
১. ভূমিকা
এই ল্যাবটি একটি ক্লায়েন্ট এজেন্ট সার্ভিসের বাস্তবায়ন এবং স্থাপনের উপর আলোকপাত করে। আপনি এজেন্ট ডেভেলপমেন্ট কিট (ADK) ব্যবহার করে একটি এআই এজেন্ট তৈরি করবেন, যা ল্যাব ১- এ তৈরি করা এমসিপি সার্ভারের মতো রিমোট টুল ব্যবহার করে। এখানে প্রদর্শিত মূল স্থাপত্য নীতিটি হলো ‘সেপারেশন অফ কনসার্নস’, যেখানে একটি স্বতন্ত্র রিজনিং লেয়ার (এজেন্ট) একটি সুরক্ষিত এপিআই-এর মাধ্যমে একটি স্বতন্ত্র টুলিং লেয়ারের (এমসিপি সার্ভার) সাথে যোগাযোগ করে।
ল্যাব ১-এ, আপনি একটি এমসিপি (MCP) সার্ভার তৈরি করেছিলেন যা এলএলএম-দের (LLMs) একটি কাল্পনিক চিড়িয়াখানার প্রাণীদের সম্পর্কে তথ্য সরবরাহ করে, উদাহরণস্বরূপ জেমিনি সিএলআই (Gemini CLI) ব্যবহার করার সময়। এই ল্যাবে, আমরা সেই কাল্পনিক চিড়িয়াখানাটির জন্য একটি ট্যুর গাইড এজেন্ট তৈরি করছি। এজেন্টটি চিড়িয়াখানার প্রাণীদের সম্পর্কে বিস্তারিত তথ্য অ্যাক্সেস করার জন্য ল্যাব ১-এর সেই একই এমসিপি সার্ভারটি ব্যবহার করবে এবং সেরা ট্যুর গাইড অভিজ্ঞতা তৈরি করতে উইকিপিডিয়াও ব্যবহার করবে।

অবশেষে, আমরা ট্যুর গাইড এজেন্টটিকে গুগল ক্লাউড রান-এ স্থাপন করব, যাতে এটি শুধু স্থানীয়ভাবে চলার পরিবর্তে চিড়িয়াখানার সকল দর্শনার্থী ব্যবহার করতে পারে।
পূর্বশর্ত
- ক্লাউড রান-এ চলমান একটি এমসিপি সার্ভার অথবা এর সংশ্লিষ্ট সার্ভিস ইউআরএল।
- বিলিং সক্ষম একটি গুগল ক্লাউড প্রজেক্ট।
আপনি যা শিখবেন
- ADK ডেপ্লয়মেন্টের জন্য একটি পাইথন প্রজেক্ট কীভাবে গঠন করতে হয়।
- google-adk ব্যবহার করে কীভাবে একটি টুল-ব্যবহারকারী এজেন্ট বাস্তবায়ন করা যায়।
- একটি এজেন্টকে তার টুলসেটের জন্য কীভাবে একটি রিমোট এমসিপি সার্ভারের সাথে সংযুক্ত করবেন।
- ক্লাউড রান-এ কীভাবে একটি পাইথন অ্যাপ্লিকেশনকে সার্ভারলেস কন্টেইনার হিসেবে ডেপ্লয় করবেন।
- IAM রোল ব্যবহার করে কীভাবে সুরক্ষিত, সার্ভিস-টু-সার্ভিস অথেন্টিকেশন কনফিগার করবেন।
- ভবিষ্যতে খরচ এড়ানোর জন্য কীভাবে ক্লাউড রিসোর্স ডিলিট করবেন।
আপনার যা যা লাগবে
- একটি গুগল ক্লাউড অ্যাকাউন্ট এবং গুগল ক্লাউড প্রজেক্ট
- ক্রোমের মতো একটি ওয়েব ব্রাউজার
২. ক্লাউড রান-এ কেন ডেপ্লয় করবেন?
ADK এজেন্ট হোস্ট করার জন্য ক্লাউড রান একটি চমৎকার পছন্দ, কারণ এটি একটি সার্ভারবিহীন প্ল্যাটফর্ম। এর মানে হলো, আপনি অন্তর্নিহিত পরিকাঠামো পরিচালনার পরিবর্তে আপনার কোডের উপর মনোযোগ দিতে পারবেন। আমরা আপনার জন্য পরিচালন সংক্রান্ত কাজগুলো সামলে নিই।
এটিকে একটি পপ-আপ শপের মতো ভাবুন: এটি কেবল তখনই খোলে এবং প্রয়োজনীয় উপকরণ ব্যবহার করে যখন গ্রাহক (অনুরোধ) আসে। যখন কোনো গ্রাহক থাকে না, তখন এটি পুরোপুরি বন্ধ হয়ে যায় এবং আপনাকে একটি খালি দোকানের জন্য কোনো অর্থ প্রদান করতে হয় না।
মূল বৈশিষ্ট্য
যেকোনো স্থানে কন্টেইনার চালায়:
- আপনি এমন একটি কন্টেইনার (ডকার ইমেজ) নিয়ে আসেন যার ভেতরে আপনার অ্যাপটি রয়েছে।
- ক্লাউড রান এটি গুগলের পরিকাঠামোতে পরিচালনা করে।
- ওএস প্যাচিং, ভিএম সেটআপ বা স্কেলিং নিয়ে কোনো ঝামেলা নেই।
স্বয়ংক্রিয় স্কেলিং:
- যদি ০ জন আপনার অ্যাপ ব্যবহার করে → ০টি ইনস্ট্যান্স চলবে (এটি ইনস্ট্যান্সের সংখ্যা শূন্যে নামিয়ে আনে, যা সাশ্রয়ী)।
- যদি ১০০০টি অনুরোধ আসে → তবে এটি প্রয়োজনমতো অনুলিপি তৈরি করে।
ডিফল্টরূপে রাষ্ট্রহীন:
- প্রতিটি অনুরোধ একটি ভিন্ন ইনস্ট্যান্সে যেতে পারে।
- স্টেট সংরক্ষণ করার প্রয়োজন হলে ক্লাউড এসকিউএল, ফায়ারস্টোর বা মেমোরিস্টোরের মতো বাহ্যিক পরিষেবা ব্যবহার করুন।
যেকোনো ভাষা বা ফ্রেমওয়ার্ক সমর্থন করে:
- যতক্ষণ এটি একটি লিনাক্স কন্টেইনারে চলে, ততক্ষণ এটি পাইথন, গো, নোড.জেএস, জাভা বা ডটনেট কিনা তা ক্লাউড রানের কাছে কোনো বিষয় নয়।
আপনি যা ব্যবহার করেন তার জন্য মূল্য পরিশোধ করুন:
- অনুরোধ-ভিত্তিক বিলিং : প্রতিটি অনুরোধ এবং গণনার সময় (সর্বনিম্ন ১০০ মিলিসেকেন্ড পর্যন্ত) অনুযায়ী বিল করা হয়।
- ইনস্ট্যান্স-ভিত্তিক বিলিং : ইনস্ট্যান্সের সম্পূর্ণ জীবনকালের জন্য বিল করা হয় (প্রতি-অনুরোধের জন্য কোনো ফি নেই)।
৩. শুরু করার আগে
স্ব-গতিতে পরিবেশ সেটআপ
- Google Cloud Console- এ সাইন-ইন করুন এবং একটি নতুন প্রজেক্ট তৈরি করুন অথবা বিদ্যমান কোনো প্রজেক্ট পুনরায় ব্যবহার করুন। যদি আপনার আগে থেকে Gmail বা Google Workspace অ্যাকাউন্ট না থাকে, তবে আপনাকে অবশ্যই একটি তৈরি করতে হবে।

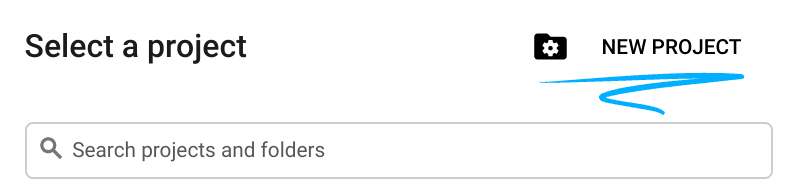
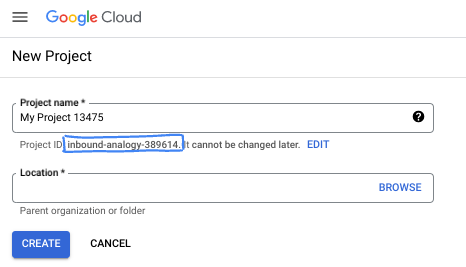
- প্রজেক্টের নামটি হলো এই প্রজেক্টের অংশগ্রহণকারীদের প্রদর্শিত নাম। এটি একটি ক্যারেক্টার স্ট্রিং যা গুগল এপিআই ব্যবহার করে না। আপনি যেকোনো সময় এটি আপডেট করতে পারেন।
- প্রজেক্ট আইডি সমস্ত গুগল ক্লাউড প্রজেক্ট জুড়ে অনন্য এবং অপরিবর্তনীয় (একবার সেট করার পর এটি পরিবর্তন করা যায় না)। ক্লাউড কনসোল স্বয়ংক্রিয়ভাবে একটি অনন্য স্ট্রিং তৈরি করে; সাধারণত এটি কী তা নিয়ে আপনার মাথা ঘামানোর দরকার নেই। বেশিরভাগ কোডল্যাবে, আপনাকে আপনার প্রজেক্ট আইডি উল্লেখ করতে হবে (যা সাধারণত
PROJECT_IDহিসাবে চিহ্নিত করা হয়)। তৈরি করা আইডিটি আপনার পছন্দ না হলে, আপনি এলোমেলোভাবে আরেকটি তৈরি করতে পারেন। বিকল্পভাবে, আপনি আপনার নিজের আইডি দিয়ে চেষ্টা করে দেখতে পারেন যে সেটি উপলব্ধ আছে কিনা। এই ধাপের পরে এটি পরিবর্তন করা যাবে না এবং প্রজেক্টের পুরো সময়কাল জুড়ে এটি অপরিবর্তিত থাকবে। - আপনার অবগতির জন্য জানাচ্ছি যে, তৃতীয় একটি ভ্যালু রয়েছে, যা হলো প্রজেক্ট নম্বর , এবং কিছু এপিআই এটি ব্যবহার করে থাকে। ডকুমেন্টেশনে এই তিনটি ভ্যালু সম্পর্কে আরও বিস্তারিত জানুন।
- এরপর, ক্লাউড রিসোর্স/এপিআই ব্যবহার করার জন্য আপনাকে ক্লাউড কনসোলে বিলিং চালু করতে হবে। এই কোডল্যাবটি সম্পন্ন করতে খুব বেশি খরচ হবে না, এমনকি আদৌ কোনো খরচ নাও হতে পারে। এই টিউটোরিয়ালের পর বিলিং এড়াতে রিসোর্সগুলো বন্ধ করার জন্য, আপনি আপনার তৈরি করা রিসোর্সগুলো অথবা প্রজেক্টটি ডিলিট করে দিতে পারেন। নতুন গুগল ক্লাউড ব্যবহারকারীরা ৩০০ মার্কিন ডলারের ফ্রি ট্রায়াল প্রোগ্রামের জন্য যোগ্য।
ক্লাউড শেল শুরু করুন
- ক্লাউড শেল এডিটরে যান
- যদি স্ক্রিনের নীচে টার্মিনালটি দেখা না যায়, তাহলে এটি খুলুন:
- টার্মিনালে ক্লিক করুন
- নতুন টার্মিনালে ক্লিক করুন
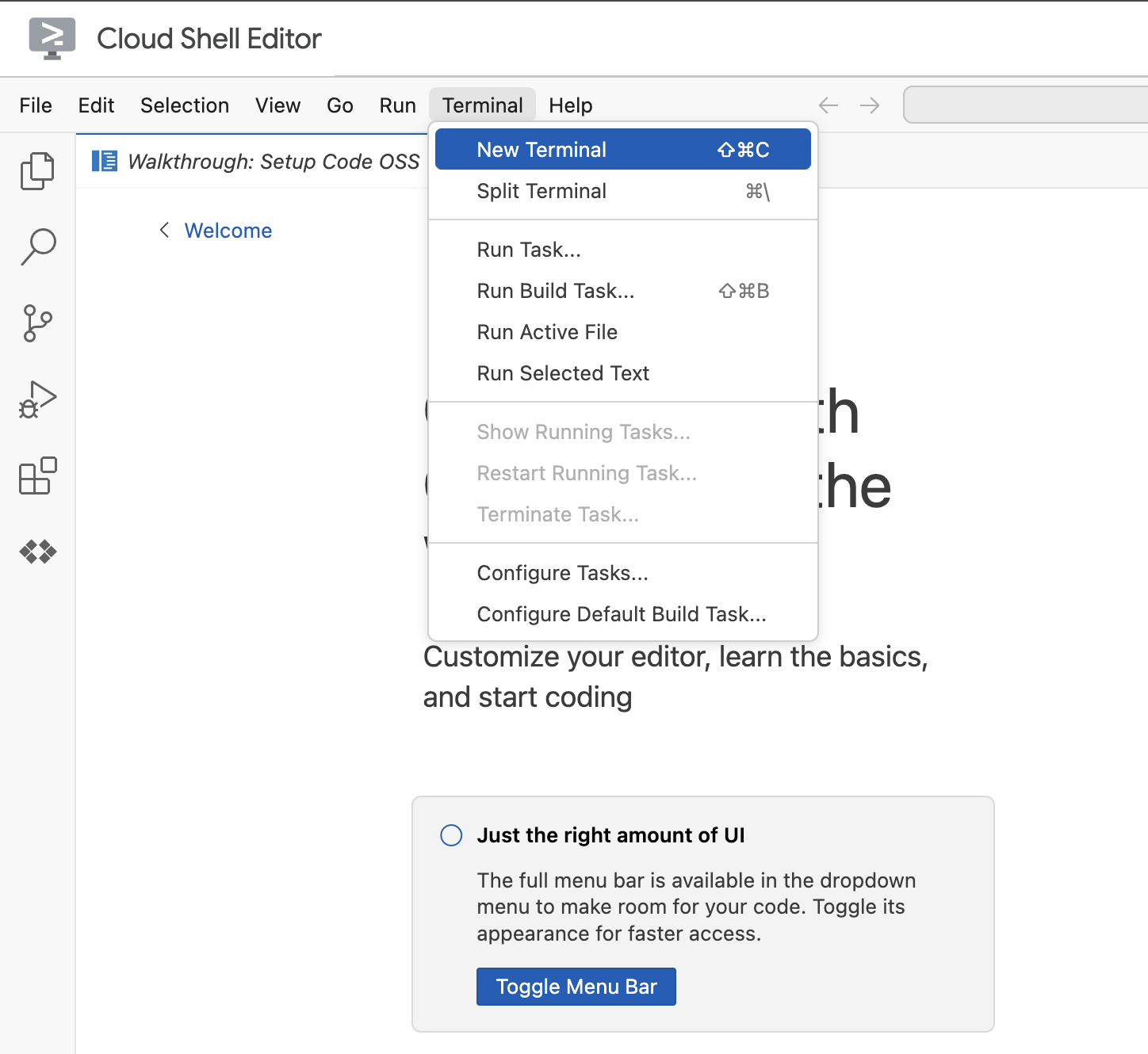
- টার্মিনালে এই কমান্ডটি দিয়ে আপনার প্রজেক্ট সেট করুন। আপনি যদি ল্যাব ১ সম্পন্ন করে থাকেন, তবে নিশ্চিত করুন যে আপনি একই প্রজেক্ট আইডি ব্যবহার করছেন:
gcloud config set project [YOUR-PROJECT-ID]gcloud projects list | awk '/PROJECT_ID/{print $2}' - অনুমোদন করতে বলা হলে, চালিয়ে যাওয়ার জন্য 'Authorize'-এ ক্লিক করুন।
- আপনি এই বার্তাটি দেখতে পাবেন:
Updated property [core/project].
WARNINGদেখতে পান এবং আপনাকেDo you want to continue (Y/n)?জিজ্ঞাসা করা হয়, তাহলে সম্ভবত আপনি প্রজেক্ট আইডি ভুলভাবে প্রবেশ করিয়েছেন।nচাপুন,Enterচাপুন এবংgcloud config set projectকমান্ডটি আবার চালানোর চেষ্টা করুন।
৪. আপনার পরিবেশ প্রস্তুত করুন
এপিআই সক্রিয় করুন এবং পরিবেশ ভেরিয়েবল সেট করুন
সকল প্রয়োজনীয় পরিষেবা সক্রিয় করুন:
gcloud services enable \
run.googleapis.com \
artifactregistry.googleapis.com \
cloudbuild.googleapis.com \
aiplatform.googleapis.com
প্রত্যাশিত আউটপুট
Operation "operations/acat.p2-[GUID]" finished successfully.
প্রজেক্ট ডিরেক্টরি তৈরি করুন।
এই কমান্ডটি এজেন্টের সোর্স কোডের জন্য ল্যাবের একটি প্রধান ফোল্ডার তৈরি করে।
cd && mkdir zoo_guide_agent && cd zoo_guide_agent
requirements.txt ফাইলটি তৈরি করুন। এই ফাইলে আপনার এজেন্টের প্রয়োজনীয় পাইথন লাইব্রেরিগুলোর তালিকা থাকে। নিচের কমান্ডটি ফাইলটি তৈরি করে এবং এতে তথ্য যোগ করে।
cloudshell edit requirements.txt
google-adk==1.14.0
langchain-community==0.3.27
wikipedia==1.4.0
আপনার বর্তমান প্রজেক্ট আইডি ও প্রজেক্ট নম্বরের জন্য ভ্যারিয়েবল সেট করুন এবং আপনার প্রজেক্টের জন্য একটি ডেডিকেটেড সার্ভিস অ্যাকাউন্টও তৈরি করুন। এই কমান্ডগুলো চালানোর জন্য এটি একটি আরও নির্ভরযোগ্য উপায়।
export PROJECT_ID=$(gcloud config get-value project)
export PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")
export SA_NAME=lab2-cr-service
export SERVICE_ACCOUNT="${SA_NAME}@${PROJECT_ID}.iam.gserviceaccount.com"
gcloud iam service-accounts create ${SA_NAME} \
--display-name="Service Account for lab 2 "
zoo_guide_agent ডিরেক্টরিতে এজেন্টকে প্রমাণীকরণের জন্য একটি .env ফাইল তৈরি করে খুলুন।
cloudshell edit .env
cloudshell-এর edit কমান্ডটি টার্মিনালের উপরের এডিটরে .env ফাইলটি খুলবে। .env ফাইলে নিম্নলিখিতটি লিখুন এবং টার্মিনালে ফিরে যান।
MODEL="gemini-2.5-flash"
এমসিপি সার্ভার ইউআরএল যোগ করা। আপনি যদি ল্যাব ১ সম্পন্ন করে থাকেন, তবে সেখানে তৈরি করা এমসিপি সার্ভারটি ব্যবহার করার জন্য এই ধাপগুলো অনুসরণ করুন:
এজেন্টের সার্ভিস অ্যাকাউন্টকে Vertex AI-তে Gemini ব্যবহার করার এবং রিমোট MCP সার্ভারকে কল করার অনুমতি দিন:
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT" \
--role="roles/aiplatform.user"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT" \
--role="roles/run.invoker"
ল্যাব ১ থেকে প্রাপ্ত এমসিপি সার্ভার ইউআরএলটি একটি এনভায়রনমেন্ট ভেরিয়েবলে সংরক্ষণ করুন।
echo -e "\nMCP_SERVER_URL=https://zoo-mcp-server-${PROJECT_NUMBER}.us-west1.run.app/mcp" >> .env
আপনি যদি একটি পাবলিক এমসিপি সার্ভার লিঙ্ক ব্যবহার করেন, তাহলে নিম্নলিখিতটি চালান এবং PROJECT_NUMBER জায়গায় প্রদত্ত মানটি বসান।
echo -e "\nMCP_SERVER_URL=https://zoo-mcp-server-${PROJECT_NUMBER}.us-west1.run.app/mcp" >> .env
৫. এজেন্ট ওয়ার্কফ্লো তৈরি করুন
init.py ফাইল তৈরি করুন
init.py ফাইলটি তৈরি করুন। এই ফাইলটি পাইথনকে জানায় যে zoo_guide_agent ডিরেক্টরিটি একটি প্যাকেজ।
cloudshell edit __init__.py
পূর্ববর্তী কমান্ডটি কোড এডিটর খুলে দেয়। __init__.py ফাইলে নিম্নলিখিত কোডটি যোগ করুন:
from . import agent
প্রধান agent.py ফাইল তৈরি করুন
মূল agent.py ফাইলটি তৈরি করুন। এই কমান্ডটি পাইথন ফাইলটি তৈরি করে এবং আপনার মাল্টি-এজেন্ট সিস্টেমের জন্য সম্পূর্ণ কোডটি পেস্ট করে দেয়।
cloudshell edit agent.py
আমদানি এবং প্রাথমিক সেটআপ
এই প্রথম ব্লকটি ADK এবং গুগল ক্লাউড থেকে সমস্ত প্রয়োজনীয় লাইব্রেরি নিয়ে আসে। এটি লগিংও সেট আপ করে এবং আপনার .env ফাইল থেকে এনভায়রনমেন্ট ভেরিয়েবল লোড করে, যা আপনার মডেল এবং সার্ভার URL অ্যাক্সেস করার জন্য অত্যন্ত গুরুত্বপূর্ণ।
আপনার agent.py ফাইলে নিম্নলিখিত কোডটি যোগ করুন:
import os
import logging
import google.cloud.logging
from dotenv import load_dotenv
from google.adk import Agent
from google.adk.agents import SequentialAgent
from google.adk.tools.mcp_tool.mcp_toolset import MCPToolset, StreamableHTTPConnectionParams
from google.adk.tools.tool_context import ToolContext
from google.adk.tools.langchain_tool import LangchainTool
from langchain_community.tools import WikipediaQueryRun
from langchain_community.utilities import WikipediaAPIWrapper
import google.auth
import google.auth.transport.requests
import google.oauth2.id_token
# --- Setup Logging and Environment ---
cloud_logging_client = google.cloud.logging.Client()
cloud_logging_client.setup_logging()
load_dotenv()
model_name = os.getenv("MODEL")
সরঞ্জামসমূহের সংজ্ঞা (এজেন্টের সক্ষমতা)

একটি এজেন্ট ততটাই ভালো, যতটা ভালো টুল সে ব্যবহার করতে পারে। এই অংশে, আমরা আমাদের এজেন্টের সমস্ত সক্ষমতা সংজ্ঞায়িত করব, যার মধ্যে রয়েছে ডেটা সংরক্ষণের জন্য একটি কাস্টম ফাংশন, আমাদের সুরক্ষিত এমসিপি সার্ভারের সাথে সংযোগকারী একটি এমসিপি টুল এবং একটি উইকিপিডিয়া টুল।
agent.py ফাইলের শেষে নিম্নলিখিত কোডটি যোগ করুন:
# Greet user and save their prompt
def add_prompt_to_state(
tool_context: ToolContext, prompt: str
) -> dict[str, str]:
"""Saves the user's initial prompt to the state."""
tool_context.state["PROMPT"] = prompt
logging.info(f"[State updated] Added to PROMPT: {prompt}")
return {"status": "success"}
# Configuring the MCP Tool to connect to the Zoo MCP server
mcp_server_url = os.getenv("MCP_SERVER_URL")
if not mcp_server_url:
raise ValueError("The environment variable MCP_SERVER_URL is not set.")
def get_id_token():
"""Get an ID token to authenticate with the MCP server."""
target_url = os.getenv("MCP_SERVER_URL")
audience = target_url.split('/mcp/')[0]
request = google.auth.transport.requests.Request()
id_token = google.oauth2.id_token.fetch_id_token(request, audience)
return id_token
"""
# Use this code if you are using the public MCP Server and comment out the code below defining mcp_tools
mcp_tools = MCPToolset(
connection_params=StreamableHTTPConnectionParams(
url=mcp_server_url
)
)
"""
mcp_tools = MCPToolset(
connection_params=StreamableHTTPConnectionParams(
url=mcp_server_url,
headers={
"Authorization": f"Bearer {get_id_token()}",
},
),
)
# Configuring the Wikipedia Tool
wikipedia_tool = LangchainTool(
tool=WikipediaQueryRun(api_wrapper=WikipediaAPIWrapper())
)
তিনটি সরঞ্জামের ব্যাখ্যা
-
add_prompt_to_state📝
এই টুলটি চিড়িয়াখানার কোনো পরিদর্শকের জিজ্ঞাসা মনে রাখে। যখন কোনো পরিদর্শক জিজ্ঞাসা করেন, "সিংহগুলো কোথায়?", তখন এই টুলটি সেই নির্দিষ্ট প্রশ্নটি এজেন্টের মেমরিতে সংরক্ষণ করে রাখে, যাতে ওয়ার্কফ্লোতে থাকা অন্য এজেন্টরা জানতে পারে যে তাদের কী অনুসন্ধান করতে হবে।
পদ্ধতি: এটি একটি পাইথন ফাংশন যা ভিজিটরের প্রম্পটকে শেয়ার্ড tool_context.state ডিকশনারিতে লিখে রাখে। এই টুল কনটেক্সট একটিমাত্র কথোপকথনের জন্য এজেন্টের স্বল্পমেয়াদী স্মৃতিকে প্রতিনিধিত্ব করে। একজন এজেন্ট দ্বারা স্টেটে সংরক্ষিত ডেটা ওয়ার্কফ্লোতে থাকা পরবর্তী এজেন্ট পড়তে পারে।
-
MCPToolset🦁
এটি ল্যাব ১-এ তৈরি করা চিড়িয়াখানার এমসিপি সার্ভারের সাথে ট্যুর গাইড এজেন্টকে সংযুক্ত করতে ব্যবহৃত হয়। এই সার্ভারে আমাদের পশুদের সম্পর্কে নির্দিষ্ট তথ্য, যেমন তাদের নাম, বয়স এবং খাঁচা খুঁজে বের করার জন্য বিশেষ সরঞ্জাম রয়েছে।
পদ্ধতি: এটি চিড়িয়াখানার নিজস্ব সার্ভার ইউআরএল-এর সাথে নিরাপদে সংযোগ স্থাপন করে। নিজের পরিচয় প্রমাণ করতে এবং প্রবেশাধিকার পেতে এটি get_id_token ব্যবহার করে স্বয়ংক্রিয়ভাবে একটি সুরক্ষিত "কী-কার্ড" (একটি সার্ভিস অ্যাকাউন্ট আইডি টোকেন) সংগ্রহ করে।
-
LangchainTool🌍
এটি ট্যুর গাইড এজেন্টকে সাধারণ বিশ্ব জ্ঞান প্রদান করে। যখন কোনো দর্শনার্থী এমন কোনো প্রশ্ন জিজ্ঞাসা করেন যা চিড়িয়াখানার ডেটাবেসে নেই, যেমন "বন্য পরিবেশে সিংহরা কী খায়?", তখন এই টুলটি এজেন্টকে উইকিপিডিয়া থেকে উত্তরটি খুঁজে বের করতে সাহায্য করে।
কীভাবে: এটি একটি অ্যাডাপ্টার হিসেবে কাজ করে, যা আমাদের এজেন্টকে LangChain লাইব্রেরি থেকে আগে থেকে তৈরি WikipediaQueryRun টুলটি ব্যবহার করার সুযোগ দেয়।
সম্পদ:
বিশেষজ্ঞ এজেন্টদের সংজ্ঞায়িত করা

এরপরে আমরা গবেষক এজেন্ট এবং প্রতিক্রিয়া ফরম্যাটার এজেন্টকে সংজ্ঞায়িত করব। গবেষক এজেন্ট হলো আমাদের অপারেশনের 'মস্তিষ্ক'। এই এজেন্ট শেয়ার্ড State থেকে ব্যবহারকারীর প্রম্পট গ্রহণ করে, এর শক্তিশালী টুলগুলো (চিড়িয়াখানার এমসিপি সার্ভার টুল এবং উইকিপিডিয়া টুল) পরীক্ষা করে এবং উত্তর খুঁজে বের করার জন্য কোনগুলো ব্যবহার করতে হবে তা সিদ্ধান্ত নেয়।
প্রতিক্রিয়া বিন্যাসকারী এজেন্টের ভূমিকা হলো উপস্থাপন। এটি নতুন তথ্য খুঁজে বের করার জন্য কোনো সরঞ্জাম ব্যবহার করে না। পরিবর্তে, এটি গবেষক এজেন্ট দ্বারা সংগৃহীত কাঁচা ডেটা (যা স্টেটের মাধ্যমে পাঠানো হয়) গ্রহণ করে এবং এলএলএম-এর ভাষাগত দক্ষতা ব্যবহার করে সেটিকে একটি বন্ধুত্বপূর্ণ, কথোপকথনমূলক উত্তরে রূপান্তরিত করে।
agent.py ফাইলের শেষে নিম্নলিখিত কোডটি যোগ করুন:
# 1. Researcher Agent
comprehensive_researcher = Agent(
name="comprehensive_researcher",
model=model_name,
description="The primary researcher that can access both internal zoo data and external knowledge from Wikipedia.",
instruction="""
You are a helpful research assistant. Your goal is to fully answer the user's PROMPT.
You have access to two tools:
1. A tool for getting specific data about animals AT OUR ZOO (names, ages, locations).
2. A tool for searching Wikipedia for general knowledge (facts, lifespan, diet, habitat).
First, analyze the user's PROMPT.
- If the prompt can be answered by only one tool, use that tool.
- If the prompt is complex and requires information from both the zoo's database AND Wikipedia,
you MUST use both tools to gather all necessary information.
- Synthesize the results from the tool(s) you use into preliminary data outputs.
PROMPT:
{{ PROMPT }}
""",
tools=[
mcp_tools,
wikipedia_tool
],
output_key="RESEARCH_DATA" # A key to store the combined findings
)
# 2. Response Formatter Agent
response_formatter = Agent(
name="response_formatter",
model=model_name,
description="Synthesizes all information into a friendly, readable response.",
instruction="""
You are the friendly voice of the Zoo Tour Guide. Your task is to take the
RESEARCH_DATA and present it to the user in a complete and helpful answer.
- First, present the specific information from the zoo (like names, ages, and where to find them).
- Then, add the interesting general facts from the research.
- If some information is missing, just present the information you have.
- Be conversational and engaging.
RESEARCH_DATA:
{{ RESEARCH_DATA }}
"""
)
ওয়ার্কফ্লো এজেন্ট
ওয়ার্কফ্লো এজেন্টটি চিড়িয়াখানা ভ্রমণের জন্য 'ব্যাক-অফিস' ম্যানেজার হিসেবে কাজ করে। এটি গবেষণার অনুরোধ গ্রহণ করে এবং নিশ্চিত করে যে আমরা উপরে সংজ্ঞায়িত দুটি এজেন্ট তাদের কাজ সঠিক ক্রমে সম্পাদন করছে: প্রথমে গবেষণা, তারপর বিন্যাস। এটি একজন পরিদর্শকের প্রশ্নের উত্তর দেওয়ার জন্য একটি অনুমানযোগ্য এবং নির্ভরযোগ্য প্রক্রিয়া তৈরি করে।
কীভাবে: এটি একটি SequentialAgent , এক বিশেষ ধরনের এজেন্ট যা নিজে থেকে চিন্তা করে না। এর একমাত্র কাজ হলো একটি নির্দিষ্ট ক্রমে sub_agents (গবেষক এবং ফরম্যাটার) একটি তালিকা চালানো এবং স্বয়ংক্রিয়ভাবে এক এজেন্ট থেকে অন্য এজেন্টে শেয়ার্ড মেমোরি স্থানান্তর করা।
agent.py ফাইলের শেষে এই কোড ব্লকটি যোগ করুন:
tour_guide_workflow = SequentialAgent(
name="tour_guide_workflow",
description="The main workflow for handling a user's request about an animal.",
sub_agents=[
comprehensive_researcher, # Step 1: Gather all data
response_formatter, # Step 2: Format the final response
]
)
মূল কর্মপ্রবাহ একত্রিত করুন 
এই এজেন্টটিকে root_agent হিসেবে চিহ্নিত করা হয়েছে, যাকে ADK ফ্রেমওয়ার্ক সমস্ত নতুন কথোপকথনের সূচনা বিন্দু হিসেবে ব্যবহার করে। এর প্রধান ভূমিকা হলো পুরো প্রক্রিয়াটিকে সমন্বয় করা। এটি প্রাথমিক নিয়ন্ত্রক হিসেবে কাজ করে এবং কথোপকথনের প্রথম পর্বটি পরিচালনা করে।
agent.py ফাইলের শেষে এই চূড়ান্ত কোড ব্লকটি যোগ করুন:
root_agent = Agent(
name="greeter",
model=model_name,
description="The main entry point for the Zoo Tour Guide.",
instruction="""
- Let the user know you will help them learn about the animals we have in the zoo.
- When the user responds, use the 'add_prompt_to_state' tool to save their response.
After using the tool, transfer control to the 'tour_guide_workflow' agent.
""",
tools=[add_prompt_to_state],
sub_agents=[tour_guide_workflow]
)
আপনার agent.py ফাইলটি এখন সম্পূর্ণ! এভাবে তৈরি করার মাধ্যমে আপনি দেখতে পাচ্ছেন যে, কীভাবে প্রতিটি উপাদান—টুলস, ওয়ার্কার এজেন্ট এবং ম্যানেজার এজেন্ট—চূড়ান্ত, বুদ্ধিমান সিস্টেমটি তৈরিতে একটি নির্দিষ্ট ভূমিকা পালন করে। এরপর আসছে ডেপ্লয়মেন্ট!
৬. ADK CLI ব্যবহার করে এজেন্টটি স্থাপন করুন।
আপনার লোকাল কোড এবং গুগল ক্লাউড প্রজেক্ট প্রস্তুত হয়ে গেলে, এখন এজেন্টটি ডেপ্লয় করার পালা। এর জন্য আপনি adk deploy cloud_run কমান্ডটি ব্যবহার করবেন, যা একটি সুবিধাজনক টুল এবং সম্পূর্ণ ডেপ্লয়মেন্ট ওয়ার্কফ্লোকে স্বয়ংক্রিয় করে তোলে। এই একটিমাত্র কমান্ড আপনার কোডকে প্যাকেজ করে, একটি কন্টেইনার ইমেজ তৈরি করে, সেটিকে আর্টিফ্যাক্ট রেজিস্ট্রি-তে পুশ করে এবং ক্লাউড রান-এ সার্ভিসটি চালু করে, যার ফলে এটি ওয়েবে অ্যাক্সেসযোগ্য হয়ে ওঠে।
মোতায়েন করুন
আপনার এজেন্ট স্থাপন করতে নিম্নলিখিত কমান্ডগুলি চালান। uvx কমান্ডটি আপনাকে পাইথন প্যাকেজ হিসাবে প্রকাশিত কমান্ড লাইন টুলগুলি চালাতে দেয়, যার জন্য সেই টুলগুলির বিশ্বব্যাপী ইনস্টলেশনের প্রয়োজন হয় না।
# Run the deployment command
uvx --from google-adk==1.14.0 \
adk deploy cloud_run \
--project=$PROJECT_ID \
--region=us-west1 \
--service_name=zoo-tour-guide \
--with_ui \
. \
-- \
--labels=dev-tutorial=codelab-adk \
--service-account=$SERVICE_ACCOUNT
প্রম্পট গ্রহণ করুন
আপনাকে নিম্নলিখিত বিষয়গুলো জিজ্ঞাসা করা হতে পারে:
Deploying from source requires an Artifact Registry Docker repository to store built containers. A repository named [cloud-run-source-deploy] in region [us-west1] will be created. Do you want to continue (Y/n)?
Y টাইপ করে ENTER চাপুন।
আপনাকে নিম্নলিখিত বিষয়গুলো জিজ্ঞাসা করা হতে পারে:
Allow unauthenticated invocations to [your-service-name] (y/N)?.
এই ল্যাবে সহজ পরীক্ষার জন্য আমরা প্রমাণীকরণ ছাড়াই ব্যবহারের অনুমতি দিতে চাই, এর জন্য y টাইপ করে এন্টার চাপুন।
ডিপ্লয়মেন্ট লিঙ্কটি পান
সফলভাবে কার্যকর হলে, কমান্ডটি ডেপ্লয় করা ক্লাউড রান সার্ভিসের URL প্রদান করবে। (এটি দেখতে অনেকটা https://zoo-tour-guide-123456789.us-west1.run.app এর মতো হবে)। পরবর্তী কাজের জন্য এই URL-টি কপি করুন।
৭. স্থাপন করা এজেন্টটি পরীক্ষা করুন
আপনার এজেন্ট এখন ক্লাউড রান-এ লাইভ হয়ে গেলে, ডেপ্লয়মেন্ট সফল হয়েছে এবং এজেন্টটি প্রত্যাশা অনুযায়ী কাজ করছে কিনা তা নিশ্চিত করতে আপনি একটি পরীক্ষা চালাবেন। ADK-এর ওয়েব ইন্টারফেস অ্যাক্সেস করতে এবং এজেন্টের সাথে ইন্টারঅ্যাক্ট করতে আপনি পাবলিক সার্ভিস ইউআরএল (যেমন https://zoo-tour-guide-123456789.us-west1.run.app/ ) ব্যবহার করবেন।
আপনার ওয়েব ব্রাউজারে পাবলিক ক্লাউড রান সার্ভিস ইউআরএলটি খুলুন। যেহেতু আপনি --with_ui flag ব্যবহার করেছেন, তাই আপনি ADK ডেভেলপার UI দেখতে পাবেন।
উপরের ডানদিকে Token Streaming চালু করুন।
আপনি এখন চিড়িয়াখানার এজেন্টের সাথে যোগাযোগ করতে পারবেন।
নতুন কথোপকথন শুরু করতে hello টাইপ করে এন্টার চাপুন।
ফলাফলটি পর্যবেক্ষণ করুন। এজেন্টটির উচিত দ্রুত তার অভিবাদন দিয়ে সাড়া দেওয়া:
"Hello! I'm your Zoo Tour Guide. I can help you learn about the amazing animals we have here. What would you like to know or explore today?"
এজেন্টকে এই ধরনের প্রশ্ন জিজ্ঞাসা করুন:
Where can I find the polar bears in the zoo and what is their diet?
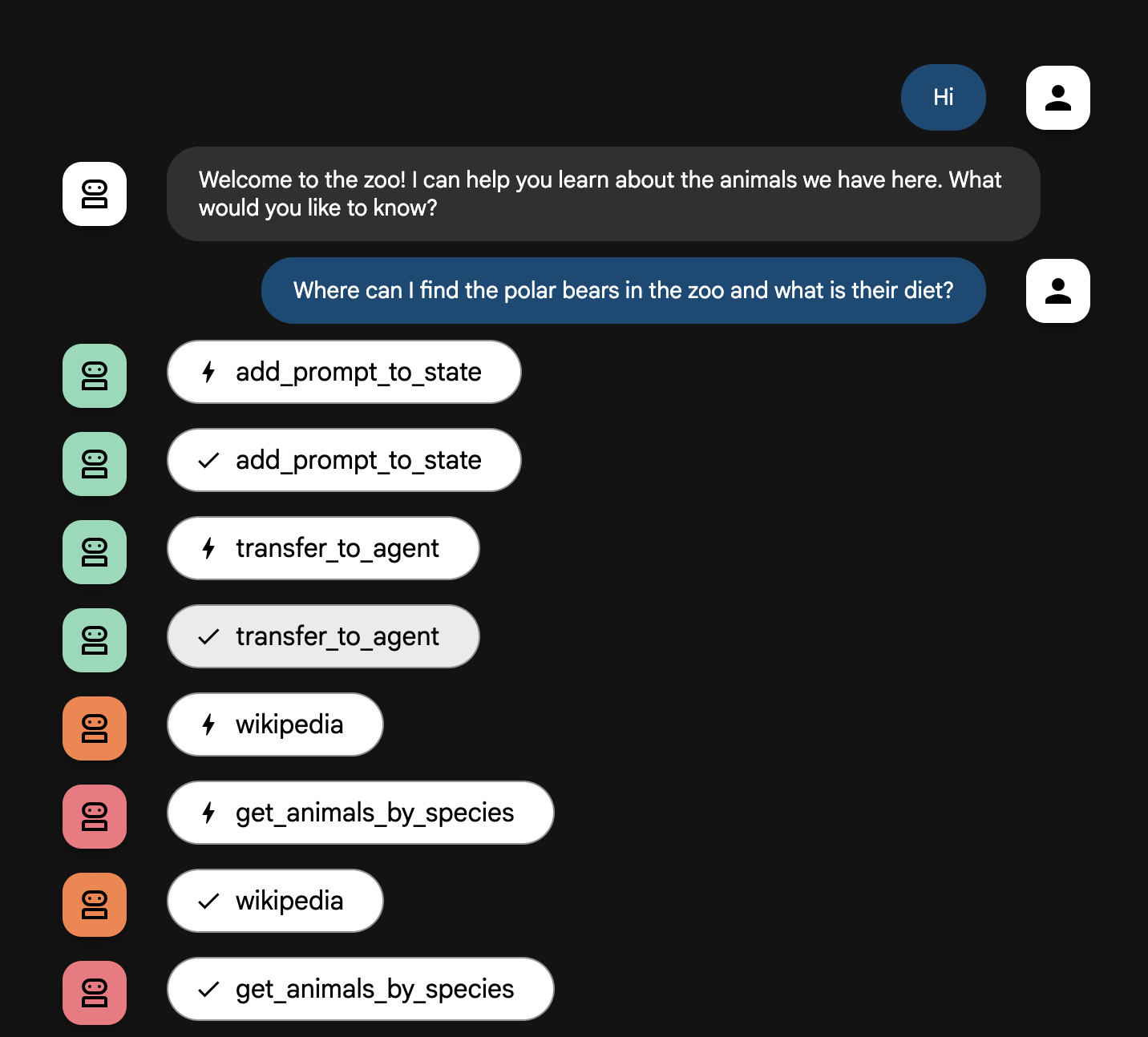

এজেন্ট প্রবাহের ব্যাখ্যা
আপনার সিস্টেম একটি বুদ্ধিমান, বহু-এজেন্ট দল হিসেবে কাজ করে। ব্যবহারকারীর প্রশ্ন থেকে চূড়ান্ত, বিস্তারিত উত্তর পর্যন্ত একটি মসৃণ এবং কার্যকর প্রবাহ নিশ্চিত করার জন্য প্রক্রিয়াটি একটি সুস্পষ্ট অনুক্রম দ্বারা পরিচালিত হয়।
১. চিড়িয়াখানার অভ্যর্থনাকারী (স্বাগত ডেস্ক )
সম্পূর্ণ প্রক্রিয়াটি অভ্যর্থনাকারী এজেন্টের মাধ্যমে শুরু হয়।
এর কাজ: কথোপকথন শুরু করা। এর নির্দেশ হলো ব্যবহারকারীকে অভিবাদন জানানো এবং জিজ্ঞাসা করা যে তিনি কোন প্রাণী সম্পর্কে জানতে চান।
এর টুল: যখন ব্যবহারকারী উত্তর দেয়, তখন গ্রিটার তার add_prompt_to_state টুল ব্যবহার করে ব্যবহারকারীর হুবহু কথাগুলো (যেমন, "আমাকে সিংহদের সম্পর্কে বলুন") গ্রহণ করে এবং সিস্টেমের মেমরিতে সংরক্ষণ করে।
হস্তান্তর: প্রম্পটটি সংরক্ষণ করার পর, এটি অবিলম্বে তার সাব-এজেন্ট, tour_guide_workflow-এর কাছে নিয়ন্ত্রণ হস্তান্তর করে।
২. সর্বাঙ্গীণ গবেষক (মহাগবেষক)
এটি মূল কার্যপ্রবাহের প্রথম ধাপ এবং অপারেশনের 'মস্তিষ্ক'। একটি বড় দলের পরিবর্তে, এখন আপনার কাছে একজনই অত্যন্ত দক্ষ এজেন্ট রয়েছে, যিনি সমস্ত উপলব্ধ তথ্য অ্যাক্সেস করতে পারেন।
এর কাজ হলো: ব্যবহারকারীর প্রশ্ন বিশ্লেষণ করে একটি বুদ্ধিদীপ্ত পরিকল্পনা তৈরি করা। এটি ল্যাঙ্গুয়েজ মডেলের শক্তিশালী টুল ব্যবহারের সক্ষমতা কাজে লাগিয়ে সিদ্ধান্ত নেয় যে এর প্রয়োজন আছে কি না:
- চিড়িয়াখানার রেকর্ড থেকে প্রাপ্ত অভ্যন্তরীণ তথ্য (এমসিপি সার্ভারের মাধ্যমে)।
- ওয়েব থেকে প্রাপ্ত সাধারণ জ্ঞান (উইকিপিডিয়া এপিআই-এর মাধ্যমে)।
- অথবা, জটিল প্রশ্নের ক্ষেত্রে, উভয়ই।
এর কাজ: এটি প্রয়োজনীয় সমস্ত কাঁচা ডেটা সংগ্রহ করার জন্য প্রয়োজনীয় টুল(গুলি) চালায়। উদাহরণস্বরূপ, যদি জিজ্ঞাসা করা হয় "আমাদের সিংহদের বয়স কত এবং তারা বন্য পরিবেশে কী খায়?", তবে এটি বয়সের জন্য এমসিপি সার্ভারকে এবং খাদ্যাভ্যাসের তথ্যের জন্য উইকিপিডিয়া টুলকে কল করবে।
৩. প্রতিক্রিয়া বিন্যাসকারী (উপস্থাপক)
একবার বিশদ গবেষক সমস্ত তথ্য সংগ্রহ করে ফেললে, এটিই চালানোর জন্য সর্বশেষ এজেন্ট।
এর কাজ হলো চিড়িয়াখানার ট্যুর গাইডের বন্ধুত্বপূর্ণ কণ্ঠস্বর হিসেবে কাজ করা। এটি কাঁচা ডেটা (যা এক বা উভয় উৎস থেকে আসতে পারে) গ্রহণ করে এবং সেটিকে পরিমার্জন করে।
এর কার্যপ্রণালী: এটি সমস্ত তথ্যকে সংশ্লেষণ করে একটি একক, সুসংহত এবং আকর্ষণীয় উত্তর তৈরি করে। এর নির্দেশাবলী অনুসরণ করে, এটি প্রথমে চিড়িয়াখানা সম্পর্কিত নির্দিষ্ট তথ্য উপস্থাপন করে এবং তারপরে আকর্ষণীয় সাধারণ তথ্যগুলো যুক্ত করে।
চূড়ান্ত ফলাফল: এই এজেন্টের দ্বারা তৈরি করা লেখাটিই হলো সম্পূর্ণ ও বিস্তারিত উত্তর, যা ব্যবহারকারী চ্যাট উইন্ডোতে দেখতে পান।
এজেন্ট তৈরি করার বিষয়ে আরও জানতে আগ্রহী হলে, নিম্নলিখিত রিসোর্সগুলো দেখুন:
৮. পরিবেশ পরিষ্কার করুন
gcloud run services delete zoo-tour-guide --region=us-west1 --quiet
gcloud artifacts repositories delete cloud-run-source-deploy --location=us-west1 --quiet
৯. অভিনন্দন
কোডল্যাবটি সম্পন্ন করার জন্য অভিনন্দন।
আমরা যা আলোচনা করেছি
- ADK কমান্ড-লাইন ইন্টারফেস ব্যবহার করে ডেপ্লয়মেন্টের জন্য একটি পাইথন প্রজেক্ট কীভাবে গঠন করতে হয়
- SequentialAgent এবং ParallelAgent ব্যবহার করে কীভাবে একটি মাল্টি-এজেন্ট ওয়ার্কফ্লো বাস্তবায়ন করা যায়।
- MCPToolset ব্যবহার করে একটি রিমোট MCP সার্ভারে কীভাবে সংযোগ স্থাপন করে এর টুলগুলো ব্যবহার করা যায়।
- উইকিপিডিয়া এপিআই-এর মতো বাহ্যিক টুল একীভূত করে কীভাবে অভ্যন্তরীণ ডেটা সমৃদ্ধ করা যায়।
- adk deploy কমান্ড ব্যবহার করে কীভাবে ক্লাউড রান-এ একটি এজেন্টকে সার্ভারলেস কন্টেইনার হিসেবে ডেপ্লয় করতে হয়।