
1. Pengantar
Ringkasan
Di lab ini, Anda akan men-deploy agen Agent Development Kit (ADK) yang siap produksi dengan backend Gemma yang dipercepat GPU. Fokusnya adalah pada pola deployment penting: menyiapkan layanan Cloud Run yang mendukung GPU, mengintegrasikan backend model dengan agen ADK, dan mengamati perilaku penskalaan otomatis saat beban.
Yang akan Anda lakukan
Dalam lab ini, Anda akan berfokus pada aspek penting deployment produksi:
- Men-deploy Gemma ke Cloud Run dengan GPU - Menyiapkan backend model Gemma berperforma tinggi
- Mengintegrasikan deployment Gemma dengan agen ADK - Menghubungkan agen Anda ke model yang diakselerasi GPU
- Menguji dengan antarmuka Web ADK - Memvalidasi agen percakapan Anda berfungsi dengan benar
- Lakukan pengujian elastisitas - Amati cara kedua instance Cloud Run menangani beban
Penekanannya adalah pada pola deployment produksi, bukan pengembangan agen yang ekstensif.
Yang akan Anda pelajari
- Men-deploy model Gemma yang diakselerasi GPU ke Cloud Run untuk penggunaan produksi
- Mengintegrasikan deployment model eksternal dengan agen ADK
- Mengonfigurasi dan menguji deployment agen AI yang siap produksi
- Memahami perilaku Cloud Run saat berada di bawah beban
- Mengamati cara beberapa instance Cloud Run berkoordinasi selama lonjakan traffic
- Menerapkan pengujian elastisitas untuk memvalidasi performa
2. Penyiapan Project
- Jika belum memiliki Akun Google, Anda harus membuat Akun Google.
- Gunakan akun pribadi, bukan akun kantor atau sekolah. Akun kantor dan sekolah mungkin memiliki batasan yang mencegah Anda mengaktifkan API yang diperlukan untuk lab ini.
- Login ke Konsol Google Cloud.
- Aktifkan penagihan di Konsol Cloud.
- Menyelesaikan lab ini akan dikenai biaya kurang dari $1 USD untuk resource Cloud.
- Anda dapat mengikuti langkah-langkah di akhir lab ini untuk menghapus resource agar tidak dikenai biaya lebih lanjut.
- Pengguna baru memenuhi syarat untuk mengikuti Uji Coba Gratis senilai$300 USD.
- Buat project baru atau pilih untuk menggunakan kembali project yang ada.
- Jika Anda melihat error tentang kuota project, gunakan kembali project yang ada atau hapus project yang ada untuk membuat project baru.
3. Buka Cloud Shell Editor
- Klik link ini untuk langsung membuka Cloud Shell Editor
- Jika diminta untuk memberikan otorisasi kapan saja hari ini, klik Authorize untuk melanjutkan.
- Jika terminal tidak muncul di bagian bawah layar, buka terminal:
- Klik Lihat
- Klik Terminal
- Di terminal, tetapkan project Anda dengan perintah ini:
- Format:
gcloud config set project [PROJECT_ID] - Contoh:
gcloud config set project lab-project-id-example - Jika Anda tidak ingat project ID Anda:
- Anda dapat mencantumkan semua project ID Anda dengan:
gcloud projects list | awk '/PROJECT_ID/{print $2}'
- Anda dapat mencantumkan semua project ID Anda dengan:
- Format:
- Anda akan melihat pesan ini:
Updated property [core/project].
WARNINGdan dimintaDo you want to continue (Y/n)?, berarti Anda kemungkinan telah memasukkan ID project dengan salah. Tekann, tekanEnter, lalu coba jalankan perintahgcloud config set projectlagi.
4. Mengaktifkan API dan Menetapkan Region Default
Sebelum dapat men-deploy layanan Cloud Run dengan dukungan GPU, kita perlu mengaktifkan Google Cloud API yang diperlukan dan mengonfigurasi setelan project Anda.
- Di terminal, aktifkan API:
gcloud services enable \
run.googleapis.com \
artifactregistry.googleapis.com \
cloudbuild.googleapis.com \
aiplatform.googleapis.com
Jika diminta untuk memberikan otorisasi, klik Authorize untuk melanjutkan.
Pemrosesan perintah ini mungkin membutuhkan waktu beberapa menit, tetapi pada akhirnya akan menghasilkan pesan keberhasilan yang mirip dengan yang berikut:
Operation "operations/acf.p2-73d90d00-47ee-447a-b600" finished successfully.
- Tetapkan region Cloud Run default Anda.
gcloud config set run/region europe-west4
5. Menyiapkan project Python
Mari kita siapkan kode awal yang berisi struktur dasar untuk layanan backend Gemma dan agen ADK.
- Buat clone repositori awal:
cd ~ npx -y giget@latest gh+git:GoogleCloudPlatform/devrel-demos/agents/accelerate-ai-with-cloud-run/accelerate-ai-lab3-starter accelerate-ai-lab3-starter cd accelerate-ai-lab3-starter - Periksa struktur project:
ls -Raccelerate-ai-lab3-starter/ ├── README.md # Project overview ├── ollama-backend/ # Ollama backend (separate deployment) │ └── Dockerfile # Backend container (🚧 to implement) └── adk-agent/ # ADK agent (separate deployment) ├── pyproject.toml # Python dependencies (✅ completed) ├── server.py # FastAPI server (🚧 to implement) ├── Dockerfile # Container config (🚧 to implement) ├── elasticity_test.py # Elasticity testing (🚧 to implement) └── production_agent/ # Agent implementation ├── __init__.py # Package init (✅ completed) └── agent.py # Agent logic (🚧 to implement)
6. Ringkasan Arsitektur
Sebelum menerapkan, mari kita pahami arsitektur dua layanan:
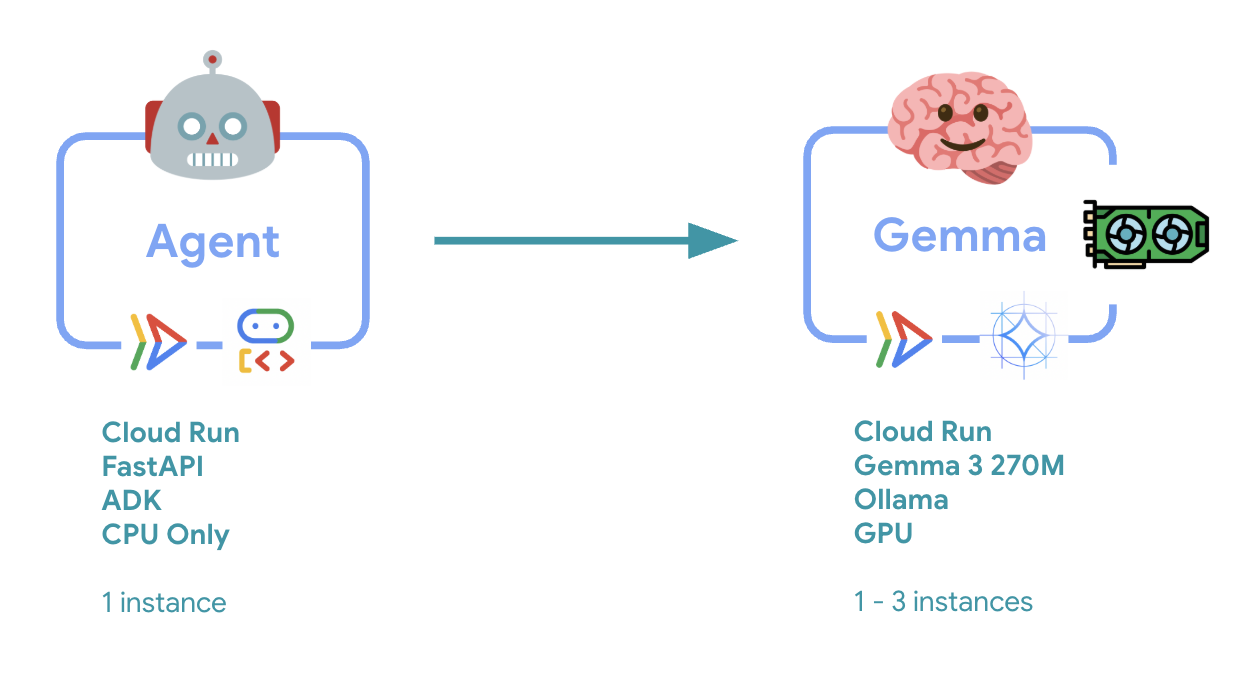
Insight utama: Selama pengujian elastisitas, Anda akan mengamati kedua layanan menangani beban kerja secara independen - backend GPU (layanan bottleneck) menggunakan GPU-nya untuk menangani beban, sementara agen ADK mengandalkan CPU-nya untuk menangani permintaan yang tidak terlalu intensif resource-nya.
7. Men-deploy Backend Gemma ke Cloud Run dengan GPU
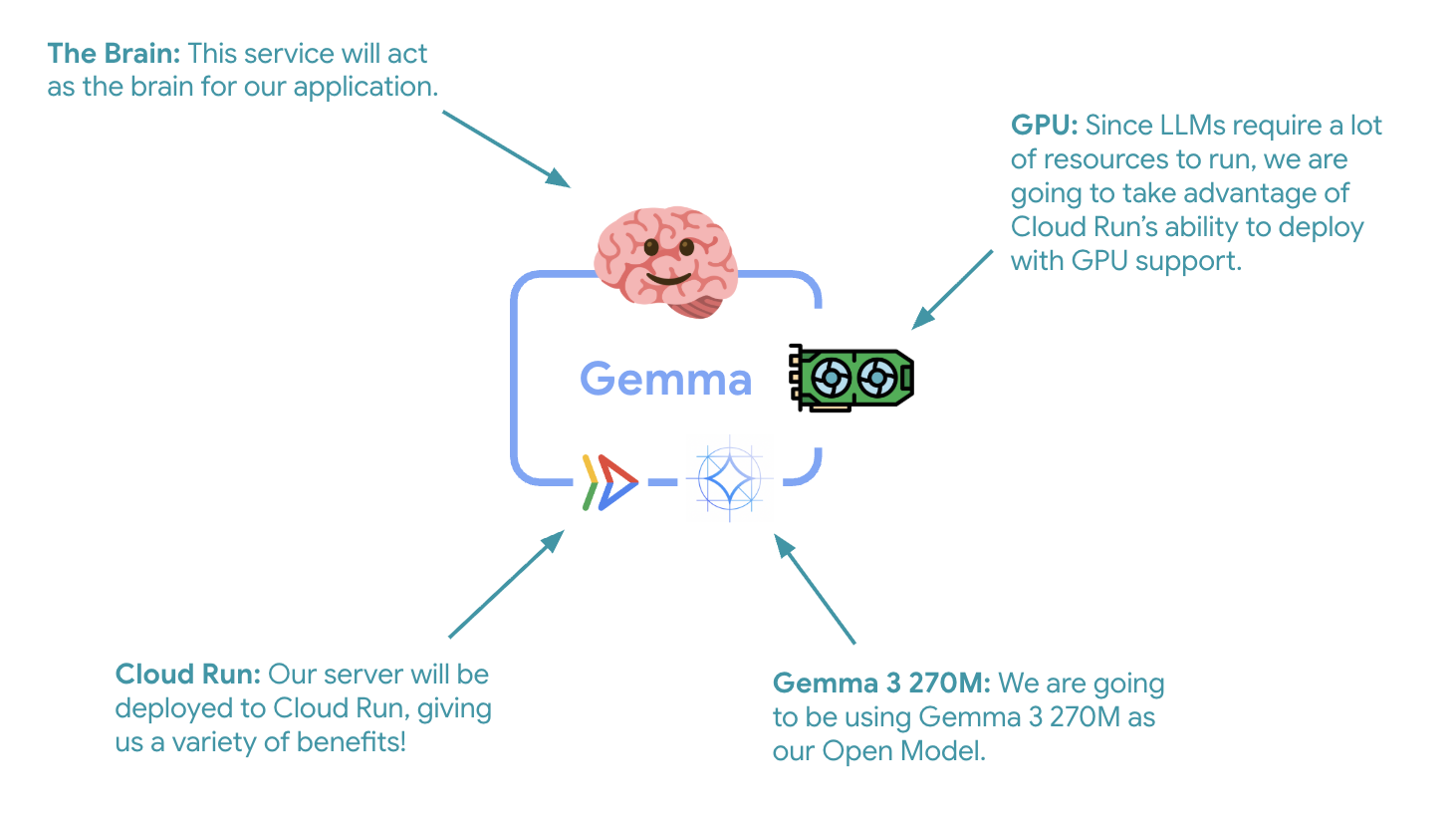
Langkah penting pertama adalah men-deploy model Gemma yang dipercepat GPU, yang akan berfungsi sebagai otak untuk agen ADK Anda. Memiliki LLM yang di-deploy dan dipisahkan mungkin lebih baik dalam arsitektur yang memerlukan model yang disesuaikan secara terpisah, atau memerlukan penskalaan yang terisolasi.
- Buka direktori backend Ollama:
cd ollama-backend - Buka dan terapkan Dockerfile Ollama:
cloudshell edit DockerfileFROM ollama/ollama:latest # Listen on all interfaces, port 8080 ENV OLLAMA_HOST 0.0.0.0:8080 # Store model weight files in /models ENV OLLAMA_MODELS /models # Reduce logging verbosity ENV OLLAMA_DEBUG false # Never unload model weights from the GPU ENV OLLAMA_KEEP_ALIVE -1 # Store the model weights in the container image ENV MODEL gemma3:270m RUN ollama serve & sleep 5 && ollama pull $MODEL # Start Ollama ENTRYPOINT ["ollama", "serve"]- Menggunakan image Ollama resmi sebagai fondasi
- Menetapkan
OLLAMA_HOSTuntuk menerima koneksi dari alamat IP mana pun - Mengekspos port 8080
- Deploy backend Gemma dengan dukungan GPU:
gcloud run deploy ollama-gemma3-270m-gpu \
--source . \
--region europe-west4 \
--concurrency 7 \
--cpu 8 \
--set-env-vars OLLAMA_NUM_PARALLEL=4 \
--gpu 1 \
--gpu-type nvidia-l4 \
--max-instances 1 \
--memory 16Gi \
--allow-unauthenticated \
--no-cpu-throttling \
--no-gpu-zonal-redundancy \
--timeout 600 \
--labels dev-tutorial=codelab-agent-gpu
Jika Anda menerima pesan "Deploying from source requires an Artifact Registry Docker repository to store built containers. Pesan "Repositori bernama [cloud-run-source-deploy] di region [europe-west4] akan dibuat", lanjutkan.
⚙️ Penjelasan konfigurasi utama:
- GPU: NVIDIA L4 dipilih karena rasio harga dan performanya yang sangat baik untuk workload inferensi. L4 menyediakan memori GPU 24 GB dan operasi tensor yang dioptimalkan, sehingga ideal untuk model parameter 270M seperti Gemma
- Memori: Memori sistem 16 GB untuk menangani pemuatan model, operasi CUDA, dan pengelolaan memori Ollama
- CPU: 8 core untuk penanganan I/O dan tugas praproses yang optimal
- Konkurensi: 7 permintaan per instance menyeimbangkan throughput dengan penggunaan memori GPU
- Waktu tunggu: 600 detik untuk mengakomodasi pemuatan model awal dan pengaktifan penampung
💰 Pertimbangan Biaya: Instance GPU jauh lebih mahal daripada instance khusus CPU (~$2-4/jam vs ~$0,10/jam). Setelan --max-instances 1 membantu mengontrol biaya dengan mencegah penskalaan instance GPU yang tidak perlu.
- Tunggu hingga deployment selesai dan catat URL layanan:
export OLLAMA_URL=$(gcloud run services describe ollama-gemma3-270m-gpu \ --region=europe-west4 \ --format='value(status.url)') echo "🎉 Gemma backend deployed at: $OLLAMA_URL"
8. Menerapkan Integrasi Agen ADK
Sekarang, mari kita buat agen ADK minimal yang terhubung ke backend Gemma yang di-deploy.
- Buka direktori agen ADK:
cd ../adk-agent - Buka dan terapkan konfigurasi agen:
cloudshell edit production_agent/agent.pyimport os from pathlib import Path from dotenv import load_dotenv from google.adk.agents import Agent from google.adk.models.lite_llm import LiteLlm import google.auth # Load environment variables root_dir = Path(__file__).parent.parent dotenv_path = root_dir / ".env" load_dotenv(dotenv_path=dotenv_path) # Configure Google Cloud try: _, project_id = google.auth.default() os.environ.setdefault("GOOGLE_CLOUD_PROJECT", project_id) except Exception: pass os.environ.setdefault("GOOGLE_CLOUD_LOCATION", "europe-west4") # Configure model connection gemma_model_name = os.getenv("GEMMA_MODEL_NAME", "gemma3:270m") api_base = os.getenv("OLLAMA_API_BASE", "localhost:10010") # Location of Ollama server # Production Gemma Agent - GPU-accelerated conversational assistant production_agent = Agent( model=LiteLlm(model=f"ollama_chat/{gemma_model_name}", api_base=api_base), name="production_agent", description="A production-ready conversational assistant powered by GPU-accelerated Gemma.", instruction="""You are 'Gem', a friendly, knowledgeable, and enthusiastic zoo tour guide. Your main goal is to make a zoo visit more fun and educational for guests by answering their questions. You can provide general information and interesting facts about different animal species, such as: - Their natural habitats and diet. 🌲🍓 - Typical lifespan and behaviors. - Conservation status and unique characteristics. IMPORTANT: You do NOT have access to any tools. This means you cannot look up real-time, specific information about THIS zoo. You cannot provide: - The names or ages of specific animals currently at the zoo. - The exact location or enclosure for an animal. - The daily schedule for feedings or shows. Always answer based on your general knowledge about the animal kingdom. Keep your tone cheerful, engaging, and welcoming for visitors of all ages. 🦁✨""", tools=[], # Gemma focuses on conversational capabilities ) # Set as root agent root_agent = production_agent- Menghubungkan ke backend Gemma yang di-deploy melalui LiteLlm
- Membuat agen percakapan sederhana
- Mengonfigurasi integrasi Google Cloud
- Buka dan terapkan server FastAPI:
cloudshell edit server.pyimport os from dotenv import load_dotenv from fastapi import FastAPI from google.adk.cli.fast_api import get_fast_api_app # Load environment variables load_dotenv() AGENT_DIR = os.path.dirname(os.path.abspath(__file__)) app_args = {"agents_dir": AGENT_DIR, "web": True} # Create FastAPI app with ADK integration app: FastAPI = get_fast_api_app(**app_args) # Update app metadata app.title = "Production ADK Agent - Lab 3" app.description = "Gemma agent with GPU-accelerated backend" app.version = "1.0.0" @app.get("/health") def health_check(): return {"status": "healthy", "service": "production-adk-agent"} @app.get("/") def root(): return { "service": "Production ADK Agent - Lab 3", "description": "GPU-accelerated Gemma agent", "docs": "/docs", "health": "/health" } if __name__ == "__main__": import uvicorn uvicorn.run(app, host="0.0.0.0", port=8080, log_level="info")- Membuat server FastAPI dengan integrasi ADK
- Mengaktifkan antarmuka web untuk pengujian
- Menyediakan endpoint health check
- Buka dan terapkan Dockerfile:
cloudshell edit DockerfileFROM python:3.13-slim # Copy uv from the official image COPY --from=ghcr.io/astral-sh/uv:latest /uv /usr/local/bin/uv # Install system dependencies RUN apt-get update && apt-get install -y curl && rm -rf /var/lib/apt/lists/* # Set working directory WORKDIR /app # Copy all files COPY . . # Install Python dependencies RUN uv sync # Expose port EXPOSE 8080 # Run the application CMD ["uv", "run", "uvicorn", "server:app", "--host", "0.0.0.0", "--port", "8080"]- uv: Pengelola paket Python modern yang 10-100x lebih cepat daripada pip. Cloud Build menggunakan cache global dan download paralel, sehingga secara signifikan mengurangi waktu build container
- Python 3.13-slim: Versi Python terbaru dengan dependensi sistem minimal, sehingga mengurangi ukuran container dan permukaan serangan
- Build multi-tahap: Menyalin uv dari image resminya memastikan kita mendapatkan biner yang dioptimalkan terbaru
9. Mengonfigurasi Lingkungan dan Men-deploy Agen
Sekarang kita akan mengonfigurasi agen ADK untuk terhubung ke backend Gemma yang di-deploy dan men-deploy-nya sebagai layanan Cloud Run. Hal ini melibatkan penyiapan variabel lingkungan dan men-deploy agen dengan konfigurasi yang tepat.
- Siapkan konfigurasi lingkungan Anda:
cat << EOF > .env GOOGLE_CLOUD_PROJECT=$(gcloud config get-value project) GOOGLE_CLOUD_LOCATION=europe-west4 GEMMA_MODEL_NAME=gemma3:270m OLLAMA_API_BASE=$OLLAMA_URL EOF
Memahami Variabel Lingkungan di Cloud Run
Variabel lingkungan adalah pasangan nilai kunci yang mengonfigurasi aplikasi Anda saat runtime. Fitur ini sangat berguna untuk:
- Endpoint API dan URL layanan (seperti backend Ollama kami)
- Konfigurasi yang berubah di antara lingkungan (dev, staging, prod)
- Data sensitif yang tidak boleh di-hardcode
Men-deploy agen ADK:
export PROJECT_ID=$(gcloud config get-value project)
gcloud run deploy production-adk-agent \
--source . \
--region europe-west4 \
--allow-unauthenticated \
--memory 4Gi \
--cpu 2 \
--max-instances 1 \
--concurrency 50 \
--timeout 300 \
--set-env-vars GOOGLE_CLOUD_PROJECT=$PROJECT_ID \
--set-env-vars GOOGLE_CLOUD_LOCATION=europe-west4 \
--set-env-vars GEMMA_MODEL_NAME=gemma3:270m \
--set-env-vars OLLAMA_API_BASE=$OLLAMA_URL \
--labels dev-tutorial=codelab-agent-gpu
⚙️ Konfigurasi utama:
- Penskalaan otomatis: Tetap pada 1 instance (penanganan permintaan ringan)
- Konkurensi: 50 permintaan per instance
- Memori: 4 GB untuk agen ADK
- Environment: Terhubung ke backend Gemma Anda
🔒 Catatan Keamanan: Lab ini menggunakan --allow-unauthenticated untuk mempermudah. Dalam produksi, terapkan autentikasi yang tepat menggunakan:
- Autentikasi antar-layanan Cloud Run dengan akun layanan
- Kebijakan Identity and Access Management (IAM)
- Kunci API atau OAuth untuk akses eksternal
- Pertimbangkan penggunaan
gcloud run services add-iam-policy-bindinguntuk mengontrol akses
Dapatkan URL layanan agen Anda:
export AGENT_URL=$(gcloud run services describe production-adk-agent \
--region=europe-west4 \
--format='value(status.url)')
echo "🎉 ADK Agent deployed at: $AGENT_URL"
✅ Praktik terbaik variabel lingkungan berdasarkan dokumentasi variabel lingkungan Cloud Run:
- Hindari variabel yang dicadangkan: Jangan tetapkan
PORT(jika Anda perlu mengubah variabel lingkungan, gunakan tanda –port) atau variabel yang dimulai denganX_GOOGLE_ - Gunakan nama deskriptif: Beri awalan pada variabel Anda untuk menghindari konflik (misalnya,
GEMMA_MODEL_NAME, bukanMODEL) - Escape koma: Jika nilai Anda berisi koma, gunakan pemisah yang berbeda:
--set-env-vars "^@^KEY1=value1,value2@KEY2=..." - Perbarui vs. Ganti: Gunakan
--update-env-varsuntuk menambahkan/mengubah variabel tertentu tanpa memengaruhi variabel lainnya
Cara menyetel variabel di Cloud Run:
- Dari file:
gcloud run deploy SERVICE_NAME --env-vars-file .env --labels dev-tutorial codelab-adk(memuat beberapa variabel dari file) - Beberapa tanda: Ulangi
--set-env-varsuntuk nilai kompleks yang tidak dapat dipisahkan dengan koma
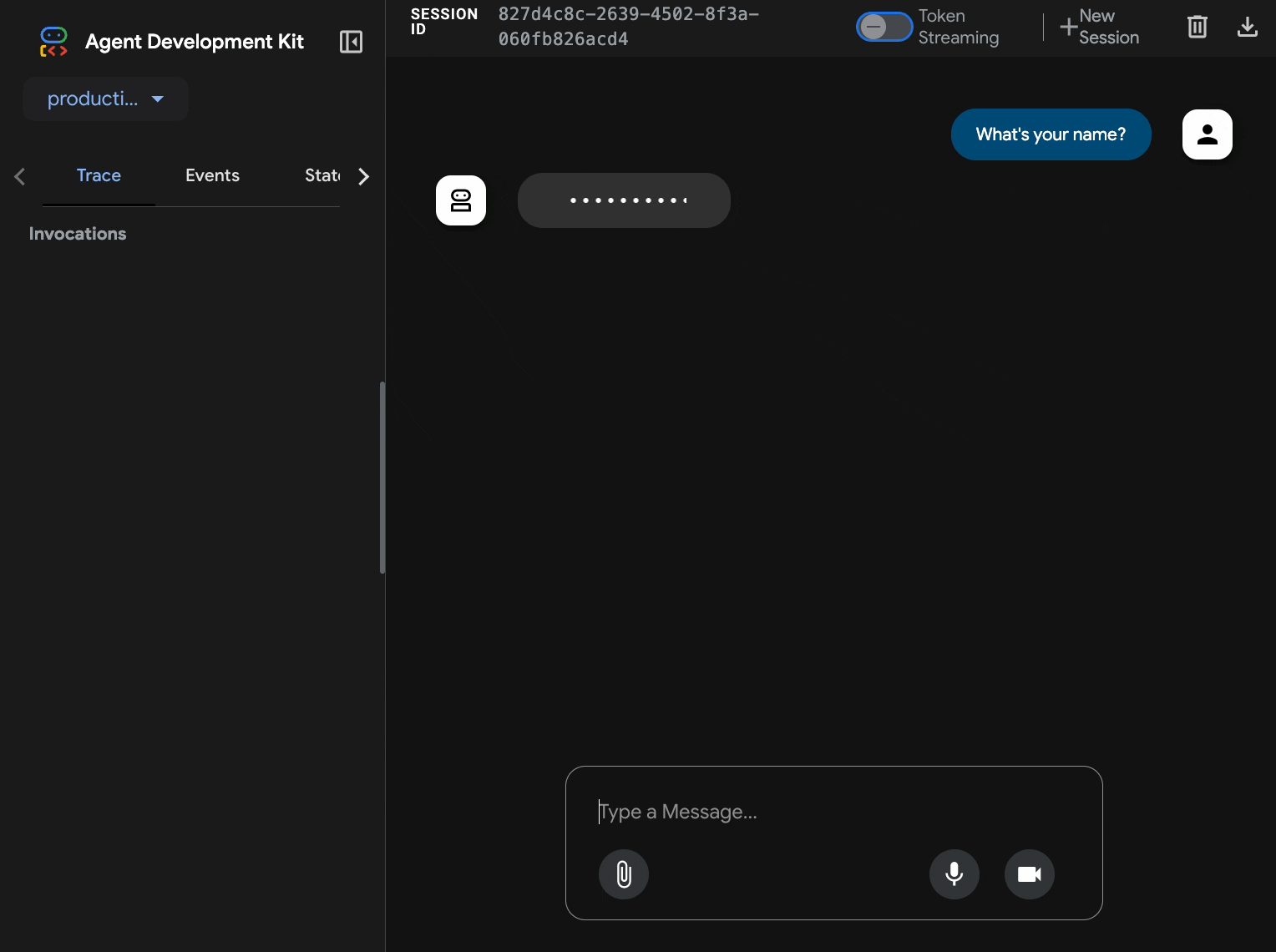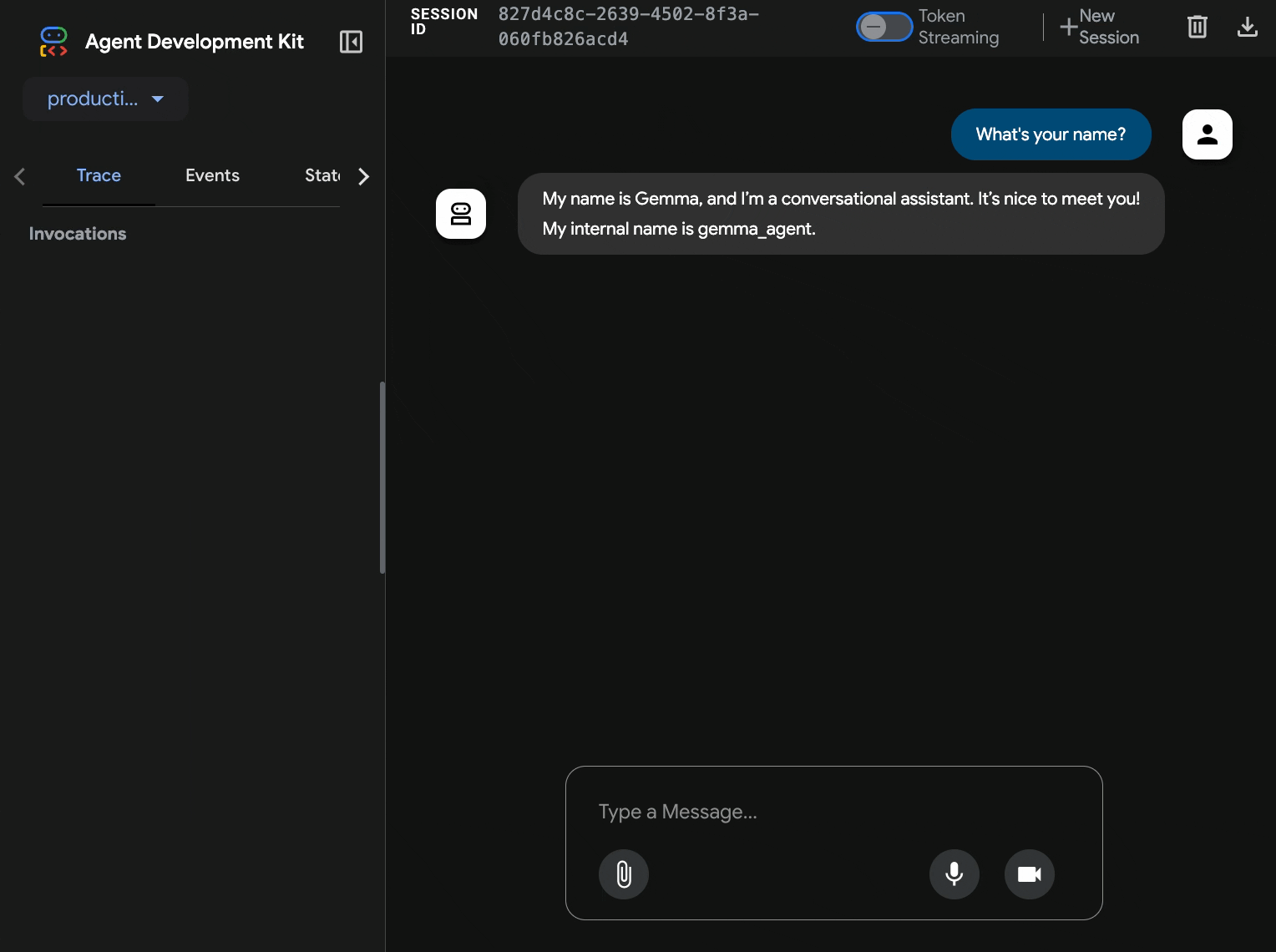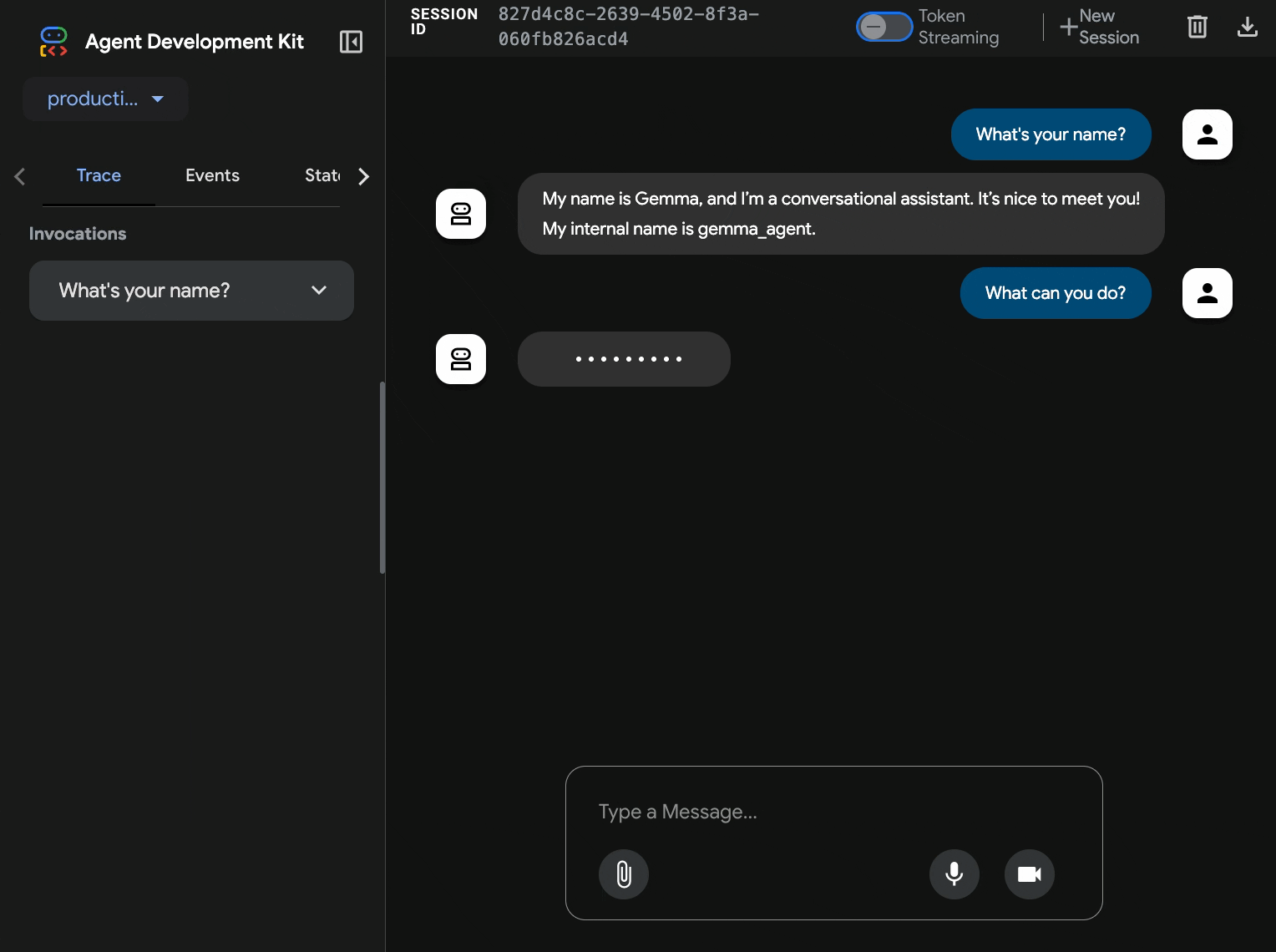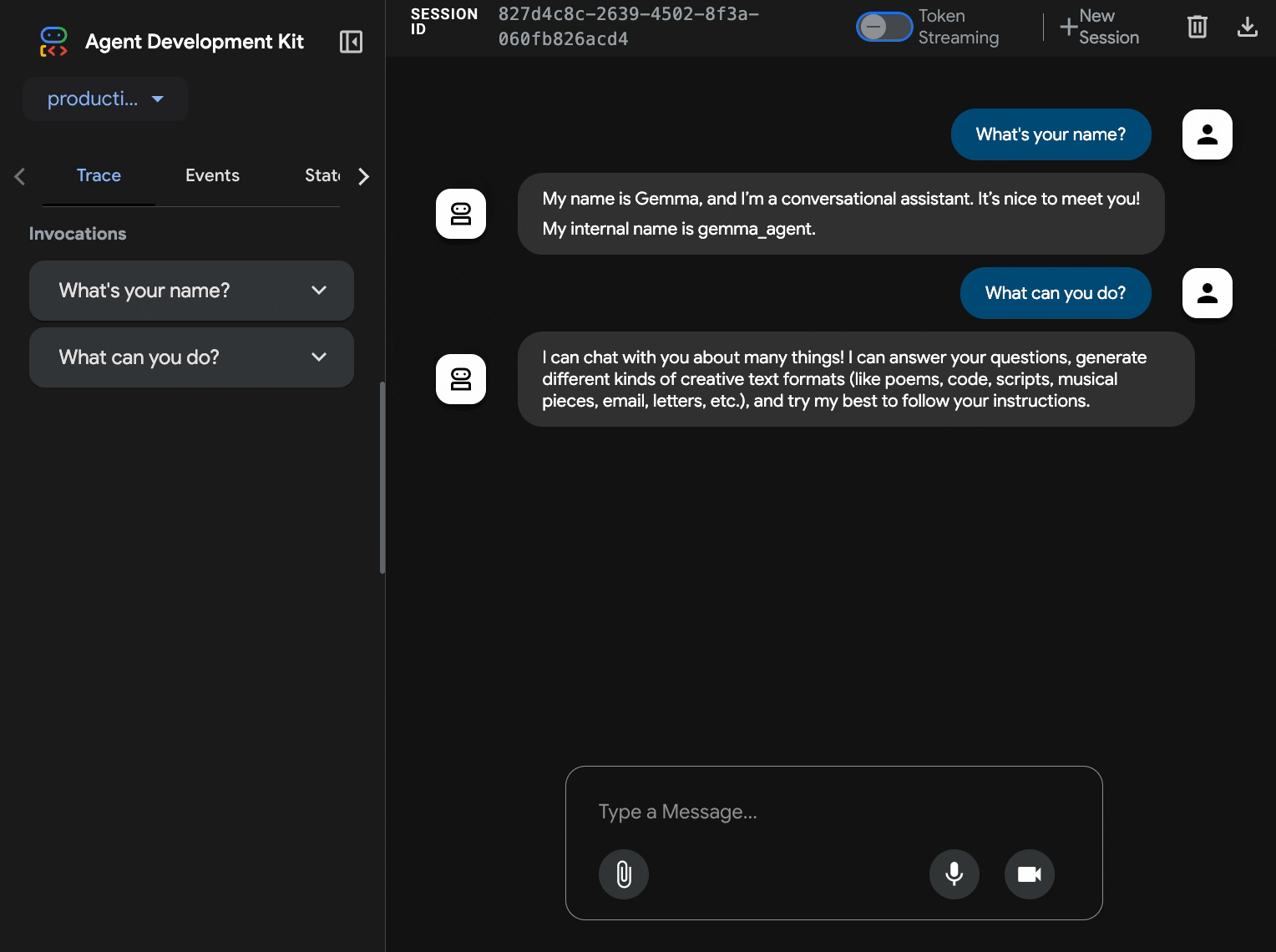
10. Menguji dengan Antarmuka Web ADK
Setelah kedua layanan di-deploy, saatnya memvalidasi bahwa agen ADK Anda dapat berkomunikasi dengan backend Gemma yang dipercepat GPU dan merespons kueri pengguna dengan berhasil.
- Uji endpoint health:
curl $AGENT_URL/health{ "status": "healthy", "service": "production-adk-agent" } - Berinteraksi dengan agen Anda dengan memasukkan URL untuk
production-adk-agentke tab browser baru. Anda akan melihat antarmuka web ADK. - Uji agen Anda dengan contoh percakapan berikut:
- "Apa yang biasanya dimakan panda merah di alam liar?"
- "Can you tell me an interesting fact about snow leopards?" (Bisa ceritakan fakta menarik tentang macan tutul salju?)
- "Mengapa katak panah beracun memiliki warna yang cerah?"
- "Di mana saya dapat menemukan bayi kanguru baru di kebun binatang?"
- Agen merespons menggunakan model Gemma yang di-deploy. Anda dapat memverifikasi hal ini dengan mengamati log untuk layanan Gemma yang di-deploy. Kita akan melakukannya di bagian berikutnya
- Respons dihasilkan oleh backend yang diakselerasi GPU
- Antarmuka web memberikan pengalaman chat yang bersih
11. Menerapkan dan Menjalankan Pengujian Elastisitas
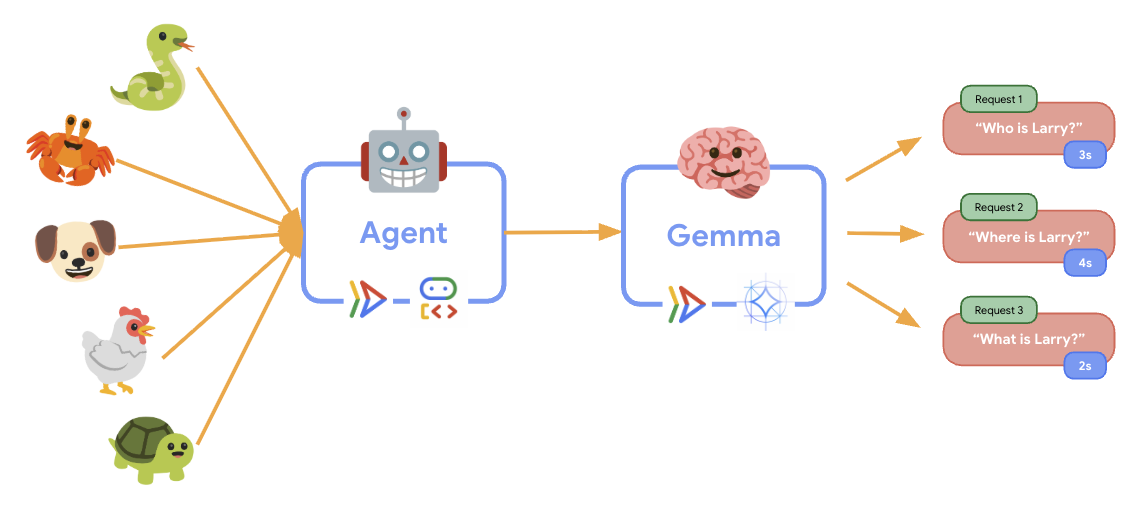
Untuk memahami cara penyiapan produksi Anda menangani traffic dunia nyata, kami akan menerapkan pengujian elastisitas yang akan menguji kemampuan sistem untuk beradaptasi dengan beban kerja produksi "simulasi" yang lebih tinggi.
- Buka dan terapkan skrip pengujian elastisitas:
cloudshell edit elasticity_test.pyimport random import uuid from locust import HttpUser, task, between class ProductionAgentUser(HttpUser): """Elasticity test user for the Production ADK Agent.""" wait_time = between(1, 3) # Faster requests to trigger scaling def on_start(self): """Set up user session when starting.""" self.user_id = f"user_{uuid.uuid4()}" self.session_id = f"session_{uuid.uuid4()}" # Create session for the Gemma agent using proper ADK API format session_data = {"state": {"user_type": "elasticity_test_user"}} self.client.post( f"/apps/production_agent/users/{self.user_id}/sessions/{self.session_id}", headers={"Content-Type": "application/json"}, json=session_data, ) @task(4) def test_conversations(self): """Test conversational capabilities - high frequency.""" topics = [ "What do red pandas typically eat in the wild?", "Can you tell me an interesting fact about snow leopards?", "Why are poison dart frogs so brightly colored?", "Where can I find the new baby kangaroo in the zoo?", "What is the name of your oldest gorilla?", "What time is the penguin feeding today?" ] # Use proper ADK API format for sending messages message_data = { "app_name": "production_agent", "user_id": self.user_id, "session_id": self.session_id, "new_message": { "role": "user", "parts": [{ "text": random.choice(topics) }] } } self.client.post( "/run", headers={"Content-Type": "application/json"}, json=message_data, ) @task(1) def health_check(self): """Test the health endpoint.""" self.client.get("/health")- Pembuatan Sesi: Menggunakan format ADK API yang tepat dengan POST ke
/apps/production_agent/users/{user_id}/sessions/{session_id}. Setelah membuatsession_iddanuser_id, permintaan dapat dibuat ke agen. - Format Pesan: Mengikuti spesifikasi ADK dengan
app_name,user_id,session_id, dan objeknew_messageterstruktur - Conversation Endpoint: Menggunakan endpoint
/rununtuk mengumpulkan semua peristiwa sekaligus (direkomendasikan untuk pengujian beban) - Pemuatan Realistis: Membuat pemuatan percakapan dengan waktu tunggu yang lebih singkat
- Pembuatan Sesi: Menggunakan format ADK API yang tepat dengan POST ke
- Instal dependensi:
uv sync - Locust adalah alat pengujian beban berbasis Python open source yang dirancang untuk pengujian performa dan beban aplikasi web serta sistem lainnya. Karakteristik utamanya adalah skenario pengujian dan perilaku pengguna ditentukan menggunakan kode Python standar, sehingga menawarkan fleksibilitas dan ekspresivitas yang tinggi dibandingkan dengan alat yang mengandalkan antarmuka pengguna grafis atau bahasa khusus domain. Kita akan menggunakan Locust untuk menyimulasikan traffic pengguna ke layanan kita.Jalankan pengujian.
uv run locust -f elasticity_test.py \ -H $AGENT_URL \ --headless \ -t 60s \ -u 20 \ -r 5- Durasi: 60 detik
- Pengguna: 20 pengguna serentak
- Kecepatan kemunculan: 5 pengguna per detik
- Target: Memicu penskalaan otomatis pada kedua layanan
12. Mengamati Perilaku Penskalaan Otomatis
Saat uji elastisitas berjalan, Anda dapat mengamati dukungan Cloud Run untuk beban kerja yang lebih tinggi. Di sinilah Anda akan melihat manfaat arsitektur utama dari pemisahan agen ADK dari backend GPU.
Selama pengujian elastisitas, pantau cara kedua layanan Cloud Run menangani traffic di konsol Anda.
- Di Konsol Cloud, buka:
- Cloud Run → production-adk-agent → Metrik
- Cloud Run → ollama-gemma3-270m-gpu → Metrik
👀 Yang harus Anda amati:
🤖 Layanan Agen ADK:
- Harus tetap stabil pada 1 instance saat traffic meningkat
- Lonjakan penggunaan CPU dan memori selama traffic tinggi
- Menangani pengelolaan sesi dan pemilihan rute permintaan secara efisien
🎮 Layanan Backend Gemma (Hambatan):
- Harus tetap stabil pada 1 instance saat traffic meningkat
- Penggunaan GPU meningkat secara signifikan saat beban
- Layanan ini menjadi hambatan karena inferensi model yang intensif GPU
- Waktu inferensi model tetap konsisten karena akselerasi GPU
💡 Insight Utama:
- Kedua layanan tetap konsisten dan tidak ditingkatkan skalanya, karena kita menetapkan instance maksimum ke
1 - Kedua layanan ini diskalakan secara independen berdasarkan karakteristik beban masing-masing
- GPU membantu mempertahankan performa dalam berbagai kondisi beban
13. Kesimpulan
Selamat! Anda telah berhasil men-deploy agen ADK siap produksi dengan backend Gemma yang dipercepat GPU, sekaligus menguji workload produksi yang disimulasikan.
✅ Yang telah Anda capai
- ✅ Men-deploy backend model Gemma yang diakselerasi GPU di Cloud Run
- ✅ Membuat dan men-deploy agen ADK yang terintegrasi dengan backend Gemma
- ✅ Menguji agen menggunakan antarmuka web ADK
- ✅ Mengamati perilaku penskalaan otomatis di dua layanan Cloud Run yang terkoordinasi
💡 Insight utama dari lab ini
- 🎮 Akselerasi GPU: GPU NVIDIA L4 secara signifikan meningkatkan performa inferensi model
- 🔗 Koordinasi Layanan: Dua layanan Cloud Run dapat bekerja sama dengan lancar
- 📈 Penskalaan Independen: Setiap layanan diskalakan berdasarkan karakteristik beban masing-masing
- 🚀 Kesiapan Produksi: Arsitektur menangani pola traffic dunia nyata secara efektif
🔄 Langkah berikutnya
- Lakukan eksperimen dengan berbagai pola beban dan amati perilaku penskalaan
- Coba berbagai ukuran model Gemma (sesuaikan memori dan GPU dengan tepat)
- Menerapkan pemantauan dan pemberitahuan untuk deployment produksi
- Mempelajari deployment multi-region untuk ketersediaan global
🧹 Membersihkan
Untuk menghindari timbulnya biaya, hapus resource setelah Anda selesai:
gcloud run services delete production-adk-agent --region=europe-west4
gcloud run services delete ollama-gemma3-270m-gpu --region=europe-west4
📖 Referensi
- Repositori Starter
- Solusi Lengkap
- Dokumentasi ADK Google
- Panduan Pengujian ADK - Referensi lengkap untuk endpoint API ADK dan pola pengujian
- Pengujian Beban di Cloud Run
- Dokumentasi Agent Development Kit (ADK)
- Dokumentasi GPU Cloud Run
- Ollama Model Library
- Dokumentasi Google Cloud Trace
- Praktik Terbaik Keamanan Cloud Run
- Pengelola Paket Python UV
- Framework Pengujian Beban Locust