
1. Introduzione
Questo lab è incentrato sull'implementazione e sul deployment di un servizio di agent client. Utilizzerai l'Agent Development Kit (ADK) per creare un agente AI che utilizza strumenti remoti come il server MCP creato nel Lab 1. Il principio architettonico chiave dimostrato è la separazione delle competenze, con un livello di ragionamento distinto (l'agente) che comunica con un livello di strumenti distinto (il server MCP) tramite un'API sicura.
Nel lab 1 hai creato un server MCP che fornisce dati sugli animali di uno zoo fittizio ai LLM, ad esempio quando utilizzi Gemini CLI. In questo lab, creeremo un agente guida turistica per lo zoo fittizio. L'agente utilizzerà lo stesso server MCP del lab 1 per accedere ai dettagli sugli animali dello zoo e utilizzerà anche Wikipedia per creare la migliore esperienza di guida turistica.

Infine, eseguiremo il deployment dell'agente guida turistica in Google Cloud Run, in modo che possa essere accessibile a tutti i visitatori dello zoo anziché essere eseguito solo localmente.
Prerequisiti
- Un server MCP in esecuzione su Cloud Run o il relativo URL del servizio.
- Un progetto Google Cloud con la fatturazione abilitata.
Cosa imparerai a fare
- Come strutturare un progetto Python per il deployment di ADK.
- Come implementare un agente che utilizza strumenti con google-adk.
- Come connettere un agente a un server MCP remoto per il relativo set di strumenti.
- Come eseguire il deployment di un'applicazione Python come container serverless in Cloud Run.
- Come configurare l'autenticazione sicura tra servizi utilizzando i ruoli IAM.
- Come eliminare le risorse cloud per evitare costi futuri.
Che cosa ti serve
- Un account Google Cloud e un progetto Google Cloud
- Un browser web come Chrome
2. Perché eseguire il deployment in Cloud Run?
Cloud Run è un'ottima scelta per l'hosting degli agenti ADK perché è una piattaforma serverless, il che significa che puoi concentrarti sul codice e non sulla gestione dell'infrastruttura sottostante. Ci occupiamo noi del lavoro operativo.
È come un pop-up shop: si apre e utilizza le risorse solo quando arrivano i clienti (richieste). Quando non ci sono clienti, chiude completamente e non paghi per un negozio vuoto.
Funzionalità principali
Esegue Containers Anywhere:
- Porti un container (immagine Docker) che contiene la tua app.
- Cloud Run lo esegue sull'infrastruttura di Google.
- Nessun problema di applicazione di patch del sistema operativo, configurazione della VM o scalabilità.
Scalabilità automatica:
- Se 0 persone utilizzano la tua app → vengono eseguite 0 istanze (ridimensionamento a zero istanze, il che è conveniente).
- Se riceve 1000 richieste, crea tutte le copie necessarie.
Stateless by Default:
- Ogni richiesta potrebbe essere inviata a un'istanza diversa.
- Se devi archiviare lo stato, utilizza un servizio esterno come Cloud SQL, Firestore o Memorystore.
Supporta qualsiasi lingua o framework:
- Finché viene eseguito in un container Linux, Cloud Run non si preoccupa se si tratta di Python, Go, Node.js, Java o .NET.
Pagamento a consumo:
- Fatturazione basata sulle richieste: fatturazione per richiesta + tempo di calcolo (fino a 100 ms).
- Fatturazione basata sulle istanze: fatturazione per l'intera durata dell'istanza (nessuna tariffa per richiesta).
3. Prima di iniziare
Configurazione dell'ambiente autonomo
- Accedi alla console Google Cloud e crea un nuovo progetto o riutilizzane uno esistente. Se non hai ancora un account Gmail o Google Workspace, devi crearne uno.

- Il nome del progetto è il nome visualizzato per i partecipanti a questo progetto. È una stringa di caratteri non utilizzata dalle API di Google. Puoi sempre aggiornarlo.
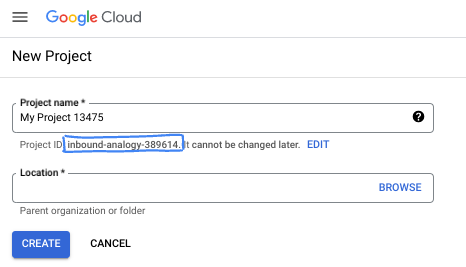
- L'ID progetto è univoco in tutti i progetti Google Cloud ed è immutabile (non può essere modificato dopo l'impostazione). La console Cloud genera automaticamente una stringa univoca, di solito non ti interessa di cosa si tratta. Nella maggior parte dei codelab, dovrai fare riferimento all'ID progetto (in genere identificato come
PROJECT_ID). Se l'ID generato non ti piace, puoi generarne un altro casuale. In alternativa, puoi provare a crearne uno e vedere se è disponibile. Non può essere modificato dopo questo passaggio e rimane per tutta la durata del progetto. - Per tua informazione, esiste un terzo valore, un numero di progetto, utilizzato da alcune API. Scopri di più su tutti e tre questi valori nella documentazione.
- Successivamente, devi abilitare la fatturazione in Cloud Console per utilizzare le risorse/API Cloud. Completare questo codelab non costa molto, se non nulla. Per arrestare le risorse ed evitare addebiti oltre a quelli previsti in questo tutorial, puoi eliminare le risorse che hai creato o il progetto. I nuovi utenti di Google Cloud possono beneficiare del programma prova senza costi di 300$.
Avvia Cloud Shell
- Vai all'editor di Cloud Shell.
- Se il terminale non viene visualizzato nella parte inferiore dello schermo, aprilo:
- Fai clic su Terminale.
- Fai clic su Nuovo terminale.
- Nel terminale, imposta il tuo progetto con questo comando. Se hai completato il lab 1, assicurati di utilizzare lo stesso ID progetto:
gcloud config set project [YOUR-PROJECT-ID]gcloud projects list | awk '/PROJECT_ID/{print $2}' - Se ti viene richiesto di concedere l'autorizzazione, fai clic su Autorizza per continuare.
- Dovresti visualizzare questo messaggio:
Updated property [core/project].
WARNINGe ti viene chiestoDo you want to continue (Y/n)?, probabilmente hai inserito l'ID progetto in modo errato. Premin, premiEntere prova a eseguire di nuovo il comandogcloud config set project.
4. Configura l'ambiente
Abilita le API e imposta le variabili di ambiente
Attiva tutti i servizi necessari:
gcloud services enable \
run.googleapis.com \
artifactregistry.googleapis.com \
cloudbuild.googleapis.com \
aiplatform.googleapis.com
Output previsto:
Operation "operations/acat.p2-[GUID]" finished successfully.
Crea la directory del progetto.
Questo comando crea una cartella principale per il lab per il codice sorgente dell'agente.
cd && mkdir zoo_guide_agent && cd zoo_guide_agent
Crea il file requirements.txt. Questo file elenca le librerie Python necessarie per l'agente. Il comando seguente crea il file e lo compila.
cloudshell edit requirements.txt
google-adk==1.14.0
langchain-community==0.3.27
wikipedia==1.4.0
Imposta le variabili per l'ID progetto e il numero di progetto attuali e crea anche un service account dedicato per il tuo progetto. Questo è un modo più efficace per eseguire questi comandi.
export PROJECT_ID=$(gcloud config get-value project)
export PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")
export SA_NAME=lab2-cr-service
export SERVICE_ACCOUNT="${SA_NAME}@${PROJECT_ID}.iam.gserviceaccount.com"
gcloud iam service-accounts create ${SA_NAME} \
--display-name="Service Account for lab 2 "
Crea e apri un file .env per autenticare l'agente nella directory zoo_guide_agent.
cloudshell edit .env
Il comando cloudshell edit aprirà il file .env nell'editor sopra il terminale. Inserisci quanto segue nel file .env e torna al terminale.
MODEL="gemini-2.5-flash"
Aggiunta dell'URL del server MCP. Se hai completato il lab 1, segui questi passaggi per utilizzare il server MCP che hai creato nel lab 1:
Concedi al service account dell'agente le autorizzazioni per utilizzare Gemini su Vertex AI e per chiamare il server MCP remoto:
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT" \
--role="roles/aiplatform.user"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT" \
--role="roles/run.invoker"
Salva l'URL del server MCP del lab 1 in una variabile di ambiente.
echo -e "\nMCP_SERVER_URL=https://zoo-mcp-server-${PROJECT_NUMBER}.us-west1.run.app/mcp" >> .env
Se utilizzi un link pubblico al server MCP, esegui il comando riportato di seguito e sostituisci PROJECT_NUMBER con il valore fornito.
echo -e "\nMCP_SERVER_URL=https://zoo-mcp-server-${PROJECT_NUMBER}.us-west1.run.app/mcp" >> .env
5. Creazione flusso di lavoro agente
Crea il file init.py
Crea il file init.py. Questo file indica a Python che la directory zoo_guide_agent è un pacchetto.
cloudshell edit __init__.py
Il comando precedente apre l'editor di codice. Aggiungi il codice seguente a __init__.py:
from . import agent
Crea il file main agent.py
Crea il file principale agent.py. Questo comando crea il file Python e incolla il codice completo per il sistema multi-agente.
cloudshell edit agent.py
Importazioni e configurazione iniziale
Questo primo blocco importa tutte le librerie necessarie da ADK e Google Cloud. Configura anche la registrazione e carica le variabili di ambiente dal file .env, che è fondamentale per accedere all'URL del modello e del server.
Aggiungi il seguente codice al file agent.py:
import os
import logging
import google.cloud.logging
from dotenv import load_dotenv
from google.adk import Agent
from google.adk.agents import SequentialAgent
from google.adk.tools.mcp_tool.mcp_toolset import MCPToolset, StreamableHTTPConnectionParams
from google.adk.tools.tool_context import ToolContext
from google.adk.tools.langchain_tool import LangchainTool
from langchain_community.tools import WikipediaQueryRun
from langchain_community.utilities import WikipediaAPIWrapper
import google.auth
import google.auth.transport.requests
import google.oauth2.id_token
# --- Setup Logging and Environment ---
cloud_logging_client = google.cloud.logging.Client()
cloud_logging_client.setup_logging()
load_dotenv()
model_name = os.getenv("MODEL")
Definizione degli strumenti (le funzionalità dell'agente)

Un agente è efficace solo se può utilizzare gli strumenti. In questa sezione definiamo tutte le funzionalità che avrà il nostro agente, tra cui una funzione personalizzata per salvare i dati, uno strumento MCP che si connette al nostro server MCP sicuro e uno strumento Wikipedia.
Aggiungi il seguente codice alla fine di agent.py:
# Greet user and save their prompt
def add_prompt_to_state(
tool_context: ToolContext, prompt: str
) -> dict[str, str]:
"""Saves the user's initial prompt to the state."""
tool_context.state["PROMPT"] = prompt
logging.info(f"[State updated] Added to PROMPT: {prompt}")
return {"status": "success"}
# Configuring the MCP Tool to connect to the Zoo MCP server
mcp_server_url = os.getenv("MCP_SERVER_URL")
if not mcp_server_url:
raise ValueError("The environment variable MCP_SERVER_URL is not set.")
def get_id_token():
"""Get an ID token to authenticate with the MCP server."""
target_url = os.getenv("MCP_SERVER_URL")
audience = target_url.split('/mcp/')[0]
request = google.auth.transport.requests.Request()
id_token = google.oauth2.id_token.fetch_id_token(request, audience)
return id_token
"""
# Use this code if you are using the public MCP Server and comment out the code below defining mcp_tools
mcp_tools = MCPToolset(
connection_params=StreamableHTTPConnectionParams(
url=mcp_server_url
)
)
"""
mcp_tools = MCPToolset(
connection_params=StreamableHTTPConnectionParams(
url=mcp_server_url,
headers={
"Authorization": f"Bearer {get_id_token()}",
},
),
)
# Configuring the Wikipedia Tool
wikipedia_tool = LangchainTool(
tool=WikipediaQueryRun(api_wrapper=WikipediaAPIWrapper())
)
Spiegazione dei tre strumenti
add_prompt_to_state📝
Questo strumento ricorda le domande di un visitatore dello zoo. Quando un visitatore chiede: "Dove sono i leoni?", questo strumento salva la domanda specifica nella memoria dell'agente, in modo che gli altri agenti del flusso di lavoro sappiano cosa cercare.
Come: è una funzione Python che scrive il prompt del visitatore nel dizionario tool_context.state condiviso. Il contesto dello strumento rappresenta la memoria a breve termine dell'agente per una singola conversazione. I dati salvati nello stato da un agente possono essere letti dall'agente successivo nel flusso di lavoro.
MCPToolset🦁
Viene utilizzato per connettere l'agente guida turistica al server MCP dello zoo creato nel lab 1. Questo server dispone di strumenti speciali per cercare informazioni specifiche sui nostri animali, come nome, età e recinto.
Come: si connette in modo sicuro all'URL del server privato dello zoo. Utilizza get_id_token per ottenere automaticamente una "chiave" sicura (un token ID service account) per dimostrare la sua identità e ottenere l'accesso.
LangchainTool🌍
In questo modo, l'agente della guida turistica acquisisce conoscenze generali sul mondo. Quando un visitatore pone una domanda che non è presente nel database dello zoo, ad esempio "Cosa mangiano i leoni in natura?", questo strumento consente all'agente di cercare la risposta su Wikipedia.
Come funziona:funge da adattatore, consentendo al nostro agente di utilizzare lo strumento predefinito WikipediaQueryRun della libreria LangChain.
Risorse:
Definizione degli agenti specializzati

Successivamente, definiamo l'agente di ricerca e l'agente di formattazione delle risposte. L'agente di ricerca è il "cervello" della nostra operazione. Questo agente prende il prompt dell'utente dal State condiviso, esamina i suoi potenti strumenti (lo strumento server MCP di Zoo e lo strumento Wikipedia) e decide quali utilizzare per trovare la risposta.
Il ruolo dell'agente di formattazione delle risposte è la presentazione. Non utilizza strumenti per trovare nuove informazioni. Al contrario, prende i dati non elaborati raccolti dall'agente Ricercatore (trasmessi tramite lo stato) e utilizza le competenze linguistiche del LLM per trasformarli in una risposta amichevole e conversazionale.
Aggiungi il seguente codice in fondo a agent.py:
# 1. Researcher Agent
comprehensive_researcher = Agent(
name="comprehensive_researcher",
model=model_name,
description="The primary researcher that can access both internal zoo data and external knowledge from Wikipedia.",
instruction="""
You are a helpful research assistant. Your goal is to fully answer the user's PROMPT.
You have access to two tools:
1. A tool for getting specific data about animals AT OUR ZOO (names, ages, locations).
2. A tool for searching Wikipedia for general knowledge (facts, lifespan, diet, habitat).
First, analyze the user's PROMPT.
- If the prompt can be answered by only one tool, use that tool.
- If the prompt is complex and requires information from both the zoo's database AND Wikipedia,
you MUST use both tools to gather all necessary information.
- Synthesize the results from the tool(s) you use into preliminary data outputs.
PROMPT:
{{ PROMPT }}
""",
tools=[
mcp_tools,
wikipedia_tool
],
output_key="RESEARCH_DATA" # A key to store the combined findings
)
# 2. Response Formatter Agent
response_formatter = Agent(
name="response_formatter",
model=model_name,
description="Synthesizes all information into a friendly, readable response.",
instruction="""
You are the friendly voice of the Zoo Tour Guide. Your task is to take the
RESEARCH_DATA and present it to the user in a complete and helpful answer.
- First, present the specific information from the zoo (like names, ages, and where to find them).
- Then, add the interesting general facts from the research.
- If some information is missing, just present the information you have.
- Be conversational and engaging.
RESEARCH_DATA:
{{ RESEARCH_DATA }}
"""
)
L'agente del workflow
L'agente del flusso di lavoro funge da gestore di "back office" per il tour dello zoo. Prende la richiesta di ricerca e garantisce che i due agenti definiti sopra svolgano il loro lavoro nell'ordine corretto: prima la ricerca, poi la formattazione. In questo modo, la procedura per rispondere alla domanda di un visitatore è prevedibile e affidabile.
Come: è un SequentialAgent, un tipo speciale di agente che non pensa in modo autonomo. Il suo unico compito è eseguire un elenco di sub_agents (il ricercatore e il formattatore) in una sequenza fissa, passando automaticamente la memoria condivisa da uno all'altro.
Aggiungi questo blocco di codice in fondo a agent.py:
tour_guide_workflow = SequentialAgent(
name="tour_guide_workflow",
description="The main workflow for handling a user's request about an animal.",
sub_agents=[
comprehensive_researcher, # Step 1: Gather all data
response_formatter, # Step 2: Format the final response
]
)
Assembla il workflow principale 
Questo agente è designato come root_agent, che il framework ADK utilizza come punto di partenza per tutte le nuove conversazioni. Il suo ruolo principale è quello di orchestrare l'intero processo. Funge da controller iniziale, gestendo il primo turno della conversazione.
Aggiungi questo blocco di codice finale in fondo a agent.py:
root_agent = Agent(
name="greeter",
model=model_name,
description="The main entry point for the Zoo Tour Guide.",
instruction="""
- Let the user know you will help them learn about the animals we have in the zoo.
- When the user responds, use the 'add_prompt_to_state' tool to save their response.
After using the tool, transfer control to the 'tour_guide_workflow' agent.
""",
tools=[add_prompt_to_state],
sub_agents=[tour_guide_workflow]
)
Il tuo file agent.py è stato completato. In questo modo, puoi vedere come ogni componente (strumenti, agenti worker e agenti manager) abbia un ruolo specifico nella creazione del sistema intelligente finale. Il passaggio successivo è il deployment.
6. Esegui il deployment dell'agente utilizzando ADK CLI
Ora che il codice locale è pronto e il progetto Google Cloud è preparato, è il momento di eseguire il deployment dell'agente. Utilizzerai il comando adk deploy cloud_run, uno strumento pratico che automatizza l'intero flusso di lavoro di deployment. Questo singolo comando pacchettizza il codice, crea un'immagine container, la invia ad Artifact Registry e avvia il servizio su Cloud Run, rendendolo accessibile sul web.
Esegui il deployment
Esegui questi comandi per eseguire il deployment dell'agente. Il comando uvx consente di eseguire strumenti a riga di comando pubblicati come pacchetti Python senza richiedere un'installazione globale di questi strumenti.
# Run the deployment command
uvx --from google-adk==1.14.0 \
adk deploy cloud_run \
--project=$PROJECT_ID \
--region=us-west1 \
--service_name=zoo-tour-guide \
--with_ui \
. \
-- \
--labels=dev-tutorial=codelab-adk \
--service-account=$SERVICE_ACCOUNT
Accetta i prompt
Potresti visualizzare il seguente messaggio:
Deploying from source requires an Artifact Registry Docker repository to store built containers. A repository named [cloud-run-source-deploy] in region [us-west1] will be created. Do you want to continue (Y/n)?
Digita Y e premi Invio.
Potresti visualizzare il seguente messaggio:
Allow unauthenticated invocations to [your-service-name] (y/N)?.
Per questo lab vogliamo consentire le chiamate non autenticate per semplificare i test. Digita y e premi Invio.
Ottenere il link di deployment
Se l'esecuzione va a buon fine, il comando fornirà l'URL del servizio Cloud Run di cui è stato eseguito il deployment. Avrà un aspetto simile a https://zoo-tour-guide-123456789.us-west1.run.app. Copia questo URL per l'attività successiva.
7. Testa l'agente di cui è stato eseguito il deployment
Ora che l'agente è attivo su Cloud Run, esegui un test per verificare che il deployment sia stato eseguito correttamente e che l'agente funzioni come previsto. Utilizzerai l'URL del servizio pubblico (ad esempio https://zoo-tour-guide-123456789.us-west1.run.app/) per accedere all'interfaccia web dell'ADK e interagire con l'agente.
Apri l'URL del servizio Cloud Run pubblico nel browser web. Poiché hai utilizzato --with_ui flag, dovresti visualizzare la UI per sviluppatori dell'ADK.
Attiva Token Streaming in alto a destra.
Ora puoi interagire con l'agente dello zoo.
Digita hello e premi Invio per iniziare una nuova conversazione.
Osserva il risultato. L'agente deve rispondere rapidamente con il suo saluto:
"Hello! I'm your Zoo Tour Guide. I can help you learn about the amazing animals we have here. What would you like to know or explore today?"
Poni all'agente domande come:
Where can I find the polar bears in the zoo and what is their diet?
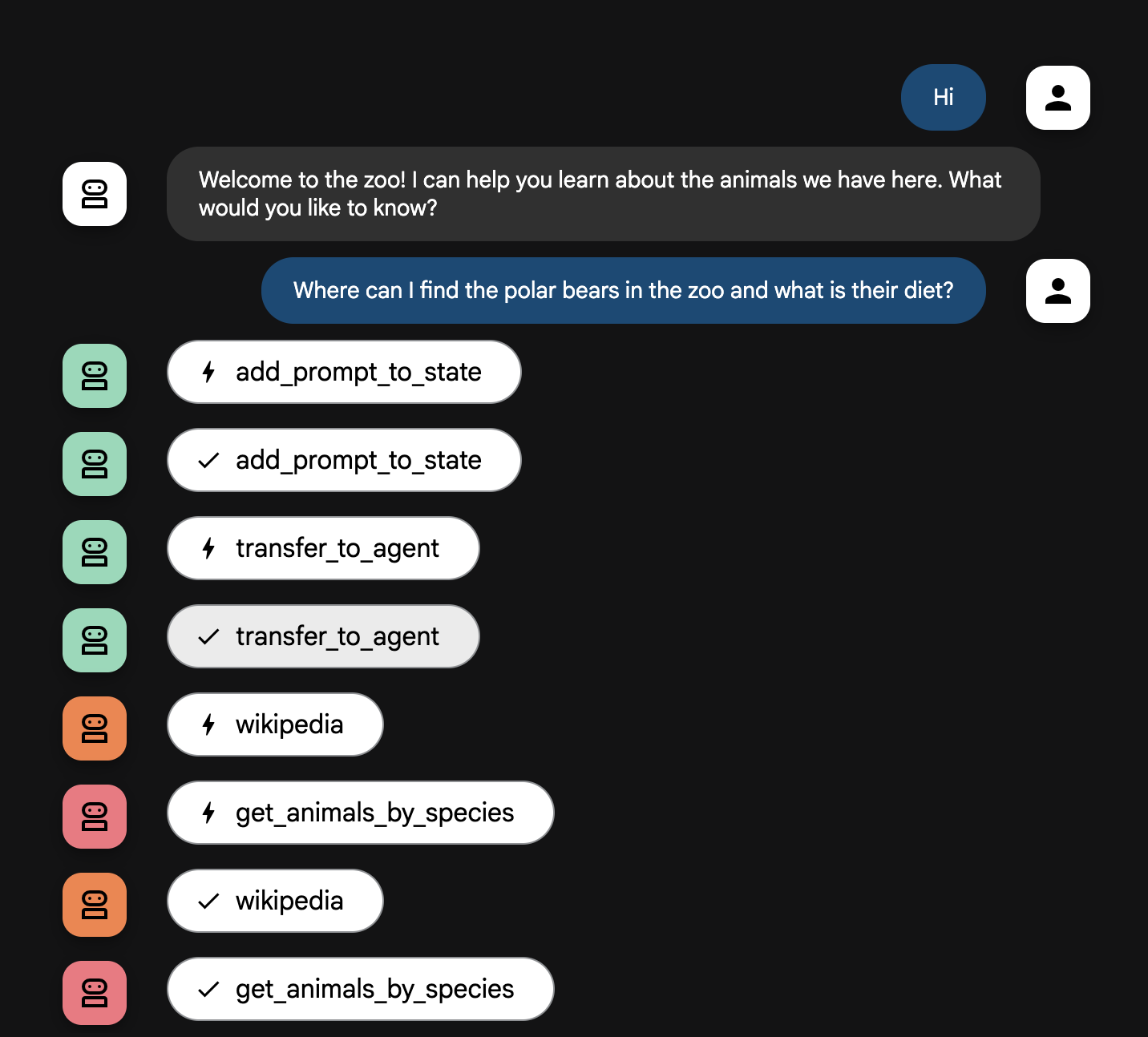

Spiegazione del flusso dell'agente
Il sistema funziona come un team multi-agente intelligente. La procedura è gestita da una sequenza chiara per garantire un flusso fluido ed efficiente dalla domanda di un utente alla risposta finale e dettagliata.
1. L'addetto all'accoglienza dello zoo (il banco di accoglienza)
L'intero processo inizia con l'agente di accoglienza.
Il suo compito: avviare la conversazione. La sua istruzione è di salutare l'utente e chiedergli di quale animale vorrebbe saperne di più.
Il suo strumento:quando l'utente risponde, il Greeter utilizza lo strumento add_prompt_to_state per acquisire le sue parole esatte (ad es. "parlami dei leoni") e salvarle nella memoria del sistema.
Il trasferimento: dopo aver salvato il prompt, il controllo passa immediatamente al suo agente secondario, tour_guide_workflow.
2. Il ricercatore completo (il super ricercatore)
Questo è il primo passaggio del flusso di lavoro principale e il "cervello" dell'operazione. Al posto di un team numeroso, ora hai un unico agente altamente qualificato che può accedere a tutte le informazioni disponibili.
Il suo compito: analizzare la domanda dell'utente e formulare un piano intelligente. Utilizza la potente funzionalità di utilizzo degli strumenti del modello linguistico per decidere se ha bisogno di:
- Dati interni dai registri dello zoo (tramite il server MCP).
- Conoscenze generali dal web (tramite l'API Wikipedia).
- Oppure, per domande complesse, entrambe.
Azione: esegue gli strumenti necessari per raccogliere tutti i dati non elaborati richiesti. Ad esempio, se gli viene chiesto "Quanti anni hanno i nostri leoni e cosa mangiano in natura?", chiamerà il server MCP per le età e lo strumento Wikipedia per le informazioni sulla dieta.
3. The Response Formatter (The Presenter)
Una volta che il ricercatore completo ha raccolto tutti i fatti, questo è l'ultimo agente da eseguire.
Il suo lavoro: fare da voce amichevole della guida del tour dello zoo. Prende i dati non elaborati (che potrebbero provenire da una o entrambe le origini) e li perfeziona.
La sua azione:sintetizza tutte le informazioni in un'unica risposta coerente e coinvolgente. Seguendo le istruzioni, presenta prima le informazioni specifiche sullo zoo e poi aggiunge i fatti generali interessanti.
Il risultato finale:il testo generato da questo agente è la risposta completa e dettagliata che l'utente vede nella finestra di chat.
Se ti interessa saperne di più sulla creazione di agenti, consulta le seguenti risorse:
8. Liberare spazio
gcloud run services delete zoo-tour-guide --region=us-west1 --quiet
gcloud artifacts repositories delete cloud-run-source-deploy --location=us-west1 --quiet
9. Complimenti
Congratulazioni per aver completato il codelab.
Argomenti trattati
- Come strutturare un progetto Python per il deployment con l'interfaccia a riga di comando ADK.
- Come implementare un workflow multi-agente utilizzando SequentialAgent e ParallelAgent.
- Come connettersi a un server MCP remoto utilizzando MCPToolset per utilizzare i relativi strumenti.
- Come arricchire i dati interni integrando strumenti esterni come l'API Wikipedia.
- Come eseguire il deployment di un agente come container serverless in Cloud Run utilizzando il comando adk deploy.