
1. Giới thiệu
Tổng quan
Trong phòng thí nghiệm này, bạn sẽ triển khai một tác nhân Bộ công cụ phát triển tác nhân (ADK) sẵn sàng cho môi trường sản xuất với phần phụ trợ Gemma được tăng tốc bằng GPU. Trọng tâm là các mẫu triển khai quan trọng: thiết lập các dịch vụ Cloud Run có GPU, tích hợp các phần phụ trợ mô hình với các tác nhân ADK và quan sát hành vi tự động điều chỉnh quy mô khi tải.
Bạn sẽ thực hiện
Trong lớp học lập trình này, bạn sẽ tập trung vào các khía cạnh quan trọng của việc triển khai sản xuất:
- Triển khai Gemma lên Cloud Run bằng GPU – Thiết lập một phần phụ trợ mô hình Gemma hiệu suất cao
- Tích hợp việc triển khai Gemma với một tác nhân ADK – Kết nối tác nhân của bạn với mô hình được tăng tốc bằng GPU
- Kiểm thử bằng giao diện web ADK – Xác thực rằng tác nhân đàm thoại của bạn hoạt động chính xác
- Thực hiện kiểm thử độ co giãn – Quan sát cách cả hai phiên bản Cloud Run xử lý tải
Trọng tâm là các mẫu triển khai sản xuất thay vì phát triển nhân viên hỗ trợ trên diện rộng.
Kiến thức bạn sẽ học được
- Triển khai các mô hình Gemma được tăng tốc bằng GPU vào Cloud Run để sử dụng trong thực tế
- Tích hợp việc triển khai mô hình bên ngoài với các tác nhân ADK
- Định cấu hình và kiểm thử việc triển khai tác nhân AI sẵn sàng cho sản xuất
- Tìm hiểu hành vi của Cloud Run khi chịu tải
- Quan sát cách nhiều phiên bản Cloud Run phối hợp trong thời gian lưu lượng truy cập tăng đột biến
- Áp dụng kiểm thử độ co giãn để xác thực hiệu suất
2. Thiết lập dự án
- Nếu chưa có Tài khoản Google, bạn phải tạo một Tài khoản Google.
- Sử dụng tài khoản cá nhân thay vì tài khoản trường học hoặc tài khoản do nơi làm việc cấp. Tài khoản do nơi làm việc hoặc trường học cấp có thể có các hạn chế khiến bạn không bật được những API cần thiết cho lớp học này.
- Đăng nhập vào Google Cloud Console.
- Bật tính năng thanh toán trong Cloud Console.
- Việc hoàn thành bài thực hành này sẽ tốn ít hơn 1 USD cho các tài nguyên trên đám mây.
- Bạn có thể làm theo các bước ở cuối bài thực hành này để xoá tài nguyên nhằm tránh bị tính thêm phí.
- Người dùng mới đủ điều kiện dùng thử miễn phí trị giá 300 USD.
- Tạo một dự án mới hoặc chọn sử dụng lại một dự án hiện có.
- Nếu bạn thấy lỗi về hạn mức dự án, hãy sử dụng lại một dự án hiện có hoặc xoá một dự án hiện có để tạo dự án mới.
3. Mở Trình chỉnh sửa Cloud Shell
- Nhấp vào đường liên kết này để chuyển trực tiếp đến Cloud Shell Editor
- Nếu được nhắc uỷ quyền vào bất kỳ thời điểm nào trong ngày hôm nay, hãy nhấp vào Uỷ quyền để tiếp tục.
- Nếu thiết bị đầu cuối không xuất hiện ở cuối màn hình, hãy mở thiết bị đầu cuối:
- Nhấp vào Xem
- Nhấp vào Terminal (Thiết bị đầu cuối)
- Trong thiết bị đầu cuối, hãy thiết lập dự án bằng lệnh sau:
- Định dạng:
gcloud config set project [PROJECT_ID] - Ví dụ:
gcloud config set project lab-project-id-example - Nếu bạn không nhớ mã dự án của mình, hãy làm như sau:
- Bạn có thể liệt kê tất cả mã dự án bằng cách sử dụng:
gcloud projects list | awk '/PROJECT_ID/{print $2}'
- Bạn có thể liệt kê tất cả mã dự án bằng cách sử dụng:
- Định dạng:
- Bạn sẽ thấy thông báo sau:
Updated property [core/project].
WARNINGvà được yêu cầuDo you want to continue (Y/n)?, thì có thể bạn đã nhập sai mã dự án. Nhấnn, nhấnEnterrồi thử chạy lại lệnhgcloud config set project.
4. Bật API và đặt khu vực mặc định
Để có thể triển khai các dịch vụ Cloud Run có hỗ trợ GPU, bạn cần bật các Cloud API bắt buộc của Google Cloud và định cấu hình chế độ cài đặt dự án.
- Trong dòng lệnh, hãy bật các API:
gcloud services enable \
run.googleapis.com \
artifactregistry.googleapis.com \
cloudbuild.googleapis.com \
aiplatform.googleapis.com
Nếu được nhắc uỷ quyền, hãy nhấp vào Uỷ quyền để tiếp tục.
Lệnh này có thể mất vài phút để hoàn tất, nhưng cuối cùng sẽ tạo ra một thông báo thành công tương tự như thông báo này:
Operation "operations/acf.p2-73d90d00-47ee-447a-b600" finished successfully.
- Đặt khu vực Cloud Run mặc định.
gcloud config set run/region europe-west4
5. Chuẩn bị dự án Python
Hãy thiết lập mã khởi đầu có chứa cấu trúc cơ bản cho cả dịch vụ phụ trợ Gemma và dịch vụ tác nhân ADK.
- Sao chép kho lưu trữ dự án khởi đầu:
cd ~ npx -y giget@latest gh+git:GoogleCloudPlatform/devrel-demos/agents/accelerate-ai-with-cloud-run/accelerate-ai-lab3-starter accelerate-ai-lab3-starter cd accelerate-ai-lab3-starter - Tìm hiểu cấu trúc dự án:
ls -Raccelerate-ai-lab3-starter/ ├── README.md # Project overview ├── ollama-backend/ # Ollama backend (separate deployment) │ └── Dockerfile # Backend container (🚧 to implement) └── adk-agent/ # ADK agent (separate deployment) ├── pyproject.toml # Python dependencies (✅ completed) ├── server.py # FastAPI server (🚧 to implement) ├── Dockerfile # Container config (🚧 to implement) ├── elasticity_test.py # Elasticity testing (🚧 to implement) └── production_agent/ # Agent implementation ├── __init__.py # Package init (✅ completed) └── agent.py # Agent logic (🚧 to implement)
6. Tổng quan về Cấu trúc (Architecture)
Trước khi triển khai, hãy tìm hiểu về cấu trúc hai dịch vụ:
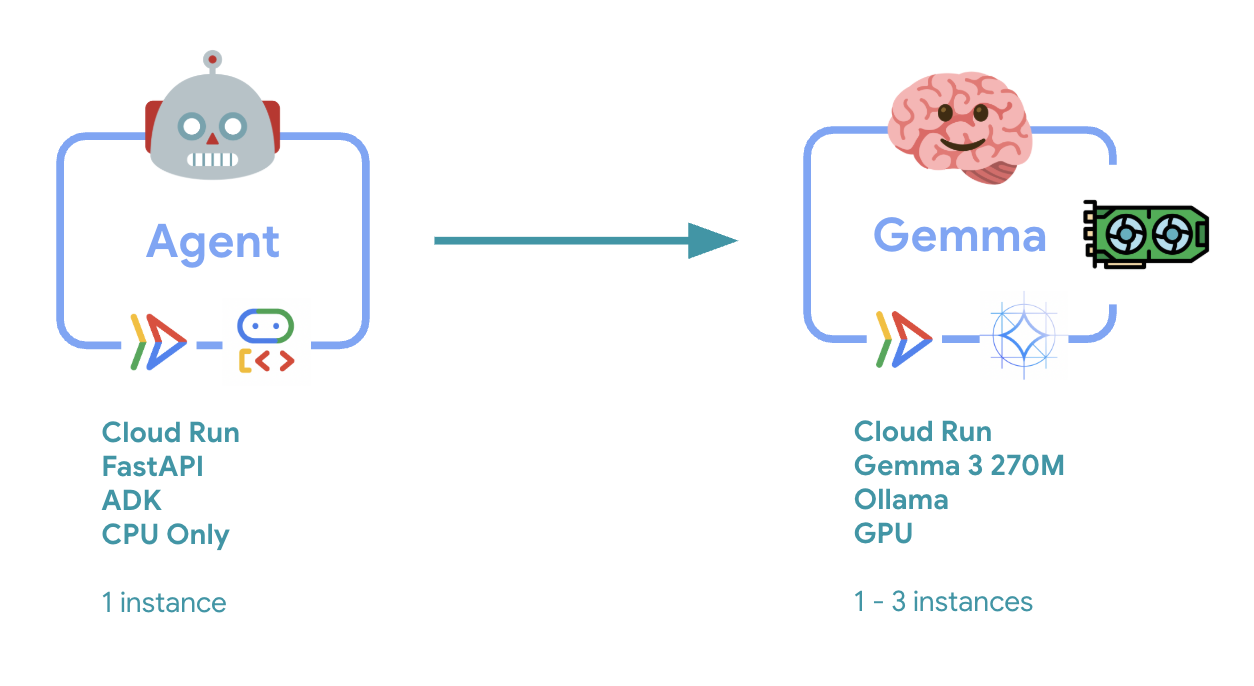
Thông tin chi tiết quan trọng: Trong quá trình kiểm thử độ co giãn, bạn sẽ thấy cả hai dịch vụ xử lý khối lượng công việc một cách độc lập – phần phụ trợ GPU (dịch vụ điểm tắc nghẽn) sử dụng GPU để xử lý tải, trong khi tác nhân ADK dựa vào CPU để xử lý các yêu cầu không tốn nhiều tài nguyên.
7. Triển khai phần phụ trợ Gemma lên Cloud Run bằng GPU
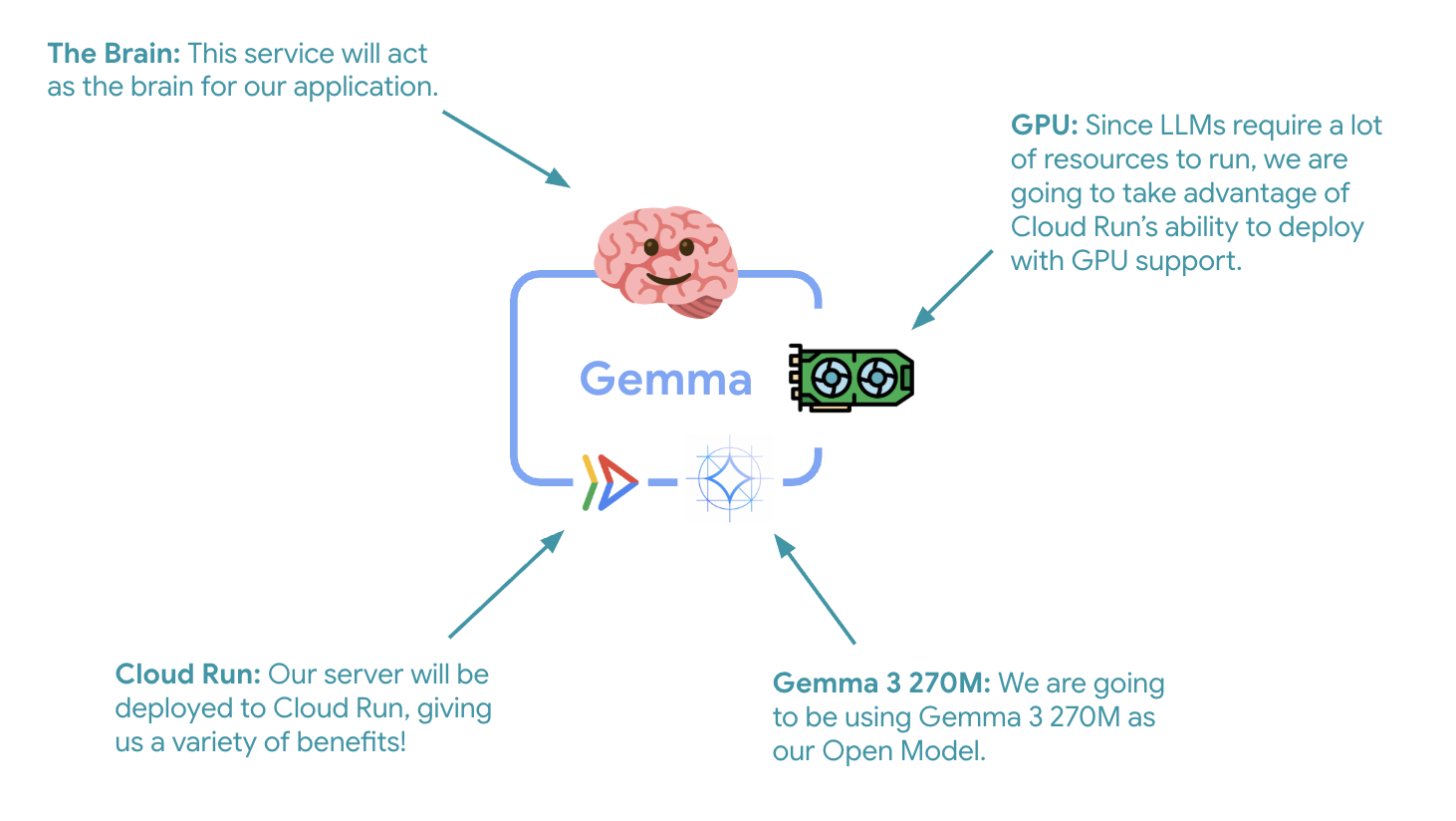
Bước quan trọng đầu tiên là triển khai một mô hình Gemma được tăng tốc bằng GPU. Mô hình này sẽ đóng vai trò là bộ não cho tác nhân ADK của bạn. Việc có một LLM được tách rời và triển khai có thể mang lại lợi ích trong các cấu trúc mà bạn cần một mô hình được tinh chỉnh riêng biệt hoặc yêu cầu mở rộng quy mô riêng biệt.
- Chuyển đến thư mục phụ trợ Ollama:
cd ollama-backend - Mở và triển khai Ollama Dockerfile:
cloudshell edit DockerfileFROM ollama/ollama:latest # Listen on all interfaces, port 8080 ENV OLLAMA_HOST 0.0.0.0:8080 # Store model weight files in /models ENV OLLAMA_MODELS /models # Reduce logging verbosity ENV OLLAMA_DEBUG false # Never unload model weights from the GPU ENV OLLAMA_KEEP_ALIVE -1 # Store the model weights in the container image ENV MODEL gemma3:270m RUN ollama serve & sleep 5 && ollama pull $MODEL # Start Ollama ENTRYPOINT ["ollama", "serve"]- Sử dụng hình ảnh Ollama chính thức làm nền tảng
- Đặt
OLLAMA_HOSTđể chấp nhận các kết nối từ mọi địa chỉ IP - Hiển thị cổng 8080
- Triển khai phần phụ trợ Gemma có hỗ trợ GPU:
gcloud run deploy ollama-gemma3-270m-gpu \
--source . \
--region europe-west4 \
--concurrency 7 \
--cpu 8 \
--set-env-vars OLLAMA_NUM_PARALLEL=4 \
--gpu 1 \
--gpu-type nvidia-l4 \
--max-instances 1 \
--memory 16Gi \
--allow-unauthenticated \
--no-cpu-throttling \
--no-gpu-zonal-redundancy \
--timeout 600 \
--labels dev-tutorial=codelab-agent-gpu
Nếu bạn nhận được thông báo "Deploying from source requires an Artifact Registry Docker repository to store built containers. Một kho lưu trữ có tên [cloud-run-source-deploy] ở vùng [europe-west4] sẽ được tạo.", hãy tiếp tục.
⚙️ Giải thích về cấu hình chính:
- GPU: NVIDIA L4 được chọn vì có tỷ lệ hiệu suất trên giá tuyệt vời cho khối lượng công việc suy luận. L4 cung cấp bộ nhớ GPU 24 GB và các hoạt động tối ưu hoá tensor, khiến đây là lựa chọn lý tưởng cho các mô hình có 270 triệu tham số như Gemma
- Bộ nhớ: Bộ nhớ hệ thống 16 GB để xử lý việc tải mô hình, các thao tác CUDA và hoạt động quản lý bộ nhớ của Ollama
- CPU: 8 lõi để xử lý I/O và các tác vụ tiền xử lý tối ưu
- Đồng thời: 7 yêu cầu trên mỗi phiên bản cân bằng thông lượng với mức sử dụng bộ nhớ GPU
- Thời gian chờ: 600 giây để đáp ứng việc tải mô hình ban đầu và khởi động vùng chứa
💰 Cân nhắc chi phí: Các phiên bản GPU đắt hơn đáng kể so với các phiên bản chỉ có CPU (khoảng 2 – 4 USD/giờ so với khoảng 0,1 USD/giờ). Chế độ cài đặt --max-instances 1 giúp kiểm soát chi phí bằng cách ngăn chặn việc mở rộng quy mô phiên bản GPU không cần thiết.
- Chờ quá trình triển khai hoàn tất và ghi lại URL của dịch vụ:
export OLLAMA_URL=$(gcloud run services describe ollama-gemma3-270m-gpu \ --region=europe-west4 \ --format='value(status.url)') echo "🎉 Gemma backend deployed at: $OLLAMA_URL"
8. Triển khai tính năng tích hợp Agent ADK
Bây giờ, hãy tạo một tác nhân ADK tối thiểu kết nối với phần phụ trợ Gemma mà bạn đã triển khai.
- Chuyển đến thư mục tác nhân ADK:
cd ../adk-agent - Mở và triển khai cấu hình tác nhân:
cloudshell edit production_agent/agent.pyimport os from pathlib import Path from dotenv import load_dotenv from google.adk.agents import Agent from google.adk.models.lite_llm import LiteLlm import google.auth # Load environment variables root_dir = Path(__file__).parent.parent dotenv_path = root_dir / ".env" load_dotenv(dotenv_path=dotenv_path) # Configure Google Cloud try: _, project_id = google.auth.default() os.environ.setdefault("GOOGLE_CLOUD_PROJECT", project_id) except Exception: pass os.environ.setdefault("GOOGLE_CLOUD_LOCATION", "europe-west4") # Configure model connection gemma_model_name = os.getenv("GEMMA_MODEL_NAME", "gemma3:270m") api_base = os.getenv("OLLAMA_API_BASE", "localhost:10010") # Location of Ollama server # Production Gemma Agent - GPU-accelerated conversational assistant production_agent = Agent( model=LiteLlm(model=f"ollama_chat/{gemma_model_name}", api_base=api_base), name="production_agent", description="A production-ready conversational assistant powered by GPU-accelerated Gemma.", instruction="""You are 'Gem', a friendly, knowledgeable, and enthusiastic zoo tour guide. Your main goal is to make a zoo visit more fun and educational for guests by answering their questions. You can provide general information and interesting facts about different animal species, such as: - Their natural habitats and diet. 🌲🍓 - Typical lifespan and behaviors. - Conservation status and unique characteristics. IMPORTANT: You do NOT have access to any tools. This means you cannot look up real-time, specific information about THIS zoo. You cannot provide: - The names or ages of specific animals currently at the zoo. - The exact location or enclosure for an animal. - The daily schedule for feedings or shows. Always answer based on your general knowledge about the animal kingdom. Keep your tone cheerful, engaging, and welcoming for visitors of all ages. 🦁✨""", tools=[], # Gemma focuses on conversational capabilities ) # Set as root agent root_agent = production_agent- Kết nối với phần phụ trợ Gemma đã triển khai thông qua LiteLlm
- Tạo một tác nhân đàm thoại đơn giản
- Định cấu hình chế độ tích hợp với Google Cloud
- Mở và triển khai máy chủ FastAPI:
cloudshell edit server.pyimport os from dotenv import load_dotenv from fastapi import FastAPI from google.adk.cli.fast_api import get_fast_api_app # Load environment variables load_dotenv() AGENT_DIR = os.path.dirname(os.path.abspath(__file__)) app_args = {"agents_dir": AGENT_DIR, "web": True} # Create FastAPI app with ADK integration app: FastAPI = get_fast_api_app(**app_args) # Update app metadata app.title = "Production ADK Agent - Lab 3" app.description = "Gemma agent with GPU-accelerated backend" app.version = "1.0.0" @app.get("/health") def health_check(): return {"status": "healthy", "service": "production-adk-agent"} @app.get("/") def root(): return { "service": "Production ADK Agent - Lab 3", "description": "GPU-accelerated Gemma agent", "docs": "/docs", "health": "/health" } if __name__ == "__main__": import uvicorn uvicorn.run(app, host="0.0.0.0", port=8080, log_level="info")- Tạo một máy chủ FastAPI có tích hợp ADK
- Bật giao diện web để kiểm thử
- Cung cấp các điểm cuối kiểm tra tình trạng
- Mở và triển khai Dockerfile:
cloudshell edit DockerfileFROM python:3.13-slim # Copy uv from the official image COPY --from=ghcr.io/astral-sh/uv:latest /uv /usr/local/bin/uv # Install system dependencies RUN apt-get update && apt-get install -y curl && rm -rf /var/lib/apt/lists/* # Set working directory WORKDIR /app # Copy all files COPY . . # Install Python dependencies RUN uv sync # Expose port EXPOSE 8080 # Run the application CMD ["uv", "run", "uvicorn", "server:app", "--host", "0.0.0.0", "--port", "8080"]- uv: Trình quản lý gói Python hiện đại, nhanh hơn pip từ 10 đến 100 lần. Công cụ này sử dụng bộ nhớ đệm chung và các lượt tải xuống song song, giúp giảm đáng kể thời gian tạo vùng chứa
- Python 3.13-slim: Phiên bản Python mới nhất với các phần phụ thuộc hệ thống tối thiểu, giảm kích thước vùng chứa và bề mặt tấn công
- Bản dựng nhiều giai đoạn: Việc sao chép uv từ hình ảnh chính thức của nó đảm bảo chúng ta nhận được tệp nhị phân được tối ưu hoá mới nhất
9. Định cấu hình môi trường và triển khai tác nhân
Bây giờ, chúng ta sẽ định cấu hình tác nhân ADK để kết nối với phần phụ trợ Gemma đã triển khai và triển khai tác nhân này dưới dạng một dịch vụ Cloud Run. Việc này bao gồm thiết lập các biến môi trường và triển khai tác nhân với cấu hình phù hợp.
- Thiết lập cấu hình môi trường:
cat << EOF > .env GOOGLE_CLOUD_PROJECT=$(gcloud config get-value project) GOOGLE_CLOUD_LOCATION=europe-west4 GEMMA_MODEL_NAME=gemma3:270m OLLAMA_API_BASE=$OLLAMA_URL EOF
Tìm hiểu về các biến môi trường trong Cloud Run
Biến môi trường là các cặp khoá-giá trị giúp định cấu hình ứng dụng của bạn trong thời gian chạy. Các chỉ số này đặc biệt hữu ích cho:
- Điểm cuối API và URL dịch vụ (chẳng hạn như phụ trợ Ollama của chúng tôi)
- Cấu hình thay đổi giữa các môi trường (phát triển, dàn dựng, sản xuất)
- Dữ liệu nhạy cảm không nên được mã hoá cứng
Triển khai tác nhân ADK:
export PROJECT_ID=$(gcloud config get-value project)
gcloud run deploy production-adk-agent \
--source . \
--region europe-west4 \
--allow-unauthenticated \
--memory 4Gi \
--cpu 2 \
--max-instances 1 \
--concurrency 50 \
--timeout 300 \
--set-env-vars GOOGLE_CLOUD_PROJECT=$PROJECT_ID \
--set-env-vars GOOGLE_CLOUD_LOCATION=europe-west4 \
--set-env-vars GEMMA_MODEL_NAME=gemma3:270m \
--set-env-vars OLLAMA_API_BASE=$OLLAMA_URL \
--labels dev-tutorial=codelab-agent-gpu
⚙️ Cấu hình chính:
- Phương thức tự động cấp tài nguyên bổ sung: Cố định ở 1 thực thể (xử lý yêu cầu đơn giản)
- Tính đồng thời: 50 yêu cầu trên mỗi phiên bản
- Bộ nhớ: 4 GB cho tác nhân ADK
- Môi trường: Kết nối với phần phụ trợ Gemma
🔒 Lưu ý về bảo mật: Để đơn giản, phòng thí nghiệm này sử dụng --allow-unauthenticated. Trong quá trình sản xuất, hãy triển khai phương thức xác thực phù hợp bằng cách sử dụng:
- Xác thực dịch vụ với dịch vụ Cloud Run bằng tài khoản dịch vụ
- Chính sách Quản lý danh tính và quyền truy cập (IAM)
- Khoá API hoặc OAuth để truy cập bên ngoài
- Cân nhắc sử dụng
gcloud run services add-iam-policy-bindingđể kiểm soát quyền truy cập
Lấy URL dịch vụ của nhân viên hỗ trợ:
export AGENT_URL=$(gcloud run services describe production-adk-agent \
--region=europe-west4 \
--format='value(status.url)')
echo "🎉 ADK Agent deployed at: $AGENT_URL"
✅ Các phương pháp hay nhất về biến môi trường dựa trên tài liệu về biến môi trường Cloud Run:
- Tránh các biến được dành riêng: Đừng đặt
PORT(nếu bạn cần thay đổi biến môi trường, hãy dùng cờ –port) hoặc các biến bắt đầu bằngX_GOOGLE_ - Sử dụng tên mô tả: Thêm tiền tố vào các biến để tránh xung đột (ví dụ:
GEMMA_MODEL_NAMEthay vìMODEL) - Ký tự thoát dấu phẩy: Nếu giá trị của bạn có chứa dấu phẩy, hãy sử dụng dấu phân cách khác:
--set-env-vars "^@^KEY1=value1,value2@KEY2=..." - Cập nhật so với Thay thế: Sử dụng
--update-env-varsđể thêm/thay đổi các biến cụ thể mà không ảnh hưởng đến các biến khác
Cách thiết lập các biến trong Cloud Run:
- Từ tệp:
gcloud run deploy SERVICE_NAME --env-vars-file .env --labels dev-tutorial codelab-adk(tải nhiều biến từ một tệp) - Nhiều cờ: Lặp lại
--set-env-varscho các giá trị phức tạp không thể phân tách bằng dấu phẩy
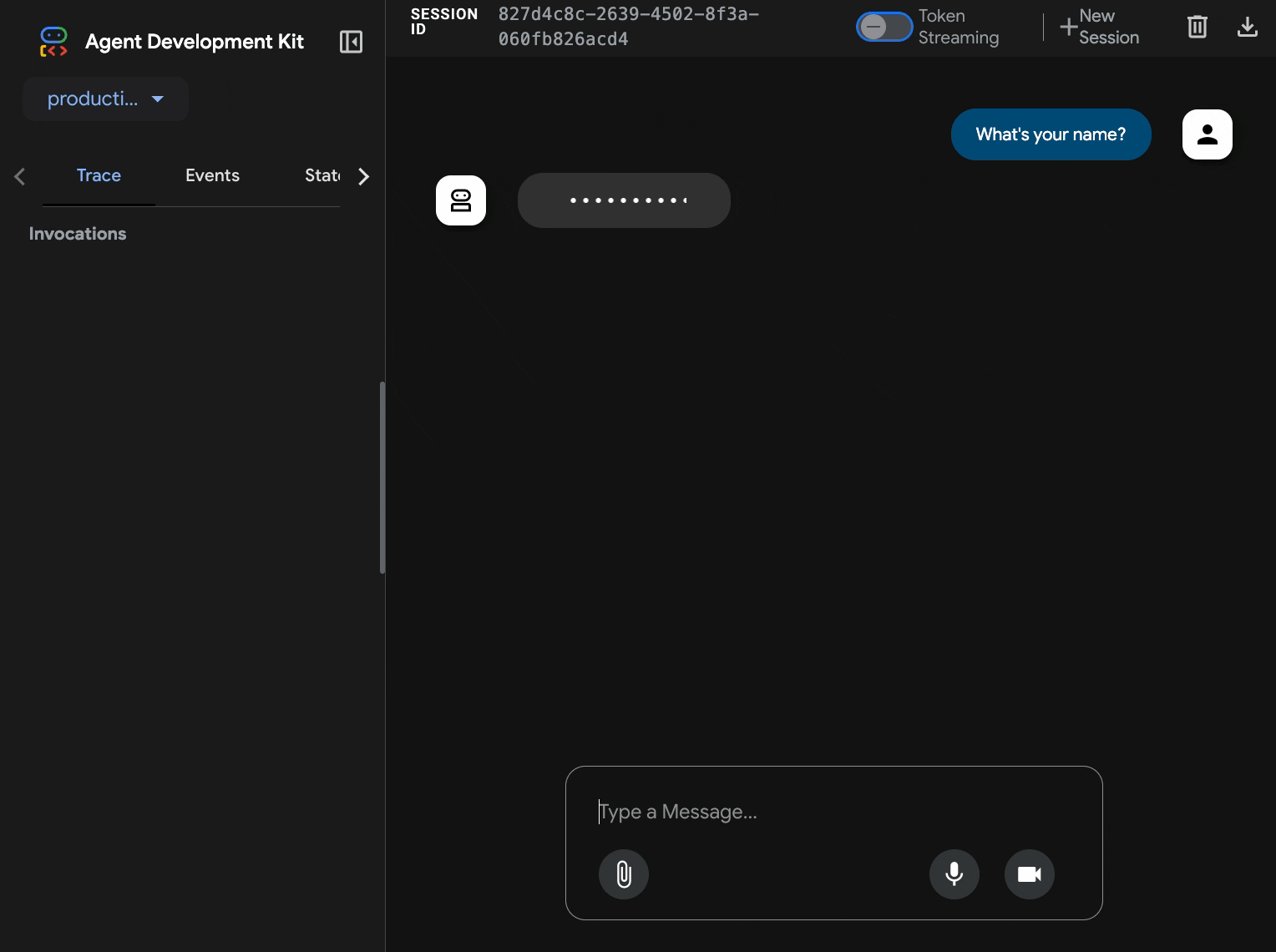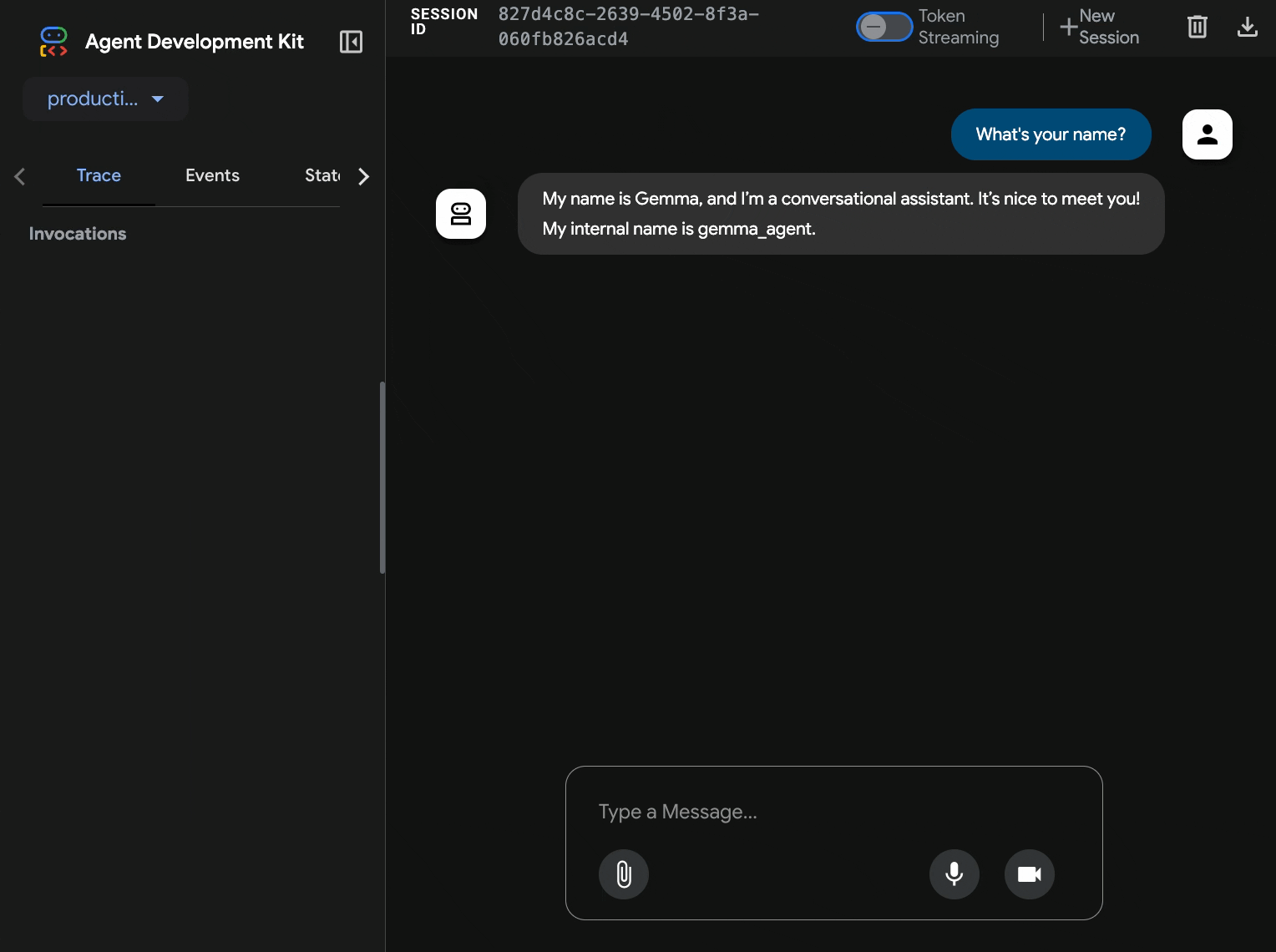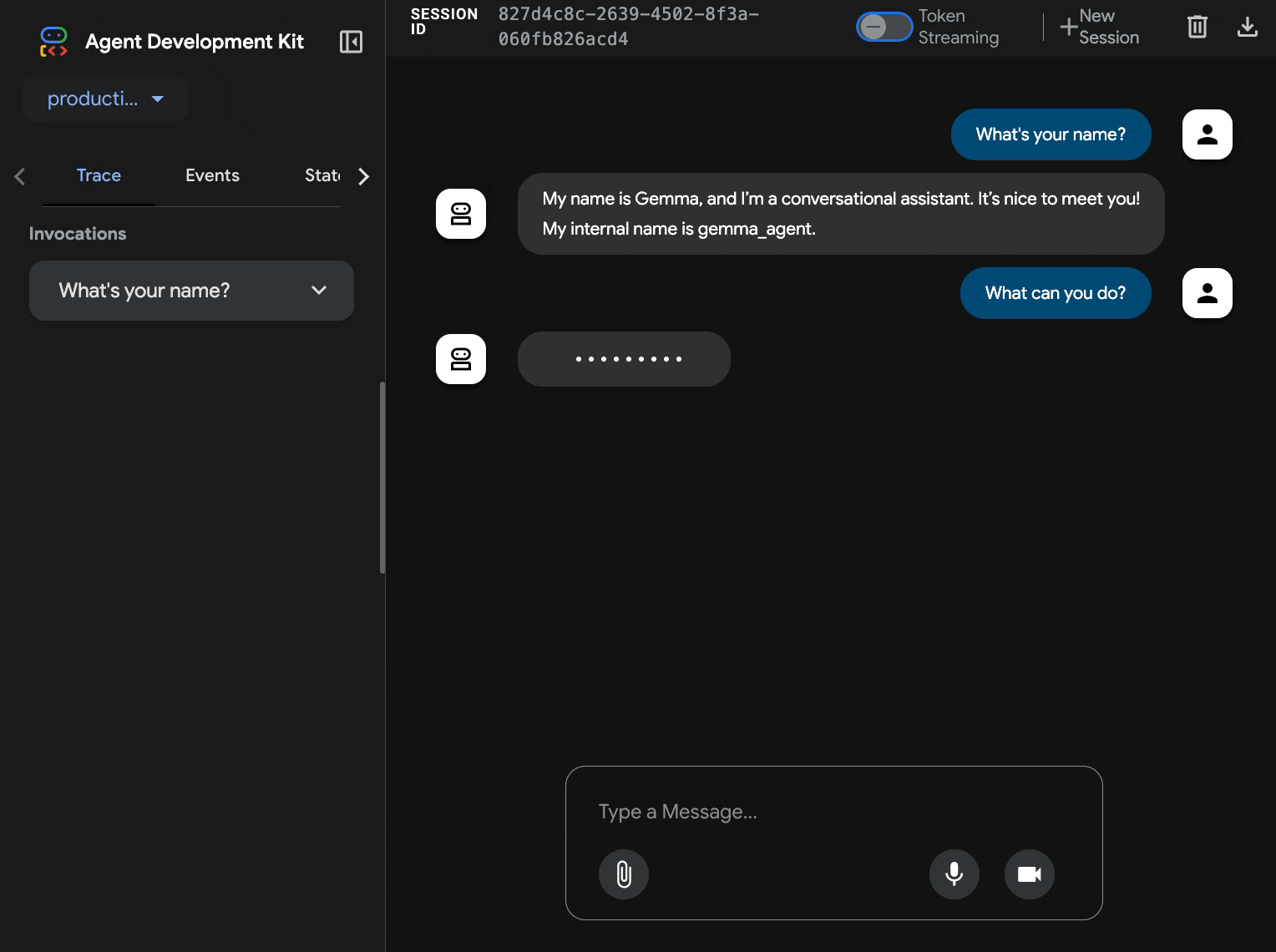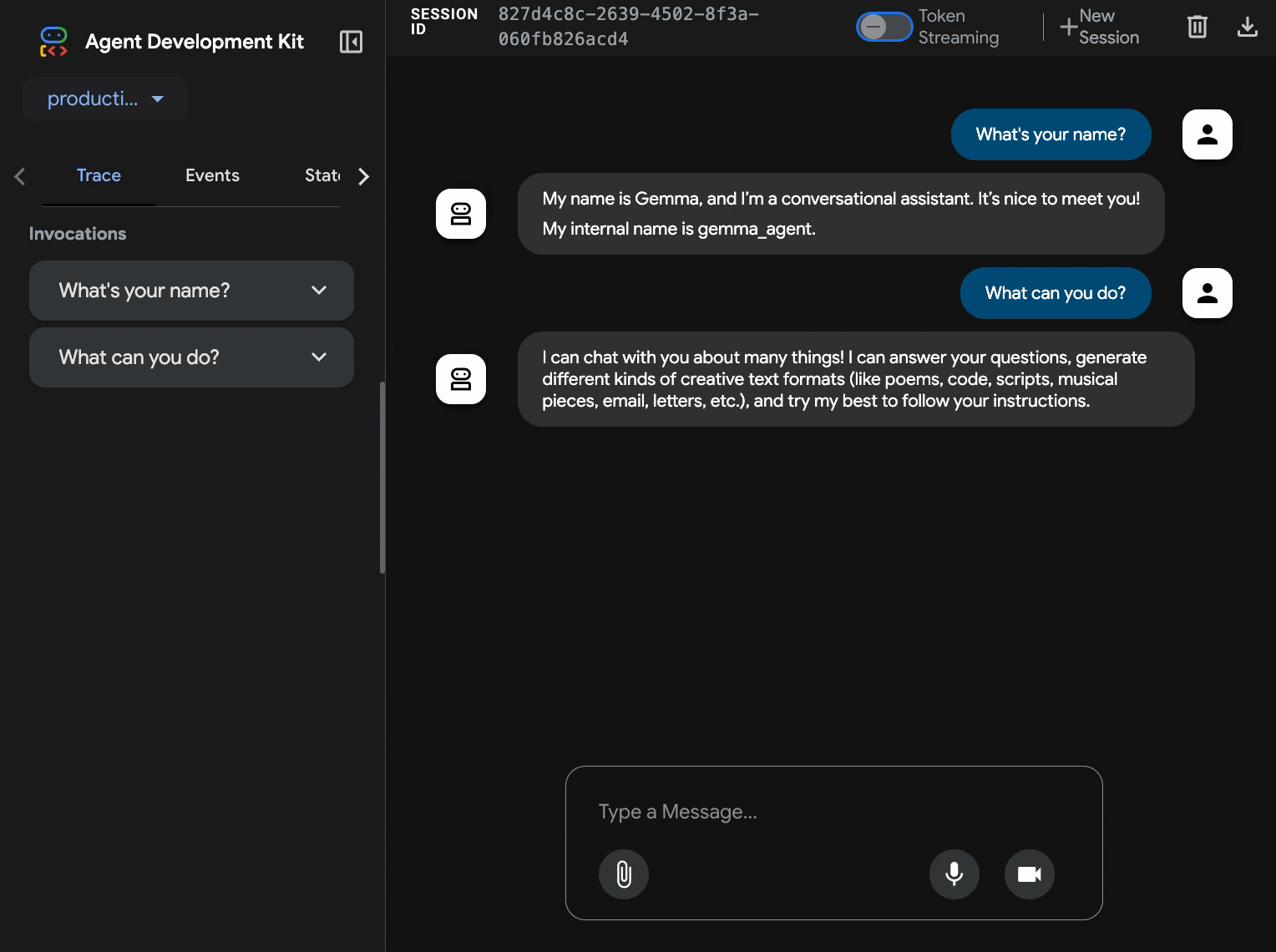
10. Kiểm thử bằng Giao diện web ADK
Sau khi triển khai cả hai dịch vụ, bạn cần xác thực rằng tác nhân ADK có thể giao tiếp thành công với phần phụ trợ Gemma được tăng tốc bằng GPU và phản hồi các truy vấn của người dùng.
- Kiểm thử điểm cuối về tình trạng:
curl $AGENT_URL/health{ "status": "healthy", "service": "production-adk-agent" } - Tương tác với tác nhân bằng cách nhập URL cho
production-adk-agentvào một thẻ trình duyệt mới. Bạn sẽ thấy giao diện web ADK. - Kiểm thử nhân viên hỗ trợ bằng những cuộc trò chuyện mẫu sau:
- "Gấu trúc đỏ thường ăn gì trong tự nhiên?"
- "Bạn có thể cho tôi biết một thông tin thú vị về báo tuyết không?"
- "Tại sao ếch phi tiêu độc lại có màu sắc tươi sáng?"
- "Tôi có thể tìm thấy chú kangaroo con mới ở đâu trong vườn thú?"
- Nhân viên hỗ trợ phản hồi bằng mô hình Gemma mà bạn đã triển khai. Bạn có thể xác minh điều này bằng cách quan sát nhật ký cho dịch vụ Gemma đã triển khai. Chúng ta sẽ làm việc này trong phần tiếp theo
- Câu trả lời do phần phụ trợ tăng tốc bằng GPU tạo ra
- Giao diện web mang đến trải nghiệm trò chuyện rõ ràng
11. Triển khai và chạy kiểm thử độ co giãn
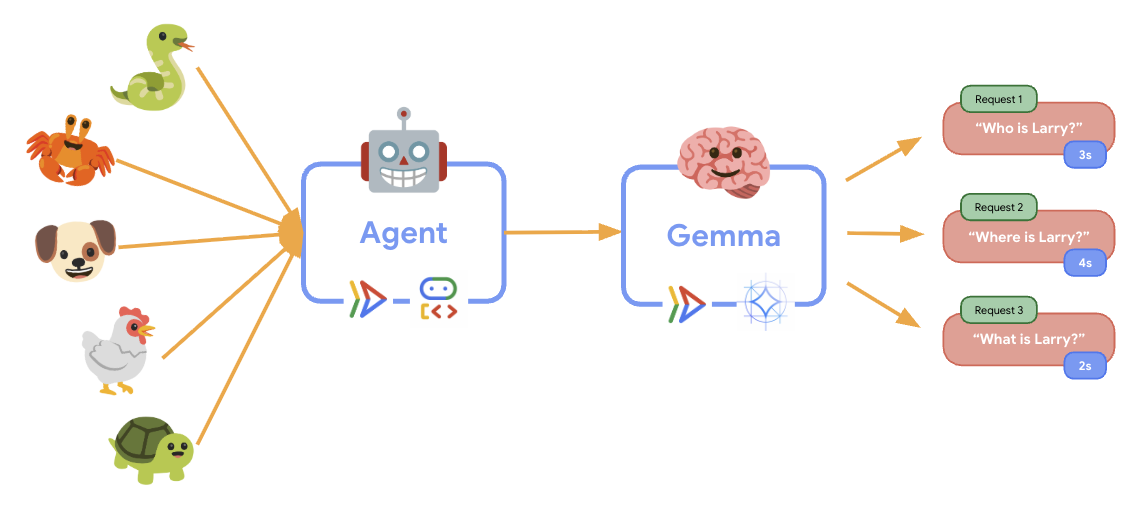
Để hiểu cách hoạt động triển khai sản xuất của bạn xử lý lưu lượng truy cập trong thực tế, chúng tôi sẽ triển khai một kiểm thử độ co giãn để kiểm thử khả năng thích ứng của hệ thống với khối lượng công việc sản xuất "mô phỏng" cao hơn.
- Mở và triển khai tập lệnh kiểm thử độ linh hoạt:
cloudshell edit elasticity_test.pyimport random import uuid from locust import HttpUser, task, between class ProductionAgentUser(HttpUser): """Elasticity test user for the Production ADK Agent.""" wait_time = between(1, 3) # Faster requests to trigger scaling def on_start(self): """Set up user session when starting.""" self.user_id = f"user_{uuid.uuid4()}" self.session_id = f"session_{uuid.uuid4()}" # Create session for the Gemma agent using proper ADK API format session_data = {"state": {"user_type": "elasticity_test_user"}} self.client.post( f"/apps/production_agent/users/{self.user_id}/sessions/{self.session_id}", headers={"Content-Type": "application/json"}, json=session_data, ) @task(4) def test_conversations(self): """Test conversational capabilities - high frequency.""" topics = [ "What do red pandas typically eat in the wild?", "Can you tell me an interesting fact about snow leopards?", "Why are poison dart frogs so brightly colored?", "Where can I find the new baby kangaroo in the zoo?", "What is the name of your oldest gorilla?", "What time is the penguin feeding today?" ] # Use proper ADK API format for sending messages message_data = { "app_name": "production_agent", "user_id": self.user_id, "session_id": self.session_id, "new_message": { "role": "user", "parts": [{ "text": random.choice(topics) }] } } self.client.post( "/run", headers={"Content-Type": "application/json"}, json=message_data, ) @task(1) def health_check(self): """Test the health endpoint.""" self.client.get("/health")- Tạo phiên: Sử dụng đúng định dạng API ADK với POST đến
/apps/production_agent/users/{user_id}/sessions/{session_id}. Sau khi tạosession_idvàuser_id, bạn có thể gửi yêu cầu đến tác nhân. - Định dạng thông báo: Tuân theo quy cách ADK với
app_name,user_id,session_idvà đối tượngnew_messagecó cấu trúc - Điểm cuối của cuộc trò chuyện: Sử dụng điểm cuối
/runđể thu thập tất cả sự kiện cùng một lúc (nên dùng cho kiểm thử tải) - Tải thực tế: Tạo tải đàm thoại với thời gian chờ ngắn hơn
- Tạo phiên: Sử dụng đúng định dạng API ADK với POST đến
- Cài đặt các phần phụ thuộc:
uv sync - Locust là một công cụ kiểm thử tải mã nguồn mở, dựa trên Python, được thiết kế để kiểm thử hiệu suất và tải của các ứng dụng web và các hệ thống khác. Đặc điểm chính của công cụ này là các tình huống kiểm thử và hành vi của người dùng được xác định bằng mã Python tiêu chuẩn, mang lại tính linh hoạt và khả năng biểu đạt cao so với những công cụ dựa vào giao diện người dùng đồ hoạ hoặc ngôn ngữ dành riêng cho miền. Chúng ta sẽ sử dụng Locust để mô phỏng lưu lượng truy cập của người dùng vào các dịch vụ của mình.Chạy thử nghiệm.
uv run locust -f elasticity_test.py \ -H $AGENT_URL \ --headless \ -t 60s \ -u 20 \ -r 5- Thời lượng: 60 giây
- Người dùng: 20 người dùng đồng thời
- Tốc độ tạo: 5 người dùng/giây
- Mục tiêu: Kích hoạt tính năng tự động mở rộng quy mô trên cả hai dịch vụ
12. Quan sát hành vi của tính năng AutoScaling
Khi chạy kiểm thử độ co giãn, bạn sẽ có thể quan sát khả năng hỗ trợ khối lượng công việc cao hơn của Cloud Run trong thực tế. Đây là nơi bạn sẽ thấy những lợi ích chính về cấu trúc khi tách tác nhân ADK khỏi phần phụ trợ GPU.
Trong quá trình kiểm tra độ co giãn, hãy theo dõi cách cả hai dịch vụ Cloud Run xử lý lưu lượng truy cập trong bảng điều khiển.
- Trong Cloud Console, hãy chuyển đến:
- Cloud Run → production-adk-agent → Metrics
- Cloud Run → ollama-gemma3-270m-gpu → Metrics
👀 Những điều bạn nên quan sát:
🤖 Dịch vụ ADK Agent:
- Vẫn giữ nguyên ở 1 phiên bản trong khi lưu lượng truy cập tăng lên
- Mức sử dụng CPU và bộ nhớ tăng đột biến trong thời gian có lưu lượng truy cập cao
- Xử lý hiệu quả việc quản lý phiên và định tuyến yêu cầu
🎮 Dịch vụ phụ trợ Gemma (Điểm nghẽn):
- Vẫn giữ nguyên ở 1 phiên bản trong khi lưu lượng truy cập tăng lên
- Mức sử dụng GPU tăng đáng kể khi chịu tải
- Dịch vụ này trở thành điểm tắc nghẽn do suy luận mô hình chuyên sâu về GPU
- Thời gian suy luận mô hình vẫn nhất quán nhờ tính năng tăng tốc GPU
💡 Thông tin chi tiết chính:
- Cả hai dịch vụ đều duy trì tính nhất quán và không tăng quy mô, vì chúng ta đã đặt số lượng phiên bản tối đa là
1 - Cả hai dịch vụ đều mở rộng quy mô độc lập dựa trên đặc điểm tải riêng của chúng
- GPU giúp duy trì hiệu suất trong các điều kiện tải khác nhau
13. Kết luận
Xin chúc mừng! Bạn đã triển khai thành công một tác nhân ADK sẵn sàng cho môi trường sản xuất với phần phụ trợ Gemma tăng tốc bằng GPU, trong khi thử nghiệm một khối lượng công việc mô phỏng trong môi trường sản xuất.
✅ Thành tích bạn đạt được
- ✅ Triển khai một mô hình Gemma được tăng tốc bằng GPU ở phần phụ trợ trên Cloud Run
- ✅ Tạo và triển khai một tác nhân ADK tích hợp với phần phụ trợ Gemma
- ✅ Đã kiểm thử tác nhân bằng giao diện web ADK
- ✅ Quan sát hành vi tự động mở rộng quy mô trên 2 dịch vụ Cloud Run phối hợp
💡 Thông tin chi tiết chính từ lớp học này
- 🎮 Tăng tốc bằng GPU: GPU NVIDIA L4 cải thiện đáng kể hiệu suất suy luận mô hình
- 🔗 Điều phối dịch vụ: Hai dịch vụ Cloud Run có thể phối hợp hoạt động một cách liền mạch
- 📈 Mở rộng quy mô độc lập: Mỗi dịch vụ mở rộng quy mô dựa trên đặc điểm tải riêng
- 🚀 Mức độ sẵn sàng phát hành công khai: Cấu trúc xử lý hiệu quả các mẫu lưu lượng truy cập trong thế giới thực
🔄 Các bước tiếp theo
- Thử nghiệm nhiều mẫu tải và quan sát hành vi mở rộng quy mô
- Thử các kích thước mô hình Gemma khác nhau (điều chỉnh bộ nhớ và GPU cho phù hợp)
- Triển khai tính năng giám sát và cảnh báo cho các quy trình triển khai sản xuất
- Khám phá các hoạt động triển khai ở nhiều khu vực để có phạm vi cung cấp trên toàn cầu
🧹 Dọn dẹp
Để tránh bị tính phí, hãy xoá các tài nguyên khi bạn hoàn tất:
gcloud run services delete production-adk-agent --region=europe-west4
gcloud run services delete ollama-gemma3-270m-gpu --region=europe-west4
📖 Tài nguyên
- Kho lưu trữ dành cho người mới bắt đầu
- Giải pháp hoàn chỉnh
- Tài liệu về ADK của Google
- Hướng dẫn kiểm thử ADK – Tài liệu tham khảo đầy đủ về các điểm cuối API ADK và mẫu kiểm thử
- Kiểm thử tải trên Cloud Run
- Tài liệu về Agent Development Kit (ADK)
- Tài liệu về GPU trên Cloud Run
- Thư viện mô hình Ollama
- Tài liệu về Google Cloud Trace
- Các phương pháp bảo mật hay nhất cho Cloud Run
- Trình quản lý gói UV Python
- Khung kiểm thử tải Locust