
1. Introdução
Visão geral
Neste laboratório, você vai implantar um agente do Kit de Desenvolvimento de Agente (ADK) pronto para produção com um back-end do Gemma acelerado por GPU. O foco está em padrões de implantação críticos: configuração de serviços do Cloud Run com GPU, integração de back-ends de modelos com agentes do ADK e observação do comportamento de escalonamento automático sob carga.
Atividades deste laboratório
Neste laboratório, você vai se concentrar nos aspectos críticos da implantação de produção:
- Implantar o Gemma no Cloud Run com GPU: configurar um back-end de modelo do Gemma de alta performance
- Integrar a implantação do Gemma a um agente do ADK: conecte seu agente ao modelo acelerado por GPU.
- Teste com a interface da Web do ADK: valide se o agente de conversação funciona corretamente.
- Realizar testes de elasticidade: observe como as duas instâncias do Cloud Run lidam com a carga.
A ênfase está nos padrões de implantação de produção, e não no desenvolvimento extensivo de agentes.
O que você vai aprender
- Implantar modelos da Gemma acelerados por GPU no Cloud Run para uso em produção
- Integrar implantações de modelos externos com agentes do ADK
- Configurar e testar implantações de agentes de IA prontas para produção
- Entender o comportamento do Cloud Run sob carga
- Observe como várias instâncias do Cloud Run se coordenam durante picos de tráfego
- Aplicar testes de elasticidade para validar a performance
2. Configuração do projeto
- Se você ainda não tiver uma Conta do Google, crie uma.
- Use uma conta pessoal em vez de uma conta escolar ou de trabalho. As contas escolares e de trabalho podem ter restrições que impedem a ativação das APIs necessárias para este laboratório.
- Faça login no Console do Google Cloud.
- Ative o faturamento no console do Cloud.
- A conclusão deste laboratório custa menos de US $1 em recursos do Cloud.
- Siga as etapas no final deste laboratório para excluir recursos e evitar mais cobranças.
- Novos usuários podem aproveitar o teste sem custos financeiros de US$300.
- Crie um projeto ou reutilize um projeto existente.
- Se você receber um erro sobre a cota do projeto, reutilize ou exclua um projeto para criar outro.
3. Abrir editor do Cloud Shell
- Clique neste link para navegar diretamente até o editor do Cloud Shell.
- Se for preciso autorizar em algum momento, clique em Autorizar para continuar.
- Se o terminal não aparecer na parte de baixo da tela, abra-o:
- Clique em Visualizar.
- Clique em Terminal
 .
.
- No terminal, defina o projeto com este comando:
- Formato:
gcloud config set project [PROJECT_ID] - Exemplo:
gcloud config set project lab-project-id-example - Se você não se lembrar do ID do projeto:
- Para listar todos os IDs de projeto, use:
gcloud projects list | awk '/PROJECT_ID/{print $2}'
- Para listar todos os IDs de projeto, use:
- Formato:
- Você vai receber esta mensagem:
Updated property [core/project].
WARNINGe for perguntadoDo you want to continue (Y/n)?, provavelmente inseriu o ID do projeto incorretamente. Pressionen,Entere tente executar o comandogcloud config set projectnovamente.
4. Ativar APIs e definir a região padrão
Antes de implantar serviços do Cloud Run com suporte a GPU, precisamos ativar as APIs necessárias do Google Cloud e configurar as configurações do projeto.
- No terminal, ative as APIs:
gcloud services enable \
run.googleapis.com \
artifactregistry.googleapis.com \
cloudbuild.googleapis.com \
aiplatform.googleapis.com
Se for preciso autorizar, clique em Autorizar para continuar.
Esse comando pode levar alguns minutos para ser concluído, mas vai gerar uma mensagem de sucesso semelhante a esta:
Operation "operations/acf.p2-73d90d00-47ee-447a-b600" finished successfully.
- Defina sua região padrão do Cloud Run.
gcloud config set run/region europe-west4
5. Preparar seu projeto Python
Vamos configurar o código inicial que contém a estrutura básica para os serviços de back-end da Gemma e do agente do ADK.
- Clone o repositório inicial:
cd ~ npx -y giget@latest gh+git:GoogleCloudPlatform/devrel-demos/agents/accelerate-ai-with-cloud-run/accelerate-ai-lab3-starter accelerate-ai-lab3-starter cd accelerate-ai-lab3-starter - Examine a estrutura do projeto:
ls -Raccelerate-ai-lab3-starter/ ├── README.md # Project overview ├── ollama-backend/ # Ollama backend (separate deployment) │ └── Dockerfile # Backend container (🚧 to implement) └── adk-agent/ # ADK agent (separate deployment) ├── pyproject.toml # Python dependencies (✅ completed) ├── server.py # FastAPI server (🚧 to implement) ├── Dockerfile # Container config (🚧 to implement) ├── elasticity_test.py # Elasticity testing (🚧 to implement) └── production_agent/ # Agent implementation ├── __init__.py # Package init (✅ completed) └── agent.py # Agent logic (🚧 to implement)
6. Visão geral da arquitetura
Antes de implementar, vamos entender a arquitetura de dois serviços:
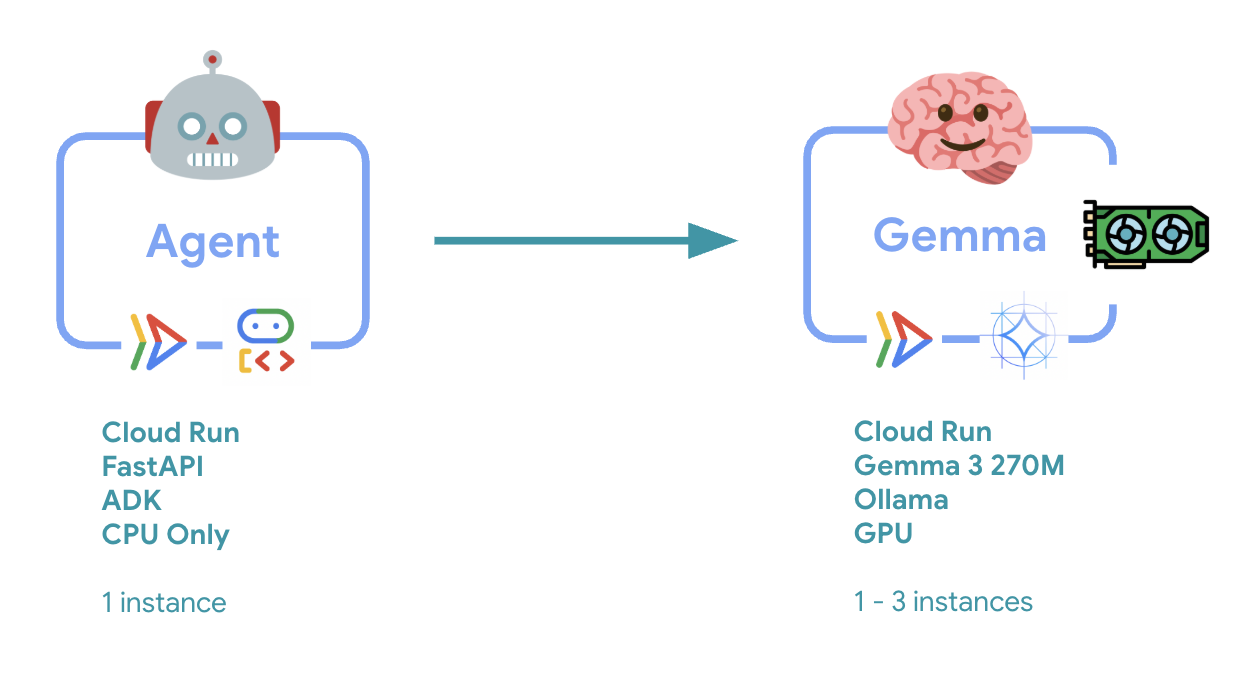
Insight principal: durante o teste de elasticidade, você vai observar os dois serviços processando a carga de trabalho de forma independente. O back-end de GPU (serviço de gargalo) usa a GPU para processar a carga, enquanto o agente do ADK depende da CPU para processar as solicitações que não exigem muitos recursos.
7. Implantar o back-end do Gemma no Cloud Run com GPU
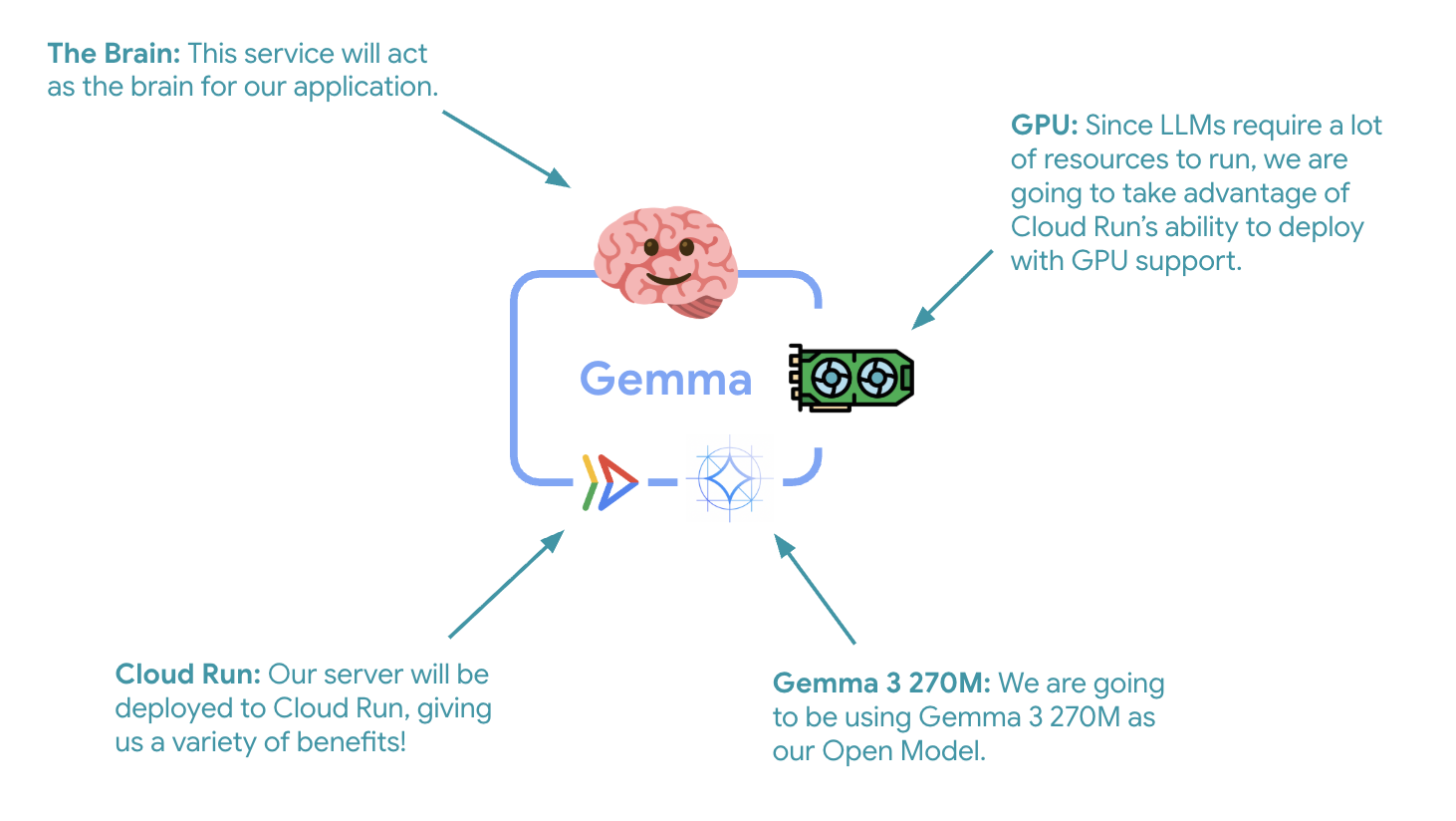
A primeira etapa essencial é implantar um modelo da Gemma acelerado por GPU, que vai servir como o cérebro do seu agente do ADK. Ter um LLM desacoplado e implantado pode ser favorável em arquiteturas em que você precisa de um modelo ajustado separado ou exige escalonamento isolado.
- Navegue até o diretório de back-end do Ollama:
cd ollama-backend - Abra e implemente o Dockerfile do Ollama:
cloudshell edit DockerfileFROM ollama/ollama:latest # Listen on all interfaces, port 8080 ENV OLLAMA_HOST 0.0.0.0:8080 # Store model weight files in /models ENV OLLAMA_MODELS /models # Reduce logging verbosity ENV OLLAMA_DEBUG false # Never unload model weights from the GPU ENV OLLAMA_KEEP_ALIVE -1 # Store the model weights in the container image ENV MODEL gemma3:270m RUN ollama serve & sleep 5 && ollama pull $MODEL # Start Ollama ENTRYPOINT ["ollama", "serve"]- Usa a imagem oficial do Ollama como base
- Define
OLLAMA_HOSTpara aceitar conexões de qualquer endereço IP - Expõe a porta 8080
- Implante o back-end do Gemma com suporte a GPU:
gcloud run deploy ollama-gemma3-270m-gpu \
--source . \
--region europe-west4 \
--concurrency 7 \
--cpu 8 \
--set-env-vars OLLAMA_NUM_PARALLEL=4 \
--gpu 1 \
--gpu-type nvidia-l4 \
--max-instances 1 \
--memory 16Gi \
--allow-unauthenticated \
--no-cpu-throttling \
--no-gpu-zonal-redundancy \
--timeout 600 \
--labels dev-tutorial=codelab-agent-gpu
Se você receber a mensagem "A implantação da origem exige um repositório do Docker do Artifact Registry para armazenar contêineres criados. Uma mensagem "Um repositório chamado [cloud-run-source-deploy] na região [europe-west4] será criado" vai aparecer. Continue.
⚙️ Explicação da configuração principal:
- GPU: NVIDIA L4 escolhida pela excelente relação custo-benefício para cargas de trabalho de inferência. A L4 oferece 24 GB de memória de GPU e operações de tensor otimizadas, o que a torna ideal para modelos de 270 milhões de parâmetros, como o Gemma.
- Memória: 16 GB de memória do sistema para lidar com o carregamento de modelos, operações CUDA e gerenciamento de memória do Ollama
- CPU: 8 núcleos para processamento ideal de E/S e tarefas de pré-processamento
- Concorrência: 7 solicitações por instância equilibram a capacidade de processamento com o uso da memória da GPU.
- Tempo limite: 600 segundos para acomodar o carregamento inicial do modelo e a inicialização do contêiner
💰 Consideração de custo: as instâncias de GPU são significativamente mais caras do que as instâncias somente de CPU (US$2 a 4/hora contra US$0,10/hora). A configuração --max-instances 1 ajuda a controlar os custos, evitando o escalonamento desnecessário de instâncias de GPU.
- Aguarde a conclusão da implantação e anote o URL do serviço:
export OLLAMA_URL=$(gcloud run services describe ollama-gemma3-270m-gpu \ --region=europe-west4 \ --format='value(status.url)') echo "🎉 Gemma backend deployed at: $OLLAMA_URL"
8. Implementar a integração do agente do ADK
Agora vamos criar um agente ADK mínimo que se conecta ao back-end do Gemma implantado.
- Navegue até o diretório do agente do ADK:
cd ../adk-agent - Abra e implemente a configuração do agente:
cloudshell edit production_agent/agent.pyimport os from pathlib import Path from dotenv import load_dotenv from google.adk.agents import Agent from google.adk.models.lite_llm import LiteLlm import google.auth # Load environment variables root_dir = Path(__file__).parent.parent dotenv_path = root_dir / ".env" load_dotenv(dotenv_path=dotenv_path) # Configure Google Cloud try: _, project_id = google.auth.default() os.environ.setdefault("GOOGLE_CLOUD_PROJECT", project_id) except Exception: pass os.environ.setdefault("GOOGLE_CLOUD_LOCATION", "europe-west4") # Configure model connection gemma_model_name = os.getenv("GEMMA_MODEL_NAME", "gemma3:270m") api_base = os.getenv("OLLAMA_API_BASE", "localhost:10010") # Location of Ollama server # Production Gemma Agent - GPU-accelerated conversational assistant production_agent = Agent( model=LiteLlm(model=f"ollama_chat/{gemma_model_name}", api_base=api_base), name="production_agent", description="A production-ready conversational assistant powered by GPU-accelerated Gemma.", instruction="""You are 'Gem', a friendly, knowledgeable, and enthusiastic zoo tour guide. Your main goal is to make a zoo visit more fun and educational for guests by answering their questions. You can provide general information and interesting facts about different animal species, such as: - Their natural habitats and diet. 🌲🍓 - Typical lifespan and behaviors. - Conservation status and unique characteristics. IMPORTANT: You do NOT have access to any tools. This means you cannot look up real-time, specific information about THIS zoo. You cannot provide: - The names or ages of specific animals currently at the zoo. - The exact location or enclosure for an animal. - The daily schedule for feedings or shows. Always answer based on your general knowledge about the animal kingdom. Keep your tone cheerful, engaging, and welcoming for visitors of all ages. 🦁✨""", tools=[], # Gemma focuses on conversational capabilities ) # Set as root agent root_agent = production_agent- Conecta-se ao back-end do Gemma implantado via LiteLlm.
- Cria um agente de conversação simples
- Configura a integração com o Google Cloud.
- Abra e implemente o servidor FastAPI:
cloudshell edit server.pyimport os from dotenv import load_dotenv from fastapi import FastAPI from google.adk.cli.fast_api import get_fast_api_app # Load environment variables load_dotenv() AGENT_DIR = os.path.dirname(os.path.abspath(__file__)) app_args = {"agents_dir": AGENT_DIR, "web": True} # Create FastAPI app with ADK integration app: FastAPI = get_fast_api_app(**app_args) # Update app metadata app.title = "Production ADK Agent - Lab 3" app.description = "Gemma agent with GPU-accelerated backend" app.version = "1.0.0" @app.get("/health") def health_check(): return {"status": "healthy", "service": "production-adk-agent"} @app.get("/") def root(): return { "service": "Production ADK Agent - Lab 3", "description": "GPU-accelerated Gemma agent", "docs": "/docs", "health": "/health" } if __name__ == "__main__": import uvicorn uvicorn.run(app, host="0.0.0.0", port=8080, log_level="info")- Cria um servidor FastAPI com integração do ADK.
- Ativa a interface da Web para testes.
- Fornece endpoints de verificação de integridade
- Abra e implemente o Dockerfile:
cloudshell edit DockerfileFROM python:3.13-slim # Copy uv from the official image COPY --from=ghcr.io/astral-sh/uv:latest /uv /usr/local/bin/uv # Install system dependencies RUN apt-get update && apt-get install -y curl && rm -rf /var/lib/apt/lists/* # Set working directory WORKDIR /app # Copy all files COPY . . # Install Python dependencies RUN uv sync # Expose port EXPOSE 8080 # Run the application CMD ["uv", "run", "uvicorn", "server:app", "--host", "0.0.0.0", "--port", "8080"]- uv: gerenciador de pacotes Python moderno que é de 10 a 100 vezes mais rápido que o pip. Ele usa um cache global e downloads paralelos, reduzindo significativamente os tempos de build do contêiner.
- Python 3.13-slim: a versão mais recente do Python com dependências mínimas do sistema, reduzindo o tamanho do contêiner e a superfície de ataque.
- Build de vários estágios: copiar o uv da imagem oficial garante que vamos receber o binário otimizado mais recente.
9. Configurar o ambiente e implantar o agente
Agora vamos configurar o agente do ADK para se conectar ao back-end da Gemma implantado e implantá-lo como um serviço do Cloud Run. Isso envolve configurar variáveis de ambiente e implantar o agente com a configuração certa.
- Configure a configuração do ambiente:
cat << EOF > .env GOOGLE_CLOUD_PROJECT=$(gcloud config get-value project) GOOGLE_CLOUD_LOCATION=europe-west4 GEMMA_MODEL_NAME=gemma3:270m OLLAMA_API_BASE=$OLLAMA_URL EOF
Noções básicas sobre variáveis de ambiente no Cloud Run
As variáveis de ambiente são pares de chave-valor que configuram seu aplicativo durante a execução. Eles são especialmente úteis para:
- Endpoints de API e URLs de serviço (como nosso back-end do Ollama)
- Configuração que muda entre ambientes (desenvolvimento, preparo e produção)
- Dados sensíveis que não devem ser codificados
Implante o agente do ADK:
export PROJECT_ID=$(gcloud config get-value project)
gcloud run deploy production-adk-agent \
--source . \
--region europe-west4 \
--allow-unauthenticated \
--memory 4Gi \
--cpu 2 \
--max-instances 1 \
--concurrency 50 \
--timeout 300 \
--set-env-vars GOOGLE_CLOUD_PROJECT=$PROJECT_ID \
--set-env-vars GOOGLE_CLOUD_LOCATION=europe-west4 \
--set-env-vars GEMMA_MODEL_NAME=gemma3:270m \
--set-env-vars OLLAMA_API_BASE=$OLLAMA_URL \
--labels dev-tutorial=codelab-agent-gpu
⚙️ Configuração principal:
- Escalonamento automático: fixado em uma instância (processamento de solicitações leves)
- Simultaneidade: 50 solicitações por instância
- Memória: 4 GB para o agente do ADK
- Ambiente: conecta-se ao back-end do Gemma.
🔒 Observação de segurança: este laboratório usa --allow-unauthenticated para simplificar. Em produção, implemente a autenticação adequada usando:
- Autenticação de serviço a serviço do Cloud Run com contas de serviço
- Políticas de gerenciamento de identidade e acesso (IAM)
- Chaves de API ou OAuth para acesso externo
- Considere usar
gcloud run services add-iam-policy-bindingpara controlar o acesso
Consiga o URL do serviço do agente:
export AGENT_URL=$(gcloud run services describe production-adk-agent \
--region=europe-west4 \
--format='value(status.url)')
echo "🎉 ADK Agent deployed at: $AGENT_URL"
✅ Práticas recomendadas de variáveis de ambiente com base na documentação de variáveis de ambiente do Cloud Run:
- Evite variáveis reservadas: não defina
PORT. Se precisar mudar a variável de ambiente, use a flag "–port". Também não use variáveis que comecem comX_GOOGLE_. - Use nomes descritivos: adicione um prefixo às variáveis para evitar conflitos (por exemplo,
GEMMA_MODEL_NAMEem vez deMODEL). - Faça o escape de vírgulas: se os valores contiverem vírgulas, use um delimitador diferente:
--set-env-vars "^@^KEY1=value1,value2@KEY2=..." - Atualizar x substituir: use
--update-env-varspara adicionar/mudar variáveis específicas sem afetar outras.
Como definir variáveis no Cloud Run:
- De arquivo:
gcloud run deploy SERVICE_NAME --env-vars-file .env --labels dev-tutorial codelab-adk(carrega várias variáveis de um arquivo) - Várias flags: repita
--set-env-varspara valores complexos que não podem ser separados por vírgulas.
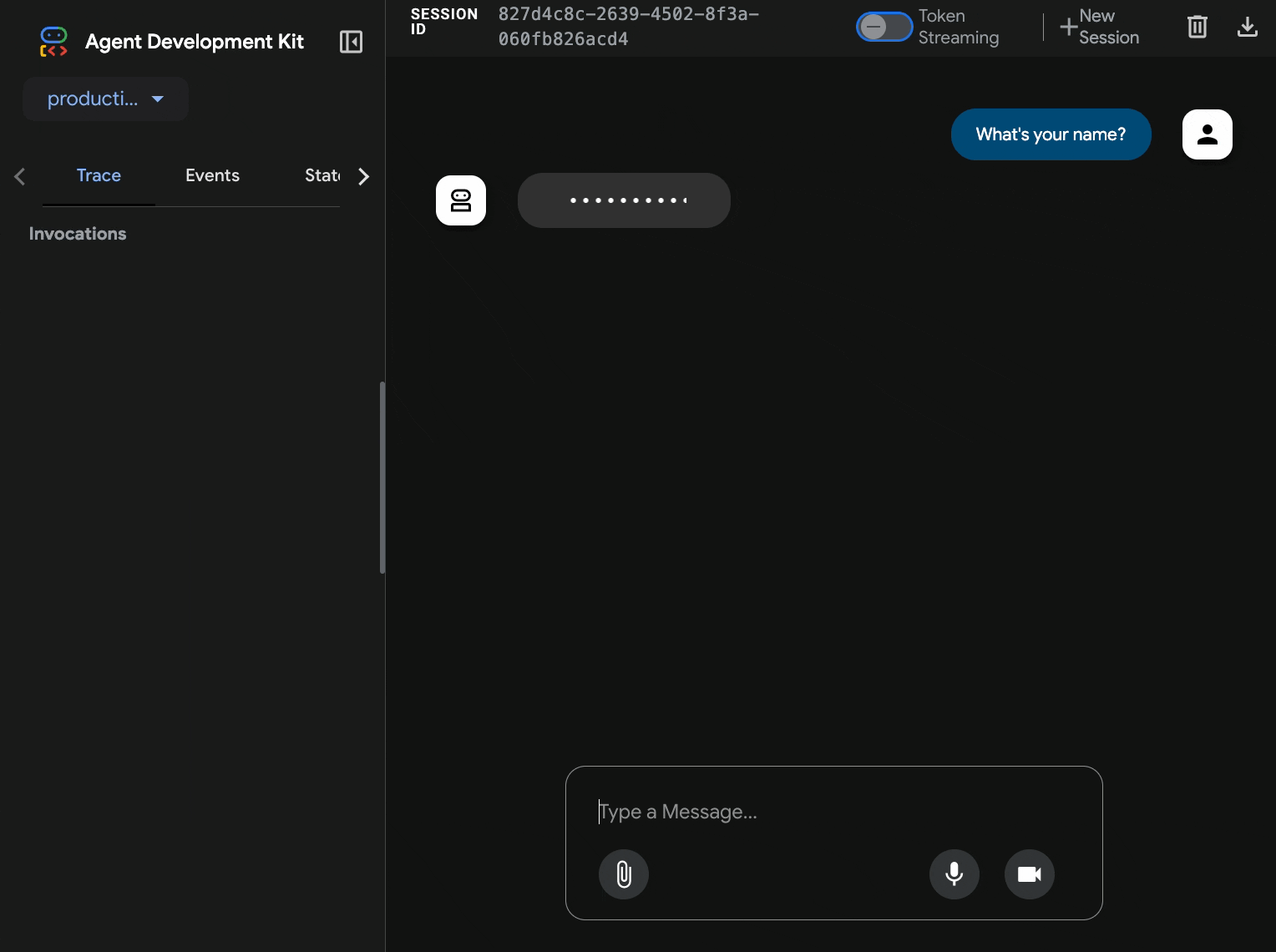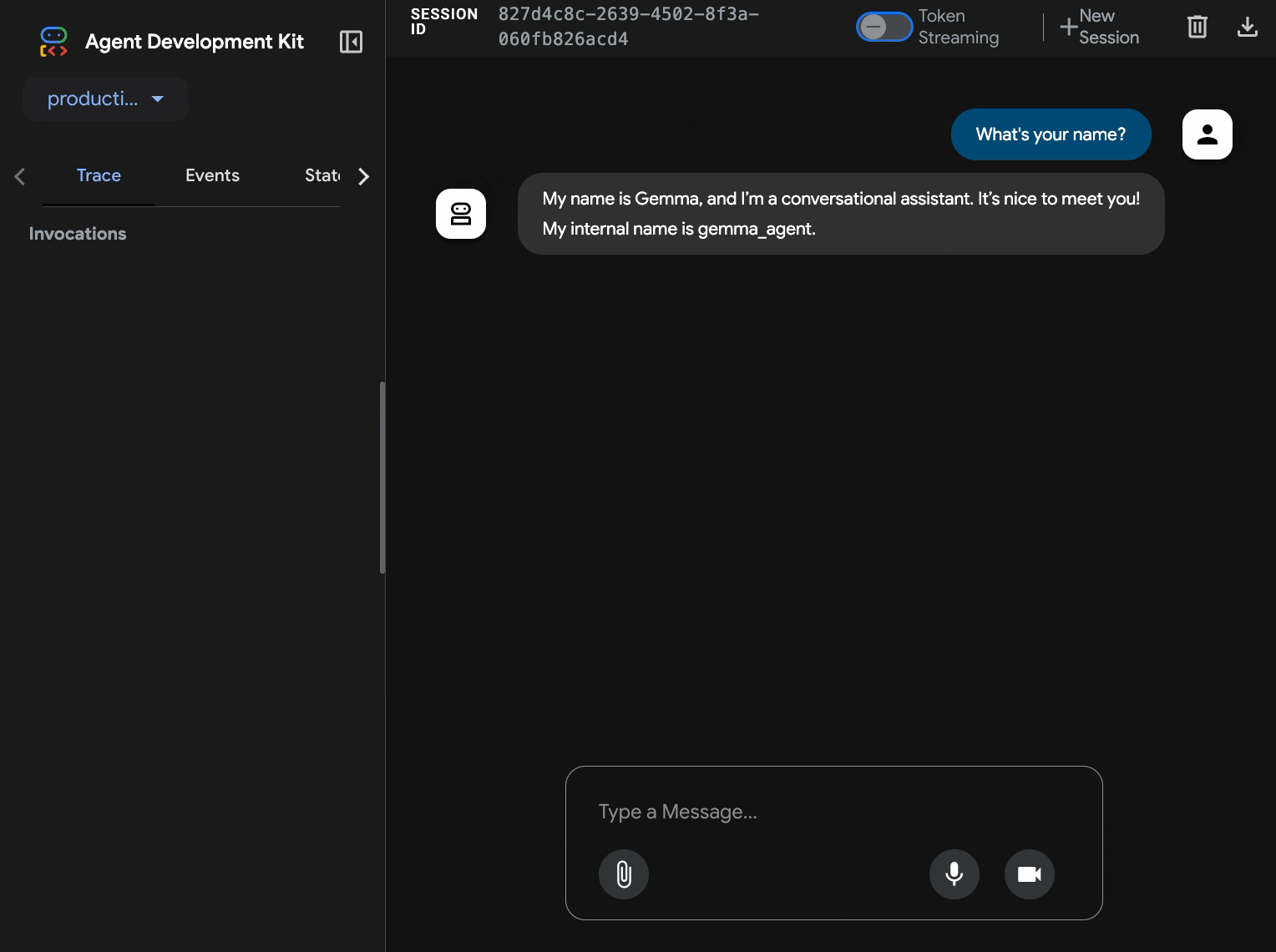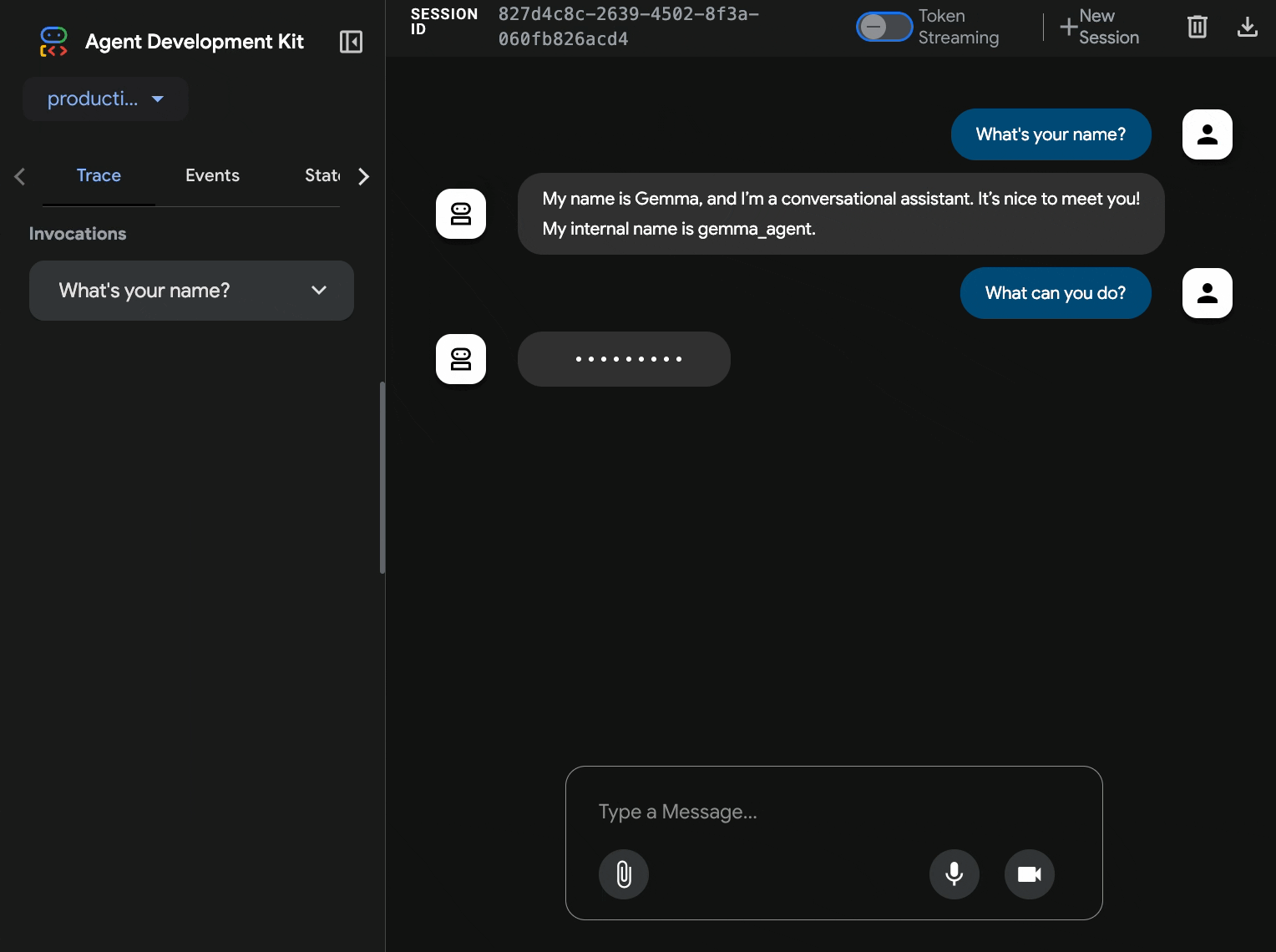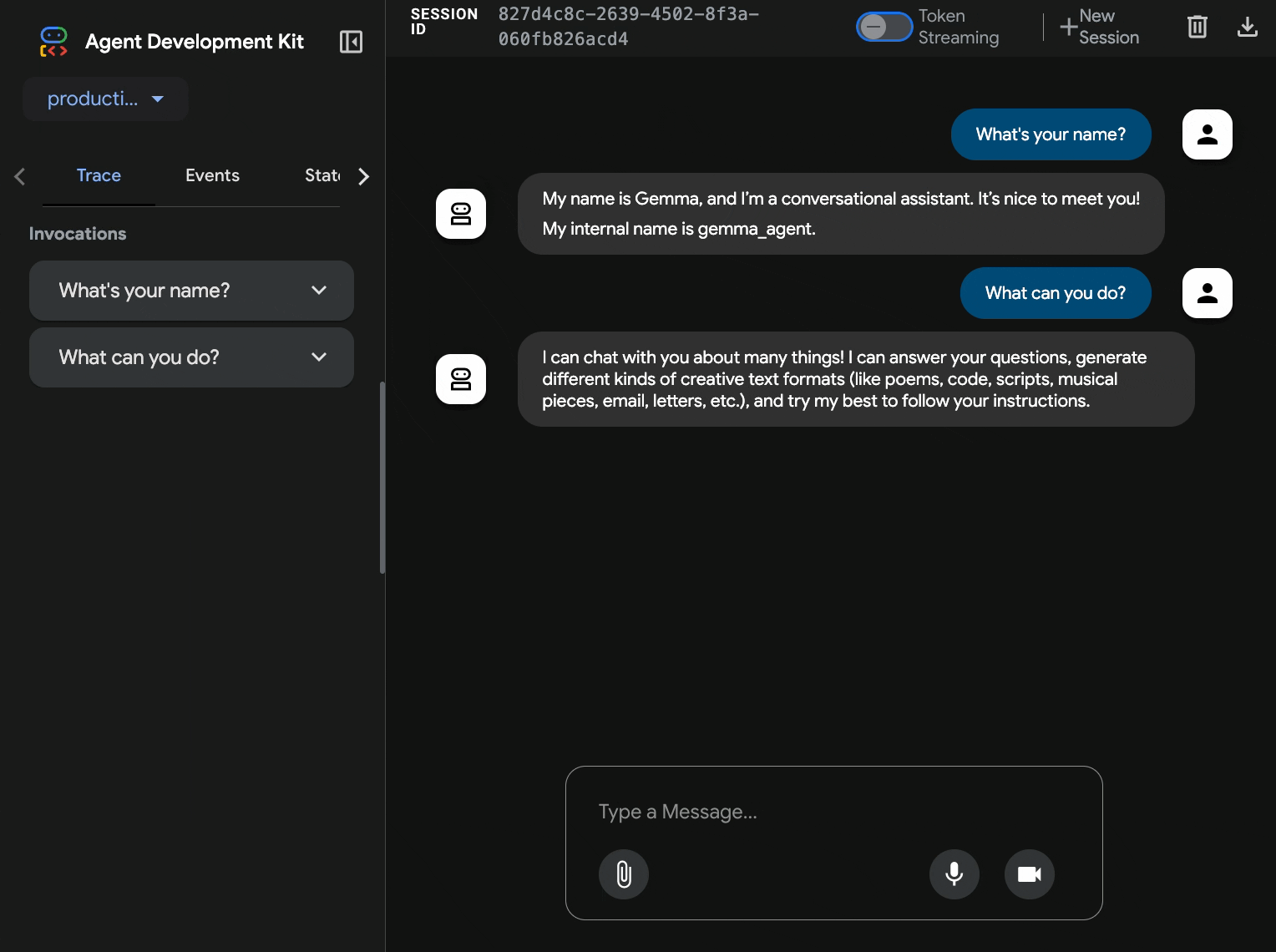
10. Teste com a interface da Web do ADK
Com os dois serviços implantados, é hora de validar se o agente do ADK consegue se comunicar com o back-end do Gemma acelerado por GPU e responder às consultas do usuário.
- Teste o endpoint de integridade:
curl $AGENT_URL/health{ "status": "healthy", "service": "production-adk-agent" } - Interaja com o agente inserindo o URL do seu
production-adk-agentem uma nova guia do navegador. A interface da Web do ADK vai aparecer. - Teste seu agente com estas conversas de exemplo:
- "O que os pandas-vermelhos costumam comer na natureza?"
- "Você pode me contar algo interessante sobre os leopardos-das-neves?"
- "Por que os sapos venenosos são tão coloridos?"
- "Onde posso encontrar o novo canguru bebê no zoológico?"
- O agente responde usando o modelo Gemma implantado. Para verificar isso, observe os registros do serviço Gemma implantado. Vamos fazer isso na próxima seção.
- As respostas são geradas pelo back-end acelerado por GPU.
- A interface da Web oferece uma experiência de chat limpa
11. Implementar e executar um teste de elasticidade
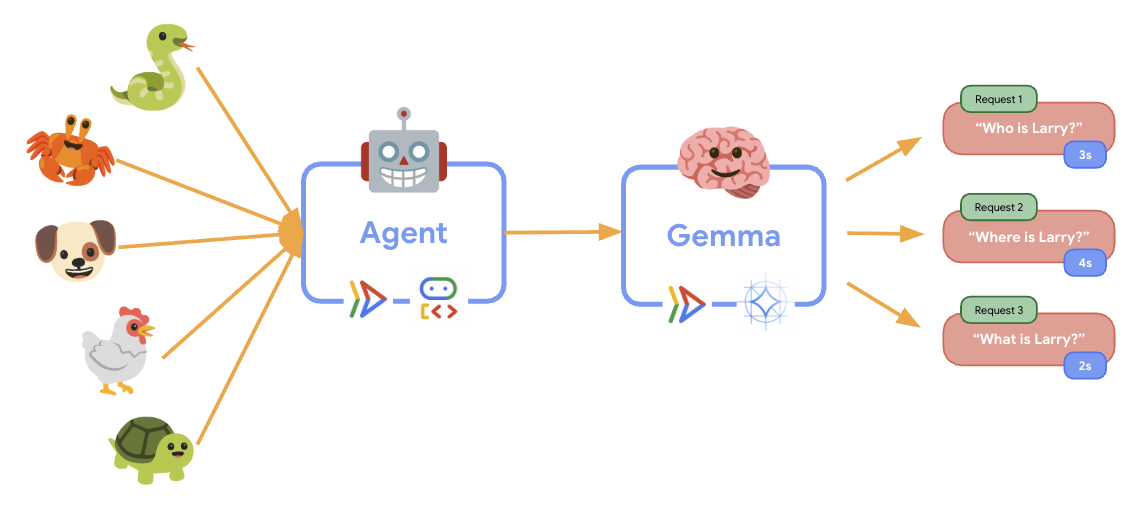
Para entender como sua implantação de produção lida com o tráfego do mundo real, vamos implementar um teste de elasticidade que vai testar a capacidade do sistema de se adaptar a uma carga de trabalho de produção "simulada" maior.
- Abra e implemente o script de teste de elasticidade:
cloudshell edit elasticity_test.pyimport random import uuid from locust import HttpUser, task, between class ProductionAgentUser(HttpUser): """Elasticity test user for the Production ADK Agent.""" wait_time = between(1, 3) # Faster requests to trigger scaling def on_start(self): """Set up user session when starting.""" self.user_id = f"user_{uuid.uuid4()}" self.session_id = f"session_{uuid.uuid4()}" # Create session for the Gemma agent using proper ADK API format session_data = {"state": {"user_type": "elasticity_test_user"}} self.client.post( f"/apps/production_agent/users/{self.user_id}/sessions/{self.session_id}", headers={"Content-Type": "application/json"}, json=session_data, ) @task(4) def test_conversations(self): """Test conversational capabilities - high frequency.""" topics = [ "What do red pandas typically eat in the wild?", "Can you tell me an interesting fact about snow leopards?", "Why are poison dart frogs so brightly colored?", "Where can I find the new baby kangaroo in the zoo?", "What is the name of your oldest gorilla?", "What time is the penguin feeding today?" ] # Use proper ADK API format for sending messages message_data = { "app_name": "production_agent", "user_id": self.user_id, "session_id": self.session_id, "new_message": { "role": "user", "parts": [{ "text": random.choice(topics) }] } } self.client.post( "/run", headers={"Content-Type": "application/json"}, json=message_data, ) @task(1) def health_check(self): """Test the health endpoint.""" self.client.get("/health")- Criação de sessão: usa o formato correto da API ADK com POST para
/apps/production_agent/users/{user_id}/sessions/{session_id}. Depois de criar umsession_ide umuser_id, é possível fazer uma solicitação ao agente. - Formato da mensagem: segue a especificação do ADK com
app_name,user_id,session_ide objetonew_messageestruturado - Endpoint de conversa: usa o endpoint
/runpara coletar todos os eventos de uma só vez (recomendado para teste de carga). - Carga realista: cria carga de conversação com tempos de espera mais curtos.
- Criação de sessão: usa o formato correto da API ADK com POST para
- Instale as dependências:
uv sync - O Locust é uma ferramenta de teste de carga de código aberto baseada em Python projetada para testes de desempenho e carga de aplicativos da Web e outros sistemas. A principal característica é que os cenários de teste e o comportamento do usuário são definidos usando código Python padrão, oferecendo alta flexibilidade e expressividade em comparação com ferramentas que dependem de interfaces gráficas do usuário ou linguagens específicas do domínio. Vamos usar o Locust para simular o tráfego de usuários nos nossos serviços.Execute o teste.
uv run locust -f elasticity_test.py \ -H $AGENT_URL \ --headless \ -t 60s \ -u 20 \ -r 5- Duração: 60 segundos
- Usuários: 20 usuários simultâneos
- Taxa de geração: 5 usuários por segundo
- Destino: acionar o escalonamento automático nos dois serviços
12. Observar o comportamento do Auto Scaling
À medida que o teste de elasticidade é executado, você pode observar o suporte do Cloud Run para cargas de trabalho maiores em ação. É aqui que você vai ver os principais benefícios arquitetônicos de separar o agente do ADK do back-end da GPU.
Durante o teste de elasticidade, monitore como os dois serviços do Cloud Run lidam com o tráfego no console.
- No Console do Cloud, navegue até:
- Cloud Run → production-adk-agent → Métricas
- Cloud Run → ollama-gemma3-270m-gpu → Métricas
👀 O que você precisa observar:
🤖 Serviço do agente do ADK:
- Precisa permanecer estável em uma instância enquanto o tráfego aumenta
- Pico de uso da memória e CPU durante tráfego intenso
- Gerencia o roteamento de solicitações e o gerenciamento de sessões com eficiência
🎮 Serviço de back-end do Gemma (gargalo):
- Precisa permanecer estável em uma instância enquanto o tráfego aumenta
- O uso da GPU aumenta significativamente sob carga
- Esse serviço se torna o gargalo devido à inferência de modelo com uso intensivo de GPU.
- Os tempos de inferência do modelo permanecem consistentes devido à aceleração da GPU
💡 Insights importantes:
- Os dois serviços permanecem consistentes e não escalonam verticalmente, porque definimos o máximo de instâncias como
1. - Os dois serviços são escalonados de forma independente com base nas características de carga individuais.
- A GPU ajuda a manter a performance em condições de carga variadas.
13. Conclusão
Parabéns! Você implantou um agente do ADK pronto para produção com um back-end do Gemma acelerado por GPU, enquanto testava uma carga de trabalho de produção simulada.
✅ O que você realizou
- ✅ Implantou um back-end de modelo Gemma acelerado por GPU no Cloud Run
- ✅ Criou e implantou um agente do ADK que se integra ao back-end da Gemma
- ✅ Testou o agente usando a interface da Web do ADK
- ✅ Observou o comportamento de escalonamento automático em dois serviços coordenados do Cloud Run
💡 Principais insights deste laboratório
- 🎮 Aceleração de GPU: a GPU NVIDIA L4 melhora significativamente o desempenho da inferência do modelo.
- 🔗 Coordenação de serviços: dois serviços do Cloud Run podem trabalhar juntos sem problemas
- 📈 Escalabilidade independente: cada serviço é escalonado com base nas características de carga individuais.
- 🚀 Prontidão para produção: a arquitetura lida com padrões de tráfego do mundo real de maneira eficaz.
🔄 Próximas etapas
- Teste diferentes padrões de carga e observe o comportamento de escalonamento
- Teste diferentes tamanhos de modelo da Gemma (ajuste a memória e a GPU de acordo com a necessidade)
- Implementar monitoramento e alertas para implantações de produção
- Conheça as implantações multirregionais para disponibilidade global
🧹 Limpeza
Para evitar cobranças, exclua os recursos quando terminar:
gcloud run services delete production-adk-agent --region=europe-west4
gcloud run services delete ollama-gemma3-270m-gpu --region=europe-west4
📖 Recursos
- Repositório inicial
- Solução completa
- Documentação do ADK do Google
- Guia de testes do ADK: referência completa para endpoints da API do ADK e padrões de teste
- Teste de carga no Cloud Run
- Documentação do Kit de Desenvolvimento de Agente (ADK)
- Documentação sobre GPUs do Cloud Run
- Biblioteca de modelos do Ollama
- Documentação do Google Cloud Trace
- Práticas recomendadas de segurança do Cloud Run
- Gerenciador de pacotes Python UV
- Framework de teste de carga do Locust