
1. Introduzione
Panoramica
In questo lab, eseguirai il deployment di un agente Agent Development Kit (ADK) pronto per la produzione con un backend Gemma con accelerazione GPU. L'attenzione è rivolta ai pattern di deployment critici: configurazione dei servizi Cloud Run abilitati alla GPU, integrazione dei backend dei modelli con gli agenti ADK e osservazione del comportamento di scalabilità automatica sotto carico.
In questo lab proverai a:
In questo lab ci concentreremo sugli aspetti critici del deployment di produzione:
- Esegui il deployment di Gemma su Cloud Run con GPU: configura un backend del modello Gemma ad alte prestazioni
- Integra il deployment di Gemma con un agente ADK: collega l'agente al modello con accelerazione GPU
- Test con l'interfaccia web ADK: verifica che l'agente conversazionale funzioni correttamente
- Esegui test di elasticità: osserva come le istanze Cloud Run gestiscono il carico
L'accento è posto sui pattern di deployment di produzione anziché sullo sviluppo esteso di agent.
Obiettivi didattici
- Esegui il deployment di modelli Gemma con accelerazione GPU in Cloud Run per l'uso in produzione
- Integrare i deployment di modelli esterni con gli agenti ADK
- Configurare e testare i deployment di agenti AI pronti per la produzione
- Comprendere il comportamento di Cloud Run sotto carico
- Osserva come si coordinano più istanze Cloud Run durante i picchi di traffico
- Applica i test di elasticità per convalidare il rendimento
2. Configurazione del progetto
- Se non hai ancora un Account Google, devi crearne uno.
- Utilizza un account personale anziché un account di lavoro o della scuola. Gli account di lavoro e della scuola potrebbero avere limitazioni che impediscono l'attivazione delle API necessarie per questo lab.
- Accedi a Google Cloud Console.
- Abilita la fatturazione nella console Cloud.
- Il completamento di questo lab dovrebbe costare meno di 1 $in risorse cloud.
- Per evitare ulteriori addebiti, puoi seguire i passaggi alla fine di questo lab per eliminare le risorse.
- I nuovi utenti hanno diritto alla prova senza costi di 300$.
- Crea un nuovo progetto o scegli di riutilizzarne uno esistente.
- Se visualizzi un errore relativo alla quota del progetto, riutilizza un progetto esistente o eliminalo per crearne uno nuovo.
3. Apri editor di Cloud Shell
- Fai clic su questo link per andare direttamente all'editor di Cloud Shell.
- Se ti viene richiesto di concedere l'autorizzazione in qualsiasi momento della giornata, fai clic su Autorizza per continuare.
- Se il terminale non viene visualizzato nella parte inferiore dello schermo, aprilo:
- Fai clic su Visualizza.
- Fai clic su Terminale
 .
.
- Nel terminale, imposta il tuo progetto con questo comando:
- Formato:
gcloud config set project [PROJECT_ID] - Esempio:
gcloud config set project lab-project-id-example - Se non ricordi l'ID progetto:
- Puoi elencare tutti gli ID progetto con:
gcloud projects list | awk '/PROJECT_ID/{print $2}'
- Puoi elencare tutti gli ID progetto con:
- Formato:
- Dovresti visualizzare questo messaggio:
Updated property [core/project].
WARNINGe ti viene chiestoDo you want to continue (Y/n)?, probabilmente hai inserito l'ID progetto in modo errato. Premin, premiEntere prova a eseguire di nuovo il comandogcloud config set project.
4. Abilita le API e imposta la regione predefinita
Prima di poter eseguire il deployment dei servizi Cloud Run con supporto GPU, dobbiamo abilitare le API Cloud richieste e configurare le impostazioni progetto.
- Nel terminale, abilita le API:
gcloud services enable \
run.googleapis.com \
artifactregistry.googleapis.com \
cloudbuild.googleapis.com \
aiplatform.googleapis.com
Se ti viene richiesto di concedere l'autorizzazione, fai clic su Autorizza per continuare.
Il completamento di questo comando potrebbe richiedere alcuni minuti, ma alla fine dovrebbe essere visualizzato un messaggio di operazione riuscita simile a questo:
Operation "operations/acf.p2-73d90d00-47ee-447a-b600" finished successfully.
- Imposta la regione Cloud Run predefinita.
gcloud config set run/region europe-west4
5. Prepara il progetto Python
Configuriamo il codice di avvio che contiene la struttura di base sia per il backend Gemma sia per i servizi dell'agente ADK.
- Clona il repository iniziale:
cd ~ npx -y giget@latest gh+git:GoogleCloudPlatform/devrel-demos/agents/accelerate-ai-with-cloud-run/accelerate-ai-lab3-starter accelerate-ai-lab3-starter cd accelerate-ai-lab3-starter - Esamina la struttura del progetto:
ls -Raccelerate-ai-lab3-starter/ ├── README.md # Project overview ├── ollama-backend/ # Ollama backend (separate deployment) │ └── Dockerfile # Backend container (🚧 to implement) └── adk-agent/ # ADK agent (separate deployment) ├── pyproject.toml # Python dependencies (✅ completed) ├── server.py # FastAPI server (🚧 to implement) ├── Dockerfile # Container config (🚧 to implement) ├── elasticity_test.py # Elasticity testing (🚧 to implement) └── production_agent/ # Agent implementation ├── __init__.py # Package init (✅ completed) └── agent.py # Agent logic (🚧 to implement)
6. Panoramica dell'architettura
Prima dell'implementazione, vediamo l'architettura a due servizi:
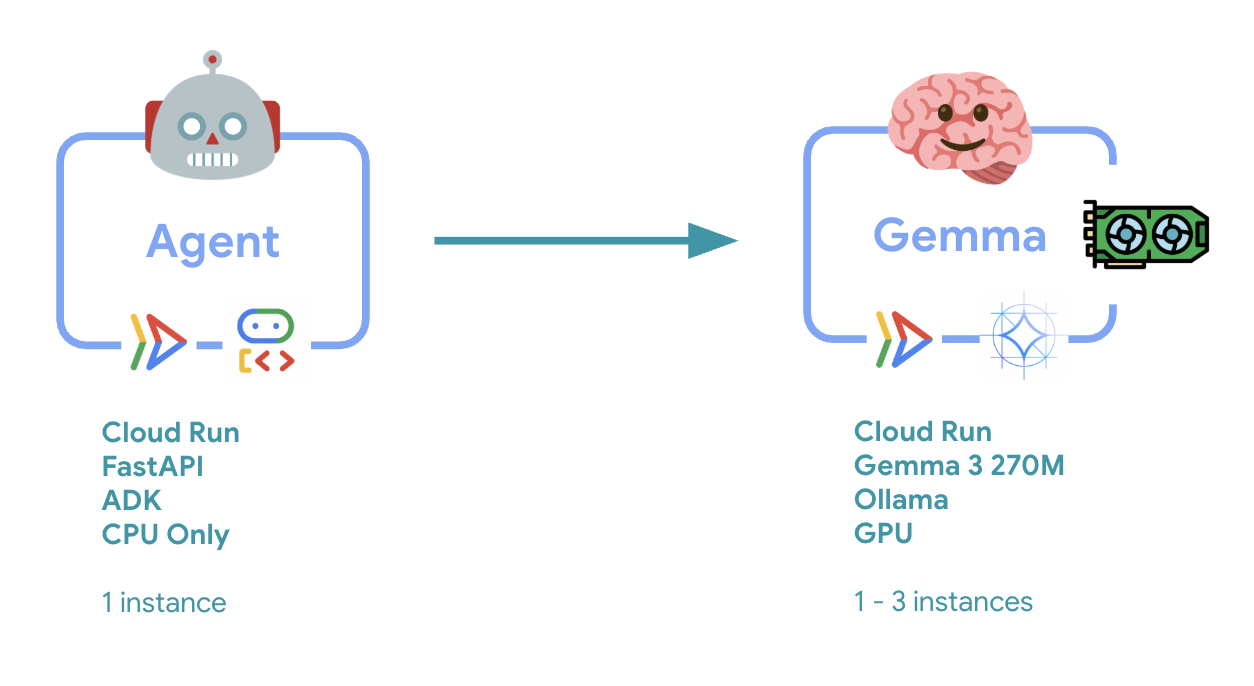
Informazioni chiave: durante il test di elasticità, osserverai entrambi i servizi gestire il carico di lavoro in modo indipendente: il backend GPU (servizio collo di bottiglia) utilizza la GPU per gestire il carico, mentre l'agente ADK si affida alla CPU per gestire le richieste non intensive in termini di risorse.
7. Esegui il deployment del backend Gemma su Cloud Run con GPU
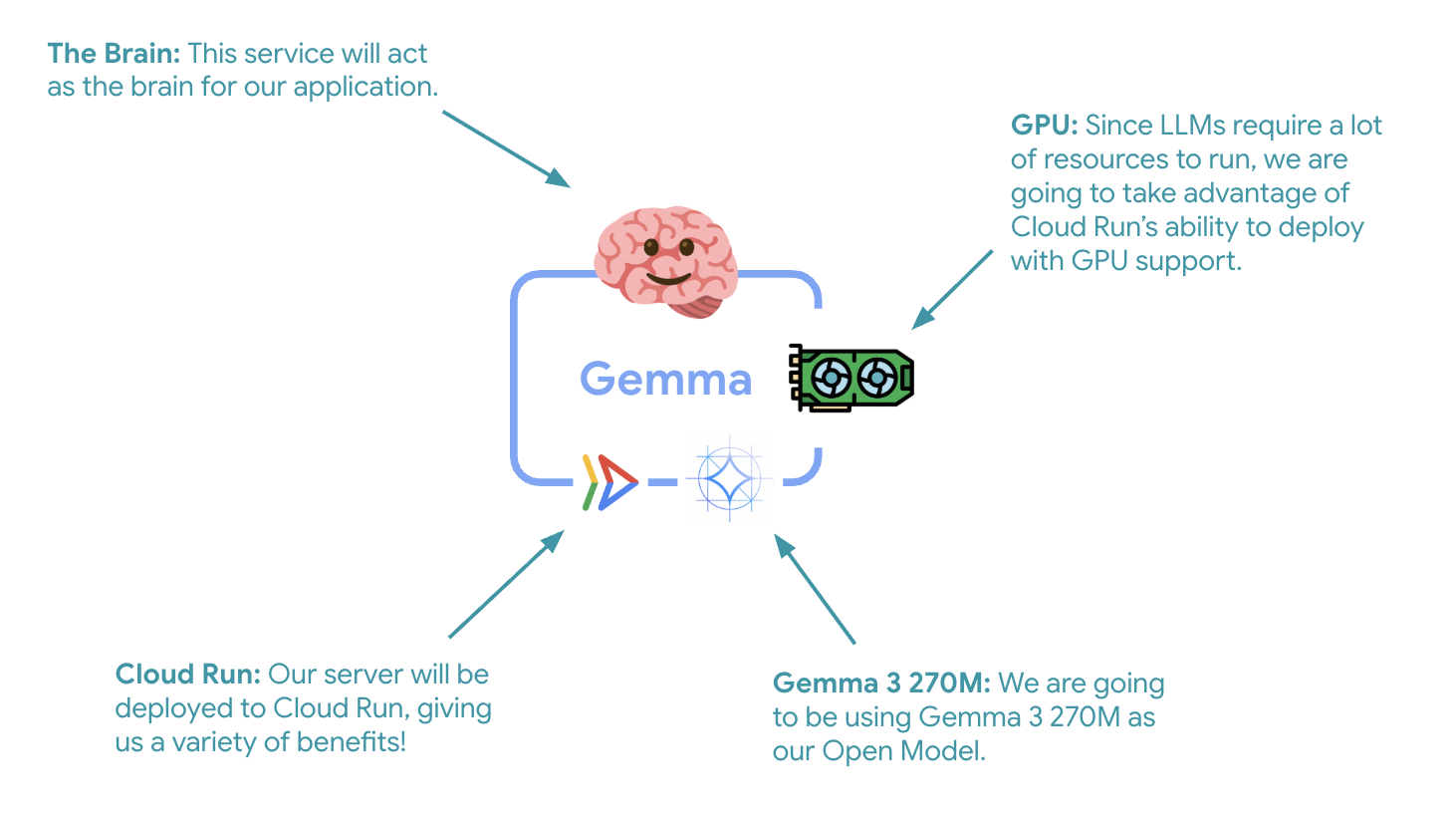
Il primo passaggio fondamentale è il deployment di un modello Gemma con accelerazione GPU, che fungerà da cervello per l'agente ADK. Avere un LLM disaccoppiato e di cui è stato eseguito il deployment può essere vantaggioso nelle architetture in cui è necessario un modello ottimizzato separato o è necessario uno scaling isolato.
- Vai alla directory di backend di Ollama:
cd ollama-backend - Apri e implementa il Dockerfile di Ollama:
cloudshell edit DockerfileFROM ollama/ollama:latest # Listen on all interfaces, port 8080 ENV OLLAMA_HOST 0.0.0.0:8080 # Store model weight files in /models ENV OLLAMA_MODELS /models # Reduce logging verbosity ENV OLLAMA_DEBUG false # Never unload model weights from the GPU ENV OLLAMA_KEEP_ALIVE -1 # Store the model weights in the container image ENV MODEL gemma3:270m RUN ollama serve & sleep 5 && ollama pull $MODEL # Start Ollama ENTRYPOINT ["ollama", "serve"]- Utilizza l'immagine ufficiale di Ollama come base
- Imposta
OLLAMA_HOSTin modo che accetti connessioni da qualsiasi indirizzo IP - Espone la porta 8080
- Esegui il deployment del backend Gemma con il supporto GPU:
gcloud run deploy ollama-gemma3-270m-gpu \
--source . \
--region europe-west4 \
--concurrency 7 \
--cpu 8 \
--set-env-vars OLLAMA_NUM_PARALLEL=4 \
--gpu 1 \
--gpu-type nvidia-l4 \
--max-instances 1 \
--memory 16Gi \
--allow-unauthenticated \
--no-cpu-throttling \
--no-gpu-zonal-redundancy \
--timeout 600 \
--labels dev-tutorial=codelab-agent-gpu
Se ricevi il messaggio "Il deployment dall'origine richiede un repository Docker Artifact Registry per archiviare i container creati. A repository named [cloud-run-source-deploy] in region [europe-west4] will be created." message, continue.
⚙️ Spiegazione della configurazione delle chiavi:
- GPU: NVIDIA L4 scelta per l'eccellente rapporto prezzo/prestazioni per i carichi di lavoro di inferenza. L4 fornisce 24 GB di memoria GPU e operazioni tensoriali ottimizzate, il che lo rende ideale per modelli con 270 milioni di parametri come Gemma
- Memoria: 16 GB di memoria di sistema per gestire il caricamento dei modelli, le operazioni CUDA e la gestione della memoria di Ollama
- CPU: 8 core per la gestione ottimale dell'I/O e delle attività di pre-elaborazione
- Concurrency: 7 richieste per istanza bilanciano la velocità effettiva con la memoria utilizzata della GPU
- Timeout: 600 secondi per il caricamento iniziale del modello e l'avvio del container
💰 Considerazione sui costi: le istanze GPU sono molto più costose delle istanze solo CPU (circa 2-4 $/ora contro circa 0,10 $/ora). L'impostazione --max-instances 1 contribuisce a controllare i costi impedendo lo scaling non necessario delle istanze GPU.
- Attendi il completamento del deployment e prendi nota dell'URL del servizio:
export OLLAMA_URL=$(gcloud run services describe ollama-gemma3-270m-gpu \ --region=europe-west4 \ --format='value(status.url)') echo "🎉 Gemma backend deployed at: $OLLAMA_URL"
8. Implementare l'integrazione dell'agente ADK
Ora creiamo un agente ADK minimale che si connette al backend Gemma di cui è stato eseguito il deployment.
- Vai alla directory dell'agente ADK:
cd ../adk-agent - Apri e implementa la configurazione dell'agente:
cloudshell edit production_agent/agent.pyimport os from pathlib import Path from dotenv import load_dotenv from google.adk.agents import Agent from google.adk.models.lite_llm import LiteLlm import google.auth # Load environment variables root_dir = Path(__file__).parent.parent dotenv_path = root_dir / ".env" load_dotenv(dotenv_path=dotenv_path) # Configure Google Cloud try: _, project_id = google.auth.default() os.environ.setdefault("GOOGLE_CLOUD_PROJECT", project_id) except Exception: pass os.environ.setdefault("GOOGLE_CLOUD_LOCATION", "europe-west4") # Configure model connection gemma_model_name = os.getenv("GEMMA_MODEL_NAME", "gemma3:270m") api_base = os.getenv("OLLAMA_API_BASE", "localhost:10010") # Location of Ollama server # Production Gemma Agent - GPU-accelerated conversational assistant production_agent = Agent( model=LiteLlm(model=f"ollama_chat/{gemma_model_name}", api_base=api_base), name="production_agent", description="A production-ready conversational assistant powered by GPU-accelerated Gemma.", instruction="""You are 'Gem', a friendly, knowledgeable, and enthusiastic zoo tour guide. Your main goal is to make a zoo visit more fun and educational for guests by answering their questions. You can provide general information and interesting facts about different animal species, such as: - Their natural habitats and diet. 🌲🍓 - Typical lifespan and behaviors. - Conservation status and unique characteristics. IMPORTANT: You do NOT have access to any tools. This means you cannot look up real-time, specific information about THIS zoo. You cannot provide: - The names or ages of specific animals currently at the zoo. - The exact location or enclosure for an animal. - The daily schedule for feedings or shows. Always answer based on your general knowledge about the animal kingdom. Keep your tone cheerful, engaging, and welcoming for visitors of all ages. 🦁✨""", tools=[], # Gemma focuses on conversational capabilities ) # Set as root agent root_agent = production_agent- Si connette al backend Gemma di cui è stato eseguito il deployment tramite LiteLlm
- Crea un agente conversazionale semplice
- Configura l'integrazione di Google Cloud
- Apri e implementa il server FastAPI:
cloudshell edit server.pyimport os from dotenv import load_dotenv from fastapi import FastAPI from google.adk.cli.fast_api import get_fast_api_app # Load environment variables load_dotenv() AGENT_DIR = os.path.dirname(os.path.abspath(__file__)) app_args = {"agents_dir": AGENT_DIR, "web": True} # Create FastAPI app with ADK integration app: FastAPI = get_fast_api_app(**app_args) # Update app metadata app.title = "Production ADK Agent - Lab 3" app.description = "Gemma agent with GPU-accelerated backend" app.version = "1.0.0" @app.get("/health") def health_check(): return {"status": "healthy", "service": "production-adk-agent"} @app.get("/") def root(): return { "service": "Production ADK Agent - Lab 3", "description": "GPU-accelerated Gemma agent", "docs": "/docs", "health": "/health" } if __name__ == "__main__": import uvicorn uvicorn.run(app, host="0.0.0.0", port=8080, log_level="info")- Crea un server FastAPI con l'integrazione di ADK
- Attiva l'interfaccia web per i test
- Fornisce endpoint di controllo di integrità
- Apri e implementa il Dockerfile:
cloudshell edit DockerfileFROM python:3.13-slim # Copy uv from the official image COPY --from=ghcr.io/astral-sh/uv:latest /uv /usr/local/bin/uv # Install system dependencies RUN apt-get update && apt-get install -y curl && rm -rf /var/lib/apt/lists/* # Set working directory WORKDIR /app # Copy all files COPY . . # Install Python dependencies RUN uv sync # Expose port EXPOSE 8080 # Run the application CMD ["uv", "run", "uvicorn", "server:app", "--host", "0.0.0.0", "--port", "8080"]- uv: gestore dei pacchetti Python moderno 10-100 volte più veloce di pip. Utilizza una cache globale e download paralleli, riducendo significativamente i tempi di creazione dei container
- Python 3.13-slim: l'ultima versione di Python con dipendenze di sistema minime, che riduce le dimensioni del container e la superficie di attacco
- Build multifase: la copia di uv dalla sua immagine ufficiale garantisce di ottenere l'ultimo binario ottimizzato
9. Configura l'ambiente e implementa l'agente
Ora configureremo l'agente ADK per connetterlo al backend Gemma di cui è stato eseguito il deployment e lo eseguiremo il deployment come servizio Cloud Run. Ciò comporta la configurazione delle variabili di ambiente e il deployment dell'agente con la configurazione corretta.
- Configura la configurazione dell'ambiente:
cat << EOF > .env GOOGLE_CLOUD_PROJECT=$(gcloud config get-value project) GOOGLE_CLOUD_LOCATION=europe-west4 GEMMA_MODEL_NAME=gemma3:270m OLLAMA_API_BASE=$OLLAMA_URL EOF
Informazioni sulle variabili di ambiente in Cloud Run
Le variabili di ambiente sono coppie chiave-valore che configurano l'applicazione in fase di runtime. Sono particolarmente utili per:
- Endpoint API e URL di servizio (come il nostro backend Ollama)
- Configurazione che cambia tra gli ambienti (sviluppo, staging, produzione)
- Dati sensibili che non devono essere hardcoded
Esegui il deployment dell'agente ADK:
export PROJECT_ID=$(gcloud config get-value project)
gcloud run deploy production-adk-agent \
--source . \
--region europe-west4 \
--allow-unauthenticated \
--memory 4Gi \
--cpu 2 \
--max-instances 1 \
--concurrency 50 \
--timeout 300 \
--set-env-vars GOOGLE_CLOUD_PROJECT=$PROJECT_ID \
--set-env-vars GOOGLE_CLOUD_LOCATION=europe-west4 \
--set-env-vars GEMMA_MODEL_NAME=gemma3:270m \
--set-env-vars OLLAMA_API_BASE=$OLLAMA_URL \
--labels dev-tutorial=codelab-agent-gpu
⚙️ Configurazione chiave:
- Scalabilità automatica: fissa a 1 istanza (gestione leggera delle richieste)
- Concorrenza: 50 richieste per istanza
- Memoria: 4 GB per l'agente ADK
- Environment: si connette al backend di Gemma
🔒 Nota sulla sicurezza: questo lab utilizza --allow-unauthenticated per semplicità. In produzione, implementa l'autenticazione corretta utilizzando:
- Autenticazione da servizio a servizio Cloud Run con service account
- Criteri IAM (Identity and Access Management)
- Chiavi API o OAuth per l'accesso esterno
- Valuta la possibilità di utilizzare
gcloud run services add-iam-policy-bindingper controllare l'accesso
Ottieni l'URL del servizio agent:
export AGENT_URL=$(gcloud run services describe production-adk-agent \
--region=europe-west4 \
--format='value(status.url)')
echo "🎉 ADK Agent deployed at: $AGENT_URL"
✅ Best practice per le variabili di ambiente basate sulla documentazione sulle variabili di ambiente di Cloud Run:
- Evita le variabili riservate: non impostare
PORT(se devi modificare la variabile di ambiente, utilizza invece il flag -port) o le variabili che iniziano conX_GOOGLE_ - Utilizza nomi descrittivi: aggiungi un prefisso alle variabili per evitare conflitti (ad es.
GEMMA_MODEL_NAMEanzichéMODEL). - Virgole di escape: se i valori contengono virgole, utilizza un delimitatore diverso:
--set-env-vars "^@^KEY1=value1,value2@KEY2=..." - Aggiornamento e sostituzione: utilizza
--update-env-varsper aggiungere/modificare variabili specifiche senza influire sulle altre
Come impostare le variabili in Cloud Run:
- Da file:
gcloud run deploy SERVICE_NAME --env-vars-file .env --labels dev-tutorial codelab-adk(carica più variabili da un file) - Più flag: ripeti
--set-env-varsper valori complessi che non possono essere separati da virgole
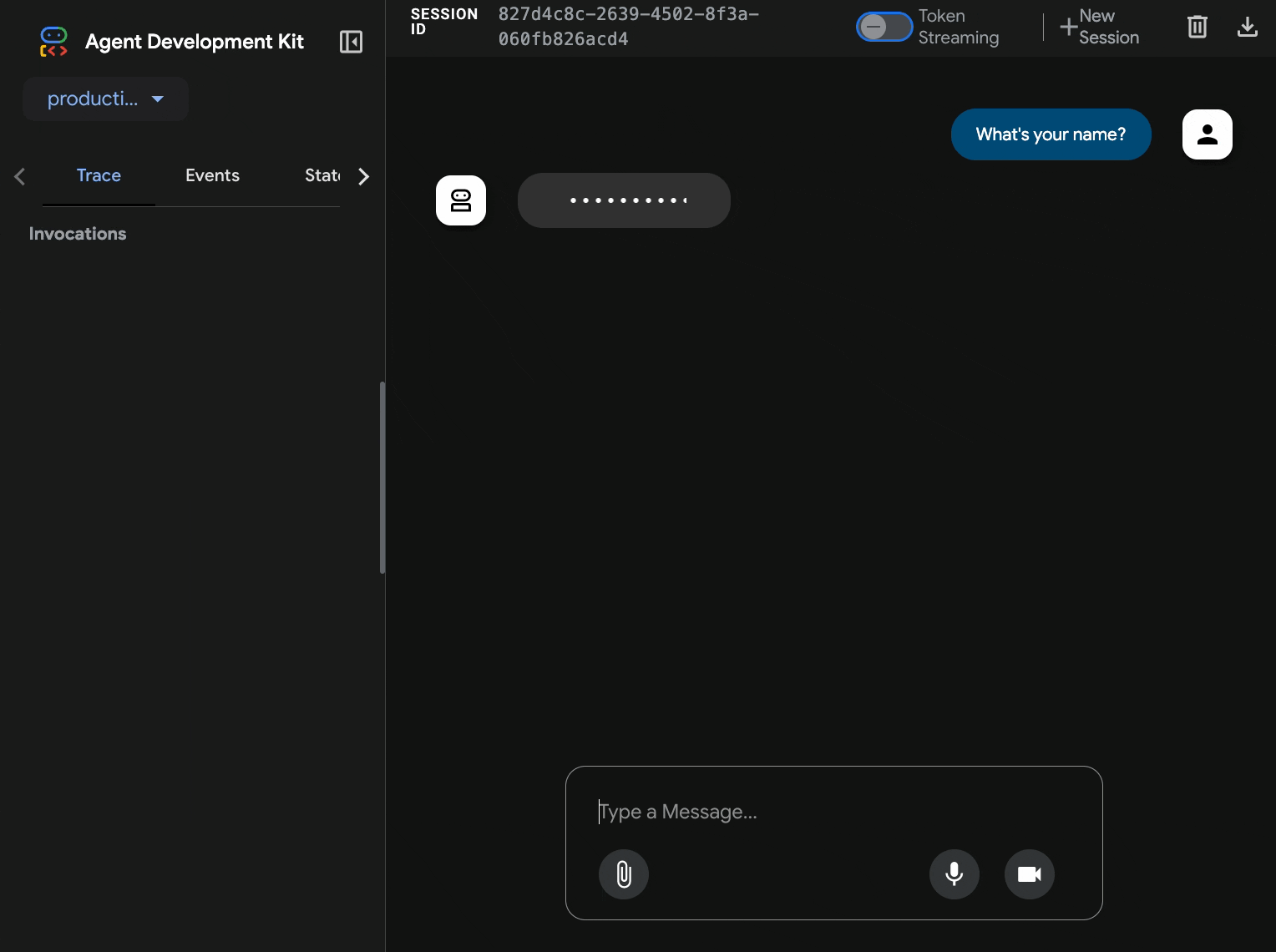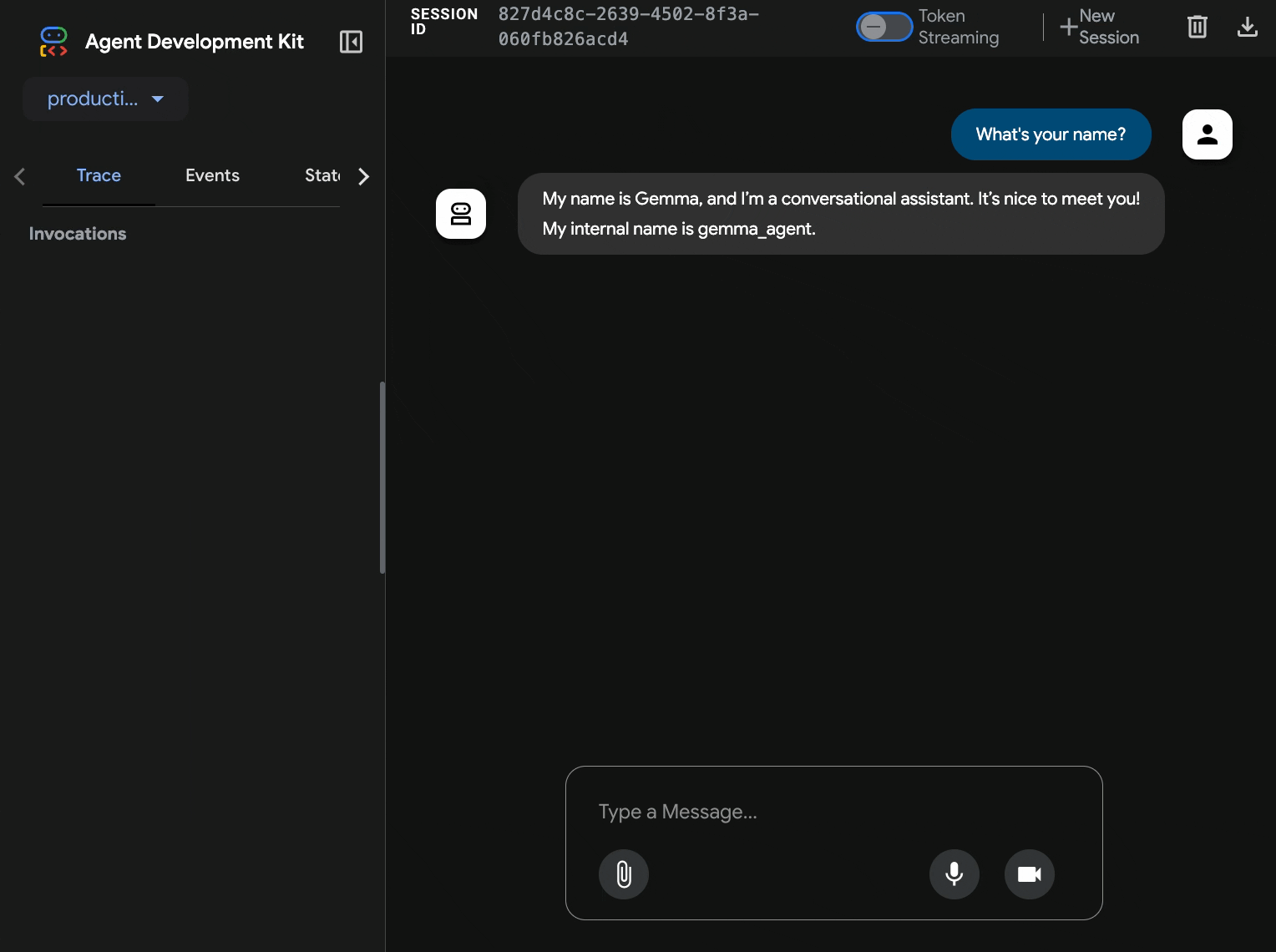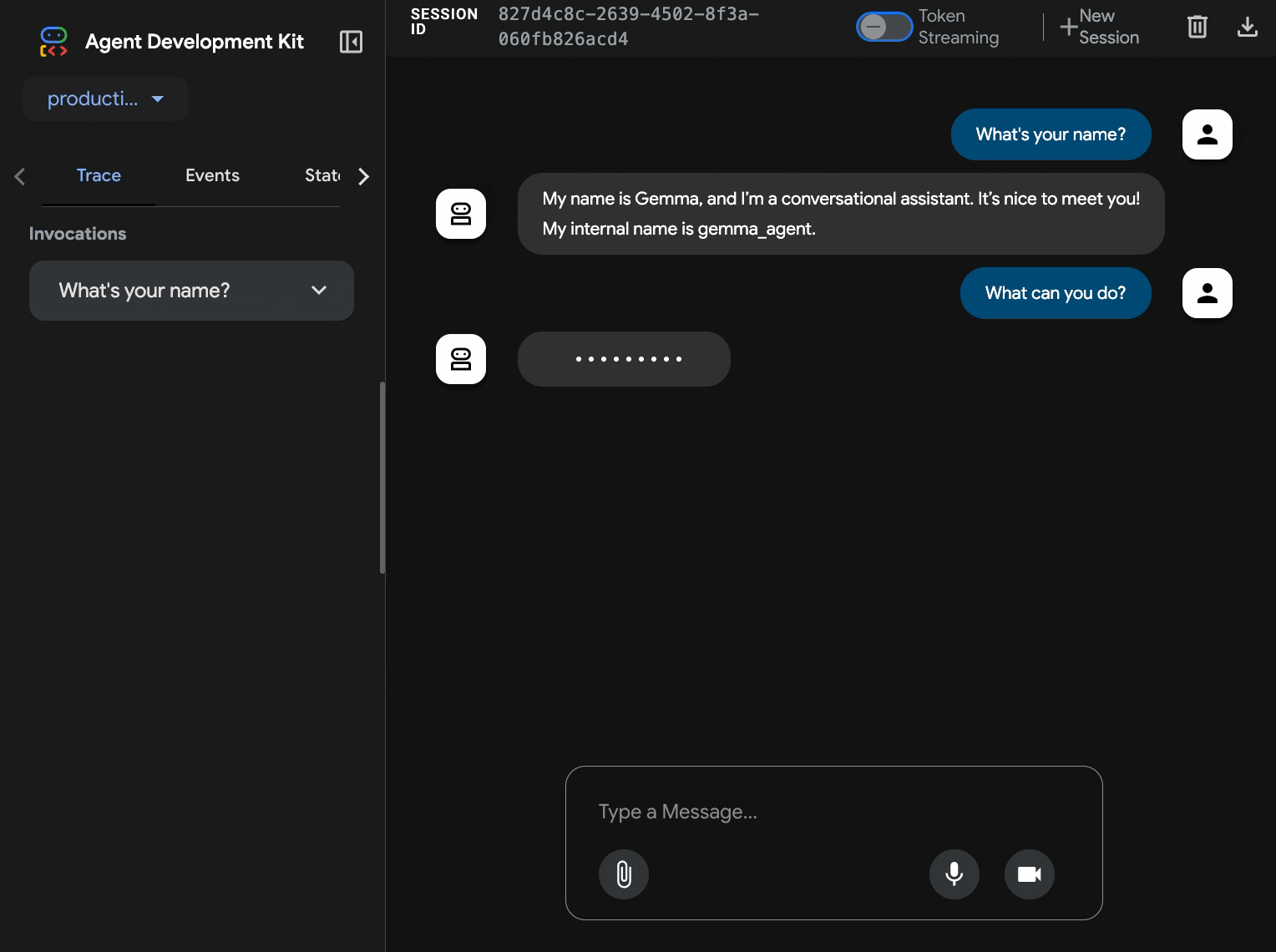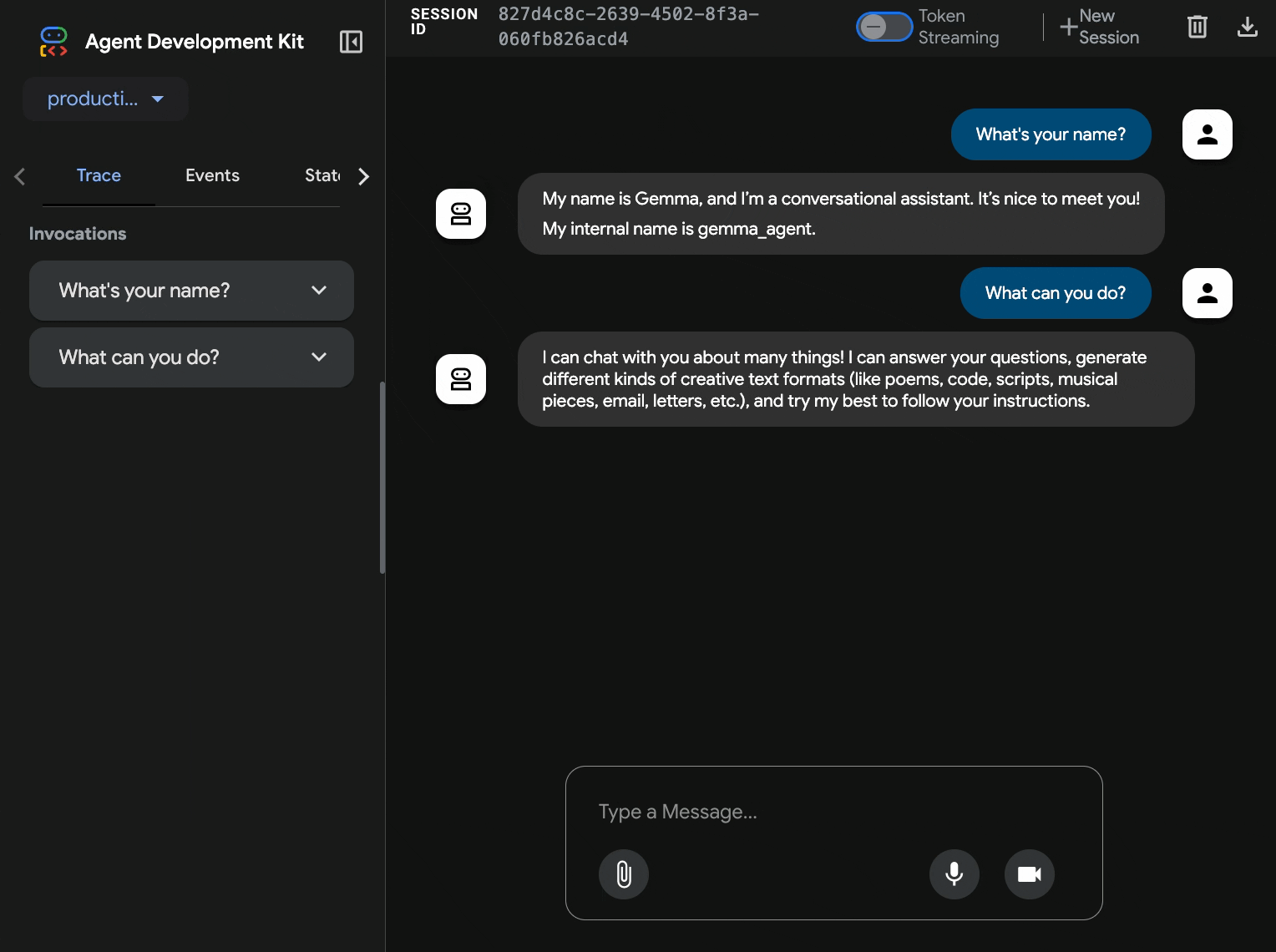
10. Test con l'interfaccia web dell'ADK
Con entrambi i servizi di cui è stato eseguito il deployment, è il momento di verificare che l'agente ADK possa comunicare correttamente con il backend Gemma con accelerazione GPU e rispondere alle query degli utenti.
- Testa l'endpoint di integrità:
curl $AGENT_URL/health{ "status": "healthy", "service": "production-adk-agent" } - Interagisci con l'agente inserendo l'URL del tuo
production-adk-agentin una nuova scheda del browser. Dovresti visualizzare l'interfaccia web dell'ADK. - Prova l'agente con queste conversazioni di esempio:
- "Cosa mangiano in genere i panda rossi in natura?"
- "Puoi dirmi un fatto interessante sui leopardi delle nevi?"
- "Perché le rane freccia sono così colorate?"
- "Dove posso trovare il nuovo cucciolo di canguro allo zoo?"
- L'agente risponde utilizzando il modello Gemma che hai implementato. Puoi verificarlo osservando i log del servizio Gemma di cui hai eseguito il deployment. Lo faremo nella prossima sezione.
- Le risposte vengono generate dal backend accelerato dalla GPU
- L'interfaccia web offre un'esperienza di chat pulita
11. Implementa ed esegui un test di elasticità
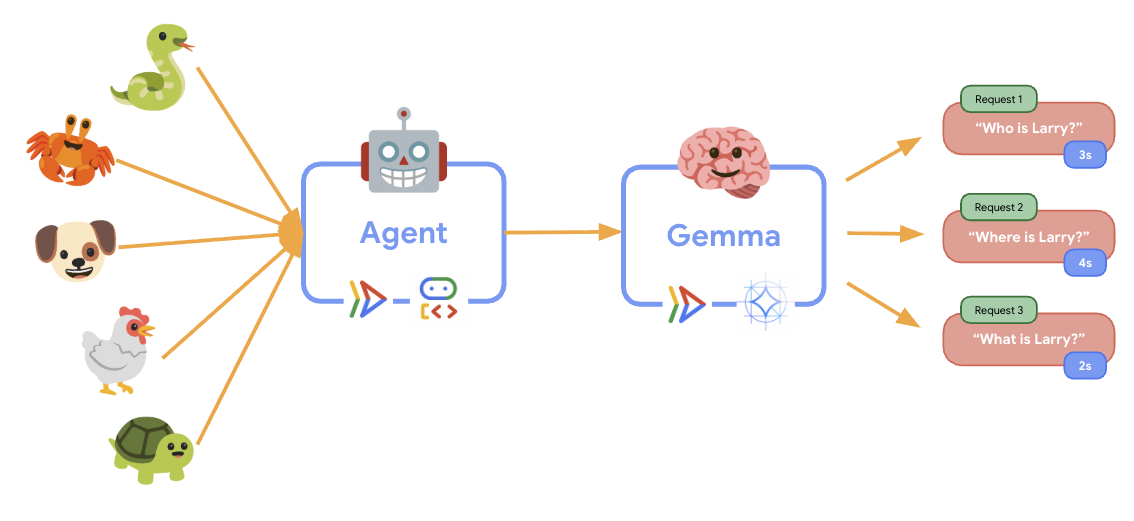
Per capire come la tua implementazione di produzione gestisce il traffico reale, implementeremo un test di elasticità che verificherà la capacità del sistema di adattarsi a un workload di produzione "simulato" più elevato.
- Apri e implementa lo script di test di elasticità:
cloudshell edit elasticity_test.pyimport random import uuid from locust import HttpUser, task, between class ProductionAgentUser(HttpUser): """Elasticity test user for the Production ADK Agent.""" wait_time = between(1, 3) # Faster requests to trigger scaling def on_start(self): """Set up user session when starting.""" self.user_id = f"user_{uuid.uuid4()}" self.session_id = f"session_{uuid.uuid4()}" # Create session for the Gemma agent using proper ADK API format session_data = {"state": {"user_type": "elasticity_test_user"}} self.client.post( f"/apps/production_agent/users/{self.user_id}/sessions/{self.session_id}", headers={"Content-Type": "application/json"}, json=session_data, ) @task(4) def test_conversations(self): """Test conversational capabilities - high frequency.""" topics = [ "What do red pandas typically eat in the wild?", "Can you tell me an interesting fact about snow leopards?", "Why are poison dart frogs so brightly colored?", "Where can I find the new baby kangaroo in the zoo?", "What is the name of your oldest gorilla?", "What time is the penguin feeding today?" ] # Use proper ADK API format for sending messages message_data = { "app_name": "production_agent", "user_id": self.user_id, "session_id": self.session_id, "new_message": { "role": "user", "parts": [{ "text": random.choice(topics) }] } } self.client.post( "/run", headers={"Content-Type": "application/json"}, json=message_data, ) @task(1) def health_check(self): """Test the health endpoint.""" self.client.get("/health")- Creazione della sessione: utilizza il formato API ADK corretto con POST a
/apps/production_agent/users/{user_id}/sessions/{session_id}. Dopo aver creato unsession_ide unuser_id, è possibile inviare una richiesta all'agente. - Formato messaggio: segue la specifica ADK con
app_name,user_id,session_ide oggettonew_messagestrutturato - Endpoint conversazione: utilizza l'endpoint
/runper raccogliere tutti gli eventi contemporaneamente (opzione consigliata per il test di carico) - Carico realistico: crea un carico conversazionale con tempi di attesa più brevi
- Creazione della sessione: utilizza il formato API ADK corretto con POST a
- Installa le dipendenze:
uv sync - Locust è uno strumento open source per il test del carico basato su Python, progettato per testare le prestazioni e il carico di applicazioni web e altri sistemi. La sua caratteristica principale è che gli scenari di test e il comportamento degli utenti vengono definiti utilizzando il codice Python standard, offrendo un'elevata flessibilità ed espressività rispetto agli strumenti che si basano su interfacce utente grafiche o linguaggi specifici del dominio. Utilizzeremo Locust per simulare il traffico degli utenti verso i nostri servizi.Esegui il test.
uv run locust -f elasticity_test.py \ -H $AGENT_URL \ --headless \ -t 60s \ -u 20 \ -r 5- Durata: 60 secondi
- Utenti: 20 utenti simultanei
- Tasso di generazione: 5 utenti al secondo
- Target: attiva la scalabilità automatica su entrambi i servizi
12. Osserva il comportamento di scalabilità automatica
Durante l'esecuzione del test di elasticità, potrai osservare il supporto di Cloud Run per carichi di lavoro più elevati in azione. Qui vedrai i principali vantaggi architetturali della separazione dell'agente ADK dal backend della GPU.
Durante il test di elasticità, monitora il modo in cui entrambi i servizi Cloud Run gestiscono il traffico nella console.
- Nella console Cloud, vai a:
- Cloud Run → production-adk-agent → Metriche
- Cloud Run → ollama-gemma3-270m-gpu → Metriche
👀 Cosa dovresti osservare:
🤖 Servizio agente ADK:
- Deve rimanere stabile a 1 istanza mentre il traffico aumenta
- Picco di utilizzo di CPU e memoria durante il traffico elevato
- Gestisce in modo efficiente la gestione delle sessioni e il routing delle richieste
🎮 Servizio di backend Gemma (collo di bottiglia):
- Deve rimanere stabile a 1 istanza mentre il traffico aumenta
- L'utilizzo della GPU aumenta in modo significativo sotto carico
- Questo servizio diventa il collo di bottiglia a causa dell'inferenza del modello che richiede un uso intensivo della GPU
- I tempi di inferenza del modello rimangono coerenti grazie all'accelerazione GPU
💡 Approfondimenti chiave:
- Entrambi i servizi rimangono coerenti e non fanno lo scale up, poiché abbiamo impostato il numero massimo di istanze su
1 - Entrambi i servizi scalano in modo indipendente in base alle caratteristiche di carico individuali
- La GPU contribuisce a mantenere le prestazioni in condizioni di carico variabili
13. Conclusione
Complimenti! Hai eseguito il deployment di un agente ADK pronto per la produzione con un backend Gemma accelerato dalla GPU, durante il test di un carico di lavoro di produzione simulato.
✅ Cosa hai realizzato
- ✅ È stato eseguito il deployment di un backend del modello Gemma accelerato da GPU su Cloud Run
- ✅ Hai creato e implementato un agente ADK che si integra con il backend Gemma
- ✅ L'agente è stato testato utilizzando l'interfaccia web ADK
- ✅ Comportamento della scalabilità automatica osservato in due servizi Cloud Run coordinati
💡 Approfondimenti chiave di questo lab
- 🎮 Accelerazione GPU: la GPU NVIDIA L4 migliora significativamente le prestazioni di inferenza del modello
- 🔗 Coordinamento dei servizi: due servizi Cloud Run possono funzionare insieme senza problemi
- 📈 Scalabilità indipendente: ogni servizio viene scalato in base alle sue caratteristiche di carico individuali
- 🚀 Idoneità alla produzione: l'architettura gestisce in modo efficace i pattern di traffico reali
🔄 Passaggi successivi
- Sperimenta diversi pattern di carico e osserva il comportamento di scalabilità
- Prova diverse dimensioni del modello Gemma (regola di conseguenza la memoria e la GPU)
- Implementa il monitoraggio e gli avvisi per i deployment di produzione
- Esplorare i deployment multiregionali per la disponibilità globale
🧹 Libera spazio
Per evitare addebiti, elimina le risorse al termine:
gcloud run services delete production-adk-agent --region=europe-west4
gcloud run services delete ollama-gemma3-270m-gpu --region=europe-west4
📖 Risorse
- Repository iniziale
- Soluzione completa
- Documentazione di Google ADK
- Guida ai test dell'ADK: riferimento completo per gli endpoint API ADK e i pattern di test
- Test di carico su Cloud Run
- Documentazione di Agent Development Kit (ADK)
- Documentazione sulla GPU Cloud Run
- Libreria di modelli Ollama
- Documentazione di Google Cloud Trace
- Best practice per la sicurezza di Cloud Run
- UV Python Package Manager
- Framework di test di carico Locust