
1. Introduction
Dans cet atelier, vous allez créer un agent avec Agent Development Kit (ADK). Vous apprendrez à créer un agent assistant pour les bugs logiciels à l'aide d'ADK et de différents types d'outils. Vous commencerez par un agent de base et ajouterez progressivement des outils pour améliorer ses capacités, y compris des outils de fonction, des outils intégrés, des outils tiers et des outils MCP (Model Context Protocol).

Points abordés
- Configurer un projet Python pour le développement ADK
- Découvrez comment créer un agent ADK de base.
- Implémenter et utiliser les outils de fonction
- Comment intégrer des outils intégrés tels que la recherche Google.
- Comment exploiter des outils tiers provenant de frameworks comme LangChain dans ADK.
- Découvrez comment utiliser les outils MCP pour interagir avec les bases de données (Cloud SQL) et les API.
2. Présentation
Imaginez que vous êtes gestionnaire de projet chez QuantumRoast, une entreprise mondiale de machines à café.
![]()
Vous aidez vos coéquipiers à naviguer dans un océan de feuilles de route d'ingénierie, de changements de stratégie soudains (nous faisons du matcha maintenant !), et de tickets entrants de clients (tout, des systèmes de facturation bogués à une machine à café qui émet un bruit aigu 24h/24 et 7j/7).
En temps normal, vous avez une cinquantaine d'onglets de navigateur ouverts : le système de tickets interne, les e-mails, le chat, GitHub, la recherche Google, StackOverflow, etc. Vous aimez votre travail et vos coéquipiers, mais certains jours, vous vous sentez dépassé.

Et si nous pouvions créer un assistant pour vous aider à créer et à trier les tickets logiciels, et à déboguer les problèmes ? C'est ce que permet un agent d'IA.

Agent Development Kit (ADK)
Agent Development Kit (ADK) est un framework flexible et modulaire permettant de développer et de déployer des agents IA. Bien qu'optimisé pour Gemini et l'écosystème Google, l'ADK est indépendant des modèles et des déploiements, et est conçu pour être compatible avec d'autres frameworks. ADK a été conçu pour que le développement d'agents ressemble davantage au développement logiciel. Il permet aux développeurs de créer, de déployer et d'orchestrer plus facilement des architectures agentiques allant de tâches simples à des workflows complexes.
ADK est le framework que nous utiliserons pour créer notre assistant de bug logiciel QuantumRoast.
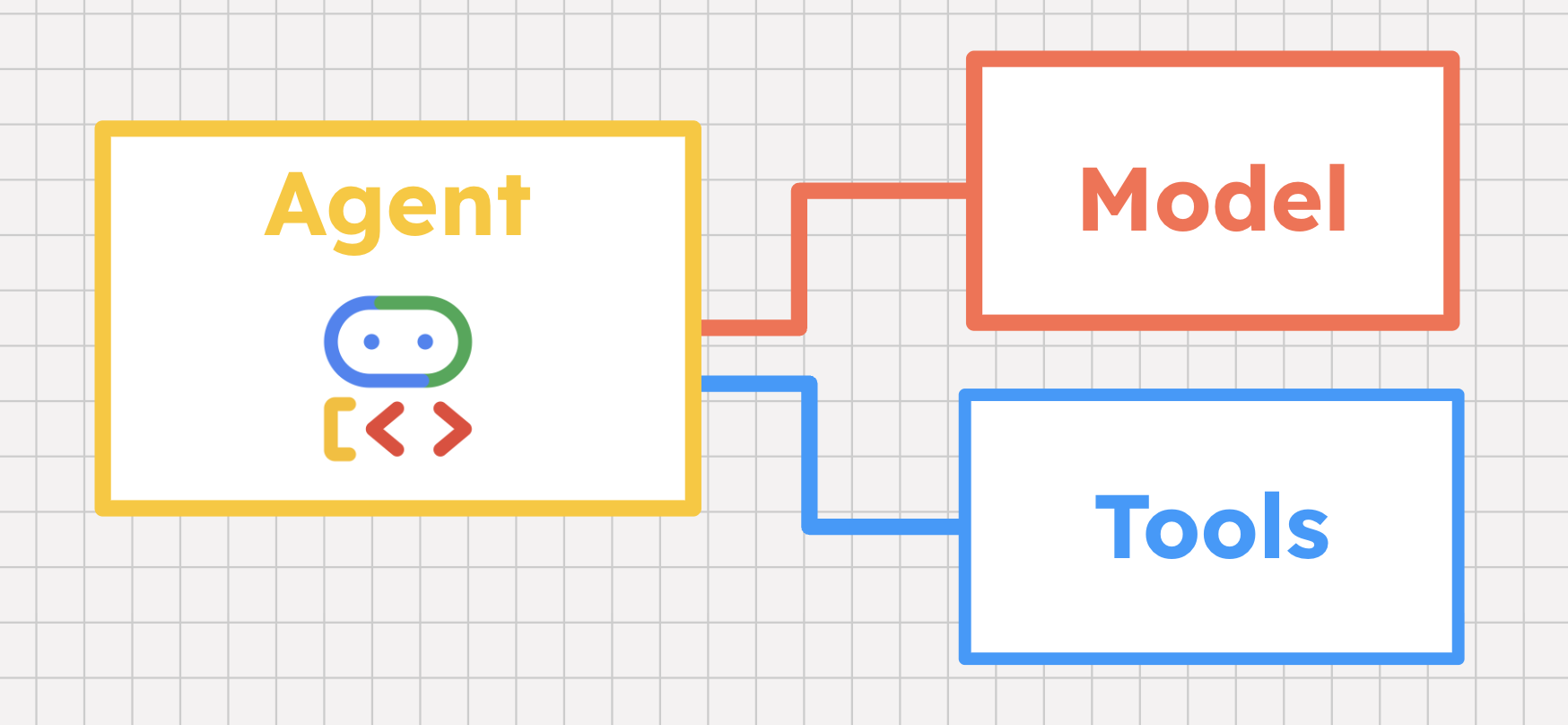
Outils 101
Les agents d'IA utilisent des modèles, et pas seulement une logique codée en dur, pour résoudre un problème. Mais au-delà du simple raisonnement basé sur les LLM, les agents d'IA sont particulièrement efficaces pour collecter des données externes et prendre des mesures au nom de l'utilisateur. Au lieu de vous expliquer comment résoudre un problème, un agent IA peut vous aider à le résoudre concrètement. Comment parvenons-nous à de tels résultats ? Avec les outils !
Un outil est une fonctionnalité qui aide un agent d'IA à interagir avec le monde. Un outil peut être presque n'importe quoi : une fonction intégrée, une base de données hébergée, une API tierce ou même un autre agent. Les frameworks d'agents d'IA tels que Agent Development Kit (ADK) sont compatibles avec les outils et prennent en charge différents types d'outils que nous aborderons dans un instant.
Mais comment un agent sait-il non seulement quand appeler un certain outil, mais aussi comment l'appeler ? Le modèle de l'agent joue plusieurs rôles clés ici.
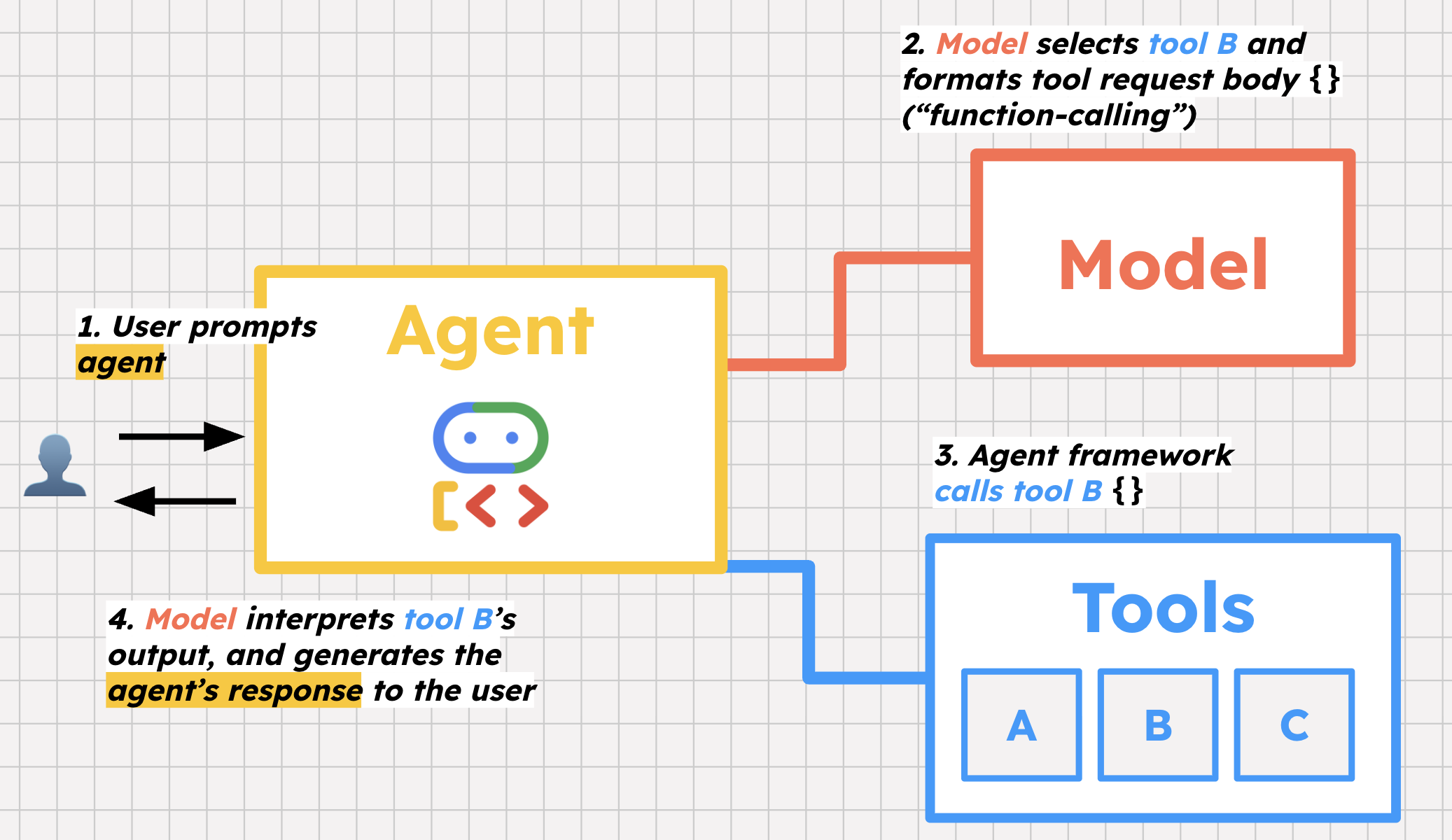
La première est la sélection d'outils. Nous fournissons à notre agent une liste d'outils et des instructions sur la façon de les utiliser. Lorsqu'un utilisateur interroge l'agent, le modèle de l'agent l'aide à décider quels outils appeler et pourquoi, afin d'aider l'utilisateur.
La deuxième étape clé est l'appel de fonction. L'appel de fonction est un terme un peu trompeur, car le modèle n'appelle pas réellement l'outil. Il se prépare plutôt à l'appeler en mettant en forme le corps de la requête que le framework utilise ensuite pour appeler l'outil.
Enfin, le modèle aide à interpréter la réponse de cet outil (par exemple, une liste de bugs ouverts provenant de la base de données) et décide s'il doit prendre d'autres mesures ou répondre à l'utilisateur avec ces informations.
Pour voir tout cela en action, il est temps de créer l'agent assistant de bug QuantumRoast à l'aide d'ADK Python.
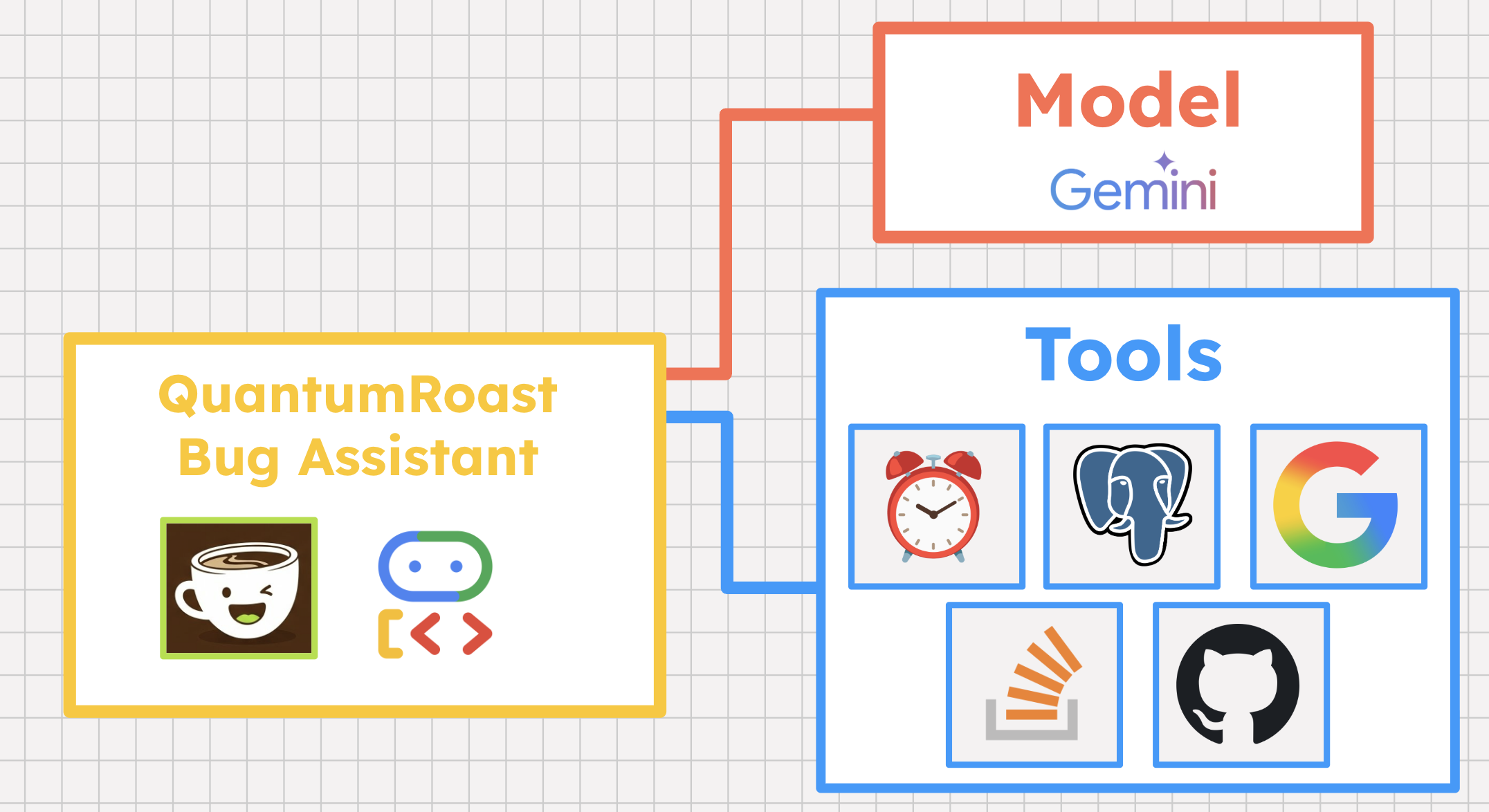
3. Avant de commencer
Configuration du projet Google Cloud
- Si vous ne possédez pas encore de compte Google, vous devez en créer un.
- Utilisez un compte personnel au lieu d'un compte professionnel ou scolaire. Il est possible que des restrictions s'appliquent aux comptes professionnels et scolaires, ce qui vous empêche d'activer les API nécessaires pour cet atelier.
- Connectez-vous à la console Google Cloud.
- Activez la facturation dans la console Cloud.
- Cet atelier devrait vous coûter moins de 1 USD en ressources Cloud.
- Vous pouvez suivre les étapes à la fin de cet atelier pour supprimer les ressources et éviter ainsi des frais supplémentaires.
- Les nouveaux utilisateurs peuvent bénéficier d'un essai sans frais pour bénéficier d'un crédit de 300$.
- Créez un projet ou réutilisez-en un existant.
Ouvrir l'éditeur Cloud Shell
- Accédez à l'éditeur Cloud Shell.
- Si le terminal ne s'affiche pas en bas de l'écran, ouvrez-le :
- Cliquez sur le menu hamburger
 .
. - Cliquez sur Terminal
- Cliquez sur Nouveau terminal
- Cliquez sur le menu hamburger
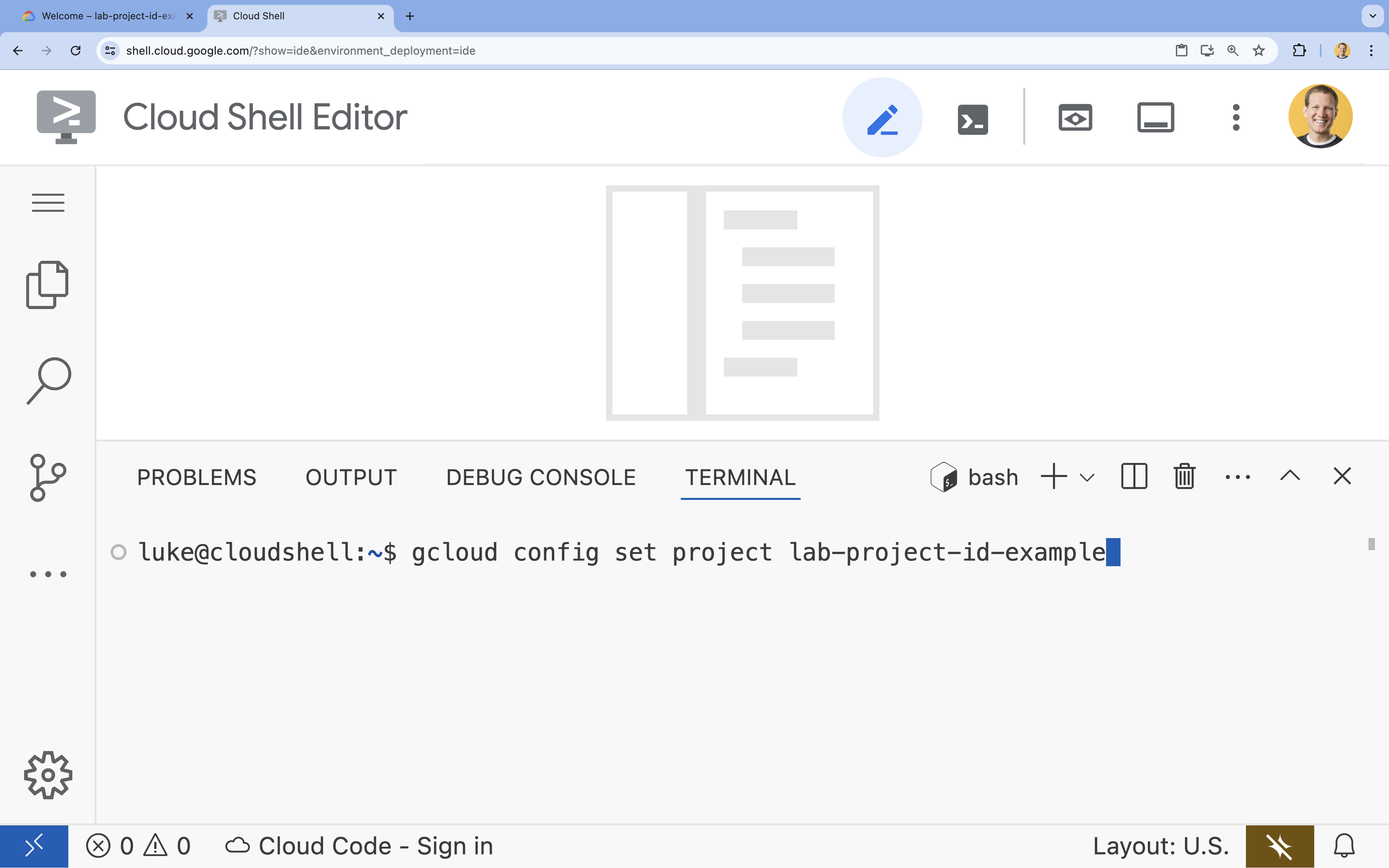
- Dans le terminal, définissez votre projet à l'aide de la commande suivante (en remplaçant
YOUR_PROJECT_ID) :- Format :
gcloud config set project YOUR_PROJECT_ID - Exemple :
gcloud config set project lab-project-id-example - Si vous ne vous souvenez pas de l'ID de votre projet :
- Vous pouvez lister tous vos ID de projet avec :
gcloud projects list | awk '/PROJECT_ID/{print $2}'
- Vous pouvez lister tous vos ID de projet avec :
- Format :
- Si vous êtes invité à autoriser l'accès, cliquez sur Autoriser pour continuer.
- Le message suivant doit s'afficher :
Updated property [core/project].
WARNINGs'affiche et que vous êtes invité àDo you want to continue (Y/N)?, cela signifie probablement que vous avez saisi l'ID de projet de manière incorrecte. Appuyez surN, puis surEnter, et réessayez d'exécuter la commandegcloud config set project. - Dans le terminal, définissez la variable d'environnement
PROJECT_IDà utiliser lors des étapes ultérieures.export PROJECT_ID=$(gcloud config get project)
Activer les API
Dans le terminal, exécutez la commande suivante pour activer les API Google Cloud nécessaires :
gcloud services enable sqladmin.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
secretmanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com \
run.googleapis.com \
artifactregistry.googleapis.com \
cloudbuild.googleapis.com
Créer une instance Cloud SQL pour PostgreSQL
QuantumRoast dispose d'une base de données de tickets de bug qui contient tous les tickets internes. Commençons par configurer une instance Cloud SQL pour PostgreSQL.
gcloud sql instances create software-assistant \
--database-version=POSTGRES_16 \
--tier=db-custom-1-3840 \
--region=europe-west4 \
--edition=ENTERPRISE \
--enable-google-ml-integration \
--database-flags cloudsql.enable_google_ml_integration=on \
--root-password=admin
Attendez que l'instance soit créée (cela peut prendre quelques minutes).
Une fois l'instance créée, vous pouvez l'afficher dans la console Cloud ici.
Créer une base de données Cloud SQL
Créez une base de données SQL (tickets-db) et accordez au compte de service Cloud SQL l'accès à Vertex AI (afin que nous puissions créer des embeddings pour effectuer une recherche par similarité).
gcloud sql databases create tickets-db --instance=software-assistant
SERVICE_ACCOUNT_EMAIL=$(gcloud sql instances describe software-assistant --format="value(serviceAccountEmailAddress)")
echo $SERVICE_ACCOUNT_EMAIL
gcloud projects add-iam-policy-binding $PROJECT_ID --member="serviceAccount:$SERVICE_ACCOUNT_EMAIL" --role="roles/aiplatform.user"
Configurer la table tickets
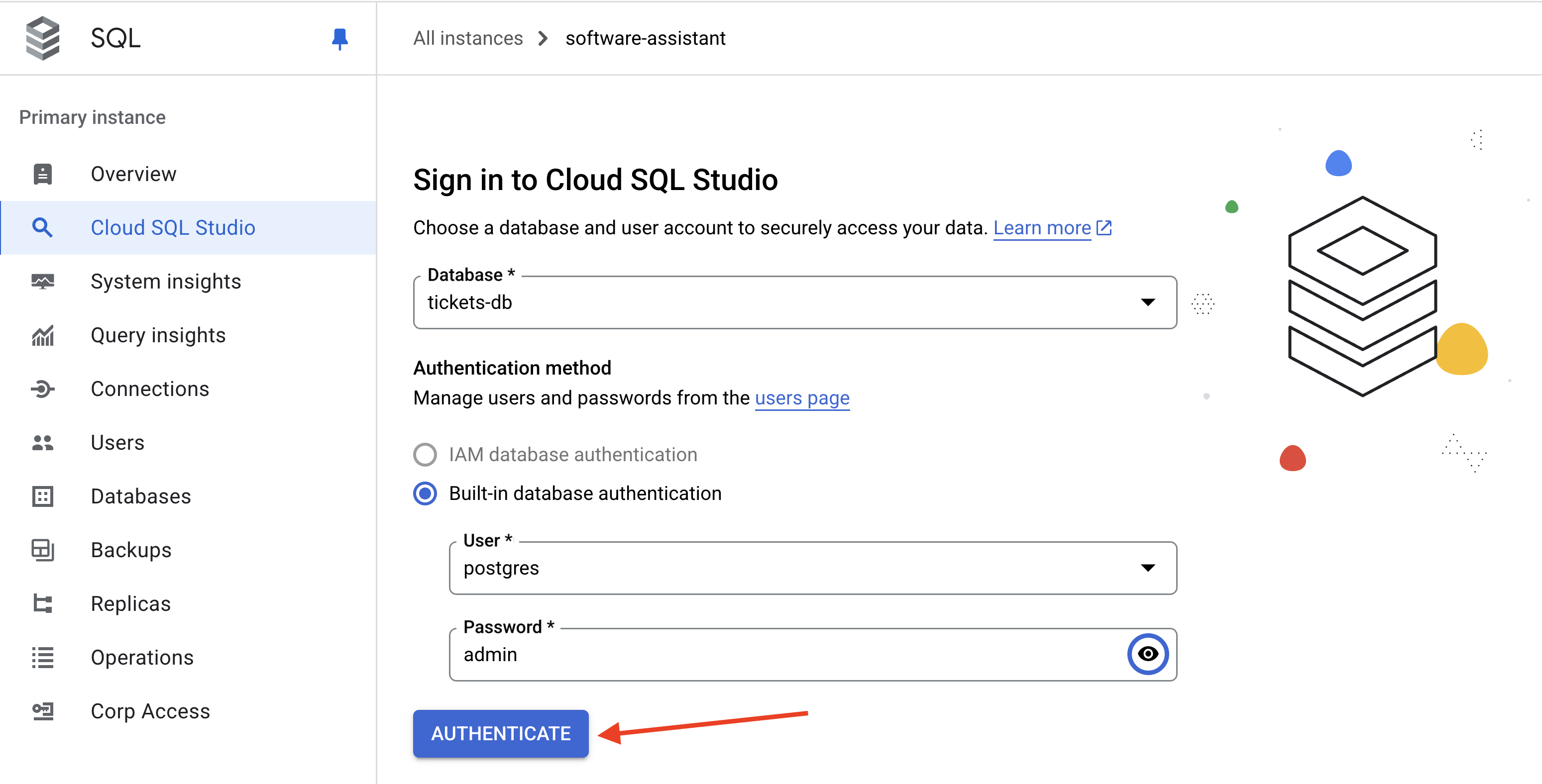
Dans la console Cloud (Cloud SQL), ouvrez Cloud SQL Studio pour l'instance software-assistant.
Connectez-vous à la base de données tickets-db à l'aide de l'utilisateur postgres et du mot de passe admin.
Ouvrez un nouvel onglet Editor.
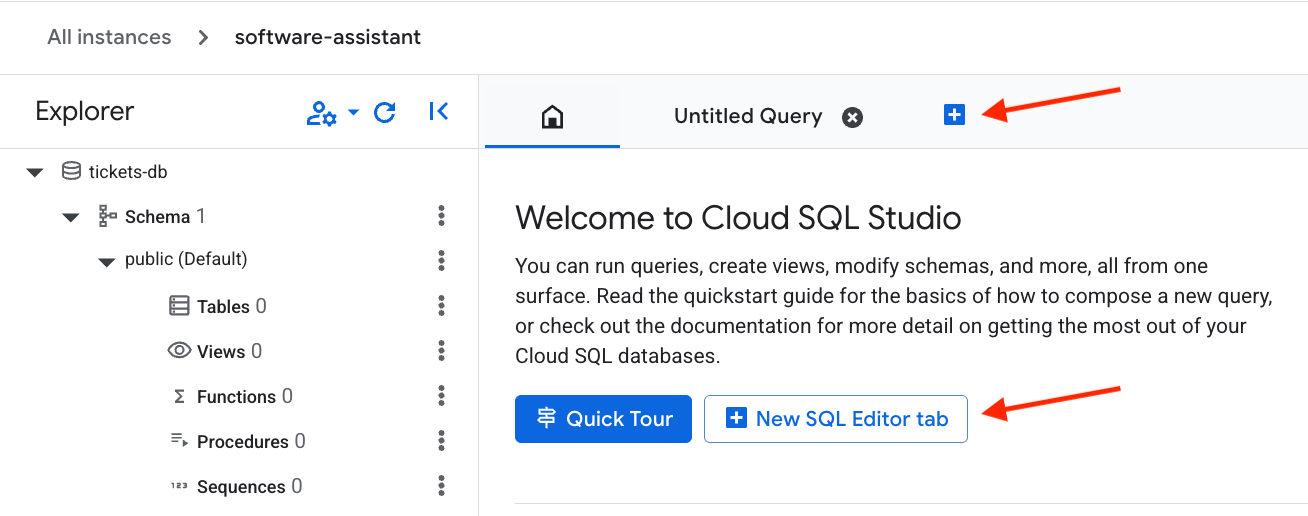
Collez ensuite le code SQL suivant pour configurer la table et créer des embeddings vectoriels. Appuyez sur le bouton Run pour exécuter la commande.
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector CASCADE;
GRANT EXECUTE ON FUNCTION embedding TO postgres;
CREATE TABLE tickets (
ticket_id SERIAL PRIMARY KEY, -- PostgreSQL's auto-incrementing integer type (SERIAL is equivalent to INT AUTO_INCREMENT)
title VARCHAR(255) NOT NULL, -- A concise summary or title of the bug/issue.
description TEXT, -- A detailed description of the bug.
assignee VARCHAR(100), -- The name or email of the person/team assigned to the ticket.
priority VARCHAR(50), -- The priority level (e.g., 'P0 - Critical', 'P1 - High').
status VARCHAR(50) DEFAULT 'Open', -- The current status of the ticket (e.g., 'Open', 'In Progress', 'Resolved'). Default is 'Open'.
creation_time TIMESTAMP WITH TIME ZONE DEFAULT CURRENT_TIMESTAMP, -- Timestamp when the ticket was first created. 'WITH TIME ZONE' is recommended for clarity and compatibility.
updated_time TIMESTAMP WITH TIME ZONE DEFAULT CURRENT_TIMESTAMP -- Timestamp when the ticket was last updated. Will be managed by a trigger.
);
La table tickets a été créée. Cliquez sur Clear pour effacer l'ancienne requête.
Insérez maintenant les exemples de données et cliquez de nouveau sur le bouton Run.
INSERT INTO tickets (title, description, assignee, priority, status) VALUES
('Login Page Freezes After Multiple Failed Attempts', 'Users are reporting that after 3 failed login attempts, the login page becomes unresponsive and requires a refresh. No specific error message is displayed.', 'samuel.green@example.com', 'P0 - Critical', 'Open');
INSERT INTO tickets (title, description, assignee, priority, status) VALUES
('Dashboard Sales Widget Intermittent Data Loading Failure', 'The "Sales Overview" widget on the main dashboard intermittently shows a loading spinner but no data. Primarily affects Chrome browser users.', 'maria.rodriguez@example.com', 'P1 - High', 'In Progress');
INSERT INTO tickets (title, description, assignee, priority, status) VALUES
('Broken Link in Footer - Privacy Policy', 'The "Privacy Policy" hyperlink located in the website footer leads to a 404 "Page Not Found" error.', 'maria.rodriguez@example.com', 'P3 - Low', 'Resolved');
INSERT INTO tickets (title, description, assignee, priority, status) VALUES
('UI Misalignment on Mobile Landscape View (iOS)', 'On specific iOS devices (e.g., iPhone 14 models), the top navigation bar shifts downwards when the device is viewed in landscape orientation, obscuring content.', 'maria.rodriguez@example.com', 'P2 - Medium', 'In Progress');
INSERT INTO tickets (title, description, assignee, priority, status) VALUES
('Critical XZ Utils Backdoor Detected in Core Dependency (CVE-2024-3094)', 'Urgent: A sophisticated supply chain compromise (CVE-2024-3094) has been identified in XZ Utils versions 5.6.0 and 5.6.1. This malicious code potentially allows unauthorized remote SSH access by modifying liblzma. Immediate investigation and action required for affected Linux/Unix systems and services relying on XZ Utils.', 'frank.white@example.com', 'P0 - Critical', 'Open');
INSERT INTO tickets (title, description, assignee, priority, status) VALUES
('Database Connection Timeouts During Peak Usage', 'The application is experiencing frequent database connection timeouts, particularly during peak hours (10 AM - 12 PM EDT), affecting all users and causing service interruptions.', 'frank.white@example.com', 'P1 - High', 'Open');
INSERT INTO tickets (title, description, assignee, priority, status) VALUES
('Export to PDF Truncates Long Text Fields in Reports', 'When generating PDF exports of reports containing extensive text fields, the text is abruptly cut off at the end of the page instead of wrapping or continuing to the next page.', 'samuel.green@example.com', 'P1 - High', 'Open');
INSERT INTO tickets (title, description, assignee, priority, status) VALUES
('Search Filter "Date Range" Not Applying Correctly', 'The "Date Range" filter on the search results page does not filter records accurately; results outside the specified date range are still displayed.', 'samuel.green@example.com', 'P2 - Medium', 'Resolved');
INSERT INTO tickets (title, description, assignee, priority, status) VALUES
('Typo in Error Message: "Unathorized Access"', 'The error message displayed when a user attempts an unauthorized action reads "Unathorized Access" instead of "Unauthorized Access."', 'maria.rodriguez@example.com', 'P3 - Low', 'Resolved');
INSERT INTO tickets (title, description, assignee, priority, status) VALUES
('Intermittent File Upload Failures for Large Files', 'Users are intermittently reporting that file uploads fail without a clear error message or explanation, especially for files exceeding 10MB in size.', 'frank.white@example.com', 'P1 - High', 'Open');
Chez QuantumRoast, nous pouvons avoir besoin de savoir quand un bug/une demande a été mis à jour pour la dernière fois.
Pour ce faire, nous pouvons créer un déclencheur pour mettre à jour le champ updated_time chaque fois qu'un enregistrement est modifié.
Cliquez sur Clear, puis collez le code SQL suivant pour implémenter un déclencheur.
Cliquez sur le bouton Run pour exécuter la requête.
CREATE OR REPLACE FUNCTION update_updated_time_tickets()
RETURNS TRIGGER AS $$
BEGIN
NEW.updated_time = NOW(); -- Set the updated_time to the current timestamp
RETURN NEW; -- Return the new row
END;
$$ language 'plpgsql';
CREATE TRIGGER update_tickets_updated_time
BEFORE UPDATE ON tickets
FOR EACH ROW -- This means the trigger fires for each row affected by the UPDATE statement
EXECUTE PROCEDURE update_updated_time_tickets();
Créez des embeddings vectoriels à partir du champ description. Cela permettra à notre agent d'effectuer une recherche par similarité dans notre base de données. Par exemple, "Y a-t-il des problèmes ouverts liés à la page d'accueil du site Web ?".
ALTER TABLE tickets ADD COLUMN embedding vector(768) GENERATED ALWAYS AS (embedding('text-embedding-005',description)) STORED;
Vous pouvez maintenant interroger la base de données pour vérifier qu'elle est prête.
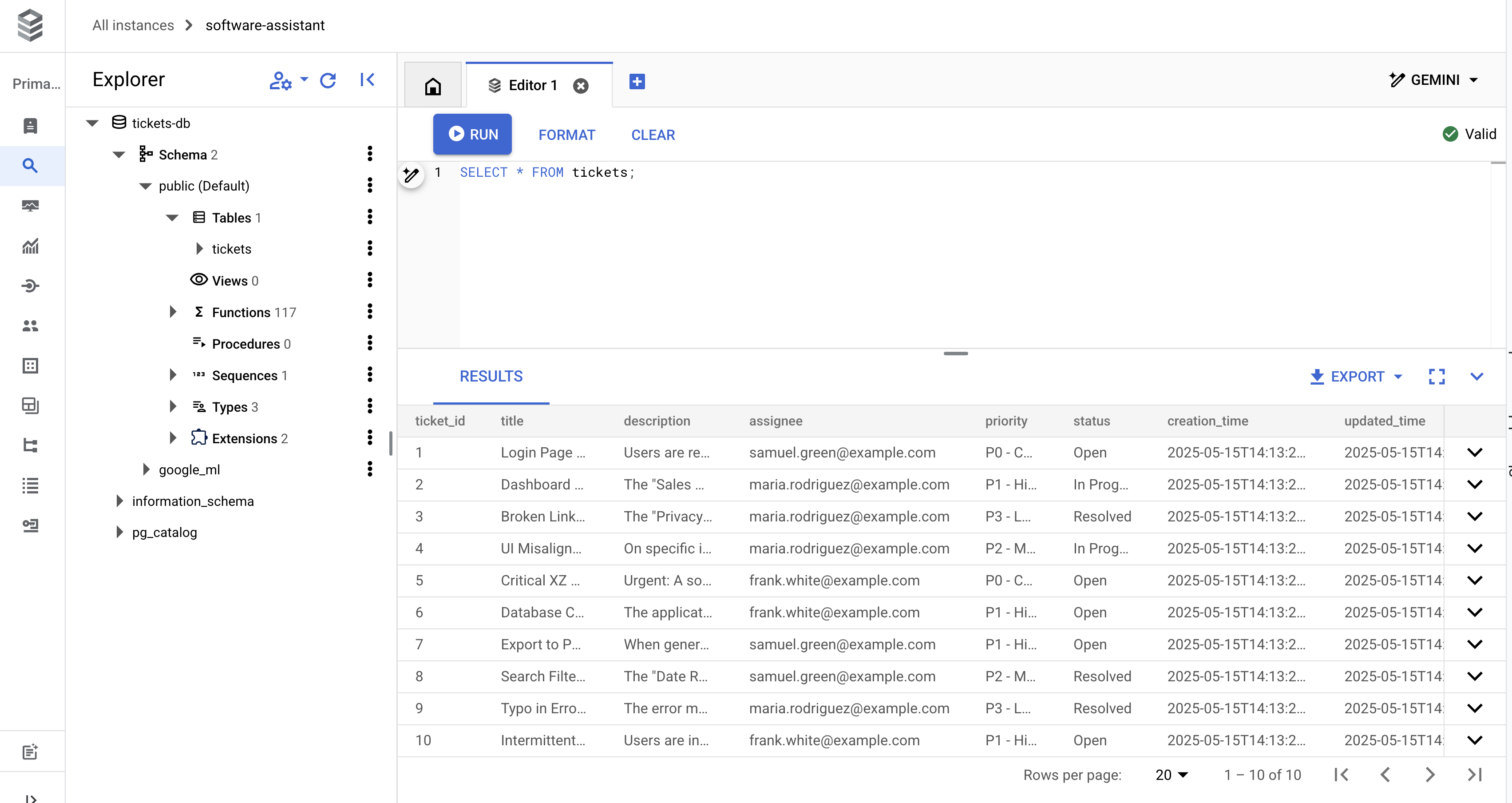
SELECT * FROM tickets;
Vous devriez obtenir 10 lignes semblables à celles-ci :
Vous êtes maintenant prêt à passer à la partie amusante : le code !
4. Configuration du projet Python
Avant de commencer à créer notre agent, nous devons nous assurer d'avoir configuré correctement un projet Python. Nous allons tout faire dans Cloud Shell !
Commencez par créer un dossier quantum-roast et utilisez cd pour y accéder :
mkdir quantum-roast && cd quantum-roast
Maintenant que nous avons un dossier pour notre projet, il est temps de l'initialiser et de créer les fichiers correspondants dont nous aurons besoin.
Nous allons utiliser uv (gestionnaire de paquets et de projets Python extrêmement rapide), qui est préinstallé dans Cloud Shell, pour gérer notre projet et nos dépendances. Uv nous aidera à configurer certains de nos fichiers et à gérer les environnements virtuels, les dépendances, etc.
Initialisez un projet avec uv init :
uv init --description "QuantumRoast Software Bug Assistant with ADK" --bare --python 3.10
Après avoir exécuté la commande, nous devrions avoir un fichier pyproject.toml pour notre projet. Pour vérifier, exécutez cat pyproject.toml dans le terminal Cloud Shell :
cat pyproject.toml
Le résultat suivant devrait s'afficher :
[project] name = "quantum-roast" version = "0.1.0" description = "QuantumRoast Software Bug Assistant with ADK" requires-python = ">=3.10" dependencies = []
Il est temps d'ajouter google-adk (ADK) en tant que dépendance à notre projet à l'aide de uv add.
uv add google-adk==1.11.0
Cela ajoute google-adk à la liste dependencies de notre pyproject.toml.
Pour obtenir les meilleurs résultats, ADK s'attend à une certaine structure de projet.
quantum-roast/
software_bug_assistant/
__init__.py
agent.py
.env
Créez le dossier software_bug_assistant et les fichiers qu'il contient :
mkdir software_bug_assistant && touch software_bug_assistant/__init__.py \
software_bug_assistant/agent.py \
software_bug_assistant/tools.py \
software_bug_assistant/.env
Vérifiez la création des fichiers à l'aide de ls :
ls -a software_bug_assistant/
Le résultat suivant doit s'afficher :
__init__.py . .. .env agent.py tools.py
Il est temps de remplir le fichier .env avec les variables d'environnement requises pour qu'ADK puisse appeler correctement les modèles Gemini. Nous accéderons à Gemini via l'API Vertex.
echo "GOOGLE_GENAI_USE_VERTEXAI=TRUE" >> software_bug_assistant/.env \
&& echo "GOOGLE_CLOUD_PROJECT=$PROJECT_ID" >> software_bug_assistant/.env \
&& echo "GOOGLE_CLOUD_LOCATION=europe-west4" >> software_bug_assistant/.env
Pour vérifier que .env a été renseigné correctement, exécutez la commande suivante :
cat software_bug_assistant/.env
Vous devriez voir ce qui suit, où your-project-id correspond à l'ID de votre projet :
GOOGLE_GENAI_USE_VERTEXAI=TRUE GOOGLE_CLOUD_PROJECT=your-project-id GOOGLE_CLOUD_LOCATION=europe-west4
Nous sommes maintenant prêts à commencer à créer notre agent ADK.
5. Agent ADK de base
Commençons par configurer un agent ADK de base auquel nous pourrons ajouter des outils un par un au cours de cet atelier pour créer un puissant assistant de bug !
Ouvrez agent.py dans l'éditeur Cloud Shell :
cloudshell edit software_bug_assistant/agent.py
Collez le code suivant dans agent.py et enregistrez le fichier Ctrl + s :
from google.adk.agents import Agent
# --- Agent Definition (model, instructions, tools) ---
root_agent = Agent(
model="gemini-2.5-flash",
name="software_assistant",
instruction="""
You are a skilled expert in triaging and debugging software issues for a
coffee machine company, QuantumRoast.
""",
tools=[],
)
Exécutez l'agent que vous venez de créer en démarrant l'UI de développement d'ADK (adk web). Si vous le faites avec uv run, un environnement virtuel avec ADK installé sera automatiquement créé.
uv run adk web --port 8080 --reload_agents
Dans la console, vous devriez voir le serveur Web ADK démarrer correctement.
INFO: Started server process [1557] INFO: Waiting for application startup. +-----------------------------------------------------------------------------+ | ADK Web Server started | | | | For local testing, access at http://localhost:8080. | +-----------------------------------------------------------------------------+ INFO: Application startup complete. INFO: Uvicorn running on http://127.0.0.1:8080 (Press CTRL+C to quit)
Ouvrez l'aperçu sur le Web de Cloud Shell pour afficher l'UI.
L'interface utilisateur Web de l'ADK devrait s'afficher.
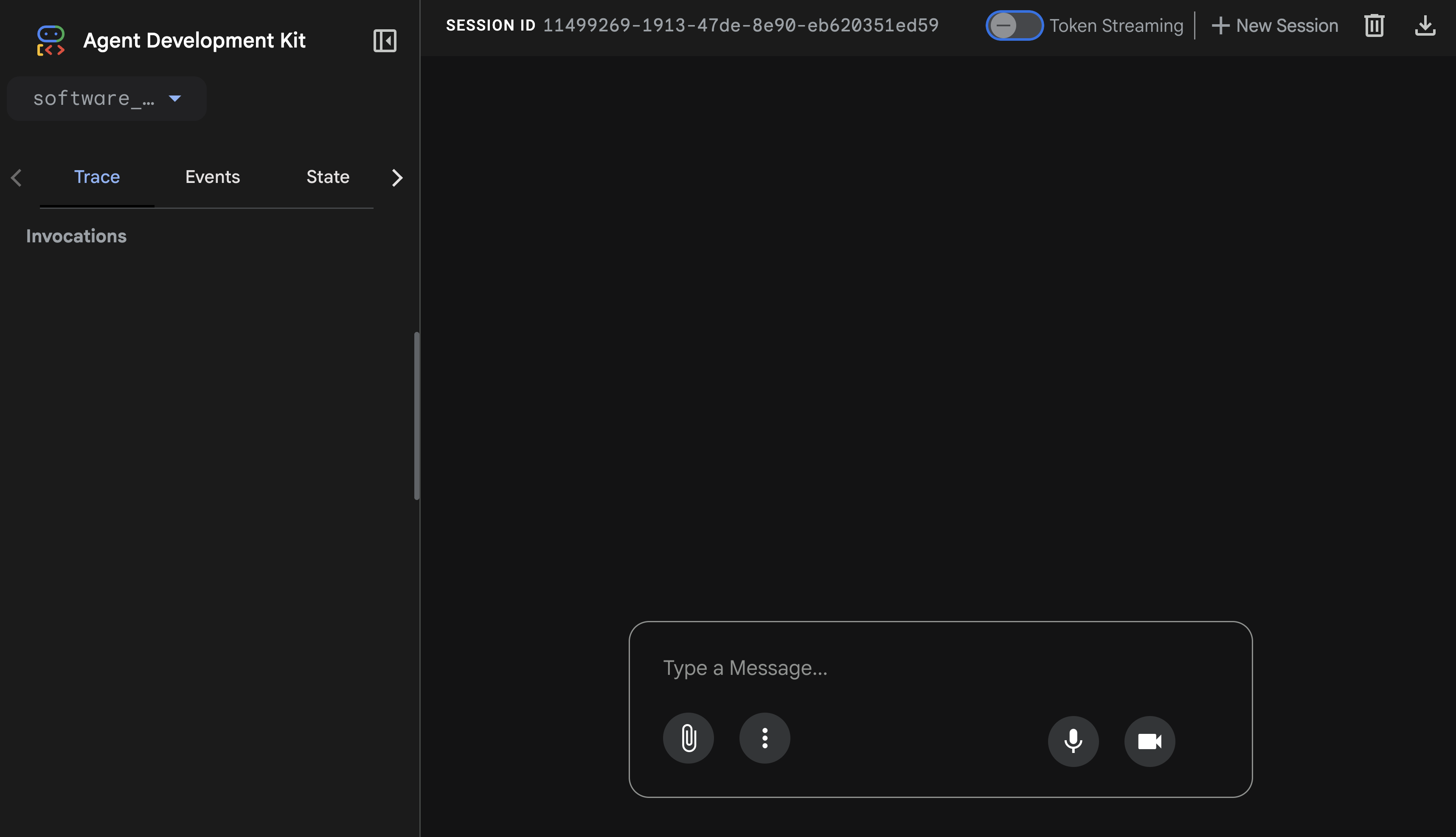
N'hésitez pas à discuter avec l'agent ADK.
Demandez à l'agent What day is it today?.
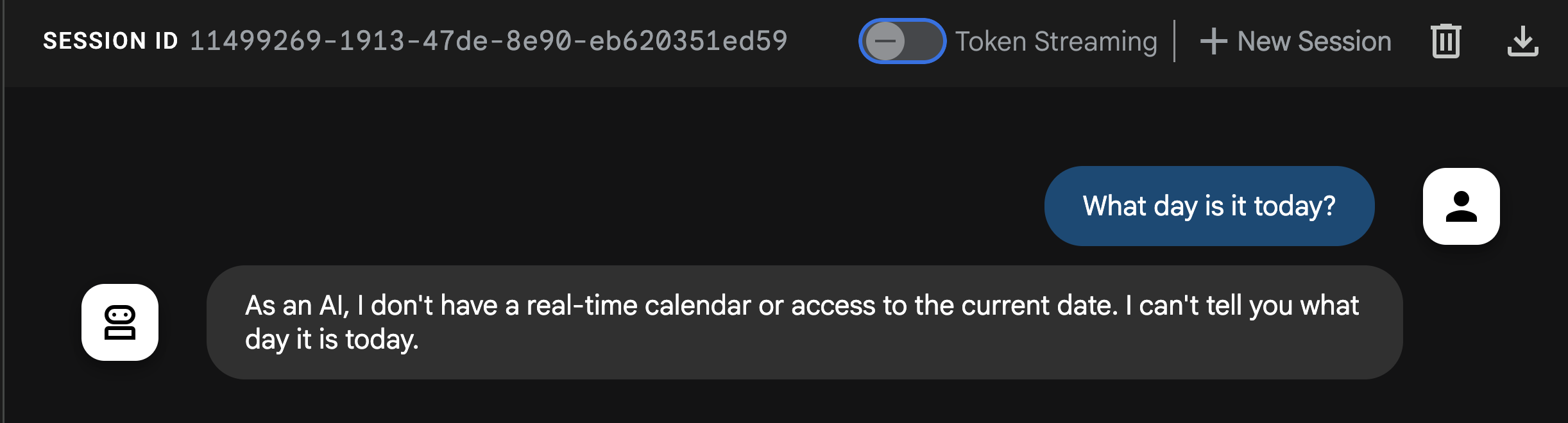
Vous remarquerez dans la réponse que l'agent ne peut pas répondre à cette question de base. Rappelons que les LLM sont des systèmes isolés, entraînés sur des données passées. Ils n'ont pas de contexte en temps réel sur les événements récents ni même sur la date actuelle… sauf si vous leur donnez des outils !
Il est temps d'implémenter le premier type d'outil d'ADK, un outil de fonction.
6. Outil de fonction
Le premier et le plus simple type d'outil ADK est l'outil de fonction. Comme son nom l'indique, il s'agit d'une fonction Python appelée par l'agent.

Les outils de fonction sont très puissants, car ils vous permettent d'écrire du code personnalisé que l'agent peut appeler en tant qu'outil, par exemple pour effectuer un calcul, appeler une API ou interroger une base de données. Il peut s'agir de fonctions simples ou complexes, c'est à vous de choisir.
Chez QuantumRoast , nous souhaitons définir une fonction de base pour obtenir la date du jour, afin de pouvoir traiter ultérieurement des requêtes telles que "montre-moi les bugs de la semaine dernière" ou"quel jour sommes-nous aujourd'hui ?" (cela nous arrive à tous).
Le fichier tools.py du dossier /software_bug_assistant nous permettra d'organiser tous les outils que nous allons créer dans cet atelier.
Ouvrez un NOUVEAU terminal en cliquant sur l'icône +.
Dans le nouveau terminal, définissez PROJECT_ID et ouvrez tools.py :
cd quantum-roast
export PROJECT_ID=$(gcloud config get project)
cloudshell edit software_bug_assistant/tools.py
Définissez maintenant la fonction get_current_date qui sera utilisée comme outil de fonction.
from datetime import datetime
# ----- Example of a Function tool -----
def get_current_date() -> dict:
"""
Get the current date in the format YYYY-MM-DD
"""
return {"current_date": datetime.now().strftime("%Y-%m-%d")}
La fonction est maintenant définie. Il est temps de le transmettre à l'agent en tant qu'outil.
Ouvrez agent.py dans l'éditeur Cloud Shell :
cloudshell edit software_bug_assistant/agent.py
Nous souhaitons importer la fonction get_current_date à partir de tools.py et transmettre la fonction à l'argument tools de l'agent.
Le composable agent.py mis à jour se présente comme suit :
from google.adk.agents import Agent
from .tools import get_current_date
# --- Agent Definition (model, instructions, tools) ---
root_agent = Agent(
model="gemini-2.5-flash",
name="software_assistant",
instruction="""
You are a skilled expert in triaging and debugging software issues for a
coffee machine company, QuantumRoast.
""",
tools=[get_current_date],
)
Maintenant, si vous revenez à l'onglet "Aperçu sur le Web" exécutant l'UI Web d'ADK et que vous demandez à nouveau What day is it today?…
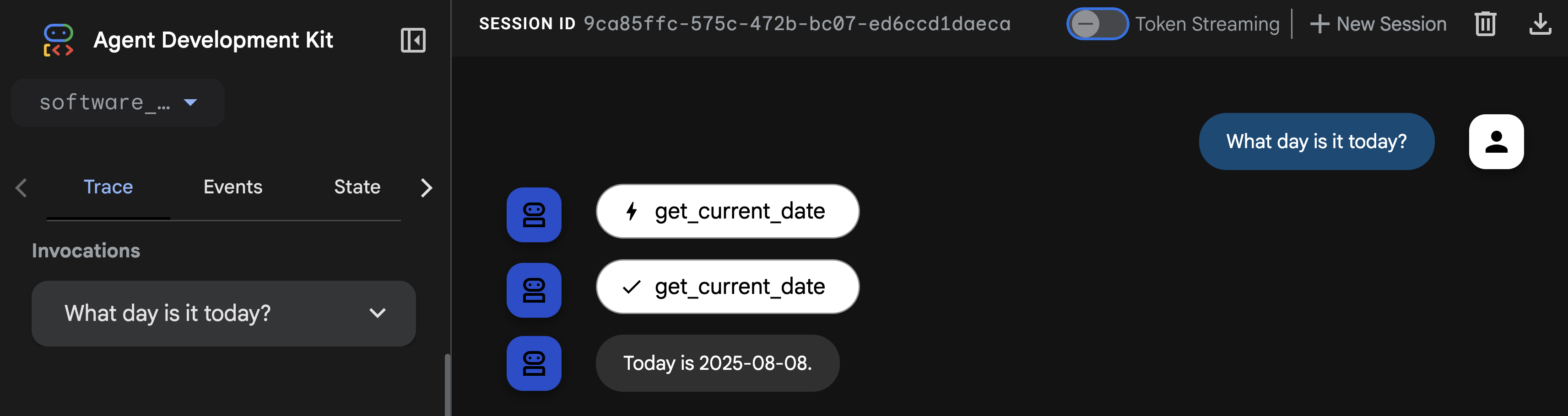
L'agent peut indiquer la date en appelant l'outil de fonction get_current_date. 🎉
Il est temps d'explorer le prochain type d'outil ADK.
7. Outil intégré
Un autre type d'outil ADK est l'outil intégré. Il s'agit d'outils qui fonctionnent avec les principales fonctionnalités du modèle de Google, comme l'exécution de code à l'intérieur du modèle lui-même. Nous pouvons associer l'outil intégré Recherche Google à notre agent d'assistance pour les bugs afin de l'ancrer dans un contexte pertinent en lui donnant accès à la recherche sur le Web. Cela permettra à l'agent de recueillir des informations plus récentes sur un bug ou une faille de sécurité connue.

Ouvrez le fichier tools.py pour ajouter la prise en charge de l'outil intégré Recherche Google.
cloudshell edit software_bug_assistant/tools.py
Ajoutez les lignes suivantes en bas de tools.py :
# ----- Built-in Tool Imports -----
from google.adk.agents import Agent
from google.adk.tools import google_search
from google.adk.tools.agent_tool import AgentTool
# ----- Example of a Built-in Tool -----
search_agent = Agent(
model="gemini-2.5-flash",
name="search_agent",
description="A specialist in Google Search.",
instruction="""
You're a specialist in Google Search.
""",
tools=[google_search],
)
search_tool = AgentTool(search_agent)
Ici, nous enveloppons en fait cet outil de recherche Google dans son propre agent avec ses propres instructions système, en utilisant efficacement un agent comme outil.
Nous pouvons maintenant importer et transmettre le search_tool à l'agent racine dans agent.py :
cloudshell edit software_bug_assistant/agent.py
Vous pouvez remplacer agent.py par le code suivant pour inclure search_tool :
from google.adk.agents import Agent
from .tools import get_current_date, search_tool
# --- Agent Definition (model, instructions, tools) ---
root_agent = Agent(
model="gemini-2.5-flash",
name="software_assistant",
instruction="""
You are a skilled expert in triaging and debugging software issues for a
coffee machine company, QuantumRoast.
""",
tools=[get_current_date, search_tool],
)
Enregistrez le fichier et revenez à l'onglet ouvert sur lequel l'interface utilisateur Web de l'ADK est en cours d'exécution.
Chez QuantumRoast, nous voulons nous assurer que notre site Web et nos logiciels sont protégés contre les failles et expositions courantes (CVE, Common Vulnerabilities and Exposures), qui sont des failles de cybersécurité publiques. Nous pouvons utiliser le nouvel outil de recherche Google de notre agent pour rechercher les CVE les plus récemment découvertes sur le Web.
Exécutez la requête suivante : Do a web search for 5 of the most recent CVEs?.
Notre agent doit appeler search_agent pour effectuer une recherche sur le Web.
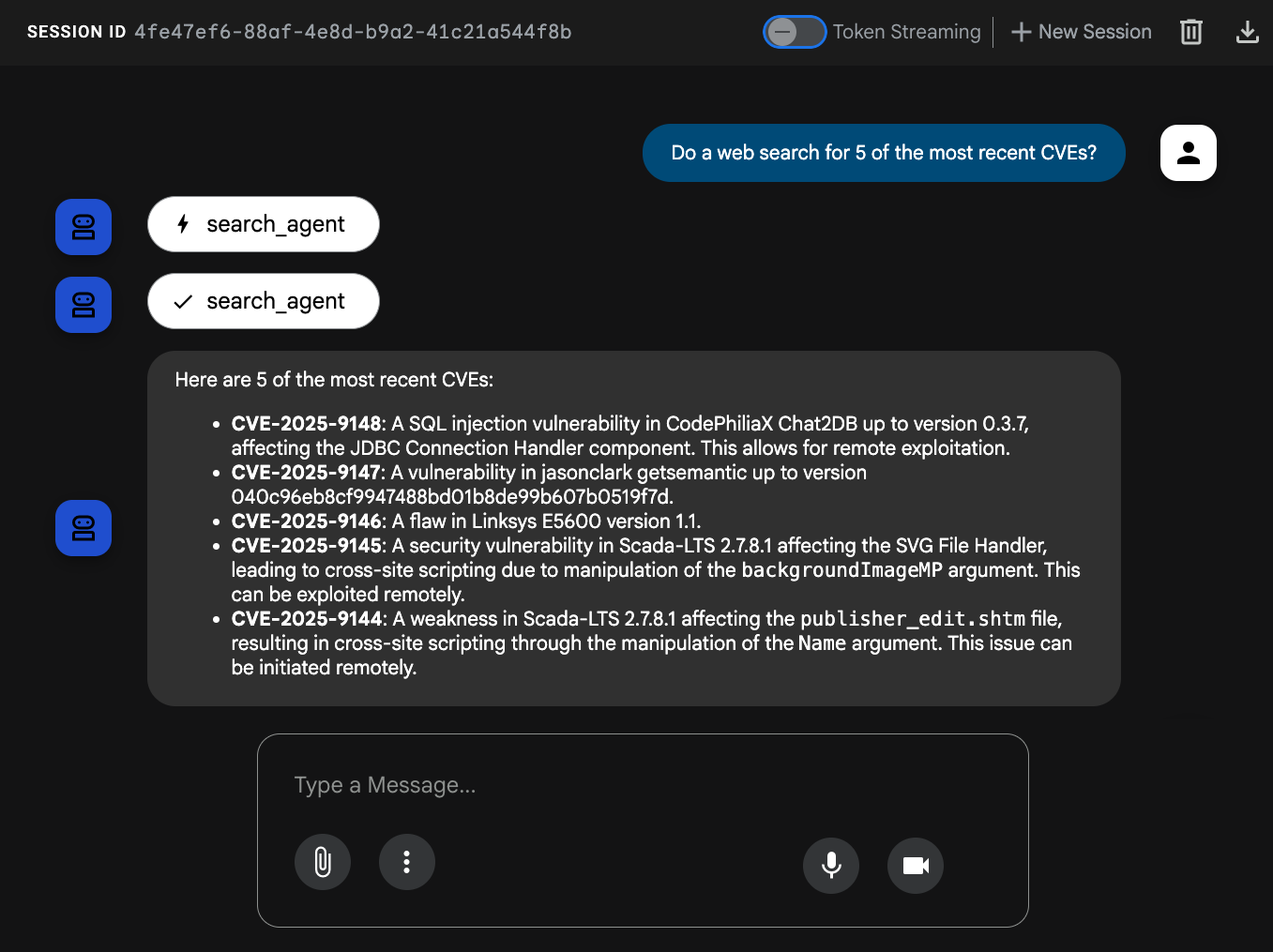
Notre agent a maintenant réussi à débloquer la possibilité d'effectuer des recherches sur le Web grâce à l'outil intégré d'ADK pour la recherche Google. 🎉
Passons au type d'outil ADK suivant.
8. Outil tiers
ADK est conçu pour être hautement extensible, ce qui vous permet d'intégrer facilement des outils provenant d'autres frameworks d'agents d'IA tiers comme CrewAI et LangChain. Cette interopérabilité est essentielle, car elle permet de réduire le temps de développement et de réutiliser les outils existants.

Pour connecter notre agent de bug aux puissantes données de questions/réponses de Stack Overflow, nous pouvons utiliser la bibliothèque d'outils étendue de LangChain, en particulier l'outil StackExchange API Wrapper. ADK est compatible avec les outils tiers comme LangChain. Il suffit donc de quelques lignes de code pour ajouter cet outil à notre agent ADK.
Nous devons d'abord ajouter de nouvelles dépendances pour LangChain et Stack Overflow (langchain-community et stackapi) à notre projet :
uv add langchain-community==0.3.27 stackapi==0.3.1
Ouvrez le fichier tools.py pour ajouter la compatibilité avec l'outil LangChain StackExchange.
cloudshell edit software_bug_assistant/tools.py
Ajoutez les lignes suivantes en bas de tools.py :
# ----- Example of a Third-Party Tool -----
from google.adk.tools.langchain_tool import LangchainTool
from langchain_community.tools import StackExchangeTool
from langchain_community.utilities import StackExchangeAPIWrapper
stack_exchange_tool = StackExchangeTool(api_wrapper=StackExchangeAPIWrapper())
langchain_tool = LangchainTool(stack_exchange_tool)
Nous pouvons maintenant importer et transmettre le langchain_tool à l'agent racine dans agent.py :
cloudshell edit software_bug_assistant/agent.py
Vous pouvez remplacer agent.py par le code suivant pour inclure langchain_tool :
from google.adk.agents import Agent
from .tools import get_current_date, langchain_tool, search_tool
# --- Agent Definition (model, instructions, tools) ---
root_agent = Agent(
model="gemini-2.5-flash",
name="software_assistant",
instruction="""
You are a skilled expert in triaging and debugging software issues for a
coffee machine company, QuantumRoast.
""",
tools=[get_current_date, search_tool, langchain_tool],
)
Enregistrez le fichier et revenez à l'onglet ouvert avec l'interface utilisateur Web ADK.
Essayez de poser à l'agent une question sur les CVE précédentes, "Are there similar issues on stack exchange?", ou sur une nouvelle, comme "Our database queries with SQLAlchemy seem to be timing out, is there anything on StackExchange relevant to this?".
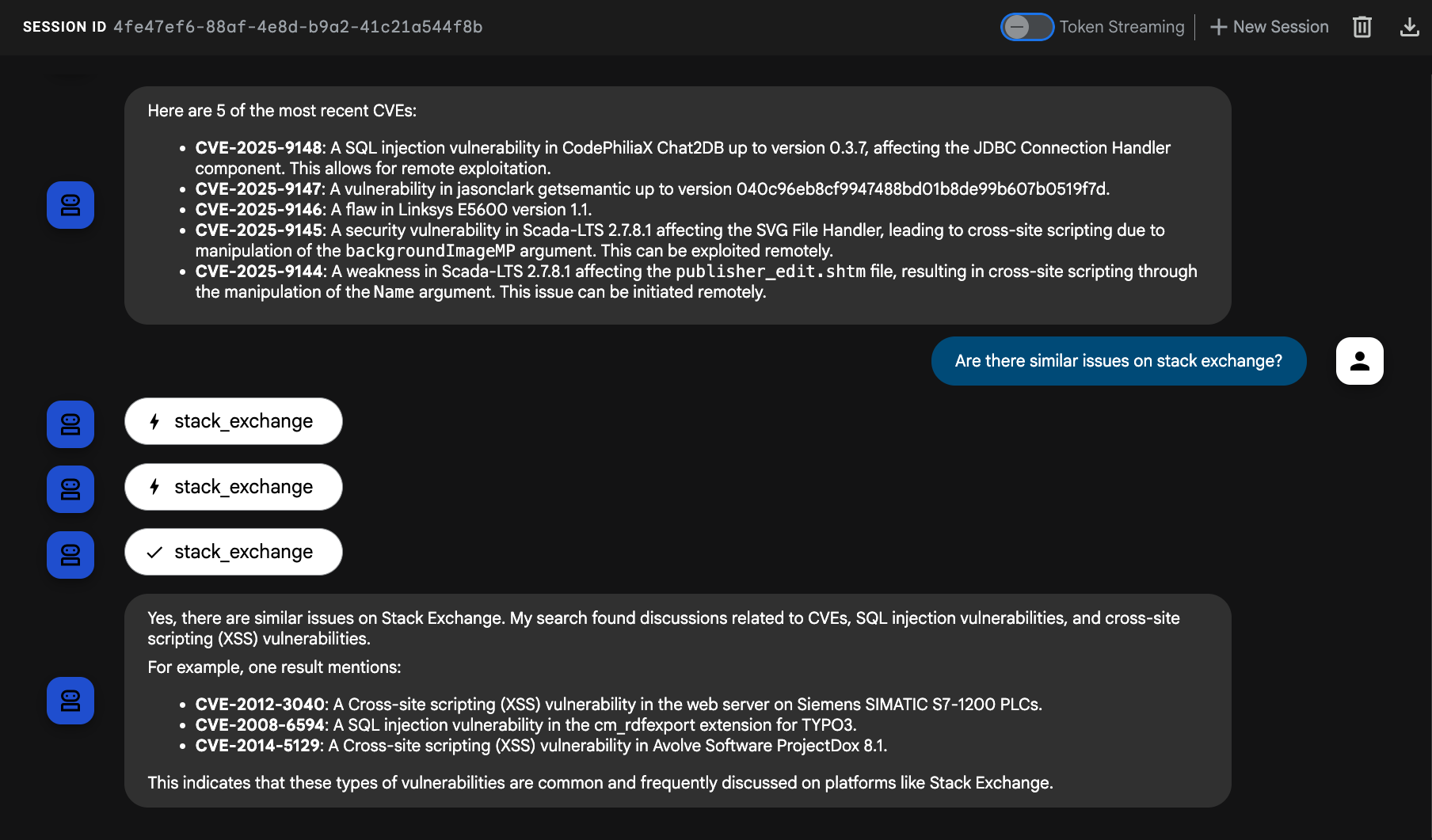
Notre agent a maintenant utilisé un outil LangChain dans ADK pour interroger Stack Overflow. 🥳
Passons au type d'outil ADK suivant… Outils MCP !
9. Outil MCP (base de données)
MCP signifie Model Context Protocol. Il s'agit d'un protocole ouvert introduit par Anthropic en 2024. MCP fournit une couche d'abstraction entre votre agent d'IA et les "backends" d'outils (API, bases de données).
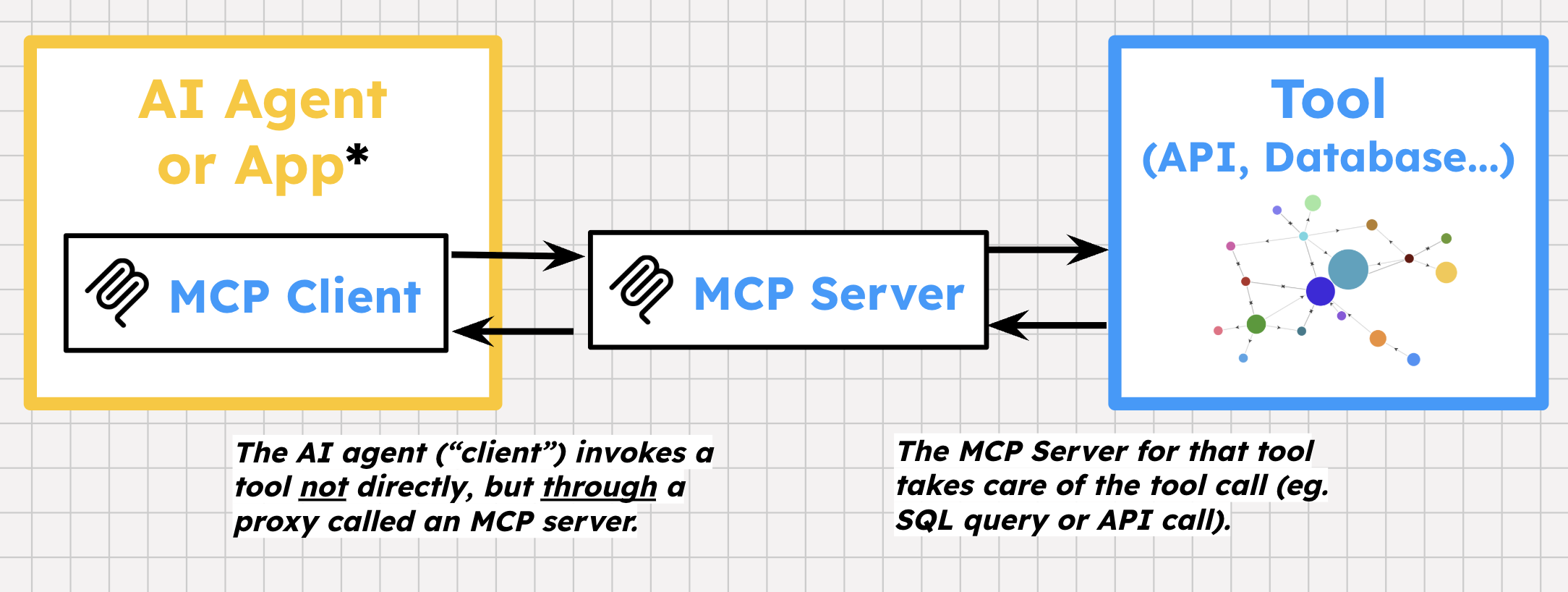
Le MCP présente des spécifications uniques. Contrairement au protocole HTTP standard, le protocole MCP fournit une connexion bidirectionnelle avec état entre le client et le serveur. Il possède sa propre façon de définir les outils et les messages d'erreur spécifiques aux outils. Un fournisseur d'outils peut ensuite créer des serveurs MCP au-dessus de ses API, en exposant un ou plusieurs outils prédéfinis pour les développeurs et les utilisateurs. Les frameworks d'agent peuvent ensuite initialiser des clients MCP dans une application d'agent pour découvrir et appeler ces outils.
Chez QuantumRoast, nous disposons d'une base de données Cloud SQL pour PostgreSQL pour les bugs logiciels internes. Nous souhaitons créer des outils ADK pour que notre agent puisse effectuer certaines requêtes sur notre base de données.

La méthode la plus simple consiste à utiliser MCP Toolbox for Databases , un serveur MCP Open Source pour les bases de données. Toolbox est compatible avec plus de 15 bases de données, dont Cloud SQL.
La boîte à outils fournit les éléments suivants :
- Développement simplifié : intégrez des outils à votre agent en moins de 10 lignes de code, réutilisez des outils entre plusieurs agents ou frameworks, et déployez plus facilement de nouvelles versions d'outils.
- Meilleures performances : bonnes pratiques telles que le regroupement de connexions, l'authentification, etc.
- Sécurité renforcée : authentification intégrée pour un accès plus sécurisé à vos données
- Observabilité de bout en bout : métriques et traçage prêts à l'emploi avec prise en charge intégrée d'OpenTelemetry.
ADK est compatible avec les outils MCP Toolbox for Databases, ce qui permet une intégration rapide.

Déployer le serveur MCP Toolbox for Databases sur Cloud Run
Nous allons d'abord déployer le serveur MCP Toolbox for Databases sur Cloud Run et le pointer vers notre instance Cloud SQL.
Toolbox nécessite un fichier YAML pour la configuration, dans lequel vous décrivez la source de données et les outils à configurer.
Créez un fichier tools.yaml pour le déploiement.
cloudshell edit tools.yaml
Collez le contenu suivant dans le fichier tools.yaml :
sources:
postgresql:
kind: cloud-sql-postgres
project: ${PROJECT_ID}
region: europe-west4
instance: software-assistant
database: tickets-db
user: postgres
password: admin
tools:
search-tickets:
kind: postgres-sql
source: postgresql
description: Search for similar tickets based on their descriptions.
parameters:
- name: query
type: string
description: The query to perform vector search with.
statement: |
SELECT ticket_id, title, description, assignee, priority, status, (embedding <=> embedding('text-embedding-005', $1)::vector) as distance
FROM tickets
ORDER BY distance ASC
LIMIT 3;
get-ticket-by-id:
kind: postgres-sql
source: postgresql
description: Retrieve a ticket's details using its unique ID.
parameters:
- name: ticket_id
type: string
description: The unique ID of the ticket.
statement: SELECT * FROM tickets WHERE ticket_id = $1;
get-tickets-by-assignee:
kind: postgres-sql
source: postgresql
description: Search for tickets based on assignee (email).
parameters:
- name: assignee
type: string
description: The email of the assignee.
statement: SELECT * FROM tickets WHERE assignee ILIKE '%' || $1 || '%';
update-ticket-priority:
kind: postgres-sql
source: postgresql
description: Update the priority of a ticket based on its ID.
parameters:
- name: priority
type: string
description: The priority of the ticket. Can be one of 'P0 - Critical', 'P1 - High', 'P2 - Medium', or 'P3 - Low'.
- name: ticket_id
type: string
description: The ID of the ticket.
statement: UPDATE tickets SET priority = $1 WHERE ticket_id = $2;
update-ticket-status:
kind: postgres-sql
source: postgresql
description: Update the status of a ticket based on its ID.
parameters:
- name: status
type: string
description: The new status of the ticket (e.g., 'Open', 'In Progress', 'Closed', 'Resolved').
- name: ticket_id
type: string
description: The ID of the ticket.
statement: UPDATE tickets SET status = $1 WHERE ticket_id = $2;
get-tickets-by-status:
kind: postgres-sql
source: postgresql
description: Search for tickets based on their current status.
parameters:
- name: status
type: string
description: The status of the tickets to retrieve (e.g., 'Open', 'In Progress', 'Closed', 'Resolved').
statement: SELECT * FROM tickets WHERE status ILIKE '%' || $1 || '%';
get-tickets-by-priority:
kind: postgres-sql
source: postgresql
description: Search for tickets based on their priority.
parameters:
- name: priority
type: string
description: The priority of the tickets to retrieve (e.g., 'P0 - Critical', 'P1 - High', 'P2 - Medium', 'P3 - Low').
statement: SELECT * FROM tickets WHERE priority ILIKE '%' || $1 || '%';
create-new-ticket:
kind: postgres-sql
source: postgresql
description: Create a new software ticket.
parameters:
- name: title
type: string
description: The title of the new ticket.
- name: description
type: string
description: A detailed description of the bug or issue.
- name: assignee
type: string
description: (Optional) The email of the person to whom the ticket should be assigned.
- name: priority
type: string
description: (Optional) The priority of the ticket. Can be 'P0 - Critical', 'P1 - High', 'P2 - Medium', or 'P3 - Low'. Default is 'P3 - Low'.
- name: status
type: string
description: (Optional) The initial status of the ticket. Default is 'Open'.
statement: INSERT INTO tickets (title, description, assignee, priority, status) VALUES ($1, $2, $3, COALESCE($4, 'P3 - Low'), COALESCE($5, 'Open')) RETURNING ticket_id;
get-tickets-by-date-range:
kind: postgres-sql
source: postgresql
description: Retrieve tickets created or updated within a specific date range.
parameters:
- name: start_date
type: string
description: The start date (inclusive) for the range (e.g., 'YYYY-MM-DD').
- name: end_date
type: string
description: The end date (inclusive) for the range (e.g., 'YYYY-MM-DD').
- name: date_field
type: string
description: The date field to filter by ('creation_time' or 'updated_time').
statement: SELECT * FROM tickets WHERE CASE WHEN $3 = 'creation_time' THEN creation_time ELSE updated_time END BETWEEN $1::timestamp AND $2::timestamp;
toolsets:
tickets_toolset:
- search-tickets
- get-ticket-by-id
- get-tickets-by-assignee
- get-tickets-by-status
- get-tickets-by-priority
- get-tickets-by-date-range
- update-ticket-priority
- update-ticket-status
- create-new-ticket
Le fichier YAML définit neuf outils liés à la base de données des tickets QuantumRoast.
Il est temps de configurer un compte de service pour le service Cloud Run de la boîte à outils, de lui accorder l'autorisation d'accéder à Cloud SQL et Secret Manager, et de créer un secret Secret Manager pour notre fichier tools.yaml.
Nous allons stocker notre fichier tools.yaml dans Secret Manager, car il contient des identifiants Cloud SQL sensibles.
gcloud iam service-accounts create toolbox-identity
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member serviceAccount:toolbox-identity@$PROJECT_ID.iam.gserviceaccount.com \
--role roles/secretmanager.secretAccessor
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member serviceAccount:toolbox-identity@$PROJECT_ID.iam.gserviceaccount.com \
--role roles/cloudsql.client
gcloud secrets create tools --data-file=tools.yaml
Il est temps de déployer MCP Toolbox for Databases sur Cloud Run. Nous allons utiliser la dernière version de l'image de conteneur MCP Toolbox.
gcloud run deploy toolbox \
--image us-central1-docker.pkg.dev/database-toolbox/toolbox/toolbox:latest \
--service-account toolbox-identity \
--region europe-west4 \
--set-secrets "/app/tools.yaml=tools:latest" \
--set-env-vars="PROJECT_ID=$PROJECT_ID" \
--args="--tools-file=/app/tools.yaml","--address=0.0.0.0","--port=8080" \
--labels=dev-tutorial=codelab-toolbox \
--no-invoker-iam-check
Attendez la fin du déploiement…
Vérifiez que Toolbox est en cours d'exécution en interrogeant les journaux Cloud Run :
gcloud run services logs read toolbox --region europe-west4 --limit 10
Vous devriez obtenir le résultat suivant :
2025-08-20 18:03:55 2025-08-20T18:03:55.465847801Z INFO "Initialized 1 sources." 2025-08-20 18:03:55 2025-08-20T18:03:55.466152914Z INFO "Initialized 0 authServices." 2025-08-20 18:03:55 2025-08-20T18:03:55.466374245Z INFO "Initialized 9 tools." 2025-08-20 18:03:55 2025-08-20T18:03:55.466477938Z INFO "Initialized 2 toolsets." 2025-08-20 18:03:55 2025-08-20T18:03:55.467492303Z INFO "Server ready to serve!"
Enregistrez l'URL Cloud Run du service Toolbox en tant que variable d'environnement afin que l'agent ADK sache où la trouver.
export MCP_TOOLBOX_URL=$(gcloud run services describe toolbox --region europe-west4 --format "value(status.url)")
echo MCP_TOOLBOX_URL=$MCP_TOOLBOX_URL >> software_bug_assistant/.env
Mettre à jour l'agent QuantumRoast
Ensuite, nous devons ajouter la dépendance pour le SDK MCP Toolbox for Databases (toolbox-core) à notre projet :
uv add toolbox-core==0.5.0
Ouvrez le fichier tools.py pour ajouter la compatibilité avec les outils MCP Toolbox.
cloudshell edit software_bug_assistant/tools.py
Ajoutez les lignes suivantes en bas de tools.py :
# ----- Example MCP Toolbox for Databases tools -----
import os
from toolbox_core import ToolboxSyncClient
TOOLBOX_URL = os.getenv("MCP_TOOLBOX_URL", "http://127.0.0.1:5000")
# Initialize Toolbox client
toolbox = ToolboxSyncClient(TOOLBOX_URL)
# Load all the tools from toolset
toolbox_tools = toolbox.load_toolset("tickets_toolset")
Nous pouvons maintenant importer et transmettre le toolbox_tools à l'agent racine dans agent.py :
cloudshell edit software_bug_assistant/agent.py
Vous pouvez remplacer agent.py par le code suivant pour inclure toolbox_tools :
from google.adk.agents import Agent
from .tools import get_current_date, langchain_tool, search_tool, toolbox_tools
# --- Agent Definition (model, instructions, tools) ---
root_agent = Agent(
model="gemini-2.5-flash",
name="software_assistant",
instruction="""
You are a skilled expert in triaging and debugging software issues for a
coffee machine company, QuantumRoast.
""",
tools=[get_current_date, search_tool, langchain_tool, *toolbox_tools],
)
Enregistrez le fichier et revenez à l'onglet ouvert avec l'interface utilisateur Web ADK.
Vous pouvez désormais poser des questions sur les tickets stockés dans notre base de données interne Cloud SQL.
Posez une question comme l'une des suivantes :
I am seeing an issue with database timeouts, has anyone else seen a similar issue?How many bugs are assigned to samuel.green@example.com? Show a table.Can you bump the priority of ticket with ID 6 to to P0 - Critical priorityCreate a new ticket(laissez l'agent vous guider pour créer un bug)
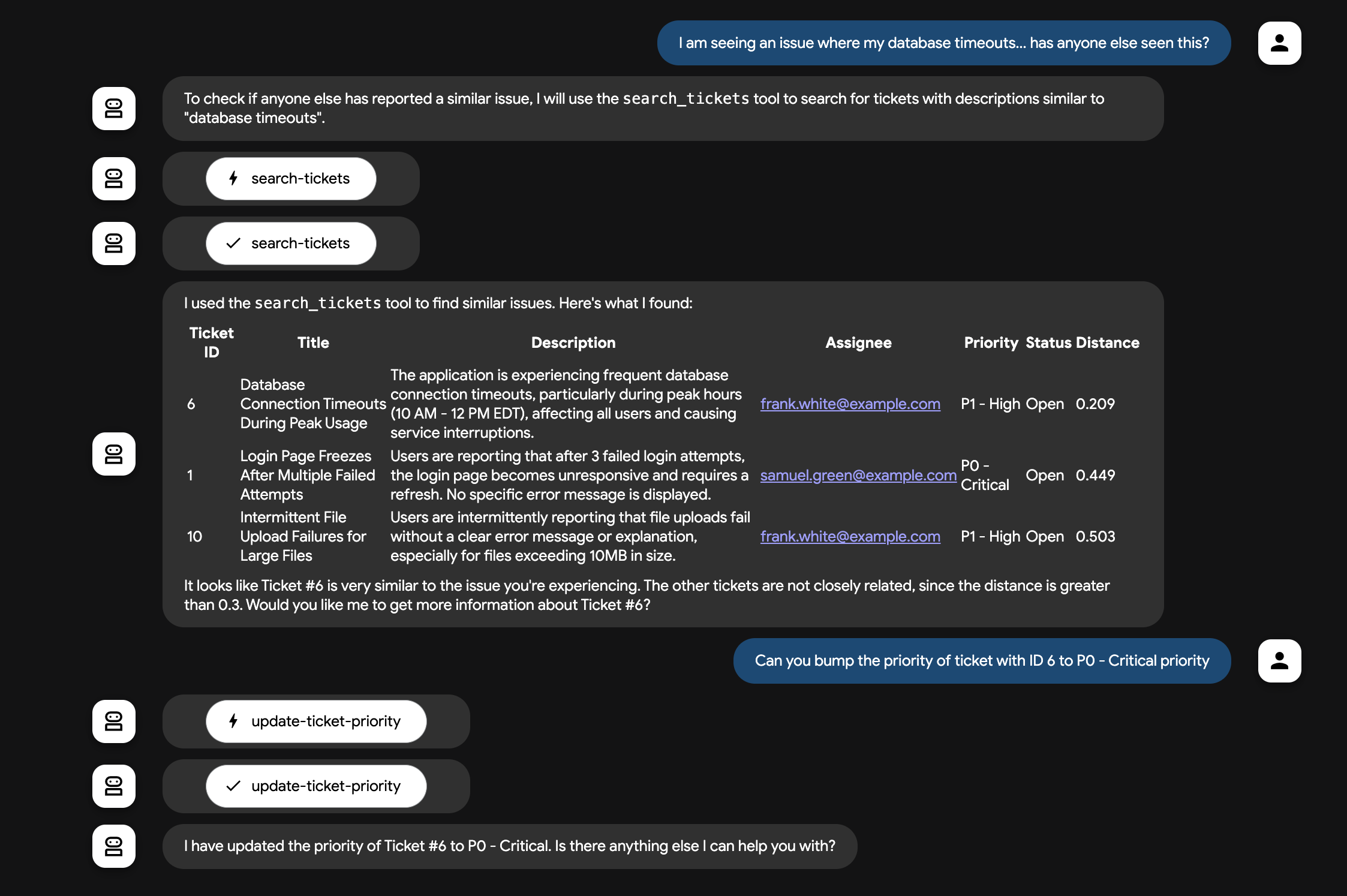
Notre agent ADK a maintenant interrogé notre base de données avec succès à l'aide des outils MCP Toolbox for Databases. 🚀
10. Facultatif : Outil MCP (API)
Qu'en est-il de la connexion de notre agent ADK aux outils MCP qui n'ont pas leur propre SDK, comme MCP Toolbox for Databases ?
ADK est compatible avec les outils MCP génériques grâce à sa classe MCPToolset. La classe MCPToolset est le principal mécanisme d'ADK pour l'intégration des outils d'un serveur MCP.

MCPToolset peut être utilisé pour se connecter à des serveurs MCP locaux ou distants. Chez QuantumRoast, nous souhaitons connecter notre agent au serveur MCP distant de GitHub afin d'appeler facilement les API de GitHub. Cela permettra à notre agent d'extraire des informations sur les problèmes à partir de dépôts de logiciels publics ou même de nos propres bases de code. Le serveur MCP GitHub expose différentes parties des fonctionnalités de GitHub, des problèmes et des demandes d'extraction aux notifications et à la sécurité du code.

Jeton d'accès personnel (PAT) GitHub
Pour vous authentifier auprès du serveur MCP GitHub, vous avez besoin d'un jeton d'accès personnel GitHub.
Pour en obtenir un, procédez comme suit :
- Accédez aux paramètres de développeur GitHub.
- Cliquez sur "Personal access tokens" (Jetons d'accès personnels) > "Tokens (classic)" (Jetons (classique)).
- Cliquez sur "Générer un nouveau jeton" > "Générer un nouveau jeton (classique)".
- Attribuez un nom descriptif à votre jeton.
- Définissez une date d'expiration pour votre jeton.
- Important : Pour des raisons de sécurité, accordez à votre jeton les niveaux d'accès les plus limités nécessaires. Pour un accès en lecture seule aux dépôts, les niveaux d'accès
repo:status,public_repoetread:usersont souvent suffisants. Évitez d'accorder des autorisations d'administrateur ou d'accès complet au dépôt, sauf en cas d'absolue nécessité. - Cliquez sur
Generate token. - Copiez le jeton généré.
Dans le terminal Cloud Shell, exécutez la commande suivante pour définir votre PAT GitHub afin que l'agent puisse l'utiliser. Remplacez YOUR_GITHUB_PAT par le PAT que vous avez généré.
export GITHUB_PAT=YOUR_GITHUB_PAT
Mettre à jour l'agent QuantumRoast
Pour notre assistant de bug, nous n'exposerons que certains outils GitHub en lecture seule, afin de permettre aux employés de QuantumRoast de trouver les problèmes liés aux dépendances Open Source et de voir si cela peut aider à identifier la cause première des bugs qu'ils rencontrent dans le système de tickets interne. Pour ce faire, nous utiliserons MCPToolset de l'ADK avec un tool_filter. tool-filter n'expose que les outils GitHub dont nous avons besoin. Cela permet non seulement de masquer les outils auxquels nous ne voulons pas que les utilisateurs aient accès (par exemple, les actions sensibles sur les dépôts), mais aussi de protéger le modèle de l'agent contre la surcharge lorsqu'il essaie de choisir le bon outil pour la tâche.
Ouvrez le fichier tools.py pour ajouter la compatibilité avec les outils GitHub.
cloudshell edit software_bug_assistant/tools.py
Ajoutez les lignes suivantes en bas de tools.py :
# ----- Example MCP Tools with MCPToolset (GitHub) -----
from google.adk.tools.mcp_tool import MCPToolset, StreamableHTTPConnectionParams
mcp_tools = MCPToolset(
connection_params=StreamableHTTPConnectionParams(
url="https://api.githubcopilot.com/mcp/",
headers={
"Authorization": "Bearer " + os.getenv("GITHUB_PAT"),
},
),
# Read only tools
tool_filter=[
"search_repositories",
"search_issues",
"list_issues",
"get_issue",
"list_pull_requests",
"get_pull_request",
],
)
Notez que nous devons également fournir le jeton d'accès personnel (PAT) GitHub à notre définition MCPToolset, tout comme vous fourniriez un jeton d'authentification lors de la configuration d'un client API standard dans votre code. Ce PAT est limité à l'accès aux données de dépôt public, sans aucun champ d'application concernant les actions sensibles des utilisateurs ou des dépôts.
Nous pouvons maintenant importer et transmettre le mcp_tools à l'agent racine dans agent.py :
cloudshell edit software_bug_assistant/agent.py
Vous pouvez remplacer agent.py par le code suivant pour inclure mcp_tools :
from google.adk.agents import Agent
from .tools import get_current_date, langchain_tool, mcp_tools, search_tool, toolbox_tools
# --- Agent Definition (model, instructions, tools) ---
root_agent = Agent(
model="gemini-2.5-flash",
name="software_assistant",
instruction="""
You are a skilled expert in triaging and debugging software issues for a
coffee machine company, QuantumRoast.
""",
tools=[get_current_date, search_tool, langchain_tool, *toolbox_tools, mcp_tools],
)
Enregistrez le fichier et revenez à l'onglet ouvert avec l'interface utilisateur Web ADK.
Nous disposons maintenant d'un ensemble d'outils GitHub MCP que notre agent peut appeler. Les services de QuantumRoast reposent sur XZ Utils, un outil de compression de données. Notre système interne de suivi des demandes d'assistance pour les bugs suit une CVE (faille de sécurité) de l'année dernière, que nous pouvons retrouver dans le dépôt GitHub XZ Utils à l'aide des outils StackOverflow et Recherche Google. Nous pouvons ensuite utiliser l'un des outils MCP de GitHub, search_issues, pour déterminer quand et comment cette CVE a été corrigée :
Posez la question suivante à l'agent :
Find the official XZ Utils GitHub repositorySearch the repository for issues related to CVE-2024-3094
Vous devriez voir les outils GitHub appelés par l'agent.
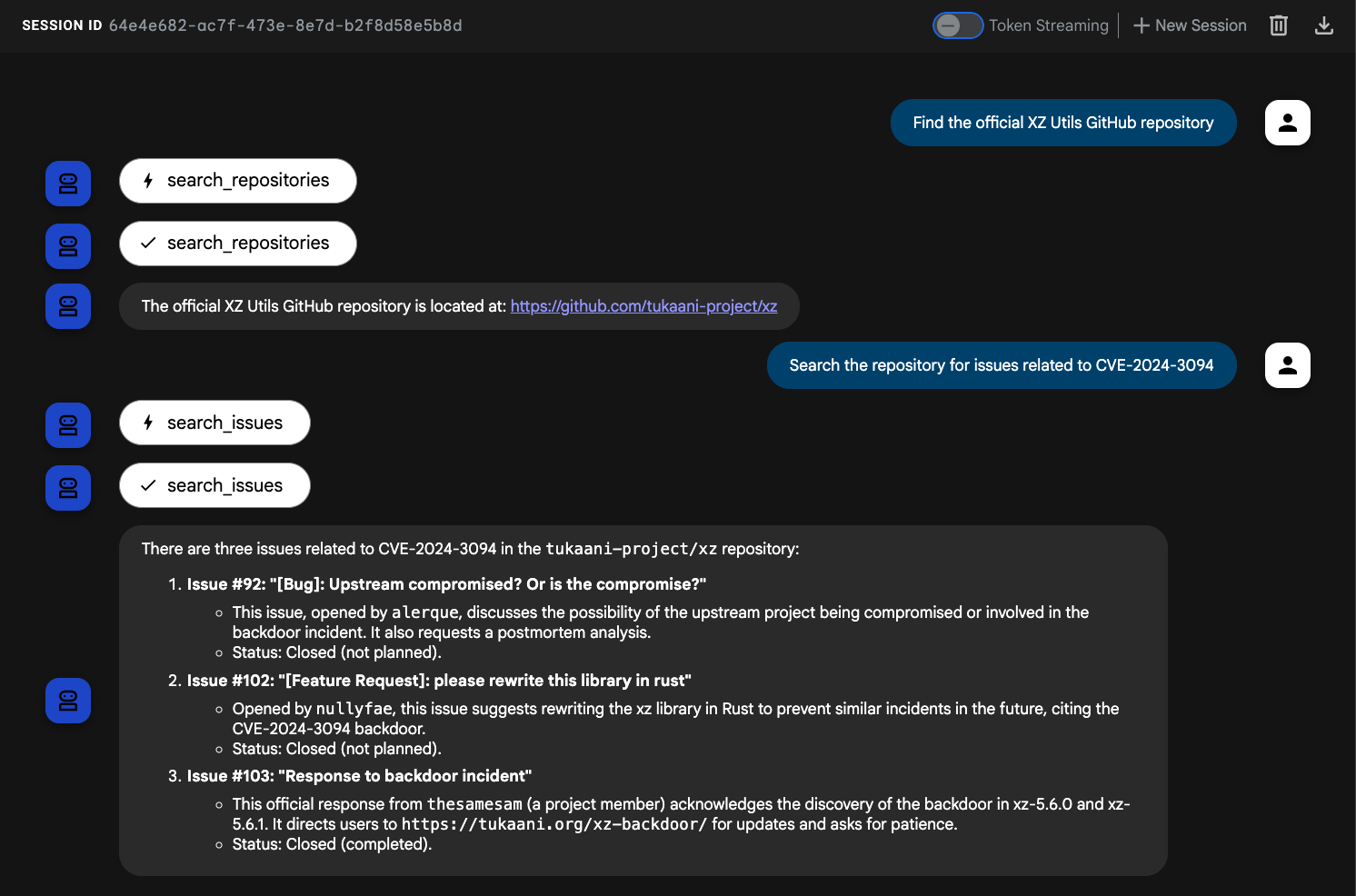
L'agent QuantumRoast ADK peut désormais interagir avec les outils du serveur MCP GitHub. 🤩
11. Félicitations
Félicitations ! Vous avez réussi à créer l'agent assistant de bug QuantumRoast à l'aide d'Agent Development Kit (ADK) et à intégrer différents types d'outils pour améliorer ses capacités. Vous avez commencé avec un agent de base et avez progressivement ajouté des outils de fonction, des outils intégrés, des outils tiers et des outils MCP.
Points abordés
- Configurer un projet Python pour le développement ADK
- Découvrez comment créer un agent ADK de base.
- Implémenter et utiliser les outils de fonction
- Comment intégrer des outils intégrés tels que la recherche Google.
- Comment exploiter des outils tiers provenant de frameworks comme LangChain dans ADK.
- Découvrez comment utiliser les outils MCP pour interagir avec les bases de données (Cloud SQL) et les API.

Nettoyage
Vous pouvez supprimer votre projet Cloud pour éviter des frais supplémentaires.
Bien que Cloud Run ne facture pas lorsque le service n'est pas utilisé, il se peut que des frais vous soient facturés pour le stockage de l'image de conteneur dans Artifact Registry. La suppression de votre projet Cloud arrête la facturation de toutes les ressources utilisées dans ce projet.
Si vous le souhaitez, supprimez le projet :
gcloud projects delete $GOOGLE_CLOUD_PROJECT
Vous pouvez également supprimer les ressources inutiles de votre disque Cloud Shell. Vous pouvez :
- Supprimez le répertoire du projet de l'atelier de programmation :
rm -rf ~/quantum-roast - Avertissement ! Cette prochaine action est irréversible. Si vous souhaitez supprimer tous les éléments de votre Cloud Shell pour libérer de l'espace, vous pouvez supprimer l'intégralité de votre répertoire personnel. Veillez à enregistrer ailleurs tout ce que vous souhaitez conserver.
sudo rm -rf $HOME