
1. 概览
上次更新日期:2020 年 7 月 23 日
什么是 Cloud Spanner?
Google Cloud Spanner 是一种遍布全球且符合 ACID 标准的数据库,可自动进行副本、分片和事务处理,因此您可以快速扩容以满足任何使用模式的要求,确保产品获得成功。
主要功能
- 可灵活扩缩的关系型数据库:从架构、SQL 查询到 ACID 事务,关系型数据库应有的一切功能都具备,久经考验,且随时可以在全球范围内扩缩。
- 可用性达 99.999%:Cloud Spanner 可为多区域实例提供业界领先的 99.999% 可用性(与 99.99% 的可用性相比,停机时间是其十分之一),还可跨单区域和多区域配置提供透明的同步复制功能。
- 自动分片:Cloud Spanner 可根据请求负载和数据大小自动分片,从而提升性能。因此,您不必太担心如何对数据库进行扩容,从而可以专注于扩展业务。
学习内容
- 使用 Google Cloud 控制台创建 Cloud Spanner 实例。
- 在 Cloud Spanner 实例中创建新数据库。
- 使用 sampledb 加载和查询示例数据。
- 删除 Cloud Spanner 实例。
2. 设置和要求
自定进度的环境设置
如果您还没有 Google 账号(Gmail 或 Google Apps),则必须创建一个。登录 Google Cloud Platform Console ( console.cloud.google.com) 并创建一个新项目:

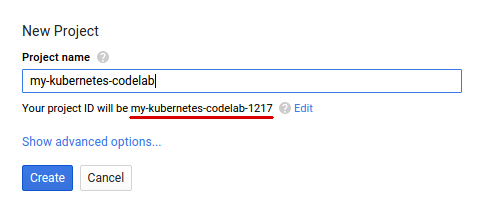
请记住项目 ID,它在所有 Google Cloud 项目中都是唯一的名称(上述名称已被占用,您无法使用,抱歉!)。它稍后将在此 Codelab 中被称为 PROJECT_ID。
接下来,您需要在 Cloud Console 中启用结算功能,才能使用 Google Cloud 资源。
在此 Codelab 中运行仅花费几美元,但是如果您决定使用更多资源或继续让它们运行,费用可能更高(请参阅本文档末尾的“清理”部分)。
Google Cloud 的新用户有资格获享$300 免费试用。
3. 在 Cloud 控制台中打开 Spanner
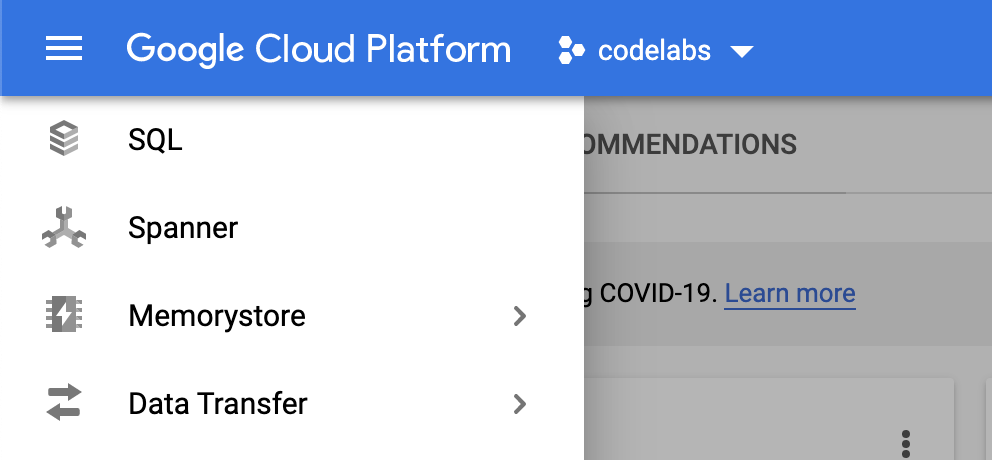
在 Google Cloud 控制台中,点击屏幕左上角的“菜单”图标,打开左侧导航栏。
向下滚动,然后选择“扳手”:
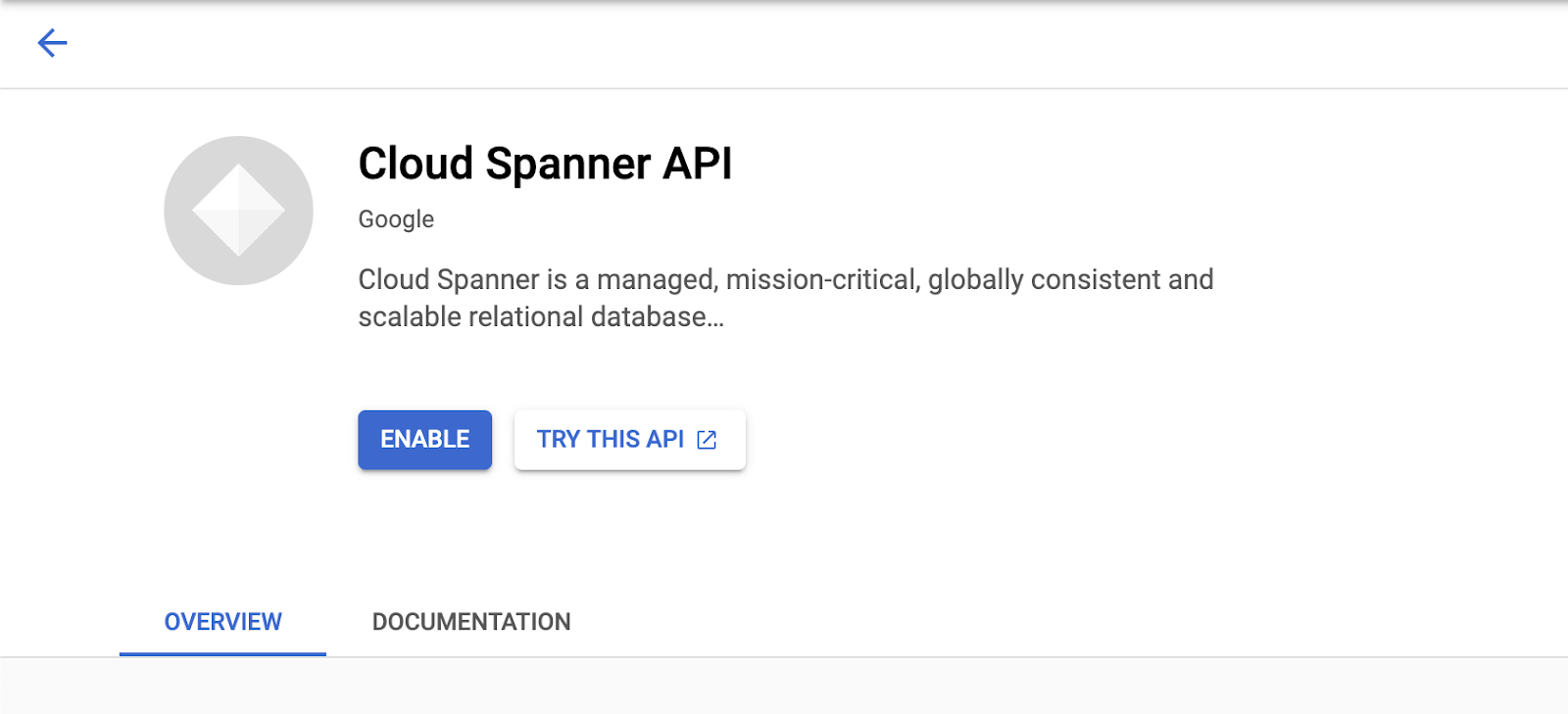
您现在应该会看到 Cloud Spanner 界面,并且假设您使用的是尚未启用 Cloud Spanner API 的项目,您会看到一个对话框,要求您启用该 API。如果您已启用该 API,则可以跳过此步骤。
点击“启用”以继续:
4. 创建实例
首先,您将创建一个 Cloud Spanner 实例。在界面中,点击“创建实例”以创建新实例:
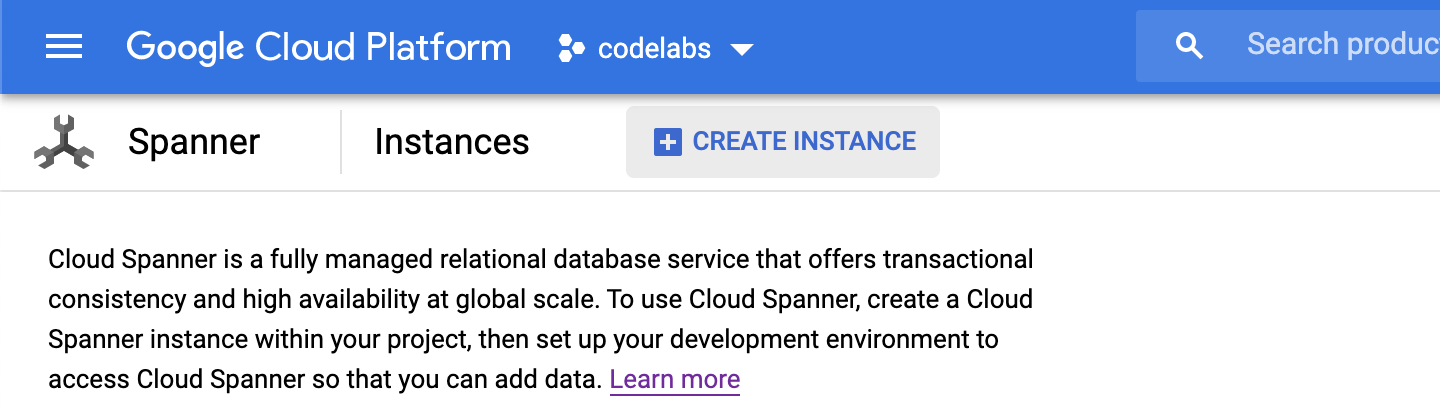
点击“创建实例”后,您将进入一个页面来创建实例。输入实例名称,然后选择配置。
您可以选择单区域或多区域设置。区域设置会将所有副本放在同一区域中,而多区域设置会在多个区域中创建只读副本。您可以点击“比较区域配置”来比较配置。
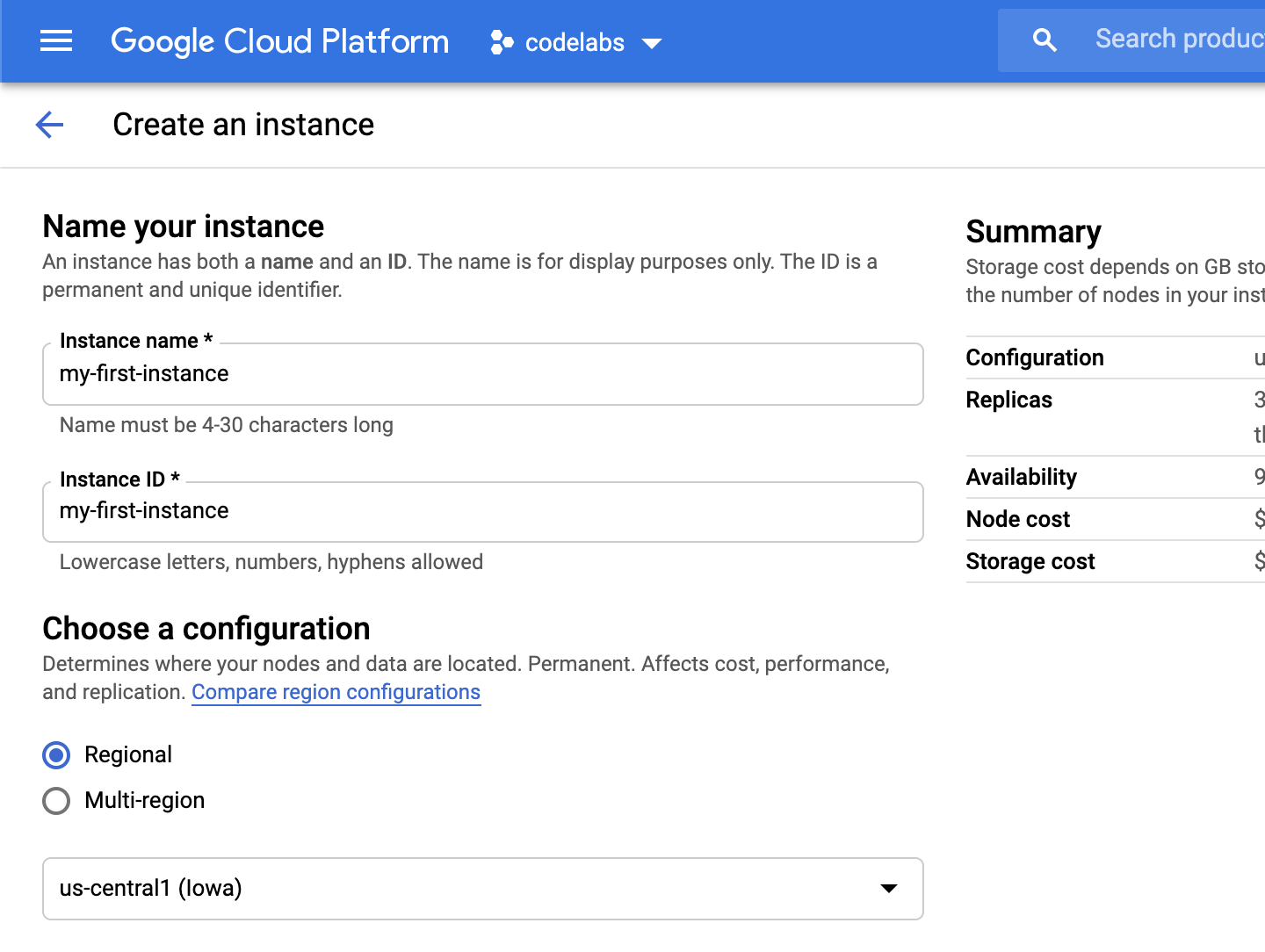
选择配置后,右侧面板中会显示摘要:

日后,您可以增加节点数量,为实例提供更多资源;如果实例不需要额外资源,则可以减少节点数量。
点击“创建”以创建实例。

您的 Cloud Spanner 实例现在可以使用了。
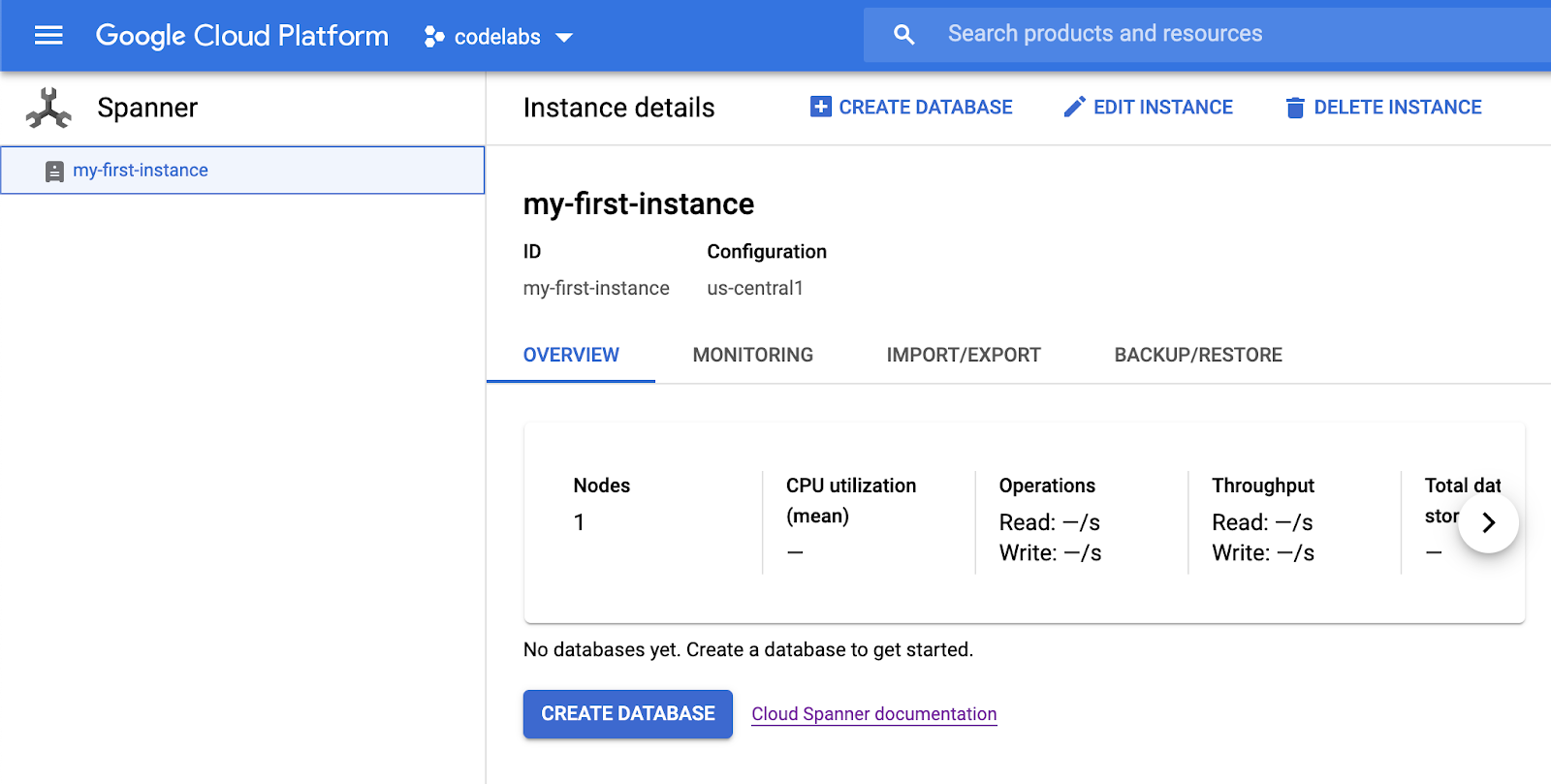
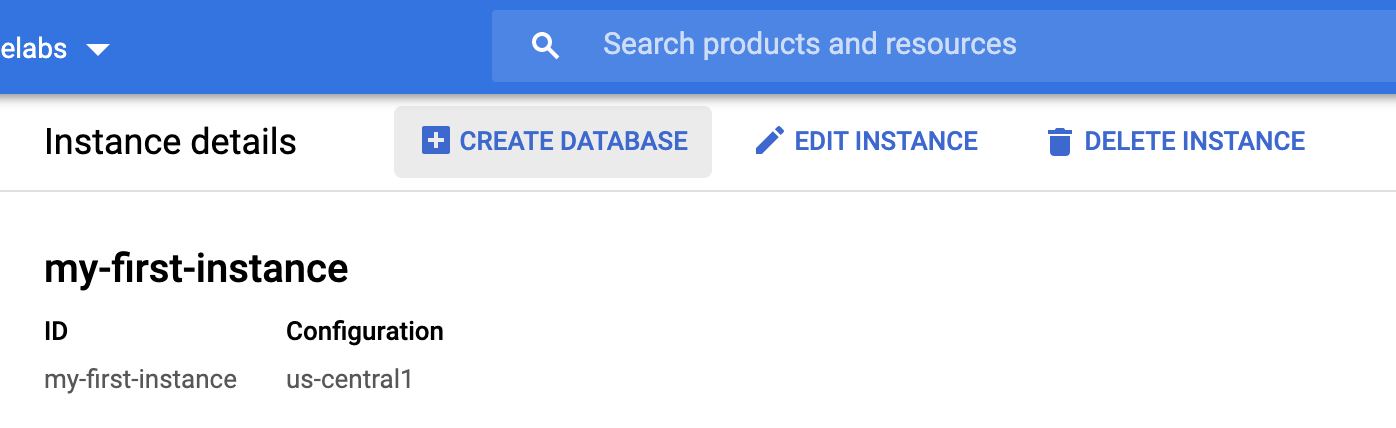
5. 创建数据库
如需创建新数据库,请点击“创建数据库”:
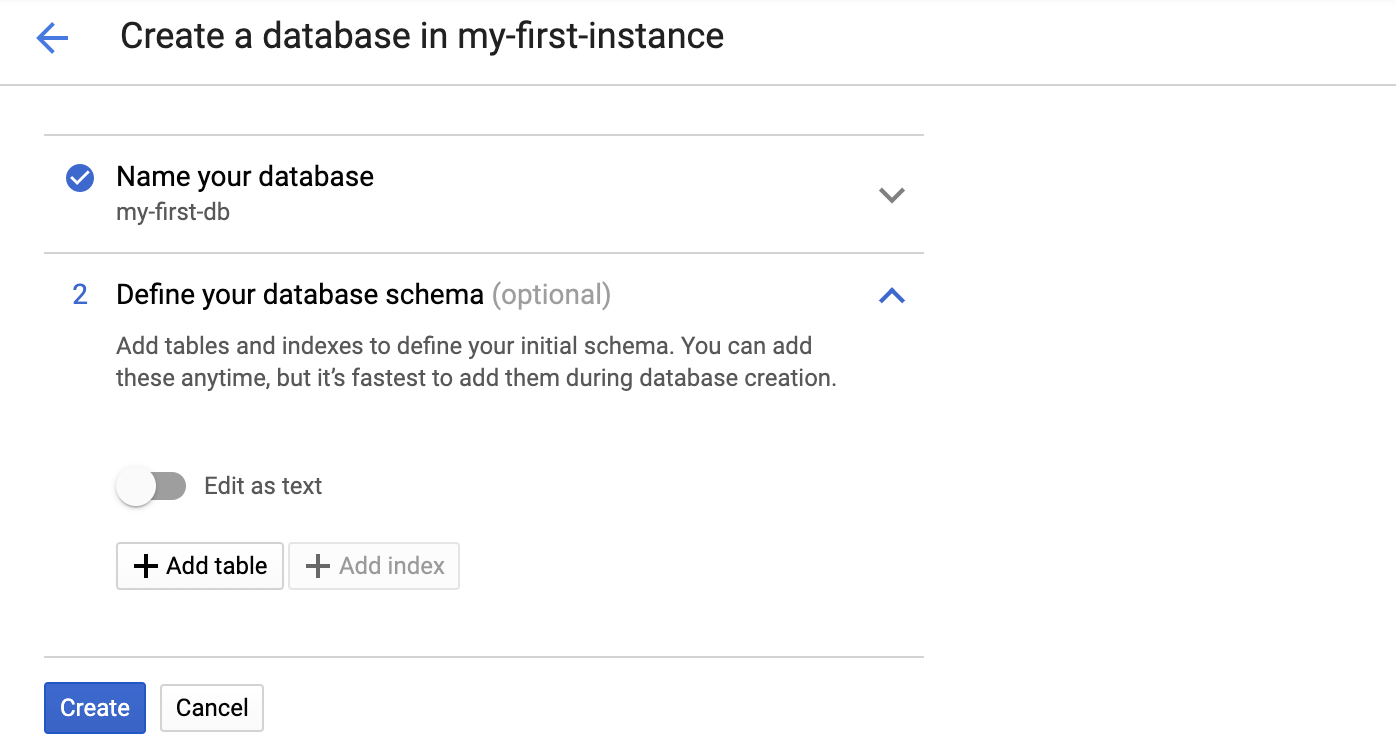
为新数据库输入名称。您也可以选择在此处提供架构。
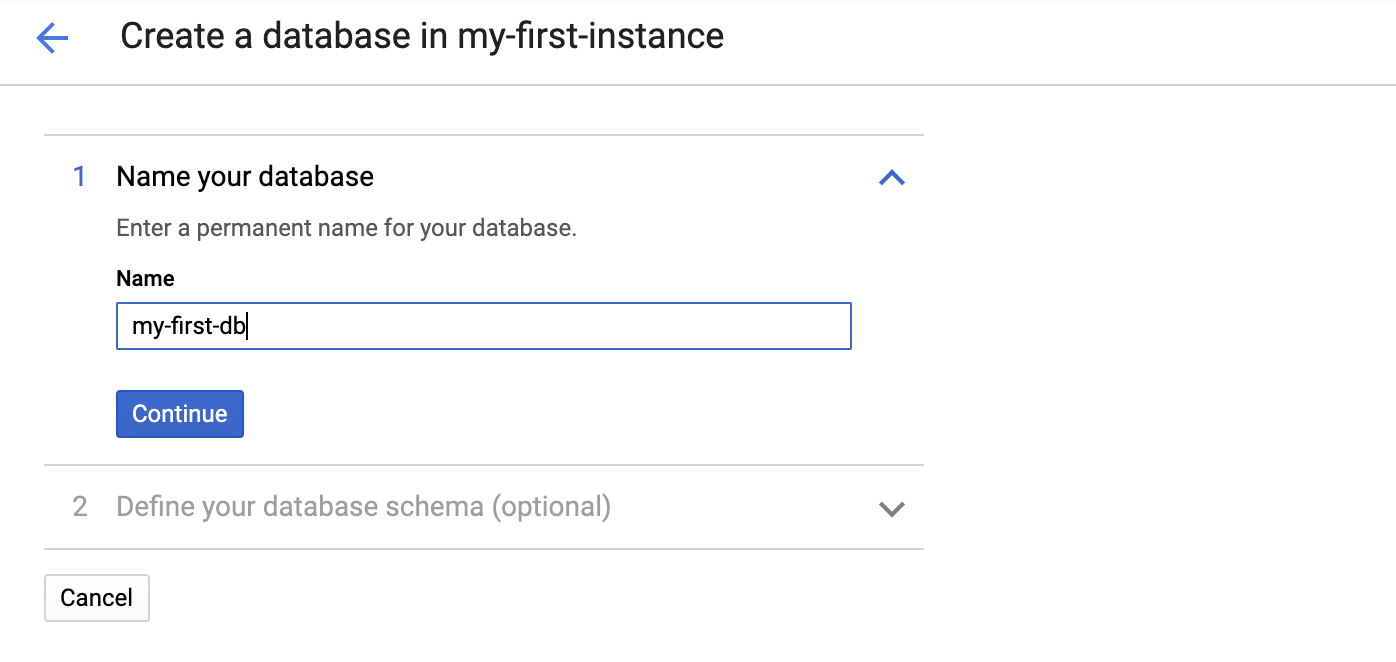
在此步骤中,我们将跳过提供架构,然后点击“创建”以创建一个空数据库。
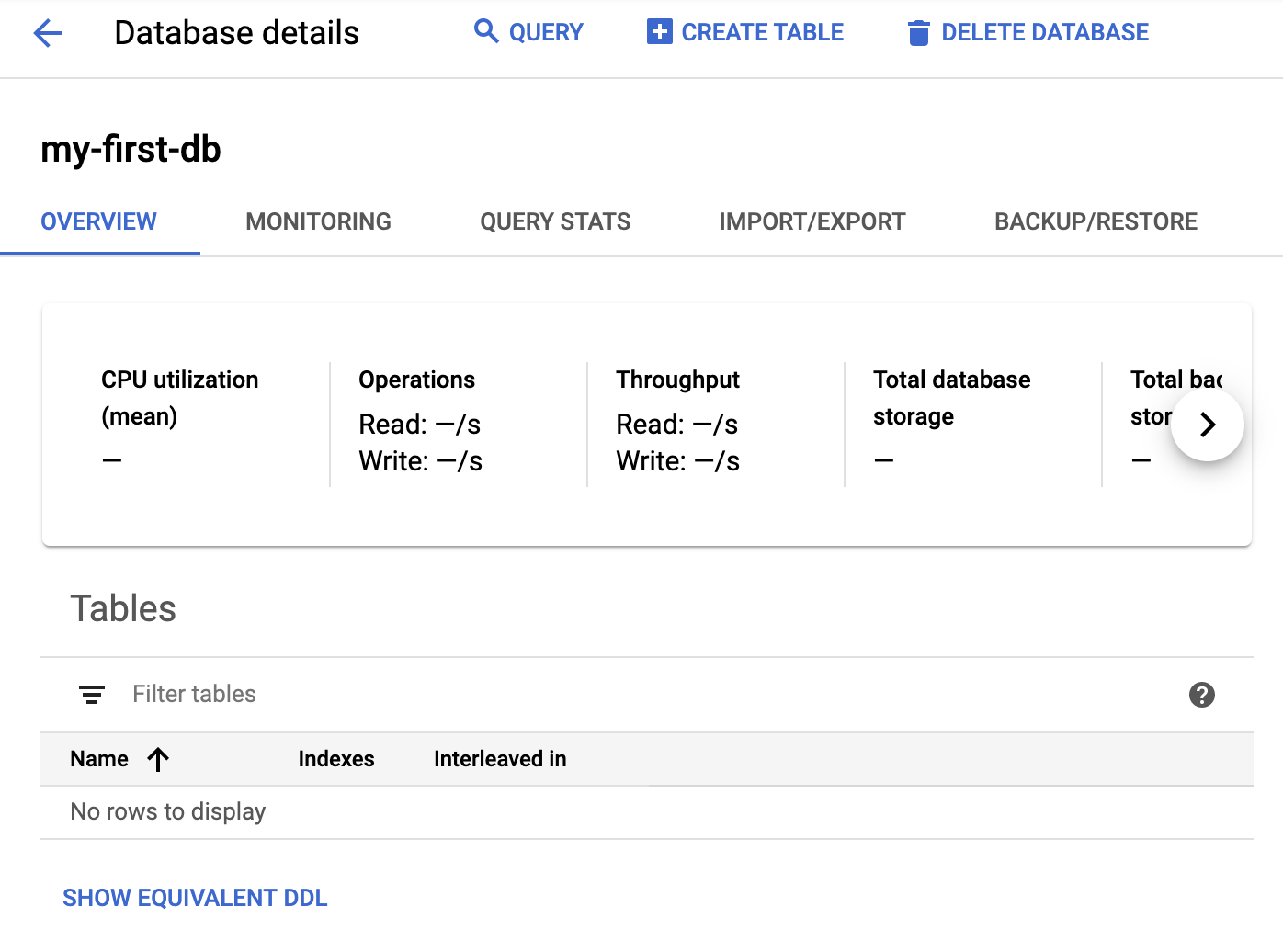
点击“创建”后,系统会创建一个新数据库:
6. 加载和查询示例数据
在此 Codelab 中,我们将使用 sampledb 加载和查询示例数据。Sampledb 包含各种数据集,并且可以将数据导入到现有数据库中。
我们将在 Google Cloud Shell 中运行该程序。如果您是首次为此项目使用 Google Cloud Shell,则会在顶部导航栏中看到 Google Cloud Shell 徽标。按一下即可激活 Cloud Shell。

激活后,您会在底部看到一个控制台:
在控制台中,克隆 sampledb 代码库,然后按照说明安装依赖项:
$ git clone https://github.com/cloudspannerecosystem/sampledb.git
成功克隆代码库后,进入新目录,创建虚拟环境并安装所需的要求:
$ cd sampledb $ virtualenv env $ source env/bin/activate $ pip install -r requirements.txt
安装依赖项后,您可以运行 sampledb 来创建包含示例数据的新数据库:
$ python batch_import.py my-first-instance my-sample-db
成功后,您将能够看到“my-sample-db”,其中包含两个新表(comments 和 stories):
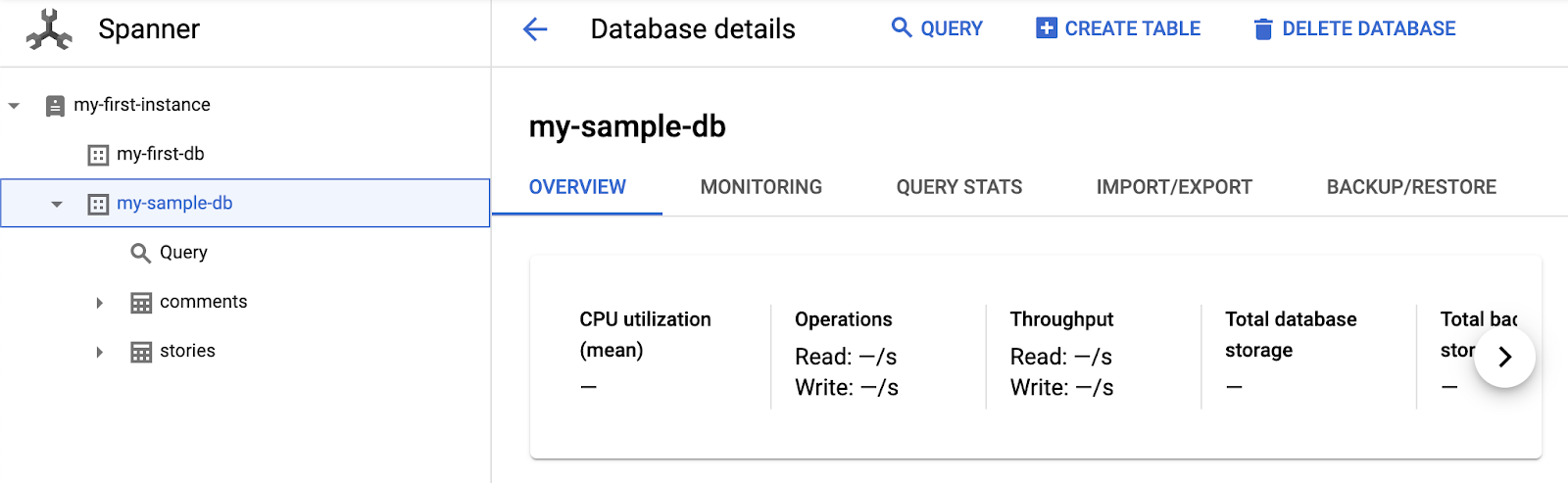
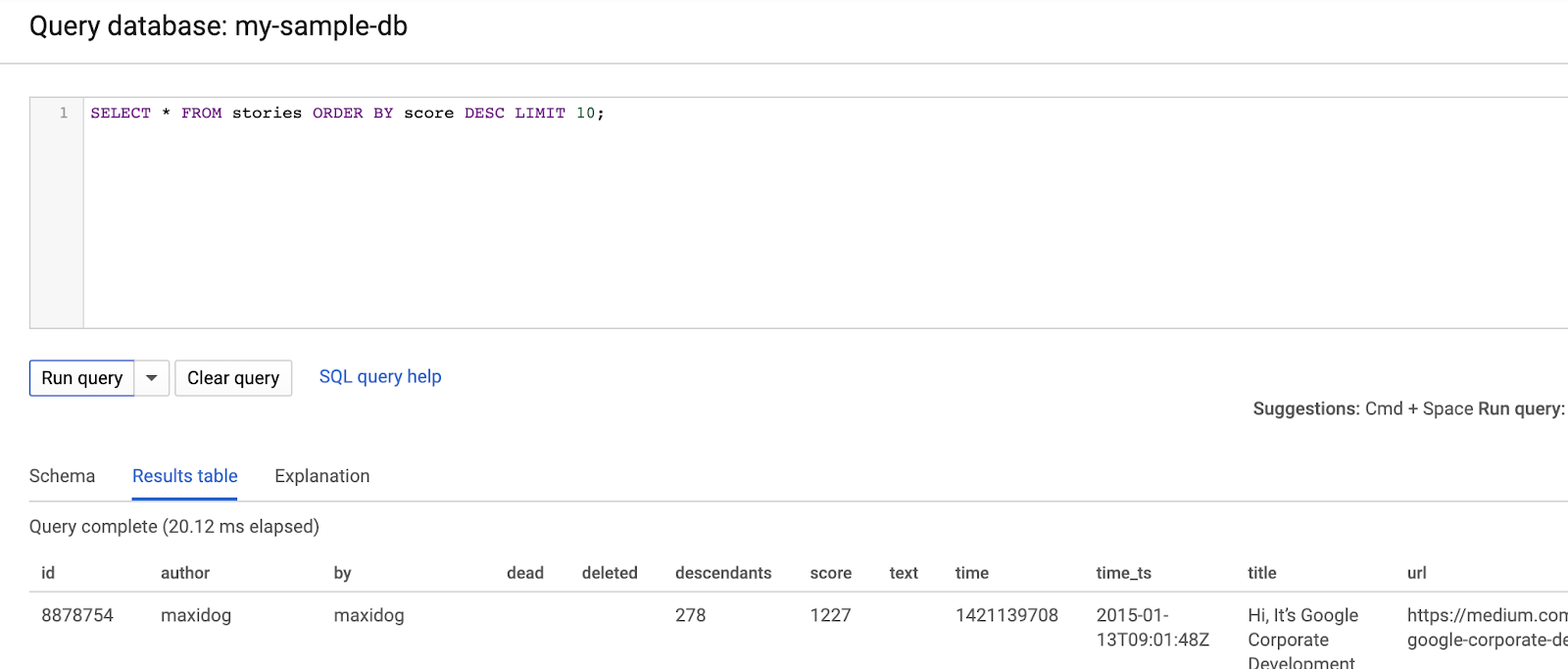
示例数据集包含来自 Hacker News 的故事和评论。您可以点击“查询”开始查询和浏览数据:
7. 清理
这是可选步骤。如果您想继续实验 Cloud Spanner 实例,则无需立即清理该实例。不过,您使用的项目仍需继续支付实例费用。如果您不再需要此实例,则应立即将其删除,以免产生这些费用。
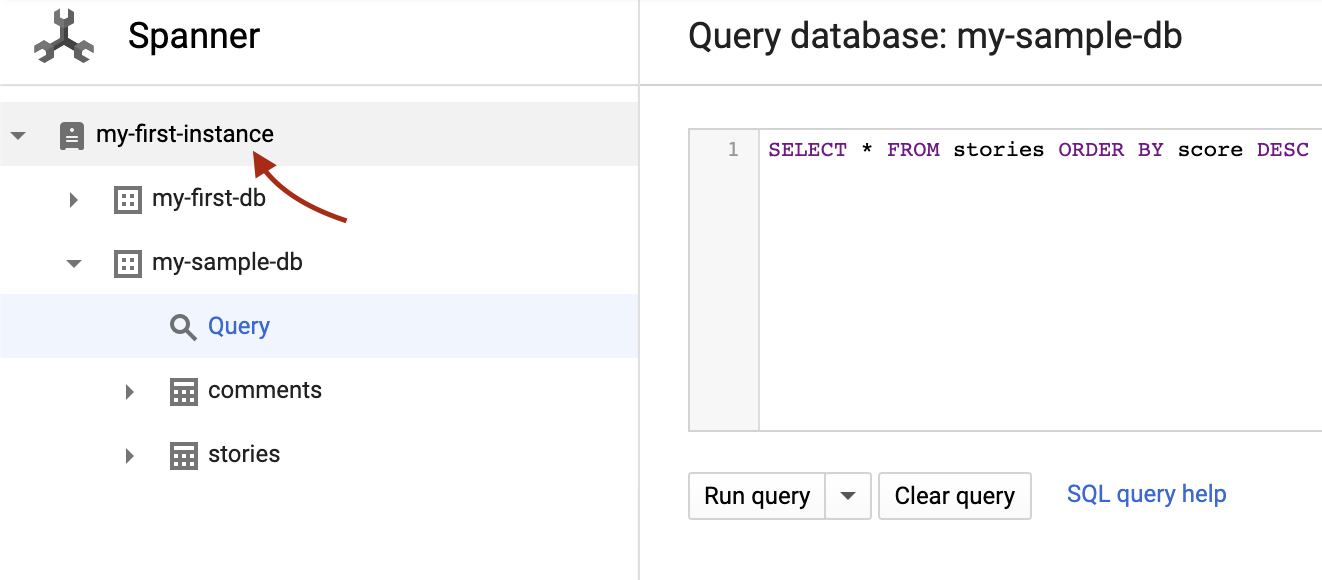
点击左上角的“my-first-instance”,返回实例页面:
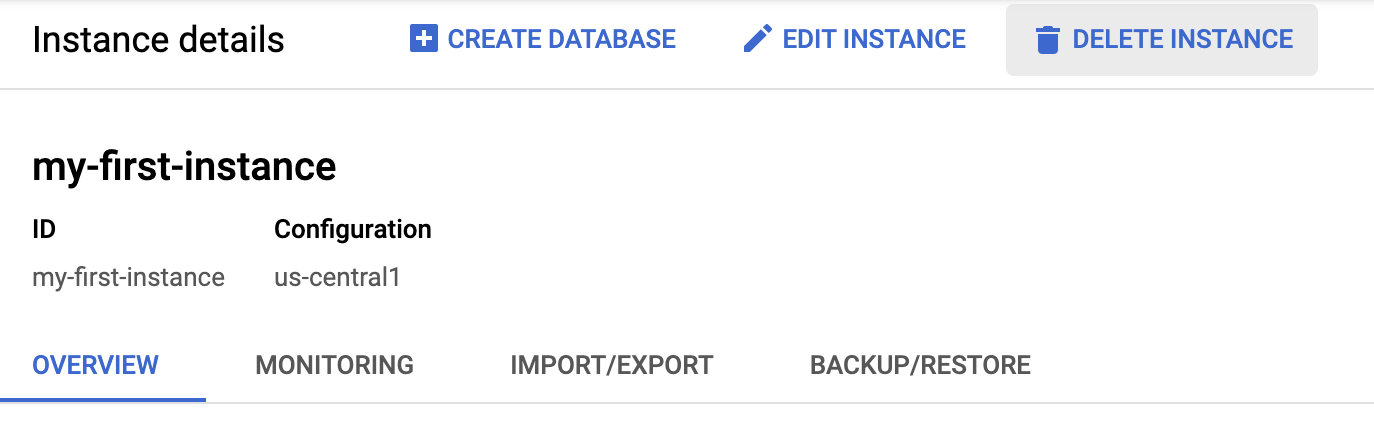
点击“删除”按钮以删除实例:
删除实例是一项永久性操作!相应实例中的数据无法恢复。为帮助防止意外删除错误的实例,您必须在确认对话框中输入实例名称来确认删除:
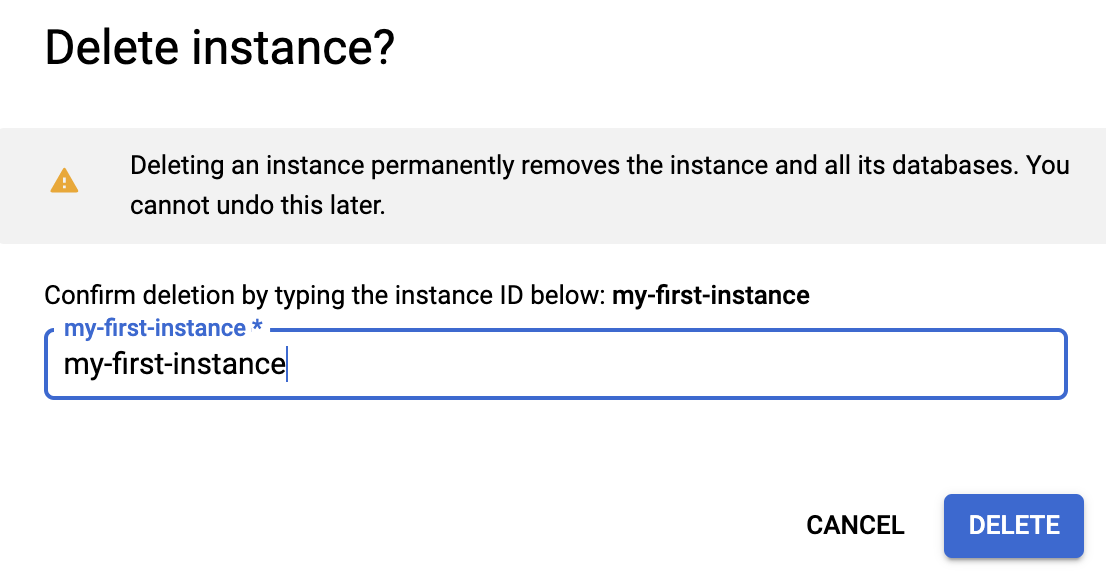
输入实例名称,然后按“删除”。
8. 恭喜!
您已创建新的 Cloud Spanner 实例、创建空数据库、加载示例数据,并(可选)删除 Cloud Spanner 实例。
所学内容
- 通过 Google Cloud 控制台创建 Cloud Spanner 实例。
- 在 Cloud Spanner 实例中创建新数据库。
- 使用 sampledb 加载和查询示例数据。
- 删除 Cloud Spanner 实例。