
1. Введение
Обзор
В этой лабораторной работе вы развернете готовый к использованию в производственной среде агент Agent Development Kit (ADK) с ускоренным на графическом процессоре бэкендом Gemma. Основное внимание будет уделено критически важным сценариям развертывания: настройке сервисов Cloud Run с поддержкой графических процессоров, интеграции бэкендов моделей с агентами ADK и наблюдению за поведением автомасштабирования под нагрузкой.
Что вы будете делать
В этой лабораторной работе вы сосредоточитесь на важнейших аспектах развертывания в производственной среде:
- Развертывание Gemma в облаке с использованием графического процессора — настройка высокопроизводительного бэкэнда модели Gemma.
- Интегрируйте развертывание Gemma с агентом ADK — подключите свой агент к модели с ускорением на графическом процессоре.
- Протестируйте с помощью веб-интерфейса ADK — убедитесь, что ваш диалоговый агент работает корректно.
- Проведите тестирование на эластичность нагрузки — понаблюдайте, как оба экземпляра Cloud Run справляются с нагрузкой.
Основной упор делается на модели развертывания в производственной среде, а не на масштабную разработку агентов.
Что вы узнаете
- Развертывайте модели Gemma с ускорением на графическом процессоре в Cloud Run для использования в производственной среде.
- Интеграция развертывания внешних моделей с агентами ADK.
- Настройка и тестирование готовых к использованию в производственной среде развертываний агентов ИИ.
- Понимание поведения Cloud Run под нагрузкой.
- Проследите за тем, как несколько экземпляров Cloud Run координируют свои действия во время пиковых нагрузок.
- Для проверки работоспособности примените тест на эластичность.
2. Настройка проекта
- Если у вас еще нет учетной записи Google, вам необходимо ее создать .
- Используйте личный аккаунт вместо рабочего или учебного. Рабочие и учебные аккаунты могут иметь ограничения, которые не позволят вам включить API, необходимые для этой лабораторной работы.
- Войдите в консоль Google Cloud .
- Включите выставление счетов в облачной консоли.
- Выполнение этой лабораторной работы должно обойтись менее чем в 1 доллар США в виде облачных ресурсов.
- В конце этой лабораторной работы вы можете выполнить действия по удалению ресурсов, чтобы избежать дальнейших списаний средств.
- Новые пользователи могут воспользоваться бесплатной пробной версией стоимостью 300 долларов США .
- Создайте новый проект или выберите вариант повторного использования существующего проекта.
- Если вы видите ошибку, связанную с квотой проекта, используйте существующий проект повторно или удалите существующий проект, чтобы создать новый.
3. Откройте редактор Cloud Shell.
- Нажмите на эту ссылку, чтобы перейти непосредственно в редактор Cloud Shell.
- Если сегодня вам будет предложено авторизоваться, нажмите «Авторизовать» , чтобы продолжить.
- Если терминал не отображается внизу экрана, откройте его:
- Нажмите «Просмотреть».
- Нажмите «Терминал»
- В терминале настройте свой проект с помощью этой команды:
- Формат:
gcloud config set project [PROJECT_ID] - Пример:
gcloud config set project lab-project-id-example - Если вы не помните идентификатор своего проекта:
- Вы можете вывести список всех идентификаторов ваших проектов с помощью:
gcloud projects list | awk '/PROJECT_ID/{print $2}'
- Вы можете вывести список всех идентификаторов ваших проектов с помощью:
- Формат:
- Вы должны увидеть следующее сообщение:
Updated property [core/project].
WARNINGи вас спрашиваютDo you want to continue (Y/n)?, то, скорее всего, вы неправильно ввели идентификатор проекта. Нажмитеn, затемEnterи попробуйте снова выполнить командуgcloud config set project.
4. Включите API и установите регион по умолчанию.
Прежде чем развертывать сервисы Cloud Run с поддержкой графических процессоров, необходимо включить необходимые API Google Cloud и настроить параметры проекта.
- В терминале включите API:
gcloud services enable \
run.googleapis.com \
artifactregistry.googleapis.com \
cloudbuild.googleapis.com \
aiplatform.googleapis.com
Если появится запрос на авторизацию, нажмите «Авторизовать» , чтобы продолжить.
Выполнение этой команды может занять несколько минут, но в итоге должно отобразиться сообщение об успешном завершении, похожее на это:
Operation "operations/acf.p2-73d90d00-47ee-447a-b600" finished successfully.
- Укажите регион Cloud Run по умолчанию.
gcloud config set run/region europe-west4
5. Подготовьте свой проект на Python.
Давайте создадим стартовый код, содержащий базовую структуру как для нашего бэкэнда Gemma, так и для агентских сервисов ADK.
- Клонируйте стартовый репозиторий:
cd ~ npx -y giget@latest gh+git:GoogleCloudPlatform/devrel-demos/agents/accelerate-ai-with-cloud-run/accelerate-ai-lab3-starter accelerate-ai-lab3-starter cd accelerate-ai-lab3-starter - Изучите структуру проекта:
ls -Raccelerate-ai-lab3-starter/ ├── README.md # Project overview ├── ollama-backend/ # Ollama backend (separate deployment) │ └── Dockerfile # Backend container (🚧 to implement) └── adk-agent/ # ADK agent (separate deployment) ├── pyproject.toml # Python dependencies (✅ completed) ├── server.py # FastAPI server (🚧 to implement) ├── Dockerfile # Container config (🚧 to implement) ├── elasticity_test.py # Elasticity testing (🚧 to implement) └── production_agent/ # Agent implementation ├── __init__.py # Package init (✅ completed) └── agent.py # Agent logic (🚧 to implement)
6. Обзор архитектуры
Прежде чем приступать к реализации, давайте разберемся в двухсервисной архитектуре:
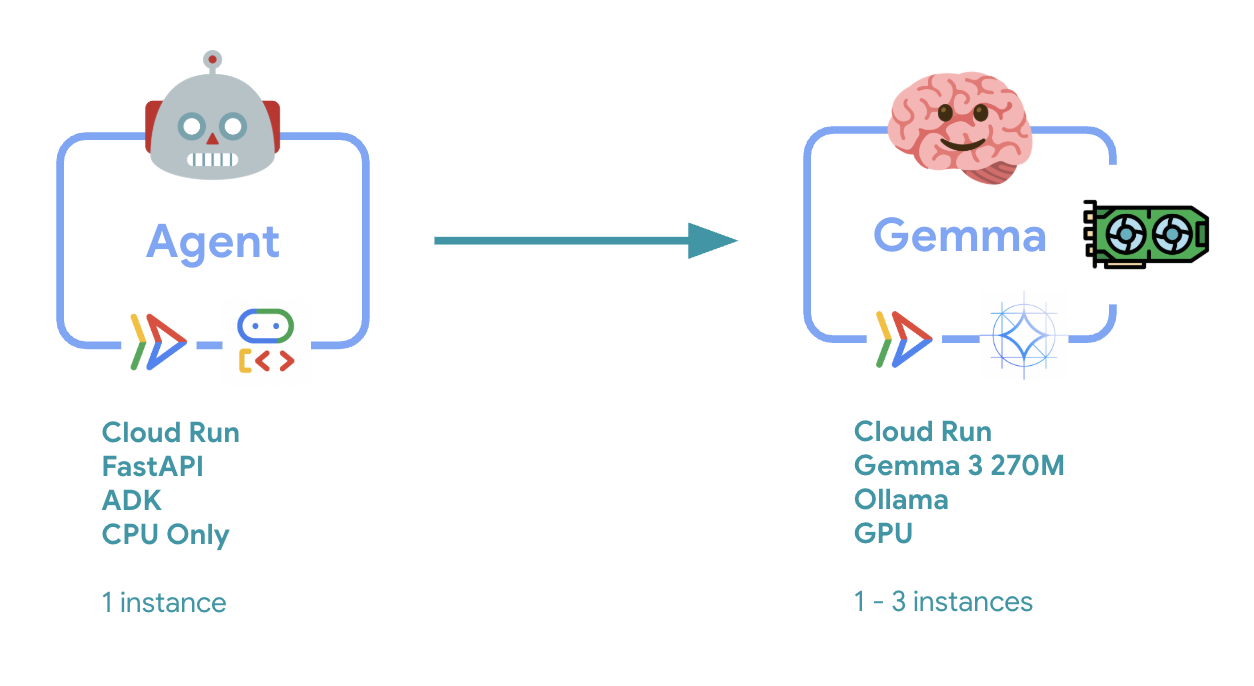
Ключевой вывод : во время тестирования на масштабируемость вы увидите, как оба сервиса обрабатывают рабочую нагрузку независимо друг от друга: бэкенд с графическим процессором (сервис-«узкое место») использует свой графический процессор для обработки нагрузки, в то время как агент ADK использует свой центральный процессор для обработки запросов, не требующих больших ресурсов.
7. Разверните бэкенд Gemma в облаке с использованием графического процессора.
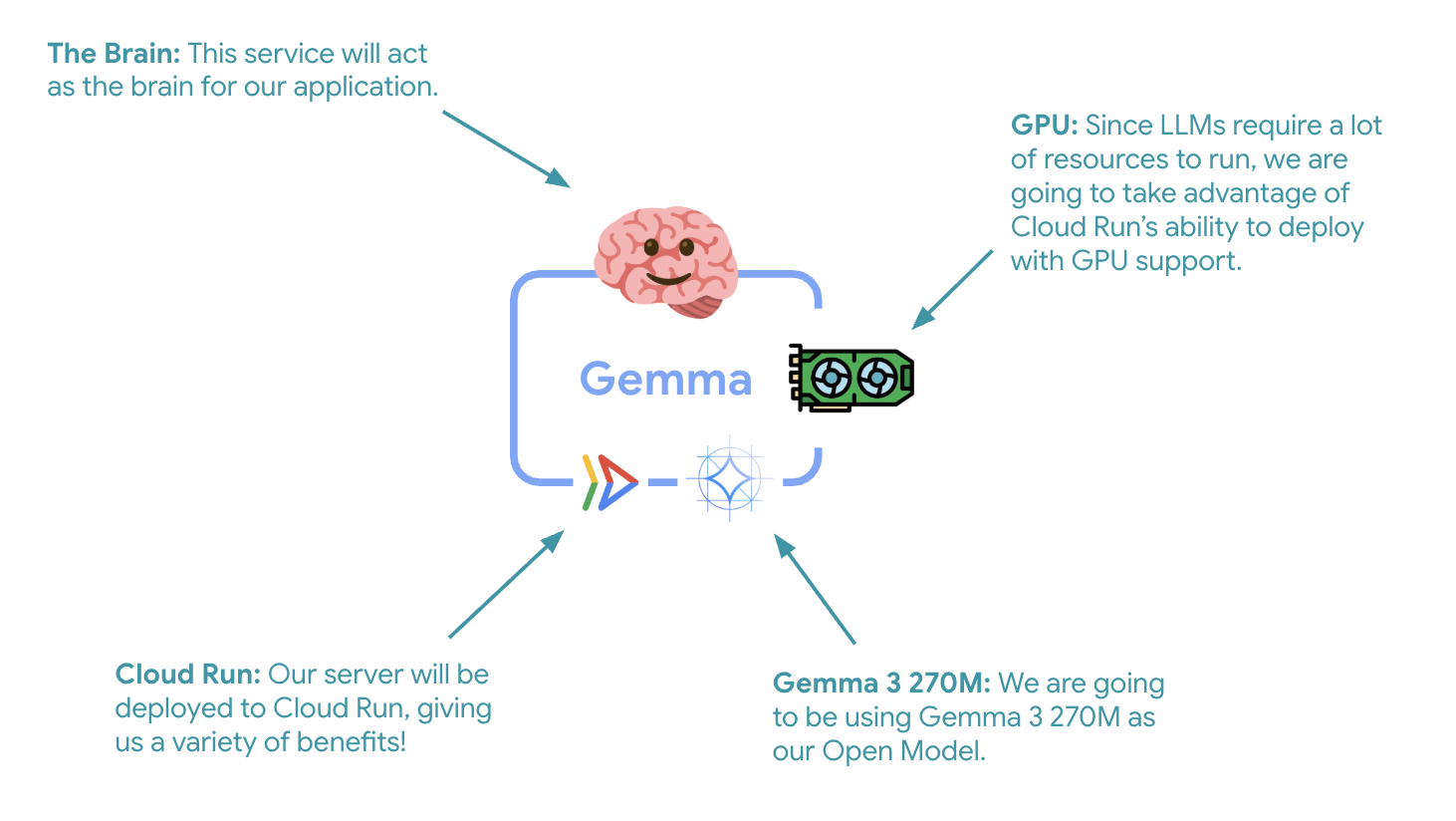
Первым важным шагом является развертывание модели Gemma с ускорением на графическом процессоре, которая будет служить «мозгом» для вашего агента ADK. Наличие отдельной, развернутой модели LLM может быть предпочтительным в архитектурах, где требуется отдельная тонко настроенная модель или требуется изолированное масштабирование.
- Перейдите в каталог бэкэнда Ollama:
cd ollama-backend - Откройте и внедрите Dockerfile Ollama:
cloudshell edit DockerfileFROM ollama/ollama:latest # Listen on all interfaces, port 8080 ENV OLLAMA_HOST 0.0.0.0:8080 # Store model weight files in /models ENV OLLAMA_MODELS /models # Reduce logging verbosity ENV OLLAMA_DEBUG false # Never unload model weights from the GPU ENV OLLAMA_KEEP_ALIVE -1 # Store the model weights in the container image ENV MODEL gemma3:270m RUN ollama serve & sleep 5 && ollama pull $MODEL # Start Ollama ENTRYPOINT ["ollama", "serve"]- В качестве основы используется официальный образ Олламы.
- Устанавливает
OLLAMA_HOSTдля приема подключений с любого IP-адреса. - Открывает доступ к порту 8080
- Разверните бэкенд Gemma с поддержкой графического процессора:
gcloud run deploy ollama-gemma3-270m-gpu \
--source . \
--region europe-west4 \
--concurrency 7 \
--cpu 8 \
--set-env-vars OLLAMA_NUM_PARALLEL=4 \
--gpu 1 \
--gpu-type nvidia-l4 \
--max-instances 1 \
--memory 16Gi \
--allow-unauthenticated \
--no-cpu-throttling \
--no-gpu-zonal-redundancy \
--timeout 600 \
--labels dev-tutorial=codelab-agent-gpu
Если вы получили сообщение "Для развертывания из исходного кода требуется репозиторий Docker в реестре артефактов для хранения собранных контейнеров. Будет создан репозиторий с именем [cloud-run-source-deploy] в регионе [europe-west4]", продолжайте.
⚙️ Пояснение к настройке клавиш:
- Графический процессор : NVIDIA L4 выбран за отличное соотношение цены и производительности для задач инференции. L4 предоставляет 24 ГБ памяти GPU и оптимизированные операции с тензорами, что делает его идеальным для моделей с 270 миллионами параметров, таких как Gemma.
- Память : 16 ГБ системной памяти для обработки загрузки моделей, операций CUDA и управления памятью Ollama.
- Процессор : 8 ядер для оптимальной обработки операций ввода-вывода и задач предварительной обработки.
- Параллелизм : 7 запросов на экземпляр обеспечивают баланс между пропускной способностью и использованием памяти графического процессора.
- Тайм-аут : 600 секунд — это время, необходимое для первоначальной загрузки модели и запуска контейнера.
💰 Учет стоимости : Экземпляры с использованием GPU значительно дороже, чем экземпляры только с использованием CPU (примерно 2-4 доллара в час против примерно 0,10 доллара в час). Параметр --max-instances 1 помогает контролировать затраты, предотвращая ненужное масштабирование экземпляров с использованием GPU.
- Дождитесь завершения развертывания и запишите URL-адрес сервиса:
export OLLAMA_URL=$(gcloud run services describe ollama-gemma3-270m-gpu \ --region=europe-west4 \ --format='value(status.url)') echo "🎉 Gemma backend deployed at: $OLLAMA_URL"
8. Реализация интеграции с агентом ADK.
Теперь давайте создадим минимальный агент ADK, который будет подключаться к развернутому вами бэкенду Gemma.
- Перейдите в каталог агента ADK:
cd ../adk-agent - Откройте и примените конфигурацию агента:
cloudshell edit production_agent/agent.pyimport os from pathlib import Path from dotenv import load_dotenv from google.adk.agents import Agent from google.adk.models.lite_llm import LiteLlm import google.auth # Load environment variables root_dir = Path(__file__).parent.parent dotenv_path = root_dir / ".env" load_dotenv(dotenv_path=dotenv_path) # Configure Google Cloud try: _, project_id = google.auth.default() os.environ.setdefault("GOOGLE_CLOUD_PROJECT", project_id) except Exception: pass os.environ.setdefault("GOOGLE_CLOUD_LOCATION", "europe-west4") # Configure model connection gemma_model_name = os.getenv("GEMMA_MODEL_NAME", "gemma3:270m") api_base = os.getenv("OLLAMA_API_BASE", "localhost:10010") # Location of Ollama server # Production Gemma Agent - GPU-accelerated conversational assistant production_agent = Agent( model=LiteLlm(model=f"ollama_chat/{gemma_model_name}", api_base=api_base), name="production_agent", description="A production-ready conversational assistant powered by GPU-accelerated Gemma.", instruction="""You are 'Gem', a friendly, knowledgeable, and enthusiastic zoo tour guide. Your main goal is to make a zoo visit more fun and educational for guests by answering their questions. You can provide general information and interesting facts about different animal species, such as: - Their natural habitats and diet. 🌲🍓 - Typical lifespan and behaviors. - Conservation status and unique characteristics. IMPORTANT: You do NOT have access to any tools. This means you cannot look up real-time, specific information about THIS zoo. You cannot provide: - The names or ages of specific animals currently at the zoo. - The exact location or enclosure for an animal. - The daily schedule for feedings or shows. Always answer based on your general knowledge about the animal kingdom. Keep your tone cheerful, engaging, and welcoming for visitors of all ages. 🦁✨""", tools=[], # Gemma focuses on conversational capabilities ) # Set as root agent root_agent = production_agent- Подключается к развернутому бэкэнду Gemma через LiteLlm.
- Создает простого диалогового агента.
- Настраивает интеграцию с Google Cloud.
- Откройте и разверните сервер FastAPI:
cloudshell edit server.pyimport os from dotenv import load_dotenv from fastapi import FastAPI from google.adk.cli.fast_api import get_fast_api_app # Load environment variables load_dotenv() AGENT_DIR = os.path.dirname(os.path.abspath(__file__)) app_args = {"agents_dir": AGENT_DIR, "web": True} # Create FastAPI app with ADK integration app: FastAPI = get_fast_api_app(**app_args) # Update app metadata app.title = "Production ADK Agent - Lab 3" app.description = "Gemma agent with GPU-accelerated backend" app.version = "1.0.0" @app.get("/health") def health_check(): return {"status": "healthy", "service": "production-adk-agent"} @app.get("/") def root(): return { "service": "Production ADK Agent - Lab 3", "description": "GPU-accelerated Gemma agent", "docs": "/docs", "health": "/health" } if __name__ == "__main__": import uvicorn uvicorn.run(app, host="0.0.0.0", port=8080, log_level="info")- Создает сервер FastAPI с интеграцией ADK.
- Включает веб-интерфейс для тестирования.
- Предоставляет конечные точки для проверки состояния здоровья.
- Откройте и внедрите Dockerfile:
cloudshell edit DockerfileFROM python:3.13-slim # Copy uv from the official image COPY --from=ghcr.io/astral-sh/uv:latest /uv /usr/local/bin/uv # Install system dependencies RUN apt-get update && apt-get install -y curl && rm -rf /var/lib/apt/lists/* # Set working directory WORKDIR /app # Copy all files COPY . . # Install Python dependencies RUN uv sync # Expose port EXPOSE 8080 # Run the application CMD ["uv", "run", "uvicorn", "server:app", "--host", "0.0.0.0", "--port", "8080"]- uv : Современный менеджер пакетов Python, работающий в 10-100 раз быстрее, чем pip. Он использует глобальный кэш и параллельную загрузку, что значительно сокращает время сборки контейнеров.
- Python 3.13-slim : последняя версия Python с минимальным количеством системных зависимостей, уменьшающая размер контейнера и поверхность атаки.
- Многоэтапная сборка : копирование uv из официального образа гарантирует получение последней оптимизированной бинарной версии.
9. Настройка среды и развертывание агента.
Теперь мы настроим агент ADK для подключения к развернутому бэкенду Gemma и развернем его в качестве сервиса Cloud Run. Это включает в себя настройку переменных среды и развертывание агента с правильной конфигурацией.
- Настройте конфигурацию среды:
cat << EOF > .env GOOGLE_CLOUD_PROJECT=$(gcloud config get-value project) GOOGLE_CLOUD_LOCATION=europe-west4 GEMMA_MODEL_NAME=gemma3:270m OLLAMA_API_BASE=$OLLAMA_URL EOF
Понимание переменных среды в Cloud Run
Переменные среды — это пары «ключ-значение», которые настраивают ваше приложение во время выполнения. Они особенно полезны для:
- API-интерфейсы и URL-адреса сервисов (например, наш бэкэнд Ollama)
- Конфигурация, которая изменяется между средами (разработка, тестирование, производство).
- Конфиденциальные данные, которые не следует закодировать жестко.
Разверните агент ADK:
export PROJECT_ID=$(gcloud config get-value project)
gcloud run deploy production-adk-agent \
--source . \
--region europe-west4 \
--allow-unauthenticated \
--memory 4Gi \
--cpu 2 \
--max-instances 1 \
--concurrency 50 \
--timeout 300 \
--set-env-vars GOOGLE_CLOUD_PROJECT=$PROJECT_ID \
--set-env-vars GOOGLE_CLOUD_LOCATION=europe-west4 \
--set-env-vars GEMMA_MODEL_NAME=gemma3:270m \
--set-env-vars OLLAMA_API_BASE=$OLLAMA_URL \
--labels dev-tutorial=codelab-agent-gpu
⚙️ Настройка клавиш:
- Автомасштабирование : Фиксировано на 1 экземпляре (облегченная обработка запросов)
- Параллелизм : 50 запросов на экземпляр
- Память : 4 ГБ для агента ADK.
- Окружение : Подключается к вашей серверной части Gemma.
🔒 Примечание по безопасности : В этой лабораторной работе для простоты используется --allow-unauthenticated . В рабочей среде следует реализовать надлежащую аутентификацию с помощью:
- Cloud Run: аутентификация между сервисами с использованием учетных записей сервисов.
- Политики управления идентификацией и доступом (IAM)
- Для внешнего доступа используются ключи API или OAut.
- Рекомендуется использовать
gcloud run services add-iam-policy-bindingдля управления доступом.
Получите URL-адрес вашей агентской службы:
export AGENT_URL=$(gcloud run services describe production-adk-agent \
--region=europe-west4 \
--format='value(status.url)')
echo "🎉 ADK Agent deployed at: $AGENT_URL"
✅ Рекомендации по использованию переменных среды на основе документации по переменным среды Cloud Run :
- Избегайте использования зарезервированных переменных : не устанавливайте
PORT(если вам нужно изменить переменную окружения, используйте вместо этого флаг –port) или переменные, начинающиеся сX_GOOGLE_ - Используйте описательные имена : добавляйте префиксы к вашим переменным, чтобы избежать конфликтов (например,
GEMMA_MODEL_NAMEвместоMODEL). - Экранирование запятых : Если ваши значения содержат запятые, используйте другой разделитель:
--set-env-vars "^@^KEY1=value1,value2@KEY2=..." - Обновление против замены : используйте
--update-env-varsдля добавления/изменения определенных переменных без влияния на другие.
Как задать переменные в Cloud Run :
- Из файла :
gcloud run deploy SERVICE_NAME --env-vars-file .env --labels dev-tutorial codelab-adk(загружает несколько переменных из файла) - Несколько флагов : Повторите
--set-env-varsдля сложных значений, которые не могут быть разделены запятыми.
10. Тестирование с помощью веб-интерфейса ADK.
После развертывания обеих служб необходимо убедиться, что ваш агент ADK может успешно взаимодействовать с ускоренным графическим процессором бэкэндом Gemma и отвечать на запросы пользователей.
- Проверьте работоспособность конечной точки:
curl $AGENT_URL/health{ "status": "healthy", "service": "production-adk-agent" } - Для взаимодействия с агентом введите URL-адрес вашего
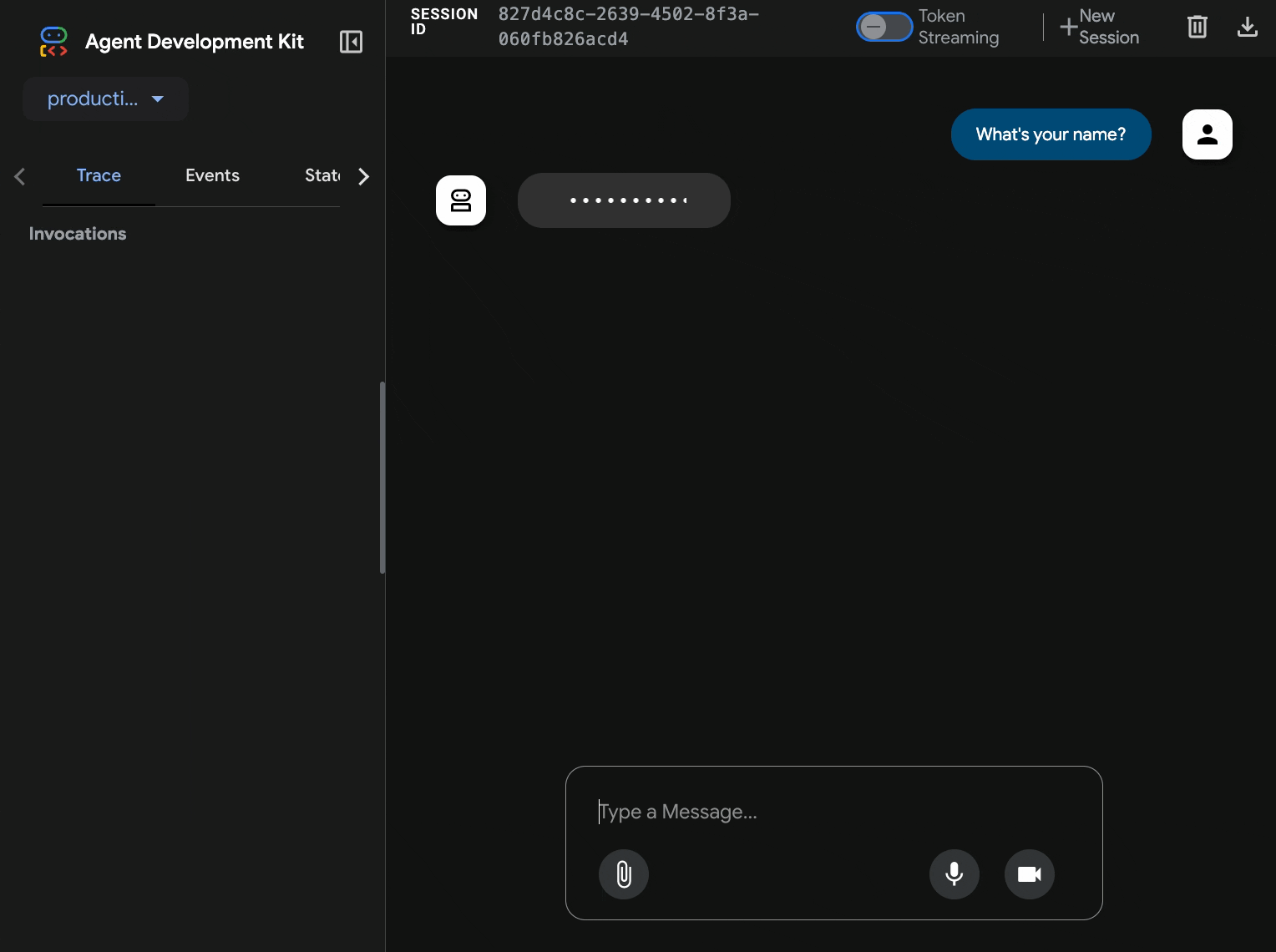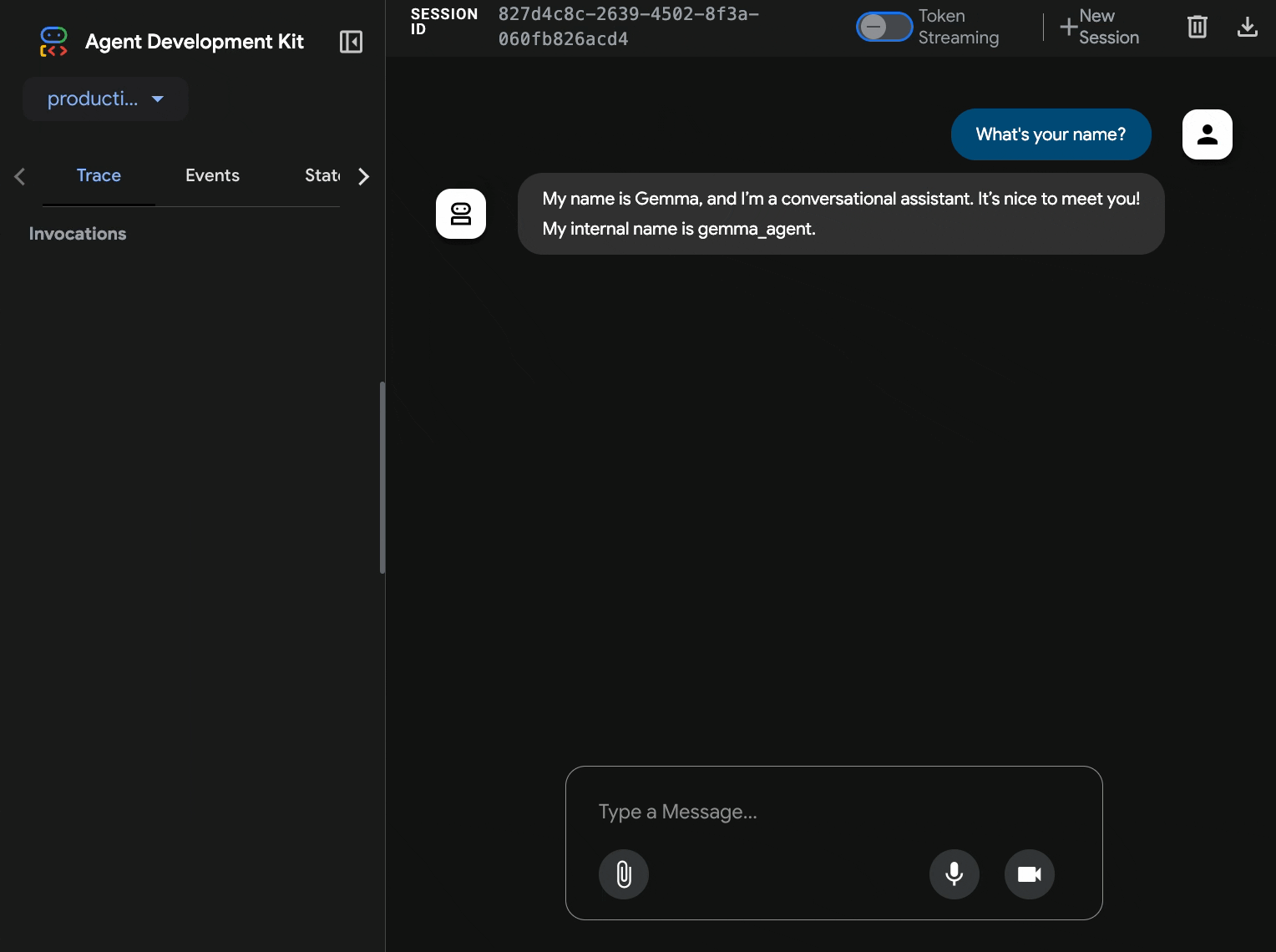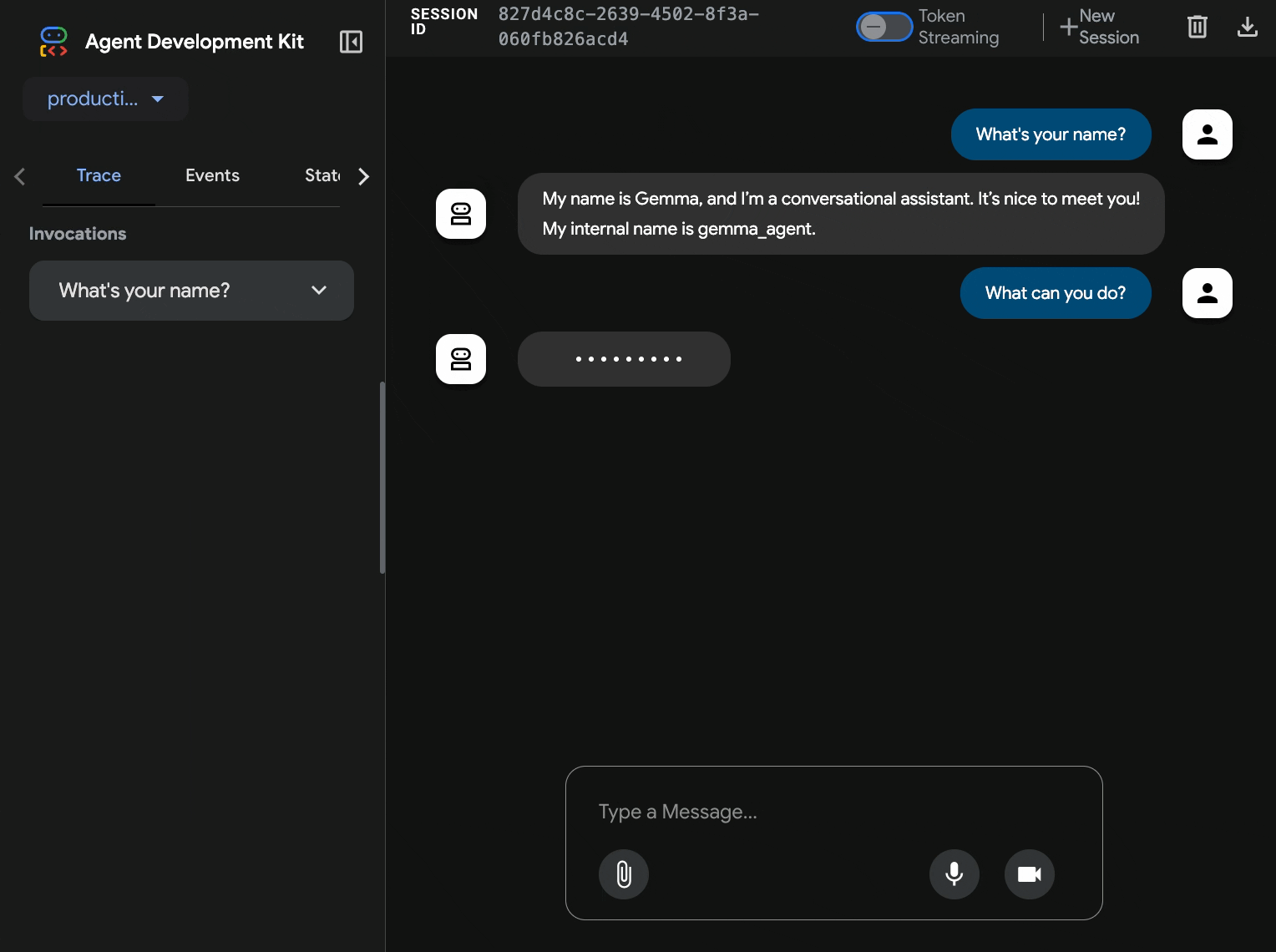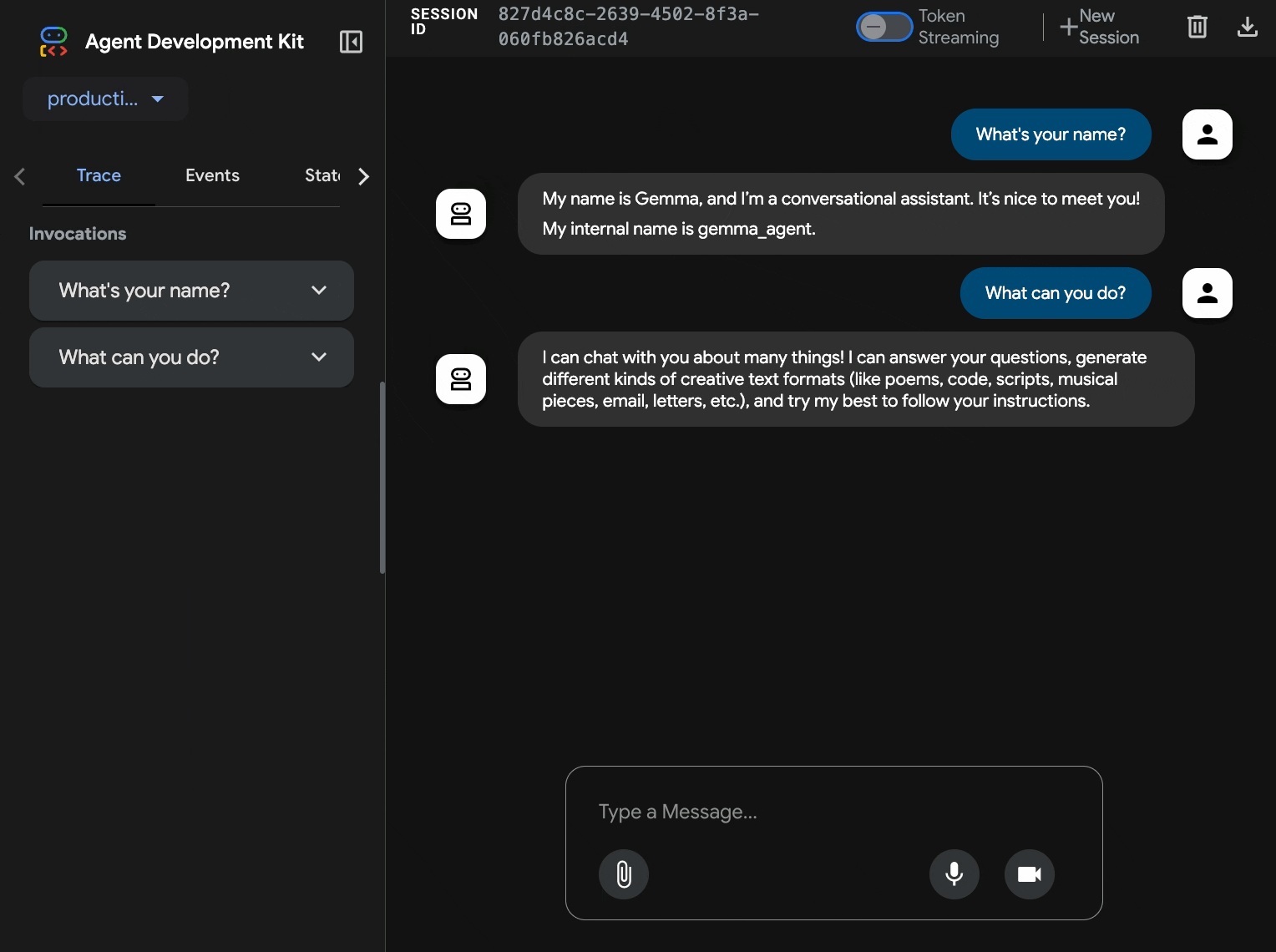
production-adk-agentв новой вкладке браузера. Вы должны увидеть веб-интерфейс ADK. - Проверьте работу своего агента, используя эти примеры диалогов:
- «Чем обычно питаются красные панды в дикой природе?»
- «Не могли бы вы рассказать мне какой-нибудь интересный факт о снежных барсах?»
- «Почему ядовитые древесные лягушки такие ярко окрашенные?»
- «Где в зоопарке можно найти новорожденного детеныша кенгуру?»
- Агент отвечает, используя развернутую вами модель Gemma. Вы можете убедиться в этом, просмотрев журналы развернутой службы Gemma. Мы сделаем это в следующем разделе.
- Ответы генерируются с помощью графического процессора (GPU) в качестве бэкэнда.
- Веб-интерфейс обеспечивает удобный и интуитивно понятный чат.
11. Внедрить и провести тест на эластичность.
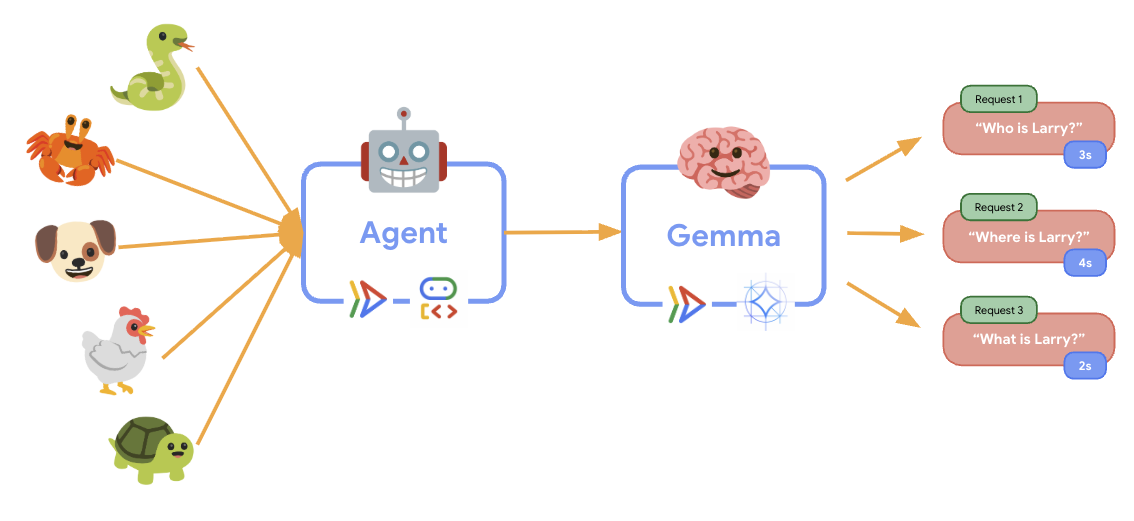
Чтобы понять, как ваша рабочая среда обрабатывает реальный трафик, мы проведем тест на эластичность, который проверит способность системы адаптироваться к более высокой «имитируемой» рабочей нагрузке в производственной среде.
- Откройте и запустите скрипт для тестирования эластичности:
cloudshell edit elasticity_test.pyimport random import uuid from locust import HttpUser, task, between class ProductionAgentUser(HttpUser): """Elasticity test user for the Production ADK Agent.""" wait_time = between(1, 3) # Faster requests to trigger scaling def on_start(self): """Set up user session when starting.""" self.user_id = f"user_{uuid.uuid4()}" self.session_id = f"session_{uuid.uuid4()}" # Create session for the Gemma agent using proper ADK API format session_data = {"state": {"user_type": "elasticity_test_user"}} self.client.post( f"/apps/production_agent/users/{self.user_id}/sessions/{self.session_id}", headers={"Content-Type": "application/json"}, json=session_data, ) @task(4) def test_conversations(self): """Test conversational capabilities - high frequency.""" topics = [ "What do red pandas typically eat in the wild?", "Can you tell me an interesting fact about snow leopards?", "Why are poison dart frogs so brightly colored?", "Where can I find the new baby kangaroo in the zoo?", "What is the name of your oldest gorilla?", "What time is the penguin feeding today?" ] # Use proper ADK API format for sending messages message_data = { "app_name": "production_agent", "user_id": self.user_id, "session_id": self.session_id, "new_message": { "role": "user", "parts": [{ "text": random.choice(topics) }] } } self.client.post( "/run", headers={"Content-Type": "application/json"}, json=message_data, ) @task(1) def health_check(self): """Test the health endpoint.""" self.client.get("/health")- Создание сессии : Используется соответствующий формат API ADK с методом POST на адрес
/apps/production_agent/users/{user_id}/sessions/{session_id}. После созданияsession_idиuser_idможно отправить запрос агенту. - Формат сообщения : соответствует спецификации ADK и включает в себя
app_name,user_id,session_idи структурированный объектnew_message - Конечная точка для диалога : Использует конечную точку
/runдля сбора всех событий одновременно (рекомендуется для нагрузочного тестирования). - Реалистичная нагрузка : Создает нагрузку на диалоговые окна с более коротким временем ожидания.
- Создание сессии : Используется соответствующий формат API ADK с методом POST на адрес
- Установите зависимости:
uv sync - Locust — это инструмент нагрузочного тестирования с открытым исходным кодом, основанный на Python, предназначенный для тестирования производительности и нагрузки веб-приложений и других систем. Его ключевая особенность заключается в том, что тестовые сценарии и поведение пользователей определяются с помощью стандартного кода Python, что обеспечивает высокую гибкость и выразительность по сравнению с инструментами, которые полагаются на графический пользовательский интерфейс или предметно-ориентированные языки. Мы будем использовать Locust для имитации пользовательского трафика к нашим сервисам. Запустите тест.
uv run locust -f elasticity_test.py \ -H $AGENT_URL \ --headless \ -t 60s \ -u 20 \ -r 5- Продолжительность : 60 секунд
- Пользователи : 20 одновременно подключенных пользователей
- Частота появления пользователей : 5 пользователей в секунду
- Цель : Запустить автоматическое масштабирование для обеих служб.
12. Наблюдайте за поведением автоматического масштабирования.
В ходе теста на масштабируемость вы сможете наблюдать за тем, как Cloud Run поддерживает более высокие нагрузки. Именно здесь вы увидите ключевые архитектурные преимущества разделения агента ADK и бэкэнда GPU.
В ходе теста на масштабируемость отслеживайте в консоли, как обе службы Cloud Run обрабатывают трафик.
- В консоли Cloud перейдите по следующему пути:
- Cloud Run → production-adk-agent → Metrics
- Cloud Run → ollama-gemma3-270m-gpu → Метрики
👀 На что следует обратить внимание:
🤖 Агентская служба ADK:
- Должен оставаться стабильным на уровне 1 точки по мере увеличения трафика.
- В периоды высокой нагрузки резко возрастает использование процессора и памяти.
- Эффективно управляет сессиями и маршрутизацией запросов.
🎮 Сервис бэкэнда Gemma (узкое место):
- Должен оставаться стабильным на уровне 1 точки по мере увеличения трафика.
- При нагрузке значительно возрастает загрузка графического процессора.
- Эта услуга становится узким местом из-за ресурсоемкого процесса вывода модели на графическом процессоре.
- Благодаря ускорению с помощью графического процессора время выполнения модели остается стабильным.
💡 Ключевые выводы:
- Обе службы работают стабильно и не масштабируются, поскольку мы установили максимальное количество экземпляров равным
1 - Обе службы масштабируются независимо друг от друга в зависимости от индивидуальных характеристик нагрузки.
- Графический процессор помогает поддерживать производительность при изменяющихся условиях нагрузки.
13. Заключение
Поздравляем! Вы успешно развернули готовый к использованию в производственной среде агент ADK с ускорением GPU на бэкенде Gemma, протестировав при этом смоделированную рабочую нагрузку.
✅ Чего вы достигли
- ✅ Развернуто ускоренное с помощью графического процессора бэкэнд-приложение для модели Gemma на платформе Cloud Run.
- ✅ Создан и развернут агент ADK, интегрирующийся с бэкэндом Gemma.
- ✅ Протестировал агент с помощью веб-интерфейса ADK.
- ✅ Наблюдалось автоматическое масштабирование двух скоординированных сервисов Cloud Run.
💡 Ключевые выводы из этой лаборатории
- 🎮 Ускорение с помощью графического процессора : графический процессор NVIDIA L4 значительно повышает производительность вывода модели.
- 🔗 Координация сервисов : Два облачных сервиса могут бесперебойно взаимодействовать друг с другом.
- 📈 Независимое масштабирование : масштабирование каждой службы происходит в зависимости от индивидуальных характеристик нагрузки.
- 🚀 Готовность к внедрению в производство : архитектура эффективно обрабатывает реальные схемы трафика.
🔄 Следующие шаги
- Поэкспериментируйте с различными схемами нагрузки и понаблюдайте за зависимостью от масштаба.
- Попробуйте разные размеры моделей Gemma (настройте память и видеокарту соответствующим образом).
- Внедрить системы мониторинга и оповещения для развертывания в производственной среде.
- Изучите возможности развертывания в нескольких регионах для обеспечения глобальной доступности.
🧹 Уборка
Чтобы избежать дополнительных расходов, удаляйте ресурсы по завершении работы:
gcloud run services delete production-adk-agent --region=europe-west4
gcloud run services delete ollama-gemma3-270m-gpu --region=europe-west4
📖 Ресурсы
- Стартовый репозиторий
- Комплексное решение
- Документация Google ADK
- Руководство по тестированию ADK — полный справочник по конечным точкам API ADK и шаблонам тестирования.
- Нагрузочное тестирование в облачной среде.
- Документация по комплекту разработки агентов (ADK)
- Документация по Cloud Run GPU
- Образцовая библиотека Оллама
- Документация Google Cloud Trace
- Рекомендации по обеспечению безопасности в облачной среде
- Менеджер пакетов UV Python
- Структура тестирования нагрузки Locust