
1. Wprowadzenie
Opis
W tym module wdrożysz gotowego do użytku produkcyjnego agenta Agent Development Kit (ADK) z backendem Gemma akcelerowanym przez GPU. Skupiamy się na najważniejszych wzorcach wdrażania: konfigurowaniu usług Cloud Run z obsługą GPU, integrowaniu backendów modeli z agentami ADK i obserwowaniu zachowania autoskalowania pod obciążeniem.
Jakie zadania wykonasz
W tym module skupisz się na najważniejszych aspektach wdrażania w środowisku produkcyjnym:
- Wdrażanie Gemma w Cloud Run z GPU – skonfigurujesz backend modelu Gemma o wysokiej wydajności
- Integracja wdrożenia Gemma z agentem ADK – połączysz agenta z modelem akcelerowanym przez GPU.
- Testowanie za pomocą interfejsu internetowego ADK – sprawdzisz, czy agent konwersacyjny działa prawidłowo.
- Przeprowadzanie testu elastyczności – zaobserwujesz, jak instancje Cloud Run radzą sobie z obciążeniem.
Skupiamy się na wzorcach wdrożeń produkcyjnych, a nie na rozbudowanym tworzeniu agentów.
Czego się nauczysz
- Wdrażanie modeli Gemma z akceleracją GPU w Cloud Run do użytku produkcyjnego
- Integrowanie wdrożeń modeli zewnętrznych z agentami ADK
- Konfigurowanie i testowanie wdrożeń agentów AI gotowych do wdrożenia w środowisku produkcyjnym
- Rozumienie zachowania Cloud Run pod obciążeniem
- Obserwowanie, jak wiele instancji Cloud Run koordynuje działania podczas nagłych wzrostów ruchu
- Przeprowadzanie testów elastyczności w celu weryfikacji wydajności
2. Konfiguracja projektu
- Jeśli nie masz jeszcze konta Google, musisz je utworzyć.
- Używaj konta osobistego zamiast konta służbowego lub szkolnego. Konta służbowe i szkolne mogą mieć ograniczenia, które uniemożliwiają włączenie interfejsów API potrzebnych do tego ćwiczenia.
- Zaloguj się w konsoli Google Cloud.
- Włącz płatności w konsoli Google Cloud.
- Pod względem opłat za zasoby chmury ukończenie tego modułu powinno kosztować mniej niż 1 USD.
- Jeśli chcesz uniknąć dalszych opłat, wykonaj czynności opisane na końcu tego modułu, aby usunąć zasoby.
- Nowi użytkownicy mogą skorzystać z bezpłatnego okresu próbnego, w którym mają do dyspozycji środki w wysokości 300 USD.
- Utwórz nowy projekt lub użyj już istniejącego.
- Jeśli zobaczysz błąd dotyczący limitu projektu, użyj ponownie istniejącego projektu lub usuń go, aby utworzyć nowy.
3. Otwórz edytor Cloud Shell
- Kliknij ten link, aby przejść bezpośrednio do edytora Cloud Shell
- Jeśli w dowolnym momencie pojawi się prośba o autoryzację, kliknij Autoryzuj, aby kontynuować.
- Jeśli terminal nie pojawi się u dołu ekranu, otwórz go:
- Kliknij Wyświetl.
- Kliknij Terminal
 .
.
- W terminalu ustaw projekt za pomocą tego polecenia:
- Format:
gcloud config set project [PROJECT_ID] - Przykład:
gcloud config set project lab-project-id-example - Jeśli nie pamiętasz identyfikatora projektu:
- Aby wyświetlić listę wszystkich identyfikatorów projektów, użyj tego polecenia:
gcloud projects list | awk '/PROJECT_ID/{print $2}'
- Aby wyświetlić listę wszystkich identyfikatorów projektów, użyj tego polecenia:
- Format:
- Powinien wyświetlić się ten komunikat:
Updated property [core/project].
WARNINGi pojawia się pytanieDo you want to continue (Y/n)?, prawdopodobnie identyfikator projektu został wpisany nieprawidłowo. Naciśnijn, a następnieEnteri spróbuj ponownie uruchomić poleceniegcloud config set project.
4. Włączanie interfejsów API i ustawianie regionu domyślnego
Zanim wdrożymy usługi Cloud Run z obsługą GPU, musimy włączyć wymagane interfejsy Google Cloud API i skonfigurować ustawienia projektu.
- W terminalu włącz interfejsy API:
gcloud services enable \
run.googleapis.com \
artifactregistry.googleapis.com \
cloudbuild.googleapis.com \
aiplatform.googleapis.com
Jeśli pojawi się prośba o autoryzację, kliknij Autoryzuj, aby przejść dalej.
Wykonanie tego polecenia może potrwać kilka minut, ale powinno ostatecznie wyświetlić komunikat o sukcesie podobny do tego:
Operation "operations/acf.p2-73d90d00-47ee-447a-b600" finished successfully.
- Ustaw domyślny region Cloud Run.
gcloud config set run/region europe-west4
5. Przygotowywanie projektu w Pythonie
Skonfigurujmy kod startowy, który zawiera podstawową strukturę zarówno backendu Gemma, jak i usług agenta ADK.
- Sklonuj repozytorium początkowe:
cd ~ npx -y giget@latest gh+git:GoogleCloudPlatform/devrel-demos/agents/accelerate-ai-with-cloud-run/accelerate-ai-lab3-starter accelerate-ai-lab3-starter cd accelerate-ai-lab3-starter - Sprawdź strukturę projektu:
ls -Raccelerate-ai-lab3-starter/ ├── README.md # Project overview ├── ollama-backend/ # Ollama backend (separate deployment) │ └── Dockerfile # Backend container (🚧 to implement) └── adk-agent/ # ADK agent (separate deployment) ├── pyproject.toml # Python dependencies (✅ completed) ├── server.py # FastAPI server (🚧 to implement) ├── Dockerfile # Container config (🚧 to implement) ├── elasticity_test.py # Elasticity testing (🚧 to implement) └── production_agent/ # Agent implementation ├── __init__.py # Package init (✅ completed) └── agent.py # Agent logic (🚧 to implement)
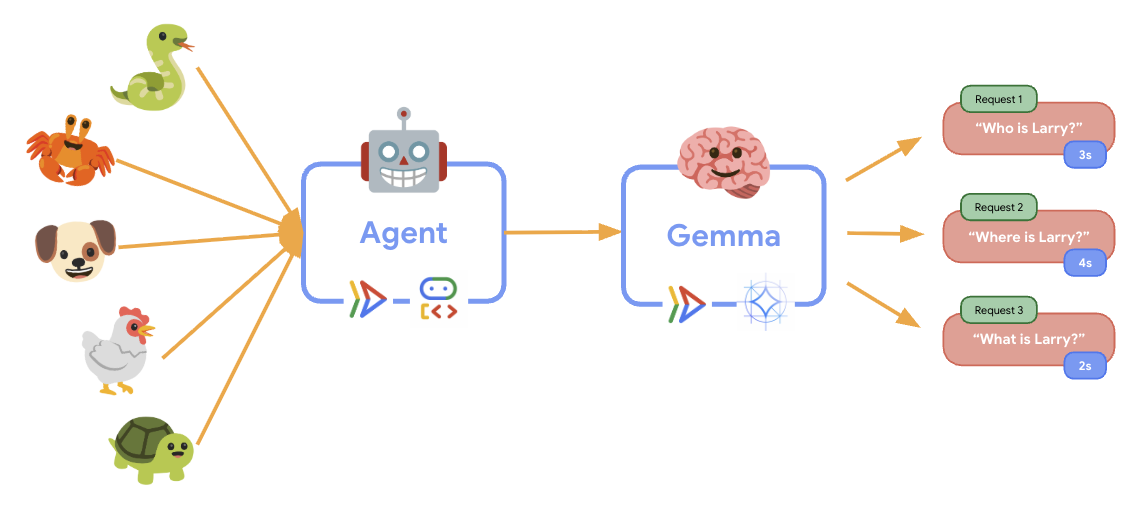
6. Omówienie architektury
Zanim wdrożysz architekturę 2 usług, zapoznaj się z nią:
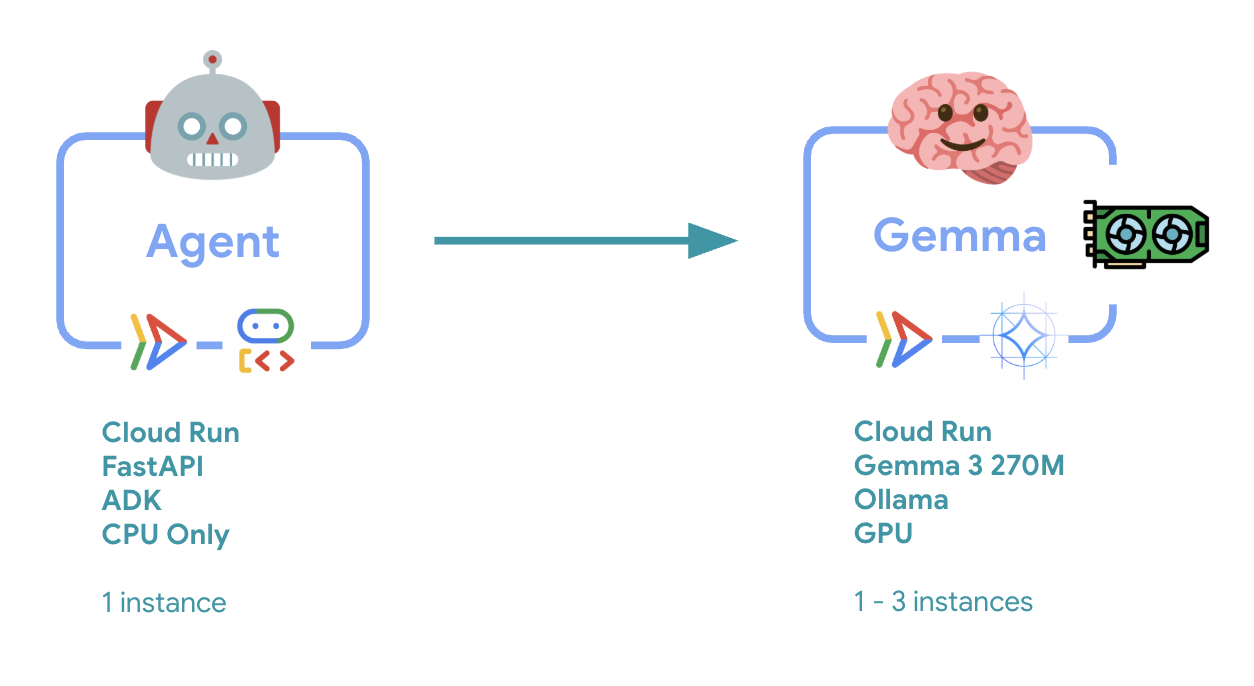
Kluczowa obserwacja: podczas testowania elastyczności zauważysz, że obie usługi obsługują obciążenie niezależnie od siebie – backend GPU (usługa stanowiąca wąskie gardło) używa procesora graficznego do obsługi obciążenia, a agent ADK korzysta z procesora do obsługi żądań, które nie wymagają dużych zasobów.
7. Wdrażanie backendu Gemma w Cloud Run z GPU
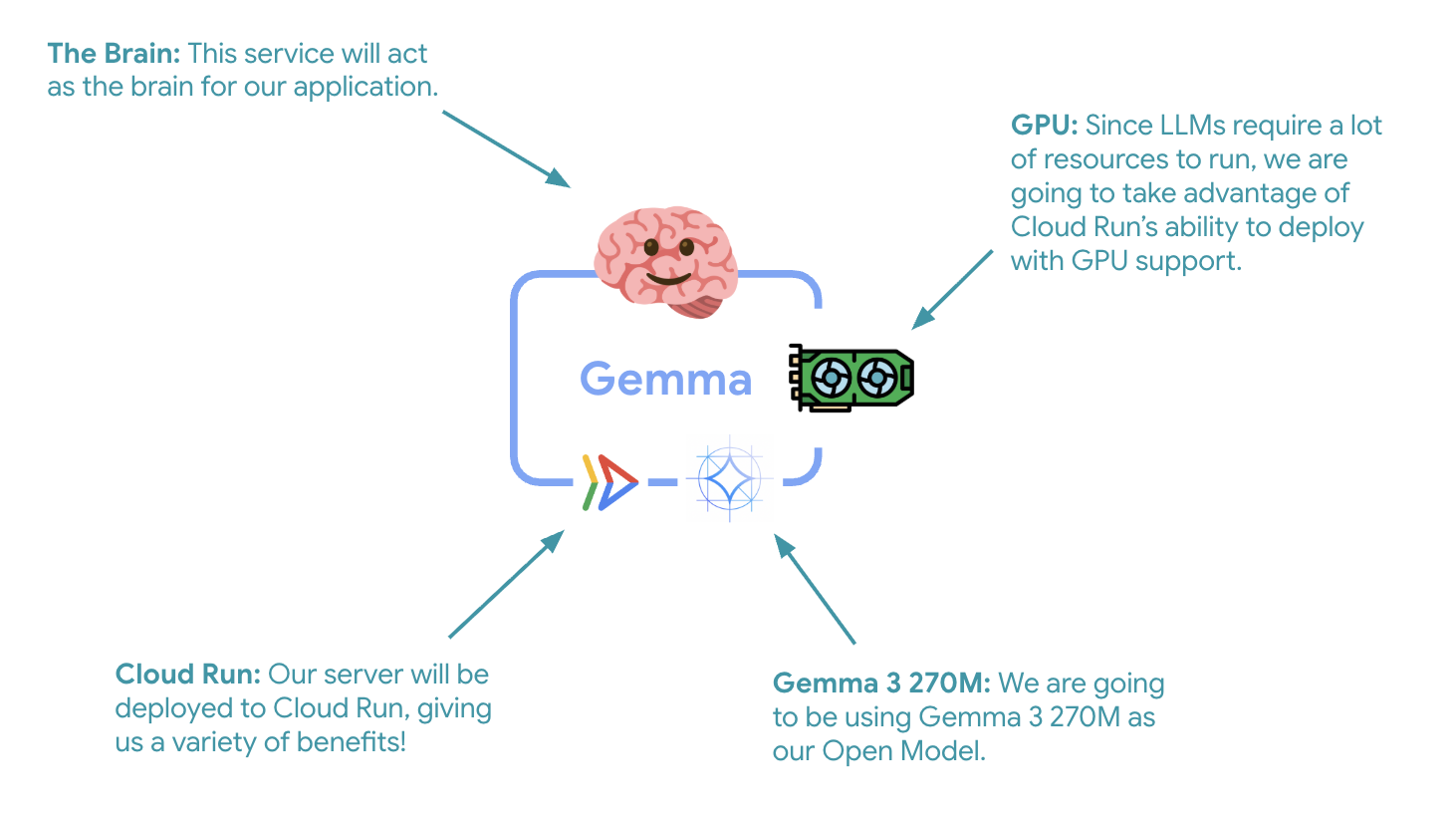
Pierwszym ważnym krokiem jest wdrożenie modelu Gemma z akceleracją GPU, który będzie mózgiem Twojego agenta ADK. Oddzielny, wdrożony model LLM może być korzystny w architekturach, w których potrzebujesz osobnego dostrojonego modelu lub izolowanego skalowania.
- Przejdź do katalogu backendu Ollama:
cd ollama-backend - Otwórz i wdroż plik Dockerfile Ollama:
cloudshell edit DockerfileFROM ollama/ollama:latest # Listen on all interfaces, port 8080 ENV OLLAMA_HOST 0.0.0.0:8080 # Store model weight files in /models ENV OLLAMA_MODELS /models # Reduce logging verbosity ENV OLLAMA_DEBUG false # Never unload model weights from the GPU ENV OLLAMA_KEEP_ALIVE -1 # Store the model weights in the container image ENV MODEL gemma3:270m RUN ollama serve & sleep 5 && ollama pull $MODEL # Start Ollama ENTRYPOINT ["ollama", "serve"]- wykorzystuje oficjalny obraz Ollamy jako podstawę;
- Ustawia
OLLAMA_HOSTtak, aby akceptował połączenia z dowolnego adresu IP. - Udostępnia port 8080.
- Wdróż backend Gemy z obsługą GPU:
gcloud run deploy ollama-gemma3-270m-gpu \
--source . \
--region europe-west4 \
--concurrency 7 \
--cpu 8 \
--set-env-vars OLLAMA_NUM_PARALLEL=4 \
--gpu 1 \
--gpu-type nvidia-l4 \
--max-instances 1 \
--memory 16Gi \
--allow-unauthenticated \
--no-cpu-throttling \
--no-gpu-zonal-redundancy \
--timeout 600 \
--labels dev-tutorial=codelab-agent-gpu
Jeśli otrzymasz komunikat „Deploying from source requires an Artifact Registry Docker repository to store built containers. Pojawi się komunikat „A repository named [cloud-run-source-deploy] in region [europe-west4] will be created." (Utworzymy repozytorium o nazwie [cloud-run-source-deploy] w regionie [europe-west4]). W takim przypadku kontynuuj.
⚙️ Wyjaśnienie kluczowych ustawień:
- GPU: NVIDIA L4, wybrany ze względu na doskonały stosunek ceny do wydajności w przypadku zbiorów zadań wymagających wnioskowania. L4 ma 24 GB pamięci GPU i zoptymalizowane operacje tensorowe, dzięki czemu idealnie nadaje się do modeli z 270 milionami parametrów, takich jak Gemma.
- Pamięć: 16 GB pamięci systemowej do obsługi wczytywania modelu, operacji CUDA i zarządzania pamięcią przez Ollamę.
- CPU: 8 rdzeni do optymalnego obsługiwania wejścia/wyjścia i zadań przetwarzania wstępnego
- Równoczesność: 7 żądań na instancję równoważy przepustowość z wykorzystaniem pamięci przez GPU.
- Czas oczekiwania: 600 sekund na początkowe wczytanie modelu i uruchomienie kontenera.
💰 Koszty: instancje GPU są znacznie droższe niż instancje tylko z CPU (ok. 2–4 USD za godzinę w porównaniu z ok. 0,10 USD za godzinę). Ustawienie --max-instances 1 pomaga kontrolować koszty, zapobiegając niepotrzebnemu skalowaniu instancji GPU.
- Poczekaj na zakończenie wdrażania i zanotuj adres URL usługi:
export OLLAMA_URL=$(gcloud run services describe ollama-gemma3-270m-gpu \ --region=europe-west4 \ --format='value(status.url)') echo "🎉 Gemma backend deployed at: $OLLAMA_URL"
8. Wdrażanie integracji agenta ADK
Teraz utworzymy minimalnego agenta ADK, który łączy się z wdrożonym backendem Gemma.
- Przejdź do katalogu agenta ADK:
cd ../adk-agent - Otwórz i wdroż konfigurację agenta:
cloudshell edit production_agent/agent.pyimport os from pathlib import Path from dotenv import load_dotenv from google.adk.agents import Agent from google.adk.models.lite_llm import LiteLlm import google.auth # Load environment variables root_dir = Path(__file__).parent.parent dotenv_path = root_dir / ".env" load_dotenv(dotenv_path=dotenv_path) # Configure Google Cloud try: _, project_id = google.auth.default() os.environ.setdefault("GOOGLE_CLOUD_PROJECT", project_id) except Exception: pass os.environ.setdefault("GOOGLE_CLOUD_LOCATION", "europe-west4") # Configure model connection gemma_model_name = os.getenv("GEMMA_MODEL_NAME", "gemma3:270m") api_base = os.getenv("OLLAMA_API_BASE", "localhost:10010") # Location of Ollama server # Production Gemma Agent - GPU-accelerated conversational assistant production_agent = Agent( model=LiteLlm(model=f"ollama_chat/{gemma_model_name}", api_base=api_base), name="production_agent", description="A production-ready conversational assistant powered by GPU-accelerated Gemma.", instruction="""You are 'Gem', a friendly, knowledgeable, and enthusiastic zoo tour guide. Your main goal is to make a zoo visit more fun and educational for guests by answering their questions. You can provide general information and interesting facts about different animal species, such as: - Their natural habitats and diet. 🌲🍓 - Typical lifespan and behaviors. - Conservation status and unique characteristics. IMPORTANT: You do NOT have access to any tools. This means you cannot look up real-time, specific information about THIS zoo. You cannot provide: - The names or ages of specific animals currently at the zoo. - The exact location or enclosure for an animal. - The daily schedule for feedings or shows. Always answer based on your general knowledge about the animal kingdom. Keep your tone cheerful, engaging, and welcoming for visitors of all ages. 🦁✨""", tools=[], # Gemma focuses on conversational capabilities ) # Set as root agent root_agent = production_agent- Łączy się z wdrożonym backendem Gemma za pomocą LiteLLM.
- Tworzy prostego agenta konwersacyjnego.
- Konfiguruje integrację z Google Cloud.
- Otwórz i wdroż serwer FastAPI:
cloudshell edit server.pyimport os from dotenv import load_dotenv from fastapi import FastAPI from google.adk.cli.fast_api import get_fast_api_app # Load environment variables load_dotenv() AGENT_DIR = os.path.dirname(os.path.abspath(__file__)) app_args = {"agents_dir": AGENT_DIR, "web": True} # Create FastAPI app with ADK integration app: FastAPI = get_fast_api_app(**app_args) # Update app metadata app.title = "Production ADK Agent - Lab 3" app.description = "Gemma agent with GPU-accelerated backend" app.version = "1.0.0" @app.get("/health") def health_check(): return {"status": "healthy", "service": "production-adk-agent"} @app.get("/") def root(): return { "service": "Production ADK Agent - Lab 3", "description": "GPU-accelerated Gemma agent", "docs": "/docs", "health": "/health" } if __name__ == "__main__": import uvicorn uvicorn.run(app, host="0.0.0.0", port=8080, log_level="info")- Tworzy serwer FastAPI z integracją ADK
- Włącza interfejs internetowy do testowania.
- Udostępnia punkty końcowe kontroli stanu.
- Otwórz i wdroż plik Dockerfile:
cloudshell edit DockerfileFROM python:3.13-slim # Copy uv from the official image COPY --from=ghcr.io/astral-sh/uv:latest /uv /usr/local/bin/uv # Install system dependencies RUN apt-get update && apt-get install -y curl && rm -rf /var/lib/apt/lists/* # Set working directory WORKDIR /app # Copy all files COPY . . # Install Python dependencies RUN uv sync # Expose port EXPOSE 8080 # Run the application CMD ["uv", "run", "uvicorn", "server:app", "--host", "0.0.0.0", "--port", "8080"]- uv: nowoczesny system zarządzania pakietami Pythona, który jest 10–100 razy szybszy niż pip. Korzysta z globalnej pamięci podręcznej i pobierania równoległego, co znacznie skraca czas tworzenia kontenera.
- Python 3.13-slim: najnowsza wersja Pythona z minimalnymi zależnościami systemowymi, co zmniejsza rozmiar kontenera i powierzchnię ataku.
- Wielostopniowa kompilacja: kopiowanie uv z oficjalnego obrazu zapewnia uzyskanie najnowszej zoptymalizowanej wersji binarnej.
9. Konfigurowanie środowiska i wdrażanie agenta
Teraz skonfigurujemy agenta ADK, aby połączyć go z wdrożonym backendem Gemma, i wdrożymy go jako usługę Cloud Run. Obejmuje to skonfigurowanie zmiennych środowiskowych i wdrożenie agenta z odpowiednią konfiguracją.
- Skonfiguruj środowisko:
cat << EOF > .env GOOGLE_CLOUD_PROJECT=$(gcloud config get-value project) GOOGLE_CLOUD_LOCATION=europe-west4 GEMMA_MODEL_NAME=gemma3:270m OLLAMA_API_BASE=$OLLAMA_URL EOF
Zmienne środowiskowe w Cloud Run
Zmienne środowiskowe to pary klucz-wartość, które konfigurują aplikację w czasie działania. Są one szczególnie przydatne w przypadku:
- punktów końcowych interfejsu API i adresów URL usług (np. naszego backendu Ollama);
- konfiguracji, która zmienia się w zależności od środowiska (deweloperskiego, testowego, produkcyjnego);
- danych wrażliwych, które nie powinny być zakodowane na stałe.
Wdróż agenta ADK:
export PROJECT_ID=$(gcloud config get-value project)
gcloud run deploy production-adk-agent \
--source . \
--region europe-west4 \
--allow-unauthenticated \
--memory 4Gi \
--cpu 2 \
--max-instances 1 \
--concurrency 50 \
--timeout 300 \
--set-env-vars GOOGLE_CLOUD_PROJECT=$PROJECT_ID \
--set-env-vars GOOGLE_CLOUD_LOCATION=europe-west4 \
--set-env-vars GEMMA_MODEL_NAME=gemma3:270m \
--set-env-vars OLLAMA_API_BASE=$OLLAMA_URL \
--labels dev-tutorial=codelab-agent-gpu
⚙️ Kluczowa konfiguracja:
- Autoskalowanie: stała liczba instancji – 1 (obsługa lekkich żądań)
- Równoczesność: 50 żądań na instancję
- Pamięć: 4 GB w przypadku agenta ADK
- Środowisko: łączy się z backendem Gemma.
🔒 Uwaga dotycząca bezpieczeństwa: w tym module dla uproszczenia używamy --allow-unauthenticated. W wersji produkcyjnej zaimplementuj odpowiednie uwierzytelnianie za pomocą:
- uwierzytelniania między usługami Cloud Run za pomocą kont usługi,
- zasad zarządzania tożsamościami i dostępem (uprawnień),
- kluczy interfejsu API lub OAuth na potrzeby dostępu zewnętrznego,
- Rozważ użycie
gcloud run services add-iam-policy-bindingdo kontrolowania dostępu.
Uzyskaj adres URL usługi agenta:
export AGENT_URL=$(gcloud run services describe production-adk-agent \
--region=europe-west4 \
--format='value(status.url)')
echo "🎉 ADK Agent deployed at: $AGENT_URL"
✅ Sprawdzone metody dotyczące zmiennych środowiskowych na podstawie dokumentacji zmiennych środowiskowych Cloud Run:
- Unikaj zarezerwowanych zmiennych: nie ustawiaj zmiennej
PORT(jeśli musisz zmienić zmienną środowiskową, użyj zamiast tego flagi –port) ani zmiennych zaczynających się odX_GOOGLE_. - Używaj opisowych nazw: dodawaj do zmiennych prefiksy, aby uniknąć konfliktów (np.
GEMMA_MODEL_NAMEzamiastMODEL). - Zastąp przecinki: jeśli wartości zawierają przecinki, użyj innego separatora:
--set-env-vars "^@^KEY1=value1,value2@KEY2=..." - Aktualizacja a zastępowanie: użyj
--update-env-vars, aby dodać lub zmienić określone zmienne bez wpływu na inne.
Jak ustawić zmienne w Cloud Run:
- Z pliku:
gcloud run deploy SERVICE_NAME --env-vars-file .env --labels dev-tutorial codelab-adk(wczytuje wiele zmiennych z pliku) - Wiele flag: powtórz
--set-env-varsw przypadku złożonych wartości, których nie można rozdzielić przecinkami.
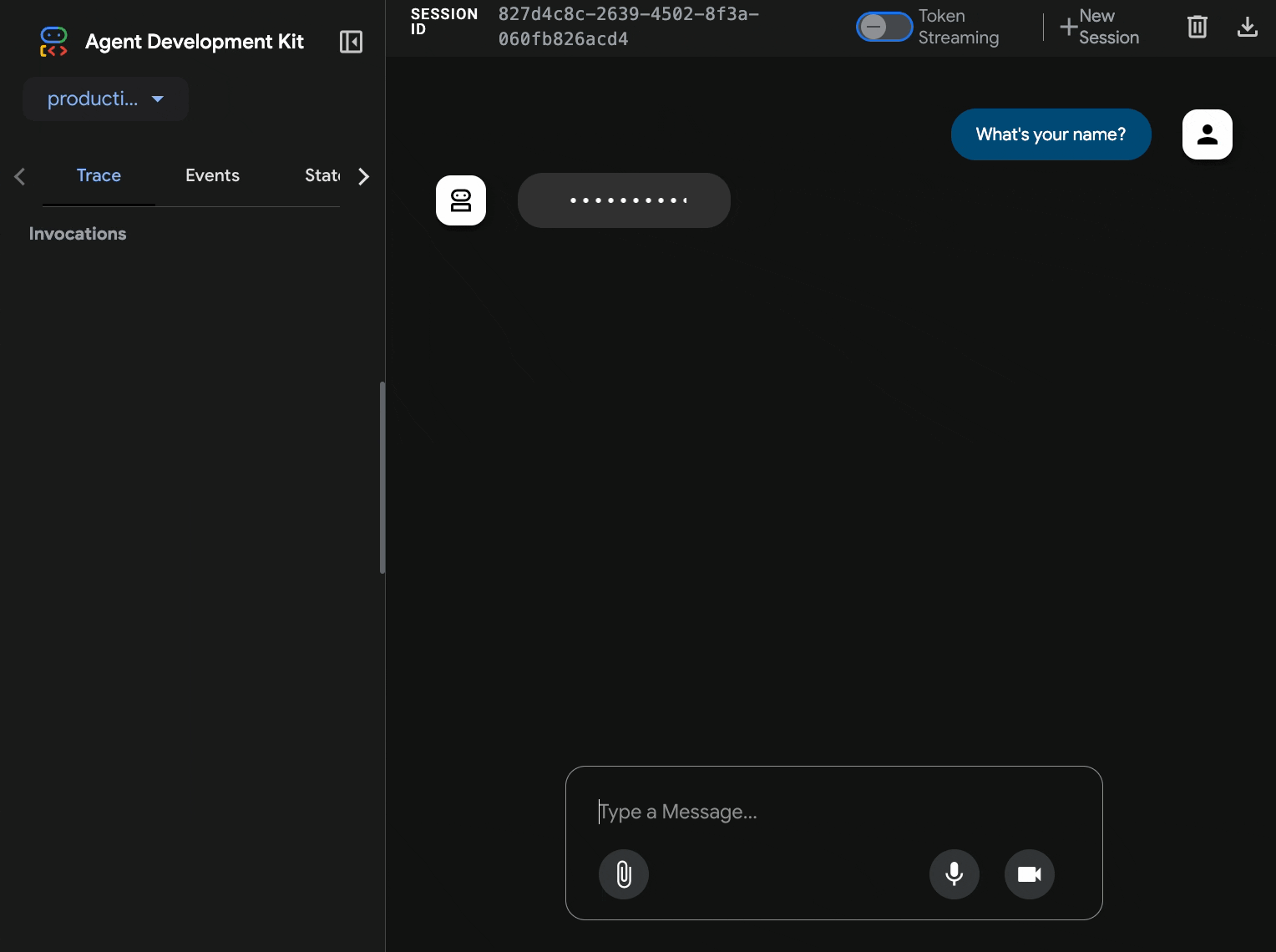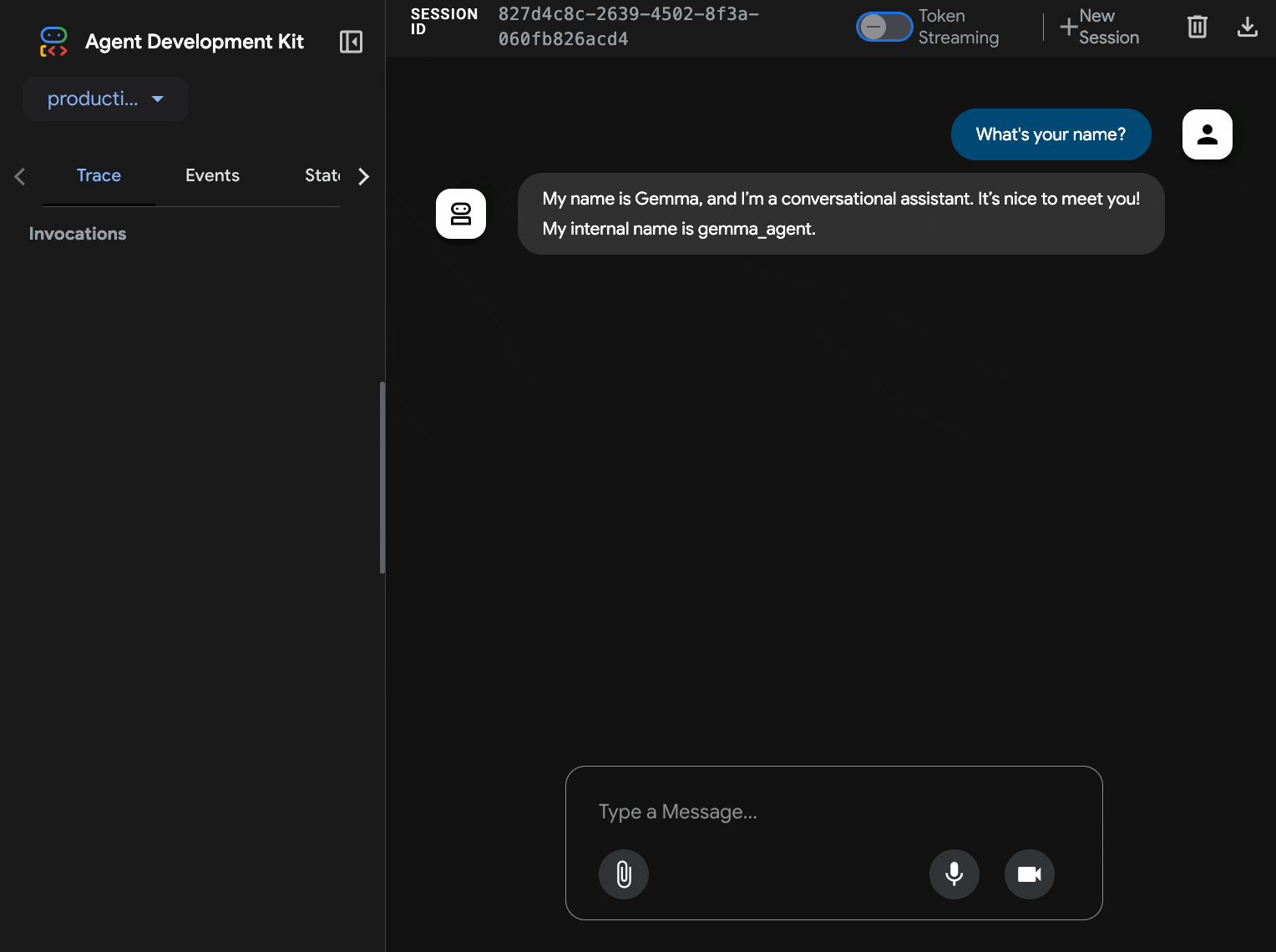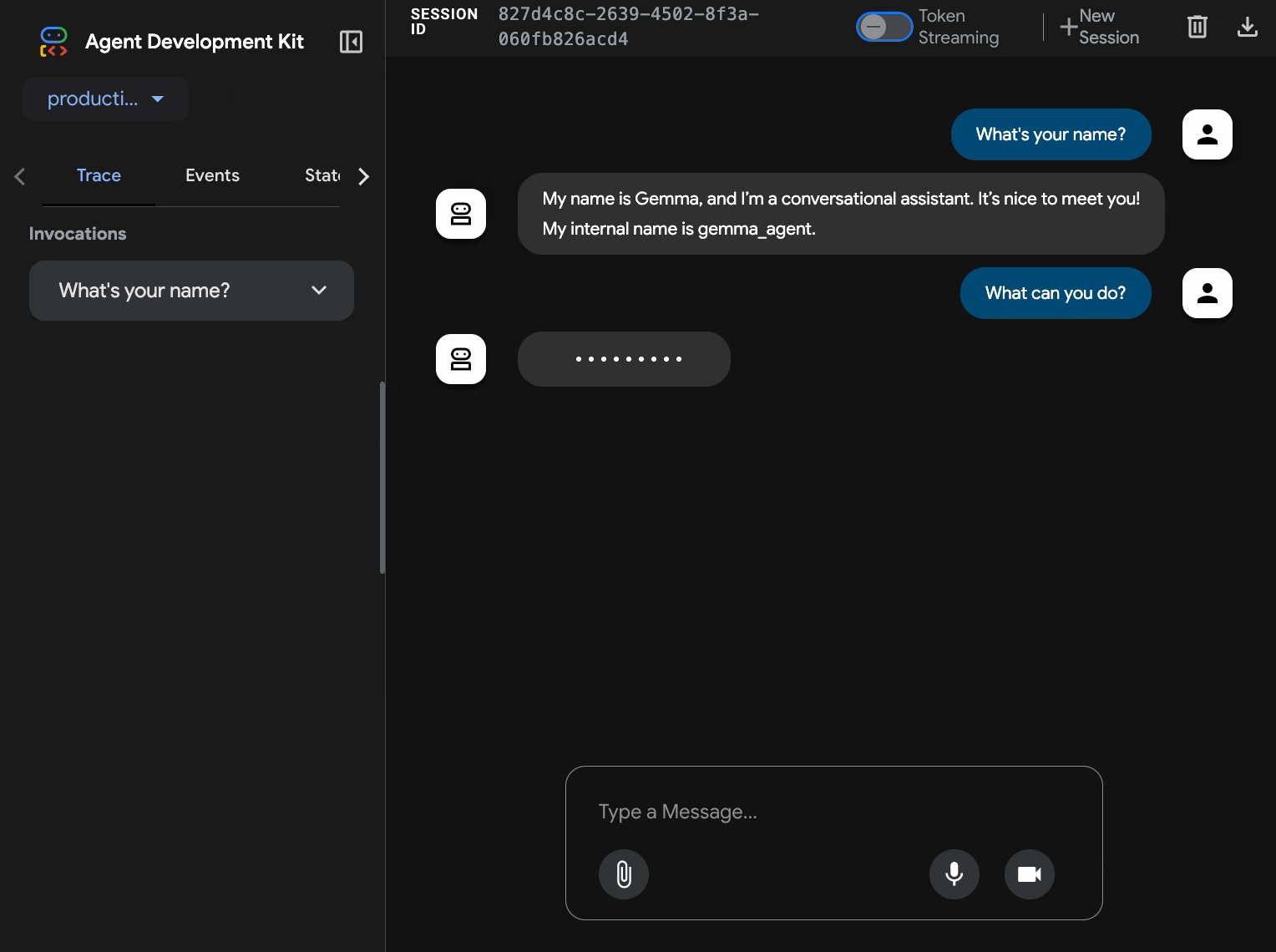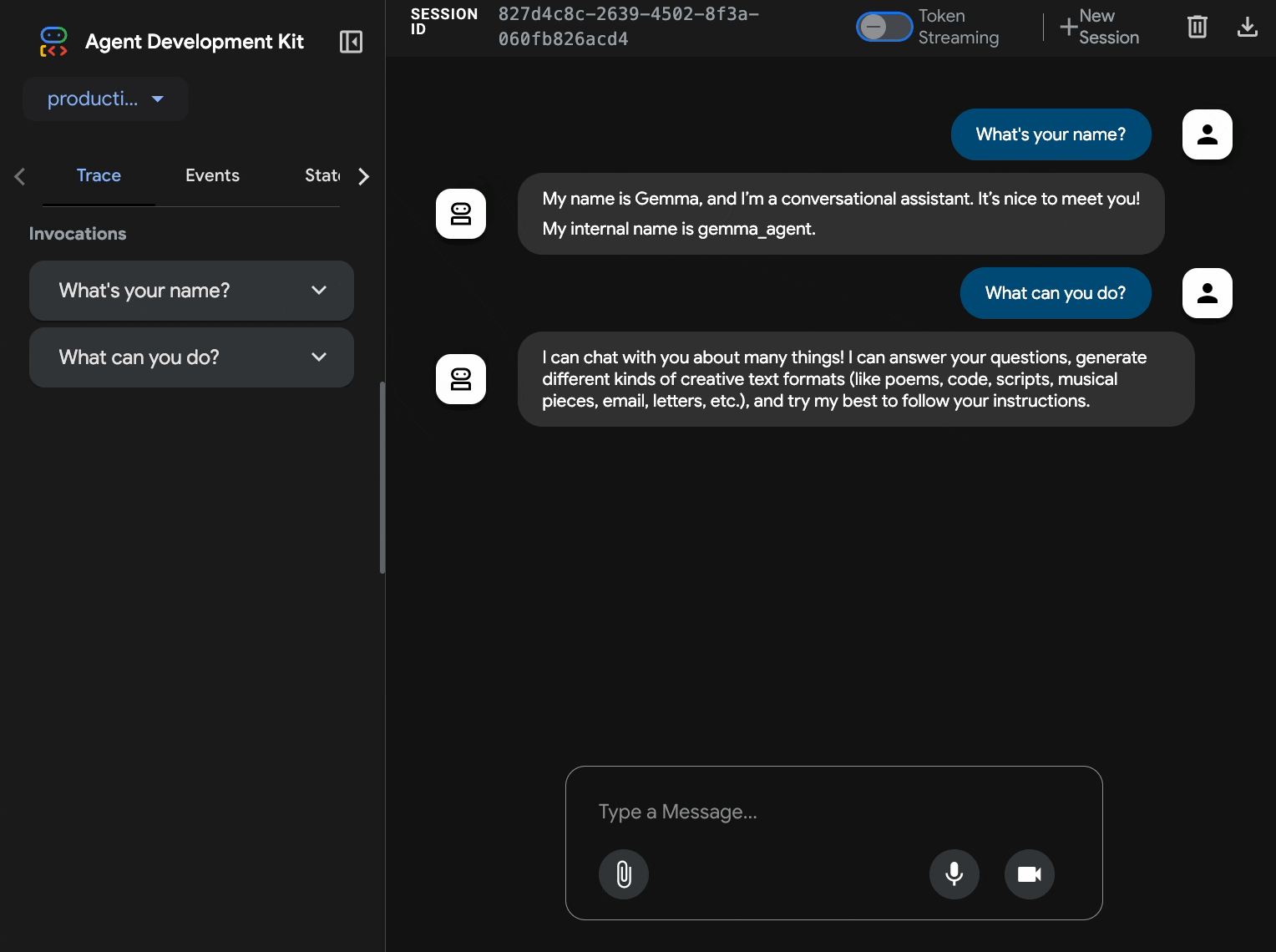
10. Testowanie za pomocą interfejsu internetowego ADK
Po wdrożeniu obu usług możesz sprawdzić, czy agent ADK może komunikować się z backendem Gemma akcelerowanym przez GPU i odpowiadać na zapytania użytkowników.
- Przetestuj punkt końcowy stanu:
curl $AGENT_URL/health{ "status": "healthy", "service": "production-adk-agent" } - Wejdź w interakcję z agentem, wpisując adres URL
production-adk-agentw nowej karcie przeglądarki. Powinien pojawić się interfejs internetowy ADK. - Przetestuj agenta, korzystając z tych przykładowych rozmów:
- „Co pandki rude jedzą na wolności?”
- „Możesz mi powiedzieć coś ciekawego o irbisach?”
- „Dlaczego żaby z rodziny drzewołazów mają tak jaskrawe kolory?”
- „W którym zoo urodziły się małe kangurzątka?”
- Agent odpowiada, korzystając z wdrożonego modelu Gemma. Możesz to sprawdzić, obserwując logi wdrożonej usługi Gemma. Zrobimy to w następnej sekcji.
- Odpowiedzi są generowane przez backend z akceleracją przez GPU.
- Interfejs internetowy zapewnia przejrzystą obsługę czatu.
11. Wdrażanie i przeprowadzanie testu elastyczności
Aby sprawdzić, jak wdrożenie produkcyjne radzi sobie z ruchem w rzeczywistym świecie, przeprowadzimy test elastyczności, który sprawdzi zdolność systemu do dostosowywania się do większego „symulowanego” obciążenia produkcyjnego.
- Otwórz i wdroż skrypt testowania elastyczności:
cloudshell edit elasticity_test.pyimport random import uuid from locust import HttpUser, task, between class ProductionAgentUser(HttpUser): """Elasticity test user for the Production ADK Agent.""" wait_time = between(1, 3) # Faster requests to trigger scaling def on_start(self): """Set up user session when starting.""" self.user_id = f"user_{uuid.uuid4()}" self.session_id = f"session_{uuid.uuid4()}" # Create session for the Gemma agent using proper ADK API format session_data = {"state": {"user_type": "elasticity_test_user"}} self.client.post( f"/apps/production_agent/users/{self.user_id}/sessions/{self.session_id}", headers={"Content-Type": "application/json"}, json=session_data, ) @task(4) def test_conversations(self): """Test conversational capabilities - high frequency.""" topics = [ "What do red pandas typically eat in the wild?", "Can you tell me an interesting fact about snow leopards?", "Why are poison dart frogs so brightly colored?", "Where can I find the new baby kangaroo in the zoo?", "What is the name of your oldest gorilla?", "What time is the penguin feeding today?" ] # Use proper ADK API format for sending messages message_data = { "app_name": "production_agent", "user_id": self.user_id, "session_id": self.session_id, "new_message": { "role": "user", "parts": [{ "text": random.choice(topics) }] } } self.client.post( "/run", headers={"Content-Type": "application/json"}, json=message_data, ) @task(1) def health_check(self): """Test the health endpoint.""" self.client.get("/health")- Tworzy sesję: używa prawidłowego formatu interfejsu API ADK z żądaniem POST do
/apps/production_agent/users/{user_id}/sessions/{session_id}. Po utworzeniusession_idiuser_idmożna wysłać do agenta żądanie. - Format wiadomości: zgodny ze specyfikacją ADK dla obiektów
app_name,user_id,session_idi uporządkowanego obiektunew_message. - Punkt końcowy konwersacji: używa punktu końcowego
/rundo zbierania wszystkich zdarzeń naraz (zalecany w przypadku testów obciążeniowych). - Realistic Load (Realistyczne obciążenie): tworzy obciążenie konwersacyjne z krótszymi czasami oczekiwania.
- Tworzy sesję: używa prawidłowego formatu interfejsu API ADK z żądaniem POST do
- Zainstaluj zależności:
uv sync - Locust to narzędzie open source do testowania obciążenia oparte na Pythonie, które służy do testowania wydajności i obciążenia aplikacji internetowych i innych systemów. Jego kluczową cechą jest to, że scenariusze testowe i zachowania użytkowników są definiowane za pomocą standardowego kodu w Pythonie, co zapewnia dużą elastyczność i wyrazistość w porównaniu z narzędziami opartymi na graficznych interfejsach użytkownika lub językach specyficznych dla domeny. Będziemy używać narzędzia Locust do symulowania ruchu użytkowników w naszych usługach.Uruchom test.
uv run locust -f elasticity_test.py \ -H $AGENT_URL \ --headless \ -t 60s \ -u 20 \ -r 5- Czas trwania: 60 sekund
- Użytkownicy: 20 użytkowników jednocześnie
- Szybkość generowania: 5 użytkowników na sekundę
- Cel: wywoływanie autoskalowania w przypadku obu usług
12. Obserwowanie zachowania autoskalowania
Podczas testu elastyczności możesz obserwować, jak Cloud Run obsługuje większe obciążenia. W tym miejscu zobaczysz najważniejsze zalety architektoniczne oddzielenia agenta ADK od backendu GPU.
Podczas testu elastyczności obserwuj w konsoli, jak obie usługi Cloud Run obsługują ruch.
- W konsoli Cloud otwórz:
- Cloud Run → production-adk-agent → Wskaźniki
- Cloud Run → ollama-gemma3-270m-gpu → Wskaźniki
👀 Na co zwrócić uwagę:
🤖 Usługa agenta ADK:
- Powinna utrzymywać się na poziomie 1 instancji, gdy ruch wzrasta.
- Wykorzystanie procesora i pamięci gwałtownie rośnie podczas dużego natężenia ruchu.
- Skutecznie zarządza sesjami i kieruje żądania.
🎮 Usługa backendu Gemma (wąskie gardło):
- Powinna utrzymywać się na poziomie 1 instancji, gdy ruch wzrasta.
- Wykorzystanie GPU znacznie wzrasta pod obciążeniem.
- Ta usługa staje się wąskim gardłem ze względu na wnioskowanie na modelu wymagającym dużej mocy obliczeniowej GPU.
- Czasy wnioskowania modelu pozostają spójne dzięki akceleracji GPU.
💡 Kluczowe obserwacje:
- Obie usługi pozostają spójne i nie są skalowane w górę, ponieważ ustawiliśmy maksymalną liczbę instancji na
1. - Obie usługi skalują się niezależnie od siebie na podstawie indywidualnych charakterystyk obciążenia.
- Procesor graficzny pomaga utrzymać wydajność w różnych warunkach obciążenia.
13. Podsumowanie
Gratulacje! Udało Ci się wdrożyć gotowego do użytku produkcyjnego agenta ADK z backendem Gemma akcelerowanym przez GPU, a także przetestować symulowane zadanie produkcyjne.
✅ Co udało Ci się osiągnąć
- ✅ Wdrożenie backendu modelu Gemma z akceleracją GPU w Cloud Run.
- ✅ Utworzenie i wdrożenie agenta ADK, który integruje się z backendem Gemma.
- ✅ Przetestowanie agenta za pomocą interfejsu internetowego ADK.
- ✅ Zaobserwowano zachowanie autoskalowania w przypadku 2 skoordynowanych usług Cloud Run.
💡 Najważniejsze obserwacje z tego modułu
- 🎮 Akceleracja GPU: procesor graficzny NVIDIA L4 znacznie zwiększa wydajność wnioskowania modelu.
- 🔗 Koordynacja usług: 2 usługi Cloud Run mogą ze sobą bezproblemowo współpracować.
- 📈 Niezależne skalowanie: każda usługa jest skalowana na podstawie indywidualnych charakterystyk obciążenia.
- 🚀 Gotowość do wdrożenia wersji produkcyjnej: architektura skutecznie obsługuje rzeczywiste wzorce ruchu.
🔄 Dalsze kroki
- Eksperymentuj z różnymi wzorcami obciążenia i obserwuj zachowanie skalowania.
- Wypróbuj różne rozmiary modelu Gemma (dostosuj pamięć i procesor graficzny).
- Wdrażaj monitorowanie i alerty w przypadku wdrożeń produkcyjnych.
- Poznaj wdrożenia w wielu regionach, aby zapewnić globalną dostępność.
🧹 Zwalnianie miejsca
Aby uniknąć obciążenia konta opłatami, po zakończeniu pracy usuń zasoby:
gcloud run services delete production-adk-agent --region=europe-west4
gcloud run services delete ollama-gemma3-270m-gpu --region=europe-west4
📖 Zasoby
- Starter Repository
- Kompletne rozwiązanie
- Dokumentacja pakietu Google ADK
- Przewodnik po testowaniu pakietu ADK – pełna dokumentacja punktów końcowych interfejsu API pakietu ADK i wzorców testowania.
- Testowanie obciążenia w Cloud Run
- Dokumentacja pakietu Agent Development Kit (ADK)
- Dokumentacja GPU Cloud Run
- Biblioteka modeli Ollama
- Dokumentacja Google Cloud Trace
- Sprawdzone metody zapewniania bezpieczeństwa w Cloud Run
- UV – system zarządzania pakietami Pythona
- Locust – platforma testowania obciążeń