
1. 概要
最終更新日: 2020 年 7 月 23 日
Cloud Spanner とは
Google Cloud Spanner は、レプリカ、シャーディング、トランザクション処理を自動的に処理する、グローバルに分散された ACID 準拠のデータベースです。あらゆる使用パターンに応じて迅速にスケールしてサービスを成功に導きます。
主な機能
- スケーリングの実現に向けて設計されたリレーショナル データベース: スキーマ、SQL クエリ、ACID トランザクションなど、リレーショナル データベースに求められる機能はすべて実証済みであり、グローバルなスケーリングが可能です。
- 99.999% の可用性: Cloud Spanner はマルチリージョン インスタンスで業界トップクラスの 99.999% の可用性を実現します。これはダウンタイムに換算すると、99.99% の場合の 10 分の 1 となります。リージョンとマルチリージョンの構成両方で透過的な同期レプリケーションを行えます。
- 自動シャーディング: Cloud Spanner は、リクエスト負荷やデータサイズに基づいてデータを自動的にシャーディングしてパフォーマンスを最適化します。その結果、データベースのスケーリング方法について悩む時間が減り、代わりにビジネスの拡大に注力できます。
学習内容
- Google Cloud コンソールを使用して Cloud Spanner インスタンスを作成する。
- Cloud Spanner インスタンスに新しいデータベースを作成する。
- sampledb を使用してサンプルデータを読み込み、クエリを実行します。
- Cloud Spanner インスタンスを削除します。
2. 設定と要件
セルフペース型の環境設定
Google アカウント(Gmail または Google Apps)をお持ちでない場合は、1 つ作成する必要があります。Google Cloud Platform のコンソール(console.cloud.google.com)にログインし、新しいプロジェクトを作成します。


プロジェクト ID を忘れないようにしてください。プロジェクト ID はすべての Google Cloud プロジェクトを通じて一意の名前にする必要があります(上記の名前はすでに使用されているので使用できません)。以降、この Codelab では PROJECT_ID と呼びます。
次に、Google Cloud リソースを使用するために、Cloud Console で課金を有効にする必要があります。
この Codelab の操作をすべて行っても、費用は数ドル程度です。ただし、その他のリソースを使いたい場合や、実行したままにしておきたいステップがある場合は、追加コストがかかる可能性があります(このドキュメントの最後にある「クリーンアップ」セクションをご覧ください)。
Google Cloud の新規ユーザーは、300 ドル分の無料トライアルの特典があります。
3. Cloud コンソールで Spanner を開く
Google Cloud コンソールで、画面左上のメニュー アイコンをクリックして左側のナビゲーションを開きます。
下にスクロールして [スパナ] を選択します。

Cloud Spanner UI が表示されます。Cloud Spanner API がまだ有効になっていないプロジェクトを使用している場合は、有効にするかどうかを尋ねるダイアログが表示されます。すでに API を有効にしている場合は、この手順をスキップできます。
[有効にする] をクリックして続行します。

4. インスタンスを作成する
まず、Cloud Spanner インスタンスを作成します。UI で [インスタンスを作成] をクリックして、新しいインスタンスを作成します。

[インスタンスを作成] をクリックすると、インスタンスを作成するページに移動します。インスタンス名を入力し、構成を選択します。
リージョンまたはマルチリージョンの設定を選択できます。リージョン設定ではすべてのレプリカが同じリージョンに配置され、マルチリージョン設定では複数のリージョンにリードレプリカが作成されます。[リージョン構成の比較] をクリックして、構成を比較できます。

構成を選択すると、右側のパネルに概要が表示されます。

今後、インスタンスにリソースを追加する場合はノード数を増やし、インスタンスに追加のリソースが必要ない場合はノード数を減らすことができます。
[作成] をクリックしてインスタンスを作成します。

これで、Cloud Spanner インスタンスを使用できるようになりました。

5. データベースを作成する
新しいデータベースを作成するには、[Create Database] をクリックします。

新しいデータベースの名前を入力します。必要に応じて、この時点でスキーマを指定することもできます。

この手順ではスキーマの指定をスキップし、[作成] をクリックして空のデータベースを作成します。

[作成] をクリックすると、新しいデータベースが作成されます。
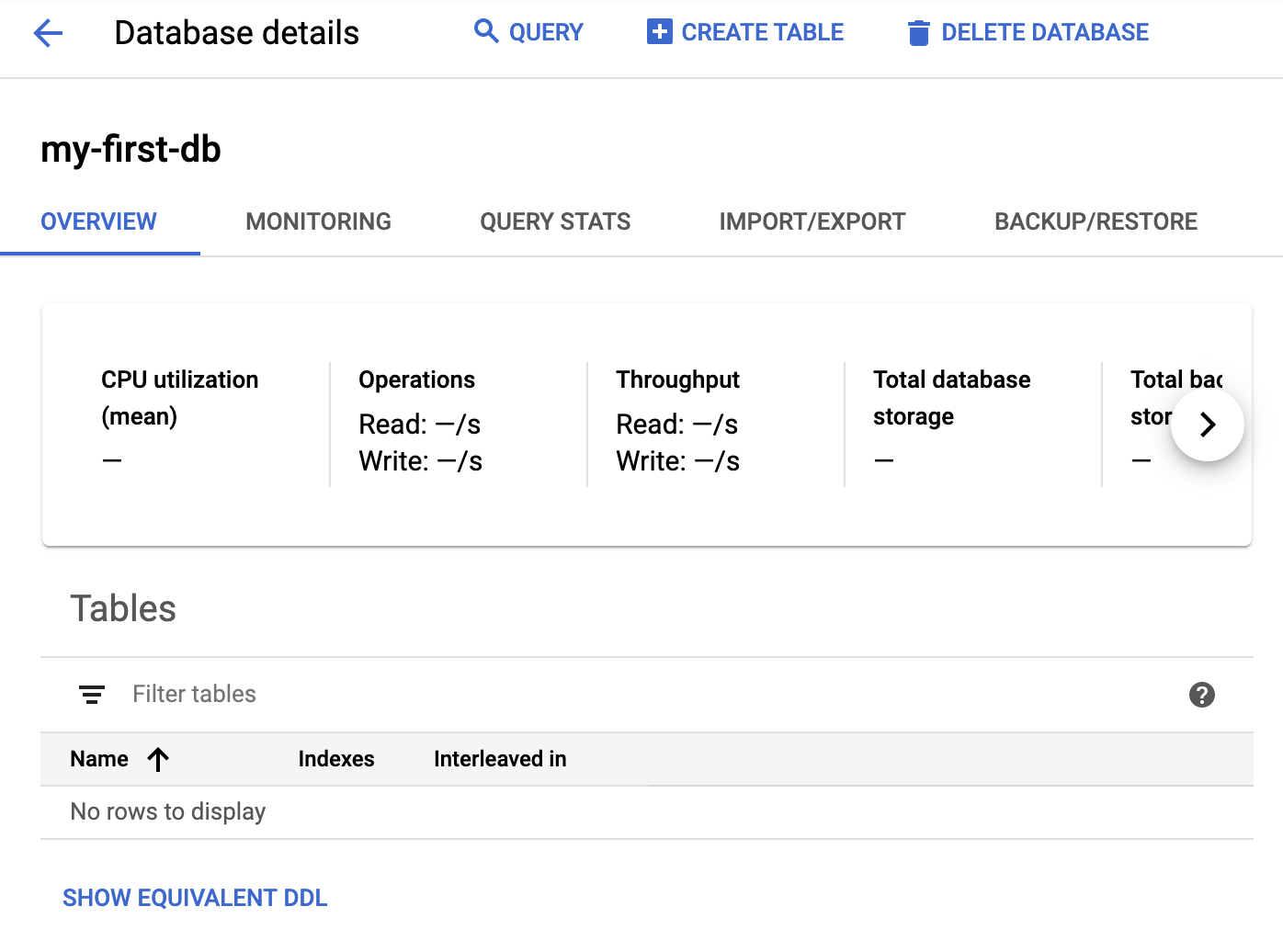
6. サンプルデータの読み込みとクエリ
この Codelab では、sampledb を使用してサンプルデータを読み込み、クエリを実行します。Sampledb にはさまざまなデータセットが含まれており、既存のデータベースにデータをインポートできます。
このプログラムは Google Cloud Shell で実行します。このプロジェクトで Google Cloud Shell を初めて使用する場合は、上部のナビゲーション バーに Google Cloud Shell のロゴが表示されます。Cloud Shell を長押しして有効にします。

有効にすると、下部にコンソールが表示されます。
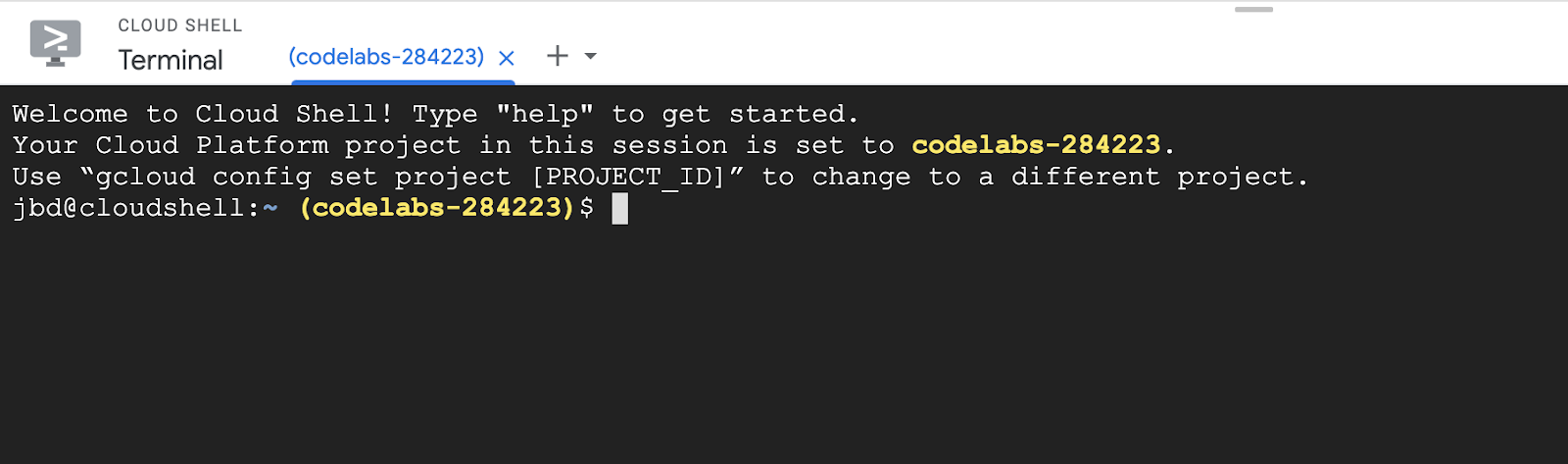
コンソールで、sampledb リポジトリのクローンを作成し、手順に沿って依存関係をインストールします。
$ git clone https://github.com/cloudspannerecosystem/sampledb.git
リポジトリのクローン作成が正常に完了したら、新しいディレクトリに移動し、仮想環境を作成して必要な要件をインストールします。
$ cd sampledb $ virtualenv env $ source env/bin/activate $ pip install -r requirements.txt
依存関係がインストールされたら、sampledb を実行してサンプルデータを含む新しいデータベースを作成できます。
$ python batch_import.py my-first-instance my-sample-db
成功すると、「my-sample-db」に 2 つの新しいテーブル(comments と stories)が表示されます。
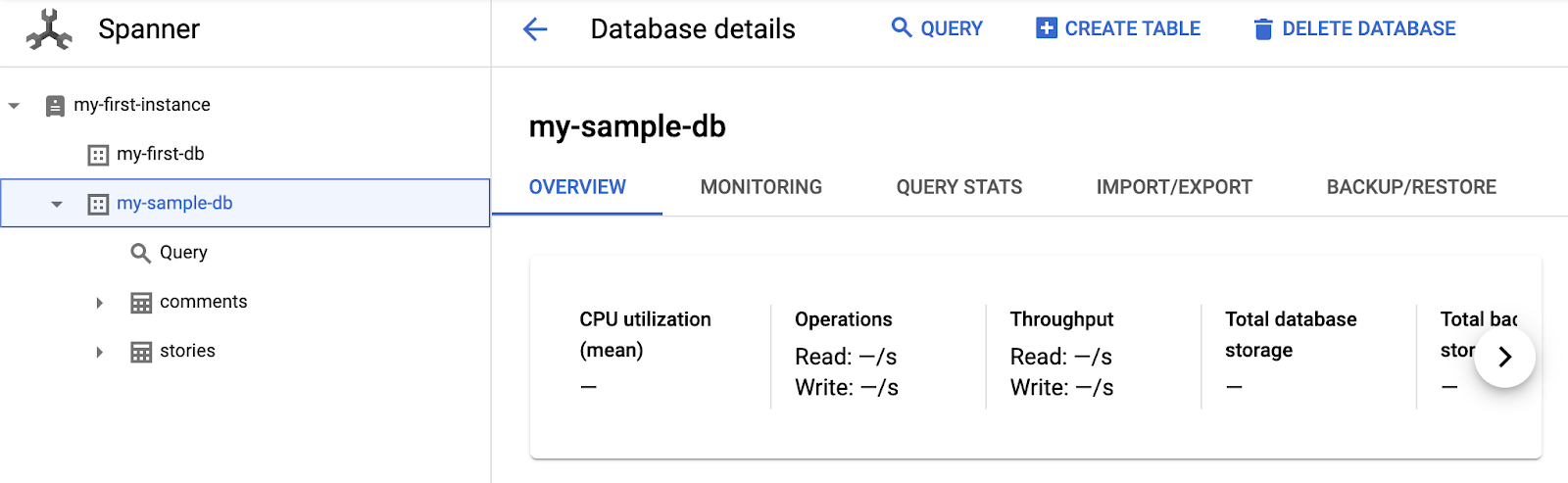
サンプル データセットには、Hacker News の記事とコメントが含まれています。[クエリ] をクリックして、データのクエリとブラウジングを開始できます。

7. クリーンアップ
この手順は省略可能です。Cloud Spanner インスタンスのテストを続ける場合は、現時点でクリーンアップする必要はありません。ただし、使用しているプロジェクトには、インスタンスの料金が引き続き請求されます。このインスタンスが不要になった場合は、この時点で削除して、これらの料金が発生しないようにする必要があります。
左上の [my-first-instance] をクリックして、インスタンス ページに戻ります。

[削除] ボタンをクリックしてインスタンスを削除します。

インスタンスを削除すると、元に戻すことはできません。そのインスタンスのデータは復元できません。誤って間違ったインスタンスを削除しないように、確認ダイアログでインスタンス名を入力して削除を確定する必要があります。

インスタンス名を入力して [削除] を押します。
8. 完了
新しい Cloud Spanner インスタンスを作成し、空のデータベースを作成して、サンプルデータを読み込みました。また、必要に応じて Cloud Spanner インスタンスを削除しました。
学習した内容
- Google Cloud コンソールを使用して Cloud Spanner インスタンスを作成する。
- Cloud Spanner インスタンスに新しいデータベースを作成する。
- sampledb を使用してサンプルデータを読み込み、クエリを実行します。
- Cloud Spanner インスタンスを削除します。
詳細
- Google Cloud Spanner のドキュメントをご覧ください。
- Google Cloud Spanner API とクライアント ライブラリについて確認する。