
1. はじめに
Cloud Spanner はフルマネージドで水平スケール可能なグローバルに分散されたリレーショナル データベース サービスで、パフォーマンスと高可用性を損なうことなく ACID トランザクションと SQL セマンティクスを提供します。
GKE Autopilot は、ノード、スケーリング、セキュリティ、その他の事前構成された設定などのクラスタ構成を Google が管理し、ベスト プラクティスに沿って運用する GKE の運用モードです。たとえば、GKE Autopilot では、Workload Identity を使用してサービス権限を管理できます。
このラボの目標は、GKE Autopilot で実行されている複数のバックエンド サービスを Cloud Spanner データベースに接続するプロセスを説明することです。

このラボでは、まずプロジェクトを設定して Cloud Shell を起動します。次に、Terraform を使用してインフラストラクチャをデプロイします。
完了したら、Cloud Build と Cloud Deploy を操作して、Games データベースの初期スキーマ移行を実行し、バックエンド サービスをデプロイしてから、ワークロードをデプロイします。
この Codelab のサービスは、Cloud Spanner: ゲーム開発のスタートガイド Codelab のサービスと同じです。この Codelab を完了することは、GKE でサービスを実行して Spanner に接続するための要件ではありません。Spanner で動作するこれらのサービスの詳細については、こちらをご覧ください。
ワークロードとバックエンド サービスが実行されたら、負荷の生成を開始し、サービスが連携して動作する様子を観察できます。
最後に、このラボで作成したリソースをクリーンアップします。
作成するアプリの概要
このラボでは、次の作業を行います。
- Terraform を使用してインフラストラクチャをプロビジョニングする
- Cloud Build のスキーマ移行プロセスを使用してデータベース スキーマを作成する
- Workload Identity を利用して Cloud Spanner に接続する 4 つの Golang バックエンド サービスをデプロイする
- バックエンド サービスの負荷をシミュレートするために使用される 4 つのワークロード サービスをデプロイします。
学習内容
- Terraform を使用して GKE Autopilot、Cloud Spanner、Cloud Deploy パイプラインをプロビジョニングする方法
- Workload Identity を使用して GKE のサービスがサービス アカウントの権限を借用し、Cloud Spanner を操作するための IAM 権限にアクセスする方法
- Locust.io を使用して GKE と Cloud Spanner に本番環境のような負荷を生成する方法
必要なもの
2. 設定と要件
プロジェクトを作成する
Google アカウント(Gmail または Google Apps)をお持ちでない場合は、1 つ作成する必要があります。Google Cloud Platform のコンソール(console.cloud.google.com)にログインし、新しいプロジェクトを作成します。
すでにプロジェクトが存在する場合は、コンソールの左上にあるプロジェクト選択プルダウン メニューをクリックします。

表示されたダイアログで [NEW PROJECT] ボタンをクリックして、新しいプロジェクトを作成します。
まだプロジェクトが存在しない場合は、次のような最初のプロジェクトを作成するためのダイアログが表示されます。
続いて表示されるプロジェクト作成ダイアログでは、新しいプロジェクトの詳細を入力できます。

プロジェクト ID を忘れないようにしてください。プロジェクト ID は、すべての Google Cloud プロジェクトを通じて一意の名前にする必要があります(上記の名前はすでに使用されているため使用できません)。以降、この Codelab では PROJECT_ID と表します。
次に、Google Cloud リソースを使用し、Cloud Spanner API を有効にするために、Developers Console で課金を有効にする必要があります。

この Codelab の操作をすべて行っても、費用は数ドル程度です。ただし、その他のリソースを使いたい場合や、実行したままにしておきたいステップがある場合は、追加コストがかかる可能性があります(このドキュメントの最後にある「クリーンアップ」セクションをご覧ください)。Google Cloud Spanner の料金についてはこちら、GKE Autopilot についてはこちらをご覧ください。
Google Cloud Platform の新規ユーザーの皆さんには、$300 の無料トライアルをご利用いただけます。その場合は、この Codelab を完全に無料でご利用いただけます。
Cloud Shell の設定
Google Cloud と Spanner はノートパソコンからリモートで操作でき、この Codelab では、Google Cloud Shell(Cloud 上で動作するコマンドライン環境)を使用します。
この Debian ベースの仮想マシンには、必要な開発ツールがすべて用意されています。仮想マシンは Google Cloud で稼働し、永続的なホーム ディレクトリが 5 GB 用意されているため、ネットワークのパフォーマンスと認証が大幅に向上しています。つまり、この Codelab に必要なのはブラウザだけです(Chromebook でも動作します)。
- Cloud Console から Cloud Shell を有効にするには、[Cloud Shell をアクティブにする]
 をクリックします(環境のプロビジョニングと接続に若干時間を要します)。
をクリックします(環境のプロビジョニングと接続に若干時間を要します)。


Cloud Shell に接続すると、すでに認証は完了しており、プロジェクトに各自の PROJECT_ID が設定されていることがわかります。
gcloud auth list
コマンド出力
Credentialed accounts:
- <myaccount>@<mydomain>.com (active)
gcloud config list project
コマンド出力
[core]
project = <PROJECT_ID>
なんらかの理由でプロジェクトが設定されていない場合は、次のコマンドを実行します。
gcloud config set project <PROJECT_ID>
PROJECT_ID が見つからない場合は、設定手順で使用した ID を確認するか、Cloud Console ダッシュボードで検索します。

Cloud Shell では、デフォルトで環境変数もいくつか設定されます。これらの変数は、以降のコマンドを実行する際に有用なものです。
echo $GOOGLE_CLOUD_PROJECT
コマンド出力
<PROJECT_ID>
コードをダウンロードする
Cloud Shell で、このラボのコードをダウンロードできます。
git clone https://github.com/cloudspannerecosystem/spanner-gaming-sample.git
コマンド出力
Cloning into 'spanner-gaming-sample'...
*snip*
この Codelab は v0.1.3 リリースに基づいているため、そのタグをチェックアウトしてください。
cd spanner-gaming-sample
git fetch --all --tags
# Check out v0.1.3 release
git checkout tags/v0.1.3 -b v0.1.3-branch
コマンド出力
Switched to a new branch 'v0.1.3-branch'
現在の作業ディレクトリを DEMO_HOME 環境変数として設定します。これにより、Codelab のさまざまな部分を簡単に移動できるようになります。
export DEMO_HOME=$(pwd)
概要
この手順では、新しいプロジェクトを設定し、Cloud Shell を有効にして、このラボのコードをダウンロードしました。
次のステップ
次に、Terraform を使用してインフラストラクチャをプロビジョニングします。
3. インフラストラクチャをプロビジョニングする
概要
プロジェクトの準備が整ったら、インフラストラクチャの実行を開始します。これには、VPC ネットワーキング、Cloud Spanner、GKE Autopilot、GKE で実行されるイメージを保存する Artifact Registry、バックエンド サービスとワークロード用の Cloud Deploy パイプライン、最後にこれらのサービスを使用するためのサービス アカウントと IAM 権限が含まれます。
これは大変な作業です。幸いなことに、Terraform を使用すると、この設定を簡単に実行できます。Terraform は「Infrastructure as Code」ツールです。このツールを使用すると、このプロジェクトに必要なものを一連の「.tf」ファイルで指定できます。これにより、インフラストラクチャのプロビジョニングが簡単になります。
この Codelab を完了するうえで、Terraform に精通している必要はありません。次の手順の内容を確認する場合は、infrastructure ディレクトリにある次のファイルで作成された内容を確認してください。
- vpc.tf
- backend_gke.tf
- spanner.tf
- artifact_registry.tf
- pipelines.tf
- iam.tf
Terraform を構成する
Cloud Shell で、infrastructure ディレクトリに移動して Terraform を初期化します。
cd $DEMO_HOME/infrastructure
terraform init
コマンド出力
Initializing the backend...
Initializing provider plugins...
*snip*
Terraform has been successfully initialized!
You may now begin working with Terraform. Try running "terraform plan" to see
any changes that are required for your infrastructure. All Terraform commands
should now work.
If you ever set or change modules or backend configuration for Terraform,
rerun this command to reinitialize your working directory. If you forget, other
commands will detect it and remind you to do so if necessary.
次に、terraform.tfvars.sample をコピーしてプロジェクト値を変更し、Terraform を構成します。他の変数も変更できますが、環境で動作するように変更する必要があるのはプロジェクトだけです。
cp terraform.tfvars.sample terraform.tfvars
# edit gcp_project using the project environment variable
sed -i "s/PROJECT/$GOOGLE_CLOUD_PROJECT/" terraform.tfvars
インフラストラクチャをプロビジョニングする
それでは、インフラストラクチャをプロビジョニングしましょう。
terraform apply
# review the list of things to be created
# type 'yes' when asked
コマンド出力
Plan: 46 to add, 0 to change, 0 to destroy.
Do you want to perform these actions?
Terraform will perform the actions described above.
Only 'yes' will be accepted to approve.
Enter a value: yes
google_project_service.project["container.googleapis.com"]: Creating...
*snip*
Apply complete! Resources: 46 added, 0 changed, 0 destroyed.
作成されたものを確認する
作成された内容を確認するには、Cloud Console でプロダクトを確認します。
Cloud Spanner
まず、ハンバーガー メニューに移動して Spanner をクリックし、Cloud Spanner を確認します。リストに表示されない場合は、[商品をもっと見る] をクリックしてください。
Spanner インスタンスのリストが表示されます。インスタンスをクリックすると、データベースが表示されます。次のようになります。

GKE Autopilot
次に、ハンバーガー メニューに移動して Kubernetes Engine => Clusters をクリックし、GKE を確認します。ここでは、Autopilot モードで実行されている sample-games-gke クラスタが表示されます。

Artifact Registry
次に、画像の保存先を確認します。ハンバーガー メニューをクリックして、Artifact Registry=>Repositories を探します。Artifact Registry は、メニューの [CI/CD] セクションにあります。
ここに、spanner-game-images という名前の Docker レジストリが表示されます。現時点では空です。

Cloud Deploy
Cloud Deploy は、Cloud Build がイメージをビルドして GKE クラスタにデプロイする手順を提供できるように、パイプラインが作成された場所です。
ハンバーガー メニューに移動し、メニューの [CI/CD] セクションにある Cloud Deploy を見つけます。
バックエンド サービス用とワークロード用の 2 つのパイプラインが表示されます。どちらも同じ GKE クラスタにイメージをデプロイしますが、これによりデプロイを分離できます。

IAM
最後に、Cloud Console の IAM ページで、作成されたサービス アカウントを確認します。ハンバーガー メニューに移動し、IAM and Admin=>Service accounts を見つけます。次のようになります。

Terraform によって作成されるサービス アカウントは合計 6 つです。
- デフォルトのコンピューティング サービス アカウント。この Codelab では使用されません。
- cloudbuild-cicd アカウントは、Cloud Build と Cloud Deploy のステップで使用されます。
- Cloud Spanner とのやり取りにバックエンド サービスで使用される 4 つの「アプリ」アカウント。
次に、GKE クラスタとやり取りするように kubectl を構成します。
kubectl を構成する
# Name of GKE cluster from terraform.tfvars file
export GKE_CLUSTER=sample-game-gke
# get GKE credentials
gcloud container clusters get-credentials $GKE_CLUSTER --region us-central1
# Check that no errors occur
kubectl get serviceaccounts
コマンド出力
#export GKE_CLUSTER=sample-game-gke
# gcloud container clusters get-credentials $GKE_CLUSTER --region us-central1
Fetching cluster endpoint and auth data.
kubeconfig entry generated for sample-game-gke.
# kubectl get serviceaccounts
NAME SECRETS AGE
default 0 37m
item-app 0 35m
matchmaking-app 0 35m
profile-app 0 35m
tradepost-app 0 35m
概要
これで、Cloud Spanner インスタンスと GKE Autopilot クラスタをすべてプライベート ネットワーキング用の VPC にプロビジョニングできました。
また、バックエンド サービスとワークロード用に 2 つの Cloud Deploy パイプラインが作成され、ビルドされたイメージを保存する Artifact Registry リポジトリも作成されました。
最後に、サービス アカウントが作成され、Workload Identity と連携するように構成されました。これにより、バックエンド サービスで Cloud Spanner を使用できるようになります。
また、バックエンド サービスとワークロードをデプロイした後、Cloud Shell で GKE クラスタとやり取りするように kubectl を構成します。
次のステップ
サービスを使用する前に、データベース スキーマを定義する必要があります。これは次のステップで設定します。
4. データベース スキーマを作成する
概要
バックエンド サービスを実行する前に、データベース スキーマが設定されていることを確認する必要があります。
デモ リポジトリの $DEMO_HOME/schema/migrations ディレクトリのファイルを見ると、スキーマを定義する一連の .sql ファイルが表示されます。これは、スキーマの変更がリポジトリ自体で追跡され、アプリケーションの特定の機能に関連付けられる開発サイクルを模倣したものです。
このサンプル環境では、wrench は Cloud Build を使用してスキーマ移行を適用するツールです。
Cloud Build
$DEMO_HOME/schema/cloudbuild.yaml ファイルには、実行される手順が記述されています。
serviceAccount: projects/${PROJECT_ID}/serviceAccounts/cloudbuild-cicd@${PROJECT_ID}.iam.gserviceaccount.com
steps:
- name: gcr.io/cloud-builders/curl
id: fetch-wrench
args: ['-Lo', '/workspace/wrench.tar.gz', 'https://github.com/cloudspannerecosystem/wrench/releases/download/v1.4.1/wrench-1.4.1-linux-amd64.tar.gz' ]
- name: gcr.io/cloud-builders/gcloud
id: migrate-spanner-schema
entrypoint: sh
args:
- '-xe'
- '-c'
- |
tar -xzvf wrench.tar.gz
chmod +x /workspace/wrench
# Assumes only a single spanner instance and database. Fine for this demo in a dedicated project
export SPANNER_PROJECT_ID=${PROJECT_ID}
export SPANNER_INSTANCE_ID=$(gcloud spanner instances list | tail -n1 | awk '{print $1}')
export SPANNER_DATABASE_ID=$(gcloud spanner databases list --instance=$$SPANNER_INSTANCE_ID | tail -n1 | awk '{print $1}')
if [ -d ./migrations ]; then
/workspace/wrench migrate up --directory .
else
echo "[Error] Missing migrations directory"
fi
timeout: 600s
基本的な手順は次の 2 つです。
- レンチを Cloud Build ワークスペースにダウンロードする
- レンチの移行を実行する
レンチが書き込みエンドポイントに接続するには、Spanner のプロジェクト、インスタンス、データベースの環境変数が必要です。
Cloud Build は cloudbuild-cicd@${PROJECT_ID}.iam.gserviceaccount.com サービス アカウントとして実行されているため、これらの変更を行うことができます。
serviceAccount: projects/${PROJECT_ID}/serviceAccounts/cloudbuild-cicd@${PROJECT_ID}.iam.gserviceaccount.com
このサービス アカウントには、Terraform によって追加された spanner.databaseUser ロールが付与されています。これにより、サービス アカウントは DDL を更新できます。
スキーマの移行
$DEMO_HOME/schema/migrations ディレクトリ内のファイルに基づいて実行される移行手順は 5 つあります。players テーブルとインデックスを作成する 000001.sql ファイルの例を次に示します。
CREATE TABLE players (
playerUUID STRING(36) NOT NULL,
player_name STRING(64) NOT NULL,
email STRING(MAX) NOT NULL,
password_hash BYTES(60) NOT NULL,
created TIMESTAMP,
updated TIMESTAMP,
stats JSON,
account_balance NUMERIC NOT NULL DEFAULT (0.00),
is_logged_in BOOL,
last_login TIMESTAMP,
valid_email BOOL,
current_game STRING(36)
) PRIMARY KEY (playerUUID);
CREATE UNIQUE INDEX PlayerAuthentication ON players(email) STORING(password_hash);
CREATE UNIQUE INDEX PlayerName ON players(player_name);
CREATE INDEX PlayerGame ON players(current_game);
スキーマ移行を送信する
スキーマ移行を実行するビルドを送信するには、schema ディレクトリに切り替えて、次の gcloud コマンドを実行します。
cd $DEMO_HOME/schema gcloud builds submit --config=cloudbuild.yaml
コマンド出力
Creating temporary tarball archive of 8 file(s) totalling 11.2 KiB before compression.
Uploading tarball of [.] to [gs://(project)_cloudbuild/source/(snip).tgz]
Created [https://cloudbuild.googleapis.com/v1/projects/(project)/locations/global/builds/7defe982-(snip)].
Logs are available at [ https://console.cloud.google.com/cloud-build/builds/7defe982-(snip)?project=(snip) ].
gcloud builds submit only displays logs from Cloud Storage. To view logs from Cloud Logging, run:
gcloud beta builds submit
ID: 7defe982-(snip)
CREATE_TIME: (created time)
DURATION: 3M11S
SOURCE: gs://(project)_cloudbuild/source/(snip).tgz
IMAGES: -
STATUS: SUCCESS
上記の出力には、Created クラウドビルド プロセスへのリンクがあります。クリックすると、Cloud Console のビルドに移動し、ビルドの進行状況をモニタリングして、ビルドの処理内容を確認できます。
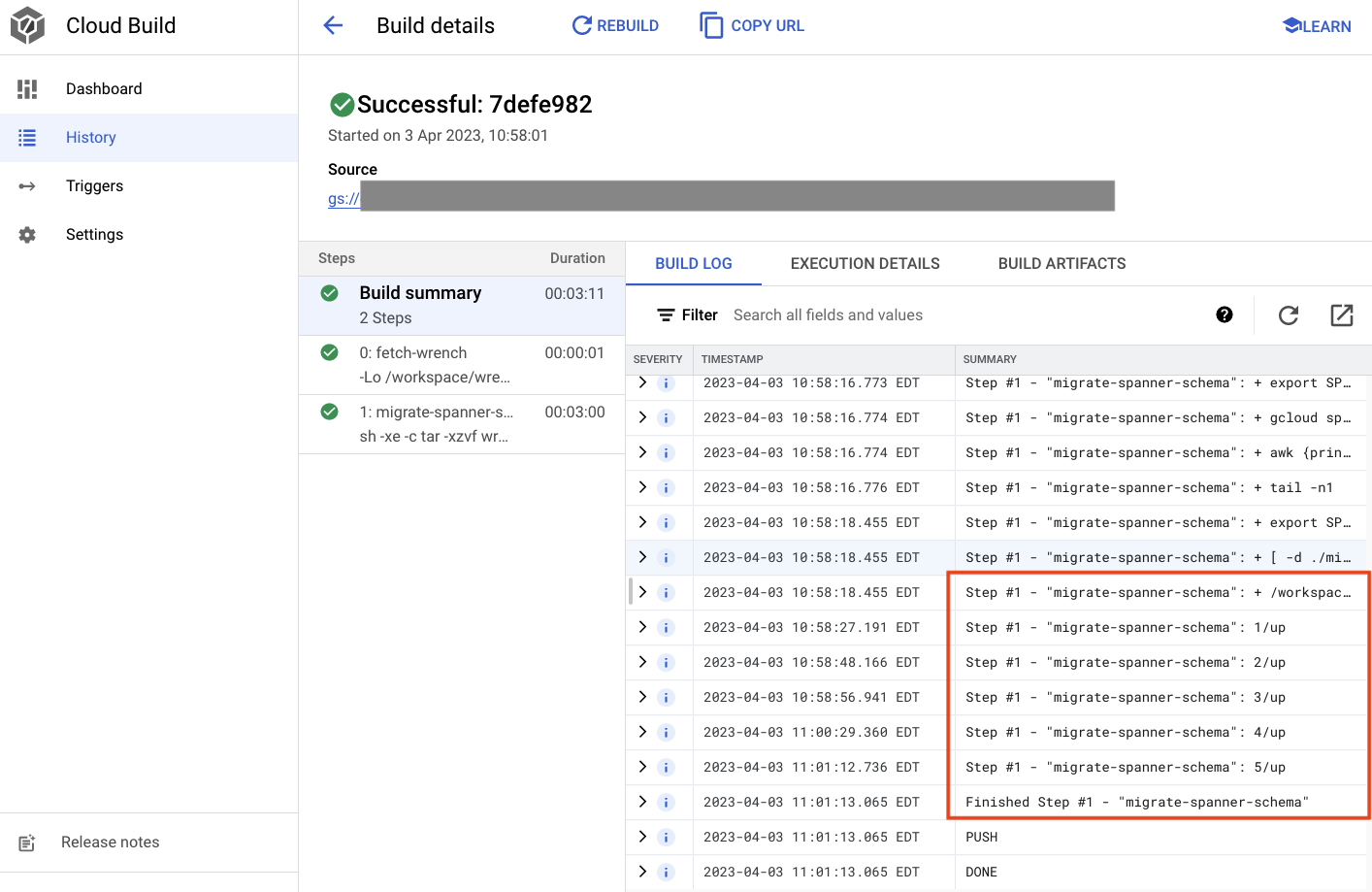
概要
この手順では、Cloud Build を使用して、5 つの異なる DDL オペレーションを適用する初期スキーマ移行を送信しました。これらのオペレーションは、データベース スキーマの変更が必要な機能が追加された時点を表します。
通常の開発シナリオでは、停止を回避するために、スキーマの変更を現在のアプリケーションと下位互換性のあるものにする必要があります。
下位互換性のない変更の場合は、停止を回避するために、アプリケーションとスキーマへの変更を段階的にデプロイします。
次のステップ
スキーマが配置されたら、次のステップはバックエンド サービスのデプロイです。
5. バックエンド サービスをデプロイする
概要
この Codelab のバックエンド サービスは、4 つの異なるサービスを表す golang REST API です。
- Profile: プレーヤーがサンプル「ゲーム」に登録して認証できるようにします。
- マッチング: プレーヤー データとやり取りしてマッチング機能をサポートし、作成されたゲームに関する情報を追跡し、ゲームが終了したときにプレーヤーの統計情報を更新します。
- アイテム: プレーヤーがゲームをプレイする過程でゲームアイテムやお金を獲得できるようにします。
- 交易所: プレーヤーが交易所でアイテムを売買できるようにする

これらのサービスについて詳しくは、Cloud Spanner: ゲーム開発のスタートガイド Codelab をご覧ください。ここでは、これらのサービスを GKE Autopilot クラスタで実行します。
これらのサービスは、Spanner データを変更できる必要があります。そのため、各サービスには「databaseUser」ロールを付与するサービス アカウントが作成されています。
Workload Identity を使用すると、Terraform の次の手順で、Kubernetes サービス アカウントがサービスの Google Cloud サービス アカウントを偽装できます。
- サービスの Google Cloud サービス アカウント(
GSA)リソースを作成する - そのサービス アカウントに databaseUser ロールを割り当てる
- そのサービス アカウントに workloadIdentityUser ロールを割り当てる
- GSA を参照する Kubernetes サービス アカウント(
KSA)を作成する
概略図は次のようになります。

Terraform によって、サービス アカウントと Kubernetes サービス アカウントが作成されました。kubectl を使用して Kubernetes サービス アカウントを確認できます。
# kubectl get serviceaccounts
NAME SECRETS AGE
default 0 37m
item-app 0 35m
matchmaking-app 0 35m
profile-app 0 35m
tradepost-app 0 35m
ビルドの仕組みは次のとおりです。
- Terraform は、次のような
$DEMO_HOME/backend_services/cloudbuild.yamlファイルを生成しました。
serviceAccount: projects/${PROJECT_ID}/serviceAccounts/cloudbuild-cicd@${PROJECT_ID}.iam.gserviceaccount.com
steps:
#
# Building of images
#
- name: gcr.io/cloud-builders/docker
id: profile
args: ["build", ".", "-t", "${_PROFILE_IMAGE}"]
dir: profile
waitFor: ['-']
- name: gcr.io/cloud-builders/docker
id: matchmaking
args: ["build", ".", "-t", "${_MATCHMAKING_IMAGE}"]
dir: matchmaking
waitFor: ['-']
- name: gcr.io/cloud-builders/docker
id: item
args: ["build", ".", "-t", "${_ITEM_IMAGE}"]
dir: item
waitFor: ['-']
- name: gcr.io/cloud-builders/docker
id: tradepost
args: ["build", ".", "-t", "${_TRADEPOST_IMAGE}"]
dir: tradepost
waitFor: ['-']
#
# Deployment
#
- name: gcr.io/google.com/cloudsdktool/cloud-sdk
id: cloud-deploy-release
entrypoint: gcloud
args:
[
"deploy", "releases", "create", "${_REL_NAME}",
"--delivery-pipeline", "sample-game-services",
"--skaffold-file", "skaffold.yaml",
"--skaffold-version", "1.39",
"--images", "profile=${_PROFILE_IMAGE},matchmaking=${_MATCHMAKING_IMAGE},item=${_ITEM_IMAGE},tradepost=${_TRADEPOST_IMAGE}",
"--region", "us-central1"
]
artifacts:
images:
- ${_REGISTRY}/profile
- ${_REGISTRY}/matchmaking
- ${_REGISTRY}/item
- ${_REGISTRY}/tradepost
substitutions:
_PROFILE_IMAGE: ${_REGISTRY}/profile:${BUILD_ID}
_MATCHMAKING_IMAGE: ${_REGISTRY}/matchmaking:${BUILD_ID}
_ITEM_IMAGE: ${_REGISTRY}/item:${BUILD_ID}
_TRADEPOST_IMAGE: ${_REGISTRY}/tradepost:${BUILD_ID}
_REGISTRY: us-docker.pkg.dev/${PROJECT_ID}/spanner-game-images
_REL_NAME: rel-${BUILD_ID:0:8}
options:
dynamic_substitutions: true
machineType: E2_HIGHCPU_8
logging: CLOUD_LOGGING_ONLY
- Cloud Build コマンドはこのファイルを読み取り、リストされている手順を実行します。まず、サービス イメージをビルドします。次に、
gcloud deploy createコマンドを実行します。これにより、各デプロイ ファイルの場所を定義する$DEMO_HOME/backend_services/skaffold.yamlファイルが読み取られます。
apiVersion: skaffold/v2beta29
kind: Config
deploy:
kubectl:
manifests:
- spanner_config.yaml
- profile/deployment.yaml
- matchmaking/deployment.yaml
- item/deployment.yaml
- tradepost/deployment.yaml
- Cloud Deploy は、各サービスの
deployment.yamlファイルの定義に従います。サービスのデプロイ ファイルには、サービス(この場合はポート 80 で実行されている clusterIP)の作成に必要な情報が含まれています。
ClusterIP タイプでは、バックエンド サービス Pod に外部 IP が割り当てられないため、内部 GKE ネットワークに接続できるエンティティのみがバックエンド サービスにアクセスできます。これらのサービスは Spanner データにアクセスして変更するため、プレーヤーが直接アクセスできないようにする必要があります。
apiVersion: v1
kind: Service
metadata:
name: profile
spec:
type: ClusterIP
selector:
app: profile
ports:
- port: 80
targetPort: 80
Cloud Deploy は、Kubernetes Service の作成に加えて、Kubernetes Deployment も作成します。profile サービスのデプロイ セクションを見てみましょう。
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: profile
spec:
replicas: 2 # EDIT: Number of instances of deployment
selector:
matchLabels:
app: profile
template:
metadata:
labels:
app: profile
spec:
serviceAccountName: profile-app
containers:
- name: profile-service
image: profile
ports:
- containerPort: 80
envFrom:
- configMapRef:
name: spanner-config
env:
- name: SERVICE_HOST
value: "0.0.0.0"
- name: SERVICE_PORT
value: "80"
resources:
requests:
cpu: "1"
memory: "1Gi"
ephemeral-storage: "100Mi"
limits:
cpu: "1"
memory: "1Gi"
ephemeral-storage: "100Mi"
上部には、サービスに関するメタデータが表示されます。この中で最も重要なのは、このデプロイで作成されるレプリカの数を定義することです。
replicas: 2 # EDIT: Number of instances of deployment
次に、アプリを実行するサービス アカウントと、使用するイメージを確認します。これらは、Terraform から作成された Kubernetes サービス アカウントと、Cloud Build ステップで作成されたイメージと一致します。
spec:
serviceAccountName: profile-app
containers:
- name: profile-service
image: profile
次に、ネットワーキングと環境変数に関する情報を指定します。
spanner_config は、アプリケーションが Spanner に接続するために必要なプロジェクト、インスタンス、データベース情報を指定する Kubernetes ConfigMap です。
apiVersion: v1
kind: ConfigMap
metadata:
name: spanner-config
data:
SPANNER_PROJECT_ID: ${project_id}
SPANNER_INSTANCE_ID: ${instance_id}
SPANNER_DATABASE_ID: ${database_id}
ports:
- containerPort: 80
envFrom:
- configMapRef:
name: spanner-config
env:
- name: SERVICE_HOST
value: "0.0.0.0"
- name: SERVICE_PORT
value: "80"
SERVICE_HOST と SERVICE_PORT は、サービスがバインド先を認識するために必要な追加の環境変数です。
最後のセクションでは、このデプロイの各レプリカに許可するリソースの数を GKE に伝えます。これは、GKE Autopilot が必要に応じてクラスタをスケーリングするために使用するものでもあります。
resources:
requests:
cpu: "1"
memory: "1Gi"
ephemeral-storage: "100Mi"
limits:
cpu: "1"
memory: "1Gi"
ephemeral-storage: "100Mi"
この情報を使用して、バックエンド サービスをデプロイします。
バックエンド サービスをデプロイする
前述のように、バックエンド サービスのデプロイには Cloud Build を使用します。スキーマの移行と同様に、gcloud コマンドラインを使用してビルド リクエストを送信できます。
cd $DEMO_HOME/backend_services gcloud builds submit --config=cloudbuild.yaml
コマンド出力
Creating temporary tarball archive of 66 file(s) totalling 864.6 KiB before compression.
Uploading tarball of [.] to [gs://(project)_cloudbuild/source/(snip).tgz]
Created [https://cloudbuild.googleapis.com/v1/projects/(project)/locations/global/builds/30207dd1-(snip)].
Logs are available at [ https://console.cloud.google.com/cloud-build/builds/30207dd1-(snip)?project=(snip) ].
gcloud builds submit only displays logs from Cloud Storage. To view logs from Cloud Logging, run:
gcloud beta builds submit
ID: 30207dd1-(snip)
CREATE_TIME: (created time)
DURATION: 3M17S
SOURCE: gs://(project)_cloudbuild/source/(snip).tgz
IMAGES: us-docker.pkg.dev/(project)/spanner-game-images/profile:30207dd1-(snip) (+3 more)
STATUS: SUCCESS
schema migration ステップの出力とは異なり、このビルドの出力は、作成されたイメージがあることを示しています。これらは Artifact Registry リポジトリに保存されます。
gcloud build ステップの出力には、Cloud Console へのリンクが含まれます。そちらをご覧ください。
Cloud Build から成功通知を受け取ったら、Cloud Deploy に移動し、sample-game-services パイプラインに移動して、デプロイの進行状況をモニタリングします。

サービスがデプロイされたら、kubectl を確認して Pod のステータスを確認できます。
kubectl get pods
コマンド出力
NAME READY STATUS RESTARTS AGE
item-6b9d5f678c-4tbk2 1/1 Running 0 83m
matchmaking-5bcf799b76-lg8zf 1/1 Running 0 80m
profile-565bbf4c65-kphdl 1/1 Running 0 83m
profile-565bbf4c65-xw74j 1/1 Running 0 83m
tradepost-68b87ccd44-gw55r 1/1 Running 0 79m
次に、サービスをチェックして ClusterIP が動作していることを確認します。
kubectl get services
コマンド出力
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
item ClusterIP 10.172.XXX.XXX <none> 80/TCP 84m
kubernetes ClusterIP 10.172.XXX.XXX <none> 443/TCP 137m
matchmaking ClusterIP 10.172.XXX.XXX <none> 80/TCP 84m
profile ClusterIP 10.172.XXX.XXX <none> 80/TCP 84m
tradepost ClusterIP 10.172.XXX.XXX <none> 80/TCP 84m
Cloud Console の GKE UI に移動して、Workloads、Services、ConfigMaps を確認することもできます。
ワークロード

サービス

ConfigMap


概要
この手順では、4 つのバックエンド サービスを GKE Autopilot にデプロイしました。Cloud Build ステップを実行し、Cloud Deploy と Cloud Console の Kubernetes で進行状況を確認できました。
また、これらのサービスが Workload Identity を使用して、Spanner データベースに対するデータの読み取りと書き込みの適切な権限を持つサービス アカウントの権限を借用する方法についても説明しました。
次のステップ
次のセクションでは、ワークロードをデプロイします。
6. ワークロードをデプロイする
概要
バックエンド サービスがクラスタで実行されているので、ワークロードをデプロイします。

ワークロードは外部からアクセス可能で、この Codelab の目的のためにバックエンド サービスごとに 1 つあります。
これらのワークロードは、これらのサンプル サービスで想定される実際のアクセス パターンを模倣した Locust ベースの負荷生成スクリプトです。
Cloud Build プロセスのファイルがあります。
$DEMO_HOME/workloads/cloudbuild.yaml(Terraform によって生成)$DEMO_HOME/workloads/skaffold.yaml- ワークロードごとに 1 つの
deployment.yamlファイル
ワークロードの deployment.yaml ファイルは、バックエンド サービス デプロイ ファイルとは若干異なります。
matchmaking-workload の例を次に示します。
apiVersion: v1
kind: Service
metadata:
name: matchmaking-workload
spec:
type: LoadBalancer
selector:
app: matchmaking-workload
ports:
- port: 8089
targetPort: 8089
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: matchmaking-workload
spec:
replicas: 1 # EDIT: Number of instances of deployment
selector:
matchLabels:
app: matchmaking-workload
template:
metadata:
labels:
app: matchmaking-workload
spec:
serviceAccountName: default
containers:
- name: matchmaking-workload
image: matchmaking-workload
ports:
- containerPort: 8089
resources:
requests:
cpu: "500m"
memory: "512Mi"
ephemeral-storage: "100Mi"
limits:
cpu: "500m"
memory: "512Mi"
ephemeral-storage: "100Mi"
ファイルの上部でサービスを定義します。この場合、LoadBalancer が作成され、ワークロードはポート 8089 で実行されます。
LoadBalancer は、ワークロードへの接続に使用できる外部 IP を提供します。
apiVersion: v1
kind: Service
metadata:
name: matchmaking-workload
spec:
type: LoadBalancer
selector:
app: matchmaking-workload
ports:
- port: 8089
targetPort: 8089
デプロイ セクションの上部は、ワークロードに関するメタデータです。この場合、デプロイされるレプリカは 1 つだけです。
replicas: 1
ただし、コンテナ仕様は異なります。たとえば、default Kubernetes サービス アカウントを使用しています。このアカウントには特別な権限はありません。ワークロードは、GKE クラスタで実行されているバックエンド サービス以外の Google Cloud リソースに接続する必要がないためです。
もう 1 つの違いは、これらのワークロードに必要な環境変数がないことです。その結果、デプロイ仕様が短くなります。
spec:
serviceAccountName: default
containers:
- name: matchmaking-workload
image: matchmaking-workload
ports:
- containerPort: 8089
リソース設定はバックエンド サービスと似ています。これは、GKE Autopilot がクラスタで実行されているすべての Pod のリクエストを満たすために必要なリソースの数を把握する方法です。
ワークロードをデプロイしてください。
ワークロードをデプロイする
これまでと同様に、gcloud コマンドラインを使用してビルド リクエストを送信できます。
cd $DEMO_HOME/workloads gcloud builds submit --config=cloudbuild.yaml
コマンド出力
Creating temporary tarball archive of 18 file(s) totalling 26.2 KiB before compression.
Some files were not included in the source upload.
Check the gcloud log [/tmp/tmp.4Z9EqdPo6d/logs/(snip).log] to see which files and the contents of the
default gcloudignore file used (see `$ gcloud topic gcloudignore` to learn
more).
Uploading tarball of [.] to [gs://(project)_cloudbuild/source/(snip).tgz]
Created [https://cloudbuild.googleapis.com/v1/projects/(project)/locations/global/builds/(snip)].
Logs are available at [ https://console.cloud.google.com/cloud-build/builds/0daf20f6-(snip)?project=(snip) ].
gcloud builds submit only displays logs from Cloud Storage. To view logs from Cloud Logging, run:
gcloud beta builds submit
ID: 0daf20f6-(snip)
CREATE_TIME: (created_time)
DURATION: 1M41S
SOURCE: gs://(project)_cloudbuild/source/(snip).tgz
IMAGES: us-docker.pkg.dev/(project)/spanner-game-images/profile-workload:0daf20f6-(snip) (+4 more)
STATUS: SUCCESS
Cloud Console で Cloud Build ログと Cloud Deploy パイプラインを確認して、ステータスを確認してください。ワークロードの場合、Cloud Deploy パイプラインは sample-game-workloads です。
デプロイが完了したら、Cloud Shell で kubectl を使用してステータスを確認します。
kubectl get pods
コマンド出力
NAME READY STATUS RESTARTS AGE
game-workload-7ff44cb657-pxxq2 1/1 Running 0 12m
item-6b9d5f678c-cr29w 1/1 Running 0 9m6s
item-generator-7bb4f57cf8-5r85b 1/1 Running 0 12m
matchmaking-5bcf799b76-lg8zf 1/1 Running 0 117m
matchmaking-workload-76df69dbdf-jds9z 1/1 Running 0 12m
profile-565bbf4c65-kphdl 1/1 Running 0 121m
profile-565bbf4c65-xw74j 1/1 Running 0 121m
profile-workload-76d6db675b-kzwng 1/1 Running 0 12m
tradepost-68b87ccd44-gw55r 1/1 Running 0 116m
tradepost-workload-56c55445b5-b5822 1/1 Running 0 12m
次に、ワークロード サービスをチェックして、LoadBalancer が動作していることを確認します。
kubectl get services
コマンド出力
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
game-workload LoadBalancer *snip* 35.XX.XX.XX 8089:32483/TCP 12m
item ClusterIP *snip* <none> 80/TCP 121m
item-generator LoadBalancer *snip* 34.XX.XX.XX 8089:32581/TCP 12m
kubernetes ClusterIP *snip* <none> 443/TCP 174m
matchmaking ClusterIP *snip* <none> 80/TCP 121m
matchmaking-workload LoadBalancer *snip* 34.XX.XX.XX 8089:31735/TCP 12m
profile ClusterIP *snip* <none> 80/TCP 121m
profile-workload LoadBalancer *snip* 34.XX.XX.XX 8089:32532/TCP 12m
tradepost ClusterIP *snip* <none> 80/TCP 121m
tradepost-workload LoadBalancer *snip* 34.XX.XX.XX 8089:30002/TCP 12m
概要
これで、ワークロードが GKE クラスタにデプロイされました。これらのワークロードには追加の IAM 権限は必要なく、LoadBalancer サービスを使用してポート 8089 で外部からアクセスできます。
次のステップ
バックエンド サービスとワークロードが実行されたので、ゲームを「プレイ」しましょう。
7. ゲームのプレイを開始する
概要
これで、サンプル「ゲーム」のバックエンド サービスが実行され、ワークロードを使用してこれらのサービスとやり取りする「プレーヤー」を生成する手段も用意されました。
各ワークロードは Locust を使用して、サービス API に対する実際の負荷をシミュレートします。このステップでは、いくつかのワークロードを実行して、GKE クラスタと Spanner に負荷を生成し、Spanner にデータを保存します。
各ワークロードの説明は次のとおりです。
item-generatorワークロードは、プレーヤーがゲームの「プレイ」中に獲得できる game_items のリストを生成するクイック ワークロードです。profile-workloadは、プレーヤーの登録とログインをシミュレートします。matchmaking-workloadは、ゲームに割り当てられるためにキューに並ぶプレーヤーをシミュレートします。game-workloadは、ゲームのプレイ中にプレーヤーがゲームアイテムやお金を獲得する様子をシミュレートします。tradepost-workloadは、プレーヤーが取引所でアイテムを売買できることをシミュレートします。
この Codelab では、item-generator と profile-workload の実行に焦点を当てます。
item-generator を実行する
item-generator は item バックエンド サービス エンドポイントを使用して、game_items を Spanner に追加します。これらの項目は、game-workload と tradepost-workload が正しく機能するために必要です。
最初の手順は、item-generator サービスの外部 IP を取得することです。Cloud Shell で次のコマンドを実行します。
# The external IP is the 4th column of the output
kubectl get services | grep item-generator | awk '{print $4}'
コマンド出力
{ITEMGENERATOR_EXTERNAL_IP}
新しいブラウザタブを開き、http://{ITEMGENERATOR_EXTERNAL_IP}:8089に移動します。次のようなページが表示されます。
users と spawn はデフォルトの 1 のままにします。host に「http://item」と入力します。詳細オプションをクリックし、実行時間に 10s と入力します。
構成は次のようになります。

[Start swarming] をクリックします。
POST /items エンドポイントで発行されたリクエストの統計情報が表示されます。10 秒後に負荷が停止します。
Charts をクリックすると、これらのリクエストのパフォーマンスに関するグラフが表示されます。

次に、データが Spanner データベースに入力されているかどうかを確認します。
そのためには、ハンバーガー メニューをクリックして [Spanner] に移動します。このページから、sample-instance と sample-database に移動します。[Query] をクリックします。
game_itemsの数を選択します。
SELECT COUNT(*) FROM game_items;
下部に結果が表示されます。
game_items のシードはそれほど多く必要ありません。しかし、今ではプレイヤーが獲得できるようになりました。
profile-workload を実行する
game_items をシードしたら、次のステップとして、プレーヤーがゲームをプレイできるように登録します。
profile-workload は Locust を使用して、プレーヤーがアカウントを作成し、ログイン、プロフィール情報の取得、ログアウトを行う様子をシミュレートします。これらのテストはすべて、一般的な本番環境のようなワークロードで profile バックエンド サービスのエンドポイントをテストします。
これを実行するには、profile-workload の外部 IP を取得します。
# The external IP is the 4th column of the output
kubectl get services | grep profile-workload | awk '{print $4}'
コマンド出力
{PROFILEWORKLOAD_EXTERNAL_IP}
新しいブラウザタブを開き、http://{PROFILEWORKLOAD_EXTERNAL_IP}:8089に移動します。前のページと同様の Locust ページが表示されます。
この場合、ホストには http://profile を使用します。また、詳細オプションでランタイムを指定することもありません。また、users を 4 に指定して、一度に 4 つのユーザー リクエストをシミュレートします。
profile-workload テストは次のようになります。

[Start swarming] をクリックします。
以前と同様に、さまざまな profile REST エンドポイントの統計情報が表示されます。[チャート] をクリックすると、すべてのパフォーマンスの概要が表示されます。

概要
このステップでは、いくつかの game_items を生成し、Cloud Console の Spanner クエリ UI を使用して game_items テーブルにクエリを実行しました。
また、プレーヤーがゲームに登録できるようにし、Locust がバックエンド サービスに対して本番環境のようなワークロードを作成できることを確認しました。
次のステップ
ワークロードを実行したら、GKE クラスタと Spanner インスタンスの動作を確認します。
8. GKE と Spanner の使用状況を確認する
プロファイル サービスが実行されたら、GKE Autopilot クラスタと Cloud Spanner の動作を確認します。
GKE クラスタを確認する
Kubernetes クラスタに移動します。ワークロードとサービスをデプロイしたので、クラスタに vCPU とメモリの合計に関する詳細が追加されています。クラスタにワークロードがない場合、この情報は使用できませんでした。

sample-game-gke クラスタをクリックし、オブザーバビリティ タブに切り替えます。

ワークロードとバックエンド サービスは default で実行されるため、default Kubernetes Namespace の CPU 使用率は kube-system Namespace を超えているはずです。更新されていない場合は、profile workload がまだ実行されていることを確認し、グラフが更新されるまで数分待ちます。
最も多くのリソースを使用しているワークロードを確認するには、Workloads ダッシュボードに移動します。
各ワークロードに個別に移動するのではなく、ダッシュボードの [オブザーバビリティ] タブに直接移動します。profile と profile-workload の CPU が増加していることがわかります。

Cloud Spanner を確認します。
Cloud Spanner インスタンスを確認する
Cloud Spanner のパフォーマンスを確認するには、Spanner に移動して、sample-instance インスタンスと sample-game データベースをクリックします。
左側のメニューに [システム分析情報] タブが表示されます。

ここでは、CPU utilization、transaction latency and locking、query throughput など、Spanner インスタンスの一般的なパフォーマンスを把握するのに役立つグラフが多数用意されています。
システム分析に加えて、[モニタリング] セクションの他のリンクを確認することで、クエリ ワークロードに関する詳細情報を取得できます。
- クエリ分析情報は、Spanner でリソースを使用している上位 N 個のクエリを特定するのに役立ちます。
- トランザクションとロックの分析情報は、レイテンシの高いトランザクションを特定するのに役立ちます。
- Key Visualizer は、アクセス パターンを可視化し、データ内のホットスポットを特定するのに役立ちます。
概要
このステップでは、GKE Autopilot と Spanner の両方で基本的なパフォーマンス指標を確認する方法を学習しました。
たとえば、プロファイル ワークロードを実行した状態で、players テーブルをクエリして、そこに保存されているデータに関する詳細情報を取得します。
次のステップ
次に、クリーンアップを行います。
9. クリーンアップ
クリーンアップする前に、説明していない他のワークロードを自由に確認してください。具体的には、matchmaking-workload、 game-workload、tradepost-workload です。
ゲームの「プレイ」が完了したら、プレイグラウンドをクリーンアップできます。幸い、この操作は非常に簡単です。
まず、ブラウザで profile-workload がまだ実行されている場合は、それを停止します。

テストしたワークロードごとに同じ操作を行います。
次に、Cloud Shell でインフラストラクチャ フォルダに移動します。Terraform を使用してインフラストラクチャを destroy します。
cd $DEMO_HOME/infrastructure
terraform destroy
# type 'yes' when asked
コマンド出力
Plan: 0 to add, 0 to change, 46 to destroy.
Do you really want to destroy all resources?
Terraform will destroy all your managed infrastructure, as shown above.
There is no undo. Only 'yes' will be accepted to confirm.
Enter a value: yes
*snip*
Destroy complete! Resources: 46 destroyed.
Cloud コンソールで Spanner、Kubernetes Cluster、Artifact Registry、Cloud Deploy、IAM に移動し、すべてのリソースが削除されていることを確認します。
10. 完了
おめでとうございます。GKE Autopilot にサンプル golang アプリケーションをデプロイし、Workload Identity を使用して Cloud Spanner に接続しました。
このインフラストラクチャは、Terraform を使用して簡単に設定および削除でき、繰り返し使用できます。
この Codelab で使用した Google Cloud サービスの詳細については、以下をご覧ください。
次のステップ
GKE Autopilot と Cloud Spanner の連携方法の基本を理解したら、次のステップとして、これらのサービスと連携する独自のアプリケーションの構築を始めてみませんか?