
1. Giriş
Genel Bakış
Bu laboratuvarda, GPU hızlandırmalı Gemma arka ucuyla üretime hazır bir Agent Development Kit (ADK) ajanı dağıtacaksınız. Bu eğitimde, GPU özellikli Cloud Run hizmetleri oluşturma, model arka uçlarını ADK aracılarıyla entegre etme ve yük altındaki otomatik ölçeklendirme davranışını gözlemleme gibi kritik dağıtım kalıplarına odaklanılmaktadır.
Yapacaklarınız
Bu laboratuvarda, önemli üretim dağıtımı yönlerine odaklanacaksınız:
- GPU ile Gemma'yı Cloud Run'a dağıtma: Yüksek performanslı bir Gemma modeli arka ucu oluşturma
- Gemma dağıtımını bir ADK aracısıyla entegre etme: Aracınızı GPU hızlandırmalı modele bağlayın.
- ADK Web arayüzüyle test etme: Sohbet aracınızın doğru şekilde çalıştığını doğrulayın.
- Esneklik testi gerçekleştirme: Cloud Run örneklerinin yükü nasıl işlediğini gözlemleyin.
Burada kapsamlı aracı geliştirme yerine üretim dağıtım kalıplarına odaklanılır.
Neler öğreneceksiniz?
- GPU hızlandırmalı Gemma modellerini üretimde kullanmak üzere Cloud Run'a dağıtma
- Harici model dağıtımlarını ADK aracılarıyla entegre etme
- Üretime hazır yapay zeka aracısı dağıtımlarını yapılandırma ve test etme
- Yük altındaki Cloud Run davranışını anlama
- Trafik artışları sırasında birden fazla Cloud Run örneğinin nasıl koordine olduğunu gözlemleyin.
- Performansı doğrulamak için esneklik testi uygulama
2. Proje Ayarları
- Google Hesabınız yoksa Google Hesabı oluşturmanız gerekir.
- İş veya okul hesabı yerine kişisel hesap kullanıyorsanız. İş ve okul hesaplarında, bu laboratuvar için gereken API'leri etkinleştirmenizi engelleyen kısıtlamalar olabilir.
- Google Cloud Console'da oturum açın.
- Cloud Console'da faturalandırmayı etkinleştirin.
- Bu laboratuvarı tamamlamak için 1 ABD dolarından daha az tutarda bulut kaynağı kullanmanız gerekir.
- Daha fazla ücret ödememek için bu laboratuvarın sonundaki adımları uygulayarak kaynakları silebilirsiniz.
- Yeni kullanıcılar 300 ABD doları değerinde ücretsiz deneme sürümünden yararlanabilir.
- Yeni bir proje oluşturun veya mevcut bir projeyi yeniden kullanmayı seçin.
- Proje kotasıyla ilgili bir hata görürseniz yeni bir proje oluşturmak için mevcut bir projeyi yeniden kullanın veya mevcut bir projeyi silin.
3. Cloud Shell Düzenleyici'yi açma
- Doğrudan Cloud Shell Düzenleyici'ye gitmek için bu bağlantıyı tıklayın.
- Bugün herhangi bir noktada yetkilendirmeniz istenirse devam etmek için Yetkilendir'i tıklayın.
- Terminal ekranın alt kısmında görünmüyorsa açın:
- Görünüm'ü tıklayın.
- Terminal'i tıklayın.
- Terminalde şu komutla projenizi ayarlayın:
- Biçim:
gcloud config set project [PROJECT_ID] - Örnek:
gcloud config set project lab-project-id-example - Proje kimliğinizi hatırlamıyorsanız:
- Tüm proje kimliklerinizi şu komutla listeleyebilirsiniz:
gcloud projects list | awk '/PROJECT_ID/{print $2}'
- Tüm proje kimliklerinizi şu komutla listeleyebilirsiniz:
- Biçim:
- Şu mesajı görmeniz gerekir:
Updated property [core/project].
WARNINGsimgesini görüyorsanız veDo you want to continue (Y/n)?soruluyorsa proje kimliğini yanlış girmiş olabilirsiniz.ntuşuna,Entertuşuna basın vegcloud config set projectkomutunu tekrar çalıştırmayı deneyin.
4. API'leri etkinleştirme ve varsayılan bölgeyi ayarlama
GPU destekli Cloud Run hizmetlerini dağıtabilmemiz için gerekli Google Cloud API'lerini etkinleştirmemiz ve proje ayarlarınızı yapılandırmamız gerekir.
- Terminalde API'leri etkinleştirin:
gcloud services enable \
run.googleapis.com \
artifactregistry.googleapis.com \
cloudbuild.googleapis.com \
aiplatform.googleapis.com
Yetkilendirmeniz istenirse devam etmek için Yetkilendir'i tıklayın.
Bu komutun tamamlanması birkaç dakika sürebilir ancak sonunda aşağıdakine benzer bir başarılı mesaj üretmesi gerekir:
Operation "operations/acf.p2-73d90d00-47ee-447a-b600" finished successfully.
- Varsayılan Cloud Run bölgenizi ayarlayın.
gcloud config set run/region europe-west4
5. Python projenizi hazırlama
Hem Gemma arka ucumuz hem de ADK aracısı hizmetlerimiz için temel yapıyı içeren başlangıç kodunu ayarlayalım.
- Başlangıç deposunu klonlayın:
cd ~ npx -y giget@latest gh+git:GoogleCloudPlatform/devrel-demos/agents/accelerate-ai-with-cloud-run/accelerate-ai-lab3-starter accelerate-ai-lab3-starter cd accelerate-ai-lab3-starter - Proje yapısını inceleyin:
ls -Raccelerate-ai-lab3-starter/ ├── README.md # Project overview ├── ollama-backend/ # Ollama backend (separate deployment) │ └── Dockerfile # Backend container (🚧 to implement) └── adk-agent/ # ADK agent (separate deployment) ├── pyproject.toml # Python dependencies (✅ completed) ├── server.py # FastAPI server (🚧 to implement) ├── Dockerfile # Container config (🚧 to implement) ├── elasticity_test.py # Elasticity testing (🚧 to implement) └── production_agent/ # Agent implementation ├── __init__.py # Package init (✅ completed) └── agent.py # Agent logic (🚧 to implement)
6. Mimarisine Genel Bakış
Uygulamadan önce iki hizmetli mimariyi anlayalım:
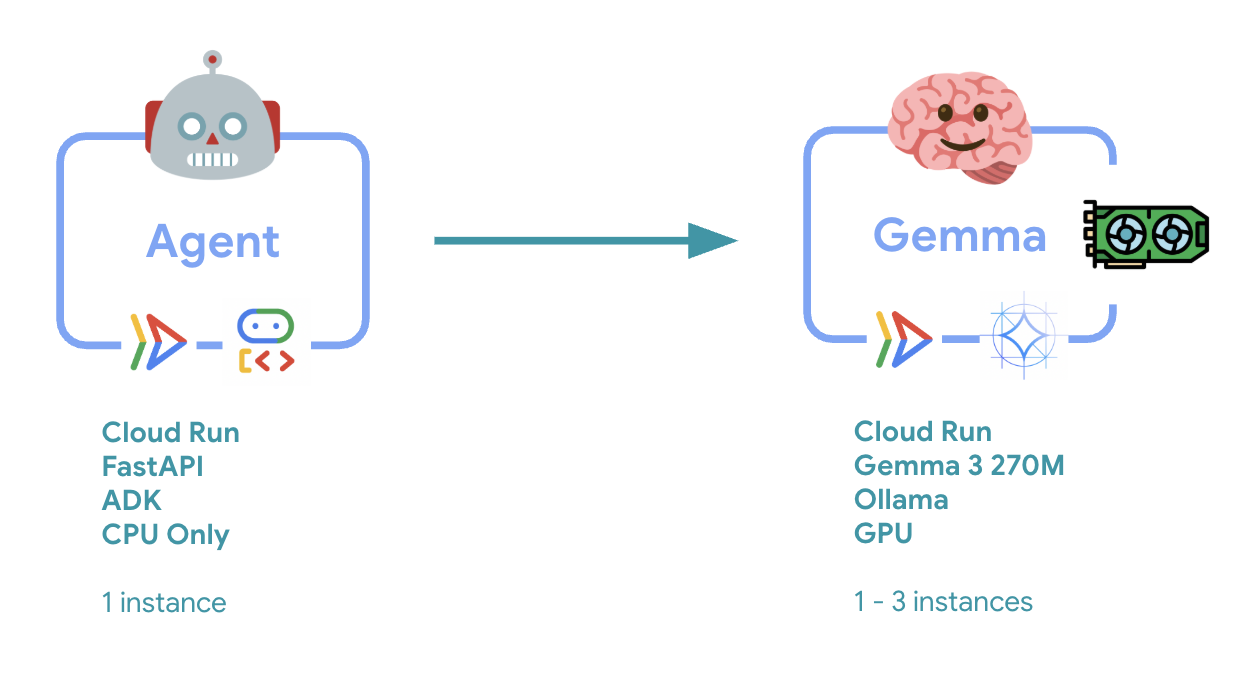
Önemli bilgi: Esneklik testi sırasında, her iki hizmetin de iş yükünü bağımsız olarak işlediğini görürsünüz. GPU arka ucu (darboğaz hizmeti), yükü işlemek için GPU'sunu kullanırken ADK aracısı, kaynak yoğun olmayan istekleri işlemek için CPU'sunu kullanır.
7. GPU ile Gemma arka ucunu Cloud Run'a dağıtma
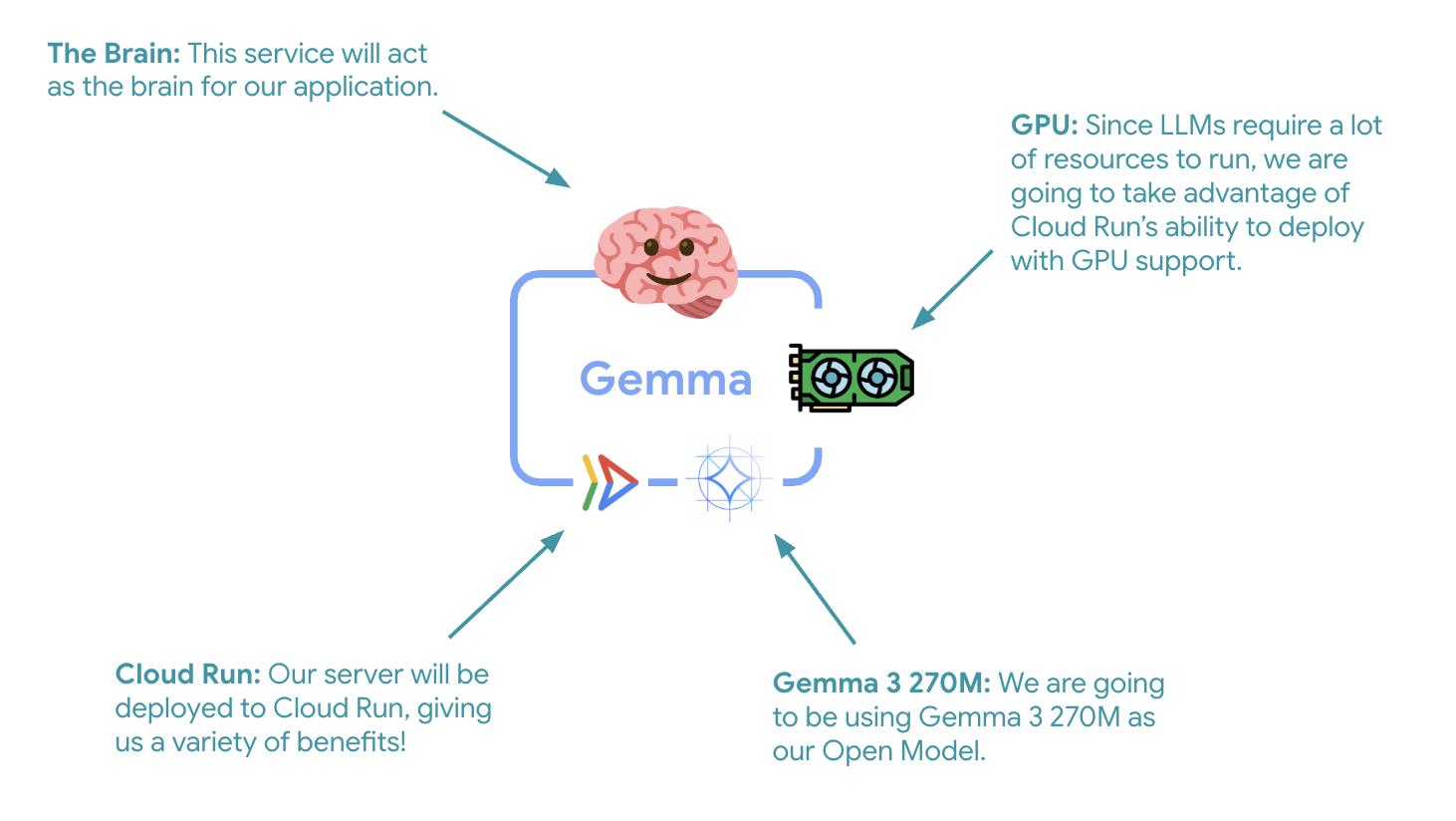
İlk kritik adım, ADK aracınızın beyni olarak hizmet verecek GPU hızlandırmalı bir Gemma modeli dağıtmaktır. Ayrı bir ince ayar yapılmış modele ihtiyaç duyduğunuz veya izole ölçeklendirme gerektiren mimarilerde, bağlantısı kaldırılmış ve dağıtılmış bir LLM kullanmak avantajlı olabilir.
- Ollama arka uç dizinine gidin:
cd ollama-backend - Ollama Dockerfile'ı açın ve uygulayın:
cloudshell edit DockerfileFROM ollama/ollama:latest # Listen on all interfaces, port 8080 ENV OLLAMA_HOST 0.0.0.0:8080 # Store model weight files in /models ENV OLLAMA_MODELS /models # Reduce logging verbosity ENV OLLAMA_DEBUG false # Never unload model weights from the GPU ENV OLLAMA_KEEP_ALIVE -1 # Store the model weights in the container image ENV MODEL gemma3:270m RUN ollama serve & sleep 5 && ollama pull $MODEL # Start Ollama ENTRYPOINT ["ollama", "serve"]- Temel olarak resmi Ollama görüntüsünü kullanır.
OLLAMA_HOSTürününün herhangi bir IP adresinden gelen bağlantıları kabul etmesini sağlar.- 8080 numaralı bağlantı noktasını kullanıma açar.
- GPU desteğiyle Gemma arka ucunu dağıtın:
gcloud run deploy ollama-gemma3-270m-gpu \
--source . \
--region europe-west4 \
--concurrency 7 \
--cpu 8 \
--set-env-vars OLLAMA_NUM_PARALLEL=4 \
--gpu 1 \
--gpu-type nvidia-l4 \
--max-instances 1 \
--memory 16Gi \
--allow-unauthenticated \
--no-cpu-throttling \
--no-gpu-zonal-redundancy \
--timeout 600 \
--labels dev-tutorial=codelab-agent-gpu
"Kaynak koddan dağıtım için derlenen kapsayıcıları depolamak üzere bir Artifact Registry Docker deposu gerekir. [europe-west4] bölgesinde [cloud-run-source-deploy] adlı bir depo oluşturulacak." mesajını görürseniz devam edin.
⚙️ Temel yapılandırma açıklanıyor:
- GPU: Çıkarım iş yükleri için mükemmel fiyat-performans oranı nedeniyle NVIDIA L4 seçilmiştir. L4, 24 GB GPU belleği ve optimize edilmiş tensör işlemleri sunar. Bu nedenle Gemma gibi 270 milyon parametreli modeller için idealdir.
- Bellek: Model yükleme, CUDA işlemleri ve Ollama'nın bellek yönetimini gerçekleştirmek için 16 GB sistem belleği
- CPU: Optimum G/Ç işleme ve ön işleme görevleri için 8 çekirdek
- Eşzamanlılık: Örnek başına 7 istek, GPU bellek kullanımıyla işleme hızını dengeler.
- Zaman aşımı: 600 saniye, ilk model yükleme ve kapsayıcı başlatma işlemlerini kapsar.
💰 Maliyet Değerlendirmesi: GPU örnekleri, yalnızca CPU içeren örneklerden önemli ölçüde daha pahalıdır (saat başına ~2-4 ABD doları ile saat başına ~0,10 ABD doları). --max-instances 1 ayarı, gereksiz GPU örneği ölçeklendirmesini önleyerek maliyetleri kontrol etmenize yardımcı olur.
- Dağıtımın tamamlanmasını bekleyin ve hizmet URL'sini not edin:
export OLLAMA_URL=$(gcloud run services describe ollama-gemma3-270m-gpu \ --region=europe-west4 \ --format='value(status.url)') echo "🎉 Gemma backend deployed at: $OLLAMA_URL"
8. ADK Agent entegrasyonunu uygulama
Şimdi, dağıtılan Gemma arka ucunuza bağlanan minimum bir ADK aracısı oluşturalım.
- ADK temsilci dizinine gidin:
cd ../adk-agent - Temsilci yapılandırmasını açın ve uygulayın:
cloudshell edit production_agent/agent.pyimport os from pathlib import Path from dotenv import load_dotenv from google.adk.agents import Agent from google.adk.models.lite_llm import LiteLlm import google.auth # Load environment variables root_dir = Path(__file__).parent.parent dotenv_path = root_dir / ".env" load_dotenv(dotenv_path=dotenv_path) # Configure Google Cloud try: _, project_id = google.auth.default() os.environ.setdefault("GOOGLE_CLOUD_PROJECT", project_id) except Exception: pass os.environ.setdefault("GOOGLE_CLOUD_LOCATION", "europe-west4") # Configure model connection gemma_model_name = os.getenv("GEMMA_MODEL_NAME", "gemma3:270m") api_base = os.getenv("OLLAMA_API_BASE", "localhost:10010") # Location of Ollama server # Production Gemma Agent - GPU-accelerated conversational assistant production_agent = Agent( model=LiteLlm(model=f"ollama_chat/{gemma_model_name}", api_base=api_base), name="production_agent", description="A production-ready conversational assistant powered by GPU-accelerated Gemma.", instruction="""You are 'Gem', a friendly, knowledgeable, and enthusiastic zoo tour guide. Your main goal is to make a zoo visit more fun and educational for guests by answering their questions. You can provide general information and interesting facts about different animal species, such as: - Their natural habitats and diet. 🌲🍓 - Typical lifespan and behaviors. - Conservation status and unique characteristics. IMPORTANT: You do NOT have access to any tools. This means you cannot look up real-time, specific information about THIS zoo. You cannot provide: - The names or ages of specific animals currently at the zoo. - The exact location or enclosure for an animal. - The daily schedule for feedings or shows. Always answer based on your general knowledge about the animal kingdom. Keep your tone cheerful, engaging, and welcoming for visitors of all ages. 🦁✨""", tools=[], # Gemma focuses on conversational capabilities ) # Set as root agent root_agent = production_agent- LiteLlm aracılığıyla dağıtılan Gemma arka ucunuza bağlanır.
- Basit bir sohbet aracısı oluşturur.
- Google Cloud entegrasyonunu yapılandırır.
- FastAPI sunucusunu açın ve uygulayın:
cloudshell edit server.pyimport os from dotenv import load_dotenv from fastapi import FastAPI from google.adk.cli.fast_api import get_fast_api_app # Load environment variables load_dotenv() AGENT_DIR = os.path.dirname(os.path.abspath(__file__)) app_args = {"agents_dir": AGENT_DIR, "web": True} # Create FastAPI app with ADK integration app: FastAPI = get_fast_api_app(**app_args) # Update app metadata app.title = "Production ADK Agent - Lab 3" app.description = "Gemma agent with GPU-accelerated backend" app.version = "1.0.0" @app.get("/health") def health_check(): return {"status": "healthy", "service": "production-adk-agent"} @app.get("/") def root(): return { "service": "Production ADK Agent - Lab 3", "description": "GPU-accelerated Gemma agent", "docs": "/docs", "health": "/health" } if __name__ == "__main__": import uvicorn uvicorn.run(app, host="0.0.0.0", port=8080, log_level="info")- ADK entegrasyonuyla FastAPI sunucusu oluşturur.
- Test için web arayüzünü etkinleştirir.
- Durum denetimi uç noktaları sağlar
- Dockerfile'ı açın ve uygulayın:
cloudshell edit DockerfileFROM python:3.13-slim # Copy uv from the official image COPY --from=ghcr.io/astral-sh/uv:latest /uv /usr/local/bin/uv # Install system dependencies RUN apt-get update && apt-get install -y curl && rm -rf /var/lib/apt/lists/* # Set working directory WORKDIR /app # Copy all files COPY . . # Install Python dependencies RUN uv sync # Expose port EXPOSE 8080 # Run the application CMD ["uv", "run", "uvicorn", "server:app", "--host", "0.0.0.0", "--port", "8080"]- uv: pip'ten 10-100 kat daha hızlı olan modern Python paket yöneticisi. Global önbellek ve paralel indirmeler kullanarak container derleme sürelerini önemli ölçüde kısaltır.
- Python 3.13-slim: En son Python sürümü, minimum sistem bağımlılıklarıyla container boyutunu ve saldırı yüzeyini azaltır.
- Çok kademeli derleme: uv'yi resmi görüntüsünden kopyalamak, en yeni optimize edilmiş ikili dosyayı elde etmemizi sağlar.
9. Ortamı Yapılandırma ve Aracıyı Dağıtma
Şimdi ADK aracısını, dağıtılan Gemma arka ucunuza bağlanacak şekilde yapılandırıp Cloud Run hizmeti olarak dağıtacağız. Bu işlem, ortam değişkenlerini ayarlamayı ve aracıyı doğru yapılandırmayla dağıtmayı içerir.
- Ortam yapılandırmanızı ayarlayın:
cat << EOF > .env GOOGLE_CLOUD_PROJECT=$(gcloud config get-value project) GOOGLE_CLOUD_LOCATION=europe-west4 GEMMA_MODEL_NAME=gemma3:270m OLLAMA_API_BASE=$OLLAMA_URL EOF
Cloud Run'daki ortam değişkenlerini anlama
Ortam değişkenleri, uygulamanızı çalışma zamanında yapılandıran anahtar/değer çiftleridir. Bu tür reklamlar özellikle şu durumlarda yararlıdır:
- API uç noktaları ve hizmet URL'leri (ör. Ollama arka ucumuz)
- Ortamlar (geliştirme, hazırlama, üretim) arasında değişen yapılandırma
- Sabit kodlanmaması gereken hassas veriler
ADK aracısını dağıtın:
export PROJECT_ID=$(gcloud config get-value project)
gcloud run deploy production-adk-agent \
--source . \
--region europe-west4 \
--allow-unauthenticated \
--memory 4Gi \
--cpu 2 \
--max-instances 1 \
--concurrency 50 \
--timeout 300 \
--set-env-vars GOOGLE_CLOUD_PROJECT=$PROJECT_ID \
--set-env-vars GOOGLE_CLOUD_LOCATION=europe-west4 \
--set-env-vars GEMMA_MODEL_NAME=gemma3:270m \
--set-env-vars OLLAMA_API_BASE=$OLLAMA_URL \
--labels dev-tutorial=codelab-agent-gpu
⚙️ Anahtar yapılandırması:
- Otomatik ölçeklendirme: 1 örnekte sabitlenmiştir (basit istek işleme)
- Eşzamanlılık: Örnek başına 50 istek
- Bellek: ADK aracısı için 4 GB
- Environment: Gemma arka ucunuza bağlanır.
🔒 Güvenlik Notu: Bu laboratuvarda basitlik için --allow-unauthenticated kullanılır. Üretimde, aşağıdakileri kullanarak uygun kimlik doğrulama uygulayın:
- Hizmet hesaplarıyla Cloud Run hizmetler arası kimlik doğrulaması
- Kimlik ve Erişim Yönetimi (IAM) politikaları
- Harici erişim için API anahtarları veya OAuth
- Erişimi kontrol etmek için
gcloud run services add-iam-policy-bindingkullanmayı düşünün.
Aracı hizmeti URL'nizi alın:
export AGENT_URL=$(gcloud run services describe production-adk-agent \
--region=europe-west4 \
--format='value(status.url)')
echo "🎉 ADK Agent deployed at: $AGENT_URL"
Cloud Run ortam değişkenleri belgelerine dayalı ✅ Ortam değişkenleriyle ilgili en iyi uygulamalar:
- Ayrılmış değişkenlerden kaçının:
PORT(ortam değişkenini değiştirmeniz gerekiyorsa bunun yerine –port işaretini kullanın) veyaX_GOOGLE_ile başlayan değişkenleri ayarlamayın. - Açıklayıcı adlar kullanın: Çakışmaları önlemek için değişkenlerinize önek ekleyin (ör.
MODELyerineGEMMA_MODEL_NAME). - Virgüllerden kaçma: Değerleriniz virgül içeriyorsa farklı bir ayırıcı kullanın:
--set-env-vars "^@^KEY1=value1,value2@KEY2=..." - Güncelleme ve Değiştirme: Diğer değişkenleri etkilemeden belirli değişkenleri eklemek/değiştirmek için
--update-env-varssimgesini kullanın.
Cloud Run'da değişkenleri ayarlama:
- Dosyadan:
gcloud run deploy SERVICE_NAME --env-vars-file .env --labels dev-tutorial codelab-adk(bir dosyadan birden fazla değişken yükler) - Birden fazla işaret: Virgülle ayrılamayan karmaşık değerler için
--set-env-varsöğesini tekrarlayın.
10. ADK web arayüzü ile test etme
Her iki hizmet de dağıtıldıktan sonra ADK aracınızın GPU hızlandırmalı Gemma arka ucuyla başarılı bir şekilde iletişim kurabildiğini ve kullanıcı sorgularına yanıt verebildiğini doğrulamanız gerekir.
- Durum uç noktasını test edin:
curl $AGENT_URL/health{ "status": "healthy", "service": "production-adk-agent" } production-adk-agentURL'nizi yeni bir tarayıcı sekmesine girerek temsilcinizle etkileşimde bulunun. ADK web arayüzünü görürsünüz.- Temsilcinizi aşağıdaki örnek görüşmelerle test edin:
- "Kızıl pandalar vahşi doğada genellikle ne yer?"
- "Kar leoparları hakkında ilginç bir bilgi verebilir misin?"
- "Neden zehirli ok kurbağaları bu kadar parlak renklidir?"
- "Hayvanat bahçesinde yeni doğan kanguruyu nerede bulabilirim?"
- Temsilci, dağıtılmış Gemma modelinizi kullanarak yanıt verir. Dağıtılan Gemma hizmetinizin günlüklerini inceleyerek bunu doğrulayabilirsiniz. Bu işlemi bir sonraki bölümde yapacağız.
- Yanıtlar, GPU hızlandırmalı arka uç tarafından oluşturulur.
- Web arayüzü, temiz bir sohbet deneyimi sunar.
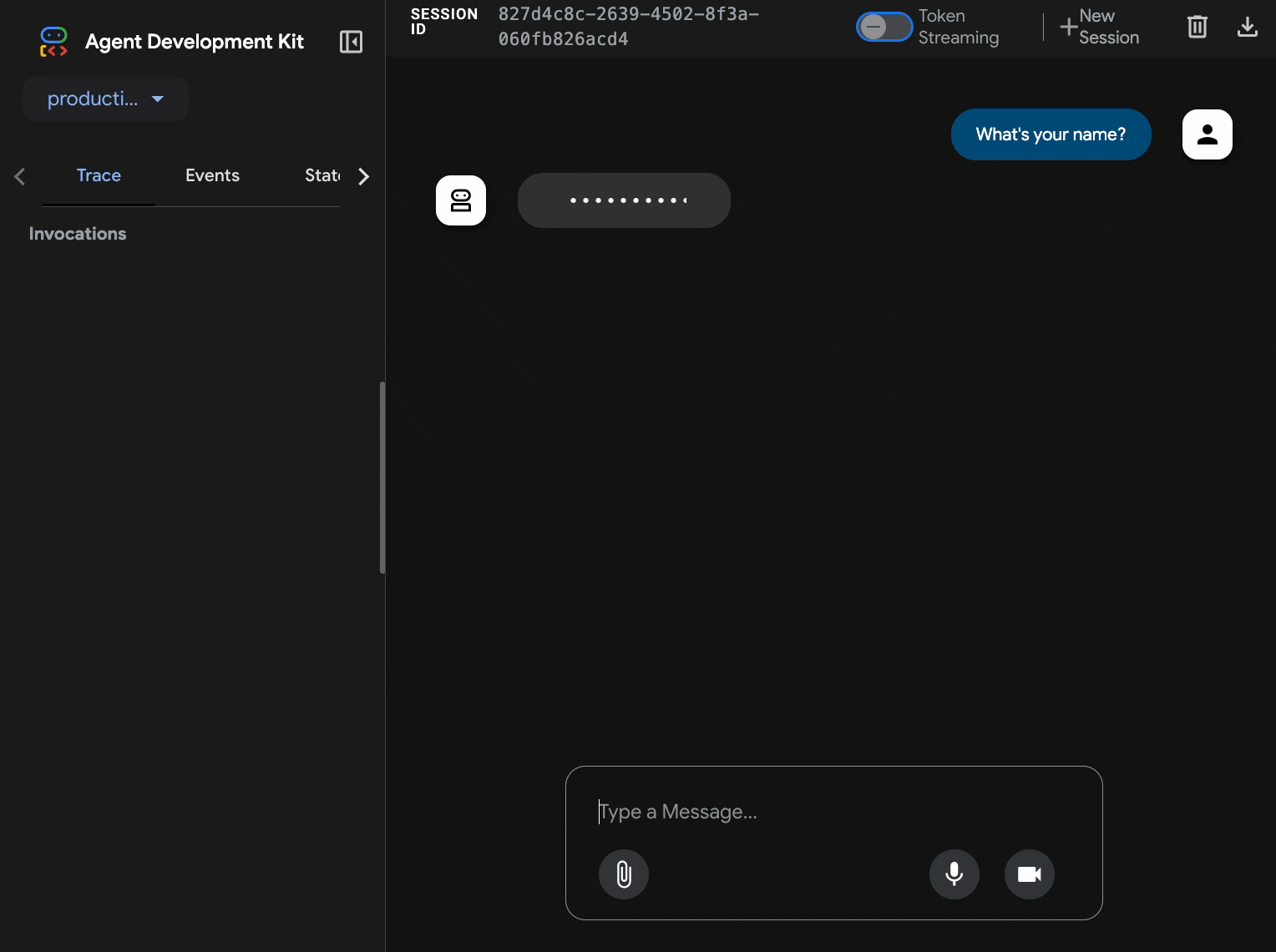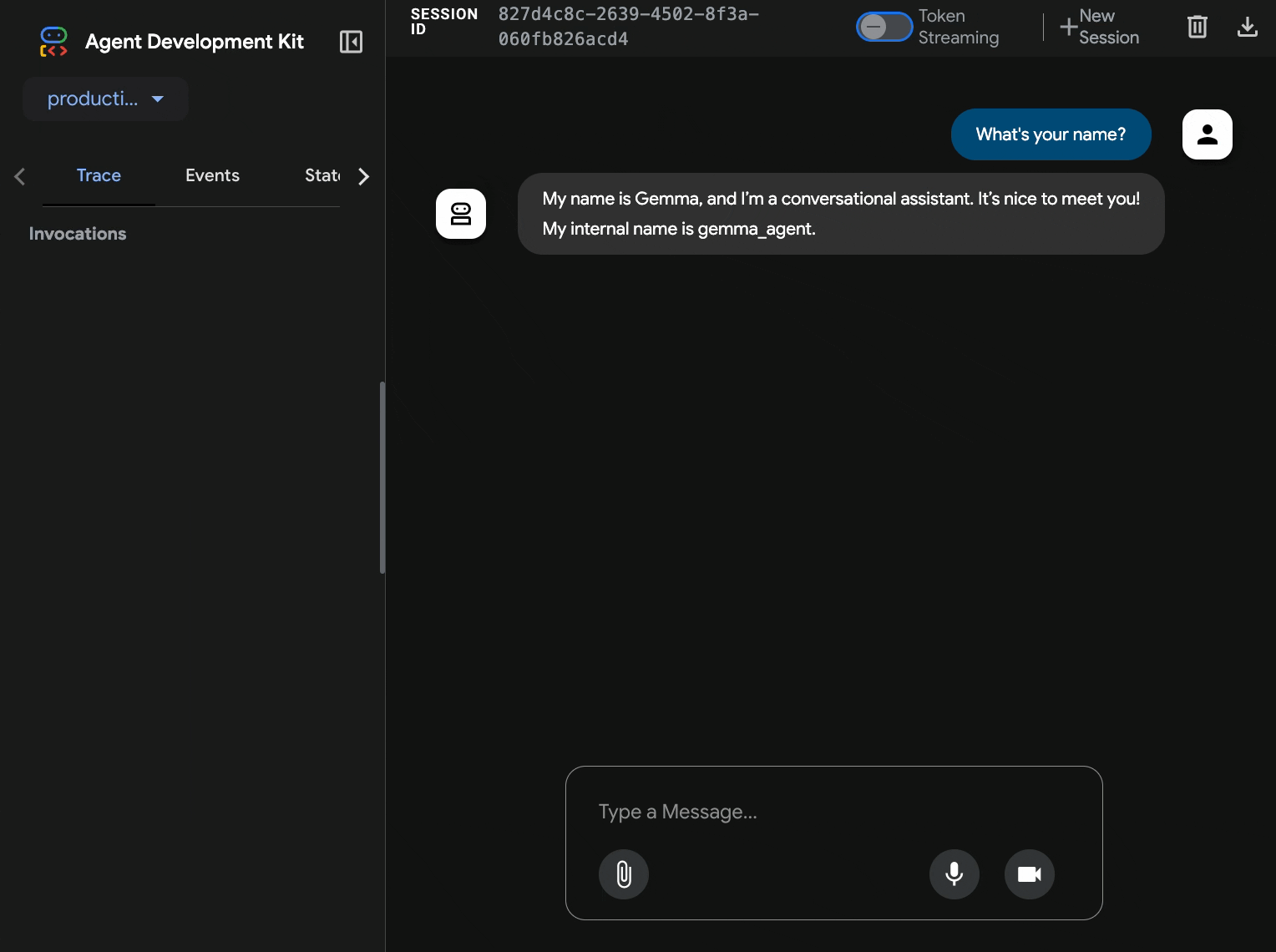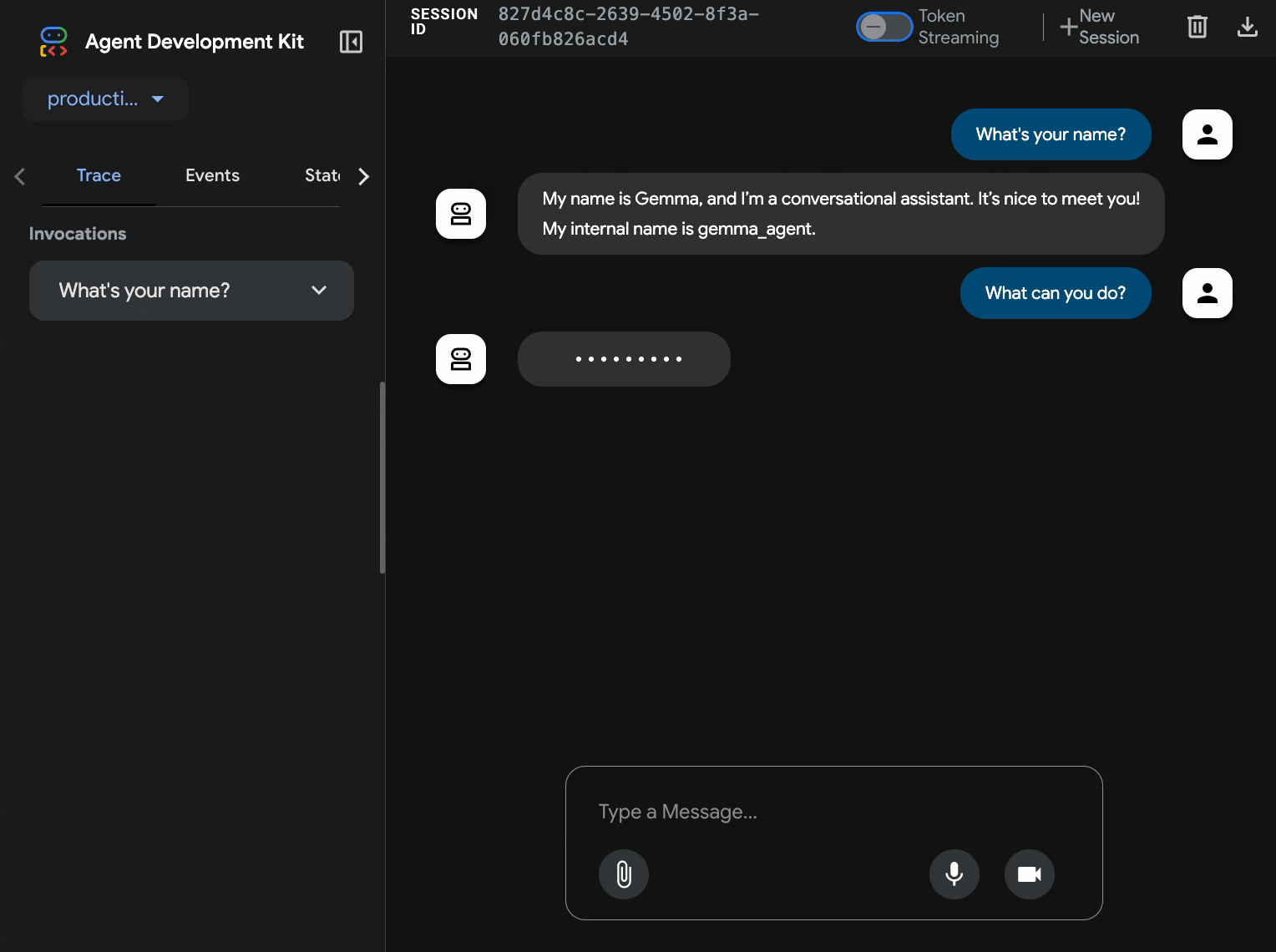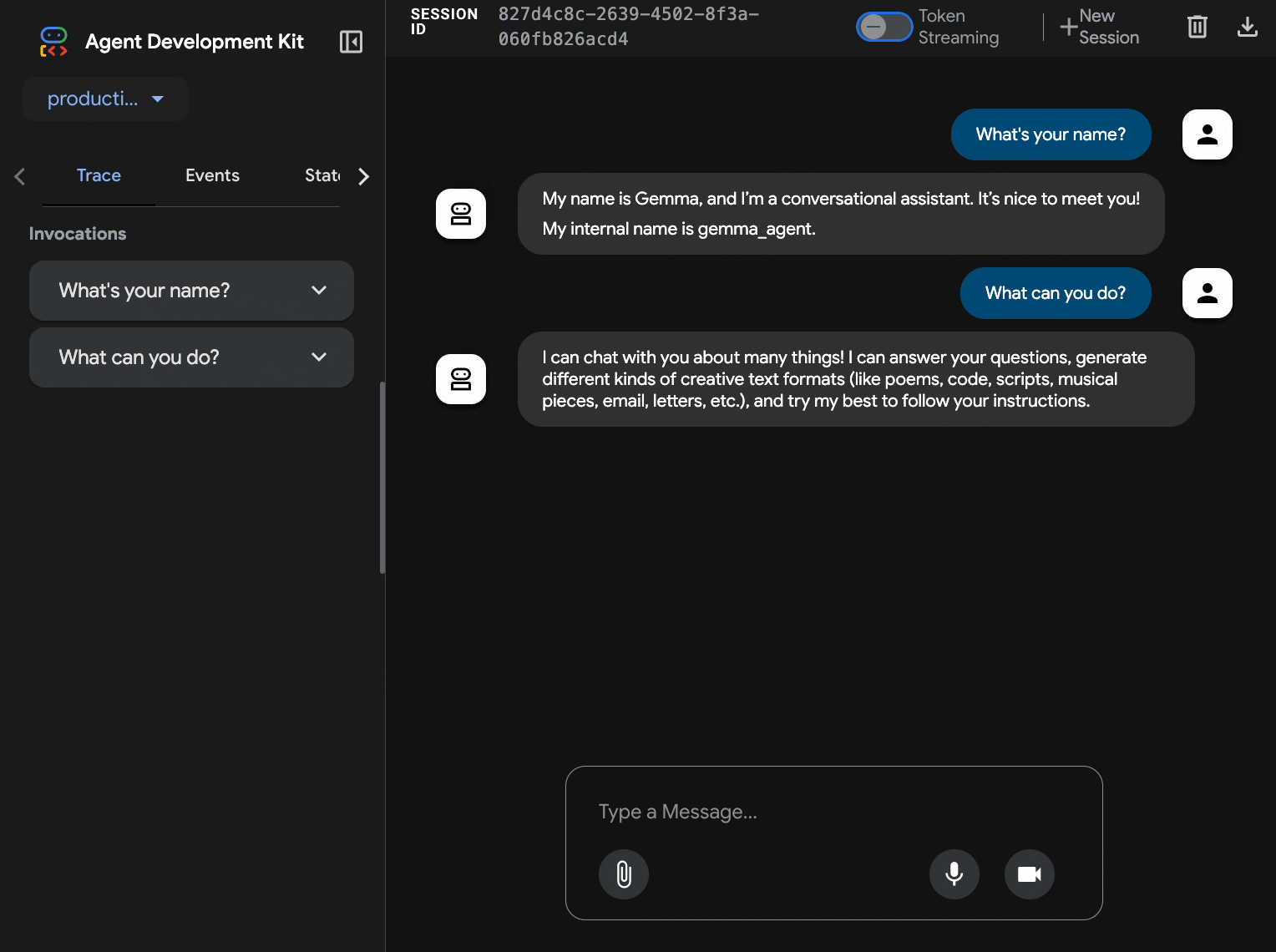
11. Esneklik testi uygulama ve çalıştırma
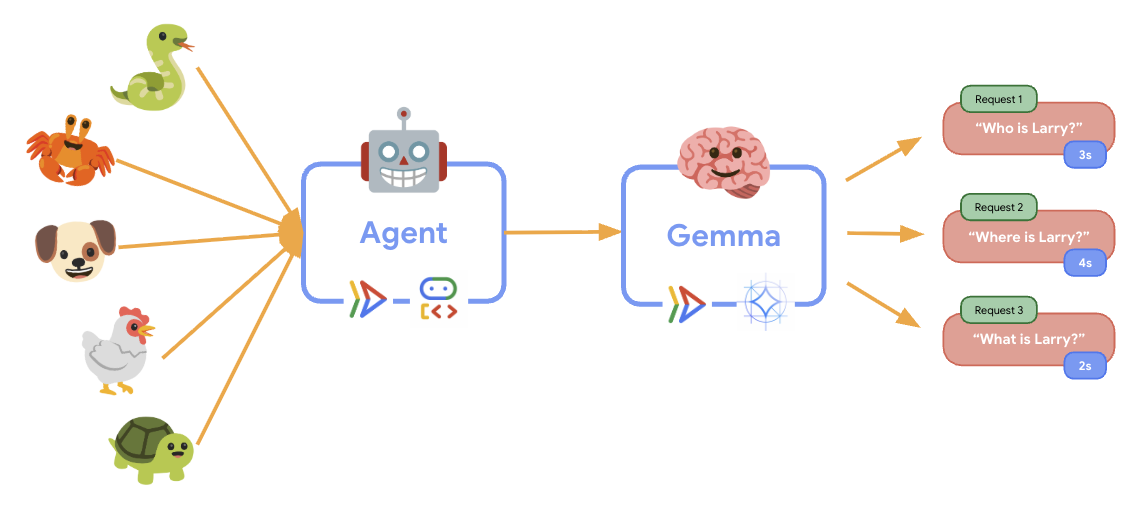
Üretim dağıtımınızın gerçek dünyadaki trafiği nasıl işlediğini anlamak için sistemin daha yüksek bir "simüle edilmiş" üretim iş yüküne uyum sağlama yeteneğini test edecek bir esneklik testi uygulayacağız.
- Esneklik testi komut dosyasını açın ve uygulayın:
cloudshell edit elasticity_test.pyimport random import uuid from locust import HttpUser, task, between class ProductionAgentUser(HttpUser): """Elasticity test user for the Production ADK Agent.""" wait_time = between(1, 3) # Faster requests to trigger scaling def on_start(self): """Set up user session when starting.""" self.user_id = f"user_{uuid.uuid4()}" self.session_id = f"session_{uuid.uuid4()}" # Create session for the Gemma agent using proper ADK API format session_data = {"state": {"user_type": "elasticity_test_user"}} self.client.post( f"/apps/production_agent/users/{self.user_id}/sessions/{self.session_id}", headers={"Content-Type": "application/json"}, json=session_data, ) @task(4) def test_conversations(self): """Test conversational capabilities - high frequency.""" topics = [ "What do red pandas typically eat in the wild?", "Can you tell me an interesting fact about snow leopards?", "Why are poison dart frogs so brightly colored?", "Where can I find the new baby kangaroo in the zoo?", "What is the name of your oldest gorilla?", "What time is the penguin feeding today?" ] # Use proper ADK API format for sending messages message_data = { "app_name": "production_agent", "user_id": self.user_id, "session_id": self.session_id, "new_message": { "role": "user", "parts": [{ "text": random.choice(topics) }] } } self.client.post( "/run", headers={"Content-Type": "application/json"}, json=message_data, ) @task(1) def health_check(self): """Test the health endpoint.""" self.client.get("/health")- Oturum oluşturma:
/apps/production_agent/users/{user_id}/sessions/{session_id}için POST ile uygun ADK API biçimini kullanır.session_idveuser_idoluşturulduktan sonra aracıya istek gönderilebilir. - Mesaj Biçimi:
app_name,user_id,session_idve yapılandırılmışnew_messagenesnesiyle ADK spesifikasyonuna uygundur. - Conversation Endpoint: Tüm etkinlikleri tek seferde toplamak için
/runuç noktasını kullanır (yük testi için önerilir). - Gerçekçi Yük: Daha kısa bekleme süreleriyle etkileşimli yük oluşturur.
- Oturum oluşturma:
- Bağımlılıkları yükleyin:
uv sync - Locust, web uygulamalarının ve diğer sistemlerin performans ve yük testi için tasarlanmış, Python tabanlı açık kaynaklı bir yük testi aracıdır. Temel özelliği, test senaryolarının ve kullanıcı davranışının standart Python kodu kullanılarak tanımlanmasıdır. Bu sayede, grafik kullanıcı arayüzlerine veya alana özgü dillere dayanan araçlara kıyasla yüksek esneklik ve ifade gücü sunar. Hizmetlerimize yönelik kullanıcı trafiğini simüle etmek için Locust'u kullanacağız.Testi çalıştırın.
uv run locust -f elasticity_test.py \ -H $AGENT_URL \ --headless \ -t 60s \ -u 20 \ -r 5- Süre: 60 saniye
- Kullanıcılar: 20 eşzamanlı kullanıcı
- Oluşturma hızı: Saniyede 5 kullanıcı
- Hedef: Her iki hizmette de otomatik ölçeklendirmeyi tetikleyin.
12. Otomatik ölçeklendirme davranışını gözlemleme
Esneklik testi çalışırken Cloud Run'ın daha yüksek iş yüklerini desteklediğini gözlemleyebilirsiniz. ADK aracısını GPU arka ucundan ayırmanın temel mimari avantajlarını burada görebilirsiniz.
Esneklik testi sırasında, her iki Cloud Run hizmetinin de konsolunuzdaki trafiği nasıl işlediğini izleyin.
- Cloud Console'da şu bölüme gidin:
- Cloud Run → production-adk-agent → Metrikler
- Cloud Run → ollama-gemma3-270m-gpu → Metrikler
👀 Dikkat etmeniz gerekenler:
🤖 ADK Agent Service:
- Trafik artarken 1 örnekte sabit kalmalıdır.
- Yüksek trafik sırasında CPU ve bellek kullanımında ani artış
- Oturum yönetimini ve istek yönlendirmeyi verimli bir şekilde gerçekleştirir.
🎮 Gemma Arka Uç Hizmeti (Performans Sorunu):
- Trafik artarken 1 örnekte sabit kalmalıdır.
- Yük altında GPU kullanımı önemli ölçüde artıyor
- Bu hizmet, GPU yoğun model çıkarımı nedeniyle performans sorunu haline gelir.
- GPU hızlandırma sayesinde model çıkarım süreleri tutarlı kalır.
💡 Önemli Analizler:
- Maksimum örnek sayımızı
1olarak ayarladığımız için her iki hizmet de tutarlı kalır ve ölçeği artırmaz. - Her iki hizmet de kendi yük özelliklerine göre bağımsız olarak ölçeklendirilir.
- GPU, farklı yük koşullarında performansı korumaya yardımcı olur.
13. Sonuç
Tebrikler! Simüle edilmiş bir üretim iş yükünü test ederken GPU hızlandırmalı Gemma arka ucuyla üretime hazır bir ADK aracısını başarıyla dağıttınız.
✅ Başarılarınız
- ✅ Cloud Run'da GPU hızlandırmalı bir Gemma modeli arka ucu dağıtıldı
- ✅ Gemma arka ucuyla entegre olan bir ADK aracısı oluşturup dağıtma
- ✅ ADK web arayüzünü kullanarak aracıyı test etme
- ✅ İki koordineli Cloud Run hizmetinde otomatik ölçeklendirme davranışı gözlemlendi.
💡 Bu laboratuvarda öne çıkan önemli noktalar
- 🎮 GPU Hızlandırma: NVIDIA L4 GPU, model çıkarım performansını önemli ölçüde artırır.
- 🔗 Hizmet Koordinasyonu: İki Cloud Run hizmeti sorunsuz bir şekilde birlikte çalışabilir.
- 📈 Bağımsız Ölçeklendirme: Her hizmet, kendi yük özelliklerine göre ölçeklendirilir.
- 🚀 Üretime Hazır Olma: Mimaride gerçek dünyadaki trafik kalıpları etkili bir şekilde ele alınır.
🔄 Sonraki adımlar
- Farklı yükleme kalıplarıyla denemeler yapın ve ölçeklendirme davranışını gözlemleyin
- Farklı Gemma modeli boyutlarını deneyin (belleği ve GPU'yu buna göre ayarlayın)
- Üretim dağıtımları için izleme ve uyarı oluşturma işlevlerini uygulama
- Küresel kullanılabilirlik için çok bölgeli dağıtımları keşfetme
🧹 Temizleme
Ücretlendirilmemek için işiniz bittiğinde kaynakları silin:
gcloud run services delete production-adk-agent --region=europe-west4
gcloud run services delete ollama-gemma3-270m-gpu --region=europe-west4
📖 Kaynaklar
- Başlangıç deposu
- Complete Solution
- Google ADK Belgeleri
- ADK Test Kılavuzu: ADK API uç noktaları ve test kalıpları için eksiksiz referans
- Cloud Run'da Yük Testi
- Aracı Geliştirme Kiti (ADK) Dokümanları
- Cloud Run GPU Belgeleri
- Ollama Model Library
- Google Cloud Trace Belgeleri
- Cloud Run Güvenliğiyle İlgili En İyi Uygulamalar
- UV Python Paket Yöneticisi
- Locust Yük Testi Çerçevesi