
1. Introduction
Cloud Spanner est un service de base de données relationnelle entièrement géré, distribué à l'échelle mondiale et évolutif horizontalement qui fournit des transactions ACID et une sémantique SQL sans compromis sur les performances et la haute disponibilité.
GKE Autopilot est un mode de fonctionnement de GKE dans lequel Google gère la configuration de votre cluster, y compris vos nœuds, le scaling, la sécurité et d'autres paramètres préconfigurés, afin de suivre les bonnes pratiques. Par exemple, GKE Autopilot permet à Workload Identity de gérer les autorisations de service.
L'objectif de cet atelier est de vous guider dans le processus de connexion de plusieurs services de backend exécutés sur GKE Autopilot à une base de données Cloud Spanner.
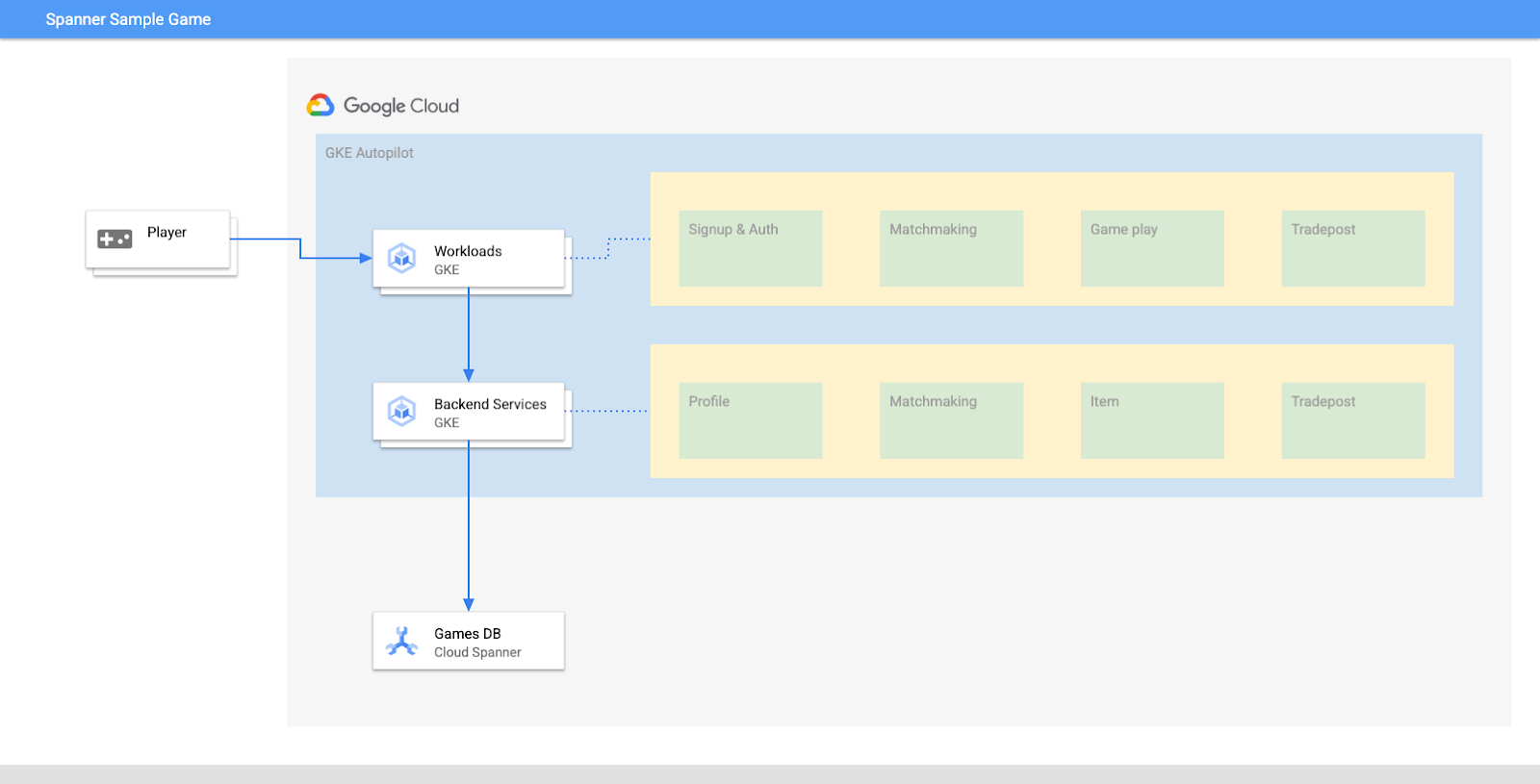
Dans cet atelier, vous allez d'abord configurer un projet et lancer Cloud Shell. Vous déploierez ensuite l'infrastructure à l'aide de Terraform.
Une fois cette étape terminée, vous interagirez avec Cloud Build et Cloud Deploy pour effectuer une migration initiale du schéma de la base de données Games, déployer les services de backend, puis déployer les charges de travail.
Les services de cet atelier de programmation sont les mêmes que ceux de l'atelier de programmation Premiers pas avec Cloud Spanner pour le développement de jeux. Il n'est pas obligatoire de suivre cet atelier de programmation pour exécuter les services sur GKE et se connecter à Spanner. Toutefois, si vous souhaitez en savoir plus sur les spécificités de ces services fonctionnant sur Spanner, consultez-le.
Une fois les charges de travail et les services de backend en cours d'exécution, vous pouvez commencer à générer de la charge et observer comment les services fonctionnent ensemble.
Enfin, vous nettoierez les ressources créées dans cet atelier.
Ce que vous allez faire
Au cours de cet atelier, vous allez :
- Provisionner l'infrastructure à l'aide de Terraform
- Créer le schéma de base de données à l'aide d'un processus de migration de schéma dans Cloud Build
- Déployer les quatre services de backend Golang qui utilisent Workload Identity pour se connecter à Cloud Spanner
- Déployez les quatre services de charge de travail qui sont utilisés pour simuler la charge des services de backend.
Points abordés
- Provisionner des pipelines GKE Autopilot, Cloud Spanner et Cloud Deploy à l'aide de Terraform
- Comment Workload Identity permet aux services sur GKE d'emprunter l'identité des comptes de service pour accéder aux autorisations IAM permettant d'utiliser Cloud Spanner
- Générer une charge de production sur GKE et Cloud Spanner à l'aide de Locust.io
Prérequis
2. Préparation
Créer un projet
Si vous ne possédez pas encore de compte Google (Gmail ou Google Apps), vous devez en créer un. Connectez-vous à la console Google Cloud Platform ( console.cloud.google.com) et créez un projet.
Si vous avez déjà un projet, cliquez sur le menu déroulant de sélection du projet dans l'angle supérieur gauche de la console :

Cliquez ensuite sur le bouton NEW PROJECT (NOUVEAU PROJET) dans la boîte de dialogue qui s'affiche pour créer un projet :
Si vous n'avez pas encore de projet, une boîte de dialogue semblable à celle-ci apparaîtra pour vous permettre d'en créer un :
La boîte de dialogue de création de projet suivante vous permet de saisir les détails de votre nouveau projet :
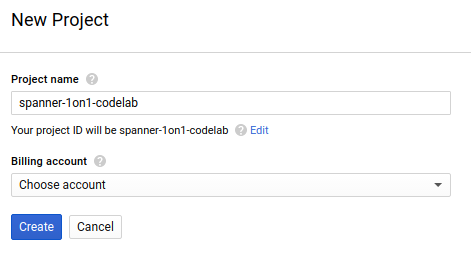
Notez l'ID du projet. Il s'agit d'un nom unique pour tous les projets Google Cloud, ce qui implique que le nom ci-dessus n'est plus disponible pour vous… Désolé ! Tout au long de cet atelier de programmation, nous utiliserons PROJECT_ID pour faire référence à cet ID.
Ensuite, si ce n'est pas déjà fait, vous devez activer la facturation dans Developers Console afin de pouvoir utiliser les ressources Google Cloud puis activer l'API Cloud Spanner.
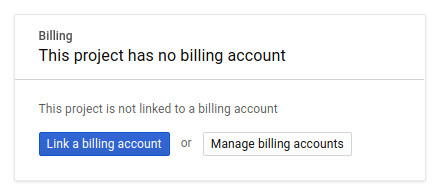
Suivre cet atelier de programmation ne devrait pas vous coûter plus d'un euro. Cependant, cela peut s'avérer plus coûteux si vous décidez d'utiliser davantage de ressources ou si vous n'interrompez pas les ressources (voir la section "Effectuer un nettoyage" à la fin du présent document). Les tarifs de Google Cloud Spanner sont décrits sur cette page, et ceux de GKE Autopilot sur cette page.
Les nouveaux utilisateurs de Google Cloud Platform peuvent bénéficier d'un essai sans frais avec 300$de crédits afin de suivre sans frais le présent atelier.
Configuration de Cloud Shell
Bien que Google Cloud et Spanner puissent être utilisés à distance depuis votre ordinateur portable, nous allons utiliser Google Cloud Shell pour cet atelier de programmation, un environnement de ligne de commande exécuté dans le cloud.
Cette machine virtuelle basée sur Debian contient tous les outils de développement dont vous aurez besoin. Elle intègre un répertoire d'accueil persistant de 5 Go et s'exécute sur Google Cloud, ce qui améliore nettement les performances du réseau et l'authentification. Cela signifie que tout ce dont vous avez besoin pour cet atelier de programmation est un navigateur (oui, tout fonctionne sur un Chromebook).
- Pour activer Cloud Shell à partir de la console Cloud, cliquez simplement sur Activer Cloud Shell
 (le provisionnement de l'environnement et la connexion ne devraient prendre que quelques minutes).
(le provisionnement de l'environnement et la connexion ne devraient prendre que quelques minutes).
Une fois connecté à Cloud Shell, vous êtes normalement déjà authentifié et le projet PROJECT_ID est sélectionné :
gcloud auth list
Résultat de la commande
Credentialed accounts:
- <myaccount>@<mydomain>.com (active)
gcloud config list project
Résultat de la commande
[core]
project = <PROJECT_ID>
Si, pour une raison quelconque, le projet n'est pas défini, exécutez simplement la commande suivante :
gcloud config set project <PROJECT_ID>
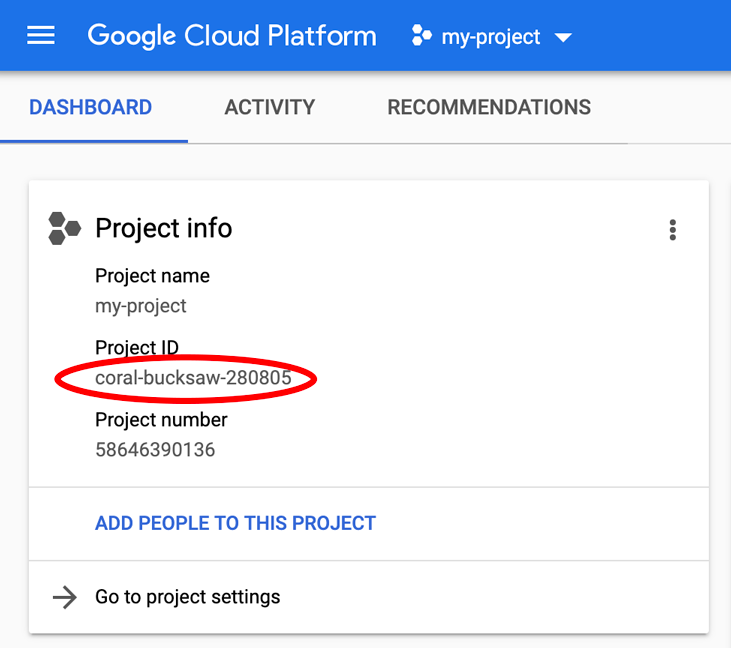
Vous recherchez votre PROJECT_ID ? Vérifiez l'ID que vous avez utilisé pendant les étapes de configuration ou recherchez-le dans le tableau de bord Cloud Console :
Par défaut, Cloud Shell définit certaines variables d'environnement qui pourront s'avérer utiles pour exécuter certaines commandes dans le futur.
echo $GOOGLE_CLOUD_PROJECT
Résultat de la commande
<PROJECT_ID>
Télécharger le code
Dans Cloud Shell, vous pouvez télécharger le code de cet atelier :
git clone https://github.com/cloudspannerecosystem/spanner-gaming-sample.git
Résultat de la commande
Cloning into 'spanner-gaming-sample'...
*snip*
Cet atelier de programmation est basé sur la version v0.1.3. Vérifiez donc cette balise :
cd spanner-gaming-sample
git fetch --all --tags
# Check out v0.1.3 release
git checkout tags/v0.1.3 -b v0.1.3-branch
Résultat de la commande
Switched to a new branch 'v0.1.3-branch'
Définissez maintenant le répertoire de travail actuel comme variable d'environnement DEMO_HOME. Cela vous permettra de naviguer plus facilement dans les différentes parties de l'atelier de programmation.
export DEMO_HOME=$(pwd)
Résumé
Dans cette étape, vous avez configuré un nouveau projet, activé Cloud Shell et téléchargé le code pour cet atelier.
Étape suivante
Vous allez ensuite provisionner l'infrastructure à l'aide de Terraform.
3. Provisionner l'infrastructure
Présentation
Maintenant que votre projet est prêt, il est temps de faire fonctionner l'infrastructure. Cela inclut la mise en réseau VPC, Cloud Spanner, GKE Autopilot, Artifact Registry pour stocker les images qui s'exécuteront sur GKE, les pipelines Cloud Deploy pour les services et charges de travail de backend, et enfin les comptes de service et les droits IAM pour pouvoir utiliser ces services.
C'est beaucoup. Heureusement, Terraform peut simplifier cette configuration. Terraform est un outil "Infrastructure as Code" qui nous permet de spécifier ce dont nous avons besoin pour ce projet dans une série de fichiers ".tf". Cela simplifie le provisionnement de l'infrastructure.
Il n'est pas nécessaire de connaître Terraform pour suivre cet atelier de programmation. Toutefois, si vous souhaitez voir ce que font les prochaines étapes, vous pouvez consulter ce qui est créé dans ces fichiers situés dans le répertoire infrastructure :
- vpc.tf
- backend_gke.tf
- spanner.tf
- artifact_registry.tf
- pipelines.tf
- iam.tf
Configurer Terraform
Dans Cloud Shell, accédez au répertoire infrastructure et initialisez Terraform :
cd $DEMO_HOME/infrastructure
terraform init
Résultat de la commande
Initializing the backend...
Initializing provider plugins...
*snip*
Terraform has been successfully initialized!
You may now begin working with Terraform. Try running "terraform plan" to see
any changes that are required for your infrastructure. All Terraform commands
should now work.
If you ever set or change modules or backend configuration for Terraform,
rerun this command to reinitialize your working directory. If you forget, other
commands will detect it and remind you to do so if necessary.
Ensuite, configurez Terraform en copiant terraform.tfvars.sample et en modifiant la valeur du projet. Vous pouvez également modifier les autres variables, mais le projet est la seule qui doit être modifiée pour fonctionner avec votre environnement.
cp terraform.tfvars.sample terraform.tfvars
# edit gcp_project using the project environment variable
sed -i "s/PROJECT/$GOOGLE_CLOUD_PROJECT/" terraform.tfvars
Provisionner l'infrastructure
Il est maintenant temps de provisionner l'infrastructure.
terraform apply
# review the list of things to be created
# type 'yes' when asked
Résultat de la commande
Plan: 46 to add, 0 to change, 0 to destroy.
Do you want to perform these actions?
Terraform will perform the actions described above.
Only 'yes' will be accepted to approve.
Enter a value: yes
google_project_service.project["container.googleapis.com"]: Creating...
*snip*
Apply complete! Resources: 46 added, 0 changed, 0 destroyed.
Vérifier ce qui a été créé
Pour vérifier ce qui a été créé, vous devez consulter les produits dans la console Cloud.
Cloud Spanner
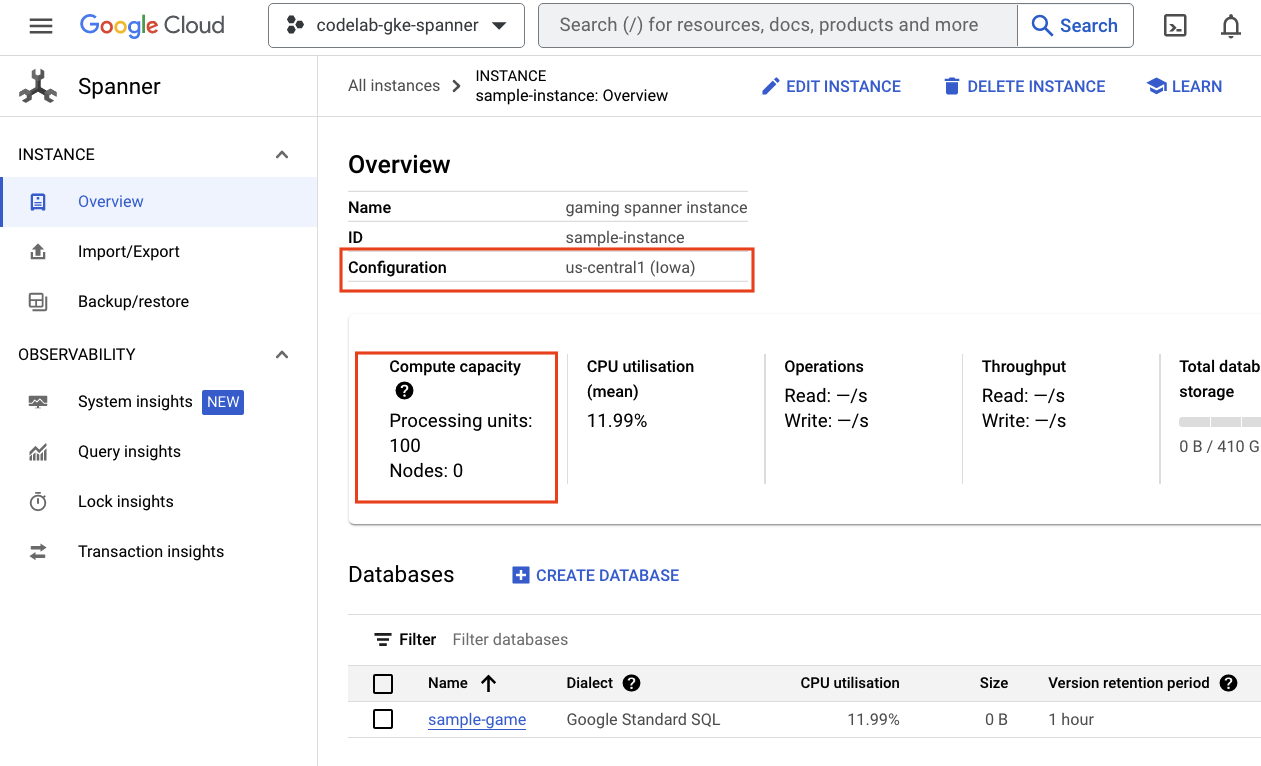
Commencez par vérifier Cloud Spanner en accédant au menu hamburger et en cliquant sur Spanner. Vous devrez peut-être cliquer sur "Afficher plus de produits" pour le trouver dans la liste.
Vous êtes redirigé vers la liste des instances Spanner. Cliquez sur l'instance pour afficher les bases de données. Voici un exemple :
GKE Autopilot
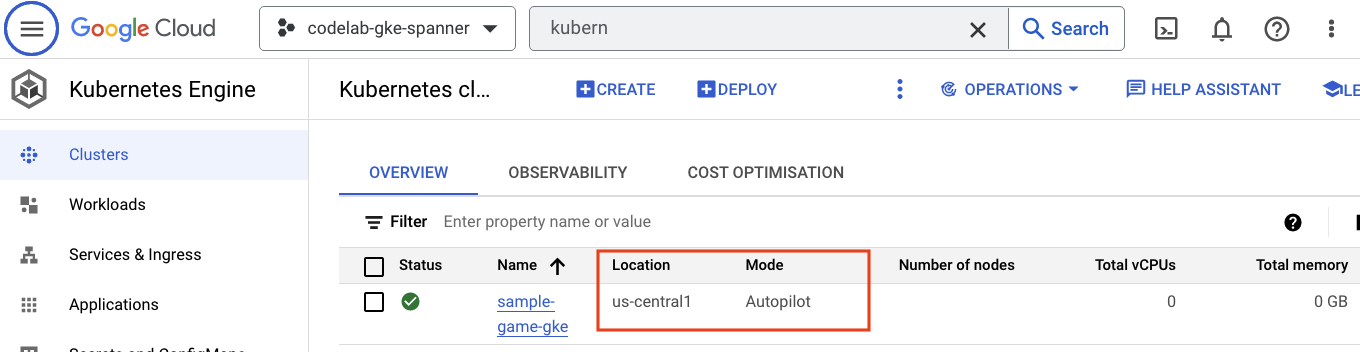
Ensuite, découvrez GKE en accédant au menu à trois barres et en cliquant sur Kubernetes Engine => Clusters. Vous y verrez le cluster sample-games-gke s'exécuter en mode Autopilot.
Artifact Registry
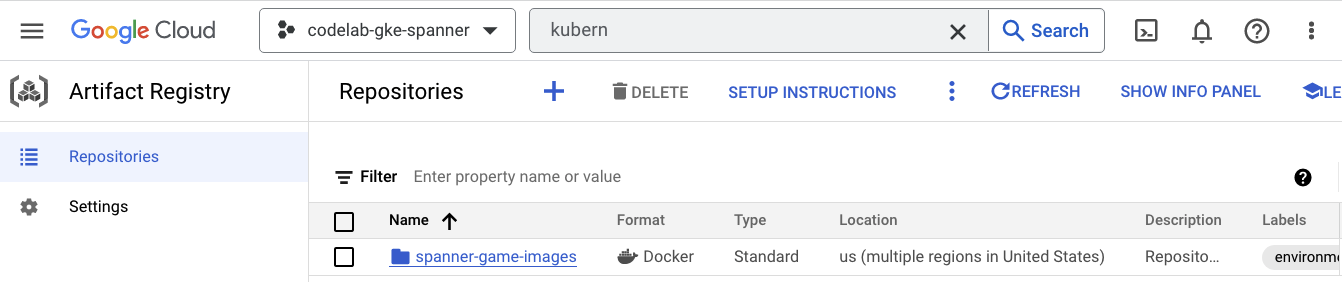
Vous devez maintenant déterminer où les images seront stockées. Cliquez sur le menu hamburger et recherchez Artifact Registry=>Repositories. Artifact Registry se trouve dans la section "CI/CD" du menu.
Vous y trouverez un registre Docker nommé spanner-game-images. Ce champ sera vide pour le moment.
Cloud Deploy
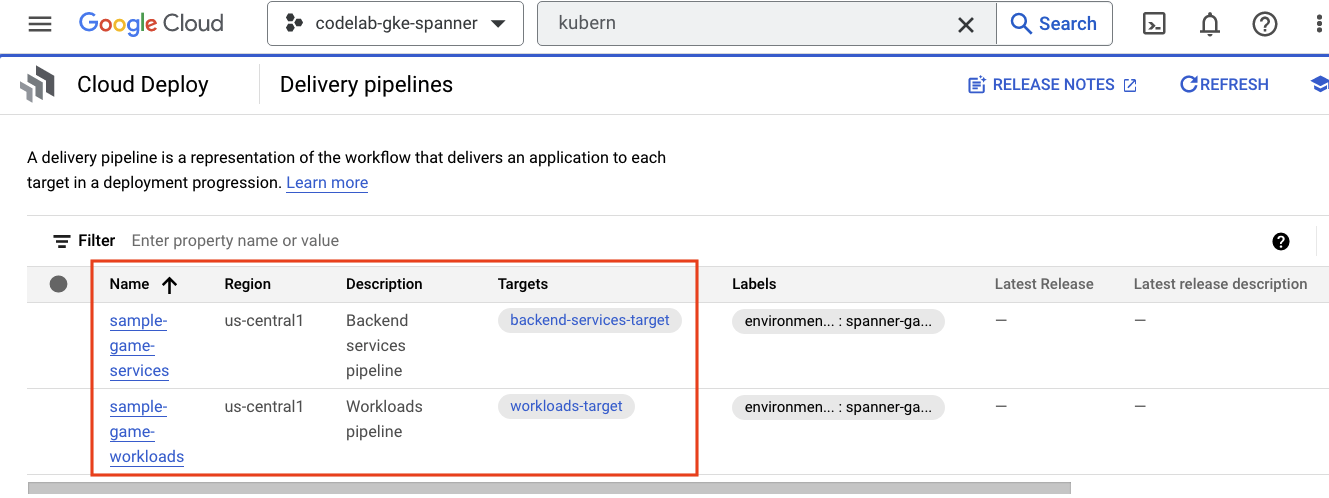
Cloud Deploy est l'endroit où les pipelines ont été créés afin que Cloud Build puisse fournir des étapes pour créer les images, puis les déployer sur notre cluster GKE.
Accédez au menu hamburger et recherchez Cloud Deploy, qui se trouve également dans la section CI/CD du menu.
Vous remarquerez deux pipelines : un pour les services de backend et un pour les charges de travail. Les deux déploient les images sur le même cluster GKE, mais cela permet de séparer nos déploiements.
IAM
Enfin, consultez la page IAM de la console Cloud pour vérifier les comptes de service qui ont été créés. Accédez au menu hamburger et recherchez IAM and Admin=>Service accounts. Voici un exemple :
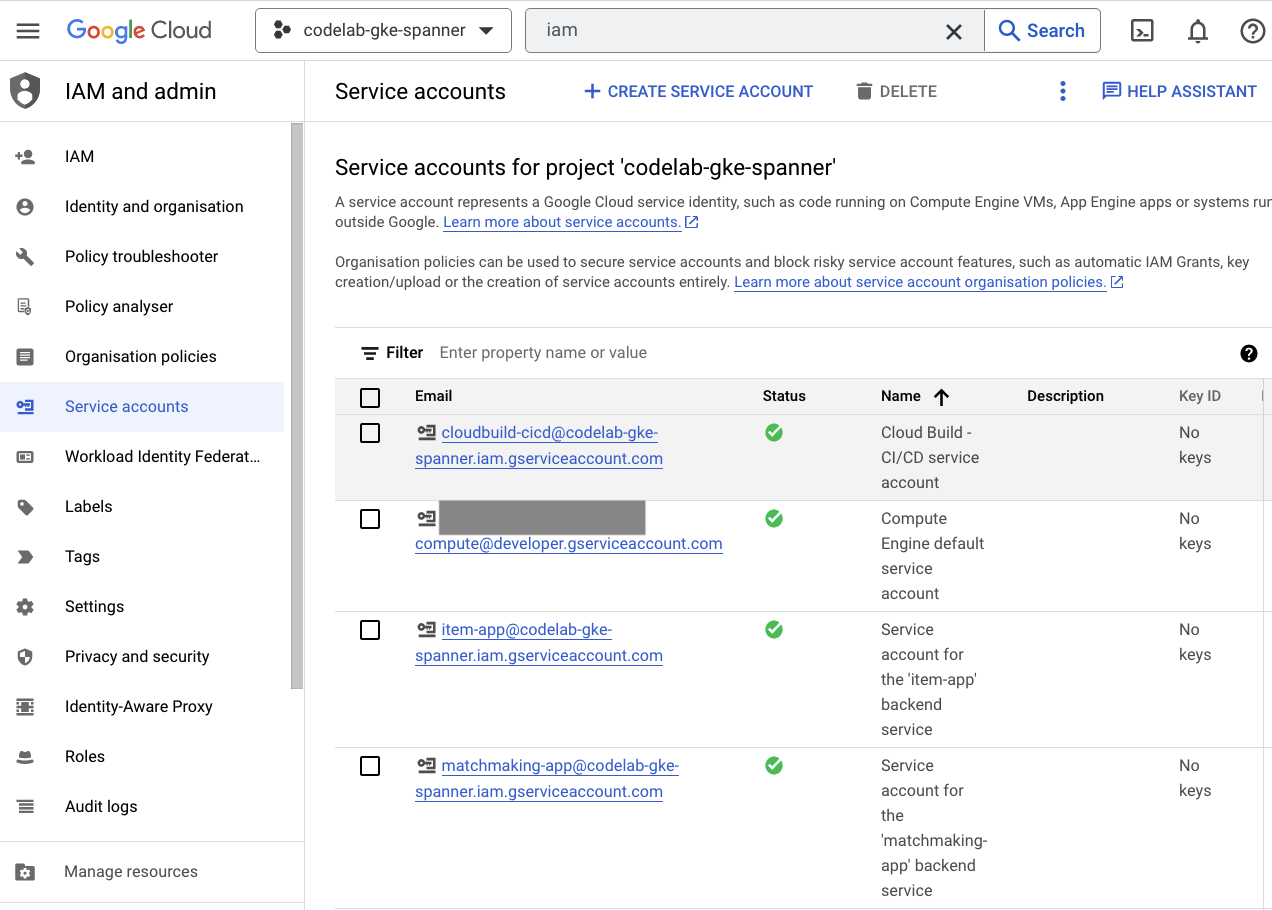
Terraform crée six comptes de service au total :
- Le compte de service Compute par défaut. Ce paramètre n'est pas utilisé dans cet atelier de programmation.
- Le compte cloudbuild-cicd est utilisé pour les étapes Cloud Build et Cloud Deploy.
- Quatre comptes "app" utilisés par nos services de backend pour interagir avec Cloud Spanner.
Vous devez ensuite configurer kubectl pour interagir avec le cluster GKE.
Configurer kubectl
# Name of GKE cluster from terraform.tfvars file
export GKE_CLUSTER=sample-game-gke
# get GKE credentials
gcloud container clusters get-credentials $GKE_CLUSTER --region us-central1
# Check that no errors occur
kubectl get serviceaccounts
Résultat de la commande
#export GKE_CLUSTER=sample-game-gke
# gcloud container clusters get-credentials $GKE_CLUSTER --region us-central1
Fetching cluster endpoint and auth data.
kubeconfig entry generated for sample-game-gke.
# kubectl get serviceaccounts
NAME SECRETS AGE
default 0 37m
item-app 0 35m
matchmaking-app 0 35m
profile-app 0 35m
tradepost-app 0 35m
Résumé
Parfait ! Vous avez pu provisionner une instance Cloud Spanner et un cluster GKE Autopilot, le tout dans un VPC pour la mise en réseau privée.
De plus, deux pipelines Cloud Deploy ont été créés pour les services de backend et les charges de travail, ainsi qu'un dépôt Artifact Registry pour stocker les images créées.
Enfin, les comptes de service ont été créés et configurés pour fonctionner avec Workload Identity afin que les services de backend puissent utiliser Cloud Spanner.
Vous avez également configuré kubectl pour interagir avec le cluster GKE dans Cloud Shell après avoir déployé les services et les charges de travail de backend.
Étape suivante
Avant de pouvoir utiliser les services, vous devez définir le schéma de la base de données. Vous le configurerez ensuite.
4. Créer le schéma de base de données
Présentation
Avant de pouvoir exécuter les services de backend, vous devez vous assurer que le schéma de base de données est en place.
Si vous examinez les fichiers du répertoire $DEMO_HOME/schema/migrations du dépôt de démonstration, vous verrez une série de fichiers .sql qui définissent notre schéma. Cela imite un cycle de développement où les modifications de schéma sont suivies dans le dépôt lui-même et peuvent être liées à certaines fonctionnalités des applications.
Pour cet exemple d'environnement, wrench est l'outil qui appliquera nos migrations de schéma à l'aide de Cloud Build.
Cloud Build
Le fichier $DEMO_HOME/schema/cloudbuild.yaml décrit les étapes à suivre :
serviceAccount: projects/${PROJECT_ID}/serviceAccounts/cloudbuild-cicd@${PROJECT_ID}.iam.gserviceaccount.com
steps:
- name: gcr.io/cloud-builders/curl
id: fetch-wrench
args: ['-Lo', '/workspace/wrench.tar.gz', 'https://github.com/cloudspannerecosystem/wrench/releases/download/v1.4.1/wrench-1.4.1-linux-amd64.tar.gz' ]
- name: gcr.io/cloud-builders/gcloud
id: migrate-spanner-schema
entrypoint: sh
args:
- '-xe'
- '-c'
- |
tar -xzvf wrench.tar.gz
chmod +x /workspace/wrench
# Assumes only a single spanner instance and database. Fine for this demo in a dedicated project
export SPANNER_PROJECT_ID=${PROJECT_ID}
export SPANNER_INSTANCE_ID=$(gcloud spanner instances list | tail -n1 | awk '{print $1}')
export SPANNER_DATABASE_ID=$(gcloud spanner databases list --instance=$$SPANNER_INSTANCE_ID | tail -n1 | awk '{print $1}')
if [ -d ./migrations ]; then
/workspace/wrench migrate up --directory .
else
echo "[Error] Missing migrations directory"
fi
timeout: 600s
Il y a deux étapes à suivre :
- Télécharger l'outil wrench dans l'espace de travail Cloud Build
- exécuter la migration de la clé
Les variables d'environnement du projet, de l'instance et de la base de données Spanner sont nécessaires pour que wrench se connecte au point de terminaison d'écriture.
Cloud Build peut effectuer ces modifications, car il s'exécute en tant que compte de service cloudbuild-cicd@${PROJECT_ID}.iam.gserviceaccount.com :
serviceAccount: projects/${PROJECT_ID}/serviceAccounts/cloudbuild-cicd@${PROJECT_ID}.iam.gserviceaccount.com
Terraform a ajouté le rôle spanner.databaseUser à ce compte de service, ce qui lui permet de mettre à jour le langage DDL.
Migrations de schéma
Cinq étapes de migration sont effectuées en fonction des fichiers du répertoire $DEMO_HOME/schema/migrations. Voici un exemple de fichier 000001.sql qui crée une table et des index players :
CREATE TABLE players (
playerUUID STRING(36) NOT NULL,
player_name STRING(64) NOT NULL,
email STRING(MAX) NOT NULL,
password_hash BYTES(60) NOT NULL,
created TIMESTAMP,
updated TIMESTAMP,
stats JSON,
account_balance NUMERIC NOT NULL DEFAULT (0.00),
is_logged_in BOOL,
last_login TIMESTAMP,
valid_email BOOL,
current_game STRING(36)
) PRIMARY KEY (playerUUID);
CREATE UNIQUE INDEX PlayerAuthentication ON players(email) STORING(password_hash);
CREATE UNIQUE INDEX PlayerName ON players(player_name);
CREATE INDEX PlayerGame ON players(current_game);
Envoyer la migration du schéma
Pour envoyer la compilation afin d'effectuer la migration du schéma, passez au répertoire schema et exécutez la commande gcloud suivante :
cd $DEMO_HOME/schema gcloud builds submit --config=cloudbuild.yaml
Résultat de la commande
Creating temporary tarball archive of 8 file(s) totalling 11.2 KiB before compression.
Uploading tarball of [.] to [gs://(project)_cloudbuild/source/(snip).tgz]
Created [https://cloudbuild.googleapis.com/v1/projects/(project)/locations/global/builds/7defe982-(snip)].
Logs are available at [ https://console.cloud.google.com/cloud-build/builds/7defe982-(snip)?project=(snip) ].
gcloud builds submit only displays logs from Cloud Storage. To view logs from Cloud Logging, run:
gcloud beta builds submit
ID: 7defe982-(snip)
CREATE_TIME: (created time)
DURATION: 3M11S
SOURCE: gs://(project)_cloudbuild/source/(snip).tgz
IMAGES: -
STATUS: SUCCESS
Dans le résultat ci-dessus, vous remarquerez un lien vers le processus Cloud Build Created. Si vous cliquez dessus, vous serez redirigé vers la compilation dans la console Cloud afin de pouvoir surveiller sa progression et voir ce qu'elle fait.
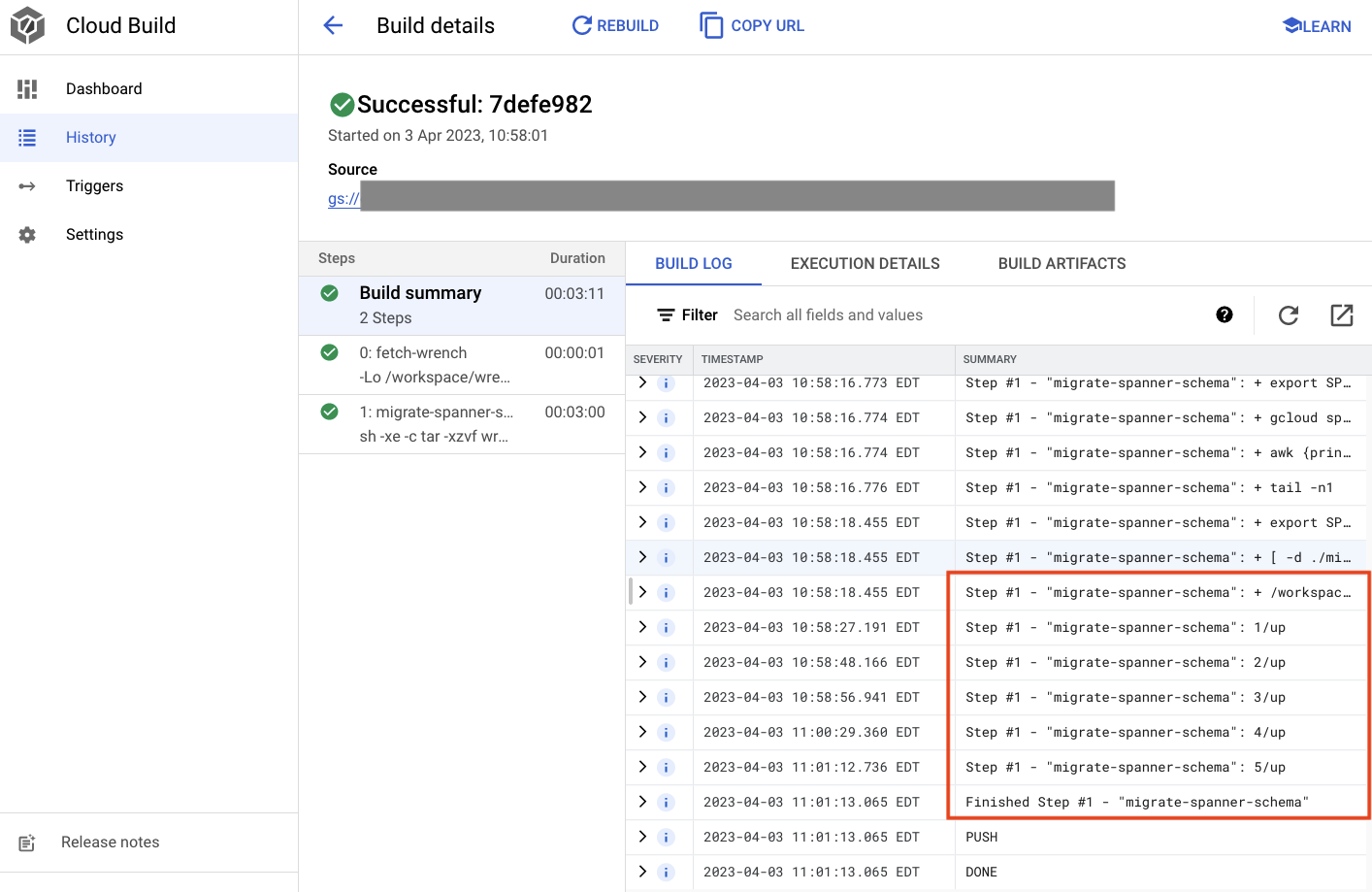
Résumé
Au cours de cette étape, vous avez utilisé Cloud Build pour envoyer la migration initiale du schéma qui a appliqué cinq opérations DDL différentes. Ces opérations représentent les moments où des fonctionnalités nécessitant des modifications du schéma de base de données ont été ajoutées.
Dans un scénario de développement normal, vous souhaiterez rendre les modifications de schéma rétrocompatibles avec l'application actuelle pour éviter les interruptions de service.
Pour les modifications qui ne sont pas rétrocompatibles, vous devez déployer les modifications apportées à l'application et au schéma par étapes pour éviter toute interruption.
Étape suivante
Maintenant que le schéma est en place, l'étape suivante consiste à déployer les services de backend.
5. Déployer les services de backend
Présentation
Les services de backend de cet atelier de programmation sont des API REST Golang qui représentent quatre services différents :
- Profil : permet aux joueurs de s'inscrire et de s'authentifier à notre "jeu" exemple.
- Matchmaking : interagir avec les données des joueurs pour faciliter la fonction de matchmaking, suivre les informations sur les parties créées et mettre à jour les statistiques des joueurs lorsque les parties sont terminées.
- Article : permet aux joueurs d'acquérir des articles et de l'argent en jouant.
- Comptoir commercial : permet aux joueurs d'acheter et de vendre des objets sur un comptoir commercial.
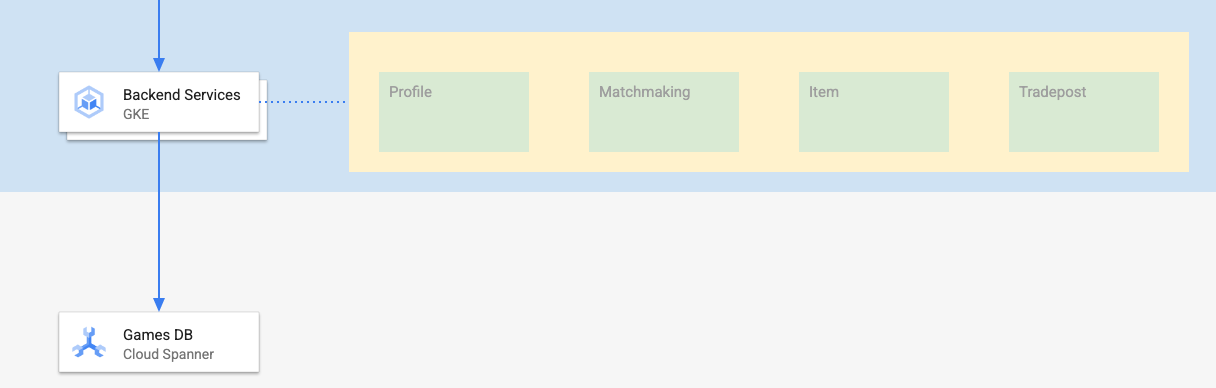
Pour en savoir plus sur ces services, consultez l'atelier de programmation Premiers pas avec Cloud Spanner pour le développement de jeux. Pour nos besoins, nous souhaitons que ces services s'exécutent sur notre cluster GKE Autopilot.
Ces services doivent pouvoir modifier les données Spanner. Pour ce faire, un compte de service est créé pour chaque service, ce qui lui accorde le rôle "databaseUser".
Workload Identity permet à un compte de service Kubernetes d'emprunter l'identité du compte de service Google Cloud des services en suivant les étapes ci-dessous dans Terraform :
- Créez la ressource de compte de service Google Cloud du service (
GSA). - Attribuez le rôle databaseUser à ce compte de service.
- Attribuez le rôle workloadIdentityUser à ce compte de service.
- Créez un compte de service Kubernetes (
KSA) qui fait référence au compte de service Google.
Voici à quoi pourrait ressembler un schéma approximatif :
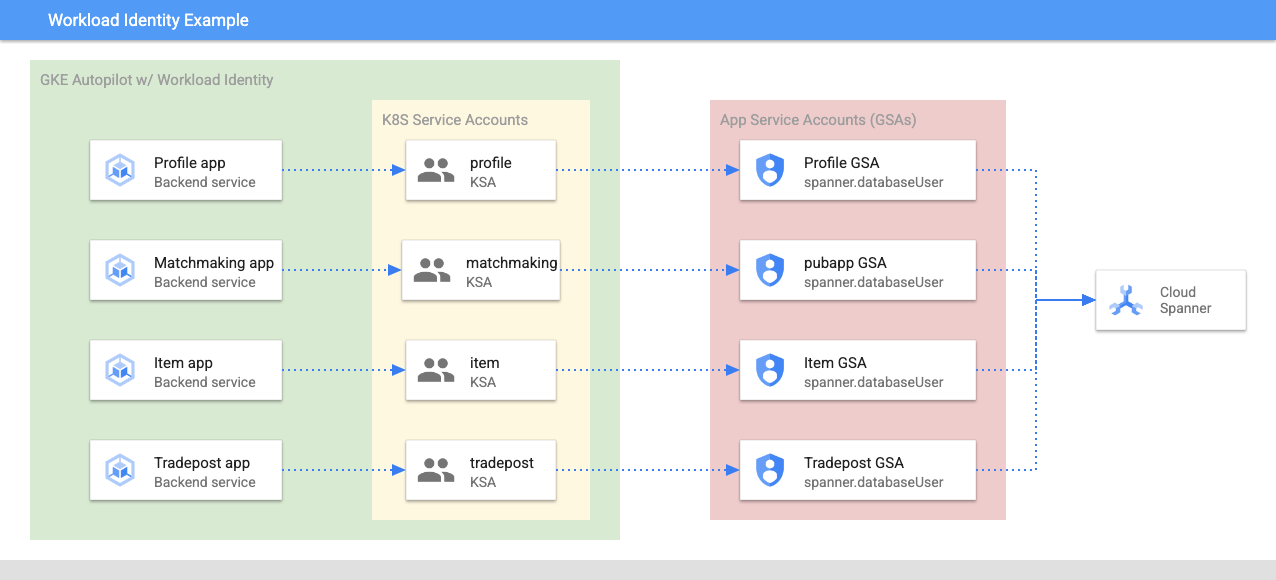
Terraform a créé les comptes de service et les comptes de service Kubernetes pour vous. Vous pouvez vérifier les comptes de service Kubernetes à l'aide de kubectl :
# kubectl get serviceaccounts
NAME SECRETS AGE
default 0 37m
item-app 0 35m
matchmaking-app 0 35m
profile-app 0 35m
tradepost-app 0 35m
Voici comment fonctionne la compilation :
- Terraform a généré un fichier
$DEMO_HOME/backend_services/cloudbuild.yamlqui ressemble à ceci :
serviceAccount: projects/${PROJECT_ID}/serviceAccounts/cloudbuild-cicd@${PROJECT_ID}.iam.gserviceaccount.com
steps:
#
# Building of images
#
- name: gcr.io/cloud-builders/docker
id: profile
args: ["build", ".", "-t", "${_PROFILE_IMAGE}"]
dir: profile
waitFor: ['-']
- name: gcr.io/cloud-builders/docker
id: matchmaking
args: ["build", ".", "-t", "${_MATCHMAKING_IMAGE}"]
dir: matchmaking
waitFor: ['-']
- name: gcr.io/cloud-builders/docker
id: item
args: ["build", ".", "-t", "${_ITEM_IMAGE}"]
dir: item
waitFor: ['-']
- name: gcr.io/cloud-builders/docker
id: tradepost
args: ["build", ".", "-t", "${_TRADEPOST_IMAGE}"]
dir: tradepost
waitFor: ['-']
#
# Deployment
#
- name: gcr.io/google.com/cloudsdktool/cloud-sdk
id: cloud-deploy-release
entrypoint: gcloud
args:
[
"deploy", "releases", "create", "${_REL_NAME}",
"--delivery-pipeline", "sample-game-services",
"--skaffold-file", "skaffold.yaml",
"--skaffold-version", "1.39",
"--images", "profile=${_PROFILE_IMAGE},matchmaking=${_MATCHMAKING_IMAGE},item=${_ITEM_IMAGE},tradepost=${_TRADEPOST_IMAGE}",
"--region", "us-central1"
]
artifacts:
images:
- ${_REGISTRY}/profile
- ${_REGISTRY}/matchmaking
- ${_REGISTRY}/item
- ${_REGISTRY}/tradepost
substitutions:
_PROFILE_IMAGE: ${_REGISTRY}/profile:${BUILD_ID}
_MATCHMAKING_IMAGE: ${_REGISTRY}/matchmaking:${BUILD_ID}
_ITEM_IMAGE: ${_REGISTRY}/item:${BUILD_ID}
_TRADEPOST_IMAGE: ${_REGISTRY}/tradepost:${BUILD_ID}
_REGISTRY: us-docker.pkg.dev/${PROJECT_ID}/spanner-game-images
_REL_NAME: rel-${BUILD_ID:0:8}
options:
dynamic_substitutions: true
machineType: E2_HIGHCPU_8
logging: CLOUD_LOGGING_ONLY
- La commande Cloud Build lit ce fichier et suit les étapes listées. Tout d'abord, il crée les images de service. Il exécute ensuite une commande
gcloud deploy create. Cela permet de lire le fichier$DEMO_HOME/backend_services/skaffold.yaml, qui définit l'emplacement de chaque fichier de déploiement :
apiVersion: skaffold/v2beta29
kind: Config
deploy:
kubectl:
manifests:
- spanner_config.yaml
- profile/deployment.yaml
- matchmaking/deployment.yaml
- item/deployment.yaml
- tradepost/deployment.yaml
- Cloud Deploy suivra les définitions du fichier
deployment.yamlde chaque service. Le fichier de déploiement du service contient les informations permettant de créer un service, qui dans ce cas est un clusterIP s'exécutant sur le port 80.
Le type "ClusterIP" empêche les pods de service de backend d'avoir une adresse IP externe. Seules les entités pouvant se connecter au réseau GKE interne peuvent donc accéder aux services de backend. Les joueurs ne doivent pas avoir accès directement à ces services, car ils accèdent aux données Spanner et les modifient.
apiVersion: v1
kind: Service
metadata:
name: profile
spec:
type: ClusterIP
selector:
app: profile
ports:
- port: 80
targetPort: 80
En plus de créer un service Kubernetes, Cloud Deploy crée également un déploiement Kubernetes. Examinons la section de déploiement du service profile :
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: profile
spec:
replicas: 2 # EDIT: Number of instances of deployment
selector:
matchLabels:
app: profile
template:
metadata:
labels:
app: profile
spec:
serviceAccountName: profile-app
containers:
- name: profile-service
image: profile
ports:
- containerPort: 80
envFrom:
- configMapRef:
name: spanner-config
env:
- name: SERVICE_HOST
value: "0.0.0.0"
- name: SERVICE_PORT
value: "80"
resources:
requests:
cpu: "1"
memory: "1Gi"
ephemeral-storage: "100Mi"
limits:
cpu: "1"
memory: "1Gi"
ephemeral-storage: "100Mi"
La partie supérieure fournit des métadonnées sur le service. L'élément le plus important est de définir le nombre de répliques qui seront créées par ce déploiement.
replicas: 2 # EDIT: Number of instances of deployment
Nous voyons ensuite quel compte de service doit exécuter l'application et quelle image il doit utiliser. Ils correspondent au compte de service Kubernetes créé à partir de Terraform et à l'image créée lors de l'étape Cloud Build.
spec:
serviceAccountName: profile-app
containers:
- name: profile-service
image: profile
Nous spécifions ensuite des informations sur la mise en réseau et les variables d'environnement.
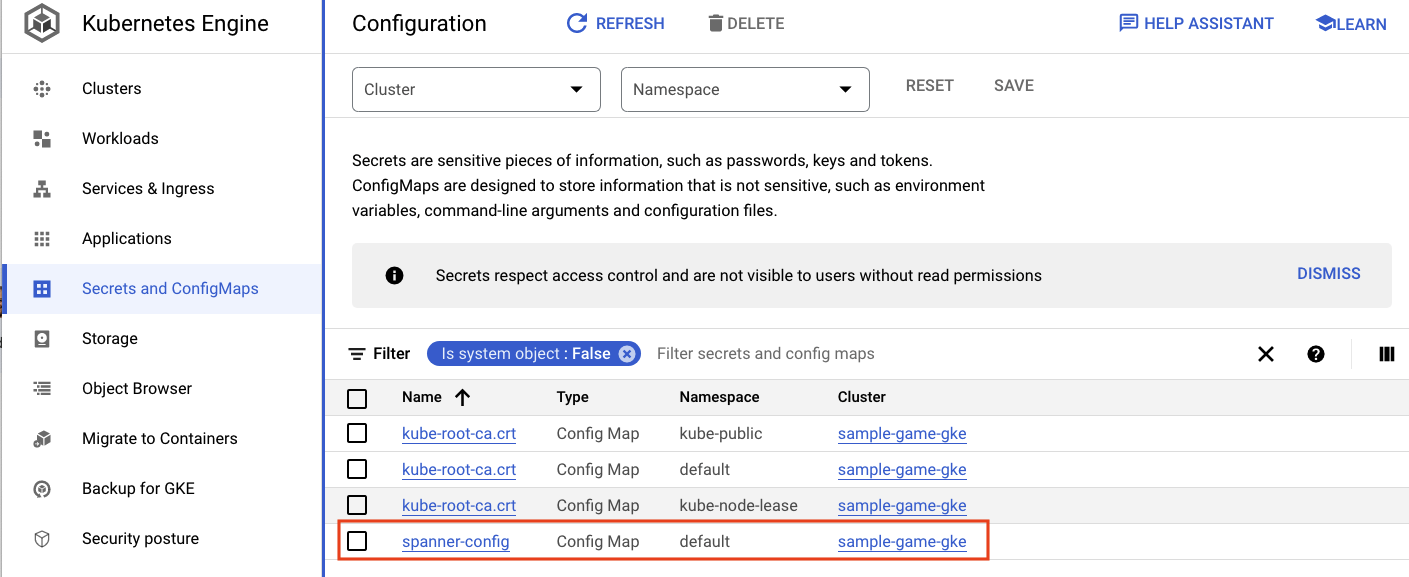
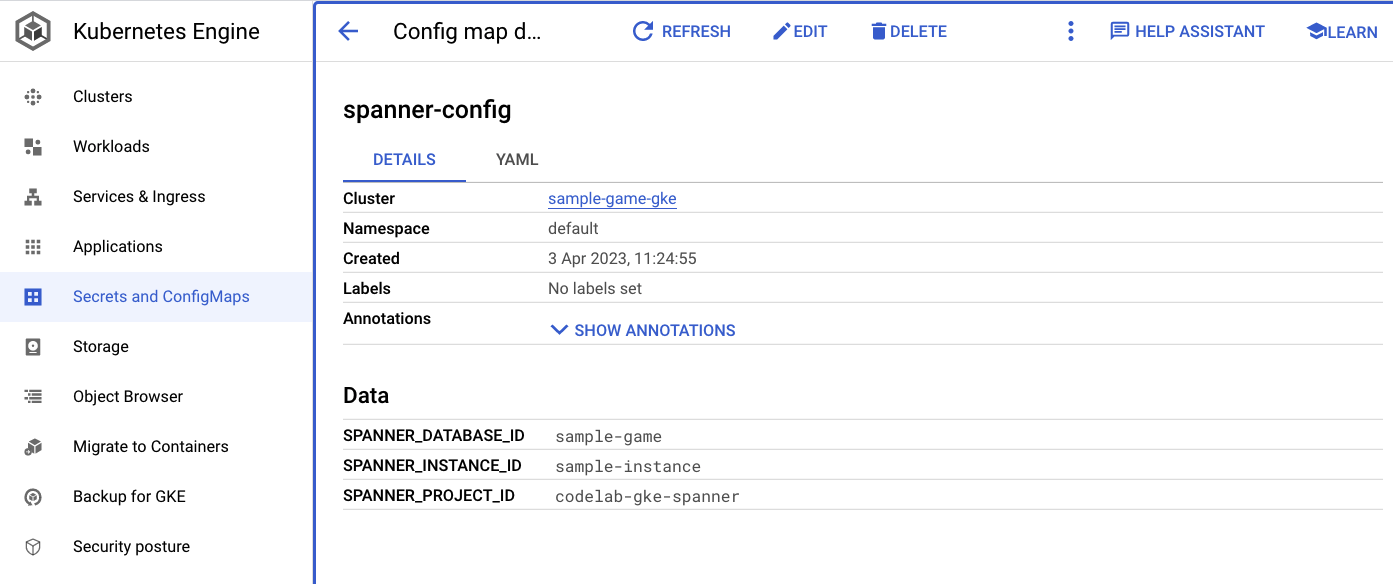
spanner_config est un ConfigMap Kubernetes qui spécifie les informations sur le projet, l'instance et la base de données nécessaires à l'application pour se connecter à Spanner.
apiVersion: v1
kind: ConfigMap
metadata:
name: spanner-config
data:
SPANNER_PROJECT_ID: ${project_id}
SPANNER_INSTANCE_ID: ${instance_id}
SPANNER_DATABASE_ID: ${database_id}
ports:
- containerPort: 80
envFrom:
- configMapRef:
name: spanner-config
env:
- name: SERVICE_HOST
value: "0.0.0.0"
- name: SERVICE_PORT
value: "80"
SERVICE_HOST et SERVICE_PORT sont des variables d'environnement supplémentaires dont le service a besoin pour savoir où effectuer la liaison.
La dernière section indique à GKE le nombre de ressources à allouer à chaque réplique de ce déploiement. C'est également ce que GKE Autopilot utilise pour mettre à l'échelle le cluster selon les besoins.
resources:
requests:
cpu: "1"
memory: "1Gi"
ephemeral-storage: "100Mi"
limits:
cpu: "1"
memory: "1Gi"
ephemeral-storage: "100Mi"
Avec ces informations, il est temps de déployer les services de backend.
Déployer les services de backend
Comme indiqué, le déploiement des services de backend utilise Cloud Build. Comme pour les migrations de schéma, vous pouvez envoyer la demande de compilation à l'aide de la ligne de commande gcloud :
cd $DEMO_HOME/backend_services gcloud builds submit --config=cloudbuild.yaml
Résultat de la commande
Creating temporary tarball archive of 66 file(s) totalling 864.6 KiB before compression.
Uploading tarball of [.] to [gs://(project)_cloudbuild/source/(snip).tgz]
Created [https://cloudbuild.googleapis.com/v1/projects/(project)/locations/global/builds/30207dd1-(snip)].
Logs are available at [ https://console.cloud.google.com/cloud-build/builds/30207dd1-(snip)?project=(snip) ].
gcloud builds submit only displays logs from Cloud Storage. To view logs from Cloud Logging, run:
gcloud beta builds submit
ID: 30207dd1-(snip)
CREATE_TIME: (created time)
DURATION: 3M17S
SOURCE: gs://(project)_cloudbuild/source/(snip).tgz
IMAGES: us-docker.pkg.dev/(project)/spanner-game-images/profile:30207dd1-(snip) (+3 more)
STATUS: SUCCESS
Contrairement à la sortie de l'étape schema migration, la sortie de cette compilation indique que des images ont été créées. Ils seront stockés dans votre dépôt Artifact Registry.
Le résultat de l'étape gcloud build inclut un lien vers la console Cloud. Jetez-y un coup d'œil.
Une fois que vous avez reçu la notification de réussite de Cloud Build, accédez à Cloud Deploy, puis au pipeline sample-game-services pour suivre la progression du déploiement.
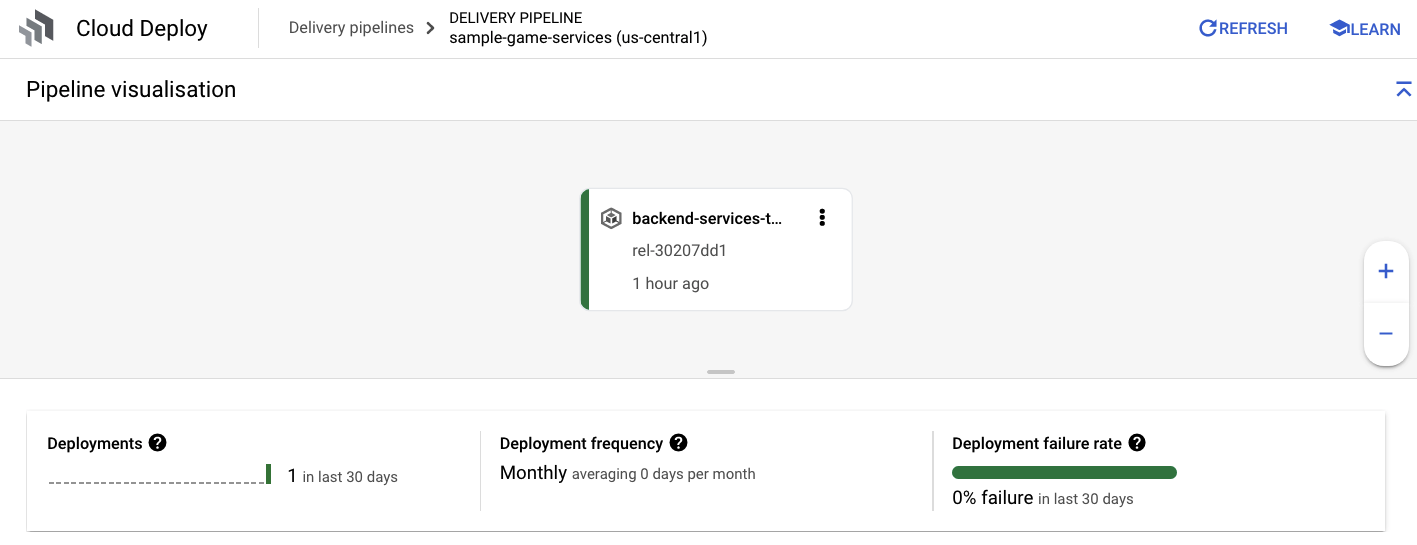
Une fois les services déployés, vous pouvez vérifier l'état des pods en consultant kubectl :
kubectl get pods
Résultat de la commande
NAME READY STATUS RESTARTS AGE
item-6b9d5f678c-4tbk2 1/1 Running 0 83m
matchmaking-5bcf799b76-lg8zf 1/1 Running 0 80m
profile-565bbf4c65-kphdl 1/1 Running 0 83m
profile-565bbf4c65-xw74j 1/1 Running 0 83m
tradepost-68b87ccd44-gw55r 1/1 Running 0 79m
Ensuite, vérifiez les services pour voir ClusterIP en action :
kubectl get services
Résultat de la commande
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
item ClusterIP 10.172.XXX.XXX <none> 80/TCP 84m
kubernetes ClusterIP 10.172.XXX.XXX <none> 443/TCP 137m
matchmaking ClusterIP 10.172.XXX.XXX <none> 80/TCP 84m
profile ClusterIP 10.172.XXX.XXX <none> 80/TCP 84m
tradepost ClusterIP 10.172.XXX.XXX <none> 80/TCP 84m
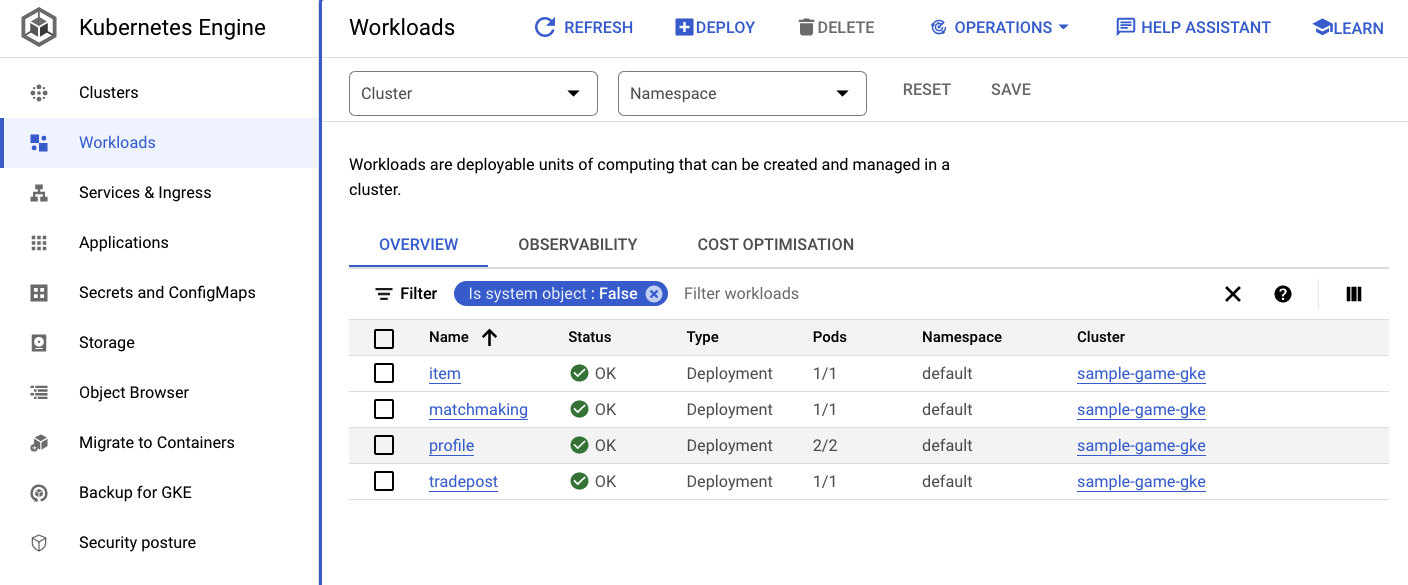
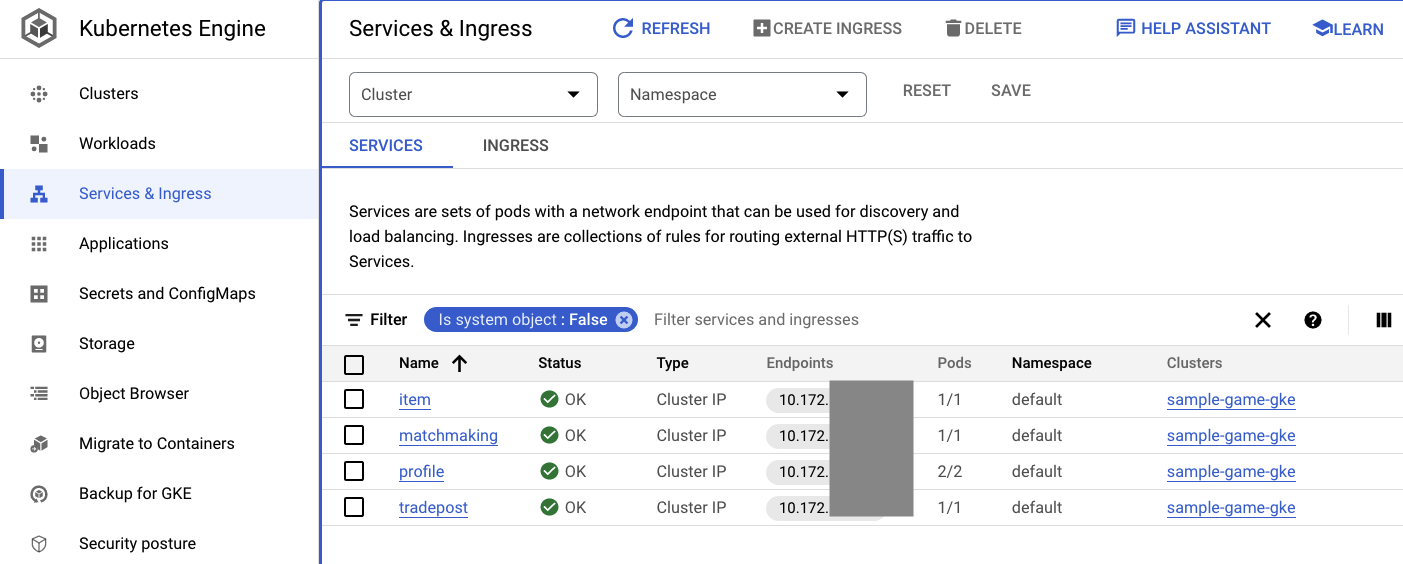
Vous pouvez également accéder à l'interface utilisateur GKE dans la console Cloud pour afficher Workloads, Services et ConfigMaps.
Charges de travail
Services
ConfigMaps
Résumé
Au cours de cette étape, vous avez déployé les quatre services de backend sur GKE Autopilot. Vous avez pu exécuter l'étape Cloud Build et vérifier la progression dans Cloud Deploy et sur Kubernetes dans la console Cloud.
Vous avez également appris comment ces services utilisent Workload Identity pour emprunter l'identité d'un compte de service disposant des autorisations appropriées pour lire et écrire des données dans la base de données Spanner.
Étapes suivantes
Dans la section suivante, vous allez déployer les charges de travail.
6. Déployer les charges de travail
Présentation
Maintenant que les services de backend s'exécutent sur le cluster, vous allez déployer les charges de travail.

Les charges de travail sont accessibles en externe. Il y en a une pour chaque service de backend dans cet atelier de programmation.
Ces charges de travail sont des scripts de génération de charge basés sur Locust qui imitent les modèles d'accès réels attendus par ces exemples de services.
Il existe des fichiers pour le processus Cloud Build :
$DEMO_HOME/workloads/cloudbuild.yaml(généré par Terraform)$DEMO_HOME/workloads/skaffold.yaml- un fichier
deployment.yamlpour chaque charge de travail.
Les fichiers de charge de travail deployment.yaml sont légèrement différents des fichiers de déploiement du service backend.
Voici un exemple tiré de matchmaking-workload :
apiVersion: v1
kind: Service
metadata:
name: matchmaking-workload
spec:
type: LoadBalancer
selector:
app: matchmaking-workload
ports:
- port: 8089
targetPort: 8089
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: matchmaking-workload
spec:
replicas: 1 # EDIT: Number of instances of deployment
selector:
matchLabels:
app: matchmaking-workload
template:
metadata:
labels:
app: matchmaking-workload
spec:
serviceAccountName: default
containers:
- name: matchmaking-workload
image: matchmaking-workload
ports:
- containerPort: 8089
resources:
requests:
cpu: "500m"
memory: "512Mi"
ephemeral-storage: "100Mi"
limits:
cpu: "500m"
memory: "512Mi"
ephemeral-storage: "100Mi"
La partie supérieure du fichier définit le service. Dans ce cas, un LoadBalancer est créé et la charge de travail s'exécute sur le port 8089.
LoadBalancer fournira une adresse IP externe qui pourra être utilisée pour se connecter à la charge de travail.
apiVersion: v1
kind: Service
metadata:
name: matchmaking-workload
spec:
type: LoadBalancer
selector:
app: matchmaking-workload
ports:
- port: 8089
targetPort: 8089
En haut de la section de déploiement se trouvent les métadonnées sur la charge de travail. Dans ce cas, une seule réplique est déployée :
replicas: 1
Toutefois, la spécification du conteneur est différente. Tout d'abord, nous utilisons un compte de service Kubernetes default. Ce compte ne dispose d'aucun privilège spécial, car la charge de travail n'a pas besoin de se connecter à des ressources Google Cloud, à l'exception des services de backend exécutés sur le cluster GKE.
L'autre différence est qu'aucune variable d'environnement n'est requise pour ces charges de travail. La spécification de déploiement est ainsi plus courte.
spec:
serviceAccountName: default
containers:
- name: matchmaking-workload
image: matchmaking-workload
ports:
- containerPort: 8089
Les paramètres de ressources sont semblables à ceux des services de backend. N'oubliez pas que c'est ainsi que GKE Autopilot sait combien de ressources sont nécessaires pour répondre aux demandes de tous les pods exécutés sur le cluster.
Déployez les charges de travail.
Déployer les charges de travail
Comme avant, vous pouvez envoyer la demande de compilation à l'aide de la ligne de commande gcloud :
cd $DEMO_HOME/workloads gcloud builds submit --config=cloudbuild.yaml
Résultat de la commande
Creating temporary tarball archive of 18 file(s) totalling 26.2 KiB before compression.
Some files were not included in the source upload.
Check the gcloud log [/tmp/tmp.4Z9EqdPo6d/logs/(snip).log] to see which files and the contents of the
default gcloudignore file used (see `$ gcloud topic gcloudignore` to learn
more).
Uploading tarball of [.] to [gs://(project)_cloudbuild/source/(snip).tgz]
Created [https://cloudbuild.googleapis.com/v1/projects/(project)/locations/global/builds/(snip)].
Logs are available at [ https://console.cloud.google.com/cloud-build/builds/0daf20f6-(snip)?project=(snip) ].
gcloud builds submit only displays logs from Cloud Storage. To view logs from Cloud Logging, run:
gcloud beta builds submit
ID: 0daf20f6-(snip)
CREATE_TIME: (created_time)
DURATION: 1M41S
SOURCE: gs://(project)_cloudbuild/source/(snip).tgz
IMAGES: us-docker.pkg.dev/(project)/spanner-game-images/profile-workload:0daf20f6-(snip) (+4 more)
STATUS: SUCCESS
Veillez à consulter les journaux Cloud Build et le pipeline Cloud Deploy dans la console Cloud pour vérifier l'état. Pour les charges de travail, le pipeline Cloud Deploy est sample-game-workloads :
Une fois le déploiement terminé, vérifiez l'état avec kubectl dans Cloud Shell :
kubectl get pods
Résultat de la commande
NAME READY STATUS RESTARTS AGE
game-workload-7ff44cb657-pxxq2 1/1 Running 0 12m
item-6b9d5f678c-cr29w 1/1 Running 0 9m6s
item-generator-7bb4f57cf8-5r85b 1/1 Running 0 12m
matchmaking-5bcf799b76-lg8zf 1/1 Running 0 117m
matchmaking-workload-76df69dbdf-jds9z 1/1 Running 0 12m
profile-565bbf4c65-kphdl 1/1 Running 0 121m
profile-565bbf4c65-xw74j 1/1 Running 0 121m
profile-workload-76d6db675b-kzwng 1/1 Running 0 12m
tradepost-68b87ccd44-gw55r 1/1 Running 0 116m
tradepost-workload-56c55445b5-b5822 1/1 Running 0 12m
Ensuite, vérifiez les services de charge de travail pour voir LoadBalancer en action :
kubectl get services
Résultat de la commande
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
game-workload LoadBalancer *snip* 35.XX.XX.XX 8089:32483/TCP 12m
item ClusterIP *snip* <none> 80/TCP 121m
item-generator LoadBalancer *snip* 34.XX.XX.XX 8089:32581/TCP 12m
kubernetes ClusterIP *snip* <none> 443/TCP 174m
matchmaking ClusterIP *snip* <none> 80/TCP 121m
matchmaking-workload LoadBalancer *snip* 34.XX.XX.XX 8089:31735/TCP 12m
profile ClusterIP *snip* <none> 80/TCP 121m
profile-workload LoadBalancer *snip* 34.XX.XX.XX 8089:32532/TCP 12m
tradepost ClusterIP *snip* <none> 80/TCP 121m
tradepost-workload LoadBalancer *snip* 34.XX.XX.XX 8089:30002/TCP 12m
Résumé
Vous avez maintenant déployé les charges de travail sur le cluster GKE. Ces charges de travail ne nécessitent aucune autorisation IAM supplémentaire et sont accessibles en externe sur le port 8089 à l'aide du service LoadBalancer.
Étapes suivantes
Maintenant que les services et les charges de travail de backend sont en cours d'exécution, il est temps de jouer !
7. Commencer à jouer
Présentation
Les services de backend de votre exemple de "jeu" sont désormais en cours d'exécution. Vous disposez également des moyens nécessaires pour générer des "joueurs" interagissant avec ces services à l'aide des charges de travail.
Chaque charge de travail utilise Locust pour simuler la charge réelle sur nos API de service. Dans cette étape, vous allez exécuter plusieurs charges de travail pour générer une charge sur le cluster GKE et sur Spanner, et stocker des données sur Spanner.
Voici une description de chaque charge de travail :
- La charge de travail
item-generatorest une charge de travail rapide qui permet de générer une liste d'game_items que les joueurs peuvent acquérir en "jouant" au jeu. profile-workloadsimule l'inscription et la connexion des joueurs.- L'icône
matchmaking-workloadsimule les joueurs qui font la queue pour être affectés à des parties. game-workloadsimule les joueurs qui acquièrent des game_items et de l'argent en jouant au jeu.- Le
tradepost-workloadsimule la possibilité pour les joueurs de vendre et d'acheter des objets au comptoir d'échange.
Cet atelier de programmation mettra en évidence l'exécution spécifique de item-generator et de profile-workload.
Exécuter le générateur d'éléments
item-generator utilise le point de terminaison du service de backend item pour ajouter game_items à Spanner. Ces éléments sont nécessaires au bon fonctionnement de game-workload et tradepost-workload.
La première étape consiste à obtenir l'adresse IP externe du service item-generator. Dans Cloud Shell, exécutez la commande ci-dessous.
# The external IP is the 4th column of the output
kubectl get services | grep item-generator | awk '{print $4}'
Résultat de la commande
{ITEMGENERATOR_EXTERNAL_IP}
Ouvrez un nouvel onglet de navigateur et accédez à http://{ITEMGENERATOR_EXTERNAL_IP}:8089. Vous devriez obtenir une page semblable à celle-ci :
Vous allez laisser les valeurs par défaut de users et spawn à 1. Pour host,saisissez http://item. Cliquez sur les options avancées, puis saisissez 10s pour la durée.
Voici à quoi doit ressembler la configuration :
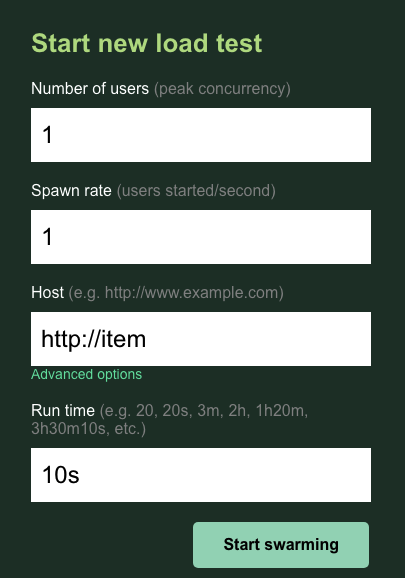
Cliquez sur "Start swarming" (Démarrer le travail en essaim) !
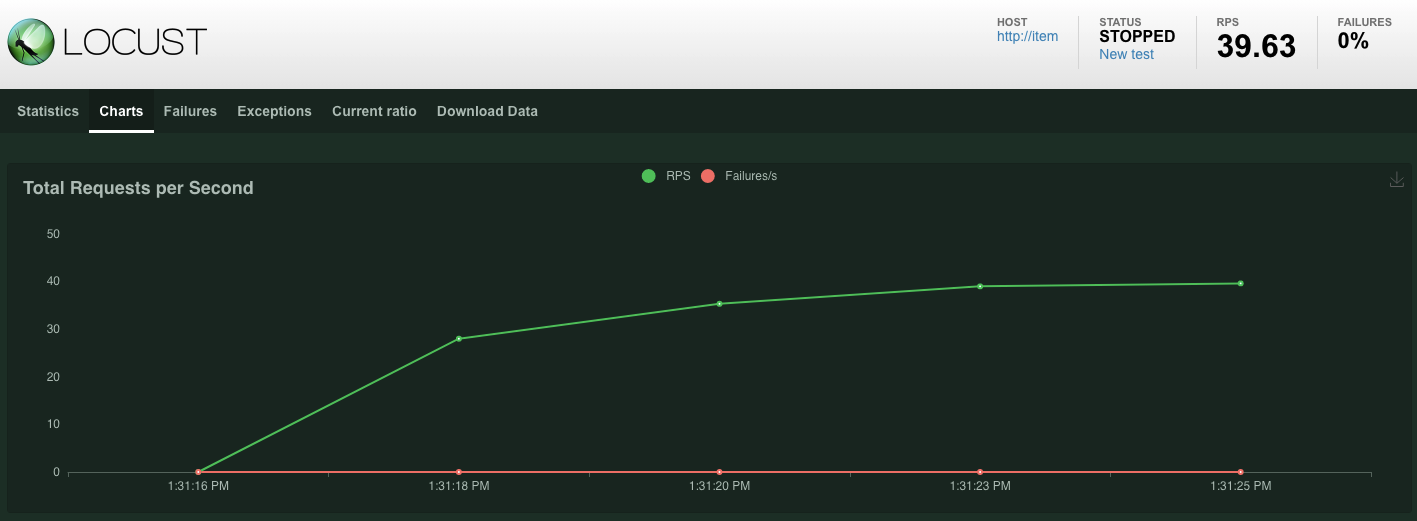
Les statistiques commenceront à s'afficher pour les requêtes émises sur le point de terminaison POST /items. Au bout de 10 secondes, le chargement s'arrête.
Cliquez sur Charts pour afficher des graphiques sur les performances de ces demandes.
Vous souhaitez maintenant vérifier si les données ont été saisies dans la base de données Spanner.
Pour ce faire, cliquez sur le menu hamburger et accédez à "Spanner". Sur cette page, accédez à sample-instance et à sample-database. Cliquez ensuite sur Query.
Nous voulons sélectionner le nombre de game_items:
SELECT COUNT(*) FROM game_items;
Le résultat s'affiche en bas de l'écran.
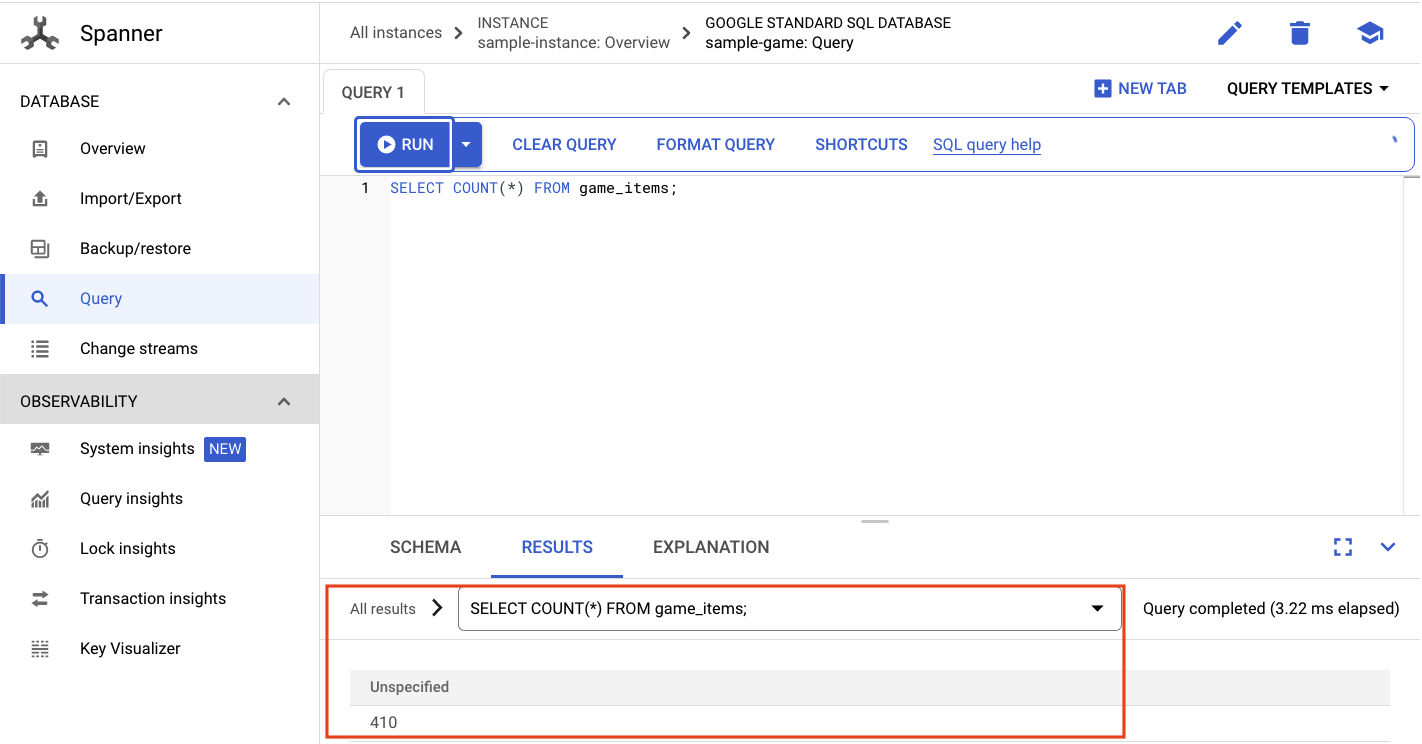
Nous n'avons pas besoin de beaucoup de game_items pour commencer. Mais ils sont désormais disponibles pour les joueurs !
Exécuter la charge de travail de profilage
Une fois votre game_items initialisé, l'étape suivante consiste à inscrire les joueurs pour qu'ils puissent jouer.
profile-workload utilisera Locust pour simuler des joueurs qui créent des comptes, se connectent, récupèrent des informations de profil et se déconnectent. Tous ces tests portent sur les points de terminaison du service de backend profile dans une charge de travail typique de type production.
Pour exécuter cette commande, obtenez l'adresse IP externe de profile-workload :
# The external IP is the 4th column of the output
kubectl get services | grep profile-workload | awk '{print $4}'
Résultat de la commande
{PROFILEWORKLOAD_EXTERNAL_IP}
Ouvrez un nouvel onglet de navigateur et accédez à http://{PROFILEWORKLOAD_EXTERNAL_IP}:8089. Vous devriez obtenir une page Locust semblable à la précédente.
Dans ce cas, vous utiliserez http://profile pour l'hôte. Vous ne spécifierez pas d'environnement d'exécution dans les options avancées. Spécifiez également users sur 4, ce qui simulera quatre requêtes utilisateur à la fois.
Le test profile-workload devrait se présenter comme suit :
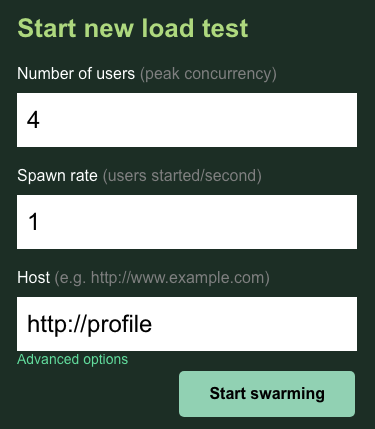
Cliquez sur "Start swarming" (Démarrer le travail en essaim) !
Comme précédemment, les statistiques des différents points de terminaison REST profile commenceront à s'afficher. Cliquez sur "Graphiques" pour voir les performances de chaque élément.
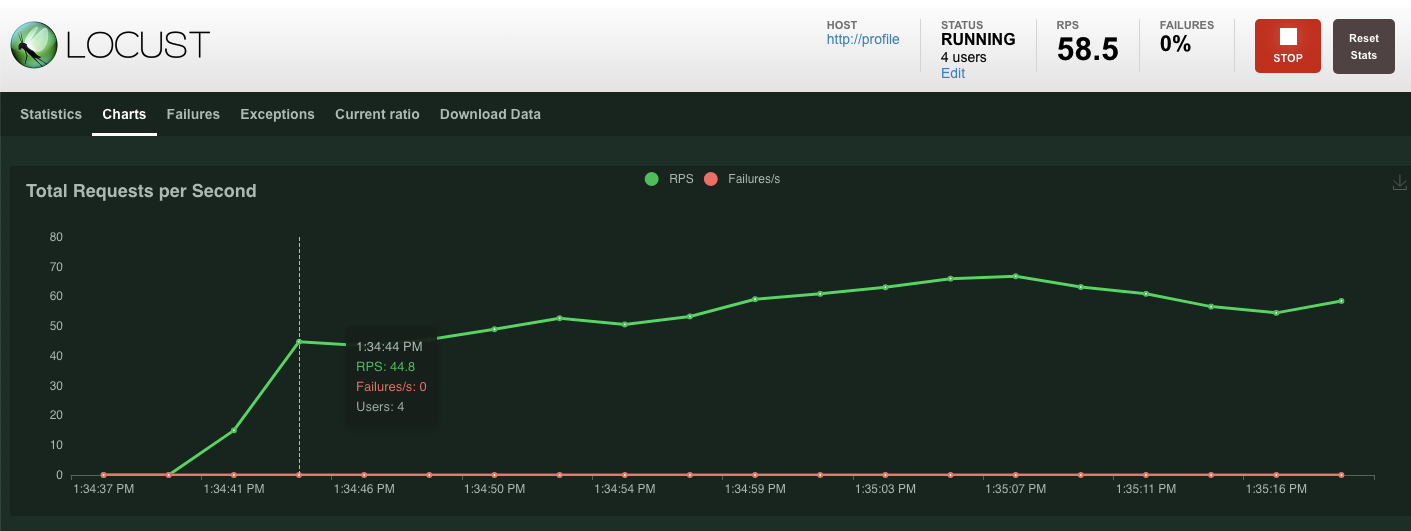
Résumé
Lors de cette étape, vous avez généré des game_items, puis interrogé la table game_items à l'aide de l'interface utilisateur des requêtes Spanner dans la console Cloud.
Vous avez également permis aux joueurs de s'inscrire à votre jeu et vous avez vu comment Locust est capable de créer des charges de travail de type production pour vos services de backend.
Étapes suivantes
Après avoir exécuté les charges de travail, vous voudrez vérifier le comportement du cluster GKE et de l'instance Spanner.
8. Examiner l'utilisation de GKE et Spanner
Maintenant que le service de profil est en cours d'exécution, il est temps de voir comment se comportent votre cluster GKE Autopilot et Cloud Spanner.
Vérifier le cluster GKE
Accédez au cluster Kubernetes. Notez que, comme vous avez déployé les charges de travail et les services, des détails ont été ajoutés au cluster concernant le nombre total de processeurs virtuels et la mémoire. Ces informations n'étaient pas disponibles lorsqu'il n'y avait aucune charge de travail sur le cluster.
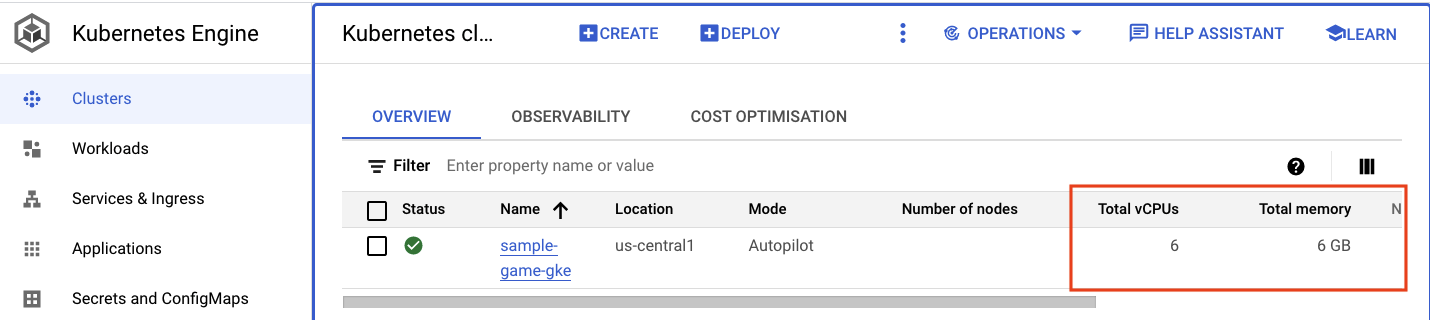
Cliquez à présent sur le cluster sample-game-gke et passez à l'onglet "Observability" (Observabilité) :
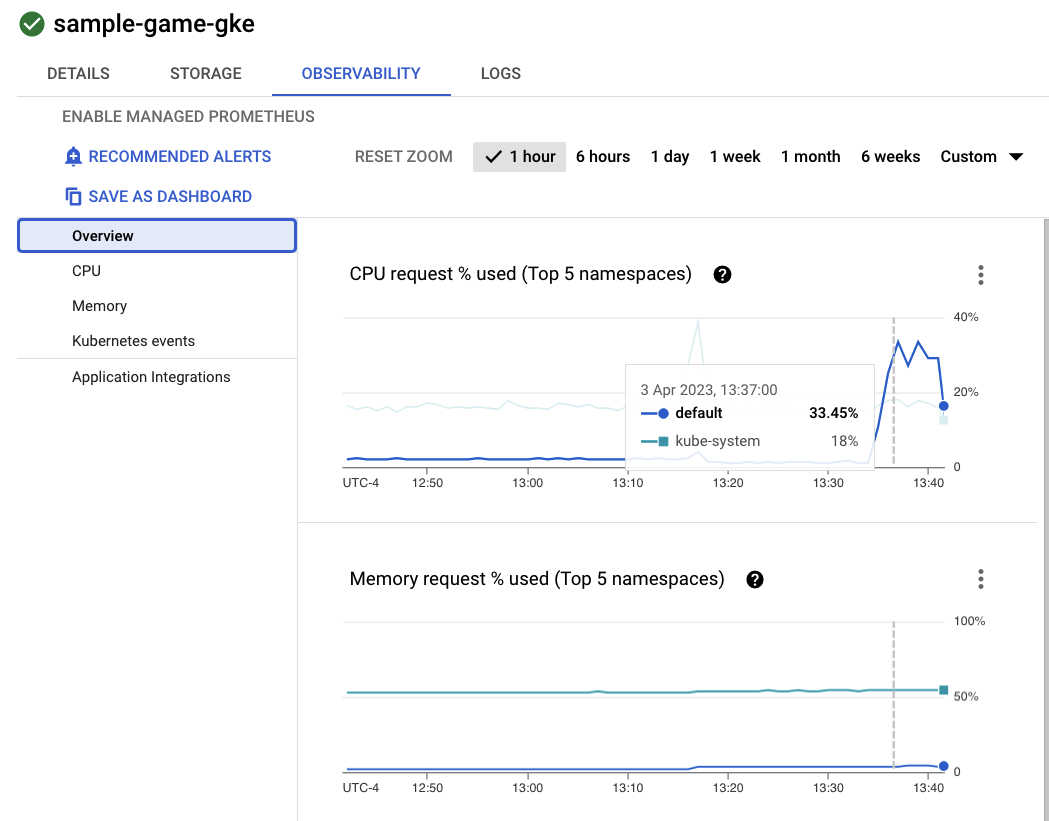
L'espace de noms Kubernetes default devrait avoir dépassé l'espace de noms kube-system en termes d'utilisation du processeur, car nos charges de travail et nos services de backend s'exécutent sur default. Si ce n'est pas le cas, assurez-vous que profile workload est toujours en cours d'exécution et attendez quelques minutes que les graphiques se mettent à jour.
Pour identifier les charges de travail qui consomment le plus de ressources, accédez au tableau de bord Workloads.
Au lieu d'examiner chaque charge de travail individuellement, accédez directement à l'onglet "Observabilité" du tableau de bord. Vous devriez constater que l'utilisation du processeur profile et profile-workload a augmenté.
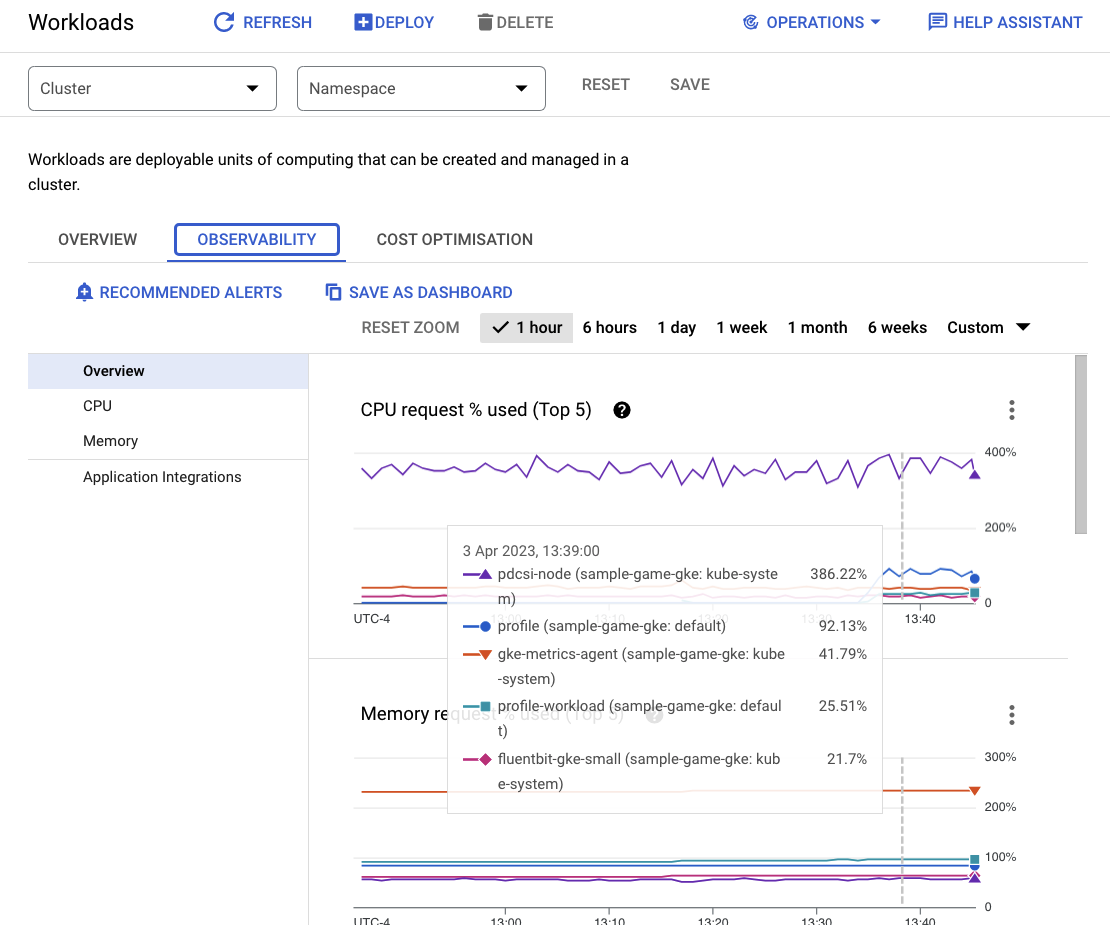
Accédez maintenant à Cloud Spanner.
Vérifier l'instance Cloud Spanner
Pour vérifier les performances de Cloud Spanner, accédez à Spanner, puis cliquez sur l'instance sample-instance et la base de données sample-game.
Vous verrez alors un onglet Insights système dans le menu de gauche :
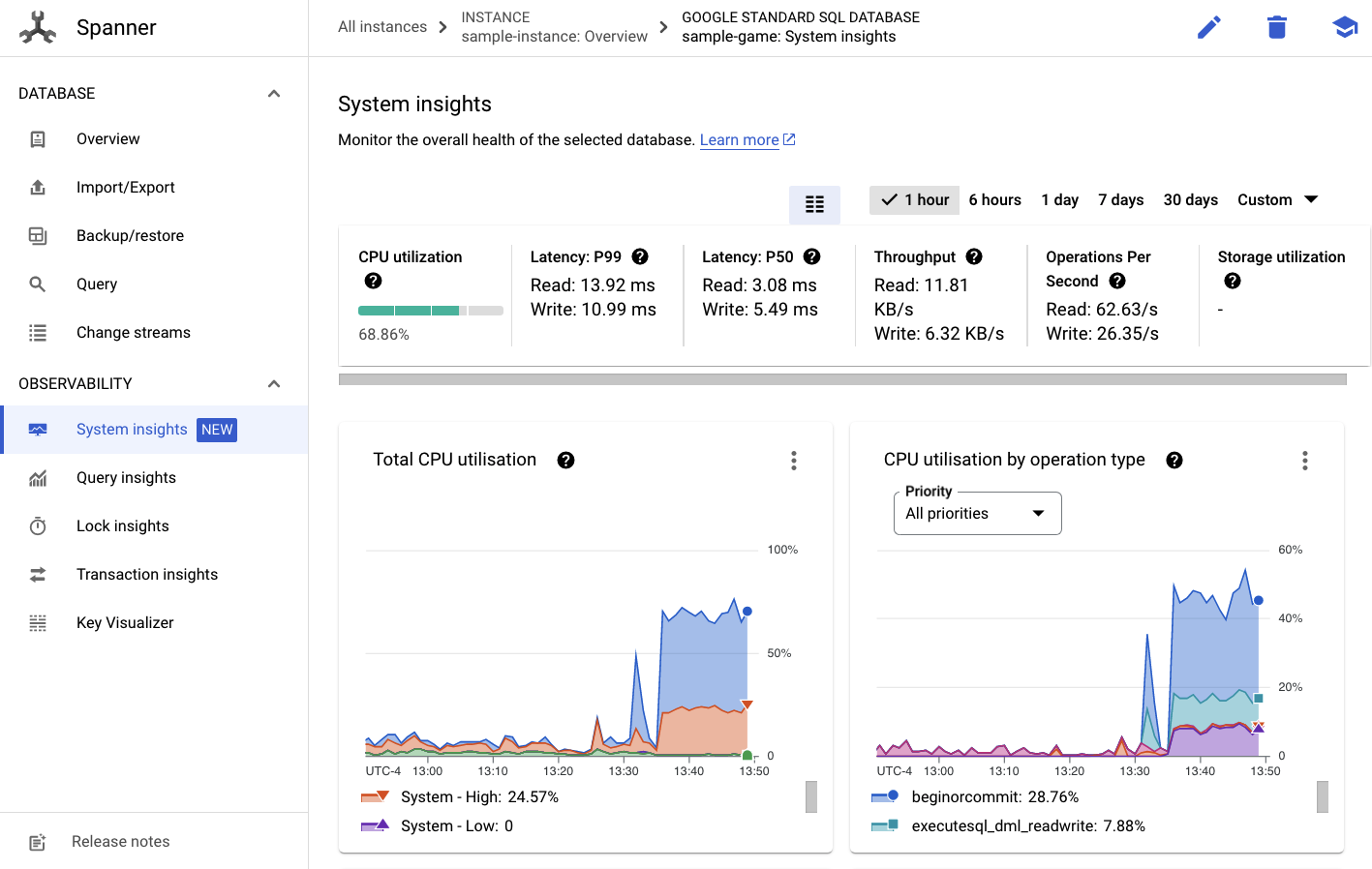
De nombreux graphiques sont disponibles pour vous aider à comprendre les performances générales de votre instance Spanner, y compris CPU utilization, transaction latency and locking et query throughput.
En plus de System Insights, vous pouvez obtenir des informations plus détaillées sur la charge de travail des requêtes en consultant les autres liens de la section "Observabilité" :
- Les insights sur les requêtes vous aident à identifier les N requêtes les plus importantes qui utilisent des ressources sur Spanner.
- Les insights Transaction et Verrouillage vous aident à identifier les transactions présentant des latences élevées.
- Key Visualizer vous aide à visualiser les schémas d'accès et à identifier les points chauds dans les données.
Résumé
Dans cette étape, vous avez appris à vérifier certaines métriques de performances de base pour GKE Autopilot et Spanner.
Par exemple, lorsque votre charge de travail de profil est en cours d'exécution, interrogez la table players pour obtenir plus d'informations sur les données qui y sont stockées.
Étapes suivantes
Il est maintenant temps de faire le ménage !
9. Nettoyer
Avant de procéder au nettoyage, n'hésitez pas à explorer les autres charges de travail qui n'ont pas été abordées. Plus précisément, matchmaking-workload, game-workload et tradepost-workload.
Lorsque vous avez terminé de "jouer" au jeu, vous pouvez nettoyer votre bac à sable. Heureusement, c'est assez simple.
Tout d'abord, si votre profile-workload est toujours en cours d'exécution dans le navigateur, arrêtez-le :
Faites de même pour chaque charge de travail que vous avez pu tester.
Ensuite, dans Cloud Shell, accédez au dossier d'infrastructure. Vous allez destroy l'infrastructure à l'aide de Terraform :
cd $DEMO_HOME/infrastructure
terraform destroy
# type 'yes' when asked
Résultat de la commande
Plan: 0 to add, 0 to change, 46 to destroy.
Do you really want to destroy all resources?
Terraform will destroy all your managed infrastructure, as shown above.
There is no undo. Only 'yes' will be accepted to confirm.
Enter a value: yes
*snip*
Destroy complete! Resources: 46 destroyed.
Dans la console Cloud, accédez à Spanner, Kubernetes Cluster, Artifact Registry, Cloud Deploy et IAM pour vérifier que toutes les ressources ont été supprimées.
10. Félicitations !
Félicitations ! Vous avez déployé des exemples d'applications Go sur GKE Autopilot et les avez connectés à Cloud Spanner à l'aide de Workload Identity.
En prime, cette infrastructure a été facilement configurée et supprimée de manière reproductible à l'aide de Terraform.
Pour en savoir plus sur les services Google Cloud avec lesquels vous avez interagi dans cet atelier de programmation, consultez les ressources suivantes :
Étape suivante
Maintenant que vous avez compris les bases du fonctionnement conjoint de GKE Autopilot et de Cloud Spanner, pourquoi ne pas passer à l'étape suivante et commencer à créer votre propre application pour qu'elle fonctionne avec ces services ?