
1. はじめに
概要
このラボでは、GPU アクセラレーションを備えた Gemma バックエンドを使用して、プロダクション レディな Agent Development Kit(ADK)エージェントをデプロイします。GPU 対応の Cloud Run サービスの設定、モデル バックエンドと ADK エージェントの統合、負荷時の自動スケーリングの動作の観察など、重要なデプロイ パターンに焦点を当てます。
演習内容
このラボでは、本番環境へのデプロイの重要な側面に焦点を当てます。
- GPU を使用して Gemma を Cloud Run にデプロイする - 高性能な Gemma モデル バックエンドを設定する
- Gemma デプロイを ADK エージェントと統合する - エージェントを GPU アクセラレーションを備えたモデルに接続する
- ADK ウェブ インターフェースでテストする - 会話型エージェントが正しく動作することを確認する
- 伸縮性のテストを実施する - Cloud Run インスタンスが負荷を処理する方法を確認する
エージェントの開発に重点を置くのではなく、本番環境へのデプロイ パターンに重点を置きます。
学習内容
- GPU アクセラレーションを備えた Gemma モデルを Cloud Run にデプロイして本番環境で使用する
- 外部モデルのデプロイを ADK エージェントと統合する
- プロダクション レディな AI エージェント Deployment を構成してテストする
- 負荷時の Cloud Run の動作を理解する
- トラフィックの急増時に複数の Cloud Run インスタンスが連携する方法を確認する
- 弾力性のテストを適用してパフォーマンスを検証する
2. プロジェクトの設定
- Google アカウントをお持ちでない場合は、Google アカウントを作成する必要があります。
- 仕事用または学校用アカウントではなく、個人用アカウントを使用してください。仕事用アカウントと学校用アカウントには、このラボに必要な API を有効にできない制限がある場合があります。
- Google Cloud コンソール にログインします。
- Cloud Console で課金を有効にします。
- このラボを完了すると、Cloud リソースの費用は 1 米ドル未満になります。
- このラボの最後の手順に沿ってリソースを削除すると、追加の料金が発生しなくなります。
- 新規ユーザーは、300 米ドル分の無料トライアルをご利用いただけます。
- 新しいプロジェクトを作成するか、既存のプロジェクトを再利用します。
- プロジェクトの割り当てに関するエラーが表示された場合は、既存のプロジェクトを再利用するか、既存のプロジェクトを削除して新しいプロジェクトを作成します。
3. Cloud Shell エディタを開く
- このリンクをクリックして、Cloud Shell エディタに直接移動します。
- 承認を求められたら、[承認] をクリックして続行します。
- 画面の下部にターミナルが表示されない場合は、次のようにして開きます。
- [表示] をクリックします。
- [Terminal]
- ターミナルで、次のコマンドを使用してプロジェクトを設定します。
- 形式:
gcloud config set project [PROJECT_ID] - 例:
gcloud config set project lab-project-id-example - プロジェクト ID がわからない場合:
- 次のコマンドでプロジェクト ID を一覧表示できます。
gcloud projects list | awk '/PROJECT_ID/{print $2}'
- 次のコマンドでプロジェクト ID を一覧表示できます。
- 形式:
- 次のようなメッセージが表示されます。
Updated property [core/project].
WARNINGが表示され、Do you want to continue (Y/n)?と表示された場合は、プロジェクト ID が正しく入力されていない可能性があります。nを押してEnterを押し、gcloud config set projectコマンドをもう一度実行します。
4. API を有効にしてデフォルト リージョンを設定する
GPU をサポートする Cloud Run サービスをデプロイする前に、必要な Google Cloud API を有効にして、プロジェクト設定を構成する必要があります。
- ターミナルで API を有効にします。
gcloud services enable \
run.googleapis.com \
artifactregistry.googleapis.com \
cloudbuild.googleapis.com \
aiplatform.googleapis.com
承認を求められたら、[承認] をクリックして続行します。
このコマンドが完了するまでに数分かかる場合がありますが、最終的には次のような成功メッセージが表示されます。
Operation "operations/acf.p2-73d90d00-47ee-447a-b600" finished successfully.
- デフォルトの Cloud Run リージョンを設定します。
gcloud config set run/region europe-west4
5. Python プロジェクトを準備する
Gemma バックエンドと ADK エージェント サービスの両方の基本的な構造を含むスターター コードを設定しましょう。
- スターター リポジトリのクローンを作成します。
cd ~ npx -y giget@latest gh+git:GoogleCloudPlatform/devrel-demos/agents/accelerate-ai-with-cloud-run/accelerate-ai-lab3-starter accelerate-ai-lab3-starter cd accelerate-ai-lab3-starter - プロジェクトの構造を確認します。
ls -Raccelerate-ai-lab3-starter/ ├── README.md # Project overview ├── ollama-backend/ # Ollama backend (separate deployment) │ └── Dockerfile # Backend container (🚧 to implement) └── adk-agent/ # ADK agent (separate deployment) ├── pyproject.toml # Python dependencies (✅ completed) ├── server.py # FastAPI server (🚧 to implement) ├── Dockerfile # Container config (🚧 to implement) ├── elasticity_test.py # Elasticity testing (🚧 to implement) └── production_agent/ # Agent implementation ├── __init__.py # Package init (✅ completed) └── agent.py # Agent logic (🚧 to implement)
6. アーキテクチャの概要
実装する前に、2 つのサービス アーキテクチャについて説明します。
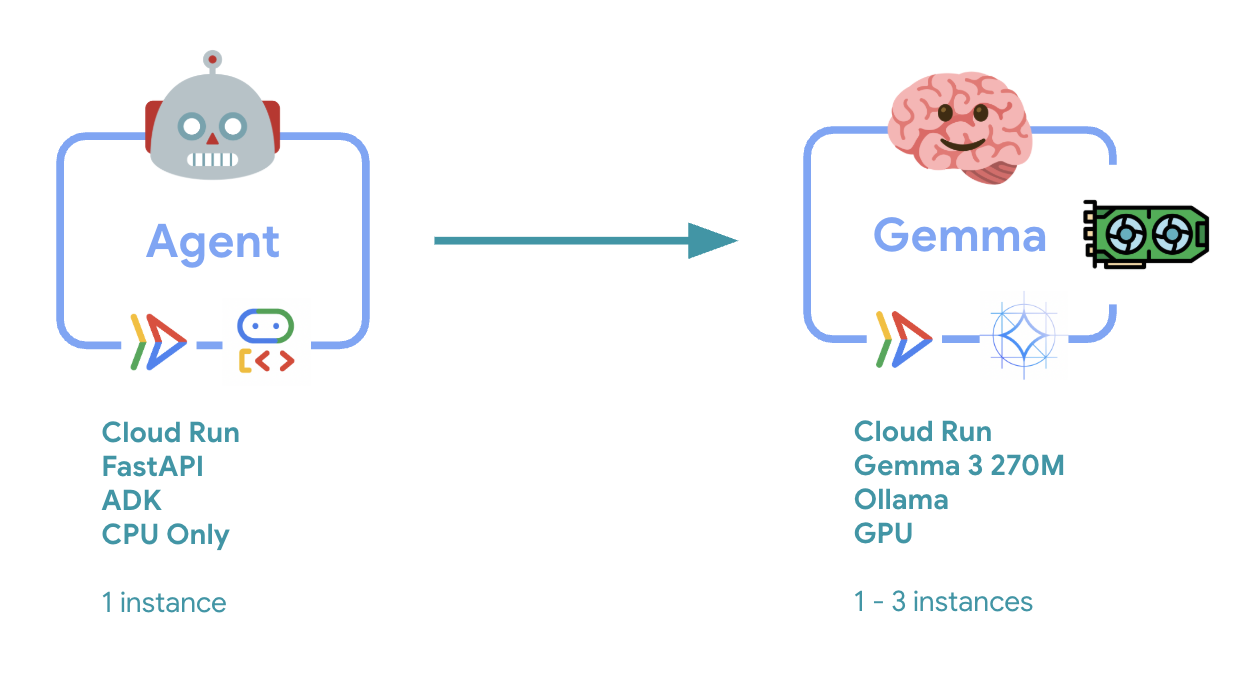
主なインサイト: 伸縮性のテストでは、両方のサービスがワークロードを個別に処理します。GPU バックエンド(ボトルネック サービス)は GPU を使用して負荷を処理し、ADK エージェントは CPU を使用してリソースを大量に消費しないリクエストを処理します。
7. GPU を使用して Gemma バックエンドを Cloud Run にデプロイする
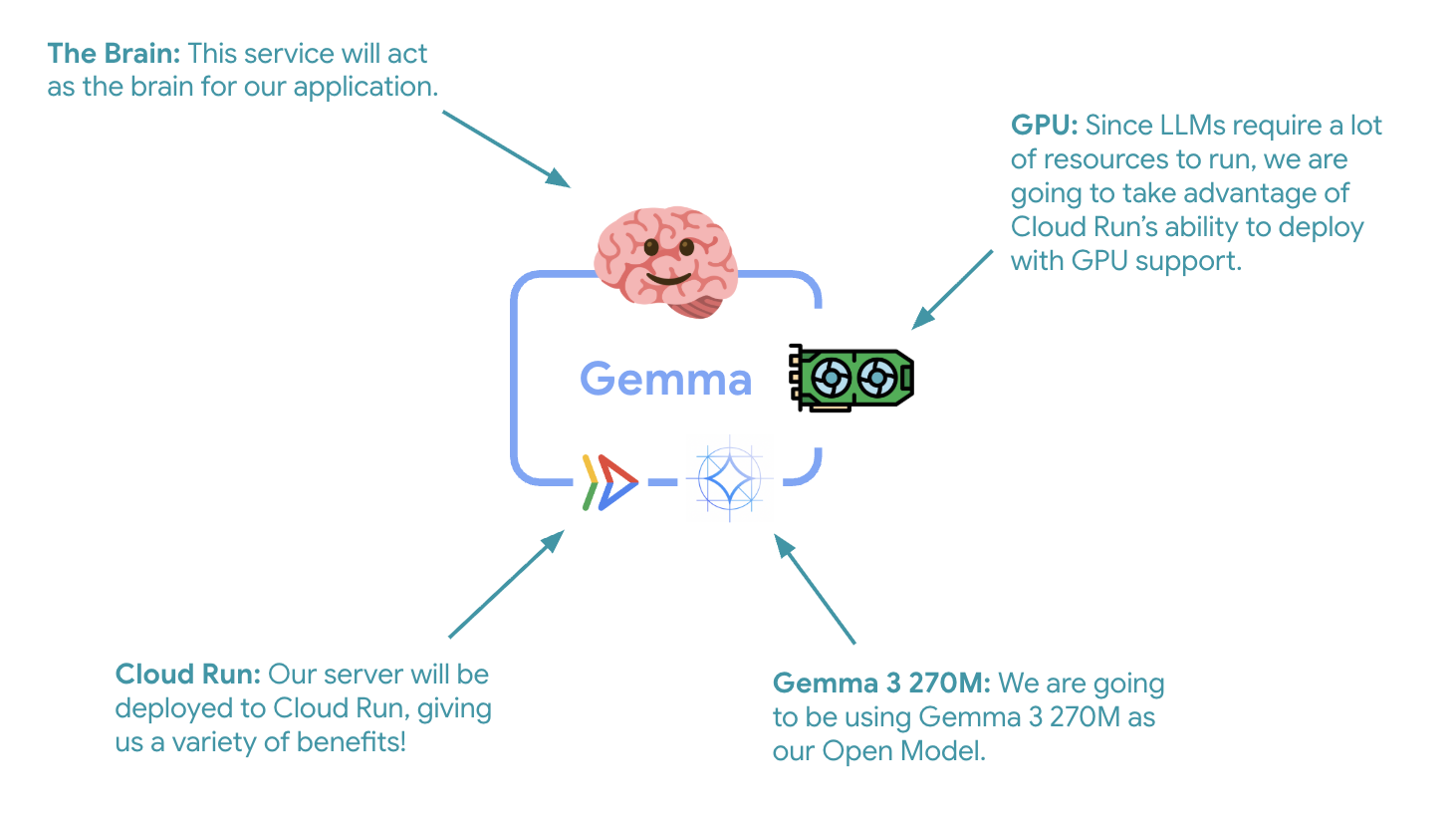
最初の重要なステップは、GPU アクセラレーションを備えた Gemma モデルをデプロイすることです。これは、ADK エージェントの頭脳として機能します。分離されたデプロイ済み LLM は、個別のファインチューニング済みモデルが必要なアーキテクチャや、分離されたスケーリングが必要なアーキテクチャで役立ちます。
- Ollama バックエンド ディレクトリに移動します。
cd ollama-backend - Ollama Dockerfile を開いて実装します。
cloudshell edit DockerfileFROM ollama/ollama:latest # Listen on all interfaces, port 8080 ENV OLLAMA_HOST 0.0.0.0:8080 # Store model weight files in /models ENV OLLAMA_MODELS /models # Reduce logging verbosity ENV OLLAMA_DEBUG false # Never unload model weights from the GPU ENV OLLAMA_KEEP_ALIVE -1 # Store the model weights in the container image ENV MODEL gemma3:270m RUN ollama serve & sleep 5 && ollama pull $MODEL # Start Ollama ENTRYPOINT ["ollama", "serve"]- 公式の Ollama イメージを基盤として使用する
OLLAMA_HOSTを設定して、任意の IP アドレスからの接続を受け入れる- ポート 8080 を公開する
- GPU をサポートする Gemma バックエンドをデプロイします。
gcloud run deploy ollama-gemma3-270m-gpu \
--source . \
--region europe-west4 \
--concurrency 7 \
--cpu 8 \
--set-env-vars OLLAMA_NUM_PARALLEL=4 \
--gpu 1 \
--gpu-type nvidia-l4 \
--max-instances 1 \
--memory 16Gi \
--allow-unauthenticated \
--no-cpu-throttling \
--no-gpu-zonal-redundancy \
--timeout 600 \
--labels dev-tutorial=codelab-agent-gpu
「ソースからのデプロイには、ビルドされたコンテナを保存する Artifact Registry Docker リポジトリが必要です。リージョン [europe-west4] に [cloud-run-source-deploy] という名前のリポジトリが作成されます。」というメッセージが表示されたら、続行します。
⚙️ 主な構成の説明:
- GPU: 推論ワークロードの費用対効果に優れた NVIDIA L4 を選択しました。L4 は 24 GB の GPU メモリと最適化されたテンソル演算を提供するため、Gemma などの 270M パラメータ モデルに最適です。
- メモリ: モデルの読み込み、CUDA オペレーション、Ollama のメモリ管理を処理する 16 GB のシステム メモリ
- CPU: 最適な I/O 処理と前処理タスクのための 8 コア
- 同時実行: インスタンスあたり 7 リクエストで、スループットと GPU メモリ使用量のバランスを取る
- タイムアウト: 600 秒で、最初のモデルの読み込みとコンテナの起動に対応
💰 費用に関する考慮事項: GPU インスタンスは、CPU のみのインスタンスよりも大幅に高価です(1 時間あたり約$2 ~ 4 対 1 時間あたり約$0.10)。--max-instances 1 設定は、不要な GPU インスタンスのスケーリングを防ぐことで費用を抑えるのに役立ちます。
- デプロイが完了するまで待って、サービス URL をメモします。
export OLLAMA_URL=$(gcloud run services describe ollama-gemma3-270m-gpu \ --region=europe-west4 \ --format='value(status.url)') echo "🎉 Gemma backend deployed at: $OLLAMA_URL"
8. ADK エージェントの統合を実装する
デプロイした Gemma バックエンドに接続する最小限の ADK エージェントを作成しましょう。
- ADK エージェント ディレクトリに移動します。
cd ../adk-agent - エージェント構成を開いて実装します。
cloudshell edit production_agent/agent.pyimport os from pathlib import Path from dotenv import load_dotenv from google.adk.agents import Agent from google.adk.models.lite_llm import LiteLlm import google.auth # Load environment variables root_dir = Path(__file__).parent.parent dotenv_path = root_dir / ".env" load_dotenv(dotenv_path=dotenv_path) # Configure Google Cloud try: _, project_id = google.auth.default() os.environ.setdefault("GOOGLE_CLOUD_PROJECT", project_id) except Exception: pass os.environ.setdefault("GOOGLE_CLOUD_LOCATION", "europe-west4") # Configure model connection gemma_model_name = os.getenv("GEMMA_MODEL_NAME", "gemma3:270m") api_base = os.getenv("OLLAMA_API_BASE", "localhost:10010") # Location of Ollama server # Production Gemma Agent - GPU-accelerated conversational assistant production_agent = Agent( model=LiteLlm(model=f"ollama_chat/{gemma_model_name}", api_base=api_base), name="production_agent", description="A production-ready conversational assistant powered by GPU-accelerated Gemma.", instruction="""You are 'Gem', a friendly, knowledgeable, and enthusiastic zoo tour guide. Your main goal is to make a zoo visit more fun and educational for guests by answering their questions. You can provide general information and interesting facts about different animal species, such as: - Their natural habitats and diet. 🌲🍓 - Typical lifespan and behaviors. - Conservation status and unique characteristics. IMPORTANT: You do NOT have access to any tools. This means you cannot look up real-time, specific information about THIS zoo. You cannot provide: - The names or ages of specific animals currently at the zoo. - The exact location or enclosure for an animal. - The daily schedule for feedings or shows. Always answer based on your general knowledge about the animal kingdom. Keep your tone cheerful, engaging, and welcoming for visitors of all ages. 🦁✨""", tools=[], # Gemma focuses on conversational capabilities ) # Set as root agent root_agent = production_agent- LiteLlm 経由でデプロイした Gemma バックエンドに接続する
- シンプルな会話型エージェントを作成する
- Google Cloud の統合を構成する
- FastAPI サーバーを開いて実装します。
cloudshell edit server.pyimport os from dotenv import load_dotenv from fastapi import FastAPI from google.adk.cli.fast_api import get_fast_api_app # Load environment variables load_dotenv() AGENT_DIR = os.path.dirname(os.path.abspath(__file__)) app_args = {"agents_dir": AGENT_DIR, "web": True} # Create FastAPI app with ADK integration app: FastAPI = get_fast_api_app(**app_args) # Update app metadata app.title = "Production ADK Agent - Lab 3" app.description = "Gemma agent with GPU-accelerated backend" app.version = "1.0.0" @app.get("/health") def health_check(): return {"status": "healthy", "service": "production-adk-agent"} @app.get("/") def root(): return { "service": "Production ADK Agent - Lab 3", "description": "GPU-accelerated Gemma agent", "docs": "/docs", "health": "/health" } if __name__ == "__main__": import uvicorn uvicorn.run(app, host="0.0.0.0", port=8080, log_level="info")- ADK 統合を使用して FastAPI サーバーを作成する
- テスト用のウェブ インターフェースを有効にする
- ヘルスチェック エンドポイントを提供する
- Dockerfile を開いて実装します。
cloudshell edit DockerfileFROM python:3.13-slim # Copy uv from the official image COPY --from=ghcr.io/astral-sh/uv:latest /uv /usr/local/bin/uv # Install system dependencies RUN apt-get update && apt-get install -y curl && rm -rf /var/lib/apt/lists/* # Set working directory WORKDIR /app # Copy all files COPY . . # Install Python dependencies RUN uv sync # Expose port EXPOSE 8080 # Run the application CMD ["uv", "run", "uvicorn", "server:app", "--host", "0.0.0.0", "--port", "8080"]- uv: pip より 10 ~ 100 倍高速な最新の Python パッケージ マネージャー。グローバル キャッシュと並列ダウンロードを使用することで、コンテナのビルド時間を大幅に短縮します。
- Python 3.13-slim: システム依存関係が最小限の最新の Python バージョン。コンテナサイズと攻撃対象領域を削減します。
- マルチステージ ビルド: 公式イメージから uv をコピーすることで、最新の最適化されたバイナリを取得できます。
9. 環境を構成してエージェントをデプロイする
デプロイした Gemma バックエンドに接続するように ADK エージェントを構成し、Cloud Run サービスとしてデプロイします。これには、環境変数の設定と、適切な構成でのエージェントのデプロイが含まれます。
- 環境構成を設定します。
cat << EOF > .env GOOGLE_CLOUD_PROJECT=$(gcloud config get-value project) GOOGLE_CLOUD_LOCATION=europe-west4 GEMMA_MODEL_NAME=gemma3:270m OLLAMA_API_BASE=$OLLAMA_URL EOF
Cloud Run の環境変数について
環境変数は、実行時にアプリケーションを構成する Key-Value ペアです。特に次のような場合に便利です。
- API エンドポイントとサービス URL(Ollama バックエンドなど)
- 環境(開発、ステージング、本番環境)によって変化する構成
- ハードコードすべきでないセンシティブ データ
ADK エージェントをデプロイします。
export PROJECT_ID=$(gcloud config get-value project)
gcloud run deploy production-adk-agent \
--source . \
--region europe-west4 \
--allow-unauthenticated \
--memory 4Gi \
--cpu 2 \
--max-instances 1 \
--concurrency 50 \
--timeout 300 \
--set-env-vars GOOGLE_CLOUD_PROJECT=$PROJECT_ID \
--set-env-vars GOOGLE_CLOUD_LOCATION=europe-west4 \
--set-env-vars GEMMA_MODEL_NAME=gemma3:270m \
--set-env-vars OLLAMA_API_BASE=$OLLAMA_URL \
--labels dev-tutorial=codelab-agent-gpu
⚙️ 主な構成:
- 自動スケーリング: 1 インスタンスに固定(軽量リクエスト処理)
- 同時実行: インスタンスあたり 50 リクエスト
- メモリ: ADK エージェント用に 4 GB
- 環境: Gemma バックエンドに接続する
🔒 セキュリティに関する注意: このラボでは、簡略化のため --allow-unauthenticated を使用します。本番環境では、次の方法で適切な認証を実装します。
- サービス アカウントを使用した Cloud Run サービス間認証
- Identity and Access Management(IAM)ポリシー
- 外部アクセス用の API キーまたは OAuth
gcloud run services add-iam-policy-bindingを使用してアクセスを制御することを検討してください。
エージェント サービスの URL を取得します。
export AGENT_URL=$(gcloud run services describe production-adk-agent \
--region=europe-west4 \
--format='value(status.url)')
echo "🎉 ADK Agent deployed at: $AGENT_URL"
✅ 環境変数のベスト プラクティス(Cloud Run 環境変数のドキュメントに基づく):
- 予約変数を避ける:
PORTを設定しないでください(環境変数を変更する必要がある場合は、代わりに –port フラグを使用してください)。また、X_GOOGLE_で始まる変数も設定しないでください。 - わかりやすい名前を使用する: 変数に接頭辞を付けて、競合を回避します(例:
MODELではなくGEMMA_MODEL_NAME)。 - カンマをエスケープする: 値にカンマが含まれている場合は、別の区切り文字を使用します。
--set-env-vars "^@^KEY1=value1,value2@KEY2=..." - 更新と置換:
--update-env-varsを使用すると、他の変数に影響を与えることなく特定の変数を追加または変更できます。
Cloud Run で変数を設定する方法:
- ファイルから:
gcloud run deploy SERVICE_NAME --env-vars-file .env --labels dev-tutorial codelab-adk(ファイルから複数の変数を読み込む) - 複数のフラグ: カンマ区切りにできない複雑な値の場合は、
--set-env-varsを繰り返します。
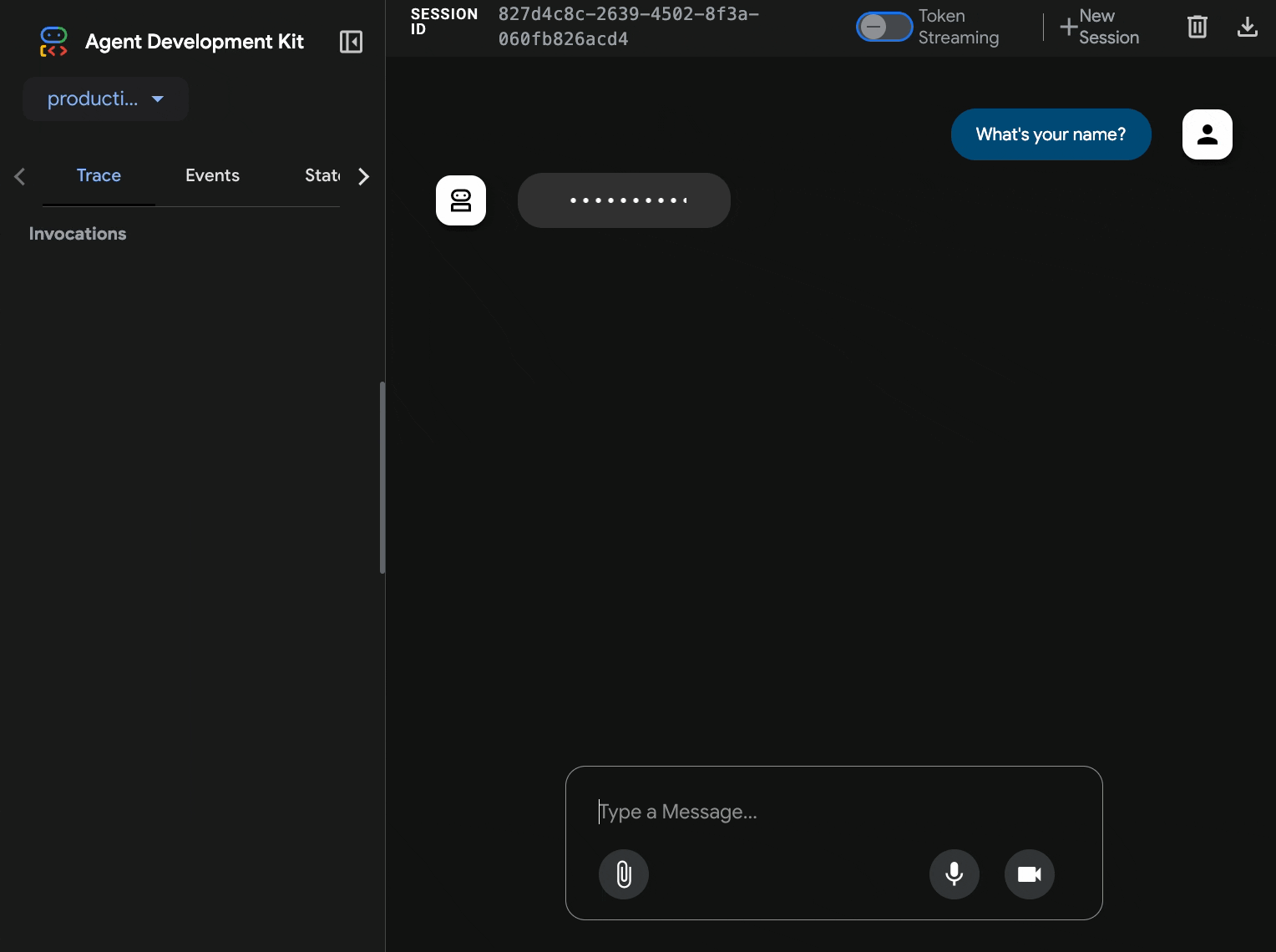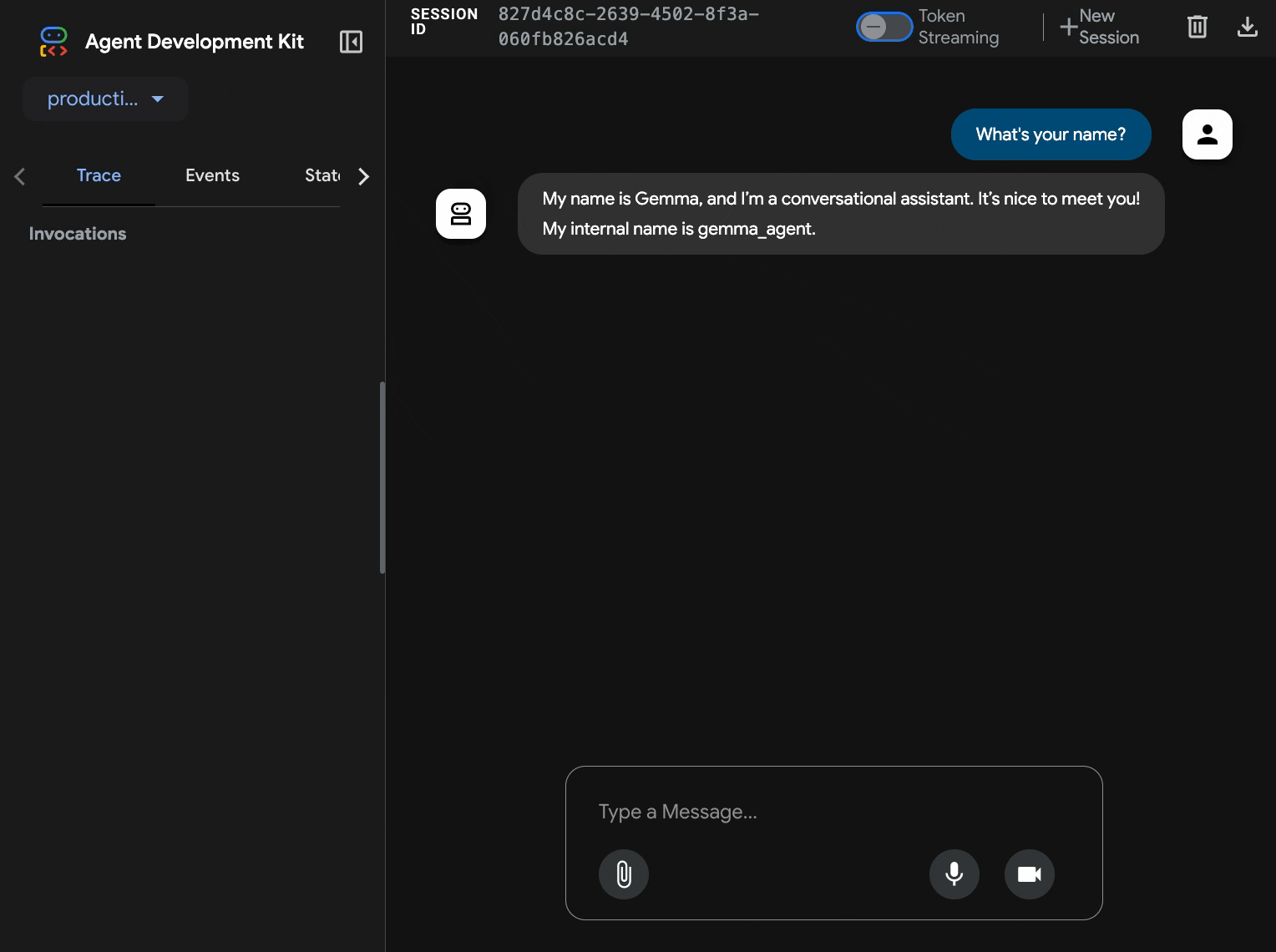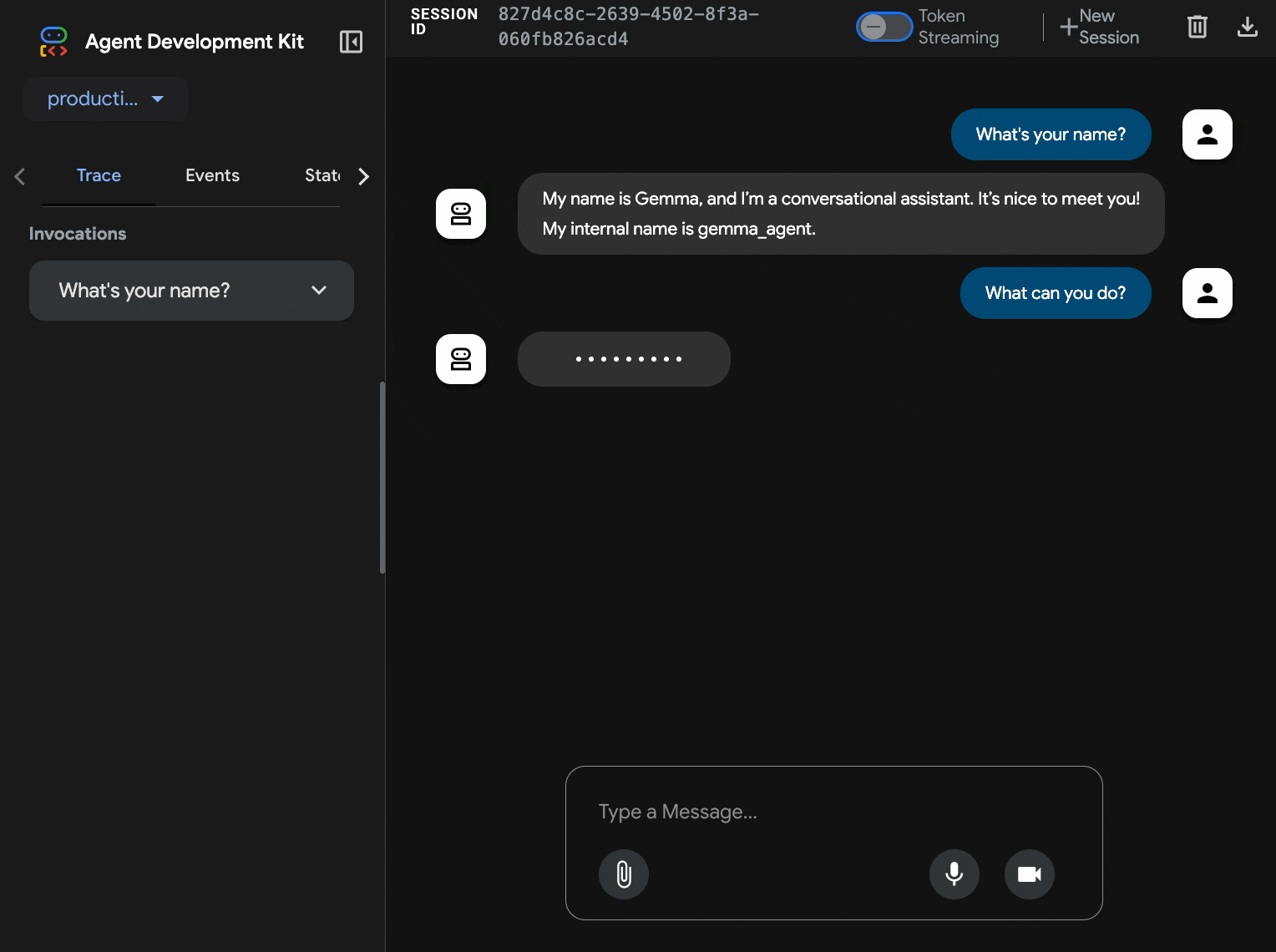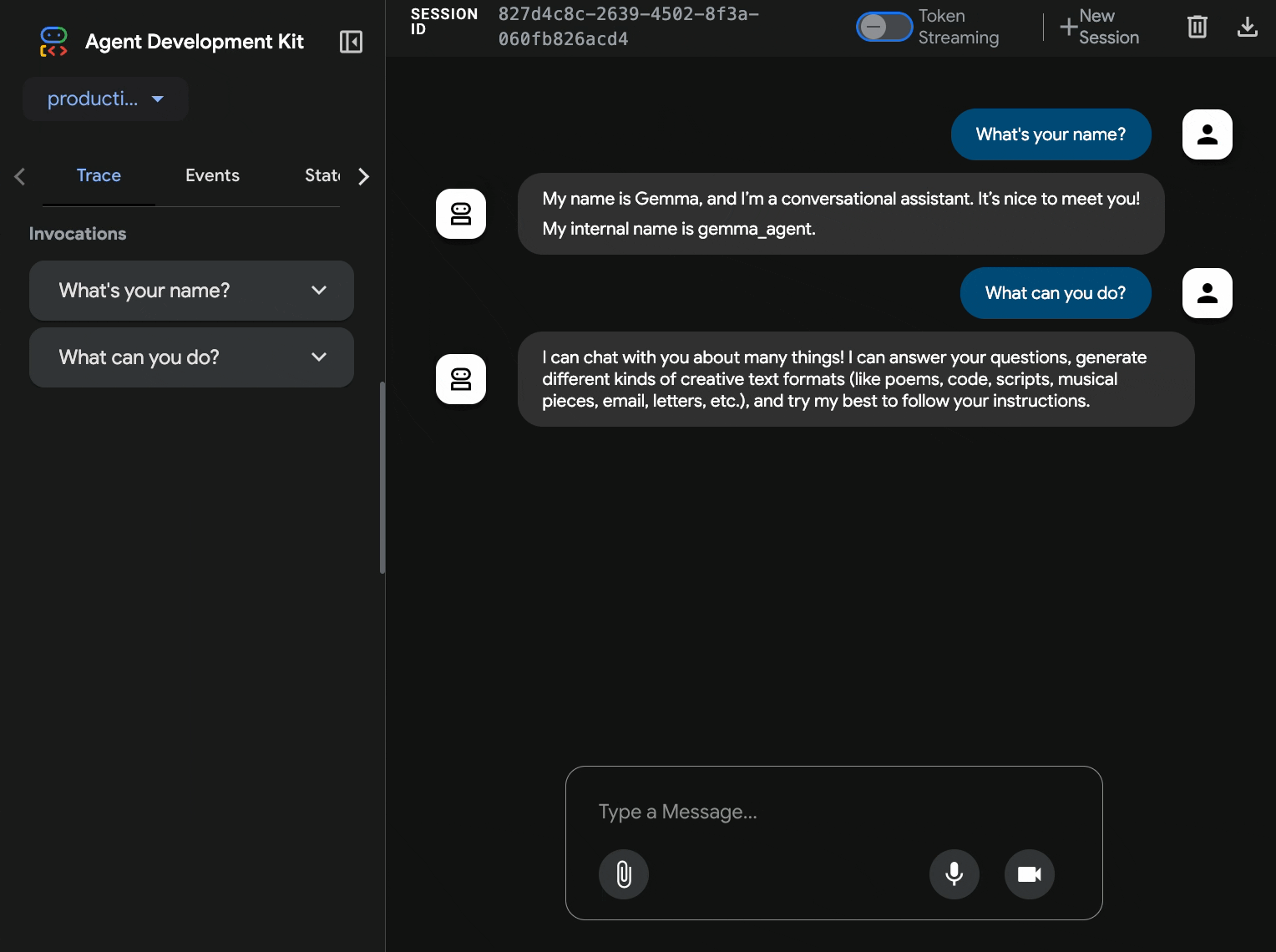
10. ADK ウェブ インターフェースでテストする
両方のサービスがデプロイされたので、ADK エージェントが GPU アクセラレーションを備えた Gemma バックエンドと正常に通信し、ユーザーのクエリに応答できることを検証します。
- ヘルス エンドポイントをテストします。
curl $AGENT_URL/health{ "status": "healthy", "service": "production-adk-agent" } - ブラウザの新しいタブに
production-adk-agentの URL を入力して、エージェントを操作します。ADK ウェブ インターフェースが表示されます。 - 次のサンプル会話を使用してエージェントをテストします。
- 「レッサーパンダは通常、野生で何を食べていますか?」
- 「ユキヒョウについて興味深いことを教えてください。」
- 「ヤドクガエルはなぜ鮮やかな色をしているのですか?」
- 「動物園で新しいカンガルーの赤ちゃんはどこにいますか?」
- エージェントは、デプロイした Gemma モデルを使用して応答します。これは、デプロイした Gemma サービスのログを確認することで確認できます。これについては次のセクションで説明します。
- レスポンスは GPU アクセラレーションを備えたバックエンドによって生成されます。
- ウェブ インターフェースはクリーンなチャット エクスペリエンスを提供します。
11. 伸縮性のテストを実装して実行する
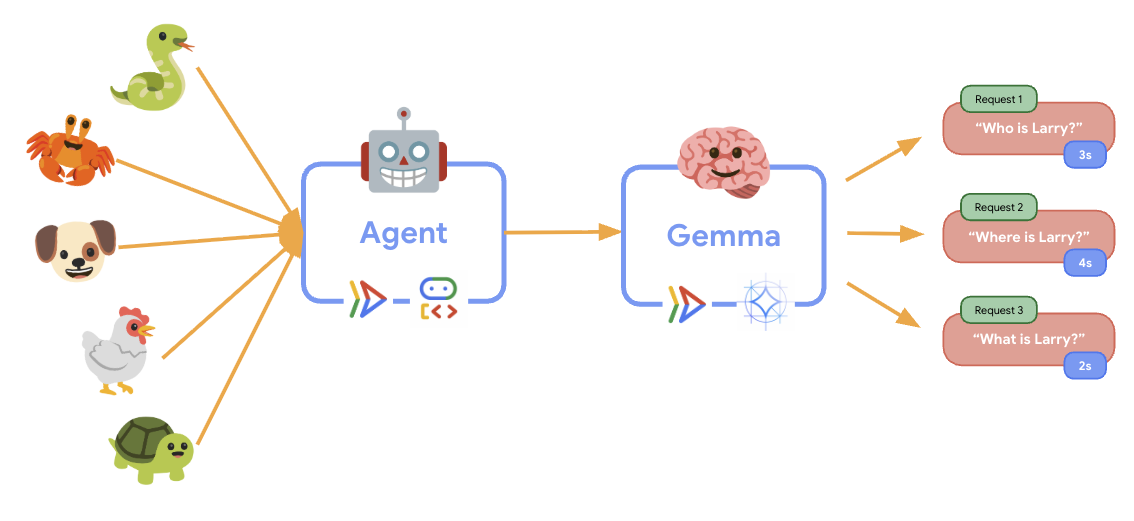
本番環境へのデプロイが実際のトラフィックをどのように処理するかを理解するために、システムの「シミュレートされた」本番環境ワークロードへの適応能力をテストする弾力性のテストを実装します。
- 伸縮性のテスト スクリプトを開いて実装します。
cloudshell edit elasticity_test.pyimport random import uuid from locust import HttpUser, task, between class ProductionAgentUser(HttpUser): """Elasticity test user for the Production ADK Agent.""" wait_time = between(1, 3) # Faster requests to trigger scaling def on_start(self): """Set up user session when starting.""" self.user_id = f"user_{uuid.uuid4()}" self.session_id = f"session_{uuid.uuid4()}" # Create session for the Gemma agent using proper ADK API format session_data = {"state": {"user_type": "elasticity_test_user"}} self.client.post( f"/apps/production_agent/users/{self.user_id}/sessions/{self.session_id}", headers={"Content-Type": "application/json"}, json=session_data, ) @task(4) def test_conversations(self): """Test conversational capabilities - high frequency.""" topics = [ "What do red pandas typically eat in the wild?", "Can you tell me an interesting fact about snow leopards?", "Why are poison dart frogs so brightly colored?", "Where can I find the new baby kangaroo in the zoo?", "What is the name of your oldest gorilla?", "What time is the penguin feeding today?" ] # Use proper ADK API format for sending messages message_data = { "app_name": "production_agent", "user_id": self.user_id, "session_id": self.session_id, "new_message": { "role": "user", "parts": [{ "text": random.choice(topics) }] } } self.client.post( "/run", headers={"Content-Type": "application/json"}, json=message_data, ) @task(1) def health_check(self): """Test the health endpoint.""" self.client.get("/health")- セッションの作成:
/apps/production_agent/users/{user_id}/sessions/{session_id}に POST を使用して、適切な ADK API 形式を使用します。session_idとuser_idを作成したら、エージェントにリクエストを送信できます。 - メッセージ形式:
app_name、user_id、session_id、構造化されたnew_messageオブジェクトを使用して、ADK 仕様に準拠します。 - 会話エンドポイント:
/runエンドポイントを使用して、すべてのイベントを一度に収集します(負荷テストにおすすめ)。 - 現実的な負荷: 待機時間が短い会話型負荷を作成します。
- セッションの作成:
- 依存関係をインストールします。
uv sync - Locust は、ウェブ アプリケーションやその他のシステムのパフォーマンスと負荷のテスト用に設計された、Python ベースのオープンソースの負荷テストツールです。主な特徴は、テスト シナリオとユーザーの行動が標準の Python コードを使用して定義されることです。これにより、グラフィカル ユーザー インターフェースやドメイン固有言語に依存するツールと比較して、高い柔軟性と表現力を実現できます。Locust を使用して、サービスへのユーザー トラフィックをシミュレートします。テストを実行します。
uv run locust -f elasticity_test.py \ -H $AGENT_URL \ --headless \ -t 60s \ -u 20 \ -r 5- 期間: 60 秒
- ユーザー: 20 人の同時ユーザー
- 生成率: 1 秒あたり 5 ユーザー
- ターゲット: 両方のサービスで自動スケーリングをトリガーする
12. 自動スケーリングの動作を確認する
伸縮性のテストを実行すると、Cloud Run がより高いワークロードをサポートしていることを確認できます。ここでは、ADK エージェントを GPU バックエンドから分離することによるアーキテクチャ上の主なメリットを確認できます。
伸縮性のテスト中に、両方の Cloud Run サービスがコンソールでトラフィックを処理する方法をモニタリングします。
- Cloud Console で、次の場所に移動します。
- Cloud Run → production-adk-agent → [指標]
- Cloud Run → ollama-gemma3-270m-gpu → [指標]
👀 確認する内容:
🤖 ADK エージェント サービス:
- トラフィックが増加しても 1 インスタンスで安定している
- トラフィックが多いときに CPU とメモリ使用量が急増する
- セッション管理とリクエスト ルーティングを効率的に処理する
🎮 Gemma バックエンド サービス(ボトルネック):
- トラフィックが増加しても 1 インスタンスで安定している
- 負荷時に GPU 使用率が大幅に増加する
- GPU を大量に使用するモデル推論により、このサービスがボトルネックになる
- GPU アクセラレーションにより、モデル推論時間が一定に保たれる
💡 主なインサイト:
- 最大インスタンス数を
1に設定しているため、両方のサービスは一貫性を保ち、スケールアップしない - 両方のサービスは、個々の負荷特性に基づいて個別にスケーリングする
- GPU は、さまざまな負荷条件下でパフォーマンスを維持するのに役立つ
13. まとめ
おめでとうございます!シミュレートされた本番環境ワークロードをテストしながら、GPU アクセラレーションを備えた Gemma バックエンドを使用して、本番環境対応の ADK エージェントを正常にデプロイできました。
✅ 達成したこと
- ✅ GPU アクセラレーションを備えた Gemma モデル バックエンドを Cloud Run にデプロイした
- ✅ Gemma バックエンドと統合する ADK エージェントを作成してデプロイした
- ✅ ADK ウェブ インターフェースを使用してエージェントをテストした
- ✅ 連携する 2 つの Cloud Run サービスで自動スケーリングの動作を確認した
💡 このラボの主なインサイト
- 🎮 GPU アクセラレーション: NVIDIA L4 GPU により、モデル推論のパフォーマンスが大幅に向上する
- 🔗 サービスの連携: 2 つの Cloud Run サービスがシームレスに連携できる
- 📈 独立したスケーリング: 各サービスは、個々の負荷特性に基づいてスケーリングする
- 🚀 本番環境対応: このアーキテクチャは、実際のトラフィック パターンを効果的に処理する
🔄 次の手順
- さまざまな負荷パターンを試して、スケーリングの動作を確認する
- さまざまな Gemma モデルサイズを試す(メモリと GPU を適宜調整)
- 本番環境へのデプロイのモニタリングとアラートを実装する
- グローバルな可用性を実現するために、マルチリージョン デプロイを検討する
🧹 クリーンアップ
料金が発生しないように、完了したらリソースを削除します。
gcloud run services delete production-adk-agent --region=europe-west4
gcloud run services delete ollama-gemma3-270m-gpu --region=europe-west4