
1. Introduction
Cet atelier porte sur l'implémentation et le déploiement d'un service d'agent client. Vous allez utiliser l'Agent Development Kit (ADK) pour créer un agent d'IA qui utilise des outils distants, comme le serveur MCP créé dans l'atelier 1. Le principe architectural clé illustré est la séparation des préoccupations : une couche de raisonnement (l'agent) communique avec une autre couche séparée pour les outils (le serveur MCP) via une API sécurisée.
Dans l'atelier 1, vous avez créé un serveur MCP qui fournit des données sur les animaux d'un zoo fictif aux LLM, par exemple lorsque vous utilisez la Gemini CLI. Dans cet atelier, nous allons créer un agent de guide touristique pour le zoo fictif. L'agent utilisera le même serveur MCP que dans l'atelier 1 pour accéder aux informations sur les animaux du zoo et Wikipédia pour créer la meilleure expérience de visite guidée possible.

Enfin, nous déploierons l'agent de guide touristique sur Google Cloud Run, afin qu'il soit accessible à tous les visiteurs du zoo et pas seulement en local.
Prérequis
- Un serveur MCP en cours d'exécution sur Cloud Run ou son URL de service associée
- Un projet Google Cloud dans lequel la facturation est activée
Points abordés
- Structurer un projet Python pour le déployer avec ADK
- Implémenter un agent utilisant des outils avec google-adk
- Comment connecter un agent à un serveur MCP distant pour utiliser son ensemble d'outils
- Découvrez comment déployer une application Python en tant que conteneur sans serveur sur Cloud Run.
- Configurer une authentification sécurisée de service à service à l'aide de rôles IAM
- Comment supprimer les ressources Cloud pour éviter d'accumuler des coûts
Prérequis
- Un compte Google Cloud et un projet Google Cloud
- Un navigateur Web tel que Chrome
2. Pourquoi effectuer le déploiement sur Cloud Run ?
Cloud Run est parfait pour héberger des agents ADK, car il s'agit d'une plate-forme sans serveur : vous pouvez donc vous concentrer sur votre code sans avoir à gérer l'infrastructure sous-jacente. Nous gérons les tâches opérationnelles à votre place.
Il fonctionne un peu comme une boutique éphémère, qui n'ouvre et n'utilise des ressources que lorsque des clients (en l'occurrence, des requêtes) se présentent. Lorsqu'il n'y a pas de clients, la boutique est complètement fermée, ce qui évite d'avoir à payer quand elle est vide.
Principales fonctionnalités
Exécute des conteneurs partout :
- Vous fournissez un conteneur (image Docker) contenant votre application.
- Cloud Run l'exécute sur l'infrastructure de Google.
- Vous n'avez pas besoin de gérer les correctifs de l'OS, la configuration des VM ni le scaling.
Scaling automatique :
- Si personne n'utilise votre application, aucune instance n'est exécutée (l'application est mise à l'échelle sur zéro instance, ce qui est économique).
- Si vous recevez soudain 1 000 requêtes, Cloud Run lance autant de ressources que nécessaire pour les traiter.
Sans état par défaut :
- Chaque requête peut être envoyée à une instance différente.
- Si vous devez stocker l'état, utilisez un service externe comme Cloud SQL, Firestore ou Memorystore.
Compatible avec n'importe quel langage ou framework :
- Tant qu'il s'exécute dans un conteneur Linux, Cloud Run est compatible avec Python, Go, Node.js, Java ou .NET.
Payez seulement ce que vous utilisez :
- Facturation basée sur les requêtes : facturation par requête + temps de calcul (avec une précision à 100 ms).
- Facturation basée sur les instances : facturation pour toute la durée de vie de l'instance (aucun frais par requête).
3. Avant de commencer
Configuration de l'environnement au rythme de chacun
- Connectez-vous à la console Google Cloud, puis créez un projet ou réutilisez un projet existant. Si vous n'avez pas encore de compte Gmail ou Google Workspace, vous devez en créer un.

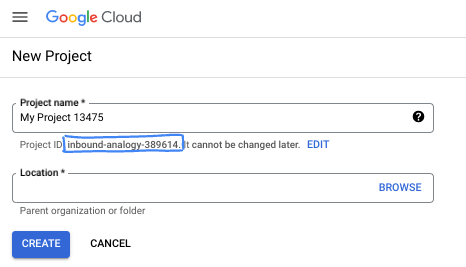
- Le nom du projet est le nom à afficher pour les participants au projet. Il s'agit d'une chaîne de caractères non utilisée par les API Google. Vous pourrez toujours le modifier.
- L'ID du projet est unique parmi tous les projets Google Cloud et non modifiable une fois défini. La console Cloud génère automatiquement une chaîne unique (en général, vous n'y accordez d'importance particulière). Dans la plupart des ateliers de programmation, vous devrez indiquer l'ID de votre projet (généralement identifié par
PROJECT_ID). Si l'ID généré ne vous convient pas, vous pouvez en générer un autre de manière aléatoire. Vous pouvez également en spécifier un et voir s'il est disponible. Après cette étape, l'ID n'est plus modifiable et restera donc le même pour toute la durée du projet. - Pour information, il existe une troisième valeur (le numéro de projet) que certaines API utilisent. Pour en savoir plus sur ces trois valeurs, consultez la documentation.
- Vous devez ensuite activer la facturation dans la console Cloud pour utiliser les ressources/API Cloud. L'exécution de cet atelier de programmation est très peu coûteuse, voire sans frais. Pour désactiver les ressources et éviter ainsi que des frais ne vous soient facturés après ce tutoriel, vous pouvez supprimer le projet ou les ressources que vous avez créées. Les nouveaux utilisateurs de Google Cloud peuvent participer au programme d'essai sans frais pour bénéficier d'un crédit de 300 $.
Démarrer Cloud Shell
- Accédez à l'éditeur Cloud Shell.
- Si le terminal ne s'affiche pas en bas de l'écran, ouvrez-le :
- Cliquez sur Terminal
- Cliquez sur Nouveau terminal.
- Dans le terminal, définissez votre projet à l'aide de la commande suivante. Si vous avez terminé l'atelier 1, assurez-vous d'utiliser le même ID de projet :
gcloud config set project [YOUR-PROJECT-ID]gcloud projects list | awk '/PROJECT_ID/{print $2}' - Si vous êtes invité à autoriser l'accès, cliquez sur Autoriser pour continuer.
- Le message suivant doit s'afficher :
Updated property [core/project].
WARNINGs'affiche et que vous êtes invité àDo you want to continue (Y/n)?, cela signifie probablement que vous avez saisi l'ID de projet de manière incorrecte. Appuyez surn, puis surEnter, et réessayez d'exécuter la commandegcloud config set project.
4. Configurez votre environnement.
Activer les API et définir les variables d'environnement
Activez tous les services nécessaires :
gcloud services enable \
run.googleapis.com \
artifactregistry.googleapis.com \
cloudbuild.googleapis.com \
aiplatform.googleapis.com
Résultat attendu
Operation "operations/acat.p2-[GUID]" finished successfully.
Créez le répertoire du projet.
Cette commande crée un dossier principal dans l'atelier pour le code source de l'agent.
cd && mkdir zoo_guide_agent && cd zoo_guide_agent
Créez le fichier requirements.txt. Ce fichier liste les bibliothèques Python dont votre agent a besoin. La commande suivante crée le fichier et le remplit.
cloudshell edit requirements.txt
google-adk==1.14.0
langchain-community==0.3.27
wikipedia==1.4.0
Définissez des variables pour l'ID et le numéro de votre projet actuel, et créez un compte de service dédié pour votre projet. Il s'agit d'une méthode plus robuste pour exécuter ces commandes.
export PROJECT_ID=$(gcloud config get-value project)
export PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")
export SA_NAME=lab2-cr-service
export SERVICE_ACCOUNT="${SA_NAME}@${PROJECT_ID}.iam.gserviceaccount.com"
gcloud iam service-accounts create ${SA_NAME} \
--display-name="Service Account for lab 2 "
Créez et ouvrez un fichier .env pour authentifier l'agent dans le répertoire zoo_guide_agent.
cloudshell edit .env
La commande cloudshell edit ouvre le fichier .env dans l'éditeur au-dessus du terminal. Saisissez les éléments suivants dans le fichier .env, puis revenez au terminal.
MODEL="gemini-2.5-flash"
Ajoutez l'URL du serveur MCP. Si vous avez terminé l'atelier 1, suivez ces étapes pour utiliser le serveur MCP que vous avez créé dans l'atelier 1 :
Accordez au compte de service de l'agent les autorisations nécessaires pour utiliser Gemini sur Vertex AI et appeler le serveur MCP à distance :
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT" \
--role="roles/aiplatform.user"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT" \
--role="roles/run.invoker"
Enregistrez l'URL du serveur MCP de l'atelier 1 dans une variable d'environnement.
echo -e "\nMCP_SERVER_URL=https://zoo-mcp-server-${PROJECT_NUMBER}.us-west1.run.app/mcp" >> .env
Si vous utilisez un lien de serveur MCP public, exécutez la commande suivante et remplacez PROJECT_NUMBER par la valeur fournie.
echo -e "\nMCP_SERVER_URL=https://zoo-mcp-server-${PROJECT_NUMBER}.us-west1.run.app/mcp" >> .env
5. Créer un workflow d'agent
Créer le fichier init.py
Créez le fichier init.py. Ce fichier indique à Python que le répertoire zoo_guide_agent est un package.
cloudshell edit __init__.py
La commande précédente ouvre l'éditeur de code. Ajoutez le code suivant à __init__.py :
from . import agent
Créer le fichier principal agent.py
Créez le fichier principal agent.py. Cette commande crée le fichier Python et y colle le code complet de votre système multi-agent.
cloudshell edit agent.py
Importations et configuration initiale
Ce premier bloc importe toutes les bibliothèques nécessaires depuis ADK et Google Cloud. Il configure également la journalisation et charge les variables d'environnement à partir de votre fichier .env, ce qui est essentiel pour accéder au modèle et à l'URL du serveur.
Ajoutez le code suivant à votre fichier agent.py :
import os
import logging
import google.cloud.logging
from dotenv import load_dotenv
from google.adk import Agent
from google.adk.agents import SequentialAgent
from google.adk.tools.mcp_tool.mcp_toolset import MCPToolset, StreamableHTTPConnectionParams
from google.adk.tools.tool_context import ToolContext
from google.adk.tools.langchain_tool import LangchainTool
from langchain_community.tools import WikipediaQueryRun
from langchain_community.utilities import WikipediaAPIWrapper
import google.auth
import google.auth.transport.requests
import google.oauth2.id_token
# --- Setup Logging and Environment ---
cloud_logging_client = google.cloud.logging.Client()
cloud_logging_client.setup_logging()
load_dotenv()
model_name = os.getenv("MODEL")
Définir les outils (les capacités de l'agent)

Un agent n'est efficace que s'il dispose des bons outils. Dans cette section, nous allons définir toutes les fonctionnalités de notre agent, y compris une fonction personnalisée pour enregistrer des données, un outil MCP qui se connecte à notre serveur MCP sécurisé, ainsi qu'un outil Wikipédia.
Ajoutez le code suivant à la fin de agent.py :
# Greet user and save their prompt
def add_prompt_to_state(
tool_context: ToolContext, prompt: str
) -> dict[str, str]:
"""Saves the user's initial prompt to the state."""
tool_context.state["PROMPT"] = prompt
logging.info(f"[State updated] Added to PROMPT: {prompt}")
return {"status": "success"}
# Configuring the MCP Tool to connect to the Zoo MCP server
mcp_server_url = os.getenv("MCP_SERVER_URL")
if not mcp_server_url:
raise ValueError("The environment variable MCP_SERVER_URL is not set.")
def get_id_token():
"""Get an ID token to authenticate with the MCP server."""
target_url = os.getenv("MCP_SERVER_URL")
audience = target_url.split('/mcp/')[0]
request = google.auth.transport.requests.Request()
id_token = google.oauth2.id_token.fetch_id_token(request, audience)
return id_token
"""
# Use this code if you are using the public MCP Server and comment out the code below defining mcp_tools
mcp_tools = MCPToolset(
connection_params=StreamableHTTPConnectionParams(
url=mcp_server_url
)
)
"""
mcp_tools = MCPToolset(
connection_params=StreamableHTTPConnectionParams(
url=mcp_server_url,
headers={
"Authorization": f"Bearer {get_id_token()}",
},
),
)
# Configuring the Wikipedia Tool
wikipedia_tool = LangchainTool(
tool=WikipediaQueryRun(api_wrapper=WikipediaAPIWrapper())
)
Présentation des trois outils
add_prompt_to_state📝
Cet outil mémorise les questions posées par les visiteurs du zoo. Lorsqu'un visiteur demande "Où sont les lions ?", il enregistre cette question spécifique dans la mémoire de l'agent afin que les autres agents du workflow sachent ce qu'ils doivent rechercher.
Comment ? Une fonction Python écrit la requête du visiteur dans le dictionnaire partagé tool_context.state. Ce dictionnaire représente la mémoire à court terme de l'agent pour une conversation unique. Les données enregistrées dans l'état de session par un agent peuvent être lues par l'agent suivant dans le workflow.
MCPToolset🦁
Il permet de connecter l'agent de visite guidée au serveur MCP du zoo créé dans l'atelier 1. Ce serveur dispose d'outils dédiés à la recherche d'informations spécifiques sur nos animaux, comme leur nom, leur âge et leur enclos.
Comment ? Il se connecte de manière sécurisée à l'URL du serveur privé du zoo. Il utilise get_id_token pour obtenir automatiquement une "carte d'accès" sécurisée (jeton d'ID de compte de service) afin de prouver son identité et d'obtenir l'accès.
LangchainTool🌍
Cela permet à l'agent de guide touristique d'acquérir des connaissances générales sur le monde. Si un visiteur pose une question qui ne figure pas dans la base de données du zoo (par exemple, "Que mangent les lions dans leur habitat naturel ?"), cet outil permet à l'agent de rechercher la réponse sur Wikipédia.
Comment ? Il sert d'adaptateur permettant à l'agent d'utiliser l'outil WikipediaQueryRun prédéfini depuis la bibliothèque LangChain.
Ressources :
Définir les agents spécialisés

Nous allons ensuite définir l'agent de recherche et l'agent de mise en forme des réponses. L'agent de recherche est le "cerveau" de notre opération. Cet agent interprète le prompt de l'utilisateur à partir de l'State partagé, interroge ses outils avancés (le serveur MCP du zoo et Wikipédia) et détermine celui qu'il doit utiliser pour trouver la réponse.
Le rôle de l'agent de mise en forme des réponses est la présentation. Il ne recherche aucune information nouvelle dans les outils. Son rôle est de transformer les données brutes collectées par l'agent de recherche (transmises via l'état de session) en réponse conviviale et conversationnelle en utilisant les compétences linguistiques du LLM.
Ajoutez le code suivant en bas de agent.py :
# 1. Researcher Agent
comprehensive_researcher = Agent(
name="comprehensive_researcher",
model=model_name,
description="The primary researcher that can access both internal zoo data and external knowledge from Wikipedia.",
instruction="""
You are a helpful research assistant. Your goal is to fully answer the user's PROMPT.
You have access to two tools:
1. A tool for getting specific data about animals AT OUR ZOO (names, ages, locations).
2. A tool for searching Wikipedia for general knowledge (facts, lifespan, diet, habitat).
First, analyze the user's PROMPT.
- If the prompt can be answered by only one tool, use that tool.
- If the prompt is complex and requires information from both the zoo's database AND Wikipedia,
you MUST use both tools to gather all necessary information.
- Synthesize the results from the tool(s) you use into preliminary data outputs.
PROMPT:
{{ PROMPT }}
""",
tools=[
mcp_tools,
wikipedia_tool
],
output_key="RESEARCH_DATA" # A key to store the combined findings
)
# 2. Response Formatter Agent
response_formatter = Agent(
name="response_formatter",
model=model_name,
description="Synthesizes all information into a friendly, readable response.",
instruction="""
You are the friendly voice of the Zoo Tour Guide. Your task is to take the
RESEARCH_DATA and present it to the user in a complete and helpful answer.
- First, present the specific information from the zoo (like names, ages, and where to find them).
- Then, add the interesting general facts from the research.
- If some information is missing, just present the information you have.
- Be conversational and engaging.
RESEARCH_DATA:
{{ RESEARCH_DATA }}
"""
)
L'agent de workflow
L'agent de workflow est l'entité qui gère la visite du zoo en coulisses. Une fois la demande de recherche envoyée, il s'assure que les deux agents que nous avons définis ci-dessus interviennent dans le bon ordre : d'abord la recherche, puis la mise en forme. Il garantit que le processus consistant à répondre aux questions des visiteurs est fiable et rigoureux.
Comment ? Il s'agit d'un SequentialAgent, un type d'agent spécifique qui ne réfléchit pas par lui-même. Son seul rôle est d'exécuter une liste de sub_agents (l'agent de recherche et l'agent de mise en forme) dans un ordre fixe, en transmettant automatiquement la mémoire partagée de l'un à l'autre.
Ajoutez ce bloc de code en bas de agent.py :
tour_guide_workflow = SequentialAgent(
name="tour_guide_workflow",
description="The main workflow for handling a user's request about an animal.",
sub_agents=[
comprehensive_researcher, # Step 1: Gather all data
response_formatter, # Step 2: Format the final response
]
)
Assembler le workflow principal 
Cet agent est désigné par root_agent, qui sert de point de départ à toutes les nouvelles conversations dans le framework ADK. Son rôle principal est d'orchestrer le processus global. Il agit comme le contrôleur initial qui gère le premier tour de la conversation.
Ajoutez ce dernier bloc de code à la fin de agent.py :
root_agent = Agent(
name="greeter",
model=model_name,
description="The main entry point for the Zoo Tour Guide.",
instruction="""
- Let the user know you will help them learn about the animals we have in the zoo.
- When the user responds, use the 'add_prompt_to_state' tool to save their response.
After using the tool, transfer control to the 'tour_guide_workflow' agent.
""",
tools=[add_prompt_to_state],
sub_agents=[tour_guide_workflow]
)
Votre fichier agent.py est maintenant terminé. Les différentes étapes vous ont permis de comprendre le rôle spécifique de chaque composant (outils, agents de traitement et agents de gestion) dans la création du système intelligent final. Passons maintenant au déploiement.
6. Déployer l'agent à l'aide de la CLI ADK
Maintenant que votre code local et votre projet Google Cloud sont prêts, il est temps de déployer l'agent. Vous allez utiliser la commande adk deploy cloud_run, qui permet d'automatiser l'ensemble du workflow de déploiement en toute simplicité. Cette commande unique crée un package à partir du code, génère une image de conteneur, la transmet à Artifact Registry et lance le service sur Cloud Run pour le rendre accessible sur le Web.
Déployer
Exécutez les commandes suivantes pour déployer votre agent. La commande uvx vous permet d'exécuter des outils de ligne de commande publiés en tant que packages Python sans nécessiter leur installation globale.
# Run the deployment command
uvx --from google-adk==1.14.0 \
adk deploy cloud_run \
--project=$PROJECT_ID \
--region=us-west1 \
--service_name=zoo-tour-guide \
--with_ui \
. \
-- \
--labels=dev-tutorial=codelab-adk \
--service-account=$SERVICE_ACCOUNT
Accepter les requêtes
Le message suivant peut s'afficher :
Deploying from source requires an Artifact Registry Docker repository to store built containers. A repository named [cloud-run-source-deploy] in region [us-west1] will be created. Do you want to continue (Y/n)?
Saisissez Y et appuyez sur ENTRÉE.
Le message suivant peut s'afficher :
Allow unauthenticated invocations to [your-service-name] (y/N)?.
Pour cet atelier, nous voulons autoriser les appels non authentifiés afin de faciliter les tests. Saisissez y et appuyez sur Entrée.
Obtenir le lien de déploiement
Une fois l'exécution réussie, la commande fournit l'URL du service Cloud Run déployé. (Elle doit ressembler à https://zoo-tour-guide-123456789.us-west1.run.app.) Copiez cette URL pour la tâche suivante.
7. Tester l'agent déployé
Maintenant que votre agent est en service sur Cloud Run, vous allez effectuer un test pour vérifier que le déploiement a réussi et que l'agent fonctionne comme prévu. Vous utiliserez l'URL du service public (par exemple, https://zoo-tour-guide-123456789.us-west1.run.app/) pour accéder à l'interface Web de l'ADK et interagir avec l'agent.
Ouvrez l'URL publique du service Cloud Run dans votre navigateur Web. Comme vous avez utilisé --with_ui flag, vous devriez voir l'UI de développement ADK.
En haut à droite, activez Token Streaming.
Vous pouvez maintenant interagir avec l'agent du zoo.
Saisissez hello et appuyez sur Entrée pour démarrer une nouvelle conversation.
Observez le résultat. L'agent doit répondre rapidement en présentant son message de bienvenue :
"Hello! I'm your Zoo Tour Guide. I can help you learn about the amazing animals we have here. What would you like to know or explore today?"
Posez des questions à l'agent, par exemple :
Where can I find the polar bears in the zoo and what is their diet?
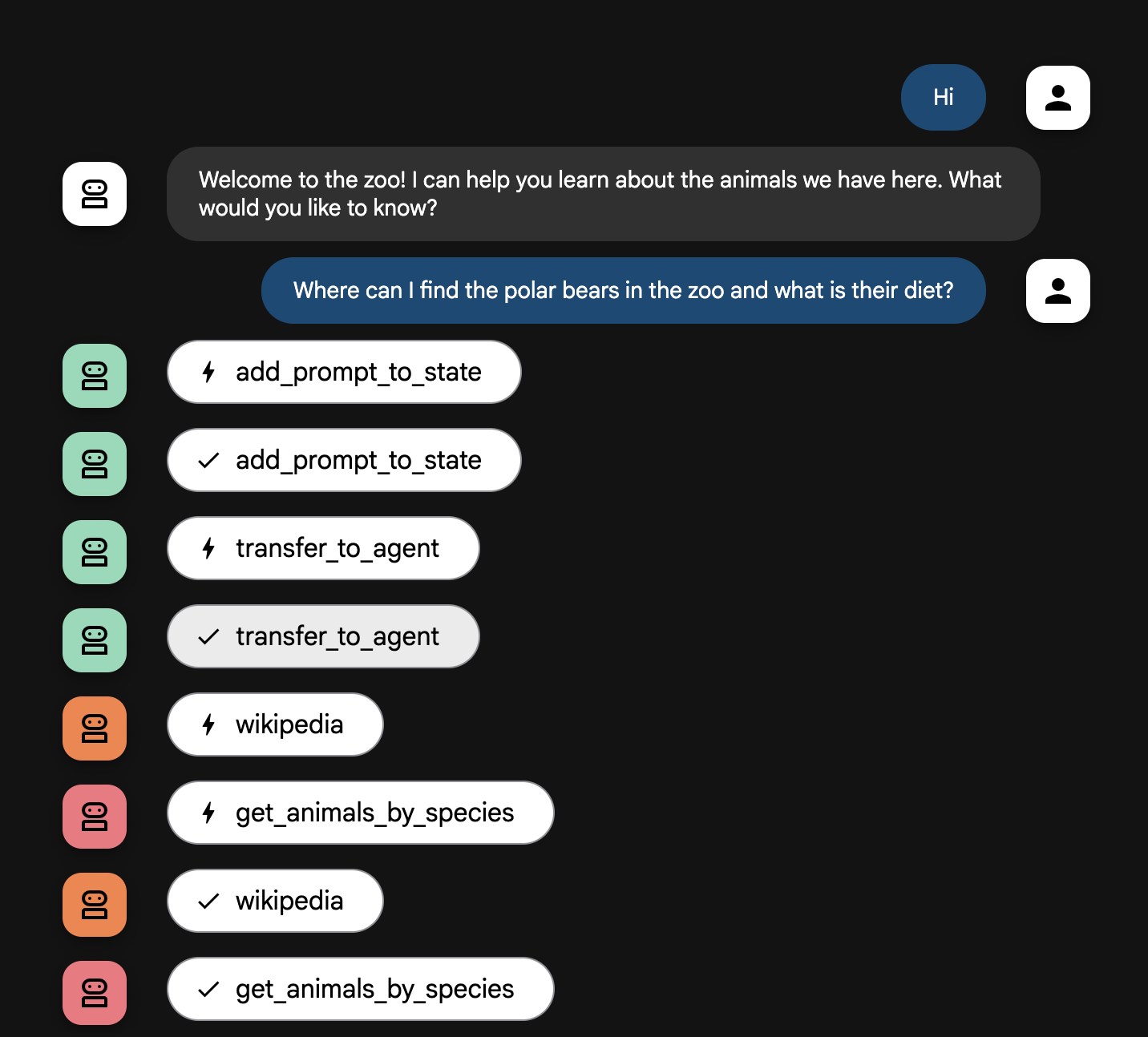

Explication du flux de l'agent
Votre système fonctionne comme une équipe intelligente multi-agents. Le processus est géré par une séquence claire pour assurer un flux efficace et fluide, de la question de l'utilisateur à la réponse détaillée finale.
1. L'accueil du zoo ("La réception")
L'ensemble du processus commence par l'agent qui accueille les utilisateurs.
Son rôle : lancer la conversation. Sa consigne est de saluer l'utilisateur et de lui demander quel animal l'intéresse.
Son outil : lorsque l'utilisateur répond, cet agent utilise l'outil add_prompt_to_state pour recueillir ses mots exacts (par exemple, "je veux en savoir plus sur les lions") et les enregistrer dans la mémoire du système.
Le transfert : après avoir enregistré le prompt, il passe immédiatement le contrôle au sous-agent tour_guide_workflow.
2. Le chercheur complet ("Le superchercheur")
Cet agent intervient en premier dans le workflow principal et représente le "cerveau" de l'opération. Au lieu d'une grande équipe, vous disposez désormais d'un seul agent hautement qualifié qui peut accéder à toutes les informations disponibles.
Son rôle : analyser la question de l'utilisateur et élaborer un plan intelligent. Il utilise la fonctionnalité avancée d'exploitation des outils intégrée au modèle de langage pour déterminer s'il a besoin :
- des données internes issues des registres du zoo (via le serveur MCP) ;
- des informations générales issues du Web (via l'API Wikipédia) ;
- ou des deux, pour les questions complexes.
Son action : il exécute les outils nécessaires pour collecter toutes les données brutes requises. Par exemple, si on lui demande "Quel âge ont vos lions et de quoi se nourrissent-ils dans leur habitat naturel ?", il appellera le serveur MCP pour obtenir l'âge et l'outil Wikipédia pour obtenir des informations sur leur régime alimentaire.
3. L'outil de formulation des réponses ("Le présentateur")
Une fois que l'agent de recherche a rassemblé tous les faits, c'est le dernier agent à entrer en action.
Son rôle : incarner la voix bienveillante du guide du zoo. Il prend les données brutes (qui peuvent provenir d'une seule source ou des deux) et les affine.
Son action : il synthétise toutes les informations en une seule réponse cohérente et dynamique. En suivant ses instructions, il présente d'abord les informations spécifiques au zoo, puis ajoute les informations générales pertinentes.
Résultat final : le texte généré par cet agent constitue la réponse complète et détaillée que l'utilisateur voit dans la fenêtre de discussion.
Si vous souhaitez en savoir plus sur la création d'agents, consultez les ressources suivantes :
8. Nettoyer l'environnement
gcloud run services delete zoo-tour-guide --region=us-west1 --quiet
gcloud artifacts repositories delete cloud-run-source-deploy --location=us-west1 --quiet
9. Félicitations
Bravo ! Vous avez terminé cet atelier de programmation.
Points abordés
- Comment structurer un projet Python pour le déployer avec l'interface de ligne de commande ADK
- Comment implémenter un workflow multi-agent à l'aide de SequentialAgent et ParallelAgent.
- Comment se connecter à un serveur MCP distant à l'aide de MCPToolset pour utiliser ses outils
- Comment enrichir les données internes en intégrant des outils externes comme l'API Wikipédia.
- Découvrez comment déployer un agent en tant que conteneur sans serveur sur Cloud Run à l'aide de la commande adk deploy.