
1. מבוא
Cloud Spanner הוא שירות מנוהל של מסד נתונים רלציוני, שניתן להרחבה אופקית, מבוזר גלובלית ומספק עסקאות ACID וסמנטיקה של SQL, בלי להתפשר על ביצועים וזמינות גבוהה.
GKE Autopilot הוא מצב פעולה ב-GKE שבו Google מנהלת את הגדרת האשכול, כולל הצמתים, ההתאמה לגודל, האבטחה והגדרות אחרות שהוגדרו מראש, כדי לפעול בהתאם לשיטות המומלצות. לדוגמה, ב-GKE Autopilot מופעלת התכונה Workload Identity לניהול הרשאות שירות.
בשיעור ה-Lab הזה נסביר איך לחבר כמה שירותי קצה עורפי שפועלים ב-GKE Autopilot למסד נתונים של Cloud Spanner.
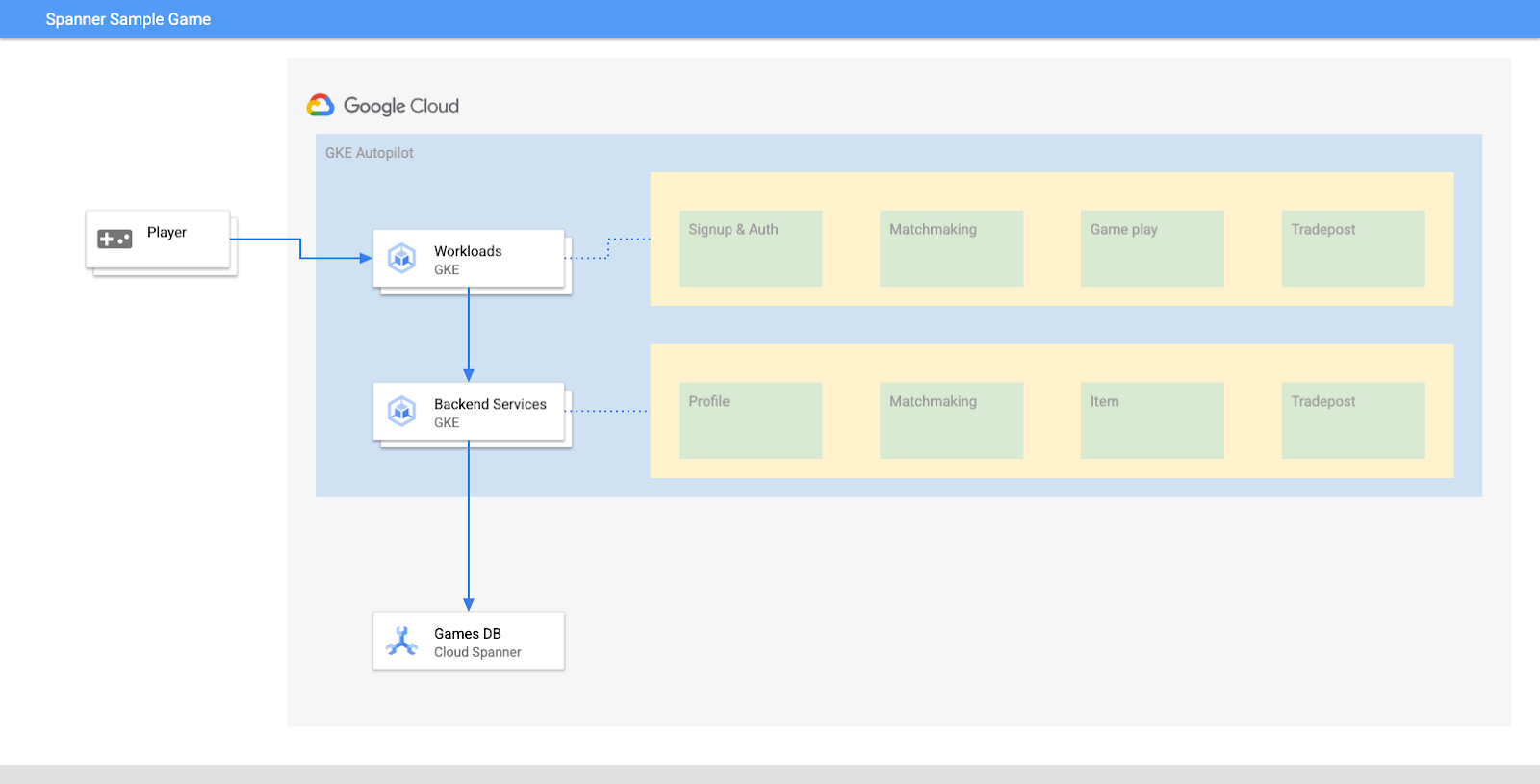
בשיעור ה-Lab הזה, קודם תגדירו פרויקט ותפעילו את Cloud Shell. לאחר מכן תפרסו את התשתית באמצעות Terraform.
אחרי שהתהליך יסתיים, תשתמשו ב-Cloud Build וב-Cloud Deploy כדי לבצע העברה ראשונית של הסכימה למסד הנתונים של המשחקים, לפרוס את שירותי ה-Backend ואז לפרוס את עומסי העבודה.
השירותים ב-codelab הזה זהים לאלה שב-codelab Cloud Spanner Getting Started with Games Development. לא צריך לעבור את ה-codelab הזה כדי להפעיל את השירותים ב-GKE ולהתחבר ל-Spanner. אבל אם אתם רוצים לקבל פרטים נוספים על השירותים הספציפיים האלה שפועלים ב-Spanner, כדאי לעיין בו.
אחרי שהעומסים ושירותי ה-Backend פועלים, אפשר להתחיל ליצור עומס ולראות איך השירותים פועלים יחד.
לבסוף, תסירו את המשאבים שנוצרו בשיעור ה-Lab הזה.
מה תפַתחו
במסגרת ה-Lab הזה:
- הקצאת התשתית באמצעות Terraform
- יצירת סכימת מסד הנתונים באמצעות תהליך העברת סכימה ב-Cloud Build
- פריסת ארבעת שירותי הקצה העורפי של Golang שמסתמכים על Workload Identity כדי להתחבר ל-Cloud Spanner
- פורסים את ארבעת שירותי עומס העבודה שמשמשים לסימולציה של עומס בשירותי הקצה העורפי.
מה תלמדו
- איך מקצים צינורות עיבוד נתונים של GKE Autopilot, Cloud Spanner ו-Cloud Deploy באמצעות Terraform
- איך Workload Identity מאפשר לשירותים ב-GKE להתחזות לחשבונות שירות כדי לגשת להרשאות IAM ולעבוד עם Cloud Spanner
- איך ליצור עומס שדומה לעומס בסביבת ייצור ב-GKE וב-Cloud Spanner באמצעות Locust.io
הדרישות
2. הגדרה ודרישות
יצירת פרויקט
אם עדיין אין לכם חשבון Google (Gmail או Google Apps), אתם צריכים ליצור חשבון. נכנסים אל Google Cloud Platform Console ( console.cloud.google.com) ויוצרים פרויקט חדש.
אם כבר יש לכם פרויקט, לוחצים על התפריט הנפתח לבחירת פרויקט בפינה הימנית העליונה של המסוף:

ולוחצים על הלחצן פרויקט חדש בתיבת הדו-שיח שמופיעה כדי ליצור פרויקט חדש:
אם עדיין אין לכם פרויקט, תופיע תיבת דו-שיח כמו זו שבהמשך כדי ליצור את הפרויקט הראשון:
בתיבת הדו-שיח הבאה ליצירת פרויקט, אפשר להזין את הפרטים של הפרויקט החדש:
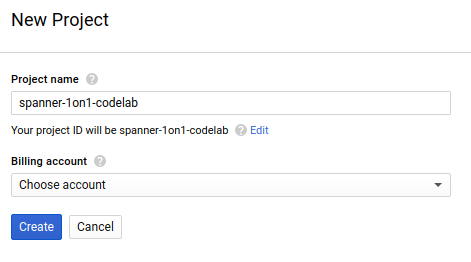
חשוב לזכור את מזהה הפרויקט, שהוא שם ייחודי בכל הפרויקטים ב-Google Cloud (השם שלמעלה כבר תפוס ולא יתאים לכם, מצטערים!). בהמשך ה-codelab הזה נתייחס אליו כאל PROJECT_ID.
לאחר מכן, אם עדיין לא עשיתם זאת, תצטרכו להפעיל את החיוב במסוף למפתחים כדי להשתמש במשאבים של Google Cloud ולהפעיל את Cloud Spanner API.
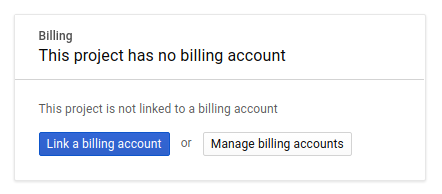
העלות של ה-Codelab הזה לא אמורה להיות גבוהה מכמה דולרים, אבל היא יכולה להיות גבוהה יותר אם תחליטו להשתמש ביותר משאבים או אם תשאירו אותם פועלים (ראו את הקטע 'ניקוי נתונים' בסוף המסמך הזה). התמחור של Google Cloud Spanner מתועד כאן, והתמחור של GKE Autopilot מתועד כאן.
משתמשים חדשים ב-Google Cloud Platform זכאים לתקופת ניסיון בחינם בשווי 300$, כך שסדנת ה-codelab הזו אמורה להיות בחינם לגמרי.
הגדרה של Cloud Shell
אפשר להפעיל את Google Cloud ואת Spanner מרחוק מהמחשב הנייד, אבל ב-codelab הזה נשתמש ב-Google Cloud Shell, סביבת שורת פקודה שפועלת בענן.
המכונה הווירטואלית הזו מבוססת על Debian, וטעונים בה כל הכלים הדרושים למפתחים. יש בה ספריית בית בנפח מתמיד של 5GB והיא פועלת ב-Google Cloud, מה שמשפר מאוד את הביצועים והאימות ברשת. כלומר, כל מה שצריך כדי לבצע את ההוראות במאמר הזה הוא דפדפן (כן, זה עובד ב-Chromebook).
- כדי להפעיל את Cloud Shell ממסוף Cloud, פשוט לוחצים על 'הפעלת Cloud Shell'
 (הקצאת המשאבים והחיבור לסביבה אמורים להימשך רק כמה רגעים).
(הקצאת המשאבים והחיבור לסביבה אמורים להימשך רק כמה רגעים).
אחרי שמתחברים ל-Cloud Shell, אמור להופיע אימות שכבר בוצע, ושהפרויקט כבר הוגדר ל-PROJECT_ID.
gcloud auth list
פלט הפקודה
Credentialed accounts:
- <myaccount>@<mydomain>.com (active)
gcloud config list project
פלט הפקודה
[core]
project = <PROJECT_ID>
אם מסיבה כלשהי הפרויקט לא מוגדר, פשוט מריצים את הפקודה הבאה:
gcloud config set project <PROJECT_ID>
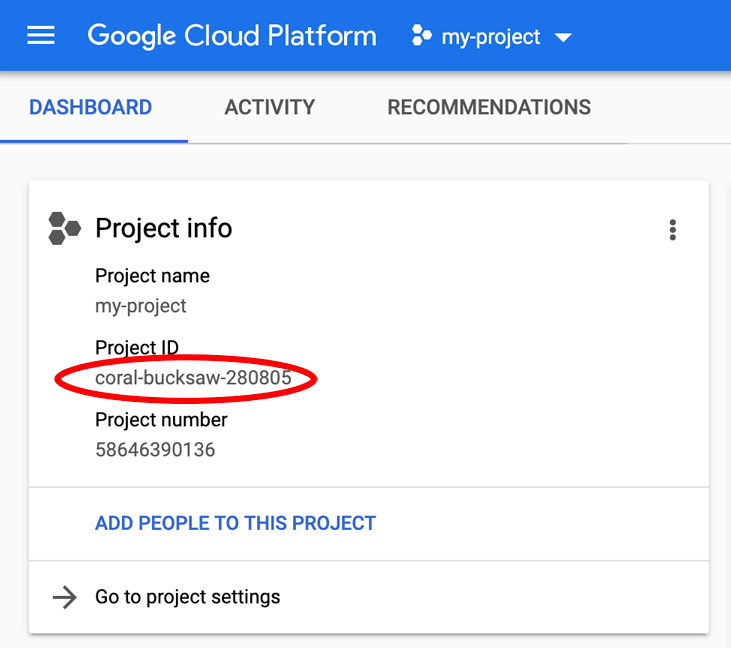
מחפש את PROJECT_ID? כדאי לבדוק באיזה מזהה השתמשתם בשלבי ההגדרה, או לחפש אותו בלוח הבקרה של Cloud Console:
ב-Cloud Shell מוגדרים גם כמה משתני סביבה כברירת מחדל, שיכולים להיות שימושיים כשמריצים פקודות בעתיד.
echo $GOOGLE_CLOUD_PROJECT
פלט הפקודה
<PROJECT_ID>
הורדת הקוד
ב-Cloud Shell, אפשר להוריד את הקוד לשיעור ה-Lab הזה:
git clone https://github.com/cloudspannerecosystem/spanner-gaming-sample.git
פלט הפקודה
Cloning into 'spanner-gaming-sample'...
*snip*
ה-Codelab הזה מבוסס על גרסה v0.1.3, לכן צריך לבדוק את התג הזה:
cd spanner-gaming-sample
git fetch --all --tags
# Check out v0.1.3 release
git checkout tags/v0.1.3 -b v0.1.3-branch
פלט הפקודה
Switched to a new branch 'v0.1.3-branch'
עכשיו מגדירים את ספריית העבודה הנוכחית כמשתנה הסביבה DEMO_HOME. כך יהיה קל יותר לנווט בין החלקים השונים של ה-codelab.
export DEMO_HOME=$(pwd)
סיכום
בשלב הזה הגדרתם פרויקט חדש, הפעלתם את Cloud Shell והורדתם את הקוד לשיעור ה-Lab הזה.
הבא בתור
בשלב הבא, תספקו את התשתית באמצעות Terraform.
3. הקצאת תשתית
סקירה כללית
אחרי שהפרויקט מוכן, הגיע הזמן להפעיל את התשתית. השירותים האלה כוללים את רשתות ה-VPC, Cloud Spanner, GKE Autopilot, Artifact Registry לאחסון התמונות שיפעלו ב-GKE, את צינורות העיבוד של Cloud Deploy לשירותי הקצה העורפי ולעומסי העבודה, ולבסוף את חשבונות השירות ואת הרשאות ה-IAM שנדרשות כדי להשתמש בשירותים האלה.
זה המון. אבל למזלנו, אפשר להשתמש ב-Terraform כדי לפשט את ההגדרה. Terraform הוא כלי של 'תשתית כקוד' (IaC), שמאפשר לנו לציין מה אנחנו צריכים לפרויקט הזה בסדרה של קבצים מסוג .tf. כך קל להקצות תשתית.
לא נדרש ידע ב-Terraform כדי להשלים את ה-codelab הזה. אבל אם רוצים לראות מה קורה בשלבים הבאים, אפשר לבדוק מה נוצר בקבצים האלה שנמצאים בספרייה infrastructure:
- vpc.tf
- backend_gke.tf
- spanner.tf
- artifact_registry.tf
- pipelines.tf
- iam.tf
הגדרת Terraform
ב-Cloud Shell, עוברים לספרייה infrastructure ומפעילים את Terraform:
cd $DEMO_HOME/infrastructure
terraform init
פלט הפקודה
Initializing the backend...
Initializing provider plugins...
*snip*
Terraform has been successfully initialized!
You may now begin working with Terraform. Try running "terraform plan" to see
any changes that are required for your infrastructure. All Terraform commands
should now work.
If you ever set or change modules or backend configuration for Terraform,
rerun this command to reinitialize your working directory. If you forget, other
commands will detect it and remind you to do so if necessary.
לאחר מכן, מגדירים את Terraform על ידי העתקת terraform.tfvars.sample ושינוי ערך הפרויקט. אפשר לשנות גם את המשתנים האחרים, אבל הפרויקט הוא היחיד שצריך לשנות כדי לעבוד עם הסביבה שלכם.
cp terraform.tfvars.sample terraform.tfvars
# edit gcp_project using the project environment variable
sed -i "s/PROJECT/$GOOGLE_CLOUD_PROJECT/" terraform.tfvars
הקצאת התשתית
עכשיו הגיע הזמן להקצות את התשתית.
terraform apply
# review the list of things to be created
# type 'yes' when asked
פלט הפקודה
Plan: 46 to add, 0 to change, 0 to destroy.
Do you want to perform these actions?
Terraform will perform the actions described above.
Only 'yes' will be accepted to approve.
Enter a value: yes
google_project_service.project["container.googleapis.com"]: Creating...
*snip*
Apply complete! Resources: 46 added, 0 changed, 0 destroyed.
בדיקה של מה שנוצר
כדי לוודא מה נוצר, כדאי לבדוק את המוצרים ב-Cloud Console.
Cloud Spanner
קודם בודקים את Cloud Spanner. כדי לעשות את זה, עוברים לתפריט ההמבורגר ולוחצים על Spanner. יכול להיות שתצטרכו ללחוץ על 'הצגת מוצרים נוספים' כדי למצוא אותו ברשימה.
תועברו לרשימה של מכונות Spanner. לוחצים על המופע כדי לראות את מסדי הנתונים. הוא אמור להיראות כך:
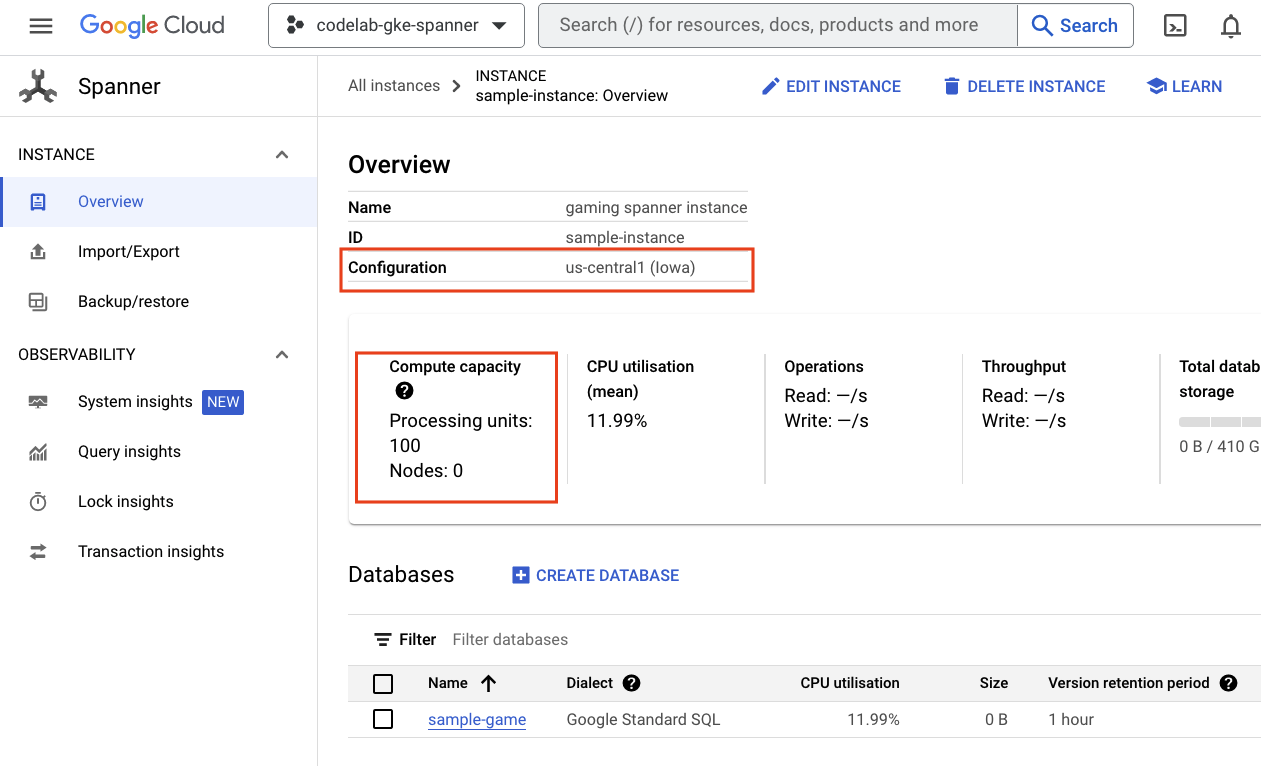
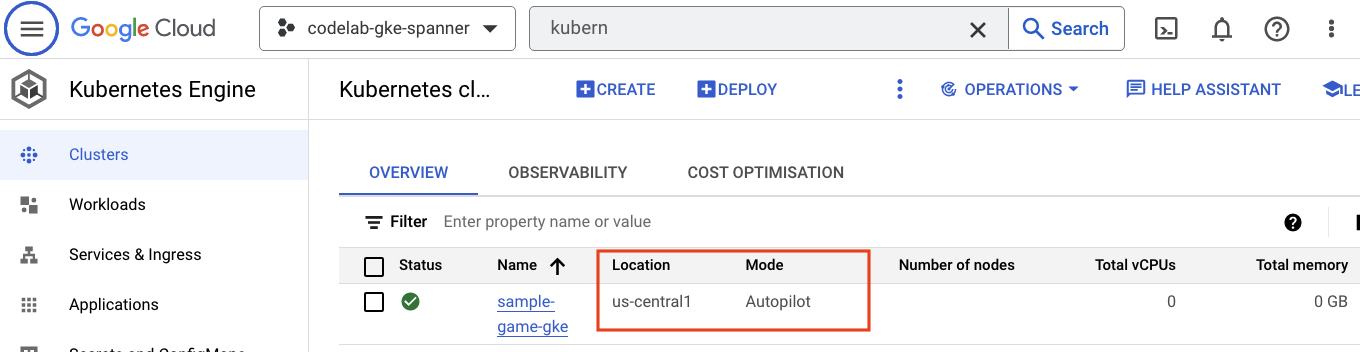
GKE Autopilot
לאחר מכן, כדי לבדוק את GKE, עוברים לתפריט ההמבורגר ולוחצים על Kubernetes Engine => Clusters. כאן יופיע אשכול sample-games-gke שפועל במצב Autopilot.
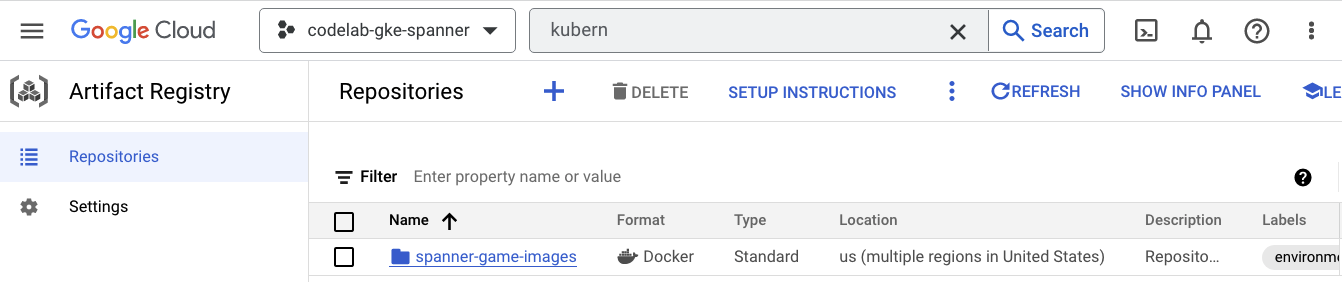
Artifact Registry
עכשיו צריך לראות איפה התמונות יישמרו. לכן, לוחצים על סמל האפשרויות הנוספות (3 קווים) ומחפשים את Artifact Registry=>Repositories. Artifact Registry נמצא בקטע CI/CD בתפריט.
כאן יופיע מאגר Docker בשם spanner-game-images. בשלב הזה, השדה הזה יהיה ריק.
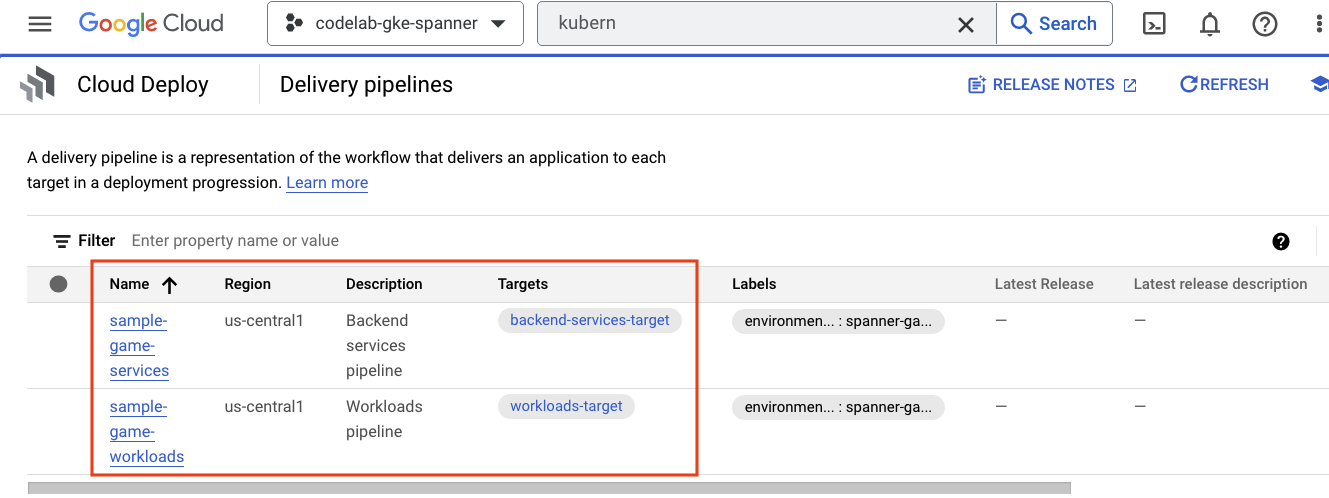
Cloud Deploy
צינורות העיבוד נוצרו ב-Cloud Deploy, כדי ש-Cloud Build יוכל לספק שלבים לבניית התמונות ואז לפרוס אותן באשכול GKE שלנו.
עוברים לתפריט ההמבורגר ומחפשים את Cloud Deploy, שנמצא גם בקטע CI/CD בתפריט.
כאן תראו שני צינורות: אחד לשירותי קצה עורפי ואחד לעומסי עבודה. שניהם פורסים את התמונות לאותו אשכול GKE, אבל זה מאפשר לנו להפריד את הפריסות.
IAM
לבסוף, בודקים את הדף IAM במסוף Cloud כדי לוודא שחשבונות השירות נוצרו. מנווטים לתפריט ההמבורגר ומוצאים את האפשרות IAM and Admin=>Service accounts. הוא אמור להיראות כך:
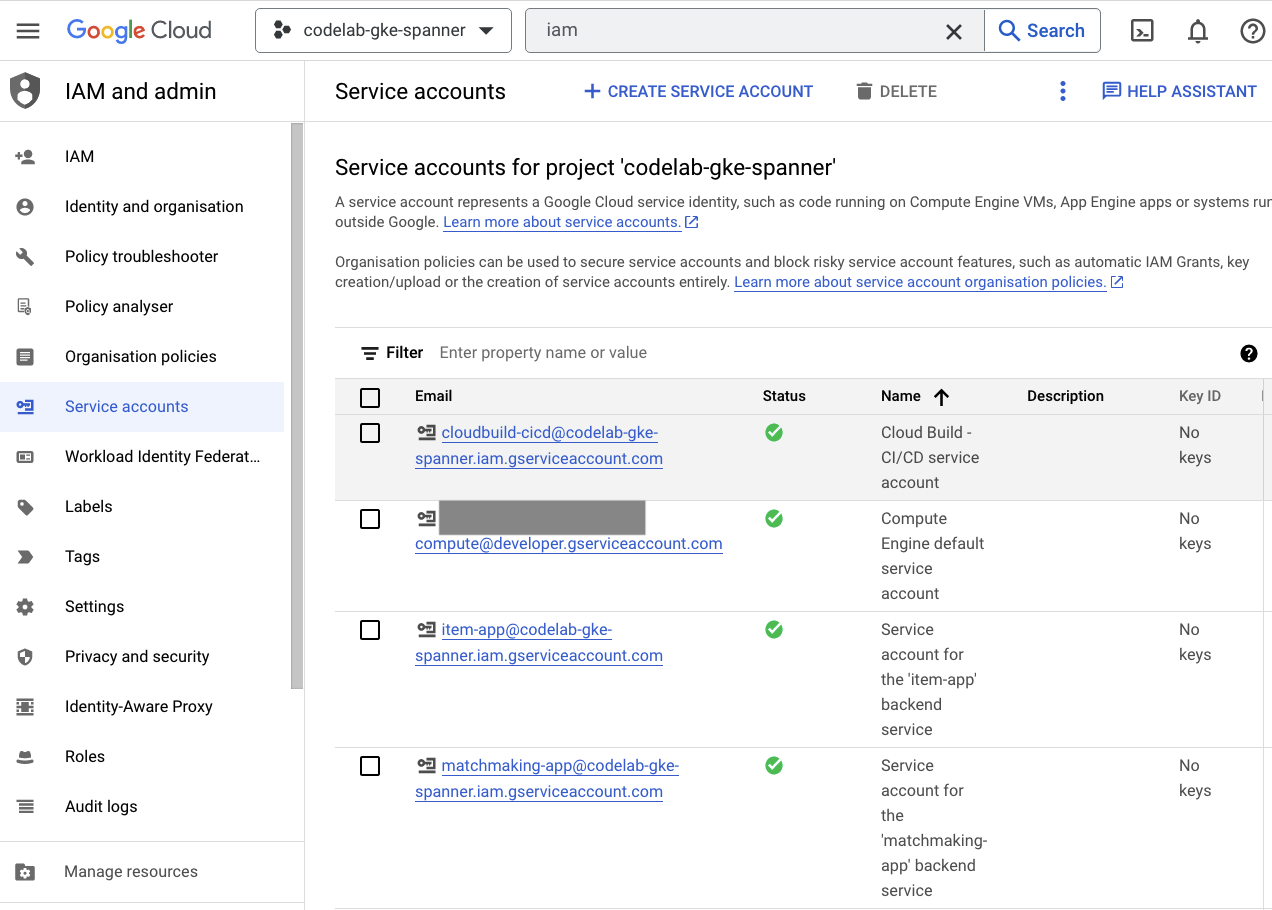
יש שישה חשבונות שירות בסך הכול שנוצרים על ידי Terraform:
- חשבון השירות של המחשב שמוגדר כברירת מחדל. המאפיין הזה לא בשימוש ב-Codelab הזה.
- החשבון cloudbuild-cicd משמש לשלבים של Cloud Build ו-Cloud Deploy.
- ארבעה חשבונות 'אפליקציה' שמשמשים את שירותי ה-Backend שלנו לאינטראקציה עם Cloud Spanner.
בשלב הבא, צריך להגדיר את kubectl כך שיפעל עם אשכול GKE.
הגדרת kubectl
# Name of GKE cluster from terraform.tfvars file
export GKE_CLUSTER=sample-game-gke
# get GKE credentials
gcloud container clusters get-credentials $GKE_CLUSTER --region us-central1
# Check that no errors occur
kubectl get serviceaccounts
פלט הפקודה
#export GKE_CLUSTER=sample-game-gke
# gcloud container clusters get-credentials $GKE_CLUSTER --region us-central1
Fetching cluster endpoint and auth data.
kubeconfig entry generated for sample-game-gke.
# kubectl get serviceaccounts
NAME SECRETS AGE
default 0 37m
item-app 0 35m
matchmaking-app 0 35m
profile-app 0 35m
tradepost-app 0 35m
סיכום
מצוין! הצלחתם להקצות משאבים למופע Cloud Spanner, לאשכול GKE Autopilot, והכול ב-VPC לצורך רשת פרטית.
בנוסף, נוצרו שני צינורות של Cloud Deploy לשירותי הקצה העורפי ולעומסי העבודה, וגם מאגר Artifact Registry לאחסון קובצי האימג' שנוצרו.
לבסוף, חשבונות השירות נוצרו והוגדרו לעבודה עם Workload Identity, כך ששירותי ה-Backend יכולים להשתמש ב-Cloud Spanner.
בנוסף, אחרי פריסת שירותי העורף ועומסי העבודה, כלי kubectl מוגדר ליצירת אינטראקציה עם אשכול GKE ב-Cloud Shell.
הבא בתור
כדי להשתמש בשירותים, צריך להגדיר את סכימת מסד הנתונים. תגדירו את זה בשלב הבא.
4. יצירת סכימת מסד הנתונים
סקירה כללית
כדי להפעיל את שירותי ה-Backend, צריך לוודא שסכימת מסד הנתונים קיימת.
אם תעיינו בקבצים בספרייה $DEMO_HOME/schema/migrations ממאגר ההדגמה, תראו סדרה של קבצי .sql שמגדירים את הסכימה שלנו. התהליך הזה דומה למחזור פיתוח שבו השינויים בסכימה מתועדים במאגר עצמו, ויכולים להיות קשורים לתכונות מסוימות של האפליקציות.
בסביבת הדוגמה הזו, הכלי שיחיל את העברות הסכימה באמצעות Cloud Build הוא wrench.
Cloud Build
בקובץ $DEMO_HOME/schema/cloudbuild.yaml מתואר אילו פעולות יבוצעו:
serviceAccount: projects/${PROJECT_ID}/serviceAccounts/cloudbuild-cicd@${PROJECT_ID}.iam.gserviceaccount.com
steps:
- name: gcr.io/cloud-builders/curl
id: fetch-wrench
args: ['-Lo', '/workspace/wrench.tar.gz', 'https://github.com/cloudspannerecosystem/wrench/releases/download/v1.4.1/wrench-1.4.1-linux-amd64.tar.gz' ]
- name: gcr.io/cloud-builders/gcloud
id: migrate-spanner-schema
entrypoint: sh
args:
- '-xe'
- '-c'
- |
tar -xzvf wrench.tar.gz
chmod +x /workspace/wrench
# Assumes only a single spanner instance and database. Fine for this demo in a dedicated project
export SPANNER_PROJECT_ID=${PROJECT_ID}
export SPANNER_INSTANCE_ID=$(gcloud spanner instances list | tail -n1 | awk '{print $1}')
export SPANNER_DATABASE_ID=$(gcloud spanner databases list --instance=$$SPANNER_INSTANCE_ID | tail -n1 | awk '{print $1}')
if [ -d ./migrations ]; then
/workspace/wrench migrate up --directory .
else
echo "[Error] Missing migrations directory"
fi
timeout: 600s
יש שני שלבים בסיסיים:
- הורדת wrench לסביבת העבודה של Cloud Build
- הפעלת ההעברה של סמל המפתח
כדי להתחבר לנקודת הקצה של הכתיבה, צריך את משתני הסביבה של הפרויקט, המופע ומסד הנתונים של Spanner.
Cloud Build יכול לבצע את השינויים האלה כי הוא פועל כחשבון השירות cloudbuild-cicd@${PROJECT_ID}.iam.gserviceaccount.com:
serviceAccount: projects/${PROJECT_ID}/serviceAccounts/cloudbuild-cicd@${PROJECT_ID}.iam.gserviceaccount.com
לחשבון השירות הזה נוסף התפקיד spanner.databaseUser על ידי Terraform, שמאפשר לחשבון השירות לעדכן את ה-DDL.
העברות של סכימות
יש חמישה שלבי העברה שמתבצעים על סמך הקבצים בספרייה $DEMO_HOME/schema/migrations. דוגמה לקובץ 000001.sql שיוצר טבלה ומדדים של players:
CREATE TABLE players (
playerUUID STRING(36) NOT NULL,
player_name STRING(64) NOT NULL,
email STRING(MAX) NOT NULL,
password_hash BYTES(60) NOT NULL,
created TIMESTAMP,
updated TIMESTAMP,
stats JSON,
account_balance NUMERIC NOT NULL DEFAULT (0.00),
is_logged_in BOOL,
last_login TIMESTAMP,
valid_email BOOL,
current_game STRING(36)
) PRIMARY KEY (playerUUID);
CREATE UNIQUE INDEX PlayerAuthentication ON players(email) STORING(password_hash);
CREATE UNIQUE INDEX PlayerName ON players(player_name);
CREATE INDEX PlayerGame ON players(current_game);
שליחת העברת הסכימה
כדי לשלוח את ה-build לביצוע העברת הסכימה, עוברים לספרייה schema ומריצים את פקודת gcloud הבאה:
cd $DEMO_HOME/schema gcloud builds submit --config=cloudbuild.yaml
פלט הפקודה
Creating temporary tarball archive of 8 file(s) totalling 11.2 KiB before compression.
Uploading tarball of [.] to [gs://(project)_cloudbuild/source/(snip).tgz]
Created [https://cloudbuild.googleapis.com/v1/projects/(project)/locations/global/builds/7defe982-(snip)].
Logs are available at [ https://console.cloud.google.com/cloud-build/builds/7defe982-(snip)?project=(snip) ].
gcloud builds submit only displays logs from Cloud Storage. To view logs from Cloud Logging, run:
gcloud beta builds submit
ID: 7defe982-(snip)
CREATE_TIME: (created time)
DURATION: 3M11S
SOURCE: gs://(project)_cloudbuild/source/(snip).tgz
IMAGES: -
STATUS: SUCCESS
בפלט שלמעלה, תראו קישור לתהליך Created של Cloud Build. אם תלחצו על הקישור, תועברו אל הגרסה במסוף Cloud כדי שתוכלו לעקוב אחרי התקדמות הבנייה ולראות מה קורה.
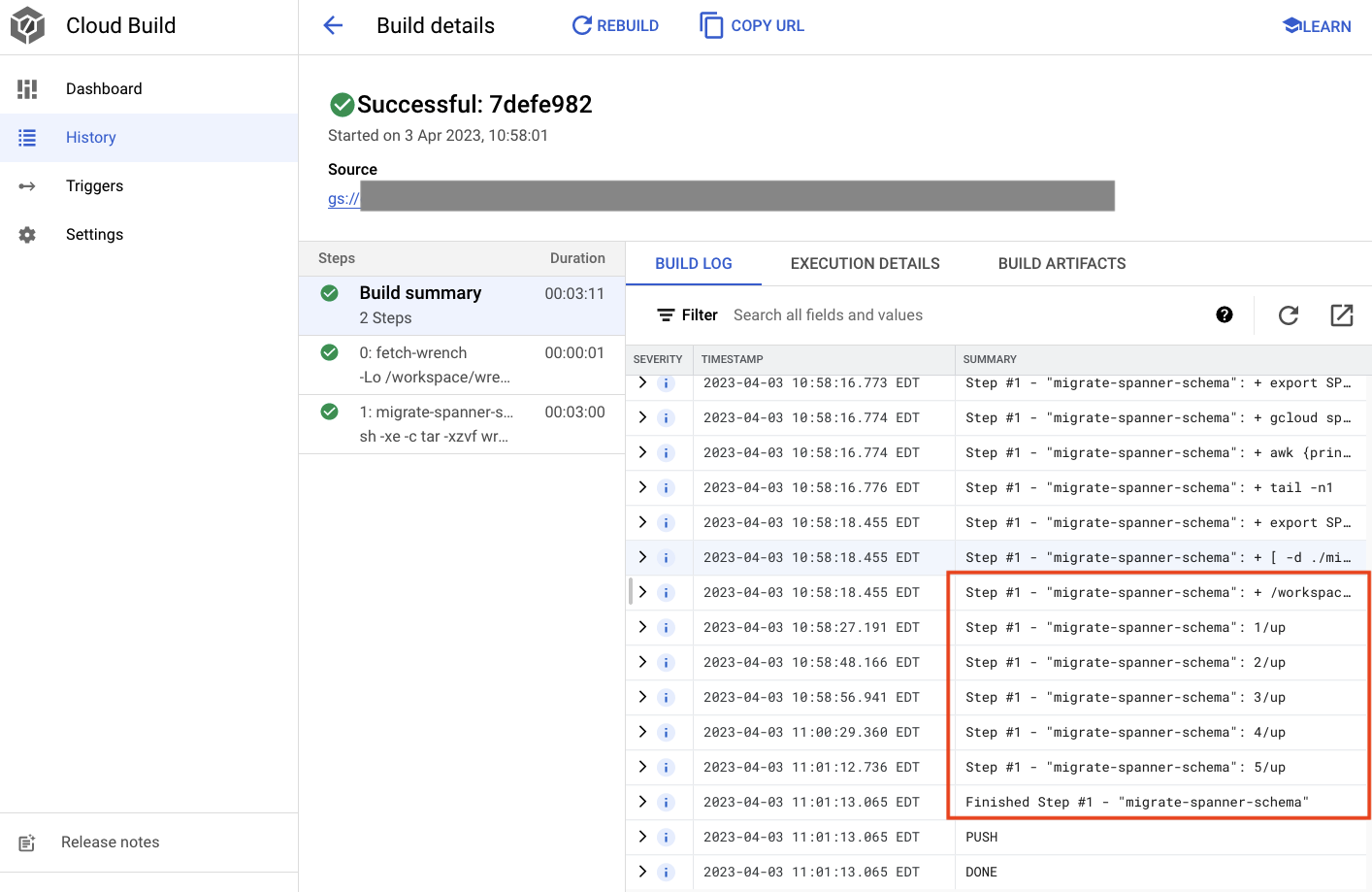
סיכום
בשלב הזה השתמשתם ב-Cloud Build כדי לשלוח את ההעברה הראשונית של הסכימה, שהחילה 5 פעולות שונות של DDL. הפעולות האלה מייצגות מקרים שבהם נוספו תכונות שדרשו שינויים בסכימת מסד הנתונים.
בתרחיש פיתוח רגיל, כדאי לבצע שינויים בסכימה כך שתהיה תאימות לאחור עם האפליקציה הנוכחית כדי למנוע השבתות.
במקרה של שינויים שלא תואמים לאחור, כדאי לפרוס את השינויים באפליקציה ובסכימה בשלבים, כדי למנוע השבתות.
הבא בתור
אחרי שיוצרים את הסכימה, השלב הבא הוא לפרוס את שירותי ה-Backend.
5. פריסת השירותים לקצה העורפי
סקירה כללית
השירותים לקצה העורפי ב-Codelab הזה הם ממשקי API בארכיטקטורת REST של golang שמייצגים ארבעה שירותים שונים:
- פרופיל: מאפשר לשחקנים להירשם ולבצע אימות לדוגמה של ה'משחק' שלנו.
- חיפוש יריבים למשחק: אינטראקציה עם נתוני שחקנים כדי לעזור בפונקציית חיפוש יריבים למשחק, מעקב אחרי מידע על משחקים שנוצרו ועדכון נתוני שחקנים כשמשחקים נסגרים.
- פריט: מאפשר לשחקנים לרכוש פריטים וכסף במשחק במהלך המשחק.
- עמדת מסחר: מאפשרת לשחקנים לקנות ולמכור פריטים בעמדת מסחר
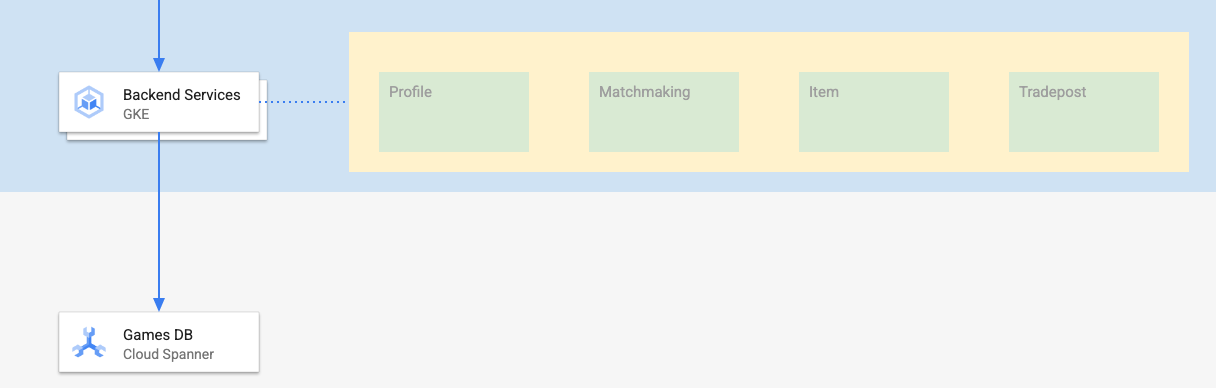
מידע נוסף על השירותים האלה זמין ב-codelab תחילת העבודה עם פיתוח משחקים ב-Cloud Spanner. למטרות שלנו, אנחנו רוצים שהשירותים האלה יפעלו באשכול GKE Autopilot.
השירותים האלה צריכים להיות מסוגלים לשנות את הנתונים ב-Spanner. לשם כך, לכל שירות נוצר חשבון שירות שמעניק לו את התפקיד databaseUser.
באמצעות Workload Identity, חשבון שירות של Kubernetes יכול להתחזות לחשבון שירות של Google Cloud של השירותים. לשם כך, צריך לבצע את השלבים הבאים ב-Terraform:
- יצירת משאב של חשבון שירות Google Cloud של השירות (
GSA) - מקצים לחשבון השירות את התפקיד databaseUser.
- מקצים לחשבון השירות את התפקיד workloadIdentityUser.
- יוצרים חשבון שירות של Kubernetes (
KSA) שמפנה אל חשבון השירות של Google
תרשים גס ייראה כך:
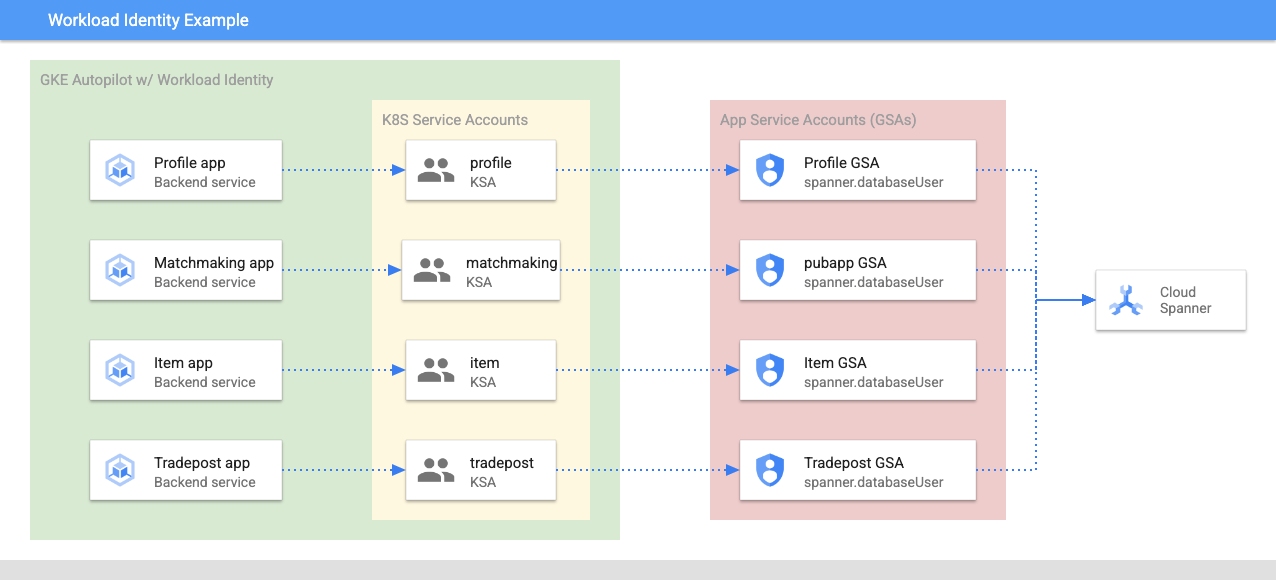
Terraform יצר בשבילכם את חשבונות השירות ואת חשבונות השירות של Kubernetes. אפשר לבדוק את חשבונות השירות של Kubernetes באמצעות הפקודה kubectl:
# kubectl get serviceaccounts
NAME SECRETS AGE
default 0 37m
item-app 0 35m
matchmaking-app 0 35m
profile-app 0 35m
tradepost-app 0 35m
כך מתבצעת הבנייה:
- Terraform יצר קובץ
$DEMO_HOME/backend_services/cloudbuild.yamlשנראה בערך כך:
serviceAccount: projects/${PROJECT_ID}/serviceAccounts/cloudbuild-cicd@${PROJECT_ID}.iam.gserviceaccount.com
steps:
#
# Building of images
#
- name: gcr.io/cloud-builders/docker
id: profile
args: ["build", ".", "-t", "${_PROFILE_IMAGE}"]
dir: profile
waitFor: ['-']
- name: gcr.io/cloud-builders/docker
id: matchmaking
args: ["build", ".", "-t", "${_MATCHMAKING_IMAGE}"]
dir: matchmaking
waitFor: ['-']
- name: gcr.io/cloud-builders/docker
id: item
args: ["build", ".", "-t", "${_ITEM_IMAGE}"]
dir: item
waitFor: ['-']
- name: gcr.io/cloud-builders/docker
id: tradepost
args: ["build", ".", "-t", "${_TRADEPOST_IMAGE}"]
dir: tradepost
waitFor: ['-']
#
# Deployment
#
- name: gcr.io/google.com/cloudsdktool/cloud-sdk
id: cloud-deploy-release
entrypoint: gcloud
args:
[
"deploy", "releases", "create", "${_REL_NAME}",
"--delivery-pipeline", "sample-game-services",
"--skaffold-file", "skaffold.yaml",
"--skaffold-version", "1.39",
"--images", "profile=${_PROFILE_IMAGE},matchmaking=${_MATCHMAKING_IMAGE},item=${_ITEM_IMAGE},tradepost=${_TRADEPOST_IMAGE}",
"--region", "us-central1"
]
artifacts:
images:
- ${_REGISTRY}/profile
- ${_REGISTRY}/matchmaking
- ${_REGISTRY}/item
- ${_REGISTRY}/tradepost
substitutions:
_PROFILE_IMAGE: ${_REGISTRY}/profile:${BUILD_ID}
_MATCHMAKING_IMAGE: ${_REGISTRY}/matchmaking:${BUILD_ID}
_ITEM_IMAGE: ${_REGISTRY}/item:${BUILD_ID}
_TRADEPOST_IMAGE: ${_REGISTRY}/tradepost:${BUILD_ID}
_REGISTRY: us-docker.pkg.dev/${PROJECT_ID}/spanner-game-images
_REL_NAME: rel-${BUILD_ID:0:8}
options:
dynamic_substitutions: true
machineType: E2_HIGHCPU_8
logging: CLOUD_LOGGING_ONLY
- הפקודה Cloud Build קוראת את הקובץ הזה ומבצעת את השלבים שמופיעים בו. קודם, המערכת יוצרת את תמונות השירות. לאחר מכן, היא מפעילה פקודה
gcloud deploy create. הפעולה הזו קוראת את הקובץ$DEMO_HOME/backend_services/skaffold.yaml, שמוגדר בו איפה נמצא כל קובץ פריסה:
apiVersion: skaffold/v2beta29
kind: Config
deploy:
kubectl:
manifests:
- spanner_config.yaml
- profile/deployment.yaml
- matchmaking/deployment.yaml
- item/deployment.yaml
- tradepost/deployment.yaml
- Cloud Deploy יפעל לפי ההגדרות בקובץ
deployment.yamlשל כל שירות. קובץ הפריסה של השירות מכיל את המידע ליצירת שירות, שבמקרה הזה הוא ClusterIP שפועל ביציאה 80.
הסוג ClusterIP מונע מ-pods של שירותי קצה עורפיים לקבל כתובת IP חיצונית, כך שרק ישויות שיכולות להתחבר לרשת הפנימית של GKE יכולות לגשת לשירותי הקצה העורפיים. השחקנים לא אמורים לקבל גישה ישירה לשירותים האלה, כי הם ניגשים לנתוני Spanner ומשנים אותם.
apiVersion: v1
kind: Service
metadata:
name: profile
spec:
type: ClusterIP
selector:
app: profile
ports:
- port: 80
targetPort: 80
בנוסף ליצירת שירות Kubernetes, Cloud Deploy יוצר גם פריסת Kubernetes. בואו נבדוק את הקטע של פריסת profileהשירות:
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: profile
spec:
replicas: 2 # EDIT: Number of instances of deployment
selector:
matchLabels:
app: profile
template:
metadata:
labels:
app: profile
spec:
serviceAccountName: profile-app
containers:
- name: profile-service
image: profile
ports:
- containerPort: 80
envFrom:
- configMapRef:
name: spanner-config
env:
- name: SERVICE_HOST
value: "0.0.0.0"
- name: SERVICE_PORT
value: "80"
resources:
requests:
cpu: "1"
memory: "1Gi"
ephemeral-storage: "100Mi"
limits:
cpu: "1"
memory: "1Gi"
ephemeral-storage: "100Mi"
בחלק העליון מופיעים מטא-נתונים מסוימים על השירות. החלק הכי חשוב כאן הוא הגדרת מספר הרפליקות שייווצרו על ידי הפריסה הזו.
replicas: 2 # EDIT: Number of instances of deployment
אחר כך רואים איזה חשבון שירות צריך להריץ את האפליקציה ואיזה תמונה צריך להשתמש. הם תואמים לחשבון השירות של Kubernetes שנוצר מ-Terraform ולתמונה שנוצרה במהלך השלב של Cloud Build.
spec:
serviceAccountName: profile-app
containers:
- name: profile-service
image: profile
לאחר מכן, מציינים פרטים על משתני רשת וסביבה.
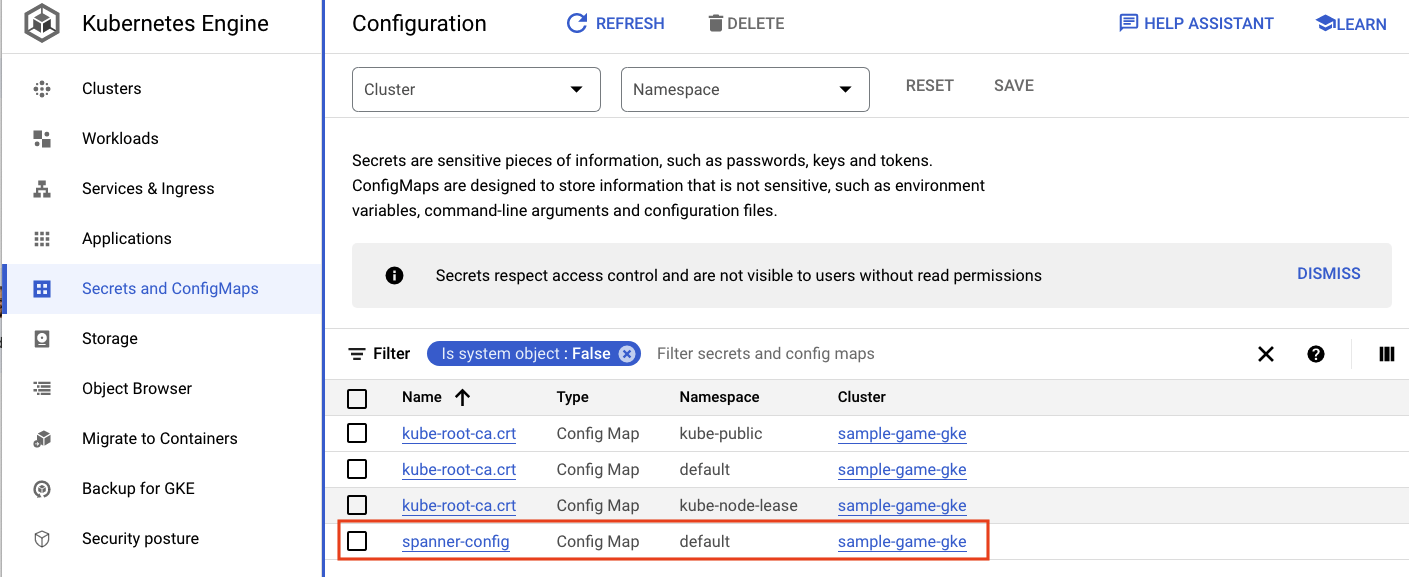
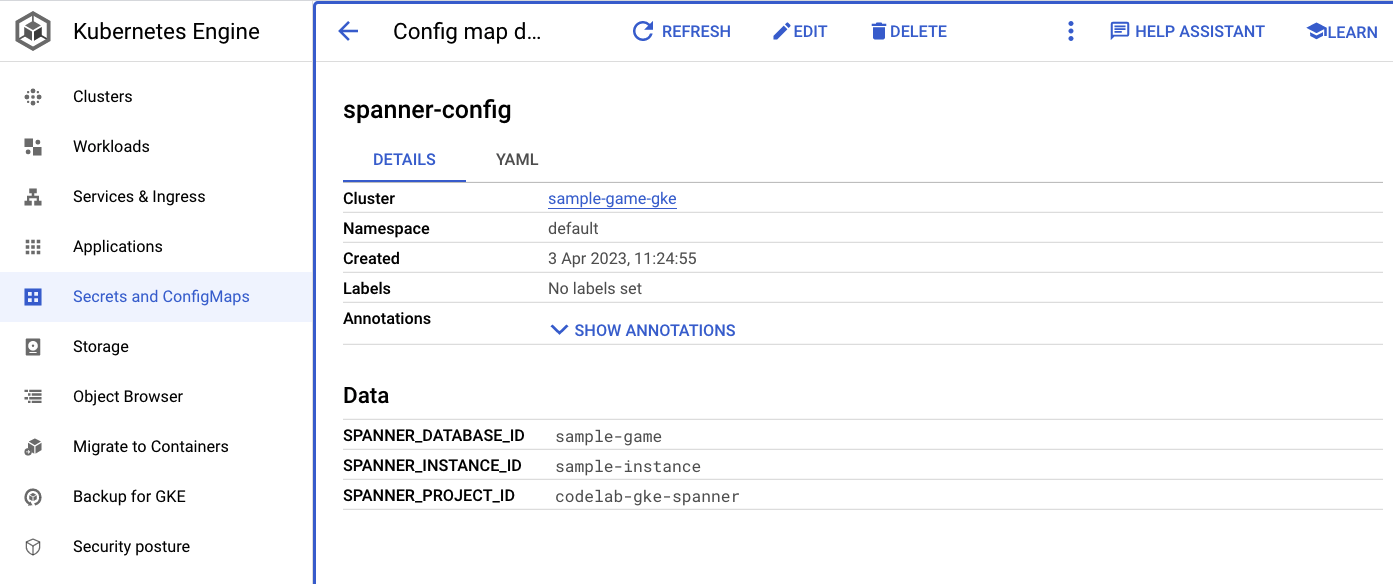
spanner_config הוא Kubernetes ConfigMap שמציין את הפרויקט, המופע ופרטי מסד הנתונים שנדרשים לאפליקציה כדי להתחבר ל-Spanner.
apiVersion: v1
kind: ConfigMap
metadata:
name: spanner-config
data:
SPANNER_PROJECT_ID: ${project_id}
SPANNER_INSTANCE_ID: ${instance_id}
SPANNER_DATABASE_ID: ${database_id}
ports:
- containerPort: 80
envFrom:
- configMapRef:
name: spanner-config
env:
- name: SERVICE_HOST
value: "0.0.0.0"
- name: SERVICE_PORT
value: "80"
SERVICE_HOST ו-SERVICE_PORT הם משתני סביבה נוספים שהשירות צריך כדי לדעת לאיזה כתובת IP לקשר את עצמו.
בקטע האחרון מציינים ל-GKE כמה משאבים להקצות לכל עותק משוכפל בפריסה הזו. זו גם הדרך שבה GKE Autopilot משתמש כדי לשנות את גודל האשכול לפי הצורך.
resources:
requests:
cpu: "1"
memory: "1Gi"
ephemeral-storage: "100Mi"
limits:
cpu: "1"
memory: "1Gi"
ephemeral-storage: "100Mi"
עכשיו, אחרי שיש לכם את המידע הזה, הגיע הזמן לפרוס את שירותי ה-Backend.
פריסת השירותים לקצה העורפי
כמו שצוין, פריסת שירותי ה-Backend מתבצעת באמצעות Cloud Build. בדומה להעברות סכימה, אפשר לשלוח את בקשת הבנייה באמצעות שורת הפקודה gcloud:
cd $DEMO_HOME/backend_services gcloud builds submit --config=cloudbuild.yaml
פלט הפקודה
Creating temporary tarball archive of 66 file(s) totalling 864.6 KiB before compression.
Uploading tarball of [.] to [gs://(project)_cloudbuild/source/(snip).tgz]
Created [https://cloudbuild.googleapis.com/v1/projects/(project)/locations/global/builds/30207dd1-(snip)].
Logs are available at [ https://console.cloud.google.com/cloud-build/builds/30207dd1-(snip)?project=(snip) ].
gcloud builds submit only displays logs from Cloud Storage. To view logs from Cloud Logging, run:
gcloud beta builds submit
ID: 30207dd1-(snip)
CREATE_TIME: (created time)
DURATION: 3M17S
SOURCE: gs://(project)_cloudbuild/source/(snip).tgz
IMAGES: us-docker.pkg.dev/(project)/spanner-game-images/profile:30207dd1-(snip) (+3 more)
STATUS: SUCCESS
בניגוד לפלט של השלב schema migration, הפלט של הבנייה הזו מציין שנוצרו כמה תמונות. הם יישמרו במאגר Artifact Registry.
בפלט של שלב gcloud build יופיע קישור ל-Cloud Console. כדאי לעיין בהם.
אחרי שתקבלו את ההתראה על סיום מוצלח של Cloud Build, תוכלו לעבור אל Cloud Deploy ואז אל צינור עיבוד הנתונים sample-game-services כדי לעקוב אחרי התקדמות הפריסה.
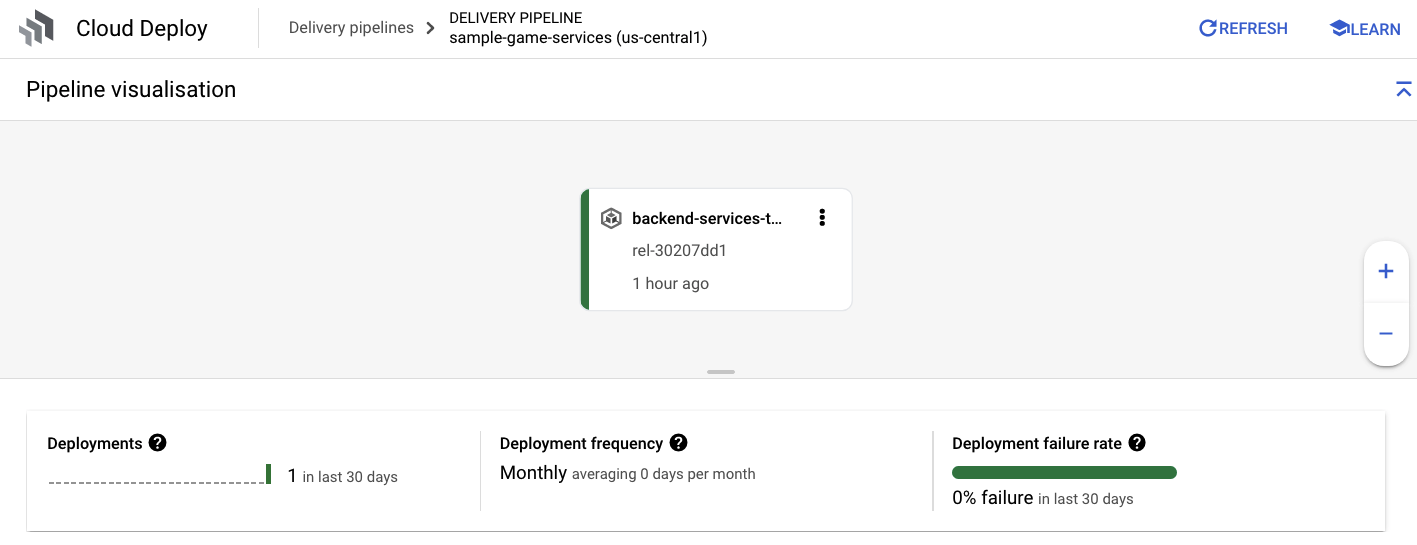
אחרי פריסת השירותים, אפשר לבדוק את הסטטוס של ה-pods ב-kubectl:
kubectl get pods
פלט הפקודה
NAME READY STATUS RESTARTS AGE
item-6b9d5f678c-4tbk2 1/1 Running 0 83m
matchmaking-5bcf799b76-lg8zf 1/1 Running 0 80m
profile-565bbf4c65-kphdl 1/1 Running 0 83m
profile-565bbf4c65-xw74j 1/1 Running 0 83m
tradepost-68b87ccd44-gw55r 1/1 Running 0 79m
לאחר מכן, בודקים את השירותים כדי לראות את ClusterIP בפעולה:
kubectl get services
פלט הפקודה
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
item ClusterIP 10.172.XXX.XXX <none> 80/TCP 84m
kubernetes ClusterIP 10.172.XXX.XXX <none> 443/TCP 137m
matchmaking ClusterIP 10.172.XXX.XXX <none> 80/TCP 84m
profile ClusterIP 10.172.XXX.XXX <none> 80/TCP 84m
tradepost ClusterIP 10.172.XXX.XXX <none> 80/TCP 84m
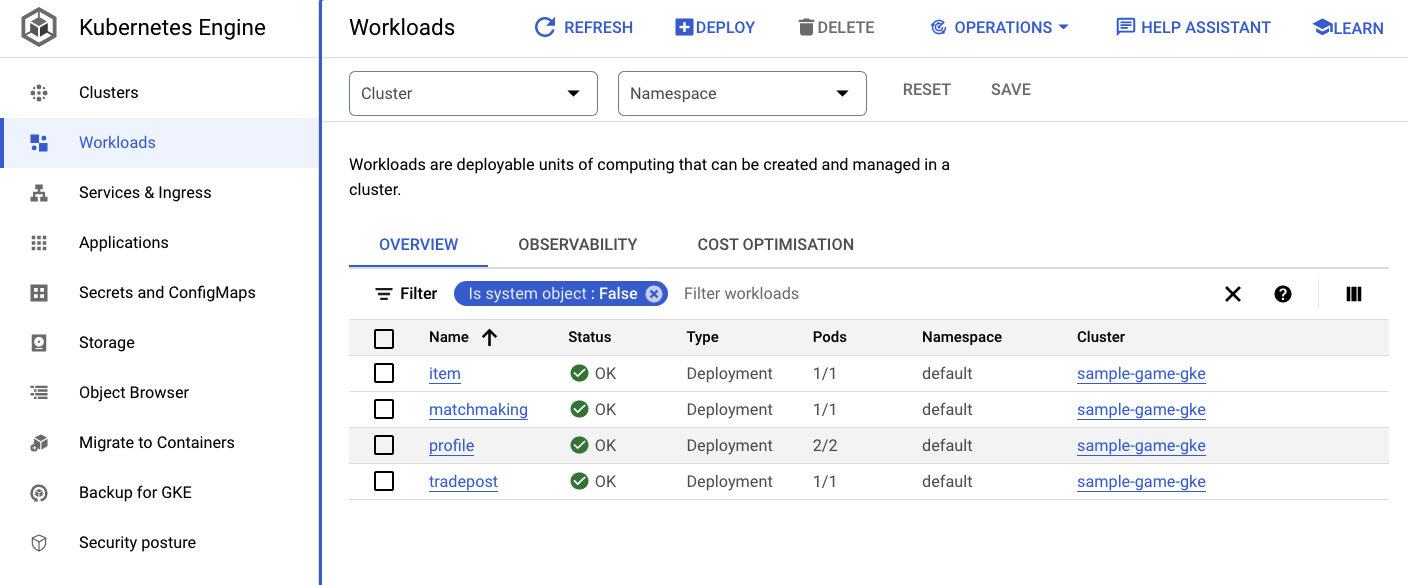
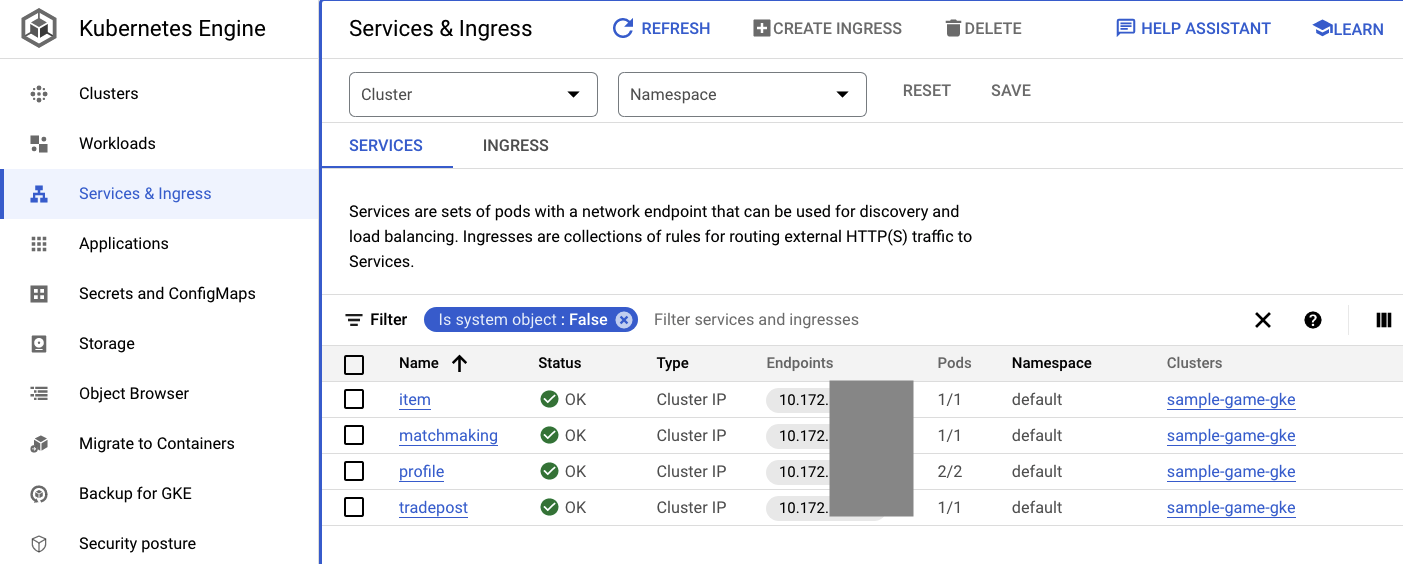
אפשר גם לעבור לממשק המשתמש של GKE במסוף Cloud כדי לראות את Workloads, Services ו-ConfigMaps.
עומסי עבודה
שירותים
ConfigMaps
סיכום
בשלב הזה פרסתם את ארבעת שירותי ה-Backend ל-GKE Autopilot. הצלחתם להריץ את השלב Cloud Build ולבדוק את ההתקדמות ב-Cloud Deploy וב-Kubernetes במסוף Cloud.
למדתם גם איך השירותים האלה משתמשים ב-Workload Identity כדי להתחזות לחשבון שירות שיש לו את ההרשאות המתאימות לקריאה ולכתיבה של נתונים במסד הנתונים של Spanner.
השלבים הבאים
בקטע הבא נסביר איך פורסים את עומסי העבודה.
6. פריסת עומסי העבודה
סקירה כללית
עכשיו, אחרי ששירותי ה-Backend פועלים באשכול, אפשר לפרוס את עומסי העבודה.

עומסי העבודה נגישים חיצונית, ויש אחד לכל שירות קצה עורפי לצורך ה-codelab הזה.
עומסי העבודה האלה הם סקריפטים ליצירת עומס שמבוססים על Locust ומדמים דפוסי גישה אמיתיים שצפויים בשירותים לדוגמה האלה.
יש קבצים לתהליך Cloud Build:
-
$DEMO_HOME/workloads/cloudbuild.yaml(נוצר על ידי Terraform) $DEMO_HOME/workloads/skaffold.yaml- קובץ
deployment.yamlלכל עומס עבודה
הקבצים של עומס העבודה deployment.yaml נראים קצת שונה מהקבצים של פריסת שירות ה-Backend.
לדוגמה, מתוך matchmaking-workload:
apiVersion: v1
kind: Service
metadata:
name: matchmaking-workload
spec:
type: LoadBalancer
selector:
app: matchmaking-workload
ports:
- port: 8089
targetPort: 8089
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: matchmaking-workload
spec:
replicas: 1 # EDIT: Number of instances of deployment
selector:
matchLabels:
app: matchmaking-workload
template:
metadata:
labels:
app: matchmaking-workload
spec:
serviceAccountName: default
containers:
- name: matchmaking-workload
image: matchmaking-workload
ports:
- containerPort: 8089
resources:
requests:
cpu: "500m"
memory: "512Mi"
ephemeral-storage: "100Mi"
limits:
cpu: "500m"
memory: "512Mi"
ephemeral-storage: "100Mi"
החלק העליון של הקובץ מגדיר את השירות. במקרה כזה, נוצר LoadBalancer ועומס העבודה פועל ביציאה 8089.
מאזן העומסים יספק כתובת IP חיצונית שאפשר להשתמש בה כדי להתחבר לעומס העבודה.
apiVersion: v1
kind: Service
metadata:
name: matchmaking-workload
spec:
type: LoadBalancer
selector:
app: matchmaking-workload
ports:
- port: 8089
targetPort: 8089
בחלק העליון של קטע הפריסה מופיעים המטא-נתונים של עומס העבודה. במקרה הזה, רק רפליקה אחת נפרסת:
replicas: 1
אבל מפרט מאגר התגים שונה. לדוגמה, אנחנו משתמשים בחשבון שירות של default Kubernetes. לחשבון הזה אין הרשאות מיוחדות, כי עומס העבודה לא צריך להתחבר למשאבים ב-Google Cloud, למעט שירותי ה-Backend שפועלים באשכול GKE.
הבדל נוסף הוא שלא נדרשים משתני סביבה לעומסי העבודה האלה. התוצאה היא מפרט פריסה קצר יותר.
spec:
serviceAccountName: default
containers:
- name: matchmaking-workload
image: matchmaking-workload
ports:
- containerPort: 8089
הגדרות המשאבים דומות להגדרות של שירותי הקצה העורפי. חשוב לזכור שכך GKE Autopilot יודע כמה משאבים נדרשים כדי למלא את הבקשות של כל הפודים שפועלים באשכול.
אפשר לפרוס את עומסי העבודה.
פריסת עומסי העבודה
כמו קודם, אפשר לשלוח את בקשת הבנייה באמצעות שורת הפקודה gcloud:
cd $DEMO_HOME/workloads gcloud builds submit --config=cloudbuild.yaml
פלט הפקודה
Creating temporary tarball archive of 18 file(s) totalling 26.2 KiB before compression.
Some files were not included in the source upload.
Check the gcloud log [/tmp/tmp.4Z9EqdPo6d/logs/(snip).log] to see which files and the contents of the
default gcloudignore file used (see `$ gcloud topic gcloudignore` to learn
more).
Uploading tarball of [.] to [gs://(project)_cloudbuild/source/(snip).tgz]
Created [https://cloudbuild.googleapis.com/v1/projects/(project)/locations/global/builds/(snip)].
Logs are available at [ https://console.cloud.google.com/cloud-build/builds/0daf20f6-(snip)?project=(snip) ].
gcloud builds submit only displays logs from Cloud Storage. To view logs from Cloud Logging, run:
gcloud beta builds submit
ID: 0daf20f6-(snip)
CREATE_TIME: (created_time)
DURATION: 1M41S
SOURCE: gs://(project)_cloudbuild/source/(snip).tgz
IMAGES: us-docker.pkg.dev/(project)/spanner-game-images/profile-workload:0daf20f6-(snip) (+4 more)
STATUS: SUCCESS
כדי לבדוק את הסטטוס, חשוב לעיין ביומנים של Cloud Build ובצינור עיבוד הנתונים של Cloud Deploy במסוף Cloud. עבור עומסי העבודה, צינור עיבוד הנתונים של Cloud Deploy הוא sample-game-workloads:
אחרי הפריסה, בודקים את הסטטוס באמצעות kubectl ב-Cloud Shell:
kubectl get pods
פלט הפקודה
NAME READY STATUS RESTARTS AGE
game-workload-7ff44cb657-pxxq2 1/1 Running 0 12m
item-6b9d5f678c-cr29w 1/1 Running 0 9m6s
item-generator-7bb4f57cf8-5r85b 1/1 Running 0 12m
matchmaking-5bcf799b76-lg8zf 1/1 Running 0 117m
matchmaking-workload-76df69dbdf-jds9z 1/1 Running 0 12m
profile-565bbf4c65-kphdl 1/1 Running 0 121m
profile-565bbf4c65-xw74j 1/1 Running 0 121m
profile-workload-76d6db675b-kzwng 1/1 Running 0 12m
tradepost-68b87ccd44-gw55r 1/1 Running 0 116m
tradepost-workload-56c55445b5-b5822 1/1 Running 0 12m
לאחר מכן, בודקים את שירותי העומס כדי לראות את LoadBalancer בפעולה:
kubectl get services
פלט הפקודה
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
game-workload LoadBalancer *snip* 35.XX.XX.XX 8089:32483/TCP 12m
item ClusterIP *snip* <none> 80/TCP 121m
item-generator LoadBalancer *snip* 34.XX.XX.XX 8089:32581/TCP 12m
kubernetes ClusterIP *snip* <none> 443/TCP 174m
matchmaking ClusterIP *snip* <none> 80/TCP 121m
matchmaking-workload LoadBalancer *snip* 34.XX.XX.XX 8089:31735/TCP 12m
profile ClusterIP *snip* <none> 80/TCP 121m
profile-workload LoadBalancer *snip* 34.XX.XX.XX 8089:32532/TCP 12m
tradepost ClusterIP *snip* <none> 80/TCP 121m
tradepost-workload LoadBalancer *snip* 34.XX.XX.XX 8089:30002/TCP 12m
סיכום
עכשיו עומסי העבודה (workloads) נפרסים באשכול GKE. לעומסי העבודה האלה לא נדרשות הרשאות IAM נוספות, ואפשר לגשת אליהם חיצונית דרך יציאה 8089 באמצעות שירות LoadBalancer.
השלבים הבאים
אחרי שהשירותים והעומסים של ה-Backend פועלים, הגיע הזמן לשחק במשחק.
7. התחלת המשחק
סקירה כללית
שירותי הבק-אנד של דוגמת ה'משחק' פועלים עכשיו, ויש לכם גם את האמצעים ליצור 'שחקנים' שמבצעים אינטראקציה עם השירותים האלה באמצעות עומסי העבודה.
כל עומס עבודה משתמש ב-Locust כדי לדמות עומס בפועל על ממשקי ה-API של השירותים שלנו. בשלב הזה תריצו כמה עומסי עבודה כדי ליצור עומס על אשכול GKE ועל Spanner, וגם כדי לאחסן נתונים ב-Spanner.
הנה תיאור של כל עומס עבודה:
- עומס העבודה
item-generatorהוא עומס עבודה מהיר שיוצר רשימה של game_items ששחקנים יכולים להשיג במהלך המשחק. - הכלי
profile-workloadמדמה שחקנים שנרשמים ונכנסים לחשבון. - ה-
matchmaking-workloadמדמה שחקנים שממתינים בתור כדי להיות משובצים למשחקים. - המשחק
game-workloadמדמה שחקנים שרוכשים פריטים במשחק וכסף במהלך המשחק. - התכונה
tradepost-workloadמדמה מצב שבו שחקנים יכולים למכור ולקנות פריטים בנקודת המסחר.
ב-Codelab הזה נתמקד בהרצת item-generator ו-profile-workload.
הפעלת הכלי ליצירת פריטים
item-generator משתמש בנקודת הקצה של שירות ה-Backend item כדי להוסיף את game_items ל-Spanner. הפריטים האלה נדרשים כדי שהתגים game-workload ו-tradepost-workload יפעלו בצורה תקינה.
השלב הראשון הוא לקבל את כתובת ה-IP החיצונית של שירות item-generator. ב-Cloud Shell, מריצים את הפקודה הבאה:
# The external IP is the 4th column of the output
kubectl get services | grep item-generator | awk '{print $4}'
פלט הפקודה
{ITEMGENERATOR_EXTERNAL_IP}
עכשיו פותחים כרטיסייה חדשה בדפדפן ומפנים אותה אל http://{ITEMGENERATOR_EXTERNAL_IP}:8089. אמור להופיע דף כזה:
תצאו מהחדר users ומהחדר spawn עם הגדרת ברירת המחדל 1. בשדה host, מזינים http://item. לוחצים על האפשרויות המתקדמות ומזינים 10s כזמן הריצה.
כך צריכה להיראות ההגדרה:
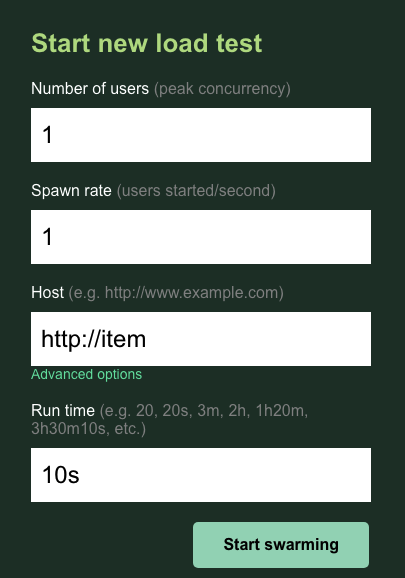
לוחצים על 'התחלת ההצפה'.
הנתונים הסטטיסטיים יתחילו להופיע לגבי בקשות שמונפקות בנקודת הקצה POST /items. אחרי 10 שניות הטעינה תיפסק.
לוחצים על Charts ויוצגו כמה תרשימים לגבי הביצועים של הבקשות האלה.
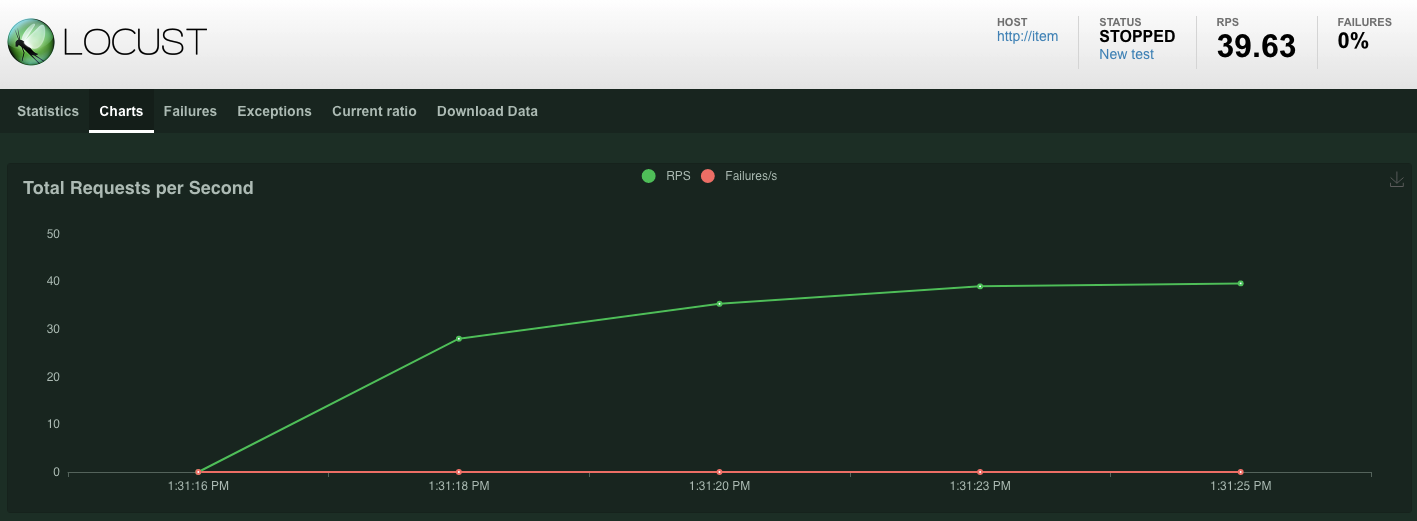
עכשיו אתם רוצים לבדוק אם הנתונים הוזנו למסד הנתונים של Spanner.
כדי לעשות את זה, לוחצים על סמל האפשרויות הנוספות (3 קווים) ועוברים אל Spanner. בדף הזה, עוברים אל sample-instance ואל sample-database. לוחצים על Query.
אנחנו רוצים לבחור את מספר game_items:
SELECT COUNT(*) FROM game_items;
התוצאה תופיע בחלק התחתון של המסך.
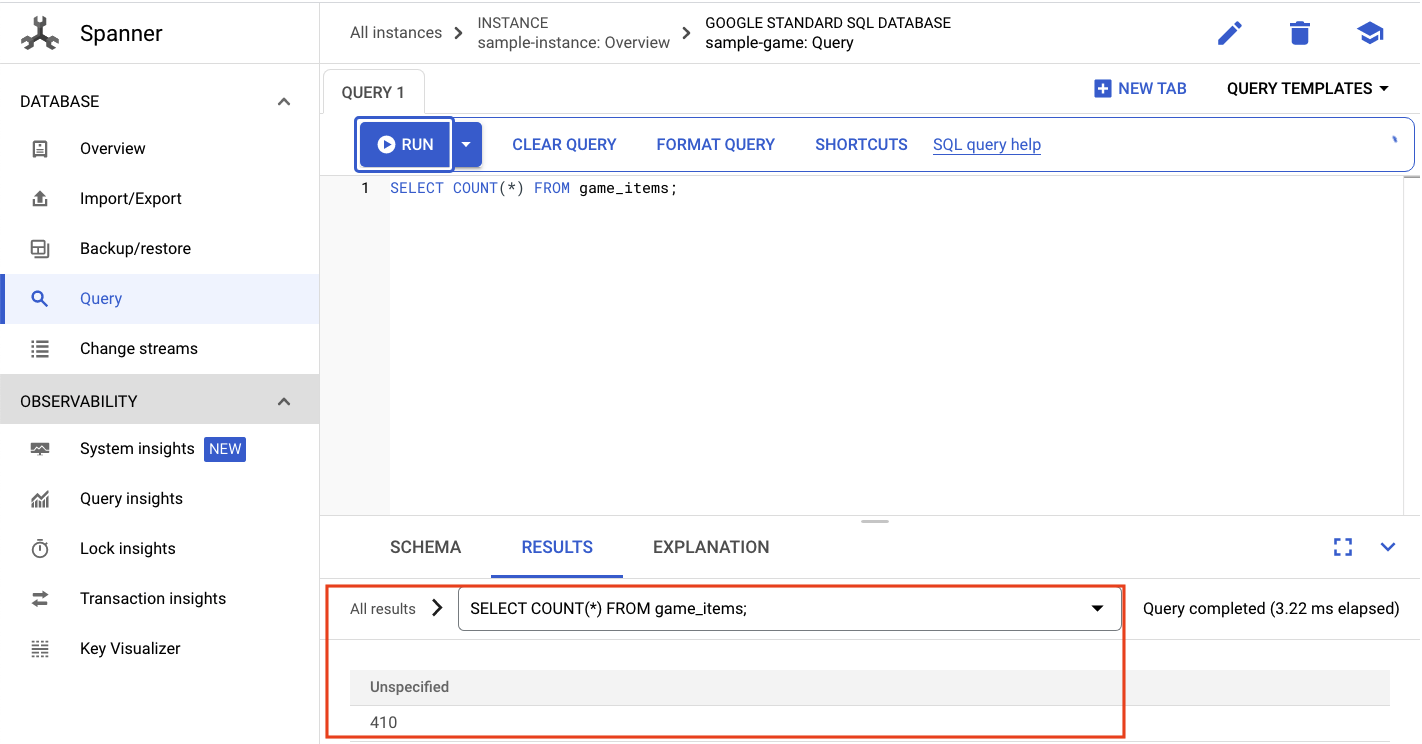
אנחנו לא צריכים הרבה game_items. אבל עכשיו השחקנים יכולים להשיג אותם!
להריץ את פרופיל העומס
אחרי שgame_items מוכן, השלב הבא הוא לגרום לשחקנים להירשם כדי שיוכלו לשחק במשחקים.
profile-workload ישתמש ב-Locust כדי לדמות שחקנים שיוצרים חשבונות, מתחברים, מאחזרים פרטי פרופיל ומתנתקים. כל הבדיקות האלה בודקות את נקודות הקצה של profile שירות הקצה העורפי בעומס עבודה טיפוסי שדומה לסביבת ייצור.
כדי להריץ את הפקודה הזו, צריך לקבל את כתובת ה-IP החיצונית profile-workload:
# The external IP is the 4th column of the output
kubectl get services | grep profile-workload | awk '{print $4}'
פלט הפקודה
{PROFILEWORKLOAD_EXTERNAL_IP}
עכשיו פותחים כרטיסייה חדשה בדפדפן ומפנים אותה אל http://{PROFILEWORKLOAD_EXTERNAL_IP}:8089. אמורה להופיע דף Locust דומה לזה שמופיע למעלה.
במקרה הזה, תשתמשו ב-http://profile בשביל המארח. בנוסף, לא תציינו זמן ריצה באפשרויות המתקדמות. בנוסף, צריך לציין את users כ-4, כדי לדמות 4 בקשות משתמשים בכל פעם.
הבדיקה profile-workload אמורה להיראות כך:
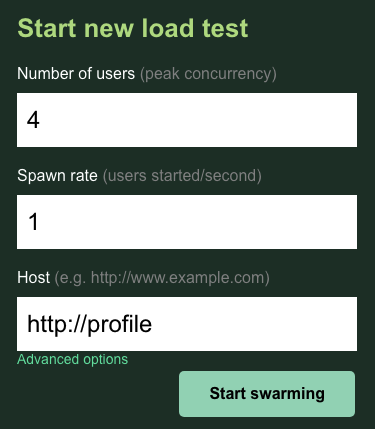
לוחצים על 'התחלת ההצפה'.
בדיוק כמו קודם, הנתונים הסטטיסטיים של נקודות הקצה השונות של profile REST יתחילו להופיע. כדי לראות תצוגה של רמת הביצועים של כל הרכיבים, לוחצים על 'תרשימים'.
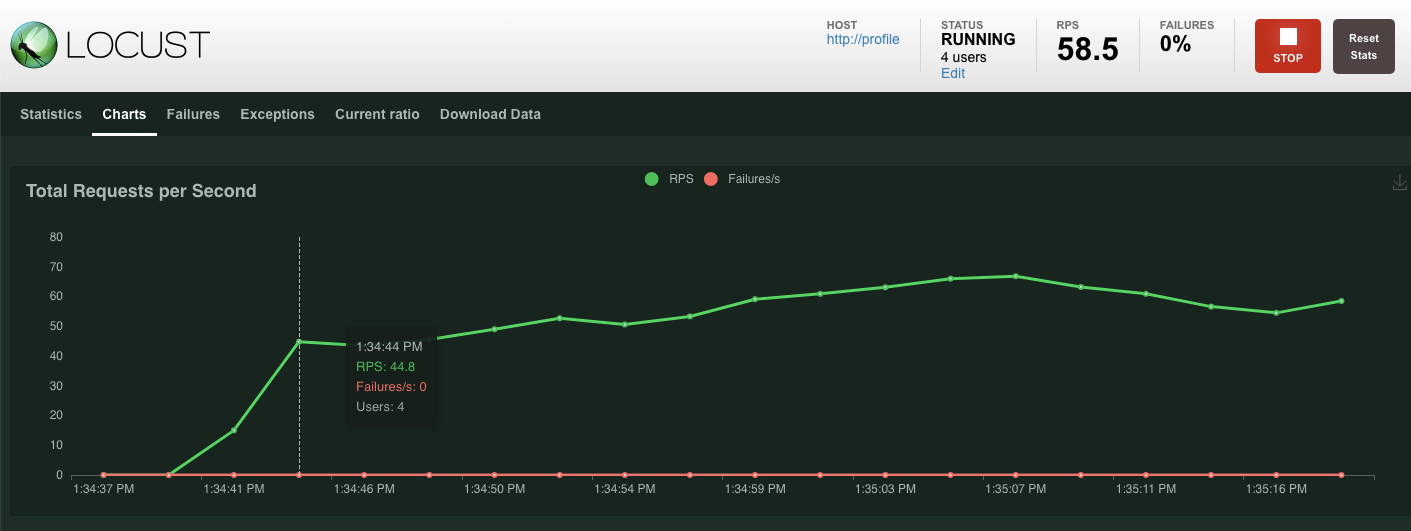
סיכום
בשלב הזה יצרתם כמה game_items, ואז שלחתם שאילתה לטבלת game_items באמצעות ממשק המשתמש של Spanner Query ב-Cloud Console.
בנוסף, אפשרתם לשחקנים להירשם למשחק שלכם וראיתם איך Locust יכול ליצור עומסי עבודה שדומים לעומסי עבודה בסביבת ייצור מול שירותי ה-Backend שלכם.
השלבים הבאים
אחרי שמריצים את עומסי העבודה, כדאי לבדוק את ההתנהגות של אשכול GKE ושל מכונת Spanner.
8. בדיקת השימוש ב-GKE וב-Spanner
אחרי שהפעלתם את שירות הפרופילים, הגיע הזמן לבדוק איך אשכול GKE Autopilot ו-Cloud Spanner מתנהגים.
בדיקה של אשכול GKE
עוברים אל אשכול Kubernetes. שימו לב: מאז שפרסתם את עומסי העבודה והשירותים, נוספו לאשכול פרטים על סך ה-vCPU והזיכרון. המידע הזה לא היה זמין כשלא היו עומסי עבודה באשכול.
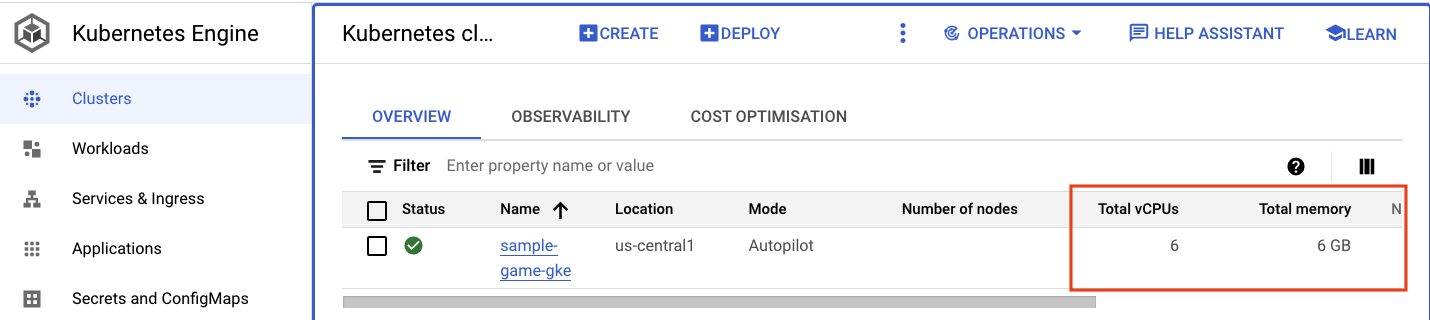
עכשיו לוחצים על אשכול sample-game-gke ועוברים לכרטיסייה 'יכולת צפייה':
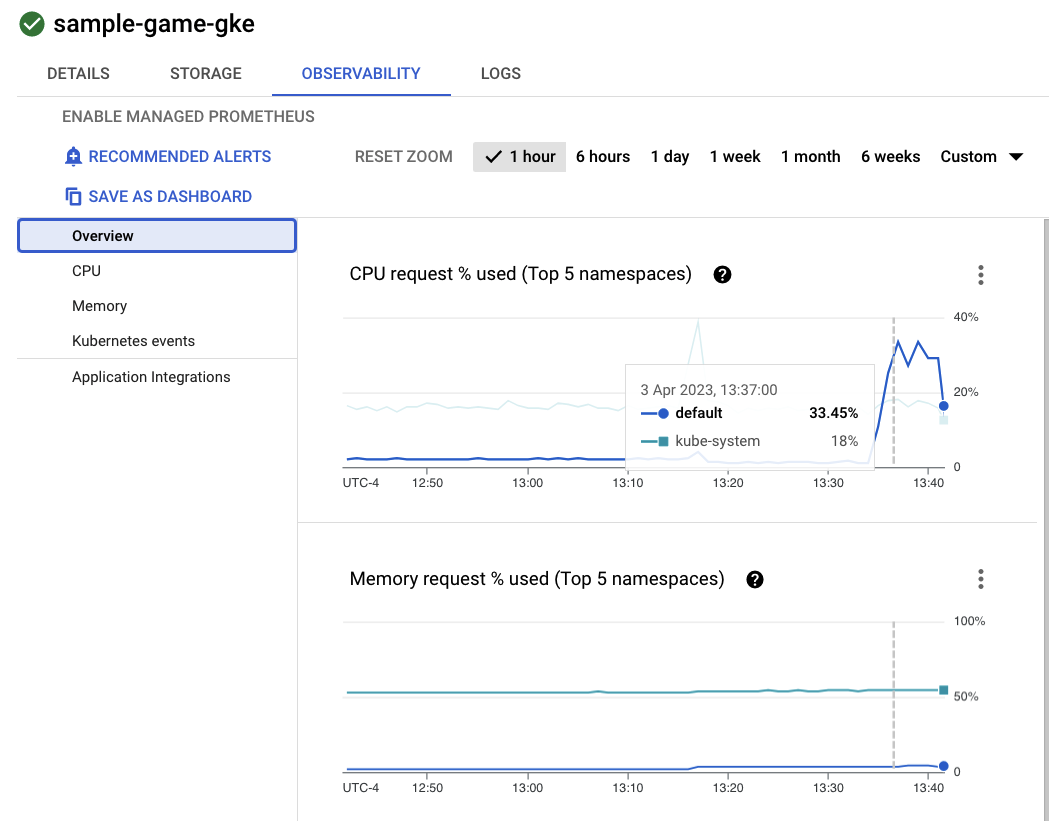
השימוש ב-CPU במרחב השמות default kubernetes צריך להיות גבוה יותר מהשימוש ב-CPU במרחב השמות kube-system, כי עומסי העבודה ושירותי ה-Backend שלנו פועלים ב-default. אם לא, מוודאים שהכלי profile workload עדיין פועל וממתינים כמה דקות עד שהתרשימים יתעדכנו.
כדי לראות אילו עומסי עבודה צורכים הכי הרבה משאבים, עוברים לWorkloads לוח הבקרה.
במקום להיכנס לכל עומס עבודה בנפרד, אפשר לעבור ישירות לכרטיסייה Observability (יכולת צפייה) בלוח הבקרה. אפשר לראות שהשימוש ב-CPU של profile ושל profile-workload עלה.
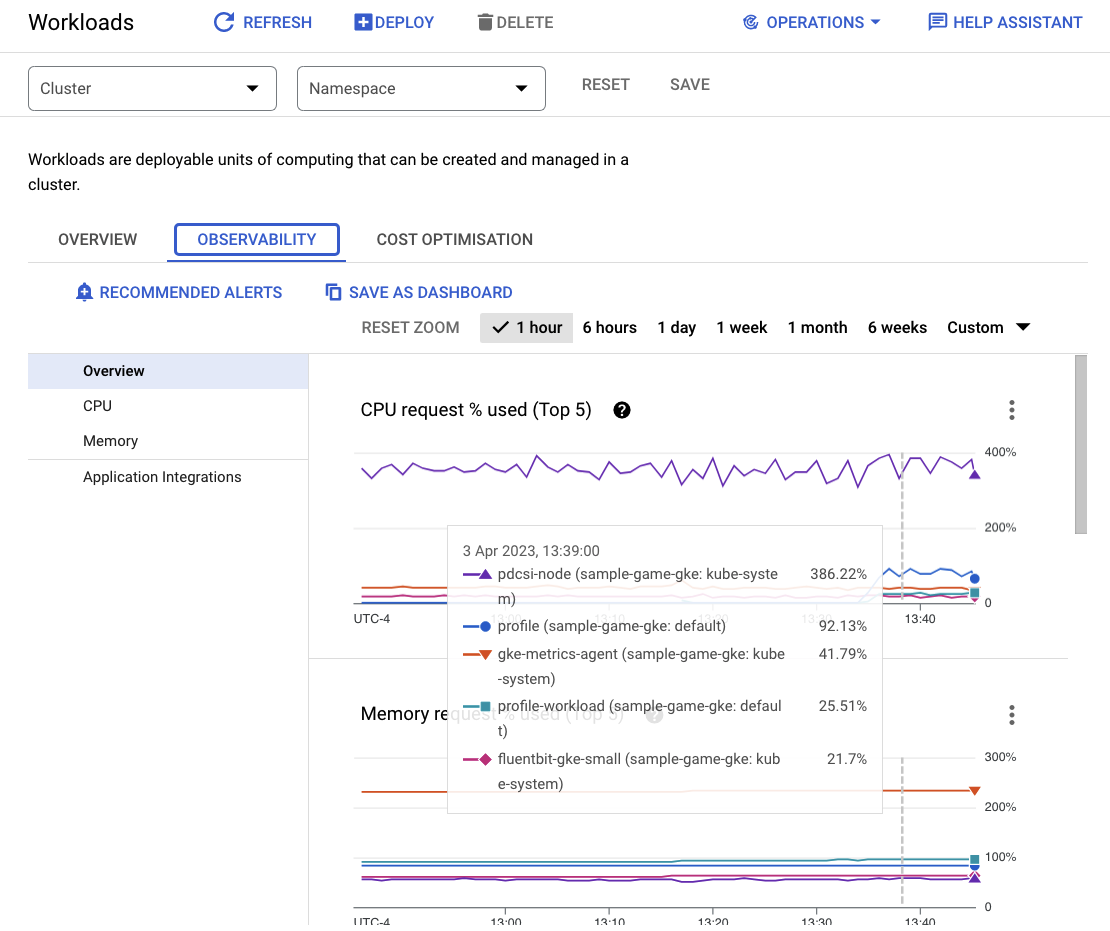
עכשיו אפשר לבדוק את Cloud Spanner.
בדיקה של מכונת Cloud Spanner
כדי לבדוק את הביצועים של Cloud Spanner, עוברים אל Spanner ולוחצים על sample-instance המכונה ועל sample-game מסד הנתונים.
בתפריט הימני, תופיע הכרטיסייה תובנות לגבי המערכת:
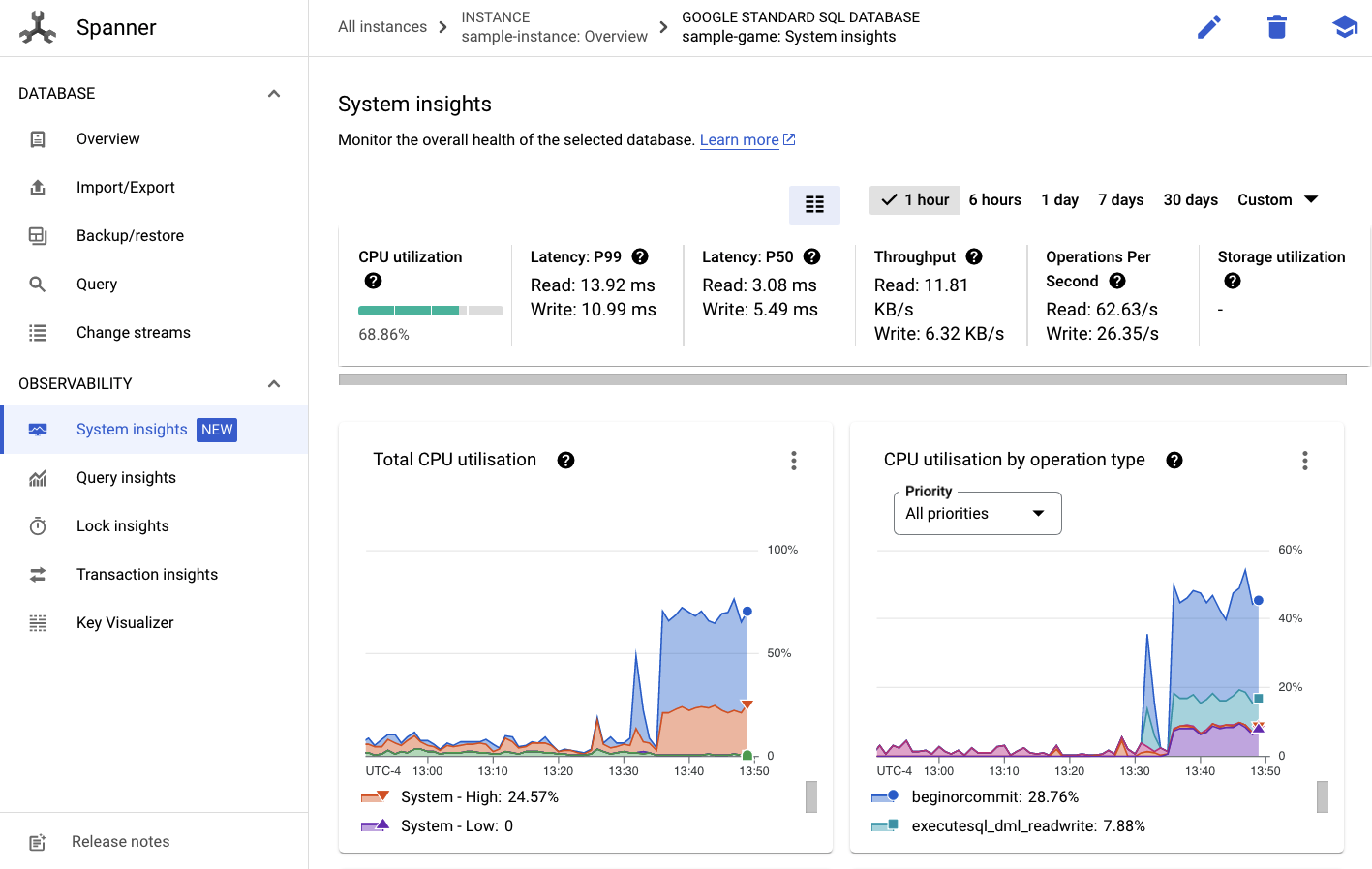
יש כאן תרשימים רבים שיעזרו לכם להבין את הביצועים הכלליים של מכונת Spanner, כולל CPU utilization, transaction latency and locking ו-query throughput.
בנוסף ל-System Insights, אפשר לקבל מידע מפורט יותר על עומס העבודה של השאילתות על ידי עיון בקישורים האחרים בקטע Observability:
- תובנות לגבי שאילתות עוזרות לזהות את N השאילתות המובילות שמשתמשות במשאבים ב-Spanner.
- תובנות לגבי עסקאות ונעילות עוזרות לזהות עסקאות עם זמן אחזור גבוה.
- Key Visualizer עוזר להמחיש דפוסי גישה ויכול לעזור לאתר נקודות חמות בנתונים.
סיכום
בשלב הזה למדתם איך לבדוק כמה מדדי ביצועים בסיסיים גם ב-GKE Autopilot וגם ב-Spanner.
לדוגמה, כשעומס העבודה של הפרופיל פועל, אפשר להריץ שאילתה בטבלה players כדי לקבל מידע נוסף על הנתונים שמאוחסנים בה.
השלבים הבאים
עכשיו הגיע הזמן לנקות!
9. סידור וארגון
לפני שמבצעים ניקוי, אפשר לעיין בעומסי העבודה האחרים שלא נכללו במאמר הזה. במיוחד matchmaking-workload, game-workload ו-tradepost-workload.
כשמסיימים לשחק במשחק, אפשר לנקות את המגרש. למזלכם, זה די פשוט.
קודם כל, אם profile-workload עדיין פועל בדפדפן, עוברים אליו ומפסיקים אותו:
חוזרים על הפעולה לכל עומס עבודה שבדקתם.
לאחר מכן, ב-Cloud Shell, עוברים לתיקיית התשתית. תשתמשו ב-Terraform כדי destroy את התשתית:
cd $DEMO_HOME/infrastructure
terraform destroy
# type 'yes' when asked
פלט הפקודה
Plan: 0 to add, 0 to change, 46 to destroy.
Do you really want to destroy all resources?
Terraform will destroy all your managed infrastructure, as shown above.
There is no undo. Only 'yes' will be accepted to confirm.
Enter a value: yes
*snip*
Destroy complete! Resources: 46 destroyed.
במסוף Cloud, עוברים אל Spanner, Kubernetes Cluster, Artifact Registry, Cloud Deploy ו-IAM כדי לוודא שכל המשאבים הוסרו.
10. מעולה!
הצלחתם לפרוס אפליקציות לדוגמה של golang ב-GKE Autopilot ולחבר אותן ל-Cloud Spanner באמצעות Workload Identity.
בנוסף, היה קל להגדיר את התשתית הזו ולהסיר אותה באופן שניתן לשחזור באמצעות Terraform.
ב-codelab הזה יצרתם אינטראקציה עם שירותי Google Cloud הבאים:
מה השלב הבא?
עכשיו, אחרי שקיבלתם מושג בסיסי לגבי האופן שבו GKE Autopilot ו-Cloud Spanner יכולים לעבוד יחד, למה שלא תעברו לשלב הבא ותתחילו ליצור אפליקציה משלכם שתפעל עם השירותים האלה?