
1. บทนำ
ภาพรวม
ในแล็บนี้ คุณจะได้ติดตั้งใช้งาน Agent Development Kit (ADK) Agent ที่พร้อมใช้งานจริงพร้อมแบ็กเอนด์ Gemma ที่เร่งด้วย GPU โดยเน้นที่รูปแบบการติดตั้งใช้งานที่สำคัญ ได้แก่ การตั้งค่าบริการ Cloud Run ที่เปิดใช้ GPU, การผสานรวมแบ็กเอนด์ของโมเดลกับตัวแทน ADK และการสังเกตพฤติกรรมการปรับขนาดอัตโนมัติภายใต้ภาระงาน
สิ่งที่คุณต้องดำเนินการ
ในแล็บนี้ คุณจะมุ่งเน้นที่แง่มุมที่สำคัญของการติดตั้งใช้งานจริง ได้แก่
- ติดตั้งใช้งาน Gemma ใน Cloud Run ด้วย GPU - ตั้งค่าแบ็กเอนด์โมเดล Gemma ประสิทธิภาพสูง
- ผสานรวมการติดตั้งใช้งาน Gemma กับ Agent ของ ADK - เชื่อมต่อ Agent กับโมเดลที่เร่งความเร็วด้วย GPU
- ทดสอบด้วยอินเทอร์เฟซเว็บของ ADK - ตรวจสอบว่าเอเจนต์สนทนาทำงานได้อย่างถูกต้อง
- ทำการทดสอบความยืดหยุ่น - สังเกตวิธีที่อินสแตนซ์ Cloud Run ทั้ง 2 รายการจัดการโหลด
โดยจะเน้นที่รูปแบบการติดตั้งใช้งานจริงมากกว่าการพัฒนาเอเจนต์อย่างละเอียด
สิ่งที่คุณจะได้เรียนรู้
- ติดตั้งใช้งานโมเดล Gemma ที่เร่งความเร็วด้วย GPU ใน Cloud Run เพื่อใช้ในการผลิต
- ผสานรวมการทำให้โมเดลภายนอกใช้งานได้กับ Agent ของ ADK
- กำหนดค่าและทดสอบการติดตั้งใช้งาน AI Agent ที่พร้อมใช้งานจริง
- ทําความเข้าใจลักษณะการทํางานของ Cloud Run ภายใต้ภาระงาน
- สังเกตวิธีที่อินสแตนซ์ Cloud Run หลายรายการประสานงานกันในช่วงที่มีการเข้าชมเพิ่มขึ้น
- ใช้การทดสอบความยืดหยุ่นเพื่อตรวจสอบประสิทธิภาพ
2. การตั้งค่าโปรเจ็กต์
- หากยังไม่มีบัญชี Google คุณต้องสร้างบัญชี Google
- ใช้บัญชีส่วนตัวแทนบัญชีงานหรือบัญชีโรงเรียน บัญชีงานและบัญชีโรงเรียนอาจมีข้อจำกัดที่ทำให้คุณเปิดใช้ API ที่จำเป็นสำหรับ Lab นี้ไม่ได้
- ลงชื่อเข้าใช้ คอนโซล Google Cloud
- เปิดใช้การเรียกเก็บเงินใน Cloud Console
- การทำ Lab นี้ควรมีค่าใช้จ่ายน้อยกว่า $1 USD ในทรัพยากรระบบคลาวด์
- คุณสามารถทำตามขั้นตอนที่ส่วนท้ายของแล็บนี้เพื่อลบทรัพยากรเพื่อหลีกเลี่ยงการเรียกเก็บเงินเพิ่มเติม
- ผู้ใช้ใหม่มีสิทธิ์ใช้ช่วงทดลองใช้ฟรีมูลค่า$300 USD
- สร้างโปรเจ็กต์ใหม่หรือเลือกใช้โปรเจ็กต์ที่มีอยู่ซ้ำ
- หากเห็นข้อผิดพลาดเกี่ยวกับโควต้าโปรเจ็กต์ ให้ใช้โปรเจ็กต์ที่มีอยู่ซ้ำหรือลบโปรเจ็กต์ที่มีอยู่เพื่อสร้างโปรเจ็กต์ใหม่
3. เปิดเครื่องมือแก้ไข Cloud Shell
- คลิกลิงก์นี้เพื่อไปยัง Cloud Shell Editor โดยตรง
- หากระบบแจ้งให้ให้สิทธิ์ในวันนี้ ให้คลิกให้สิทธิ์เพื่อดำเนินการต่อ
- หากเทอร์มินัลไม่ปรากฏที่ด้านล่างของหน้าจอ ให้เปิดโดยทำดังนี้
- คลิกดู
- คลิก Terminal
- ในเทอร์มินัล ให้ตั้งค่าโปรเจ็กต์ด้วยคำสั่งนี้
- รูปแบบ:
gcloud config set project [PROJECT_ID] - ตัวอย่าง
gcloud config set project lab-project-id-example - หากจำรหัสโปรเจ็กต์ไม่ได้ ให้ทำดังนี้
- คุณแสดงรหัสโปรเจ็กต์ทั้งหมดได้โดยใช้คำสั่งต่อไปนี้
gcloud projects list | awk '/PROJECT_ID/{print $2}'
- คุณแสดงรหัสโปรเจ็กต์ทั้งหมดได้โดยใช้คำสั่งต่อไปนี้
- รูปแบบ:
- คุณควรเห็นข้อความต่อไปนี้
Updated property [core/project].
WARNINGและระบบขอให้คุณDo you want to continue (Y/n)?แสดงว่าคุณอาจป้อนรหัสโปรเจ็กต์ไม่ถูกต้อง กดnกดEnterแล้วลองเรียกใช้คำสั่งgcloud config set projectอีกครั้ง
4. เปิดใช้ API และตั้งค่าภูมิภาคเริ่มต้น
ก่อนที่จะติดตั้งใช้งานบริการ Cloud Run ที่รองรับ GPU ได้ เราต้องเปิดใช้ Google Cloud API ที่จำเป็นและกำหนดค่าการตั้งค่าโปรเจ็กต์
- เปิดใช้ API ในเทอร์มินัลโดยทำดังนี้
gcloud services enable \
run.googleapis.com \
artifactregistry.googleapis.com \
cloudbuild.googleapis.com \
aiplatform.googleapis.com
หากได้รับแจ้งให้ให้สิทธิ์ ให้คลิกให้สิทธิ์เพื่อดำเนินการต่อ
คำสั่งนี้อาจใช้เวลาสักครู่จึงจะเสร็จสมบูรณ์ แต่ในที่สุดควรจะแสดงข้อความว่าสำเร็จคล้ายกับข้อความนี้
Operation "operations/acf.p2-73d90d00-47ee-447a-b600" finished successfully.
- ตั้งค่าภูมิภาค Cloud Run เริ่มต้น
gcloud config set run/region europe-west4
5. เตรียมโปรเจ็กต์ Python
มาตั้งค่าโค้ดเริ่มต้นที่มีโครงสร้างพื้นฐานสำหรับทั้งบริการแบ็กเอนด์ของ Gemma และ Agent ADK กัน
- โคลนที่เก็บเริ่มต้น
cd ~ npx -y giget@latest gh+git:GoogleCloudPlatform/devrel-demos/agents/accelerate-ai-with-cloud-run/accelerate-ai-lab3-starter accelerate-ai-lab3-starter cd accelerate-ai-lab3-starter - ตรวจสอบโครงสร้างโปรเจ็กต์
ls -Raccelerate-ai-lab3-starter/ ├── README.md # Project overview ├── ollama-backend/ # Ollama backend (separate deployment) │ └── Dockerfile # Backend container (🚧 to implement) └── adk-agent/ # ADK agent (separate deployment) ├── pyproject.toml # Python dependencies (✅ completed) ├── server.py # FastAPI server (🚧 to implement) ├── Dockerfile # Container config (🚧 to implement) ├── elasticity_test.py # Elasticity testing (🚧 to implement) └── production_agent/ # Agent implementation ├── __init__.py # Package init (✅ completed) └── agent.py # Agent logic (🚧 to implement)
6. ภาพรวมสถาปัตยกรรม
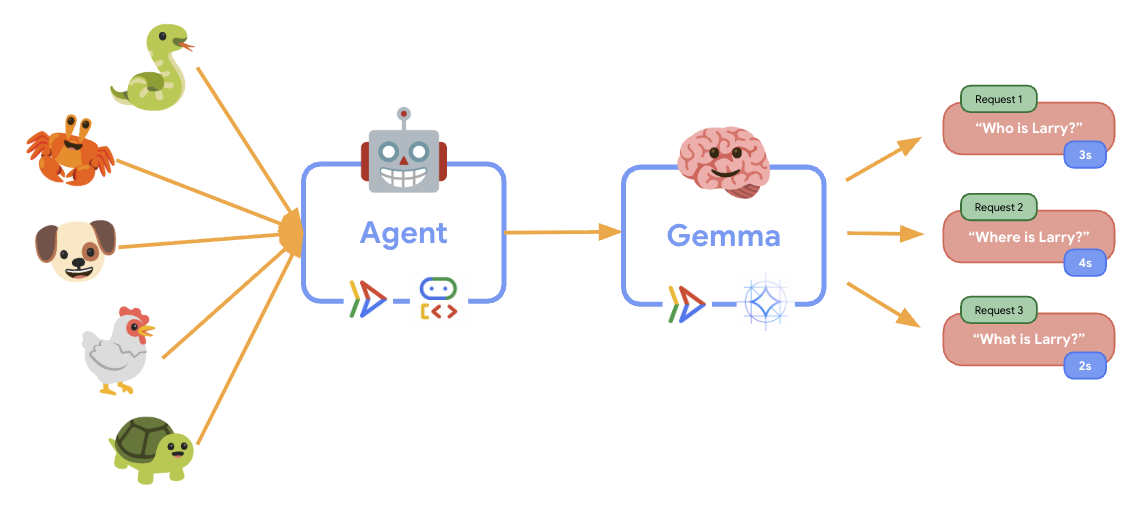
ก่อนที่จะนำไปใช้ เรามาทำความเข้าใจสถาปัตยกรรมแบบ 2 บริการกันก่อน
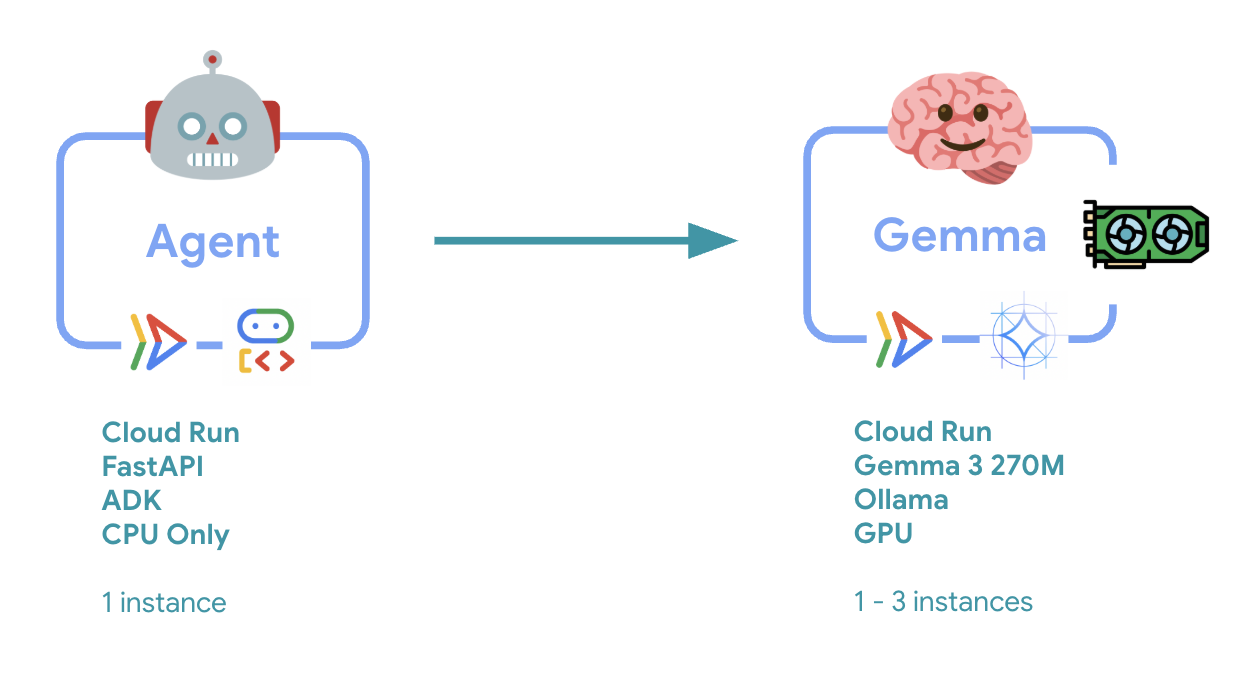
ข้อมูลเชิงลึกที่สำคัญ: ในระหว่างการทดสอบความยืดหยุ่น คุณจะเห็นว่าทั้ง 2 บริการจัดการภาระงานแยกกัน โดยแบ็กเอนด์ของ GPU (บริการที่เป็นจุดคอขวด) จะใช้ GPU เพื่อจัดการภาระงาน ในขณะที่ตัวแทน ADK จะใช้ CPU เพื่อจัดการคำขอที่ไม่ต้องใช้ทรัพยากรมาก
7. ติดตั้งใช้งานแบ็กเอนด์ Gemma ใน Cloud Run ด้วย GPU
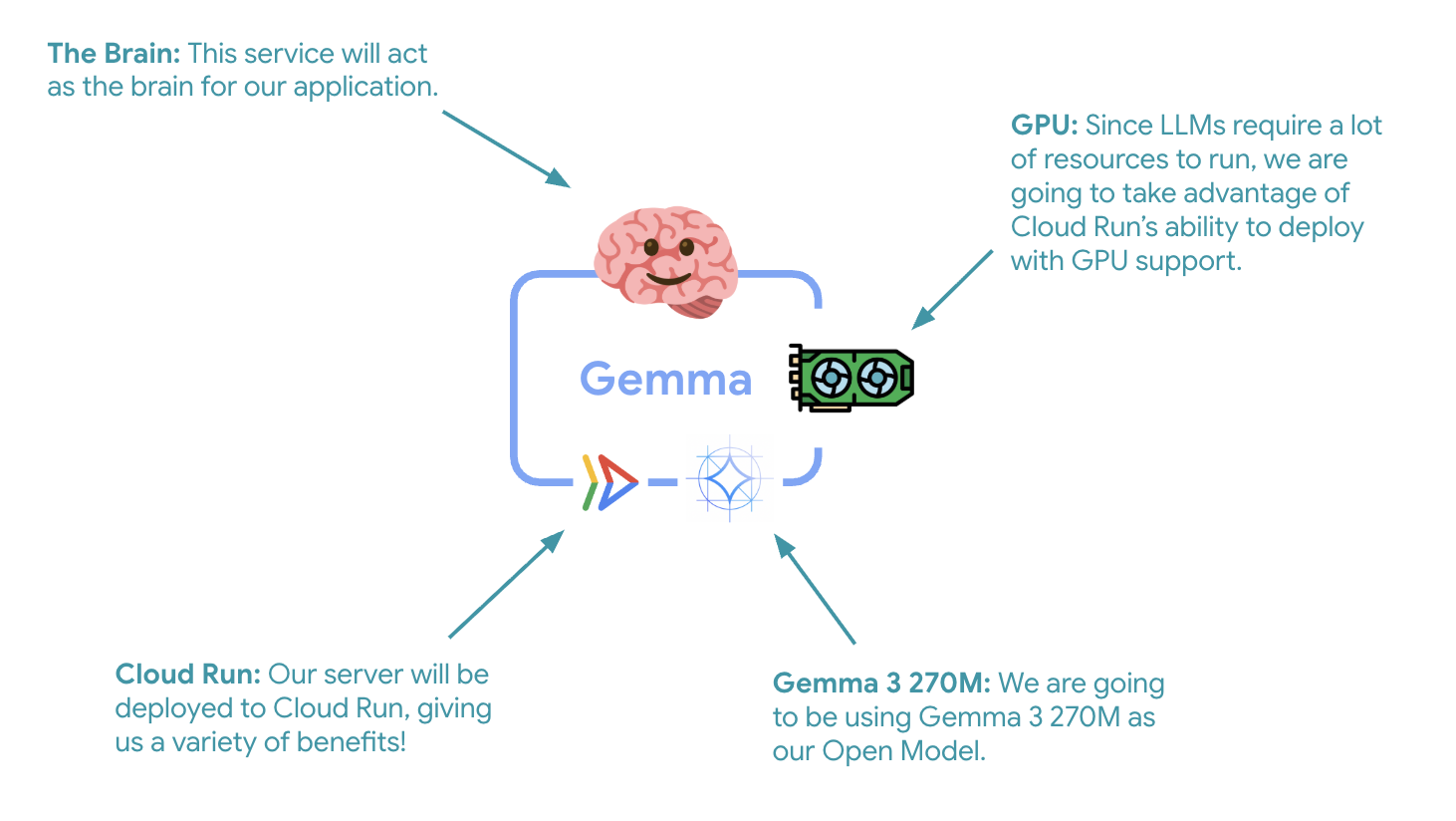
ขั้นตอนสำคัญแรกคือการติดตั้งใช้งานโมเดล Gemma ที่เร่งความเร็วด้วย GPU ซึ่งจะทำหน้าที่เป็นสมองของเอเจนต์ ADK การมี LLM ที่แยกส่วนและที่ใช้งานจริงอาจเป็นประโยชน์ในสถาปัตยกรรมที่คุณต้องการโมเดลที่ปรับแต่งแยกต่างหาก หรือต้องมีการปรับขนาดแบบแยก
- ไปที่ไดเรกทอรีแบ็กเอนด์ของ Ollama โดยใช้คำสั่งต่อไปนี้
cd ollama-backend - เปิดและใช้ Dockerfile ของ Ollama โดยทำดังนี้
cloudshell edit DockerfileFROM ollama/ollama:latest # Listen on all interfaces, port 8080 ENV OLLAMA_HOST 0.0.0.0:8080 # Store model weight files in /models ENV OLLAMA_MODELS /models # Reduce logging verbosity ENV OLLAMA_DEBUG false # Never unload model weights from the GPU ENV OLLAMA_KEEP_ALIVE -1 # Store the model weights in the container image ENV MODEL gemma3:270m RUN ollama serve & sleep 5 && ollama pull $MODEL # Start Ollama ENTRYPOINT ["ollama", "serve"]- ใช้รูปภาพ Ollama อย่างเป็นทางการเป็นพื้นฐาน
- ตั้งค่า
OLLAMA_HOSTให้ยอมรับการเชื่อมต่อจากที่อยู่ IP ใดก็ได้ - เปิดเผยพอร์ต 8080
- ติดตั้งใช้งานแบ็กเอนด์ Gemma ที่รองรับ GPU
gcloud run deploy ollama-gemma3-270m-gpu \
--source . \
--region europe-west4 \
--concurrency 7 \
--cpu 8 \
--set-env-vars OLLAMA_NUM_PARALLEL=4 \
--gpu 1 \
--gpu-type nvidia-l4 \
--max-instances 1 \
--memory 16Gi \
--allow-unauthenticated \
--no-cpu-throttling \
--no-gpu-zonal-redundancy \
--timeout 600 \
--labels dev-tutorial=codelab-agent-gpu
หากได้รับข้อความ "การติดตั้งใช้งานจากแหล่งที่มาต้องใช้ที่เก็บ Docker ของ Artifact Registry เพื่อจัดเก็บคอนเทนเนอร์ที่สร้างขึ้น ข้อความ "ระบบจะสร้างที่เก็บชื่อ [cloud-run-source-deploy] ในภูมิภาค [europe-west4]" ให้ดำเนินการต่อ
⚙️ อธิบายการกำหนดค่าที่สำคัญ
- GPU: NVIDIA L4 ได้รับเลือกเนื่องจากมีอัตราส่วนราคาต่อประสิทธิภาพที่ยอดเยี่ยมสำหรับปริมาณงานการอนุมาน L4 มีหน่วยความจำ GPU ขนาด 24 GB และการดำเนินการ Tensor ที่ได้รับการเพิ่มประสิทธิภาพ จึงเหมาะสำหรับโมเดลพารามิเตอร์ 270 ล้านรายการ เช่น Gemma
- หน่วยความจำ: หน่วยความจำระบบ 16 GB เพื่อรองรับการโหลดโมเดล การดำเนินการ CUDA และการจัดการหน่วยความจำของ Ollama
- CPU: 8 คอร์เพื่อการจัดการ I/O และการประมวลผลล่วงหน้าที่ดีที่สุด
- การทำงานพร้อมกัน: คำขอ 7 รายการต่ออินสแตนซ์จะปรับสมดุลอัตราการส่งผ่านข้อมูลกับการใช้งานหน่วยความจำ GPU
- ระยะหมดเวลา: 600 วินาทีรองรับการโหลดโมเดลเริ่มต้นและการเริ่มต้นคอนเทนเนอร์
💰 การพิจารณาต้นทุน: อินสแตนซ์ GPU มีราคาแพงกว่าอินสแตนซ์ CPU อย่างเดียวมาก (~$2-4/ชั่วโมง เทียบกับ ~$0.10/ชั่วโมง) --max-instances 1 การตั้งค่าช่วยควบคุมค่าใช้จ่ายโดยป้องกันไม่ให้มีการปรับขนาดอินสแตนซ์ GPU โดยไม่จำเป็น
- รอให้การทำให้ใช้งานได้เสร็จสมบูรณ์และจด URL ของบริการ
export OLLAMA_URL=$(gcloud run services describe ollama-gemma3-270m-gpu \ --region=europe-west4 \ --format='value(status.url)') echo "🎉 Gemma backend deployed at: $OLLAMA_URL"
8. ติดตั้งใช้งานการผสานรวม ADK Agent
ตอนนี้มาสร้างเอเจนต์ ADK ขั้นต่ำที่เชื่อมต่อกับแบ็กเอนด์ Gemma ที่คุณติดตั้งใช้งานกัน
- ไปที่ไดเรกทอรีของเอเจนต์ ADK โดยทำดังนี้
cd ../adk-agent - เปิดและใช้การกำหนดค่า Agent โดยทำดังนี้
cloudshell edit production_agent/agent.pyimport os from pathlib import Path from dotenv import load_dotenv from google.adk.agents import Agent from google.adk.models.lite_llm import LiteLlm import google.auth # Load environment variables root_dir = Path(__file__).parent.parent dotenv_path = root_dir / ".env" load_dotenv(dotenv_path=dotenv_path) # Configure Google Cloud try: _, project_id = google.auth.default() os.environ.setdefault("GOOGLE_CLOUD_PROJECT", project_id) except Exception: pass os.environ.setdefault("GOOGLE_CLOUD_LOCATION", "europe-west4") # Configure model connection gemma_model_name = os.getenv("GEMMA_MODEL_NAME", "gemma3:270m") api_base = os.getenv("OLLAMA_API_BASE", "localhost:10010") # Location of Ollama server # Production Gemma Agent - GPU-accelerated conversational assistant production_agent = Agent( model=LiteLlm(model=f"ollama_chat/{gemma_model_name}", api_base=api_base), name="production_agent", description="A production-ready conversational assistant powered by GPU-accelerated Gemma.", instruction="""You are 'Gem', a friendly, knowledgeable, and enthusiastic zoo tour guide. Your main goal is to make a zoo visit more fun and educational for guests by answering their questions. You can provide general information and interesting facts about different animal species, such as: - Their natural habitats and diet. 🌲🍓 - Typical lifespan and behaviors. - Conservation status and unique characteristics. IMPORTANT: You do NOT have access to any tools. This means you cannot look up real-time, specific information about THIS zoo. You cannot provide: - The names or ages of specific animals currently at the zoo. - The exact location or enclosure for an animal. - The daily schedule for feedings or shows. Always answer based on your general knowledge about the animal kingdom. Keep your tone cheerful, engaging, and welcoming for visitors of all ages. 🦁✨""", tools=[], # Gemma focuses on conversational capabilities ) # Set as root agent root_agent = production_agent- เชื่อมต่อกับแบ็กเอนด์ Gemma ที่คุณติดตั้งใช้งานผ่าน LiteLlm
- สร้างเอเจนต์สนทนาโต้ตอบที่เรียบง่าย
- กำหนดค่าการผสานรวม Google Cloud
- เปิดและใช้งานเซิร์ฟเวอร์ FastAPI
cloudshell edit server.pyimport os from dotenv import load_dotenv from fastapi import FastAPI from google.adk.cli.fast_api import get_fast_api_app # Load environment variables load_dotenv() AGENT_DIR = os.path.dirname(os.path.abspath(__file__)) app_args = {"agents_dir": AGENT_DIR, "web": True} # Create FastAPI app with ADK integration app: FastAPI = get_fast_api_app(**app_args) # Update app metadata app.title = "Production ADK Agent - Lab 3" app.description = "Gemma agent with GPU-accelerated backend" app.version = "1.0.0" @app.get("/health") def health_check(): return {"status": "healthy", "service": "production-adk-agent"} @app.get("/") def root(): return { "service": "Production ADK Agent - Lab 3", "description": "GPU-accelerated Gemma agent", "docs": "/docs", "health": "/health" } if __name__ == "__main__": import uvicorn uvicorn.run(app, host="0.0.0.0", port=8080, log_level="info")- สร้างเซิร์ฟเวอร์ FastAPI ด้วยการผสานรวม ADK
- เปิดใช้อินเทอร์เฟซเว็บสำหรับการทดสอบ
- ระบุปลายทางการตรวจสอบประสิทธิภาพการทำงาน
- เปิดและใช้ Dockerfile โดยทำดังนี้
cloudshell edit DockerfileFROM python:3.13-slim # Copy uv from the official image COPY --from=ghcr.io/astral-sh/uv:latest /uv /usr/local/bin/uv # Install system dependencies RUN apt-get update && apt-get install -y curl && rm -rf /var/lib/apt/lists/* # Set working directory WORKDIR /app # Copy all files COPY . . # Install Python dependencies RUN uv sync # Expose port EXPOSE 8080 # Run the application CMD ["uv", "run", "uvicorn", "server:app", "--host", "0.0.0.0", "--port", "8080"]- uv: เครื่องมือจัดการแพ็กเกจ Python ที่ทันสมัยซึ่งเร็วกว่า pip 10-100 เท่า โดยจะใช้แคชส่วนกลางและการดาวน์โหลดแบบขนาน ซึ่งจะช่วยลดเวลาในการสร้างคอนเทนเนอร์ได้อย่างมาก
- Python 3.13-slim: เวอร์ชัน Python ล่าสุดที่มีการพึ่งพาระบบน้อยที่สุด ซึ่งจะช่วยลดขนาดคอนเทนเนอร์และพื้นผิวการโจมตี
- การบิลด์แบบหลายขั้นตอน: การคัดลอก uv จากอิมเมจอย่างเป็นทางการช่วยให้เราได้รับไบนารีที่ได้รับการเพิ่มประสิทธิภาพล่าสุด
9. กำหนดค่าสภาพแวดล้อมและติดตั้งใช้งาน Agent
ตอนนี้เราจะกำหนดค่าเอเจนต์ ADK ให้เชื่อมต่อกับแบ็กเอนด์ Gemma ที่ทำให้ใช้งานได้ และทำให้ใช้งานได้เป็นบริการ Cloud Run ซึ่งรวมถึงการตั้งค่าตัวแปรสภาพแวดล้อมและการติดตั้งใช้งานเอเจนต์ด้วยการกำหนดค่าที่เหมาะสม
- ตั้งค่าการกำหนดค่าสภาพแวดล้อม
cat << EOF > .env GOOGLE_CLOUD_PROJECT=$(gcloud config get-value project) GOOGLE_CLOUD_LOCATION=europe-west4 GEMMA_MODEL_NAME=gemma3:270m OLLAMA_API_BASE=$OLLAMA_URL EOF
ทำความเข้าใจตัวแปรสภาพแวดล้อมใน Cloud Run
ตัวแปรสภาพแวดล้อมคือคู่คีย์-ค่าที่กำหนดค่าแอปพลิเคชันของคุณในระหว่างรันไทม์ ซึ่งมีประโยชน์อย่างยิ่งในกรณีต่อไปนี้
- ปลายทาง API และ URL ของบริการ (เช่น แบ็กเอนด์ Ollama ของเรา)
- การกำหนดค่าที่เปลี่ยนแปลงระหว่างสภาพแวดล้อม (dev, staging, prod)
- ข้อมูลที่ละเอียดอ่อนซึ่งไม่ควรฮาร์ดโค้ด
ติดตั้งใช้งาน Agent ประเภท ADK
export PROJECT_ID=$(gcloud config get-value project)
gcloud run deploy production-adk-agent \
--source . \
--region europe-west4 \
--allow-unauthenticated \
--memory 4Gi \
--cpu 2 \
--max-instances 1 \
--concurrency 50 \
--timeout 300 \
--set-env-vars GOOGLE_CLOUD_PROJECT=$PROJECT_ID \
--set-env-vars GOOGLE_CLOUD_LOCATION=europe-west4 \
--set-env-vars GEMMA_MODEL_NAME=gemma3:270m \
--set-env-vars OLLAMA_API_BASE=$OLLAMA_URL \
--labels dev-tutorial=codelab-agent-gpu
⚙️ การกำหนดค่าที่สำคัญ:
- การปรับขนาดอัตโนมัติ: คงที่ที่ 1 อินสแตนซ์ (การจัดการคำขอแบบเบา)
- การทำงานพร้อมกัน: 50 คำขอต่ออินสแตนซ์
- หน่วยความจำ: 4 GB สำหรับตัวแทน ADK
- สภาพแวดล้อม: เชื่อมต่อกับแบ็กเอนด์ของ Gemma
🔒 หมายเหตุเกี่ยวกับความปลอดภัย: Labs นี้ใช้ --allow-unauthenticated เพื่อความสะดวก ในเวอร์ชันที่ใช้งานจริง ให้ใช้การตรวจสอบสิทธิ์ที่เหมาะสมโดยใช้สิ่งต่อไปนี้
- การตรวจสอบสิทธิ์จากบริการหนึ่งไปยังอีกบริการหนึ่งของ Cloud Run ด้วยบัญชีบริการ
- นโยบาย Identity and Access Management (IAM)
- คีย์ API หรือ OAuth สำหรับการเข้าถึงภายนอก
- พิจารณาใช้
gcloud run services add-iam-policy-bindingเพื่อควบคุมการเข้าถึง
รับ URL ของบริการตัวแทนโดยทำดังนี้
export AGENT_URL=$(gcloud run services describe production-adk-agent \
--region=europe-west4 \
--format='value(status.url)')
echo "🎉 ADK Agent deployed at: $AGENT_URL"
✅ แนวทางปฏิบัติแนะนำเกี่ยวกับตัวแปรสภาพแวดล้อมตามเอกสารประกอบเกี่ยวกับตัวแปรสภาพแวดล้อมของ Cloud Run มีดังนี้
- หลีกเลี่ยงตัวแปรที่สงวนไว้: อย่าตั้งค่า
PORT(หากต้องการเปลี่ยนตัวแปรสภาพแวดล้อม ให้ใช้แฟล็ก –port แทน) หรือตัวแปรที่ขึ้นต้นด้วยX_GOOGLE_ - ใช้ชื่อที่สื่อความหมาย: ใส่คำนำหน้าตัวแปรเพื่อหลีกเลี่ยงการขัดกัน (เช่น
GEMMA_MODEL_NAMEแทนMODEL) - หลีกเลี่ยงคอมมา: หากค่ามีคอมมา ให้ใช้ตัวคั่นอื่น
--set-env-vars "^@^KEY1=value1,value2@KEY2=..." - อัปเดตเทียบกับแทนที่: ใช้
--update-env-varsเพื่อเพิ่ม/เปลี่ยนตัวแปรที่เฉพาะเจาะจงโดยไม่ส่งผลกระทบต่อตัวแปรอื่นๆ
วิธีตั้งค่าตัวแปรใน Cloud Run
- จากไฟล์:
gcloud run deploy SERVICE_NAME --env-vars-file .env --labels dev-tutorial codelab-adk(โหลดตัวแปรหลายรายการจากไฟล์) - หลายแฟล็ก: ทำซ้ำ
--set-env-varsสำหรับค่าที่ซับซ้อนซึ่งคั่นด้วยคอมมาไม่ได้
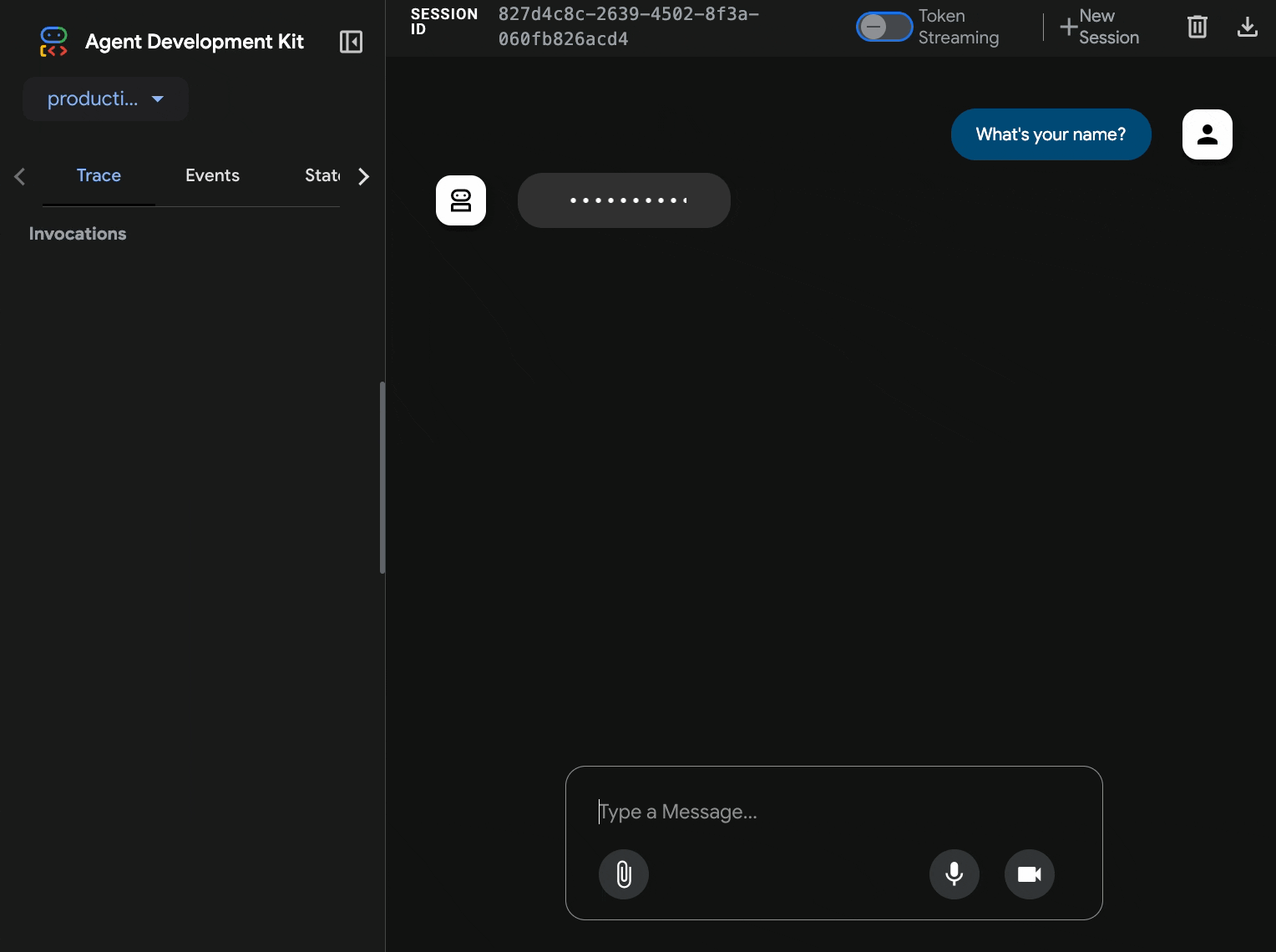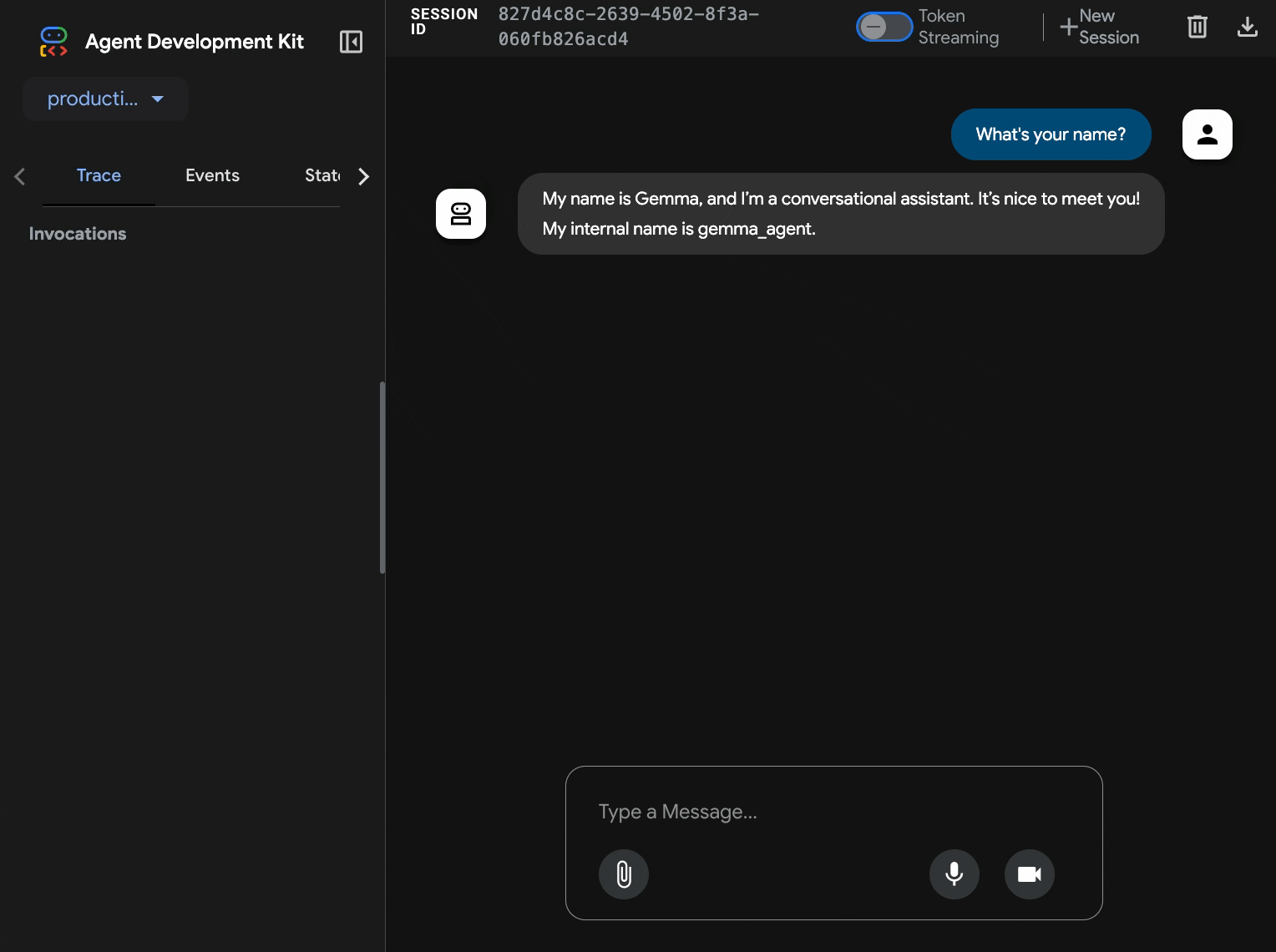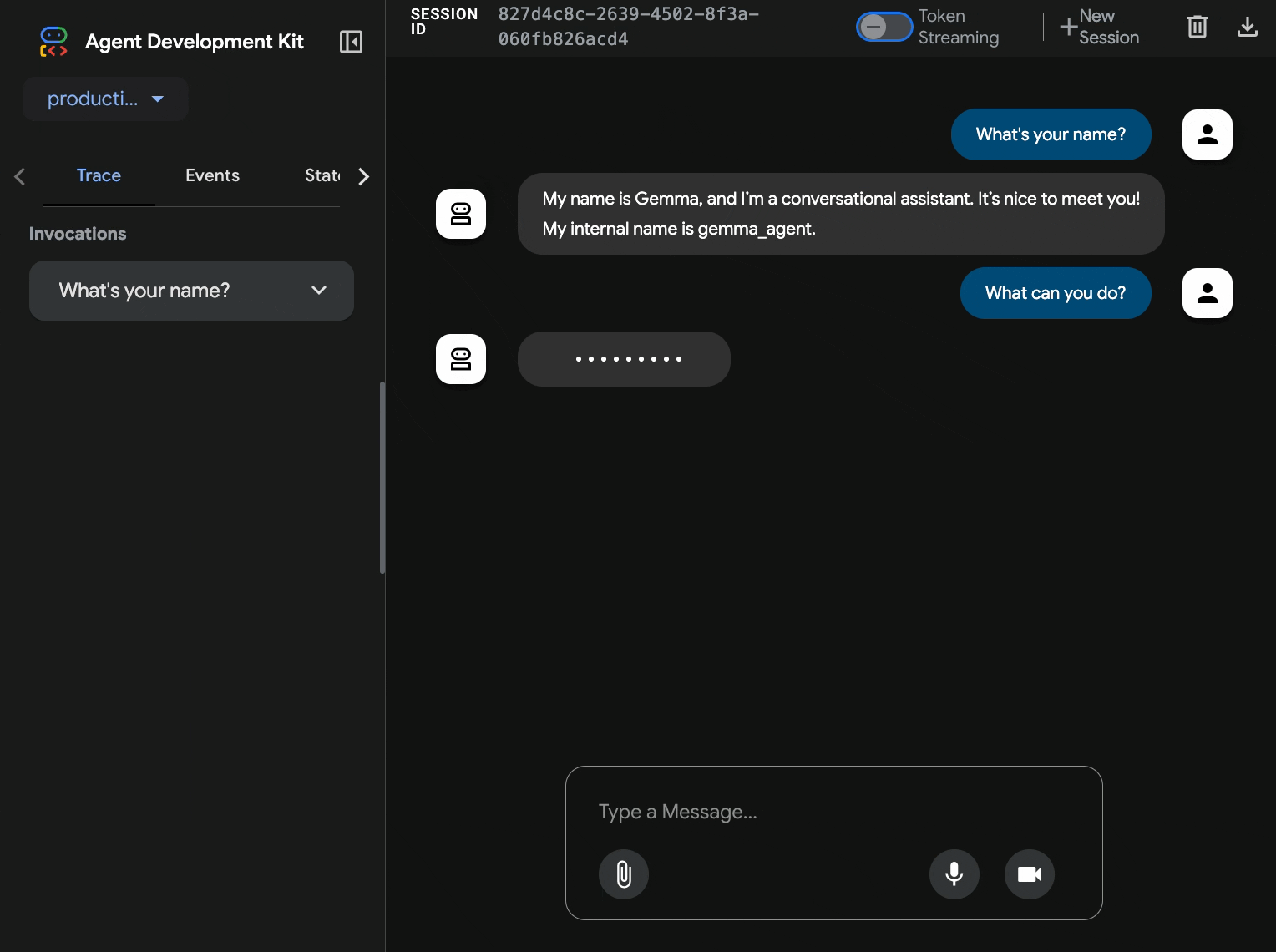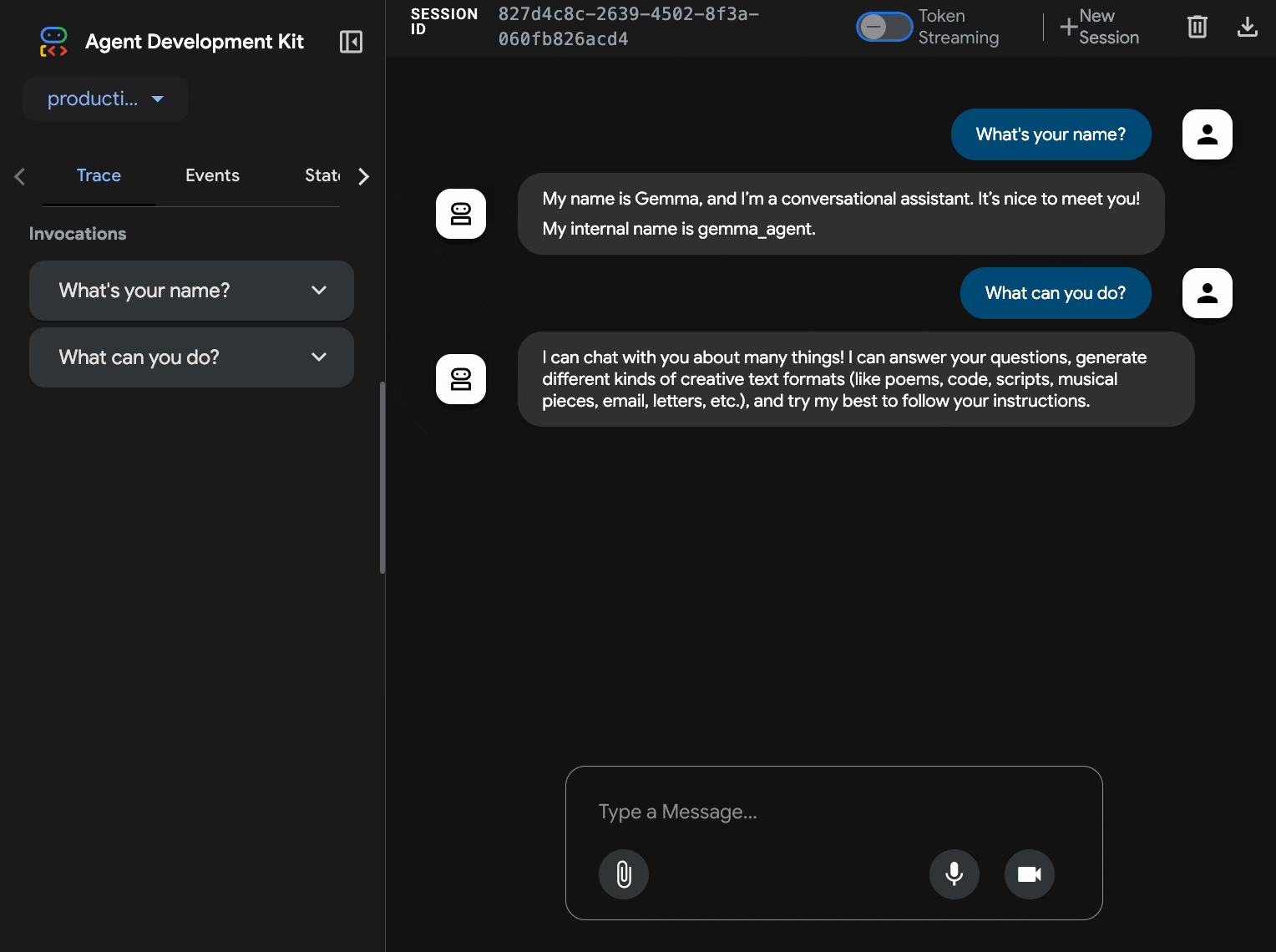
10. ทดสอบด้วยอินเทอร์เฟซเว็บ ADK
เมื่อติดตั้งใช้งานทั้ง 2 บริการแล้ว ก็ถึงเวลาตรวจสอบว่าเอเจนต์ ADK สามารถสื่อสารกับแบ็กเอนด์ Gemma ที่เร่งด้วย GPU และตอบคำค้นหาของผู้ใช้ได้สำเร็จ
- ทดสอบปลายทางการตรวจสอบประสิทธิภาพการทำงาน
curl $AGENT_URL/health{ "status": "healthy", "service": "production-adk-agent" } - โต้ตอบกับตัวแทนโดยป้อน URL สำหรับ
production-adk-agentในแท็บเบราว์เซอร์ใหม่ คุณควรเห็นอินเทอร์เฟซเว็บของ ADK - ทดสอบตัวแทนด้วยการสนทนาตัวอย่างต่อไปนี้
- "โดยปกติแล้วแพนด้าแดงกินอะไรในป่า"
- "คุณบอกข้อเท็จจริงที่น่าสนใจเกี่ยวกับเสือดาวหิมะให้ฉันฟังหน่อยได้ไหม"
- "ทำไมกบลูกศรพิษถึงมีสีสันสดใส"
- "ฉันจะเห็นลูกจิงโจ้ตัวใหม่ในสวนสัตว์ได้ที่ไหน"
- เอเจนต์จะตอบกลับโดยใช้โมเดล Gemma ที่คุณใช้งาน คุณยืนยันได้โดยดูบันทึกของบริการ Gemma ที่คุณติดตั้งใช้งาน เราจะดำเนินการนี้ในส่วนถัดไป
- คำตอบสร้างขึ้นโดยแบ็กเอนด์ที่เร่งด้วย GPU
- อินเทอร์เฟซเว็บมอบประสบการณ์การแชทที่สะอาดตา
11. ใช้และทำการทดสอบความยืดหยุ่น
เพื่อทำความเข้าใจว่าการติดตั้งใช้งานเวอร์ชันที่ใช้งานจริงจัดการการเข้าชมจริงได้อย่างไร เราจะทำการทดสอบความยืดหยุ่นเพื่อทดสอบความสามารถของระบบในการปรับให้เข้ากับปริมาณงานเวอร์ชันที่ใช้งานจริงที่ "จำลอง" สูงขึ้น
- เปิดและใช้สคริปต์การทดสอบความยืดหยุ่น
cloudshell edit elasticity_test.pyimport random import uuid from locust import HttpUser, task, between class ProductionAgentUser(HttpUser): """Elasticity test user for the Production ADK Agent.""" wait_time = between(1, 3) # Faster requests to trigger scaling def on_start(self): """Set up user session when starting.""" self.user_id = f"user_{uuid.uuid4()}" self.session_id = f"session_{uuid.uuid4()}" # Create session for the Gemma agent using proper ADK API format session_data = {"state": {"user_type": "elasticity_test_user"}} self.client.post( f"/apps/production_agent/users/{self.user_id}/sessions/{self.session_id}", headers={"Content-Type": "application/json"}, json=session_data, ) @task(4) def test_conversations(self): """Test conversational capabilities - high frequency.""" topics = [ "What do red pandas typically eat in the wild?", "Can you tell me an interesting fact about snow leopards?", "Why are poison dart frogs so brightly colored?", "Where can I find the new baby kangaroo in the zoo?", "What is the name of your oldest gorilla?", "What time is the penguin feeding today?" ] # Use proper ADK API format for sending messages message_data = { "app_name": "production_agent", "user_id": self.user_id, "session_id": self.session_id, "new_message": { "role": "user", "parts": [{ "text": random.choice(topics) }] } } self.client.post( "/run", headers={"Content-Type": "application/json"}, json=message_data, ) @task(1) def health_check(self): """Test the health endpoint.""" self.client.get("/health")- การสร้างเซสชัน: ใช้รูปแบบ API ของ ADK ที่เหมาะสมกับ POST ไปยัง
/apps/production_agent/users/{user_id}/sessions/{session_id}หลังจากสร้างsession_idและuser_idแล้ว คุณสามารถส่งคำขอไปยังตัวแทนได้ - รูปแบบข้อความ: เป็นไปตามข้อกำหนดของ ADK ที่มีออบเจ็กต์
app_name,user_id,session_idและnew_messageที่มีโครงสร้าง - ปลายทางการสนทนา: ใช้ปลายทาง
/runเพื่อรวบรวมเหตุการณ์ทั้งหมดพร้อมกัน (แนะนําสําหรับการทดสอบโหลด) - โหลดตามจริง: สร้างโหลดการสนทนาโดยมีเวลารอสายที่สั้นลง
- การสร้างเซสชัน: ใช้รูปแบบ API ของ ADK ที่เหมาะสมกับ POST ไปยัง
- ติดตั้งการอ้างอิงด้วยคำสั่งต่อไปนี้
uv sync - Locust เป็นเครื่องมือทดสอบโหลดแบบโอเพนซอร์สที่ใช้ Python ซึ่งออกแบบมาเพื่อทดสอบประสิทธิภาพและโหลดของเว็บแอปพลิเคชันและระบบอื่นๆ ลักษณะสำคัญของเครื่องมือนี้คือการกำหนดสถานการณ์การทดสอบและพฤติกรรมของผู้ใช้โดยใช้โค้ด Python มาตรฐาน ซึ่งมีความยืดหยุ่นและสื่อความหมายได้สูงเมื่อเทียบกับเครื่องมือที่ต้องอาศัยอินเทอร์เฟซผู้ใช้แบบกราฟิกหรือภาษาเฉพาะโดเมน เราจะใช้ Locust เพื่อจำลองการเข้าชมของผู้ใช้ในบริการของเรา เรียกใช้การทดสอบ
uv run locust -f elasticity_test.py \ -H $AGENT_URL \ --headless \ -t 60s \ -u 20 \ -r 5- ระยะเวลา: 60 วินาที
- ผู้ใช้: ผู้ใช้พร้อมกัน 20 คน
- อัตราการเกิด: ผู้ใช้ 5 คนต่อวินาที
- เป้าหมาย: เรียกใช้การปรับขนาดอัตโนมัติในทั้ง 2 บริการ
12. สังเกตพฤติกรรมการปรับขนาดอัตโนมัติ
ขณะที่การทดสอบความยืดหยุ่นทำงานอยู่ คุณจะเห็นการรองรับภาระงานที่สูงขึ้นของ Cloud Run ในการทำงาน คุณจะเห็นประโยชน์ด้านสถาปัตยกรรมที่สำคัญของการแยกเอเจนต์ ADK ออกจากแบ็กเอนด์ของ GPU ได้ที่นี่
ในระหว่างการทดสอบความยืดหยุ่น ให้ตรวจสอบวิธีที่บริการ Cloud Run ทั้ง 2 รายการจัดการการรับส่งข้อมูลในคอนโซล
- ใน Cloud Console ให้ไปที่
- Cloud Run → production-adk-agent → เมตริก
- Cloud Run → ollama-gemma3-270m-gpu → เมตริก
👀 สิ่งที่คุณควรสังเกต
🤖 บริการ ADK Agent:
- ควรคงที่ที่ 1 อินสแตนซ์ในขณะที่การเข้าชมเพิ่มขึ้น
- การใช้งาน CPU และหน่วยความจำเพิ่มขึ้นอย่างรวดเร็วในช่วงที่มีการเข้าชมสูง
- จัดการเซสชันและการกำหนดเส้นทางการส่งคำขออย่างมีประสิทธิภาพ
🎮 บริการแบ็กเอนด์ของ Gemma (จุดคอขวด):
- ควรคงที่ที่ 1 อินสแตนซ์ในขณะที่การเข้าชมเพิ่มขึ้น
- การใช้งาน GPU เพิ่มขึ้นอย่างมากภายใต้ภาระงาน
- บริการนี้กลายเป็นจุดคอขวดเนื่องจากการอนุมานโมเดลที่ใช้ GPU อย่างหนัก
- เวลาการอนุมานของโมเดลยังคงสม่ำเสมอเนื่องจากการเร่งด้วย GPU
💡 ข้อมูลเชิงลึกที่สำคัญ:
- ทั้ง 2 บริการจะยังคงสอดคล้องกันและไม่เพิ่มทรัพยากร เนื่องจากเราตั้งค่าอินสแตนซ์สูงสุดเป็น
1 - ทั้ง 2 บริการจะปรับขนาดแยกกันตามลักษณะการโหลดของแต่ละบริการ
- GPU ช่วยรักษาประสิทธิภาพภายใต้สภาวะโหลดที่แตกต่างกัน
13. บทสรุป
ยินดีด้วย คุณได้ติดตั้งใช้งานเอเจนต์ ADK ที่พร้อมใช้งานจริงเรียบร้อยแล้วด้วยแบ็กเอนด์ Gemma ที่เร่งด้วย GPU ขณะทดสอบปริมาณงานการผลิตจำลอง
✅ สิ่งที่คุณทำสำเร็จ
- ✅ ทำให้แบ็กเอนด์โมเดล Gemma ที่เร่งด้วย GPU ใช้งานได้บน Cloud Run
- ✅ สร้างและติดตั้งใช้งาน Agent ประเภท ADK ที่ผสานรวมกับแบ็กเอนด์ของ Gemma
- ✅ ทดสอบ Agent โดยใช้อินเทอร์เฟซเว็บ ADK
- ✅ สังเกตพฤติกรรมการปรับขนาดอัตโนมัติในบริการ Cloud Run 2 รายการที่ประสานงานกัน
💡 ข้อมูลเชิงลึกที่สำคัญจากห้องทดลองนี้
- 🎮 การเร่งความเร็วด้วย GPU: GPU รุ่น L4 ของ NVIDIA ช่วยปรับปรุงประสิทธิภาพการอนุมานโมเดลได้อย่างมาก
- 🔗 การประสานงานบริการ: บริการ Cloud Run 2 รายการทำงานร่วมกันได้อย่างราบรื่น
- 📈 การปรับขนาดแยกกัน: แต่ละบริการจะปรับขนาดตามลักษณะการโหลดของแต่ละบริการ
- 🚀 ความพร้อมของเวอร์ชันที่ใช้งานจริง: สถาปัตยกรรมจัดการรูปแบบการเข้าชมในโลกแห่งความเป็นจริงได้อย่างมีประสิทธิภาพ
🔄 ขั้นตอนถัดไป
- ทดสอบรูปแบบการโหลดต่างๆ และสังเกตลักษณะการทำงานของการปรับขนาด
- ลองใช้โมเดล Gemma ขนาดต่างๆ (ปรับหน่วยความจำและ GPU ตามนั้น)
- ใช้การตรวจสอบและการแจ้งเตือนสำหรับการติดตั้งใช้งานเวอร์ชันที่ใช้งานจริง
- สำรวจการติดตั้งใช้งานแบบหลายภูมิภาคเพื่อความพร้อมให้บริการทั่วโลก
🧹 ล้างข้อมูล
โปรดลบทรัพยากรเมื่อดำเนินการเสร็จสิ้นเพื่อไม่ให้มีการเรียกเก็บเงิน
gcloud run services delete production-adk-agent --region=europe-west4
gcloud run services delete ollama-gemma3-270m-gpu --region=europe-west4
📖 แหล่งข้อมูล
- ที่เก็บเริ่มต้น
- โซลูชันที่สมบูรณ์
- เอกสารประกอบของ Google ADK
- คู่มือการทดสอบ ADK - ข้อมูลอ้างอิงที่สมบูรณ์สำหรับปลายทาง API ของ ADK และรูปแบบการทดสอบ
- การทดสอบโหลดใน Cloud Run
- เอกสารประกอบของชุดพัฒนาเอเจนต์ (ADK)
- เอกสารประกอบ GPU ของ Cloud Run
- คลังโมเดล Ollama
- เอกสารประกอบของ Google Cloud Trace
- แนวทางปฏิบัติแนะนำด้านความปลอดภัยของ Cloud Run
- UV Python Package Manager
- เฟรมเวิร์กการทดสอบการโหลด Locust