
১. ভূমিকা
ক্লাউড স্প্যানার হলো একটি সম্পূর্ণভাবে পরিচালিত, হরাইজন্টালি স্কেলেবল, বিশ্বব্যাপী বিতরণযোগ্য রিলেশনাল ডাটাবেস পরিষেবা, যা পারফরম্যান্স ও উচ্চ প্রাপ্যতা বজায় রেখে ACID ট্রানজ্যাকশন এবং SQL সিম্যান্টিকস প্রদান করে।
GKE অটোপাইলট হলো GKE-এর একটি কার্যপ্রণালী, যার মাধ্যমে গুগল সর্বোত্তম অনুশীলন অনুসরণ করে আপনার ক্লাস্টার কনফিগারেশন পরিচালনা করে। এর মধ্যে আপনার নোড, স্কেলিং, নিরাপত্তা এবং অন্যান্য পূর্ব-কনফিগার করা সেটিংস অন্তর্ভুক্ত থাকে। উদাহরণস্বরূপ, GKE অটোপাইলট সার্ভিস পারমিশন পরিচালনার জন্য ওয়ার্কলোড আইডেন্টিটিকে সক্ষম করে।
এই ল্যাবের উদ্দেশ্য হলো GKE Autopilot-এ চলমান কয়েকটি ব্যাকএন্ড সার্ভিসকে একটি Cloud Spanner ডেটাবেসের সাথে সংযুক্ত করার প্রক্রিয়াটি আপনাকে ধাপে ধাপে দেখানো।

এই ল্যাবে, আপনি প্রথমে একটি প্রজেক্ট সেট আপ করবেন এবং ক্লাউড শেল চালু করবেন। তারপর টেরাফর্ম ব্যবহার করে ইনফ্রাস্ট্রাকচারটি ডেপ্লয় করবেন।
সেটি সম্পন্ন হলে, আপনি গেমস ডেটাবেসের জন্য একটি প্রাথমিক স্কিমা মাইগ্রেশন করতে, ব্যাকএন্ড সার্ভিসগুলো ডেপ্লয় করতে এবং তারপর ওয়ার্কলোডগুলো ডেপ্লয় করতে ক্লাউড বিল্ড এবং ক্লাউড ডেপ্লয় ব্যবহার করবেন।
এই কোডল্যাবের সার্ভিসগুলো ‘ ক্লাউড স্প্যানার গেটিং স্টার্টেড উইথ গেমস ডেভেলপমেন্ট’ কোডল্যাবের মতোই। GKE-তে সার্ভিসগুলো চালু করতে এবং স্প্যানারের সাথে সংযোগ স্থাপন করতে ওই কোডল্যাবটি সম্পন্ন করা আবশ্যক নয়। কিন্তু স্প্যানারে কাজ করে এমন সার্ভিসগুলোর নির্দিষ্ট বিবরণ সম্পর্কে আপনি যদি আরও বিস্তারিত জানতে আগ্রহী হন, তবে সেটি দেখে নিতে পারেন।
ওয়ার্কলোড এবং ব্যাকএন্ড সার্ভিসগুলো চালু হয়ে গেলে, আপনি লোড তৈরি করা শুরু করতে পারেন এবং সার্ভিসগুলো কীভাবে একসঙ্গে কাজ করে তা পর্যবেক্ষণ করতে পারেন।
অবশেষে, এই ল্যাবে তৈরি করা রিসোর্সগুলো আপনি পরিষ্কার করবেন।
আপনি যা তৈরি করবেন
এই ল্যাবের অংশ হিসেবে, আপনি যা করবেন:
- টেরাফর্ম ব্যবহার করে পরিকাঠামোটি প্রস্তুত করুন
- ক্লাউড বিল্ড-এ স্কিমা মাইগ্রেশন প্রক্রিয়া ব্যবহার করে ডাটাবেস স্কিমা তৈরি করুন।
- ক্লাউড স্প্যানারের সাথে সংযোগ স্থাপনের জন্য ওয়ার্কলোড আইডেন্টিটি ব্যবহারকারী চারটি গোল্যাং ব্যাকএন্ড সার্ভিস ডিপ্লয় করুন।
- ব্যাকএন্ড সার্ভিসগুলোর লোড সিমুলেট করতে ব্যবহৃত চারটি ওয়ার্কলোড সার্ভিস ডিপ্লয় করুন।
আপনি যা শিখবেন
- টেরাফর্ম ব্যবহার করে কীভাবে GKE Autopilot, Cloud Spanner, এবং Cloud Deploy পাইপলাইনগুলি প্রোভিশন করতে হয়
- ক্লাউড স্প্যানারের সাথে কাজ করার জন্য IAM অনুমতিগুলো অ্যাক্সেস করতে, ওয়ার্কলোড আইডেন্টিটি কীভাবে GKE-তে থাকা পরিষেবাগুলোকে সার্ভিস অ্যাকাউন্টগুলোর ছদ্মবেশ ধারণ করতে দেয়
- Locust.io ব্যবহার করে GKE এবং Cloud Spanner-এ কীভাবে প্রোডাকশন-সদৃশ লোড তৈরি করা যায়
আপনার যা যা লাগবে
- একটি গুগল ক্লাউড প্রজেক্ট যা একটি বিলিং অ্যাকাউন্টের সাথে সংযুক্ত।
- একটি ওয়েব ব্রাউজার, যেমন ক্রোম বা ফায়ারফক্স ।
২. সেটআপ এবং প্রয়োজনীয়তা
একটি প্রকল্প তৈরি করুন
আপনার যদি আগে থেকে কোনো গুগল অ্যাকাউন্ট (জিমেইল বা গুগল অ্যাপস) না থাকে, তবে আপনাকে অবশ্যই একটি তৈরি করতে হবে। গুগল ক্লাউড প্ল্যাটফর্ম কনসোলে ( console.cloud.google.com ) সাইন-ইন করুন এবং একটি নতুন প্রজেক্ট তৈরি করুন।
আপনার যদি আগে থেকেই কোনো প্রজেক্ট থাকে, তাহলে কনসোলের উপরের বাম দিকের প্রজেক্ট সিলেকশন পুল-ডাউন মেনুতে ক্লিক করুন:

এবং একটি নতুন প্রজেক্ট তৈরি করতে, প্রাপ্ত ডায়ালগ বক্সে থাকা ' NEW PROJECT ' বোতামটিতে ক্লিক করুন:
আপনার যদি আগে থেকে কোনো প্রজেক্ট না থাকে, তাহলে আপনার প্রথম প্রজেক্টটি তৈরি করার জন্য এইরকম একটি ডায়ালগ বক্স দেখতে পাবেন:

পরবর্তী প্রজেক্ট তৈরির ডায়ালগ বক্সে আপনি আপনার নতুন প্রজেক্টের বিবরণ লিখতে পারবেন:

প্রজেক্ট আইডিটি মনে রাখবেন, যা সমস্ত গুগল ক্লাউড প্রজেক্ট জুড়ে একটি অনন্য নাম (উপরের নামটি ইতিমধ্যে ব্যবহৃত হয়েছে এবং আপনার জন্য কাজ করবে না, দুঃখিত!)। এই কোডল্যাবে এটিকে পরবর্তীতে PROJECT_ID হিসাবে উল্লেখ করা হবে।
এরপরে, যদি আপনি আগে থেকে তা না করে থাকেন, তাহলে Google Cloud রিসোর্স ব্যবহার করতে এবং Cloud Spanner API সক্রিয় করতে আপনাকে ডেভেলপার কনসোলে বিলিং চালু করতে হবে।

এই কোডল্যাবটি চালাতে আপনার কয়েক ডলারের বেশি খরচ হওয়ার কথা নয়, কিন্তু আপনি যদি আরও রিসোর্স ব্যবহার করার সিদ্ধান্ত নেন অথবা সেগুলোকে চালু রাখেন, তাহলে খরচ আরও বেশি হতে পারে (এই ডকুমেন্টের শেষে 'ক্লিনআপ' অংশটি দেখুন)। গুগল ক্লাউড স্প্যানারের মূল্য তালিকা এখানে এবং জিকেই অটোপাইলটের মূল্য তালিকা এখানে দেওয়া আছে।
গুগল ক্লাউড প্ল্যাটফর্মের নতুন ব্যবহারকারীরা ৩০০ ডলারের একটি ফ্রি ট্রায়ালের জন্য যোগ্য, যার ফলে এই কোডল্যাবটি সম্পূর্ণ বিনামূল্যে পাওয়া যাবে।
ক্লাউড শেল সেটআপ
যদিও গুগল ক্লাউড এবং স্প্যানার আপনার ল্যাপটপ থেকে দূরবর্তীভাবে পরিচালনা করা যায়, এই কোডল্যাবে আমরা গুগল ক্লাউড শেল ব্যবহার করব, যা ক্লাউডে চালিত একটি কমান্ড লাইন পরিবেশ।
এই ডেবিয়ান-ভিত্তিক ভার্চুয়াল মেশিনটিতে আপনার প্রয়োজনীয় সমস্ত ডেভেলপমেন্ট টুলস লোড করা আছে। এটি একটি স্থায়ী ৫ জিবি হোম ডিরেক্টরি প্রদান করে এবং গুগল ক্লাউডে চলে, যা নেটওয়ার্ক পারফরম্যান্স ও অথেনটিকেশনকে ব্যাপকভাবে উন্নত করে। এর মানে হলো, এই কোডল্যাবের জন্য আপনার শুধু একটি ব্রাউজার প্রয়োজন হবে (হ্যাঁ, এটি ক্রোমবুকেও কাজ করে)।
- ক্লাউড কনসোল থেকে ক্লাউড শেল সক্রিয় করতে, কেবল 'Activate Cloud Shell'-এ ক্লিক করুন।
 (পরিবেশের জন্য ব্যবস্থা করতে এবং সংযোগ স্থাপন করতে মাত্র কয়েক মুহূর্ত সময় লাগা উচিত)।
(পরিবেশের জন্য ব্যবস্থা করতে এবং সংযোগ স্থাপন করতে মাত্র কয়েক মুহূর্ত সময় লাগা উচিত)।
ক্লাউড শেলে সংযুক্ত হওয়ার পর, আপনি দেখতে পাবেন যে আপনাকে ইতিমধ্যেই প্রমাণীকৃত করা হয়েছে এবং প্রজেক্টটি আপনার PROJECT_ID তে সেট করা আছে।
gcloud auth list
কমান্ড আউটপুট
Credentialed accounts:
- <myaccount>@<mydomain>.com (active)
gcloud config list project
কমান্ড আউটপুট
[core]
project = <PROJECT_ID>
যদি কোনো কারণে প্রজেক্টটি সেট করা না থাকে, তাহলে নিম্নলিখিত কমান্ডটি দিন:
gcloud config set project <PROJECT_ID>
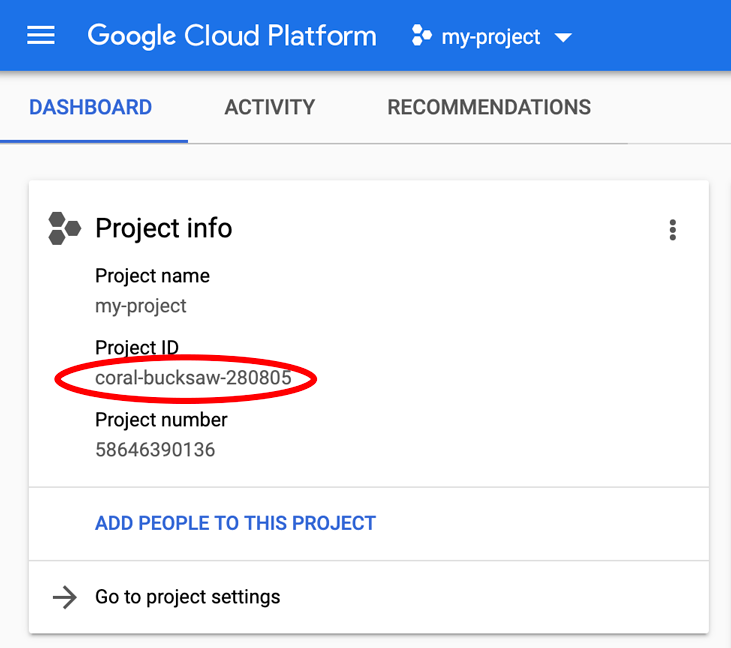
আপনার PROJECT_ID খুঁজছেন? সেটআপের ধাপগুলিতে আপনি কোন আইডি ব্যবহার করেছিলেন তা দেখে নিন অথবা ক্লাউড কনসোল ড্যাশবোর্ডে এটি খুঁজে দেখুন:
ক্লাউড শেল ডিফল্টরূপে কিছু এনভায়রনমেন্ট ভেরিয়েবলও সেট করে, যা ভবিষ্যতে কমান্ড চালানোর সময় কাজে লাগতে পারে।
echo $GOOGLE_CLOUD_PROJECT
কমান্ড আউটপুট
<PROJECT_ID>
কোডটি ডাউনলোড করুন
ক্লাউড শেলে, আপনি এই ল্যাবের কোডটি ডাউনলোড করতে পারেন:
git clone https://github.com/cloudspannerecosystem/spanner-gaming-sample.git
কমান্ড আউটপুট
Cloning into 'spanner-gaming-sample'...
*snip*
এই কোডল্যাবটি v0.1.3 রিলিজের উপর ভিত্তি করে তৈরি, তাই ওই ট্যাগটি দেখে নিন:
cd spanner-gaming-sample
git fetch --all --tags
# Check out v0.1.3 release
git checkout tags/v0.1.3 -b v0.1.3-branch
কমান্ড আউটপুট
Switched to a new branch 'v0.1.3-branch'
এখন, বর্তমান ওয়ার্কিং ডিরেক্টরিটিকে DEMO_HOME এনভায়রনমেন্ট ভেরিয়েবল হিসেবে সেট করুন। এর ফলে কোডল্যাবের বিভিন্ন অংশে কাজ করার সময় আপনার পক্ষে নেভিগেট করা সহজ হবে।
export DEMO_HOME=$(pwd)
সারসংক্ষেপ
এই ধাপে আপনি একটি নতুন প্রজেক্ট সেট আপ করেছেন, ক্লাউড শেল সক্রিয় করেছেন এবং এই ল্যাবের জন্য কোড ডাউনলোড করেছেন।
এরপরে
এরপরে, আপনি Terraform ব্যবহার করে পরিকাঠামোটি প্রস্তুত করবেন।
৩. অবকাঠামো সরবরাহ
সংক্ষিপ্ত বিবরণ
আপনার প্রজেক্ট প্রস্তুত হয়ে গেলে, এখন ইনফ্রাস্ট্রাকচার চালু করার পালা। এর মধ্যে রয়েছে VPC নেটওয়ার্কিং, ক্লাউড স্প্যানার, GKE অটোপাইলট, GKE-তে চালিত ইমেজগুলো সংরক্ষণের জন্য আর্টিফ্যাক্ট রেজিস্ট্রি, ব্যাকএন্ড সার্ভিস ও ওয়ার্কলোডের জন্য ক্লাউড ডিপ্লয় পাইপলাইন, এবং সবশেষে সেই সার্ভিসগুলো ব্যবহার করার জন্য সার্ভিস অ্যাকাউন্ট ও IAM প্রিভিলেজ।
ব্যাপারটা বেশ জটিল। কিন্তু সৌভাগ্যবশত, টেরাফর্ম এই সেটআপটিকে সহজ করে তুলতে পারে। টেরাফর্ম হলো একটি "ইনফ্রাস্ট্রাকচার অ্যাজ কোড" টুল, যা আমাদেরকে একাধিক '.tf' ফাইলের মাধ্যমে এই প্রোজেক্টের জন্য প্রয়োজনীয় বিষয়গুলো নির্দিষ্ট করে দেওয়ার সুযোগ দেয়। এর ফলে ইনফ্রাস্ট্রাকচার প্রোভিশনিং সহজ হয়ে যায়।
এই কোডল্যাবটি সম্পন্ন করার জন্য টেরাফর্ম সম্পর্কে পরিচিতি থাকা আবশ্যক নয়। কিন্তু পরবর্তী কয়েকটি ধাপে কী করা হচ্ছে তা যদি আপনি দেখতে চান, তাহলে ইনফ্রাস্ট্রাকচার ডিরেক্টরিতে অবস্থিত এই ফাইলগুলোতে কী কী তৈরি করা হয়েছে তা দেখে নিতে পারেন:
- vpc.tf
- backend_gke.tf
- স্প্যানার.টিএফ
- আর্টিফ্যাক্ট_রেজিস্ট্রি.টিএফ
- pipelines.tf
- iam.tf
টেরাফর্ম কনফিগার করুন
ক্লাউড শেলে, আপনি infrastructure ডিরেক্টরিতে প্রবেশ করবেন এবং টেরাফর্ম ইনিশিয়ালাইজ করবেন:
cd $DEMO_HOME/infrastructure
terraform init
কমান্ড আউটপুট
Initializing the backend...
Initializing provider plugins...
*snip*
Terraform has been successfully initialized!
You may now begin working with Terraform. Try running "terraform plan" to see
any changes that are required for your infrastructure. All Terraform commands
should now work.
If you ever set or change modules or backend configuration for Terraform,
rerun this command to reinitialize your working directory. If you forget, other
commands will detect it and remind you to do so if necessary.
এরপর, terraform.tfvars.sample ফাইলটি কপি করে project ভ্যালুটি পরিবর্তন করে Terraform কনফিগার করুন। অন্যান্য ভ্যারিয়েবলগুলোও পরিবর্তন করা যেতে পারে, কিন্তু আপনার এনভায়রনমেন্টের সাথে কাজ করার জন্য শুধুমাত্র project-টিই পরিবর্তন করতে হবে।
cp terraform.tfvars.sample terraform.tfvars
# edit gcp_project using the project environment variable
sed -i "s/PROJECT/$GOOGLE_CLOUD_PROJECT/" terraform.tfvars
অবকাঠামো সরবরাহ করুন
এখন পরিকাঠামো প্রস্তুত করার সময়!
terraform apply
# review the list of things to be created
# type 'yes' when asked
কমান্ড আউটপুট
Plan: 46 to add, 0 to change, 0 to destroy.
Do you want to perform these actions?
Terraform will perform the actions described above.
Only 'yes' will be accepted to approve.
Enter a value: yes
google_project_service.project["container.googleapis.com"]: Creating...
*snip*
Apply complete! Resources: 46 added, 0 changed, 0 destroyed.
কী তৈরি করা হয়েছিল তা পরীক্ষা করুন
কী তৈরি করা হয়েছে তা যাচাই করতে, আপনাকে ক্লাউড কনসোলে প্রোডাক্টগুলো দেখতে হবে।
ক্লাউড স্প্যানার
প্রথমে, হ্যামবার্গার মেনুতে গিয়ে ' Spanner -এ ক্লিক করে ক্লাউড স্প্যানার খুঁজে দেখুন। তালিকায় এটি খুঁজে পেতে আপনাকে 'আরও পণ্য দেখুন'-এ ক্লিক করতে হতে পারে।
এটি আপনাকে স্প্যানার ইনস্ট্যান্সগুলোর তালিকায় নিয়ে যাবে। ইনস্ট্যান্সটিতে ক্লিক করলে আপনি ডেটাবেসগুলো দেখতে পাবেন। এটি দেখতে অনেকটা এইরকম হবে:

জিকেই অটোপাইলট
এরপর, হ্যামবার্গার মেনুতে গিয়ে Kubernetes Engine => Clusters এ ক্লিক করে GKE দেখে নিন। এখানে আপনি অটোপাইলট মোডে চলমান sample-games-gke ক্লাস্টারটি দেখতে পাবেন।

প্রত্নবস্তু রেজিস্ট্রি
এখন আপনি দেখতে চাইবেন ইমেজগুলো কোথায় সংরক্ষিত হবে। এজন্য হ্যামবার্গার মেনুতে ক্লিক করুন এবং Artifact Registry=>Repositories খুঁজুন। Artifact Registry মেনুটির CI/CD সেকশনে রয়েছে।
এখানে, আপনি spanner-game-images নামের একটি ডকার রেজিস্ট্রি দেখতে পাবেন। এটি আপাতত খালি থাকবে।

ক্লাউড ডিপ্লয়
ক্লাউড ডিপ্লয়-এ পাইপলাইনগুলো তৈরি করা হয়েছিল, যাতে ক্লাউড বিল্ড ইমেজগুলো বিল্ড করার ধাপগুলো সরবরাহ করতে এবং তারপর সেগুলোকে আমাদের GKE ক্লাস্টারে ডিপ্লয় করতে পারে।
হ্যামবার্গার মেনুতে যান এবং Cloud Deploy খুঁজুন, যেটি মেনুর CI/CD সেকশনেই রয়েছে।
এখানে আপনি দুটি পাইপলাইন দেখতে পাবেন: একটি ব্যাকএন্ড সার্ভিসের জন্য এবং অন্যটি ওয়ার্কলোডের জন্য। উভয়ই একই GKE ক্লাস্টারে ইমেজগুলো ডেপ্লয় করে, কিন্তু এটি আমাদের ডেপ্লয়মেন্টগুলোকে আলাদা করার সুযোগ করে দেয়।
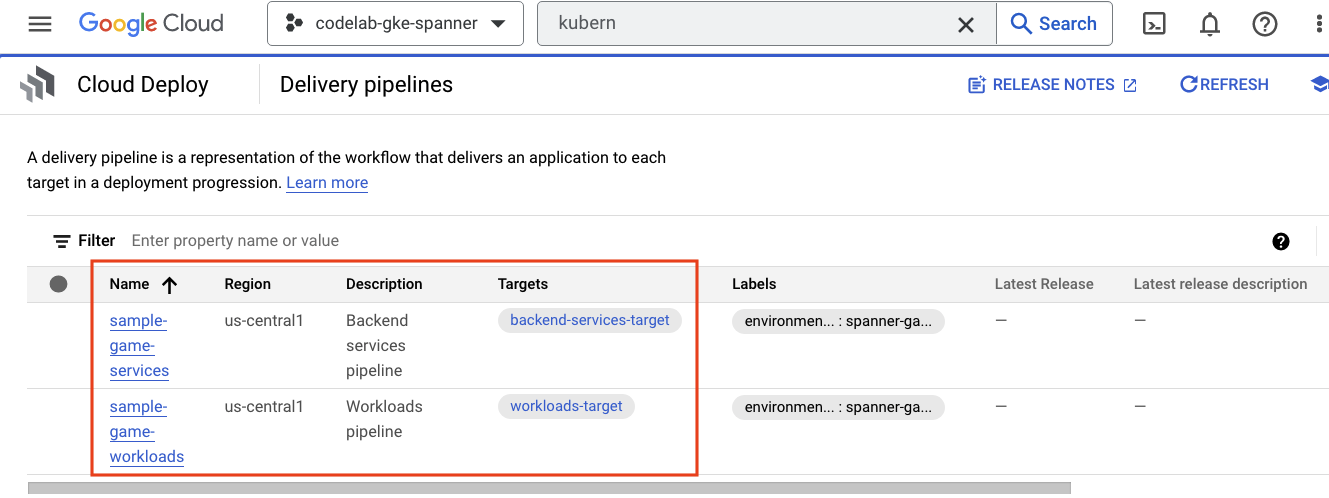
আইএএম
অবশেষে, তৈরি হওয়া সার্ভিস অ্যাকাউন্টগুলো যাচাই করতে ক্লাউড কনসোলের IAM পেজটি দেখুন। হ্যামবার্গার মেনুতে যান এবং IAM and Admin=>Service accounts খুঁজুন। এটি দেখতে অনেকটা এইরকম হবে:

টেরাফর্ম দ্বারা তৈরি মোট ছয়টি সার্ভিস অ্যাকাউন্ট রয়েছে:
- ডিফল্ট কম্পিউটার সার্ভিস অ্যাকাউন্ট। এই কোডল্যাবে এটি ব্যবহৃত হয় না।
- cloudbuild-cicd অ্যাকাউন্টটি ক্লাউড বিল্ড এবং ক্লাউড ডিপ্লয় ধাপগুলোর জন্য ব্যবহৃত হয়।
- চারটি 'অ্যাপ' অ্যাকাউন্ট, যেগুলো আমাদের ব্যাকএন্ড পরিষেবাগুলো ক্লাউড স্প্যানারের সাথে যোগাযোগ করার জন্য ব্যবহার করে।
এরপরে আপনাকে GKE ক্লাস্টারের সাথে যোগাযোগ করার জন্য kubectl কনফিগার করতে হবে।
kubectl কনফিগার করুন
# Name of GKE cluster from terraform.tfvars file
export GKE_CLUSTER=sample-game-gke
# get GKE credentials
gcloud container clusters get-credentials $GKE_CLUSTER --region us-central1
# Check that no errors occur
kubectl get serviceaccounts
কমান্ড আউটপুট
#export GKE_CLUSTER=sample-game-gke
# gcloud container clusters get-credentials $GKE_CLUSTER --region us-central1
Fetching cluster endpoint and auth data.
kubeconfig entry generated for sample-game-gke.
# kubectl get serviceaccounts
NAME SECRETS AGE
default 0 37m
item-app 0 35m
matchmaking-app 0 35m
profile-app 0 35m
tradepost-app 0 35m
সারসংক্ষেপ
চমৎকার! আপনি প্রাইভেট নেটওয়ার্কিংয়ের জন্য একটি VPC-তে একটি ক্লাউড স্প্যানার ইনস্ট্যান্স এবং একটি GKE অটোপাইলট ক্লাস্টার স্থাপন করতে পেরেছেন।
এছাড়াও, ব্যাকএন্ড পরিষেবা এবং ওয়ার্কলোডগুলির জন্য দুটি ক্লাউড ডিপ্লয় পাইপলাইন তৈরি করা হয়েছিল, এবং সেইসাথে বিল্ড করা ইমেজগুলি সংরক্ষণের জন্য একটি আর্টিফ্যাক্ট রেজিস্ট্রি রিপোজিটরিও তৈরি করা হয়েছিল।
এবং অবশেষে, সার্ভিস অ্যাকাউন্টগুলো তৈরি ও কনফিগার করা হয়েছিল যাতে সেগুলো ওয়ার্কলোড আইডেন্টিটির সাথে কাজ করতে পারে এবং ব্যাকএন্ড সার্ভিসগুলো ক্লাউড স্প্যানার ব্যবহার করতে পারে।
ব্যাকএন্ড পরিষেবা এবং ওয়ার্কলোডগুলি স্থাপন করার পরে, ক্লাউড শেলে GKE ক্লাস্টারের সাথে যোগাযোগ করার জন্য আপনাকে kubectl ও কনফিগার করতে হবে।
এরপরে
সার্ভিসগুলো ব্যবহার করার আগে, ডাটাবেস স্কিমা নির্ধারণ করতে হবে। এরপরে আপনি সেটি সেট আপ করবেন।
৪. ডাটাবেস স্কিমা তৈরি করুন
সংক্ষিপ্ত বিবরণ
ব্যাকএন্ড সার্ভিসগুলো চালানোর আগে, আপনাকে নিশ্চিত করতে হবে যে ডাটাবেস স্কিমাটি যথাযথভাবে তৈরি আছে।
আপনি যদি ডেমো রিপোজিটরির $DEMO_HOME/schema/migrations ডিরেক্টরির ফাইলগুলো দেখেন, তাহলে আপনি বেশ কিছু .sql ফাইল দেখতে পাবেন যা আমাদের স্কিমা নির্ধারণ করে। এটি এমন একটি উন্নয়ন চক্রের অনুকরণ করে যেখানে স্কিমার পরিবর্তনগুলো রিপোজিটরির মধ্যেই ট্র্যাক করা হয় এবং অ্যাপ্লিকেশনগুলোর নির্দিষ্ট ফিচারের সাথে সংযুক্ত করা যায়।
এই নমুনা পরিবেশের জন্য, রেঞ্চ (wrench) হলো সেই টুল যা ক্লাউড বিল্ড (Cloud Build) ব্যবহার করে আমাদের স্কিমা মাইগ্রেশনগুলো প্রয়োগ করবে।
ক্লাউড বিল্ড
$DEMO_HOME/schema/cloudbuild.yaml ফাইলটিতে বর্ণনা করা হয়েছে কী কী পদক্ষেপ নেওয়া হবে:
serviceAccount: projects/${PROJECT_ID}/serviceAccounts/cloudbuild-cicd@${PROJECT_ID}.iam.gserviceaccount.com
steps:
- name: gcr.io/cloud-builders/curl
id: fetch-wrench
args: ['-Lo', '/workspace/wrench.tar.gz', 'https://github.com/cloudspannerecosystem/wrench/releases/download/v1.4.1/wrench-1.4.1-linux-amd64.tar.gz' ]
- name: gcr.io/cloud-builders/gcloud
id: migrate-spanner-schema
entrypoint: sh
args:
- '-xe'
- '-c'
- |
tar -xzvf wrench.tar.gz
chmod +x /workspace/wrench
# Assumes only a single spanner instance and database. Fine for this demo in a dedicated project
export SPANNER_PROJECT_ID=${PROJECT_ID}
export SPANNER_INSTANCE_ID=$(gcloud spanner instances list | tail -n1 | awk '{print $1}')
export SPANNER_DATABASE_ID=$(gcloud spanner databases list --instance=$$SPANNER_INSTANCE_ID | tail -n1 | awk '{print $1}')
if [ -d ./migrations ]; then
/workspace/wrench migrate up --directory .
else
echo "[Error] Missing migrations directory"
fi
timeout: 600s
মূলত দুটি ধাপ রয়েছে:
- ক্লাউড বিল্ড ওয়ার্কস্পেসে রেঞ্চ ডাউনলোড করুন
- রেঞ্চ মাইগ্রেশন চালান
রেঞ্চকে রাইট এন্ডপয়েন্টে সংযোগ করার জন্য স্প্যানার প্রজেক্ট, ইনস্ট্যান্স এবং ডাটাবেস এনভায়রনমেন্ট ভেরিয়েবল প্রয়োজন।
ক্লাউড বিল্ড এই পরিবর্তনগুলি করতে সক্ষম, কারণ এটি cloudbuild-cicd@${PROJECT_ID}.iam.gserviceaccount.com সার্ভিস অ্যাকাউন্ট হিসেবে চলছে:
serviceAccount: projects/${PROJECT_ID}/serviceAccounts/cloudbuild-cicd@${PROJECT_ID}.iam.gserviceaccount.com
এবং এই সার্ভিস অ্যাকাউন্টে Terraform দ্বারা যুক্ত spanner.databaseUser রোলটি রয়েছে, যা সার্ভিস অ্যাকাউন্টটিকে updateDDL করার অনুমতি দেয়।
স্কিমা স্থানান্তর
$DEMO_HOME/schema/migrations ডিরেক্টরিতে থাকা ফাইলগুলোর উপর ভিত্তি করে পাঁচটি মাইগ্রেশন ধাপ সম্পন্ন করা হয়। নিচে 000001.sql ফাইলটির একটি উদাহরণ দেওয়া হলো, যা একটি players টেবিল এবং ইনডেক্স তৈরি করে:
CREATE TABLE players (
playerUUID STRING(36) NOT NULL,
player_name STRING(64) NOT NULL,
email STRING(MAX) NOT NULL,
password_hash BYTES(60) NOT NULL,
created TIMESTAMP,
updated TIMESTAMP,
stats JSON,
account_balance NUMERIC NOT NULL DEFAULT (0.00),
is_logged_in BOOL,
last_login TIMESTAMP,
valid_email BOOL,
current_game STRING(36)
) PRIMARY KEY (playerUUID);
CREATE UNIQUE INDEX PlayerAuthentication ON players(email) STORING(password_hash);
CREATE UNIQUE INDEX PlayerName ON players(player_name);
CREATE INDEX PlayerGame ON players(current_game);
স্কিমা মাইগ্রেশন জমা দিন
স্কিমা মাইগ্রেশন সম্পন্ন করার জন্য বিল্ডটি জমা দিতে, schema ডিরেক্টরিতে যান এবং নিম্নলিখিত gcloud কমান্ডটি চালান:
cd $DEMO_HOME/schema gcloud builds submit --config=cloudbuild.yaml
কমান্ড আউটপুট
Creating temporary tarball archive of 8 file(s) totalling 11.2 KiB before compression.
Uploading tarball of [.] to [gs://(project)_cloudbuild/source/(snip).tgz]
Created [https://cloudbuild.googleapis.com/v1/projects/(project)/locations/global/builds/7defe982-(snip)].
Logs are available at [ https://console.cloud.google.com/cloud-build/builds/7defe982-(snip)?project=(snip) ].
gcloud builds submit only displays logs from Cloud Storage. To view logs from Cloud Logging, run:
gcloud beta builds submit
ID: 7defe982-(snip)
CREATE_TIME: (created time)
DURATION: 3M11S
SOURCE: gs://(project)_cloudbuild/source/(snip).tgz
IMAGES: -
STATUS: SUCCESS
উপরের আউটপুটে, আপনি Created ক্লাউড বিল্ড প্রসেসটির একটি লিঙ্ক দেখতে পাবেন। আপনি যদি সেটিতে ক্লিক করেন, তাহলে এটি আপনাকে ক্লাউড কনসোলে থাকা বিল্ডটিতে নিয়ে যাবে, যাতে আপনি বিল্ডটির অগ্রগতি পর্যবেক্ষণ করতে এবং এটি কী করছে তা দেখতে পারেন।

সারসংক্ষেপ
এই ধাপে, আপনি ক্লাউড বিল্ড ব্যবহার করে প্রাথমিক স্কিমা মাইগ্রেশন জমা দিয়েছেন, যেখানে ৫টি ভিন্ন ডিডিএল অপারেশন প্রয়োগ করা হয়েছে। এই অপারেশনগুলো নির্দেশ করে কখন এমন ফিচার যোগ করা হয়েছিল যার জন্য ডাটাবেস স্কিমাতে পরিবর্তনের প্রয়োজন ছিল।
সাধারণ ডেভেলপমেন্ট পরিস্থিতিতে, বিভ্রাট এড়ানোর জন্য স্কিমা পরিবর্তনগুলোকে বর্তমান অ্যাপ্লিকেশনের সাথে ব্যাকওয়ার্ড কম্প্যাটিবল রাখা হয়।
যেসব পরিবর্তন পূর্ববর্তী সংস্করণের সাথে সামঞ্জস্যপূর্ণ নয়, সেগুলোর ক্ষেত্রে কোনো বিভ্রাট যাতে না ঘটে তা নিশ্চিত করতে অ্যাপ্লিকেশন এবং স্কিমাতে পরিবর্তনগুলো পর্যায়ক্রমে প্রয়োগ করা উচিত।
এরপরে
স্কিমা তৈরি হয়ে গেলে, পরবর্তী ধাপ হলো ব্যাকএন্ড সার্ভিসগুলো ডেপ্লয় করা!
৫. ব্যাকএন্ড সার্ভিসগুলো ডিপ্লয় করুন
সংক্ষিপ্ত বিবরণ
এই কোডল্যাবের ব্যাকএন্ড সার্ভিসগুলো হলো গোল্যাং REST API, যা চারটি ভিন্ন সার্ভিসকে প্রতিনিধিত্ব করে:
- প্রোফাইল: খেলোয়াড়দের আমাদের নমুনা "গেম"-টিতে সাইন আপ এবং প্রমাণীকরণের সুযোগ প্রদান করা।
- ম্যাচমেকিং: ম্যাচমেকিং ফাংশনে সাহায্য করার জন্য প্লেয়ার ডেটার সাথে ইন্টারঅ্যাক্ট করুন, তৈরি হওয়া গেমগুলোর তথ্য ট্র্যাক করুন এবং গেম বন্ধ হয়ে গেলে প্লেয়ারের স্ট্যাটস আপডেট করুন।
- আইটেম: যা খেলোয়াড়দেরকে গেম খেলার মাধ্যমে গেমের আইটেম এবং অর্থ অর্জন করতে সক্ষম করে।
- ট্রেডপোস্ট: খেলোয়াড়দেরকে একটি ট্রেডপোস্টে জিনিসপত্র কেনা ও বেচার সুযোগ করে দেয়।
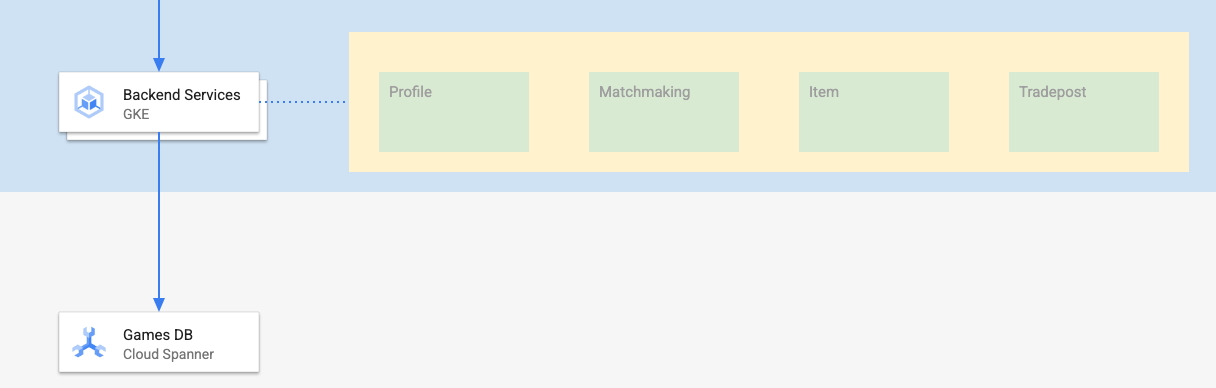
আপনি ক্লাউড স্প্যানারের 'গেটিং স্টার্টেড উইথ গেমস ডেভেলপমেন্ট ' কোডল্যাবে এই পরিষেবাগুলি সম্পর্কে আরও জানতে পারবেন। আমাদের প্রয়োজনের জন্য, আমরা এই পরিষেবাগুলি আমাদের GKE অটোপাইলট ক্লাস্টারে চালু রাখতে চাই।
এই সার্ভিসগুলোকে অবশ্যই স্প্যানার ডেটা পরিবর্তন করতে সক্ষম হতে হবে। তা করার জন্য, প্রতিটি সার্ভিসের জন্য একটি সার্ভিস অ্যাকাউন্ট তৈরি করা হয়, যা তাদেরকে 'databaseUser' রোলটি প্রদান করে।
ওয়ার্কলোড আইডেন্টিটি আমাদের টেরাফর্মে নিম্নলিখিত ধাপগুলি অনুসরণ করে একটি কুবারনেটিস সার্ভিস অ্যাকাউন্টকে সার্ভিসটির গুগল ক্লাউড সার্ভিস অ্যাকাউন্টের ছদ্মবেশ ধারণ করার সুযোগ দেয়:
- পরিষেবাটির গুগল ক্লাউড সার্ভিস অ্যাকাউন্ট (
GSA) রিসোর্স তৈরি করুন। - ওই সার্ভিস অ্যাকাউন্টে databaseUser রোলটি অ্যাসাইন করুন।
- ওই সার্ভিস অ্যাকাউন্টে workloadIdentityUser রোলটি অ্যাসাইন করুন।
- একটি Kubernetes সার্ভিস অ্যাকাউন্ট (
KSA) তৈরি করুন যা GSA-কে রেফারেন্স করে।
একটি মোটামুটি চিত্র দেখতে এইরকম হবে:

টেরাফর্ম আপনার জন্য সার্ভিস অ্যাকাউন্ট এবং কুবারনেটিস সার্ভিস অ্যাকাউন্ট তৈরি করে দিয়েছে। এবং আপনি kubectl ব্যবহার করে কুবারনেটিস সার্ভিস অ্যাকাউন্টগুলো যাচাই করতে পারেন:
# kubectl get serviceaccounts
NAME SECRETS AGE
default 0 37m
item-app 0 35m
matchmaking-app 0 35m
profile-app 0 35m
tradepost-app 0 35m
নির্মাণ প্রক্রিয়াটি নিম্নরূপ:
- টেরাফর্ম
$DEMO_HOME/backend_services/cloudbuild.yamlএকটি ফাইল তৈরি করেছে যা দেখতে অনেকটা এইরকম:
serviceAccount: projects/${PROJECT_ID}/serviceAccounts/cloudbuild-cicd@${PROJECT_ID}.iam.gserviceaccount.com
steps:
#
# Building of images
#
- name: gcr.io/cloud-builders/docker
id: profile
args: ["build", ".", "-t", "${_PROFILE_IMAGE}"]
dir: profile
waitFor: ['-']
- name: gcr.io/cloud-builders/docker
id: matchmaking
args: ["build", ".", "-t", "${_MATCHMAKING_IMAGE}"]
dir: matchmaking
waitFor: ['-']
- name: gcr.io/cloud-builders/docker
id: item
args: ["build", ".", "-t", "${_ITEM_IMAGE}"]
dir: item
waitFor: ['-']
- name: gcr.io/cloud-builders/docker
id: tradepost
args: ["build", ".", "-t", "${_TRADEPOST_IMAGE}"]
dir: tradepost
waitFor: ['-']
#
# Deployment
#
- name: gcr.io/google.com/cloudsdktool/cloud-sdk
id: cloud-deploy-release
entrypoint: gcloud
args:
[
"deploy", "releases", "create", "${_REL_NAME}",
"--delivery-pipeline", "sample-game-services",
"--skaffold-file", "skaffold.yaml",
"--skaffold-version", "1.39",
"--images", "profile=${_PROFILE_IMAGE},matchmaking=${_MATCHMAKING_IMAGE},item=${_ITEM_IMAGE},tradepost=${_TRADEPOST_IMAGE}",
"--region", "us-central1"
]
artifacts:
images:
- ${_REGISTRY}/profile
- ${_REGISTRY}/matchmaking
- ${_REGISTRY}/item
- ${_REGISTRY}/tradepost
substitutions:
_PROFILE_IMAGE: ${_REGISTRY}/profile:${BUILD_ID}
_MATCHMAKING_IMAGE: ${_REGISTRY}/matchmaking:${BUILD_ID}
_ITEM_IMAGE: ${_REGISTRY}/item:${BUILD_ID}
_TRADEPOST_IMAGE: ${_REGISTRY}/tradepost:${BUILD_ID}
_REGISTRY: us-docker.pkg.dev/${PROJECT_ID}/spanner-game-images
_REL_NAME: rel-${BUILD_ID:0:8}
options:
dynamic_substitutions: true
machineType: E2_HIGHCPU_8
logging: CLOUD_LOGGING_ONLY
- ক্লাউড বিল্ড কমান্ড এই ফাইলটি পড়ে এবং তালিকাভুক্ত ধাপগুলো অনুসরণ করে। প্রথমে, এটি সার্ভিস ইমেজগুলো বিল্ড করে। তারপর, এটি একটি
gcloud deploy createকমান্ড এক্সিকিউট করে। এটি$DEMO_HOME/backend_services/skaffold.yamlফাইলটি পড়ে, যা প্রতিটি ডিপ্লয়মেন্ট ফাইলের অবস্থান নির্ধারণ করে দেয়:
apiVersion: skaffold/v2beta29
kind: Config
deploy:
kubectl:
manifests:
- spanner_config.yaml
- profile/deployment.yaml
- matchmaking/deployment.yaml
- item/deployment.yaml
- tradepost/deployment.yaml
- Cloud Deploy প্রতিটি সার্ভিসের
deployment.yamlফাইলের সংজ্ঞা অনুসরণ করবে। সার্ভিসের deployment ফাইলে একটি সার্ভিস তৈরির তথ্য থাকে, যা এই ক্ষেত্রে পোর্ট ৮০-তে চলমান একটি clusterIP।
" ClusterIP" টাইপটি ব্যাকএন্ড সার্ভিস পডগুলোকে এক্সটার্নাল আইপি ব্যবহার করতে বাধা দেয়, ফলে শুধুমাত্র অভ্যন্তরীণ GKE নেটওয়ার্কে সংযোগ করতে সক্ষম সত্তাগুলোই ব্যাকএন্ড সার্ভিসগুলো অ্যাক্সেস করতে পারে। এই সার্ভিসগুলো প্লেয়ারদের জন্য সরাসরি অ্যাক্সেসযোগ্য হওয়া উচিত নয়, কারণ এগুলো স্প্যানার ডেটা অ্যাক্সেস ও পরিবর্তন করে।
apiVersion: v1
kind: Service
metadata:
name: profile
spec:
type: ClusterIP
selector:
app: profile
ports:
- port: 80
targetPort: 80
Kubernetes সার্ভিস তৈরি করার পাশাপাশি, Cloud Deploy একটি Kubernetes ডিপ্লয়মেন্টও তৈরি করে। চলুন profile সার্ভিসের ডিপ্লয়মেন্ট সেকশনটি পরীক্ষা করে দেখা যাক:
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: profile
spec:
replicas: 2 # EDIT: Number of instances of deployment
selector:
matchLabels:
app: profile
template:
metadata:
labels:
app: profile
spec:
serviceAccountName: profile-app
containers:
- name: profile-service
image: profile
ports:
- containerPort: 80
envFrom:
- configMapRef:
name: spanner-config
env:
- name: SERVICE_HOST
value: "0.0.0.0"
- name: SERVICE_PORT
value: "80"
resources:
requests:
cpu: "1"
memory: "1Gi"
ephemeral-storage: "100Mi"
limits:
cpu: "1"
memory: "1Gi"
ephemeral-storage: "100Mi"
উপরের অংশে সার্ভিসটি সম্পর্কে কিছু মেটাডেটা দেওয়া থাকে। এর মধ্যে সবচেয়ে গুরুত্বপূর্ণ অংশটি হলো, এই ডেপ্লয়মেন্টের মাধ্যমে কতগুলো রেপ্লিকা তৈরি করা হবে তা নির্ধারণ করা।
replicas: 2 # EDIT: Number of instances of deployment
এরপরে, আমরা দেখব কোন সার্ভিস অ্যাকাউন্ট দিয়ে অ্যাপটি চালানো হবে এবং কোন ইমেজ ব্যবহার করা হবে। এগুলি Terraform থেকে তৈরি করা Kubernetes সার্ভিস অ্যাকাউন্ট এবং Cloud Build ধাপে তৈরি করা ইমেজের সাথে মিলে যায়।
spec:
serviceAccountName: profile-app
containers:
- name: profile-service
image: profile
এরপরে, আমরা নেটওয়ার্কিং এবং এনভায়রনমেন্ট ভেরিয়েবল সম্পর্কে কিছু তথ্য নির্দিষ্ট করি।
spanner_config হলো একটি Kubernetes ConfigMap যা অ্যাপ্লিকেশনটির স্প্যানারের সাথে সংযোগ স্থাপনের জন্য প্রয়োজনীয় প্রজেক্ট, ইনস্ট্যান্স এবং ডেটাবেস সম্পর্কিত তথ্য নির্দিষ্ট করে।
apiVersion: v1
kind: ConfigMap
metadata:
name: spanner-config
data:
SPANNER_PROJECT_ID: ${project_id}
SPANNER_INSTANCE_ID: ${instance_id}
SPANNER_DATABASE_ID: ${database_id}
ports:
- containerPort: 80
envFrom:
- configMapRef:
name: spanner-config
env:
- name: SERVICE_HOST
value: "0.0.0.0"
- name: SERVICE_PORT
value: "80"
SERVICE_HOST এবং SERVICE_PORT হলো অতিরিক্ত এনভায়রনমেন্ট ভেরিয়েবল, যা সার্ভিসটির বাইন্ড করার স্থান জানার জন্য প্রয়োজন হয়।
শেষ অংশটি GKE-কে বলে দেয় যে এই ডেপ্লয়মেন্টে প্রতিটি রেপ্লিকার জন্য কী পরিমাণ রিসোর্স বরাদ্দ করতে হবে। প্রয়োজন অনুযায়ী ক্লাস্টার স্কেল করার জন্য GKE Autopilot-ও এটিই ব্যবহার করে।
resources:
requests:
cpu: "1"
memory: "1Gi"
ephemeral-storage: "100Mi"
limits:
cpu: "1"
memory: "1Gi"
ephemeral-storage: "100Mi"
এই তথ্যের ভিত্তিতে, এখন ব্যাকএন্ড সার্ভিসগুলো ডেপ্লয় করার সময় হয়েছে।
ব্যাকএন্ড পরিষেবাগুলি স্থাপন করুন
যেমনটি উল্লেখ করা হয়েছে, ব্যাকএন্ড সার্ভিসগুলো ডেপ্লয় করতে ক্লাউড বিল্ড ব্যবহার করা হয়। স্কিমা মাইগ্রেশনের মতোই, আপনি gcloud কমান্ড লাইন ব্যবহার করে বিল্ড রিকোয়েস্ট সাবমিট করতে পারেন:
cd $DEMO_HOME/backend_services gcloud builds submit --config=cloudbuild.yaml
কমান্ড আউটপুট
Creating temporary tarball archive of 66 file(s) totalling 864.6 KiB before compression.
Uploading tarball of [.] to [gs://(project)_cloudbuild/source/(snip).tgz]
Created [https://cloudbuild.googleapis.com/v1/projects/(project)/locations/global/builds/30207dd1-(snip)].
Logs are available at [ https://console.cloud.google.com/cloud-build/builds/30207dd1-(snip)?project=(snip) ].
gcloud builds submit only displays logs from Cloud Storage. To view logs from Cloud Logging, run:
gcloud beta builds submit
ID: 30207dd1-(snip)
CREATE_TIME: (created time)
DURATION: 3M17S
SOURCE: gs://(project)_cloudbuild/source/(snip).tgz
IMAGES: us-docker.pkg.dev/(project)/spanner-game-images/profile:30207dd1-(snip) (+3 more)
STATUS: SUCCESS
schema migration ধাপের আউটপুটের বিপরীতে, এই বিল্ডের আউটপুট থেকে বোঝা যায় যে কিছু ইমেজ তৈরি হয়েছে। সেগুলো আপনার আর্টিফ্যাক্ট রেজিস্ট্রি রিপোজিটরিতে সংরক্ষিত হবে।
gcloud build স্টেপের আউটপুটে ক্লাউড কনসোলের একটি লিঙ্ক থাকবে। সেগুলো দেখে নিন।
ক্লাউড বিল্ড থেকে সফলতার নোটিফিকেশন পেয়ে গেলে, ক্লাউড ডিপ্লয়-এ যান এবং তারপর ডিপ্লয়মেন্টের অগ্রগতি পর্যবেক্ষণ করতে sample-game-services পাইপলাইনে প্রবেশ করুন।
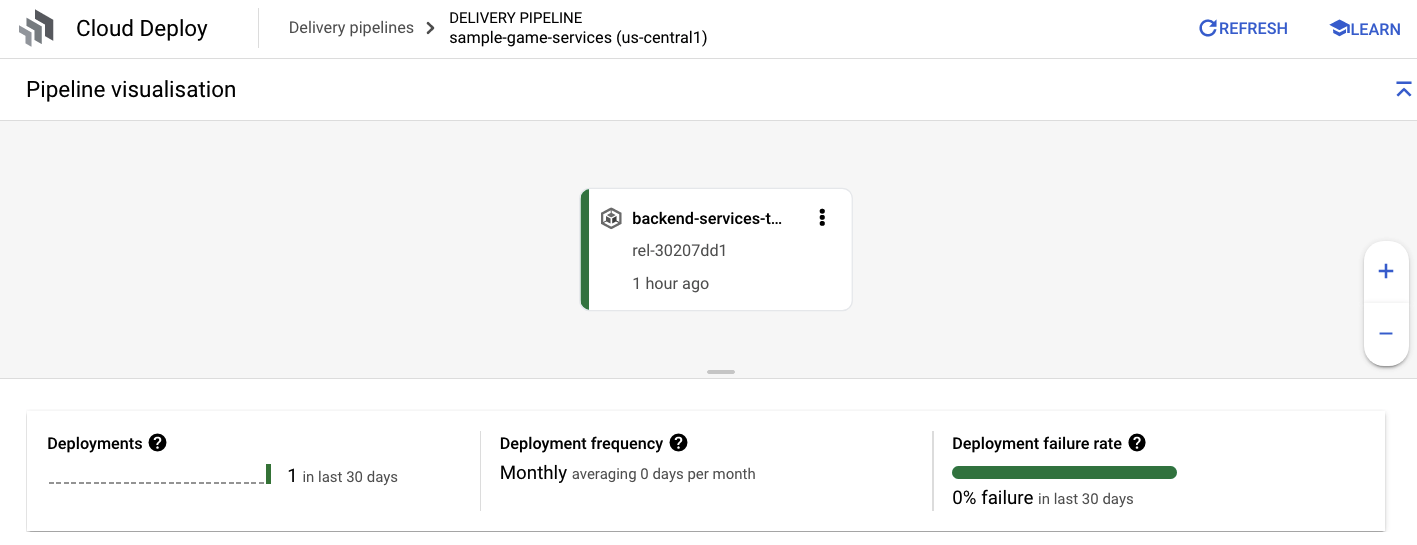
সার্ভিসগুলো ডেপ্লয় করা হয়ে গেলে, পডগুলোর স্ট্যাটাস দেখতে আপনি kubectl চেক করতে পারেন:
kubectl get pods
কমান্ড আউটপুট
NAME READY STATUS RESTARTS AGE
item-6b9d5f678c-4tbk2 1/1 Running 0 83m
matchmaking-5bcf799b76-lg8zf 1/1 Running 0 80m
profile-565bbf4c65-kphdl 1/1 Running 0 83m
profile-565bbf4c65-xw74j 1/1 Running 0 83m
tradepost-68b87ccd44-gw55r 1/1 Running 0 79m
তারপর, ClusterIP এর কার্যকারিতা দেখতে সার্ভিসগুলো চেক করুন:
kubectl get services
কমান্ড আউটপুট
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
item ClusterIP 10.172.XXX.XXX <none> 80/TCP 84m
kubernetes ClusterIP 10.172.XXX.XXX <none> 443/TCP 137m
matchmaking ClusterIP 10.172.XXX.XXX <none> 80/TCP 84m
profile ClusterIP 10.172.XXX.XXX <none> 80/TCP 84m
tradepost ClusterIP 10.172.XXX.XXX <none> 80/TCP 84m
এছাড়াও আপনি ক্লাউড কনসোলে থাকা GKE UI-তে গিয়ে Workloads , Services এবং ConfigMaps দেখতে পারেন।
কাজের চাপ
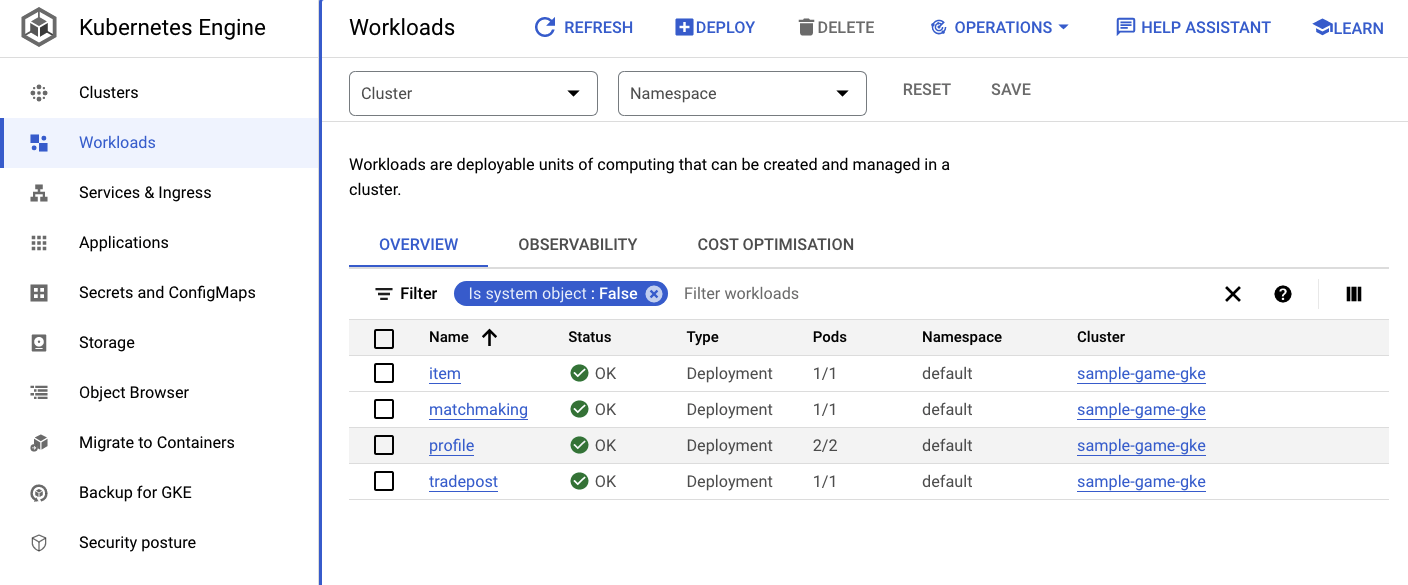
পরিষেবা
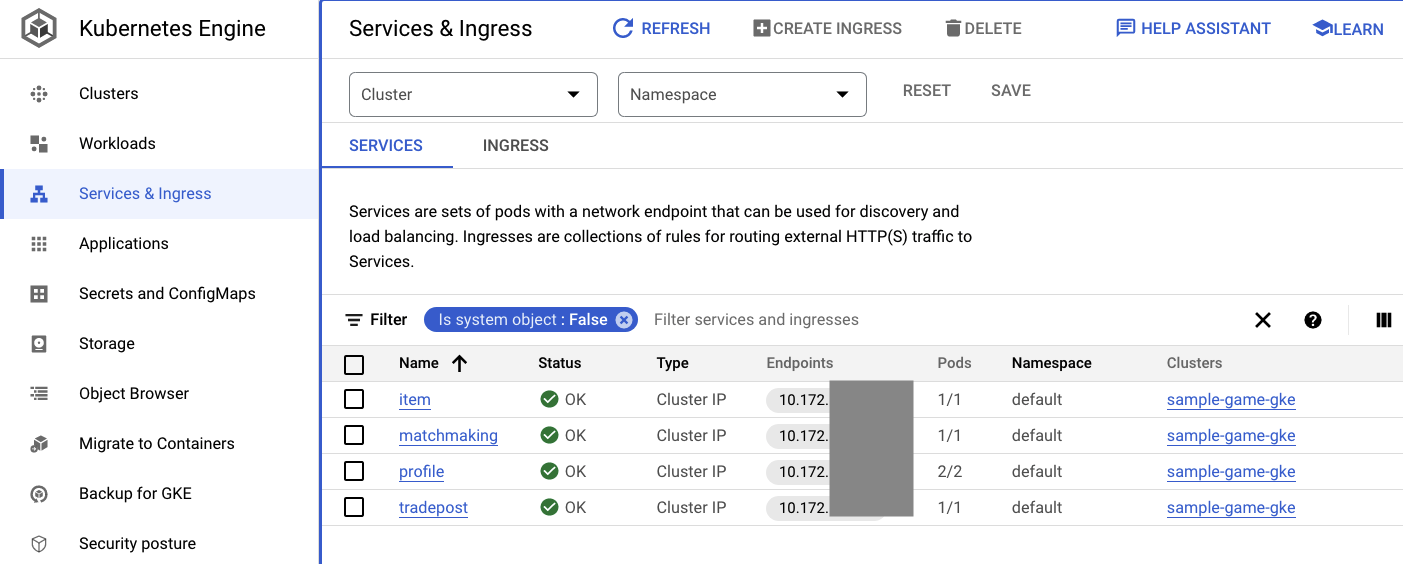
কনফিগম্যাপস


সারসংক্ষেপ
এই ধাপে, আপনি GKE Autopilot-এ চারটি ব্যাকএন্ড সার্ভিস ডেপ্লয় করেছেন। আপনি Cloud Build ধাপটি চালাতে এবং Cloud Deploy-তে ও Cloud Console-এ Kubernetes-এ এর অগ্রগতি পরীক্ষা করতে সক্ষম হয়েছেন।
আপনি আরও শিখেছেন কিভাবে এই পরিষেবাগুলি ওয়ার্কলোড আইডেন্টিটি ব্যবহার করে এমন একটি পরিষেবা অ্যাকাউন্টের ছদ্মবেশ ধারণ করে, যেটির স্প্যানার ডেটাবেসে ডেটা পড়া এবং লেখার সঠিক অনুমতি রয়েছে।
পরবর্তী পদক্ষেপ
পরবর্তী অংশে আপনি ওয়ার্কলোডগুলো ডেপ্লয় করবেন।
৬. ওয়ার্কলোডগুলো স্থাপন করুন
সংক্ষিপ্ত বিবরণ
এখন যেহেতু ক্লাস্টারে ব্যাকএন্ড সার্ভিসগুলো চালু হয়ে গেছে, আপনি ওয়ার্কলোডগুলো ডেপ্লয় করবেন।

ওয়ার্কলোডগুলো বাহ্যিকভাবে অ্যাক্সেসযোগ্য, এবং এই কোডল্যাবের উদ্দেশ্যে প্রতিটি ব্যাকএন্ড সার্ভিসের জন্য একটি করে ওয়ার্কলোড রয়েছে।
এই ওয়ার্কলোডগুলি হলো Locust- ভিত্তিক লোড জেনারেশন স্ক্রিপ্ট, যা এই নমুনা পরিষেবাগুলির দ্বারা প্রত্যাশিত বাস্তব অ্যাক্সেস প্যাটার্নগুলির অনুকরণ করে।
ক্লাউড বিল্ড প্রক্রিয়ার জন্য ফাইল রয়েছে:
-
$DEMO_HOME/workloads/cloudbuild.yaml(টেরাফর্ম দ্বারা তৈরি) -
$DEMO_HOME/workloads/skaffold.yaml - প্রতিটি ওয়ার্কলোডের জন্য একটি
deployment.yamlফাইল
ওয়ার্কলোড deployment.yaml ফাইলগুলো ব্যাকএন্ড সার্ভিস deployment ফাইলগুলো থেকে দেখতে কিছুটা ভিন্ন হয়।
matchmaking-workload থেকে এখানে একটি উদাহরণ দেওয়া হলো:
apiVersion: v1
kind: Service
metadata:
name: matchmaking-workload
spec:
type: LoadBalancer
selector:
app: matchmaking-workload
ports:
- port: 8089
targetPort: 8089
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: matchmaking-workload
spec:
replicas: 1 # EDIT: Number of instances of deployment
selector:
matchLabels:
app: matchmaking-workload
template:
metadata:
labels:
app: matchmaking-workload
spec:
serviceAccountName: default
containers:
- name: matchmaking-workload
image: matchmaking-workload
ports:
- containerPort: 8089
resources:
requests:
cpu: "500m"
memory: "512Mi"
ephemeral-storage: "100Mi"
limits:
cpu: "500m"
memory: "512Mi"
ephemeral-storage: "100Mi"
ফাইলের উপরের অংশে সার্ভিসটি সংজ্ঞায়িত করা হয়। এক্ষেত্রে, একটি LoadBalancer তৈরি করা হয়েছে এবং ওয়ার্কলোডটি 8089 পোর্টে চলে।
লোডব্যালেন্সারটি একটি এক্সটার্নাল আইপি প্রদান করবে যা ওয়ার্কলোডের সাথে সংযোগ করার জন্য ব্যবহার করা যাবে।
apiVersion: v1
kind: Service
metadata:
name: matchmaking-workload
spec:
type: LoadBalancer
selector:
app: matchmaking-workload
ports:
- port: 8089
targetPort: 8089
ডিপ্লয়মেন্ট সেকশনের শীর্ষে ওয়ার্কলোড সম্পর্কিত মেটাডেটা থাকে। এক্ষেত্রে, শুধুমাত্র একটি রেপ্লিকা ডিপ্লয় করা হচ্ছে:
replicas: 1
তবে কন্টেইনার স্পেকটি ভিন্ন। প্রথমত, আমরা একটি default কুবারনেটিস সার্ভিস অ্যাকাউন্ট ব্যবহার করছি। এই অ্যাকাউন্টের কোনো বিশেষ সুবিধা নেই, কারণ ওয়ার্কলোডটির GKE ক্লাস্টারে চলমান ব্যাকএন্ড সার্ভিসগুলো ছাড়া অন্য কোনো গুগল ক্লাউড রিসোর্সের সাথে সংযোগ করার প্রয়োজন নেই।
আরেকটি পার্থক্য হলো, এই ওয়ার্কলোডগুলোর জন্য কোনো এনভায়রনমেন্ট ভেরিয়েবলের প্রয়োজন হয় না। এর ফলে ডেপ্লয়মেন্ট স্পেসিফিকেশনটি সংক্ষিপ্ত হয়।
spec:
serviceAccountName: default
containers:
- name: matchmaking-workload
image: matchmaking-workload
ports:
- containerPort: 8089
রিসোর্স সেটিংস ব্যাকএন্ড সার্ভিসগুলোর মতোই। মনে রাখবেন, ক্লাস্টারে চলমান সমস্ত পডের অনুরোধ মেটাতে কী পরিমাণ রিসোর্সের প্রয়োজন, তা GKE Autopilot এভাবেই জানতে পারে।
এগিয়ে যান এবং ওয়ার্কলোডগুলো ডেপ্লয় করুন!
ওয়ার্কলোডগুলি স্থাপন করুন
আগের মতোই, আপনি gcloud কমান্ড লাইন ব্যবহার করে বিল্ড অনুরোধটি জমা দিতে পারেন:
cd $DEMO_HOME/workloads gcloud builds submit --config=cloudbuild.yaml
কমান্ড আউটপুট
Creating temporary tarball archive of 18 file(s) totalling 26.2 KiB before compression.
Some files were not included in the source upload.
Check the gcloud log [/tmp/tmp.4Z9EqdPo6d/logs/(snip).log] to see which files and the contents of the
default gcloudignore file used (see `$ gcloud topic gcloudignore` to learn
more).
Uploading tarball of [.] to [gs://(project)_cloudbuild/source/(snip).tgz]
Created [https://cloudbuild.googleapis.com/v1/projects/(project)/locations/global/builds/(snip)].
Logs are available at [ https://console.cloud.google.com/cloud-build/builds/0daf20f6-(snip)?project=(snip) ].
gcloud builds submit only displays logs from Cloud Storage. To view logs from Cloud Logging, run:
gcloud beta builds submit
ID: 0daf20f6-(snip)
CREATE_TIME: (created_time)
DURATION: 1M41S
SOURCE: gs://(project)_cloudbuild/source/(snip).tgz
IMAGES: us-docker.pkg.dev/(project)/spanner-game-images/profile-workload:0daf20f6-(snip) (+4 more)
STATUS: SUCCESS
অবস্থা যাচাই করার জন্য ক্লাউড কনসোলে ক্লাউড বিল্ড লগ এবং ক্লাউড ডিপ্লয় পাইপলাইন অবশ্যই পরীক্ষা করুন। ওয়ার্কলোডগুলির জন্য, ক্লাউড ডিপ্লয় পাইপলাইনটি হলো sample-game-workloads :
ডিপ্লয়মেন্ট সম্পন্ন হলে, ক্লাউড শেলে kubectl দিয়ে স্ট্যাটাস চেক করুন:
kubectl get pods
কমান্ড আউটপুট
NAME READY STATUS RESTARTS AGE
game-workload-7ff44cb657-pxxq2 1/1 Running 0 12m
item-6b9d5f678c-cr29w 1/1 Running 0 9m6s
item-generator-7bb4f57cf8-5r85b 1/1 Running 0 12m
matchmaking-5bcf799b76-lg8zf 1/1 Running 0 117m
matchmaking-workload-76df69dbdf-jds9z 1/1 Running 0 12m
profile-565bbf4c65-kphdl 1/1 Running 0 121m
profile-565bbf4c65-xw74j 1/1 Running 0 121m
profile-workload-76d6db675b-kzwng 1/1 Running 0 12m
tradepost-68b87ccd44-gw55r 1/1 Running 0 116m
tradepost-workload-56c55445b5-b5822 1/1 Running 0 12m
তারপর, LoadBalancer কীভাবে কাজ করছে তা দেখতে ওয়ার্কলোড সার্ভিসগুলো পরীক্ষা করুন:
kubectl get services
কমান্ড আউটপুট
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
game-workload LoadBalancer *snip* 35.XX.XX.XX 8089:32483/TCP 12m
item ClusterIP *snip* <none> 80/TCP 121m
item-generator LoadBalancer *snip* 34.XX.XX.XX 8089:32581/TCP 12m
kubernetes ClusterIP *snip* <none> 443/TCP 174m
matchmaking ClusterIP *snip* <none> 80/TCP 121m
matchmaking-workload LoadBalancer *snip* 34.XX.XX.XX 8089:31735/TCP 12m
profile ClusterIP *snip* <none> 80/TCP 121m
profile-workload LoadBalancer *snip* 34.XX.XX.XX 8089:32532/TCP 12m
tradepost ClusterIP *snip* <none> 80/TCP 121m
tradepost-workload LoadBalancer *snip* 34.XX.XX.XX 8089:30002/TCP 12m
সারসংক্ষেপ
আপনি এখন GKE ক্লাস্টারে ওয়ার্কলোডগুলো স্থাপন করেছেন। এই ওয়ার্কলোডগুলোর জন্য কোনো অতিরিক্ত IAM অনুমতির প্রয়োজন নেই এবং LoadBalancer পরিষেবা ব্যবহার করে পোর্ট 8089-এ এগুলো বাহ্যিকভাবে অ্যাক্সেসযোগ্য।
পরবর্তী পদক্ষেপ
ব্যাকএন্ড সার্ভিস ও ওয়ার্কলোডগুলো চালু হয়ে গেলে, এবার খেলা শুরু করার পালা!
৭. খেলাটি শুরু করুন।
সংক্ষিপ্ত বিবরণ
আপনার নমুনা "গেম"-এর জন্য ব্যাকএন্ড পরিষেবাগুলো এখন চালু আছে, এবং ওয়ার্কলোডগুলো ব্যবহার করে সেই পরিষেবাগুলোর সাথে মিথস্ক্রিয়াকারী "খেলোয়াড়" তৈরি করার উপায়ও আপনার কাছে রয়েছে।
প্রতিটি ওয়ার্কলোড আমাদের সার্ভিস এপিআই-গুলোর ওপর প্রকৃত লোড অনুকরণ করতে লোকাস্ট ব্যবহার করে। এই ধাপে, আপনি জিকেই ক্লাস্টার এবং স্প্যানারে লোড তৈরি করার জন্য কয়েকটি ওয়ার্কলোড চালাবেন, এবং সেই সাথে স্প্যানারে ডেটাও সংরক্ষণ করবেন।
এখানে প্রতিটি ওয়ার্কলোডের বিবরণ দেওয়া হলো:
-
item-generatorওয়ার্কলোডটি একটি দ্রুত ওয়ার্কলোড, যা গেম খেলার সময় খেলোয়াড়দের অর্জন করতে পারা গেম আইটেমগুলোর একটি তালিকা তৈরি করে। -
profile-workloadখেলোয়াড়দের সাইন আপ এবং লগ ইন করার প্রক্রিয়াকে অনুকরণ করে। -
matchmaking-workloadগেমে অন্তর্ভুক্ত হওয়ার জন্য খেলোয়াড়দের সারিবদ্ধভাবে অপেক্ষা করার বিষয়টিকে অনুকরণ করে। -
game-workloadগেম খেলার সময় খেলোয়াড়দের গেম আইটেম এবং অর্থ অর্জনের প্রক্রিয়াকে অনুকরণ করে। -
tradepost-workloadখেলোয়াড়দের ট্রেডিং পোস্টে জিনিসপত্র কেনা-বেচা করার সুযোগকে অনুকরণ করে।
এই কোডল্যাবে বিশেষভাবে item-generator এবং profile-workload চালানোর বিষয়টি তুলে ধরা হবে।
আইটেম-জেনারেটরটি চালান
item-generator স্প্যানারে game_items যোগ করার জন্য item ব্যাকএন্ড সার্ভিস এন্ডপয়েন্ট ব্যবহার করে। game-workload এবং tradepost-workload সঠিকভাবে কাজ করার জন্য এই আইটেমগুলো প্রয়োজন।
প্রথম ধাপ হলো item-generator সার্ভিসের এক্সটার্নাল আইপি সংগ্রহ করা। ক্লাউড শেলে নিম্নলিখিত কমান্ডটি চালান:
# The external IP is the 4th column of the output
kubectl get services | grep item-generator | awk '{print $4}'
কমান্ড আউটপুট
{ITEMGENERATOR_EXTERNAL_IP}
এখন, একটি নতুন ব্রাউজার ট্যাব খুলুন এবং http://{ITEMGENERATOR_EXTERNAL_IP}:8089 -এ যান । আপনি এইরকম একটি পৃষ্ঠা দেখতে পাবেন:
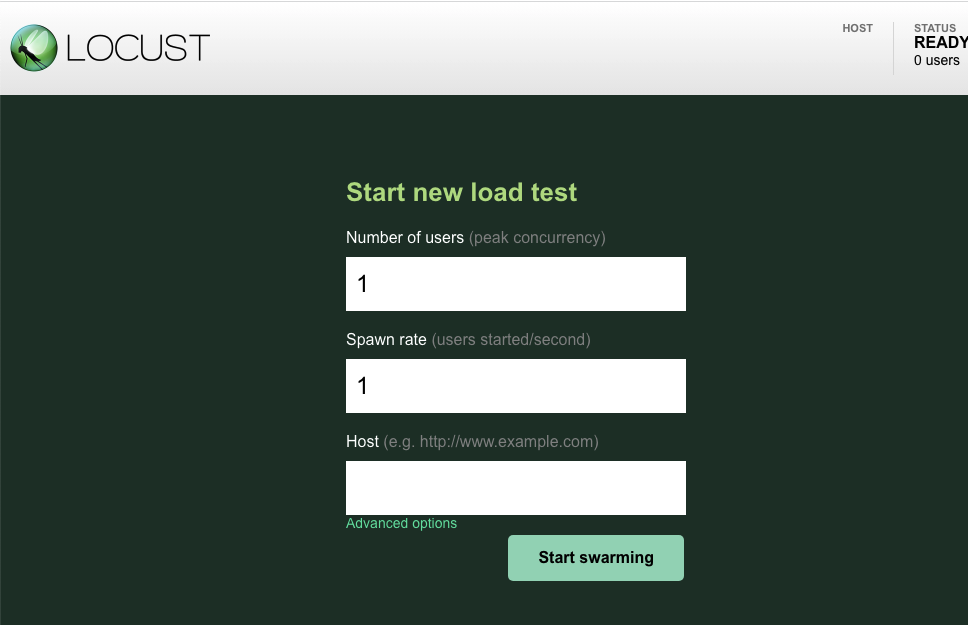
আপনি users রেখে ডিফল্ট ১-এ spawn । host জন্য , http://item লিখুন। অ্যাডভান্সড অপশনগুলিতে ক্লিক করুন এবং চলমান সময়ের জন্য 10s লিখুন।
কনফিগারেশনটি দেখতে এইরকম হওয়া উচিত:
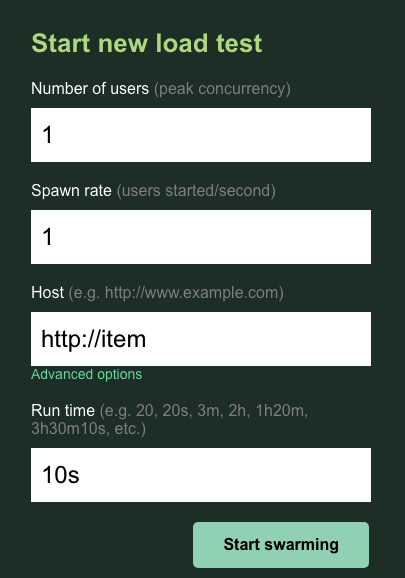
'ঝাঁক বাঁধা শুরু করুন'-এ ক্লিক করুন!
POST /items এন্ডপয়েন্টে পাঠানো অনুরোধগুলোর পরিসংখ্যান দেখানো শুরু হবে। ১০ সেকেন্ড পর লোড হওয়া বন্ধ হয়ে যাবে।
Charts ক্লিক করলে আপনি এই অনুরোধগুলোর পারফরম্যান্স সংক্রান্ত কিছু গ্রাফ দেখতে পাবেন।
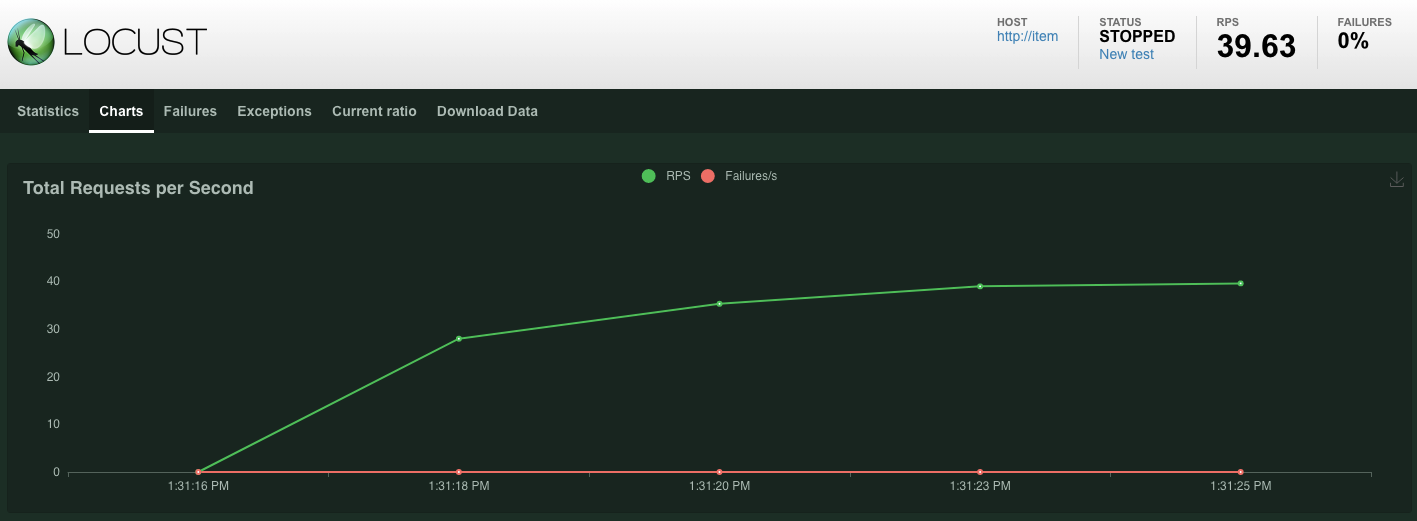
এখন, আপনি যাচাই করতে চাইবেন যে ডেটাটি স্প্যানার ডেটাবেসে প্রবেশ করানো হয়েছে কি না।
এটি করার জন্য, হ্যামবার্গার মেনুতে ক্লিক করে 'স্প্যানার'-এ যান। এই পৃষ্ঠা থেকে, sample-instance এবং sample-database -এ যান। তারপর ' Query -তে ক্লিক করুন।
আমরা game_items সংখ্যা নির্বাচন করতে চাই :
গেম_আইটেম টেবিল থেকে প্রতিটি আইটেমের সংখ্যা নির্বাচন করুন।
নিচে আপনি আপনার ফলাফল পাবেন।
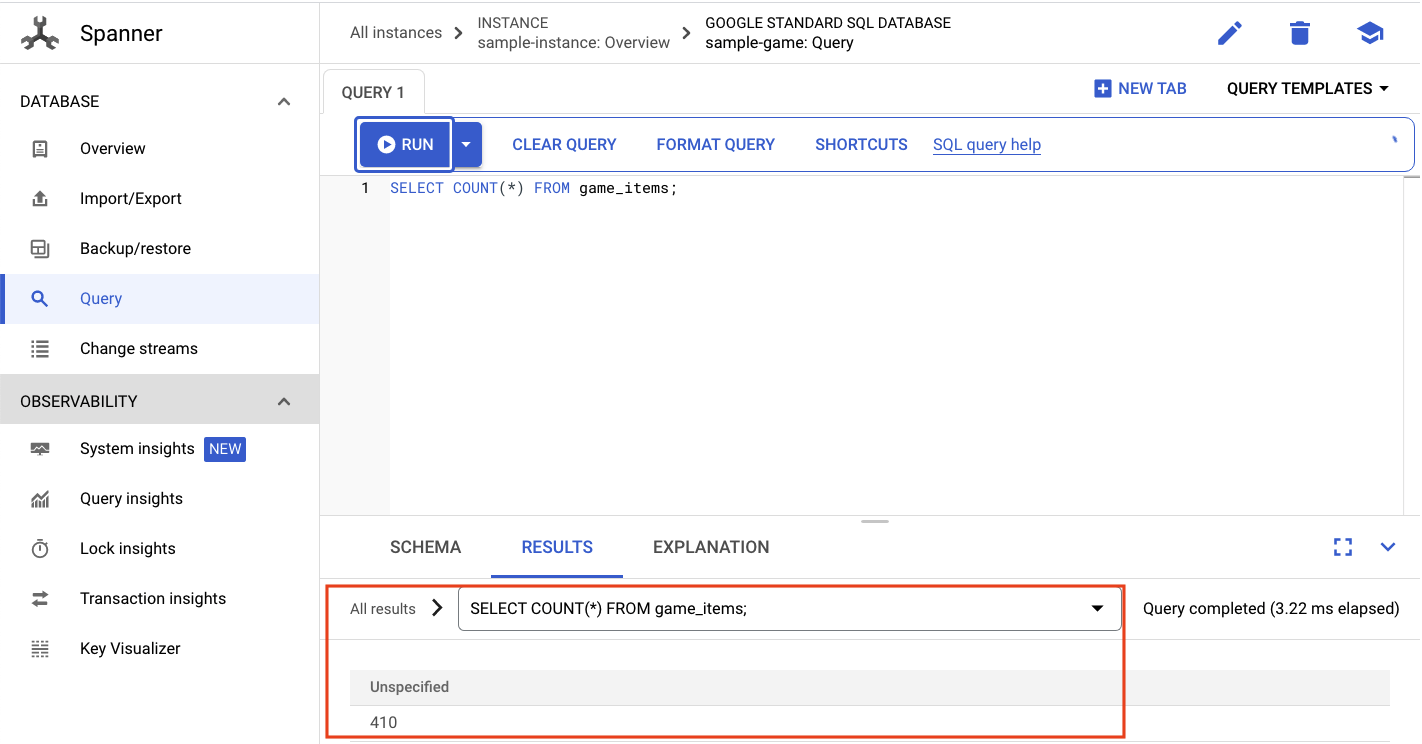
আমাদের প্রচুর পরিমাণে game_items যোগ করার প্রয়োজন নেই। কিন্তু এখন সেগুলো খেলোয়াড়দের সংগ্রহ করার জন্য উপলব্ধ!
প্রোফাইল-ওয়ার্কলোড চালান
আপনার game_items প্রস্তুত হয়ে গেলে, পরবর্তী ধাপ হলো গেম খেলার জন্য খেলোয়াড়দের সাইন আপ করানো।
profile-workload প্লেয়ারদের অ্যাকাউন্ট তৈরি করা, লগ ইন করা, প্রোফাইলের তথ্য পুনরুদ্ধার করা এবং লগ আউট করার প্রক্রিয়াগুলো সিমুলেট করতে Locust ব্যবহার করবে। এই সবগুলোই একটি সাধারণ প্রোডাকশন-সদৃশ ওয়ার্কলোডে profile ব্যাকএন্ড সার্ভিসের এন্ডপয়েন্টগুলোকে পরীক্ষা করে।
এটি চালানোর জন্য, profile-workload এক্সটার্নাল আইপি-টি নিন:
# The external IP is the 4th column of the output
kubectl get services | grep profile-workload | awk '{print $4}'
কমান্ড আউটপুট
{PROFILEWORKLOAD_EXTERNAL_IP}
এখন, একটি নতুন ব্রাউজার ট্যাব খুলুন এবং http://{PROFILEWORKLOAD_EXTERNAL_IP}:8089 -এ যান । আপনি আগেরটির মতো একটি Locust পৃষ্ঠা দেখতে পাবেন।
এক্ষেত্রে, হোস্ট হিসেবে আপনি http://profile ব্যবহার করবেন। এবং অ্যাডভান্সড অপশনে কোনো রানটাইম নির্দিষ্ট করবেন না। এছাড়াও, users সংখ্যা ৪ নির্দিষ্ট করুন, যা একই সময়ে ৪টি ব্যবহারকারীর অনুরোধ অনুকরণ করবে।
profile-workload পরীক্ষাটি দেখতে এইরকম হওয়া উচিত:

'ঝাঁক বাঁধা শুরু করুন'-এ ক্লিক করুন!
আগের মতোই, বিভিন্ন profile REST এন্ডপয়েন্টগুলোর পরিসংখ্যান দেখানো শুরু হবে। সবকিছু কতটা ভালো কাজ করছে তা দেখতে চার্ট অংশে ক্লিক করুন।
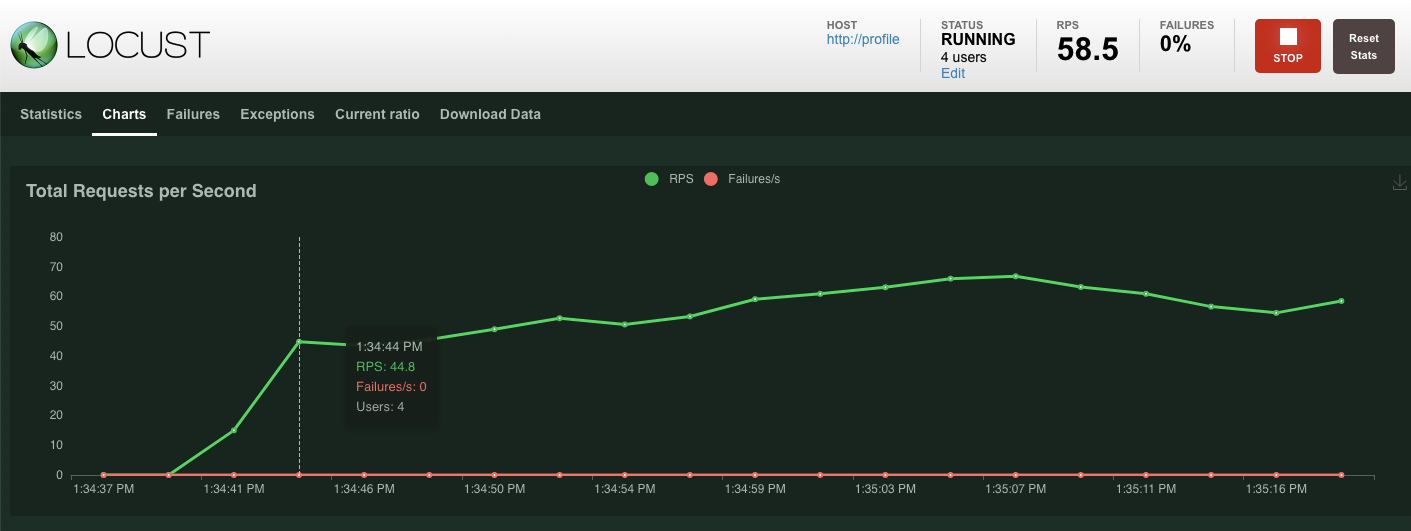
সারসংক্ষেপ
এই ধাপে, আপনি কিছু game_items তৈরি করেছেন এবং তারপর ক্লাউড কনসোলের স্প্যানার কোয়েরি UI ব্যবহার করে game_items টেবিলটি কোয়েরি করেছেন।
আপনি খেলোয়াড়দের আপনার গেমে সাইন আপ করার সুযোগও দিয়েছেন এবং দেখেছেন কীভাবে লোকাস্ট আপনার ব্যাকএন্ড সার্ভিসগুলোর বিপরীতে প্রোডাকশন-সদৃশ ওয়ার্কলোড তৈরি করতে সক্ষম।
পরবর্তী পদক্ষেপ
ওয়ার্কলোডগুলো চালানোর পরে, GKE ক্লাস্টার এবং স্প্যানার ইনস্ট্যান্স কেমন আচরণ করছে তা আপনি যাচাই করে দেখতে চাইবেন।
৮. GKE এবং স্প্যানার ব্যবহার পর্যালোচনা করুন
প্রোফাইল সার্ভিসটি চালু হয়ে গেলে, আপনার GKE Autopilot ক্লাস্টার এবং Cloud Spanner কেমন আচরণ করছে তা দেখে নেওয়ার এটাই উপযুক্ত সময়।
GKE ক্লাস্টারে পরীক্ষা করুন
Kubernetes ক্লাস্টারে যান। লক্ষ্য করুন যে, আপনি ওয়ার্কলোড এবং সার্ভিসগুলো ডেপ্লয় করার পর, ক্লাস্টারটিতে এখন মোট vCPU এবং মেমরি সম্পর্কে কিছু বিবরণ যুক্ত হয়েছে। যখন ক্লাস্টারে কোনো ওয়ার্কলোড ছিল না, তখন এই তথ্যটি উপলব্ধ ছিল না।

এখন, sample-game-gke ক্লাস্টারে ক্লিক করুন এবং অবজার্ভেবিলিটি ট্যাবে যান:

যেহেতু আমাদের ওয়ার্কলোড এবং ব্যাকএন্ড সার্ভিসগুলো default kubernetes নেমস্পেসে চলে, default সিপিইউ ব্যবহারের ক্ষেত্রে এর kube-system নেমস্পেসকে ছাড়িয়ে যাওয়ার কথা। যদি তা না হয়ে থাকে, তবে নিশ্চিত করুন যে profile workload এখনও চলছে এবং চার্টগুলো আপডেট হওয়ার জন্য কয়েক মিনিট অপেক্ষা করুন।
কোন ওয়ার্কলোডগুলো সবচেয়ে বেশি রিসোর্স ব্যবহার করছে তা দেখতে, Workloads ড্যাশবোর্ডে যান।
প্রতিটি ওয়ার্কলোড আলাদাভাবে না দেখে, সরাসরি ড্যাশবোর্ডের অবজার্ভেবিলিটি ট্যাবে যান। আপনি দেখতে পাবেন যে profile এবং profile-workload সিপিইউ বেড়ে গেছে।
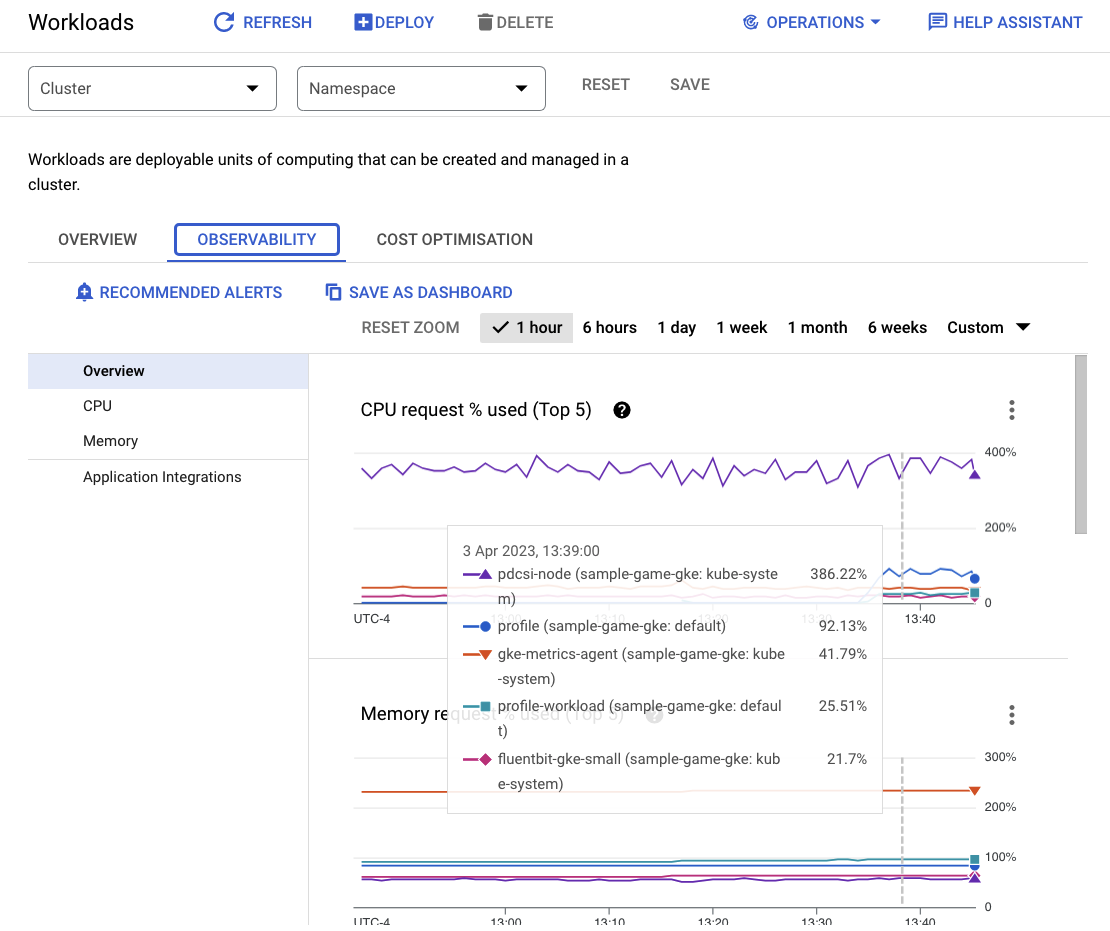
এখন, ক্লাউড স্প্যানার চেক করে দেখুন।
ক্লাউড স্প্যানার ইনস্ট্যান্সে চেক করুন
ক্লাউড স্প্যানারের পারফরম্যান্স পরীক্ষা করতে, স্প্যানারে যান এবং sample-instance ইনস্ট্যান্স ও sample-game ডেটাবেসে ক্লিক করুন।
সেখান থেকে, আপনি বাম মেনুতে একটি সিস্টেম ইনসাইটস ট্যাব দেখতে পাবেন:
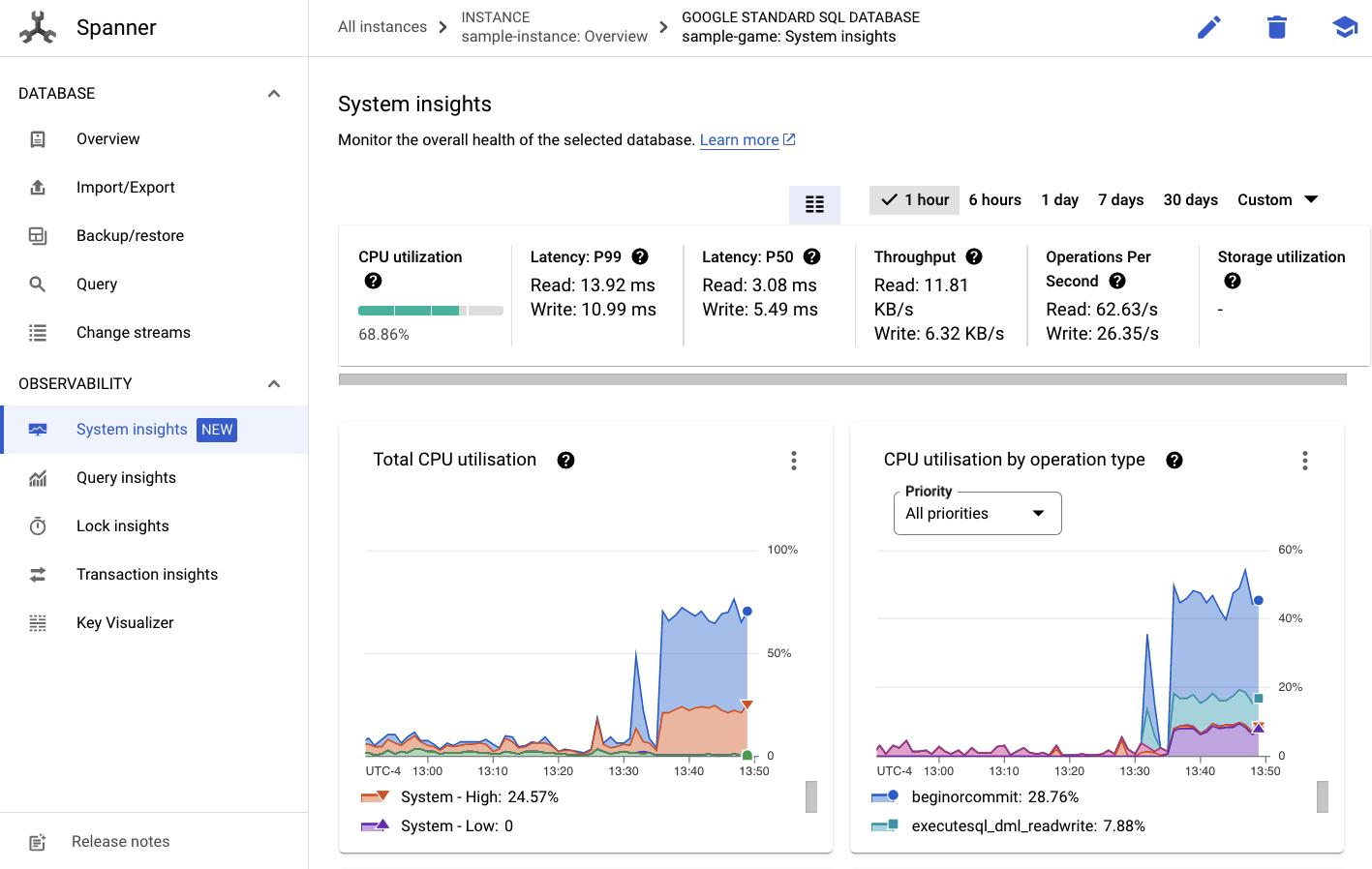
আপনার স্প্যানার ইনস্ট্যান্সের সার্বিক পারফরম্যান্স বুঝতে সাহায্য করার জন্য এখানে অনেকগুলো চার্ট রয়েছে, যার মধ্যে CPU utilization , transaction latency and locking এবং query throughput অন্তর্ভুক্ত।
সিস্টেম ইনসাইটস ছাড়াও, আপনি অবজার্ভেবিলিটি সেকশনের অন্যান্য লিঙ্কগুলো দেখে কোয়েরি ওয়ার্কলোড সম্পর্কে আরও বিস্তারিত তথ্য পেতে পারেন:
- কোয়েরি ইনসাইটস স্প্যানারের রিসোর্স ব্যবহারকারী শীর্ষ N সংখ্যক কোয়েরি শনাক্ত করতে সাহায্য করে।
- ট্রানজ্যাকশন এবং লক ইনসাইটস উচ্চ ল্যাটেন্সিযুক্ত ট্রানজ্যাকশন শনাক্ত করতে সাহায্য করে।
- কী ভিজ্যুয়ালাইজার অ্যাক্সেস প্যাটার্নগুলো কল্পনা করতে এবং ডেটার মধ্যে হটস্পটগুলো খুঁজে বের করতে সাহায্য করে।
সারসংক্ষেপ
এই ধাপে, আপনি GKE Autopilot এবং Spanner উভয়ের কিছু প্রাথমিক পারফরম্যান্স মেট্রিক কীভাবে পরীক্ষা করতে হয় তা শিখেছেন।
উদাহরণস্বরূপ, আপনার প্রোফাইল সংক্রান্ত কাজ চলার সময়, সেখানে সংরক্ষিত ডেটা সম্পর্কে আরও কিছু তথ্য পেতে প্লেয়ার্স টেবিলটি কোয়েরি করুন।
পরবর্তী পদক্ষেপ
এরপর, সবকিছু পরিষ্কার করার পালা!
৯. পরিষ্কার করা
পরিষ্কার করার আগে, যে ওয়ার্কলোডগুলো অন্তর্ভুক্ত করা হয়নি সেগুলো নির্দ্বিধায় দেখে নিতে পারেন। বিশেষ করে matchmaking-workload , game-workload এবং tradepost-workload ।
খেলা শেষ হলে তুমি তোমার খেলার জায়গাটা পরিষ্কার করতে পারো। সৌভাগ্যবশত, এই কাজটা বেশ সহজ।
প্রথমে, যদি আপনার profile-workload এখনও ব্রাউজারে চালু থাকে, তাহলে গিয়ে সেটি বন্ধ করুন:

আপনি পরীক্ষা করে দেখেছেন এমন প্রতিটি ওয়ার্কলোডের ক্ষেত্রেও একই কাজ করুন।
এরপর ক্লাউড শেলে, ইনফ্রাস্ট্রাকচার ফোল্ডারে যান। আপনি টেরাফর্ম ব্যবহার করে ইনফ্রাস্ট্রাকচারটি destroy করবেন:
cd $DEMO_HOME/infrastructure
terraform destroy
# type 'yes' when asked
কমান্ড আউটপুট
Plan: 0 to add, 0 to change, 46 to destroy.
Do you really want to destroy all resources?
Terraform will destroy all your managed infrastructure, as shown above.
There is no undo. Only 'yes' will be accepted to confirm.
Enter a value: yes
*snip*
Destroy complete! Resources: 46 destroyed.
ক্লাউড কনসোলে, Spanner , Kubernetes Cluster , Artifact Registry , Cloud Deploy , এবং IAM -এ গিয়ে যাচাই করুন যে সমস্ত রিসোর্স মুছে ফেলা হয়েছে।
১০. অভিনন্দন!
অভিনন্দন, আপনি সফলভাবে GKE Autopilot-এ নমুনা গোল্যাং অ্যাপ্লিকেশনগুলো স্থাপন করেছেন এবং Workload Identity ব্যবহার করে সেগুলোকে Cloud Spanner-এর সাথে সংযুক্ত করেছেন!
অতিরিক্ত সুবিধা হিসেবে, টেরাফর্ম ব্যবহার করে এই পরিকাঠামোটি বারবার এবং সহজে তৈরি ও অপসারণ করা যেত।
এই কোডল্যাবে আপনি যে গুগল ক্লাউড পরিষেবাগুলোর সাথে কাজ করেছেন, সে সম্পর্কে আরও পড়তে পারেন:
- GKE অটোপাইলট এবং ওয়ার্কলোড আইডেন্টিটি
- ক্লাউড স্প্যানার
- প্রত্নবস্তু রেজিস্ট্রি
- ক্লাউড বিল্ড এবং ক্লাউড ডিপ্লয়
এরপর কী?
GKE Autopilot এবং Cloud Spanner কীভাবে একসাথে কাজ করতে পারে সে সম্পর্কে এখন যেহেতু আপনার একটি প্রাথমিক ধারণা হয়েছে, তাহলে পরবর্তী পদক্ষেপ নিয়ে এই পরিষেবাগুলির সাথে কাজ করার জন্য আপনার নিজের অ্যাপ্লিকেশন তৈরি করা শুরু করছেন না কেন?