
1. 소개
개요
이 실습에서는 GPU 가속 Gemma 백엔드를 사용하여 프로덕션에 즉시 사용 가능한 에이전트 개발 키트 (ADK) 에이전트를 배포합니다. 중점은 GPU 지원 Cloud Run 서비스 설정, 모델 백엔드와 ADK 에이전트 통합, 부하 상태에서의 자동 확장 동작 관찰 등 중요한 배포 패턴에 있습니다.
실습할 내용
이 실습에서는 다음과 같은 중요한 프로덕션 배포 측면에 중점을 둡니다.
- GPU를 사용하여 Cloud Run에 Gemma 배포 - 고성능 Gemma 모델 백엔드 설정
- Gemma 배포를 ADK 에이전트와 통합 - 에이전트를 GPU 가속 모델에 연결
- ADK 웹 인터페이스로 테스트 - 대화형 에이전트가 올바르게 작동하는지 확인합니다.
- 탄력성 테스트 실행 - 두 Cloud Run 인스턴스가 부하를 처리하는 방식 관찰
광범위한 에이전트 개발보다는 프로덕션 배포 패턴에 중점을 둡니다.
학습할 내용
- 프로덕션 사용을 위해 GPU 가속 Gemma 모델을 Cloud Run에 배포
- 외부 모델 배포를 ADK 에이전트와 통합
- 프로덕션 환경에서 바로 사용할 수 있는 AI 에이전트 배포 구성 및 테스트
- 부하가 걸린 상태에서 Cloud Run 동작 이해
- 트래픽 급증 시 여러 Cloud Run 인스턴스가 어떻게 조정되는지 관찰
- 탄력성 테스트를 적용하여 성능 검증
2. 프로젝트 설정
- 아직 Google 계정이 없다면 Google 계정을 만들어야 합니다.
- 직장 또는 학교 계정 대신 개인 계정을 사용하세요. 직장 및 학교 계정에는 이 실습에 필요한 API를 사용 설정하지 못하도록 하는 제한이 있을 수 있습니다.
- Google Cloud 콘솔에 로그인합니다.
- Cloud 콘솔에서 결제를 사용 설정합니다.
- 이 실습을 완료하는 데 드는 Cloud 리소스 비용은 1달러 미만입니다.
- 이 실습이 끝나면 단계에 따라 리소스를 삭제하여 추가 요금이 발생하지 않도록 할 수 있습니다.
- 신규 사용자는 미화$300 상당의 무료 체험판을 사용할 수 있습니다.
- 새 프로젝트를 만들거나 기존 프로젝트를 재사용합니다.
- 프로젝트 할당량에 관한 오류가 표시되면 기존 프로젝트를 재사용하거나 기존 프로젝트를 삭제하여 새 프로젝트를 만드세요.
3. Cloud Shell 편집기 열기
- 이 링크를 클릭하여 Cloud Shell 편집기로 바로 이동합니다.
- 오늘 언제든지 승인하라는 메시지가 표시되면 승인을 클릭하여 계속합니다.
- 터미널이 화면 하단에 표시되지 않으면 다음 단계에 따라 엽니다.
- 보기를 클릭합니다.
- 터미널을 클릭합니다.
- 터미널에서 다음 명령어를 사용하여 프로젝트를 설정합니다.
- 형식:
gcloud config set project [PROJECT_ID] - 예:
gcloud config set project lab-project-id-example - 프로젝트 ID를 기억할 수 없는 경우 다음 단계를 따르세요.
- 다음 명령어를 사용하여 모든 프로젝트 ID를 나열할 수 있습니다.
gcloud projects list | awk '/PROJECT_ID/{print $2}'
- 다음 명령어를 사용하여 모든 프로젝트 ID를 나열할 수 있습니다.
- 형식:
- 다음 메시지가 표시되어야 합니다.
Updated property [core/project].
WARNING이 표시되고Do you want to continue (Y/n)?라는 메시지가 표시되면 프로젝트 ID를 잘못 입력한 것일 수 있습니다.n를 누르고Enter를 누른 후gcloud config set project명령어를 다시 실행해 보세요.
4. API 사용 설정 및 기본 리전 설정
GPU 지원을 사용하여 Cloud Run 서비스를 배포하려면 필요한 Google Cloud API를 사용 설정하고 프로젝트 설정을 구성해야 합니다.
- 터미널에서 API를 사용 설정합니다.
gcloud services enable \
run.googleapis.com \
artifactregistry.googleapis.com \
cloudbuild.googleapis.com \
aiplatform.googleapis.com
승인하라는 메시지가 표시되면 승인을 클릭하여 계속합니다.
이 명령어를 완료하는 데 몇 분이 걸릴 수 있지만 결국 다음과 비슷한 성공 메시지가 표시됩니다.
Operation "operations/acf.p2-73d90d00-47ee-447a-b600" finished successfully.
- 기본 Cloud Run 리전을 설정합니다.
gcloud config set run/region europe-west4
5. Python 프로젝트 준비
Gemma 백엔드와 ADK 에이전트 서비스의 기본 구조가 포함된 시작 코드를 설정해 보겠습니다.
- 시작 저장소를 클론합니다.
cd ~ npx -y giget@latest gh+git:GoogleCloudPlatform/devrel-demos/agents/accelerate-ai-with-cloud-run/accelerate-ai-lab3-starter accelerate-ai-lab3-starter cd accelerate-ai-lab3-starter - 프로젝트 구조를 확인합니다.
ls -Raccelerate-ai-lab3-starter/ ├── README.md # Project overview ├── ollama-backend/ # Ollama backend (separate deployment) │ └── Dockerfile # Backend container (🚧 to implement) └── adk-agent/ # ADK agent (separate deployment) ├── pyproject.toml # Python dependencies (✅ completed) ├── server.py # FastAPI server (🚧 to implement) ├── Dockerfile # Container config (🚧 to implement) ├── elasticity_test.py # Elasticity testing (🚧 to implement) └── production_agent/ # Agent implementation ├── __init__.py # Package init (✅ completed) └── agent.py # Agent logic (🚧 to implement)
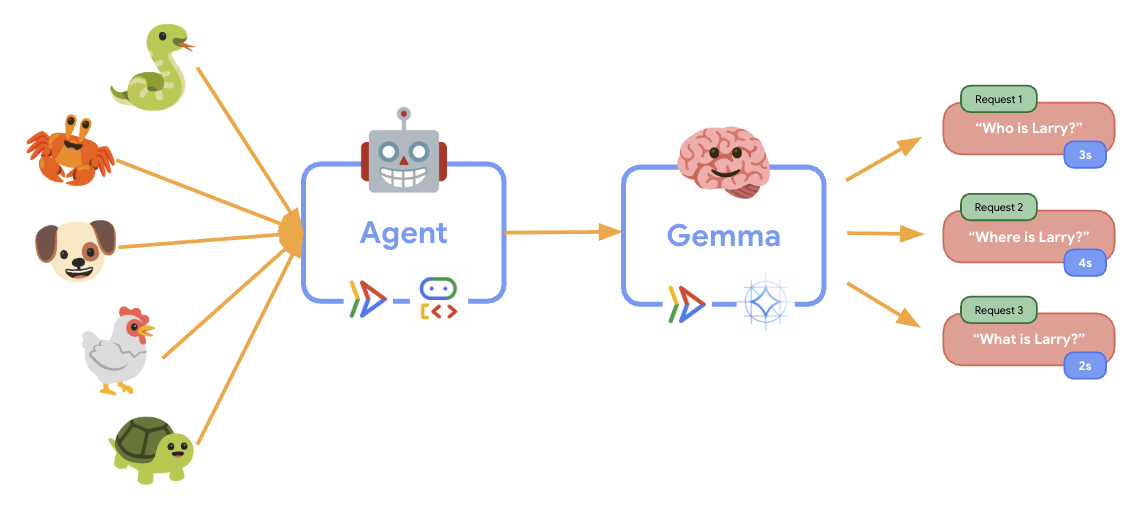
6. 아키텍처 개요
구현하기 전에 2개 서비스 아키텍처를 이해해 보겠습니다.

주요 통계: 탄력성 테스트 중에 두 서비스가 워크로드를 독립적으로 처리하는 것을 확인할 수 있습니다. GPU 백엔드 (병목 현상 서비스)는 GPU를 사용하여 부하를 처리하고 ADK 에이전트는 CPU를 사용하여 리소스 집약적이지 않은 요청을 처리합니다.
7. GPU를 사용하여 Gemma 백엔드를 Cloud Run에 배포

첫 번째 중요한 단계는 ADK 에이전트의 두뇌 역할을 할 GPU 가속 Gemma 모델을 배포하는 것입니다. 분리되고 배포된 LLM은 별도의 미세 조정된 모델이 필요하거나 격리된 확장 기능이 필요한 아키텍처에서 유용할 수 있습니다.
- Ollama 백엔드 디렉터리로 이동합니다.
cd ollama-backend - Ollama Dockerfile을 열고 구현합니다.
cloudshell edit DockerfileFROM ollama/ollama:latest # Listen on all interfaces, port 8080 ENV OLLAMA_HOST 0.0.0.0:8080 # Store model weight files in /models ENV OLLAMA_MODELS /models # Reduce logging verbosity ENV OLLAMA_DEBUG false # Never unload model weights from the GPU ENV OLLAMA_KEEP_ALIVE -1 # Store the model weights in the container image ENV MODEL gemma3:270m RUN ollama serve & sleep 5 && ollama pull $MODEL # Start Ollama ENTRYPOINT ["ollama", "serve"]- 공식 Ollama 이미지를 기반으로 사용
- 모든 IP 주소의 연결을 허용하도록
OLLAMA_HOST를 설정합니다. - 포트 8080을 노출합니다.
- GPU 지원을 사용하여 Gemma 백엔드를 배포합니다.
gcloud run deploy ollama-gemma3-270m-gpu \
--source . \
--region europe-west4 \
--concurrency 7 \
--cpu 8 \
--set-env-vars OLLAMA_NUM_PARALLEL=4 \
--gpu 1 \
--gpu-type nvidia-l4 \
--max-instances 1 \
--memory 16Gi \
--allow-unauthenticated \
--no-cpu-throttling \
--no-gpu-zonal-redundancy \
--timeout 600 \
--labels dev-tutorial=codelab-agent-gpu
'소스에서 배포하려면 빌드된 컨테이너를 저장할 Artifact Registry Docker 저장소가 필요합니다. '[europe-west4] 리전에 [cloud-run-source-deploy] 라는 저장소가 생성됩니다.'라는 메시지가 표시되면 계속합니다.
⚙️ 주요 구성 설명:
- GPU: 추론 워크로드에 대한 뛰어난 가격 대비 성능을 제공하는 NVIDIA L4가 선택되었습니다. L4는 24GB GPU 메모리와 최적화된 텐서 작업을 제공하므로 Gemma와 같은 2억 7천만 개의 매개변수 모델에 적합합니다.
- 메모리: 모델 로드, CUDA 작업, Ollama의 메모리 관리를 처리하기 위한 16GB 시스템 메모리
- CPU: 최적의 I/O 처리 및 전처리 작업을 위한 8코어
- 동시성: 인스턴스당 7개의 요청은 처리량과 GPU 메모리 사용량의 균형을 유지합니다.
- 제한 시간: 초기 모델 로드 및 컨테이너 시작을 수용하는 600초
💰 비용 고려사항: GPU 인스턴스는 CPU 전용 인스턴스보다 훨씬 비쌉니다 (시간당$2~4 vs 시간당$0.10). --max-instances 1 설정을 사용하면 불필요한 GPU 인스턴스 확장을 방지하여 비용을 관리할 수 있습니다.
- 배포가 완료될 때까지 기다리고 서비스 URL을 기록합니다.
export OLLAMA_URL=$(gcloud run services describe ollama-gemma3-270m-gpu \ --region=europe-west4 \ --format='value(status.url)') echo "🎉 Gemma backend deployed at: $OLLAMA_URL"
8. ADK 에이전트 통합 구현
이제 배포된 Gemma 백엔드에 연결되는 최소 ADK 에이전트를 만들어 보겠습니다.
- ADK 에이전트 디렉터리로 이동합니다.
cd ../adk-agent - 에이전트 구성을 열고 구현합니다.
cloudshell edit production_agent/agent.pyimport os from pathlib import Path from dotenv import load_dotenv from google.adk.agents import Agent from google.adk.models.lite_llm import LiteLlm import google.auth # Load environment variables root_dir = Path(__file__).parent.parent dotenv_path = root_dir / ".env" load_dotenv(dotenv_path=dotenv_path) # Configure Google Cloud try: _, project_id = google.auth.default() os.environ.setdefault("GOOGLE_CLOUD_PROJECT", project_id) except Exception: pass os.environ.setdefault("GOOGLE_CLOUD_LOCATION", "europe-west4") # Configure model connection gemma_model_name = os.getenv("GEMMA_MODEL_NAME", "gemma3:270m") api_base = os.getenv("OLLAMA_API_BASE", "localhost:10010") # Location of Ollama server # Production Gemma Agent - GPU-accelerated conversational assistant production_agent = Agent( model=LiteLlm(model=f"ollama_chat/{gemma_model_name}", api_base=api_base), name="production_agent", description="A production-ready conversational assistant powered by GPU-accelerated Gemma.", instruction="""You are 'Gem', a friendly, knowledgeable, and enthusiastic zoo tour guide. Your main goal is to make a zoo visit more fun and educational for guests by answering their questions. You can provide general information and interesting facts about different animal species, such as: - Their natural habitats and diet. 🌲🍓 - Typical lifespan and behaviors. - Conservation status and unique characteristics. IMPORTANT: You do NOT have access to any tools. This means you cannot look up real-time, specific information about THIS zoo. You cannot provide: - The names or ages of specific animals currently at the zoo. - The exact location or enclosure for an animal. - The daily schedule for feedings or shows. Always answer based on your general knowledge about the animal kingdom. Keep your tone cheerful, engaging, and welcoming for visitors of all ages. 🦁✨""", tools=[], # Gemma focuses on conversational capabilities ) # Set as root agent root_agent = production_agent- LiteLlm을 통해 배포된 Gemma 백엔드에 연결
- 간단한 대화형 에이전트를 만듭니다.
- Google Cloud 통합을 구성합니다.
- FastAPI 서버를 열고 구현합니다.
cloudshell edit server.pyimport os from dotenv import load_dotenv from fastapi import FastAPI from google.adk.cli.fast_api import get_fast_api_app # Load environment variables load_dotenv() AGENT_DIR = os.path.dirname(os.path.abspath(__file__)) app_args = {"agents_dir": AGENT_DIR, "web": True} # Create FastAPI app with ADK integration app: FastAPI = get_fast_api_app(**app_args) # Update app metadata app.title = "Production ADK Agent - Lab 3" app.description = "Gemma agent with GPU-accelerated backend" app.version = "1.0.0" @app.get("/health") def health_check(): return {"status": "healthy", "service": "production-adk-agent"} @app.get("/") def root(): return { "service": "Production ADK Agent - Lab 3", "description": "GPU-accelerated Gemma agent", "docs": "/docs", "health": "/health" } if __name__ == "__main__": import uvicorn uvicorn.run(app, host="0.0.0.0", port=8080, log_level="info")- ADK 통합으로 FastAPI 서버를 만듭니다.
- 테스트를 위한 웹 인터페이스를 사용 설정합니다.
- 상태 점검 엔드포인트를 제공합니다.
- Dockerfile을 열고 구현합니다.
cloudshell edit DockerfileFROM python:3.13-slim # Copy uv from the official image COPY --from=ghcr.io/astral-sh/uv:latest /uv /usr/local/bin/uv # Install system dependencies RUN apt-get update && apt-get install -y curl && rm -rf /var/lib/apt/lists/* # Set working directory WORKDIR /app # Copy all files COPY . . # Install Python dependencies RUN uv sync # Expose port EXPOSE 8080 # Run the application CMD ["uv", "run", "uvicorn", "server:app", "--host", "0.0.0.0", "--port", "8080"]- uv: pip보다 10~100배 빠른 최신 Python 패키지 관리자입니다. 전역 캐시와 병렬 다운로드를 사용하여 컨테이너 빌드 시간을 크게 줄입니다.
- Python 3.13-slim: 최소한의 시스템 종속 항목이 있는 최신 Python 버전으로, 컨테이너 크기와 공격 표면을 줄입니다.
- 다단계 빌드: 공식 이미지에서 uv를 복사하면 최신 최적화 바이너리를 가져올 수 있습니다.
9. 환경 구성 및 에이전트 배포
이제 배포된 Gemma 백엔드에 연결하도록 ADK 에이전트를 구성하고 Cloud Run 서비스로 배포합니다. 여기에는 환경 변수를 설정하고 올바른 구성으로 에이전트를 배포하는 작업이 포함됩니다.
- 환경 구성을 설정합니다.
cat << EOF > .env GOOGLE_CLOUD_PROJECT=$(gcloud config get-value project) GOOGLE_CLOUD_LOCATION=europe-west4 GEMMA_MODEL_NAME=gemma3:270m OLLAMA_API_BASE=$OLLAMA_URL EOF
Cloud Run의 환경 변수 이해
환경 변수는 런타임에 애플리케이션을 구성하는 키-값 쌍입니다. 특히 다음과 같은 경우에 유용합니다.
- API 엔드포인트 및 서비스 URL (예: Ollama 백엔드)
- 환경 (개발, 스테이징, 프로덕션) 간에 변경되는 구성
- 하드 코딩하면 안 되는 민감한 정보
ADK 에이전트를 배포합니다.
export PROJECT_ID=$(gcloud config get-value project)
gcloud run deploy production-adk-agent \
--source . \
--region europe-west4 \
--allow-unauthenticated \
--memory 4Gi \
--cpu 2 \
--max-instances 1 \
--concurrency 50 \
--timeout 300 \
--set-env-vars GOOGLE_CLOUD_PROJECT=$PROJECT_ID \
--set-env-vars GOOGLE_CLOUD_LOCATION=europe-west4 \
--set-env-vars GEMMA_MODEL_NAME=gemma3:270m \
--set-env-vars OLLAMA_API_BASE=$OLLAMA_URL \
--labels dev-tutorial=codelab-agent-gpu
⚙️ 주요 구성:
- 자동 확장: 인스턴스 1개로 고정 (경량 요청 처리)
- 동시 실행: 인스턴스당 요청 50개
- 메모리: ADK 에이전트용 4GB
- 환경: Gemma 백엔드에 연결
🔒 보안 참고사항: 이 실습에서는 편의상 --allow-unauthenticated를 사용합니다. 프로덕션에서는 다음을 사용하여 적절한 인증을 구현하세요.
- 서비스 계정을 사용한 Cloud Run 서비스 간 인증
- ID 및 액세스 관리 (IAM) 정책
- 외부 액세스를 위한 API 키 또는 OAuth
gcloud run services add-iam-policy-binding를 사용하여 액세스 제어
에이전트 서비스 URL을 가져옵니다.
export AGENT_URL=$(gcloud run services describe production-adk-agent \
--region=europe-west4 \
--format='value(status.url)')
echo "🎉 ADK Agent deployed at: $AGENT_URL"
Cloud Run 환경 변수 문서에 따른 ✅ 환경 변수 권장사항:
- 예약된 변수 피하기:
PORT(환경 변수를 변경해야 하는 경우 대신 –port 플래그 사용) 또는X_GOOGLE_로 시작하는 변수를 설정하지 마세요. - 설명이 포함된 이름 사용: 충돌을 방지하기 위해 변수에 접두사를 추가합니다 (예:
MODEL대신GEMMA_MODEL_NAME). - 쉼표 이스케이프: 값에 쉼표가 포함된 경우 다른 구분 기호(
--set-env-vars "^@^KEY1=value1,value2@KEY2=...")를 사용합니다. - 업데이트와 바꾸기:
--update-env-vars를 사용하여 다른 변수에 영향을 주지 않고 특정 변수를 추가/변경합니다.
Cloud Run에서 변수를 설정하는 방법:
- 파일에서:
gcloud run deploy SERVICE_NAME --env-vars-file .env --labels dev-tutorial codelab-adk(파일에서 여러 변수를 로드함) - 여러 플래그: 쉼표로 구분할 수 없는 복잡한 값에 대해
--set-env-vars반복
10. ADK 웹 인터페이스로 테스트
두 서비스를 모두 배포했으므로 이제 ADK 에이전트가 GPU 가속 Gemma 백엔드와 성공적으로 통신하고 사용자 쿼리에 응답할 수 있는지 확인합니다.
- 상태 엔드포인트를 테스트합니다.
curl $AGENT_URL/health{ "status": "healthy", "service": "production-adk-agent" } - 새 브라우저 탭에
production-adk-agent의 URL을 입력하여 에이전트와 상호작용합니다. ADK 웹 인터페이스가 표시됩니다. - 다음 샘플 대화로 에이전트를 테스트하세요.
- "붉은 판다는 야생에서 주로 무엇을 먹나요?"
- "눈표범에 관한 흥미로운 사실을 알려 줘."
- '독화살개구리는 왜 이렇게 화려한 색을 띠고 있어?'
- "동물원에서 새 아기 캥거루는 어디에서 볼 수 있어?"
- 에이전트가 배포된 Gemma 모델을 사용하여 응답합니다. 배포된 Gemma 서비스의 로그를 관찰하여 이를 확인할 수 있습니다. 다음 섹션에서 이 작업을 수행합니다.
- GPU 가속 백엔드에서 대답을 생성합니다.
- 웹 인터페이스는 깔끔한 채팅 환경을 제공합니다.

11. 탄력성 테스트 구현 및 실행
프로덕션 배포가 실제 트래픽을 처리하는 방식을 파악하기 위해 시스템이 더 높은 '시뮬레이션된' 프로덕션 워크로드에 적응하는 기능을 테스트하는 탄력성 테스트를 구현합니다.
- 탄력성 테스트 스크립트를 열고 구현합니다.
cloudshell edit elasticity_test.pyimport random import uuid from locust import HttpUser, task, between class ProductionAgentUser(HttpUser): """Elasticity test user for the Production ADK Agent.""" wait_time = between(1, 3) # Faster requests to trigger scaling def on_start(self): """Set up user session when starting.""" self.user_id = f"user_{uuid.uuid4()}" self.session_id = f"session_{uuid.uuid4()}" # Create session for the Gemma agent using proper ADK API format session_data = {"state": {"user_type": "elasticity_test_user"}} self.client.post( f"/apps/production_agent/users/{self.user_id}/sessions/{self.session_id}", headers={"Content-Type": "application/json"}, json=session_data, ) @task(4) def test_conversations(self): """Test conversational capabilities - high frequency.""" topics = [ "What do red pandas typically eat in the wild?", "Can you tell me an interesting fact about snow leopards?", "Why are poison dart frogs so brightly colored?", "Where can I find the new baby kangaroo in the zoo?", "What is the name of your oldest gorilla?", "What time is the penguin feeding today?" ] # Use proper ADK API format for sending messages message_data = { "app_name": "production_agent", "user_id": self.user_id, "session_id": self.session_id, "new_message": { "role": "user", "parts": [{ "text": random.choice(topics) }] } } self.client.post( "/run", headers={"Content-Type": "application/json"}, json=message_data, ) @task(1) def health_check(self): """Test the health endpoint.""" self.client.get("/health")- 세션 생성:
/apps/production_agent/users/{user_id}/sessions/{session_id}에 POST를 사용하여 적절한 ADK API 형식을 사용합니다.session_id및user_id를 만든 후 에이전트에 요청할 수 있습니다. - 메시지 형식:
app_name,user_id,session_id, 구조화된new_message객체를 사용하여 ADK 사양을 따름 - 대화 엔드포인트:
/run엔드포인트를 사용하여 모든 이벤트를 한 번에 수집합니다 (부하 테스트에 권장). - Realistic Load: 대화형 로드를 더 짧은 대기 시간으로 만듭니다.
- 세션 생성:
- 종속 항목을 설치합니다.
uv sync - Locust는 웹 애플리케이션 및 기타 시스템의 성능 및 부하 테스트를 위해 설계된 오픈소스 Python 기반 부하 테스트 도구입니다. 주요 특징은 테스트 시나리오와 사용자 동작이 표준 Python 코드를 사용하여 정의된다는 점으로, 그래픽 사용자 인터페이스나 도메인별 언어를 사용하는 도구에 비해 유연성과 표현력이 높습니다. Locust를 사용하여 서비스에 대한 사용자 트래픽을 시뮬레이션합니다.테스트를 실행합니다.
uv run locust -f elasticity_test.py \ -H $AGENT_URL \ --headless \ -t 60s \ -u 20 \ -r 5- 기간: 60초
- 사용자: 동시 사용자 20명
- 생성 속도: 초당 사용자 5명
- 대상: 두 서비스 모두에서 자동 확장 트리거
12. AutoScaling 동작 관찰
탄력성 테스트가 실행되면 Cloud Run에서 더 높은 워크로드를 지원하는 것을 확인할 수 있습니다. 여기에서 ADK 에이전트를 GPU 백엔드와 분리할 때의 주요 아키텍처 이점을 확인할 수 있습니다.
탄력성 테스트 중에 콘솔에서 두 Cloud Run 서비스가 트래픽을 처리하는 방식을 모니터링합니다.
- Cloud Console에서 다음 위치로 이동합니다.
- Cloud Run → production-adk-agent → 측정항목
- Cloud Run → ollama-gemma3-270m-gpu → 측정항목
👀 관찰해야 할 사항:
🤖 ADK 에이전트 서비스:
- 트래픽이 증가하는 동안 인스턴스 1개로 일정하게 유지되어야 합니다.
- 트래픽이 많은 동안 CPU 및 메모리 사용량 급증
- 세션 관리 및 요청 라우팅을 효율적으로 처리합니다.
🎮 Gemma 백엔드 서비스 (병목 현상):
- 트래픽이 증가하는 동안 인스턴스 1개로 유지되어야 합니다.
- 부하가 걸리면 GPU 사용률이 크게 증가함
- GPU 집약적 모델 추론으로 인해 이 서비스가 병목 현상이 됩니다.
- GPU 가속으로 인해 모델 추론 시간이 일정하게 유지됨
💡 주요 통계:
- 최대 인스턴스를
1으로 설정했으므로 두 서비스가 일관되게 유지되고 확장되지 않습니다. - 두 서비스 모두 개별 부하 특성에 따라 독립적으로 확장됩니다.
- GPU는 다양한 부하 조건에서 성능을 유지하는 데 도움이 됩니다.
13. 결론
축하합니다. 시뮬레이션된 프로덕션 워크로드를 테스트하면서 GPU 가속 Gemma 백엔드를 사용하여 프로덕션에 즉시 사용 가능한 ADK 에이전트를 배포했습니다.
✅ 학습한 내용
- ✅ Cloud Run에 GPU 가속 Gemma 모델 백엔드 배포
- ✅ Gemma 백엔드와 통합되는 ADK 에이전트를 만들고 배포했습니다.
- ✅ ADK 웹 인터페이스를 사용하여 에이전트를 테스트했습니다.
- ✅ 두 개의 조정된 Cloud Run 서비스에서 자동 확장 동작이 관찰됨
💡 이 실습의 주요 통계
- 🎮 GPU 가속: NVIDIA L4 GPU는 모델 추론 성능을 크게 향상합니다.
- 🔗 서비스 조정: 두 Cloud Run 서비스가 원활하게 함께 작동할 수 있습니다.
- 📈 독립적인 확장: 각 서비스는 개별 부하 특성에 따라 확장됩니다.
- 🚀 프로덕션 준비: 아키텍처가 실제 트래픽 패턴을 효과적으로 처리합니다.
🔄 다음 단계
- 다양한 로드 패턴을 실험하고 확장 동작 관찰
- 다양한 Gemma 모델 크기 시도 (메모리 및 GPU를 적절하게 조정)
- 프로덕션 배포를 위한 모니터링 및 알림 구현
- 전역 가용성을 위한 멀티 리전 배포 살펴보기
🧹 정리
요금이 발생하지 않도록 하려면 작업이 완료된 후 리소스를 삭제하세요.
gcloud run services delete production-adk-agent --region=europe-west4
gcloud run services delete ollama-gemma3-270m-gpu --region=europe-west4
📖 리소스
- 시작 저장소
- 전체 솔루션
- Google ADK 문서
- ADK 테스트 가이드 - ADK API 엔드포인트 및 테스트 패턴에 관한 전체 참조
- Cloud Run 부하 테스트
- 에이전트 개발 키트 (ADK) 문서
- Cloud Run GPU 문서
- Ollama 모델 라이브러리
- Google Cloud Trace 문서
- Cloud Run 보안 권장사항
- UV Python 패키지 관리자
- Locust 부하 테스트 프레임워크