
1. परिचय
खास जानकारी
इस लैब में, आपको प्रोडक्शन के लिए तैयार Agent Development Kit (ADK) एजेंट को डिप्लॉय करना होगा. इसमें जीपीयू ऐक्सेलरेटेड Gemma बैकएंड का इस्तेमाल किया जाता है. इसमें डिप्लॉयमेंट के अहम पैटर्न पर फ़ोकस किया गया है: जीपीयू की सुविधा वाली Cloud Run सेवाएं सेट अप करना, मॉडल बैकएंड को ADK एजेंट के साथ इंटिग्रेट करना, और लोड के दौरान ऑटोस्केलिंग के व्यवहार को मॉनिटर करना.
आपको क्या करना होगा
इस लैब में, प्रोडक्शन डिप्लॉयमेंट के मुख्य पहलुओं पर फ़ोकस किया जाएगा:
- जीपीयू की मदद से, Gemma को Cloud Run पर डिप्लॉय करना - बेहतर परफ़ॉर्मेंस वाला Gemma मॉडल बैकएंड सेट अप करना
- ADK एजेंट के साथ Gemma डिप्लॉयमेंट को इंटिग्रेट करना - अपने एजेंट को जीपीयू की मदद से काम करने वाले मॉडल से कनेक्ट करें
- ADK के वेब इंटरफ़ेस की मदद से टेस्ट करना - पुष्टि करें कि आपका बातचीत वाला एजेंट सही तरीके से काम कर रहा है
- इलास्टिसिटी टेस्टिंग करें - देखें कि Cloud Run के दोनों इंस्टेंस, लोड को कैसे मैनेज करते हैं
इसमें एजेंट को ज़्यादा से ज़्यादा डेवलप करने के बजाय, प्रोडक्शन डिप्लॉयमेंट पैटर्न पर ज़ोर दिया जाता है.
आपको क्या सीखने को मिलेगा
- प्रोडक्शन के लिए, जीपीयू ऐक्सेलरेटेड Gemma मॉडल को Cloud Run पर डिप्लॉय करना
- ADK एजेंटों के साथ बाहरी मॉडल डिप्लॉयमेंट को इंटिग्रेट करना
- एआई एजेंट के प्रोडक्शन-रेडी डिप्लॉयमेंट को कॉन्फ़िगर करना और उसकी जांच करना
- लोड के दौरान Cloud Run के व्यवहार को समझना
- देखें कि ट्रैफ़िक बढ़ने पर, Cloud Run के कई इंस्टेंस कैसे काम करते हैं
- परफ़ॉर्मेंस की पुष्टि करने के लिए, इलास्टिसिटी टेस्टिंग लागू करना
2. प्रोजेक्ट सेटअप करना
- अगर आपके पास पहले से कोई Google खाता नहीं है, तो आपको Google खाता बनाना होगा.
- ऑफ़िस या स्कूल वाले खाते के बजाय, निजी खाते का इस्तेमाल करें. ऑफ़िस और स्कूल वाले खातों पर कुछ पाबंदियां हो सकती हैं. इनकी वजह से, इस लैब के लिए ज़रूरी एपीआई चालू नहीं किए जा सकते.
- Google Cloud Console में साइन इन करें.
- Cloud Console में बिलिंग चालू करें.
- इस लैब को पूरा करने में, Cloud संसाधनों पर 1 डॉलर से कम का खर्च आना चाहिए.
- ज़्यादा शुल्क से बचने के लिए, इस लैब के आखिर में दिए गए निर्देशों का पालन करके संसाधनों को मिटाया जा सकता है.
- नए उपयोगकर्ता, 300 डॉलर के मुफ़्त में आज़माने की सुविधा का फ़ायदा पा सकते हैं.
- नया प्रोजेक्ट बनाएं या किसी मौजूदा प्रोजेक्ट का फिर से इस्तेमाल करें.
- अगर आपको प्रोजेक्ट के कोटे से जुड़ी कोई गड़बड़ी दिखती है, तो किसी मौजूदा प्रोजेक्ट का फिर से इस्तेमाल करें या नया प्रोजेक्ट बनाने के लिए किसी मौजूदा प्रोजेक्ट को मिटाएं.
3. Cloud Shell Editor खोलें
- सीधे Cloud Shell Editor पर जाने के लिए, इस लिंक पर क्लिक करें
- अगर आज किसी भी समय अनुमति देने के लिए कहा जाता है, तो जारी रखने के लिए अनुमति दें पर क्लिक करें.
- अगर टर्मिनल स्क्रीन पर सबसे नीचे नहीं दिखता है, तो इसे खोलें:
- देखें पर क्लिक करें
- टर्मिनल
 पर क्लिक करें
पर क्लिक करें
- टर्मिनल में, इस निर्देश का इस्तेमाल करके अपना प्रोजेक्ट सेट करें:
- फ़ॉर्मैट:
gcloud config set project [PROJECT_ID] - उदाहरण:
gcloud config set project lab-project-id-example - अगर आपको अपना प्रोजेक्ट आईडी याद नहीं है, तो:
- अपने सभी प्रोजेक्ट आईडी की सूची देखने के लिए, यह कमांड इस्तेमाल करें:
gcloud projects list | awk '/PROJECT_ID/{print $2}'
- अपने सभी प्रोजेक्ट आईडी की सूची देखने के लिए, यह कमांड इस्तेमाल करें:
- फ़ॉर्मैट:
- आपको यह मैसेज दिखेगा:
Updated property [core/project].
WARNINGदिखता है और आपसेDo you want to continue (Y/n)?पूछा जाता है, तो इसका मतलब है कि आपने प्रोजेक्ट आईडी गलत डाला है.nदबाएं,Enterदबाएं, औरgcloud config set projectनिर्देश को फिर से चलाने की कोशिश करें.
4. एपीआई चालू करना और डिफ़ॉल्ट क्षेत्र सेट करना
जीपीयू की सुविधा के साथ Cloud Run सेवाओं को डिप्लॉय करने से पहले, हमें ज़रूरी Google Cloud API चालू करने होंगे. साथ ही, आपके प्रोजेक्ट की सेटिंग कॉन्फ़िगर करनी होंगी.
- टर्मिनल में, इन एपीआई को चालू करें:
gcloud services enable \
run.googleapis.com \
artifactregistry.googleapis.com \
cloudbuild.googleapis.com \
aiplatform.googleapis.com
अगर अनुमति देने के लिए कहा जाए, तो जारी रखने के लिए अनुमति दें पर क्लिक करें.
इस कमांड को पूरा होने में कुछ मिनट लग सकते हैं. हालांकि, इसके बाद आपको इस तरह का मैसेज दिखेगा:
Operation "operations/acf.p2-73d90d00-47ee-447a-b600" finished successfully.
- Cloud Run के लिए डिफ़ॉल्ट क्षेत्र सेट करें.
gcloud config set run/region europe-west4
5. अपना Python प्रोजेक्ट तैयार करना
आइए, स्टार्टर कोड सेट अप करें. इसमें हमारे Gemma बैकएंड और एडीके एजेंट सेवाओं, दोनों के लिए बुनियादी स्ट्रक्चर शामिल है.
- स्टार्टर रिपॉज़िटरी को क्लोन करें:
cd ~ npx -y giget@latest gh+git:GoogleCloudPlatform/devrel-demos/agents/accelerate-ai-with-cloud-run/accelerate-ai-lab3-starter accelerate-ai-lab3-starter cd accelerate-ai-lab3-starter - प्रोजेक्ट के स्ट्रक्चर की जांच करें:
ls -Raccelerate-ai-lab3-starter/ ├── README.md # Project overview ├── ollama-backend/ # Ollama backend (separate deployment) │ └── Dockerfile # Backend container (🚧 to implement) └── adk-agent/ # ADK agent (separate deployment) ├── pyproject.toml # Python dependencies (✅ completed) ├── server.py # FastAPI server (🚧 to implement) ├── Dockerfile # Container config (🚧 to implement) ├── elasticity_test.py # Elasticity testing (🚧 to implement) └── production_agent/ # Agent implementation ├── __init__.py # Package init (✅ completed) └── agent.py # Agent logic (🚧 to implement)
6. आर्किटेक्चर के बारे में खास जानकारी
इसे लागू करने से पहले, आइए दो-सेवाओं वाले आर्किटेक्चर के बारे में जानते हैं:
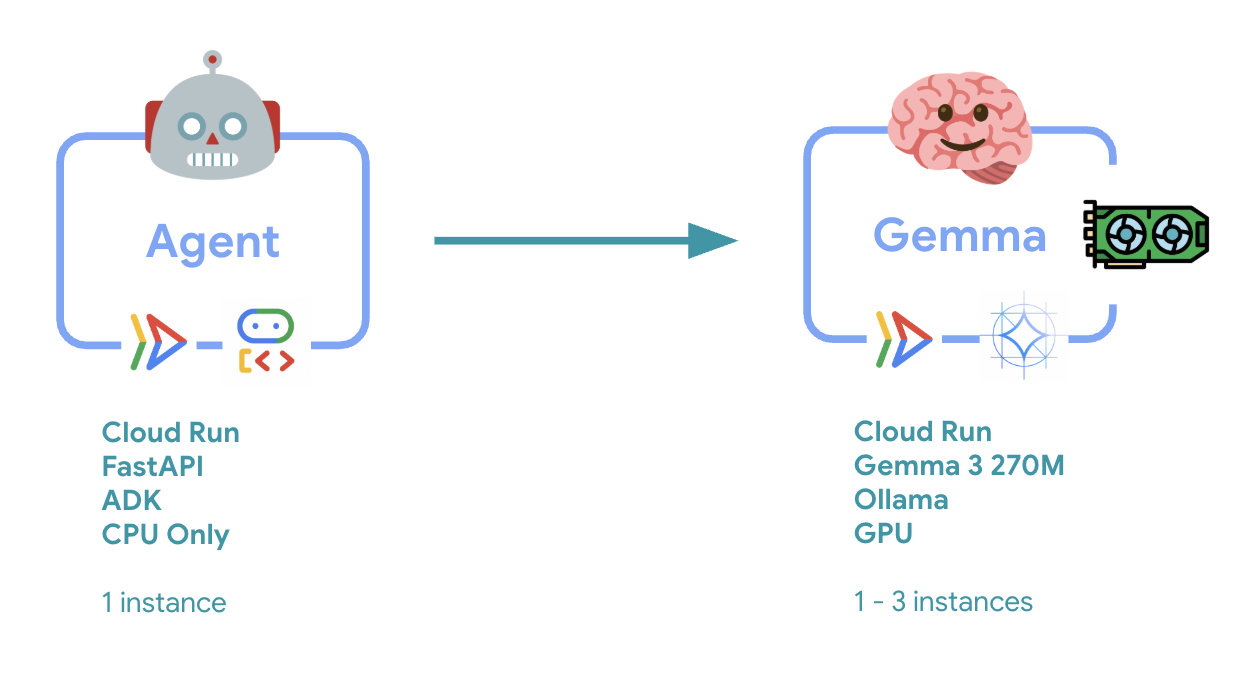
अहम जानकारी: इलास्टिसिटी टेस्टिंग के दौरान, आपको दिखेगा कि दोनों सेवाएं वर्कलोड को अलग-अलग तरीके से मैनेज कर रही हैं. जैसे, GPU बैकएंड (बॉटलनैक सेवा) लोड को मैनेज करने के लिए अपने GPU का इस्तेमाल करता है. वहीं, ADK एजेंट, संसाधन के ज़्यादा इस्तेमाल की ज़रूरत न होने वाले अनुरोधों को मैनेज करने के लिए अपने सीपीयू पर निर्भर रहता है.
7. जीपीयू की मदद से, Cloud Run पर Gemma बैकएंड डिप्लॉय करना
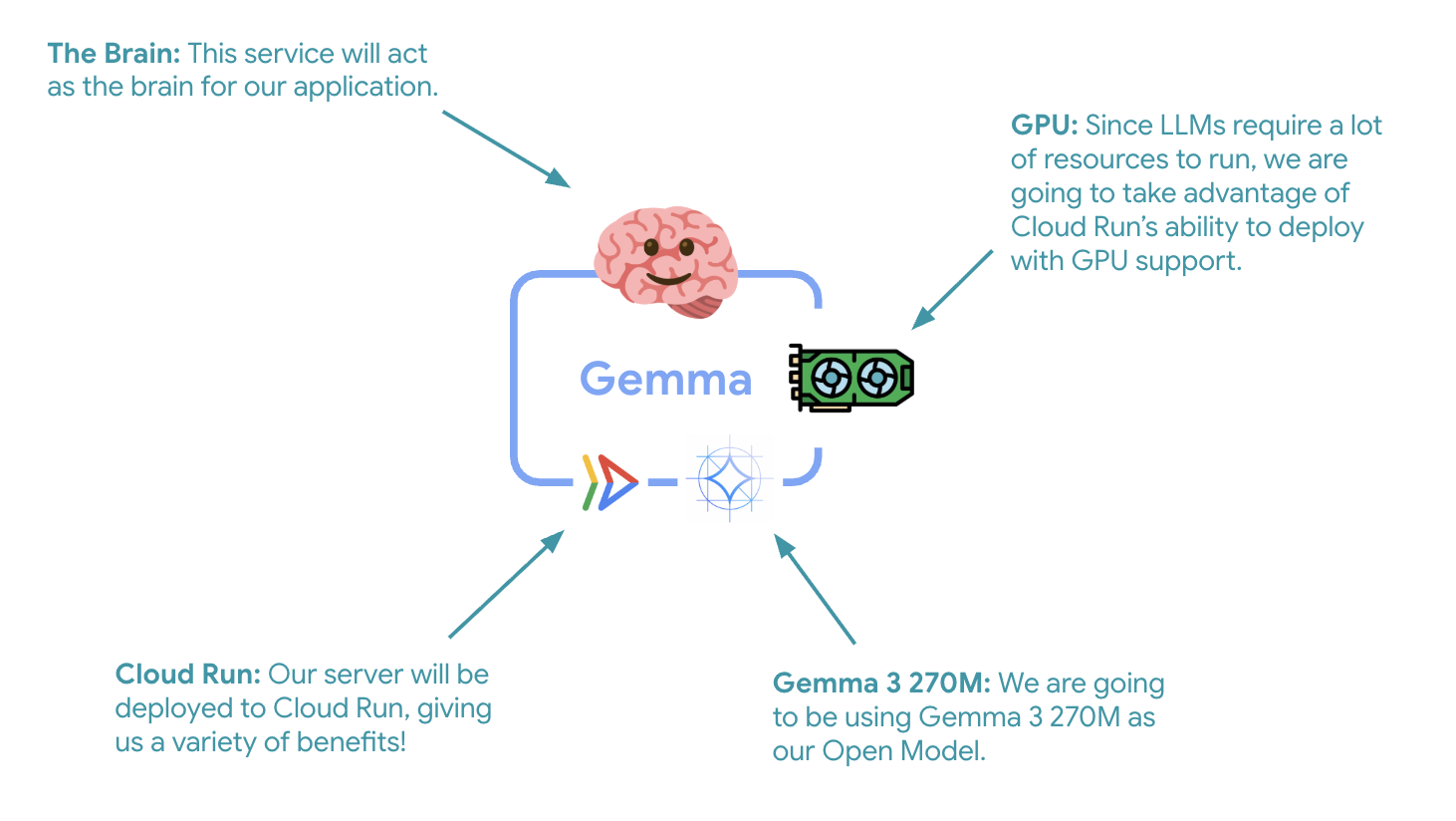
सबसे पहला और अहम चरण, जीपीयू की मदद से काम करने वाले Gemma मॉडल को डिप्लॉय करना है. यह मॉडल, आपके एडीके एजेंट के लिए दिमाग़ का काम करेगा. डिकपल किए गए और डिप्लॉय किए गए एलएलएम का इस्तेमाल उन आर्किटेक्चर में किया जा सकता है जहां आपको अलग से फ़ाइन-ट्यून किए गए मॉडल की ज़रूरत होती है या जहां आपको अलग से स्केलिंग की ज़रूरत होती है.
- Ollama बैकएंड डायरेक्ट्री पर जाएं:
cd ollama-backend - Ollama Dockerfile खोलें और लागू करें:
cloudshell edit DockerfileFROM ollama/ollama:latest # Listen on all interfaces, port 8080 ENV OLLAMA_HOST 0.0.0.0:8080 # Store model weight files in /models ENV OLLAMA_MODELS /models # Reduce logging verbosity ENV OLLAMA_DEBUG false # Never unload model weights from the GPU ENV OLLAMA_KEEP_ALIVE -1 # Store the model weights in the container image ENV MODEL gemma3:270m RUN ollama serve & sleep 5 && ollama pull $MODEL # Start Ollama ENTRYPOINT ["ollama", "serve"]- Ollama की आधिकारिक इमेज का इस्तेमाल करता है
- इस कुकी का इस्तेमाल,
OLLAMA_HOSTको किसी भी आईपी पते से कनेक्शन स्वीकार करने के लिए सेट करने के लिए किया जाता है - पोर्ट 8080 को ऐक्सेस करने की अनुमति देता है
- जीपीयू की सुविधा के साथ Gemma बैकएंड को डिप्लॉय करें:
gcloud run deploy ollama-gemma3-270m-gpu \
--source . \
--region europe-west4 \
--concurrency 7 \
--cpu 8 \
--set-env-vars OLLAMA_NUM_PARALLEL=4 \
--gpu 1 \
--gpu-type nvidia-l4 \
--max-instances 1 \
--memory 16Gi \
--allow-unauthenticated \
--no-cpu-throttling \
--no-gpu-zonal-redundancy \
--timeout 600 \
--labels dev-tutorial=codelab-agent-gpu
अगर आपको यह मैसेज मिलता है, "सोर्स से डिप्लॉय करने के लिए, Artifact Registry Docker repository की ज़रूरत होती है, ताकि बनाए गए कंटेनर को सेव किया जा सके. [europe-west4] क्षेत्र में [cloud-run-source-deploy] नाम की एक रिपॉज़िटरी बनाई जाएगी." मैसेज दिखता है, तो जारी रखें.
⚙️ मुख्य कॉन्फ़िगरेशन के बारे में जानकारी:
- जीपीयू: NVIDIA L4 को इसलिए चुना गया है, क्योंकि यह अनुमान लगाने से जुड़े वर्कलोड के लिए, कीमत और परफ़ॉर्मेंस के हिसाब से सबसे अच्छा है. L4 में 24 जीबी जीपीयू मेमोरी और ऑप्टिमाइज़ किए गए टेंसर ऑपरेशन मिलते हैं. इसलिए, यह Gemma जैसे 27 करोड़ पैरामीटर वाले मॉडल के लिए सबसे सही है
- मेमोरी: मॉडल को लोड करने, CUDA ऑपरेशनों को मैनेज करने, और Ollama की मेमोरी को मैनेज करने के लिए 16 जीबी सिस्टम मेमोरी
- सीपीयू: बेहतर I/O हैंडलिंग और प्रीप्रोसेसिंग टास्क के लिए 8 कोर
- कॉन्करेंसी: हर इंस्टेंस के लिए सात अनुरोधों से, जीपीयू मेमोरी के इस्तेमाल के साथ थ्रूपुट बैलेंस होता है
- टाइम आउट: 600 सेकंड, शुरुआती मॉडल लोडिंग और कंटेनर स्टार्टअप के लिए तय किया गया है
💰 लागत: जीपीयू इंस्टेंस, सिर्फ़ सीपीयू वाले इंस्टेंस की तुलना में काफ़ी महंगे होते हैं (~2 से 4 डॉलर/घंटा बनाम ~0.10 डॉलर/घंटा). --max-instances 1 सेटिंग की मदद से, बिना वजह जीपीयू इंस्टेंस को स्केल करने से रोककर लागत को कंट्रोल किया जा सकता है.
- डिप्लॉयमेंट पूरा होने का इंतज़ार करें और सेवा का यूआरएल नोट करें:
export OLLAMA_URL=$(gcloud run services describe ollama-gemma3-270m-gpu \ --region=europe-west4 \ --format='value(status.url)') echo "🎉 Gemma backend deployed at: $OLLAMA_URL"
8. ADK एजेंट इंटिग्रेशन लागू करना
अब एक ऐसा ADK एजेंट बनाते हैं जो डिप्लॉय किए गए Gemma बैकएंड से कनेक्ट हो.
- ADK एजेंट डायरेक्ट्री पर जाएं:
cd ../adk-agent - एजेंट कॉन्फ़िगरेशन खोलें और लागू करें:
cloudshell edit production_agent/agent.pyimport os from pathlib import Path from dotenv import load_dotenv from google.adk.agents import Agent from google.adk.models.lite_llm import LiteLlm import google.auth # Load environment variables root_dir = Path(__file__).parent.parent dotenv_path = root_dir / ".env" load_dotenv(dotenv_path=dotenv_path) # Configure Google Cloud try: _, project_id = google.auth.default() os.environ.setdefault("GOOGLE_CLOUD_PROJECT", project_id) except Exception: pass os.environ.setdefault("GOOGLE_CLOUD_LOCATION", "europe-west4") # Configure model connection gemma_model_name = os.getenv("GEMMA_MODEL_NAME", "gemma3:270m") api_base = os.getenv("OLLAMA_API_BASE", "localhost:10010") # Location of Ollama server # Production Gemma Agent - GPU-accelerated conversational assistant production_agent = Agent( model=LiteLlm(model=f"ollama_chat/{gemma_model_name}", api_base=api_base), name="production_agent", description="A production-ready conversational assistant powered by GPU-accelerated Gemma.", instruction="""You are 'Gem', a friendly, knowledgeable, and enthusiastic zoo tour guide. Your main goal is to make a zoo visit more fun and educational for guests by answering their questions. You can provide general information and interesting facts about different animal species, such as: - Their natural habitats and diet. 🌲🍓 - Typical lifespan and behaviors. - Conservation status and unique characteristics. IMPORTANT: You do NOT have access to any tools. This means you cannot look up real-time, specific information about THIS zoo. You cannot provide: - The names or ages of specific animals currently at the zoo. - The exact location or enclosure for an animal. - The daily schedule for feedings or shows. Always answer based on your general knowledge about the animal kingdom. Keep your tone cheerful, engaging, and welcoming for visitors of all ages. 🦁✨""", tools=[], # Gemma focuses on conversational capabilities ) # Set as root agent root_agent = production_agent- यह LiteLlm के ज़रिए, डिप्लॉय किए गए Gemma बैकएंड से कनेक्ट होता है
- यह बातचीत करने वाला एक आसान एजेंट बनाता है
- यह कुकी, Google Cloud इंटिग्रेशन को कॉन्फ़िगर करती है
- FastAPI सर्वर खोलें और उसे लागू करें:
cloudshell edit server.pyimport os from dotenv import load_dotenv from fastapi import FastAPI from google.adk.cli.fast_api import get_fast_api_app # Load environment variables load_dotenv() AGENT_DIR = os.path.dirname(os.path.abspath(__file__)) app_args = {"agents_dir": AGENT_DIR, "web": True} # Create FastAPI app with ADK integration app: FastAPI = get_fast_api_app(**app_args) # Update app metadata app.title = "Production ADK Agent - Lab 3" app.description = "Gemma agent with GPU-accelerated backend" app.version = "1.0.0" @app.get("/health") def health_check(): return {"status": "healthy", "service": "production-adk-agent"} @app.get("/") def root(): return { "service": "Production ADK Agent - Lab 3", "description": "GPU-accelerated Gemma agent", "docs": "/docs", "health": "/health" } if __name__ == "__main__": import uvicorn uvicorn.run(app, host="0.0.0.0", port=8080, log_level="info")- यह ADK इंटिग्रेशन के साथ FastAPI सर्वर बनाता है
- यह कुकी, टेस्टिंग के लिए वेब इंटरफ़ेस चालू करती है
- हेल्थ चेक एंडपॉइंट उपलब्ध कराता है
- Dockerfile खोलें और उसे लागू करें:
cloudshell edit DockerfileFROM python:3.13-slim # Copy uv from the official image COPY --from=ghcr.io/astral-sh/uv:latest /uv /usr/local/bin/uv # Install system dependencies RUN apt-get update && apt-get install -y curl && rm -rf /var/lib/apt/lists/* # Set working directory WORKDIR /app # Copy all files COPY . . # Install Python dependencies RUN uv sync # Expose port EXPOSE 8080 # Run the application CMD ["uv", "run", "uvicorn", "server:app", "--host", "0.0.0.0", "--port", "8080"]- uv: यह Python पैकेज मैनेजर का नया वर्शन है. यह pip से 10 से 100 गुना ज़्यादा तेज़ी से काम करता है. यह ग्लोबल कैश और पैरलल डाउनलोड का इस्तेमाल करता है. इससे कंटेनर बनाने में लगने वाला समय काफ़ी कम हो जाता है
- Python 3.13-slim: यह Python का नया वर्शन है. इसमें सिस्टम से जुड़ी कम से कम डिपेंडेंसी होती हैं. इससे कंटेनर का साइज़ और अटैक सरफेस कम हो जाता है
- मल्टी-स्टेज बिल्ड: इसकी आधिकारिक इमेज से uv को कॉपी करने से, हमें ऑप्टिमाइज़ किया गया सबसे नया बाइनरी मिलता है
9. एनवायरमेंट कॉन्फ़िगर करना और एजेंट डिप्लॉय करना
अब हम एडीके एजेंट को कॉन्फ़िगर करेंगे, ताकि वह डिप्लॉय किए गए Gemma बैकएंड से कनेक्ट हो सके. साथ ही, इसे Cloud Run सेवा के तौर पर डिप्लॉय करेंगे. इसमें एनवायरमेंट वैरिएबल सेट अप करना और एजेंट को सही कॉन्फ़िगरेशन के साथ डिप्लॉय करना शामिल है.
- अपना एनवायरमेंट कॉन्फ़िगरेशन सेट अप करें:
cat << EOF > .env GOOGLE_CLOUD_PROJECT=$(gcloud config get-value project) GOOGLE_CLOUD_LOCATION=europe-west4 GEMMA_MODEL_NAME=gemma3:270m OLLAMA_API_BASE=$OLLAMA_URL EOF
Cloud Run में एनवायरमेंट वैरिएबल को समझना
एनवायरमेंट वैरिएबल, की-वैल्यू पेयर होते हैं. ये रनटाइम पर आपके ऐप्लिकेशन को कॉन्फ़िगर करते हैं. ये खास तौर पर इन कामों के लिए मददगार होते हैं:
- एपीआई एंडपॉइंट और सेवा के यूआरएल (जैसे, हमारा Ollama बैकएंड)
- ऐसा कॉन्फ़िगरेशन जो अलग-अलग एनवायरमेंट (डेवलपमेंट, स्टेजिंग, प्रोडक्शन) के हिसाब से बदलता है
- संवेदनशील डेटा जिसे हार्डकोड नहीं किया जाना चाहिए
ADK एजेंट डिप्लॉय करें:
export PROJECT_ID=$(gcloud config get-value project)
gcloud run deploy production-adk-agent \
--source . \
--region europe-west4 \
--allow-unauthenticated \
--memory 4Gi \
--cpu 2 \
--max-instances 1 \
--concurrency 50 \
--timeout 300 \
--set-env-vars GOOGLE_CLOUD_PROJECT=$PROJECT_ID \
--set-env-vars GOOGLE_CLOUD_LOCATION=europe-west4 \
--set-env-vars GEMMA_MODEL_NAME=gemma3:270m \
--set-env-vars OLLAMA_API_BASE=$OLLAMA_URL \
--labels dev-tutorial=codelab-agent-gpu
⚙️ मुख्य कॉन्फ़िगरेशन:
- ऑटोसकेलिंग: एक इंस्टेंस पर सेट है (कम संसाधनों का इस्तेमाल करके अनुरोधों को मैनेज करना)
- एक साथ किए जाने वाले अनुरोध: हर इंस्टेंस के लिए 50 अनुरोध
- मेमोरी: ADK एजेंट के लिए 4 जीबी
- Environment: यह आपके Gemma बैकएंड से कनेक्ट होता है
🔒 सुरक्षा से जुड़ी जानकारी: इस लैब में, आसानी से समझने के लिए --allow-unauthenticated का इस्तेमाल किया गया है. प्रोडक्शन में, पुष्टि करने की सही सुविधा लागू करें. इसके लिए, इनका इस्तेमाल करें:
- सेवा खातों की मदद से, Cloud Run की सेवा से सेवा की पुष्टि करना
- आइडेंटिटी और ऐक्सेस मैनेजमेंट (आईएएम) नीतियां
- बाहरी ऐक्सेस के लिए एपीआई कुंजियां या OAuth
- ऐक्सेस कंट्रोल करने के लिए
gcloud run services add-iam-policy-bindingका इस्तेमाल करना
अपने एजेंट के लिए सर्विस यूआरएल पाएं:
export AGENT_URL=$(gcloud run services describe production-adk-agent \
--region=europe-west4 \
--format='value(status.url)')
echo "🎉 ADK Agent deployed at: $AGENT_URL"
✅ Cloud Run के एनवायरमेंट वैरिएबल के दस्तावेज़ के आधार पर, एनवायरमेंट वैरिएबल इस्तेमाल करने के सबसे सही तरीके:
- आरक्षित वैरिएबल का इस्तेमाल न करें:
PORTको सेट न करें. अगर आपको एनवायरमेंट वैरिएबल बदलना है, तो इसके बजाय –port फ़्लैग का इस्तेमाल करें. साथ ही,X_GOOGLE_से शुरू होने वाले वैरिएबल का इस्तेमाल न करें - पूरी जानकारी देने वाले नामों का इस्तेमाल करें: वैरिएबल के नाम के आगे प्रीफ़िक्स जोड़ें, ताकि नाम एक-दूसरे से मैच न हों. उदाहरण के लिए,
MODELके बजायGEMMA_MODEL_NAME - कॉमा से बचें: अगर आपकी वैल्यू में कॉमा शामिल हैं, तो किसी दूसरे डेलिमिटर का इस्तेमाल करें:
--set-env-vars "^@^KEY1=value1,value2@KEY2=..." - अपडेट करें बनाम बदलें: अन्य वैरिएबल पर असर डाले बिना, कुछ वैरिएबल जोड़ने/बदलने के लिए
--update-env-varsका इस्तेमाल करें
Cloud Run में वैरिएबल सेट करने का तरीका:
- फ़ाइल से:
gcloud run deploy SERVICE_NAME --env-vars-file .env --labels dev-tutorial codelab-adk(किसी फ़ाइल से कई वैरिएबल लोड करता है) - एक से ज़्यादा फ़्लैग: ऐसी जटिल वैल्यू के लिए
--set-env-varsको दोहराएं जिन्हें कॉमा लगाकर अलग नहीं किया जा सकता
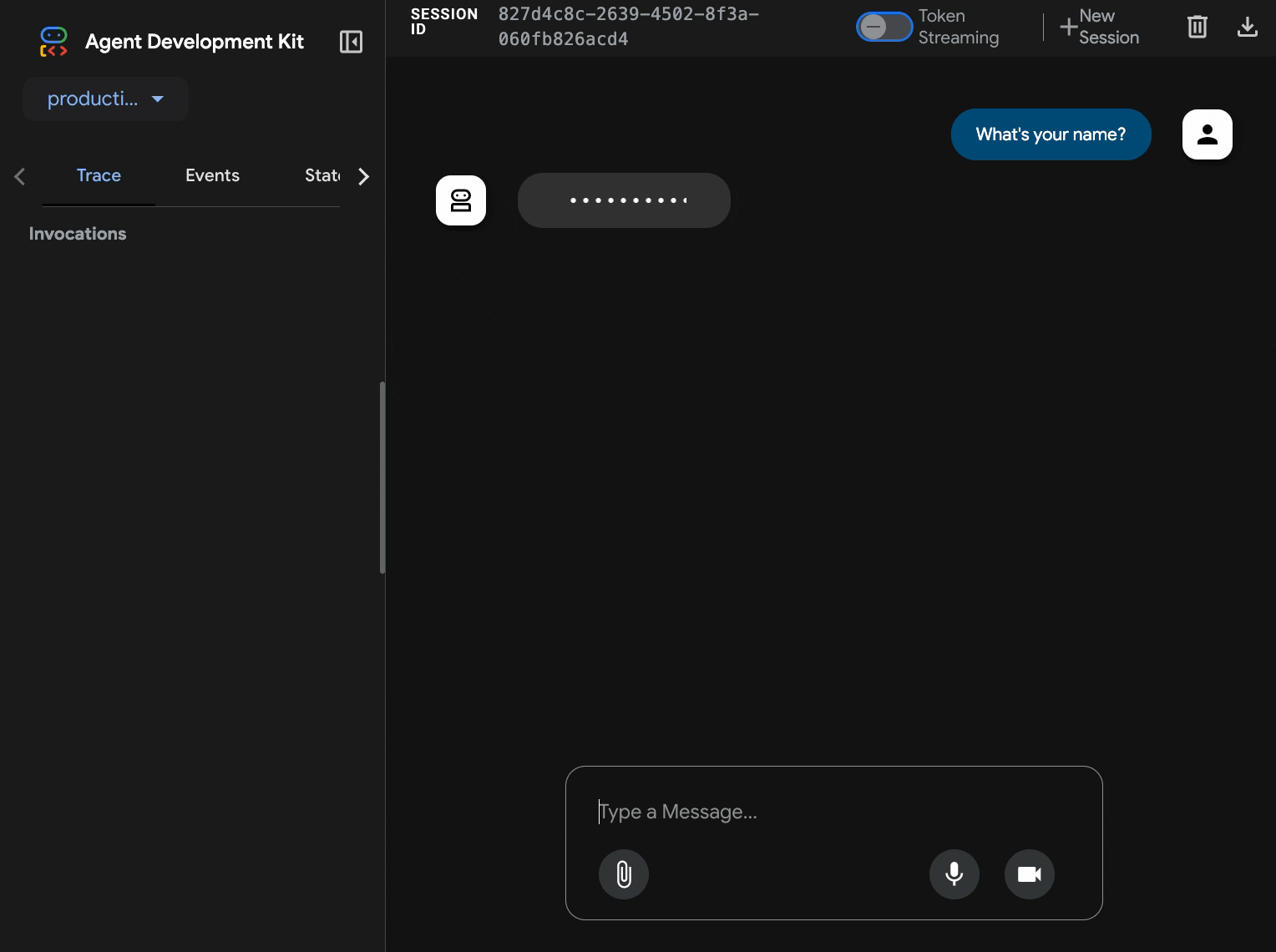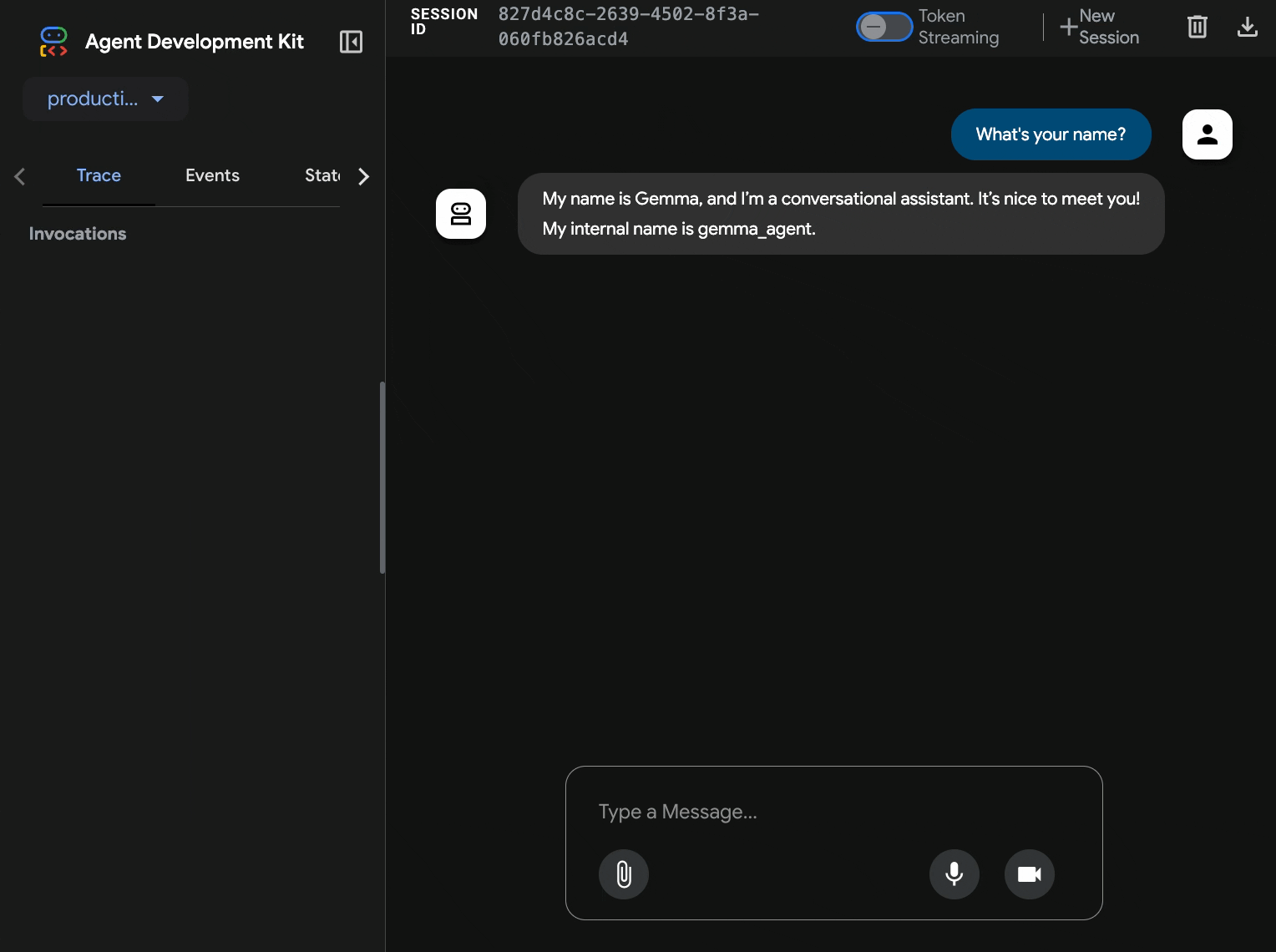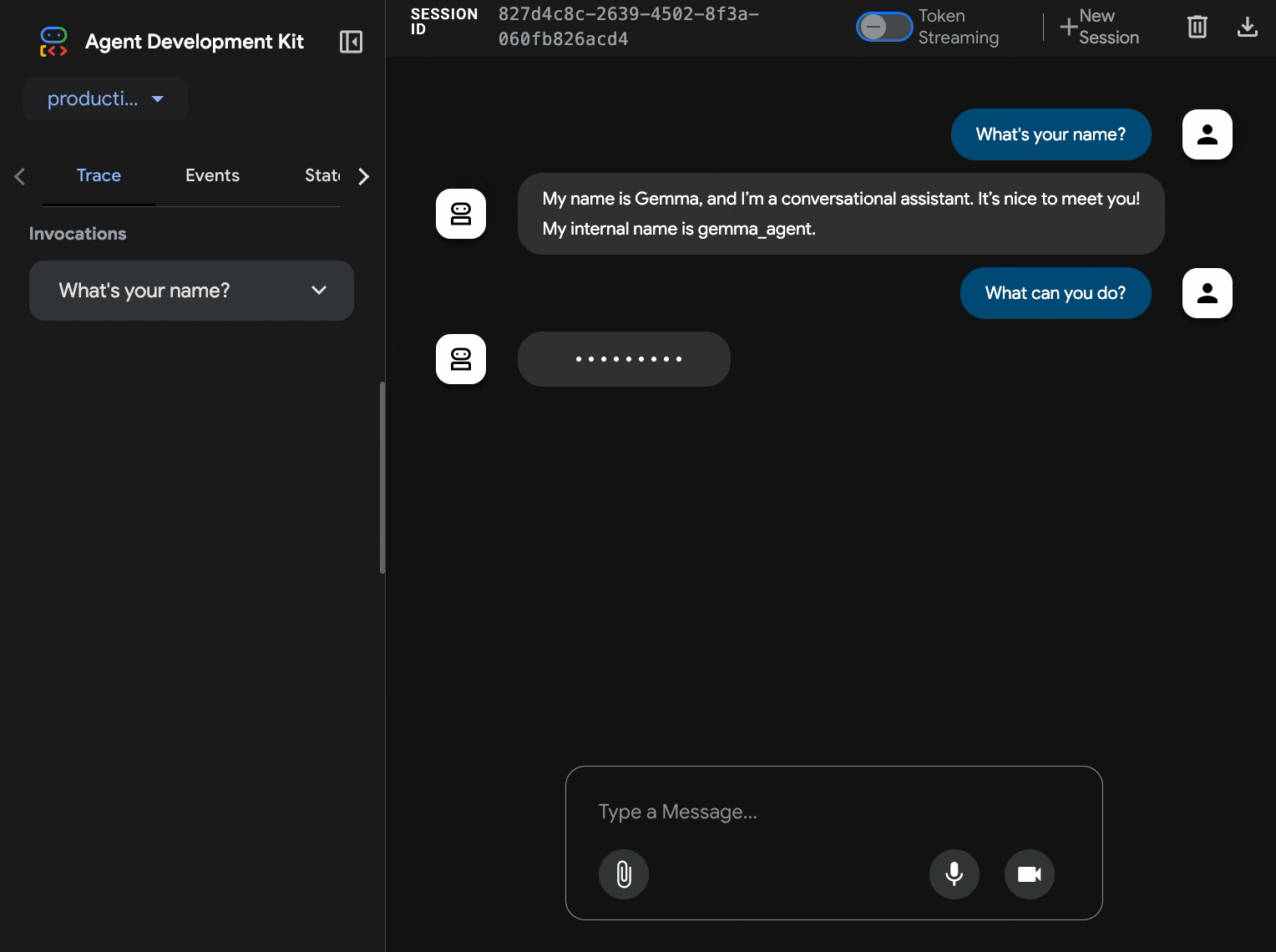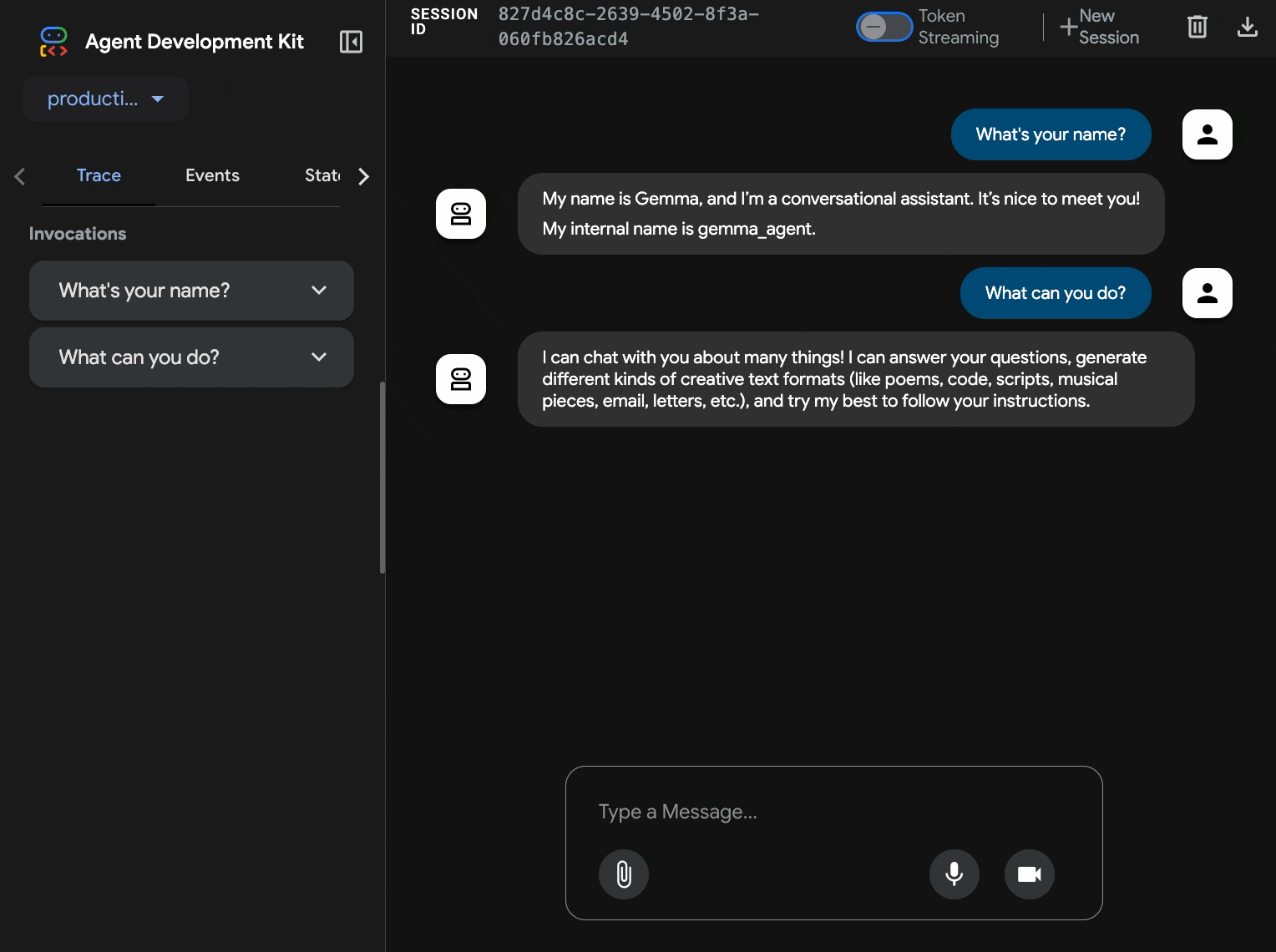
10. ADK के वेब इंटरफ़ेस की मदद से टेस्ट करना
दोनों सेवाओं को डिप्लॉय करने के बाद, अब यह पुष्टि करने का समय है कि आपका ADK एजेंट, GPU की मदद से काम करने वाले Gemma बैकएंड के साथ कम्यूनिकेट कर सकता है या नहीं. साथ ही, यह भी पुष्टि करें कि वह उपयोगकर्ता की क्वेरी के जवाब दे सकता है या नहीं.
- हेल्थ एंडपॉइंट की जांच करें:
curl $AGENT_URL/health{ "status": "healthy", "service": "production-adk-agent" } - अपने एजेंट से इंटरैक्ट करने के लिए, नए ब्राउज़र टैब में अपने
production-adk-agentका यूआरएल डालें. आपको ADK का वेब इंटरफ़ेस दिखेगा. - इन सैंपल बातचीत की मदद से, अपने एजेंट को टेस्ट करें:
- "लाल पांडा आम तौर पर, जंगल में क्या खाते हैं?"
- "क्या तुम मुझे हिम तेंदुओं के बारे में कोई दिलचस्प जानकारी दे सकते हो?"
- "ज़हरीले डार्ट फ़्रॉग इतने चटख रंग के क्यों होते हैं?"
- "मुझे चिड़ियाघर में नया कंगारू कहां मिलेगा?"
- एजेंट, डिप्लॉय किए गए Gemma मॉडल का इस्तेमाल करके जवाब देता है. तैनात की गई Gemma सेवा के लॉग देखकर, इसकी पुष्टि की जा सकती है. हम अगले सेक्शन में यह काम करेंगे
- जवाब, जीपीयू ऐक्सेलरेटेड बैकएंड से जनरेट किए जाते हैं
- वेब इंटरफ़ेस पर चैट करने का बेहतरीन अनुभव मिलता है
11. इलास्टिसिटी टेस्ट लागू करना और उसे चलाना
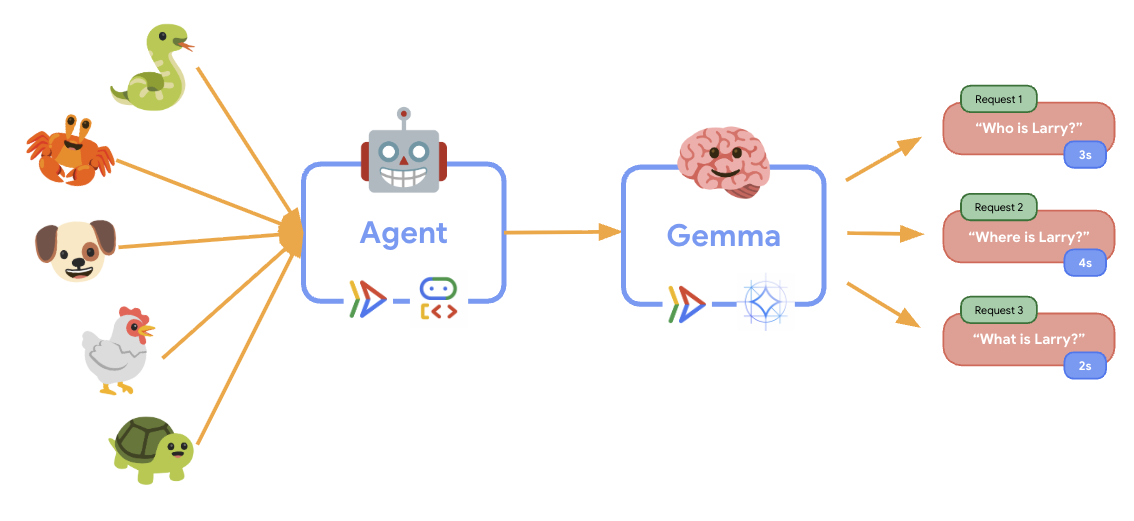
यह समझने के लिए कि प्रोडक्शन डिप्लॉयमेंट, असल दुनिया के ट्रैफ़िक को कैसे मैनेज करता है, हम इलास्टिसिटी टेस्ट लागू करेंगे. इससे यह पता चलेगा कि सिस्टम, ज़्यादा "सिमुलेटेड" प्रोडक्शन वर्कलोड के हिसाब से खुद को ढाल सकता है या नहीं.
- इलास्टिसिटी टेस्टिंग स्क्रिप्ट खोलें और लागू करें:
cloudshell edit elasticity_test.pyimport random import uuid from locust import HttpUser, task, between class ProductionAgentUser(HttpUser): """Elasticity test user for the Production ADK Agent.""" wait_time = between(1, 3) # Faster requests to trigger scaling def on_start(self): """Set up user session when starting.""" self.user_id = f"user_{uuid.uuid4()}" self.session_id = f"session_{uuid.uuid4()}" # Create session for the Gemma agent using proper ADK API format session_data = {"state": {"user_type": "elasticity_test_user"}} self.client.post( f"/apps/production_agent/users/{self.user_id}/sessions/{self.session_id}", headers={"Content-Type": "application/json"}, json=session_data, ) @task(4) def test_conversations(self): """Test conversational capabilities - high frequency.""" topics = [ "What do red pandas typically eat in the wild?", "Can you tell me an interesting fact about snow leopards?", "Why are poison dart frogs so brightly colored?", "Where can I find the new baby kangaroo in the zoo?", "What is the name of your oldest gorilla?", "What time is the penguin feeding today?" ] # Use proper ADK API format for sending messages message_data = { "app_name": "production_agent", "user_id": self.user_id, "session_id": self.session_id, "new_message": { "role": "user", "parts": [{ "text": random.choice(topics) }] } } self.client.post( "/run", headers={"Content-Type": "application/json"}, json=message_data, ) @task(1) def health_check(self): """Test the health endpoint.""" self.client.get("/health")- सेशन बनाना: इसमें ADK API के सही फ़ॉर्मैट का इस्तेमाल किया जाता है. साथ ही,
/apps/production_agent/users/{user_id}/sessions/{session_id}पर POST किया जाता है.session_idऔरuser_idबनाने के बाद, एजेंट से अनुरोध किया जा सकता है. - मैसेज फ़ॉर्मैट: ADK स्पेसिफ़िकेशन के मुताबिक,
app_name,user_id,session_id, और स्ट्रक्चर्डnew_messageऑब्जेक्ट का इस्तेमाल करता है - Conversation Endpoint: यह एक साथ सभी इवेंट इकट्ठा करने के लिए,
/runएंडपॉइंट का इस्तेमाल करता है. इसे लोड टेस्टिंग के लिए इस्तेमाल करने का सुझाव दिया जाता है - रियलिस्टिक लोड: इससे बातचीत के दौरान कम समय में जवाब मिलता है
- सेशन बनाना: इसमें ADK API के सही फ़ॉर्मैट का इस्तेमाल किया जाता है. साथ ही,
- डिपेंडेंसी इंस्टॉल करें:
uv sync - Locust एक ओपन-सोर्स टूल है. इसे Python की मदद से बनाया गया है. इसका इस्तेमाल वेब ऐप्लिकेशन और अन्य सिस्टम की परफ़ॉर्मेंस और लोड टेस्टिंग के लिए किया जाता है. इसकी मुख्य विशेषता यह है कि टेस्ट के अलग-अलग चरणों और उपयोगकर्ता के व्यवहार को स्टैंडर्ड Python कोड का इस्तेमाल करके तय किया जाता है. इससे, ग्राफ़िकल यूज़र इंटरफ़ेस या डोमेन के हिसाब से तय की गई भाषाओं पर निर्भर रहने वाले टूल की तुलना में, ज़्यादा फ़्लेक्सिबिलिटी और एक्सप्रेसिवनेस मिलती है. हम अपनी सेवाओं पर उपयोगकर्ता ट्रैफ़िक को सिम्युलेट करने के लिए, Locust का इस्तेमाल करेंगे.टेस्ट चलाएं.
uv run locust -f elasticity_test.py \ -H $AGENT_URL \ --headless \ -t 60s \ -u 20 \ -r 5- अवधि: 60 सेकंड
- उपयोगकर्ता: एक साथ 20 उपयोगकर्ता
- स्पॉन रेट: हर सेकंड में पांच उपयोगकर्ता
- टारगेट: दोनों सेवाओं पर ऑटोस्केलिंग ट्रिगर करें
12. ऑटोस्केलिंग की सुविधा के काम करने के तरीके को समझना
इलास्टिसिटी टेस्ट के दौरान, आपको Cloud Run की ज़्यादा वर्कलोड को मैनेज करने की क्षमता दिखेगी. यहां आपको ADK एजेंट को GPU बैकएंड से अलग करने के मुख्य फ़ायदों के बारे में पता चलेगा.
इलास्टिसिटी टेस्ट के दौरान, अपनी कंसोल में देखें कि Cloud Run की दोनों सेवाएं, ट्रैफ़िक को कैसे मैनेज करती हैं.
- Cloud Console में, यहां जाएं:
- Cloud Run → production-adk-agent → मेट्रिक
- Cloud Run → ollama-gemma3-270m-gpu → मेट्रिक
👀 आपको इन बातों का ध्यान रखना चाहिए:
🤖 ADK एजेंट सेवा:
- ट्रैफ़िक बढ़ने पर भी, एक ही इंस्टेंस पर स्थिर रहना चाहिए
- ज़्यादा ट्रैफ़िक के दौरान सीपीयू और मेमोरी के इस्तेमाल में अचानक बढ़ोतरी होना
- यह कुकी, सेशन मैनेजमेंट और अनुरोधों को सही तरीके से रूट करने का काम करती है
🎮 Gemma की बैकएंड सेवा (बॉटलनैक):
- ट्रैफ़िक बढ़ने पर भी, एक ही इंस्टेंस पर स्थिर रहना चाहिए
- लोड बढ़ने पर, जीपीयू का इस्तेमाल काफ़ी बढ़ जाता है
- जीपीयू का ज़्यादा इस्तेमाल करने वाले मॉडल इन्फ़रेंस की वजह से, यह सेवा बॉटलनेक बन जाती है
- GPU ऐक्सेलरेटेड होने की वजह से, मॉडल के अनुमान लगाने में लगने वाला समय एक जैसा रहता है
💡 अहम जानकारी:
- दोनों सेवाएं एक जैसी बनी रहती हैं और बढ़ती नहीं हैं, क्योंकि हमने अपने ज़्यादा से ज़्यादा इंस्टेंस को
1पर सेट किया है - दोनों सेवाएं, अपने-अपने लोड की विशेषताओं के आधार पर अलग-अलग स्केल होती हैं
- जीपीयू, अलग-अलग लोड की स्थितियों में परफ़ॉर्मेंस को बनाए रखने में मदद करता है
13. नतीजा
बधाई हो! आपने प्रोडक्शन के लिए तैयार ADK एजेंट को जीपीयू ऐक्सेलरेटेड Gemma बैकएंड के साथ डिप्लॉय कर दिया है. साथ ही, आपने सिम्युलेट किए गए प्रोडक्शन वर्कलोड की जांच कर ली है.
✅ आपने क्या-क्या हासिल किया
- ✅ Cloud Run पर, जीपीयू ऐक्सेलरेटेड Gemma मॉडल बैकएंड डिप्लॉय किया गया हो
- ✅ Gemma बैकएंड के साथ इंटिग्रेट होने वाला ADK एजेंट बनाया और डिप्लॉय किया गया हो
- ✅ ADK के वेब इंटरफ़ेस का इस्तेमाल करके एजेंट की जांच की गई हो
- ✅ दो कोऑर्डिनेटेड Cloud Run सेवाओं में, अपने-आप स्केलिंग होने की सुविधा काम करती है
💡 इस लैब से मिली अहम जानकारी
- 🎮 जीपीयू ऐक्सेलरेटेड: NVIDIA L4 जीपीयू, मॉडल के अनुमान लगाने की परफ़ॉर्मेंस को बेहतर बनाता है
- 🔗 सेवाओं के बीच तालमेल: दो Cloud Run सेवाएं एक साथ आसानी से काम कर सकती हैं
- 📈 इंडिपेंडेंट स्केलिंग: हर सेवा, अपने लोड की विशेषताओं के आधार पर स्केल होती है
- 🚀 प्रोडक्शन का ऐक्सेस पाने के लिए ज़रूरी चीज़ें: आर्किटेक्चर, असल दुनिया के ट्रैफ़िक पैटर्न को असरदार तरीके से मैनेज करता है
🔄 अगले चरण
- अलग-अलग लोड पैटर्न के साथ एक्सपेरिमेंट करें और देखें कि स्केलिंग कैसे काम करती है
- Gemma के अलग-अलग साइज़ वाले मॉडल आज़माएं. इसके लिए, मेमोरी और जीपीयू को ज़रूरत के हिसाब से अडजस्ट करें
- प्रोडक्शन डिप्लॉयमेंट के लिए मॉनिटरिंग और सूचनाएं पाने की सुविधा लागू करना
- दुनिया भर में उपलब्धता के लिए, एक से ज़्यादा क्षेत्रों में डिप्लॉयमेंट एक्सप्लोर करना
🧹 मिटाएं
शुल्क से बचने के लिए, काम पूरा होने के बाद संसाधनों को मिटा दें:
gcloud run services delete production-adk-agent --region=europe-west4
gcloud run services delete ollama-gemma3-270m-gpu --region=europe-west4
📖 संसाधन
- स्टार्टर रिपॉज़िटरी
- पूरा समाधान
- Google ADK के दस्तावेज़
- ADK की टेस्टिंग गाइड - ADK एपीआई एंडपॉइंट और टेस्टिंग पैटर्न के बारे में पूरी जानकारी
- Cloud Run पर लोड टेस्टिंग
- एजेंट डेवलपमेंट किट (एडीके) से जुड़े दस्तावेज़
- Cloud Run GPU के बारे में दस्तावेज़
- Ollama मॉडल लाइब्रेरी
- Google Cloud Trace के दस्तावेज़
- Cloud Run की सुरक्षा के लिए सबसे सही तरीके
- UV Python Package Manager
- Locust लोड टेस्टिंग फ़्रेमवर्क