
1. Introduzione
Cloud Spanner è un servizio di database relazionale completamente gestito, scalabile orizzontalmente e distribuito a livello globale che fornisce transazioni ACID e semantica SQL senza rinunciare a prestazioni e alta disponibilità.
GKE Autopilot è una modalità operativa in GKE in cui Google gestisce la configurazione del cluster, inclusi nodi, scalabilità, sicurezza e altre impostazioni preconfigurate per seguire le best practice. Ad esempio, GKE Autopilot consente a Workload Identity di gestire le autorizzazioni del servizio.
Lo scopo di questo lab è guidarti nel processo di connessione di diversi servizi di backend in esecuzione su GKE Autopilot a un database Cloud Spanner.
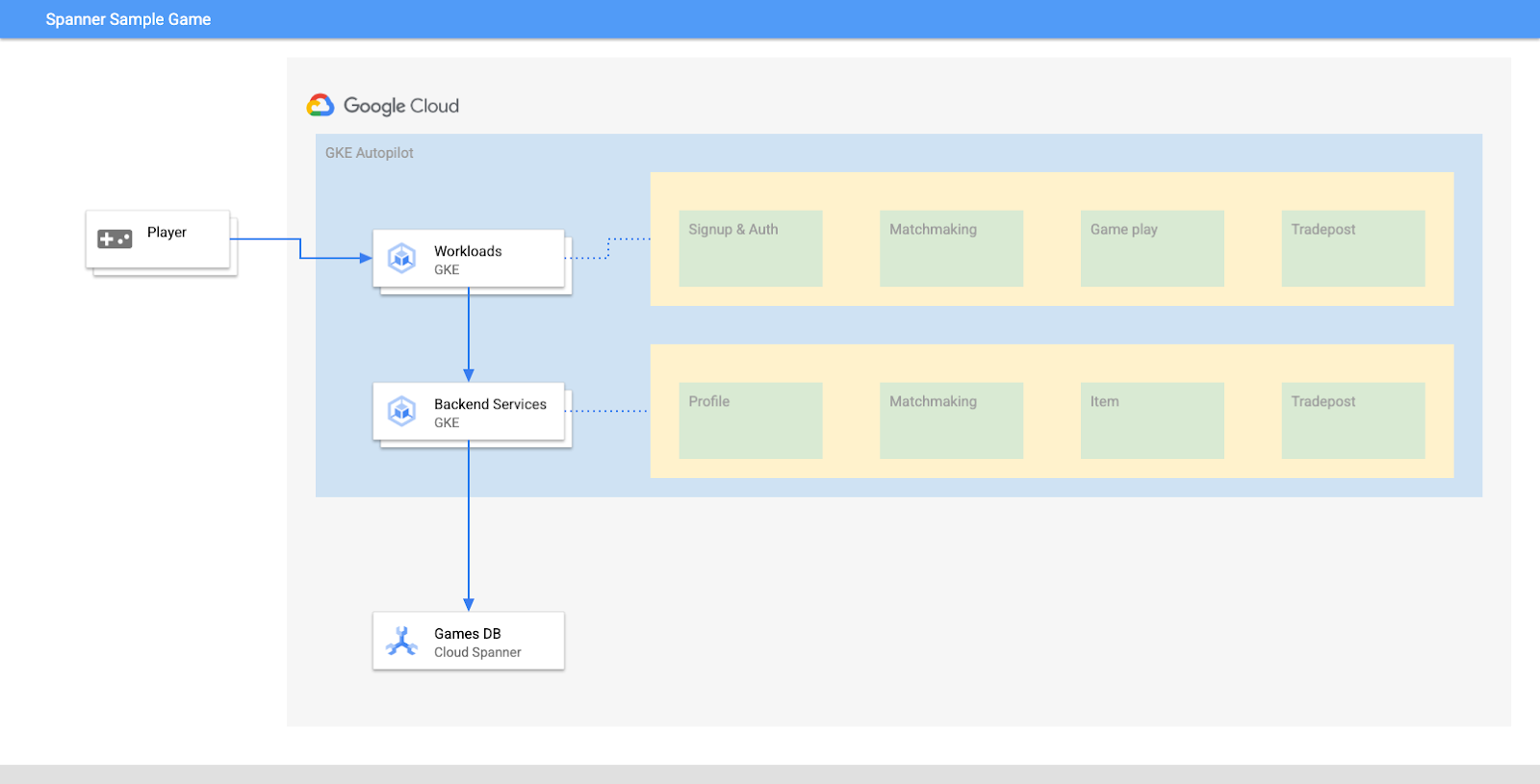
In questo lab, configurerai prima un progetto e avvierai Cloud Shell. Poi, eseguirai il deployment dell'infrastruttura utilizzando Terraform.
Al termine, interagirai con Cloud Build e Cloud Deploy per eseguire una migrazione iniziale dello schema per il database Games, eseguire il deployment dei servizi di backend e poi dei workload.
I servizi in questo codelab sono gli stessi del codelab Introduzione a Cloud Spanner per lo sviluppo di giochi. Non è necessario seguire questo codelab per eseguire i servizi su GKE e connettersi a Spanner. Se ti interessano maggiori dettagli sui servizi specifici che funzionano su Spanner, dai un'occhiata.
Con i workload e i servizi di backend in esecuzione, puoi iniziare a generare carico e osservare come funzionano insieme i servizi.
Infine, ripulirai le risorse create in questo lab.
Cosa creerai
Nell'ambito di questo lab, imparerai a:
- Eseguire il provisioning dell'infrastruttura utilizzando Terraform
- Crea lo schema del database utilizzando un processo di migrazione dello schema in Cloud Build
- Esegui il deployment dei quattro servizi di backend Golang che sfruttano Workload Identity per connettersi a Cloud Spanner
- Esegui il deployment dei quattro servizi del carico di lavoro utilizzati per simulare il carico per i servizi di backend.
Obiettivi didattici
- Come eseguire il provisioning di pipeline GKE Autopilot, Cloud Spanner e Cloud Deploy utilizzando Terraform
- In che modo Workload Identity consente ai servizi su GKE di impersonare service account per accedere alle autorizzazioni IAM per lavorare con Cloud Spanner
- Come generare un carico simile a quello di produzione su GKE e Cloud Spanner utilizzando Locust.io
Che cosa ti serve
2. Configurazione e requisiti
Crea un progetto
Se non hai ancora un Account Google (Gmail o Google Apps), devi crearne uno. Accedi alla console di Google Cloud ( console.cloud.google.com) e crea un nuovo progetto.
Se hai già un progetto, fai clic sul menu a discesa per la selezione dei progetti in alto a sinistra nella console:

e fai clic sul pulsante "NUOVO PROGETTO" nella finestra di dialogo risultante per creare un nuovo progetto:

Se non hai ancora un progetto, dovresti visualizzare una finestra di dialogo come questa per creare il primo:
La finestra di dialogo successiva per la creazione del progetto ti consente di inserire i dettagli del nuovo progetto:
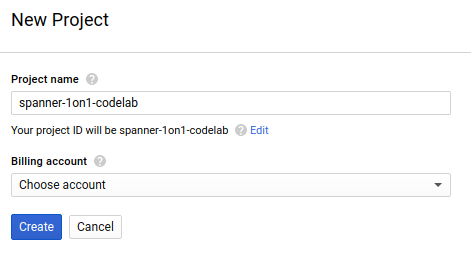
Ricorda l'ID progetto, che è un nome univoco tra tutti i progetti Google Cloud (il nome riportato sopra è già stato utilizzato e non funzionerà per te, ci dispiace). In questo codelab verrà chiamato PROJECT_ID.
Successivamente, se non l'hai ancora fatto, devi abilitare la fatturazione in Developers Console per utilizzare le risorse Google Cloud e abilitare l'API Cloud Spanner.
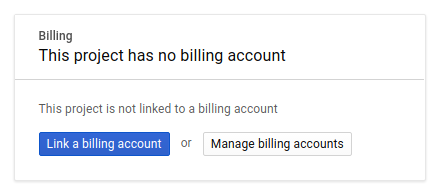
L'esecuzione di questo codelab non dovrebbe costarti più di qualche dollaro, ma potrebbe essere più cara se decidi di utilizzare più risorse o se le lasci in esecuzione (vedi la sezione "Pulizia" alla fine di questo documento). I prezzi di Google Cloud Spanner sono documentati qui e quelli di GKE Autopilot qui.
I nuovi utenti di Google Cloud Platform possono beneficiare di una prova senza costi di 300$, che dovrebbe rendere questo codelab completamente senza costi.
Configurazione di Cloud Shell
Anche se Google Cloud e Spanner possono essere gestiti da remoto dal tuo laptop, in questo codelab utilizzeremo Google Cloud Shell, un ambiente a riga di comando in esecuzione nel cloud.
Questa macchina virtuale basata su Debian viene caricata con tutti gli strumenti di sviluppo di cui avrai bisogno. Offre una home directory permanente da 5 GB e viene eseguita in Google Cloud, migliorando notevolmente le prestazioni e l'autenticazione della rete. Ciò significa che per questo codelab ti servirà solo un browser (sì, funziona su Chromebook).
- Per attivare Cloud Shell dalla console Cloud, fai clic su Attiva Cloud Shell
 (bastano pochi istanti per eseguire il provisioning e connettersi all'ambiente).
(bastano pochi istanti per eseguire il provisioning e connettersi all'ambiente).


Una volta eseguita la connessione a Cloud Shell, dovresti vedere che il tuo account è già autenticato e il progetto è già impostato sul tuo PROJECT_ID.
gcloud auth list
Output comando
Credentialed accounts:
- <myaccount>@<mydomain>.com (active)
gcloud config list project
Output comando
[core]
project = <PROJECT_ID>
Se per qualche motivo il progetto non è impostato, esegui questo comando:
gcloud config set project <PROJECT_ID>
Stai cercando PROJECT_ID? Controlla l'ID che hai utilizzato nei passaggi di configurazione o cercalo nella dashboard della console Cloud:

Cloud Shell imposta anche alcune variabili di ambiente per impostazione predefinita, che potrebbero essere utili quando esegui i comandi futuri.
echo $GOOGLE_CLOUD_PROJECT
Output comando
<PROJECT_ID>
Scarica il codice
In Cloud Shell, puoi scaricare il codice per questo lab:
git clone https://github.com/cloudspannerecosystem/spanner-gaming-sample.git
Output comando
Cloning into 'spanner-gaming-sample'...
*snip*
Questo codelab è basato sulla release v0.1.3, quindi controlla questo tag:
cd spanner-gaming-sample
git fetch --all --tags
# Check out v0.1.3 release
git checkout tags/v0.1.3 -b v0.1.3-branch
Output comando
Switched to a new branch 'v0.1.3-branch'
Ora imposta la directory di lavoro corrente come variabile di ambiente DEMO_HOME. In questo modo sarà più facile navigare mentre lavori sulle diverse parti del codelab.
export DEMO_HOME=$(pwd)
Riepilogo
In questo passaggio hai configurato un nuovo progetto, attivato Cloud Shell e scaricato il codice per questo lab.
Prossimo
Successivamente, eseguirai il provisioning dell'infrastruttura utilizzando Terraform.
3. Esegui il provisioning dell'infrastruttura
Panoramica
Ora che il progetto è pronto, è il momento di avviare l'infrastruttura. Ciò include il networking VPC, Cloud Spanner, GKE Autopilot, Artifact Registry per archiviare le immagini che verranno eseguite su GKE, le pipeline Cloud Deploy per i servizi e i carichi di lavoro di backend e infine gli account di servizio e i privilegi IAM per poter utilizzare questi servizi.
È tanto. Fortunatamente, Terraform può semplificare la configurazione. Terraform è uno strumento "Infrastructure as Code" che ci consente di specificare ciò che ci serve per questo progetto in una serie di file ".tf". In questo modo, il provisioning dell'infrastruttura è semplice.
La familiarità con Terraform non è un requisito per completare questo codelab. Tuttavia, se vuoi vedere cosa fanno i passaggi successivi, puoi dare un'occhiata a tutto ciò che viene creato in questi file che si trovano nella directory infrastructure:
- vpc.tf
- backend_gke.tf
- spanner.tf
- artifact_registry.tf
- pipelines.tf
- iam.tf
Configura Terraform
In Cloud Shell, passa alla directory infrastructure e inizializza Terraform:
cd $DEMO_HOME/infrastructure
terraform init
Output comando
Initializing the backend...
Initializing provider plugins...
*snip*
Terraform has been successfully initialized!
You may now begin working with Terraform. Try running "terraform plan" to see
any changes that are required for your infrastructure. All Terraform commands
should now work.
If you ever set or change modules or backend configuration for Terraform,
rerun this command to reinitialize your working directory. If you forget, other
commands will detect it and remind you to do so if necessary.
Successivamente, configura Terraform copiando terraform.tfvars.sample e modificando il valore del progetto. Anche le altre variabili possono essere modificate, ma il progetto è l'unico che deve essere modificato per funzionare con il tuo ambiente.
cp terraform.tfvars.sample terraform.tfvars
# edit gcp_project using the project environment variable
sed -i "s/PROJECT/$GOOGLE_CLOUD_PROJECT/" terraform.tfvars
Esegui il provisioning dell'infrastruttura
Ora è il momento di eseguire il provisioning dell'infrastruttura.
terraform apply
# review the list of things to be created
# type 'yes' when asked
Output comando
Plan: 46 to add, 0 to change, 0 to destroy.
Do you want to perform these actions?
Terraform will perform the actions described above.
Only 'yes' will be accepted to approve.
Enter a value: yes
google_project_service.project["container.googleapis.com"]: Creating...
*snip*
Apply complete! Resources: 46 added, 0 changed, 0 destroyed.
Controllare cosa è stato creato
Per verificare cosa è stato creato, controlla i prodotti in Cloud Console.
Cloud Spanner
Per prima cosa, controlla Cloud Spanner aprendo il menu a tre linee e facendo clic su Spanner. Potresti dover fare clic su "Visualizza altri prodotti" per trovarlo nell'elenco.
Verrà visualizzato l'elenco delle istanze Spanner. Fai clic sull'istanza per visualizzare i database. Il sito dovrebbe avere il seguente aspetto:

GKE Autopilot
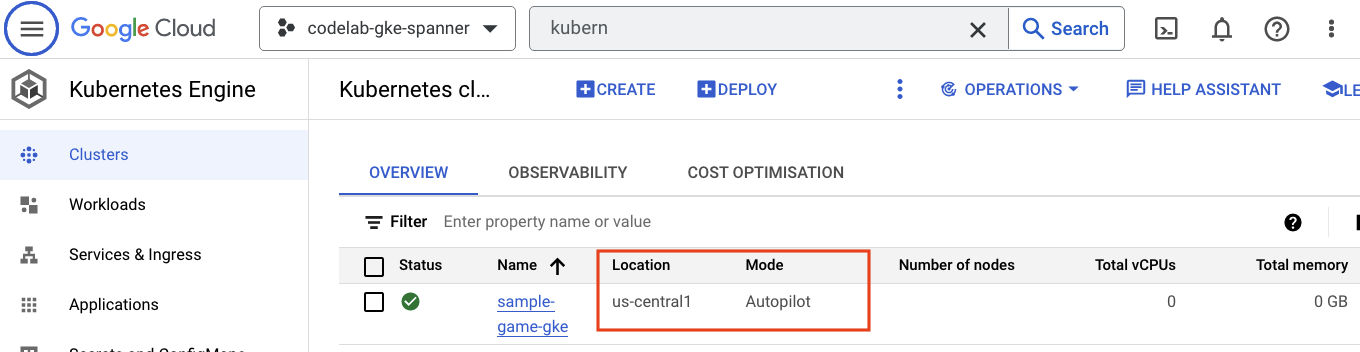
Successivamente, dai un'occhiata a GKE accedendo al menu a tre linee e facendo clic su Kubernetes Engine => Clusters. Qui vedrai il cluster sample-games-gke in esecuzione in modalità Autopilot.
Artifact Registry
Ora devi vedere dove verranno archiviate le immagini. Quindi, fai clic sul menu a tre linee e trova Artifact Registry=>Repositories. Artifact Registry si trova nella sezione CI/CD del menu.
Qui vedrai un registro Docker denominato spanner-game-images. Per il momento questo campo sarà vuoto.

Cloud Deploy
Cloud Deploy è il luogo in cui sono state create le pipeline in modo che Cloud Build potesse fornire i passaggi per creare le immagini e poi eseguirne il deployment nel nostro cluster GKE.
Vai al menu a tre linee e trova Cloud Deploy, che si trova anche nella sezione CI/CD del menu.
Qui noterai due pipeline: una per i servizi di backend e una per i workload. Entrambi eseguono il deployment delle immagini nello stesso cluster GKE, ma ciò consente di separare i deployment.

IAM
Infine, controlla la pagina IAM in Cloud Console per verificare gli account di servizio creati. Vai al menu di navigazione e trova IAM and Admin=>Service accounts. Il sito dovrebbe avere il seguente aspetto:

Terraform crea un totale di sei service account:
- Il service account Compute predefinito. Questo campo non viene utilizzato in questo codelab.
- L'account cloudbuild-cicd viene utilizzato per i passaggi di Cloud Build e Cloud Deploy.
- Quattro account "app" utilizzati dai nostri servizi di backend per interagire con Cloud Spanner.
Il passaggio successivo consiste nel configurare kubectl per interagire con il cluster GKE.
Configura kubectl
# Name of GKE cluster from terraform.tfvars file
export GKE_CLUSTER=sample-game-gke
# get GKE credentials
gcloud container clusters get-credentials $GKE_CLUSTER --region us-central1
# Check that no errors occur
kubectl get serviceaccounts
Output comando
#export GKE_CLUSTER=sample-game-gke
# gcloud container clusters get-credentials $GKE_CLUSTER --region us-central1
Fetching cluster endpoint and auth data.
kubeconfig entry generated for sample-game-gke.
# kubectl get serviceaccounts
NAME SECRETS AGE
default 0 37m
item-app 0 35m
matchmaking-app 0 35m
profile-app 0 35m
tradepost-app 0 35m
Riepilogo
Bene. Hai potuto eseguire il provisioning di un'istanza Cloud Spanner e di un cluster GKE Autopilot, il tutto in un VPC per il networking privato.
Inoltre, sono state create due pipeline Cloud Deploy per i servizi di backend e i carichi di lavoro, nonché un repository Artifact Registry per archiviare le immagini create.
Infine, i service account sono stati creati e configurati per funzionare con Workload Identity, in modo che i servizi di backend possano utilizzare Cloud Spanner.
Hai anche configurato kubectl per interagire con il cluster GKE in Cloud Shell dopo aver eseguito il deployment dei servizi e dei carichi di lavoro di backend.
Prossimo
Prima di poter utilizzare i servizi, è necessario definire lo schema del database. Lo configurerai nel passaggio successivo.
4. Crea lo schema del database
Panoramica
Prima di poter eseguire i servizi di backend, devi assicurarti che lo schema del database sia presente.
Se esamini i file nella directory $DEMO_HOME/schema/migrations del repository demo, vedrai una serie di file .sql che definiscono il nostro schema. In questo modo viene simulato un ciclo di sviluppo in cui le modifiche allo schema vengono monitorate nel repository stesso e possono essere associate a determinate funzionalità delle applicazioni.
Per questo ambiente di esempio, wrench è lo strumento che applicherà le migrazioni dello schema utilizzando Cloud Build.
Cloud Build
Il file $DEMO_HOME/schema/cloudbuild.yaml descrive i passaggi che verranno eseguiti:
serviceAccount: projects/${PROJECT_ID}/serviceAccounts/cloudbuild-cicd@${PROJECT_ID}.iam.gserviceaccount.com
steps:
- name: gcr.io/cloud-builders/curl
id: fetch-wrench
args: ['-Lo', '/workspace/wrench.tar.gz', 'https://github.com/cloudspannerecosystem/wrench/releases/download/v1.4.1/wrench-1.4.1-linux-amd64.tar.gz' ]
- name: gcr.io/cloud-builders/gcloud
id: migrate-spanner-schema
entrypoint: sh
args:
- '-xe'
- '-c'
- |
tar -xzvf wrench.tar.gz
chmod +x /workspace/wrench
# Assumes only a single spanner instance and database. Fine for this demo in a dedicated project
export SPANNER_PROJECT_ID=${PROJECT_ID}
export SPANNER_INSTANCE_ID=$(gcloud spanner instances list | tail -n1 | awk '{print $1}')
export SPANNER_DATABASE_ID=$(gcloud spanner databases list --instance=$$SPANNER_INSTANCE_ID | tail -n1 | awk '{print $1}')
if [ -d ./migrations ]; then
/workspace/wrench migrate up --directory .
else
echo "[Error] Missing migrations directory"
fi
timeout: 600s
Fondamentalmente, ci sono due passaggi:
- scarica la chiave nel workspace Cloud Build
- esegui la migrazione della chiave
Le variabili di ambiente del progetto, dell'istanza e del database Spanner sono necessarie per consentire a wrench di connettersi all'endpoint di scrittura.
Cloud Build è in grado di apportare queste modifiche perché viene eseguito come service account cloudbuild-cicd@${PROJECT_ID}.iam.gserviceaccount.com:
serviceAccount: projects/${PROJECT_ID}/serviceAccounts/cloudbuild-cicd@${PROJECT_ID}.iam.gserviceaccount.com
Questo service account ha il ruolo spanner.databaseUser aggiunto da Terraform, che consente al service account di aggiornare DDL.
Migrazioni dello schema
Esistono cinque passaggi di migrazione eseguiti in base ai file nella directory $DEMO_HOME/schema/migrations. Ecco un esempio del file 000001.sql che crea una tabella e indici players:
CREATE TABLE players (
playerUUID STRING(36) NOT NULL,
player_name STRING(64) NOT NULL,
email STRING(MAX) NOT NULL,
password_hash BYTES(60) NOT NULL,
created TIMESTAMP,
updated TIMESTAMP,
stats JSON,
account_balance NUMERIC NOT NULL DEFAULT (0.00),
is_logged_in BOOL,
last_login TIMESTAMP,
valid_email BOOL,
current_game STRING(36)
) PRIMARY KEY (playerUUID);
CREATE UNIQUE INDEX PlayerAuthentication ON players(email) STORING(password_hash);
CREATE UNIQUE INDEX PlayerName ON players(player_name);
CREATE INDEX PlayerGame ON players(current_game);
Invia la migrazione dello schema
Per inviare la build per eseguire la migrazione dello schema, passa alla directory schema ed esegui questo comando gcloud:
cd $DEMO_HOME/schema gcloud builds submit --config=cloudbuild.yaml
Output comando
Creating temporary tarball archive of 8 file(s) totalling 11.2 KiB before compression.
Uploading tarball of [.] to [gs://(project)_cloudbuild/source/(snip).tgz]
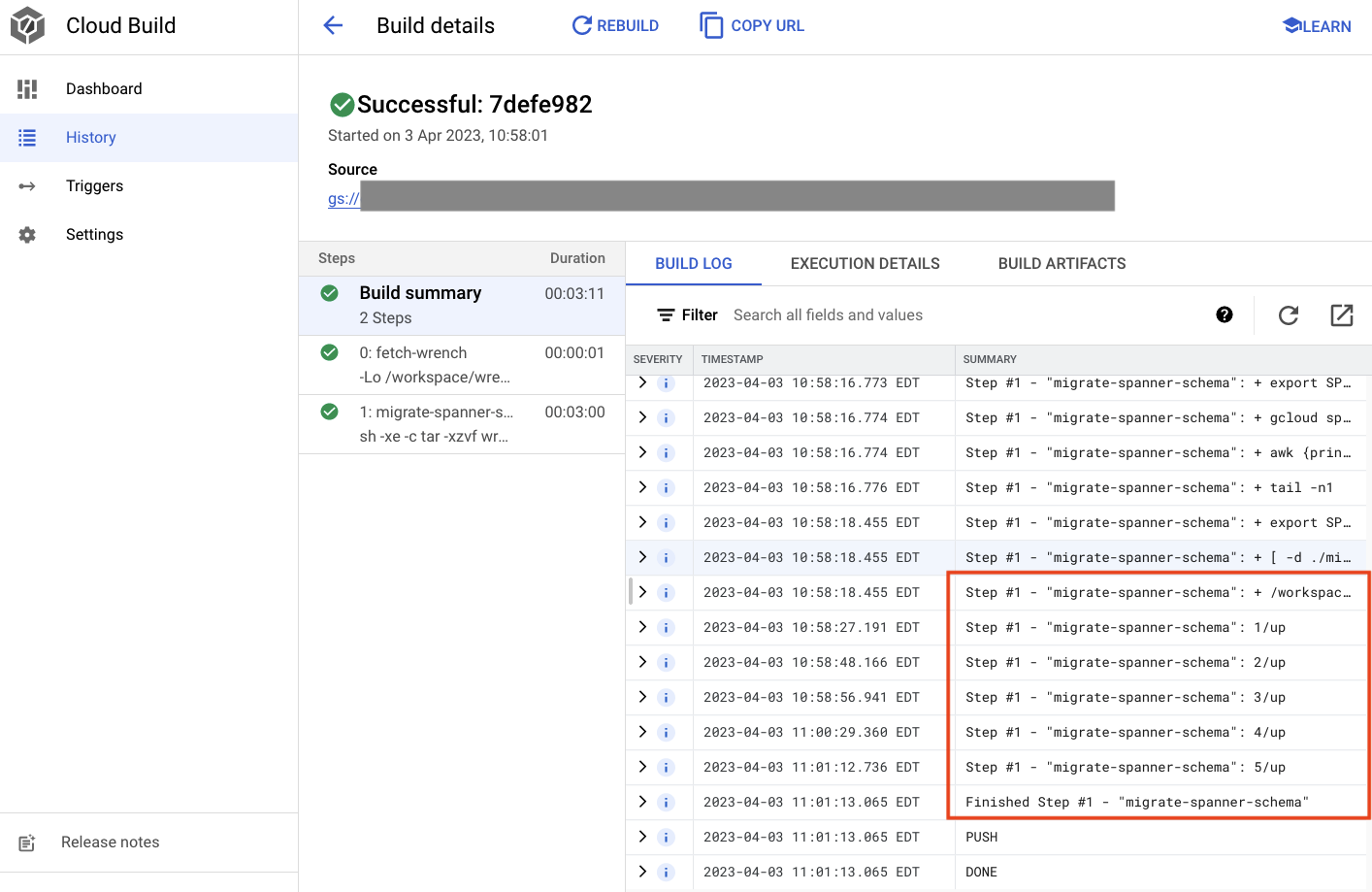
Created [https://cloudbuild.googleapis.com/v1/projects/(project)/locations/global/builds/7defe982-(snip)].
Logs are available at [ https://console.cloud.google.com/cloud-build/builds/7defe982-(snip)?project=(snip) ].
gcloud builds submit only displays logs from Cloud Storage. To view logs from Cloud Logging, run:
gcloud beta builds submit
ID: 7defe982-(snip)
CREATE_TIME: (created time)
DURATION: 3M11S
SOURCE: gs://(project)_cloudbuild/source/(snip).tgz
IMAGES: -
STATUS: SUCCESS
Nell'output riportato sopra, noterai un link al Created processo di build cloud. Se fai clic, si aprirà la build in Cloud Console, in modo da poter monitorare l'avanzamento della build e vedere cosa sta facendo.
Riepilogo
In questo passaggio, hai utilizzato Cloud Build per inviare la migrazione iniziale dello schema che ha applicato 5 diverse operazioni DDL. Queste operazioni rappresentano il momento in cui sono state aggiunte funzionalità che richiedevano modifiche allo schema del database.
In uno scenario di sviluppo normale, vorresti rendere le modifiche allo schema compatibili con la versione precedente dell'applicazione per evitare interruzioni.
Per le modifiche non compatibili con le versioni precedenti, ti consigliamo di implementare le modifiche all'applicazione e allo schema in più fasi per evitare interruzioni.
Prossimo
Con lo schema in posizione, il passaggio successivo è il deployment dei servizi di backend.
5. Esegui il deployment dei servizi di backend
Panoramica
I servizi di backend per questo codelab sono API REST Golang che rappresentano quattro servizi diversi:
- Profilo:consente ai giocatori di registrarsi e autenticarsi nel nostro "gioco" di esempio.
- Matchmaking:interagisci con i dati dei giocatori per facilitare una funzione di matchmaking, monitorare le informazioni sui giochi creati e aggiornare le statistiche dei giocatori quando i giochi vengono chiusi.
- Articolo:consente ai giocatori di acquisire articoli e denaro di gioco nel corso di una partita.
- Mercato:consente ai giocatori di acquistare e vendere oggetti in un mercato

Puoi scoprire di più su questi servizi nel codelab Cloud Spanner Getting Started with Games Development. Ai nostri scopi, vogliamo che questi servizi vengano eseguiti sul nostro cluster GKE Autopilot.
Questi servizi devono essere in grado di modificare i dati di Spanner. A questo scopo, per ogni servizio viene creato un service account che gli concede il ruolo "databaseUser".
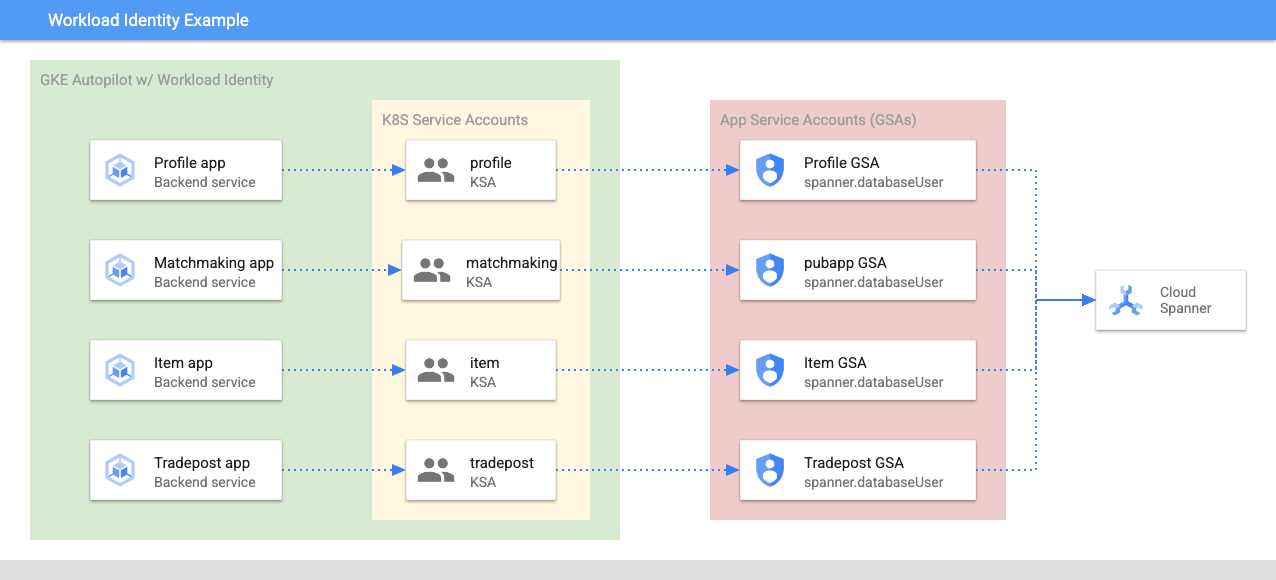
Workload Identity consente a un service account Kubernetes di rappresentare il service account Google Cloud dei servizi seguendo questi passaggi in Terraform:
- Crea la risorsa service account Google Cloud del servizio (
GSA) - Assegna il ruolo databaseUser a questo service account.
- Assegna il ruolo workloadIdentityUser a questo service account.
- Crea un service account Kubernetes (
KSA) che faccia riferimento al service account Google
Un diagramma approssimativo potrebbe essere simile a questo:
Terraform ha creato i service account e i service account Kubernetes per te. Puoi controllare i service account Kubernetes utilizzando kubectl:
# kubectl get serviceaccounts
NAME SECRETS AGE
default 0 37m
item-app 0 35m
matchmaking-app 0 35m
profile-app 0 35m
tradepost-app 0 35m
Il funzionamento della build è il seguente:
- Terraform ha generato un file
$DEMO_HOME/backend_services/cloudbuild.yamlsimile al seguente:
serviceAccount: projects/${PROJECT_ID}/serviceAccounts/cloudbuild-cicd@${PROJECT_ID}.iam.gserviceaccount.com
steps:
#
# Building of images
#
- name: gcr.io/cloud-builders/docker
id: profile
args: ["build", ".", "-t", "${_PROFILE_IMAGE}"]
dir: profile
waitFor: ['-']
- name: gcr.io/cloud-builders/docker
id: matchmaking
args: ["build", ".", "-t", "${_MATCHMAKING_IMAGE}"]
dir: matchmaking
waitFor: ['-']
- name: gcr.io/cloud-builders/docker
id: item
args: ["build", ".", "-t", "${_ITEM_IMAGE}"]
dir: item
waitFor: ['-']
- name: gcr.io/cloud-builders/docker
id: tradepost
args: ["build", ".", "-t", "${_TRADEPOST_IMAGE}"]
dir: tradepost
waitFor: ['-']
#
# Deployment
#
- name: gcr.io/google.com/cloudsdktool/cloud-sdk
id: cloud-deploy-release
entrypoint: gcloud
args:
[
"deploy", "releases", "create", "${_REL_NAME}",
"--delivery-pipeline", "sample-game-services",
"--skaffold-file", "skaffold.yaml",
"--skaffold-version", "1.39",
"--images", "profile=${_PROFILE_IMAGE},matchmaking=${_MATCHMAKING_IMAGE},item=${_ITEM_IMAGE},tradepost=${_TRADEPOST_IMAGE}",
"--region", "us-central1"
]
artifacts:
images:
- ${_REGISTRY}/profile
- ${_REGISTRY}/matchmaking
- ${_REGISTRY}/item
- ${_REGISTRY}/tradepost
substitutions:
_PROFILE_IMAGE: ${_REGISTRY}/profile:${BUILD_ID}
_MATCHMAKING_IMAGE: ${_REGISTRY}/matchmaking:${BUILD_ID}
_ITEM_IMAGE: ${_REGISTRY}/item:${BUILD_ID}
_TRADEPOST_IMAGE: ${_REGISTRY}/tradepost:${BUILD_ID}
_REGISTRY: us-docker.pkg.dev/${PROJECT_ID}/spanner-game-images
_REL_NAME: rel-${BUILD_ID:0:8}
options:
dynamic_substitutions: true
machineType: E2_HIGHCPU_8
logging: CLOUD_LOGGING_ONLY
- Il comando Cloud Build legge questo file e segue i passaggi elencati. Innanzitutto, crea le immagini del servizio. Poi esegue un comando
gcloud deploy create. Questo legge il file$DEMO_HOME/backend_services/skaffold.yaml, che definisce la posizione di ogni file di deployment:
apiVersion: skaffold/v2beta29
kind: Config
deploy:
kubectl:
manifests:
- spanner_config.yaml
- profile/deployment.yaml
- matchmaking/deployment.yaml
- item/deployment.yaml
- tradepost/deployment.yaml
- Cloud Deploy seguirà le definizioni del file
deployment.yamldi ogni servizio. Il file di deployment del servizio contiene le informazioni per la creazione di un servizio, che in questo caso è un clusterIP in esecuzione sulla porta 80.
Il tipo " ClusterIP" impedisce ai pod del servizio di backend di avere un IP esterno, quindi solo le entità che possono connettersi alla rete GKE interna possono accedere ai servizi di backend. Questi servizi non devono essere direttamente accessibili ai giocatori perché accedono ai dati Spanner e li modificano.
apiVersion: v1
kind: Service
metadata:
name: profile
spec:
type: ClusterIP
selector:
app: profile
ports:
- port: 80
targetPort: 80
Oltre a creare un servizio Kubernetes, Cloud Deploy crea anche un deployment Kubernetes. Esaminiamo la sezione di deployment del servizio profile:
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: profile
spec:
replicas: 2 # EDIT: Number of instances of deployment
selector:
matchLabels:
app: profile
template:
metadata:
labels:
app: profile
spec:
serviceAccountName: profile-app
containers:
- name: profile-service
image: profile
ports:
- containerPort: 80
envFrom:
- configMapRef:
name: spanner-config
env:
- name: SERVICE_HOST
value: "0.0.0.0"
- name: SERVICE_PORT
value: "80"
resources:
requests:
cpu: "1"
memory: "1Gi"
ephemeral-storage: "100Mi"
limits:
cpu: "1"
memory: "1Gi"
ephemeral-storage: "100Mi"
La parte superiore fornisce alcuni metadati sul servizio. La parte più importante è definire quante repliche verranno create da questo deployment.
replicas: 2 # EDIT: Number of instances of deployment
Successivamente, vediamo quale service account deve eseguire l'app e quale immagine deve utilizzare. Questi corrispondono al service account Kubernetes creato da Terraform e all'immagine creata durante il passaggio di Cloud Build.
spec:
serviceAccountName: profile-app
containers:
- name: profile-service
image: profile
Dopodiché, specifichiamo alcune informazioni su networking e variabili di ambiente.
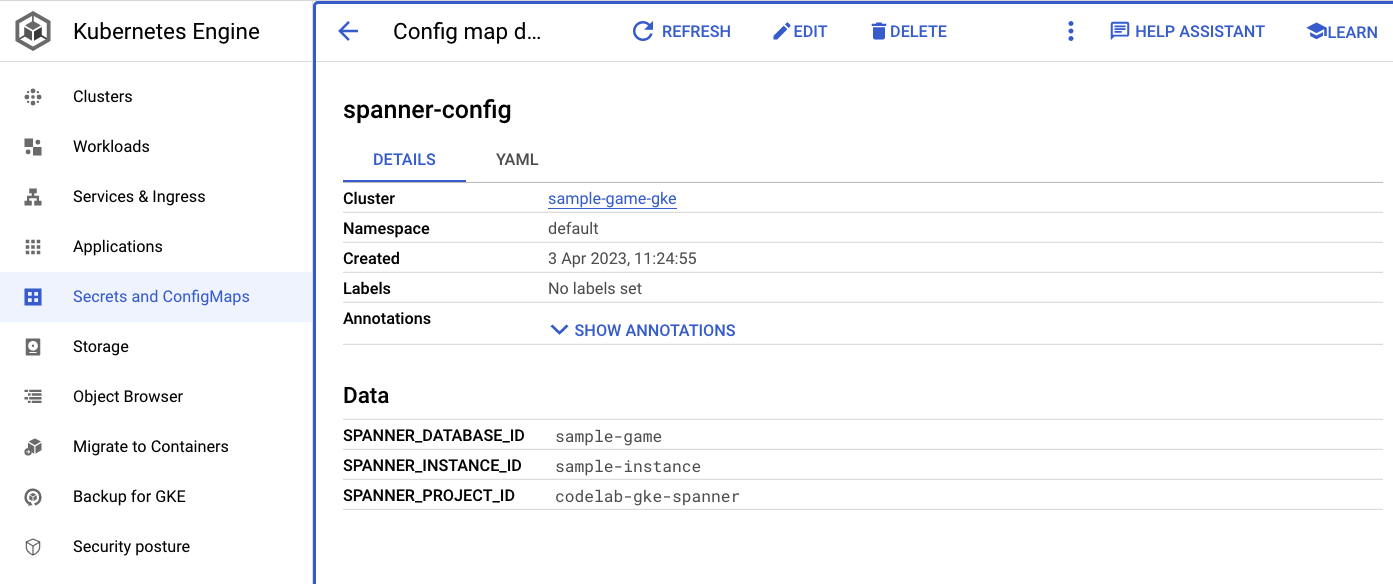
spanner_config è un ConfigMap di Kubernetes che specifica le informazioni su progetto, istanza e database necessarie all'applicazione per connettersi a Spanner.
apiVersion: v1
kind: ConfigMap
metadata:
name: spanner-config
data:
SPANNER_PROJECT_ID: ${project_id}
SPANNER_INSTANCE_ID: ${instance_id}
SPANNER_DATABASE_ID: ${database_id}
ports:
- containerPort: 80
envFrom:
- configMapRef:
name: spanner-config
env:
- name: SERVICE_HOST
value: "0.0.0.0"
- name: SERVICE_PORT
value: "80"
SERVICE_HOST e SERVICE_PORT sono variabili di ambiente aggiuntive necessarie al servizio per sapere dove eseguire il binding.
L'ultima sezione indica a GKE quante risorse consentire per ogni replica in questo deployment. Questo è anche ciò che utilizza GKE Autopilot per scalare il cluster in base alle esigenze.
resources:
requests:
cpu: "1"
memory: "1Gi"
ephemeral-storage: "100Mi"
limits:
cpu: "1"
memory: "1Gi"
ephemeral-storage: "100Mi"
Con queste informazioni, è il momento di eseguire il deployment dei servizi di backend.
Esegui il deployment dei servizi di backend
Come accennato, il deployment dei servizi di backend utilizza Cloud Build. Come per le migrazioni dello schema, puoi inviare la richiesta di build utilizzando la riga di comando gcloud:
cd $DEMO_HOME/backend_services gcloud builds submit --config=cloudbuild.yaml
Output comando
Creating temporary tarball archive of 66 file(s) totalling 864.6 KiB before compression.
Uploading tarball of [.] to [gs://(project)_cloudbuild/source/(snip).tgz]
Created [https://cloudbuild.googleapis.com/v1/projects/(project)/locations/global/builds/30207dd1-(snip)].
Logs are available at [ https://console.cloud.google.com/cloud-build/builds/30207dd1-(snip)?project=(snip) ].
gcloud builds submit only displays logs from Cloud Storage. To view logs from Cloud Logging, run:
gcloud beta builds submit
ID: 30207dd1-(snip)
CREATE_TIME: (created time)
DURATION: 3M17S
SOURCE: gs://(project)_cloudbuild/source/(snip).tgz
IMAGES: us-docker.pkg.dev/(project)/spanner-game-images/profile:30207dd1-(snip) (+3 more)
STATUS: SUCCESS
A differenza dell'output del passaggio schema migration, l'output di questa build indica che sono state create alcune immagini. Questi verranno archiviati nel repository Artifact Registry.
L'output del passaggio gcloud build conterrà un link a Cloud Console. Dai un'occhiata.
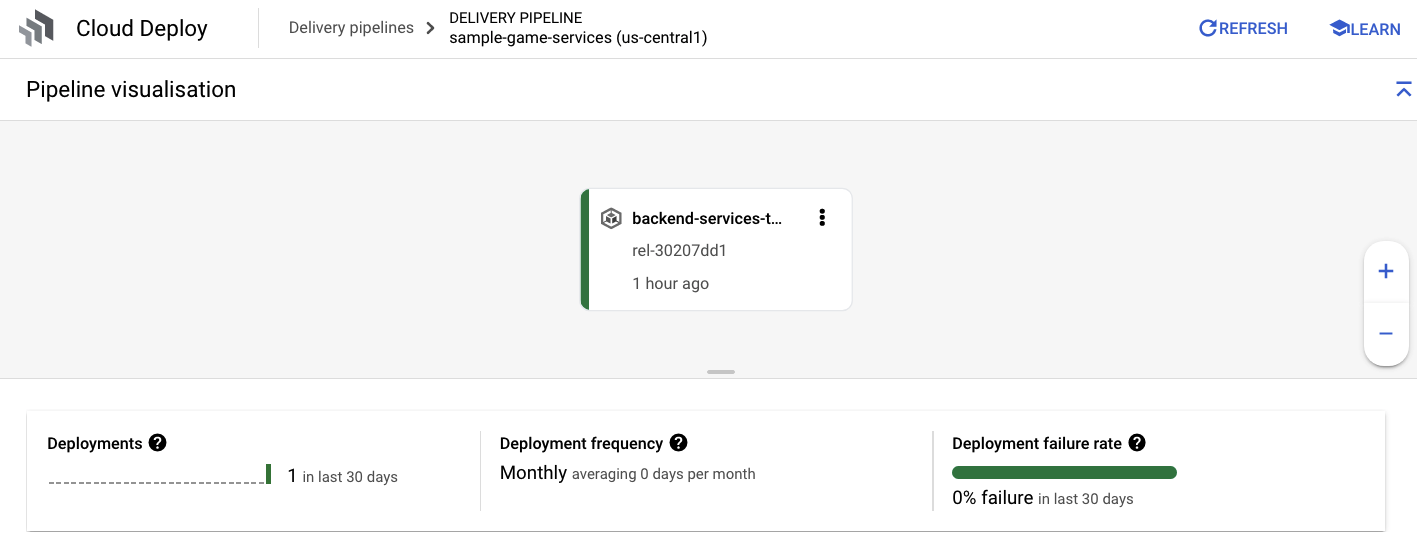
Una volta ricevuta la notifica di esito positivo da Cloud Build, vai a Cloud Deploy e poi alla pipeline sample-game-services per monitorare l'avanzamento del deployment.
Una volta eseguiti il deployment dei servizi, puoi controllare kubectl per visualizzare lo stato dei pod:
kubectl get pods
Output comando
NAME READY STATUS RESTARTS AGE
item-6b9d5f678c-4tbk2 1/1 Running 0 83m
matchmaking-5bcf799b76-lg8zf 1/1 Running 0 80m
profile-565bbf4c65-kphdl 1/1 Running 0 83m
profile-565bbf4c65-xw74j 1/1 Running 0 83m
tradepost-68b87ccd44-gw55r 1/1 Running 0 79m
Poi, controlla i servizi per vedere ClusterIP in azione:
kubectl get services
Output comando
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
item ClusterIP 10.172.XXX.XXX <none> 80/TCP 84m
kubernetes ClusterIP 10.172.XXX.XXX <none> 443/TCP 137m
matchmaking ClusterIP 10.172.XXX.XXX <none> 80/TCP 84m
profile ClusterIP 10.172.XXX.XXX <none> 80/TCP 84m
tradepost ClusterIP 10.172.XXX.XXX <none> 80/TCP 84m
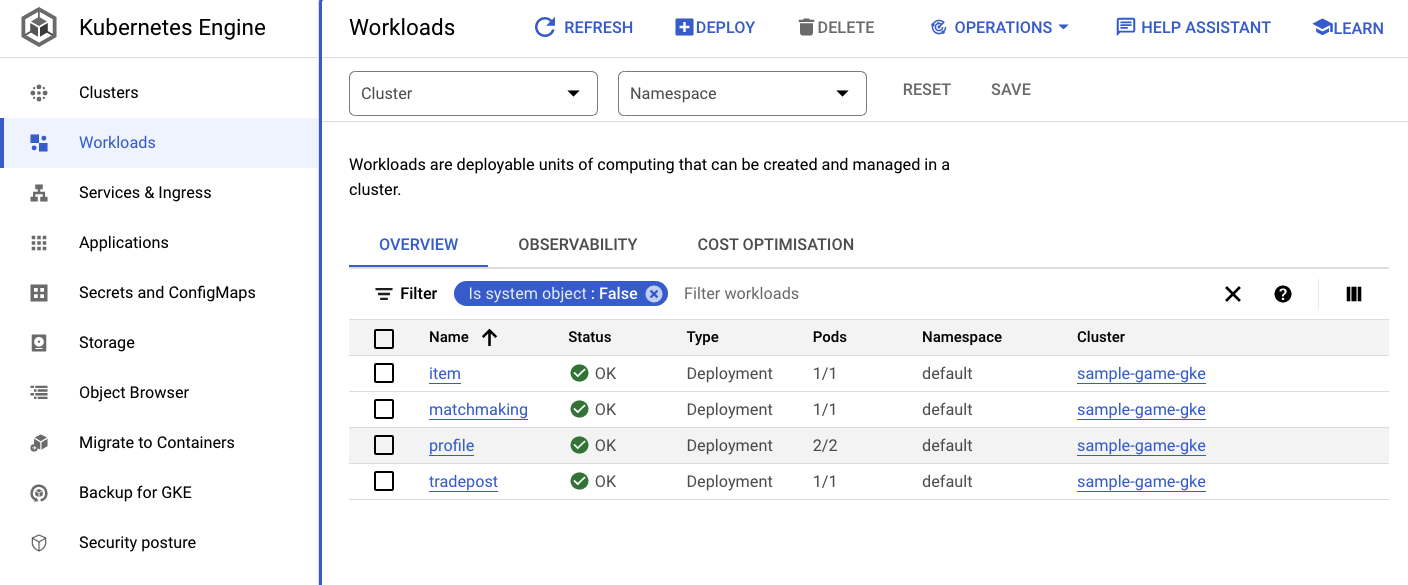
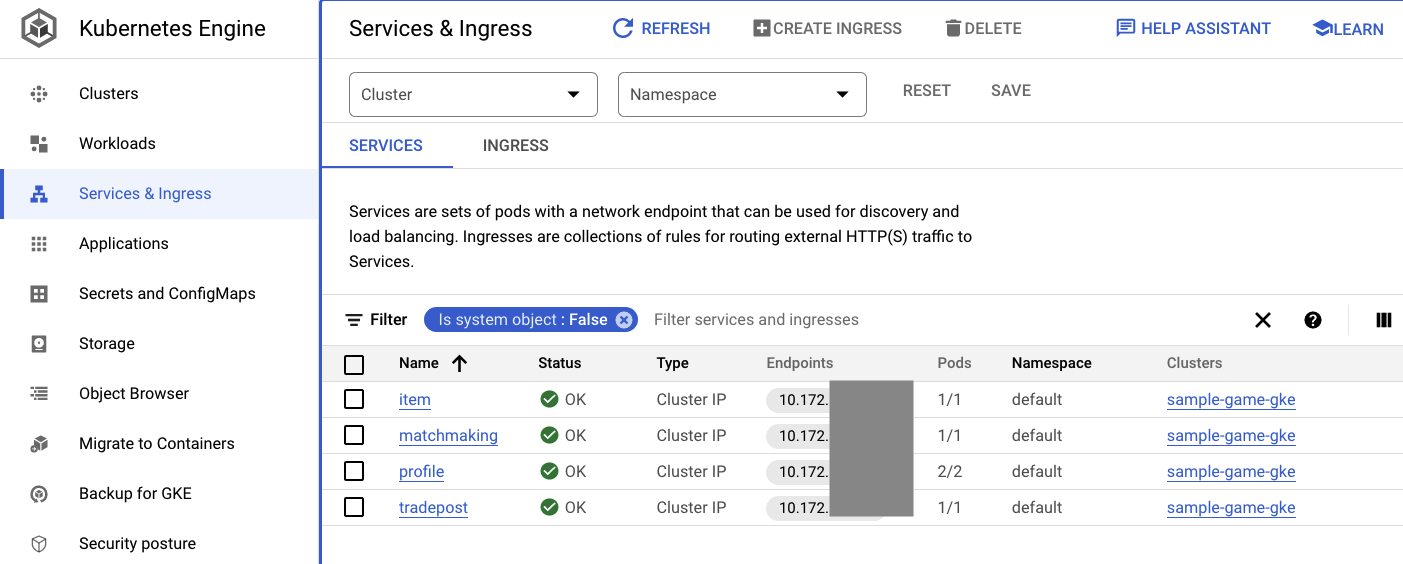
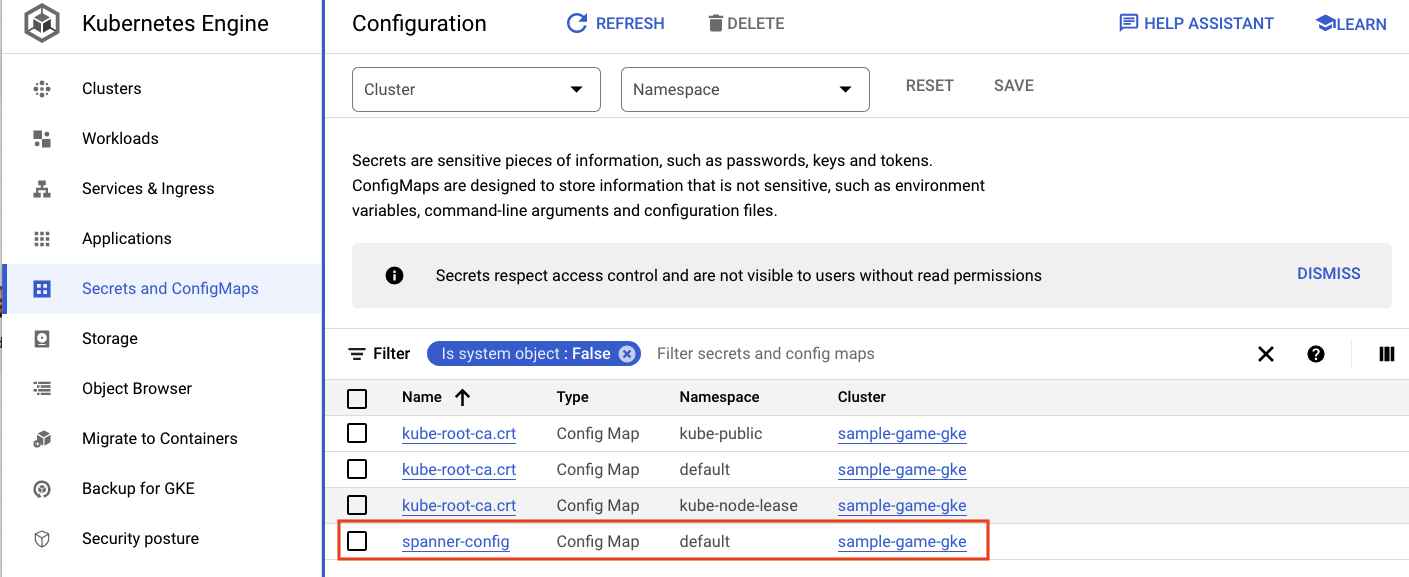
Puoi anche andare all'interfaccia utente di GKE in Cloud Console per visualizzare Workloads, Services e ConfigMaps.
Workload
Servizi
ConfigMap
Riepilogo
In questo passaggio, hai eseguito il deployment dei quattro servizi di backend in GKE Autopilot. Hai potuto eseguire il passaggio di Cloud Build e controllare l'avanzamento in Cloud Deploy e su Kubernetes in Cloud Console.
Hai anche imparato come questi servizi utilizzano Workload Identity per rappresentare un service account che dispone delle autorizzazioni corrette per leggere e scrivere dati nel database Spanner.
Passaggi successivi
Nella sezione successiva, eseguirai il deployment dei workload.
6. Esegui il deployment dei workload
Panoramica
Ora che i servizi di backend sono in esecuzione sul cluster, esegui il deployment dei carichi di lavoro.

I carichi di lavoro sono accessibili esternamente e ce n'è uno per ogni servizio di backend ai fini di questo codelab.
Questi workload sono script di generazione del carico basati su Locust che imitano i pattern di accesso reali previsti da questi servizi di esempio.
Esistono file per il processo Cloud Build:
$DEMO_HOME/workloads/cloudbuild.yaml(generato da Terraform)$DEMO_HOME/workloads/skaffold.yaml- un file
deployment.yamlper ogni workload
I file del workload deployment.yaml hanno un aspetto leggermente diverso dai file di deployment del servizio di backend.
Ecco un esempio tratto da matchmaking-workload:
apiVersion: v1
kind: Service
metadata:
name: matchmaking-workload
spec:
type: LoadBalancer
selector:
app: matchmaking-workload
ports:
- port: 8089
targetPort: 8089
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: matchmaking-workload
spec:
replicas: 1 # EDIT: Number of instances of deployment
selector:
matchLabels:
app: matchmaking-workload
template:
metadata:
labels:
app: matchmaking-workload
spec:
serviceAccountName: default
containers:
- name: matchmaking-workload
image: matchmaking-workload
ports:
- containerPort: 8089
resources:
requests:
cpu: "500m"
memory: "512Mi"
ephemeral-storage: "100Mi"
limits:
cpu: "500m"
memory: "512Mi"
ephemeral-storage: "100Mi"
La parte superiore del file definisce il servizio. In questo caso, viene creato un LoadBalancer e il workload viene eseguito sulla porta 8089.
LoadBalancer fornirà un IP esterno che può essere utilizzato per connettersi al workload.
apiVersion: v1
kind: Service
metadata:
name: matchmaking-workload
spec:
type: LoadBalancer
selector:
app: matchmaking-workload
ports:
- port: 8089
targetPort: 8089
La parte superiore della sezione di deployment contiene i metadati relativi al workload. In questo caso, viene eseguito il deployment di una sola replica:
replicas: 1
Tuttavia, la specifica del contenitore è diversa. Innanzitutto, utilizziamo un service account Kubernetes default. Questo account non dispone di privilegi speciali, poiché il workload non deve connettersi a risorse Google Cloud, ad eccezione dei servizi di backend in esecuzione sul cluster GKE.
L'altra differenza è che non sono necessarie variabili di ambiente per questi carichi di lavoro. Il risultato è una specifica di deployment più breve.
spec:
serviceAccountName: default
containers:
- name: matchmaking-workload
image: matchmaking-workload
ports:
- containerPort: 8089
Le impostazioni delle risorse sono simili a quelle dei servizi di backend. Ricorda che in questo modo GKE Autopilot sa quante risorse sono necessarie per soddisfare le richieste di tutti i pod in esecuzione sul cluster.
Procedi con il deployment dei workload.
Esegui il deployment dei workload
Come in precedenza, puoi inviare la richiesta di build utilizzando la riga di comando gcloud:
cd $DEMO_HOME/workloads gcloud builds submit --config=cloudbuild.yaml
Output comando
Creating temporary tarball archive of 18 file(s) totalling 26.2 KiB before compression.
Some files were not included in the source upload.
Check the gcloud log [/tmp/tmp.4Z9EqdPo6d/logs/(snip).log] to see which files and the contents of the
default gcloudignore file used (see `$ gcloud topic gcloudignore` to learn
more).
Uploading tarball of [.] to [gs://(project)_cloudbuild/source/(snip).tgz]
Created [https://cloudbuild.googleapis.com/v1/projects/(project)/locations/global/builds/(snip)].
Logs are available at [ https://console.cloud.google.com/cloud-build/builds/0daf20f6-(snip)?project=(snip) ].
gcloud builds submit only displays logs from Cloud Storage. To view logs from Cloud Logging, run:
gcloud beta builds submit
ID: 0daf20f6-(snip)
CREATE_TIME: (created_time)
DURATION: 1M41S
SOURCE: gs://(project)_cloudbuild/source/(snip).tgz
IMAGES: us-docker.pkg.dev/(project)/spanner-game-images/profile-workload:0daf20f6-(snip) (+4 more)
STATUS: SUCCESS
Assicurati di controllare i log di Cloud Build e la pipeline Cloud Deploy in Cloud Console per verificare lo stato. Per i workload, la pipeline Cloud Deploy è sample-game-workloads:
Una volta completato il deployment, controlla lo stato con kubectl in Cloud Shell:
kubectl get pods
Output comando
NAME READY STATUS RESTARTS AGE
game-workload-7ff44cb657-pxxq2 1/1 Running 0 12m
item-6b9d5f678c-cr29w 1/1 Running 0 9m6s
item-generator-7bb4f57cf8-5r85b 1/1 Running 0 12m
matchmaking-5bcf799b76-lg8zf 1/1 Running 0 117m
matchmaking-workload-76df69dbdf-jds9z 1/1 Running 0 12m
profile-565bbf4c65-kphdl 1/1 Running 0 121m
profile-565bbf4c65-xw74j 1/1 Running 0 121m
profile-workload-76d6db675b-kzwng 1/1 Running 0 12m
tradepost-68b87ccd44-gw55r 1/1 Running 0 116m
tradepost-workload-56c55445b5-b5822 1/1 Running 0 12m
Quindi, controlla i servizi del carico di lavoro per vedere LoadBalancer in azione:
kubectl get services
Output comando
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
game-workload LoadBalancer *snip* 35.XX.XX.XX 8089:32483/TCP 12m
item ClusterIP *snip* <none> 80/TCP 121m
item-generator LoadBalancer *snip* 34.XX.XX.XX 8089:32581/TCP 12m
kubernetes ClusterIP *snip* <none> 443/TCP 174m
matchmaking ClusterIP *snip* <none> 80/TCP 121m
matchmaking-workload LoadBalancer *snip* 34.XX.XX.XX 8089:31735/TCP 12m
profile ClusterIP *snip* <none> 80/TCP 121m
profile-workload LoadBalancer *snip* 34.XX.XX.XX 8089:32532/TCP 12m
tradepost ClusterIP *snip* <none> 80/TCP 121m
tradepost-workload LoadBalancer *snip* 34.XX.XX.XX 8089:30002/TCP 12m
Riepilogo
Ora hai eseguito il deployment dei carichi di lavoro nel cluster GKE. Questi carichi di lavoro non richiedono autorizzazioni IAM aggiuntive e sono accessibili esternamente sulla porta 8089 utilizzando il servizio LoadBalancer.
Passaggi successivi
Con i servizi di backend e i carichi di lavoro in esecuzione, è il momento di "giocare"!
7. Inizia a giocare
Panoramica
I servizi di backend per il tuo "gioco" di esempio sono ora in esecuzione e hai anche i mezzi per generare "giocatori" che interagiscono con questi servizi utilizzando i workload.
Ogni carico di lavoro utilizza Locust per simulare il carico effettivo sulle nostre API di servizio. In questo passaggio, eseguirai diversi workload per generare carico sul cluster GKE e su Spanner, nonché per archiviare i dati su Spanner.
Ecco una descrizione di ogni workload:
- Il workload
item-generatorè un workload rapido per generare un elenco di game_items che i giocatori possono acquisire durante il gioco. profile-workloadsimula la registrazione e l'accesso dei giocatori.- La
matchmaking-workloadsimula i giocatori in coda per essere assegnati alle partite. game-workloadsimula l'acquisizione di game_item e denaro da parte dei giocatori nel corso della partita.- L'
tradepost-workloadsimula la possibilità per i giocatori di vendere e acquistare oggetti nel mercato.
Questo codelab metterà in evidenza in particolare l'esecuzione di item-generator e profile-workload.
Esegui item-generator
item-generator utilizza l'endpoint del servizio di backend item per aggiungere game_items a Spanner. Questi elementi sono necessari per il corretto funzionamento di game-workload e tradepost-workload.
Il primo passaggio consiste nell'ottenere l'IP esterno del servizio item-generator. In Cloud Shell, esegui questo comando:
# The external IP is the 4th column of the output
kubectl get services | grep item-generator | awk '{print $4}'
Output comando
{ITEMGENERATOR_EXTERNAL_IP}
Ora apri una nuova scheda del browser e vai all'indirizzo http://{ITEMGENERATOR_EXTERNAL_IP}:8089. Dovresti visualizzare una pagina simile a questa:
Lascia i valori predefiniti 1 per users e spawn. Per host, inserisci http://item. Fai clic sulle opzioni avanzate e inserisci 10s per la durata.
Ecco come dovrebbe apparire la configurazione:
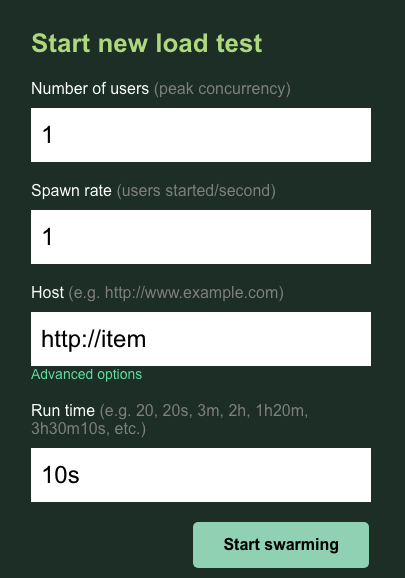
Fai clic su "Avvia sciame".
Le statistiche inizieranno a essere visualizzate per le richieste emesse sull'endpoint POST /items. Dopo 10 secondi il caricamento si interromperà.
Fai clic su Charts e vedrai alcuni grafici sul rendimento di queste richieste.

Ora vuoi verificare se i dati sono stati inseriti nel database Spanner.
Per farlo, fai clic sul menu a tre linee e vai a "Chiave". Da questa pagina, vai a sample-instance e sample-database. Quindi, fai clic su "Query".
Vogliamo selezionare il numero di game_items:
SELECT COUNT(*) FROM game_items;
In basso, vedrai il risultato.
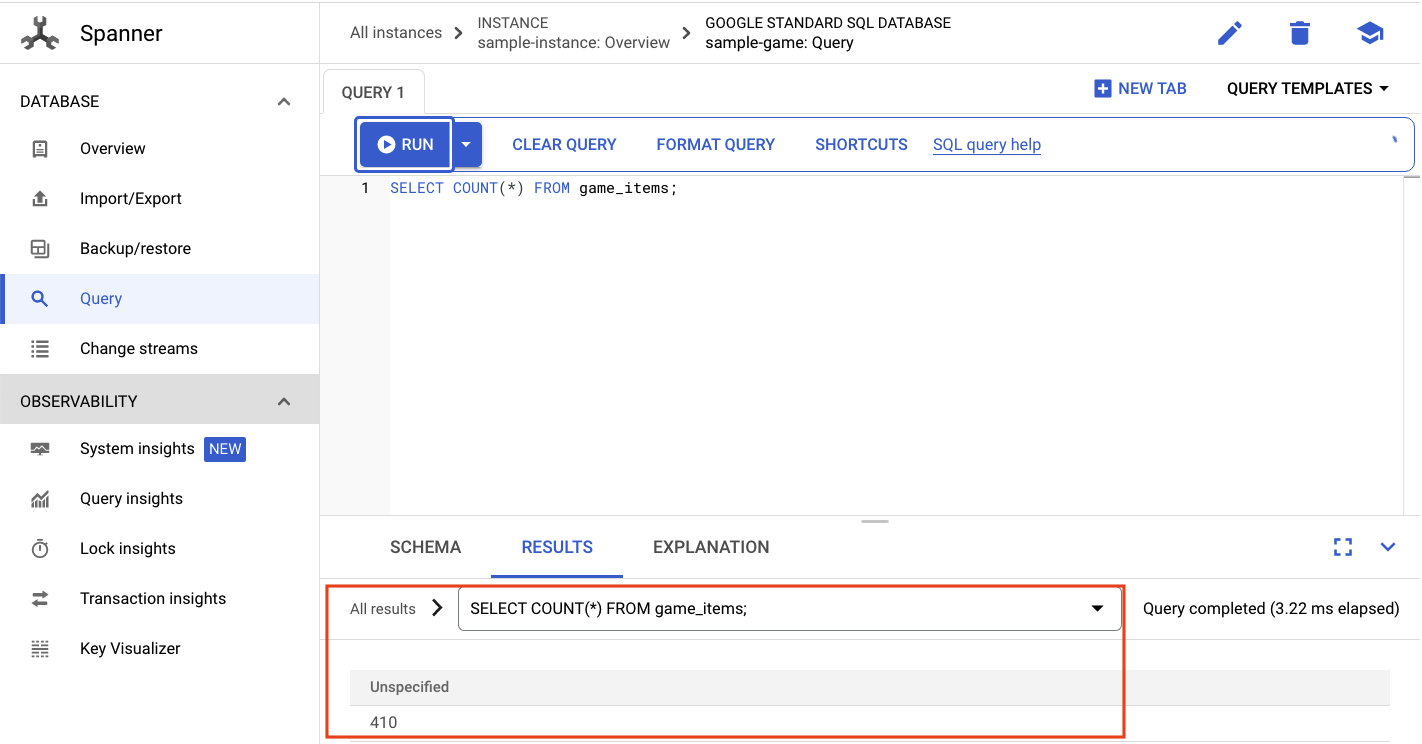
Non abbiamo bisogno di molte game_items. Ma ora sono disponibili per l'acquisto da parte dei giocatori.
Esegui il profilo di lavoro
Una volta inserito il game_items, il passaggio successivo è far registrare i giocatori per poter giocare.
profile-workload utilizzerà Locust per simulare giocatori che creano account, accedono, recuperano informazioni del profilo ed escono. Tutti questi test verificano gli endpoint del servizio di backend profile in un tipico workload simile a quello di produzione.
Per eseguire questo comando, ottieni l'IP esterno profile-workload:
# The external IP is the 4th column of the output
kubectl get services | grep profile-workload | awk '{print $4}'
Output comando
{PROFILEWORKLOAD_EXTERNAL_IP}
Ora apri una nuova scheda del browser e vai all'indirizzo http://{PROFILEWORKLOAD_EXTERNAL_IP}:8089. Dovresti visualizzare una pagina di Locust simile a quella precedente.
In questo caso, utilizzerai http://profile per l'host. Inoltre, non specificherai un runtime nelle opzioni avanzate. Inoltre, specifica users come 4, in modo da simulare 4 richieste utente alla volta.
Il test profile-workload dovrebbe avere il seguente aspetto:
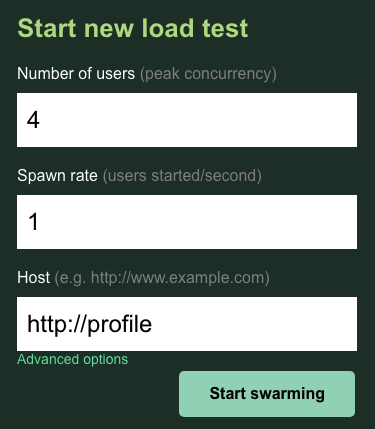
Fai clic su "Avvia sciame".
Come prima, inizieranno a essere visualizzate le statistiche per i vari endpoint REST profile. Fai clic sui grafici per visualizzare un'istantanea del rendimento.

Riepilogo
In questo passaggio, hai generato alcuni game_items e poi hai eseguito una query sulla tabella game_items utilizzando l'interfaccia utente di query Spanner nella console Cloud.
Hai anche consentito ai giocatori di registrarsi al tuo gioco e hai visto come Locust è in grado di creare carichi di lavoro simili a quelli di produzione rispetto ai tuoi servizi di backend.
Passaggi successivi
Dopo aver eseguito i carichi di lavoro, devi controllare il comportamento del cluster GKE e dell'istanza Spanner.
8. Rivedi l'utilizzo di GKE e Spanner
Con il servizio di profilazione in esecuzione, è il momento di verificare il comportamento del cluster GKE Autopilot e di Cloud Spanner.
Controlla il cluster GKE
Vai al cluster Kubernetes. Tieni presente che, dopo aver eseguito il deployment dei carichi di lavoro e dei servizi, al cluster sono stati aggiunti alcuni dettagli relativi alle vCPU e alla memoria totali. Queste informazioni non erano disponibili quando non c'erano workload sul cluster.

Ora, fai clic sul cluster sample-game-gke e passa alla scheda Osservabilità:
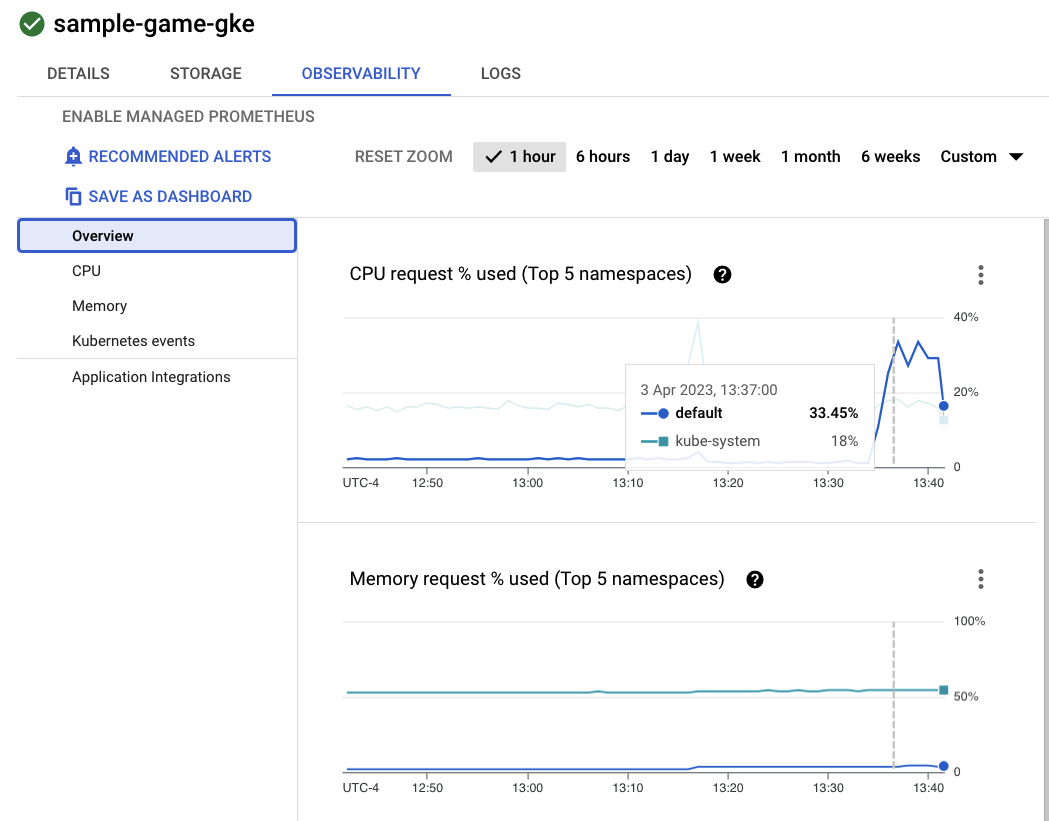
Lo spazio dei nomi Kubernetes default dovrebbe aver superato lo spazio dei nomi kube-system per l'utilizzo della CPU, poiché i nostri workload e servizi di backend vengono eseguiti su default. In caso contrario, assicurati che profile workload sia ancora in esecuzione e attendi qualche minuto per l'aggiornamento dei grafici.
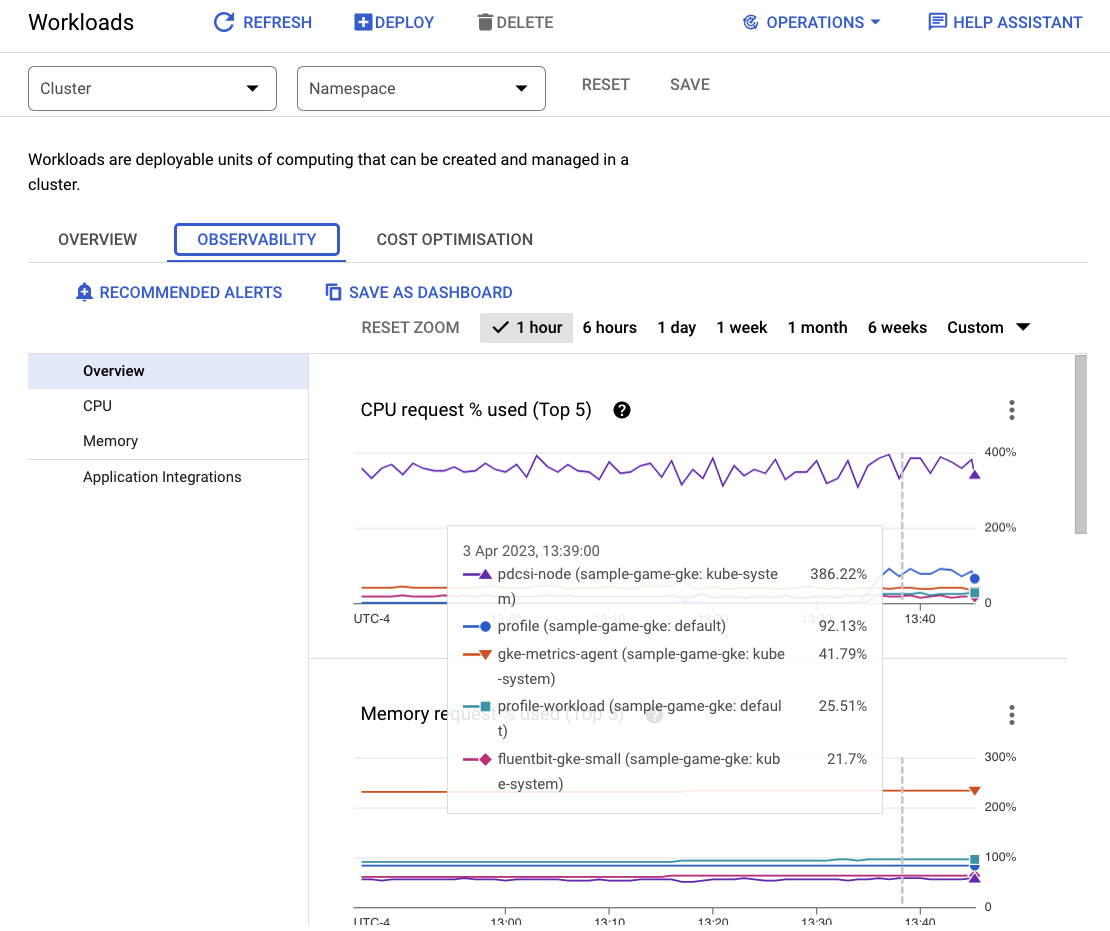
Per vedere quali carichi di lavoro utilizzano la maggior parte delle risorse, vai alla dashboard Workloads.
Invece di esaminare ogni workload singolarmente, vai direttamente alla scheda Osservabilità della dashboard. Dovresti notare che l'utilizzo della CPU di profile e profile-workload è aumentato.
Ora controlla Cloud Spanner.
Controlla l'istanza Cloud Spanner
Per controllare le prestazioni di Cloud Spanner, vai a Spanner e fai clic sull'istanza sample-instance e sul database sample-game.
Da qui, vedrai una scheda Approfondimenti di sistema nel menu a sinistra:
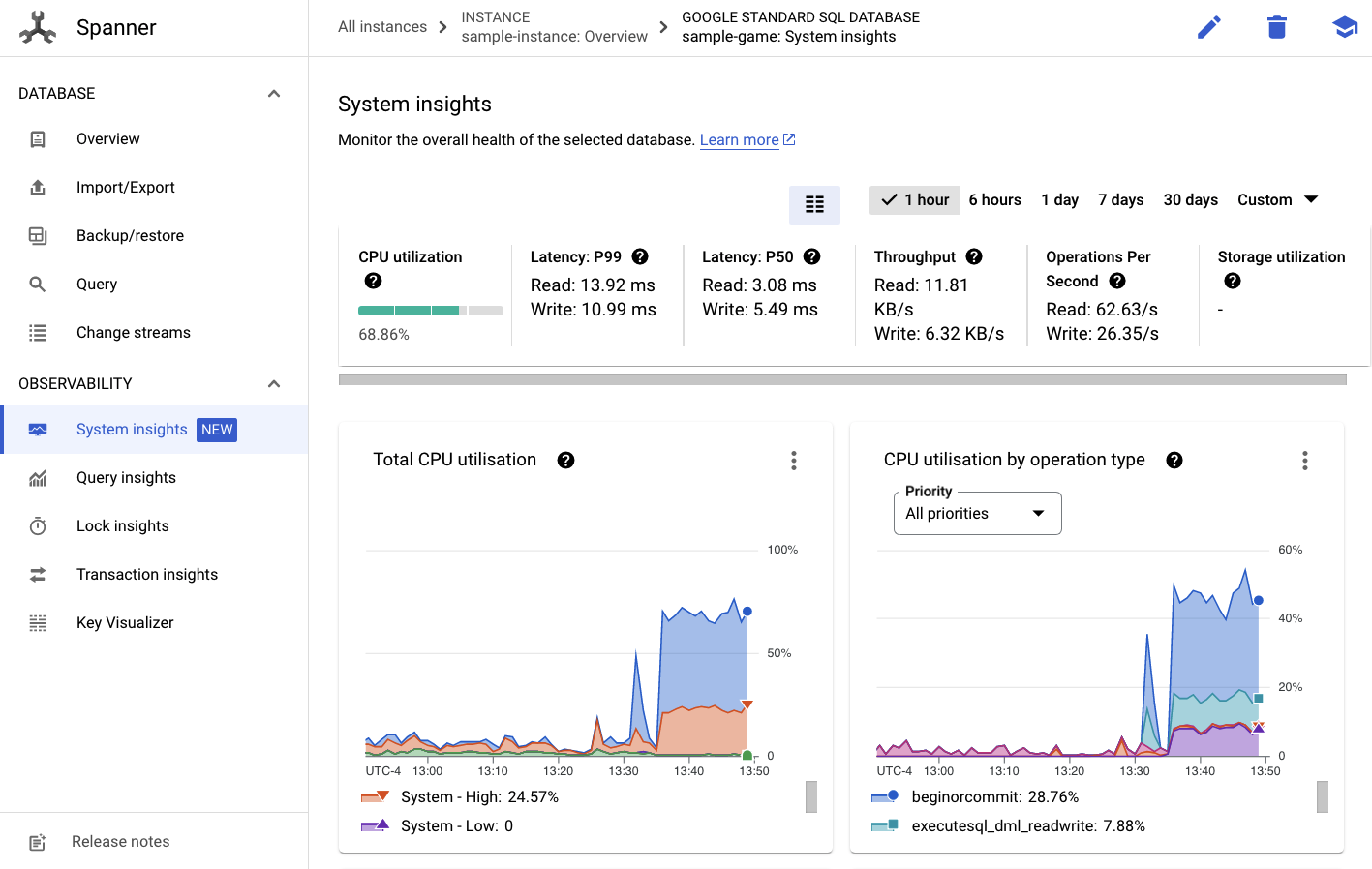
Qui sono presenti molti grafici che ti aiutano a comprendere le prestazioni generali della tua istanza Spanner, tra cui CPU utilization, transaction latency and locking e query throughput.
Oltre a System Insights, puoi ottenere informazioni più dettagliate sul carico di lavoro delle query esaminando gli altri link nella sezione Osservabilità:
- Gli insight sulle query aiutano a identificare le prime N query che utilizzano risorse su Spanner.
- Gli insight su transazioni e blocchi aiutano a identificare le transazioni con latenze elevate.
- Key Visualizer aiuta a visualizzare i pattern di accesso e può aiutarti a individuare gli hotspot nei dati.
Riepilogo
In questo passaggio, hai imparato a controllare alcune metriche di rendimento di base per GKE Autopilot e Spanner.
Ad esempio, con il workload del profilo in esecuzione, esegui una query sulla tabella players per ottenere maggiori informazioni sui dati archiviati.
Passaggi successivi
A questo punto, è il momento di fare pulizia.
9. Pulizia
Prima di eseguire la pulizia, puoi esplorare gli altri workload non trattati. Nello specifico matchmaking-workload, game-workload e tradepost-workload.
Quando hai finito di "giocare" con il gioco, puoi pulire il tuo parco giochi. Per fortuna, è piuttosto semplice.
Innanzitutto, se il tuo profile-workload è ancora in esecuzione nel browser, vai e interrompilo:
Fai lo stesso per ogni workload che potresti aver testato.
Poi, in Cloud Shell, vai alla cartella dell'infrastruttura. destroy l'infrastruttura utilizzando Terraform:
cd $DEMO_HOME/infrastructure
terraform destroy
# type 'yes' when asked
Output comando
Plan: 0 to add, 0 to change, 46 to destroy.
Do you really want to destroy all resources?
Terraform will destroy all your managed infrastructure, as shown above.
There is no undo. Only 'yes' will be accepted to confirm.
Enter a value: yes
*snip*
Destroy complete! Resources: 46 destroyed.
Nella console Cloud, vai a Spanner, Kubernetes Cluster, Artifact Registry, Cloud Deploy e IAM per verificare che tutte le risorse siano state rimosse.
10. Complimenti!
Congratulazioni, hai eseguito correttamente il deployment di applicazioni Go di esempio su GKE Autopilot e le hai connesse a Cloud Spanner utilizzando Workload Identity.
Inoltre, questa infrastruttura è stata configurata e rimossa facilmente in modo ripetibile utilizzando Terraform.
Puoi scoprire di più sui servizi Google Cloud con cui hai interagito in questo codelab:
Passaggi successivi
Ora che hai una conoscenza di base di come possono funzionare insieme GKE Autopilot e Cloud Spanner, perché non fai il passo successivo e inizi a creare la tua applicazione per utilizzare questi servizi?