
1. 소개
Cloud Spanner는 성능 및 고가용성을 희생하지 않고도 ACID 트랜잭션 및 SQL 시맨틱스를 제공하는 수평 확장이 가능하고, 전역으로 분산되었고, 완전히 관리되는 관계형 데이터베이스 서비스입니다.
GKE Autopilot은 Google이 노드, 확장, 보안, 기타 사전 구성된 설정을 포함한 클러스터 구성을 관리하여 권장사항을 따르는 GKE의 작동 모드입니다. 예를 들어 GKE Autopilot을 사용하면 워크로드 아이덴티티를 사용하여 서비스 권한을 관리할 수 있습니다.
이 실습의 목표는 GKE Autopilot에서 실행되는 여러 백엔드 서비스를 Cloud Spanner 데이터베이스에 연결하는 프로세스를 안내하는 것입니다.
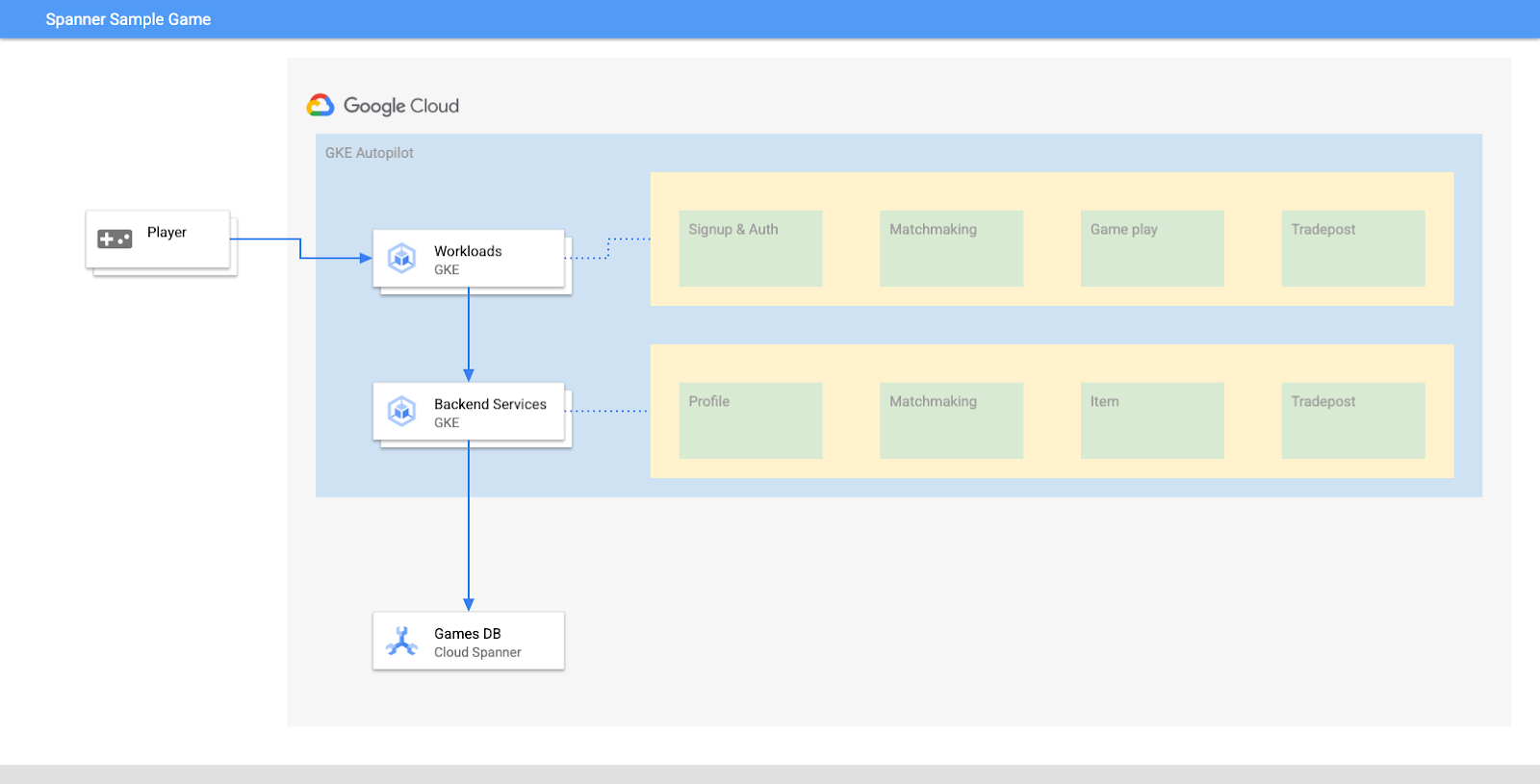
이 실습에서는 먼저 프로젝트를 설정하고 Cloud Shell을 실행합니다. 그런 다음 Terraform을 사용하여 인프라를 배포합니다.
이 작업이 완료되면 Cloud Build 및 Cloud Deploy와 상호작용하여 게임 데이터베이스의 초기 스키마 마이그레이션을 실행하고, 백엔드 서비스를 배포한 다음 워크로드를 배포합니다.
이 Codelab의 서비스는 Cloud Spanner 게임 개발 시작하기 Codelab의 서비스와 동일합니다. 이 Codelab을 거치지 않아도 GKE에서 서비스를 실행하고 Spanner에 연결할 수 있습니다. 하지만 Spanner에서 작동하는 서비스의 구체적인 세부정보에 관심이 있다면 확인해 보세요.
워크로드와 백엔드 서비스가 실행되면 부하를 생성하고 서비스가 함께 작동하는 방식을 관찰할 수 있습니다.
마지막으로 이 실습에서 만든 리소스를 정리합니다.
빌드할 항목
이 실습에서 학습할 내용은 다음과 같습니다.
- Terraform을 사용하여 인프라 프로비저닝
- Cloud Build의 스키마 마이그레이션 프로세스를 사용하여 데이터베이스 스키마 만들기
- 워크로드 아이덴티티를 활용하여 Cloud Spanner에 연결하는 네 개의 Golang 백엔드 서비스 배포
- 백엔드 서비스의 부하를 시뮬레이션하는 데 사용되는 네 개의 워크로드 서비스를 배포합니다.
학습할 내용
- Terraform을 사용하여 GKE Autopilot, Cloud Spanner, Cloud Deploy 파이프라인을 프로비저닝하는 방법
- 워크로드 아이덴티티를 통해 GKE의 서비스가 서비스 계정을 가장하여 Cloud Spanner와 함께 작동하는 IAM 권한에 액세스하는 방법
- Locust.io를 사용하여 GKE 및 Cloud Spanner에서 프로덕션과 유사한 부하를 생성하는 방법
필요한 항목
2. 설정 및 요건
프로젝트 만들기
아직 Google 계정(Gmail 또는 Google Apps)이 없으면 계정을 만들어야 합니다. Google Cloud Platform 콘솔 ( console.cloud.google.com)에 로그인하고 새 프로젝트를 만듭니다.
프로젝트가 이미 있으면 Console 왼쪽 위에서 프로젝트 선택 풀다운 메뉴를 클릭합니다.

그리고 표시된 대화상자에서 '새 프로젝트' 버튼을 클릭하여 새 프로젝트를 만듭니다.
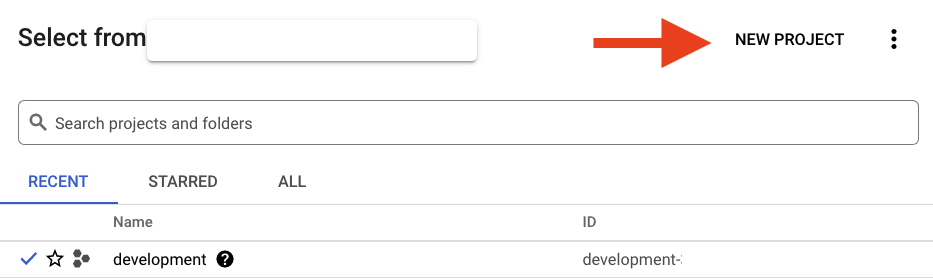
아직 프로젝트가 없으면 첫 번째 프로젝트를 만들기 위해 다음과 비슷한 대화상자가 표시됩니다.
이후의 프로젝트 만들기 대화상자에서 새 프로젝트의 세부정보를 입력할 수 있습니다.
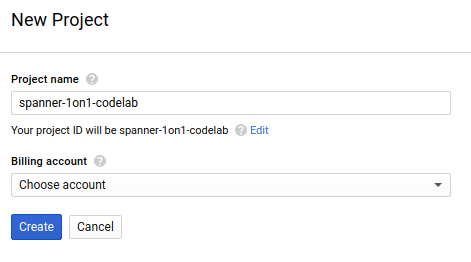
모든 Google Cloud 프로젝트에서 고유한 이름인 프로젝트 ID를 기억하세요(위의 이름은 이미 사용되었으므로 사용할 수 없습니다). 이 ID는 나중에 이 Codelab에서 PROJECT_ID라고 부릅니다.
그런 다음 Google Cloud 리소스를 사용하고 Cloud Spanner API를 사용 설정하기 위해서는 아직 완료하지 않은 경우 Developers Console에서 결제를 사용 설정해야 합니다.
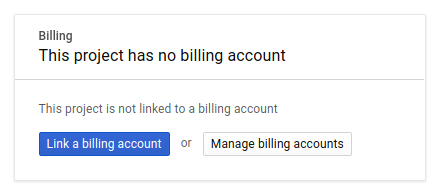
이 codelab을 실행하는 과정에는 많은 비용이 들지 않지만 더 많은 리소스를 사용하려고 하거나 실행 중일 경우 비용이 더 들 수 있습니다(이 문서 마지막의 '삭제' 섹션 참조). Google Cloud Spanner 가격 책정은 여기를 참조하고 GKE Autopilot은 여기를 참조하세요.
Google Cloud Platform 신규 사용자는 $300 상당의 무료 체험판을 사용할 수 있으므로, 이 Codelab을 완전히 무료로 사용할 수 있습니다.
Cloud Shell 설정
Google Cloud 및 Spanner를 노트북에서 원격으로 실행할 수 있지만, 이 Codelab에서는 Cloud에서 실행되는 명령줄 환경인 Google Cloud Shell을 사용합니다.
이 Debian 기반 가상 머신에는 필요한 모든 개발 도구가 로드되어 있습니다. 영구적인 5GB 홈 디렉터리를 제공하고 Google Cloud에서 실행되므로 네트워크 성능과 인증이 크게 개선됩니다. 즉, 이 Codelab에 필요한 것은 브라우저뿐입니다(Chromebook에서도 작동 가능).
- Cloud 콘솔에서 Cloud Shell을 활성화하려면 Cloud Shell 활성화
 를 클릭합니다. 환경을 프로비저닝하고 연결하는 데 몇 분 정도만 걸립니다.
를 클릭합니다. 환경을 프로비저닝하고 연결하는 데 몇 분 정도만 걸립니다.
Cloud Shell에 연결되면 사용자 인증이 이미 완료되었고 프로젝트가 내 PROJECT_ID에 설정되어 있음을 확인할 수 있습니다.
gcloud auth list
명령어 결과
Credentialed accounts:
- <myaccount>@<mydomain>.com (active)
gcloud config list project
명령어 결과
[core]
project = <PROJECT_ID>
어떤 이유로든 프로젝트가 설정되지 않았으면 다음 명령어를 실행하면 됩니다.
gcloud config set project <PROJECT_ID>
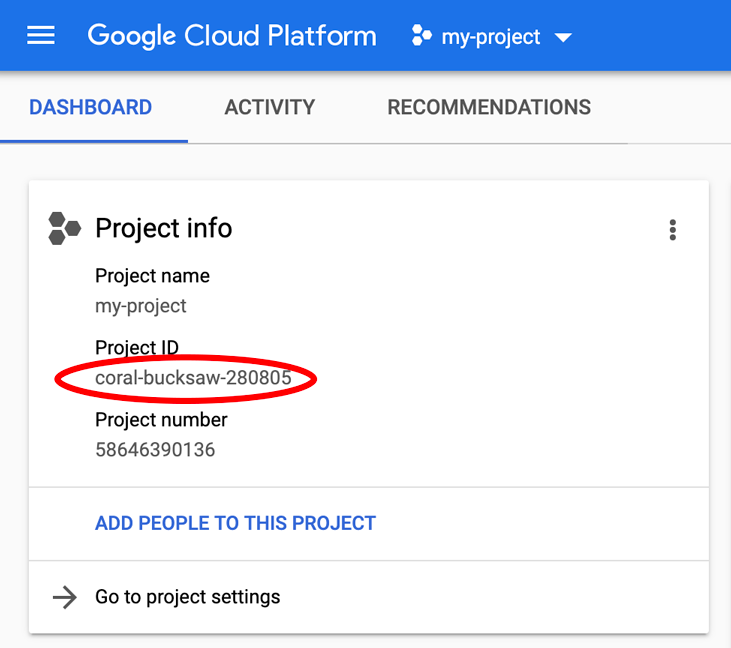
PROJECT_ID를 찾고 계신가요? 설정 단계에서 사용한 ID를 확인하거나 Cloud Console 대시보드에서 확인하세요.
또한 Cloud Shell은 기본적으로 이후 명령어를 실행할 때 유용할 수 있는 몇 가지 환경 변수를 설정합니다.
echo $GOOGLE_CLOUD_PROJECT
명령어 결과
<PROJECT_ID>
코드 다운로드
Cloud Shell에서 이 실습의 코드를 다운로드할 수 있습니다.
git clone https://github.com/cloudspannerecosystem/spanner-gaming-sample.git
명령어 결과
Cloning into 'spanner-gaming-sample'...
*snip*
이 Codelab은 v0.1.3 버전을 기반으로 하므로 해당 태그를 확인하세요.
cd spanner-gaming-sample
git fetch --all --tags
# Check out v0.1.3 release
git checkout tags/v0.1.3 -b v0.1.3-branch
명령어 결과
Switched to a new branch 'v0.1.3-branch'
이제 현재 작업 디렉터리를 DEMO_HOME 환경 변수로 설정합니다. 이렇게 하면 Codelab의 여러 부분을 진행하면서 더 쉽게 탐색할 수 있습니다.
export DEMO_HOME=$(pwd)
요약
이 단계에서는 새 프로젝트를 설정하고, Cloud Shell을 활성화하고, 이 실습의 코드를 다운로드했습니다.
다음 단계
다음으로 Terraform을 사용하여 인프라를 프로비저닝합니다.
3. 인프라 프로비저닝하기
개요
프로젝트가 준비되었으므로 이제 인프라를 실행할 차례입니다. 여기에는 VPC 네트워킹, Cloud Spanner, GKE Autopilot, GKE에서 실행될 이미지를 저장하는 Artifact Registry, 백엔드 서비스 및 워크로드용 Cloud Deploy 파이프라인, 마지막으로 이러한 서비스를 사용할 수 있는 서비스 계정 및 IAM 권한이 포함됩니다.
정말 많습니다. 하지만 다행히도 Terraform을 사용하면 이 설정을 간소화할 수 있습니다. Terraform은 '.tf' 파일 시리즈에서 이 프로젝트에 필요한 사항을 지정할 수 있는 '코드형 인프라' 도구입니다. 이렇게 하면 인프라 프로비저닝이 간단해집니다.
이 Codelab을 완료하기 위해 Terraform에 익숙할 필요는 없습니다. 하지만 다음 몇 단계에서 어떤 작업을 하는지 확인하려면 infrastructure 디렉터리에 있는 다음 파일에 생성되는 모든 항목을 살펴보세요.
- vpc.tf
- backend_gke.tf
- spanner.tf
- artifact_registry.tf
- pipelines.tf
- iam.tf
Terraform 구성
Cloud Shell에서 infrastructure 디렉터리로 변경하고 Terraform을 초기화합니다.
cd $DEMO_HOME/infrastructure
terraform init
명령어 결과
Initializing the backend...
Initializing provider plugins...
*snip*
Terraform has been successfully initialized!
You may now begin working with Terraform. Try running "terraform plan" to see
any changes that are required for your infrastructure. All Terraform commands
should now work.
If you ever set or change modules or backend configuration for Terraform,
rerun this command to reinitialize your working directory. If you forget, other
commands will detect it and remind you to do so if necessary.
그런 다음 terraform.tfvars.sample를 복사하고 프로젝트 값을 수정하여 Terraform을 구성합니다. 다른 변수도 변경할 수 있지만 환경에서 작동하려면 프로젝트만 변경하면 됩니다.
cp terraform.tfvars.sample terraform.tfvars
# edit gcp_project using the project environment variable
sed -i "s/PROJECT/$GOOGLE_CLOUD_PROJECT/" terraform.tfvars
인프라 프로비저닝
이제 인프라를 프로비저닝할 차례입니다.
terraform apply
# review the list of things to be created
# type 'yes' when asked
명령어 결과
Plan: 46 to add, 0 to change, 0 to destroy.
Do you want to perform these actions?
Terraform will perform the actions described above.
Only 'yes' will be accepted to approve.
Enter a value: yes
google_project_service.project["container.googleapis.com"]: Creating...
*snip*
Apply complete! Resources: 46 added, 0 changed, 0 destroyed.
생성된 항목 확인
생성된 항목을 확인하려면 Cloud 콘솔에서 제품을 확인해야 합니다.
Cloud Spanner
먼저 햄버거 메뉴로 이동하여 Spanner을 클릭하여 Cloud Spanner를 확인합니다. 목록에서 찾으려면 '제품 더보기'를 클릭해야 할 수도 있습니다.
그러면 Spanner 인스턴스 목록으로 이동합니다. 인스턴스를 클릭하면 데이터베이스가 표시됩니다. 예를 들면 다음과 같습니다.
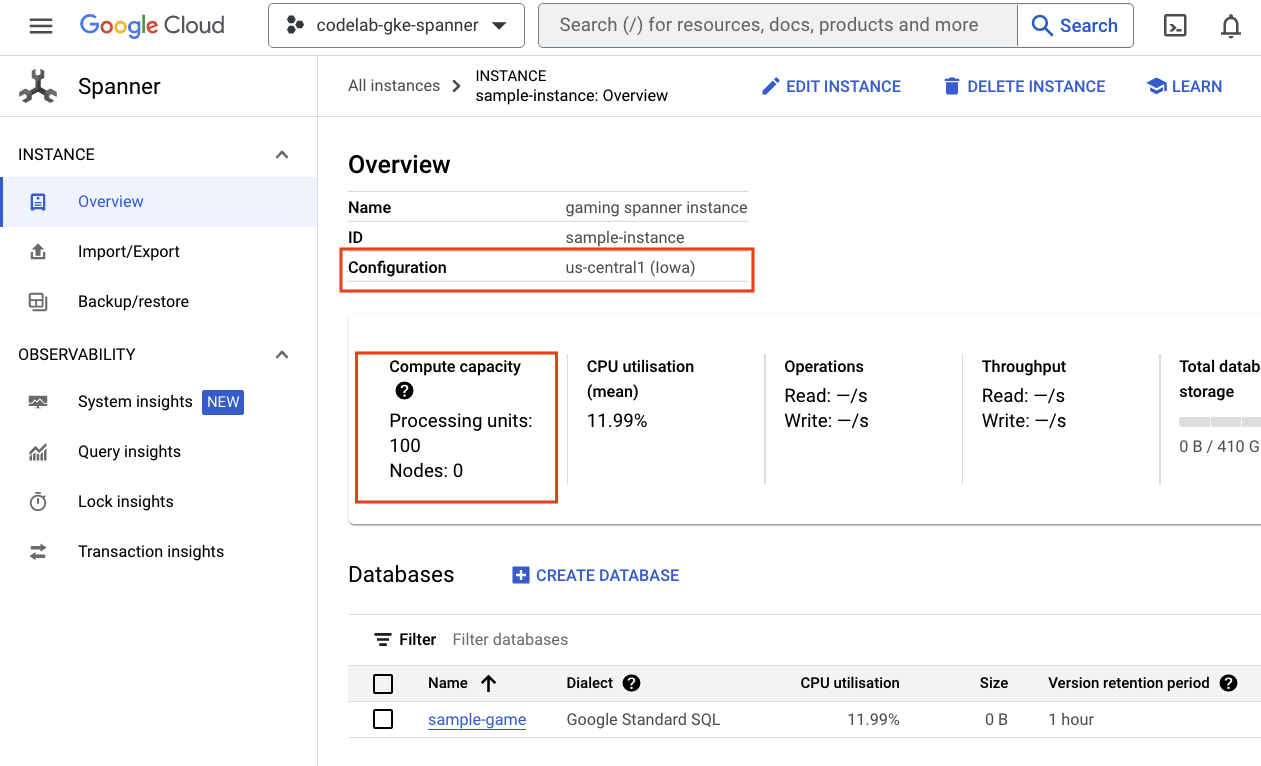
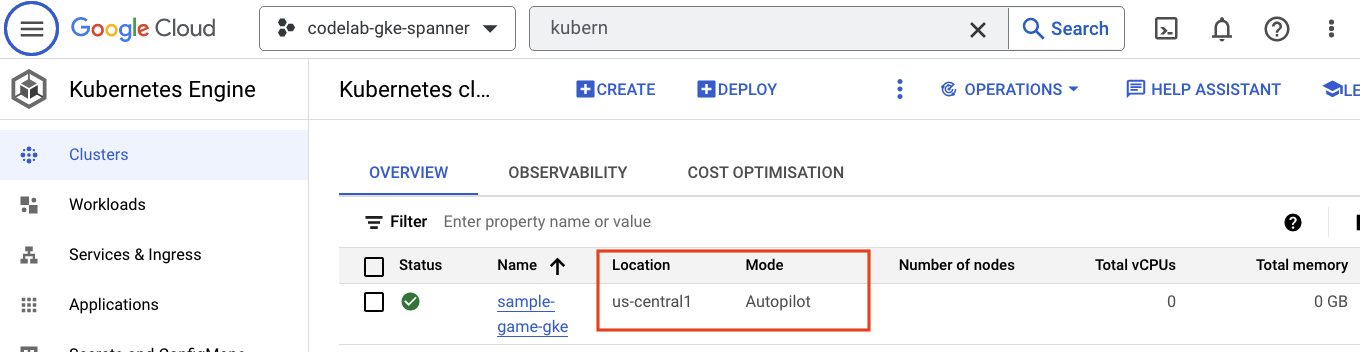
GKE Autopilot
다음으로 햄버거 메뉴로 이동하여 Kubernetes Engine => Clusters를 클릭하여 GKE를 확인합니다. 여기에서 Autopilot 모드로 실행되는 sample-games-gke 클러스터를 확인할 수 있습니다.
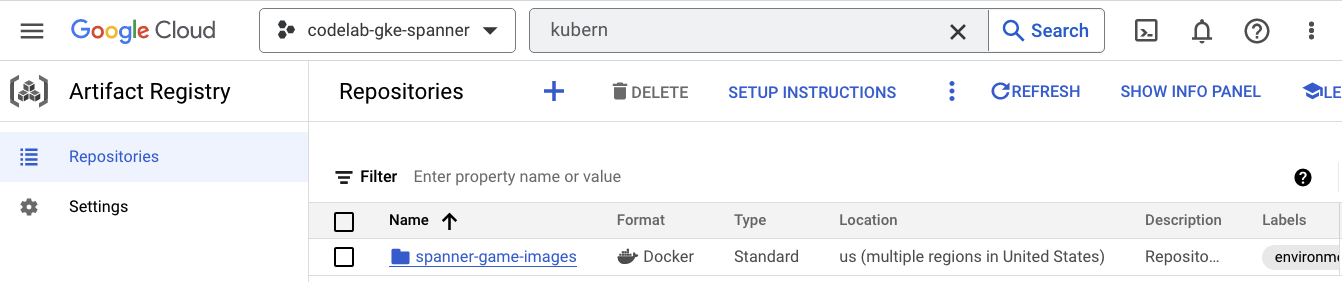
Artifact Registry
이제 이미지가 저장될 위치를 확인합니다. 햄버거 메뉴를 클릭하고 Artifact Registry=>Repositories를 찾습니다. Artifact Registry는 메뉴의 CI/CD 섹션에 있습니다.
여기에는 spanner-game-images라는 Docker 레지스트리가 표시됩니다. 현재는 비어 있습니다.
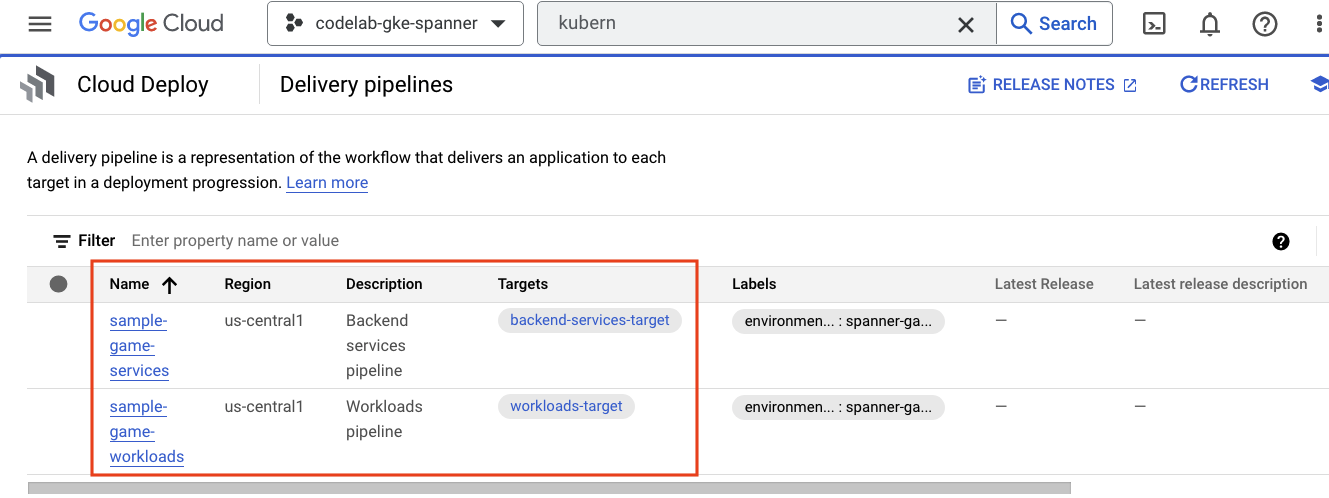
Cloud Deploy
Cloud Deploy는 Cloud Build가 이미지를 빌드한 다음 GKE 클러스터에 배포하는 단계를 제공할 수 있도록 파이프라인이 생성된 곳입니다.
햄버거 메뉴로 이동하여 메뉴의 CI/CD 섹션에 있는 Cloud Deploy를 찾습니다.
여기에는 백엔드 서비스용 파이프라인과 워크로드용 파이프라인의 두 가지 파이프라인이 표시됩니다. 두 명령 모두 이미지를 동일한 GKE 클러스터에 배포하지만 이렇게 하면 배포를 분리할 수 있습니다.
IAM
마지막으로 Cloud Console의 IAM 페이지에서 생성된 서비스 계정을 확인합니다. 햄버거 메뉴로 이동하여 IAM and Admin=>Service accounts를 찾습니다. 예를 들면 다음과 같습니다.
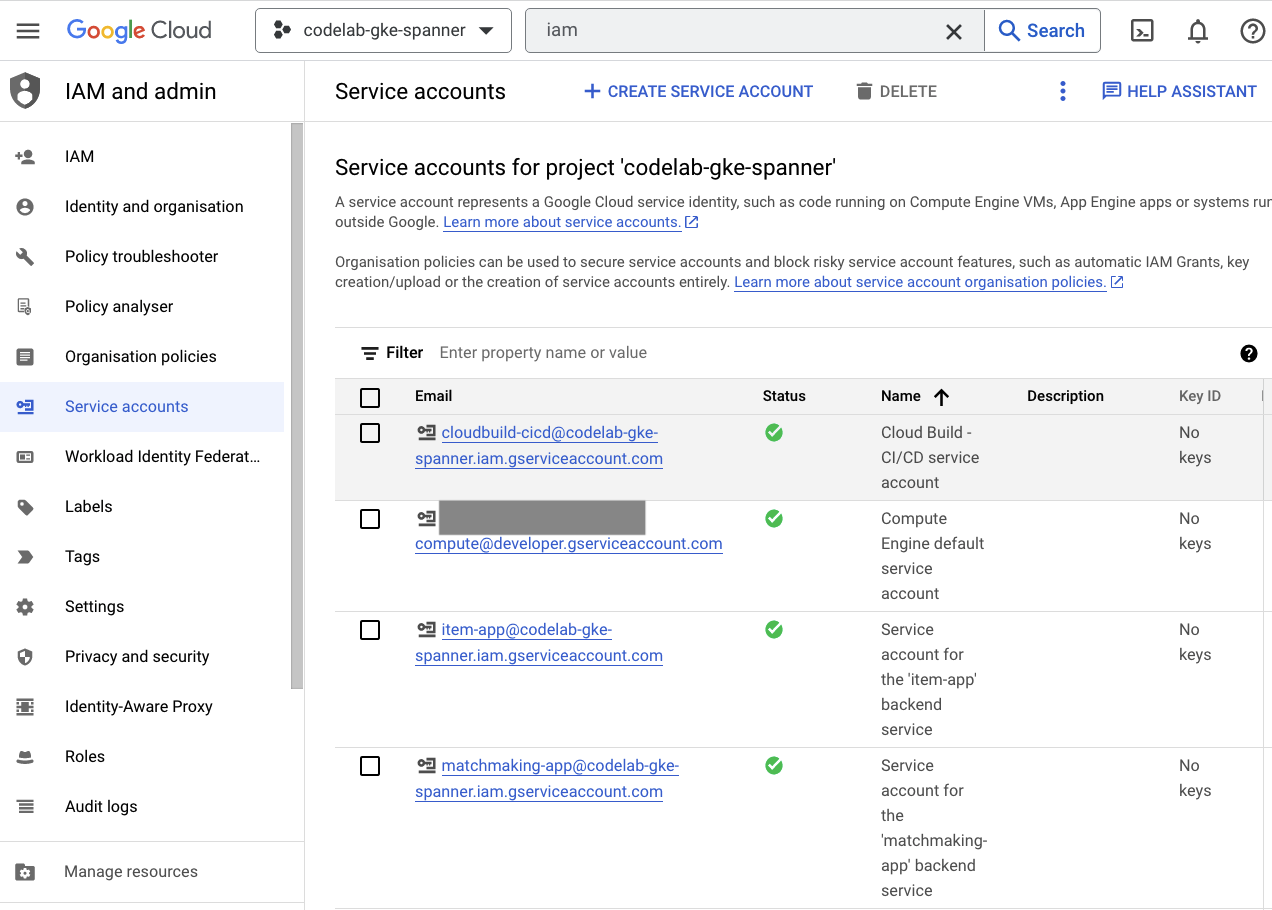
Terraform에서 생성하는 서비스 계정은 총 6개입니다.
- 기본 컴퓨터 서비스 계정입니다. 이 Codelab에서는 사용되지 않습니다.
- cloudbuild-cicd 계정은 Cloud Build 및 Cloud Deploy 단계에 사용됩니다.
- 백엔드 서비스가 Cloud Spanner와 상호작용하는 데 사용되는 'app' 계정 4개
다음으로 GKE 클러스터와 상호작용하도록 kubectl를 구성합니다.
kubectl 구성
# Name of GKE cluster from terraform.tfvars file
export GKE_CLUSTER=sample-game-gke
# get GKE credentials
gcloud container clusters get-credentials $GKE_CLUSTER --region us-central1
# Check that no errors occur
kubectl get serviceaccounts
명령어 결과
#export GKE_CLUSTER=sample-game-gke
# gcloud container clusters get-credentials $GKE_CLUSTER --region us-central1
Fetching cluster endpoint and auth data.
kubeconfig entry generated for sample-game-gke.
# kubectl get serviceaccounts
NAME SECRETS AGE
default 0 37m
item-app 0 35m
matchmaking-app 0 35m
profile-app 0 35m
tradepost-app 0 35m
요약
좋습니다. 비공개 네트워킹을 위해 VPC에서 Cloud Spanner 인스턴스, GKE Autopilot 클러스터를 모두 프로비저닝할 수 있었습니다.
또한 빌드된 이미지를 저장할 Artifact Registry 저장소와 함께 백엔드 서비스 및 워크로드를 위한 Cloud Deploy 파이프라인 2개가 생성되었습니다.
마지막으로 백엔드 서비스가 Cloud Spanner를 사용할 수 있도록 서비스 계정이 생성되고 워크로드 아이덴티티와 함께 작동하도록 구성되었습니다.
백엔드 서비스와 워크로드를 배포한 후 Cloud Shell에서 GKE 클러스터와 상호작용하도록 kubectl도 구성되어 있습니다.
다음 단계
서비스를 사용하려면 먼저 데이터베이스 스키마를 정의해야 합니다. 다음 단계에서 이 작업을 설정합니다.
4. 데이터베이스 스키마 만들기
개요
백엔드 서비스를 실행하기 전에 데이터베이스 스키마가 준비되어 있는지 확인해야 합니다.
데모 저장소의 $DEMO_HOME/schema/migrations 디렉터리에 있는 파일을 살펴보면 스키마를 정의하는 일련의 .sql 파일이 표시됩니다. 이는 스키마 변경사항이 저장소 자체에서 추적되고 애플리케이션의 특정 기능에 연결될 수 있는 개발 주기를 모방합니다.
이 샘플 환경에서 wrench는 Cloud Build를 사용하여 스키마 마이그레이션을 적용하는 도구입니다.
Cloud Build
$DEMO_HOME/schema/cloudbuild.yaml 파일은 취할 단계를 설명합니다.
serviceAccount: projects/${PROJECT_ID}/serviceAccounts/cloudbuild-cicd@${PROJECT_ID}.iam.gserviceaccount.com
steps:
- name: gcr.io/cloud-builders/curl
id: fetch-wrench
args: ['-Lo', '/workspace/wrench.tar.gz', 'https://github.com/cloudspannerecosystem/wrench/releases/download/v1.4.1/wrench-1.4.1-linux-amd64.tar.gz' ]
- name: gcr.io/cloud-builders/gcloud
id: migrate-spanner-schema
entrypoint: sh
args:
- '-xe'
- '-c'
- |
tar -xzvf wrench.tar.gz
chmod +x /workspace/wrench
# Assumes only a single spanner instance and database. Fine for this demo in a dedicated project
export SPANNER_PROJECT_ID=${PROJECT_ID}
export SPANNER_INSTANCE_ID=$(gcloud spanner instances list | tail -n1 | awk '{print $1}')
export SPANNER_DATABASE_ID=$(gcloud spanner databases list --instance=$$SPANNER_INSTANCE_ID | tail -n1 | awk '{print $1}')
if [ -d ./migrations ]; then
/workspace/wrench migrate up --directory .
else
echo "[Error] Missing migrations directory"
fi
timeout: 600s
기본적으로 두 단계가 있습니다.
- Cloud Build 작업공간에 렌치를 다운로드합니다.
- 렌치 마이그레이션 실행
wrench가 쓰기 엔드포인트에 연결하려면 Spanner 프로젝트, 인스턴스, 데이터베이스 환경 변수가 필요합니다.
Cloud Build는 cloudbuild-cicd@${PROJECT_ID}.iam.gserviceaccount.com 서비스 계정으로 실행되므로 이러한 변경사항을 적용할 수 있습니다.
serviceAccount: projects/${PROJECT_ID}/serviceAccounts/cloudbuild-cicd@${PROJECT_ID}.iam.gserviceaccount.com
또한 이 서비스 계정에는 Terraform에서 추가한 spanner.databaseUser 역할이 있어 서비스 계정이 DDL을 업데이트할 수 있습니다.
스키마 마이그레이션
$DEMO_HOME/schema/migrations 디렉터리의 파일을 기반으로 실행되는 5가지 마이그레이션 단계가 있습니다. 다음은 players 테이블과 색인을 만드는 000001.sql 파일의 예입니다.
CREATE TABLE players (
playerUUID STRING(36) NOT NULL,
player_name STRING(64) NOT NULL,
email STRING(MAX) NOT NULL,
password_hash BYTES(60) NOT NULL,
created TIMESTAMP,
updated TIMESTAMP,
stats JSON,
account_balance NUMERIC NOT NULL DEFAULT (0.00),
is_logged_in BOOL,
last_login TIMESTAMP,
valid_email BOOL,
current_game STRING(36)
) PRIMARY KEY (playerUUID);
CREATE UNIQUE INDEX PlayerAuthentication ON players(email) STORING(password_hash);
CREATE UNIQUE INDEX PlayerName ON players(player_name);
CREATE INDEX PlayerGame ON players(current_game);
스키마 마이그레이션 제출
스키마 마이그레이션을 실행하기 위해 빌드를 제출하려면 schema 디렉터리로 전환하고 다음 gcloud 명령어를 실행합니다.
cd $DEMO_HOME/schema gcloud builds submit --config=cloudbuild.yaml
명령어 결과
Creating temporary tarball archive of 8 file(s) totalling 11.2 KiB before compression.
Uploading tarball of [.] to [gs://(project)_cloudbuild/source/(snip).tgz]
Created [https://cloudbuild.googleapis.com/v1/projects/(project)/locations/global/builds/7defe982-(snip)].
Logs are available at [ https://console.cloud.google.com/cloud-build/builds/7defe982-(snip)?project=(snip) ].
gcloud builds submit only displays logs from Cloud Storage. To view logs from Cloud Logging, run:
gcloud beta builds submit
ID: 7defe982-(snip)
CREATE_TIME: (created time)
DURATION: 3M11S
SOURCE: gs://(project)_cloudbuild/source/(snip).tgz
IMAGES: -
STATUS: SUCCESS
위 출력에서 Created 클라우드 빌드 프로세스 링크를 확인할 수 있습니다. 이 링크를 클릭하면 Cloud Console의 빌드로 이동하여 빌드의 진행 상황을 모니터링하고 빌드가 수행하는 작업을 확인할 수 있습니다.
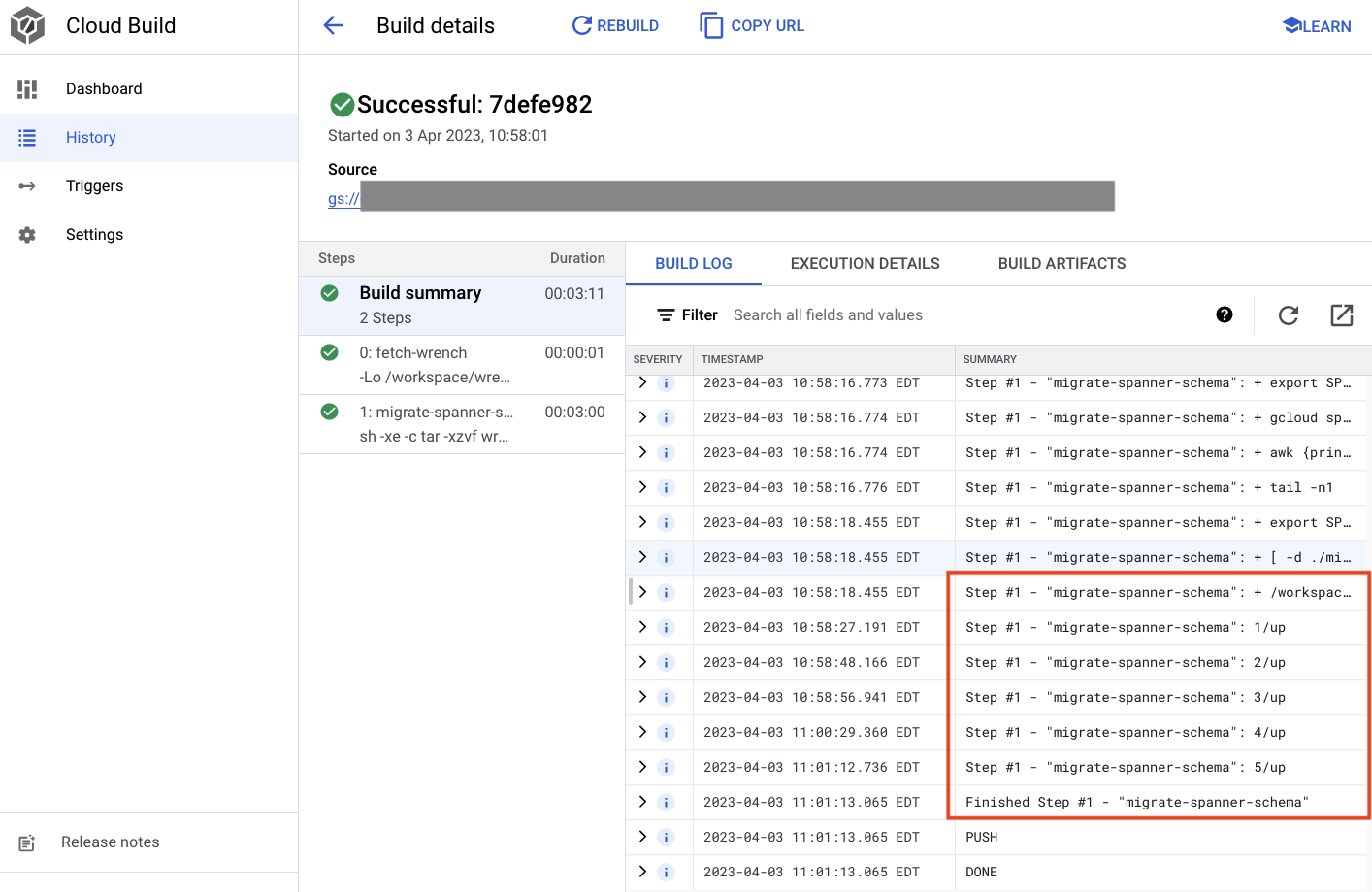
요약
이 단계에서는 Cloud Build를 사용하여 5가지 DDL 작업을 적용하는 초기 스키마 마이그레이션을 제출했습니다. 이러한 작업은 데이터베이스 스키마 변경이 필요한 기능이 추가된 시점을 나타냅니다.
일반적인 개발 시나리오에서는 중단을 방지하기 위해 현재 애플리케이션과 하위 호환되는 스키마 변경사항을 적용하는 것이 좋습니다.
하위 호환되지 않는 변경사항의 경우 서비스 중단을 방지하기 위해 애플리케이션과 스키마에 변경사항을 단계별로 배포하는 것이 좋습니다.
다음 단계
스키마가 준비되었으므로 다음 단계는 백엔드 서비스를 배포하는 것입니다.
5. 백엔드 서비스 배포
개요
이 Codelab의 백엔드 서비스는 네 가지 서비스를 나타내는 golang REST API입니다.
- 프로필: 플레이어가 샘플 '게임'에 가입하고 인증할 수 있도록 지원합니다.
- 매치메이킹: 플레이어 데이터와 상호작용하여 매치메이킹 기능을 지원하고, 생성된 게임에 관한 정보를 추적하고, 게임이 종료되면 플레이어 통계를 업데이트합니다.
- 아이템: 플레이어가 게임을 플레이하는 동안 게임 아이템과 돈을 획득할 수 있습니다.
- 거래소: 플레이어가 거래소에서 아이템을 사고팔 수 있도록 지원
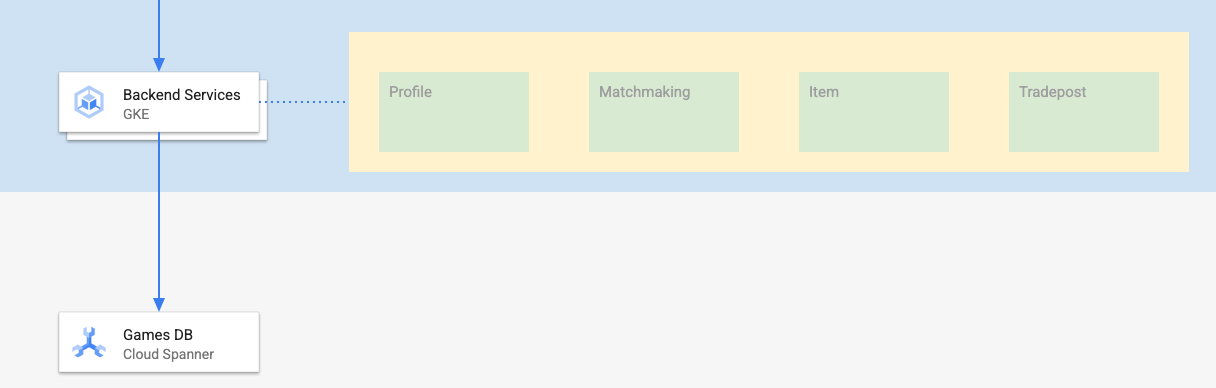
Cloud Spanner 게임 개발 시작하기 Codelab에서 이러한 서비스에 대해 자세히 알아볼 수 있습니다. 이 예에서는 이러한 서비스가 GKE Autopilot 클러스터에서 실행되기를 원합니다.
이러한 서비스는 Spanner 데이터를 수정할 수 있어야 합니다. 이를 위해 각 서비스에는 'databaseUser' 역할을 부여하는 서비스 계정이 생성됩니다.
워크로드 아이덴티티를 사용하면 Kubernetes 서비스 계정이 Terraform에서 다음 단계에 따라 서비스의 Google Cloud 서비스 계정을 가장할 수 있습니다.
- 서비스의 Google Cloud 서비스 계정 (
GSA) 리소스 만들기 - 해당 서비스 계정에 databaseUser 역할을 할당합니다.
- 해당 서비스 계정에 workloadIdentityUser 역할을 할당합니다.
- GSA를 참조하는 Kubernetes 서비스 계정 (
KSA)을 만듭니다.
대략적인 다이어그램은 다음과 같습니다.
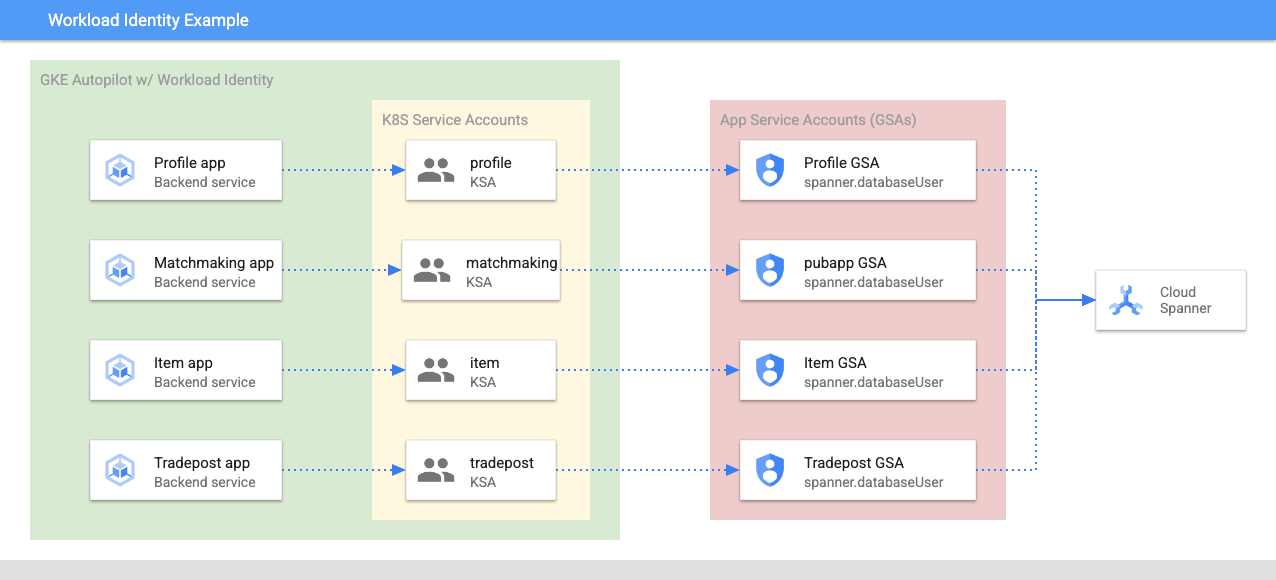
Terraform에서 서비스 계정과 Kubernetes 서비스 계정을 만들었습니다. kubectl를 사용하여 Kubernetes 서비스 계정을 확인할 수 있습니다.
# kubectl get serviceaccounts
NAME SECRETS AGE
default 0 37m
item-app 0 35m
matchmaking-app 0 35m
profile-app 0 35m
tradepost-app 0 35m
빌드가 작동하는 방식은 다음과 같습니다.
- Terraform에서 다음과 같은
$DEMO_HOME/backend_services/cloudbuild.yaml파일을 생성했습니다.
serviceAccount: projects/${PROJECT_ID}/serviceAccounts/cloudbuild-cicd@${PROJECT_ID}.iam.gserviceaccount.com
steps:
#
# Building of images
#
- name: gcr.io/cloud-builders/docker
id: profile
args: ["build", ".", "-t", "${_PROFILE_IMAGE}"]
dir: profile
waitFor: ['-']
- name: gcr.io/cloud-builders/docker
id: matchmaking
args: ["build", ".", "-t", "${_MATCHMAKING_IMAGE}"]
dir: matchmaking
waitFor: ['-']
- name: gcr.io/cloud-builders/docker
id: item
args: ["build", ".", "-t", "${_ITEM_IMAGE}"]
dir: item
waitFor: ['-']
- name: gcr.io/cloud-builders/docker
id: tradepost
args: ["build", ".", "-t", "${_TRADEPOST_IMAGE}"]
dir: tradepost
waitFor: ['-']
#
# Deployment
#
- name: gcr.io/google.com/cloudsdktool/cloud-sdk
id: cloud-deploy-release
entrypoint: gcloud
args:
[
"deploy", "releases", "create", "${_REL_NAME}",
"--delivery-pipeline", "sample-game-services",
"--skaffold-file", "skaffold.yaml",
"--skaffold-version", "1.39",
"--images", "profile=${_PROFILE_IMAGE},matchmaking=${_MATCHMAKING_IMAGE},item=${_ITEM_IMAGE},tradepost=${_TRADEPOST_IMAGE}",
"--region", "us-central1"
]
artifacts:
images:
- ${_REGISTRY}/profile
- ${_REGISTRY}/matchmaking
- ${_REGISTRY}/item
- ${_REGISTRY}/tradepost
substitutions:
_PROFILE_IMAGE: ${_REGISTRY}/profile:${BUILD_ID}
_MATCHMAKING_IMAGE: ${_REGISTRY}/matchmaking:${BUILD_ID}
_ITEM_IMAGE: ${_REGISTRY}/item:${BUILD_ID}
_TRADEPOST_IMAGE: ${_REGISTRY}/tradepost:${BUILD_ID}
_REGISTRY: us-docker.pkg.dev/${PROJECT_ID}/spanner-game-images
_REL_NAME: rel-${BUILD_ID:0:8}
options:
dynamic_substitutions: true
machineType: E2_HIGHCPU_8
logging: CLOUD_LOGGING_ONLY
- Cloud Build 명령어는 이 파일을 읽고 나열된 단계를 따릅니다. 먼저 서비스 이미지를 빌드합니다. 그런 다음
gcloud deploy create명령어를 실행합니다. 그러면 각 배포 파일의 위치를 정의하는$DEMO_HOME/backend_services/skaffold.yaml파일이 읽힙니다.
apiVersion: skaffold/v2beta29
kind: Config
deploy:
kubectl:
manifests:
- spanner_config.yaml
- profile/deployment.yaml
- matchmaking/deployment.yaml
- item/deployment.yaml
- tradepost/deployment.yaml
- Cloud Deploy는 각 서비스의
deployment.yaml파일 정의를 따릅니다. 서비스의 배포 파일에는 서비스를 만드는 정보가 포함되어 있습니다. 이 경우 포트 80에서 실행되는 clusterIP입니다.
"ClusterIP" 유형은 백엔드 서비스 포드가 외부 IP를 갖지 못하도록 하므로 내부 GKE 네트워크에 연결할 수 있는 엔티티만 백엔드 서비스에 액세스할 수 있습니다. 이러한 서비스는 Spanner 데이터에 액세스하고 이를 수정하므로 플레이어가 직접 액세스해서는 안 됩니다.
apiVersion: v1
kind: Service
metadata:
name: profile
spec:
type: ClusterIP
selector:
app: profile
ports:
- port: 80
targetPort: 80
Kubernetes 서비스를 만드는 것 외에도 Cloud Deploy는 Kubernetes 배포도 만듭니다. profile 서비스의 배포 섹션을 살펴보겠습니다.
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: profile
spec:
replicas: 2 # EDIT: Number of instances of deployment
selector:
matchLabels:
app: profile
template:
metadata:
labels:
app: profile
spec:
serviceAccountName: profile-app
containers:
- name: profile-service
image: profile
ports:
- containerPort: 80
envFrom:
- configMapRef:
name: spanner-config
env:
- name: SERVICE_HOST
value: "0.0.0.0"
- name: SERVICE_PORT
value: "80"
resources:
requests:
cpu: "1"
memory: "1Gi"
ephemeral-storage: "100Mi"
limits:
cpu: "1"
memory: "1Gi"
ephemeral-storage: "100Mi"
상단에는 서비스에 관한 메타데이터가 표시됩니다. 여기서 가장 중요한 부분은 이 배포에서 생성할 복제본 수를 정의하는 것입니다.
replicas: 2 # EDIT: Number of instances of deployment
다음으로 앱을 실행해야 하는 서비스 계정과 사용해야 하는 이미지가 표시됩니다. 이는 Terraform에서 생성된 Kubernetes 서비스 계정 및 Cloud Build 단계에서 생성된 이미지와 일치합니다.
spec:
serviceAccountName: profile-app
containers:
- name: profile-service
image: profile
그런 다음 네트워킹 및 환경 변수에 관한 정보를 지정합니다.
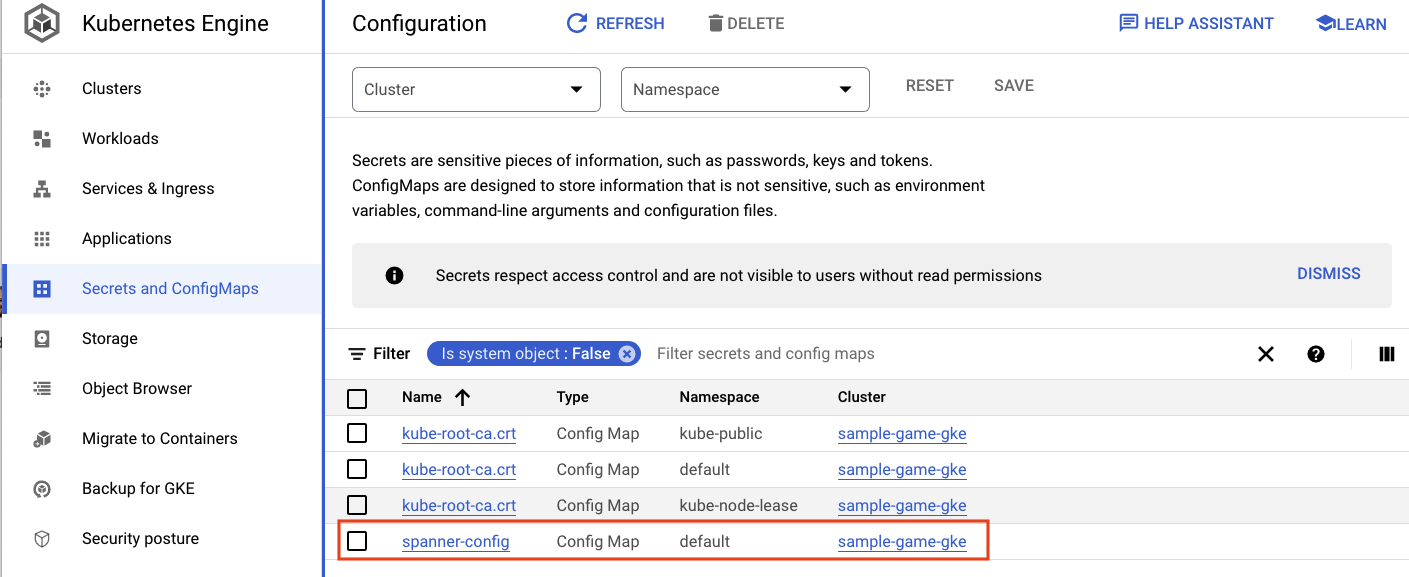
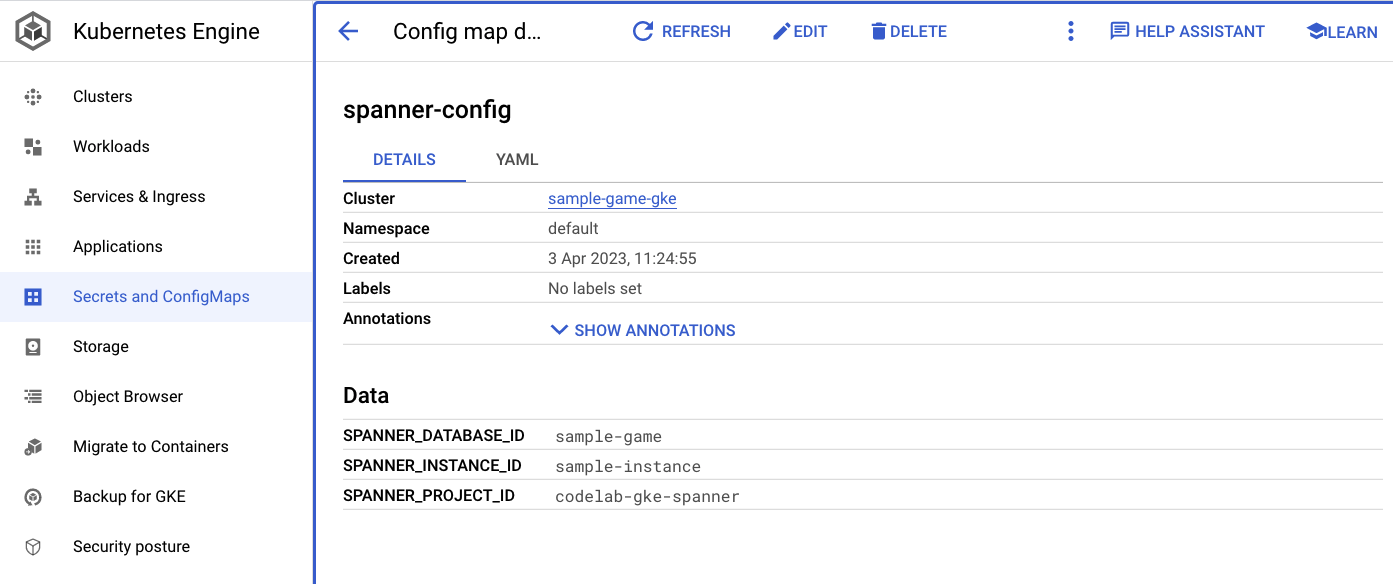
spanner_config는 애플리케이션이 Spanner에 연결하는 데 필요한 프로젝트, 인스턴스, 데이터베이스 정보를 지정하는 Kubernetes ConfigMap입니다.
apiVersion: v1
kind: ConfigMap
metadata:
name: spanner-config
data:
SPANNER_PROJECT_ID: ${project_id}
SPANNER_INSTANCE_ID: ${instance_id}
SPANNER_DATABASE_ID: ${database_id}
ports:
- containerPort: 80
envFrom:
- configMapRef:
name: spanner-config
env:
- name: SERVICE_HOST
value: "0.0.0.0"
- name: SERVICE_PORT
value: "80"
SERVICE_HOST 및 SERVICE_PORT은 서비스가 바인딩할 위치를 알기 위해 필요한 추가 환경 변수입니다.
마지막 섹션에서는 이 배포의 각 복제본에 허용할 리소스 수를 GKE에 알려줍니다. 필요에 따라 클러스터를 확장하는 데 GKE Autopilot도 이 기능을 사용합니다.
resources:
requests:
cpu: "1"
memory: "1Gi"
ephemeral-storage: "100Mi"
limits:
cpu: "1"
memory: "1Gi"
ephemeral-storage: "100Mi"
이 정보를 바탕으로 백엔드 서비스를 배포할 수 있습니다.
백엔드 서비스 배포
언급한 것처럼 백엔드 서비스 배포에는 Cloud Build가 사용됩니다. 스키마 이전과 마찬가지로 gcloud 명령줄을 사용하여 빌드 요청을 제출할 수 있습니다.
cd $DEMO_HOME/backend_services gcloud builds submit --config=cloudbuild.yaml
명령어 결과
Creating temporary tarball archive of 66 file(s) totalling 864.6 KiB before compression.
Uploading tarball of [.] to [gs://(project)_cloudbuild/source/(snip).tgz]
Created [https://cloudbuild.googleapis.com/v1/projects/(project)/locations/global/builds/30207dd1-(snip)].
Logs are available at [ https://console.cloud.google.com/cloud-build/builds/30207dd1-(snip)?project=(snip) ].
gcloud builds submit only displays logs from Cloud Storage. To view logs from Cloud Logging, run:
gcloud beta builds submit
ID: 30207dd1-(snip)
CREATE_TIME: (created time)
DURATION: 3M17S
SOURCE: gs://(project)_cloudbuild/source/(snip).tgz
IMAGES: us-docker.pkg.dev/(project)/spanner-game-images/profile:30207dd1-(snip) (+3 more)
STATUS: SUCCESS
schema migration 단계의 출력과 달리 이 빌드의 출력은 생성된 이미지가 있음을 나타냅니다. 이러한 항목은 Artifact Registry 저장소에 저장됩니다.
gcloud build 단계의 출력에는 Cloud Console 링크가 있습니다. 확인해 보세요.
Cloud Build에서 성공 알림을 받으면 Cloud Deploy로 이동한 다음 sample-game-services 파이프라인으로 이동하여 배포 진행 상황을 모니터링합니다.
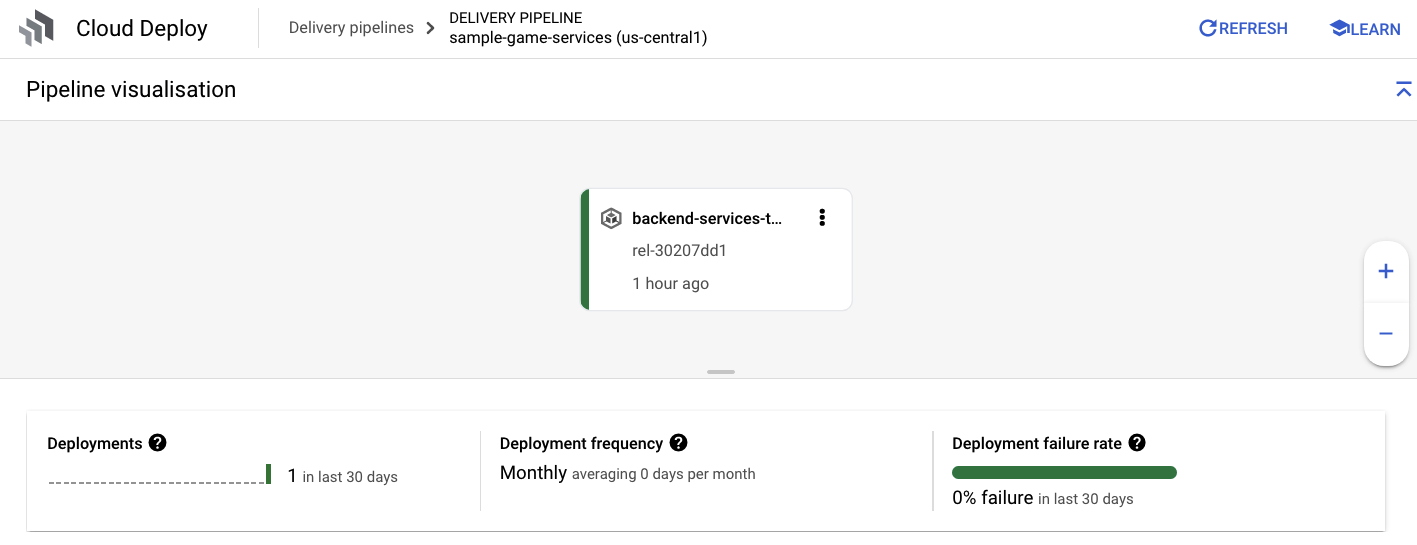
서비스가 배포되면 kubectl를 확인하여 포드의 상태를 확인할 수 있습니다.
kubectl get pods
명령어 결과
NAME READY STATUS RESTARTS AGE
item-6b9d5f678c-4tbk2 1/1 Running 0 83m
matchmaking-5bcf799b76-lg8zf 1/1 Running 0 80m
profile-565bbf4c65-kphdl 1/1 Running 0 83m
profile-565bbf4c65-xw74j 1/1 Running 0 83m
tradepost-68b87ccd44-gw55r 1/1 Running 0 79m
그런 다음 서비스를 확인하여 ClusterIP가 작동하는지 확인합니다.
kubectl get services
명령어 결과
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
item ClusterIP 10.172.XXX.XXX <none> 80/TCP 84m
kubernetes ClusterIP 10.172.XXX.XXX <none> 443/TCP 137m
matchmaking ClusterIP 10.172.XXX.XXX <none> 80/TCP 84m
profile ClusterIP 10.172.XXX.XXX <none> 80/TCP 84m
tradepost ClusterIP 10.172.XXX.XXX <none> 80/TCP 84m
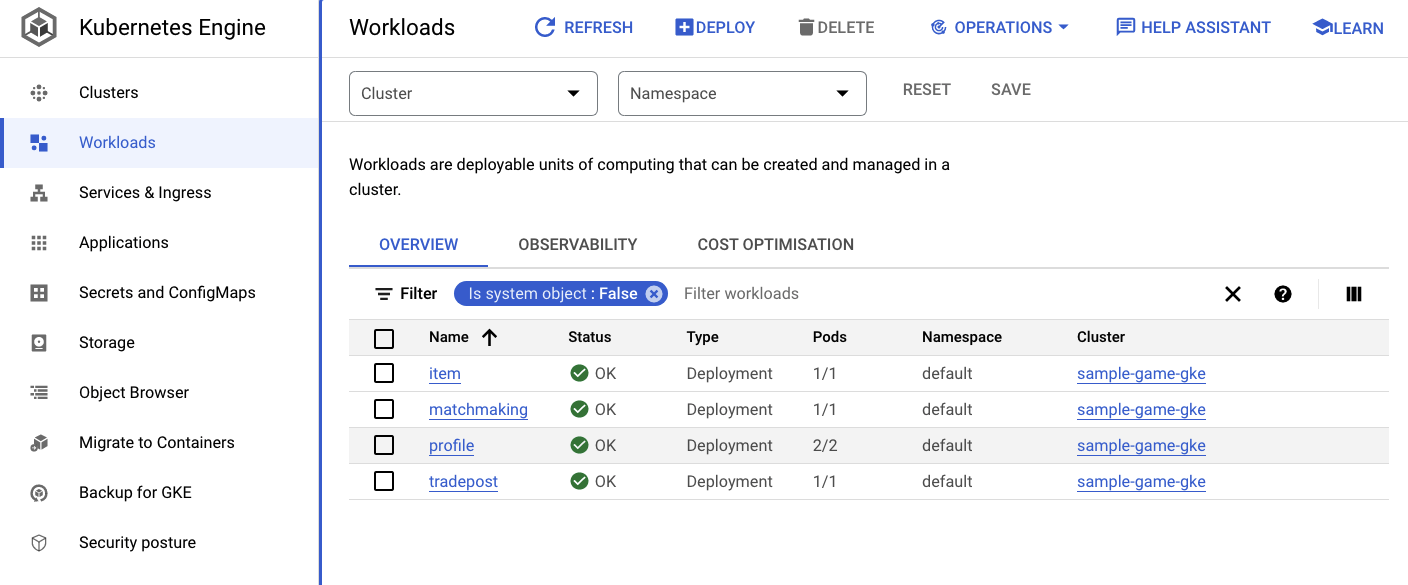
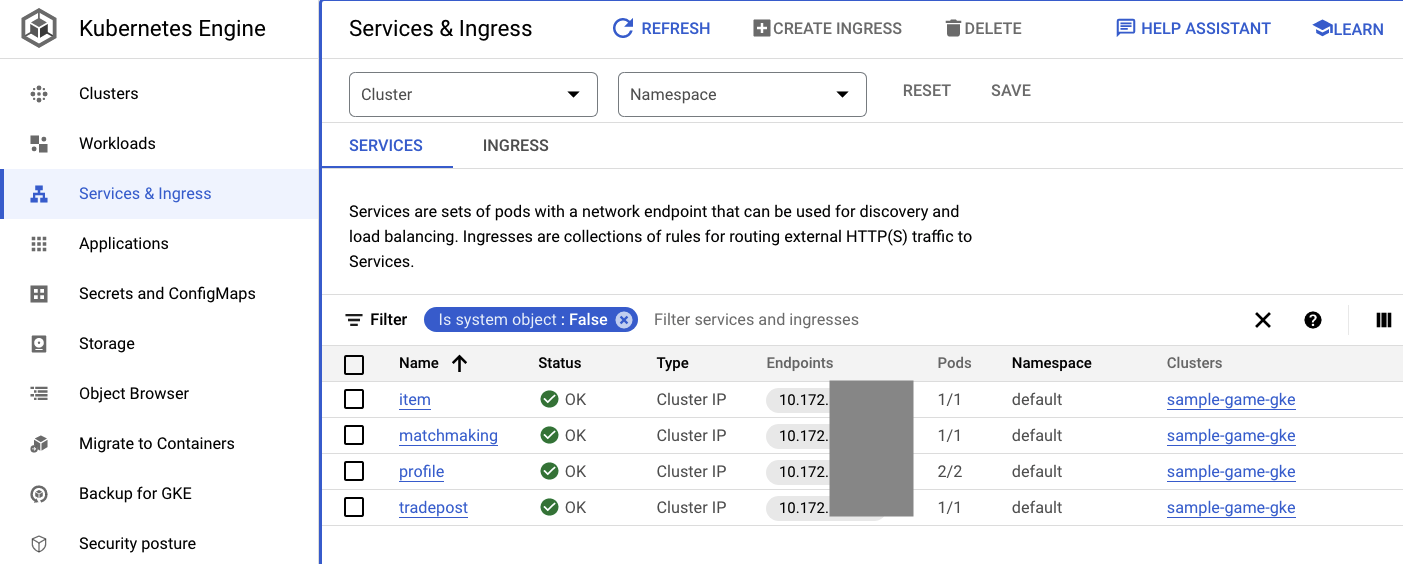
Cloud Console의 GKE UI로 이동하여 Workloads, Services, ConfigMaps를 확인할 수도 있습니다.
워크로드
서비스
ConfigMaps
요약
이 단계에서는 4개의 백엔드 서비스를 GKE Autopilot에 배포했습니다. Cloud Build 단계를 실행하고 Cloud Console의 Cloud Deploy 및 Kubernetes에서 진행 상황을 확인할 수 있었습니다.
또한 이러한 서비스가 워크로드 아이덴티티를 활용하여 Spanner 데이터베이스에 데이터를 읽고 쓸 수 있는 올바른 권한이 있는 서비스 계정을 가장하는 방법도 알아봤습니다.
다음 단계
다음 섹션에서는 워크로드를 배포합니다.
6. 워크로드 배포
개요
이제 백엔드 서비스가 클러스터에서 실행되므로 워크로드를 배포합니다.

워크로드에 외부에서 액세스할 수 있으며 이 Codelab의 목적에 따라 각 백엔드 서비스에 하나씩 있습니다.
이러한 워크로드는 이러한 샘플 서비스에서 예상되는 실제 액세스 패턴을 모방하는 Locust 기반 부하 생성 스크립트입니다.
Cloud Build 프로세스용 파일이 있습니다.
$DEMO_HOME/workloads/cloudbuild.yaml(Terraform에서 생성됨)$DEMO_HOME/workloads/skaffold.yaml- 워크로드별
deployment.yaml파일
워크로드 deployment.yaml 파일은 백엔드 서비스 배포 파일과 약간 다릅니다.
matchmaking-workload의 예는 다음과 같습니다.
apiVersion: v1
kind: Service
metadata:
name: matchmaking-workload
spec:
type: LoadBalancer
selector:
app: matchmaking-workload
ports:
- port: 8089
targetPort: 8089
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: matchmaking-workload
spec:
replicas: 1 # EDIT: Number of instances of deployment
selector:
matchLabels:
app: matchmaking-workload
template:
metadata:
labels:
app: matchmaking-workload
spec:
serviceAccountName: default
containers:
- name: matchmaking-workload
image: matchmaking-workload
ports:
- containerPort: 8089
resources:
requests:
cpu: "500m"
memory: "512Mi"
ephemeral-storage: "100Mi"
limits:
cpu: "500m"
memory: "512Mi"
ephemeral-storage: "100Mi"
파일의 상단 부분은 서비스를 정의합니다. 이 경우 LoadBalancer가 생성되고 워크로드가 포트 8089에서 실행됩니다.
LoadBalancer는 워크로드에 연결하는 데 사용할 수 있는 외부 IP를 제공합니다.
apiVersion: v1
kind: Service
metadata:
name: matchmaking-workload
spec:
type: LoadBalancer
selector:
app: matchmaking-workload
ports:
- port: 8089
targetPort: 8089
배포 섹션의 상단은 워크로드에 관한 메타데이터입니다. 이 경우 하나의 복제본만 배포됩니다.
replicas: 1
하지만 컨테이너 사양은 다릅니다. 우선 default Kubernetes 서비스 계정을 사용하고 있습니다. 이 계정에는 특별한 권한이 없습니다. 워크로드가 GKE 클러스터에서 실행되는 백엔드 서비스를 제외한 Google Cloud 리소스에 연결할 필요가 없기 때문입니다.
또 다른 차이점은 이러한 워크로드에 필요한 환경 변수가 없다는 것입니다. 그 결과 배포 사양이 짧아집니다.
spec:
serviceAccountName: default
containers:
- name: matchmaking-workload
image: matchmaking-workload
ports:
- containerPort: 8089
리소스 설정은 백엔드 서비스와 유사합니다. 이는 GKE Autopilot이 클러스터에서 실행되는 모든 포드의 요청을 충족하는 데 필요한 리소스 수를 파악하는 방법입니다.
워크로드를 배포하세요.
워크로드 배포
이전과 마찬가지로 gcloud 명령줄을 사용하여 빌드 요청을 제출할 수 있습니다.
cd $DEMO_HOME/workloads gcloud builds submit --config=cloudbuild.yaml
명령어 결과
Creating temporary tarball archive of 18 file(s) totalling 26.2 KiB before compression.
Some files were not included in the source upload.
Check the gcloud log [/tmp/tmp.4Z9EqdPo6d/logs/(snip).log] to see which files and the contents of the
default gcloudignore file used (see `$ gcloud topic gcloudignore` to learn
more).
Uploading tarball of [.] to [gs://(project)_cloudbuild/source/(snip).tgz]
Created [https://cloudbuild.googleapis.com/v1/projects/(project)/locations/global/builds/(snip)].
Logs are available at [ https://console.cloud.google.com/cloud-build/builds/0daf20f6-(snip)?project=(snip) ].
gcloud builds submit only displays logs from Cloud Storage. To view logs from Cloud Logging, run:
gcloud beta builds submit
ID: 0daf20f6-(snip)
CREATE_TIME: (created_time)
DURATION: 1M41S
SOURCE: gs://(project)_cloudbuild/source/(snip).tgz
IMAGES: us-docker.pkg.dev/(project)/spanner-game-images/profile-workload:0daf20f6-(snip) (+4 more)
STATUS: SUCCESS
Cloud Console에서 Cloud Build 로그와 Cloud Deploy 파이프라인을 확인하여 상태를 확인하세요. 워크로드의 경우 Cloud Deploy 파이프라인은 sample-game-workloads입니다.
배포가 완료되면 Cloud Shell에서 kubectl로 상태를 확인합니다.
kubectl get pods
명령어 결과
NAME READY STATUS RESTARTS AGE
game-workload-7ff44cb657-pxxq2 1/1 Running 0 12m
item-6b9d5f678c-cr29w 1/1 Running 0 9m6s
item-generator-7bb4f57cf8-5r85b 1/1 Running 0 12m
matchmaking-5bcf799b76-lg8zf 1/1 Running 0 117m
matchmaking-workload-76df69dbdf-jds9z 1/1 Running 0 12m
profile-565bbf4c65-kphdl 1/1 Running 0 121m
profile-565bbf4c65-xw74j 1/1 Running 0 121m
profile-workload-76d6db675b-kzwng 1/1 Running 0 12m
tradepost-68b87ccd44-gw55r 1/1 Running 0 116m
tradepost-workload-56c55445b5-b5822 1/1 Running 0 12m
그런 다음 워크로드 서비스를 확인하여 LoadBalancer가 작동하는지 확인합니다.
kubectl get services
명령어 결과
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
game-workload LoadBalancer *snip* 35.XX.XX.XX 8089:32483/TCP 12m
item ClusterIP *snip* <none> 80/TCP 121m
item-generator LoadBalancer *snip* 34.XX.XX.XX 8089:32581/TCP 12m
kubernetes ClusterIP *snip* <none> 443/TCP 174m
matchmaking ClusterIP *snip* <none> 80/TCP 121m
matchmaking-workload LoadBalancer *snip* 34.XX.XX.XX 8089:31735/TCP 12m
profile ClusterIP *snip* <none> 80/TCP 121m
profile-workload LoadBalancer *snip* 34.XX.XX.XX 8089:32532/TCP 12m
tradepost ClusterIP *snip* <none> 80/TCP 121m
tradepost-workload LoadBalancer *snip* 34.XX.XX.XX 8089:30002/TCP 12m
요약
이제 GKE 클러스터에 워크로드를 배포했습니다. 이러한 워크로드에는 추가 IAM 권한이 필요하지 않으며 LoadBalancer 서비스를 사용하여 포트 8089에서 외부에서 액세스할 수 있습니다.
다음 단계
백엔드 서비스와 워크로드가 실행되면 게임을 '플레이'할 수 있습니다.
7. 게임 플레이 시작
개요
이제 샘플 '게임'의 백엔드 서비스가 실행되고 있으며 워크로드를 사용하여 이러한 서비스와 상호작용하는 '플레이어'를 생성할 수 있습니다.
각 워크로드는 Locust를 사용하여 서비스 API에 대한 실제 부하를 시뮬레이션합니다. 이 단계에서는 여러 워크로드를 실행하여 GKE 클러스터와 Spanner에 부하를 생성하고 Spanner에 데이터를 저장합니다.
각 워크로드에 대한 설명은 다음과 같습니다.
item-generator워크로드는 플레이어가 게임을 '플레이'하는 동안 획득할 수 있는 game_items 목록을 생성하는 빠른 워크로드입니다.profile-workload는 플레이어의 가입 및 로그인을 시뮬레이션합니다.matchmaking-workload은 게임에 할당되기 위해 대기열에 있는 플레이어를 시뮬레이션합니다.game-workload는 플레이어가 게임을 플레이하는 동안 game_items와 money를 획득하는 것을 시뮬레이션합니다.tradepost-workload은 플레이어가 거래소에서 아이템을 판매하고 구매할 수 있는 상황을 시뮬레이션합니다.
이 Codelab에서는 item-generator 및 profile-workload 실행을 구체적으로 강조합니다.
item-generator 실행
item-generator는 item 백엔드 서비스 엔드포인트를 사용하여 Spanner에 game_items를 추가합니다. game-workload 및 tradepost-workload이 올바르게 작동하려면 이러한 항목이 필요합니다.
첫 번째 단계는 item-generator 서비스의 외부 IP를 가져오는 것입니다. Cloud Shell에서 다음을 실행합니다.
# The external IP is the 4th column of the output
kubectl get services | grep item-generator | awk '{print $4}'
명령어 결과
{ITEMGENERATOR_EXTERNAL_IP}
이제 새 브라우저 탭을 열고 http://{ITEMGENERATOR_EXTERNAL_IP}:8089로 이동합니다. 다음과 같은 페이지가 표시됩니다.
users 및 spawn은 기본값 1로 유지합니다. host에 http://item를 입력합니다. 고급 옵션을 클릭하고 실행 시간에 10s을 입력합니다.
구성은 다음과 같이 표시됩니다.
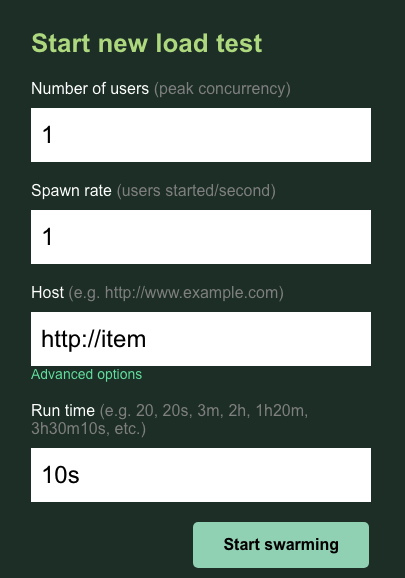
'생성 시작'을 클릭합니다.
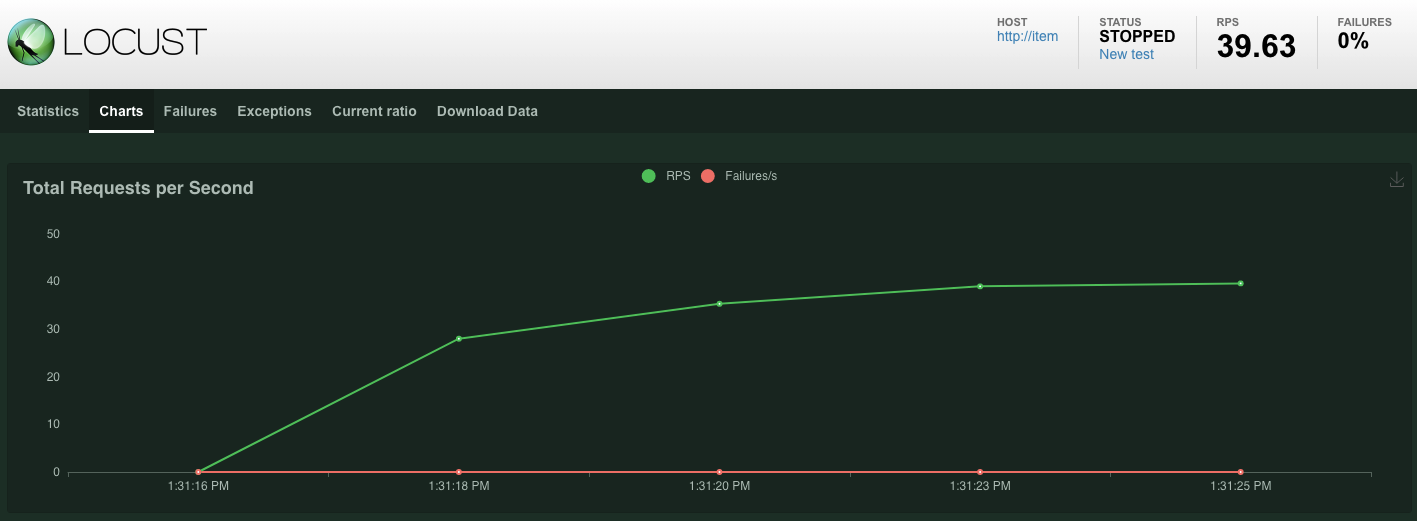
POST /items 엔드포인트에서 실행되는 요청에 대한 통계가 표시되기 시작합니다. 10초 후에 로드가 중지됩니다.
Charts를 클릭하면 이러한 요청의 실적에 관한 그래프가 표시됩니다.
이제 데이터가 Spanner 데이터베이스에 입력되었는지 확인합니다.
이렇게 하려면 햄버거 메뉴를 클릭하고 'Spanner'로 이동합니다. 이 페이지에서 sample-instance 및 sample-database로 이동합니다. 그런 다음 'Query'을 클릭합니다.
game_items:의 개수를 선택하려고 합니다.
SELECT COUNT(*) FROM game_items;
하단에 결과가 표시됩니다.
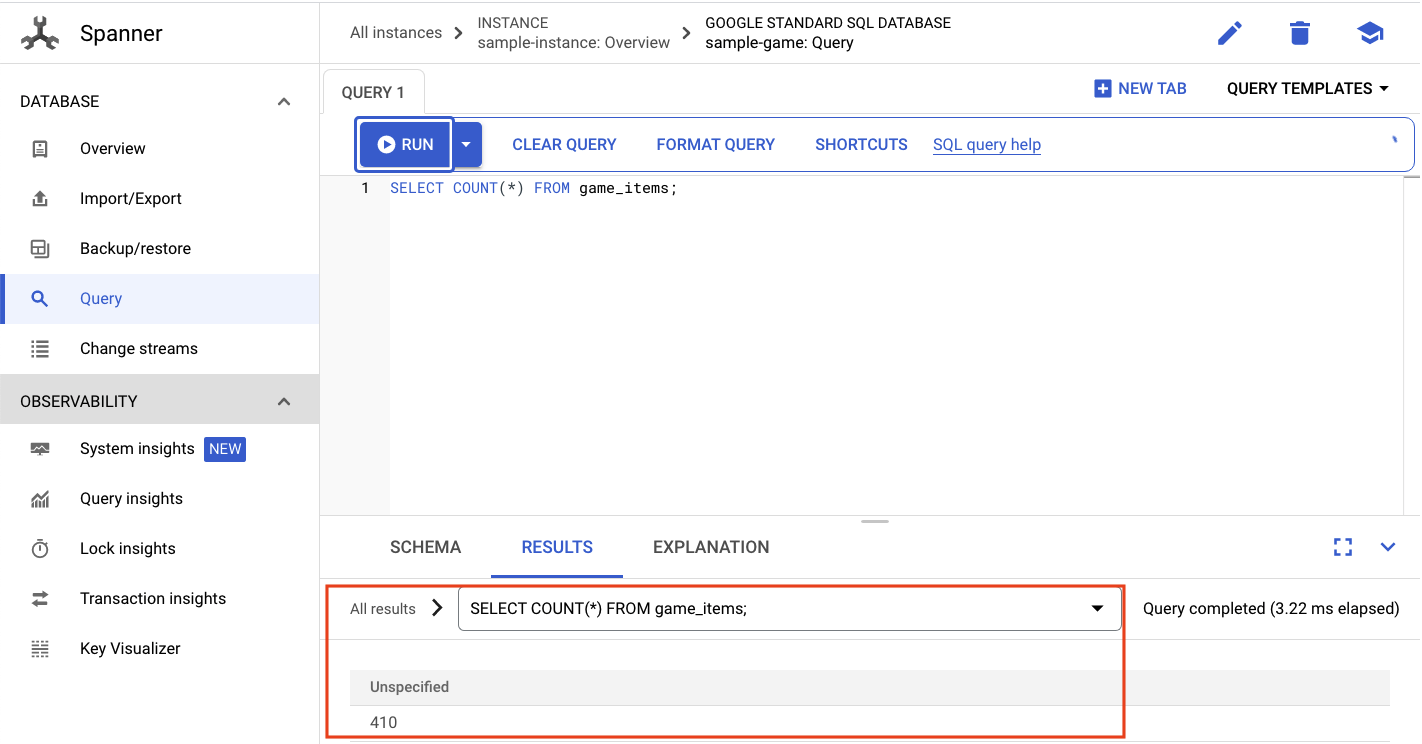
시드된 game_items가 많이 필요하지 않습니다. 이제 플레이어가 획득할 수 있습니다.
프로필 워크로드 실행
game_items가 시드되었으므로 다음 단계는 플레이어가 게임을 플레이할 수 있도록 가입하는 것입니다.
profile-workload에서는 Locust를 사용하여 계정을 만들고, 로그인하고, 프로필 정보를 가져오고, 로그아웃하는 플레이어를 시뮬레이션합니다. 이러한 테스트는 모두 일반적인 프로덕션과 유사한 워크로드에서 profile 백엔드 서비스의 엔드포인트를 테스트합니다.
이를 실행하려면 profile-workload 외부 IP를 가져옵니다.
# The external IP is the 4th column of the output
kubectl get services | grep profile-workload | awk '{print $4}'
명령어 결과
{PROFILEWORKLOAD_EXTERNAL_IP}
이제 새 브라우저 탭을 열고 http://{PROFILEWORKLOAD_EXTERNAL_IP}:8089로 이동합니다. 이전과 비슷한 Locust 페이지가 표시됩니다.
이 경우 호스트에 http://profile를 사용합니다. 고급 옵션에서 런타임을 지정하지 않습니다. 또한 users를 4로 지정하여 한 번에 4개의 사용자 요청을 시뮬레이션합니다.
profile-workload 테스트는 다음과 같이 표시됩니다.
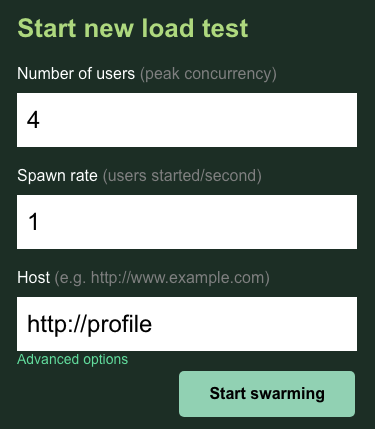
'생성 시작'을 클릭합니다.
이전과 마찬가지로 다양한 profile REST 엔드포인트의 통계가 표시되기 시작합니다. 차트를 클릭하여 모든 항목의 실적을 확인하세요.
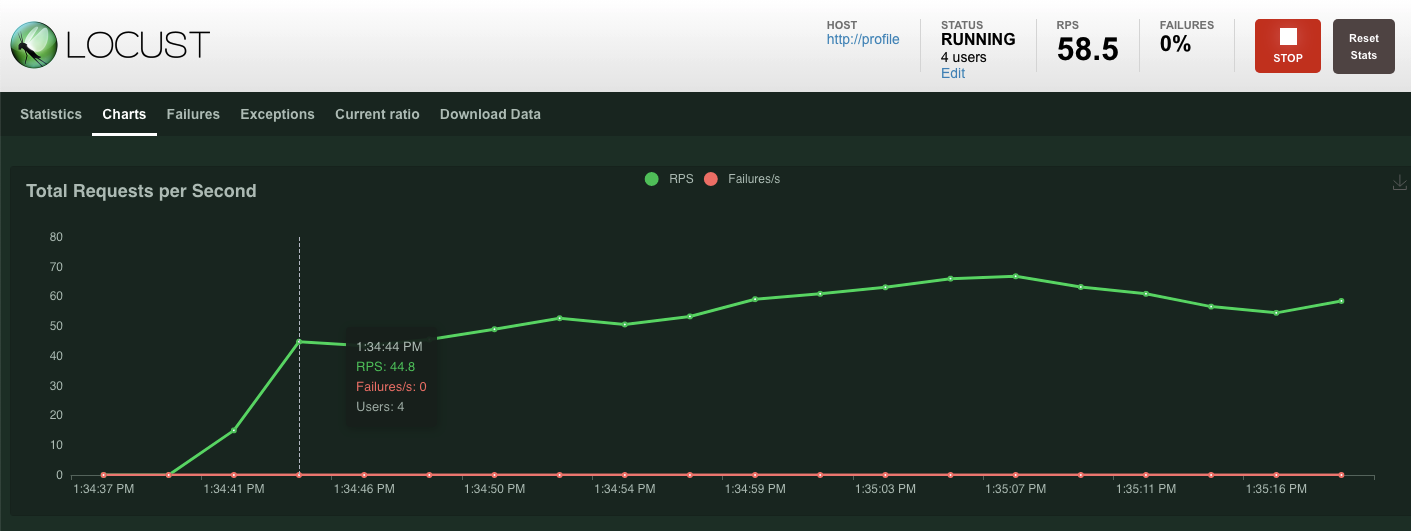
요약
이 단계에서는 일부 game_items를 생성한 다음 Cloud 콘솔의 Spanner 쿼리 UI를 사용하여 game_items 테이블을 쿼리했습니다.
또한 플레이어가 게임에 가입하도록 허용하고 Locust가 백엔드 서비스에 대해 프로덕션과 유사한 워크로드를 생성할 수 있는 방법을 확인했습니다.
다음 단계
워크로드를 실행한 후 GKE 클러스터와 Spanner 인스턴스가 어떻게 작동하는지 확인해야 합니다.
8. GKE 및 Spanner 사용량 검토
프로필 서비스가 실행되면 GKE Autopilot 클러스터와 Cloud Spanner가 어떻게 작동하는지 확인할 수 있습니다.
GKE 클러스터 확인
Kubernetes 클러스터로 이동합니다. 워크로드와 서비스를 배포했으므로 클러스터에 총 vCPU와 메모리에 관한 세부정보가 추가되었습니다. 클러스터에 워크로드가 없는 경우 이 정보를 사용할 수 없었습니다.
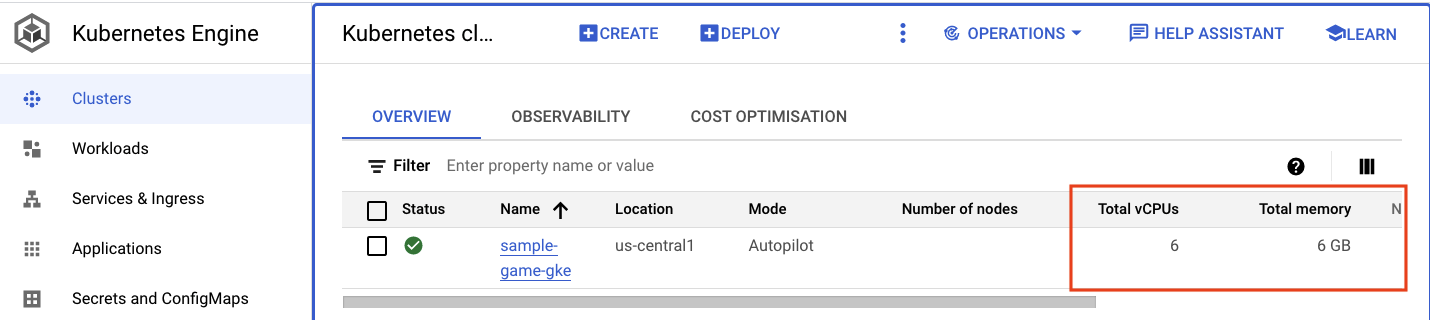
이제 sample-game-gke 클러스터를 클릭하고 모니터링 가능성 탭으로 전환합니다.
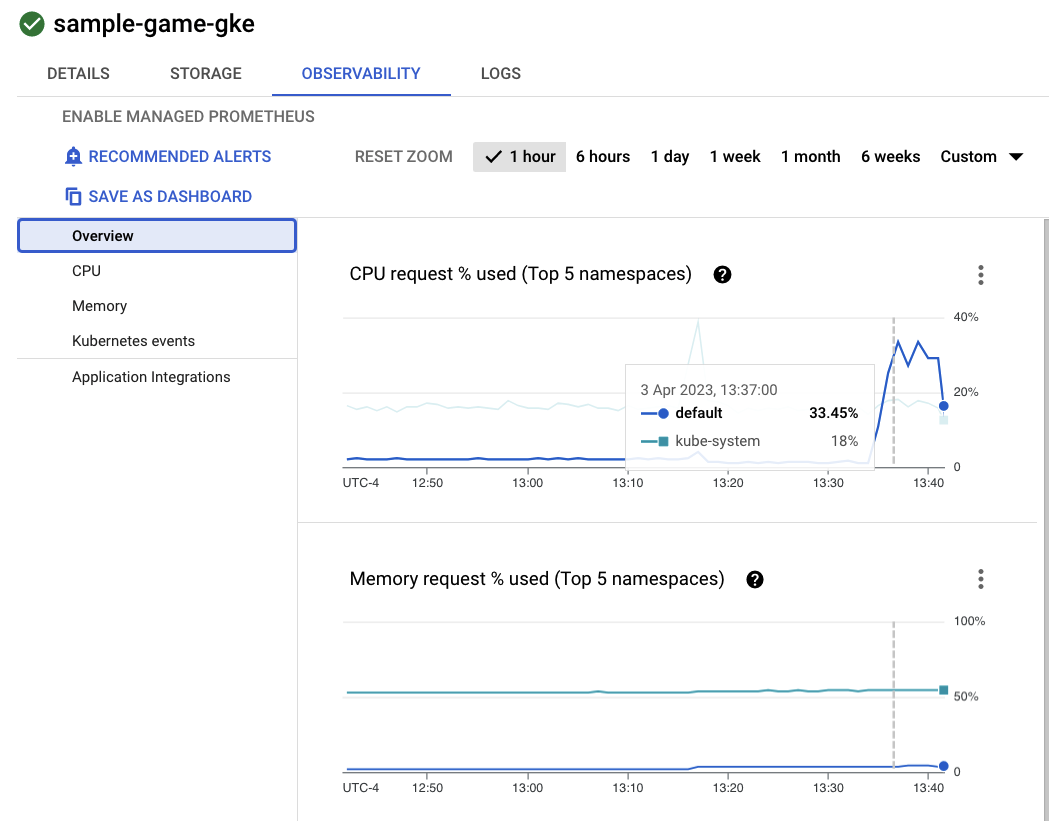
워크로드와 백엔드 서비스가 default에서 실행되므로 default Kubernetes 네임스페이스의 CPU 사용률이 kube-system 네임스페이스를 초과해야 합니다. 업데이트되지 않았다면 profile workload가 계속 실행 중인지 확인하고 차트가 업데이트될 때까지 몇 분 정도 기다립니다.
가장 많은 리소스를 사용하는 워크로드를 확인하려면 Workloads 대시보드로 이동하세요.
각 워크로드로 개별적으로 이동하는 대신 대시보드의 관측 가능성 탭으로 바로 이동합니다. profile 및 profile-workload CPU가 증가한 것을 확인할 수 있습니다.
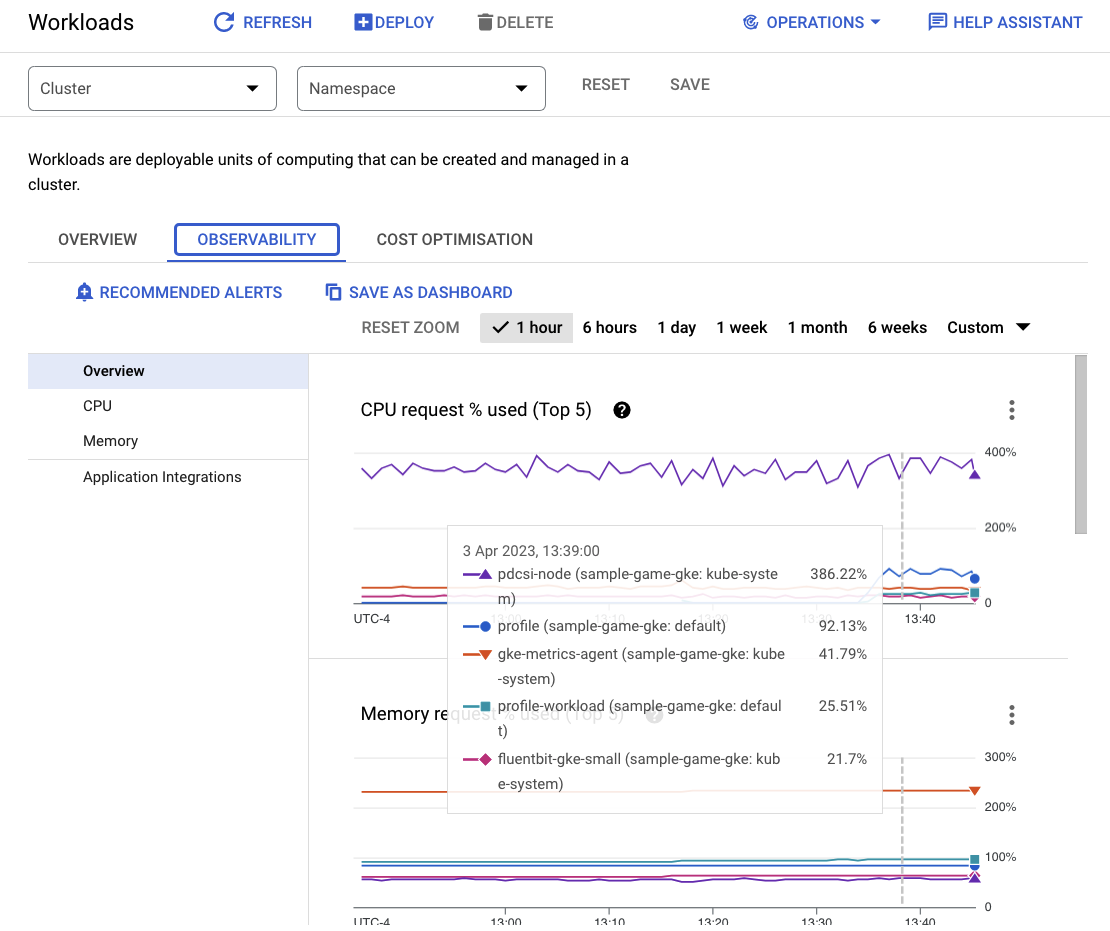
이제 Cloud Spanner를 확인합니다.
Cloud Spanner 인스턴스 확인
Cloud Spanner의 성능을 확인하려면 Spanner로 이동하여 sample-instance 인스턴스와 sample-game 데이터베이스를 클릭합니다.
왼쪽 메뉴에 시스템 통계 탭이 표시됩니다.
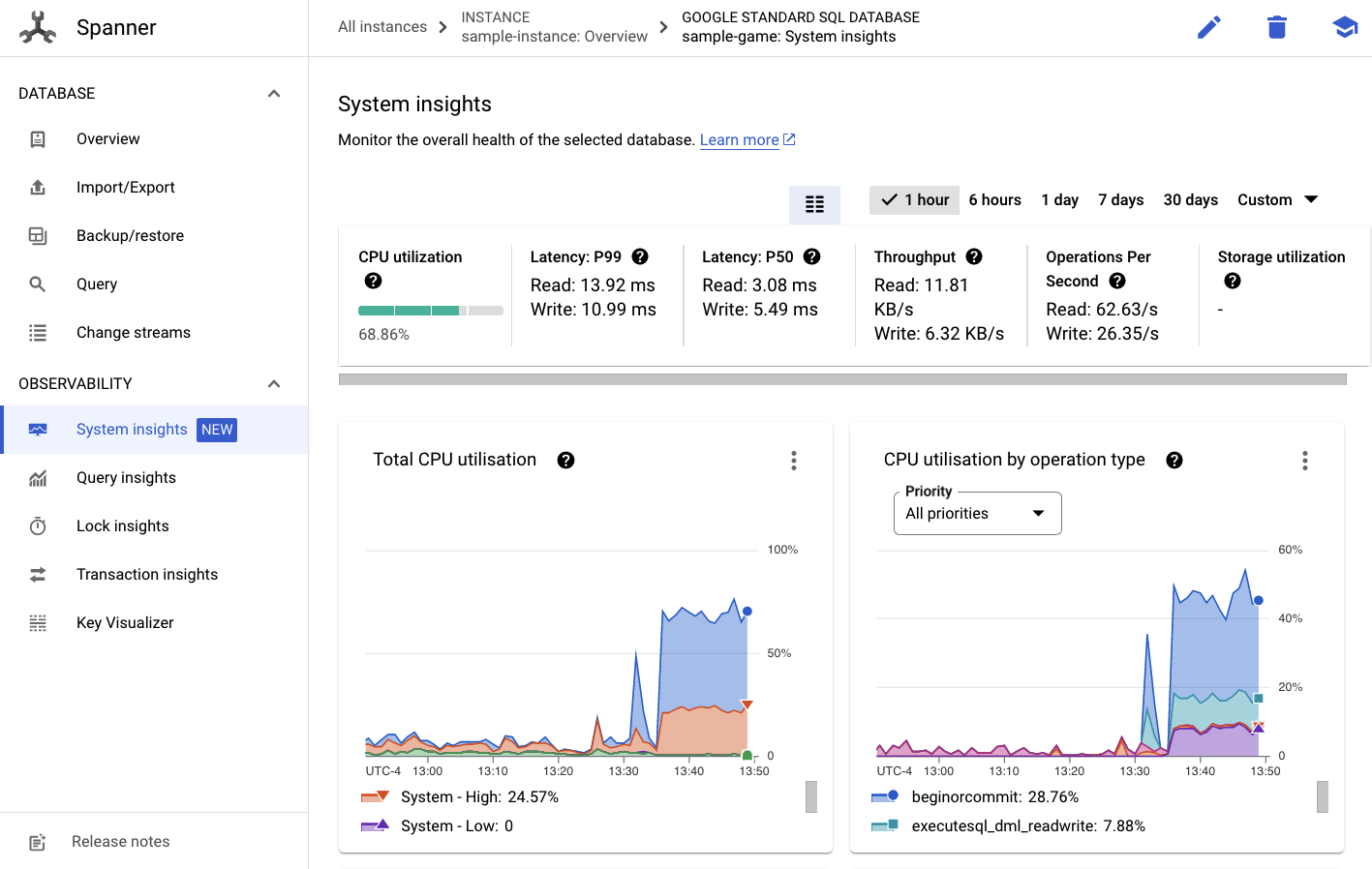
CPU utilization, transaction latency and locking, query throughput 등 Spanner 인스턴스의 일반적인 성능을 이해하는 데 도움이 되는 차트가 많이 있습니다.
시스템 통계 외에도 관측 가능성 섹션의 다른 링크를 살펴보면 쿼리 워크로드에 대한 자세한 정보를 확인할 수 있습니다.
- 쿼리 통계를 사용하면 Spanner에서 리소스를 사용하는 상위 N개 쿼리를 식별할 수 있습니다.
- 트랜잭션 및 잠금 통계는 지연 시간이 긴 트랜잭션을 식별하는 데 도움이 됩니다.
- Key Visualizer는 액세스 패턴을 시각화하는 데 도움이 되며 데이터의 핫스팟을 추적하는 데 도움이 될 수 있습니다.
요약
이 단계에서는 GKE Autopilot과 Spanner의 기본 성능 측정항목을 확인하는 방법을 알아봤습니다.
예를 들어 프로필 워크로드가 실행 중인 상태에서 players 테이블을 쿼리하여 여기에 저장된 데이터에 관한 자세한 정보를 가져옵니다.
다음 단계
이제 정리할 시간입니다.
9. 삭제
정리하기 전에 다루지 않은 다른 워크로드를 자유롭게 살펴보세요. 특히 matchmaking-workload, game-workload, tradepost-workload입니다.
게임 '플레이'가 끝나면 운동장을 정리할 수 있습니다. 다행히 이 과정은 매우 간단합니다.
먼저 profile-workload이 브라우저에서 여전히 실행 중인 경우 이동하여 중지합니다.
테스트한 각 워크로드에 대해서도 동일한 작업을 수행합니다.
그런 다음 Cloud Shell에서 인프라 폴더로 이동합니다. Terraform을 사용하여 인프라를 destroy합니다.
cd $DEMO_HOME/infrastructure
terraform destroy
# type 'yes' when asked
명령어 결과
Plan: 0 to add, 0 to change, 46 to destroy.
Do you really want to destroy all resources?
Terraform will destroy all your managed infrastructure, as shown above.
There is no undo. Only 'yes' will be accepted to confirm.
Enter a value: yes
*snip*
Destroy complete! Resources: 46 destroyed.
Cloud 콘솔에서 Spanner, Kubernetes Cluster, Artifact Registry, Cloud Deploy, IAM로 이동하여 모든 리소스가 삭제되었는지 확인합니다.
10. 축하합니다.
축하합니다. GKE Autopilot에 샘플 Go 애플리케이션을 배포하고 워크로드 아이덴티티를 사용하여 Cloud Spanner에 연결했습니다.
또한 Terraform을 사용하여 이 인프라를 반복 가능한 방식으로 쉽게 설정하고 삭제할 수 있었습니다.
이 Codelab에서 사용한 Google Cloud 서비스에 대해 자세히 알아보세요.
다음 단계
이제 GKE Autopilot과 Cloud Spanner가 함께 작동하는 방식을 기본적으로 이해했으므로 다음 단계로 나아가 이러한 서비스와 함께 작동하는 자체 애플리케이션을 빌드해 보세요.