
1. 简介
Cloud Spanner 是一种全托管式可横向扩容的全球分布式关系型数据库服务,可提供 ACID 事务和 SQL 语义,同时兼顾性能和高可用性。
GKE Autopilot 是 GKE 中的一种运维模式,在此模式下,Google 会管理您的集群配置,包括节点、扩缩、安全性和其他预配置设置,以遵循最佳实践。例如,GKE Autopilot 会启用 Workload Identity 来管理服务权限。
本实验的目标是引导您完成将 GKE Autopilot 上运行的多个后端服务连接到 Cloud Spanner 数据库的过程。
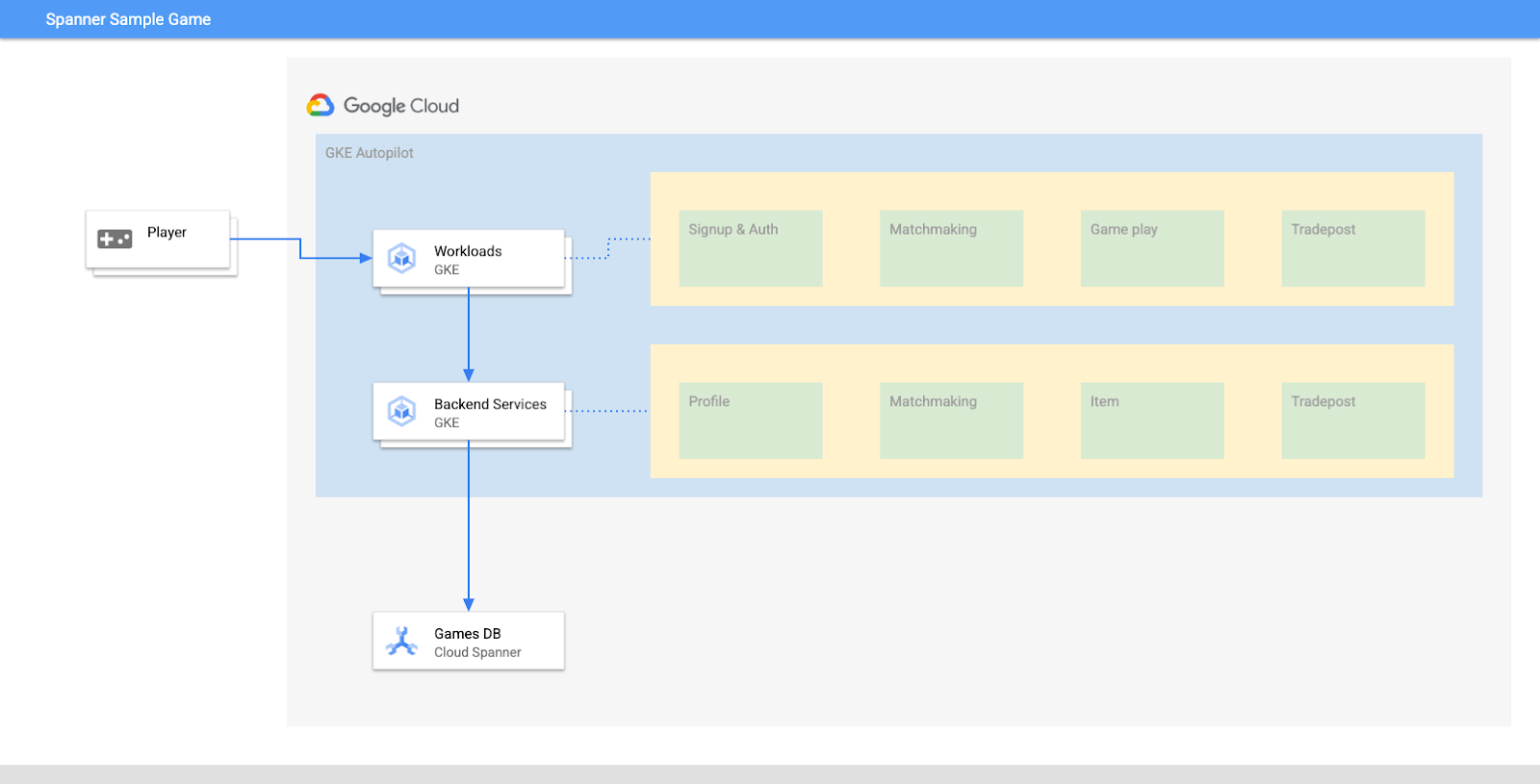
在本实验中,您将首先设置项目并启动 Cloud Shell。然后,您将使用 Terraform 部署基础架构。
完成后,您将与 Cloud Build 和 Cloud Deploy 互动,为 Games 数据库执行初始架构迁移,部署后端服务,然后部署工作负载。
此 Codelab 中的服务与 Cloud Spanner 游戏开发入门 Codelab 中的服务相同。您无需完成该 Codelab 即可在 GKE 上运行服务并连接到 Spanner。不过,如果您想详细了解可在 Spanner 上运行的这些服务的具体细节,不妨查看一下。
在工作负载和后端服务运行后,您可以开始生成负载,并观察服务如何协同工作。
最后,您将清理在本实验中创建的资源。
构建内容
在本实验中,您将:
- 使用 Terraform 预配基础架构
- 使用 Cloud Build 中的架构迁移流程创建数据库架构
- 部署利用 Workload Identity 连接到 Cloud Spanner 的四个 Golang 后端服务
- 部署用于模拟后端服务负载的四个工作负载服务。
学习内容
- 如何使用 Terraform 配置 GKE Autopilot、Cloud Spanner 和 Cloud Deploy 流水线
- Workload Identity 如何允许 GKE 上的服务模拟服务账号来访问 IAM 权限,以便使用 Cloud Spanner
- 如何使用 Locust.io 在 GKE 和 Cloud Spanner 上生成类似生产环境的负载
所需条件
2. 设置和要求
创建项目
如果您还没有 Google 账号(Gmail 或 Google Apps),则必须创建一个。登录 Google Cloud Platform Console ( console.cloud.google.com) 并创建一个新项目。
如果您已经有一个项目,请点击控制台左上方的项目选择下拉菜单:

然后在出现的对话框中点击“新建项目”按钮以创建一个新项目:
如果您还没有项目,则应该看到一个类似这样的对话框来创建您的第一个项目:
随后的项目创建对话框可让您输入新项目的详细信息:
请记住项目 ID,它在所有 Google Cloud 项目中都是唯一的名称(上述名称已被占用,您无法使用,抱歉!)。它稍后将在此 Codelab 中被称为 PROJECT_ID。
接下来,如果尚未执行此操作,则需要在 Developers Console 中启用结算功能,以便使用 Google Cloud 资源并启用 Cloud Spanner API。
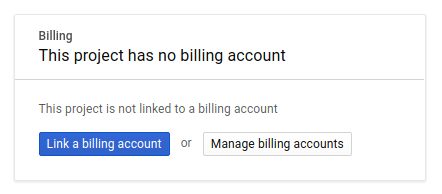
在此 Codelab 中运行仅花费几美元,但是如果您决定使用更多资源或继续让它们运行,费用可能更高(请参阅本文档末尾的“清理”部分)。如需了解 Google Cloud Spanner 价格,请参阅此处;如需了解 GKE Autopilot,请参阅此处。
Google Cloud Platform 的新用户均有资格获享 $300 赠金,免费试用此 Codelab。
Cloud Shell 设置
虽然 Google Cloud 和 Spanner 可以从笔记本电脑远程操作,但在此 Codelab 中,我们将使用 Google Cloud Shell,这是一个在云端运行的命令行环境。
基于 Debian 的这个虚拟机已加载了您需要的所有开发工具。它提供了一个持久的 5GB 主目录,并且在 Google Cloud 中运行,大大增强了网络性能和身份验证。这意味着在本 Codelab 中,您只需要一个浏览器(没错,它适用于 Chromebook)。
- 如需从 Cloud 控制台激活 Cloud Shell,只需点击“激活 Cloud Shell”图标
 (预配和连接到环境仅需花费一些时间)。
(预配和连接到环境仅需花费一些时间)。
在连接到 Cloud Shell 后,您应该会看到自己已通过身份验证,并且相关项目已设置为您的 PROJECT_ID。
gcloud auth list
命令输出
Credentialed accounts:
- <myaccount>@<mydomain>.com (active)
gcloud config list project
命令输出
[core]
project = <PROJECT_ID>
如果出于某种原因未设置项目,只需发出以下命令即可:
gcloud config set project <PROJECT_ID>
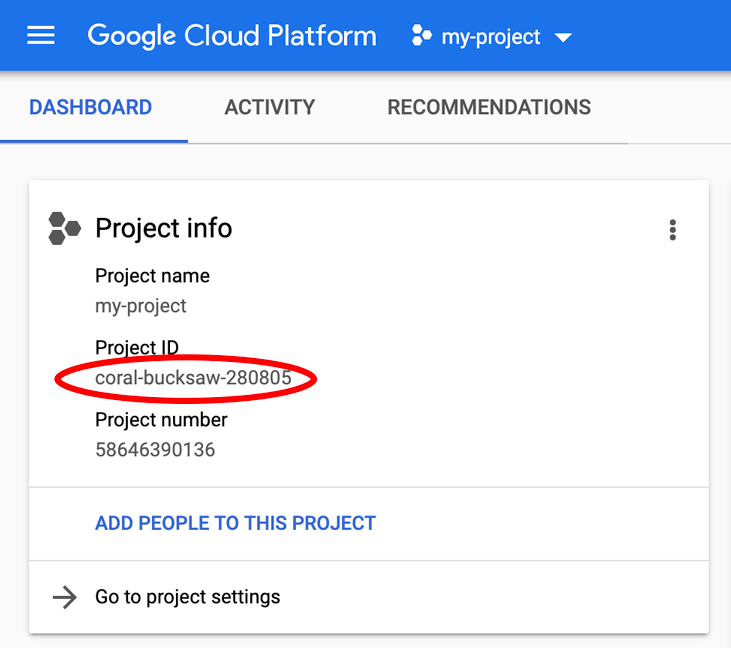
正在查找您的 PROJECT_ID?检查您在设置步骤中使用的 ID,或在 Cloud Console 信息中心查找该 ID:
默认情况下,Cloud Shell 还会设置一些环境变量,这对您日后运行命令可能会很有用。
echo $GOOGLE_CLOUD_PROJECT
命令输出
<PROJECT_ID>
下载代码
在 Cloud Shell 中,您可以下载本实验的代码:
git clone https://github.com/cloudspannerecosystem/spanner-gaming-sample.git
命令输出
Cloning into 'spanner-gaming-sample'...
*snip*
此 Codelab 基于 v0.1.3 版本,因此请签出该标记:
cd spanner-gaming-sample
git fetch --all --tags
# Check out v0.1.3 release
git checkout tags/v0.1.3 -b v0.1.3-branch
命令输出
Switched to a new branch 'v0.1.3-branch'
现在,将当前工作目录设置为 DEMO_HOME 环境变量。这样,您在完成 Codelab 的不同部分时,可以更轻松地进行导航。
export DEMO_HOME=$(pwd)
摘要
在此步骤中,您已设置新项目、激活 Cloud Shell 并下载本实验的代码。
后续步骤
接下来,您将使用 Terraform 预配基础架构。
3. 预配基础设施
概览
项目准备就绪后,就可以开始运行基础架构了。这包括 VPC 网络、Cloud Spanner、GKE Autopilot、用于存储将在 GKE 上运行的映像的 Artifact Registry、用于后端服务和工作负载的 Cloud Deploy 流水线,以及最终能够使用这些服务的服务账号和 IAM 权限。
这可不是一笔小数目。不过幸运的是,Terraform 可以简化此设置过程。Terraform 是一种“基础设施即代码”工具,可让我们在一系列“.tf”文件中指定此项目所需的内容。这使得预配基础设施变得简单。
您不必熟悉 Terraform 就能完成此 Codelab。不过,如果您想了解接下来几个步骤的作用,可以查看 infrastructure 目录中这些文件内创建的所有内容:
- vpc.tf
- backend_gke.tf
- spanner.tf
- artifact_registry.tf
- pipelines.tf
- iam.tf
配置 Terraform
在 Cloud Shell 中,您将切换到 infrastructure 目录并初始化 Terraform:
cd $DEMO_HOME/infrastructure
terraform init
命令输出
Initializing the backend...
Initializing provider plugins...
*snip*
Terraform has been successfully initialized!
You may now begin working with Terraform. Try running "terraform plan" to see
any changes that are required for your infrastructure. All Terraform commands
should now work.
If you ever set or change modules or backend configuration for Terraform,
rerun this command to reinitialize your working directory. If you forget, other
commands will detect it and remind you to do so if necessary.
接下来,复制 terraform.tfvars.sample 并修改项目值,以配置 Terraform。其他变量也可以更改,但只有项目必须更改才能与您的环境搭配使用。
cp terraform.tfvars.sample terraform.tfvars
# edit gcp_project using the project environment variable
sed -i "s/PROJECT/$GOOGLE_CLOUD_PROJECT/" terraform.tfvars
预配基础架构
现在,可以开始预配基础架构了!
terraform apply
# review the list of things to be created
# type 'yes' when asked
命令输出
Plan: 46 to add, 0 to change, 0 to destroy.
Do you want to perform these actions?
Terraform will perform the actions described above.
Only 'yes' will be accepted to approve.
Enter a value: yes
google_project_service.project["container.googleapis.com"]: Creating...
*snip*
Apply complete! Resources: 46 added, 0 changed, 0 destroyed.
查看创建的内容
如需验证创建的内容,您需要检查 Cloud 控制台中的产品。
Cloud Spanner
首先,前往汉堡式菜单,点击 Spanner,检查 Cloud Spanner。您可能需要点击“查看更多商品”才能在列表中找到该商品。
系统会将您转到 Spanner 实例列表。点击进入实例,您将看到数据库。输出应如下所示:
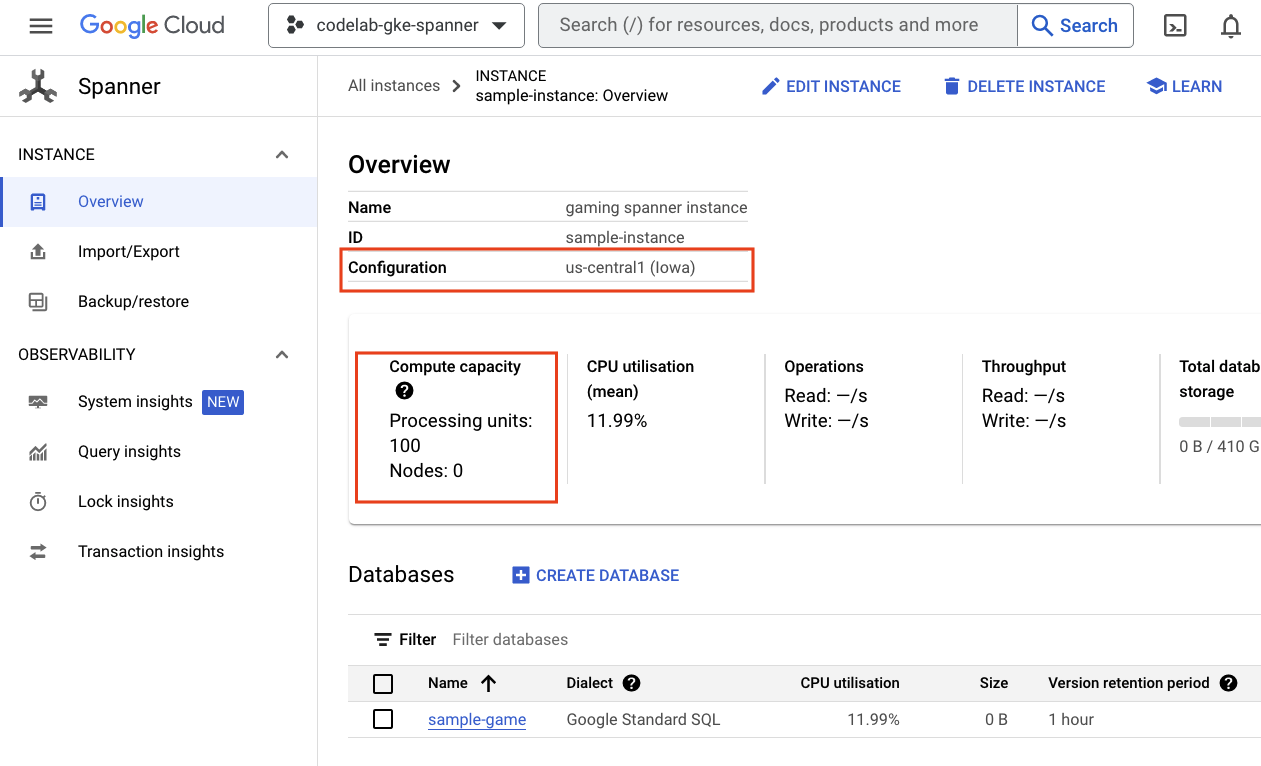
GKE Autopilot
接下来,前往汉堡菜单并点击 Kubernetes Engine => Clusters,查看 GKE。您会看到 sample-games-gke 集群以 Autopilot 模式运行。
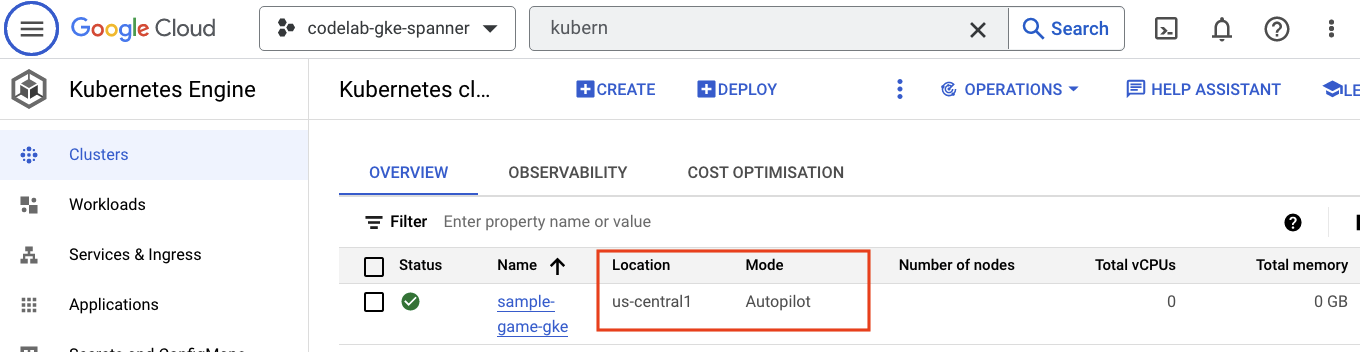
Artifact Registry
现在,您需要了解图片将存储在何处。因此,请点击汉堡式菜单,然后找到 Artifact Registry=>Repositories。Artifact Registry 位于菜单的“CI/CD”部分。
您会看到一个名为 spanner-game-images 的 Docker 注册表。目前为空。
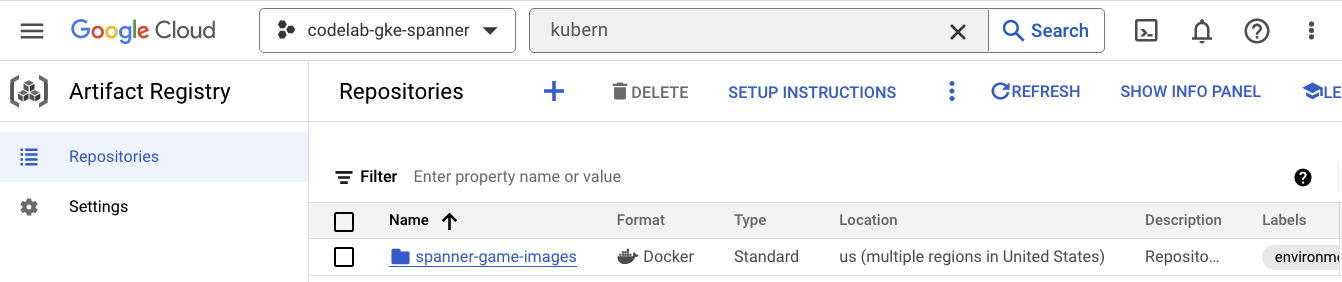
Cloud Deploy
Cloud Deploy 是创建流水线的地方,这样 Cloud Build 就可以提供构建映像的步骤,然后将映像部署到我们的 GKE 集群。
前往汉堡式菜单,找到 Cloud Deploy,该图标也位于菜单的 CI/CD 部分。
您会注意到,这里有两条流水线:一条用于后端服务,另一条用于工作负载。两者都将映像部署到同一 GKE 集群,但这样可以分离我们的部署。
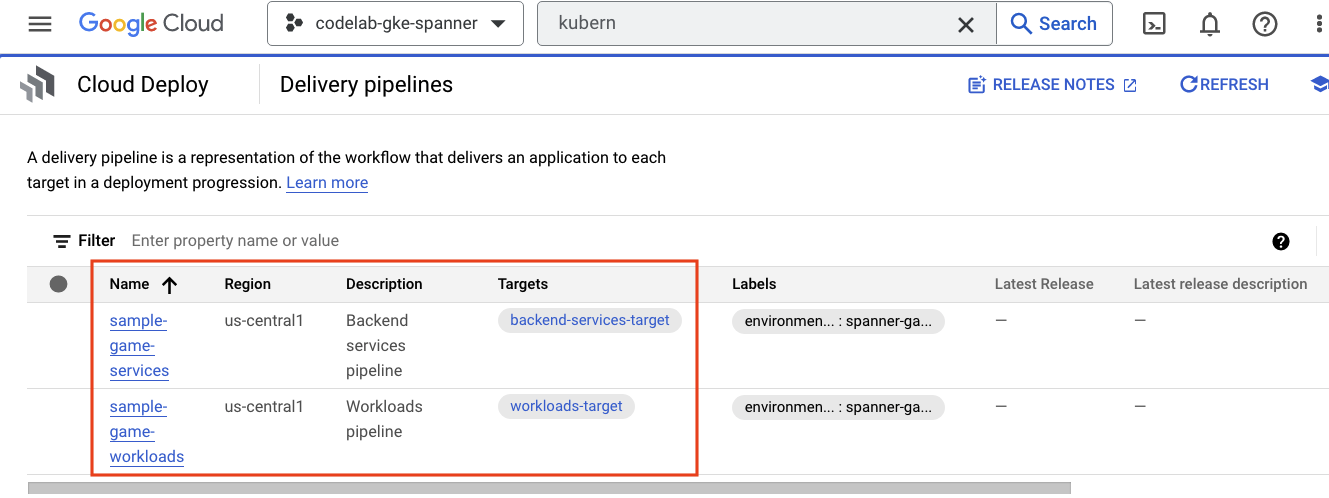
IAM
最后,查看 Cloud 控制台中的 IAM 页面,验证已创建的服务账号。前往汉堡式菜单,然后找到 IAM and Admin=>Service accounts。输出应如下所示:
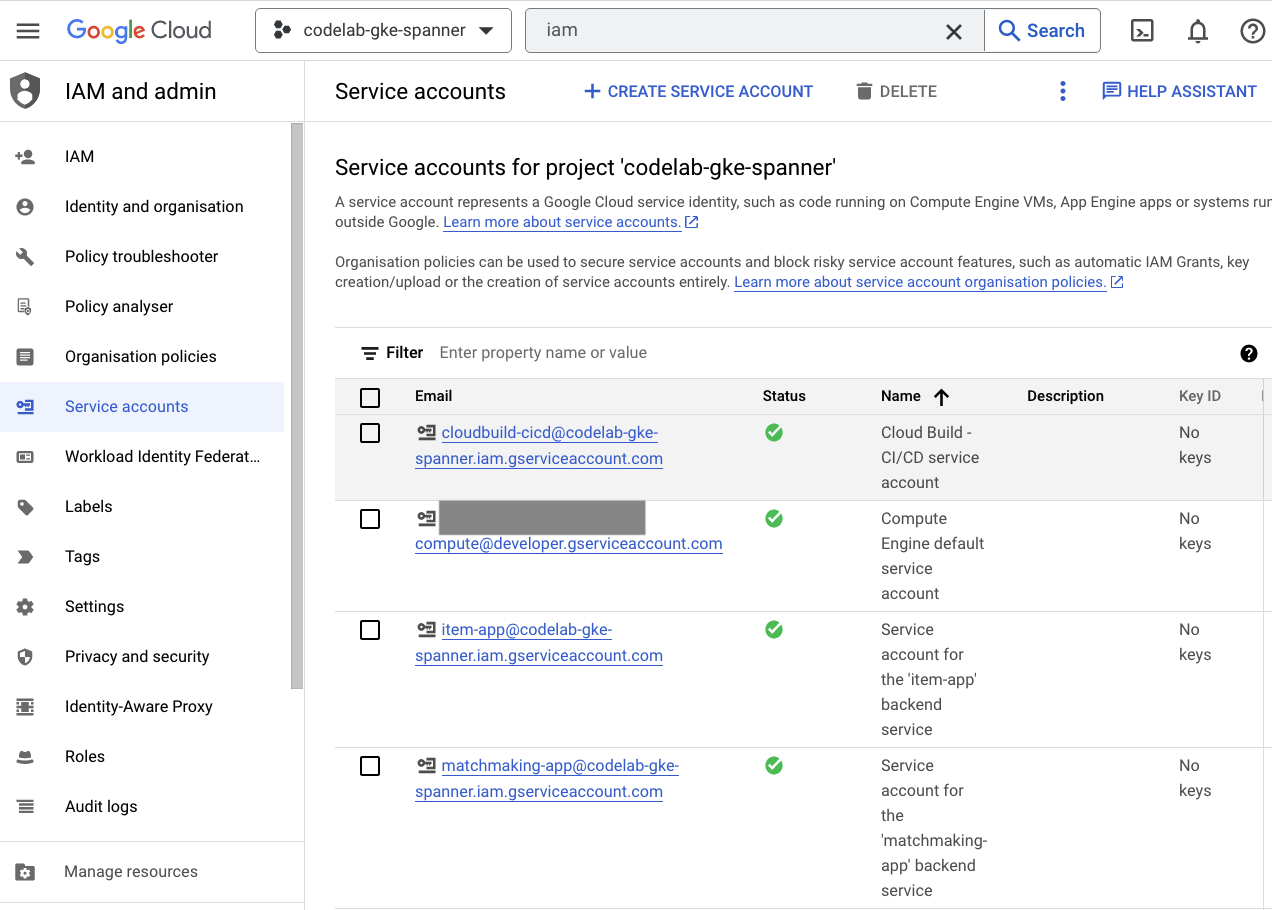
Terraform 共创建了 6 个服务账号:
- 默认计算服务账号。在本 Codelab 中,此参数未使用。
- cloudbuild-cicd 账号用于 Cloud Build 和 Cloud Deploy 步骤。
- 四个“应用”账号,供我们的后端服务用于与 Cloud Spanner 互动。
接下来,您需要配置 kubectl 以与 GKE 集群进行交互。
配置 kubectl
# Name of GKE cluster from terraform.tfvars file
export GKE_CLUSTER=sample-game-gke
# get GKE credentials
gcloud container clusters get-credentials $GKE_CLUSTER --region us-central1
# Check that no errors occur
kubectl get serviceaccounts
命令输出
#export GKE_CLUSTER=sample-game-gke
# gcloud container clusters get-credentials $GKE_CLUSTER --region us-central1
Fetching cluster endpoint and auth data.
kubeconfig entry generated for sample-game-gke.
# kubectl get serviceaccounts
NAME SECRETS AGE
default 0 37m
item-app 0 35m
matchmaking-app 0 35m
profile-app 0 35m
tradepost-app 0 35m
摘要
太棒了!您能够预配 Cloud Spanner 实例和 GKE Autopilot 集群,所有这些都在 VPC 中进行,以实现专用网络。
此外,还为后端服务和工作负载创建了两个 Cloud Deploy 流水线,以及一个用于存储已构建映像的 Artifact Registry 代码库。
最后,创建并配置了服务账号以与 Workload Identity 搭配使用,以便后端服务可以使用 Cloud Spanner。
部署后端服务和工作负载后,您还需要配置 kubectl 以与 Cloud Shell 中的 GKE 集群进行交互。
后续步骤
您需要先定义数据库架构,然后才能使用这些服务。您接下来将设置该功能。
4. 创建数据库架构
概览
在运行后端服务之前,您需要确保数据库架构已就位。
如果您查看演示版代码库中 $DEMO_HOME/schema/migrations 目录中的文件,您会看到一系列定义我们架构的 .sql 文件。这模拟了一个开发周期,其中架构更改在代码库本身中进行跟踪,并且可以与应用的某些功能相关联。
对于此示例环境,扳手是使用 Cloud Build 应用架构迁移的工具。
Cloud Build
$DEMO_HOME/schema/cloudbuild.yaml 文件描述了将要采取的步骤:
serviceAccount: projects/${PROJECT_ID}/serviceAccounts/cloudbuild-cicd@${PROJECT_ID}.iam.gserviceaccount.com
steps:
- name: gcr.io/cloud-builders/curl
id: fetch-wrench
args: ['-Lo', '/workspace/wrench.tar.gz', 'https://github.com/cloudspannerecosystem/wrench/releases/download/v1.4.1/wrench-1.4.1-linux-amd64.tar.gz' ]
- name: gcr.io/cloud-builders/gcloud
id: migrate-spanner-schema
entrypoint: sh
args:
- '-xe'
- '-c'
- |
tar -xzvf wrench.tar.gz
chmod +x /workspace/wrench
# Assumes only a single spanner instance and database. Fine for this demo in a dedicated project
export SPANNER_PROJECT_ID=${PROJECT_ID}
export SPANNER_INSTANCE_ID=$(gcloud spanner instances list | tail -n1 | awk '{print $1}')
export SPANNER_DATABASE_ID=$(gcloud spanner databases list --instance=$$SPANNER_INSTANCE_ID | tail -n1 | awk '{print $1}')
if [ -d ./migrations ]; then
/workspace/wrench migrate up --directory .
else
echo "[Error] Missing migrations directory"
fi
timeout: 600s
基本上分为两个步骤:
- 将扳手下载到 Cloud Build 工作区
- 运行扳手迁移
wrench 需要 Spanner 项目、实例和数据库环境变量才能连接到写入端点。
Cloud Build 能够进行这些更改,是因为它以 cloudbuild-cicd@${PROJECT_ID}.iam.gserviceaccount.com 服务账号的身份运行:
serviceAccount: projects/${PROJECT_ID}/serviceAccounts/cloudbuild-cicd@${PROJECT_ID}.iam.gserviceaccount.com
此服务账号还具有 Terraform 添加的 spanner.databaseUser 角色,该角色允许服务账号更新 DDL。
架构迁移
系统会根据 $DEMO_HOME/schema/migrations 目录中的文件执行以下五个迁移步骤。以下是创建 players 表和索引的 000001.sql 文件示例:
CREATE TABLE players (
playerUUID STRING(36) NOT NULL,
player_name STRING(64) NOT NULL,
email STRING(MAX) NOT NULL,
password_hash BYTES(60) NOT NULL,
created TIMESTAMP,
updated TIMESTAMP,
stats JSON,
account_balance NUMERIC NOT NULL DEFAULT (0.00),
is_logged_in BOOL,
last_login TIMESTAMP,
valid_email BOOL,
current_game STRING(36)
) PRIMARY KEY (playerUUID);
CREATE UNIQUE INDEX PlayerAuthentication ON players(email) STORING(password_hash);
CREATE UNIQUE INDEX PlayerName ON players(player_name);
CREATE INDEX PlayerGame ON players(current_game);
提交架构迁移
如需提交构建以执行架构迁移,请切换到 schema 目录并运行以下 gcloud 命令:
cd $DEMO_HOME/schema gcloud builds submit --config=cloudbuild.yaml
命令输出
Creating temporary tarball archive of 8 file(s) totalling 11.2 KiB before compression.
Uploading tarball of [.] to [gs://(project)_cloudbuild/source/(snip).tgz]
Created [https://cloudbuild.googleapis.com/v1/projects/(project)/locations/global/builds/7defe982-(snip)].
Logs are available at [ https://console.cloud.google.com/cloud-build/builds/7defe982-(snip)?project=(snip) ].
gcloud builds submit only displays logs from Cloud Storage. To view logs from Cloud Logging, run:
gcloud beta builds submit
ID: 7defe982-(snip)
CREATE_TIME: (created time)
DURATION: 3M11S
SOURCE: gs://(project)_cloudbuild/source/(snip).tgz
IMAGES: -
STATUS: SUCCESS
在上面的输出中,您会看到指向 Created Cloud Build 构建流程的链接。点击该链接后,您将前往 Cloud 控制台中的相应 build,以便监控 build 的进度并了解其正在执行的操作。
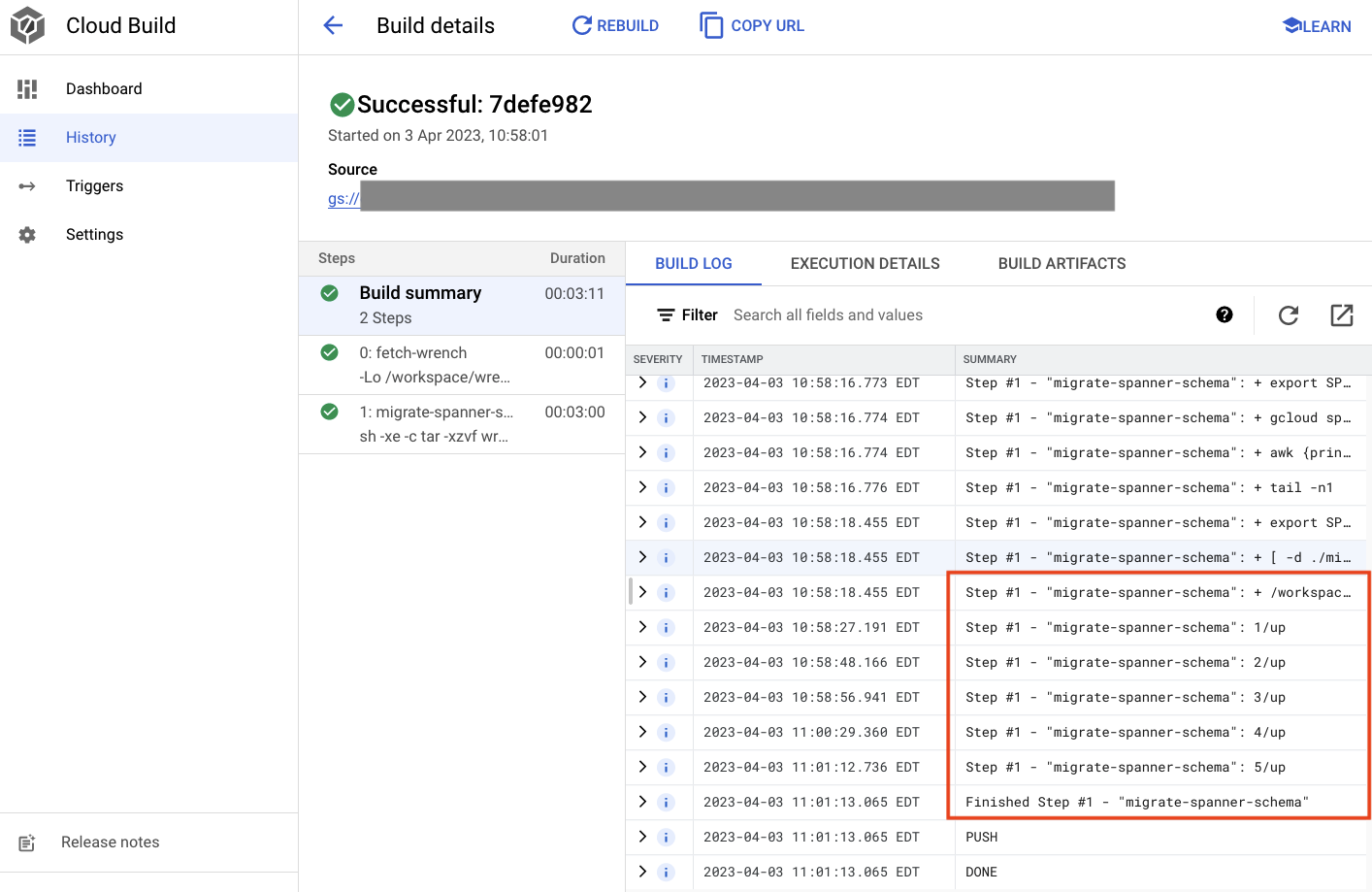
摘要
在此步骤中,您使用 Cloud Build 提交了应用 5 种不同 DDL 操作的初始架构迁移。这些操作表示添加了需要更改数据库架构的功能。
在正常的开发场景中,您需要确保架构更改向后兼容当前应用,以避免服务中断。
对于不向后兼容的更改,您需要分阶段将更改部署到应用和架构,以确保不会出现中断。
后续步骤
有了架构,下一步就是部署后端服务!
5. 部署后端服务
概览
此 Codelab 的后端服务是 golang REST API,代表四种不同的服务:
- 个人资料:让玩家能够注册并向我们的示例“游戏”进行身份验证。
- 配对:与玩家数据互动,以帮助实现配对功能、跟踪有关已创建游戏的信息,并在游戏关闭时更新玩家统计数据。
- 商品:让玩家在玩游戏的过程中获得游戏商品和金钱。
- 交易站:让玩家能够在交易站上买卖物品
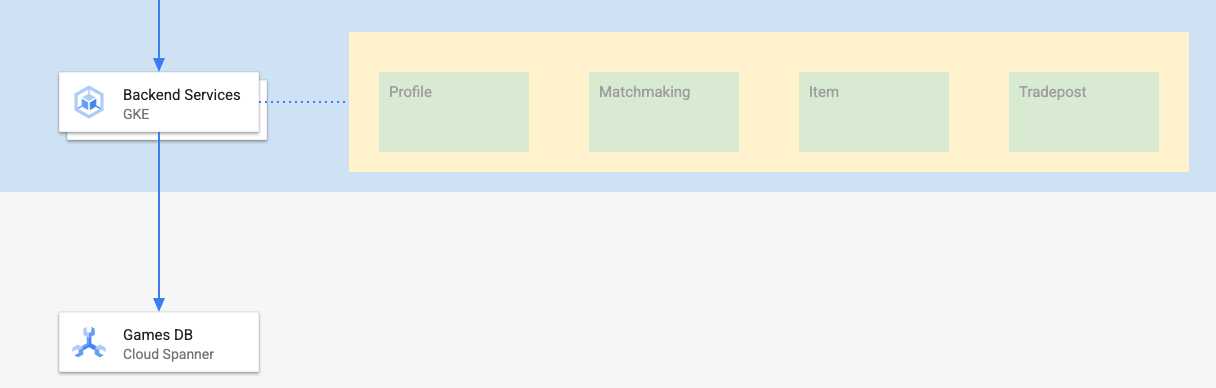
如需详细了解这些服务,请参阅 Cloud Spanner 游戏开发入门 Codelab。就我们的目的而言,我们希望这些服务在 GKE Autopilot 集群上运行。
这些服务必须能够修改 Spanner 数据。为此,每个服务都创建了一个服务账号,并向其授予了“databaseUser”角色。
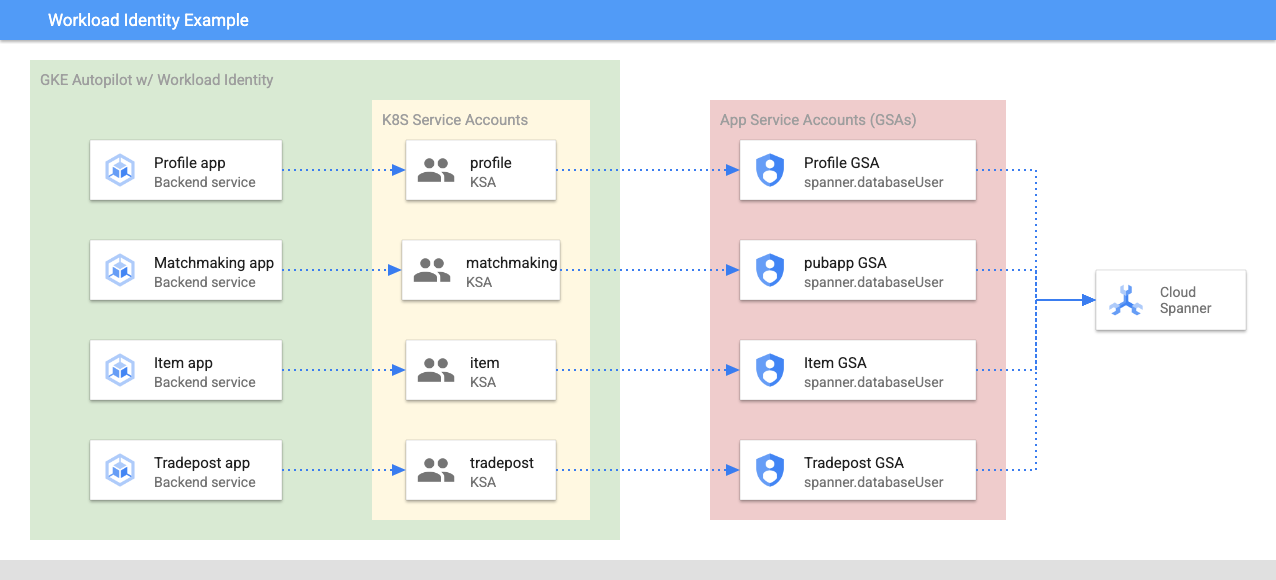
借助 Workload Identity,Kubernetes 服务账号可以通过以下 Terraform 步骤模拟服务的 Google Cloud 服务账号:
- 创建服务的 Google Cloud 服务账号 (
GSA) 资源 - 为该服务账号分配 databaseUser 角色
- 为该服务账号分配 workloadIdentityUser 角色
- 创建引用 GSA 的 Kubernetes 服务账号 (
KSA)
粗略的示意图如下所示:
Terraform 已为您创建了服务账号和 Kubernetes 服务账号。您可以使用 kubectl 检查 Kubernetes 服务账号:
# kubectl get serviceaccounts
NAME SECRETS AGE
default 0 37m
item-app 0 35m
matchmaking-app 0 35m
profile-app 0 35m
tradepost-app 0 35m
build 的工作方式如下:
- Terraform 生成了一个
$DEMO_HOME/backend_services/cloudbuild.yaml文件,如下所示:
serviceAccount: projects/${PROJECT_ID}/serviceAccounts/cloudbuild-cicd@${PROJECT_ID}.iam.gserviceaccount.com
steps:
#
# Building of images
#
- name: gcr.io/cloud-builders/docker
id: profile
args: ["build", ".", "-t", "${_PROFILE_IMAGE}"]
dir: profile
waitFor: ['-']
- name: gcr.io/cloud-builders/docker
id: matchmaking
args: ["build", ".", "-t", "${_MATCHMAKING_IMAGE}"]
dir: matchmaking
waitFor: ['-']
- name: gcr.io/cloud-builders/docker
id: item
args: ["build", ".", "-t", "${_ITEM_IMAGE}"]
dir: item
waitFor: ['-']
- name: gcr.io/cloud-builders/docker
id: tradepost
args: ["build", ".", "-t", "${_TRADEPOST_IMAGE}"]
dir: tradepost
waitFor: ['-']
#
# Deployment
#
- name: gcr.io/google.com/cloudsdktool/cloud-sdk
id: cloud-deploy-release
entrypoint: gcloud
args:
[
"deploy", "releases", "create", "${_REL_NAME}",
"--delivery-pipeline", "sample-game-services",
"--skaffold-file", "skaffold.yaml",
"--skaffold-version", "1.39",
"--images", "profile=${_PROFILE_IMAGE},matchmaking=${_MATCHMAKING_IMAGE},item=${_ITEM_IMAGE},tradepost=${_TRADEPOST_IMAGE}",
"--region", "us-central1"
]
artifacts:
images:
- ${_REGISTRY}/profile
- ${_REGISTRY}/matchmaking
- ${_REGISTRY}/item
- ${_REGISTRY}/tradepost
substitutions:
_PROFILE_IMAGE: ${_REGISTRY}/profile:${BUILD_ID}
_MATCHMAKING_IMAGE: ${_REGISTRY}/matchmaking:${BUILD_ID}
_ITEM_IMAGE: ${_REGISTRY}/item:${BUILD_ID}
_TRADEPOST_IMAGE: ${_REGISTRY}/tradepost:${BUILD_ID}
_REGISTRY: us-docker.pkg.dev/${PROJECT_ID}/spanner-game-images
_REL_NAME: rel-${BUILD_ID:0:8}
options:
dynamic_substitutions: true
machineType: E2_HIGHCPU_8
logging: CLOUD_LOGGING_ONLY
- Cloud Build 命令会读取此文件并按照其中列出的步骤执行操作。首先,它会构建服务映像。然后,它会执行
gcloud deploy create命令。此命令会读取$DEMO_HOME/backend_services/skaffold.yaml文件,该文件定义了每个部署文件的位置:
apiVersion: skaffold/v2beta29
kind: Config
deploy:
kubectl:
manifests:
- spanner_config.yaml
- profile/deployment.yaml
- matchmaking/deployment.yaml
- item/deployment.yaml
- tradepost/deployment.yaml
- Cloud Deploy 将遵循每项服务的
deployment.yaml文件的定义。服务的部署文件包含用于创建服务的信息,在本例中,该服务是运行在端口 80 上的 ClusterIP。
“ClusterIP” 类型可防止后端服务 pod 拥有外部 IP,因此只有可以连接到内部 GKE 网络的实体才能访问后端服务。这些服务不应直接供玩家访问,因为它们会访问和修改 Spanner 数据。
apiVersion: v1
kind: Service
metadata:
name: profile
spec:
type: ClusterIP
selector:
app: profile
ports:
- port: 80
targetPort: 80
除了创建 Kubernetes 服务之外,Cloud Deploy 还会创建 Kubernetes 部署。我们来检查一下 profile 服务的部署部分:
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: profile
spec:
replicas: 2 # EDIT: Number of instances of deployment
selector:
matchLabels:
app: profile
template:
metadata:
labels:
app: profile
spec:
serviceAccountName: profile-app
containers:
- name: profile-service
image: profile
ports:
- containerPort: 80
envFrom:
- configMapRef:
name: spanner-config
env:
- name: SERVICE_HOST
value: "0.0.0.0"
- name: SERVICE_PORT
value: "80"
resources:
requests:
cpu: "1"
memory: "1Gi"
ephemeral-storage: "100Mi"
limits:
cpu: "1"
memory: "1Gi"
ephemeral-storage: "100Mi"
顶部部分提供有关服务的一些元数据。其中最重要的是定义此部署将创建多少个副本。
replicas: 2 # EDIT: Number of instances of deployment
接下来,我们看到哪个服务账号应运行应用,以及应用应使用哪个映像。这些与通过 Terraform 创建的 Kubernetes 服务账号以及在 Cloud Build 步骤中创建的映像相匹配。
spec:
serviceAccountName: profile-app
containers:
- name: profile-service
image: profile
之后,我们指定一些有关网络和环境变量的信息。
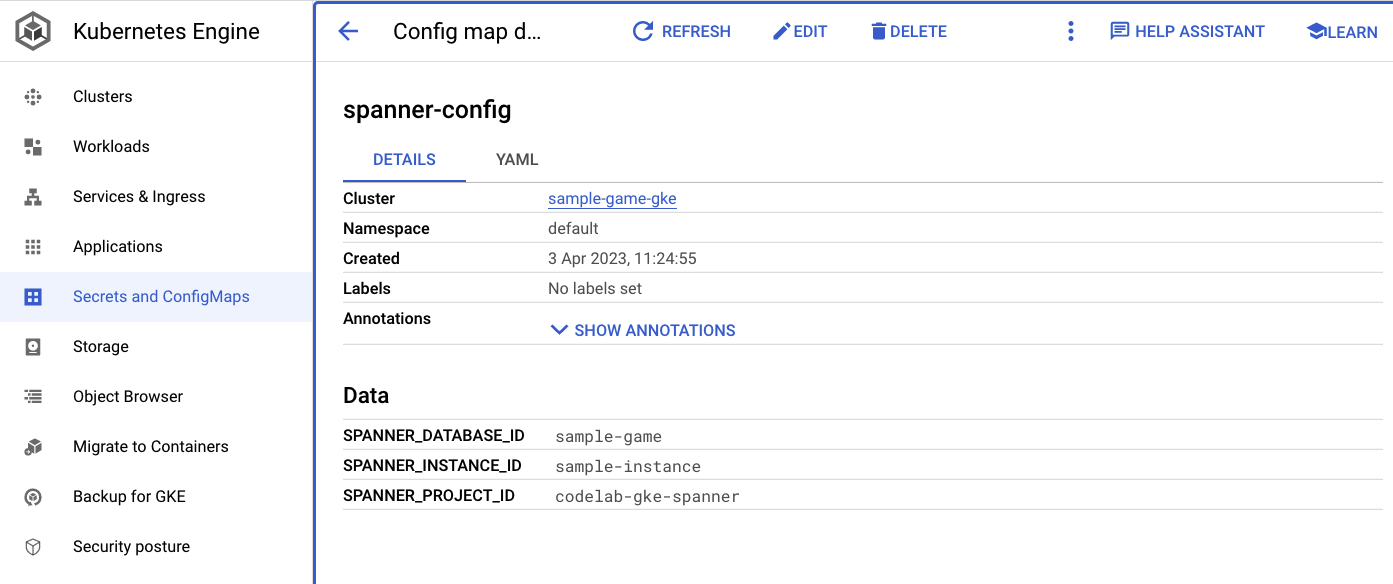
spanner_config 是一个 Kubernetes ConfigMap,用于指定应用连接到 Spanner 所需的项目、实例和数据库信息。
apiVersion: v1
kind: ConfigMap
metadata:
name: spanner-config
data:
SPANNER_PROJECT_ID: ${project_id}
SPANNER_INSTANCE_ID: ${instance_id}
SPANNER_DATABASE_ID: ${database_id}
ports:
- containerPort: 80
envFrom:
- configMapRef:
name: spanner-config
env:
- name: SERVICE_HOST
value: "0.0.0.0"
- name: SERVICE_PORT
value: "80"
SERVICE_HOST 和 SERVICE_PORT 是服务所需的额外环境变量,用于了解要绑定到的位置。
最后一部分告知 GKE 允许此部署中的每个副本使用多少资源。GKE Autopilot 也会使用此功能根据需要扩缩集群。
resources:
requests:
cpu: "1"
memory: "1Gi"
ephemeral-storage: "100Mi"
limits:
cpu: "1"
memory: "1Gi"
ephemeral-storage: "100Mi"
有了这些信息,现在可以部署后端服务了。
部署后端服务
如上所述,部署后端服务需要使用 Cloud Build。与架构迁移一样,您可以使用 gcloud 命令行提交 build 请求:
cd $DEMO_HOME/backend_services gcloud builds submit --config=cloudbuild.yaml
命令输出
Creating temporary tarball archive of 66 file(s) totalling 864.6 KiB before compression.
Uploading tarball of [.] to [gs://(project)_cloudbuild/source/(snip).tgz]
Created [https://cloudbuild.googleapis.com/v1/projects/(project)/locations/global/builds/30207dd1-(snip)].
Logs are available at [ https://console.cloud.google.com/cloud-build/builds/30207dd1-(snip)?project=(snip) ].
gcloud builds submit only displays logs from Cloud Storage. To view logs from Cloud Logging, run:
gcloud beta builds submit
ID: 30207dd1-(snip)
CREATE_TIME: (created time)
DURATION: 3M17S
SOURCE: gs://(project)_cloudbuild/source/(snip).tgz
IMAGES: us-docker.pkg.dev/(project)/spanner-game-images/profile:30207dd1-(snip) (+3 more)
STATUS: SUCCESS
与 schema migration 步骤的输出不同,此 build 的输出表明已创建一些映像。这些映像将存储在您的 Artifact Registry 代码库中。
gcloud build 步骤的输出将包含指向 Cloud 控制台的链接。不妨看看这些。
收到 Cloud Build 的成功通知后,前往 Cloud Deploy,然后前往 sample-game-services 流水线,监控部署进度。
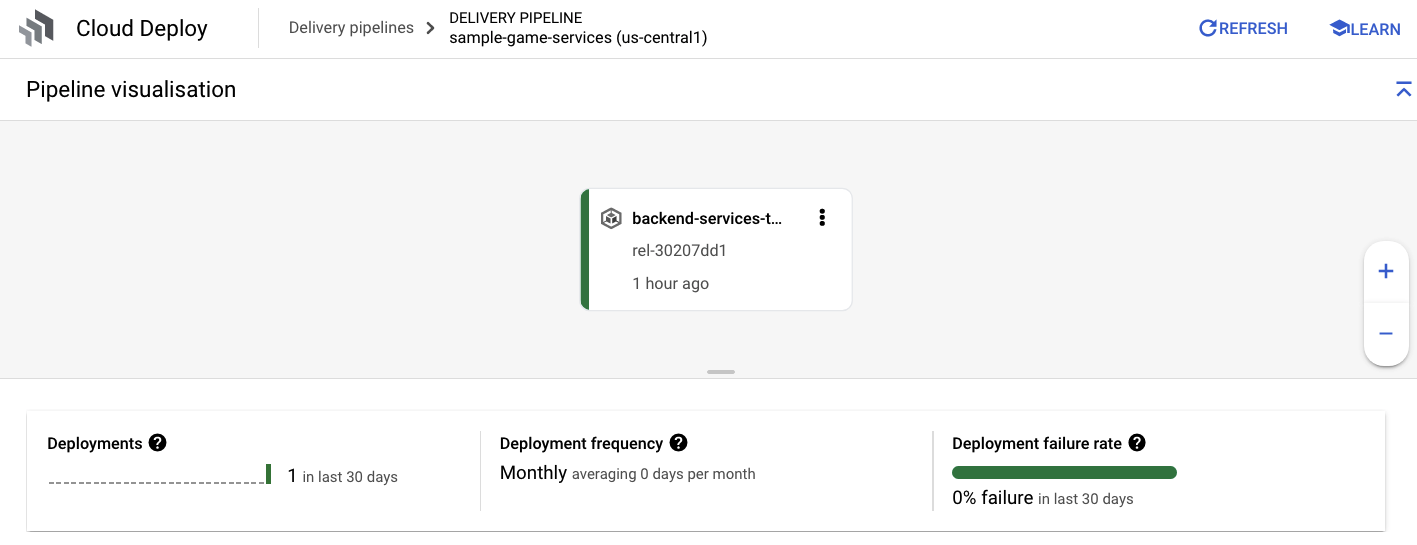
服务部署完毕后,您可以检查 kubectl 以查看 pod 的状态:
kubectl get pods
命令输出
NAME READY STATUS RESTARTS AGE
item-6b9d5f678c-4tbk2 1/1 Running 0 83m
matchmaking-5bcf799b76-lg8zf 1/1 Running 0 80m
profile-565bbf4c65-kphdl 1/1 Running 0 83m
profile-565bbf4c65-xw74j 1/1 Running 0 83m
tradepost-68b87ccd44-gw55r 1/1 Running 0 79m
然后,检查服务以查看 ClusterIP 的实际效果:
kubectl get services
命令输出
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
item ClusterIP 10.172.XXX.XXX <none> 80/TCP 84m
kubernetes ClusterIP 10.172.XXX.XXX <none> 443/TCP 137m
matchmaking ClusterIP 10.172.XXX.XXX <none> 80/TCP 84m
profile ClusterIP 10.172.XXX.XXX <none> 80/TCP 84m
tradepost ClusterIP 10.172.XXX.XXX <none> 80/TCP 84m
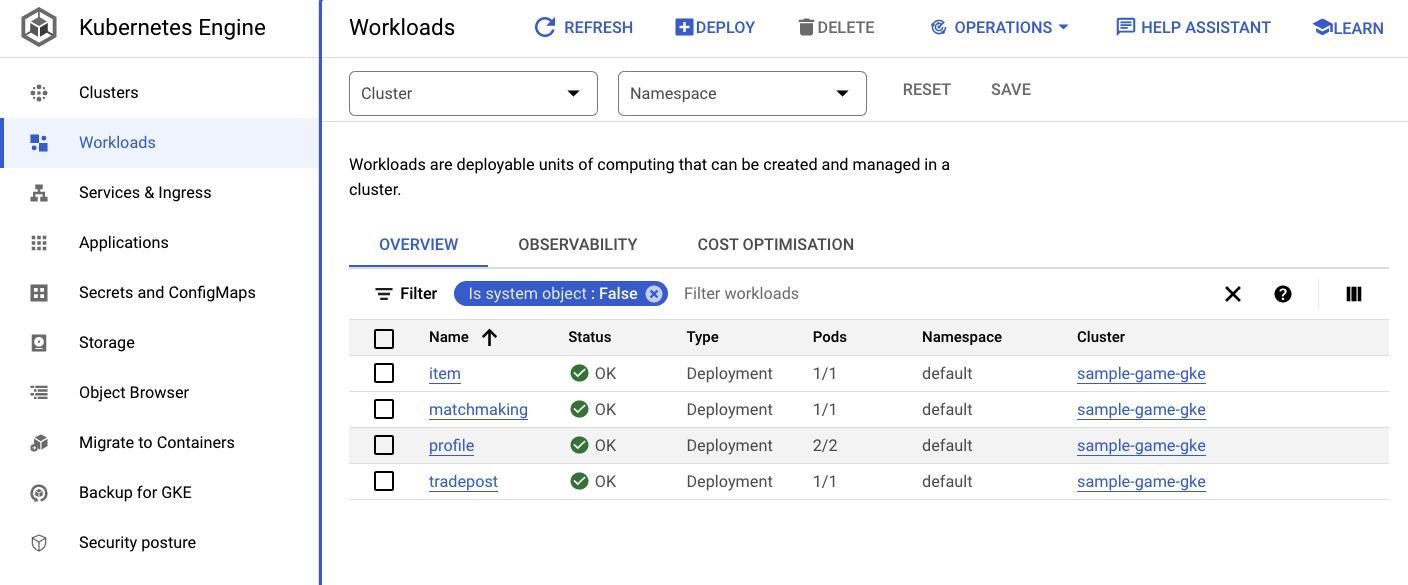
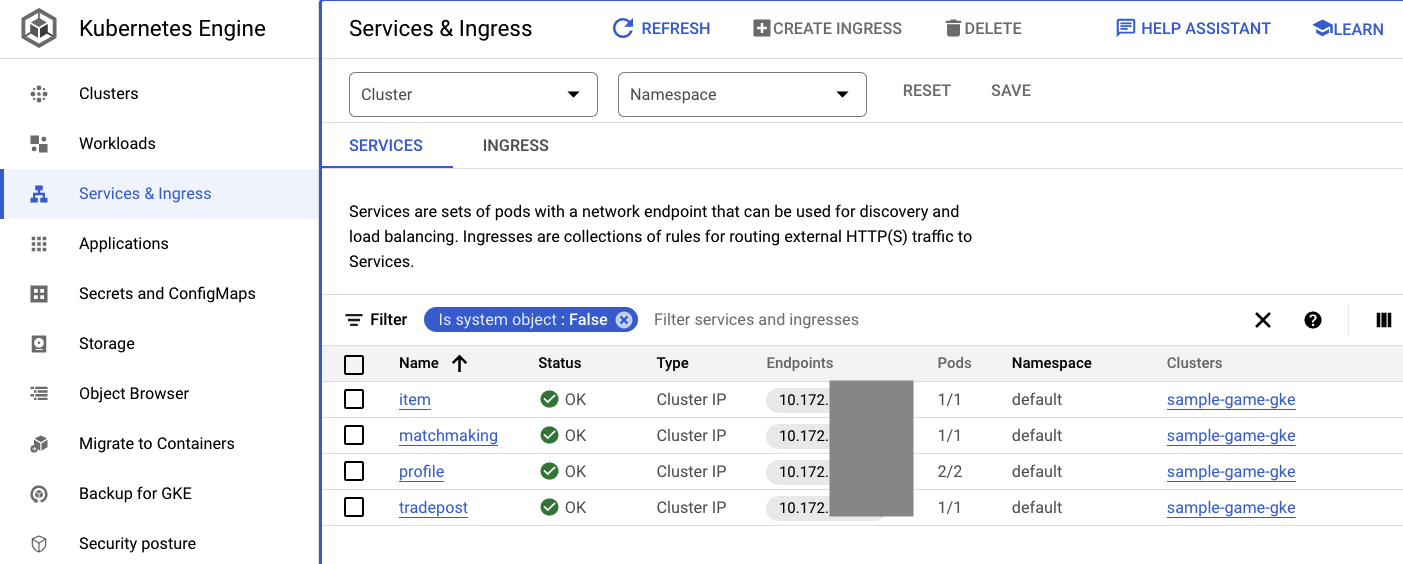
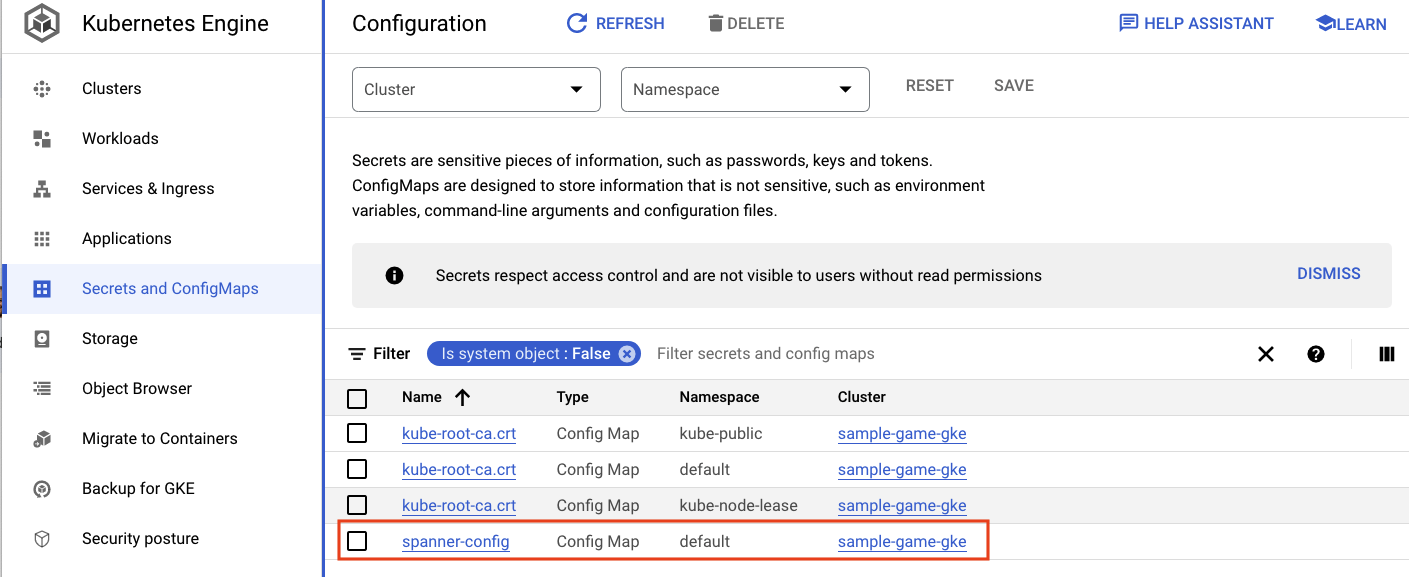
您还可以前往 Cloud 控制台中的 GKE 界面,查看 Workloads、Services 和 ConfigMaps。
工作负载
服务
ConfigMap
摘要
在此步骤中,您已将四个后端服务部署到 GKE Autopilot。您能够运行 Cloud Build 步骤,并在 Cloud Deploy 和 Cloud Console 中的 Kubernetes 上查看进度。
您还了解了这些服务如何利用 Workload Identity 来模拟具有适当权限的服务账号,以读取和写入 Spanner 数据库中的数据。
后续步骤
在下一部分中,您将部署工作负载。
6. 部署工作负载
概览
现在,后端服务已在集群上运行,接下来您将部署工作负载。

工作负载可从外部访问,并且每个后端服务都有一个工作负载,以用于此 Codelab。
这些工作负载是基于 Locust 的负载生成脚本,可模拟这些示例服务预期的真实访问模式。
以下是 Cloud Build 构建流程所需的文件:
$DEMO_HOME/workloads/cloudbuild.yaml(由 Terraform 生成)$DEMO_HOME/workloads/skaffold.yaml- 每个工作负载都有一个
deployment.yaml文件
工作负载 deployment.yaml 文件与后端服务部署文件略有不同。
以下是 matchmaking-workload 中的一个示例:
apiVersion: v1
kind: Service
metadata:
name: matchmaking-workload
spec:
type: LoadBalancer
selector:
app: matchmaking-workload
ports:
- port: 8089
targetPort: 8089
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: matchmaking-workload
spec:
replicas: 1 # EDIT: Number of instances of deployment
selector:
matchLabels:
app: matchmaking-workload
template:
metadata:
labels:
app: matchmaking-workload
spec:
serviceAccountName: default
containers:
- name: matchmaking-workload
image: matchmaking-workload
ports:
- containerPort: 8089
resources:
requests:
cpu: "500m"
memory: "512Mi"
ephemeral-storage: "100Mi"
limits:
cpu: "500m"
memory: "512Mi"
ephemeral-storage: "100Mi"
文件的顶部用于定义服务。在这种情况下,系统会创建 LoadBalancer,并且工作负载在端口 8089 上运行。
LoadBalancer 将提供一个可用于连接到工作负载的外部 IP。
apiVersion: v1
kind: Service
metadata:
name: matchmaking-workload
spec:
type: LoadBalancer
selector:
app: matchmaking-workload
ports:
- port: 8089
targetPort: 8089
部署部分顶部是有关工作负载的元数据。在这种情况下,系统只会部署一个副本:
replicas: 1
不过,容器规范有所不同。首先,我们使用的是 default Kubernetes 服务账号。此账号没有任何特殊权限,因为工作负载不需要连接到任何 Google Cloud 资源,只需连接到在 GKE 集群上运行的后端服务即可。
另一个区别是,这些工作负载不需要任何环境变量。最终,部署规范会更短。
spec:
serviceAccountName: default
containers:
- name: matchmaking-workload
image: matchmaking-workload
ports:
- containerPort: 8089
资源设置与后端服务类似。请注意,GKE Autopilot 就是通过这种方式来了解需要多少资源才能满足集群中运行的所有 Pod 的请求。
继续部署工作负载!
部署工作负载
与之前一样,您可以使用 gcloud 命令行提交 build 请求:
cd $DEMO_HOME/workloads gcloud builds submit --config=cloudbuild.yaml
命令输出
Creating temporary tarball archive of 18 file(s) totalling 26.2 KiB before compression.
Some files were not included in the source upload.
Check the gcloud log [/tmp/tmp.4Z9EqdPo6d/logs/(snip).log] to see which files and the contents of the
default gcloudignore file used (see `$ gcloud topic gcloudignore` to learn
more).
Uploading tarball of [.] to [gs://(project)_cloudbuild/source/(snip).tgz]
Created [https://cloudbuild.googleapis.com/v1/projects/(project)/locations/global/builds/(snip)].
Logs are available at [ https://console.cloud.google.com/cloud-build/builds/0daf20f6-(snip)?project=(snip) ].
gcloud builds submit only displays logs from Cloud Storage. To view logs from Cloud Logging, run:
gcloud beta builds submit
ID: 0daf20f6-(snip)
CREATE_TIME: (created_time)
DURATION: 1M41S
SOURCE: gs://(project)_cloudbuild/source/(snip).tgz
IMAGES: us-docker.pkg.dev/(project)/spanner-game-images/profile-workload:0daf20f6-(snip) (+4 more)
STATUS: SUCCESS
请务必在 Cloud 控制台中查看 Cloud Build 日志和 Cloud Deploy 流水线,以检查状态。对于工作负载,Cloud Deploy 流水线为 sample-game-workloads:
部署完成后,在 Cloud Shell 中使用 kubectl 检查状态:
kubectl get pods
命令输出
NAME READY STATUS RESTARTS AGE
game-workload-7ff44cb657-pxxq2 1/1 Running 0 12m
item-6b9d5f678c-cr29w 1/1 Running 0 9m6s
item-generator-7bb4f57cf8-5r85b 1/1 Running 0 12m
matchmaking-5bcf799b76-lg8zf 1/1 Running 0 117m
matchmaking-workload-76df69dbdf-jds9z 1/1 Running 0 12m
profile-565bbf4c65-kphdl 1/1 Running 0 121m
profile-565bbf4c65-xw74j 1/1 Running 0 121m
profile-workload-76d6db675b-kzwng 1/1 Running 0 12m
tradepost-68b87ccd44-gw55r 1/1 Running 0 116m
tradepost-workload-56c55445b5-b5822 1/1 Running 0 12m
然后,检查工作负载服务,看看 LoadBalancer 是否在运行:
kubectl get services
命令输出
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
game-workload LoadBalancer *snip* 35.XX.XX.XX 8089:32483/TCP 12m
item ClusterIP *snip* <none> 80/TCP 121m
item-generator LoadBalancer *snip* 34.XX.XX.XX 8089:32581/TCP 12m
kubernetes ClusterIP *snip* <none> 443/TCP 174m
matchmaking ClusterIP *snip* <none> 80/TCP 121m
matchmaking-workload LoadBalancer *snip* 34.XX.XX.XX 8089:31735/TCP 12m
profile ClusterIP *snip* <none> 80/TCP 121m
profile-workload LoadBalancer *snip* 34.XX.XX.XX 8089:32532/TCP 12m
tradepost ClusterIP *snip* <none> 80/TCP 121m
tradepost-workload LoadBalancer *snip* 34.XX.XX.XX 8089:30002/TCP 12m
摘要
您现在已将工作负载部署到 GKE 集群。这些工作负载不需要额外的 IAM 权限,并且可以使用 LoadBalancer 服务通过端口 8089 从外部访问。
后续步骤
后端服务和工作负载运行后,就可以开始“玩”游戏了!
7. 开始玩游戏
概览
示例“游戏”的后端服务现在正在运行,您还可以使用工作负载生成与这些服务互动的“玩家”。
每个工作负载都使用 Locust 来模拟针对我们服务 API 的实际负载。在此步骤中,您将运行多个工作负载,以在 GKE 集群和 Spanner 上生成负载,并在 Spanner 上存储数据。
以下是对每种工作负载的说明:
item-generator工作负载是一种快速生成 game_items。profile-workload会模拟玩家注册和登录。matchmaking-workload可模拟玩家排队等待分配到游戏。game-workload模拟玩家在玩游戏的过程中获得 game_items 和 money。tradepost-workload模拟了玩家能够在交易站出售和购买商品。
此 Codelab 将重点介绍如何运行 item-generator 和 profile-workload。
运行 item-generator
item-generator 使用 item 后端服务端点将 game_items 添加到 Spanner。game-workload 和 tradepost-workload 需要这些项才能正常运行。
第一步是获取 item-generator 服务的外部 IP。在 Cloud Shell 中,运行以下命令:
# The external IP is the 4th column of the output
kubectl get services | grep item-generator | awk '{print $4}'
命令输出
{ITEMGENERATOR_EXTERNAL_IP}
现在,打开一个新的浏览器标签页,并将其指向 http://{ITEMGENERATOR_EXTERNAL_IP}:8089。您应该会看到如下所示的页面:
您将保留 users 和 spawn 的默认值 1。对于 host,输入 http://item。点击高级选项,然后输入 10s 作为运行时间。
配置应如下所示:
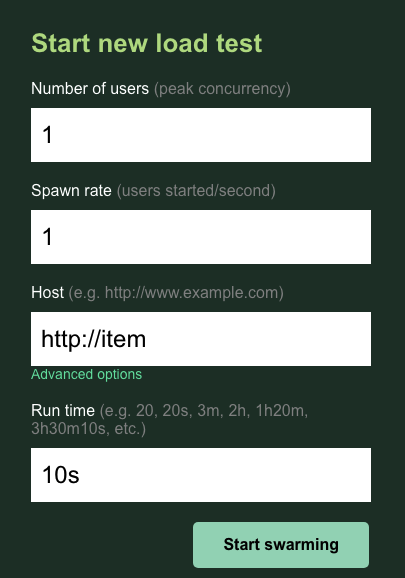
点击“开始大量生成请求”!
系统将开始显示针对 POST /items 端点发出的请求的统计信息。10 秒后,负载将停止。
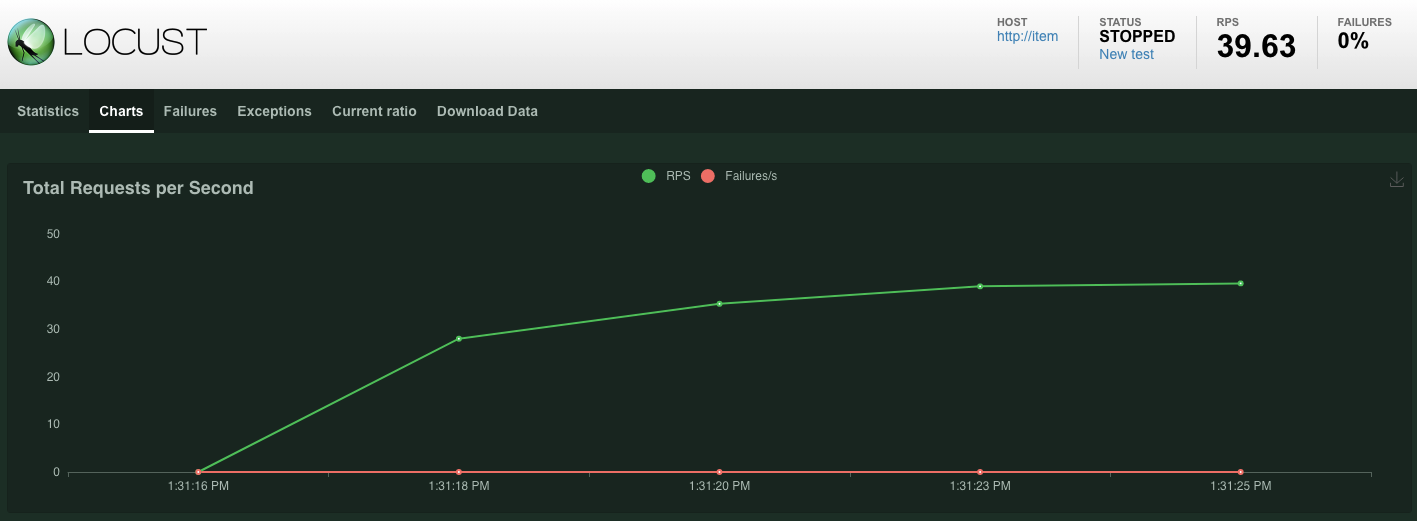
点击 Charts,您将看到一些关于这些请求的效果图表。
现在,您需要检查数据是否已输入到 Spanner 数据库中。
为此,请点击汉堡式菜单,然后前往“Spanner”。在此页面中,前往 sample-instance 和 sample-database。然后点击“Query”。
我们要选择 game_items 的数量:
SELECT COUNT(*) FROM game_items;
底部会显示结果。
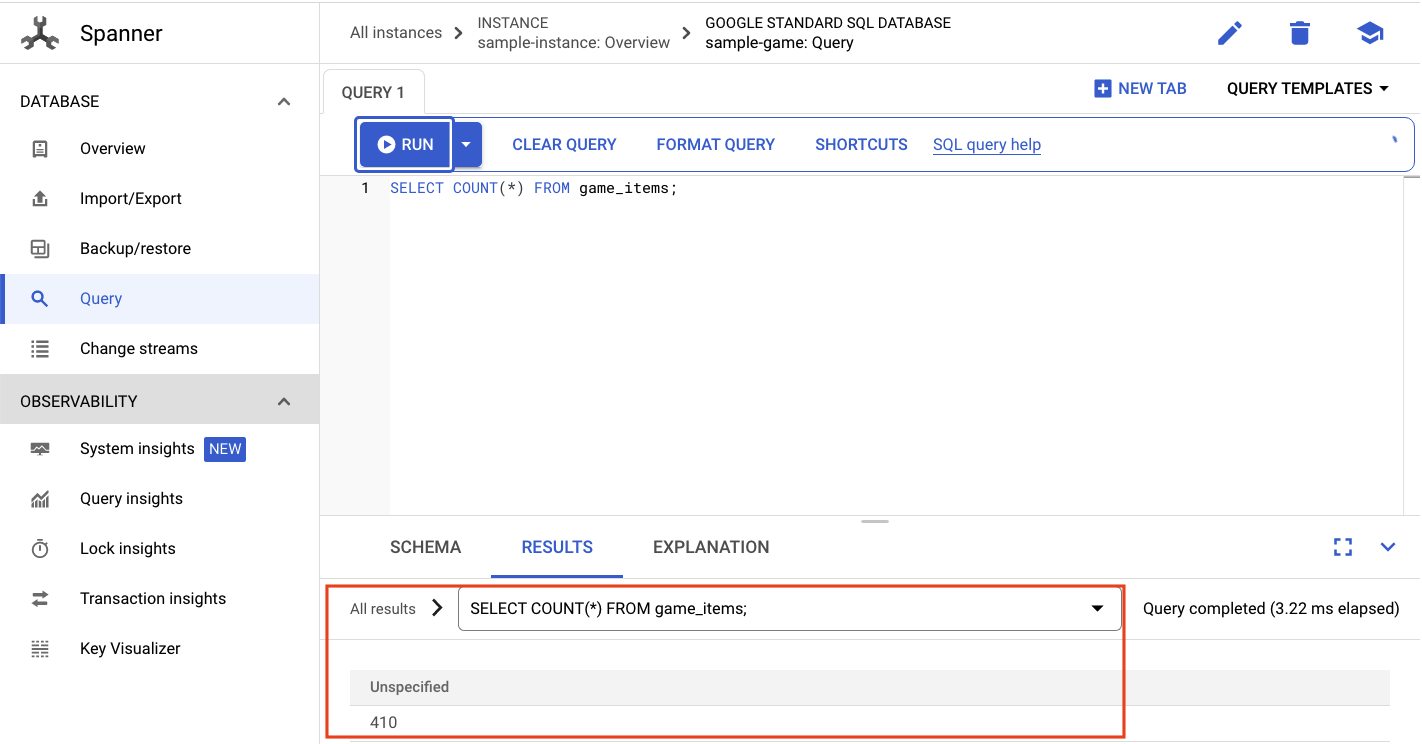
我们不需要大量 game_items 种子。不过,现在玩家可以获取这些卡片了!
运行配置文件工作负载
在您完成 game_items 播种后,下一步是让玩家注册以便能够玩游戏。
profile-workload 将使用 Locust 模拟玩家创建账号、登录、检索个人资料信息和退出。所有这些测试都旨在测试 profile 后端服务在典型类生产工作负载中的端点。
如需运行此命令,请获取 profile-workload 外部 IP:
# The external IP is the 4th column of the output
kubectl get services | grep profile-workload | awk '{print $4}'
命令输出
{PROFILEWORKLOAD_EXTERNAL_IP}
现在,打开一个新的浏览器标签页,并将其指向 http://{PROFILEWORKLOAD_EXTERNAL_IP}:8089。您应该会看到与之前类似的 Locust 页面。
在这种情况下,您将使用 http://profile 作为宿主。并且您不会在高级选项中指定运行时。此外,将 users 指定为 4,这样将同时模拟 4 个用户请求。
profile-workload 测试应如下所示:
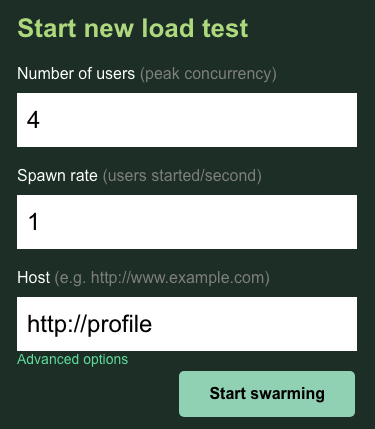
点击“开始大量生成请求”!
与之前一样,各种 profile REST 端点的统计信息将开始显示。点击图表,查看所有内容的表现情况。
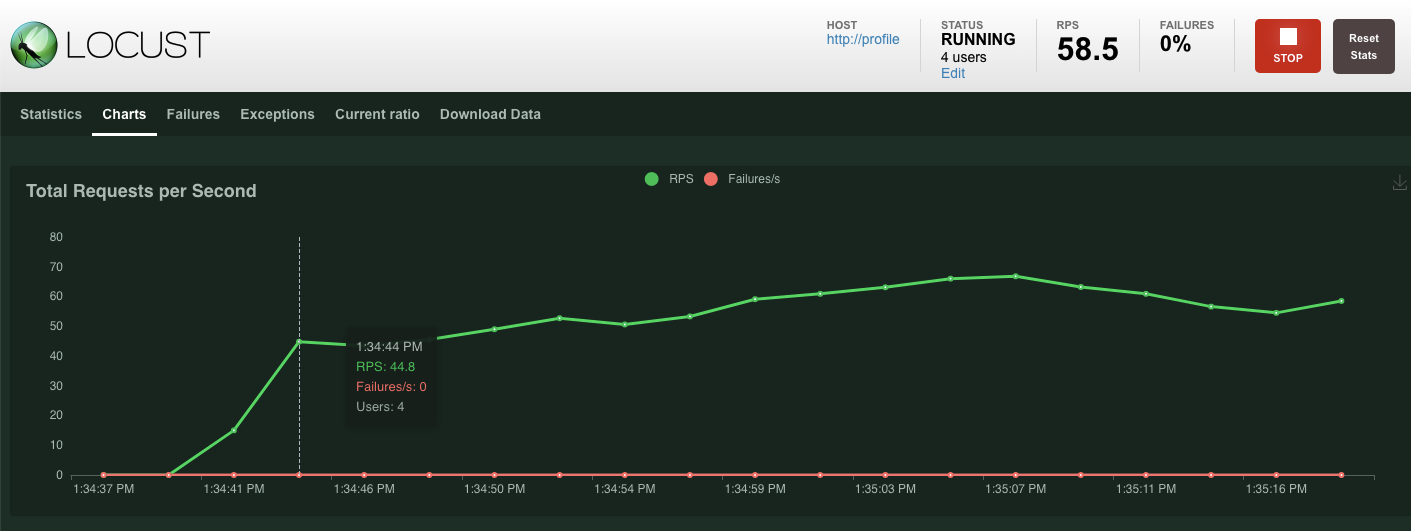
摘要
在此步骤中,您生成了一些 game_items,然后使用 Cloud 控制台中的 Spanner 查询界面查询了 game_items 表。
您还允许玩家注册您的游戏,并了解 Locust 如何能够针对您的后端服务创建类似生产环境的工作负载。
后续步骤
运行工作负载后,您需要检查 GKE 集群和 Spanner 实例的运行情况。
8. 查看 GKE 和 Spanner 用量
在个人资料服务运行后,现在可以借此机会了解 GKE Autopilot 集群和 Cloud Spanner 的行为。
检查 GKE 集群
导航到 Kubernetes 集群。请注意,由于您已部署工作负载和服务,因此集群现在添加了一些有关总 vCPU 和内存的详细信息。当集群上没有任何工作负载时,此信息不可用。
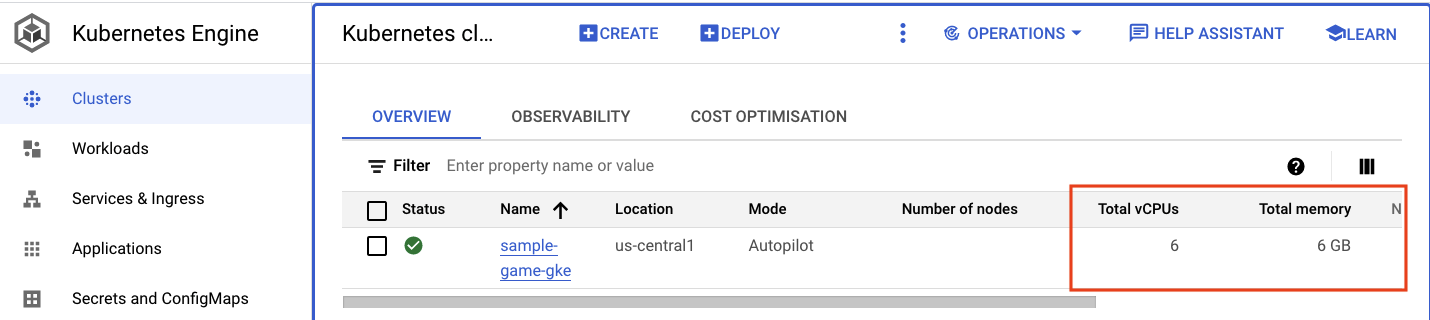
现在,点击进入 sample-game-gke 集群,然后切换到可观测性标签页:
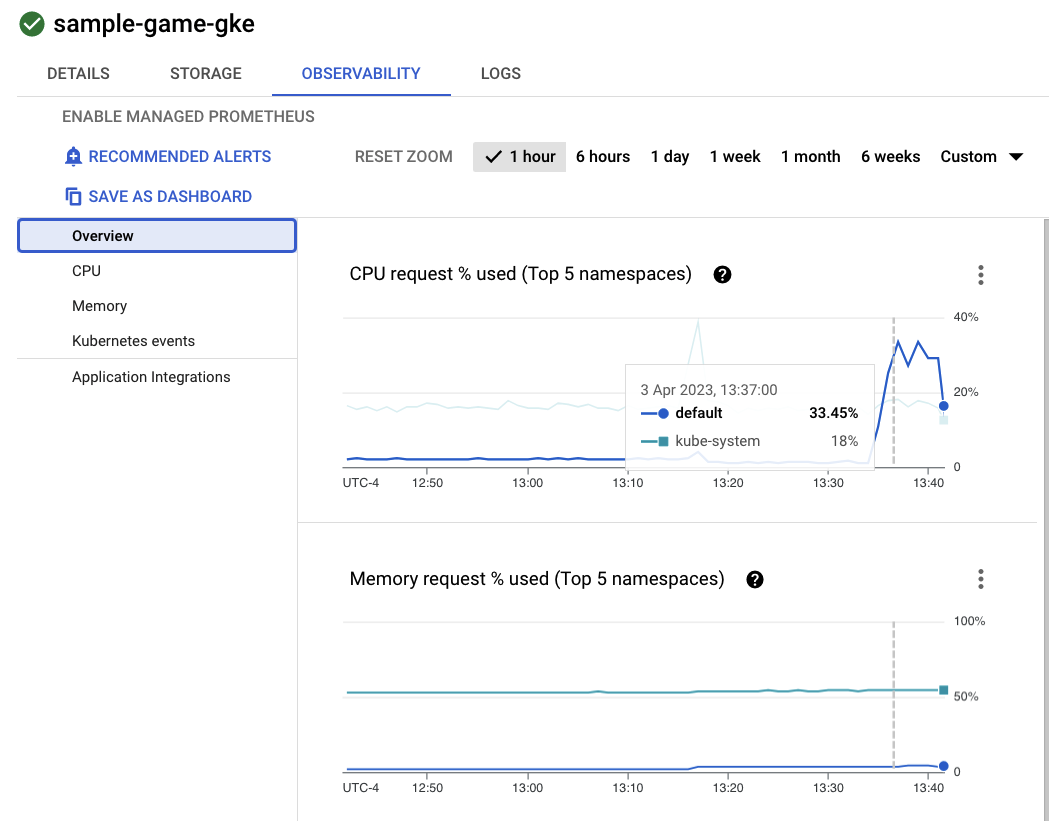
由于我们的工作负载和后端服务在 default 上运行,因此 default Kubernetes 命名空间的 CPU 利用率应高于 kube-system 命名空间。如果尚未更新,请确保 profile workload 仍在运行,并等待几分钟,直到图表更新。
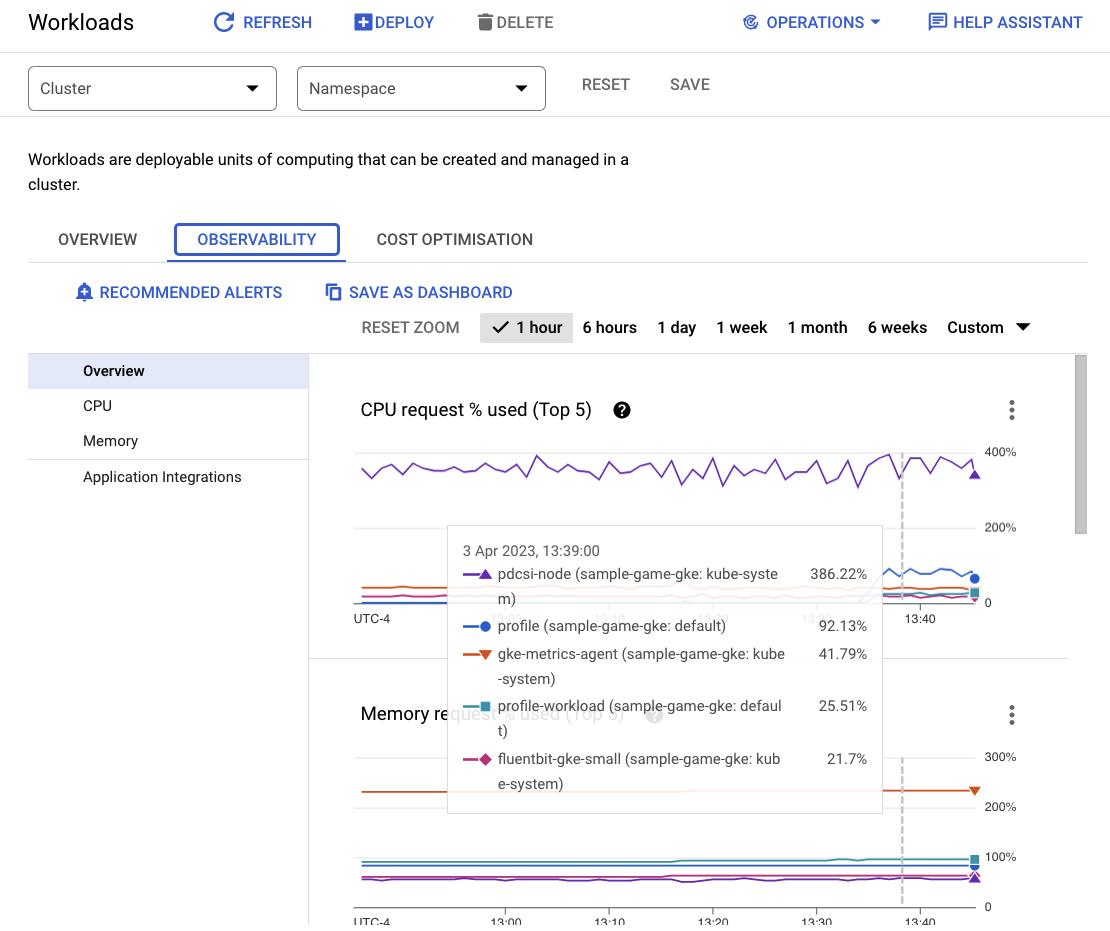
如需查看哪些工作负载占用了最多的资源,请前往 Workloads 信息中心。
无需逐个进入每个工作负载,直接前往信息中心的“可观测性”标签页。您应该会看到 profile 和 profile-workload CPU 已增加。
现在,前往 Cloud Spanner 查看。
检查 Cloud Spanner 实例
如需检查 Cloud Spanner 的性能,请前往 Spanner,然后点击 sample-instance 实例和 sample-game 数据库。
然后,您会在左侧菜单中看到系统数据分析标签页:
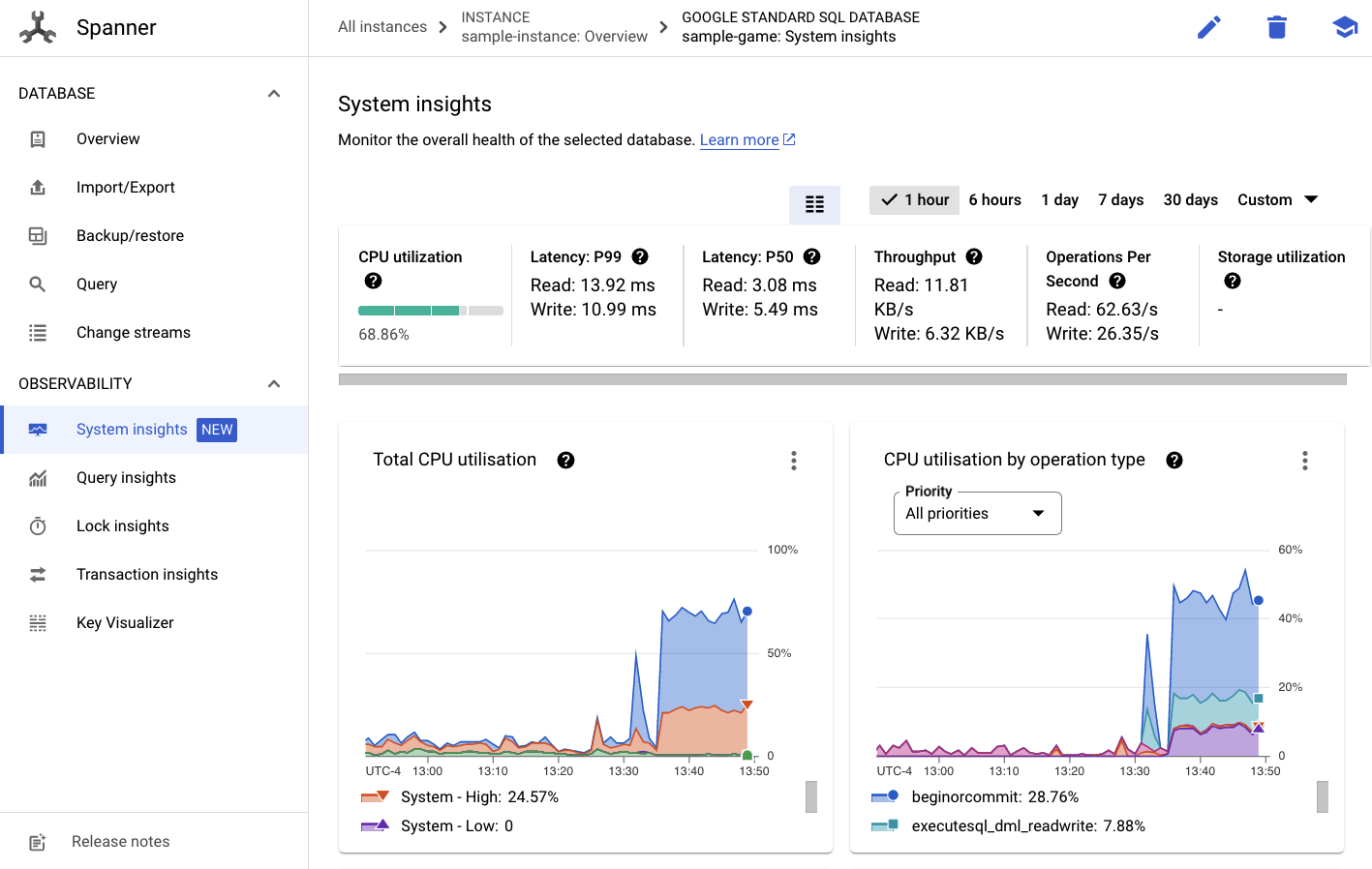
此处提供了许多图表,可帮助您了解 Spanner 实例的总体性能,包括 CPU utilization、transaction latency and locking 和 query throughput。
除了“系统洞察”之外,您还可以查看“可观测性”部分中的其他链接,以获取有关查询工作负载的更详细信息:
- 查询洞见有助于识别 Spanner 上利用资源最多的前 N 个查询。
- 事务和锁定分析洞见有助于识别高延迟事务。
- Key Visualizer 有助于直观呈现访问模式,并可帮助跟踪数据中的热点。
摘要
在此步骤中,您学习了如何检查 GKE Autopilot 和 Spanner 的一些基本性能指标。
例如,在个人资料工作负载运行的情况下,查询 players 表,以获取有关存储在其中的数据的更多信息。
后续步骤
接下来,该清理了!
9. 清理
在清理之前,您可以随意探索未涵盖的其他工作负载。具体来说,就是 matchmaking-workload、 game-workload 和 tradepost-workload。
“玩”完游戏后,您可以清理游乐场。幸运的是,这很容易做到。
首先,如果您的 profile-workload 仍在浏览器中运行,请前往并停止它:
对您可能测试过的每个工作负载执行相同的操作。
然后在 Cloud Shell 中,导航到 infrastructure 文件夹。您将使用 Terraform destroy 基础架构:
cd $DEMO_HOME/infrastructure
terraform destroy
# type 'yes' when asked
命令输出
Plan: 0 to add, 0 to change, 46 to destroy.
Do you really want to destroy all resources?
Terraform will destroy all your managed infrastructure, as shown above.
There is no undo. Only 'yes' will be accepted to confirm.
Enter a value: yes
*snip*
Destroy complete! Resources: 46 destroyed.
在 Cloud 控制台中,依次前往 Spanner、Kubernetes Cluster、Artifact Registry、Cloud Deploy 和 IAM,验证是否已移除所有资源。
10. 恭喜!
恭喜!您已成功在 GKE Autopilot 上部署了示例 Go 应用,并使用 Workload Identity 将其连接到 Cloud Spanner!
此外,使用 Terraform 可以轻松地以可重复的方式设置和移除此基础架构。
您可以详细了解本 Codelab 中使用的 Google Cloud 服务:
后续操作
现在,您已基本了解 GKE Autopilot 和 Cloud Spanner 如何协同工作,不妨迈出下一步,开始构建自己的应用以使用这些服务?