. - פורמט ההודעה: בהתאם למפרט של ADK עם
app_name,user_id,session_idואובייקט מובנהnew_message - נקודת קצה של שיחה: משתמשת בנקודת הקצה
/runלאיסוף של כל האירועים בבת אחת (מומלץ לבדיקת עומסים) - עומס מציאותי: יוצר עומס שיחות עם זמני המתנה קצרים יותר
- יצירת סשן: נעשה שימוש בפורמט הנכון של ADK API עם POST ל-
- יחסי תלות של התקנות:
uv sync - Locust הוא כלי לבדיקת עומסים בקוד פתוח שמבוסס על Python. הוא מיועד לבדיקת ביצועים ועומסים של אפליקציות אינטרנט ומערכות אחרות. המאפיין העיקרי שלו הוא שתסריטי בדיקה והתנהגות משתמש מוגדרים באמצעות קוד Python רגיל, מה שמאפשר גמישות רבה וביטוי מדויק בהשוואה לכלים שמסתמכים על ממשקי משתמש גרפיים או על שפות ספציפיות לתחום. נשתמש ב-Locust כדי לדמות תעבורת משתמשים לשירותים שלנו.מריצים את הבדיקה.
uv run locust -f elasticity_test.py \ -H $AGENT_URL \ --headless \ -t 60s \ -u 20 \ -r 5- משך: 60 שניות
- משתמשים: 20 משתמשים בו-זמנית
- קצב יצירת משתמשים: 5 משתמשים לשנייה
- טירגוט: הפעלת התאמה אוטומטית לעומס בשני השירותים
12. התבוננות בהתנהגות של התאמה לעומס (autoscaling)
במהלך הבדיקה של הגמישות, תוכלו לראות איך Cloud Run תומך בעומסי עבודה גבוהים יותר. כאן אפשר לראות את היתרונות הארכיטקטוניים העיקריים של הפרדת סוכן ה-ADK מקצה העורף של ה-GPU.
במהלך בדיקת הגמישות, עוקבים במסוף אחרי האופן שבו שירותי Cloud Run מטפלים בתנועה.
- במסוף Cloud, עוברים אל:
- Cloud Run → production-adk-agent → Metrics
- Cloud Run → ollama-gemma3-270m-gpu → מדדים
👀 מה כדאי לבדוק:
🤖 שירות סוכן ADK:
- צריך להישאר יציב על מכונה אחת בזמן עלייה בנפח התנועה
- שימוש גבוה ב-CPU ובזיכרון בזמן תנועה גבוהה
- מטפל ביעילות בניהול סשנים ובניתוב בקשות
🎮 שירות Gemma לקצה העורפי (צוואר בקבוק):
- צריך להישאר יציב על מכונה אחת בזמן עלייה בנפח התנועה
- ניצול ה-GPU עולה משמעותית בעומס
- השירות הזה הופך לצוואר בקבוק בגלל הסקת מודלים שדורשת הרבה משאבי GPU
- זמני ההסקה של המודל נשארים עקביים בזכות ההאצה באמצעות GPU
💡 תובנות מרכזיות:
- שני השירותים נשארים עקביים ולא מתרחבים, כי הגדרנו את מספר המופעים המקסימלי ל-
1 - שני השירותים ניתנים להרחבה באופן עצמאי על סמך מאפייני העומס האישיים שלהם
- ה-GPU עוזר לשמור על רמת הביצועים בתנאי עומס משתנים
13. סיכום
מעולה! הצלחתם לפרוס סוכן ADK מוכן לייצור עם קצה עורפי של Gemma מבוסס-GPU, תוך כדי בדיקה של עומס עבודה מדומה בסביבת ייצור.
✅ מה השגתם
- ✅ פריסת קצה עורפי של מודל Gemma עם האצת GPU ב-Cloud Run
- ✅ יצירה ופריסה של סוכן ADK שמשולב עם קצה העורפי של Gemma
- ✅ בדיקת הסוכן באמצעות ממשק האינטרנט של ADK
- ✅ התנהגות של התאמה לעומס (autoscaling) שנצפתה בשני שירותי Cloud Run מתואמים
💡 תובנות חשובות משיעור ה-Lab הזה
- 🎮 האצת GPU: מעבד ה-GPU NVIDIA L4 משפר באופן משמעותי את ביצועי הסקת המסקנות של המודל
- 🔗 תיאום בין שירותים: שני שירותים של Cloud Run יכולים לפעול יחד בצורה חלקה
- 📈 התאמה לעומס (scaling) באופן עצמאי: כל שירות מותאם לעומס על סמך מאפייני העומס הייחודיים שלו
- 🚀 מוכנות לסביבת הייצור: הארכיטקטורה מטפלת ביעילות בדפוסי תנועה בעולם האמיתי
🔄 השלבים הבאים
- עורכים ניסויים בדפוסי טעינה שונים ומתבוננים בהתנהגות של שינוי הגודל
- אפשר לנסות גדלים שונים של מודל Gemma (צריך להתאים את הזיכרון ואת ה-GPU בהתאם)
- הטמעה של מעקב והתראות לגבי פריסות בסביבת הייצור
- פריסה במספר אזורים לזמינות גלובלית
🧹 ניקוי
כדי להימנע מחיובים, מוחקים את המשאבים כשמסיימים:
gcloud run services delete production-adk-agent --region=europe-west4
gcloud run services delete ollama-gemma3-270m-gpu --region=europe-west4
📖 מקורות מידע
- Starter Repository
- פתרון מלא
- מאמרי העזרה של Google ADK
- מדריך לבדיקת ADK – הפניה מלאה לנקודות קצה (endpoints) של ADK API ולתבניות בדיקה
- בדיקות עומס ב-Cloud Run
- מסמכי תיעוד של Agent Development Kit (ADK)
- מסמכי תיעוד של Cloud Run GPU
- ספריית המודלים של Ollama
- מסמכי התיעוד של Cloud Trace
- שיטות מומלצות לאבטחה ב-Cloud Run
- UV Python Package Manager
- Locust Load Testing Framework