
1. Einführung
Cloud Spanner ist ein vollständig verwalteter, global verteilter, horizontal skalierbarer, relationaler Datenbankdienst, der ACID-Transaktionen und SQL-Semantik bietet, ohne Leistung und Hochverfügbarkeit zu beeinträchtigen.
GKE Autopilot ist ein Betriebsmodus in GKE, in dem Google Ihre Clusterkonfiguration verwaltet, einschließlich Knoten, Skalierung, Sicherheit und anderer vorkonfigurierter Einstellungen, um Best Practices zu folgen. In GKE Autopilot wird beispielsweise Workload Identity verwendet, um Dienstberechtigungen zu verwalten.
In diesem Lab lernen Sie, wie Sie mehrere in GKE Autopilot ausgeführte Backend-Dienste mit einer Cloud Spanner-Datenbank verbinden.

In diesem Lab richten Sie zuerst ein Projekt ein und starten Cloud Shell. Anschließend stellen Sie die Infrastruktur mit Terraform bereit.
Wenn das abgeschlossen ist, interagieren Sie mit Cloud Build und Cloud Deploy, um eine erste Schemamigration für die Games-Datenbank durchzuführen, die Backend-Dienste und dann die Arbeitslasten bereitzustellen.
Die Dienste in diesem Codelab sind dieselben wie im Codelab Erste Schritte mit Cloud Spanner für die Spieleentwicklung. Das Durchlaufen dieses Codelabs ist keine Voraussetzung, um die Dienste in GKE auszuführen und eine Verbindung zu Spanner herzustellen. Wenn Sie sich für weitere Details zu den Diensten interessieren, die in Spanner funktionieren, können Sie sich das ansehen.
Wenn die Arbeitslasten und Backend-Dienste ausgeführt werden, können Sie mit dem Generieren von Last beginnen und beobachten, wie die Dienste zusammenarbeiten.
Zum Schluss bereinigen Sie die Ressourcen, die in diesem Lab erstellt wurden.
Aufgaben
In diesem Lab haben Sie folgende Aufgaben:
- Infrastruktur mit Terraform bereitstellen
- Datenbankschema mit einem Schemamigrationsprozess in Cloud Build erstellen
- Die vier Golang-Backend-Dienste bereitstellen, die Workload Identity verwenden, um eine Verbindung zu Cloud Spanner herzustellen
- Stellen Sie die vier Arbeitslastdienste bereit, mit denen die Last für die Backend-Dienste simuliert wird.
Lerninhalte
- GKE Autopilot, Cloud Spanner und Cloud Deploy-Pipelines mit Terraform bereitstellen
- Wie Workload Identity es Diensten in GKE ermöglicht, die Identität von Dienstkonten anzunehmen, um auf die IAM-Berechtigungen für die Arbeit mit Cloud Spanner zuzugreifen
- Mit Locust.io eine produktionsähnliche Last in GKE und Cloud Spanner generieren
Voraussetzungen
2. Einrichtung und Anforderungen
Projekt erstellen
Wenn Sie noch kein Google-Konto (Gmail oder Google Apps) haben, müssen Sie eines erstellen. Melden Sie sich in der Google Cloud Console ( console.cloud.google.com) an und erstellen Sie ein neues Projekt.
Wenn Sie bereits ein Projekt haben, klicken Sie oben links in der Console auf das Drop-down-Menü zur Projektauswahl:

Klicken Sie im angezeigten Dialogfeld auf die Schaltfläche NEUES PROJEKT, um ein neues Projekt zu erstellen:
Wenn Sie noch kein Projekt haben, wird ein Dialogfeld wie das folgende angezeigt, in dem Sie Ihr erstes Projekt erstellen können:

Im nachfolgenden Dialogfeld zum Erstellen von Projekten können Sie die Details Ihres neuen Projekts eingeben:

Merken Sie sich die Projekt-ID. Sie ist für alle Google Cloud-Projekte ein eindeutiger Name. Der Name oben ist bereits vergeben und kann nicht verwendet werden. Sie wird später in diesem Codelab als PROJECT_ID bezeichnet.
Als Nächstes müssen Sie, falls noch nicht geschehen, die Abrechnung in der Entwicklerkonsole aktivieren, um Google Cloud-Ressourcen verwenden zu können, und die Cloud Spanner API aktivieren.
Dieses Codelab sollte Sie nicht mehr als ein paar Dollar kosten, aber es könnte mehr sein, wenn Sie sich für mehr Ressourcen entscheiden oder wenn Sie sie laufen lassen (siehe Abschnitt „Bereinigen“ am Ende dieses Dokuments). Die Preise für Google Cloud Spanner sind hier und die Preise für GKE Autopilot hier dokumentiert.
Neuen Nutzern der Google Cloud Platform steht eine kostenlose Testversion mit einem Guthaben von 300$ zur Verfügung. Dieses Codelab sollte damit vollständig kostenlos sein.
Cloud Shell einrichten
Während Sie Google Cloud und Spanner von Ihrem Laptop aus per Fernzugriff nutzen können, wird in diesem Codelab Google Cloud Shell verwendet, eine Befehlszeilenumgebung, die in der Cloud ausgeführt wird.
Diese Debian-basierte virtuelle Maschine verfügt über alle Entwicklungstools, die Sie benötigen. Sie bietet ein Basisverzeichnis mit 5 GB nichtflüchtigem Speicher und läuft in Google Cloud, was die Netzwerkleistung und Authentifizierung erheblich verbessert. Für dieses Codelab benötigen Sie also nur einen Browser (es funktioniert auch auf einem Chromebook).
- Klicken Sie zum Aktivieren von Cloud Shell in der Cloud Console einfach auf „Cloud Shell aktivieren“
 . Die Bereitstellung und Verbindung mit der Umgebung sollte nur wenige Augenblicke dauern.
. Die Bereitstellung und Verbindung mit der Umgebung sollte nur wenige Augenblicke dauern.
Sobald die Verbindung mit der Cloud Shell hergestellt ist, sehen Sie, dass Sie bereits authentifiziert sind und für das Projekt schon Ihre PROJECT_ID eingestellt ist.
gcloud auth list
Befehlsausgabe
Credentialed accounts:
- <myaccount>@<mydomain>.com (active)
gcloud config list project
Befehlsausgabe
[core]
project = <PROJECT_ID>
Wenn das Projekt aus irgendeinem Grund nicht festgelegt ist, führen Sie einfach den folgenden Befehl aus:
gcloud config set project <PROJECT_ID>
Suchst du nach deinem PROJECT_ID? Sehen Sie nach, welche ID Sie in den Einrichtungsschritten verwendet haben, oder suchen Sie sie im Cloud Console-Dashboard:

In Cloud Shell werden auch einige Umgebungsvariablen standardmäßig festgelegt, die für zukünftige Befehle nützlich sein können.
echo $GOOGLE_CLOUD_PROJECT
Befehlsausgabe
<PROJECT_ID>
Code herunterladen
In Cloud Shell können Sie den Code für dieses Lab herunterladen:
git clone https://github.com/cloudspannerecosystem/spanner-gaming-sample.git
Befehlsausgabe
Cloning into 'spanner-gaming-sample'...
*snip*
Dieses Codelab basiert auf der Version v0.1.3. Prüfen Sie also, ob dieses Tag vorhanden ist:
cd spanner-gaming-sample
git fetch --all --tags
# Check out v0.1.3 release
git checkout tags/v0.1.3 -b v0.1.3-branch
Befehlsausgabe
Switched to a new branch 'v0.1.3-branch'
Legen Sie nun das aktuelle Arbeitsverzeichnis als Umgebungsvariable DEMO_HOME fest. So können Sie einfacher durch die verschiedenen Abschnitte des Codelabs navigieren.
export DEMO_HOME=$(pwd)
Zusammenfassung
In diesem Schritt haben Sie ein neues Projekt eingerichtet, Cloud Shell aktiviert und den Code für dieses Lab heruntergeladen.
Nächster Schritt
Als Nächstes stellen Sie die Infrastruktur mit Terraform bereit.
3. Infrastruktur bereitstellen
Übersicht
Nachdem Sie Ihr Projekt vorbereitet haben, ist es an der Zeit, die Infrastruktur einzurichten. Dazu gehören VPC-Netzwerke, Cloud Spanner, GKE Autopilot, Artifact Registry zum Speichern der Images, die in GKE ausgeführt werden, die Cloud Deploy-Pipelines für die Backend-Dienste und ‑Arbeitslasten sowie die Dienstkonten und IAM-Berechtigungen, um diese Dienste nutzen zu können.
Das ist viel. Glücklicherweise kann Terraform die Einrichtung vereinfachen. Terraform ist ein „Infrastructure as Code“-Tool, mit dem wir in einer Reihe von „.tf“-Dateien angeben können, was wir für dieses Projekt benötigen. Dadurch wird die Bereitstellung von Infrastruktur vereinfacht.
Sie müssen sich nicht mit Terraform auskennen, um dieses Codelab durchzuarbeiten. Wenn Sie sehen möchten, was in den nächsten Schritten passiert, können Sie sich ansehen, was in den Dateien im Verzeichnis infrastructure erstellt wird:
- vpc.tf
- backend_gke.tf
- spanner.tf
- artifact_registry.tf
- pipelines.tf
- iam.tf
Terraform konfigurieren
Wechseln Sie in Cloud Shell in das Verzeichnis infrastructure und initialisieren Sie Terraform:
cd $DEMO_HOME/infrastructure
terraform init
Befehlsausgabe
Initializing the backend...
Initializing provider plugins...
*snip*
Terraform has been successfully initialized!
You may now begin working with Terraform. Try running "terraform plan" to see
any changes that are required for your infrastructure. All Terraform commands
should now work.
If you ever set or change modules or backend configuration for Terraform,
rerun this command to reinitialize your working directory. If you forget, other
commands will detect it and remind you to do so if necessary.
Konfigurieren Sie als Nächstes Terraform, indem Sie terraform.tfvars.sample kopieren und den Projektwert ändern. Die anderen Variablen können ebenfalls geändert werden, aber nur das Projekt muss geändert werden, damit es in Ihrer Umgebung funktioniert.
cp terraform.tfvars.sample terraform.tfvars
# edit gcp_project using the project environment variable
sed -i "s/PROJECT/$GOOGLE_CLOUD_PROJECT/" terraform.tfvars
Infrastruktur bereitstellen
Jetzt ist es an der Zeit, die Infrastruktur bereitzustellen.
terraform apply
# review the list of things to be created
# type 'yes' when asked
Befehlsausgabe
Plan: 46 to add, 0 to change, 0 to destroy.
Do you want to perform these actions?
Terraform will perform the actions described above.
Only 'yes' will be accepted to approve.
Enter a value: yes
google_project_service.project["container.googleapis.com"]: Creating...
*snip*
Apply complete! Resources: 46 added, 0 changed, 0 destroyed.
Erstellte Inhalte ansehen
Um zu prüfen, was erstellt wurde, sehen Sie sich die Produkte in der Cloud Console an.
Cloud Spanner
Prüfen Sie zuerst Cloud Spanner. Klicken Sie dazu auf das Dreistrich-Menü Spanner. Möglicherweise müssen Sie auf „Weitere Produkte ansehen“ klicken, um es in der Liste zu finden.
Dadurch gelangen Sie zur Liste der Spanner-Instanzen. Klicken Sie auf die Instanz, um die Datenbanken aufzurufen. Die Ausgabe sollte ungefähr so aussehen:

GKE Autopilot
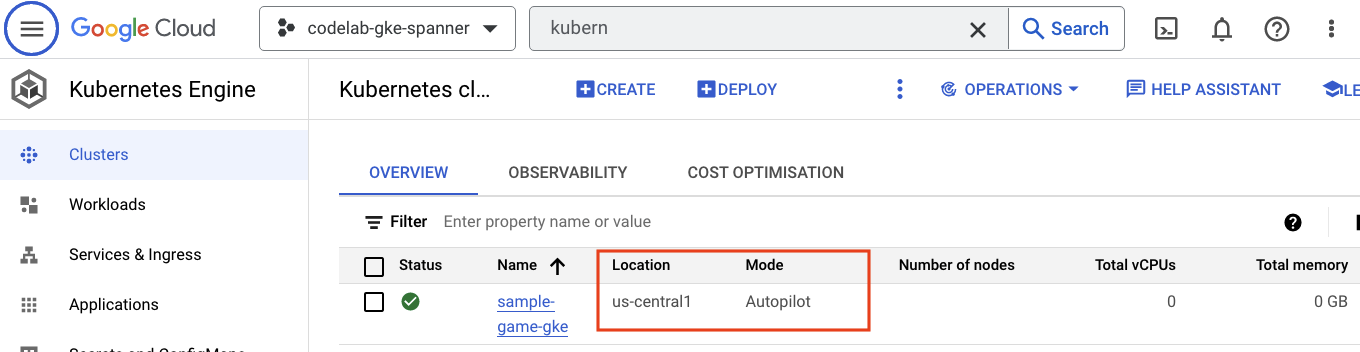
Sehen Sie sich als Nächstes GKE an. Klicken Sie dazu auf das Dreistrich-Menü und dann auf Kubernetes Engine => Clusters. Hier sehen Sie den sample-games-gke-Cluster, der im Autopilot-Modus ausgeführt wird.
Artifact Registry
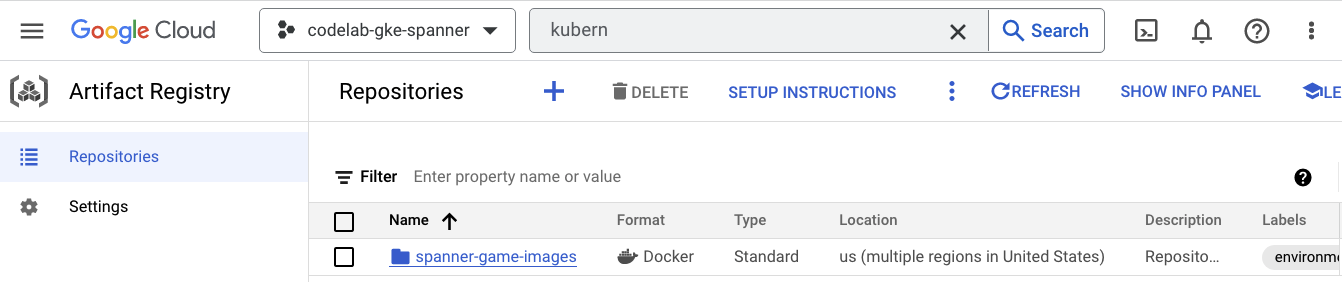
Als Nächstes sehen wir uns an, wo die Bilder gespeichert werden. Klicken Sie also auf das Dreistrich-Menü und suchen Sie nach Artifact Registry=>Repositories. Artifact Registry befindet sich im Menü unter „CI/CD“.
Dort sehen Sie eine Docker-Registry mit dem Namen spanner-game-images. Diese Liste ist derzeit leer.
Cloud Deploy
In Cloud Deploy wurden die Pipelines erstellt, damit Cloud Build Schritte zum Erstellen der Images und zum Bereitstellen in unserem GKE-Cluster bereitstellen konnte.
Rufen Sie das Dreistrich-Menü auf und suchen Sie nach Cloud Deploy, das sich auch im CI/CD-Bereich des Menüs befindet.
Hier sehen Sie zwei Pipelines: eine für Backend-Dienste und eine für Arbeitslasten. Beide stellen die Images im selben GKE-Cluster bereit, aber so können wir unsere Bereitstellungen trennen.

IAM
Prüfen Sie abschließend auf der IAM-Seite in der Cloud Console, welche Dienstkonten erstellt wurden. Rufen Sie das Dreistrich-Menü auf und suchen Sie nach IAM and Admin=>Service accounts. Die Ausgabe sollte ungefähr so aussehen:
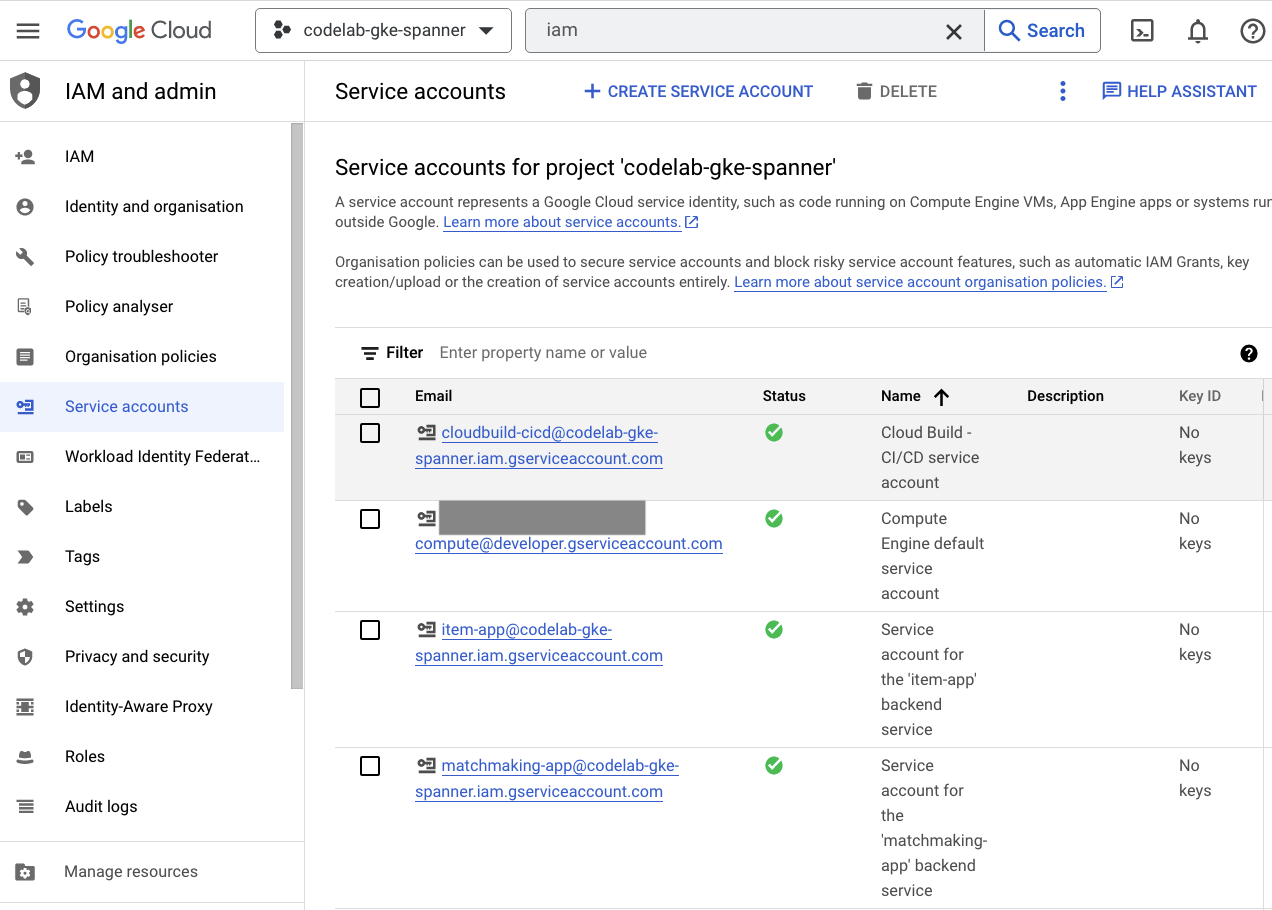
Insgesamt werden sechs Dienstkonten von Terraform erstellt:
- Das Standarddienstkonto für Compute. In diesem Codelab wird es nicht verwendet.
- Das Konto „cloudbuild-cicd“ wird für die Cloud Build- und Cloud Deploy-Schritte verwendet.
- Vier „App“-Konten, die von unseren Backend-Diensten für die Interaktion mit Cloud Spanner verwendet werden.
Als Nächstes müssen Sie kubectl für die Interaktion mit dem GKE-Cluster konfigurieren.
kubectl konfigurieren
# Name of GKE cluster from terraform.tfvars file
export GKE_CLUSTER=sample-game-gke
# get GKE credentials
gcloud container clusters get-credentials $GKE_CLUSTER --region us-central1
# Check that no errors occur
kubectl get serviceaccounts
Befehlsausgabe
#export GKE_CLUSTER=sample-game-gke
# gcloud container clusters get-credentials $GKE_CLUSTER --region us-central1
Fetching cluster endpoint and auth data.
kubeconfig entry generated for sample-game-gke.
# kubectl get serviceaccounts
NAME SECRETS AGE
default 0 37m
item-app 0 35m
matchmaking-app 0 35m
profile-app 0 35m
tradepost-app 0 35m
Zusammenfassung
Sehr gut! Sie konnten eine Cloud Spanner-Instanz und einen GKE Autopilot-Cluster in einer VPC für privates Networking bereitstellen.
Außerdem wurden zwei Cloud Deploy-Pipelines für die Backend-Dienste und die Arbeitslasten sowie ein Artifact Registry-Repository zum Speichern der erstellten Images erstellt.
Schließlich wurden die Dienstkonten erstellt und für die Verwendung mit Workload Identity konfiguriert, damit die Backend-Dienste Cloud Spanner verwenden können.
Sie haben auch kubectl konfiguriert, um nach der Bereitstellung der Back-End-Dienste und ‑Arbeitslasten in Cloud Shell mit dem GKE-Cluster zu interagieren.
Nächster Schritt
Bevor Sie die Dienste verwenden können, muss das Datenbankschema definiert werden. Dies richten Sie als Nächstes ein.
4. Datenbankschema erstellen
Übersicht
Bevor Sie die Backend-Dienste ausführen können, müssen Sie dafür sorgen, dass das Datenbankschema vorhanden ist.
Wenn Sie sich die Dateien im Verzeichnis $DEMO_HOME/schema/migrations des Demorepository ansehen, sehen Sie eine Reihe von .sql-Dateien, in denen unser Schema definiert ist. So wird ein Entwicklungszyklus simuliert, in dem Schemaänderungen im Repository selbst nachverfolgt und mit bestimmten Funktionen der Anwendungen verknüpft werden können.
In dieser Beispielumgebung ist wrench das Tool, mit dem unsere Schemamigrationen mit Cloud Build angewendet werden.
Cloud Build
In der Datei $DEMO_HOME/schema/cloudbuild.yaml wird beschrieben, welche Schritte ausgeführt werden:
serviceAccount: projects/${PROJECT_ID}/serviceAccounts/cloudbuild-cicd@${PROJECT_ID}.iam.gserviceaccount.com
steps:
- name: gcr.io/cloud-builders/curl
id: fetch-wrench
args: ['-Lo', '/workspace/wrench.tar.gz', 'https://github.com/cloudspannerecosystem/wrench/releases/download/v1.4.1/wrench-1.4.1-linux-amd64.tar.gz' ]
- name: gcr.io/cloud-builders/gcloud
id: migrate-spanner-schema
entrypoint: sh
args:
- '-xe'
- '-c'
- |
tar -xzvf wrench.tar.gz
chmod +x /workspace/wrench
# Assumes only a single spanner instance and database. Fine for this demo in a dedicated project
export SPANNER_PROJECT_ID=${PROJECT_ID}
export SPANNER_INSTANCE_ID=$(gcloud spanner instances list | tail -n1 | awk '{print $1}')
export SPANNER_DATABASE_ID=$(gcloud spanner databases list --instance=$$SPANNER_INSTANCE_ID | tail -n1 | awk '{print $1}')
if [ -d ./migrations ]; then
/workspace/wrench migrate up --directory .
else
echo "[Error] Missing migrations directory"
fi
timeout: 600s
Es gibt im Grunde zwei Schritte:
- Laden Sie das Schraubenschlüssel-Tool in den Cloud Build-Arbeitsbereich herunter.
- Führen Sie die Schraubenschlüssel-Migration aus.
Die Umgebungsvariablen für das Cloud Spanner-Projekt, die Instanz und die Datenbank sind erforderlich, damit „wrench“ eine Verbindung zum Schreibendpunkt herstellen kann.
Cloud Build kann diese Änderungen vornehmen, da es als cloudbuild-cicd@${PROJECT_ID}.iam.gserviceaccount.com-Dienstkonto ausgeführt wird:
serviceAccount: projects/${PROJECT_ID}/serviceAccounts/cloudbuild-cicd@${PROJECT_ID}.iam.gserviceaccount.com
Diesem Dienstkonto wird die Rolle spanner.databaseUser von Terraform hinzugefügt, wodurch das Dienstkonto DDL aktualisieren kann.
Schemamigrationen
Es gibt fünf Migrationsschritte, die basierend auf den Dateien im Verzeichnis $DEMO_HOME/schema/migrations ausgeführt werden. Hier ist ein Beispiel für die Datei 000001.sql, mit der eine players-Tabelle und ‑Indizes erstellt werden:
CREATE TABLE players (
playerUUID STRING(36) NOT NULL,
player_name STRING(64) NOT NULL,
email STRING(MAX) NOT NULL,
password_hash BYTES(60) NOT NULL,
created TIMESTAMP,
updated TIMESTAMP,
stats JSON,
account_balance NUMERIC NOT NULL DEFAULT (0.00),
is_logged_in BOOL,
last_login TIMESTAMP,
valid_email BOOL,
current_game STRING(36)
) PRIMARY KEY (playerUUID);
CREATE UNIQUE INDEX PlayerAuthentication ON players(email) STORING(password_hash);
CREATE UNIQUE INDEX PlayerName ON players(player_name);
CREATE INDEX PlayerGame ON players(current_game);
Schemamigration einreichen
Um den Build zu senden und die Schemamigration durchzuführen, wechseln Sie zum Verzeichnis schema und führen Sie den folgenden gcloud-Befehl aus:
cd $DEMO_HOME/schema gcloud builds submit --config=cloudbuild.yaml
Befehlsausgabe
Creating temporary tarball archive of 8 file(s) totalling 11.2 KiB before compression.
Uploading tarball of [.] to [gs://(project)_cloudbuild/source/(snip).tgz]
Created [https://cloudbuild.googleapis.com/v1/projects/(project)/locations/global/builds/7defe982-(snip)].
Logs are available at [ https://console.cloud.google.com/cloud-build/builds/7defe982-(snip)?project=(snip) ].
gcloud builds submit only displays logs from Cloud Storage. To view logs from Cloud Logging, run:
gcloud beta builds submit
ID: 7defe982-(snip)
CREATE_TIME: (created time)
DURATION: 3M11S
SOURCE: gs://(project)_cloudbuild/source/(snip).tgz
IMAGES: -
STATUS: SUCCESS
In der Ausgabe oben sehen Sie einen Link zum Cloud Build-Prozess Created. Wenn Sie darauf klicken, werden Sie zum Build in der Cloud Console weitergeleitet, damit Sie den Fortschritt des Builds überwachen und sehen können, was er gerade tut.

Zusammenfassung
In diesem Schritt haben Sie Cloud Build verwendet, um die erste Schemamigration zu senden, bei der fünf verschiedene DDL-Vorgänge angewendet wurden. Diese Vorgänge stellen dar, wann Funktionen hinzugefügt wurden, für die Änderungen am Datenbankschema erforderlich waren.
In einem normalen Entwicklungsszenario sollten Sie Schemata so ändern, dass sie abwärtskompatibel mit der aktuellen Anwendung sind, um Ausfälle zu vermeiden.
Bei Änderungen, die nicht abwärtskompatibel sind, sollten Sie Änderungen an Anwendung und Schema stufenweise bereitstellen, um Ausfälle zu vermeiden.
Nächster Schritt
Nachdem das Schema eingerichtet ist, müssen als Nächstes die Back-End-Dienste bereitgestellt werden.
5. Backend-Dienste bereitstellen
Übersicht
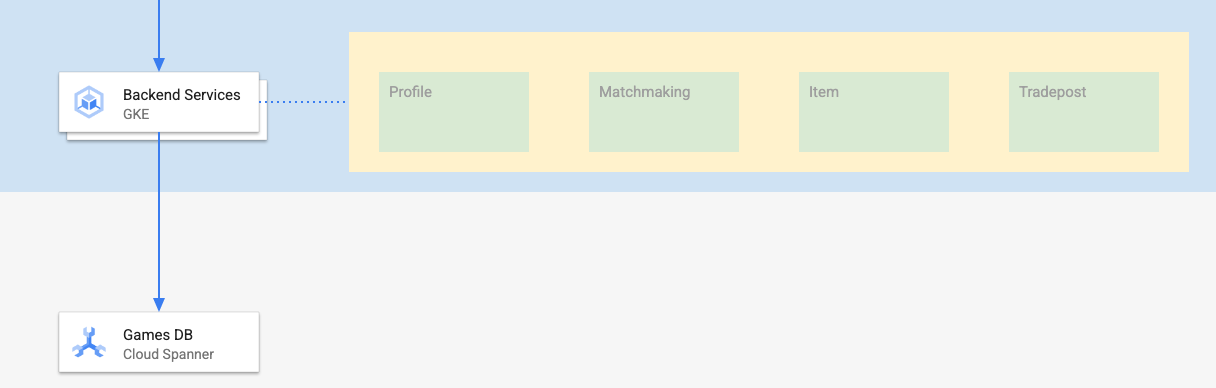
Die Backend-Dienste für dieses Codelab sind Golang-REST-APIs, die vier verschiedene Dienste darstellen:
- Profil:Spieler können sich in unserem Beispielspiel registrieren und authentifizieren.
- Matchmaking:Interaktion mit Spielerdaten zur Unterstützung einer Matchmaking-Funktion, Erfassung von Informationen zu erstellten Spielen und Aktualisierung von Spielerstatistiken, wenn Spiele beendet werden.
- Artikel:Spieler können im Laufe eines Spiels Spielartikel und Geld erwerben.
- Handelsposten:Spieler können Gegenstände an einem Handelsposten kaufen und verkaufen.
Weitere Informationen zu diesen Diensten finden Sie im Codelab Cloud Spanner – Erste Schritte für die Spieleentwicklung. Für unsere Zwecke sollen diese Dienste auf unserem GKE Autopilot-Cluster ausgeführt werden.
Diese Dienste müssen Spanner-Daten ändern können. Dazu wird für jeden Dienst ein Dienstkonto erstellt, dem die Rolle „databaseUser“ zugewiesen wird.
Mit Workload Identity kann ein Kubernetes-Dienstkonto die Identität des Google Cloud-Dienstkontos der Dienste übernehmen. Dazu sind die folgenden Schritte in unserem Terraform erforderlich:
- Erstellen Sie die Dienstkontoressource (
GSA) für den Dienst. - Weisen Sie diesem Dienstkonto die Rolle databaseUser zu.
- Weisen Sie diesem Dienstkonto die Rolle workloadIdentityUser zu.
- Erstellen Sie ein Kubernetes-Dienstkonto (
KSA), das auf das Google-Dienstkonto verweist.
Ein grobes Diagramm könnte so aussehen:

Terraform hat die Dienstkonten und die Kubernetes-Dienstkonten für Sie erstellt. Sie können die Kubernetes-Dienstkonten mit kubectl prüfen:
# kubectl get serviceaccounts
NAME SECRETS AGE
default 0 37m
item-app 0 35m
matchmaking-app 0 35m
profile-app 0 35m
tradepost-app 0 35m
So funktioniert der Build:
- Terraform hat eine
$DEMO_HOME/backend_services/cloudbuild.yaml-Datei generiert, die in etwa so aussieht:
serviceAccount: projects/${PROJECT_ID}/serviceAccounts/cloudbuild-cicd@${PROJECT_ID}.iam.gserviceaccount.com
steps:
#
# Building of images
#
- name: gcr.io/cloud-builders/docker
id: profile
args: ["build", ".", "-t", "${_PROFILE_IMAGE}"]
dir: profile
waitFor: ['-']
- name: gcr.io/cloud-builders/docker
id: matchmaking
args: ["build", ".", "-t", "${_MATCHMAKING_IMAGE}"]
dir: matchmaking
waitFor: ['-']
- name: gcr.io/cloud-builders/docker
id: item
args: ["build", ".", "-t", "${_ITEM_IMAGE}"]
dir: item
waitFor: ['-']
- name: gcr.io/cloud-builders/docker
id: tradepost
args: ["build", ".", "-t", "${_TRADEPOST_IMAGE}"]
dir: tradepost
waitFor: ['-']
#
# Deployment
#
- name: gcr.io/google.com/cloudsdktool/cloud-sdk
id: cloud-deploy-release
entrypoint: gcloud
args:
[
"deploy", "releases", "create", "${_REL_NAME}",
"--delivery-pipeline", "sample-game-services",
"--skaffold-file", "skaffold.yaml",
"--skaffold-version", "1.39",
"--images", "profile=${_PROFILE_IMAGE},matchmaking=${_MATCHMAKING_IMAGE},item=${_ITEM_IMAGE},tradepost=${_TRADEPOST_IMAGE}",
"--region", "us-central1"
]
artifacts:
images:
- ${_REGISTRY}/profile
- ${_REGISTRY}/matchmaking
- ${_REGISTRY}/item
- ${_REGISTRY}/tradepost
substitutions:
_PROFILE_IMAGE: ${_REGISTRY}/profile:${BUILD_ID}
_MATCHMAKING_IMAGE: ${_REGISTRY}/matchmaking:${BUILD_ID}
_ITEM_IMAGE: ${_REGISTRY}/item:${BUILD_ID}
_TRADEPOST_IMAGE: ${_REGISTRY}/tradepost:${BUILD_ID}
_REGISTRY: us-docker.pkg.dev/${PROJECT_ID}/spanner-game-images
_REL_NAME: rel-${BUILD_ID:0:8}
options:
dynamic_substitutions: true
machineType: E2_HIGHCPU_8
logging: CLOUD_LOGGING_ONLY
- Der Cloud Build-Befehl liest diese Datei und führt die aufgeführten Schritte aus. Zuerst werden die Dienst-Images erstellt. Anschließend wird ein
gcloud deploy create-Befehl ausgeführt. Dadurch wird die Datei$DEMO_HOME/backend_services/skaffold.yamlgelesen, in der der Speicherort der einzelnen Bereitstellungsdateien definiert ist:
apiVersion: skaffold/v2beta29
kind: Config
deploy:
kubectl:
manifests:
- spanner_config.yaml
- profile/deployment.yaml
- matchmaking/deployment.yaml
- item/deployment.yaml
- tradepost/deployment.yaml
- Cloud Deploy folgt den Definitionen der
deployment.yaml-Datei jedes Dienstes. Die Deployment-Datei des Dienstes enthält die Informationen zum Erstellen eines Dienstes, in diesem Fall eines ClusterIP-Dienstes, der auf Port 80 ausgeführt wird.
Der Typ ClusterIP verhindert, dass die Backend-Dienst-Pods eine externe IP-Adresse haben. Daher können nur Entitäten, die eine Verbindung zum internen GKE-Netzwerk herstellen können, auf die Backend-Dienste zugreifen. Auf diese Dienste sollte nicht direkt zugegriffen werden können, da sie auf die Spanner-Daten zugreifen und diese ändern.
apiVersion: v1
kind: Service
metadata:
name: profile
spec:
type: ClusterIP
selector:
app: profile
ports:
- port: 80
targetPort: 80
Zusätzlich zum Erstellen eines Kubernetes-Dienstes erstellt Cloud Deploy auch ein Kubernetes-Deployment. Sehen wir uns den Bereitstellungsabschnitt des profile-Dienstes an:
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: profile
spec:
replicas: 2 # EDIT: Number of instances of deployment
selector:
matchLabels:
app: profile
template:
metadata:
labels:
app: profile
spec:
serviceAccountName: profile-app
containers:
- name: profile-service
image: profile
ports:
- containerPort: 80
envFrom:
- configMapRef:
name: spanner-config
env:
- name: SERVICE_HOST
value: "0.0.0.0"
- name: SERVICE_PORT
value: "80"
resources:
requests:
cpu: "1"
memory: "1Gi"
ephemeral-storage: "100Mi"
limits:
cpu: "1"
memory: "1Gi"
ephemeral-storage: "100Mi"
Im oberen Bereich finden Sie einige Metadaten zum Dienst. Am wichtigsten ist dabei, wie viele Replikate durch dieses Deployment erstellt werden.
replicas: 2 # EDIT: Number of instances of deployment
Als Nächstes sehen wir, welches Dienstkonto die App ausführen soll und welches Bild verwendet werden soll. Diese stimmen mit dem Kubernetes-Dienstkonto überein, das mit Terraform erstellt wurde, und mit dem Image, das im Cloud Build-Schritt erstellt wurde.
spec:
serviceAccountName: profile-app
containers:
- name: profile-service
image: profile
Danach geben wir einige Informationen zu Netzwerk- und Umgebungsvariablen an.
spanner_config ist eine Kubernetes-ConfigMap, in der die Projekt-, Instanz- und Datenbankinformationen angegeben sind, die für die Verbindung der Anwendung mit Spanner erforderlich sind.
apiVersion: v1
kind: ConfigMap
metadata:
name: spanner-config
data:
SPANNER_PROJECT_ID: ${project_id}
SPANNER_INSTANCE_ID: ${instance_id}
SPANNER_DATABASE_ID: ${database_id}
ports:
- containerPort: 80
envFrom:
- configMapRef:
name: spanner-config
env:
- name: SERVICE_HOST
value: "0.0.0.0"
- name: SERVICE_PORT
value: "80"
SERVICE_HOST und SERVICE_PORT sind zusätzliche Umgebungsvariablen, die der Dienst benötigt, um zu wissen, wo er gebunden werden soll.
Im letzten Abschnitt wird GKE mitgeteilt, wie viele Ressourcen für jedes Replikat in diesem Deployment zulässig sind. Dies wird auch von GKE Autopilot verwendet, um den Cluster nach Bedarf zu skalieren.
resources:
requests:
cpu: "1"
memory: "1Gi"
ephemeral-storage: "100Mi"
limits:
cpu: "1"
memory: "1Gi"
ephemeral-storage: "100Mi"
Jetzt ist es an der Zeit, die Back-End-Dienste bereitzustellen.
Backend-Dienste bereitstellen
Wie bereits erwähnt, wird Cloud Build zum Bereitstellen der Backend-Dienste verwendet. Wie bei den Schemamigrationen können Sie die Build-Anfrage über die gcloud-Befehlszeile senden:
cd $DEMO_HOME/backend_services gcloud builds submit --config=cloudbuild.yaml
Befehlsausgabe
Creating temporary tarball archive of 66 file(s) totalling 864.6 KiB before compression.
Uploading tarball of [.] to [gs://(project)_cloudbuild/source/(snip).tgz]
Created [https://cloudbuild.googleapis.com/v1/projects/(project)/locations/global/builds/30207dd1-(snip)].
Logs are available at [ https://console.cloud.google.com/cloud-build/builds/30207dd1-(snip)?project=(snip) ].
gcloud builds submit only displays logs from Cloud Storage. To view logs from Cloud Logging, run:
gcloud beta builds submit
ID: 30207dd1-(snip)
CREATE_TIME: (created time)
DURATION: 3M17S
SOURCE: gs://(project)_cloudbuild/source/(snip).tgz
IMAGES: us-docker.pkg.dev/(project)/spanner-game-images/profile:30207dd1-(snip) (+3 more)
STATUS: SUCCESS
Im Gegensatz zur Ausgabe des schema migration-Schritts wird in der Ausgabe dieses Builds angegeben, dass einige Bilder erstellt wurden. Diese werden in Ihrem Artifact Registry-Repository gespeichert.
Die Ausgabe des Schritts gcloud build enthält einen Link zur Cloud Console. Sehen Sie sich diese an.
Sobald Sie die Erfolgsbenachrichtigung von Cloud Build erhalten haben, rufen Sie Cloud Deploy und dann die sample-game-services-Pipeline auf, um den Fortschritt des Deployments zu verfolgen.

Nachdem die Dienste bereitgestellt wurden, können Sie den Status der Pods mit kubectl prüfen:
kubectl get pods
Befehlsausgabe
NAME READY STATUS RESTARTS AGE
item-6b9d5f678c-4tbk2 1/1 Running 0 83m
matchmaking-5bcf799b76-lg8zf 1/1 Running 0 80m
profile-565bbf4c65-kphdl 1/1 Running 0 83m
profile-565bbf4c65-xw74j 1/1 Running 0 83m
tradepost-68b87ccd44-gw55r 1/1 Running 0 79m
Sehen Sie sich dann die Dienste an, um ClusterIP in Aktion zu sehen:
kubectl get services
Befehlsausgabe
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
item ClusterIP 10.172.XXX.XXX <none> 80/TCP 84m
kubernetes ClusterIP 10.172.XXX.XXX <none> 443/TCP 137m
matchmaking ClusterIP 10.172.XXX.XXX <none> 80/TCP 84m
profile ClusterIP 10.172.XXX.XXX <none> 80/TCP 84m
tradepost ClusterIP 10.172.XXX.XXX <none> 80/TCP 84m
Sie können auch die GKE-UI in der Cloud Console aufrufen, um die Workloads, Services und ConfigMaps zu sehen.
Arbeitslasten

Dienste

ConfigMaps


Zusammenfassung
In diesem Schritt haben Sie die vier Backend-Dienste in GKE Autopilot bereitgestellt. Sie konnten den Cloud Build-Schritt ausführen und den Fortschritt in Cloud Deploy und in Kubernetes in der Cloud Console prüfen.
Außerdem haben Sie erfahren, wie diese Dienste Workload Identity verwenden, um die Identität eines Dienstkontos zu übernehmen, das die richtigen Berechtigungen zum Lesen und Schreiben von Daten in der Spanner-Datenbank hat.
Nächste Schritte
Im nächsten Abschnitt stellen Sie die Arbeitslasten bereit.
6. Arbeitslasten bereitstellen
Übersicht
Nachdem die Back-End-Dienste auf dem Cluster ausgeführt werden, stellen Sie die Arbeitslasten bereit.

Die Arbeitslasten sind extern zugänglich und für jeden Backend-Dienst gibt es eine.
Diese Arbeitslasten sind Locust-basierte Skripts zur Generierung von Last, die die tatsächlichen Zugriffsmuster dieser Beispieldienste nachahmen.
Es gibt Dateien für den Cloud Build-Prozess:
$DEMO_HOME/workloads/cloudbuild.yaml(von Terraform generiert)$DEMO_HOME/workloads/skaffold.yaml- Eine
deployment.yaml-Datei für jede Arbeitslast
Die Dateien für die Arbeitslast deployment.yaml sehen etwas anders aus als die Bereitstellungsdateien für den Backend-Dienst.
Hier ein Beispiel aus der matchmaking-workload:
apiVersion: v1
kind: Service
metadata:
name: matchmaking-workload
spec:
type: LoadBalancer
selector:
app: matchmaking-workload
ports:
- port: 8089
targetPort: 8089
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: matchmaking-workload
spec:
replicas: 1 # EDIT: Number of instances of deployment
selector:
matchLabels:
app: matchmaking-workload
template:
metadata:
labels:
app: matchmaking-workload
spec:
serviceAccountName: default
containers:
- name: matchmaking-workload
image: matchmaking-workload
ports:
- containerPort: 8089
resources:
requests:
cpu: "500m"
memory: "512Mi"
ephemeral-storage: "100Mi"
limits:
cpu: "500m"
memory: "512Mi"
ephemeral-storage: "100Mi"
Im oberen Teil der Datei wird der Dienst definiert. In diesem Fall wird ein LoadBalancer erstellt und die Arbeitslast wird auf Port 8089 ausgeführt.
Der LoadBalancer stellt eine externe IP-Adresse bereit, die für die Verbindung zur Arbeitslast verwendet werden kann.
apiVersion: v1
kind: Service
metadata:
name: matchmaking-workload
spec:
type: LoadBalancer
selector:
app: matchmaking-workload
ports:
- port: 8089
targetPort: 8089
Oben im Bereitstellungsabschnitt finden Sie die Metadaten zur Arbeitslast. In diesem Fall wird nur ein Replikat bereitgestellt:
replicas: 1
Die Containerspezifikation ist jedoch anders. Zum einen verwenden wir ein default-Kubernetes-Dienstkonto. Dieses Konto hat keine besonderen Berechtigungen, da die Arbeitslast keine Verbindung zu Google Cloud-Ressourcen außer den Backend-Diensten herstellen muss, die im GKE-Cluster ausgeführt werden.
Der andere Unterschied besteht darin, dass für diese Arbeitslasten keine Umgebungsvariablen erforderlich sind. Das Ergebnis ist eine kürzere Bereitstellungsspezifikation.
spec:
serviceAccountName: default
containers:
- name: matchmaking-workload
image: matchmaking-workload
ports:
- containerPort: 8089
Die Ressourceneinstellungen ähneln denen der Backend-Dienste. So ermittelt GKE Autopilot, wie viele Ressourcen benötigt werden, um die Anfragen aller im Cluster ausgeführten Pods zu erfüllen.
Stellen Sie die Arbeitslasten bereit.
Arbeitslasten bereitstellen
Wie zuvor können Sie die Build-Anfrage über die gcloud-Befehlszeile senden:
cd $DEMO_HOME/workloads gcloud builds submit --config=cloudbuild.yaml
Befehlsausgabe
Creating temporary tarball archive of 18 file(s) totalling 26.2 KiB before compression.
Some files were not included in the source upload.
Check the gcloud log [/tmp/tmp.4Z9EqdPo6d/logs/(snip).log] to see which files and the contents of the
default gcloudignore file used (see `$ gcloud topic gcloudignore` to learn
more).
Uploading tarball of [.] to [gs://(project)_cloudbuild/source/(snip).tgz]
Created [https://cloudbuild.googleapis.com/v1/projects/(project)/locations/global/builds/(snip)].
Logs are available at [ https://console.cloud.google.com/cloud-build/builds/0daf20f6-(snip)?project=(snip) ].
gcloud builds submit only displays logs from Cloud Storage. To view logs from Cloud Logging, run:
gcloud beta builds submit
ID: 0daf20f6-(snip)
CREATE_TIME: (created_time)
DURATION: 1M41S
SOURCE: gs://(project)_cloudbuild/source/(snip).tgz
IMAGES: us-docker.pkg.dev/(project)/spanner-game-images/profile-workload:0daf20f6-(snip) (+4 more)
STATUS: SUCCESS
Prüfen Sie den Status in den Cloud Build-Logs und der Cloud Deploy-Pipeline in der Cloud Console. Für die Arbeitslasten ist die Cloud Deploy-Pipeline sample-game-workloads:
Prüfen Sie nach Abschluss der Bereitstellung den Status mit kubectl in Cloud Shell:
kubectl get pods
Befehlsausgabe
NAME READY STATUS RESTARTS AGE
game-workload-7ff44cb657-pxxq2 1/1 Running 0 12m
item-6b9d5f678c-cr29w 1/1 Running 0 9m6s
item-generator-7bb4f57cf8-5r85b 1/1 Running 0 12m
matchmaking-5bcf799b76-lg8zf 1/1 Running 0 117m
matchmaking-workload-76df69dbdf-jds9z 1/1 Running 0 12m
profile-565bbf4c65-kphdl 1/1 Running 0 121m
profile-565bbf4c65-xw74j 1/1 Running 0 121m
profile-workload-76d6db675b-kzwng 1/1 Running 0 12m
tradepost-68b87ccd44-gw55r 1/1 Running 0 116m
tradepost-workload-56c55445b5-b5822 1/1 Running 0 12m
Sehen Sie sich dann die Arbeitslastdienste an, um LoadBalancer in Aktion zu sehen:
kubectl get services
Befehlsausgabe
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
game-workload LoadBalancer *snip* 35.XX.XX.XX 8089:32483/TCP 12m
item ClusterIP *snip* <none> 80/TCP 121m
item-generator LoadBalancer *snip* 34.XX.XX.XX 8089:32581/TCP 12m
kubernetes ClusterIP *snip* <none> 443/TCP 174m
matchmaking ClusterIP *snip* <none> 80/TCP 121m
matchmaking-workload LoadBalancer *snip* 34.XX.XX.XX 8089:31735/TCP 12m
profile ClusterIP *snip* <none> 80/TCP 121m
profile-workload LoadBalancer *snip* 34.XX.XX.XX 8089:32532/TCP 12m
tradepost ClusterIP *snip* <none> 80/TCP 121m
tradepost-workload LoadBalancer *snip* 34.XX.XX.XX 8089:30002/TCP 12m
Zusammenfassung
Sie haben die Arbeitslasten jetzt im GKE-Cluster bereitgestellt. Für diese Arbeitslasten sind keine zusätzlichen IAM-Berechtigungen erforderlich. Sie sind über den LoadBalancer-Dienst extern über Port 8089 zugänglich.
Nächste Schritte
Nachdem Backend-Dienste und ‑Arbeitslasten ausgeführt werden, ist es an der Zeit, das Spiel zu spielen.
7. Spiel starten
Übersicht
Die Backend-Dienste für Ihr Beispielspiel werden jetzt ausgeführt und Sie haben auch die Möglichkeit, „Spieler“ zu generieren, die mit diesen Diensten interagieren.
Für jede Arbeitslast wird Locust verwendet, um die tatsächliche Last für unsere Dienst-APIs zu simulieren. In diesem Schritt führen Sie mehrere Arbeitslasten aus, um den GKE-Cluster und Spanner zu belasten und Daten in Spanner zu speichern.
Hier finden Sie eine Beschreibung der einzelnen Arbeitslasten:
- Die Arbeitslast
item-generatorist eine schnelle Arbeitslast, mit der eine Liste von game_items generiert wird, die Spieler im Laufe des Spiels erwerben können. - Mit dem
profile-workloadwird simuliert, dass sich Spieler registrieren und anmelden. - Mit
matchmaking-workloadwird simuliert, dass Spieler sich in die Warteschlange einreihen, um Spielen zugewiesen zu werden. - Mit
game-workloadwird simuliert, wie Spieler im Laufe des Spiels game_items und Geld erwerben. - Mit der
tradepost-workloadwird simuliert, dass Spieler Gegenstände auf dem Handelsposten verkaufen und kaufen können.
In diesem Codelab wird speziell die Ausführung von item-generator und profile-workload behandelt.
Elementgenerator ausführen
Mit item-generator wird der item-Back-End-Dienstendpunkt verwendet, um game_items zu Spanner hinzuzufügen. Diese Elemente sind erforderlich, damit game-workload und tradepost-workload ordnungsgemäß funktionieren.
Als Erstes müssen Sie die externe IP-Adresse des item-generator-Dienstes abrufen. Führen Sie in Cloud Shell folgenden Befehl aus:
# The external IP is the 4th column of the output
kubectl get services | grep item-generator | awk '{print $4}'
Befehlsausgabe
{ITEMGENERATOR_EXTERNAL_IP}
Öffnen Sie jetzt einen neuen Browsertab und rufen Sie http://{ITEMGENERATOR_EXTERNAL_IP}:8089 auf. Sie sollten eine Seite wie diese sehen:

Lassen Sie die Standardwerte 1 für users und spawn unverändert. Geben Sie für host http://item ein. Klicken Sie auf die erweiterten Optionen und geben Sie 10s für die Laufzeit ein.
Die Konfiguration sollte so aussehen:
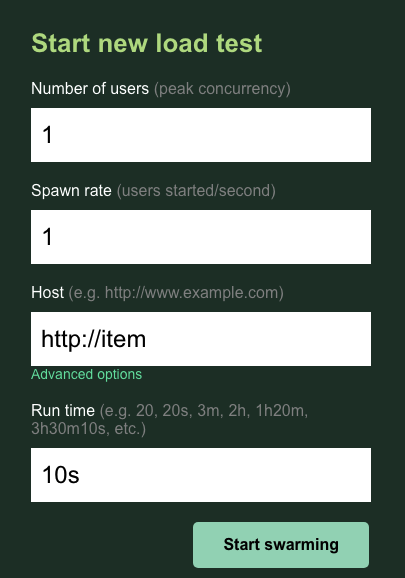
Klicken Sie auf „Start swarming“ (Swarm starten).
Statistiken werden für Anfragen angezeigt, die am Endpunkt POST /items ausgegeben werden. Nach 10 Sekunden wird der Ladevorgang beendet.
Klicken Sie auf Charts, um einige Diagramme zur Leistung dieser Anfragen aufzurufen.
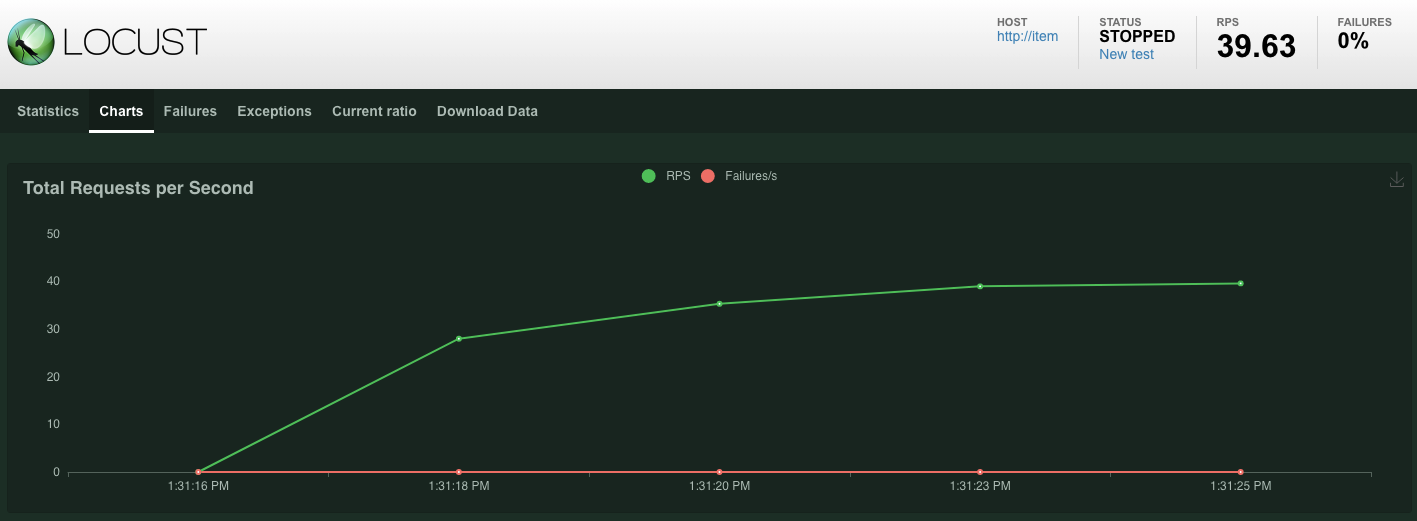
Jetzt möchten Sie prüfen, ob die Daten in die Spanner-Datenbank eingegeben wurden.
Klicken Sie dazu auf das Dreistrich-Menü und rufen Sie „Schraubenschlüssel“ auf. Rufen Sie auf dieser Seite die sample-instance und die sample-database auf. Klicken Sie dann auf Query.
Wir möchten die Anzahl der game_itemsauswählen:
SELECT COUNT(*) FROM game_items;
Unten wird das Ergebnis angezeigt.

Wir brauchen nicht viele game_items. Jetzt können sie aber von Spielern erworben werden.
Profilarbeitslast ausführen
Nachdem du deine game_items eingerichtet hast, musst du Spieler registrieren, damit sie Spiele spielen können.
Die profile-workload verwendet Locust, um zu simulieren, wie Spieler Konten erstellen, sich anmelden, Profilinformationen abrufen und sich abmelden. Bei all diesen Tests werden die Endpunkte des profile-Backend-Dienstes in einer typischen produktionsähnlichen Arbeitslast getestet.
Rufen Sie dazu die externe IP-Adresse von profile-workload ab:
# The external IP is the 4th column of the output
kubectl get services | grep profile-workload | awk '{print $4}'
Befehlsausgabe
{PROFILEWORKLOAD_EXTERNAL_IP}
Öffnen Sie jetzt einen neuen Browsertab und rufen Sie http://{PROFILEWORKLOAD_EXTERNAL_IP}:8089 auf. Sie sollten eine Locust-Seite sehen, die der vorherigen ähnelt.
In diesem Fall verwenden Sie http://profile für den Host. Sie geben keine Laufzeit in den erweiterten Optionen an. Geben Sie außerdem users als 4 an, um 4 Nutzeranfragen gleichzeitig zu simulieren.
Der profile-workload-Test sollte so aussehen:
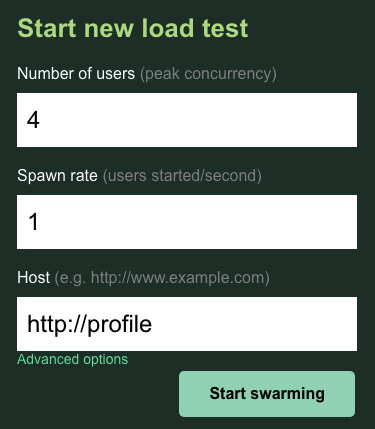
Klicken Sie auf „Start swarming“ (Swarm starten).
Wie zuvor werden die Statistiken für die verschiedenen profile-REST-Endpunkte angezeigt. Klicken Sie auf „Diagramme“, um sich die Leistung anzusehen.
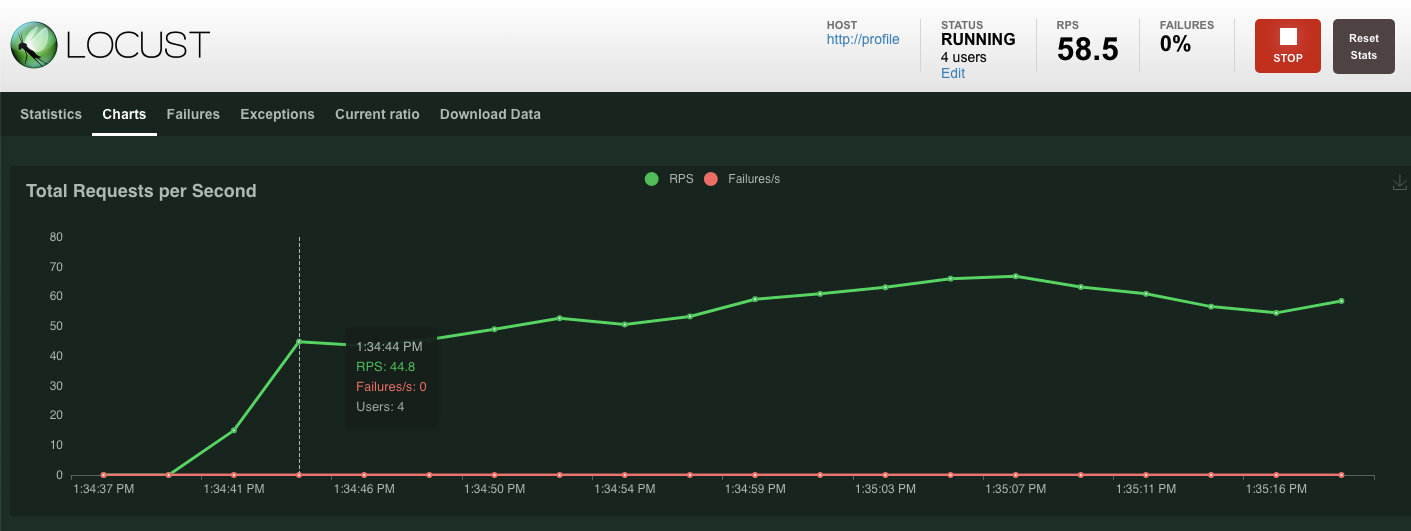
Zusammenfassung
In diesem Schritt haben Sie einige game_items generiert und dann die Tabelle game_items mit der Spanner Query-UI in der Cloud Console abgefragt.
Sie haben Spielern auch erlaubt, sich für Ihr Spiel zu registrieren, und gesehen, wie Locust produktionsähnliche Arbeitslasten für Ihre Backend-Dienste erstellen kann.
Nächste Schritte
Nachdem Sie die Arbeitslasten ausgeführt haben, sollten Sie prüfen, wie sich der GKE-Cluster und die Spanner-Instanz verhalten.
8. GKE- und Spanner-Nutzung ansehen
Nachdem der Profilservice ausgeführt wird, ist es an der Zeit, sich anzusehen, wie sich Ihr GKE Autopilot-Cluster und Cloud Spanner verhalten.
GKE-Cluster prüfen
Rufen Sie den Kubernetes-Cluster auf. Da Sie die Arbeitslasten und Dienste bereitgestellt haben, enthält der Cluster jetzt einige zusätzliche Details zur Gesamtzahl der vCPUs und zum Arbeitsspeicher. Diese Informationen waren nicht verfügbar, wenn keine Arbeitslasten im Cluster vorhanden waren.

Klicken Sie nun auf den Cluster sample-game-gke und wechseln Sie zum Tab „Beobachtbarkeit“:
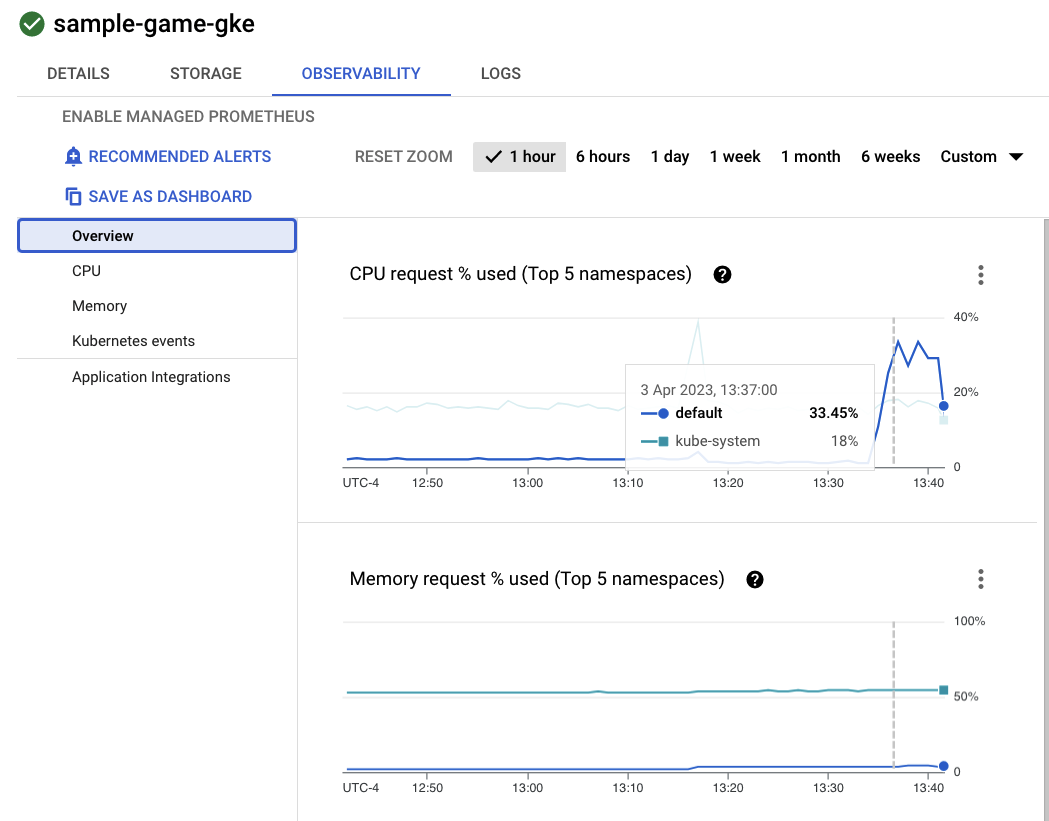
Der Kubernetes-Namespace default sollte den Namespace kube-system bei der CPU-Auslastung übertroffen haben, da unsere Arbeitslasten und Back-End-Dienste auf default ausgeführt werden. Wenn nicht, prüfen Sie, ob profile workload noch ausgeführt wird, und warten Sie einige Minuten, bis die Diagramme aktualisiert werden.
Wenn Sie sehen möchten, welche Arbeitslasten die meisten Ressourcen beanspruchen, rufen Sie das Workloads-Dashboard auf.
Anstatt jede Arbeitslast einzeln aufzurufen, können Sie direkt zum Tab „Beobachtbarkeit“ des Dashboards wechseln. Sie sollten sehen, dass die CPU-Auslastung von profile und profile-workload gestiegen ist.

Sehen Sie sich nun Cloud Spanner an.
Cloud Spanner-Instanz prüfen
Wenn Sie die Leistung von Cloud Spanner prüfen möchten, rufen Sie Spanner auf und klicken Sie auf die Instanz sample-instance und die Datenbank sample-game.
Dort sehen Sie im Menü auf der linken Seite den Tab Systemstatistiken:

Hier finden Sie viele Diagramme, die Ihnen helfen, die allgemeine Leistung Ihrer Spanner-Instanz zu verstehen, einschließlich CPU utilization, transaction latency and locking und query throughput.
Zusätzlich zu System Insights können Sie sich die anderen Links im Bereich „Observability“ ansehen, um detailliertere Informationen zur Abfragearbeitslast zu erhalten:
- Mit Abfrage-Insights können Sie die Top N-Abfragen ermitteln, die Ressourcen in Spanner nutzen.
- Transaktions- und Sperrstatistiken helfen dabei, Transaktionen mit hohen Latenzen zu identifizieren.
- Mit Key Visualizer lassen sich Zugriffsmuster visualisieren und Hotspots in den Daten aufspüren.
Zusammenfassung
In diesem Schritt haben Sie gelernt, wie Sie einige grundlegende Leistungsmesswerte für GKE Autopilot und Spanner prüfen.
Wenn Ihre Profilarbeitslast ausgeführt wird, können Sie beispielsweise die Tabelle players abfragen, um weitere Informationen zu den dort gespeicherten Daten zu erhalten.
Nächste Schritte
Als Nächstes ist es Zeit, aufzuräumen.
9. Bereinigen
Bevor Sie mit der Bereinigung beginnen, können Sie sich die anderen Arbeitslasten ansehen, die nicht behandelt wurden. Insbesondere matchmaking-workload, game-workload und tradepost-workload.
Wenn Sie mit dem „Spielen“ fertig sind, können Sie den Playground bereinigen. Zum Glück ist das ganz einfach.
Wenn profile-workload noch im Browser ausgeführt wird, beenden Sie es:

Wiederholen Sie dies für jede Arbeitslast, die Sie getestet haben.
Wechseln Sie dann in Cloud Shell zum Ordner „infrastructure“. Sie destroy die Infrastruktur mit Terraform:
cd $DEMO_HOME/infrastructure
terraform destroy
# type 'yes' when asked
Befehlsausgabe
Plan: 0 to add, 0 to change, 46 to destroy.
Do you really want to destroy all resources?
Terraform will destroy all your managed infrastructure, as shown above.
There is no undo. Only 'yes' will be accepted to confirm.
Enter a value: yes
*snip*
Destroy complete! Resources: 46 destroyed.
Rufen Sie in der Cloud Console Spanner, Kubernetes Cluster, Artifact Registry, Cloud Deploy und IAM auf, um zu prüfen, ob alle Ressourcen entfernt wurden.
10. Glückwunsch!
Herzlichen Glückwunsch! Sie haben erfolgreich Beispielanwendungen in Go in GKE Autopilot bereitgestellt und sie mithilfe von Workload Identity mit Cloud Spanner verbunden.
Außerdem konnte diese Infrastruktur mit Terraform auf einfache und wiederholbare Weise eingerichtet und entfernt werden.
Weitere Informationen zu den Google Cloud-Diensten, die Sie in diesem Codelab verwendet haben:
Nächste Schritte
Nachdem Sie nun ein grundlegendes Verständnis dafür haben, wie GKE Autopilot und Cloud Spanner zusammenarbeiten können, können Sie den nächsten Schritt wagen und Ihre eigene Anwendung entwickeln, die mit diesen Diensten funktioniert.