
1. Introducción
Este lab se enfoca en la implementación de un servicio de agente para clientes. Usarás el Kit de desarrollo de agentes (ADK) para crear un agente de IA que use herramientas remotas, como el servidor de MCP creado en el lab 1. El principio arquitectónico clave que se demuestra es la separación de responsabilidades, con una capa de razonamiento distinta (el agente) que se comunica con una capa de herramientas diferente (el servidor de MCP) a través de una API segura.
En el lab 1, creaste un servidor de MCP que proporciona datos sobre los animales en un zoológico ficticio a los LLM, por ejemplo, cuando se usa Gemini CLI. En este lab, crearemos un agente guía para el zoológico ficticio. El agente usará el mismo servidor de MCP del lab 1 para acceder a detalles sobre los animales del zoológico y también usará Wikipedia para crear una experiencia óptima de guía.

Por último, implementaremos el agente guía en Google Cloud Run para que todos los visitantes del zoológico puedan acceder a él en lugar de solo ejecutarse de forma local.
Requisitos previos
- Un servidor de MCP en ejecución en Cloud Run o su URL de servicio asociada
- Un proyecto de Google Cloud con la facturación habilitada
Qué aprenderás
- Cómo estructurar un proyecto de Python para la implementación del ADK
- Cómo implementar un agente que usa herramientas con google-adk
- Cómo conectar un agente a un servidor de MCP remoto para acceder a su conjunto de herramientas
- Cómo implementar una aplicación de Python como contenedor sin servidores en Cloud Run
- Cómo configurar la autenticación segura de servicio a servicio con roles de IAM
- Cómo borrar los recursos de Cloud para evitar generar costos futuros
Requisitos
- Una cuenta de Google Cloud y un proyecto de Google Cloud
- Un navegador web, como Chrome
2. ¿Por qué realizar la implementación en Cloud Run?
Cloud Run es una excelente opción para alojar agentes del ADK porque es una plataforma sin servidores, lo que significa que puedes enfocarte en tu código y no en administrar la infraestructura subyacente. Nos encargamos del trabajo operativo por ti.
Imagínalo como una tienda temporal: solo abre y usa recursos cuando llegan clientes (solicitudes). Cuando no hay clientes, cierra por completo y no pagas por una tienda vacía.
Características clave
Ejecuta contenedores en cualquier lugar:
- Usas un contenedor (imagen de Docker) que contiene tu app.
- Cloud Run lo ejecuta en la infraestructura de Google.
- No hay que preocuparse por aplicar parches al SO, configurar VMs o escalar la app.
Ajuste de escala automático:
- Si 0 personas usan tu app, se ejecutan 0 instancias (se reduce a cero instancias, lo que resulta rentable).
- Si recibe 1,000 solicitudes, se inician tantas copias como sean necesarias.
Sin estado de forma predeterminada:
- Cada solicitud podría ir a una instancia diferente.
- Si necesitas almacenar el estado, usa un servicio externo como Cloud SQL, Firestore o Memorystore.
Admite cualquier lenguaje o framework:
- Siempre que se ejecute en un contenedor de Linux, a Cloud Run no le importa si el lenguaje es Python, Go, Node.js, Java o .NET.
Paga por lo que usas:
- Facturación basada en solicitudes: Se factura por solicitud más tiempo de procesamiento (hasta 100 ms).
- Facturación basada en instancias: Se factura la vida útil completa de la instancia (sin cargos por solicitud).
3. Antes de comenzar
Configuración del entorno de autoaprendizaje
- Accede a Google Cloud Console y crea un proyecto nuevo o reutiliza uno existente. Si aún no tienes una cuenta de Gmail o de Google Workspace, debes crear una.

- El Nombre del proyecto es el nombre visible de los participantes de este proyecto. Es una cadena de caracteres que no se utiliza en las APIs de Google. Puedes actualizarla cuando quieras.
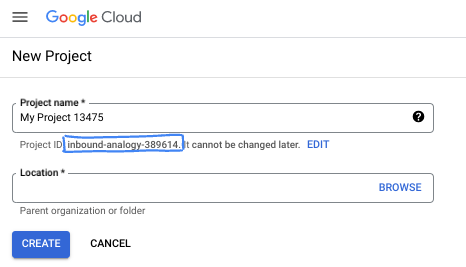
- El ID del proyecto es único en todos los proyectos de Google Cloud y es inmutable (no se puede cambiar después de configurarlo). La consola de Cloud genera automáticamente una cadena única. Por lo general, no importa cuál sea. En la mayoría de los codelabs, deberás hacer referencia al ID de tu proyecto (suele identificarse como
PROJECT_ID). Si no te gusta el ID que se generó, podrías generar otro aleatorio. También puedes probar uno propio y ver si está disponible. No se puede cambiar después de este paso y se usa el mismo durante todo el proyecto. - Recuerda que hay un tercer valor, un número de proyecto, que usan algunas APIs. Obtén más información sobre estos tres valores en la documentación.
- A continuación, deberás habilitar la facturación en la consola de Cloud para usar las APIs o los recursos de Cloud. Ejecutar este codelab no costará mucho, tal vez nada. Para cerrar recursos y evitar que se generen cobros más allá de este instructivo, puedes borrar los recursos que creaste o borrar el proyecto. Los usuarios nuevos de Google Cloud son aptos para participar en el programa Prueba gratuita de $300.
Inicia Cloud Shell
- Navega al Editor de Cloud Shell.
- Si la terminal no aparece en la parte inferior de la pantalla, ábrela:
- Haz clic en Terminal.
- Haz clic en Terminal nueva.
- En la terminal, configura tu proyecto con este comando. Si completaste el lab 1, asegúrate de usar el mismo ID del proyecto:
gcloud config set project [YOUR-PROJECT-ID]gcloud projects list | awk '/PROJECT_ID/{print $2}' - Si se te solicita autorización, haz clic en Autorizar para continuar.
- Deberías ver el siguiente mensaje:
Updated property [core/project].
WARNINGy se te preguntaDo you want to continue (Y/n)?, es probable que hayas ingresado el ID del proyecto de forma incorrecta. Presionan, presionaEntery vuelve a intentar ejecutar el comandogcloud config set project.
4. Configura tu entorno
Habilita las APIs y establece las variables de entorno
Habilita todos los servicios necesarios con el siguiente comando:
gcloud services enable \
run.googleapis.com \
artifactregistry.googleapis.com \
cloudbuild.googleapis.com \
aiplatform.googleapis.com
Resultado esperado
Operation "operations/acat.p2-[GUID]" finished successfully.
Crea el directorio del proyecto.
Este comando crea una carpeta principal para el lab en la que se almacenará el código fuente del agente.
cd && mkdir zoo_guide_agent && cd zoo_guide_agent
Crea el archivo requirements.txt. En este archivo, se encuentran las bibliotecas de Python que necesita tu agente. El siguiente comando crea el archivo y lo completa.
cloudshell edit requirements.txt
google-adk==1.14.0
langchain-community==0.3.27
wikipedia==1.4.0
Configura variables para el ID y el número de tu proyecto actual, y crea una cuenta de servicio dedicada para tu proyecto. Esta es una forma más sólida de ejecutar estos comandos.
export PROJECT_ID=$(gcloud config get-value project)
export PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")
export SA_NAME=lab2-cr-service
export SERVICE_ACCOUNT="${SA_NAME}@${PROJECT_ID}.iam.gserviceaccount.com"
gcloud iam service-accounts create ${SA_NAME} \
--display-name="Service Account for lab 2 "
Crea y abre un archivo .env para autenticar el agente en el directorio zoo_guide_agent.
cloudshell edit .env
El comando cloudshell edit abrirá el archivo .env en el editor que se encuentra sobre la terminal. Ingresa lo siguiente en el archivo .env y vuelve a la terminal.
MODEL="gemini-2.5-flash"
Se agrega la URL del servidor de MCP. Si completaste el lab 1, sigue estos pasos para usar el servidor de MCP que creaste en ese lab:
Otorga permisos a la cuenta de servicio del agente para usar Gemini en Vertex AI y llamar al servidor MCP remoto:
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT" \
--role="roles/aiplatform.user"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT" \
--role="roles/run.invoker"
Guarda la URL del servidor de MCP del lab 1 en una variable de entorno.
echo -e "\nMCP_SERVER_URL=https://zoo-mcp-server-${PROJECT_NUMBER}.us-west1.run.app/mcp" >> .env
Si usas un vínculo público del servidor de MCP, ejecuta el siguiente comando y reemplaza PROJECT_NUMBER por el valor proporcionado.
echo -e "\nMCP_SERVER_URL=https://zoo-mcp-server-${PROJECT_NUMBER}.us-west1.run.app/mcp" >> .env
5. Crea el flujo de trabajo del agente
Crea el archivo init.py
Crea el archivo init.py. Este archivo le indica a Python que el directorio zoo_guide_agent es un paquete.
cloudshell edit __init__.py
El comando anterior abre el editor de código. Agrega el siguiente código a __init__.py:
from . import agent
Crea el archivo principal agent.py
Crea el archivo principal agent.py. Este comando crea el archivo de Python y pega el código completo de tu sistema de varios agentes.
cloudshell edit agent.py
Importaciones y configuración inicial
Este primer bloque incorpora todas las bibliotecas necesarias del ADK y Google Cloud. También configura el registro y carga las variables de entorno desde tu archivo .env, lo que es fundamental para acceder a tu modelo y a la URL del servidor.
Agrega el siguiente código a tu archivo agent.py:
import os
import logging
import google.cloud.logging
from dotenv import load_dotenv
from google.adk import Agent
from google.adk.agents import SequentialAgent
from google.adk.tools.mcp_tool.mcp_toolset import MCPToolset, StreamableHTTPConnectionParams
from google.adk.tools.tool_context import ToolContext
from google.adk.tools.langchain_tool import LangchainTool
from langchain_community.tools import WikipediaQueryRun
from langchain_community.utilities import WikipediaAPIWrapper
import google.auth
import google.auth.transport.requests
import google.oauth2.id_token
# --- Setup Logging and Environment ---
cloud_logging_client = google.cloud.logging.Client()
cloud_logging_client.setup_logging()
load_dotenv()
model_name = os.getenv("MODEL")
Cómo definir las herramientas (las capacidades del agente)

La eficacia de un agente depende de las herramientas que puede usar. En esta sección, definiremos todas las capacidades que tendrá nuestro agente, incluida una función personalizada para guardar datos, una herramienta de MCP que se conecta a nuestro servidor de MCP seguro y una herramienta de Wikipedia.
Agrega el siguiente código a la parte inferior de agent.py:
# Greet user and save their prompt
def add_prompt_to_state(
tool_context: ToolContext, prompt: str
) -> dict[str, str]:
"""Saves the user's initial prompt to the state."""
tool_context.state["PROMPT"] = prompt
logging.info(f"[State updated] Added to PROMPT: {prompt}")
return {"status": "success"}
# Configuring the MCP Tool to connect to the Zoo MCP server
mcp_server_url = os.getenv("MCP_SERVER_URL")
if not mcp_server_url:
raise ValueError("The environment variable MCP_SERVER_URL is not set.")
def get_id_token():
"""Get an ID token to authenticate with the MCP server."""
target_url = os.getenv("MCP_SERVER_URL")
audience = target_url.split('/mcp/')[0]
request = google.auth.transport.requests.Request()
id_token = google.oauth2.id_token.fetch_id_token(request, audience)
return id_token
"""
# Use this code if you are using the public MCP Server and comment out the code below defining mcp_tools
mcp_tools = MCPToolset(
connection_params=StreamableHTTPConnectionParams(
url=mcp_server_url
)
)
"""
mcp_tools = MCPToolset(
connection_params=StreamableHTTPConnectionParams(
url=mcp_server_url,
headers={
"Authorization": f"Bearer {get_id_token()}",
},
),
)
# Configuring the Wikipedia Tool
wikipedia_tool = LangchainTool(
tool=WikipediaQueryRun(api_wrapper=WikipediaAPIWrapper())
)
Explicación de las tres herramientas
add_prompt_to_state📝
Esta herramienta recuerda lo que preguntan los visitantes del zoológico. Cuando un visitante pregunta: "¿Dónde están los leones?", esta herramienta guarda esa pregunta específica en la memoria del agente para que los otros agentes del flujo de trabajo sepan qué investigar.
Funcionamiento: Es una función de Python que escribe la instrucción del visitante en el diccionario compartido tool_context.state. Este contexto de la herramienta representa la memoria a corto plazo del agente para una sola conversación. Los datos que un agente guarda en el estado pueden ser leídos por el siguiente agente en el flujo de trabajo.
MCPToolset🦁
Se usa para conectar el agente de guía turístico al servidor de MCP del zoológico creado en el lab 1. Este servidor tiene herramientas especiales para buscar información específica sobre nuestros animales, como su nombre, edad y recinto.
Funcionamiento: Se conecta de forma segura a la URL del servidor privado del zoológico. Usa get_id_token para obtener automáticamente una "tarjeta llave" segura (un token de ID de cuenta de servicio) con la que verificar tu identidad y obtener acceso.
LangchainTool🌍
Esto le brinda al agente de guía turística conocimiento general del mundo. Cuando un visitante hace una pregunta que no está en la base de datos del zoológico, como "¿Qué comen los leones en la naturaleza?", esta herramienta permite que el agente busque la respuesta en Wikipedia.
Funcionamiento: Actúa como un adaptador, lo que permite que nuestro agente use la herramienta precompilada WikipediaQueryRun de la biblioteca LangChain.
Recursos:
Cómo definir los agentes especialistas

A continuación, definiremos el agente investigador y el agente formateador de respuestas. El agente investigador es el "cerebro" de nuestra operación. Este agente toma la instrucción del usuario del State compartido, examina sus potentes herramientas (la herramienta del servidor de MCP del zoológico y la herramienta de Wikipedia) y decide cuáles usar para encontrar la respuesta.
El rol del agente formateador de respuestas es la presentación. No usa ninguna herramienta para encontrar información nueva. En cambio, toma los datos sin procesar que recopila el agente investigador (que se pasan a través de State) y usa las habilidades lingüísticas del LLM para transformarlos en una respuesta amigable y de tono conversacional.
Agrega el siguiente código al final de agent.py:
# 1. Researcher Agent
comprehensive_researcher = Agent(
name="comprehensive_researcher",
model=model_name,
description="The primary researcher that can access both internal zoo data and external knowledge from Wikipedia.",
instruction="""
You are a helpful research assistant. Your goal is to fully answer the user's PROMPT.
You have access to two tools:
1. A tool for getting specific data about animals AT OUR ZOO (names, ages, locations).
2. A tool for searching Wikipedia for general knowledge (facts, lifespan, diet, habitat).
First, analyze the user's PROMPT.
- If the prompt can be answered by only one tool, use that tool.
- If the prompt is complex and requires information from both the zoo's database AND Wikipedia,
you MUST use both tools to gather all necessary information.
- Synthesize the results from the tool(s) you use into preliminary data outputs.
PROMPT:
{{ PROMPT }}
""",
tools=[
mcp_tools,
wikipedia_tool
],
output_key="RESEARCH_DATA" # A key to store the combined findings
)
# 2. Response Formatter Agent
response_formatter = Agent(
name="response_formatter",
model=model_name,
description="Synthesizes all information into a friendly, readable response.",
instruction="""
You are the friendly voice of the Zoo Tour Guide. Your task is to take the
RESEARCH_DATA and present it to the user in a complete and helpful answer.
- First, present the specific information from the zoo (like names, ages, and where to find them).
- Then, add the interesting general facts from the research.
- If some information is missing, just present the information you have.
- Be conversational and engaging.
RESEARCH_DATA:
{{ RESEARCH_DATA }}
"""
)
El agente de flujo de trabajo
El agente de flujo de trabajo actúa como el encargado de la "oficina administrativa" del recorrido por el zoológico. Toma la solicitud de investigación y garantiza que los dos agentes que definimos anteriormente realicen sus trabajos en el orden correcto: primero investigar y, luego, dar formato. Con esto, se crea un proceso predecible y confiable para responder las preguntas de los visitantes.
Funcionamiento: Es un SequentialAgent, un tipo especial de agente que no piensa por sí mismo. Su único trabajo es ejecutar una lista de sub_agents (el investigador y el formateador) en una secuencia fija y pasar automáticamente la memoria compartida de uno a otro.
Agrega este bloque de código a la parte inferior de agent.py:
tour_guide_workflow = SequentialAgent(
name="tour_guide_workflow",
description="The main workflow for handling a user's request about an animal.",
sub_agents=[
comprehensive_researcher, # Step 1: Gather all data
response_formatter, # Step 2: Format the final response
]
)
Cómo ensamblar el flujo de trabajo principal 
Este agente se designa como root_agent, que es lo que el framework de ADK usa como punto de partida para todas las conversaciones nuevas. Su función principal es organizar el proceso general. Actúa como el controlador inicial y administra el primer turno de la conversación.
Agrega este bloque de código final a la parte inferior de agent.py:
root_agent = Agent(
name="greeter",
model=model_name,
description="The main entry point for the Zoo Tour Guide.",
instruction="""
- Let the user know you will help them learn about the animals we have in the zoo.
- When the user responds, use the 'add_prompt_to_state' tool to save their response.
After using the tool, transfer control to the 'tour_guide_workflow' agent.
""",
tools=[add_prompt_to_state],
sub_agents=[tour_guide_workflow]
)
Tu archivo agent.py ya está completo. Si lo creas de esta manera, puedes ver cómo cada componente (herramientas, agentes de trabajadores y agentes de administradores) tiene un rol específico en la creación del sistema inteligente final. Ahora, pasemos a la implementación.
6. Implementa el agente con la CLI del ADK
Con el código local listo y tu proyecto de Google Cloud preparado, es hora de implementar el agente. Usarás el comando adk deploy cloud_run, una herramienta conveniente que automatiza todo el flujo de trabajo de implementación. Este único comando empaqueta tu código, crea una imagen de contenedor, la envía a Artifact Registry y lanza el servicio en Cloud Run para que sea accesible en la Web.
Implementar
Ejecuta los siguientes comandos para implementar tu agente. El comando uvx te permite ejecutar herramientas de línea de comandos publicadas como paquetes de Python sin necesidad de una instalación global de esas herramientas.
# Run the deployment command
uvx --from google-adk==1.14.0 \
adk deploy cloud_run \
--project=$PROJECT_ID \
--region=us-west1 \
--service_name=zoo-tour-guide \
--with_ui \
. \
-- \
--labels=dev-tutorial=codelab-adk \
--service-account=$SERVICE_ACCOUNT
Aceptar instrucciones
Es posible que aparezca el siguiente mensaje:
Deploying from source requires an Artifact Registry Docker repository to store built containers. A repository named [cloud-run-source-deploy] in region [us-west1] will be created. Do you want to continue (Y/n)?
Escribe Y y presiona INTRO.
Es posible que aparezca el siguiente mensaje:
Allow unauthenticated invocations to [your-service-name] (y/N)?.
Para este lab, queremos permitir invocaciones no autenticadas para facilitar las pruebas. Escribe y y presiona Intro.
Obtén el vínculo de implementación
Cuando la ejecución se realice correctamente, el comando proporcionará la URL del servicio de Cloud Run implementado. (Se verá como https://zoo-tour-guide-123456789.us-west1.run.app). Copia esta URL para la siguiente tarea.
7. Prueba el agente implementado
Ahora que tu agente está activo en Cloud Run, realizarás una prueba para confirmar que la implementación se realizó correctamente y que el agente funciona como se espera. Usarás la URL del servicio público (algo como https://zoo-tour-guide-123456789.us-west1.run.app/) para acceder a la interfaz web del ADK y, así, interactuar con el agente.
Abre la URL pública del servicio de Cloud Run en tu navegador web. Como usaste --with_ui flag, deberías ver la IU para desarrolladores del ADK.
Activa Token Streaming en la esquina superior derecha.
Ahora puedes interactuar con el agente del zoológico.
Escribe hello y presiona Intro para comenzar una nueva conversación.
Observa el resultado. El agente debería responder rápidamente con su saludo:
"Hello! I'm your Zoo Tour Guide. I can help you learn about the amazing animals we have here. What would you like to know or explore today?"
Hazle preguntas al agente, como las siguientes:
Where can I find the polar bears in the zoo and what is their diet?
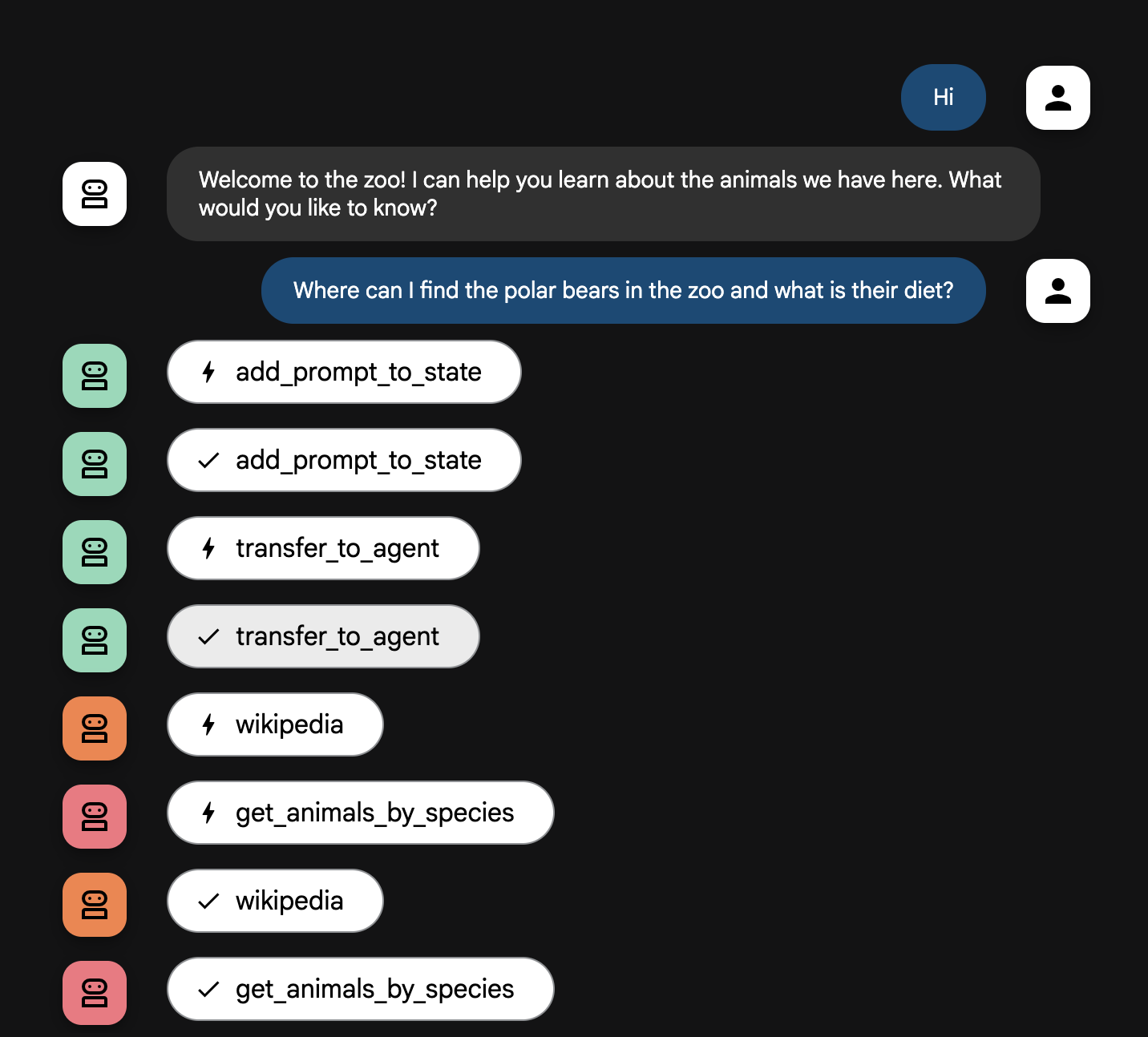

Explicación del flujo del agente
Tu sistema funciona como un equipo inteligente de múltiples agentes. El proceso se administra con una secuencia clara para garantizar un flujo eficiente y fluido desde la pregunta de un usuario hasta la respuesta final y detallada.
1. El agente de bienvenida del zoológico (el mostrador de recepción)
El proceso comienza con el agente de bienvenida.
Su trabajo: Iniciar la conversación. Su instrucción es saludar al usuario y preguntarle sobre qué animal le gustaría aprender.
Su herramienta: Cuando el usuario responde, el agente de bienvenida usa su herramienta add_prompt_to_state para capturar las palabras exactas (p. ej., "cuéntame sobre los leones") y guardarlas en la memoria del sistema.
Siguiente eslabón del proceso: Después de guardar la instrucción, le pasa inmediatamente el control a su agente secundario, tour_guide_workflow.
2. El investigador integral (el superinvestigador)
Este es el primer paso en el flujo de trabajo principal y el "cerebro" de la operación. En lugar de un equipo grande, ahora tienes un solo agente altamente capacitado que puede acceder a toda la información disponible.
Su trabajo: Analizar la pregunta del usuario y crear un plan inteligente. Utiliza la potente capacidad de uso de herramientas del modelo de lenguaje para decidir si necesita lo siguiente:
- Datos internos de los registros del zoológico (a través del servidor de MCP)
- Información general de la Web (a través de la API de Wikipedia)
- O, para preguntas complejas, ambos tipos de datos
Su acción: Ejecuta las herramientas necesarias para recopilar todos los datos sin procesar requeridos. Por ejemplo, si se le pregunta: "¿Cuántos años tienen nuestros leones y qué comen en la naturaleza?", llamará al servidor de MCP para obtener las edades y a la herramienta de Wikipedia para obtener la información sobre la dieta.
3. El formateador de respuestas (el presentador)
Una vez que el investigador integral haya recopilado todos los hechos, este es el agente final que se debe ejecutar.
Su trabajo: Actuar como la voz amigable del guía del zoológico. Toma los datos sin procesar (que podrían ser de una o ambas fuentes) y los pule.
Su acción: Sintetiza toda la información en una respuesta única, coherente y atractiva. Siguiendo sus instrucciones, primero presenta la información específica del zoológico y, luego, agrega los datos generales interesantes.
El resultado final: El texto generado por este agente es la respuesta completa y detallada que el usuario ve en la ventana de chat.
Si te interesa obtener más información sobre la creación de agentes, consulta los siguientes recursos:
8. Limpia el entorno
gcloud run services delete zoo-tour-guide --region=us-west1 --quiet
gcloud artifacts repositories delete cloud-run-source-deploy --location=us-west1 --quiet
9. Felicitaciones
Felicitaciones por completar el codelab.
Temas abordados
- Cómo estructurar un proyecto de Python para la implementación con la interfaz de línea de comandos del ADK
- Cómo implementar un flujo de trabajo multiagente con SequentialAgent y ParallelAgent
- Cómo conectarse a un servidor de MCP remoto con MCPToolset para usar sus herramientas
- Cómo aumentar los datos internos integrando herramientas externas, como la API de Wikipedia
- Cómo implementar un agente como un contenedor sin servidores en Cloud Run con el comando adk deploy