
1. 简介
概览
在本实验中,您将部署一个可用于生产用途的智能体开发套件 (ADK) 智能体,该智能体具有 GPU 加速的 Gemma 后端。重点是关键部署模式:设置支持 GPU 的 Cloud Run 服务、将模型后端与 ADK 智能体集成,以及观察负载下的自动扩缩行为。
您将执行的操作
在本实验中,您将重点了解关键的生产环境部署方面:
- 使用 GPU 将 Gemma 部署到 Cloud Run - 设置高性能 Gemma 模型后端
- 将 Gemma 部署与 ADK 智能体集成 - 将智能体连接到 GPU 加速的模型
- 使用 ADK 网页界面进行测试 - 验证对话智能体是否正常运行
- 执行弹性测试 - 观察 Cloud Run 实例如何处理负载
重点是生产环境部署模式,而不是广泛的智能体开发。
学习内容
- 将 GPU 加速的 Gemma 模型部署到 Cloud Run 以用于生产环境
- 将外部模型部署与 ADK 智能体集成
- 配置和测试可用于生产用途的 AI 智能体部署
- 了解 Cloud Run 在负载下的行为
- 观察多个 Cloud Run 实例在流量高峰期间如何协调
- 应用弹性测试来验证性能
2. 项目设置
- 如果您还没有 Google 账号,则必须先创建一个 Google 账号。
- 请使用个人账号,而不是组织或学校账号。组织和学校账号可能会受到限制,导致您无法启用本实验所需的 API。
- 登录 Google Cloud 控制台。
- 在 Cloud 控制台中启用结算功能。
- 完成本实验的 Cloud 资源费用应低于 1 美元。
- 您可以按照本实验末尾的步骤删除资源,以避免产生更多费用。
- 新用户可以享受 300 美元的免费试用额度。
- 创建新项目,或选择重复使用现有项目。
- 如果您看到有关项目配额的错误,请重复使用现有项目或删除现有项目以创建新项目。
3. 打开 Cloud Shell Editor
- 点击此链接可直接前往 Cloud Shell Editor
- 如果系统在今天的任何时间提示您授权,请点击授权以继续。
- 如果终端未显示在屏幕底部,请打开它:
- 点击查看
- 点击终端
- 在终端中,使用以下命令设置项目:
- 格式:
gcloud config set project [PROJECT_ID] - 示例:
gcloud config set project lab-project-id-example - 如果您不记得项目 ID,可以执行以下操作:
- 您可以使用以下命令列出所有项目 ID:
gcloud projects list | awk '/PROJECT_ID/{print $2}'
- 您可以使用以下命令列出所有项目 ID:
- 格式:
- 您应会看到以下消息:
Updated property [core/project].
WARNING并被问到Do you want to continue (Y/n)?,则可能是输入的项目 ID 不正确。按n,按Enter,然后尝试再次运行gcloud config set project命令。
4. 启用 API 并设置默认区域
在部署支持 GPU 的 Cloud Run 服务之前,我们需要启用所需的 Google Cloud API 并配置项目设置。
- 在终端中,启用以下 API:
gcloud services enable \
run.googleapis.com \
artifactregistry.googleapis.com \
cloudbuild.googleapis.com \
aiplatform.googleapis.com
如果系统提示您授权,请点击授权以继续。
此命令可能需要几分钟才能完成,但最终应生成类似于以下内容的成功消息:
Operation "operations/acf.p2-73d90d00-47ee-447a-b600" finished successfully.
- 设置默认 Cloud Run 区域。
gcloud config set run/region europe-west4
5. 准备 Python 项目
让我们设置包含 Gemma 后端和 ADK 智能体服务基本结构的起始代码。
- 克隆起始代码库:
cd ~ npx -y giget@latest gh+git:GoogleCloudPlatform/devrel-demos/agents/accelerate-ai-with-cloud-run/accelerate-ai-lab3-starter accelerate-ai-lab3-starter cd accelerate-ai-lab3-starter - 查看项目结构:
ls -Raccelerate-ai-lab3-starter/ ├── README.md # Project overview ├── ollama-backend/ # Ollama backend (separate deployment) │ └── Dockerfile # Backend container (🚧 to implement) └── adk-agent/ # ADK agent (separate deployment) ├── pyproject.toml # Python dependencies (✅ completed) ├── server.py # FastAPI server (🚧 to implement) ├── Dockerfile # Container config (🚧 to implement) ├── elasticity_test.py # Elasticity testing (🚧 to implement) └── production_agent/ # Agent implementation ├── __init__.py # Package init (✅ completed) └── agent.py # Agent logic (🚧 to implement)
6. 架构概览
在实现之前,让我们了解一下双服务架构:
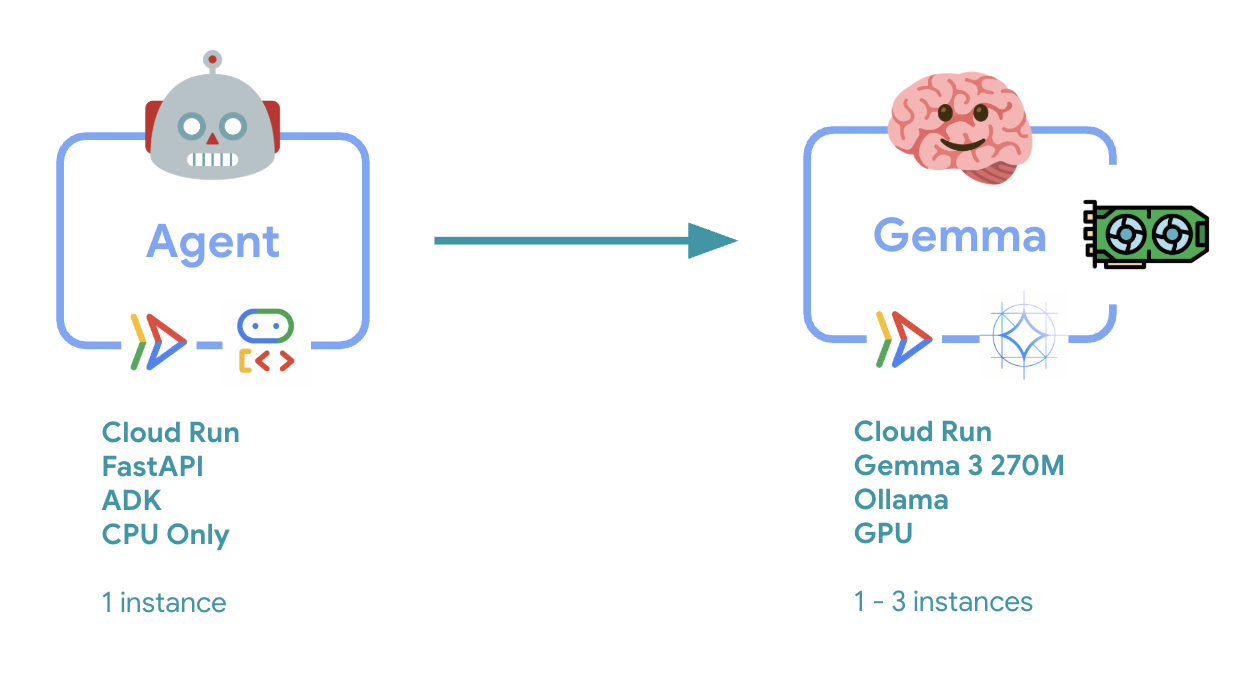
重要洞察分析:在弹性测试期间,您将观察到这两个服务独立处理工作负载 - GPU 后端(瓶颈服务)使用其 GPU 处理负载,而 ADK 智能体则依赖于其 CPU 处理非资源密集型请求。
7. 使用 GPU 将 Gemma 后端部署到 Cloud Run
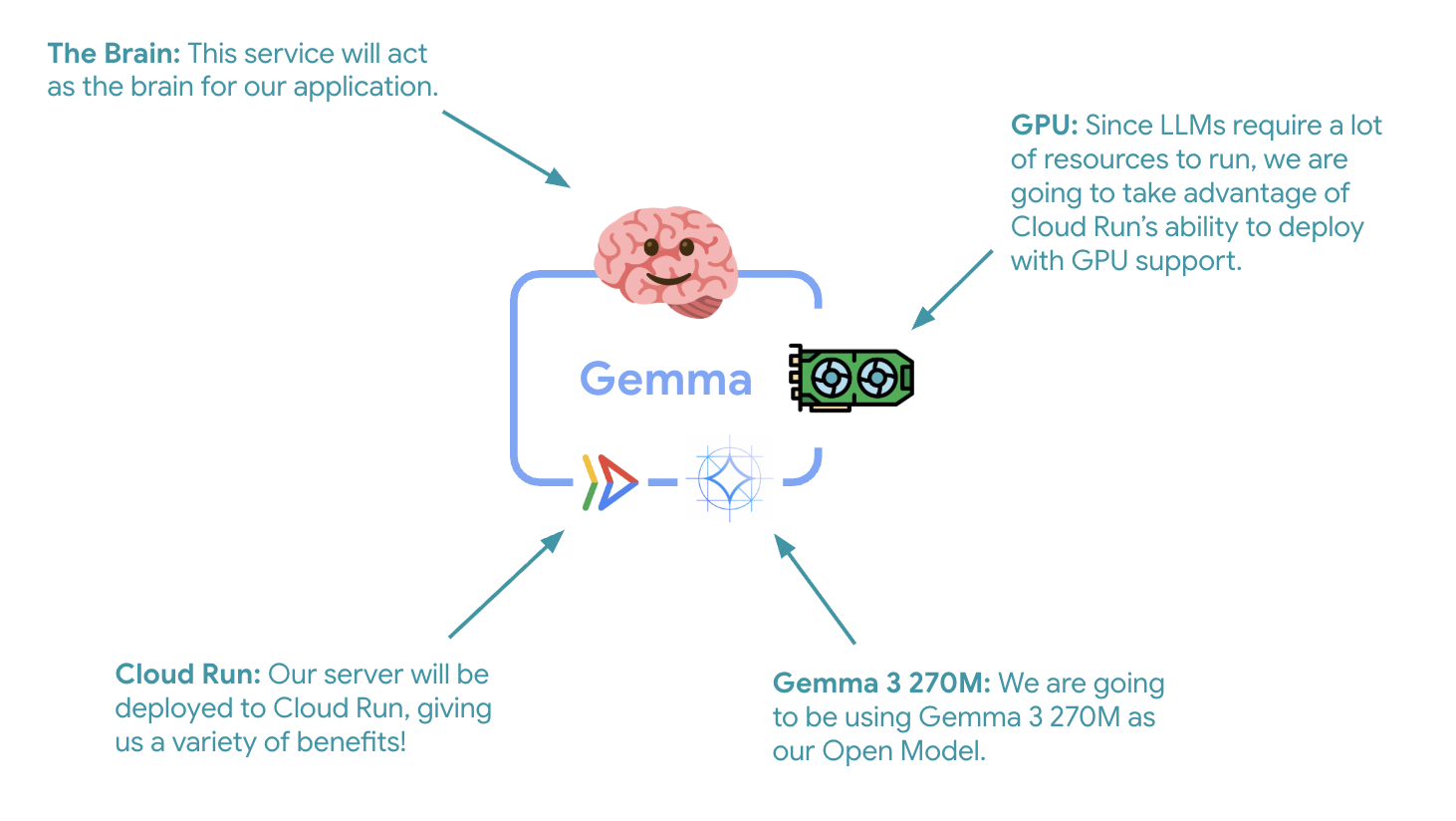
第一个关键步骤是部署 GPU 加速的 Gemma 模型,该模型将作为 ADK 智能体的“大脑”。在需要单独的微调模型或需要隔离扩缩的架构中,拥有已部署的解耦 LLM 可能是有利的。
- 前往 Ollama 后端目录:
cd ollama-backend - 打开并实现 Ollama Dockerfile:
cloudshell edit DockerfileFROM ollama/ollama:latest # Listen on all interfaces, port 8080 ENV OLLAMA_HOST 0.0.0.0:8080 # Store model weight files in /models ENV OLLAMA_MODELS /models # Reduce logging verbosity ENV OLLAMA_DEBUG false # Never unload model weights from the GPU ENV OLLAMA_KEEP_ALIVE -1 # Store the model weights in the container image ENV MODEL gemma3:270m RUN ollama serve & sleep 5 && ollama pull $MODEL # Start Ollama ENTRYPOINT ["ollama", "serve"]- 使用官方 Ollama 映像作为基础
- 将
OLLAMA_HOST设置为接受来自任何 IP 地址的连接 - 公开端口 8080
- 部署支持 GPU 的 Gemma 后端:
gcloud run deploy ollama-gemma3-270m-gpu \
--source . \
--region europe-west4 \
--concurrency 7 \
--cpu 8 \
--set-env-vars OLLAMA_NUM_PARALLEL=4 \
--gpu 1 \
--gpu-type nvidia-l4 \
--max-instances 1 \
--memory 16Gi \
--allow-unauthenticated \
--no-cpu-throttling \
--no-gpu-zonal-redundancy \
--timeout 600 \
--labels dev-tutorial=codelab-agent-gpu
如果您收到“Deploying from source requires an Artifact Registry Docker repository to store built containers. A repository named [cloud-run-source-deploy] in region [europe-west4] will be created.”消息,请继续。
⚙️ 主要配置说明:
- GPU:选择 NVIDIA L4 是因为其在推理工作负载方面具有出色的性价比。L4 提供 24GB GPU 内存和优化的张量运算,非常适合 Gemma 等 2.7 亿参数模型
- 内存:16GB 系统内存,用于处理模型加载、CUDA 运算和 Ollama 的内存管理
- CPU:8 个内核,用于优化 I/O 处理和预处理任务
- 并发:每个实例 7 个请求,可在吞吐量和 GPU 内存用量之间实现平衡
- 超时:600 秒,可满足初始模型加载和容器启动的需求
💰 费用考虑因素:GPU 实例的费用远高于仅使用 CPU 的实例(约 2-4 美元/小时,而后者约为 0.10 美元/小时)。--max-instances 1 设置有助于控制费用,防止不必要的 GPU 实例扩缩。
- 等待部署完成,并记下服务网址:
export OLLAMA_URL=$(gcloud run services describe ollama-gemma3-270m-gpu \ --region=europe-west4 \ --format='value(status.url)') echo "🎉 Gemma backend deployed at: $OLLAMA_URL"
8. 实现 ADK 智能体集成
现在,让我们创建一个连接到已部署 Gemma 后端的最小 ADK 智能体。
- 前往 ADK 智能体目录:
cd ../adk-agent - 打开并实现智能体配置:
cloudshell edit production_agent/agent.pyimport os from pathlib import Path from dotenv import load_dotenv from google.adk.agents import Agent from google.adk.models.lite_llm import LiteLlm import google.auth # Load environment variables root_dir = Path(__file__).parent.parent dotenv_path = root_dir / ".env" load_dotenv(dotenv_path=dotenv_path) # Configure Google Cloud try: _, project_id = google.auth.default() os.environ.setdefault("GOOGLE_CLOUD_PROJECT", project_id) except Exception: pass os.environ.setdefault("GOOGLE_CLOUD_LOCATION", "europe-west4") # Configure model connection gemma_model_name = os.getenv("GEMMA_MODEL_NAME", "gemma3:270m") api_base = os.getenv("OLLAMA_API_BASE", "localhost:10010") # Location of Ollama server # Production Gemma Agent - GPU-accelerated conversational assistant production_agent = Agent( model=LiteLlm(model=f"ollama_chat/{gemma_model_name}", api_base=api_base), name="production_agent", description="A production-ready conversational assistant powered by GPU-accelerated Gemma.", instruction="""You are 'Gem', a friendly, knowledgeable, and enthusiastic zoo tour guide. Your main goal is to make a zoo visit more fun and educational for guests by answering their questions. You can provide general information and interesting facts about different animal species, such as: - Their natural habitats and diet. 🌲🍓 - Typical lifespan and behaviors. - Conservation status and unique characteristics. IMPORTANT: You do NOT have access to any tools. This means you cannot look up real-time, specific information about THIS zoo. You cannot provide: - The names or ages of specific animals currently at the zoo. - The exact location or enclosure for an animal. - The daily schedule for feedings or shows. Always answer based on your general knowledge about the animal kingdom. Keep your tone cheerful, engaging, and welcoming for visitors of all ages. 🦁✨""", tools=[], # Gemma focuses on conversational capabilities ) # Set as root agent root_agent = production_agent- 通过 LiteLlm 连接到已部署的 Gemma 后端
- 创建一个简单的对话智能体
- 配置 Google Cloud 集成
- 打开并实现 FastAPI 服务器:
cloudshell edit server.pyimport os from dotenv import load_dotenv from fastapi import FastAPI from google.adk.cli.fast_api import get_fast_api_app # Load environment variables load_dotenv() AGENT_DIR = os.path.dirname(os.path.abspath(__file__)) app_args = {"agents_dir": AGENT_DIR, "web": True} # Create FastAPI app with ADK integration app: FastAPI = get_fast_api_app(**app_args) # Update app metadata app.title = "Production ADK Agent - Lab 3" app.description = "Gemma agent with GPU-accelerated backend" app.version = "1.0.0" @app.get("/health") def health_check(): return {"status": "healthy", "service": "production-adk-agent"} @app.get("/") def root(): return { "service": "Production ADK Agent - Lab 3", "description": "GPU-accelerated Gemma agent", "docs": "/docs", "health": "/health" } if __name__ == "__main__": import uvicorn uvicorn.run(app, host="0.0.0.0", port=8080, log_level="info")- 创建具有 ADK 集成的 FastAPI 服务器
- 启用网页界面以进行测试
- 提供健康检查端点
- 打开并实现 Dockerfile:
cloudshell edit DockerfileFROM python:3.13-slim # Copy uv from the official image COPY --from=ghcr.io/astral-sh/uv:latest /uv /usr/local/bin/uv # Install system dependencies RUN apt-get update && apt-get install -y curl && rm -rf /var/lib/apt/lists/* # Set working directory WORKDIR /app # Copy all files COPY . . # Install Python dependencies RUN uv sync # Expose port EXPOSE 8080 # Run the application CMD ["uv", "run", "uvicorn", "server:app", "--host", "0.0.0.0", "--port", "8080"]- uv:现代 Python 软件包管理器,速度比 pip 快 10-100 倍。它使用全局缓存和并行下载,可显著缩短容器构建时间
- Python 3.13-slim:最新 Python 版本,系统依赖项最少,可减小容器大小和攻击面
- 多阶段构建:从其官方映像复制 uv 可确保我们获得最新的优化二进制文件
9. 配置环境并部署智能体
现在,我们将配置 ADK 智能体以连接到已部署的 Gemma 后端,并将其部署为 Cloud Run 服务。这包括设置环境变量和使用正确的配置部署智能体。
- 设置环境配置:
cat << EOF > .env GOOGLE_CLOUD_PROJECT=$(gcloud config get-value project) GOOGLE_CLOUD_LOCATION=europe-west4 GEMMA_MODEL_NAME=gemma3:270m OLLAMA_API_BASE=$OLLAMA_URL EOF
了解 Cloud Run 中的环境变量
环境变量是键值对,用于在运行时配置应用。它们特别适用于:
- API 端点和服务网址(例如我们的 Ollama 后端)
- 在不同环境(开发、预演、生产)之间发生更改的配置
- 不应硬编码的敏感数据
部署 ADK 智能体:
export PROJECT_ID=$(gcloud config get-value project)
gcloud run deploy production-adk-agent \
--source . \
--region europe-west4 \
--allow-unauthenticated \
--memory 4Gi \
--cpu 2 \
--max-instances 1 \
--concurrency 50 \
--timeout 300 \
--set-env-vars GOOGLE_CLOUD_PROJECT=$PROJECT_ID \
--set-env-vars GOOGLE_CLOUD_LOCATION=europe-west4 \
--set-env-vars GEMMA_MODEL_NAME=gemma3:270m \
--set-env-vars OLLAMA_API_BASE=$OLLAMA_URL \
--labels dev-tutorial=codelab-agent-gpu
⚙️ 主要配置:
- 自动扩缩:固定为 1 个实例(轻量级请求处理)
- 并发:每个实例 50 个请求
- 内存:4GB,用于 ADK 智能体
- 环境:连接到 Gemma 后端
🔒 安全注意事项:为简单起见,本实验使用 --allow-unauthenticated。在生产环境中,请使用以下方法实现适当的身份验证:
- 使用服务账号进行 Cloud Run 服务到服务身份验证
- 身份和访问权限管理 (IAM) 政策
- 用于外部访问的 API 密钥或 OAuth
- 考虑使用
gcloud run services add-iam-policy-binding来控制访问权限
获取智能体服务网址:
export AGENT_URL=$(gcloud run services describe production-adk-agent \
--region=europe-west4 \
--format='value(status.url)')
echo "🎉 ADK Agent deployed at: $AGENT_URL"
✅ 环境变量最佳实践 (基于 Cloud Run 环境变量文档):
- 避免使用预留变量:请勿设置
PORT(如果您需要更改环境变量,请改用 –port 标志)或以X_GOOGLE_开头的变量 - 使用描述性名称:为变量添加前缀以避免冲突(例如,
GEMMA_MODEL_NAME而不是MODEL) - 转义英文逗号:如果您的值包含英文逗号,请使用其他定界符:
--set-env-vars "^@^KEY1=value1,value2@KEY2=..." - 更新与替换:使用
--update-env-vars添加/更改特定变量,而不会影响其他变量
如何在 Cloud Run 中设置变量:
- 从文件:
gcloud run deploy SERVICE_NAME --env-vars-file .env --labels dev-tutorial codelab-adk(从文件加载多个变量) - 多个标志:对于无法以逗号分隔的复杂值,请重复使用
--set-env-vars
10. 使用 ADK 网页界面进行测试
部署完这两个服务后,就可以验证 ADK 智能体是否可以成功与 GPU 加速的 Gemma 后端通信并响应用户查询。
- 测试健康端点:
curl $AGENT_URL/health{ "status": "healthy", "service": "production-adk-agent" } - 在新的浏览器标签页中输入
production-adk-agent的网址,与智能体互动。您应该会看到 ADK 网页界面。 - 使用以下示例对话测试智能体:
- 小熊猫在野外通常吃什么?
- “您能告诉我一些关于雪豹的有趣事实吗?”
- “为什么箭毒蛙的颜色如此鲜艳?”
- “我在动物园哪里可以找到新出生的小袋鼠?”
- 智能体使用您部署的 Gemma 模型进行响应。您可以通过观察已部署 Gemma 服务的日志来验证这一点。我们将在下一部分中执行此操作
- 响应由 GPU 加速的后端生成
- 网页界面提供简洁的聊天体验

11. 实现并运行弹性测试
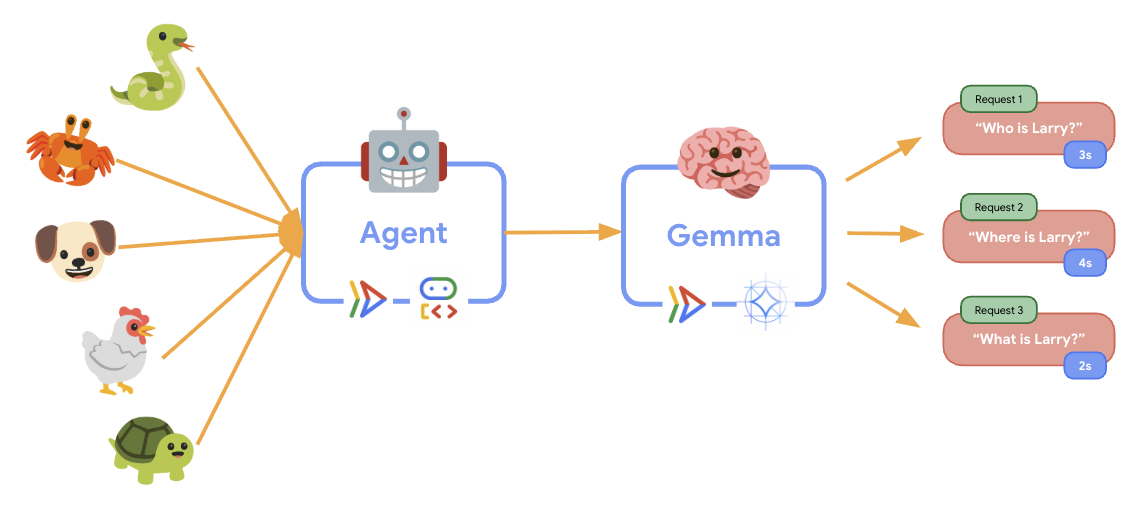
为了了解生产环境部署如何处理实际流量,我们将实现一项弹性测试,该测试将测试系统适应更高“模拟”生产工作负载的能力。
- 打开并实现弹性测试脚本:
cloudshell edit elasticity_test.pyimport random import uuid from locust import HttpUser, task, between class ProductionAgentUser(HttpUser): """Elasticity test user for the Production ADK Agent.""" wait_time = between(1, 3) # Faster requests to trigger scaling def on_start(self): """Set up user session when starting.""" self.user_id = f"user_{uuid.uuid4()}" self.session_id = f"session_{uuid.uuid4()}" # Create session for the Gemma agent using proper ADK API format session_data = {"state": {"user_type": "elasticity_test_user"}} self.client.post( f"/apps/production_agent/users/{self.user_id}/sessions/{self.session_id}", headers={"Content-Type": "application/json"}, json=session_data, ) @task(4) def test_conversations(self): """Test conversational capabilities - high frequency.""" topics = [ "What do red pandas typically eat in the wild?", "Can you tell me an interesting fact about snow leopards?", "Why are poison dart frogs so brightly colored?", "Where can I find the new baby kangaroo in the zoo?", "What is the name of your oldest gorilla?", "What time is the penguin feeding today?" ] # Use proper ADK API format for sending messages message_data = { "app_name": "production_agent", "user_id": self.user_id, "session_id": self.session_id, "new_message": { "role": "user", "parts": [{ "text": random.choice(topics) }] } } self.client.post( "/run", headers={"Content-Type": "application/json"}, json=message_data, ) @task(1) def health_check(self): """Test the health endpoint.""" self.client.get("/health")- 会话创建:使用正确的 ADK API 格式,通过 POST 向
/apps/production_agent/users/{user_id}/sessions/{session_id}发出请求。创建session_id和user_id后,即可向智能体发出请求。 - 消息格式:遵循 ADK 规范,包含
app_name、user_id、session_id和结构化new_message对象 - 对话端点:使用
/run端点一次性收集所有事件(建议用于负载测试) - 实际负载:创建等待时间较短的对话负载
- 会话创建:使用正确的 ADK API 格式,通过 POST 向
- 安装依赖项:
uv sync - Locust 是一款基于 Python 的开源负载测试工具,专为测试 Web 应用和其他系统的性能和负载而设计。其主要特点是使用标准 Python 代码定义测试场景和用户行为,与依赖图形用户界面或特定于网域的语言的工具相比,具有很高的灵活性和表现力。我们将使用 Locust 模拟对服务的用户流量。运行测试。
uv run locust -f elasticity_test.py \ -H $AGENT_URL \ --headless \ -t 60s \ -u 20 \ -r 5- 时长:60 秒
- 用户数: 20 个并发用户
- 生成速率:每秒 5 个用户
- 目标:在两个服务上触发自动扩缩
12. 观察自动扩缩行为
在弹性测试运行期间,您将能够观察到 Cloud Run 对更高工作负载的支持。您将在此处看到将 ADK 智能体与 GPU 后端分离的主要架构优势。
在弹性测试期间,请在控制台中监控两个 Cloud Run 服务如何处理流量。
- 在 Cloud 控制台中,前往:
- Cloud Run → production-adk-agent → 指标
- Cloud Run → ollama-gemma3-270m-gpu → 指标
👀 您应该观察到:
🤖 ADK 智能体服务:
- 在流量增加时,应保持 1 个实例的稳定状态
- 在高流量期间,CPU 和内存用量会飙升
- 高效处理会话管理和请求路由
🎮 Gemma 后端服务(瓶颈):
- 在流量增加时,应保持 1 个实例的稳定状态
- 在负载下,GPU 利用率显著提高
- 由于 GPU 密集型模型推理,此服务成为瓶颈
- 由于 GPU 加速,模型推理时间保持一致
💡 重要洞察分析:
- 由于我们将实例数上限设置为
1,因此这两个服务都保持一致,不会扩容 - 这两个服务都根据各自的负载特征独立扩缩
- GPU 有助于在不同的负载条件下保持性能
13. 总结
恭喜!您已成功部署可用于生产用途的 ADK 智能体,该智能体具有 GPU 加速的 Gemma 后端,同时测试了模拟的生产工作负载。
✅ 学习成果
- ✅ 在 Cloud Run 上部署了 GPU 加速的 Gemma 模型后端
- ✅ 创建并部署了与 Gemma 后端集成的 ADK 智能体
- ✅ 使用 ADK 网页界面测试了智能体
- ✅ 观察了两个协调的 Cloud Run 服务中的自动扩缩行为
💡 本实验的重要洞察分析
- 🎮 GPU 加速:NVIDIA L4 GPU 可显著提高模型推理性能
- 🔗 服务协调:两个 Cloud Run 服务可以无缝协同工作
- 📈 独立扩缩:每个服务都根据各自的负载特征进行扩缩
- 🚀 可用于生产环境:该架构可有效处理实际流量模式
🔄 后续步骤
- 尝试不同的负载模式并观察扩缩行为
- 尝试不同的 Gemma 模型大小(相应调整内存和 GPU)
- 为生产环境部署实现监控和提醒
- 探索多区域部署以实现全球可用性
🧹 清理
为避免产生费用,请在完成后删除资源:
gcloud run services delete production-adk-agent --region=europe-west4
gcloud run services delete ollama-gemma3-270m-gpu --region=europe-west4