
1. はじめに
このラボでは、Agent Development Kit(ADK)を使用してエージェントを構築します。ADK とさまざまなツールタイプを使用してソフトウェア バグ アシスタント エージェントを構築する方法を学習します。まず、基本的なエージェントから始め、関数ツール、組み込みツール、サードパーティ ツール、Model Context Protocol(MCP)ツールなど、機能を強化するためのツールを段階的に追加していきます。

学習内容
- ADK 開発用に Python プロジェクトを設定する方法。
- 基本的な ADK エージェントを作成する方法。
- 関数ツールを実装して使用する方法。
- Google 検索などの組み込みツールを統合する方法。
- ADK 内で LangChain などのフレームワークからサードパーティ製ツールを活用する方法。
- MCP ツールを使用してデータベース(Cloud SQL)と API を操作する方法。
2. 概要
あなたは、世界的なコーヒー メーカー企業、QuantumRoast のプロジェクト マネージャーであるとします。
![]()
マネージャーは、広大なエンジニアリング ロードマップの遂行、急な戦略変更(抹茶にも対応開始)、24 時間 365 日顧客から届くあらゆるチケット(請求書システムのバグからコーヒー メーカーの高音ノイズまで)の対応など、チームメンバーの取り組みをサポートしています。
日常的に、社内のチケット発行システム、メール、チャット、GitHub、Google 検索、StackOverflow など、およそ 50 個ものブラウザタブを開いています。仕事もチームメンバーも好きですが、負荷が過多になる日もときにはあります。

このような場合に、ソフトウェア チケットの作成やトリアージ、問題のデバッグを手伝ってくれるヘルパーを構築できたらいいと思いませんか?これを可能にするのが、AI エージェントです。

Agent Development Kit(ADK)
Agent Development Kit(ADK)は、AI エージェントの開発とデプロイ用に設計された、柔軟性の高いモジュラー フレームワークです。Gemini と Google エコシステム向けに最適化されていますが、モデルやデプロイに依存せず、他のフレームワークとの互換性を保つよう構築されています。ADK は、エージェント開発をソフトウェア開発のような感覚で行えるよう設計されており、デベロッパーは基本的なタスクから複雑なワークフローまで、幅広いエージェント アーキテクチャを簡単に作成、デプロイ、オーケストレートできます。
ADK は、QuantumRoast ソフトウェア バグ アシスタントの構築に使用するフレームワークです。
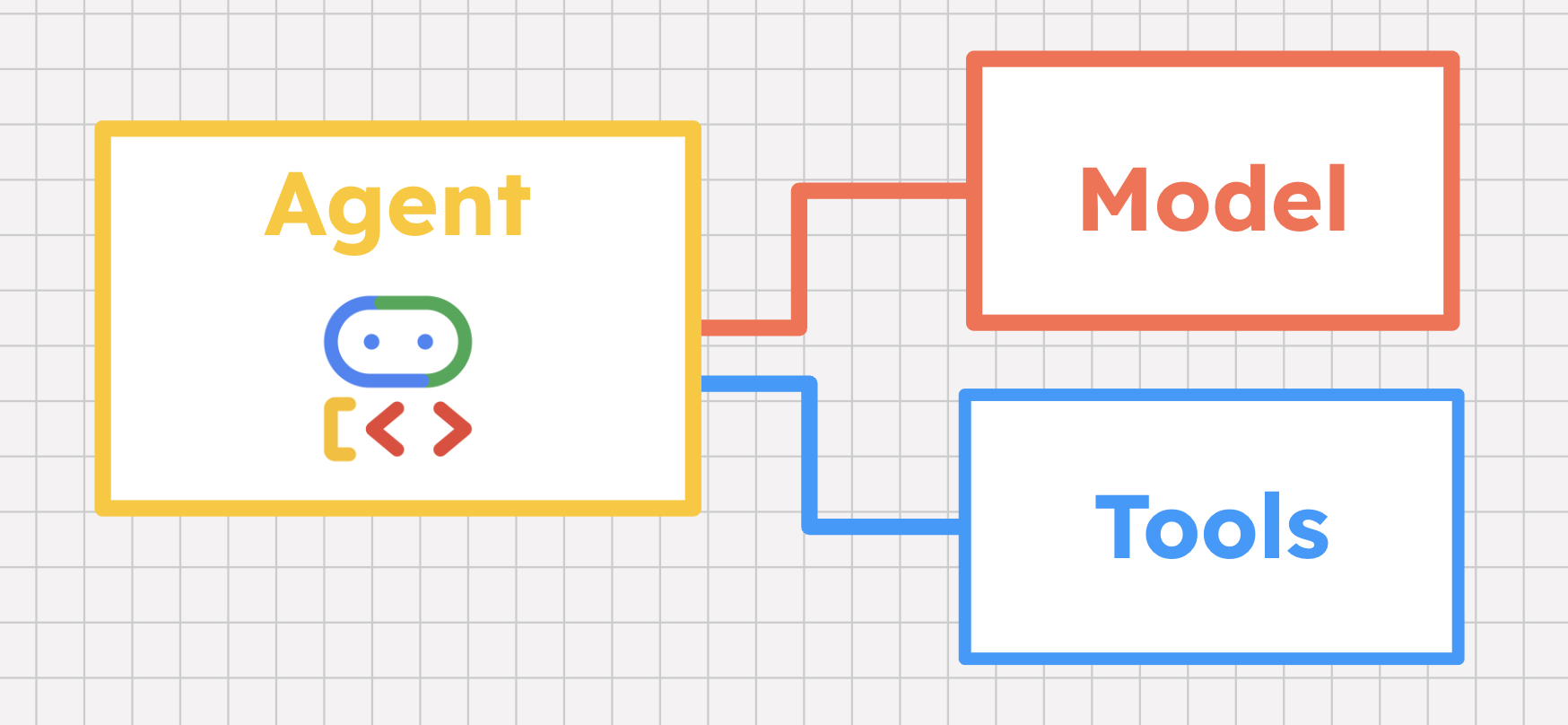
ツールの入門ガイド
AI エージェントは、ハードコードされたロジックだけでなくモデルを使用して、推論によって問題を解決していきます。ただし、AI エージェントは LLM ベースの推論ができるだけでなく、外部データを収集し、ユーザーに代わって対処するという独自の能力を備えています。AI エージェントは、問題解決の方法を教えてくれるだけでなく、実際に解決するのを手伝ってくれるのです。そのために、ツールがあります。
ツールは、AI エージェントが世界とやり取りするのに役立つ機能です。インライン関数、ホストされたデータベース、サードパーティの API、さらには別のエージェントなど、ほとんどすべてがツールとなり得ます。Agent Development Kit(ADK)などの AI エージェント フレームワークは、ツールの組み込みサポートを備えており、さまざまな種類のツールをサポートしています。これらのツールについては、後ほど説明します。
では、特定のツールを呼び出すタイミングだけでなく、これらを呼び出す方法まで、エージェントはどのように把握するのでしょうか。エージェントのモデルが、ここでいくつかの重要な役割を果たします。
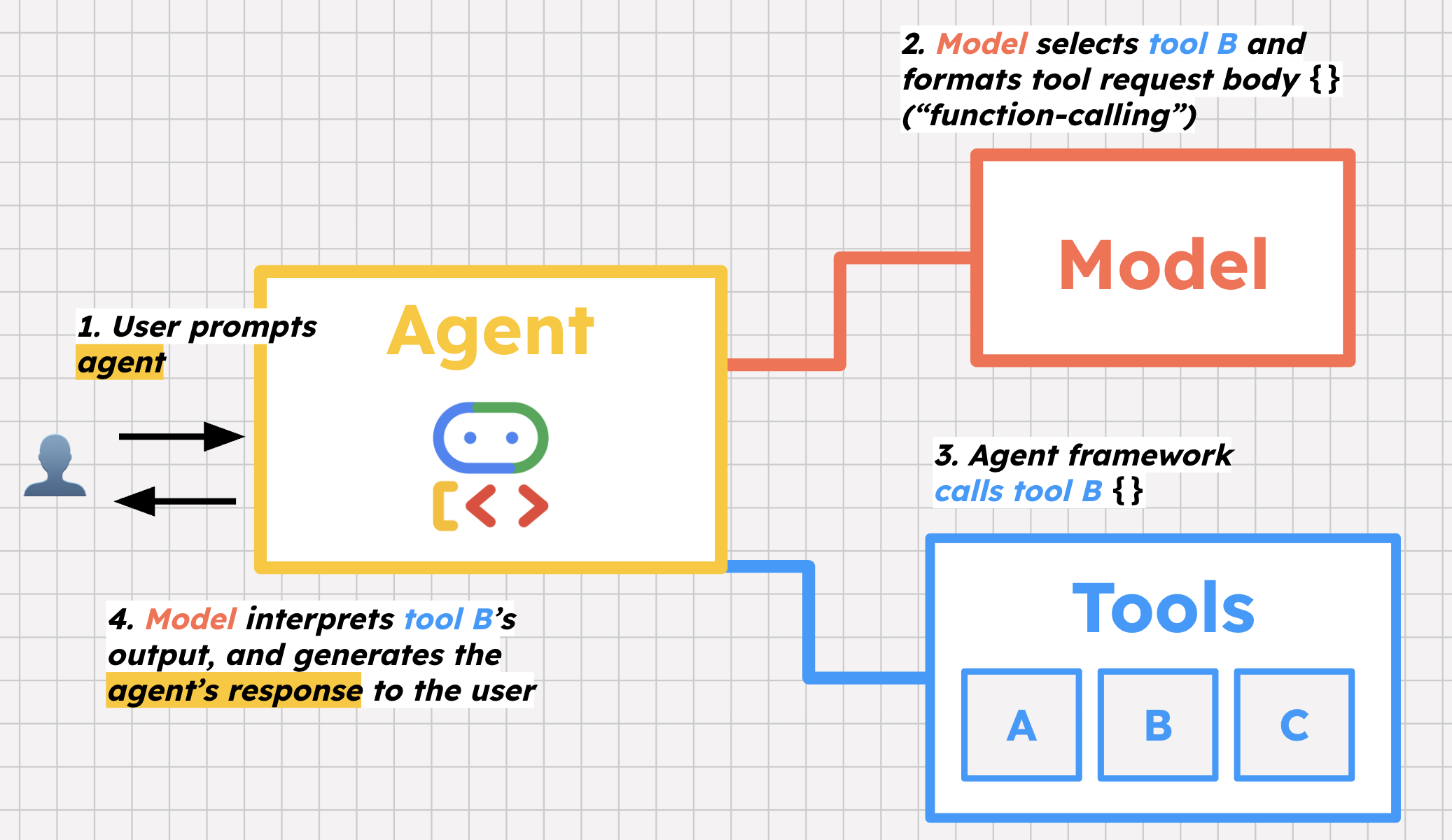
1 つ目はツールの選択です。エージェントに提供するのは、ツールのリストと、それらの使用方法に関する指示です。ユーザーがエージェントにプロンプトを入力すると、エージェントはモデルを使用して、そのユーザーを支援するために呼び出すツールとその理由を判断します。
2 つ目の重要なステップは関数呼び出しです。「関数呼び出し」といっても、文字通りの意味とは少し違います。モデルが実際にツールを呼び出すのではなく、フレームワークがツールを呼び出すために使用するリクエストの本文をフォーマットして、呼び出しの準備をします。
最後に、モデルは、そのツールからのレスポンスを解釈します。たとえば、データベースから未解決のバグのリストが返された場合、さらなるアクションを実行するか、その情報をユーザーに返答するかをモデルが決定します。
実際にこれらがどのように機能するかを確認するため、ADK Python を使用して QuantumRoast のバグ アシスタント エージェントを構築してみましょう。
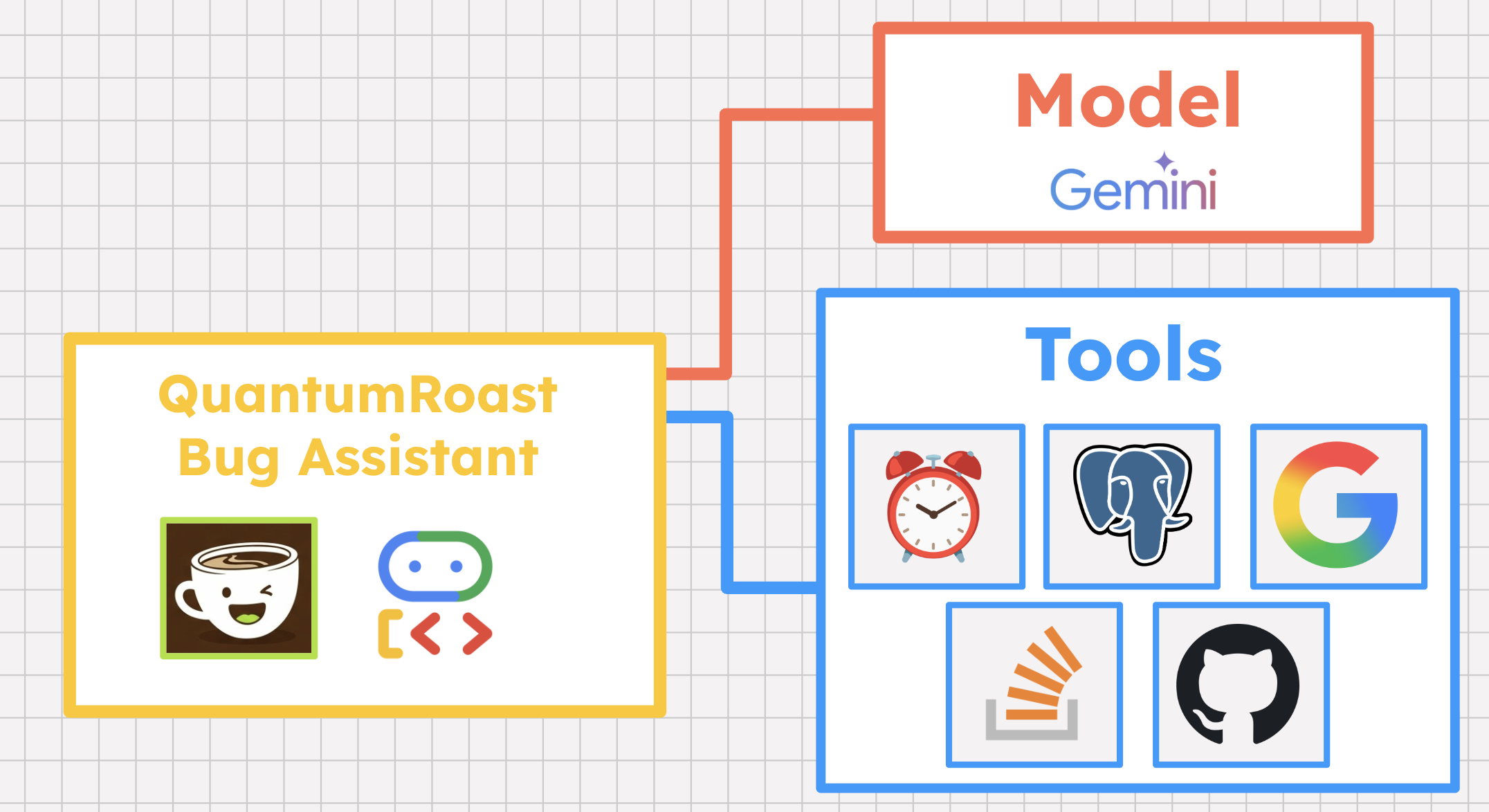
3. 始める前に
Google Cloud プロジェクトのセットアップ
- Google アカウントをまだお持ちでない場合は、Google アカウントを作成する必要があります。
- 仕事用または学校用アカウントではなく、個人アカウントを使用します。職場用アカウントと学校用アカウントには、このラボに必要な API を有効にできない制限が設定されている場合があります。
- Google Cloud コンソールにログインします。
- Cloud コンソールで課金を有効にします。
- このラボを完了するのにかかる Cloud リソースの費用は 1 米ドル未満です。
- このラボの最後の手順に沿ってリソースを削除すると、それ以上の料金は発生しません。
- 新規ユーザーは、300 米ドル分の無料トライアルをご利用いただけます。
- 新しいプロジェクトを作成するか、既存のプロジェクトを再利用します。
Cloud Shell エディタを開く
- Cloud Shell エディタに移動します。
- ターミナルが画面の下部に表示されない場合は、ターミナルを開きます。
- ハンバーガー メニュー
 をクリックします。
をクリックします。 - [Terminal] をクリックします。
- [New Terminal] をクリックします。
- ハンバーガー メニュー
- ターミナルで、次のコマンドを使用してプロジェクトを設定します(
YOUR_PROJECT_IDは置き換えます)。- 形式:
gcloud config set project YOUR_PROJECT_ID - 例:
gcloud config set project lab-project-id-example - プロジェクト ID を忘れた場合:
- 次のコマンドを使用すると、すべてのプロジェクト ID を一覧表示できます。
gcloud projects list | awk '/PROJECT_ID/{print $2}'
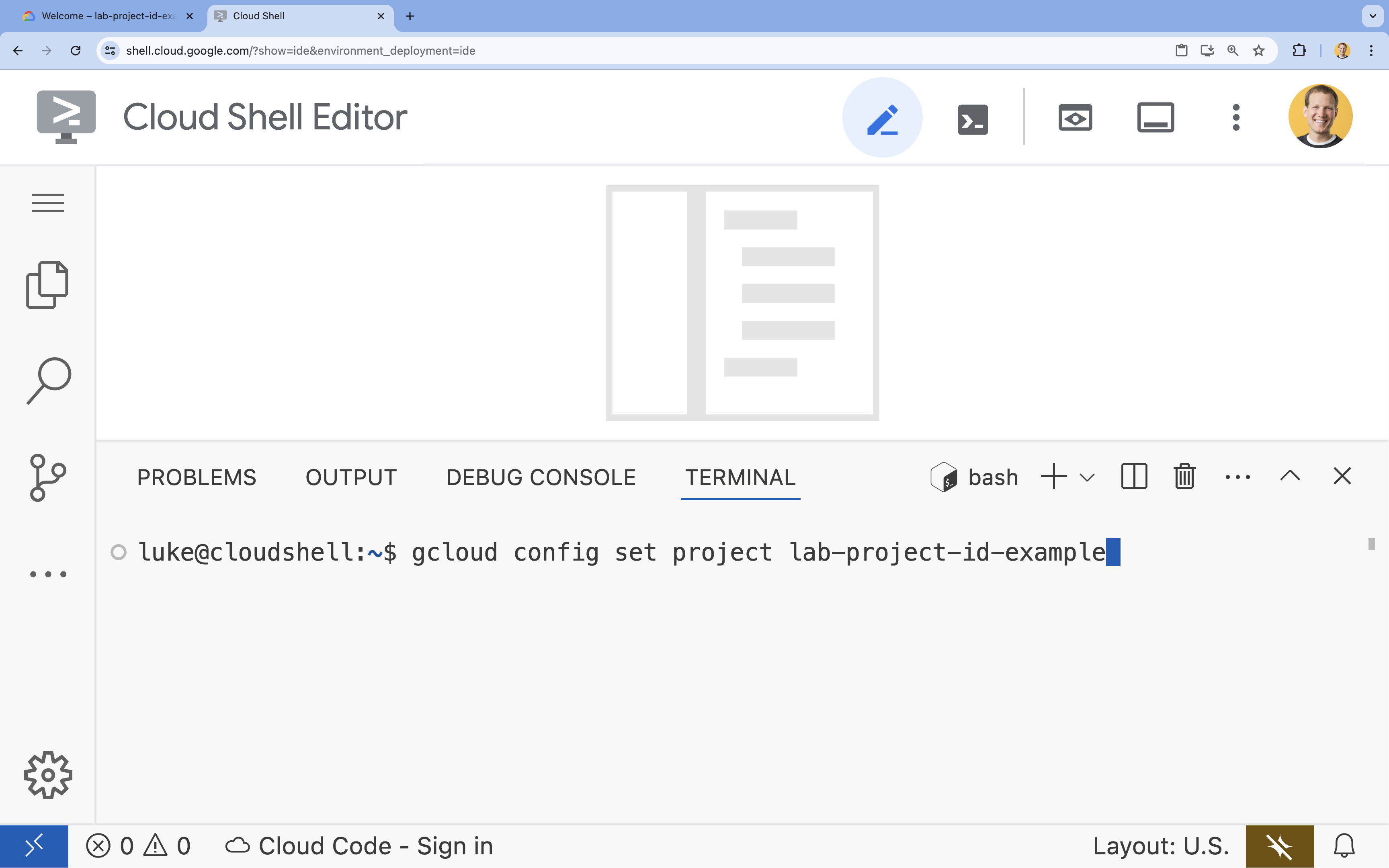
- 次のコマンドを使用すると、すべてのプロジェクト ID を一覧表示できます。
- 形式:
- 承認を求められたら、[承認] をクリックして続行します。
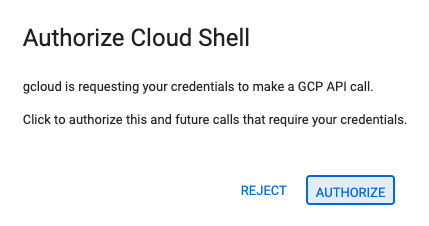
- 次のようなメッセージが表示されます。
Updated property [core/project].
WARNINGが表示され、Do you want to continue (Y/N)?と表示された場合は、プロジェクト ID が正しく入力されていない可能性があります。Nを押してEnterを押し、gcloud config set projectコマンドをもう一度実行してみてください。 - ターミナルで、後の手順で使用する
PROJECT_ID環境変数を設定します。export PROJECT_ID=$(gcloud config get project)
API を有効にする
ターミナルで次のコマンドを実行して、必要な Google Cloud API を有効にします。
gcloud services enable sqladmin.googleapis.com \
compute.googleapis.com \
cloudresourcemanager.googleapis.com \
secretmanager.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com \
run.googleapis.com \
artifactregistry.googleapis.com \
cloudbuild.googleapis.com
Cloud SQL for PostgreSQL インスタンスを作成する
QuantumRoast には、すべての内部チケットを保持するバグチケット データベースがあります。Cloud SQL for PostgreSQL インスタンスを作成して設定しましょう。
gcloud sql instances create software-assistant \
--database-version=POSTGRES_16 \
--tier=db-custom-1-3840 \
--region=europe-west4 \
--edition=ENTERPRISE \
--enable-google-ml-integration \
--database-flags cloudsql.enable_google_ml_integration=on \
--root-password=admin
インスタンスが作成されるまで待ちます(数分かかることがあります)。
作成したインスタンスは、Cloud Console で確認できます。こちらをご覧ください。
Cloud SQL データベースを作成する
SQL データベース(tickets-db)を作成し、Cloud SQL サービス アカウントに Vertex AI へのアクセス権を付与します(類似性検索を実行するエンベディングを作成できるようにするため)。
gcloud sql databases create tickets-db --instance=software-assistant
SERVICE_ACCOUNT_EMAIL=$(gcloud sql instances describe software-assistant --format="value(serviceAccountEmailAddress)")
echo $SERVICE_ACCOUNT_EMAIL
gcloud projects add-iam-policy-binding $PROJECT_ID --member="serviceAccount:$SERVICE_ACCOUNT_EMAIL" --role="roles/aiplatform.user"
tickets テーブルを設定する
Cloud Console(Cloud SQL)で、software-assistant インスタンスの Cloud SQL Studio を開きます。
postgres ユーザーとパスワード admin を使用して tickets-db データベースにログインします。
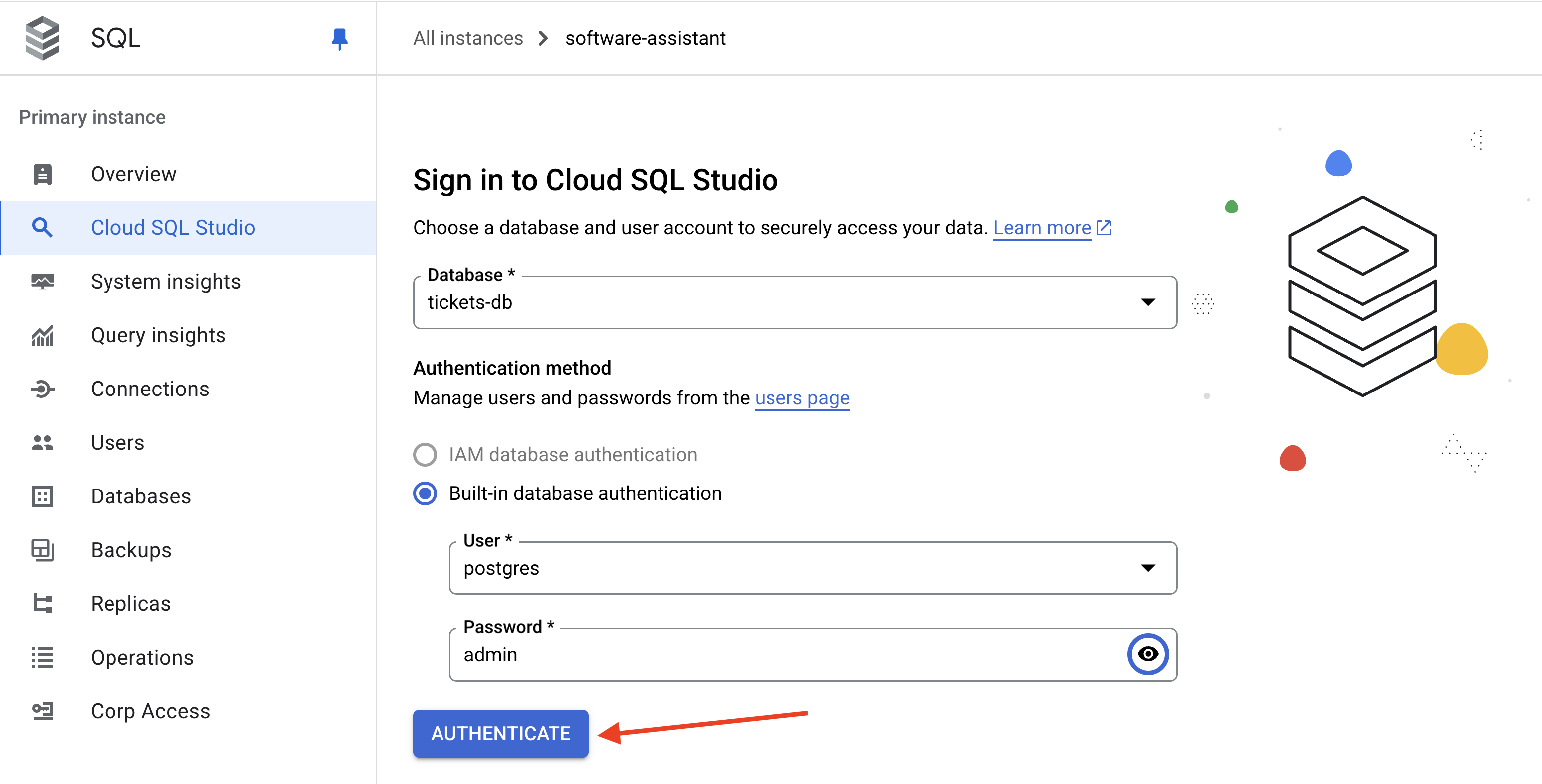
新しい Editor タブを開きます。
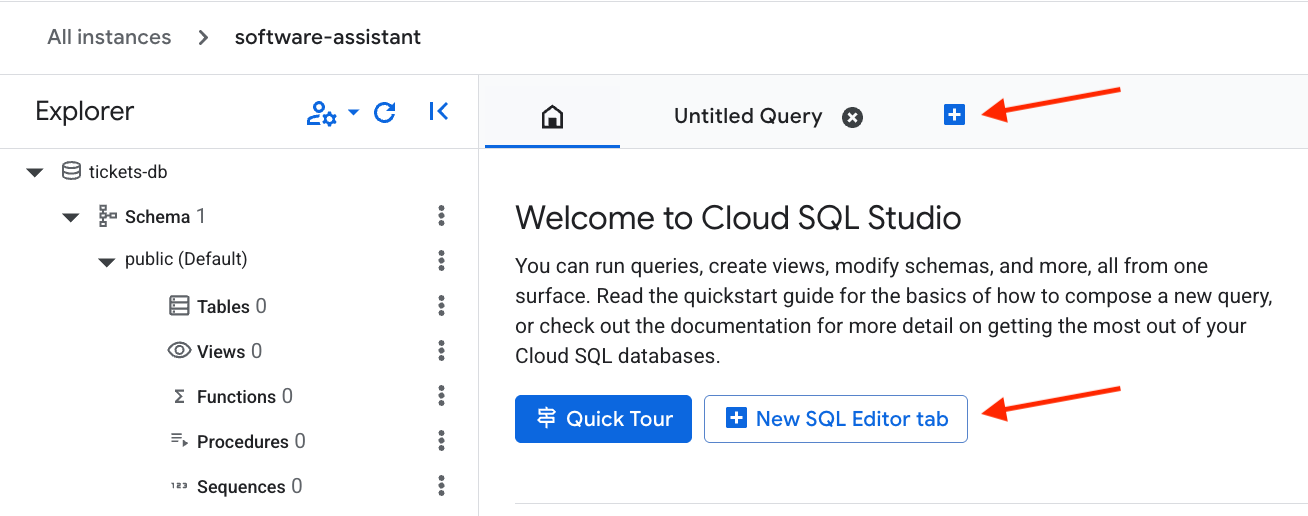
次に、次の SQL コードを貼り付けて、テーブルを設定し、ベクトル エンベディングを作成します。Run ボタンを押してコマンドを実行します。
CREATE EXTENSION IF NOT EXISTS google_ml_integration CASCADE;
CREATE EXTENSION IF NOT EXISTS vector CASCADE;
GRANT EXECUTE ON FUNCTION embedding TO postgres;
CREATE TABLE tickets (
ticket_id SERIAL PRIMARY KEY, -- PostgreSQL's auto-incrementing integer type (SERIAL is equivalent to INT AUTO_INCREMENT)
title VARCHAR(255) NOT NULL, -- A concise summary or title of the bug/issue.
description TEXT, -- A detailed description of the bug.
assignee VARCHAR(100), -- The name or email of the person/team assigned to the ticket.
priority VARCHAR(50), -- The priority level (e.g., 'P0 - Critical', 'P1 - High').
status VARCHAR(50) DEFAULT 'Open', -- The current status of the ticket (e.g., 'Open', 'In Progress', 'Resolved'). Default is 'Open'.
creation_time TIMESTAMP WITH TIME ZONE DEFAULT CURRENT_TIMESTAMP, -- Timestamp when the ticket was first created. 'WITH TIME ZONE' is recommended for clarity and compatibility.
updated_time TIMESTAMP WITH TIME ZONE DEFAULT CURRENT_TIMESTAMP -- Timestamp when the ticket was last updated. Will be managed by a trigger.
);
tickets テーブルが作成されました。[Clear] をクリックして古いクエリをクリアします。
サンプルデータを挿入し、もう一度 [Run] ボタンをクリックします。
INSERT INTO tickets (title, description, assignee, priority, status) VALUES
('Login Page Freezes After Multiple Failed Attempts', 'Users are reporting that after 3 failed login attempts, the login page becomes unresponsive and requires a refresh. No specific error message is displayed.', 'samuel.green@example.com', 'P0 - Critical', 'Open');
INSERT INTO tickets (title, description, assignee, priority, status) VALUES
('Dashboard Sales Widget Intermittent Data Loading Failure', 'The "Sales Overview" widget on the main dashboard intermittently shows a loading spinner but no data. Primarily affects Chrome browser users.', 'maria.rodriguez@example.com', 'P1 - High', 'In Progress');
INSERT INTO tickets (title, description, assignee, priority, status) VALUES
('Broken Link in Footer - Privacy Policy', 'The "Privacy Policy" hyperlink located in the website footer leads to a 404 "Page Not Found" error.', 'maria.rodriguez@example.com', 'P3 - Low', 'Resolved');
INSERT INTO tickets (title, description, assignee, priority, status) VALUES
('UI Misalignment on Mobile Landscape View (iOS)', 'On specific iOS devices (e.g., iPhone 14 models), the top navigation bar shifts downwards when the device is viewed in landscape orientation, obscuring content.', 'maria.rodriguez@example.com', 'P2 - Medium', 'In Progress');
INSERT INTO tickets (title, description, assignee, priority, status) VALUES
('Critical XZ Utils Backdoor Detected in Core Dependency (CVE-2024-3094)', 'Urgent: A sophisticated supply chain compromise (CVE-2024-3094) has been identified in XZ Utils versions 5.6.0 and 5.6.1. This malicious code potentially allows unauthorized remote SSH access by modifying liblzma. Immediate investigation and action required for affected Linux/Unix systems and services relying on XZ Utils.', 'frank.white@example.com', 'P0 - Critical', 'Open');
INSERT INTO tickets (title, description, assignee, priority, status) VALUES
('Database Connection Timeouts During Peak Usage', 'The application is experiencing frequent database connection timeouts, particularly during peak hours (10 AM - 12 PM EDT), affecting all users and causing service interruptions.', 'frank.white@example.com', 'P1 - High', 'Open');
INSERT INTO tickets (title, description, assignee, priority, status) VALUES
('Export to PDF Truncates Long Text Fields in Reports', 'When generating PDF exports of reports containing extensive text fields, the text is abruptly cut off at the end of the page instead of wrapping or continuing to the next page.', 'samuel.green@example.com', 'P1 - High', 'Open');
INSERT INTO tickets (title, description, assignee, priority, status) VALUES
('Search Filter "Date Range" Not Applying Correctly', 'The "Date Range" filter on the search results page does not filter records accurately; results outside the specified date range are still displayed.', 'samuel.green@example.com', 'P2 - Medium', 'Resolved');
INSERT INTO tickets (title, description, assignee, priority, status) VALUES
('Typo in Error Message: "Unathorized Access"', 'The error message displayed when a user attempts an unauthorized action reads "Unathorized Access" instead of "Unauthorized Access."', 'maria.rodriguez@example.com', 'P3 - Low', 'Resolved');
INSERT INTO tickets (title, description, assignee, priority, status) VALUES
('Intermittent File Upload Failures for Large Files', 'Users are intermittently reporting that file uploads fail without a clear error message or explanation, especially for files exceeding 10MB in size.', 'frank.white@example.com', 'P1 - High', 'Open');
QuantumRoast では、バグ/チケットが最後に更新された日時を確認したい場合があります。
そのため、レコードが更新されるたびに updated_time フィールドを更新するトリガーを作成できます。
Clear をクリックし、次の SQL を貼り付けてトリガーを実装します。
[Run] ボタンをクリックして実行します。
CREATE OR REPLACE FUNCTION update_updated_time_tickets()
RETURNS TRIGGER AS $$
BEGIN
NEW.updated_time = NOW(); -- Set the updated_time to the current timestamp
RETURN NEW; -- Return the new row
END;
$$ language 'plpgsql';
CREATE TRIGGER update_tickets_updated_time
BEFORE UPDATE ON tickets
FOR EACH ROW -- This means the trigger fires for each row affected by the UPDATE statement
EXECUTE PROCEDURE update_updated_time_tickets();
description フィールドからベクトル エンベディングを作成します。これにより、エージェントはデータベースで類似検索を実行できるようになります。たとえば、「ウェブサイトのホームページに関連する未解決の問題はありますか?」などです。
ALTER TABLE tickets ADD COLUMN embedding vector(768) GENERATED ALWAYS AS (embedding('text-embedding-005',description)) STORED;
これで、データベースにクエリを実行して、準備ができていることを確認できます。
SELECT * FROM tickets;
次のような 10 行が返されます。
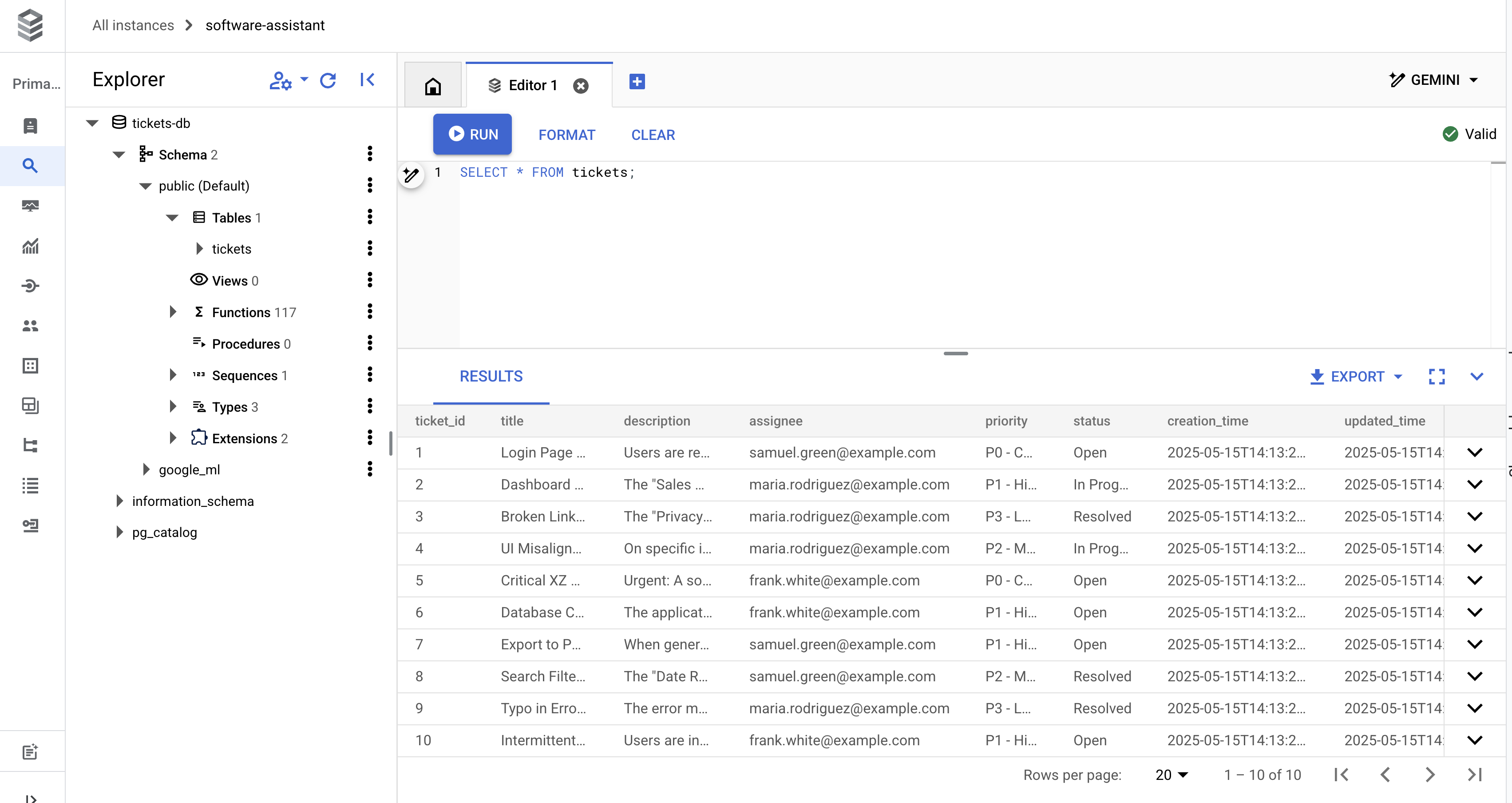
これで、楽しいコーディングに進む準備が整いました。
4. Python プロジェクトのセットアップ
エージェントの構築に入る前に、適切な Python プロジェクトが設定されていることを確認する必要があります。すべての操作を Cloud Shell で行います。
まず、quantum-roast フォルダを作成し、その中に cd を作成します。
mkdir quantum-roast && cd quantum-roast
プロジェクトのフォルダができたので、プロジェクトを初期化して、必要な対応するファイルを作成します。
プロジェクトと依存関係の管理には、uv(Python の非常に高速なパッケージとプロジェクト マネージャー)を使用します。これは Cloud Shell にプリインストールされています。Uv は、ファイルのセットアップや仮想環境、依存関係などの管理を自動化するのに役立ちます。
uv init を使用して新しいプロジェクトを初期化します。
uv init --description "QuantumRoast Software Bug Assistant with ADK" --bare --python 3.10
コマンドを実行すると、プロジェクトの pyproject.toml ファイルが作成されます。確認するには、Cloud Shell ターミナルで cat pyproject.toml を実行します。
cat pyproject.toml
出力は次のようになります。
[project] name = "quantum-roast" version = "0.1.0" description = "QuantumRoast Software Bug Assistant with ADK" requires-python = ">=3.10" dependencies = []
uv add を使用して、google-adk(ADK)を依存関係としてプロジェクトに追加します。
uv add google-adk==1.11.0
これにより、pyproject.toml の dependencies リストに google-adk が追加されます。
ADK では、最適な結果を得るために特定のプロジェクト構造が想定されています。
quantum-roast/
software_bug_assistant/
__init__.py
agent.py
.env
software_bug_assistant フォルダとその中にファイルを作成します。
mkdir software_bug_assistant && touch software_bug_assistant/__init__.py \
software_bug_assistant/agent.py \
software_bug_assistant/tools.py \
software_bug_assistant/.env
ls を使用してファイルの作成を確認します。
ls -a software_bug_assistant/
次の結果が表示されます。
__init__.py . .. .env agent.py tools.py
ADK が Gemini モデルを適切に呼び出すために必要な環境変数を .env ファイルに入力します。Vertex API を介して Gemini にアクセスします。
echo "GOOGLE_GENAI_USE_VERTEXAI=TRUE" >> software_bug_assistant/.env \
&& echo "GOOGLE_CLOUD_PROJECT=$PROJECT_ID" >> software_bug_assistant/.env \
&& echo "GOOGLE_CLOUD_LOCATION=europe-west4" >> software_bug_assistant/.env
.env が正しく入力されたことを確認するには、次のコマンドを実行します。
cat software_bug_assistant/.env
your-project-id はプロジェクト ID です。次のような出力が表示されます。
GOOGLE_GENAI_USE_VERTEXAI=TRUE GOOGLE_CLOUD_PROJECT=your-project-id GOOGLE_CLOUD_LOCATION=europe-west4
これで、ADK エージェントの作成を開始する準備が整いました。
5. ベース ADK エージェント
このワークショップでは、ツールを 1 つずつ追加して強力なバグ アシスタントを作成できる、ベースとなる ADK エージェントを設定します。
Cloud Shell エディタで agent.py を開きます。
cloudshell edit software_bug_assistant/agent.py
次のコードを agent.py に貼り付け、ファイル Ctrl + s を保存します。
from google.adk.agents import Agent
# --- Agent Definition (model, instructions, tools) ---
root_agent = Agent(
model="gemini-2.5-flash",
name="software_assistant",
instruction="""
You are a skilled expert in triaging and debugging software issues for a
coffee machine company, QuantumRoast.
""",
tools=[],
)
ADK の開発 UI(adk web)を起動して、新しく作成したエージェントを実行します。uv run を使用すると、ADK がインストールされた仮想環境が自動的に作成されます。
uv run adk web --port 8080 --reload_agents
コンソールに ADK ウェブサーバーの起動が成功したことが表示されます。
INFO: Started server process [1557] INFO: Waiting for application startup. +-----------------------------------------------------------------------------+ | ADK Web Server started | | | | For local testing, access at http://localhost:8080. | +-----------------------------------------------------------------------------+ INFO: Application startup complete. INFO: Uvicorn running on http://127.0.0.1:8080 (Press CTRL+C to quit)
Cloud Shell のウェブ プレビューを開いて、UI を確認します。
ADK ウェブ UI が表示されます。
ADK エージェントとチャットしてみましょう。
エージェントに「What day is it today?」と話しかけます。
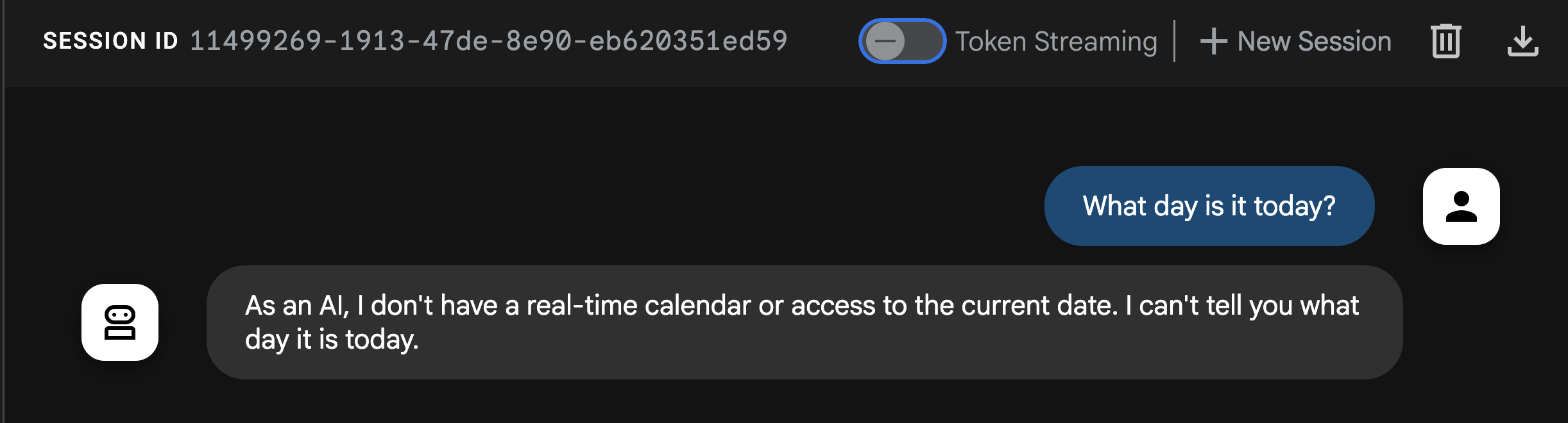
レスポンスを見ると、エージェントがこの基本的な質問に答えられないことがわかります。LLM は過去のデータでトレーニングされた独立したシステムです。ツールを提供しない限り、最近のイベントや現在の日付に関するリアルタイムのコンテキストはありません。
ADK の最初のツールタイプである関数ツールを実装しましょう。
6. 関数ツール
最初で最もシンプルな ADK ツールタイプは関数ツールです。これは、エージェントによって呼び出される Python 関数です。

関数ツールは、エージェントがツールとして呼び出すカスタムコード(計算の実行、API の呼び出し、データベースのクエリなど)を記述できるため、非常に強力です。関数は単純なものにも複雑なものにもできます。
QuantumRoast では、このラボで後ほど「先週のバグを表示して」や「今日は何日?」などのクエリを処理するために、今日の日付を取得する基本関数を定義します。(誰にでも起こりうる事象です)。
/software_bug_assistant フォルダ内の tools.py ファイルには、このラボ全体で作成するすべてのツールを整理します。
+ アイコンをクリックして、新しいターミナルを開きます。
新しいターミナルで、PROJECT_ID を設定して tools.py を開きます。
cd quantum-roast
export PROJECT_ID=$(gcloud config get project)
cloudshell edit software_bug_assistant/tools.py
次に、関数ツールとして使用される get_current_date 関数を定義します。
from datetime import datetime
# ----- Example of a Function tool -----
def get_current_date() -> dict:
"""
Get the current date in the format YYYY-MM-DD
"""
return {"current_date": datetime.now().strftime("%Y-%m-%d")}
これで関数が定義されました。ツールとしてエージェントに渡す時間です。
Cloud Shell エディタで agent.py を開きます。
cloudshell edit software_bug_assistant/agent.py
tools.py から get_current_date 関数をインポートし、その関数をエージェントの tools 引数に渡します。
更新された agent.py は次のようになります。
from google.adk.agents import Agent
from .tools import get_current_date
# --- Agent Definition (model, instructions, tools) ---
root_agent = Agent(
model="gemini-2.5-flash",
name="software_assistant",
instruction="""
You are a skilled expert in triaging and debugging software issues for a
coffee machine company, QuantumRoast.
""",
tools=[get_current_date],
)
ADK ウェブ UI を実行している [ウェブでプレビュー] タブに戻って、もう一度 What day is it today? を実行します。
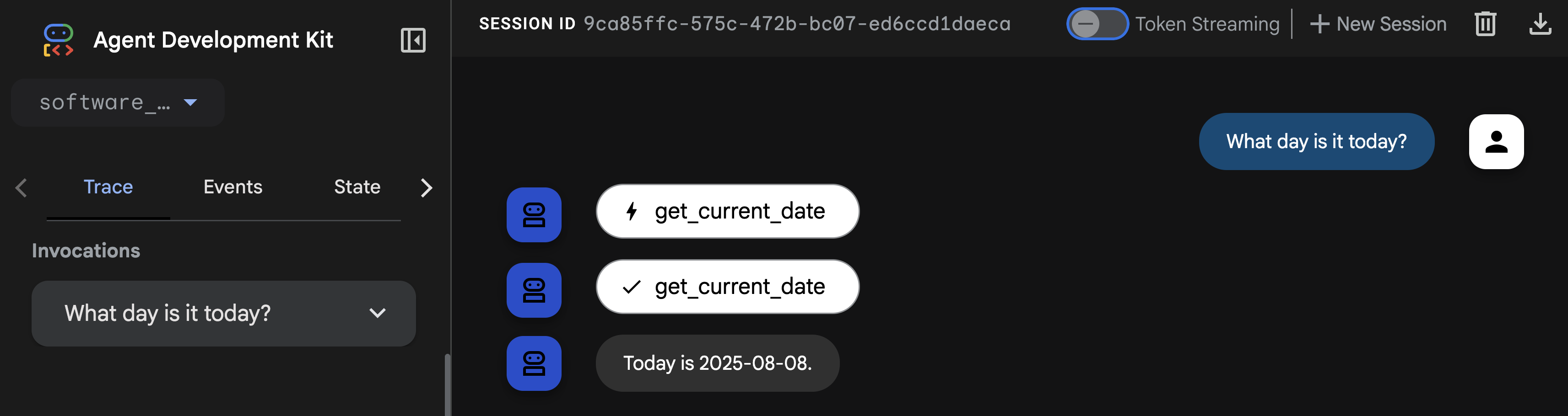
エージェントは、get_current_date 関数ツールを呼び出して日付を正しく取得できます。🎉
次の ADK ツールタイプを見てみましょう。
7. 組み込みツール
別のタイプの ADK ツールとして、組み込みツールがあります。これらは、モデル自体の中でのコード実行など、Google のフラッグシップ モデルの機能と連携するツールです。Google 検索の組み込みツールをバグ アシスタント エージェントにアタッチして、エージェントがウェブ検索にアクセスできるようにすることで、関連するコンテキストでエージェントをグラウンディングできます。これにより、エージェントはバグや既知の脆弱性に関する最新情報を収集できます。

tools.py ファイルを開いて、Google 検索の組み込みツールのサポートを追加します。
cloudshell edit software_bug_assistant/tools.py
tools.py の末尾に次の行を追加します。
# ----- Built-in Tool Imports -----
from google.adk.agents import Agent
from google.adk.tools import google_search
from google.adk.tools.agent_tool import AgentTool
# ----- Example of a Built-in Tool -----
search_agent = Agent(
model="gemini-2.5-flash",
name="search_agent",
description="A specialist in Google Search.",
instruction="""
You're a specialist in Google Search.
""",
tools=[google_search],
)
search_tool = AgentTool(search_agent)
ここでは、Google 検索ツールを独自のシステム指示を持つ独自のエージェントでラップし、エージェントをツールとして効果的に使用しています。
これで、agent.py のルート エージェントに search_tool をインポートして渡すことができます。
cloudshell edit software_bug_assistant/agent.py
agent.py を次のコードに置き換えて、search_tool を含めることができます。
from google.adk.agents import Agent
from .tools import get_current_date, search_tool
# --- Agent Definition (model, instructions, tools) ---
root_agent = Agent(
model="gemini-2.5-flash",
name="software_assistant",
instruction="""
You are a skilled expert in triaging and debugging software issues for a
coffee machine company, QuantumRoast.
""",
tools=[get_current_date, search_tool],
)
ファイルを保存して、ADK ウェブ UI が実行されているタブに戻ります。
QuantumRoast では、ウェブサイトとソフトウェアが、公開されているサイバーセキュリティの脆弱性である共通脆弱性識別子(CVE)から保護されていることを確認したいと考えています。エージェントの新しい Google 検索ツールを使用して、最近発見された CVE をウェブで検索できます。
次のクエリを実行します。Do a web search for 5 of the most recent CVEs?
エージェントは search_agent を呼び出してウェブを検索する必要があります。
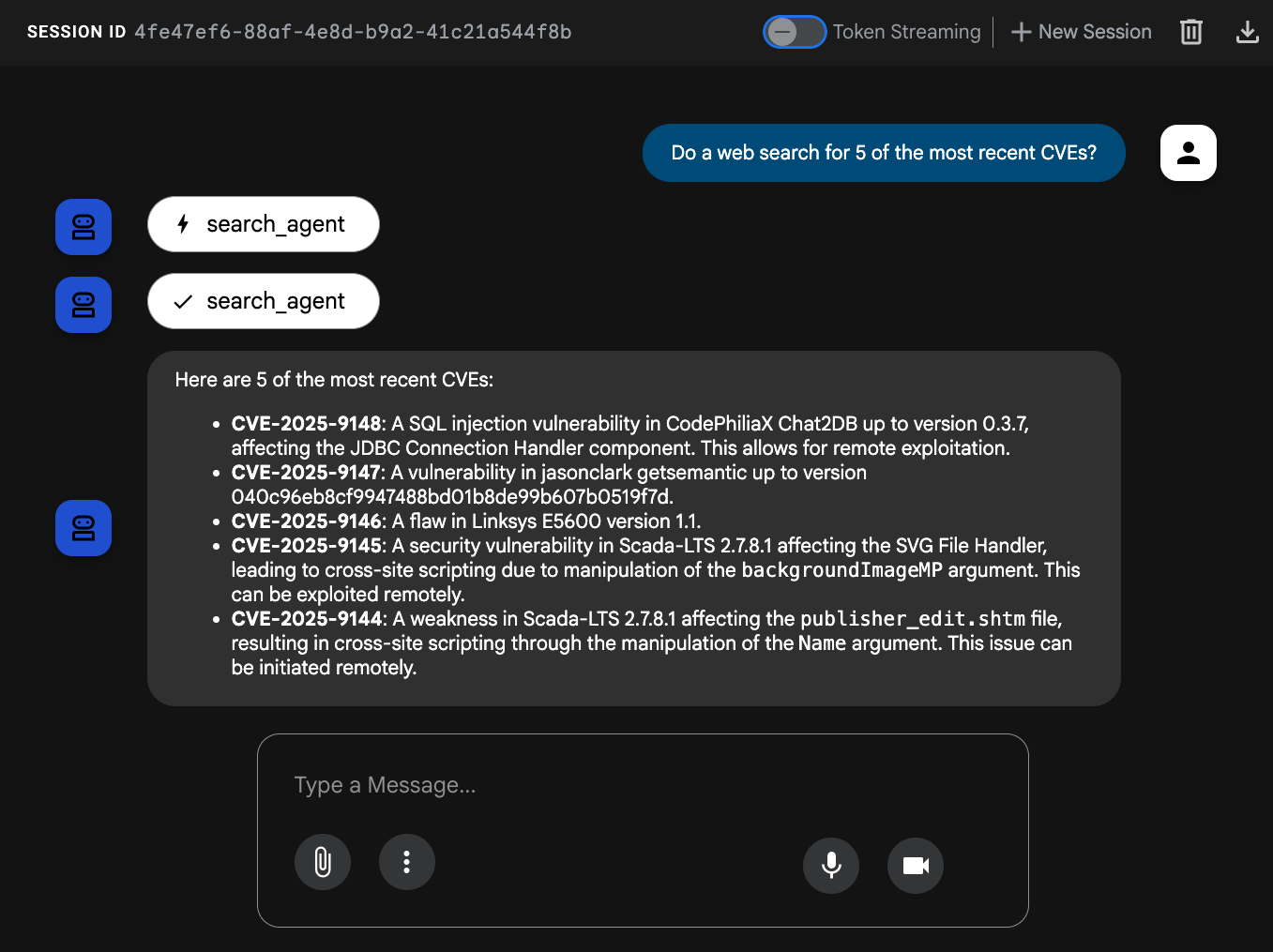
これで、エージェントは ADK の Google 検索用の組み込みツールを使用して、ウェブを検索できるようになりました。🎉
次の ADK ツールタイプに進みます。
8. サードパーティ製ツール
ADK は拡張性が高く、CrewAI や LangChain などの他のサードパーティの AI エージェント フレームワークのツールをシームレスに統合できます。この相互運用性は、開発時間の短縮と既存のツールの再利用を可能にするため、非常に重要です。

バグ エージェントを StackOverflow の強力な Q&A データに接続するために、LangChain の豊富なツール ライブラリから、具体的には StackExchange API ラッパーツールを pull できます。ADK は LangChain などのサードパーティ製ツールをサポートしているため、このツールを ADK エージェントに追加するために必要なコードは、わずか数行です。
まず、LangChain と StackOverflow(langchain-community と stackapi)の新しい依存関係をプロジェクトに追加する必要があります。
uv add langchain-community==0.3.27 stackapi==0.3.1
tools.py ファイルを開き、LangChain StackExchange ツールをサポートする機能を追加します。
cloudshell edit software_bug_assistant/tools.py
tools.py の末尾に次の行を追加します。
# ----- Example of a Third-Party Tool -----
from google.adk.tools.langchain_tool import LangchainTool
from langchain_community.tools import StackExchangeTool
from langchain_community.utilities import StackExchangeAPIWrapper
stack_exchange_tool = StackExchangeTool(api_wrapper=StackExchangeAPIWrapper())
langchain_tool = LangchainTool(stack_exchange_tool)
これで、agent.py のルート エージェントに langchain_tool をインポートして渡すことができます。
cloudshell edit software_bug_assistant/agent.py
agent.py を次のコードに置き換えて、langchain_tool を含めることができます。
from google.adk.agents import Agent
from .tools import get_current_date, langchain_tool, search_tool
# --- Agent Definition (model, instructions, tools) ---
root_agent = Agent(
model="gemini-2.5-flash",
name="software_assistant",
instruction="""
You are a skilled expert in triaging and debugging software issues for a
coffee machine company, QuantumRoast.
""",
tools=[get_current_date, search_tool, langchain_tool],
)
ファイルを保存して、ADK ウェブ UI が開いているタブに戻ります。
以前の CVE("Are there similar issues on stack exchange?")や新しい CVE("Our database queries with SQLAlchemy seem to be timing out, is there anything on StackExchange relevant to this?")についてエージェントに質問してみてください。
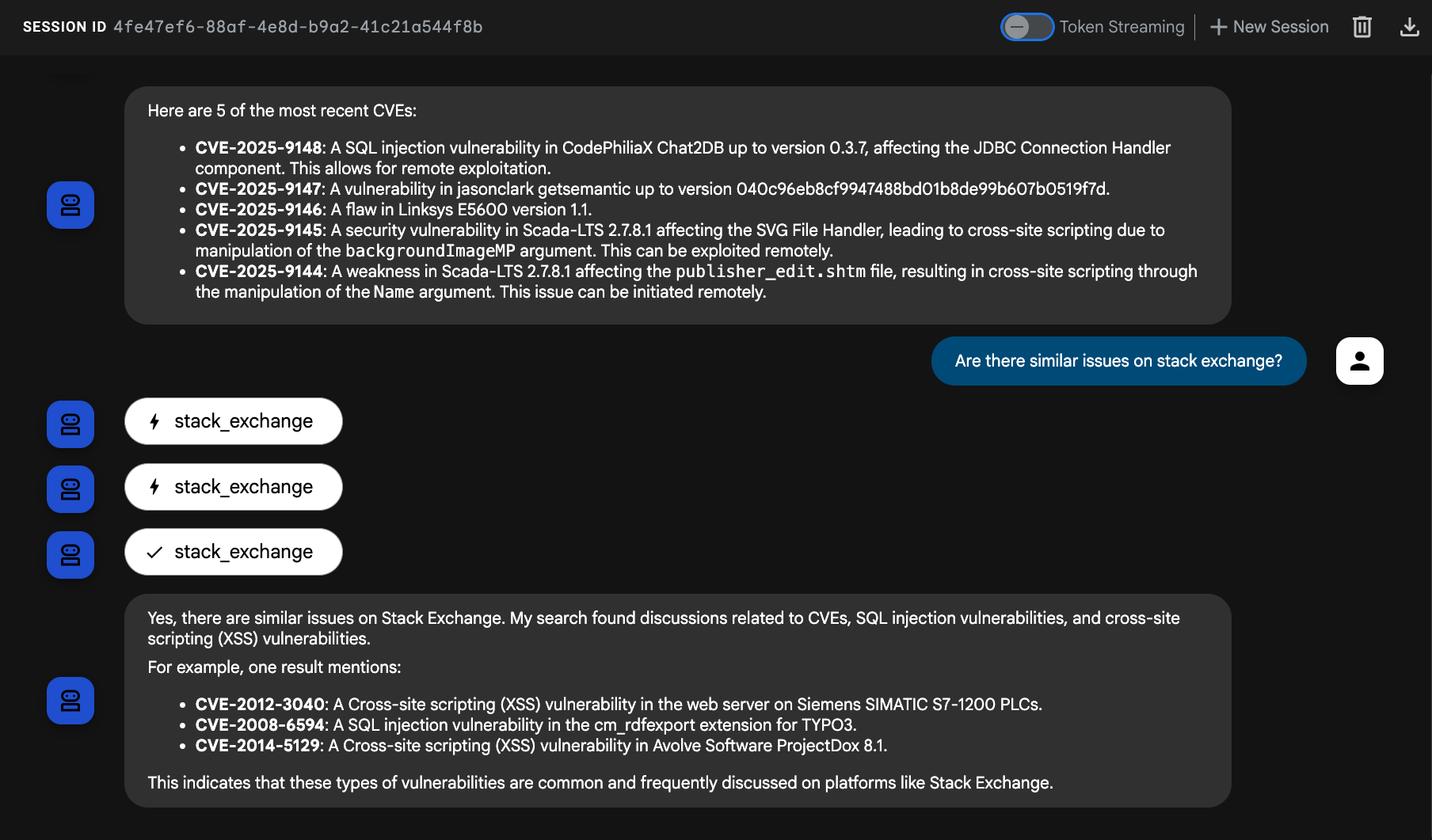
これで、エージェントは ADK の LangChain ツールを活用して StackOverflow をクエリできるようになりました。🥳
次の ADK ツールタイプに進みましょう。MCP ツール!
9. MCP ツール(データベース)
MCP は Model Context Protocol の略です。2024 年に Anthropic が公開したオープン プロトコルです。MCP は、AI エージェントとツールの「バックエンド」(API、データベース)の間に抽象化レイヤを提供します。
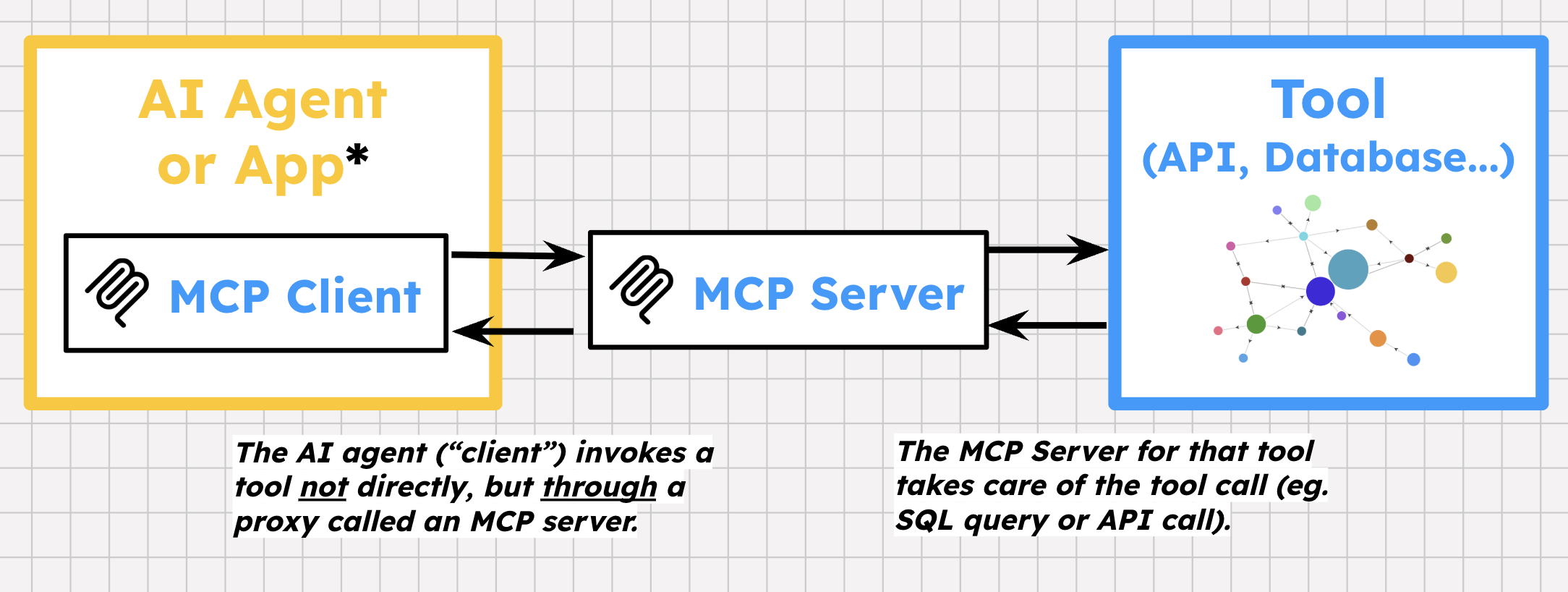
MCP には独自の仕様があります。標準の HTTP とは異なり、MCP はクライアントとサーバー間のステートフルな双方向接続を提供します。ツールとツール固有のエラー メッセージを定義する独自の方法を定めています。ツール プロバイダは、API の上に MCP サーバーを構築し、デベロッパーやユーザー向けに 1 つ以上の事前構築済みツールを公開できます。その後、エージェント フレームワークはエージェント アプリケーション内で MCP クライアントを初期化し、これらのツールを検出して呼び出すことができます。
QuantumRoast では、内部ソフトウェアのバグ用に Cloud SQL for PostgreSQL データベースを使用しています。エージェントがデータベースに対して特定のクエリを実行できるように、ADK ツールを作成したいと考えています。

最も簡単な方法は、データベース用のオープンソース MCP サーバーであるデータベース向け MCP ツールボックスを使用することです。Toolbox は 15 以上のデータベースをサポートしています。その 1 つが Cloud SQL です。
Toolbox には次の機能があります。
- 簡素化された開発: 10 行未満のコードでツールをエージェントに統合し、複数のエージェントまたはフレームワーク間でツールを再利用し、ツールの新しいバージョンをより簡単にデプロイできます。
- パフォーマンスの向上: 接続プーリングや認証などのベスト プラクティス。
- セキュリティの強化: 統合認証によるデータへの安全なアクセス
- エンドツーエンドのオブザーバビリティ: OpenTelemetry の組み込みサポートによる、すぐに使用できる指標とトレース。
ADK は MCP Toolbox for Database ツールをサポートしているため、統合を迅速に行うことができます。

MCP Toolbox for Databases サーバーを Cloud Run にデプロイする
まず、データベース用 MCP ツールボックス サーバーを Cloud Run にデプロイし、Cloud SQL インスタンスを指すようにします。
Toolbox には、構成用の YAML ファイルが必要です。このファイルで、データベース ソースと構成するツールを記述します。
デプロイ用の tools.yaml ファイルを作成します。
cloudshell edit tools.yaml
次の内容を tools.yaml に貼り付けます。
sources:
postgresql:
kind: cloud-sql-postgres
project: ${PROJECT_ID}
region: europe-west4
instance: software-assistant
database: tickets-db
user: postgres
password: admin
tools:
search-tickets:
kind: postgres-sql
source: postgresql
description: Search for similar tickets based on their descriptions.
parameters:
- name: query
type: string
description: The query to perform vector search with.
statement: |
SELECT ticket_id, title, description, assignee, priority, status, (embedding <=> embedding('text-embedding-005', $1)::vector) as distance
FROM tickets
ORDER BY distance ASC
LIMIT 3;
get-ticket-by-id:
kind: postgres-sql
source: postgresql
description: Retrieve a ticket's details using its unique ID.
parameters:
- name: ticket_id
type: string
description: The unique ID of the ticket.
statement: SELECT * FROM tickets WHERE ticket_id = $1;
get-tickets-by-assignee:
kind: postgres-sql
source: postgresql
description: Search for tickets based on assignee (email).
parameters:
- name: assignee
type: string
description: The email of the assignee.
statement: SELECT * FROM tickets WHERE assignee ILIKE '%' || $1 || '%';
update-ticket-priority:
kind: postgres-sql
source: postgresql
description: Update the priority of a ticket based on its ID.
parameters:
- name: priority
type: string
description: The priority of the ticket. Can be one of 'P0 - Critical', 'P1 - High', 'P2 - Medium', or 'P3 - Low'.
- name: ticket_id
type: string
description: The ID of the ticket.
statement: UPDATE tickets SET priority = $1 WHERE ticket_id = $2;
update-ticket-status:
kind: postgres-sql
source: postgresql
description: Update the status of a ticket based on its ID.
parameters:
- name: status
type: string
description: The new status of the ticket (e.g., 'Open', 'In Progress', 'Closed', 'Resolved').
- name: ticket_id
type: string
description: The ID of the ticket.
statement: UPDATE tickets SET status = $1 WHERE ticket_id = $2;
get-tickets-by-status:
kind: postgres-sql
source: postgresql
description: Search for tickets based on their current status.
parameters:
- name: status
type: string
description: The status of the tickets to retrieve (e.g., 'Open', 'In Progress', 'Closed', 'Resolved').
statement: SELECT * FROM tickets WHERE status ILIKE '%' || $1 || '%';
get-tickets-by-priority:
kind: postgres-sql
source: postgresql
description: Search for tickets based on their priority.
parameters:
- name: priority
type: string
description: The priority of the tickets to retrieve (e.g., 'P0 - Critical', 'P1 - High', 'P2 - Medium', 'P3 - Low').
statement: SELECT * FROM tickets WHERE priority ILIKE '%' || $1 || '%';
create-new-ticket:
kind: postgres-sql
source: postgresql
description: Create a new software ticket.
parameters:
- name: title
type: string
description: The title of the new ticket.
- name: description
type: string
description: A detailed description of the bug or issue.
- name: assignee
type: string
description: (Optional) The email of the person to whom the ticket should be assigned.
- name: priority
type: string
description: (Optional) The priority of the ticket. Can be 'P0 - Critical', 'P1 - High', 'P2 - Medium', or 'P3 - Low'. Default is 'P3 - Low'.
- name: status
type: string
description: (Optional) The initial status of the ticket. Default is 'Open'.
statement: INSERT INTO tickets (title, description, assignee, priority, status) VALUES ($1, $2, $3, COALESCE($4, 'P3 - Low'), COALESCE($5, 'Open')) RETURNING ticket_id;
get-tickets-by-date-range:
kind: postgres-sql
source: postgresql
description: Retrieve tickets created or updated within a specific date range.
parameters:
- name: start_date
type: string
description: The start date (inclusive) for the range (e.g., 'YYYY-MM-DD').
- name: end_date
type: string
description: The end date (inclusive) for the range (e.g., 'YYYY-MM-DD').
- name: date_field
type: string
description: The date field to filter by ('creation_time' or 'updated_time').
statement: SELECT * FROM tickets WHERE CASE WHEN $3 = 'creation_time' THEN creation_time ELSE updated_time END BETWEEN $1::timestamp AND $2::timestamp;
toolsets:
tickets_toolset:
- search-tickets
- get-ticket-by-id
- get-tickets-by-assignee
- get-tickets-by-status
- get-tickets-by-priority
- get-tickets-by-date-range
- update-ticket-priority
- update-ticket-status
- create-new-ticket
この YAML ファイルは、QuantumRoast チケット データベースに関連する 9 個のツールを定義します。
Toolbox Cloud Run サービスのサービス アカウントを構成し、Cloud SQL と Secret Manager にアクセスする権限を付与し、tools.yaml ファイルの Secret Manager シークレットを作成します。
tools.yaml ファイルには機密性の高い Cloud SQL 認証情報が含まれているため、Secret Manager に保存します。
gcloud iam service-accounts create toolbox-identity
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member serviceAccount:toolbox-identity@$PROJECT_ID.iam.gserviceaccount.com \
--role roles/secretmanager.secretAccessor
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member serviceAccount:toolbox-identity@$PROJECT_ID.iam.gserviceaccount.com \
--role roles/cloudsql.client
gcloud secrets create tools --data-file=tools.yaml
MCP Toolbox for Databases を Cloud Run にデプロイします。MCP ツールボックス コンテナ イメージの最新のリリース バージョンを使用します。
gcloud run deploy toolbox \
--image us-central1-docker.pkg.dev/database-toolbox/toolbox/toolbox:latest \
--service-account toolbox-identity \
--region europe-west4 \
--set-secrets "/app/tools.yaml=tools:latest" \
--set-env-vars="PROJECT_ID=$PROJECT_ID" \
--args="--tools-file=/app/tools.yaml","--address=0.0.0.0","--port=8080" \
--labels=dev-tutorial=codelab-toolbox \
--no-invoker-iam-check
デプロイが完了するまで待ちます。
Cloud Run ログをクエリして、Toolbox が実行されていることを確認します。
gcloud run services logs read toolbox --region europe-west4 --limit 10
以下のように表示されます。
2025-08-20 18:03:55 2025-08-20T18:03:55.465847801Z INFO "Initialized 1 sources." 2025-08-20 18:03:55 2025-08-20T18:03:55.466152914Z INFO "Initialized 0 authServices." 2025-08-20 18:03:55 2025-08-20T18:03:55.466374245Z INFO "Initialized 9 tools." 2025-08-20 18:03:55 2025-08-20T18:03:55.466477938Z INFO "Initialized 2 toolsets." 2025-08-20 18:03:55 2025-08-20T18:03:55.467492303Z INFO "Server ready to serve!"
ADK エージェントが Toolbox サービスを見つけられるように、Toolbox サービスの Cloud Run URL を環境変数として保存します。
export MCP_TOOLBOX_URL=$(gcloud run services describe toolbox --region europe-west4 --format "value(status.url)")
echo MCP_TOOLBOX_URL=$MCP_TOOLBOX_URL >> software_bug_assistant/.env
QuantumRoast エージェントを更新する
次に、MCP Toolbox for Databases SDK(toolbox-core)の依存関係をプロジェクトに追加する必要があります。
uv add toolbox-core==0.5.0
tools.py ファイルを開き、MCP ツールボックス ツールのサポートを追加します。
cloudshell edit software_bug_assistant/tools.py
tools.py の末尾に次の行を追加します。
# ----- Example MCP Toolbox for Databases tools -----
import os
from toolbox_core import ToolboxSyncClient
TOOLBOX_URL = os.getenv("MCP_TOOLBOX_URL", "http://127.0.0.1:5000")
# Initialize Toolbox client
toolbox = ToolboxSyncClient(TOOLBOX_URL)
# Load all the tools from toolset
toolbox_tools = toolbox.load_toolset("tickets_toolset")
これで、agent.py のルート エージェントに toolbox_tools をインポートして渡すことができます。
cloudshell edit software_bug_assistant/agent.py
agent.py を次のコードに置き換えて、toolbox_tools を含めることができます。
from google.adk.agents import Agent
from .tools import get_current_date, langchain_tool, search_tool, toolbox_tools
# --- Agent Definition (model, instructions, tools) ---
root_agent = Agent(
model="gemini-2.5-flash",
name="software_assistant",
instruction="""
You are a skilled expert in triaging and debugging software issues for a
coffee machine company, QuantumRoast.
""",
tools=[get_current_date, search_tool, langchain_tool, *toolbox_tools],
)
ファイルを保存して、ADK ウェブ UI が開いているタブに戻ります。
これで、Cloud SQL の内部チケット データベースに保存されているチケットについて質問できるようになりました。
次のような質問をします。
I am seeing an issue with database timeouts, has anyone else seen a similar issue?How many bugs are assigned to samuel.green@example.com? Show a table.Can you bump the priority of ticket with ID 6 to to P0 - Critical priorityCreate a new ticket(エージェントのガイドに沿ってバグを作成する)
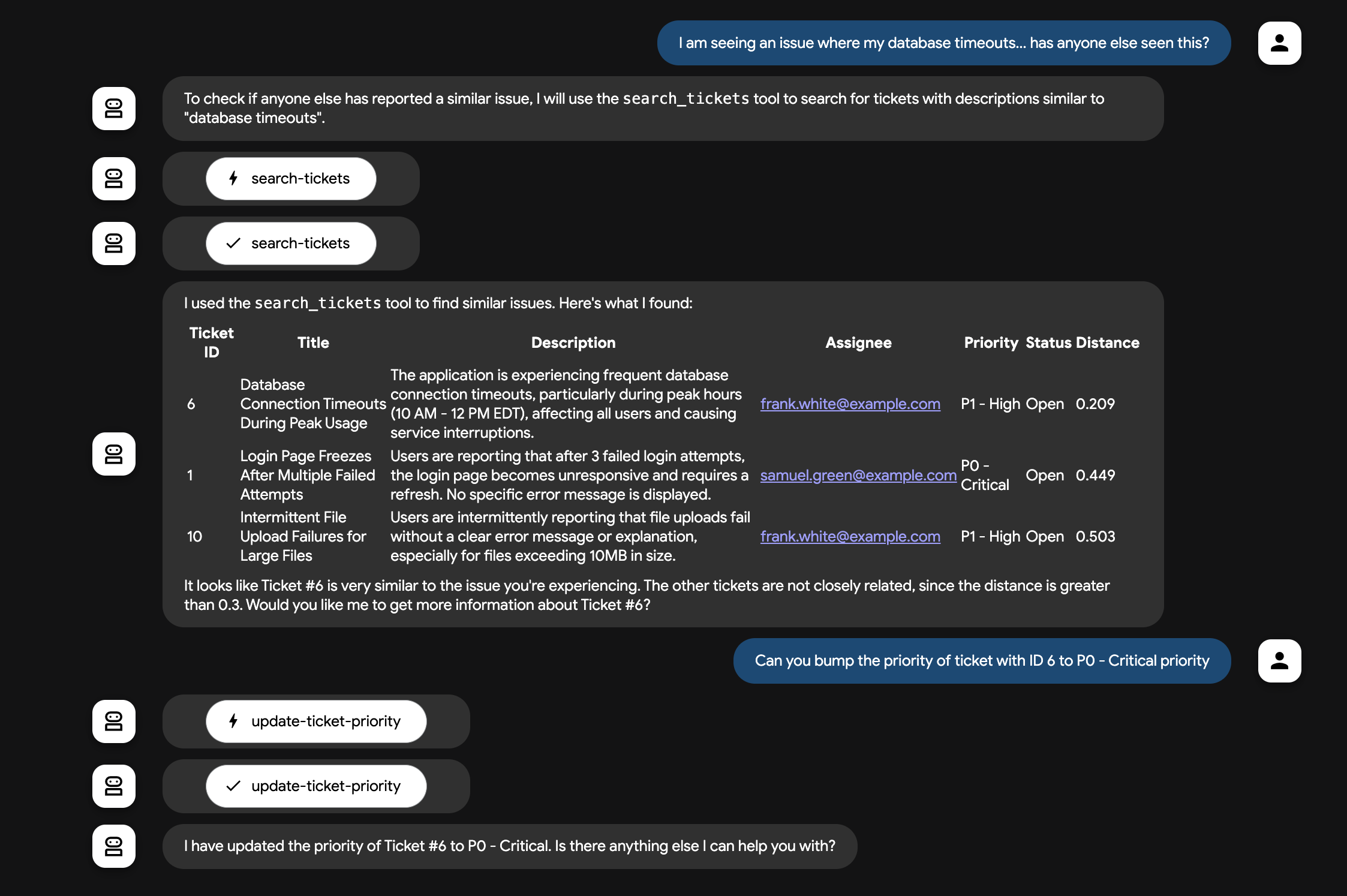
これで、ADK エージェントが データベース向け MCP ツールボックスのツールを介してデータベースにクエリを実行できました。🚀
10. 省略可: MCP ツール(API)
データベース向け MCP ツールボックスのように独自の SDK を持たない MCP ツールに ADK エージェントを接続する場合はどうすればよいですか?
ADK は、MCPToolset クラスを通じて汎用 MCP ツールをサポートしています。MCPToolset クラスは、MCP サーバーのツールを統合するための ADK の主要なメカニズムです。

MCPToolset を使用してローカルまたはリモートの MCP サーバーに接続できます。QuantumRoast では、エージェントを GitHub のリモート MCP サーバーに接続して、GitHub の API を簡単に呼び出せるようにします。これにより、エージェントは公開ソフトウェア リポジトリや Google 独自のコードベースから問題に関する情報を取得できるようになります。GitHub MCP サーバーは、問題や pull リクエストから、通知やコードのセキュリティまで、GitHub のさまざまな機能を公開しています。

GitHub 個人アクセス トークン(PAT)
GitHub MCP サーバーで認証するには、GitHub 個人用アクセス トークンが必要です。
取得する手順は次のとおりです。
- GitHub のデベロッパー設定に移動します。
- [Personal access tokens] -> [Tokens (classic)] をクリックします。
- [Generate new token] -> [Generate new token (classic)] をクリックします。
- トークンにわかりやすい名前を付けます。
- トークンの有効期限を設定します。
- 重要: セキュリティのため、トークンには必要な最小限のスコープを付与してください。リポジトリへの読み取り専用アクセス権の場合、
repo:status、public_repo、read:userのスコープで十分なことがよくあります。絶対に必要な場合を除き、リポジトリ全体または管理者の権限を付与しないでください。 - [
Generate token] をクリックします。 - 生成されたトークンをコピーします。
Cloud Shell ターミナルで次のコマンドを実行して、エージェントが使用できるように GitHub PAT を設定します。YOUR_GITHUB_PAT は、生成した PAT に置き換えます。
export GITHUB_PAT=YOUR_GITHUB_PAT
QuantumRoast エージェントを更新する
バグ アシスタントについては、読み取り専用の GitHub ツールをいくつか公開し、QuantumRoast の従業員がオープンソースの依存関係に関連する問題を見つけられるようにします。これにより、社内のチケット発行システムで確認されているバグの根本原因を特定できるかどうかを確認します。ここでは ADK の MCPToolset を使用し、tool_filter で設定を行います。tool-filter により、必要な GitHub ツールのみを表示できるため、ユーザーにアクセスを認めないツール(機密性の高いリポジトリ アクションなど)を非表示にできるだけでなく、エージェントのモデルがジョブに適したツールを選択しようとするときに過負荷になるのを防ぐこともできます。
tools.py ファイルを開き、GitHub ツールへのサポートを追加します。
cloudshell edit software_bug_assistant/tools.py
tools.py の末尾に次の行を追加します。
# ----- Example MCP Tools with MCPToolset (GitHub) -----
from google.adk.tools.mcp_tool import MCPToolset, StreamableHTTPConnectionParams
mcp_tools = MCPToolset(
connection_params=StreamableHTTPConnectionParams(
url="https://api.githubcopilot.com/mcp/",
headers={
"Authorization": "Bearer " + os.getenv("GITHUB_PAT"),
},
),
# Read only tools
tool_filter=[
"search_repositories",
"search_issues",
"list_issues",
"get_issue",
"list_pull_requests",
"get_pull_request",
],
)
また、コードで標準の API クライアントを設定するときに認証トークンを指定するのと同じように、GitHub の個人アクセス トークン(PAT)を MCPToolset 定義に指定する必要があります。この PAT は、公開リポジトリのデータにのみアクセスできるようスコープを設定し、機密性の高いユーザーやリポジトリのアクションはスコープに入れません。
これで、agent.py のルート エージェントに mcp_tools をインポートして渡すことができます。
cloudshell edit software_bug_assistant/agent.py
agent.py を次のコードに置き換えて、mcp_tools を含めることができます。
from google.adk.agents import Agent
from .tools import get_current_date, langchain_tool, mcp_tools, search_tool, toolbox_tools
# --- Agent Definition (model, instructions, tools) ---
root_agent = Agent(
model="gemini-2.5-flash",
name="software_assistant",
instruction="""
You are a skilled expert in triaging and debugging software issues for a
coffee machine company, QuantumRoast.
""",
tools=[get_current_date, search_tool, langchain_tool, *toolbox_tools, mcp_tools],
)
ファイルを保存して、ADK ウェブ UI が開いているタブに戻ります。
これで、エージェントが呼び出すことができる GitHub MCP ツールのセットができました。QuantumRoast のサービスは、データ圧縮ツールである XZ ユーティリティに依存しています。社内のバグチケット発行システムでは、昨年の CVE(セキュリティ脆弱性)が追跡されており、StackOverflow と Google 検索ツールを使用して、XZ Utils GitHub リポジトリまで遡ることができます。次に、GitHub の MCP ツールの一つである search_issues を使用することで、その CVE にいつ、どのようにパッチが適用されたかを確認できます。
エージェントに次の質問をします。
Find the official XZ Utils GitHub repositorySearch the repository for issues related to CVE-2024-3094
エージェントによって GitHub ツールが呼び出されていることがわかります。
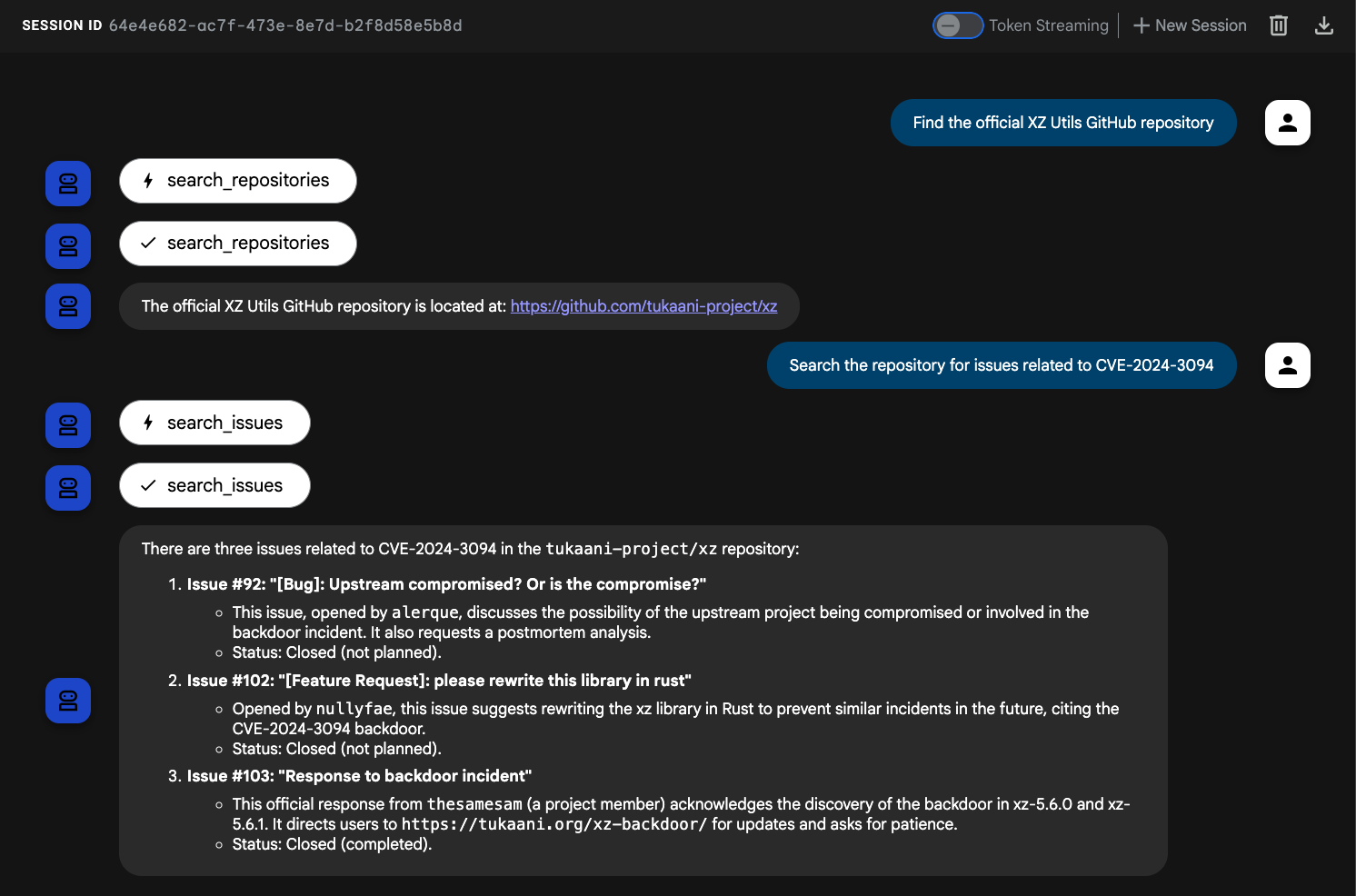
これで、QuantumRoast ADK エージェントは GitHub MCP サーバーツールとやり取りできるようになりました。🤩
11. 完了
おめでとうございます!Agent Development Kit(ADK)を使用して QuantumRoast のバグ アシスタント エージェントを構築し、さまざまな種類のツールを統合して機能を強化しました。基本的なエージェントから始めて、関数ツール、組み込みツール、サードパーティ ツール、MCP ツールを段階的に追加しました。
学習した内容
- ADK 開発用に Python プロジェクトを設定する方法。
- 基本的な ADK エージェントを作成する方法。
- 関数ツールを実装して使用する方法。
- Google 検索などの組み込みツールを統合する方法。
- ADK 内で LangChain などのフレームワークからサードパーティ製ツールを活用する方法。
- MCP ツールを使用してデータベース(Cloud SQL)と API を操作する方法。

クリーンアップ
Cloud プロジェクトを削除して、追加料金が発生しないようにすることができます。
サービスが使用されていない場合、Cloud Run の料金は発生しませんが、コンテナ イメージを Artifact Registry に保存すると課金される場合があります。Cloud プロジェクトを削除すると、そのプロジェクト内で使用されているすべてのリソースに対する課金が停止します。
必要に応じて、プロジェクトを削除します。
gcloud projects delete $GOOGLE_CLOUD_PROJECT
不要なリソースを Cloud Shell ディスクから削除することもできます。次のことが可能です。
- Codelab プロジェクト ディレクトリを削除します。
rm -rf ~/quantum-roast - 警告: この操作は元に戻せません。Cloud Shell のすべてのデータを削除して空き容量を増やす場合は、ホーム ディレクトリ全体を削除できます。残しておきたいものはすべて別の場所に保存されていることを確認してください。
sudo rm -rf $HOME