
1. Introdução
Este laboratório é voltado à implementação e à implantação de um serviço de agente cliente. Você vai usar o Kit de Desenvolvimento de Agente (ADK) para criar um agente de IA que usa ferramentas remotas, como o servidor MCP criado no Laboratório 1. O princípio arquitetônico central demonstrado é a separação de responsabilidades: a camada de raciocínio (agente) comunica-se com a camada de ferramentas (servidor MCP) por uma API segura.
No laboratório 1, você criou um servidor MCP que fornece dados sobre os animais de um zoológico fictício para LLMs, por exemplo, ao usar a CLI do Gemini. Neste laboratório, vamos criar um agente de guia turístico para o zoológico fictício. O agente vai usar o mesmo servidor MCP do laboratório 1 para acessar detalhes sobre os animais do zoológico e também usar a Wikipédia para criar a melhor experiência de guia turístico.

Por fim, vamos implantar o agente de guia turístico no Google Cloud Run para que todos os visitantes do zoológico possam acessá-lo, em vez de só na sua máquina.
Pré-requisitos
- Um servidor MCP em execução no Cloud Run ou o URL do serviço associado.
- Ter um projeto do Google Cloud com o faturamento ativado.
O que você vai aprender
- Como estruturar um projeto Python para implantação com ADK.
- Como implementar um agente que usa ferramentas com o google-adk.
- Como conectar um agente a um servidor MCP remoto para o conjunto de ferramentas dele.
- Como implantar um aplicativo Python como um contêiner sem servidor no Cloud Run.
- Como configurar a autenticação segura de serviço para serviço usando papéis do IAM.
- Como excluir recursos do Cloud para evitar custos futuros.
O que é necessário
- Uma conta e um projeto do Google Cloud
- Um navegador da Web, como o Chrome
2. Por que implantar no Cloud Run?
O Cloud Run é uma ótima opção para hospedar agentes do ADK porque é uma plataforma sem servidor, ou seja, você pode dedicar todo seu tempo ao código em vez de cuidar da infraestrutura. Nós cuidamos do trabalho operacional para você.
Pense nele como uma loja pop-up: ela só abre e usa recursos quando há clientes (solicitações). Se nenhum cliente aparece, ela fecha completamente. Assim, você não paga por uma loja vazia.
Principais características
Executa contêineres em qualquer lugar:
- É possível usar contêineres (imagens do Docker) que têm seu app dentro.
- O Cloud Run executa todos na infraestrutura do Google.
- Sem você ter a dor de cabeça de lidar com a aplicação de patches no SO, fazer escalonamentos ou configurar VMs.
Escalonamento automático:
- Se 0 pessoas estiverem usando seu app → 0 instâncias serão executadas (reduzindo para zero instâncias, o que é econômico).
- Se o serviço receber 1.000 solicitações, ele vai gerar quantas cópias forem necessárias.
Sem estado por padrão:
- Cada solicitação pode ser encaminhada a uma instância diferente.
- Se você precisar armazenar estado, use um serviço externo como Cloud SQL, Firestore ou Memorystore.
Funciona com qualquer linguagem ou framework:
- Desde que possa ser executado em um contêiner Linux, o Cloud Run não se importa se você usa Python, Go, Node.js, Java ou .Net.
Pague pelo que usar:
- Faturamento baseado em solicitação: cobrança por solicitação + tempo de computação (até 100 ms).
- Faturamento com base em instâncias: cobrado durante todo o ciclo de vida da instância (sem taxa por solicitação).
3. Antes de começar
Configuração de ambiente autoguiada
- Faça login no Console do Google Cloud e crie um novo projeto ou reutilize um existente. Crie uma conta do Gmail ou do Google Workspace, se ainda não tiver uma.

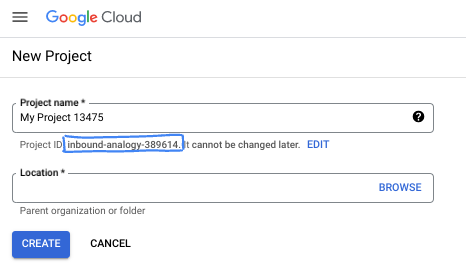
- O Nome do projeto é o nome de exibição para os participantes do projeto. É uma string de caracteres não usada pelas APIs do Google e pode ser atualizada quando você quiser.
- O ID do projeto precisa ser exclusivo em todos os projetos do Google Cloud e não pode ser mudado após a definição. O console do Cloud gera automaticamente uma string exclusiva. Em geral, não importa o que seja. Na maioria dos codelabs, é necessário fazer referência ao ID do projeto, normalmente identificado como
PROJECT_ID. Se você não gostar do ID gerado, crie outro aleatório. Se preferir, teste o seu e confira se ele está disponível. Ele não pode ser mudado após essa etapa e permanece durante o projeto. - Para sua informação, há um terceiro valor, um Número do projeto, que algumas APIs usam. Saiba mais sobre esses três valores na documentação.
- Em seguida, ative o faturamento no console do Cloud para usar os recursos/APIs do Cloud. A execução deste codelab não vai ser muito cara, se tiver algum custo. Para encerrar os recursos e evitar cobranças além deste tutorial, exclua os recursos criados ou exclua o projeto. Novos usuários do Google Cloud estão qualificados para o programa de US$ 300 de avaliação sem custos.
Inicie o Cloud Shell
- Acesse o editor do Cloud Shell.
- Se o terminal não aparecer na parte de baixo da tela, abra-o:
- Clique em Terminal.
- Clique em Novo terminal.
- No terminal, defina o projeto com este comando. Se você concluiu o laboratório 1, use o mesmo ID do projeto:
gcloud config set project [YOUR-PROJECT-ID]gcloud projects list | awk '/PROJECT_ID/{print $2}' - Se for preciso autorizar, clique em Autorizar para continuar.
- Você vai receber esta mensagem:
Updated property [core/project].
WARNINGe for perguntadoDo you want to continue (Y/n)?, provavelmente inseriu o ID do projeto incorretamente. Pressionen,Entere tente executar o comandogcloud config set projectnovamente.
4. Configurar o ambiente
Ativar APIs e definir variáveis de ambiente
Ative todos os serviços necessários:
gcloud services enable \
run.googleapis.com \
artifactregistry.googleapis.com \
cloudbuild.googleapis.com \
aiplatform.googleapis.com
Resultado esperado
Operation "operations/acat.p2-[GUID]" finished successfully.
Crie o diretório do projeto.
Esse comando cria uma pasta principal para o laboratório com o código-fonte do agente.
cd && mkdir zoo_guide_agent && cd zoo_guide_agent
Crie o arquivo requirements.txt. Ele lista as bibliotecas Python que o agente precisa. O comando a seguir cria e preenche o arquivo.
cloudshell edit requirements.txt
google-adk==1.14.0
langchain-community==0.3.27
wikipedia==1.4.0
Defina variáveis para o ID do projeto e o número do projeto atual e crie uma conta de serviço dedicada para seu projeto. Essa é uma maneira mais robusta de executar esses comandos.
export PROJECT_ID=$(gcloud config get-value project)
export PROJECT_NUMBER=$(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")
export SA_NAME=lab2-cr-service
export SERVICE_ACCOUNT="${SA_NAME}@${PROJECT_ID}.iam.gserviceaccount.com"
gcloud iam service-accounts create ${SA_NAME} \
--display-name="Service Account for lab 2 "
Crie e abra um arquivo .env para autenticar o agente no diretório zoo_guide_agent.
cloudshell edit .env
O comando "cloudshell edit" abre o arquivo .env no editor acima do terminal. Insira o seguinte no arquivo .env e volte ao terminal.
MODEL="gemini-2.5-flash"
Adicione o URL do servidor MCP. Se você concluiu o laboratório 1, siga estas etapas para usar o servidor MCP criado nele:
Conceda à conta de serviço do agente permissões para usar o Gemini na Vertex AI e chamar o servidor MCP remoto:
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT" \
--role="roles/aiplatform.user"
gcloud projects add-iam-policy-binding $PROJECT_ID \
--member="serviceAccount:$SERVICE_ACCOUNT" \
--role="roles/run.invoker"
Salve o URL do servidor MCP do laboratório 1 em uma variável de ambiente.
echo -e "\nMCP_SERVER_URL=https://zoo-mcp-server-${PROJECT_NUMBER}.us-west1.run.app/mcp" >> .env
Se você estiver usando um link público do servidor MCP, execute o seguinte e substitua PROJECT_NUMBER pelo que foi fornecido.
echo -e "\nMCP_SERVER_URL=https://zoo-mcp-server-${PROJECT_NUMBER}.us-west1.run.app/mcp" >> .env
5. Criar fluxo de trabalho do agente
Criar o arquivo init.py
Crie o arquivo init.py. Esse arquivo informa ao Python que o diretório zoo_guide_agent é um pacote.
cloudshell edit __init__.py
O comando anterior abre o editor de código. Adicione o código a seguir a __init__.py:
from . import agent
Criar o arquivo principal agent.py
Crie o arquivo principal agent.py. Esse comando cria o arquivo Python e cola o código completo do sistema multiagente.
cloudshell edit agent.py
Importações e configuração inicial
O primeiro bloco importa todas as bibliotecas necessárias do ADK e do Google Cloud. Ele também configura a criação de registros em log e carrega as variáveis de ambiente do arquivo .env, o que é essencial para acessar o modelo e o URL do servidor.
Adicione o seguinte código ao arquivo agent.py:
import os
import logging
import google.cloud.logging
from dotenv import load_dotenv
from google.adk import Agent
from google.adk.agents import SequentialAgent
from google.adk.tools.mcp_tool.mcp_toolset import MCPToolset, StreamableHTTPConnectionParams
from google.adk.tools.tool_context import ToolContext
from google.adk.tools.langchain_tool import LangchainTool
from langchain_community.tools import WikipediaQueryRun
from langchain_community.utilities import WikipediaAPIWrapper
import google.auth
import google.auth.transport.requests
import google.oauth2.id_token
# --- Setup Logging and Environment ---
cloud_logging_client = google.cloud.logging.Client()
cloud_logging_client.setup_logging()
load_dotenv()
model_name = os.getenv("MODEL")
Definir as ferramentas (recursos do agente)

A qualidade de um agente é limitada às ferramentas que ele pode usar. Nesta seção, vamos definir todos os recursos que nosso agente terá, incluindo uma função personalizada para salvar dados, uma ferramenta MCP que se conecta ao nosso servidor MCP seguro e uma ferramenta da Wikipédia.
Adicione o seguinte código à parte de baixo de agent.py:
# Greet user and save their prompt
def add_prompt_to_state(
tool_context: ToolContext, prompt: str
) -> dict[str, str]:
"""Saves the user's initial prompt to the state."""
tool_context.state["PROMPT"] = prompt
logging.info(f"[State updated] Added to PROMPT: {prompt}")
return {"status": "success"}
# Configuring the MCP Tool to connect to the Zoo MCP server
mcp_server_url = os.getenv("MCP_SERVER_URL")
if not mcp_server_url:
raise ValueError("The environment variable MCP_SERVER_URL is not set.")
def get_id_token():
"""Get an ID token to authenticate with the MCP server."""
target_url = os.getenv("MCP_SERVER_URL")
audience = target_url.split('/mcp/')[0]
request = google.auth.transport.requests.Request()
id_token = google.oauth2.id_token.fetch_id_token(request, audience)
return id_token
"""
# Use this code if you are using the public MCP Server and comment out the code below defining mcp_tools
mcp_tools = MCPToolset(
connection_params=StreamableHTTPConnectionParams(
url=mcp_server_url
)
)
"""
mcp_tools = MCPToolset(
connection_params=StreamableHTTPConnectionParams(
url=mcp_server_url,
headers={
"Authorization": f"Bearer {get_id_token()}",
},
),
)
# Configuring the Wikipedia Tool
wikipedia_tool = LangchainTool(
tool=WikipediaQueryRun(api_wrapper=WikipediaAPIWrapper())
)
Explicação das três ferramentas
add_prompt_to_state📝
Essa ferramenta lembra as perguntas dos visitantes do zoológico. Quando um visitante pergunta "Onde estão os leões?", a ferramenta salva essa pergunta específica na memória para que os outros agentes no fluxo de trabalho saibam o que pesquisar.
Como:é uma função Python que grava o comando do visitante no dicionário compartilhado tool_context.state. O contexto da ferramenta representa a memória de curto prazo do agente para uma única conversa. Os dados salvos no estado por um agente podem ser lidos pelo próximo no fluxo de trabalho.
MCPToolset🦁
Isso é usado para conectar o agente de guia turístico ao servidor MCP do zoológico criado no laboratório 1. Esse servidor tem ferramentas especiais para pesquisar informações específicas sobre os animais, como nome, idade e localização.
Como: o servidor estabelece uma conexão segura com o URL do servidor particular do zoológico. Ele usa get_id_token para receber automaticamente um "cartão de acesso" seguro (um token de ID da conta de serviço) para comprovar a identidade e ganhar acesso.
LangchainTool🌍
Isso dá ao agente de guia turístico conhecimento geral do mundo. Quando um visitante faz uma pergunta que não está no banco de dados do zoológico, como "O que leões comem na natureza?", a ferramenta permite que o agente procure a resposta na Wikipédia.
Como:a ferramenta age como um adaptador, permitindo que o agente use a ferramenta pré-criada WikipediaQueryRun da biblioteca LangChain.
Recursos:
Definição dos agentes especialistas

Em seguida, vamos definir o agente de pesquisa e o agente de formatação de respostas. O agente de pesquisa é o "cérebro" da nossa operação. Ele recebe o comando do usuário do State compartilhado, examina as ferramentas avançadas do servidor MCP do zoológico e da Wikipédia e decide as que serão usadas para encontrar a resposta.
O papel do agente de formatação de respostas é a apresentação. Ele não usa ferramentas para encontrar informações novas. Em vez disso, ele pega os dados brutos do agente de pesquisa que foram passados pelo Estado e usa a habilidade de linguagem do LLM para criar uma resposta natural e conversacional.
Adicione o seguinte código à parte de baixo de agent.py:
# 1. Researcher Agent
comprehensive_researcher = Agent(
name="comprehensive_researcher",
model=model_name,
description="The primary researcher that can access both internal zoo data and external knowledge from Wikipedia.",
instruction="""
You are a helpful research assistant. Your goal is to fully answer the user's PROMPT.
You have access to two tools:
1. A tool for getting specific data about animals AT OUR ZOO (names, ages, locations).
2. A tool for searching Wikipedia for general knowledge (facts, lifespan, diet, habitat).
First, analyze the user's PROMPT.
- If the prompt can be answered by only one tool, use that tool.
- If the prompt is complex and requires information from both the zoo's database AND Wikipedia,
you MUST use both tools to gather all necessary information.
- Synthesize the results from the tool(s) you use into preliminary data outputs.
PROMPT:
{{ PROMPT }}
""",
tools=[
mcp_tools,
wikipedia_tool
],
output_key="RESEARCH_DATA" # A key to store the combined findings
)
# 2. Response Formatter Agent
response_formatter = Agent(
name="response_formatter",
model=model_name,
description="Synthesizes all information into a friendly, readable response.",
instruction="""
You are the friendly voice of the Zoo Tour Guide. Your task is to take the
RESEARCH_DATA and present it to the user in a complete and helpful answer.
- First, present the specific information from the zoo (like names, ages, and where to find them).
- Then, add the interesting general facts from the research.
- If some information is missing, just present the information you have.
- Be conversational and engaging.
RESEARCH_DATA:
{{ RESEARCH_DATA }}
"""
)
O agente de fluxo de trabalho
O agente de fluxo de trabalho age como o gerente dos "bastidores" do passeio pelo zoológico. Ele recebe o comando de pesquisa e garante que os dois agentes definidos acima façam os trabalhos na ordem certa: primeiro a pesquisa, depois a formatação. Isso cria um processo previsível e confiável para responder às perguntas dos visitantes.
Como:ele é um SequentialAgent, um tipo especial de agente que não pensa por conta própria. Seu único trabalho é executar uma lista de sub_agents (o pesquisador e o formatador) em uma sequência fixa, transmitindo automaticamente a memória compartilhada de um para o outro.
Adicione este bloco de código à parte de baixo de agent.py:
tour_guide_workflow = SequentialAgent(
name="tour_guide_workflow",
description="The main workflow for handling a user's request about an animal.",
sub_agents=[
comprehensive_researcher, # Step 1: Gather all data
response_formatter, # Step 2: Format the final response
]
)
Montar o fluxo de trabalho principal 
Esse agente é designado como root_agent, que a estrutura do ADK usa como ponto de partida para todas as novas conversas. A função principal dele é orquestrar o processo geral. Ele age como o controlador inicial, cuidando do primeiro turno da conversa.
Adicione este último bloco de código à parte de baixo de agent.py:
root_agent = Agent(
name="greeter",
model=model_name,
description="The main entry point for the Zoo Tour Guide.",
instruction="""
- Let the user know you will help them learn about the animals we have in the zoo.
- When the user responds, use the 'add_prompt_to_state' tool to save their response.
After using the tool, transfer control to the 'tour_guide_workflow' agent.
""",
tools=[add_prompt_to_state],
sub_agents=[tour_guide_workflow]
)
Seu arquivo agent.py está concluído. Criando desse jeito, você entende como cada componente (ferramentas, agentes de worker e agentes de gerenciamento) tem um papel específico para entregar o sistema inteligente final. Próxima parada: implantação!
6. implante o agente usando a CLI do ADK
Com o código local pronto e o projeto do Google Cloud preparado, é hora de implantar o agente. Você vai usar o comando adk deploy cloud_run, uma ferramenta conveniente que automatiza todo o fluxo de trabalho de implantação. Esse comando único empacota seu código, cria uma imagem de contêiner, envia para o Artifact Registry e executa o serviço no Cloud Run, tornando-o acessível na Web.
Implantar
Execute os comandos a seguir para implantar o agente. O comando uvx permite executar ferramentas de linha de comando publicadas como pacotes Python sem exigir uma instalação global dessas ferramentas.
# Run the deployment command
uvx --from google-adk==1.14.0 \
adk deploy cloud_run \
--project=$PROJECT_ID \
--region=us-west1 \
--service_name=zoo-tour-guide \
--with_ui \
. \
-- \
--labels=dev-tutorial=codelab-adk \
--service-account=$SERVICE_ACCOUNT
Aceitar comandos
Talvez você receba a seguinte mensagem:
Deploying from source requires an Artifact Registry Docker repository to store built containers. A repository named [cloud-run-source-deploy] in region [us-west1] will be created. Do you want to continue (Y/n)?
Digite Y e pressione ENTER.
Talvez você receba a seguinte mensagem:
Allow unauthenticated invocations to [your-service-name] (y/N)?.
Para facilitar os testes neste laboratório, vamos permitir invocações não autenticadas. Digite y e pressione Enter.
Receber o link de implantação
Após a execução, o comando vai fornecer o URL do serviço implantado do Cloud Run. Ele vai ter uma aparência parecida com https://zoo-tour-guide-123456789.us-west1.run.app. Copie esse URL para a próxima tarefa.
7. teste o agente implantado
Com o agente ativo no Cloud Run, faça um teste para confirmar se a implantação foi bem-sucedida e se o agente está funcionando conforme o esperado. Você vai usar o URL do serviço público (algo como https://zoo-tour-guide-123456789.us-west1.run.app/) para acessar a interface da Web do ADK e interagir com o agente.
Abra o URL público do serviço do Cloud Run no seu navegador da Web. Como você usou o --with_ui flag, a interface do desenvolvedor do ADK vai aparecer.
Ative a opção Token Streaming no canto superior direito.
Pronto! Você já pode interagir com o agente do zoológico.
Digite hello e pressione "Enter" para iniciar uma nova conversa.
Observe o resultado. O agente deve responder rapidamente com a saudação:
"Hello! I'm your Zoo Tour Guide. I can help you learn about the amazing animals we have here. What would you like to know or explore today?"
Faça perguntas ao agente, como:
Where can I find the polar bears in the zoo and what is their diet?
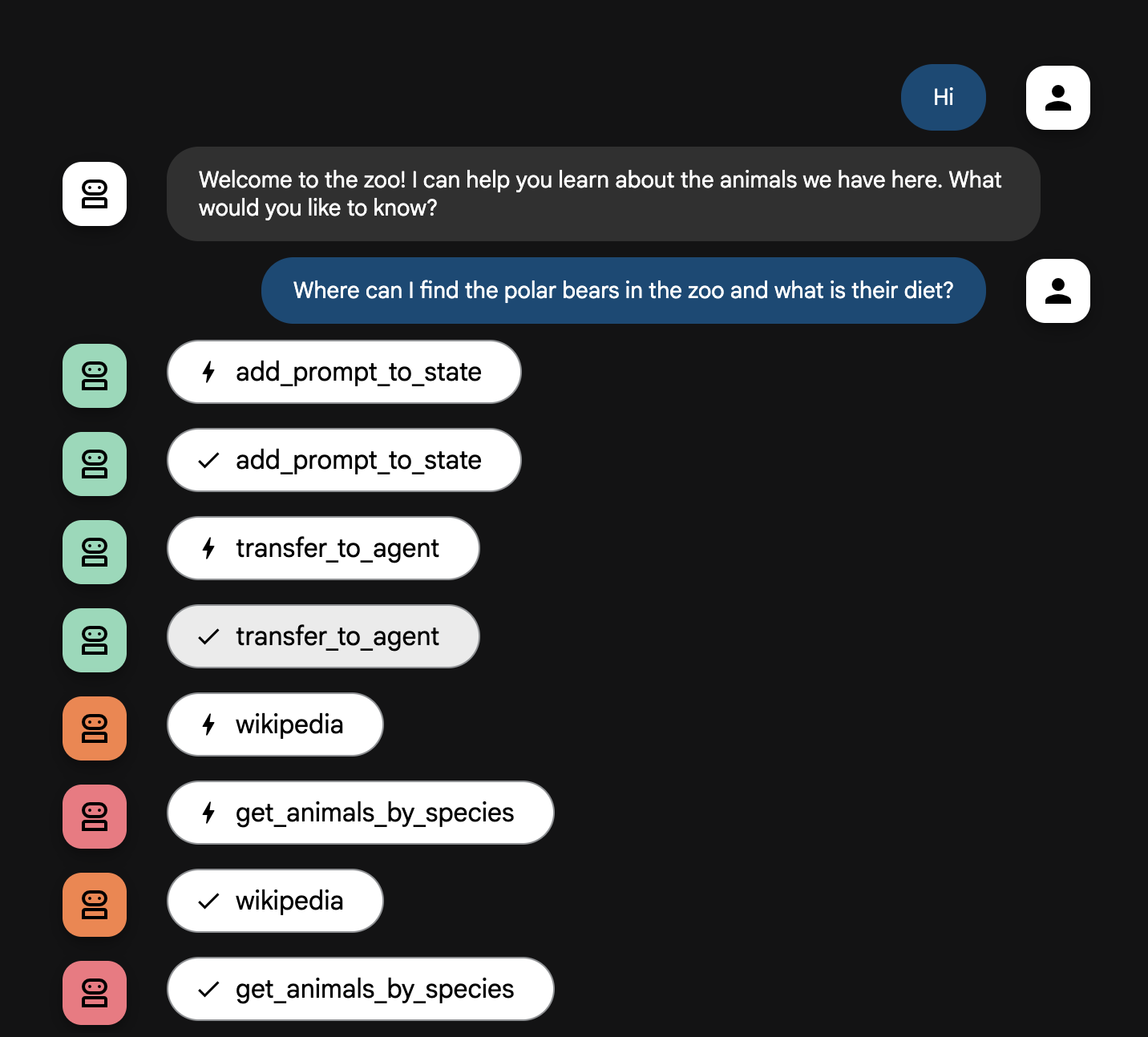

Explicação do fluxo do agente
Seu sistema opera como uma equipe inteligente com vários agentes. O processo é guiado por uma sequência clara para garantir um fluxo tranquilo e eficiente, da pergunta do usuário à resposta final detalhada.
1. Agente de boas-vindas do zoológico (a recepção)
Todo o processo começa com o agente recepcionista.
Função: começar a conversa. A instrução é cumprimentar o usuário e perguntar sobre qual animal ele quer saber mais.
Ferramenta: quando o usuário responde, o Recepcionista usa add_prompt_to_state para capturar as palavras exatas, por exemplo, "fale sobre os leões" e salvar na memória do sistema.
Transferência: depois de salvar o comando, o controle passa imediatamente para o subagente tour_guide_workflow.
2. Pesquisador Geral (o mestre das pesquisas)
Essa é a primeira etapa do fluxo de trabalho principal, o "cérebro" da operação. Em vez de uma equipe, você passa a interagir com um único agente altamente qualificado que tem acesso a todas as informações disponíveis.
Função: analisar a pergunta do usuário e criar um plano inteligente. Com o recurso avançado de uso de ferramentas do modelo de linguagem, o agente decide se precisa de:
- Dados internos dos registros do zoológico (pelo servidor MCP).
- Conhecimento geral da web (pela API Wikipedia).
- Ou dos dois, em caso de perguntas mais complexas.
Ação: o agente executa as ferramentas necessárias para coletar todos os dados brutos exigidos. Por exemplo, se perguntarem "Quantos anos os leões têm e o que eles comem na natureza?", ele vai chamar o servidor MCP para saber as idades e a ferramenta Wikipedia para encontrar informações sobre a dieta.
3. Formatador de respostas (o apresentador)
Depois que o Pesquisador Geral reúne todos os fatos, esse é o último agente a ser executado.
Função: ser nosso guia amigável do zoológico. Ele pega dados brutos de uma ou das duas fontes e melhora a qualidade deles.
Ação: resumir todas as informações em uma resposta individual, coerente e interessante. Seguindo as instruções, ele começa apresentando as informações específicas do zoológico e depois conta fatos gerais interessantes.
O resultado final: o texto gerado por esse agente é a resposta completa e detalhada que aparece na tela da conversa para o usuário.
Se você tem interesse em aprender mais sobre como criar agentes, confira estes recursos:
8. Limpar o ambiente
gcloud run services delete zoo-tour-guide --region=us-west1 --quiet
gcloud artifacts repositories delete cloud-run-source-deploy --location=us-west1 --quiet
9. Parabéns
Parabéns por concluir o codelab.
O que vimos
- Como estruturar um projeto Python para implantação com a interface de linha de comando do ADK.
- Como implementar um fluxo de trabalho multiagente usando SequentialAgent e ParallelAgent.
- Como se conectar a um servidor MCP remoto usando o MCPToolset para consumir as ferramentas dele.
- Como aumentar os dados internos integrando ferramentas externas, como a API da Wikipédia.
- Como implantar um agente como um contêiner sem servidor no Cloud Run usando o comando adk deploy.