
1. Introducción
Cloud Spanner es un servicio de bases de datos relacionales completamente administrado, distribuido a nivel global y escalable horizontalmente que proporciona transacciones ACID y semántica de SQL sin renunciar al rendimiento y la alta disponibilidad.
GKE Autopilot es un modo de operación en GKE en el que Google administra la configuración de tu clúster, incluidos los nodos, el escalamiento, la seguridad y otros parámetros de configuración ya establecidos para seguir las prácticas recomendadas. Por ejemplo, GKE Autopilot habilita Workload Identity para administrar los permisos de servicio.
El objetivo de este lab es guiarte por el proceso para conectar varios servicios de backend que se ejecutan en GKE Autopilot a una base de datos de Cloud Spanner.

En este lab, primero configurarás un proyecto y, luego, iniciarás Cloud Shell. Luego, implementarás la infraestructura con Terraform.
Cuando finalice, interactuarás con Cloud Build y Cloud Deploy para realizar una migración inicial del esquema de la base de datos de Games, implementar los servicios de backend y, luego, implementar las cargas de trabajo.
Los servicios de este codelab son los mismos que los del codelab Comienza a usar Cloud Spanner para el desarrollo de juegos. No es necesario completar ese codelab para que los servicios se ejecuten en GKE y se conecten a Spanner. Sin embargo, si te interesan más detalles sobre las especificaciones de esos servicios que funcionan en Spanner, consulta la documentación.
Con las cargas de trabajo y los servicios de backend en ejecución, puedes comenzar a generar carga y observar cómo funcionan los servicios en conjunto.
Por último, limpiarás los recursos que se crearon en este lab.
Qué compilarás
Como parte de este lab, harás lo siguiente:
- Aprovisiona la infraestructura con Terraform
- Crea el esquema de la base de datos con un proceso de migración de esquemas en Cloud Build
- Implementa los cuatro servicios de backend de Go que aprovechan Workload Identity para conectarse a Cloud Spanner
- Implementa los cuatro servicios de cargas de trabajo que se usan para simular la carga de los servicios de backend.
Qué aprenderás
- Cómo aprovisionar canalizaciones de GKE Autopilot, Cloud Spanner y Cloud Deploy con Terraform
- Cómo Workload Identity permite que los servicios en GKE actúen en nombre de las cuentas de servicio para acceder a los permisos de IAM y trabajar con Cloud Spanner
- Cómo generar una carga similar a la de producción en GKE y Cloud Spanner con Locust.io
Requisitos
2. Configuración y requisitos
Crea un proyecto
Si aún no tienes una Cuenta de Google (Gmail o Google Apps), debes crear una. Accede a Google Cloud Platform Console ( console.cloud.google.com) y crea un proyecto nuevo.
Si ya tienes un proyecto, haz clic en el menú desplegable de selección de proyectos en la parte superior izquierda de la Console:

y haz clic en el botón “PROYECTO NUEVO” en el diálogo resultante para crear un proyecto nuevo:
Si aún no tienes un proyecto, deberías ver un cuadro de diálogo como este para crear el primero:

El cuadro de diálogo de creación posterior del proyecto te permite ingresar los detalles de tu proyecto nuevo:
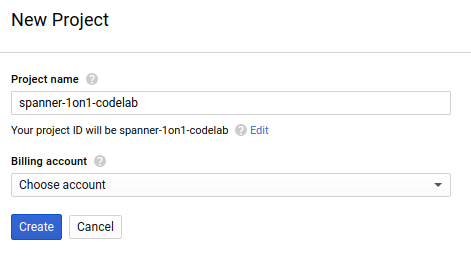
Recuerda el ID del proyecto, que es un nombre único en todos los proyectos de Google Cloud (el nombre anterior ya se encuentra en uso y no lo podrá usar). Se mencionará más adelante en este codelab como PROJECT_ID.
A continuación, si aún no lo has hecho, deberás habilitar la facturación en Developers Console para usar los recursos de Google Cloud y habilitar la API de Cloud Spanner.

Ejecutar este codelab debería costar solo unos pocos dólares, pero su costo podría aumentar si decides usar más recursos o si los dejas en ejecución (consulta la sección “Limpiar” al final de este documento). Los precios de Google Cloud Spanner se documentan aquí, y GKE Autopilot se documenta aquí.
Los usuarios nuevos de Google Cloud Platform están aptas para obtener una prueba gratuita de $300, por lo que este codelab es completamente gratuito.
Configuración de Cloud Shell
Si bien Google Cloud y Spanner se pueden operar de manera remota desde tu laptop, en este codelab usaremos Google Cloud Shell, un entorno de línea de comandos que se ejecuta en la nube.
Esta máquina virtual basada en Debian está cargada con todas las herramientas de desarrollo que necesitarás. Ofrece un directorio principal persistente de 5 GB y se ejecuta en Google Cloud, lo que permite mejorar considerablemente el rendimiento de la red y la autenticación. Esto significa que todo lo que necesitarás para este Codelab es un navegador (sí, funciona en una Chromebook).
- Para activar Cloud Shell desde la consola de Cloud, solo haz clic en Activar Cloud Shell
 (el aprovisionamiento y la conexión al entorno debería llevar solo unos minutos).
(el aprovisionamiento y la conexión al entorno debería llevar solo unos minutos).

Una vez conectado a Cloud Shell, debería ver que ya se autenticó y que el proyecto ya se configuró con tu PROJECT_ID:
gcloud auth list
Resultado del comando
Credentialed accounts:
- <myaccount>@<mydomain>.com (active)
gcloud config list project
Resultado del comando
[core]
project = <PROJECT_ID>
Si, por algún motivo, el proyecto no está configurado, solo emite el siguiente comando:
gcloud config set project <PROJECT_ID>
Si no conoce su PROJECT_ID, Observa el ID que usaste en los pasos de configuración o búscalo en el panel de la consola de Cloud:
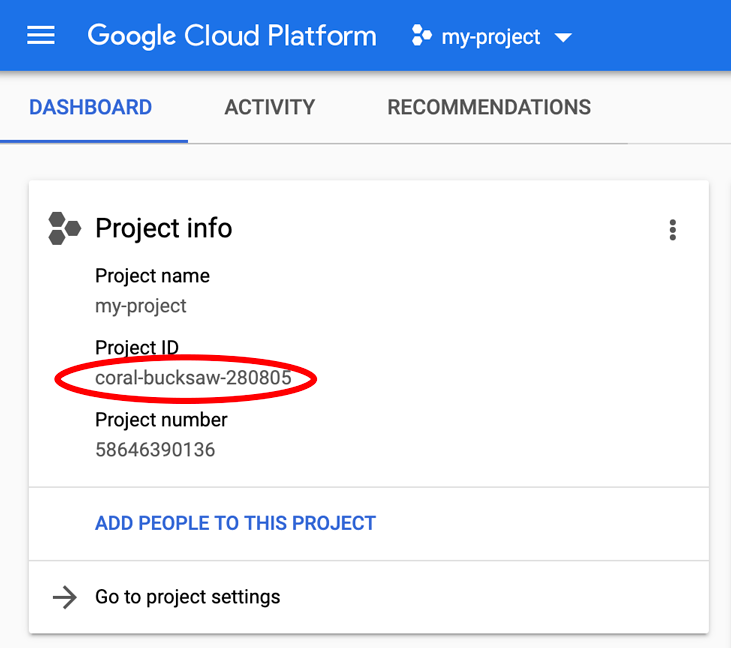
Cloud Shell también configura algunas variables de entorno de forma predeterminada, lo que puede resultar útil cuando ejecutas comandos futuros.
echo $GOOGLE_CLOUD_PROJECT
Resultado del comando
<PROJECT_ID>
Descarga el código
En Cloud Shell, puedes descargar el código de este lab:
git clone https://github.com/cloudspannerecosystem/spanner-gaming-sample.git
Resultado del comando
Cloning into 'spanner-gaming-sample'...
*snip*
Este codelab se basa en la versión v0.1.3, así que consulta esa etiqueta:
cd spanner-gaming-sample
git fetch --all --tags
# Check out v0.1.3 release
git checkout tags/v0.1.3 -b v0.1.3-branch
Resultado del comando
Switched to a new branch 'v0.1.3-branch'
Ahora, establece el directorio de trabajo actual como la variable de entorno DEMO_HOME. Esto facilitará la navegación a medida que trabajes en las diferentes partes del codelab.
export DEMO_HOME=$(pwd)
Resumen
En este paso, configuraste un proyecto nuevo, activaste Cloud Shell y descargaste el código para este lab.
Cuál es el próximo paso
A continuación, aprovisionarás la infraestructura con Terraform.
3. Cómo aprovisionar la infraestructura
Descripción general
Con tu proyecto listo, es hora de poner en funcionamiento la infraestructura. Esto incluye las redes de VPC, Cloud Spanner, GKE Autopilot, Artifact Registry para almacenar las imágenes que se ejecutarán en GKE, las canalizaciones de Cloud Deploy para los servicios y las cargas de trabajo de backend y, por último, las cuentas de servicio y los privilegios de IAM para poder usar esos servicios.
Es mucho. Pero, por suerte, Terraform puede simplificar esta configuración. Terraform es una herramienta de "infraestructura como código" que nos permite especificar lo que necesitamos para este proyecto en una serie de archivos ".tf". Esto simplifica el aprovisionamiento de la infraestructura.
No es necesario que conozcas Terraform para completar este codelab. Sin embargo, si quieres ver qué hacen los próximos pasos, puedes consultar todo lo que se crea en estos archivos ubicados en el directorio infrastructure:
- vpc.tf
- backend_gke.tf
- spanner.tf
- artifact_registry.tf
- pipelines.tf
- iam.tf
Configura Terraform
En Cloud Shell, cambiarás al directorio infrastructure y, luego, inicializarás Terraform:
cd $DEMO_HOME/infrastructure
terraform init
Resultado del comando
Initializing the backend...
Initializing provider plugins...
*snip*
Terraform has been successfully initialized!
You may now begin working with Terraform. Try running "terraform plan" to see
any changes that are required for your infrastructure. All Terraform commands
should now work.
If you ever set or change modules or backend configuration for Terraform,
rerun this command to reinitialize your working directory. If you forget, other
commands will detect it and remind you to do so if necessary.
A continuación, configura Terraform copiando terraform.tfvars.sample y modificando el valor del proyecto. Las otras variables también se pueden cambiar, pero el proyecto es el único que se debe cambiar para que funcione con tu entorno.
cp terraform.tfvars.sample terraform.tfvars
# edit gcp_project using the project environment variable
sed -i "s/PROJECT/$GOOGLE_CLOUD_PROJECT/" terraform.tfvars
Aprovisiona la infraestructura
Ahora es el momento de aprovisionar la infraestructura.
terraform apply
# review the list of things to be created
# type 'yes' when asked
Resultado del comando
Plan: 46 to add, 0 to change, 0 to destroy.
Do you want to perform these actions?
Terraform will perform the actions described above.
Only 'yes' will be accepted to approve.
Enter a value: yes
google_project_service.project["container.googleapis.com"]: Creating...
*snip*
Apply complete! Resources: 46 added, 0 changed, 0 destroyed.
Verifica lo que se creó
Para verificar lo que se creó, debes revisar los productos en la consola de Cloud.
Cloud Spanner
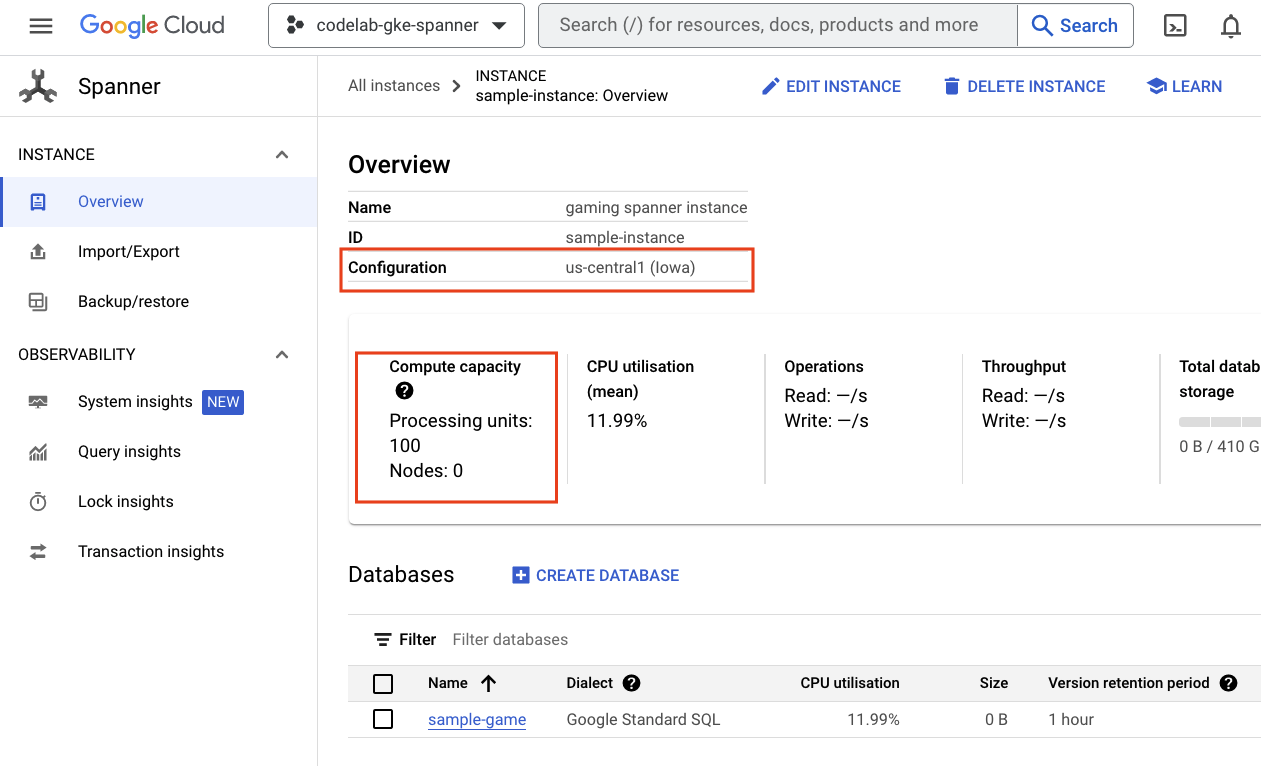
Primero, verifica Cloud Spanner. Para ello, navega al menú de hamburguesa y haz clic en Spanner. Es posible que debas hacer clic en “Ver más productos” para encontrarlo en la lista.
Esta acción te llevará a la lista de instancias de Spanner. Haz clic en la instancia y verás las bases de datos. Debería verse algo similar a esto:
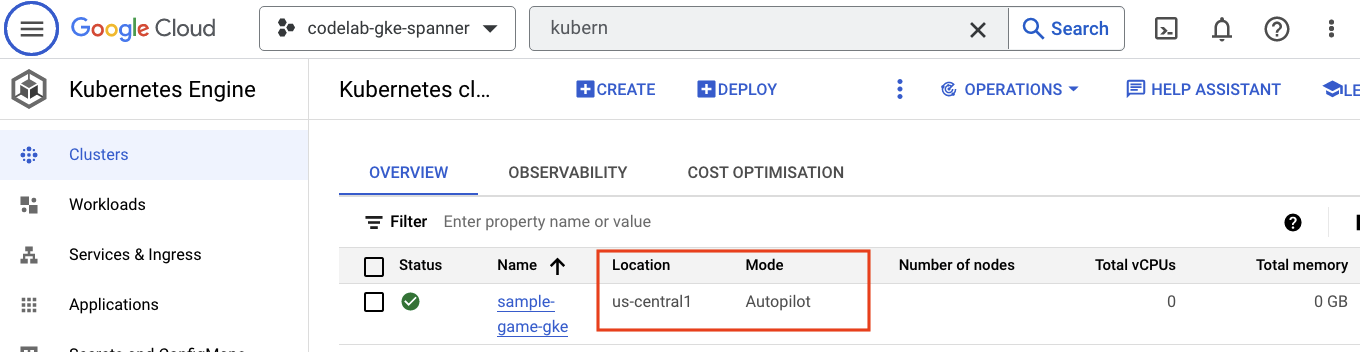
GKE Autopilot
A continuación, explora GKE. Para ello, navega al menú de hamburguesa y haz clic en Kubernetes Engine => Clusters. Aquí verás el clúster sample-games-gke que se ejecuta en modo Autopilot.
Artifact Registry
Ahora querrás ver dónde se almacenarán las imágenes. Por lo tanto, haz clic en el menú de hamburguesa y busca Artifact Registry=>Repositories. Artifact Registry se encuentra en la sección CI/CD del menú.
Aquí verás un registro de Docker llamado spanner-game-images. Por el momento, estará vacío.

Cloud Deploy
Cloud Deploy es donde se crearon las canalizaciones para que Cloud Build pudiera proporcionar los pasos para compilar las imágenes y, luego, implementarlas en nuestro clúster de GKE.
Navega al menú de hamburguesa y busca Cloud Deploy, que también se encuentra en la sección CI/CD del menú.
Aquí verás dos canalizaciones: una para los servicios de backend y otra para las cargas de trabajo. Ambos implementan las imágenes en el mismo clúster de GKE, pero esto permite separar nuestras implementaciones.

IAM
Por último, consulta la página de IAM en la consola de Cloud para verificar las cuentas de servicio que se crearon. Navega al menú de hamburguesa y busca IAM and Admin=>Service accounts. Debería verse algo similar a esto:
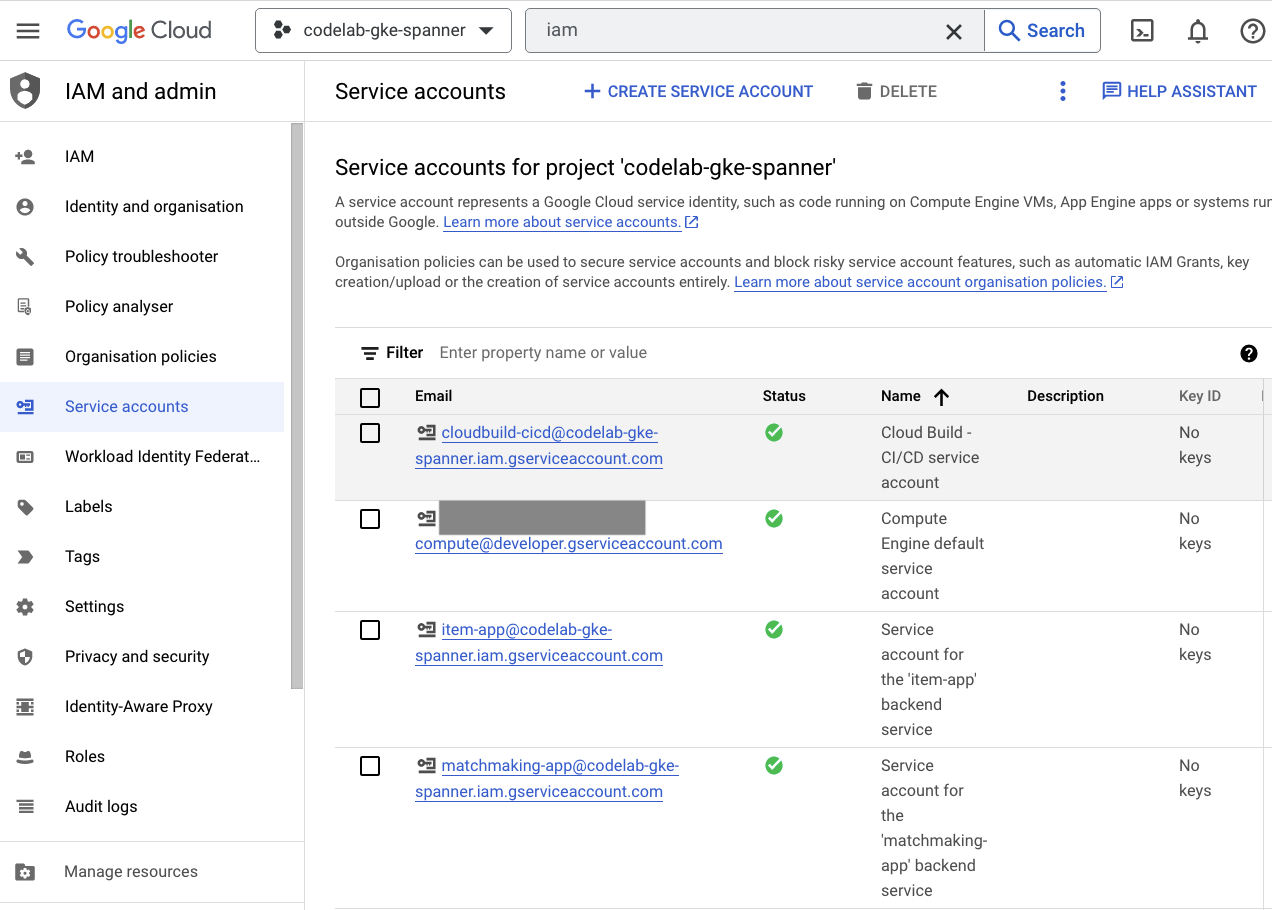
Terraform crea seis cuentas de servicio en total:
- La cuenta de servicio de procesamiento predeterminada. No se usa en este codelab.
- La cuenta cloudbuild-cicd se usa para los pasos de Cloud Build y Cloud Deploy.
- Cuatro cuentas de "app" que usan nuestros servicios de backend para interactuar con Cloud Spanner
A continuación, deberás configurar kubectl para interactuar con el clúster de GKE.
Configura kubectl
# Name of GKE cluster from terraform.tfvars file
export GKE_CLUSTER=sample-game-gke
# get GKE credentials
gcloud container clusters get-credentials $GKE_CLUSTER --region us-central1
# Check that no errors occur
kubectl get serviceaccounts
Resultado del comando
#export GKE_CLUSTER=sample-game-gke
# gcloud container clusters get-credentials $GKE_CLUSTER --region us-central1
Fetching cluster endpoint and auth data.
kubeconfig entry generated for sample-game-gke.
# kubectl get serviceaccounts
NAME SECRETS AGE
default 0 37m
item-app 0 35m
matchmaking-app 0 35m
profile-app 0 35m
tradepost-app 0 35m
Resumen
¡Genial! Pudiste aprovisionar una instancia de Cloud Spanner y un clúster de GKE Autopilot, todo en una VPC para redes privadas.
Además, se crearon dos canalizaciones de Cloud Deploy para los servicios de backend y las cargas de trabajo, así como un repositorio de Artifact Registry para almacenar las imágenes compiladas.
Por último, se crearon y configuraron las cuentas de servicio para que funcionen con Workload Identity, de modo que los servicios de backend puedan usar Cloud Spanner.
También tienes kubectl configurado para interactuar con el clúster de GKE en Cloud Shell después de implementar los servicios de backend y las cargas de trabajo.
Cuál es el próximo paso
Antes de poder usar los servicios, se debe definir el esquema de la base de datos. Lo configurarás a continuación.
4. Crea el esquema de la base de datos
Descripción general
Antes de ejecutar los servicios de backend, debes asegurarte de que el esquema de la base de datos esté en su lugar.
Si observas los archivos del directorio $DEMO_HOME/schema/migrations del repositorio de demostración, verás una serie de archivos .sql que definen nuestro esquema. Esto simula un ciclo de desarrollo en el que los cambios de esquema se registran en el repositorio y se pueden vincular a ciertas funciones de las aplicaciones.
En este entorno de ejemplo, la llave es la herramienta que aplicará nuestras migraciones de esquemas con Cloud Build.
Cloud Build
El archivo $DEMO_HOME/schema/cloudbuild.yaml describe los pasos que se seguirán:
serviceAccount: projects/${PROJECT_ID}/serviceAccounts/cloudbuild-cicd@${PROJECT_ID}.iam.gserviceaccount.com
steps:
- name: gcr.io/cloud-builders/curl
id: fetch-wrench
args: ['-Lo', '/workspace/wrench.tar.gz', 'https://github.com/cloudspannerecosystem/wrench/releases/download/v1.4.1/wrench-1.4.1-linux-amd64.tar.gz' ]
- name: gcr.io/cloud-builders/gcloud
id: migrate-spanner-schema
entrypoint: sh
args:
- '-xe'
- '-c'
- |
tar -xzvf wrench.tar.gz
chmod +x /workspace/wrench
# Assumes only a single spanner instance and database. Fine for this demo in a dedicated project
export SPANNER_PROJECT_ID=${PROJECT_ID}
export SPANNER_INSTANCE_ID=$(gcloud spanner instances list | tail -n1 | awk '{print $1}')
export SPANNER_DATABASE_ID=$(gcloud spanner databases list --instance=$$SPANNER_INSTANCE_ID | tail -n1 | awk '{print $1}')
if [ -d ./migrations ]; then
/workspace/wrench migrate up --directory .
else
echo "[Error] Missing migrations directory"
fi
timeout: 600s
Básicamente, hay dos pasos:
- Descarga la llave inglesa en el espacio de trabajo de Cloud Build.
- Ejecuta la migración de la llave
Las variables de entorno del proyecto, la instancia y la base de datos de Spanner son necesarias para que wrench se conecte al endpoint de escritura.
Cloud Build puede realizar estos cambios porque se ejecuta como la cuenta de servicio cloudbuild-cicd@${PROJECT_ID}.iam.gserviceaccount.com:
serviceAccount: projects/${PROJECT_ID}/serviceAccounts/cloudbuild-cicd@${PROJECT_ID}.iam.gserviceaccount.com
Además, esta cuenta de servicio tiene el rol spanner.databaseUser agregado por Terraform, lo que le permite actualizar el DDL.
Migraciones de esquemas
Hay cinco pasos de migración que se realizan en función de los archivos del directorio $DEMO_HOME/schema/migrations. Este es un ejemplo del archivo 000001.sql que crea una tabla players y los índices:
CREATE TABLE players (
playerUUID STRING(36) NOT NULL,
player_name STRING(64) NOT NULL,
email STRING(MAX) NOT NULL,
password_hash BYTES(60) NOT NULL,
created TIMESTAMP,
updated TIMESTAMP,
stats JSON,
account_balance NUMERIC NOT NULL DEFAULT (0.00),
is_logged_in BOOL,
last_login TIMESTAMP,
valid_email BOOL,
current_game STRING(36)
) PRIMARY KEY (playerUUID);
CREATE UNIQUE INDEX PlayerAuthentication ON players(email) STORING(password_hash);
CREATE UNIQUE INDEX PlayerName ON players(player_name);
CREATE INDEX PlayerGame ON players(current_game);
Envía la migración del esquema
Para enviar la compilación y realizar la migración del esquema, cambia al directorio schema y ejecuta el siguiente comando de gcloud:
cd $DEMO_HOME/schema gcloud builds submit --config=cloudbuild.yaml
Resultado del comando
Creating temporary tarball archive of 8 file(s) totalling 11.2 KiB before compression.
Uploading tarball of [.] to [gs://(project)_cloudbuild/source/(snip).tgz]
Created [https://cloudbuild.googleapis.com/v1/projects/(project)/locations/global/builds/7defe982-(snip)].
Logs are available at [ https://console.cloud.google.com/cloud-build/builds/7defe982-(snip)?project=(snip) ].
gcloud builds submit only displays logs from Cloud Storage. To view logs from Cloud Logging, run:
gcloud beta builds submit
ID: 7defe982-(snip)
CREATE_TIME: (created time)
DURATION: 3M11S
SOURCE: gs://(project)_cloudbuild/source/(snip).tgz
IMAGES: -
STATUS: SUCCESS
En el resultado anterior, verás un vínculo al proceso de compilación de Created Cloud Build. Si haces clic en ese vínculo, se te dirigirá a la compilación en Cloud Console para que puedas supervisar el progreso de la compilación y ver lo que está haciendo.
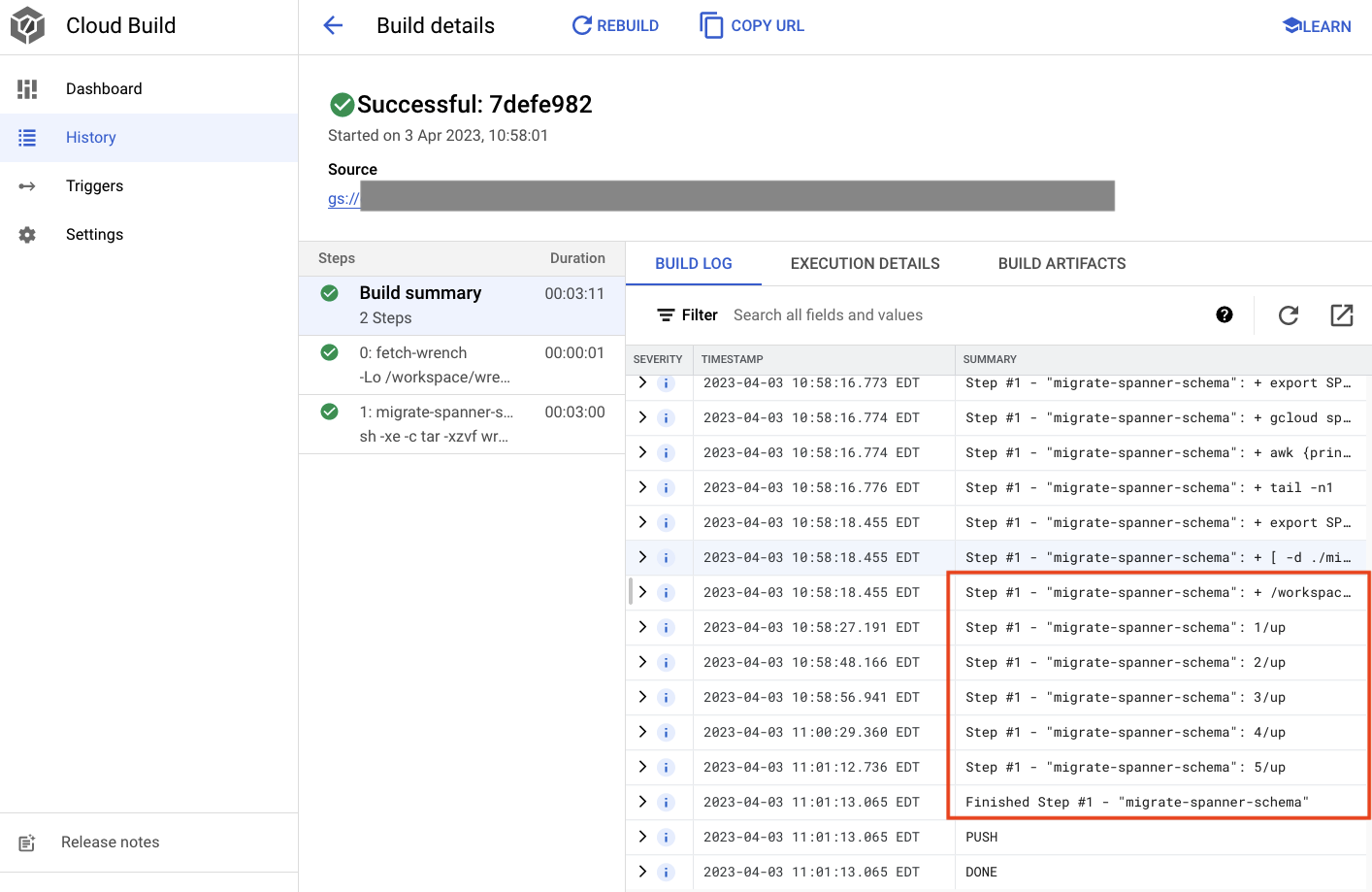
Resumen
En este paso, usaste Cloud Build para enviar la migración inicial del esquema que aplicó 5 operaciones de DDL diferentes. Estas operaciones representan los momentos en que se agregaron funciones que requerían cambios en el esquema de la base de datos.
En una situación de desarrollo normal, querrías que los cambios de esquema sean compatibles con versiones anteriores de la aplicación actual para evitar interrupciones.
En el caso de los cambios que no son retrocompatibles, te recomendamos que implementes los cambios en la aplicación y el esquema por etapas para garantizar que no haya interrupciones.
Cuál es el próximo paso
Con el esquema implementado, el siguiente paso es implementar los servicios de backend.
5. Implementa los servicios de backend
Descripción general
Los servicios de backend de este codelab son APIs de REST de Go que representan cuatro servicios diferentes:
- Perfil: Proporciona a los jugadores la capacidad de registrarse y autenticarse en nuestro "juego" de ejemplo.
- Creación de partidas: Interactúa con los datos de los jugadores para ayudar con la función de creación de partidas, hacer un seguimiento de la información sobre los juegos que se crean y actualizar las estadísticas de los jugadores cuando se cierran los juegos.
- Elemento: Permite que los jugadores adquieran dinero y elementos del juego mientras juegan.
- Puesto de comercio: Permite que los jugadores compren y vendan artículos en un puesto de comercio.
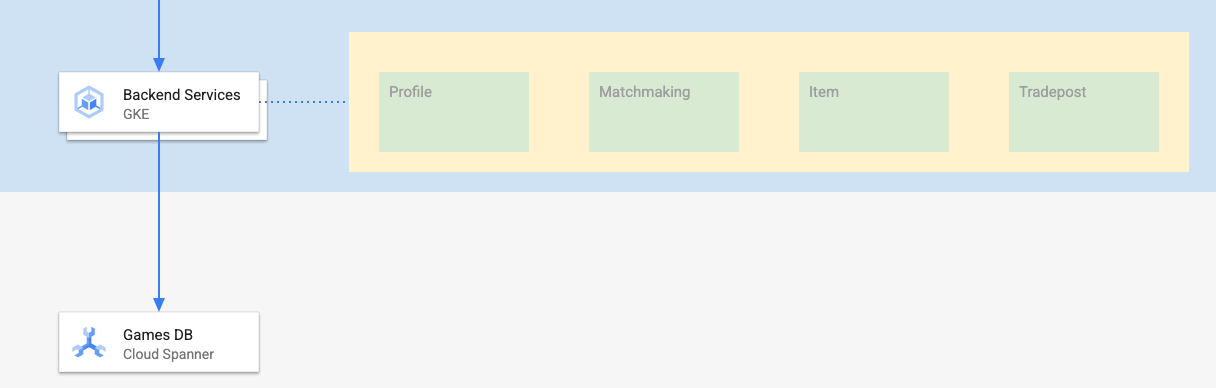
Puedes obtener más información sobre estos servicios en el codelab Cloud Spanner Getting Started with Games Development. Para nuestros fines, queremos que estos servicios se ejecuten en nuestro clúster de GKE Autopilot.
Estos servicios deben poder modificar los datos de Spanner. Para ello, cada servicio tiene una cuenta de servicio creada que le otorga el rol de "databaseUser".
Workload Identity permite que una cuenta de servicio de Kubernetes suplante la identidad de la cuenta de servicio de Google Cloud de los servicios siguiendo estos pasos en nuestro Terraform:
- Crea el recurso de la cuenta de servicio de Google Cloud del servicio (
GSA). - Asigna el rol databaseUser a esa cuenta de servicio.
- Asigna el rol workloadIdentityUser a esa cuenta de servicio.
- Crea una cuenta de servicio de Kubernetes (
KSA) que haga referencia a la GSA.
Un diagrama aproximado se vería así:
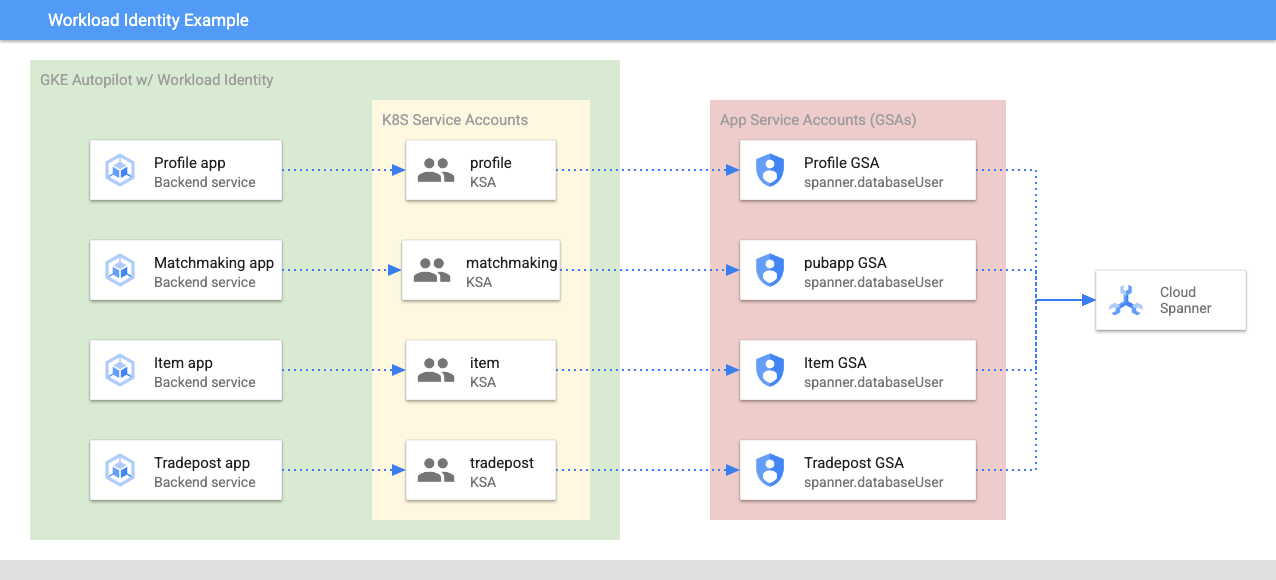
Terraform creó las cuentas de servicio y las cuentas de servicio de Kubernetes por ti. Además, puedes verificar las cuentas de servicio de Kubernetes con kubectl:
# kubectl get serviceaccounts
NAME SECRETS AGE
default 0 37m
item-app 0 35m
matchmaking-app 0 35m
profile-app 0 35m
tradepost-app 0 35m
La compilación funciona de la siguiente manera:
- Terraform generó un archivo
$DEMO_HOME/backend_services/cloudbuild.yamlque se ve de la siguiente manera:
serviceAccount: projects/${PROJECT_ID}/serviceAccounts/cloudbuild-cicd@${PROJECT_ID}.iam.gserviceaccount.com
steps:
#
# Building of images
#
- name: gcr.io/cloud-builders/docker
id: profile
args: ["build", ".", "-t", "${_PROFILE_IMAGE}"]
dir: profile
waitFor: ['-']
- name: gcr.io/cloud-builders/docker
id: matchmaking
args: ["build", ".", "-t", "${_MATCHMAKING_IMAGE}"]
dir: matchmaking
waitFor: ['-']
- name: gcr.io/cloud-builders/docker
id: item
args: ["build", ".", "-t", "${_ITEM_IMAGE}"]
dir: item
waitFor: ['-']
- name: gcr.io/cloud-builders/docker
id: tradepost
args: ["build", ".", "-t", "${_TRADEPOST_IMAGE}"]
dir: tradepost
waitFor: ['-']
#
# Deployment
#
- name: gcr.io/google.com/cloudsdktool/cloud-sdk
id: cloud-deploy-release
entrypoint: gcloud
args:
[
"deploy", "releases", "create", "${_REL_NAME}",
"--delivery-pipeline", "sample-game-services",
"--skaffold-file", "skaffold.yaml",
"--skaffold-version", "1.39",
"--images", "profile=${_PROFILE_IMAGE},matchmaking=${_MATCHMAKING_IMAGE},item=${_ITEM_IMAGE},tradepost=${_TRADEPOST_IMAGE}",
"--region", "us-central1"
]
artifacts:
images:
- ${_REGISTRY}/profile
- ${_REGISTRY}/matchmaking
- ${_REGISTRY}/item
- ${_REGISTRY}/tradepost
substitutions:
_PROFILE_IMAGE: ${_REGISTRY}/profile:${BUILD_ID}
_MATCHMAKING_IMAGE: ${_REGISTRY}/matchmaking:${BUILD_ID}
_ITEM_IMAGE: ${_REGISTRY}/item:${BUILD_ID}
_TRADEPOST_IMAGE: ${_REGISTRY}/tradepost:${BUILD_ID}
_REGISTRY: us-docker.pkg.dev/${PROJECT_ID}/spanner-game-images
_REL_NAME: rel-${BUILD_ID:0:8}
options:
dynamic_substitutions: true
machineType: E2_HIGHCPU_8
logging: CLOUD_LOGGING_ONLY
- El comando de Cloud Build lee este archivo y sigue los pasos que se indican. Primero, compila las imágenes del servicio. Luego, ejecuta un comando
gcloud deploy create. Esto lee el archivo$DEMO_HOME/backend_services/skaffold.yaml, que define dónde se encuentra cada archivo de implementación:
apiVersion: skaffold/v2beta29
kind: Config
deploy:
kubectl:
manifests:
- spanner_config.yaml
- profile/deployment.yaml
- matchmaking/deployment.yaml
- item/deployment.yaml
- tradepost/deployment.yaml
- Cloud Deploy seguirá las definiciones de cada archivo
deployment.yamldel servicio. El archivo de implementación del servicio contiene la información para crear un servicio, que, en este caso, es un ClusterIP que se ejecuta en el puerto 80.
El tipo "ClusterIP" evita que los pods del servicio de backend tengan una IP externa, por lo que solo las entidades que pueden conectarse a la red interna de GKE pueden acceder a los servicios de backend. Los jugadores no deben tener acceso directo a estos servicios, ya que acceden a los datos de Spanner y los modifican.
apiVersion: v1
kind: Service
metadata:
name: profile
spec:
type: ClusterIP
selector:
app: profile
ports:
- port: 80
targetPort: 80
Además de crear un servicio de Kubernetes, Cloud Deploy también crea una implementación de Kubernetes. Examinemos la sección de implementación del servicio profile:
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: profile
spec:
replicas: 2 # EDIT: Number of instances of deployment
selector:
matchLabels:
app: profile
template:
metadata:
labels:
app: profile
spec:
serviceAccountName: profile-app
containers:
- name: profile-service
image: profile
ports:
- containerPort: 80
envFrom:
- configMapRef:
name: spanner-config
env:
- name: SERVICE_HOST
value: "0.0.0.0"
- name: SERVICE_PORT
value: "80"
resources:
requests:
cpu: "1"
memory: "1Gi"
ephemeral-storage: "100Mi"
limits:
cpu: "1"
memory: "1Gi"
ephemeral-storage: "100Mi"
La parte superior proporciona algunos metadatos sobre el servicio. Lo más importante de esto es definir cuántas réplicas creará esta implementación.
replicas: 2 # EDIT: Number of instances of deployment
A continuación, vemos qué cuenta de servicio debe ejecutar la app y qué imagen debe usar. Estos coinciden con la cuenta de servicio de Kubernetes creada a partir de Terraform y la imagen creada durante el paso de Cloud Build.
spec:
serviceAccountName: profile-app
containers:
- name: profile-service
image: profile
Luego, especificamos información sobre las variables de entorno y las redes.
El objeto spanner_config es un ConfigMap de Kubernetes que especifica la información del proyecto, la instancia y la base de datos que necesita la aplicación para conectarse a Spanner.
apiVersion: v1
kind: ConfigMap
metadata:
name: spanner-config
data:
SPANNER_PROJECT_ID: ${project_id}
SPANNER_INSTANCE_ID: ${instance_id}
SPANNER_DATABASE_ID: ${database_id}
ports:
- containerPort: 80
envFrom:
- configMapRef:
name: spanner-config
env:
- name: SERVICE_HOST
value: "0.0.0.0"
- name: SERVICE_PORT
value: "80"
SERVICE_HOST y SERVICE_PORT son variables de entorno adicionales que necesita el servicio para saber dónde realizar la vinculación.
La sección final le indica a GKE cuántos recursos debe permitir para cada réplica en esta implementación. Esto también es lo que usa GKE Autopilot para escalar el clúster según sea necesario.
resources:
requests:
cpu: "1"
memory: "1Gi"
ephemeral-storage: "100Mi"
limits:
cpu: "1"
memory: "1Gi"
ephemeral-storage: "100Mi"
Con esta información, es hora de implementar los servicios de backend.
Implementa los servicios de backend
Como se mencionó, la implementación de los servicios de backend usa Cloud Build. Al igual que con las migraciones de esquema, puedes enviar la solicitud de compilación con la línea de comandos de gcloud:
cd $DEMO_HOME/backend_services gcloud builds submit --config=cloudbuild.yaml
Resultado del comando
Creating temporary tarball archive of 66 file(s) totalling 864.6 KiB before compression.
Uploading tarball of [.] to [gs://(project)_cloudbuild/source/(snip).tgz]
Created [https://cloudbuild.googleapis.com/v1/projects/(project)/locations/global/builds/30207dd1-(snip)].
Logs are available at [ https://console.cloud.google.com/cloud-build/builds/30207dd1-(snip)?project=(snip) ].
gcloud builds submit only displays logs from Cloud Storage. To view logs from Cloud Logging, run:
gcloud beta builds submit
ID: 30207dd1-(snip)
CREATE_TIME: (created time)
DURATION: 3M17S
SOURCE: gs://(project)_cloudbuild/source/(snip).tgz
IMAGES: us-docker.pkg.dev/(project)/spanner-game-images/profile:30207dd1-(snip) (+3 more)
STATUS: SUCCESS
A diferencia del resultado del paso schema migration, el resultado de esta compilación indica que se crearon algunas imágenes. Se almacenarán en tu repositorio de Artifact Registry.
El resultado del paso gcloud build tendrá un vínculo a la consola de Cloud. Échales un vistazo.
Una vez que recibas la notificación de éxito de Cloud Build, navega a Cloud Deploy y, luego, a la canalización sample-game-services para supervisar el progreso de la implementación.
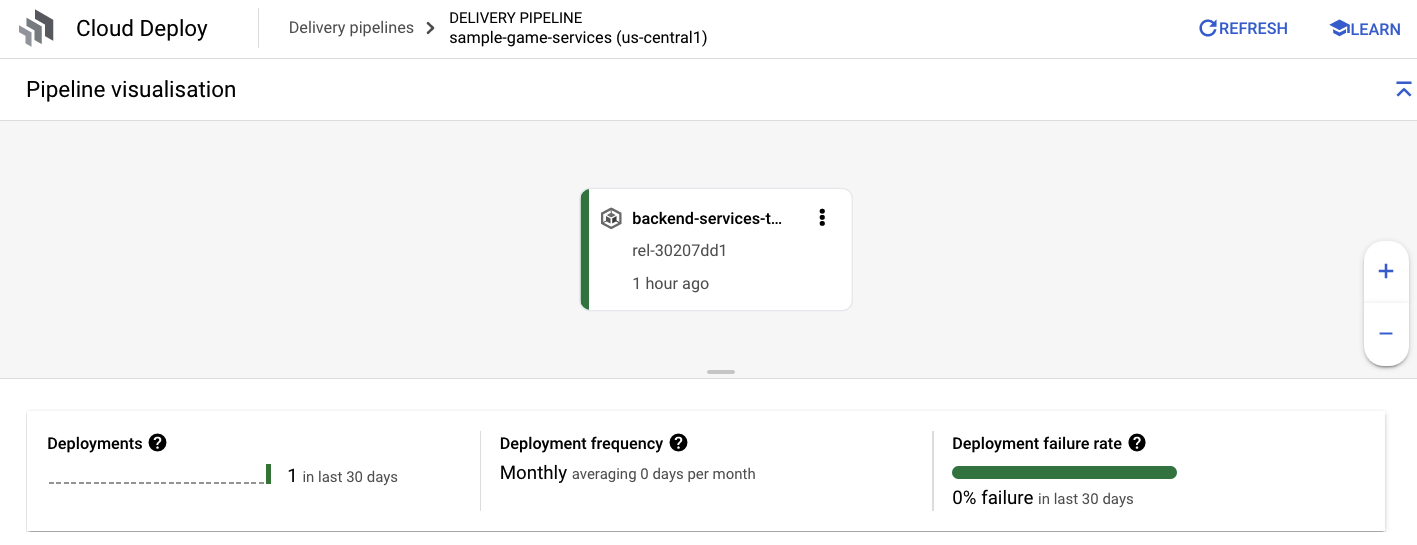
Una vez que se implementen los servicios, puedes verificar kubectl para ver el estado de los pods:
kubectl get pods
Resultado del comando
NAME READY STATUS RESTARTS AGE
item-6b9d5f678c-4tbk2 1/1 Running 0 83m
matchmaking-5bcf799b76-lg8zf 1/1 Running 0 80m
profile-565bbf4c65-kphdl 1/1 Running 0 83m
profile-565bbf4c65-xw74j 1/1 Running 0 83m
tradepost-68b87ccd44-gw55r 1/1 Running 0 79m
Luego, verifica los servicios para ver el ClusterIP en acción:
kubectl get services
Resultado del comando
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
item ClusterIP 10.172.XXX.XXX <none> 80/TCP 84m
kubernetes ClusterIP 10.172.XXX.XXX <none> 443/TCP 137m
matchmaking ClusterIP 10.172.XXX.XXX <none> 80/TCP 84m
profile ClusterIP 10.172.XXX.XXX <none> 80/TCP 84m
tradepost ClusterIP 10.172.XXX.XXX <none> 80/TCP 84m
También puedes navegar a la IU de GKE en Cloud Console para ver Workloads, Services y ConfigMaps.
Cargas de trabajo

Servicios
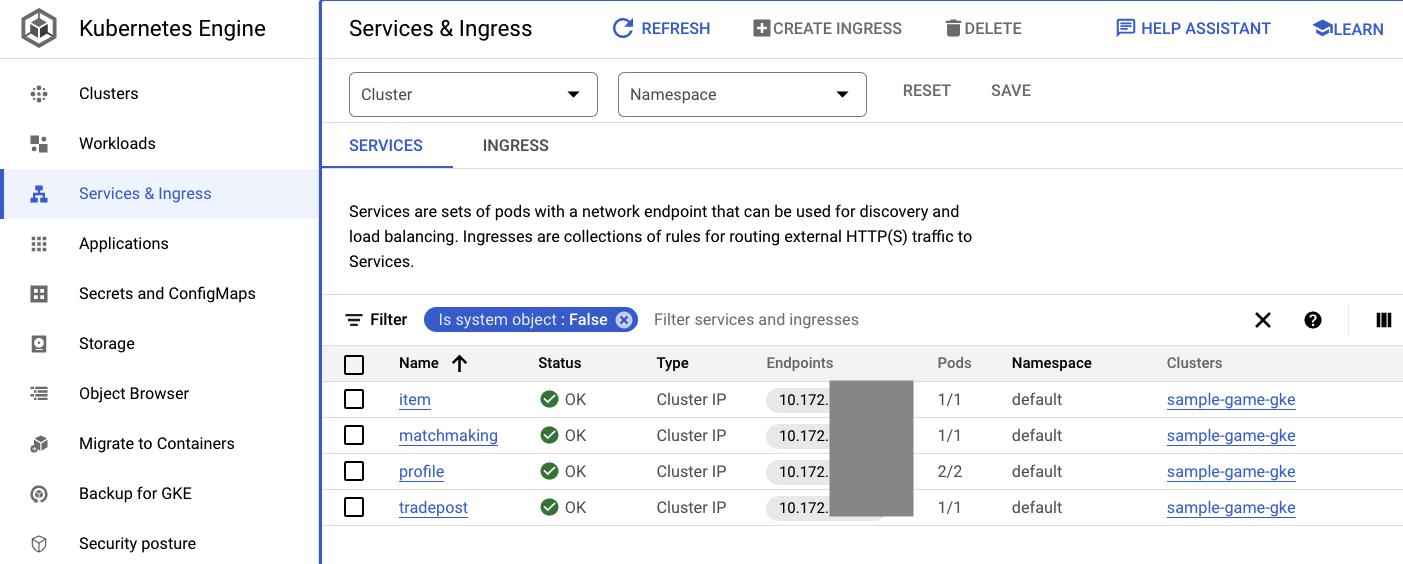
ConfigMaps


Resumen
En este paso, implementaste los cuatro servicios de backend en GKE Autopilot. Pudiste ejecutar el paso de Cloud Build y verificar el progreso en Cloud Deploy y en Kubernetes en Cloud Console.
También aprendiste cómo estos servicios utilizan Workload Identity para suplantar una cuenta de servicio que tiene los permisos adecuados para leer y escribir datos en la base de datos de Spanner.
Próximos pasos
En la siguiente sección, implementarás las cargas de trabajo.
6. Implementa las cargas de trabajo
Descripción general
Ahora que los servicios de backend se ejecutan en el clúster, implementarás las cargas de trabajo.

Se puede acceder a las cargas de trabajo de forma externa, y hay una para cada servicio de backend a los efectos de este codelab.
Estas cargas de trabajo son secuencias de comandos de generación de carga basadas en Locust que imitan los patrones de acceso reales que se esperan de estos servicios de muestra.
Hay archivos para el proceso de Cloud Build:
$DEMO_HOME/workloads/cloudbuild.yaml(generado por Terraform)$DEMO_HOME/workloads/skaffold.yaml- Un archivo
deployment.yamlpara cada carga de trabajo
Los archivos de carga de trabajo deployment.yaml se ven un poco diferentes de los archivos de implementación del servicio de backend.
Aquí tienes un ejemplo de matchmaking-workload:
apiVersion: v1
kind: Service
metadata:
name: matchmaking-workload
spec:
type: LoadBalancer
selector:
app: matchmaking-workload
ports:
- port: 8089
targetPort: 8089
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: matchmaking-workload
spec:
replicas: 1 # EDIT: Number of instances of deployment
selector:
matchLabels:
app: matchmaking-workload
template:
metadata:
labels:
app: matchmaking-workload
spec:
serviceAccountName: default
containers:
- name: matchmaking-workload
image: matchmaking-workload
ports:
- containerPort: 8089
resources:
requests:
cpu: "500m"
memory: "512Mi"
ephemeral-storage: "100Mi"
limits:
cpu: "500m"
memory: "512Mi"
ephemeral-storage: "100Mi"
La parte superior del archivo define el servicio. En este caso, se crea un LoadBalancer y la carga de trabajo se ejecuta en el puerto 8089.
El LoadBalancer proporcionará una IP externa que se puede usar para conectarse a la carga de trabajo.
apiVersion: v1
kind: Service
metadata:
name: matchmaking-workload
spec:
type: LoadBalancer
selector:
app: matchmaking-workload
ports:
- port: 8089
targetPort: 8089
La parte superior de la sección de implementación contiene los metadatos sobre la carga de trabajo. En este caso, solo se implementa una réplica:
replicas: 1
Sin embargo, la especificación del contenedor es diferente. Para empezar, usamos una cuenta de servicio de Kubernetes default. Esta cuenta no tiene privilegios especiales, ya que la carga de trabajo no necesita conectarse a ningún recurso de Google Cloud, excepto a los servicios de backend que se ejecutan en el clúster de GKE.
La otra diferencia es que no se necesitan variables de entorno para estas cargas de trabajo. El resultado es una especificación de implementación más corta.
spec:
serviceAccountName: default
containers:
- name: matchmaking-workload
image: matchmaking-workload
ports:
- containerPort: 8089
La configuración del recurso es similar a la de los servicios de backend. Recuerda que así es como GKE Autopilot sabe cuántos recursos se necesitan para satisfacer las solicitudes de todos los Pods que se ejecutan en el clúster.
¡Implementa las cargas de trabajo!
Implementa las cargas de trabajo
Al igual que antes, puedes enviar la solicitud de compilación con la línea de comandos de gcloud:
cd $DEMO_HOME/workloads gcloud builds submit --config=cloudbuild.yaml
Resultado del comando
Creating temporary tarball archive of 18 file(s) totalling 26.2 KiB before compression.
Some files were not included in the source upload.
Check the gcloud log [/tmp/tmp.4Z9EqdPo6d/logs/(snip).log] to see which files and the contents of the
default gcloudignore file used (see `$ gcloud topic gcloudignore` to learn
more).
Uploading tarball of [.] to [gs://(project)_cloudbuild/source/(snip).tgz]
Created [https://cloudbuild.googleapis.com/v1/projects/(project)/locations/global/builds/(snip)].
Logs are available at [ https://console.cloud.google.com/cloud-build/builds/0daf20f6-(snip)?project=(snip) ].
gcloud builds submit only displays logs from Cloud Storage. To view logs from Cloud Logging, run:
gcloud beta builds submit
ID: 0daf20f6-(snip)
CREATE_TIME: (created_time)
DURATION: 1M41S
SOURCE: gs://(project)_cloudbuild/source/(snip).tgz
IMAGES: us-docker.pkg.dev/(project)/spanner-game-images/profile-workload:0daf20f6-(snip) (+4 more)
STATUS: SUCCESS
Asegúrate de revisar los registros de Cloud Build y la canalización de Cloud Deploy en la consola de Cloud para verificar el estado. Para las cargas de trabajo, la canalización de Cloud Deploy es sample-game-workloads:
Una vez que se complete la implementación, verifica el estado con kubectl en Cloud Shell:
kubectl get pods
Resultado del comando
NAME READY STATUS RESTARTS AGE
game-workload-7ff44cb657-pxxq2 1/1 Running 0 12m
item-6b9d5f678c-cr29w 1/1 Running 0 9m6s
item-generator-7bb4f57cf8-5r85b 1/1 Running 0 12m
matchmaking-5bcf799b76-lg8zf 1/1 Running 0 117m
matchmaking-workload-76df69dbdf-jds9z 1/1 Running 0 12m
profile-565bbf4c65-kphdl 1/1 Running 0 121m
profile-565bbf4c65-xw74j 1/1 Running 0 121m
profile-workload-76d6db675b-kzwng 1/1 Running 0 12m
tradepost-68b87ccd44-gw55r 1/1 Running 0 116m
tradepost-workload-56c55445b5-b5822 1/1 Running 0 12m
Luego, verifica los servicios de carga de trabajo para ver el LoadBalancer en acción:
kubectl get services
Resultado del comando
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
game-workload LoadBalancer *snip* 35.XX.XX.XX 8089:32483/TCP 12m
item ClusterIP *snip* <none> 80/TCP 121m
item-generator LoadBalancer *snip* 34.XX.XX.XX 8089:32581/TCP 12m
kubernetes ClusterIP *snip* <none> 443/TCP 174m
matchmaking ClusterIP *snip* <none> 80/TCP 121m
matchmaking-workload LoadBalancer *snip* 34.XX.XX.XX 8089:31735/TCP 12m
profile ClusterIP *snip* <none> 80/TCP 121m
profile-workload LoadBalancer *snip* 34.XX.XX.XX 8089:32532/TCP 12m
tradepost ClusterIP *snip* <none> 80/TCP 121m
tradepost-workload LoadBalancer *snip* 34.XX.XX.XX 8089:30002/TCP 12m
Resumen
Ahora implementaste las cargas de trabajo en el clúster de GKE. Estas cargas de trabajo no requieren permisos de IAM adicionales y se puede acceder a ellas de forma externa en el puerto 8089 con el servicio LoadBalancer.
Próximos pasos
Con los servicios de backend y las cargas de trabajo en ejecución, es hora de "jugar" el juego.
7. Comienza a jugar
Descripción general
Los servicios de backend de tu "juego" de ejemplo ahora se están ejecutando, y también tienes los medios para generar "jugadores" que interactúen con esos servicios usando las cargas de trabajo.
Cada carga de trabajo usa Locust para simular la carga real en nuestras APIs de servicio. En este paso, ejecutarás varias cargas de trabajo para generar carga en el clúster de GKE y en Spanner, además de almacenar datos en Spanner.
A continuación, se incluye una descripción de cada carga de trabajo:
- La carga de trabajo
item-generatores una carga de trabajo rápida para generar una lista de game_items que los jugadores pueden adquirir durante el transcurso del "juego". - El objeto
profile-workloadsimula el registro y el acceso de los jugadores. - El objeto
matchmaking-workloadsimula a los jugadores que esperan en la cola para que se les asigne un juego. - El objeto
game-workloadsimula que los jugadores adquieren game_items y dinero a medida que juegan. - El
tradepost-workloadsimula que los jugadores pueden vender y comprar elementos en el puesto comercial.
En este codelab, se destacará específicamente la ejecución de item-generator y profile-workload.
Ejecuta el generador de elementos
El item-generator usa el extremo del servicio de backend item para agregar game_items a Spanner. Estos elementos son necesarios para que game-workload y tradepost-workload funcionen correctamente.
El primer paso es obtener la IP externa del servicio item-generator. En Cloud Shell, ejecuta lo siguiente:
# The external IP is the 4th column of the output
kubectl get services | grep item-generator | awk '{print $4}'
Resultado del comando
{ITEMGENERATOR_EXTERNAL_IP}
Ahora, abre una nueva pestaña del navegador y dirígela a http://{ITEMGENERATOR_EXTERNAL_IP}:8089. Deberías obtener una página como la siguiente:

Dejarás users y spawn en el valor predeterminado 1. En host, ingresa http://item. Haz clic en las opciones avanzadas y, luego, ingresa 10s para el tiempo de ejecución.
La configuración debería verse así:

Haz clic en “Start swarming”.
Las estadísticas comenzarán a aparecer para las solicitudes que se emitan en el extremo POST /items. La carga se detendrá después de 10 segundos.
Haz clic en Charts y verás algunos gráficos sobre el rendimiento de estas solicitudes.
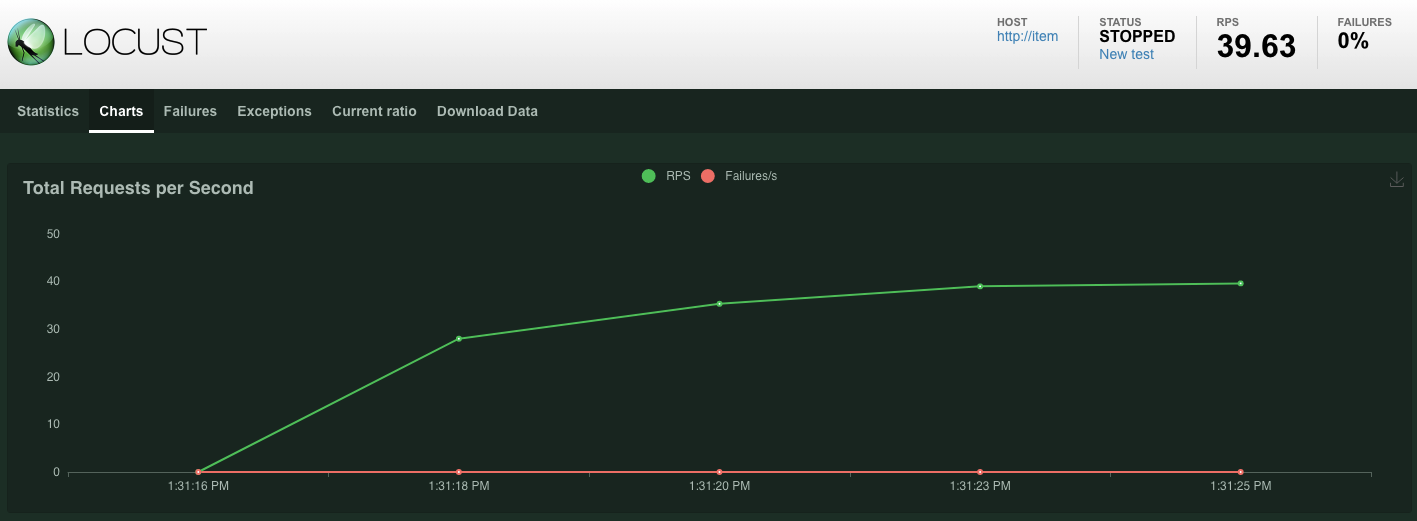
Ahora, quieres verificar si los datos se ingresaron en la base de datos de Spanner.
Para ello, haz clic en el menú de hamburguesa y navega a "Spanner". Desde esta página, navega a sample-instance y sample-database. Luego, haz clic en "Query".
Queremos seleccionar la cantidad de game_items:
SELECT COUNT(*) FROM game_items;
En la parte inferior, obtendrás el resultado.
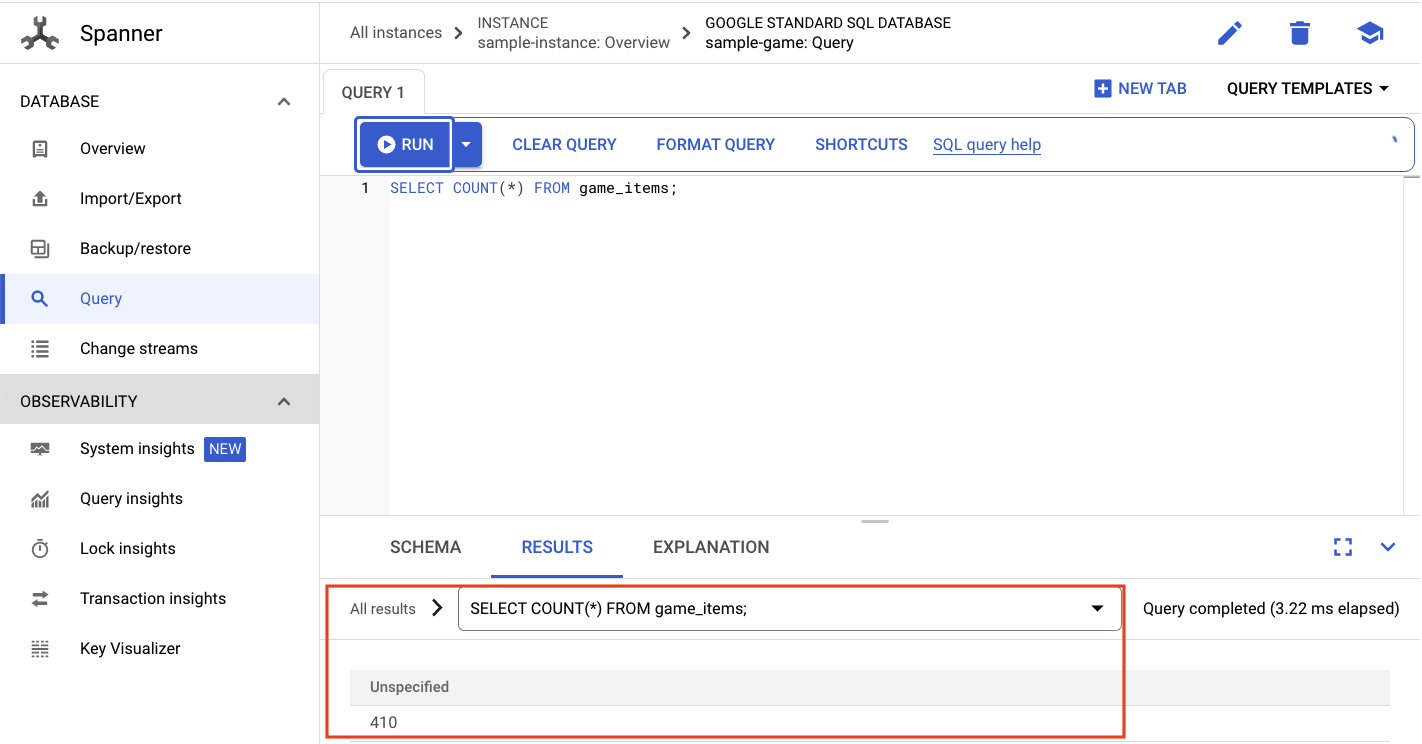
No necesitamos muchas game_items iniciales. Pero ahora los jugadores pueden adquirirlas.
Ejecuta la carga de trabajo de perfil
Con tu game_items inicializada, el siguiente paso es registrar a los jugadores para que puedan jugar.
El profile-workload usará Locust para simular jugadores que crean cuentas, acceden, recuperan información de perfil y salen. Todas estas pruebas verifican los extremos del servicio de backend profile en una carga de trabajo típica similar a la de producción.
Para ejecutarlo, obtén la IP externa de profile-workload:
# The external IP is the 4th column of the output
kubectl get services | grep profile-workload | awk '{print $4}'
Resultado del comando
{PROFILEWORKLOAD_EXTERNAL_IP}
Ahora, abre una nueva pestaña del navegador y dirígela a http://{PROFILEWORKLOAD_EXTERNAL_IP}:8089. Deberías obtener una página de Locust similar a la anterior.
En este caso, usarás http://profile para el host. Además, no especificarás un tiempo de ejecución en las opciones avanzadas. Además, especifica que users sea 4, lo que simulará 4 solicitudes de usuario a la vez.
La prueba profile-workload debería verse de la siguiente manera:
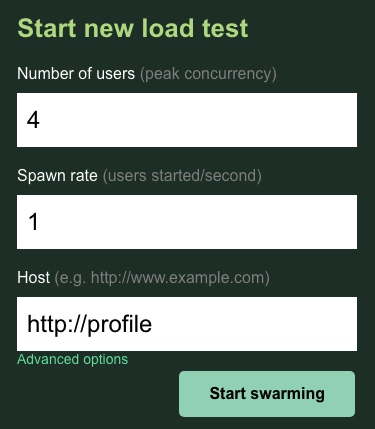
Haz clic en “Start swarming”.
Al igual que antes, comenzarán a aparecer las estadísticas de los distintos extremos de la API de REST de profile. Haz clic en los gráficos para ver qué tan bien funciona todo.
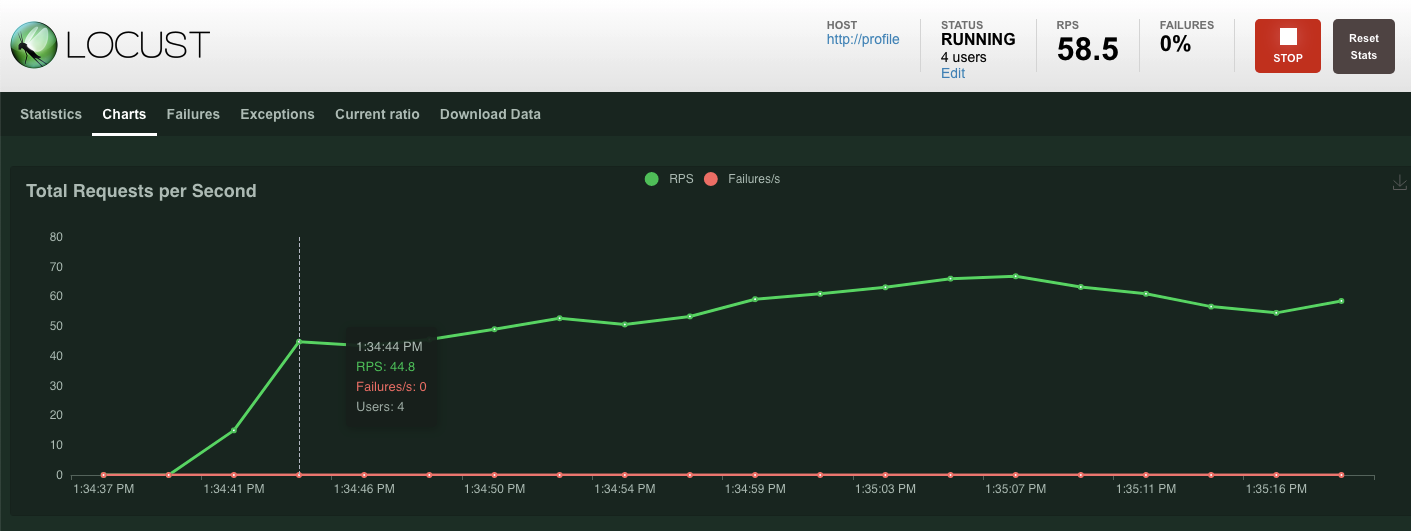
Resumen
En este paso, generaste algunos game_items y, luego, consultaste la tabla game_items con la IU de Spanner Query en la consola de Cloud.
También permitiste que los jugadores se registraran en tu juego y viste cómo Locust puede crear cargas de trabajo similares a las de producción en tus servicios de backend.
Próximos pasos
Después de ejecutar las cargas de trabajo, querrás verificar el comportamiento del clúster de GKE y la instancia de Spanner.
8. Revisa el uso de GKE y Spanner
Con el servicio de perfil en ejecución, es hora de aprovechar la oportunidad para ver cómo se comportan tu clúster de GKE Autopilot y Cloud Spanner.
Verifica el clúster de GKE
Navega al clúster de Kubernetes. Ten en cuenta que, como implementaste las cargas de trabajo y los servicios, ahora el clúster tiene algunos detalles agregados sobre la cantidad total de CPU virtuales y memoria. Esta información no estaba disponible cuando no había cargas de trabajo en el clúster.

Ahora, haz clic en el clúster sample-game-gke y cambia a la pestaña Observabilidad:

El espacio de nombres de Kubernetes default debería haber superado el espacio de nombres kube-system en cuanto a la utilización de CPU, ya que nuestras cargas de trabajo y servicios de backend se ejecutan en default. Si no es así, asegúrate de que profile workload siga en ejecución y espera unos minutos para que se actualicen los gráficos.
Para ver qué cargas de trabajo consumen más recursos, ve al panel Workloads.
En lugar de ingresar a cada carga de trabajo de forma individual, ve directamente a la pestaña Observabilidad del panel. Deberías ver que la CPU de profile y profile-workload aumentó.
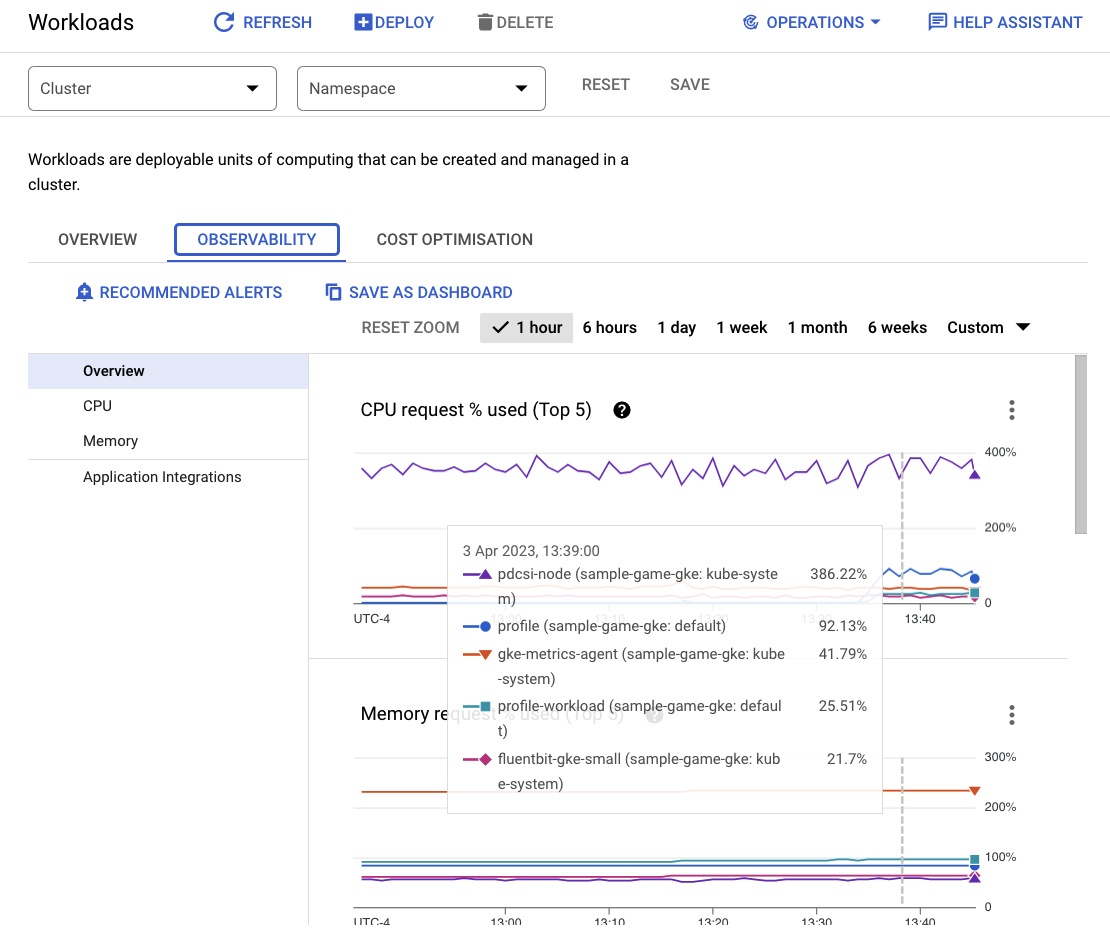
Ahora, ve a Cloud Spanner.
Verifica la instancia de Cloud Spanner
Para verificar el rendimiento de Cloud Spanner, navega a Spanner y haz clic en la instancia sample-instance y la base de datos sample-game.
Allí, verás la pestaña Estadísticas del sistema en el menú de la izquierda:
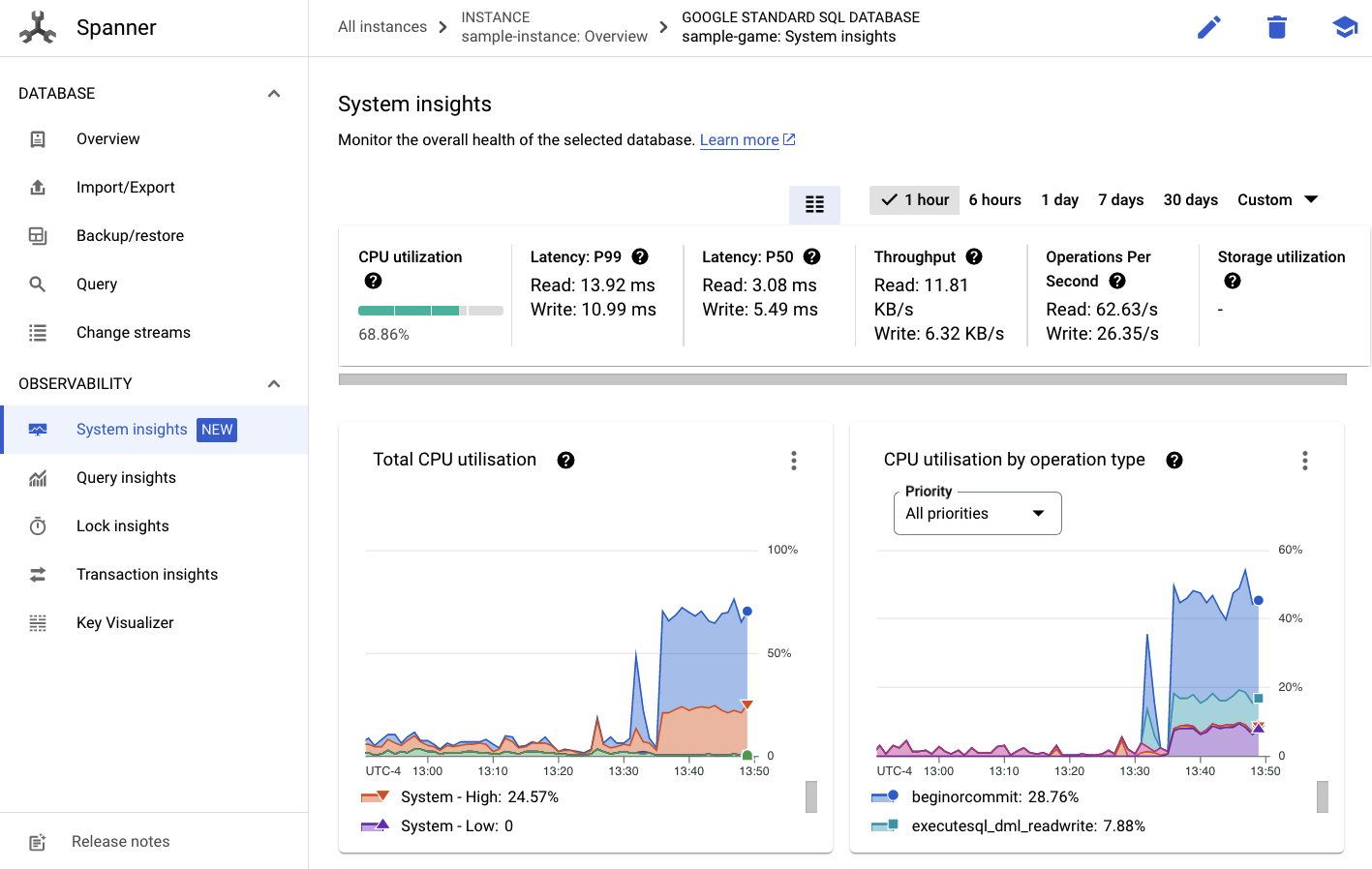
Aquí encontrarás muchos gráficos que te ayudarán a comprender el rendimiento general de tu instancia de Spanner, incluidos CPU utilization, transaction latency and locking y query throughput.
Además de System Insights, puedes obtener información más detallada sobre la carga de trabajo de las consultas a través de los otros vínculos de la sección Observabilidad:
- Las estadísticas de consultas ayudan a identificar las principales N consultas que utilizan recursos en Spanner.
- Las estadísticas de transacciones y bloqueos ayudan a identificar las transacciones con latencias altas.
- Key Visualizer ayuda a visualizar los patrones de acceso y puede ayudar a rastrear los hotspots en los datos.
Resumen
En este paso, aprendiste a verificar algunas métricas de rendimiento básicas para GKE Autopilot y Spanner.
Por ejemplo, con la carga de trabajo de tu perfil en ejecución, consulta la tabla players para obtener más información sobre los datos que se almacenan allí.
Próximos pasos
A continuación, es hora de limpiar.
9. Realiza una limpieza
Antes de limpiar, puedes explorar las otras cargas de trabajo que no se abordaron. Específicamente, matchmaking-workload, game-workload y tradepost-workload.
Cuando termines de "jugar", puedes limpiar tu zona de pruebas. Por suerte, esto es bastante fácil.
Primero, si tu profile-workload aún se está ejecutando en el navegador, ve y deténlo:
Haz lo mismo con cada carga de trabajo que hayas probado.
Luego, en Cloud Shell, navega a la carpeta de infraestructura. destroy la infraestructura con Terraform:
cd $DEMO_HOME/infrastructure
terraform destroy
# type 'yes' when asked
Resultado del comando
Plan: 0 to add, 0 to change, 46 to destroy.
Do you really want to destroy all resources?
Terraform will destroy all your managed infrastructure, as shown above.
There is no undo. Only 'yes' will be accepted to confirm.
Enter a value: yes
*snip*
Destroy complete! Resources: 46 destroyed.
En la consola de Cloud, navega a Spanner, Kubernetes Cluster, Artifact Registry, Cloud Deploy y IAM para validar que se hayan quitado todos los recursos.
10. ¡Felicitaciones!
¡Felicitaciones! Implementaste correctamente aplicaciones de muestra en Go en GKE Autopilot y las conectaste a Cloud Spanner con Workload Identity.
Como beneficio adicional, esta infraestructura se configuró y quitó fácilmente de forma repetible con Terraform.
Puedes leer más sobre los servicios de Google Cloud con los que interactuaste en este codelab:
Próximos pasos
Ahora que tienes una comprensión básica de cómo pueden trabajar juntos GKE Autopilot y Cloud Spanner, ¿por qué no das el siguiente paso y comienzas a compilar tu propia aplicación para trabajar con estos servicios?