
1. Pengantar
Cloud Spanner adalah layanan database relasional skalabel dan terkelola sepenuhnya secara horizontal yang terdistribusi secara global, yang menyediakan transaksi ACID dan semantik SQL tanpa mengorbankan performa dan ketersediaan tinggi.
GKE Autopilot adalah mode operasi di GKE yang memungkinkan Google mengelola konfigurasi cluster Anda, termasuk node, penskalaan, keamanan, dan setelan lainnya yang telah dikonfigurasi sebelumnya untuk mengikuti praktik terbaik. Misalnya, GKE Autopilot mengaktifkan Workload Identity untuk mengelola izin layanan.
Lab ini bertujuan memandu Anda melalui proses untuk menghubungkan beberapa layanan backend yang berjalan di Autopilot GKE ke database Cloud Spanner.
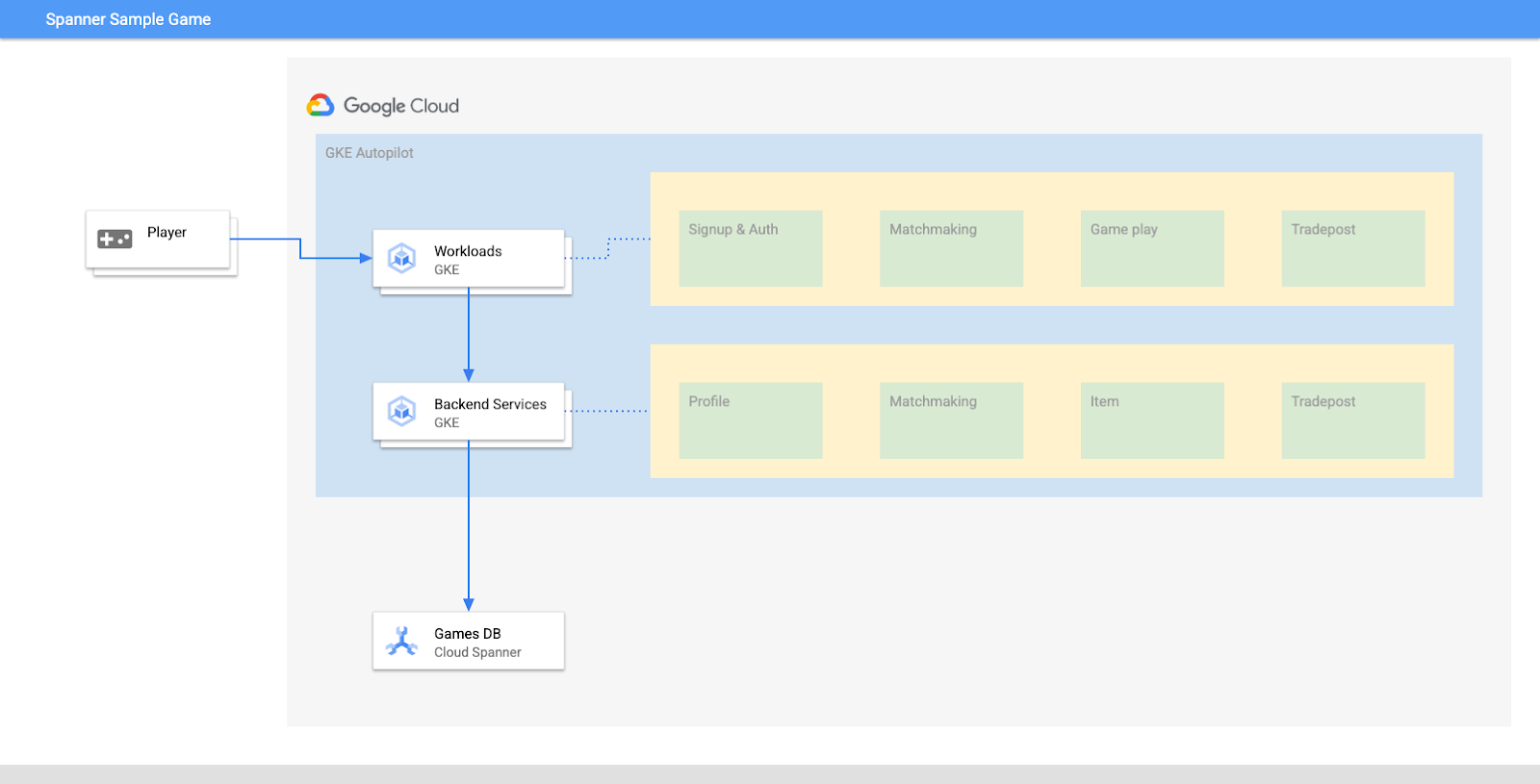
Di lab ini, Anda akan menyiapkan project terlebih dahulu dan meluncurkan Cloud Shell. Kemudian, Anda akan men-deploy infrastruktur menggunakan Terraform.
Setelah selesai, Anda akan berinteraksi dengan Cloud Build dan Cloud Deploy untuk melakukan migrasi skema awal untuk database Game, men-deploy layanan backend, lalu men-deploy workload.
Layanan dalam codelab ini sama dengan layanan dari codelab Mulai Menggunakan Cloud Spanner untuk Pengembangan Game. Menjalankan codelab tersebut tidak diperlukan untuk menjalankan layanan di GKE dan terhubung ke Spanner. Namun, jika Anda tertarik dengan detail lebih lanjut tentang layanan spesifik yang berfungsi di Spanner, lihat detailnya.
Dengan workload dan layanan backend yang berjalan, Anda dapat mulai membuat beban dan mengamati cara kerja layanan bersama-sama.
Terakhir, Anda akan membersihkan resource yang dibuat di lab ini.
Yang akan Anda build
Sebagai bagian dari lab ini, Anda akan:
- Menyediakan infrastruktur menggunakan Terraform
- Buat skema database menggunakan proses Migrasi Skema di Cloud Build
- Deploy empat layanan backend Golang yang memanfaatkan Workload Identity untuk terhubung ke Cloud Spanner
- Deploy empat layanan beban kerja yang digunakan untuk menyimulasikan beban untuk layanan backend.
Yang akan Anda pelajari
- Cara menyediakan pipeline Autopilot GKE, Cloud Spanner, dan Cloud Deploy menggunakan Terraform
- Cara Workload Identity memungkinkan layanan di GKE meniru identitas akun layanan untuk mengakses izin IAM guna menggunakan Cloud Spanner
- Cara membuat beban seperti produksi di GKE dan Cloud Spanner menggunakan Locust.io
Yang Anda butuhkan
2. Penyiapan dan persyaratan
Membuat project
Jika belum memiliki Akun Google (Gmail atau Google Apps), Anda harus membuatnya. Login ke Konsol Google Cloud Platform ( console.cloud.google.com) dan buat project baru.
Jika Anda sudah memiliki project, klik menu pull-down pilihan project di kiri atas konsol:

dan klik tombol 'PROJECT BARU' dalam dialog yang dihasilkan untuk membuat project baru:

Jika belum memiliki project, Anda akan melihat dialog seperti ini untuk membuat project pertama:

Dialog pembuatan project berikutnya memungkinkan Anda memasukkan detail project baru:

Ingat project ID yang merupakan nama unik di semua project Google Cloud (maaf, nama di atas telah digunakan dan tidak akan berfungsi untuk Anda!) Project ID tersebut selanjutnya akan dirujuk di codelab ini sebagai PROJECT_ID.
Selanjutnya, jika Anda belum melakukannya, Anda harus mengaktifkan penagihan di Developers Console untuk menggunakan resource Google Cloud dan mengaktifkan Cloud Spanner API.

Menjalankan melalui codelab ini tidak akan menghabiskan biaya lebih dari beberapa dolar, tetapi bisa lebih jika Anda memutuskan untuk menggunakan lebih banyak resource atau jika Anda membiarkannya berjalan (lihat bagian "pembersihan" di akhir dokumen ini). Harga Google Cloud Spanner didokumentasikan di sini, dan GKE Autopilot didokumentasikan di sini.
Pengguna baru Google Cloud Platform memenuhi syarat untuk mendapatkan uji coba gratis senilai $300, yang menjadikan codelab ini sepenuhnya gratis.
Penyiapan Cloud Shell
Meskipun Google Cloud dan Spanner dapat dioperasikan dari jarak jauh menggunakan laptop Anda, dalam codelab ini, kita akan menggunakan Google Cloud Shell, lingkungan command line yang berjalan di Cloud.
Mesin virtual berbasis Debian ini memuat semua alat pengembangan yang akan Anda perlukan. Layanan ini menawarkan direktori beranda tetap sebesar 5 GB dan beroperasi di Google Cloud, sehingga sangat meningkatkan performa dan autentikasi jaringan. Ini berarti bahwa semua yang Anda perlukan untuk codelab ini adalah browser (ya, ini berfungsi di Chromebook).
- Untuk mengaktifkan Cloud Shell dari Cloud Console, cukup klik Aktifkan Cloud Shell
 (hanya perlu beberapa saat untuk melakukan penyediaan dan terhubung ke lingkungan).
(hanya perlu beberapa saat untuk melakukan penyediaan dan terhubung ke lingkungan).

Setelah terhubung ke Cloud Shell, Anda akan melihat bahwa Anda sudah diautentikasi dan project sudah ditetapkan ke PROJECT_ID.
gcloud auth list
Output perintah
Credentialed accounts:
- <myaccount>@<mydomain>.com (active)
gcloud config list project
Output perintah
[core]
project = <PROJECT_ID>
Jika, untuk beberapa alasan, project belum disetel, cukup jalankan perintah berikut:
gcloud config set project <PROJECT_ID>
Mencari PROJECT_ID Anda? Periksa ID yang Anda gunakan di langkah-langkah penyiapan atau cari di dasbor Cloud Console:

Cloud Shell juga menetapkan beberapa variabel lingkungan secara default, yang mungkin berguna saat Anda menjalankan perintah di masa mendatang.
echo $GOOGLE_CLOUD_PROJECT
Output perintah
<PROJECT_ID>
Mendownload kode
Di Cloud Shell, Anda dapat mendownload kode untuk lab ini:
git clone https://github.com/cloudspannerecosystem/spanner-gaming-sample.git
Output perintah
Cloning into 'spanner-gaming-sample'...
*snip*
Codelab ini didasarkan pada rilis v0.1.3, jadi periksa tag tersebut:
cd spanner-gaming-sample
git fetch --all --tags
# Check out v0.1.3 release
git checkout tags/v0.1.3 -b v0.1.3-branch
Output perintah
Switched to a new branch 'v0.1.3-branch'
Sekarang, tetapkan direktori kerja saat ini sebagai variabel lingkungan DEMO_HOME. Hal ini akan mempermudah navigasi saat Anda mempelajari berbagai bagian codelab.
export DEMO_HOME=$(pwd)
Ringkasan
Pada langkah ini, Anda telah menyiapkan project baru, mengaktifkan Cloud Shell, dan mendownload kode untuk lab ini.
Berikutnya
Selanjutnya, Anda akan menyediakan infrastruktur menggunakan Terraform.
3. Menyediakan infrastruktur
Ringkasan
Setelah project Anda siap, saatnya menjalankan infrastruktur. Hal ini mencakup jaringan VPC, Cloud Spanner, GKE Autopilot, Artifact Registry untuk menyimpan image yang akan berjalan di GKE, pipeline Cloud Deploy untuk layanan dan workload backend, dan terakhir akun layanan serta hak istimewa IAM agar dapat menggunakan layanan tersebut.
Banyak sekali. Namun, untungnya, Terraform dapat menyederhanakan penyiapan ini. Terraform adalah alat "Infrastructure as Code" yang memungkinkan kita menentukan apa yang kita butuhkan untuk project ini dalam serangkaian file '.tf'. Hal ini menyederhanakan penyediaan infrastruktur.
Anda tidak harus memahami Terraform untuk menyelesaikan codelab ini. Namun, jika Anda ingin melihat apa yang dilakukan beberapa langkah berikutnya, Anda dapat melihat semua yang dibuat dalam file ini yang berada di direktori infrastructure:
- vpc.tf
- backend_gke.tf
- spanner.tf
- artifact_registry.tf
- pipelines.tf
- iam.tf
Mengonfigurasi Terraform
Di Cloud Shell, Anda akan berpindah ke direktori infrastructure dan melakukan inisialisasi Terraform:
cd $DEMO_HOME/infrastructure
terraform init
Output perintah
Initializing the backend...
Initializing provider plugins...
*snip*
Terraform has been successfully initialized!
You may now begin working with Terraform. Try running "terraform plan" to see
any changes that are required for your infrastructure. All Terraform commands
should now work.
If you ever set or change modules or backend configuration for Terraform,
rerun this command to reinitialize your working directory. If you forget, other
commands will detect it and remind you to do so if necessary.
Selanjutnya, konfigurasi Terraform dengan menyalin terraform.tfvars.sample dan mengubah nilai project. Variabel lainnya juga dapat diubah, tetapi project adalah satu-satunya variabel yang harus diubah agar dapat berfungsi dengan lingkungan Anda.
cp terraform.tfvars.sample terraform.tfvars
# edit gcp_project using the project environment variable
sed -i "s/PROJECT/$GOOGLE_CLOUD_PROJECT/" terraform.tfvars
Menyediakan infrastruktur
Sekarang saatnya menyediakan infrastruktur.
terraform apply
# review the list of things to be created
# type 'yes' when asked
Output perintah
Plan: 46 to add, 0 to change, 0 to destroy.
Do you want to perform these actions?
Terraform will perform the actions described above.
Only 'yes' will be accepted to approve.
Enter a value: yes
google_project_service.project["container.googleapis.com"]: Creating...
*snip*
Apply complete! Resources: 46 added, 0 changed, 0 destroyed.
Memeriksa apa yang dibuat
Untuk memverifikasi apa yang telah dibuat, Anda harus memeriksa produk di Konsol Cloud.
Cloud Spanner
Pertama, periksa Cloud Spanner dengan membuka menu tiga garis dan mengklik Spanner. Anda mungkin harus mengklik 'Lihat produk lainnya' untuk menemukannya dalam daftar.
Tindakan ini akan mengarahkan Anda ke daftar instance Spanner. Klik instance dan Anda akan melihat database. Ini akan terlihat seperti berikut:

Autopilot GKE
Selanjutnya, lihat GKE dengan membuka menu tiga garis dan mengklik Kubernetes Engine => Clusters. Di sini Anda akan melihat cluster sample-games-gke yang berjalan dalam mode Autopilot.

Artifact Registry
Sekarang Anda akan melihat tempat penyimpanan gambar. Jadi, klik menu tiga garis dan temukan Artifact Registry=>Repositories. Artifact Registry berada di bagian CI/CD pada menu.
Di sini, Anda akan melihat registry Docker bernama spanner-game-images. Kolom ini akan kosong untuk saat ini.

Cloud Deploy
Cloud Deploy adalah tempat pipeline dibuat sehingga Cloud Build dapat menyediakan langkah-langkah untuk membangun image, lalu men-deploy-nya ke cluster GKE kita.
Buka menu tiga garis dan temukan Cloud Deploy, yang juga ada di bagian CI/CD pada menu.
Di sini, Anda akan melihat dua pipeline: satu untuk layanan backend, dan satu untuk workload. Keduanya men-deploy image ke cluster GKE yang sama, tetapi hal ini memungkinkan pemisahan deployment.

IAM
Terakhir, lihat halaman IAM di Cloud Console untuk memverifikasi akun layanan yang dibuat. Buka menu tiga garis dan temukan IAM and Admin=>Service accounts. Ini akan terlihat seperti berikut:

Ada enam total akun layanan yang dibuat oleh Terraform:
- Akun layanan komputer default. Tidak digunakan dalam codelab ini.
- Akun cloudbuild-cicd digunakan untuk langkah-langkah Cloud Build dan Cloud Deploy.
- Empat akun 'aplikasi' yang digunakan oleh layanan backend kami untuk berinteraksi dengan Cloud Spanner.
Selanjutnya, Anda perlu mengonfigurasi kubectl untuk berinteraksi dengan cluster GKE.
Mengonfigurasi kubectl
# Name of GKE cluster from terraform.tfvars file
export GKE_CLUSTER=sample-game-gke
# get GKE credentials
gcloud container clusters get-credentials $GKE_CLUSTER --region us-central1
# Check that no errors occur
kubectl get serviceaccounts
Output perintah
#export GKE_CLUSTER=sample-game-gke
# gcloud container clusters get-credentials $GKE_CLUSTER --region us-central1
Fetching cluster endpoint and auth data.
kubeconfig entry generated for sample-game-gke.
# kubectl get serviceaccounts
NAME SECRETS AGE
default 0 37m
item-app 0 35m
matchmaking-app 0 35m
profile-app 0 35m
tradepost-app 0 35m
Ringkasan
Bagus! Anda dapat menyediakan instance Cloud Spanner, cluster Autopilot GKE, semuanya dalam VPC untuk jaringan pribadi.
Selain itu, dua pipeline Cloud Deploy dibuat untuk layanan backend dan beban kerja, serta repositori Artifact Registry untuk menyimpan image yang dibangun.
Terakhir, akun layanan dibuat dan dikonfigurasi untuk bekerja dengan Workload Identity sehingga layanan backend dapat menggunakan Cloud Spanner.
Anda juga telah mengonfigurasi kubectl untuk berinteraksi dengan cluster GKE di Cloud Shell setelah men-deploy layanan dan workload backend.
Berikutnya
Sebelum Anda dapat menggunakan layanan, skema database harus ditentukan. Anda akan menyiapkannya nanti.
4. Membuat skema database
Ringkasan
Sebelum dapat menjalankan layanan backend, Anda harus memastikan skema database sudah ada.
Jika Anda melihat file di direktori $DEMO_HOME/schema/migrations dari repositori demo, Anda akan melihat serangkaian file .sql yang menentukan skema kita. Hal ini meniru siklus pengembangan yang melacak perubahan skema di repositori itu sendiri, dan dapat dikaitkan dengan fitur tertentu dari aplikasi.
Untuk lingkungan contoh ini, wrench adalah alat yang akan menerapkan migrasi skema menggunakan Cloud Build.
Cloud Build
File $DEMO_HOME/schema/cloudbuild.yaml menjelaskan langkah-langkah yang akan dilakukan:
serviceAccount: projects/${PROJECT_ID}/serviceAccounts/cloudbuild-cicd@${PROJECT_ID}.iam.gserviceaccount.com
steps:
- name: gcr.io/cloud-builders/curl
id: fetch-wrench
args: ['-Lo', '/workspace/wrench.tar.gz', 'https://github.com/cloudspannerecosystem/wrench/releases/download/v1.4.1/wrench-1.4.1-linux-amd64.tar.gz' ]
- name: gcr.io/cloud-builders/gcloud
id: migrate-spanner-schema
entrypoint: sh
args:
- '-xe'
- '-c'
- |
tar -xzvf wrench.tar.gz
chmod +x /workspace/wrench
# Assumes only a single spanner instance and database. Fine for this demo in a dedicated project
export SPANNER_PROJECT_ID=${PROJECT_ID}
export SPANNER_INSTANCE_ID=$(gcloud spanner instances list | tail -n1 | awk '{print $1}')
export SPANNER_DATABASE_ID=$(gcloud spanner databases list --instance=$$SPANNER_INSTANCE_ID | tail -n1 | awk '{print $1}')
if [ -d ./migrations ]; then
/workspace/wrench migrate up --directory .
else
echo "[Error] Missing migrations directory"
fi
timeout: 600s
Pada dasarnya ada dua langkah:
- Download wrench ke ruang kerja Cloud Build
- menjalankan migrasi wrench
Variabel lingkungan project, instance, dan database Spanner diperlukan agar wrench dapat terhubung ke endpoint tulis.
Cloud Build dapat melakukan perubahan ini karena berjalan sebagai akun layanan cloudbuild-cicd@${PROJECT_ID}.iam.gserviceaccount.com:
serviceAccount: projects/${PROJECT_ID}/serviceAccounts/cloudbuild-cicd@${PROJECT_ID}.iam.gserviceaccount.com
Akun layanan ini memiliki peran spanner.databaseUser yang ditambahkan oleh Terraform, yang memungkinkan akun layanan tersebut memperbarui DDL.
Migrasi skema
Ada lima langkah migrasi yang dilakukan berdasarkan file di direktori $DEMO_HOME/schema/migrations. Berikut adalah contoh file 000001.sql yang membuat tabel dan indeks players:
CREATE TABLE players (
playerUUID STRING(36) NOT NULL,
player_name STRING(64) NOT NULL,
email STRING(MAX) NOT NULL,
password_hash BYTES(60) NOT NULL,
created TIMESTAMP,
updated TIMESTAMP,
stats JSON,
account_balance NUMERIC NOT NULL DEFAULT (0.00),
is_logged_in BOOL,
last_login TIMESTAMP,
valid_email BOOL,
current_game STRING(36)
) PRIMARY KEY (playerUUID);
CREATE UNIQUE INDEX PlayerAuthentication ON players(email) STORING(password_hash);
CREATE UNIQUE INDEX PlayerName ON players(player_name);
CREATE INDEX PlayerGame ON players(current_game);
Mengirimkan migrasi skema
Untuk mengirimkan build guna melakukan migrasi skema, beralihlah ke direktori schema dan jalankan perintah gcloud berikut:
cd $DEMO_HOME/schema gcloud builds submit --config=cloudbuild.yaml
Output perintah
Creating temporary tarball archive of 8 file(s) totalling 11.2 KiB before compression.
Uploading tarball of [.] to [gs://(project)_cloudbuild/source/(snip).tgz]
Created [https://cloudbuild.googleapis.com/v1/projects/(project)/locations/global/builds/7defe982-(snip)].
Logs are available at [ https://console.cloud.google.com/cloud-build/builds/7defe982-(snip)?project=(snip) ].
gcloud builds submit only displays logs from Cloud Storage. To view logs from Cloud Logging, run:
gcloud beta builds submit
ID: 7defe982-(snip)
CREATE_TIME: (created time)
DURATION: 3M11S
SOURCE: gs://(project)_cloudbuild/source/(snip).tgz
IMAGES: -
STATUS: SUCCESS
Pada output di atas, Anda akan melihat link ke proses build cloud Created. Jika Anda mengkliknya, Anda akan diarahkan ke build di Konsol Cloud sehingga Anda dapat memantau progres build dan melihat apa yang sedang dilakukan.

Ringkasan
Pada langkah ini, Anda menggunakan Cloud Build untuk mengirimkan migrasi skema awal yang menerapkan 5 operasi DDL yang berbeda. Operasi ini menunjukkan kapan fitur yang memerlukan perubahan skema database ditambahkan.
Dalam skenario pengembangan normal, Anda ingin membuat perubahan skema yang kompatibel dengan aplikasi saat ini untuk menghindari gangguan.
Untuk perubahan yang tidak kompatibel dengan versi sebelumnya, Anda harus men-deploy perubahan pada aplikasi dan skema secara bertahap untuk memastikan tidak ada gangguan.
Berikutnya
Setelah skema diterapkan, langkah selanjutnya adalah men-deploy layanan backend.
5. Men-deploy layanan backend
Ringkasan
Layanan backend untuk codelab ini adalah REST API golang yang merepresentasikan empat layanan berbeda:
- Profil: memberi pemain kemampuan untuk mendaftar dan melakukan autentikasi ke "game" contoh kami.
- Pencocokan: berinteraksi dengan data pemain untuk membantu fungsi pencocokan, melacak informasi tentang game yang dibuat, dan memperbarui statistik pemain saat game ditutup.
- Item: memungkinkan pemain mendapatkan item dan uang dalam game selama bermain game.
- Tempat perdagangan: memungkinkan pemain membeli dan menjual item di tempat perdagangan

Anda dapat mempelajari layanan ini lebih lanjut di codelab Memulai Pengembangan Game dengan Cloud Spanner. Untuk tujuan kami, kami ingin layanan ini berjalan di cluster GKE Autopilot kami.
Layanan ini harus dapat mengubah data Spanner. Untuk melakukannya, setiap layanan memiliki akun layanan yang dibuat yang memberikan peran 'databaseUser' kepada layanan tersebut.
Workload Identity memungkinkan akun layanan Kubernetes meniru identitas akun layanan Google Cloud layanan dengan langkah-langkah berikut di Terraform kami:
- Buat resource akun layanan Google Cloud (
GSA) layanan - Tetapkan peran databaseUser ke akun layanan tersebut
- Tetapkan peran workloadIdentityUser ke akun layanan tersebut
- Buat akun layanan Kubernetes (
KSA) yang mereferensikan GSA
Diagram kasar akan terlihat seperti ini:

Terraform telah membuat akun layanan dan akun layanan Kubernetes untuk Anda. Anda dapat memeriksa akun layanan Kubernetes menggunakan kubectl:
# kubectl get serviceaccounts
NAME SECRETS AGE
default 0 37m
item-app 0 35m
matchmaking-app 0 35m
profile-app 0 35m
tradepost-app 0 35m
Cara kerja build adalah sebagai berikut:
- Terraform menghasilkan file
$DEMO_HOME/backend_services/cloudbuild.yamlyang terlihat seperti ini:
serviceAccount: projects/${PROJECT_ID}/serviceAccounts/cloudbuild-cicd@${PROJECT_ID}.iam.gserviceaccount.com
steps:
#
# Building of images
#
- name: gcr.io/cloud-builders/docker
id: profile
args: ["build", ".", "-t", "${_PROFILE_IMAGE}"]
dir: profile
waitFor: ['-']
- name: gcr.io/cloud-builders/docker
id: matchmaking
args: ["build", ".", "-t", "${_MATCHMAKING_IMAGE}"]
dir: matchmaking
waitFor: ['-']
- name: gcr.io/cloud-builders/docker
id: item
args: ["build", ".", "-t", "${_ITEM_IMAGE}"]
dir: item
waitFor: ['-']
- name: gcr.io/cloud-builders/docker
id: tradepost
args: ["build", ".", "-t", "${_TRADEPOST_IMAGE}"]
dir: tradepost
waitFor: ['-']
#
# Deployment
#
- name: gcr.io/google.com/cloudsdktool/cloud-sdk
id: cloud-deploy-release
entrypoint: gcloud
args:
[
"deploy", "releases", "create", "${_REL_NAME}",
"--delivery-pipeline", "sample-game-services",
"--skaffold-file", "skaffold.yaml",
"--skaffold-version", "1.39",
"--images", "profile=${_PROFILE_IMAGE},matchmaking=${_MATCHMAKING_IMAGE},item=${_ITEM_IMAGE},tradepost=${_TRADEPOST_IMAGE}",
"--region", "us-central1"
]
artifacts:
images:
- ${_REGISTRY}/profile
- ${_REGISTRY}/matchmaking
- ${_REGISTRY}/item
- ${_REGISTRY}/tradepost
substitutions:
_PROFILE_IMAGE: ${_REGISTRY}/profile:${BUILD_ID}
_MATCHMAKING_IMAGE: ${_REGISTRY}/matchmaking:${BUILD_ID}
_ITEM_IMAGE: ${_REGISTRY}/item:${BUILD_ID}
_TRADEPOST_IMAGE: ${_REGISTRY}/tradepost:${BUILD_ID}
_REGISTRY: us-docker.pkg.dev/${PROJECT_ID}/spanner-game-images
_REL_NAME: rel-${BUILD_ID:0:8}
options:
dynamic_substitutions: true
machineType: E2_HIGHCPU_8
logging: CLOUD_LOGGING_ONLY
- Perintah Cloud Build membaca file ini dan mengikuti langkah-langkah yang tercantum. Pertama, image layanan akan dibangun. Kemudian, perintah
gcloud deploy createakan dijalankan. Tindakan ini membaca file$DEMO_HOME/backend_services/skaffold.yaml, yang menentukan lokasi setiap file deployment:
apiVersion: skaffold/v2beta29
kind: Config
deploy:
kubectl:
manifests:
- spanner_config.yaml
- profile/deployment.yaml
- matchmaking/deployment.yaml
- item/deployment.yaml
- tradepost/deployment.yaml
- Cloud Deploy akan mengikuti definisi file
deployment.yamlsetiap layanan. File deployment layanan berisi informasi untuk membuat layanan, yang dalam hal ini adalah clusterIP yang berjalan di port 80.
Jenis " ClusterIP" mencegah pod layanan backend memiliki IP eksternal sehingga hanya entitas yang dapat terhubung ke jaringan GKE internal yang dapat mengakses layanan backend. Layanan ini tidak boleh dapat diakses langsung oleh pemain karena layanan ini mengakses dan mengubah data Spanner.
apiVersion: v1
kind: Service
metadata:
name: profile
spec:
type: ClusterIP
selector:
app: profile
ports:
- port: 80
targetPort: 80
Selain membuat layanan Kubernetes, Cloud Deploy juga membuat deployment Kubernetes. Mari kita periksa bagian deployment layanan profile:
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: profile
spec:
replicas: 2 # EDIT: Number of instances of deployment
selector:
matchLabels:
app: profile
template:
metadata:
labels:
app: profile
spec:
serviceAccountName: profile-app
containers:
- name: profile-service
image: profile
ports:
- containerPort: 80
envFrom:
- configMapRef:
name: spanner-config
env:
- name: SERVICE_HOST
value: "0.0.0.0"
- name: SERVICE_PORT
value: "80"
resources:
requests:
cpu: "1"
memory: "1Gi"
ephemeral-storage: "100Mi"
limits:
cpu: "1"
memory: "1Gi"
ephemeral-storage: "100Mi"
Bagian atas memberikan beberapa metadata tentang layanan. Bagian terpenting dari hal ini adalah menentukan jumlah replika yang akan dibuat oleh deployment ini.
replicas: 2 # EDIT: Number of instances of deployment
Selanjutnya, kita melihat akun layanan mana yang harus menjalankan aplikasi, dan gambar mana yang harus digunakan. Ini cocok dengan akun layanan Kubernetes yang dibuat dari Terraform dan image yang dibuat selama langkah Cloud Build.
spec:
serviceAccountName: profile-app
containers:
- name: profile-service
image: profile
Setelah itu, kita menentukan beberapa informasi tentang jaringan dan variabel lingkungan.
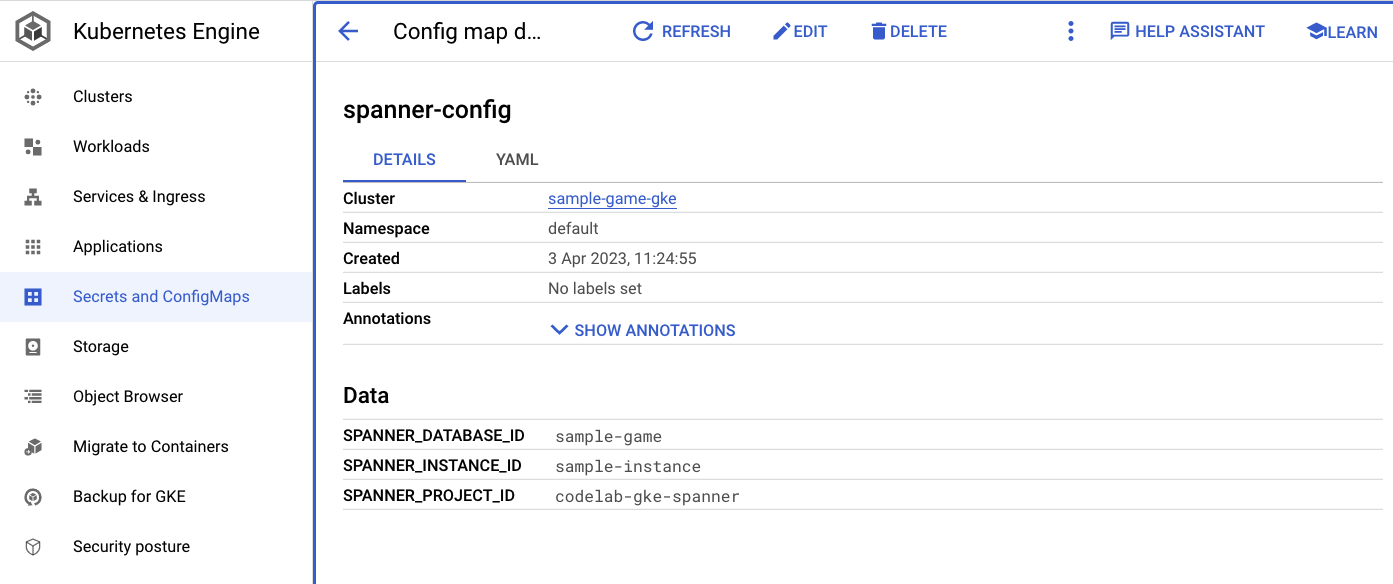
spanner_config adalah ConfigMap Kubernetes yang menentukan informasi project, instance, dan database yang diperlukan agar aplikasi terhubung ke Spanner.
apiVersion: v1
kind: ConfigMap
metadata:
name: spanner-config
data:
SPANNER_PROJECT_ID: ${project_id}
SPANNER_INSTANCE_ID: ${instance_id}
SPANNER_DATABASE_ID: ${database_id}
ports:
- containerPort: 80
envFrom:
- configMapRef:
name: spanner-config
env:
- name: SERVICE_HOST
value: "0.0.0.0"
- name: SERVICE_PORT
value: "80"
SERVICE_HOST dan SERVICE_PORT adalah variabel lingkungan tambahan yang diperlukan oleh layanan untuk mengetahui tempat pengikatan.
Bagian terakhir memberi tahu GKE berapa banyak resource yang diizinkan untuk setiap replika dalam deployment ini. Hal ini juga digunakan oleh GKE Autopilot untuk menskalakan cluster sesuai kebutuhan.
resources:
requests:
cpu: "1"
memory: "1Gi"
ephemeral-storage: "100Mi"
limits:
cpu: "1"
memory: "1Gi"
ephemeral-storage: "100Mi"
Dengan informasi ini, saatnya men-deploy layanan backend.
Men-deploy layanan backend
Seperti yang disebutkan, deployment layanan backend menggunakan Cloud Build. Sama seperti migrasi skema, Anda dapat mengirimkan permintaan build menggunakan command line gcloud:
cd $DEMO_HOME/backend_services gcloud builds submit --config=cloudbuild.yaml
Output perintah
Creating temporary tarball archive of 66 file(s) totalling 864.6 KiB before compression.
Uploading tarball of [.] to [gs://(project)_cloudbuild/source/(snip).tgz]
Created [https://cloudbuild.googleapis.com/v1/projects/(project)/locations/global/builds/30207dd1-(snip)].
Logs are available at [ https://console.cloud.google.com/cloud-build/builds/30207dd1-(snip)?project=(snip) ].
gcloud builds submit only displays logs from Cloud Storage. To view logs from Cloud Logging, run:
gcloud beta builds submit
ID: 30207dd1-(snip)
CREATE_TIME: (created time)
DURATION: 3M17S
SOURCE: gs://(project)_cloudbuild/source/(snip).tgz
IMAGES: us-docker.pkg.dev/(project)/spanner-game-images/profile:30207dd1-(snip) (+3 more)
STATUS: SUCCESS
Tidak seperti output langkah schema migration, output build ini menunjukkan bahwa ada beberapa gambar yang dibuat. Image tersebut akan disimpan di repositori Artifact Registry Anda.
Output langkah gcloud build akan memiliki link ke Konsol Cloud. Lihatlah.
Setelah Anda mendapatkan notifikasi keberhasilan dari Cloud Build, buka Cloud Deploy, lalu buka pipeline sample-game-services untuk memantau progres deployment.

Setelah layanan di-deploy, Anda dapat memeriksa kubectl untuk melihat status pod:
kubectl get pods
Output perintah
NAME READY STATUS RESTARTS AGE
item-6b9d5f678c-4tbk2 1/1 Running 0 83m
matchmaking-5bcf799b76-lg8zf 1/1 Running 0 80m
profile-565bbf4c65-kphdl 1/1 Running 0 83m
profile-565bbf4c65-xw74j 1/1 Running 0 83m
tradepost-68b87ccd44-gw55r 1/1 Running 0 79m
Kemudian, periksa layanan untuk melihat cara kerja ClusterIP:
kubectl get services
Output perintah
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
item ClusterIP 10.172.XXX.XXX <none> 80/TCP 84m
kubernetes ClusterIP 10.172.XXX.XXX <none> 443/TCP 137m
matchmaking ClusterIP 10.172.XXX.XXX <none> 80/TCP 84m
profile ClusterIP 10.172.XXX.XXX <none> 80/TCP 84m
tradepost ClusterIP 10.172.XXX.XXX <none> 80/TCP 84m
Anda juga dapat membuka UI GKE di Cloud Console untuk melihat Workloads, Services, dan ConfigMaps.
Beban kerja

Layanan

ConfigMaps

Ringkasan
Pada langkah ini, Anda telah men-deploy empat layanan backend ke GKE Autopilot. Anda dapat menjalankan langkah Cloud Build dan memeriksa progres di Cloud Deploy dan di Kubernetes di Konsol Cloud.
Anda juga mempelajari cara layanan ini menggunakan Workload Identity untuk meniru identitas akun layanan yang memiliki izin yang tepat untuk membaca dan menulis data ke database Spanner.
Langkah Berikutnya
Di bagian berikutnya, Anda akan men-deploy workload.
6. Men-deploy workload
Ringkasan
Setelah layanan backend berjalan di cluster, Anda akan men-deploy workload.

Beban kerja dapat diakses secara eksternal, dan ada satu beban kerja untuk setiap layanan backend untuk tujuan codelab ini.
Beban kerja ini adalah skrip pembuatan beban berbasis Locust yang meniru pola akses nyata yang diharapkan oleh layanan contoh ini.
Ada file untuk proses Cloud Build:
$DEMO_HOME/workloads/cloudbuild.yaml(dibuat oleh Terraform)$DEMO_HOME/workloads/skaffold.yaml- file
deployment.yamluntuk setiap beban kerja
File workload deployment.yaml terlihat sedikit berbeda dari file deployment layanan backend.
Berikut contoh dari matchmaking-workload:
apiVersion: v1
kind: Service
metadata:
name: matchmaking-workload
spec:
type: LoadBalancer
selector:
app: matchmaking-workload
ports:
- port: 8089
targetPort: 8089
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: matchmaking-workload
spec:
replicas: 1 # EDIT: Number of instances of deployment
selector:
matchLabels:
app: matchmaking-workload
template:
metadata:
labels:
app: matchmaking-workload
spec:
serviceAccountName: default
containers:
- name: matchmaking-workload
image: matchmaking-workload
ports:
- containerPort: 8089
resources:
requests:
cpu: "500m"
memory: "512Mi"
ephemeral-storage: "100Mi"
limits:
cpu: "500m"
memory: "512Mi"
ephemeral-storage: "100Mi"
Bagian atas file menentukan layanan. Dalam hal ini, LoadBalancer dibuat, dan workload berjalan di port 8089.
LoadBalancer akan menyediakan IP eksternal yang dapat digunakan untuk terhubung ke beban kerja.
apiVersion: v1
kind: Service
metadata:
name: matchmaking-workload
spec:
type: LoadBalancer
selector:
app: matchmaking-workload
ports:
- port: 8089
targetPort: 8089
Bagian atas bagian deployment adalah metadata tentang beban kerja. Dalam hal ini, hanya satu replika yang di-deploy:
replicas: 1
Namun, spesifikasi penampungnya berbeda. Salah satunya, kita menggunakan akun layanan Kubernetes default. Akun ini tidak memiliki hak istimewa khusus, karena beban kerja tidak perlu terhubung ke resource Google Cloud apa pun kecuali layanan backend yang berjalan di cluster GKE.
Perbedaan lainnya adalah tidak ada variabel lingkungan yang diperlukan untuk workload ini. Hasilnya adalah spesifikasi deployment yang lebih singkat.
spec:
serviceAccountName: default
containers:
- name: matchmaking-workload
image: matchmaking-workload
ports:
- containerPort: 8089
Setelan resource mirip dengan layanan backend. Ingatlah bahwa dengan cara inilah GKE Autopilot mengetahui jumlah resource yang diperlukan untuk memenuhi permintaan semua pod yang berjalan di cluster.
Lanjutkan dan deploy workload.
Men-deploy workload
Seperti sebelumnya, Anda dapat mengirimkan permintaan build menggunakan command line gcloud:
cd $DEMO_HOME/workloads gcloud builds submit --config=cloudbuild.yaml
Output perintah
Creating temporary tarball archive of 18 file(s) totalling 26.2 KiB before compression.
Some files were not included in the source upload.
Check the gcloud log [/tmp/tmp.4Z9EqdPo6d/logs/(snip).log] to see which files and the contents of the
default gcloudignore file used (see `$ gcloud topic gcloudignore` to learn
more).
Uploading tarball of [.] to [gs://(project)_cloudbuild/source/(snip).tgz]
Created [https://cloudbuild.googleapis.com/v1/projects/(project)/locations/global/builds/(snip)].
Logs are available at [ https://console.cloud.google.com/cloud-build/builds/0daf20f6-(snip)?project=(snip) ].
gcloud builds submit only displays logs from Cloud Storage. To view logs from Cloud Logging, run:
gcloud beta builds submit
ID: 0daf20f6-(snip)
CREATE_TIME: (created_time)
DURATION: 1M41S
SOURCE: gs://(project)_cloudbuild/source/(snip).tgz
IMAGES: us-docker.pkg.dev/(project)/spanner-game-images/profile-workload:0daf20f6-(snip) (+4 more)
STATUS: SUCCESS
Pastikan untuk memeriksa log Cloud Build dan pipeline Cloud Deploy di Konsol Cloud untuk memeriksa statusnya. Untuk workload, pipeline Cloud Deploy adalah sample-game-workloads:
Setelah deployment selesai, periksa statusnya dengan kubectl di Cloud Shell:
kubectl get pods
Output perintah
NAME READY STATUS RESTARTS AGE
game-workload-7ff44cb657-pxxq2 1/1 Running 0 12m
item-6b9d5f678c-cr29w 1/1 Running 0 9m6s
item-generator-7bb4f57cf8-5r85b 1/1 Running 0 12m
matchmaking-5bcf799b76-lg8zf 1/1 Running 0 117m
matchmaking-workload-76df69dbdf-jds9z 1/1 Running 0 12m
profile-565bbf4c65-kphdl 1/1 Running 0 121m
profile-565bbf4c65-xw74j 1/1 Running 0 121m
profile-workload-76d6db675b-kzwng 1/1 Running 0 12m
tradepost-68b87ccd44-gw55r 1/1 Running 0 116m
tradepost-workload-56c55445b5-b5822 1/1 Running 0 12m
Kemudian, periksa layanan workload untuk melihat LoadBalancer beraksi:
kubectl get services
Output perintah
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
game-workload LoadBalancer *snip* 35.XX.XX.XX 8089:32483/TCP 12m
item ClusterIP *snip* <none> 80/TCP 121m
item-generator LoadBalancer *snip* 34.XX.XX.XX 8089:32581/TCP 12m
kubernetes ClusterIP *snip* <none> 443/TCP 174m
matchmaking ClusterIP *snip* <none> 80/TCP 121m
matchmaking-workload LoadBalancer *snip* 34.XX.XX.XX 8089:31735/TCP 12m
profile ClusterIP *snip* <none> 80/TCP 121m
profile-workload LoadBalancer *snip* 34.XX.XX.XX 8089:32532/TCP 12m
tradepost ClusterIP *snip* <none> 80/TCP 121m
tradepost-workload LoadBalancer *snip* 34.XX.XX.XX 8089:30002/TCP 12m
Ringkasan
Sekarang Anda telah men-deploy workload ke cluster GKE. Beban kerja ini tidak memerlukan izin IAM tambahan dan dapat diakses secara eksternal di port 8089 menggunakan layanan LoadBalancer.
Langkah Berikutnya
Setelah layanan dan beban kerja backend berjalan, saatnya "bermain" game.
7. Mulai bermain game
Ringkasan
Layanan backend untuk "game" contoh Anda kini berjalan, dan Anda juga memiliki cara untuk membuat "pemain" yang berinteraksi dengan layanan tersebut menggunakan beban kerja.
Setiap workload menggunakan Locust untuk menyimulasikan beban aktual terhadap API layanan kami. Pada langkah ini, Anda akan menjalankan beberapa workload untuk menghasilkan beban pada cluster GKE dan Spanner, serta menyimpan data di Spanner.
Berikut deskripsi setiap beban kerja:
- Workload
item-generatoradalah workload cepat untuk membuat daftar game_items yang dapat diperoleh pemain selama "bermain" game. profile-workloadmenyimulasikan pemain yang mendaftar dan login.matchmaking-workloadmenyimulasikan pemain yang mengantre untuk ditetapkan ke game.game-workloadmensimulasikan pemain yang mendapatkan item game dan uang selama bermain game.tradepost-workloadmensimulasikan kemampuan pemain untuk menjual dan membeli item di pos perdagangan.
Codelab ini akan secara khusus menyoroti cara menjalankan item-generator dan profile-workload.
Menjalankan item-generator
item-generator menggunakan endpoint layanan backend item untuk menambahkan game_items ke Spanner. Item ini diperlukan agar game-workload dan tradepost-workload berfungsi dengan benar.
Langkah pertama adalah mendapatkan IP eksternal layanan item-generator. Di Cloud Shell, jalankan perintah berikut:
# The external IP is the 4th column of the output
kubectl get services | grep item-generator | awk '{print $4}'
Output perintah
{ITEMGENERATOR_EXTERNAL_IP}
Sekarang, buka tab browser baru dan arahkan ke http://{ITEMGENERATOR_EXTERNAL_IP}:8089. Anda akan melihat halaman seperti ini:

Anda akan membiarkan users dan spawn pada nilai default 1. Untuk host, masukkan http://item. Klik opsi lanjutan, lalu masukkan 10s untuk waktu berjalan.
Berikut tampilan konfigurasi yang benar:

Klik 'Start swarming'!
Statistik akan mulai ditampilkan untuk permintaan yang dikeluarkan di endpoint POST /items. Setelah 10 detik, pemuatan akan berhenti.
Klik Charts dan Anda akan melihat beberapa grafik tentang performa permintaan ini.

Sekarang, Anda ingin memeriksa apakah data dimasukkan ke dalam database Spanner.
Untuk melakukannya, klik menu tiga garis dan buka 'Spanner'. Dari halaman ini, buka sample-instance dan sample-database. Kemudian, klik ‘Query'.
Kita ingin memilih jumlah game_items:
SELECT COUNT(*) FROM game_items;
Di bagian bawah, Anda akan mendapatkan hasil.

Kita tidak perlu banyak game_items yang di-seed. Namun, kini mereka tersedia untuk didapatkan pemain.
Jalankan profile-workload
Setelah game_items Anda di-seed, langkah selanjutnya adalah membuat pemain mendaftar agar dapat bermain game.
profile-workload akan menggunakan Locust untuk menyimulasikan pemain yang membuat akun, login, mengambil informasi profil, dan logout. Semua pengujian ini menguji endpoint layanan backend profile dalam beban kerja yang mirip produksi pada umumnya.
Untuk menjalankannya, dapatkan IP eksternal profile-workload:
# The external IP is the 4th column of the output
kubectl get services | grep profile-workload | awk '{print $4}'
Output perintah
{PROFILEWORKLOAD_EXTERNAL_IP}
Sekarang, buka tab browser baru dan arahkan ke http://{PROFILEWORKLOAD_EXTERNAL_IP}:8089. Anda akan melihat halaman Locust yang mirip dengan halaman sebelumnya.
Dalam hal ini, Anda akan menggunakan http://profile untuk host. Selain itu, Anda tidak akan menentukan runtime di opsi lanjutan. Selain itu, tentukan users menjadi 4, yang akan menyimulasikan 4 permintaan pengguna sekaligus.
Pengujian profile-workload akan terlihat seperti ini:

Klik 'Start swarming'!
Seperti sebelumnya, statistik untuk berbagai endpoint REST profile akan mulai muncul. Buka diagram untuk melihat performa semua hal.
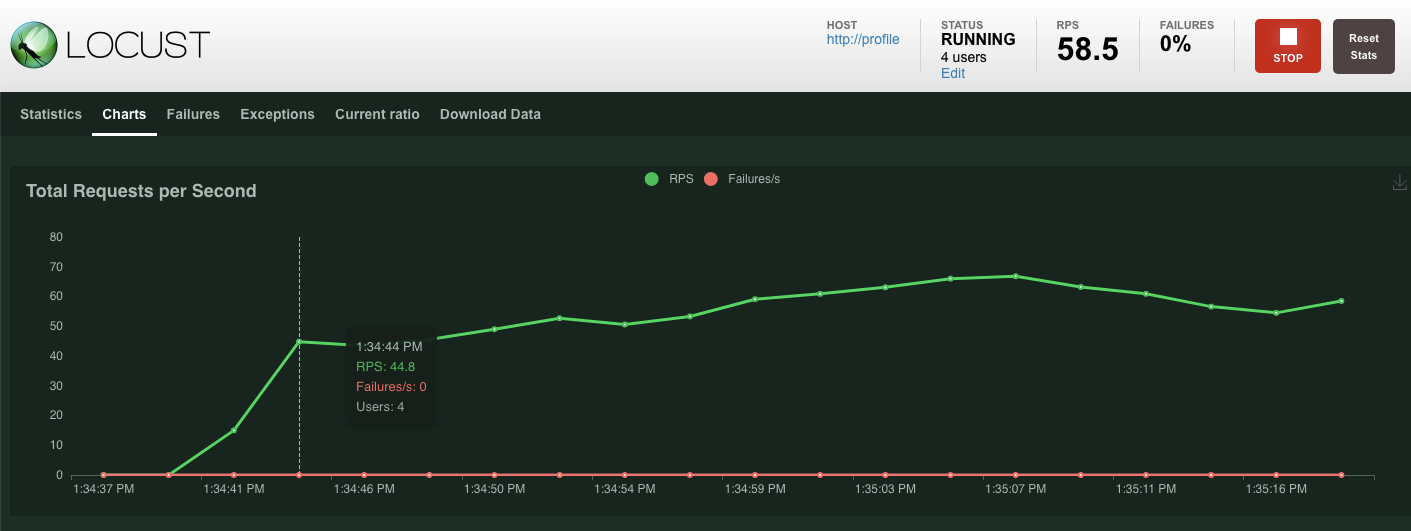
Ringkasan
Pada langkah ini, Anda membuat beberapa game_items, lalu membuat kueri tabel game_items menggunakan UI Kueri Spanner di Konsol Cloud.
Anda juga mengizinkan pemain untuk mendaftar ke game Anda dan melihat bagaimana Locust dapat membuat beban kerja seperti produksi terhadap layanan backend Anda.
Langkah Berikutnya
Setelah menjalankan workload, Anda harus memeriksa perilaku cluster GKE dan instance Spanner.
8. Meninjau penggunaan GKE dan Spanner
Setelah layanan profil berjalan, saatnya melihat perilaku cluster Autopilot GKE dan Cloud Spanner Anda.
Memeriksa cluster GKE
Buka cluster Kubernetes. Perhatikan bahwa setelah Anda men-deploy workload dan layanan, cluster kini memiliki beberapa detail yang ditambahkan tentang total vCPU dan memori. Informasi ini tidak tersedia saat tidak ada workload di cluster.
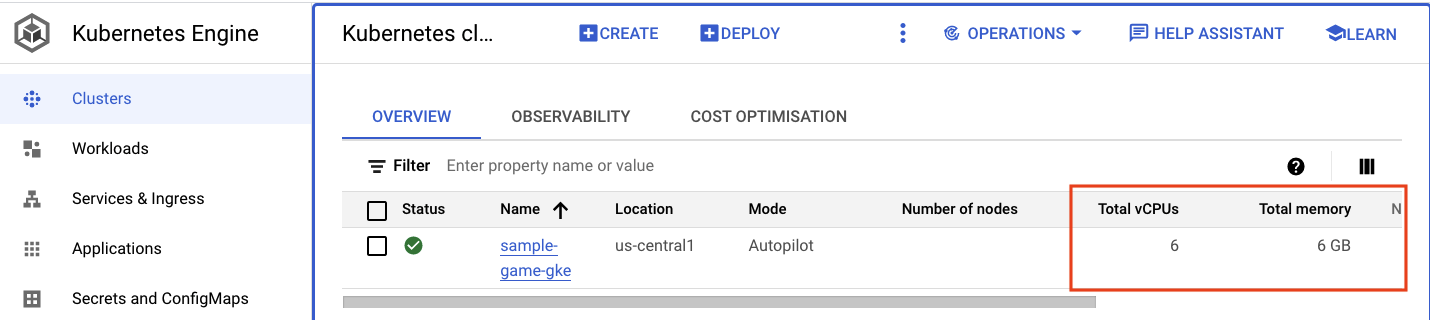
Sekarang, klik cluster sample-game-gke dan beralih ke tab observability:

Namespace default kubernetes seharusnya melampaui namespace kube-system untuk pemanfaatan CPU karena workload dan layanan backend kami berjalan di default. Jika belum, pastikan profile workload masih berjalan dan tunggu beberapa menit hingga diagram diperbarui.
Untuk melihat workload mana yang menggunakan sebagian besar resource, buka dasbor Workloads.
Daripada membuka setiap workload satu per satu, langsung buka tab Observability dasbor. Anda akan melihat bahwa CPU profile dan profile-workload telah meningkat.

Sekarang, periksa Cloud Spanner.
Periksa instance Cloud Spanner
Untuk memeriksa performa Cloud Spanner, buka Spanner, lalu klik instance sample-instance dan database sample-game.
Dari sana, Anda akan melihat tab Insight Sistem di menu kiri:
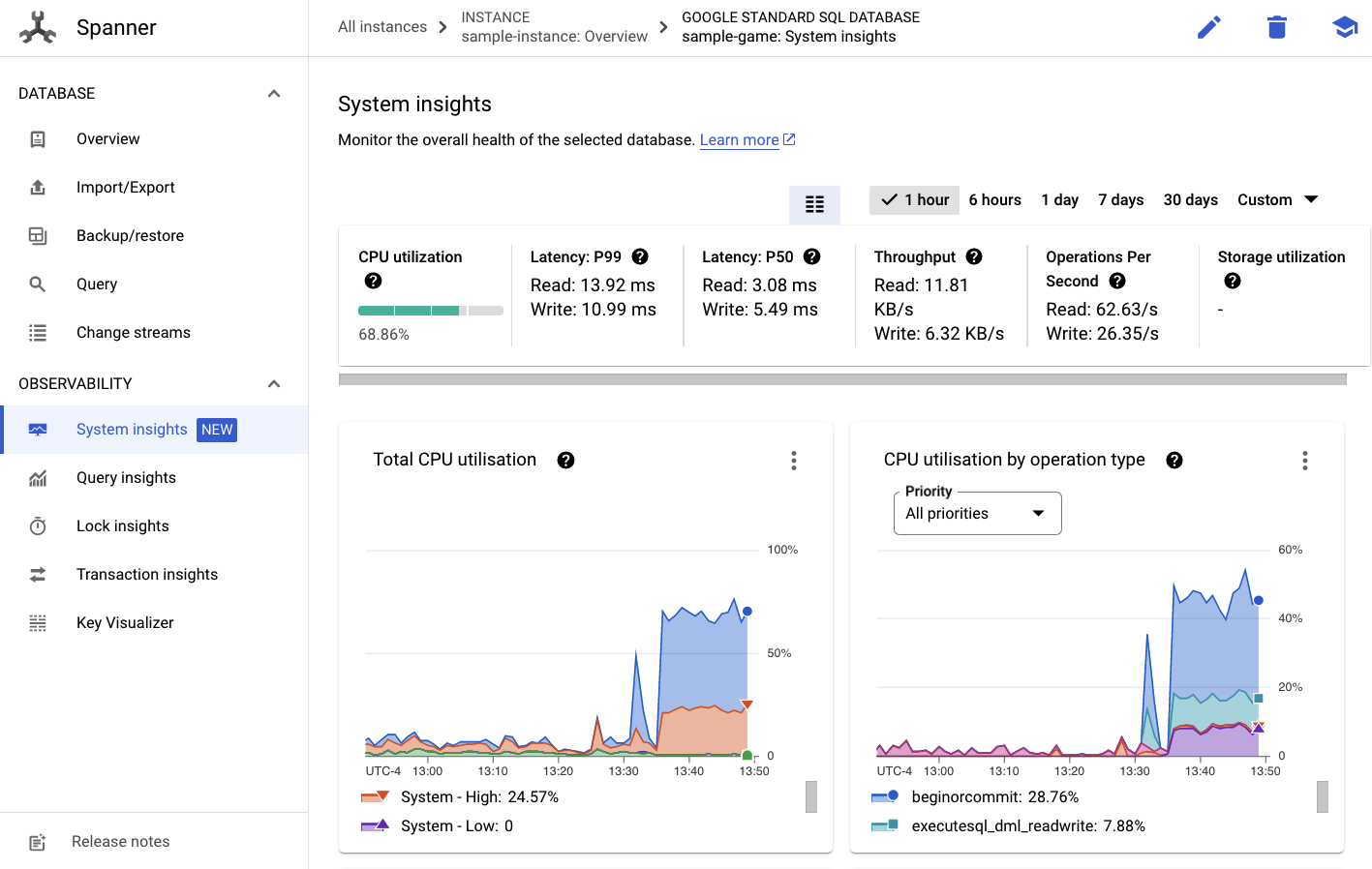
Ada banyak diagram di sini untuk membantu Anda memahami performa umum instance Spanner, termasuk CPU utilization, transaction latency and locking, dan query throughput.
Selain System Insights, Anda bisa mendapatkan informasi yang lebih mendetail tentang workload kueri dengan melihat link lain di bagian Observability:
- Insight kueri membantu mengidentifikasi kueri topN yang menggunakan resource di Spanner.
- Insight Transaksi dan Penguncian membantu mengidentifikasi transaksi dengan latensi tinggi.
- Key Visualizer membantu memvisualisasikan pola akses dan dapat membantu melacak hotspot dalam data.
Ringkasan
Pada langkah ini, Anda telah mempelajari cara memeriksa beberapa metrik performa dasar untuk GKE Autopilot dan Spanner.
Misalnya, saat workload profil Anda berjalan, buat kueri tabel players untuk mendapatkan informasi lebih lanjut tentang data yang disimpan di sana.
Langkah Berikutnya
Selanjutnya, saatnya membersihkan!
9. Pembersihan
Sebelum membersihkan, Anda dapat menjelajahi workload lain yang tidak dibahas. Khususnya matchmaking-workload, game-workload, dan tradepost-workload.
Setelah selesai "bermain" game, Anda dapat membersihkan area uji coba. Untungnya, proses ini cukup mudah.
Pertama, jika profile-workload Anda masih berjalan di browser, buka dan hentikan:

Lakukan hal yang sama untuk setiap workload yang mungkin telah Anda uji.
Kemudian di Cloud Shell, buka folder infrastruktur. Anda akan destroy infrastruktur menggunakan terraform:
cd $DEMO_HOME/infrastructure
terraform destroy
# type 'yes' when asked
Output perintah
Plan: 0 to add, 0 to change, 46 to destroy.
Do you really want to destroy all resources?
Terraform will destroy all your managed infrastructure, as shown above.
There is no undo. Only 'yes' will be accepted to confirm.
Enter a value: yes
*snip*
Destroy complete! Resources: 46 destroyed.
Di Konsol Cloud, buka Spanner, Kubernetes Cluster, Artifact Registry, Cloud Deploy, dan IAM untuk memvalidasi bahwa semua resource telah dihapus.
10. Selamat!
Selamat, Anda telah berhasil men-deploy aplikasi golang contoh di GKE Autopilot dan menghubungkannya ke Cloud Spanner menggunakan Workload Identity.
Sebagai bonus, infrastruktur ini dapat disiapkan dan dihapus dengan mudah secara berulang menggunakan Terraform.
Anda dapat membaca lebih lanjut layanan Google Cloud yang Anda gunakan dalam codelab ini:
Apa langkah selanjutnya?
Setelah memiliki pemahaman dasar tentang cara kerja Autopilot GKE dan Cloud Spanner bersama-sama, mengapa tidak mengambil langkah berikutnya dan mulai membangun aplikasi Anda sendiri untuk bekerja dengan layanan ini?