
1. Wprowadzenie
Cloud Spanner to usługa w pełni zarządzanej, skalowalnej w poziomie, globalnie rozproszonej relacyjnej bazy danych, która zapewnia transakcje ACID i semantykę SQL bez utraty wydajności i wysokiej dostępności.
Autopilot w GKE to tryb działania w GKE, w którym Google zarządza konfiguracją klastra, w tym węzłami, skalowaniem, zabezpieczeniami i innymi wstępnie skonfigurowanymi ustawieniami, aby zapewnić zgodność ze sprawdzonymi metodami. Na przykład Autopilot w GKE umożliwia zarządzanie uprawnieniami usługi za pomocą Workload Identity.
Celem tego modułu jest przeprowadzenie Cię przez proces łączenia kilku usług backendu działających w GKE Autopilot z bazą danych Cloud Spanner.

W tym module najpierw skonfigurujesz projekt i uruchomisz Cloud Shell. Następnie wdrożysz infrastrukturę za pomocą Terraform.
Po zakończeniu tego procesu będziesz korzystać z Cloud Build i Cloud Deploy, aby przeprowadzić początkową migrację schematu bazy danych Games, wdrożyć usługi backendu, a następnie wdrożyć zadania.
Usługi w tym laboratorium są takie same jak w laboratorium Cloud Spanner – pierwsze kroki w tworzeniu gier. Wykonanie tego ćwiczenia nie jest wymagane, aby uruchomić usługi w GKE i połączyć je z usługą Spanner. Jeśli jednak interesują Cię szczegóły dotyczące usług działających w Spannerze, zapoznaj się z nimi.
Po uruchomieniu zbiorów zadań i usług backendu możesz zacząć generować obciążenie i obserwować, jak usługi współpracują ze sobą.
Na koniec usuniesz zasoby utworzone w tym module.
Co utworzysz
W ramach tego modułu:
- Provisioning infrastruktury za pomocą Terraform
- Utwórz schemat bazy danych za pomocą procesu migracji schematu w Cloud Build.
- Wdróż 4 usługi backendu w Golang, które korzystają z Workload Identity do łączenia się z Cloud Spanner.
- Wdróż 4 usługi zbioru zadań, które służą do symulowania obciążenia usług backendu.
Czego się nauczysz
- Jak udostępniać potoki GKE Autopilot, Cloud Spanner i Cloud Deploy za pomocą Terraform
- Jak Workload Identity umożliwia usługom w GKE przyjmowanie tożsamości kont usługi w celu uzyskania dostępu do uprawnień IAM do pracy z Cloud Spanner
- Jak generować obciążenie podobne do produkcyjnego w GKE i Cloud Spanner za pomocą Locust.io
Czego potrzebujesz
2. Konfiguracja i wymagania
Utwórz projekt
Jeśli nie masz jeszcze konta Google (Gmail lub Google Apps), musisz je utworzyć. Zaloguj się w konsoli Google Cloud Platform ( console.cloud.google.com) i utwórz nowy projekt.
Jeśli masz już projekt, kliknij menu wyboru projektu w lewym górnym rogu konsoli:

i w wyświetlonym oknie kliknij przycisk „NOWY PROJEKT”, aby utworzyć nowy projekt:

Jeśli nie masz jeszcze projektu, powinien wyświetlić się taki dialog, w którym możesz utworzyć pierwszy projekt:
W kolejnym oknie dialogowym tworzenia projektu możesz wpisać szczegóły nowego projektu:

Zapamiętaj identyfikator projektu, który jest unikalną nazwą we wszystkich projektach Google Cloud (podana powyżej nazwa jest już zajęta i nie będzie działać w Twoim przypadku). W dalszej części tego laboratorium będzie on nazywany PROJECT_ID.
Następnie, jeśli nie zostało to jeszcze zrobione, musisz włączyć płatności w Konsoli deweloperów, aby korzystać z zasobów Google Cloud i włączyć interfejs Cloud Spanner API.

Wykonanie tego samouczka nie powinno kosztować więcej niż kilka dolarów, ale może okazać się droższe, jeśli zdecydujesz się wykorzystać więcej zasobów lub pozostawisz je uruchomione (patrz sekcja „Czyszczenie” na końcu tego dokumentu). Ceny Google Cloud Spanner są opisane tutaj, a ceny Autopilota w GKE – tutaj.
Nowi użytkownicy Google Cloud Platform mogą skorzystać z bezpłatnego okresu próbnego, w którym mają do dyspozycji środki w wysokości 300 USD, co powinno sprawić, że ten samouczek będzie całkowicie bezpłatny.
Konfigurowanie Cloud Shell
Z Google Cloud i Spanner można korzystać zdalnie na laptopie, ale w tym ćwiczeniu programistycznym będziemy używać Google Cloud Shell, czyli środowiska wiersza poleceń działającego w chmurze.
Ta maszyna wirtualna oparta na Debianie zawiera wszystkie potrzebne narzędzia dla programistów. Zawiera również stały katalog domowy o pojemności 5 GB i działa w Google Cloud, co znacznie zwiększa wydajność sieci i usprawnia proces uwierzytelniania. Oznacza to, że do ukończenia tego ćwiczenia potrzebujesz tylko przeglądarki (działa ona na Chromebooku).
- Aby aktywować Cloud Shell w konsoli Cloud, kliknij Aktywuj Cloud Shell
 (udostępnienie środowiska i połączenie się z nim powinno zająć tylko kilka chwil).
(udostępnienie środowiska i połączenie się z nim powinno zająć tylko kilka chwil).


Po połączeniu z Cloud Shell zobaczysz, że uwierzytelnianie zostało już przeprowadzone, a projekt jest już ustawiony na Twój identyfikator projektu PROJECT_ID.
gcloud auth list
Wynik polecenia
Credentialed accounts:
- <myaccount>@<mydomain>.com (active)
gcloud config list project
Wynik polecenia
[core]
project = <PROJECT_ID>
Jeśli z jakiegoś powodu projekt nie jest ustawiony, po prostu wydaj to polecenie:
gcloud config set project <PROJECT_ID>
Szukasz urządzenia PROJECT_ID? Sprawdź, jakiego identyfikatora użyto w krokach konfiguracji, lub wyszukaj go w panelu konsoli Cloud:

Cloud Shell domyślnie ustawia też niektóre zmienne środowiskowe, które mogą być przydatne podczas wykonywania kolejnych poleceń.
echo $GOOGLE_CLOUD_PROJECT
Wynik polecenia
<PROJECT_ID>
Pobieranie kodu
W Cloud Shell możesz pobrać kod na potrzeby tego modułu:
git clone https://github.com/cloudspannerecosystem/spanner-gaming-sample.git
Wynik polecenia
Cloning into 'spanner-gaming-sample'...
*snip*
To laboratorium jest oparte na wersji v0.1.3, więc sprawdź ten tag:
cd spanner-gaming-sample
git fetch --all --tags
# Check out v0.1.3 release
git checkout tags/v0.1.3 -b v0.1.3-branch
Wynik polecenia
Switched to a new branch 'v0.1.3-branch'
Teraz ustaw bieżący katalog roboczy jako zmienną środowiskową DEMO_HOME. Ułatwi to poruszanie się po różnych częściach laboratorium.
export DEMO_HOME=$(pwd)
Podsumowanie
W tym kroku utworzono nowy projekt, aktywowano Cloud Shell i pobrano kod na potrzeby tego laboratorium.
Następny
Następnie udostępnisz infrastrukturę za pomocą Terraform.
3. Provision infrastructure
Przegląd
Gdy projekt będzie gotowy, możesz uruchomić infrastrukturę. Obejmuje to sieć VPC, Cloud Spanner, GKE Autopilot, Artifact Registry do przechowywania obrazów, które będą uruchamiane w GKE, potoki Cloud Deploy dla usług backendu i zbiorów zadań, a także konta usługi i uprawnienia IAM umożliwiające korzystanie z tych usług.
To dużo. Na szczęście Terraform może uprościć ten proces. Terraform to narzędzie „infrastruktura jako kod”, które umożliwia określenie, czego potrzebujemy w tym projekcie, w serii plików „.tf”. Ułatwia to udostępnianie infrastruktury.
Znajomość Terraform nie jest wymagana do ukończenia tego ćwiczenia. Jeśli jednak chcesz zobaczyć, co się dzieje w kolejnych krokach, możesz sprawdzić, co zostało utworzone w tych plikach znajdujących się w katalogu infrastructure:
- vpc.tf
- backend_gke.tf
- spanner.tf
- artifact_registry.tf
- pipelines.tf
- iam.tf
Konfigurowanie Terraform
W Cloud Shell przejdź do katalogu infrastructure i zainicjuj Terraform:
cd $DEMO_HOME/infrastructure
terraform init
Wynik polecenia
Initializing the backend...
Initializing provider plugins...
*snip*
Terraform has been successfully initialized!
You may now begin working with Terraform. Try running "terraform plan" to see
any changes that are required for your infrastructure. All Terraform commands
should now work.
If you ever set or change modules or backend configuration for Terraform,
rerun this command to reinitialize your working directory. If you forget, other
commands will detect it and remind you to do so if necessary.
Następnie skonfiguruj Terraform, kopiując terraform.tfvars.sample i modyfikując wartość projektu. Pozostałe zmienne też można zmienić, ale tylko projekt musi zostać zmieniony, aby działał w Twoim środowisku.
cp terraform.tfvars.sample terraform.tfvars
# edit gcp_project using the project environment variable
sed -i "s/PROJECT/$GOOGLE_CLOUD_PROJECT/" terraform.tfvars
Aprowizowanie infrastruktury
Teraz nadszedł czas na udostępnienie infrastruktury.
terraform apply
# review the list of things to be created
# type 'yes' when asked
Wynik polecenia
Plan: 46 to add, 0 to change, 0 to destroy.
Do you want to perform these actions?
Terraform will perform the actions described above.
Only 'yes' will be accepted to approve.
Enter a value: yes
google_project_service.project["container.googleapis.com"]: Creating...
*snip*
Apply complete! Resources: 46 added, 0 changed, 0 destroyed.
Sprawdzanie, co zostało utworzone
Aby sprawdzić, co zostało utworzone, otwórz Cloud Console i wybierz usługi.
Cloud Spanner
Najpierw sprawdź Cloud Spanner. W tym celu otwórz menu z trzema paskami i kliknij Spanner. Aby znaleźć go na liście, może być konieczne kliknięcie „Wyświetl więcej produktów”.
Spowoduje to przejście do listy instancji Spanner. Kliknij instancję, aby wyświetlić bazy danych. Powinna wyglądać mniej więcej tak:

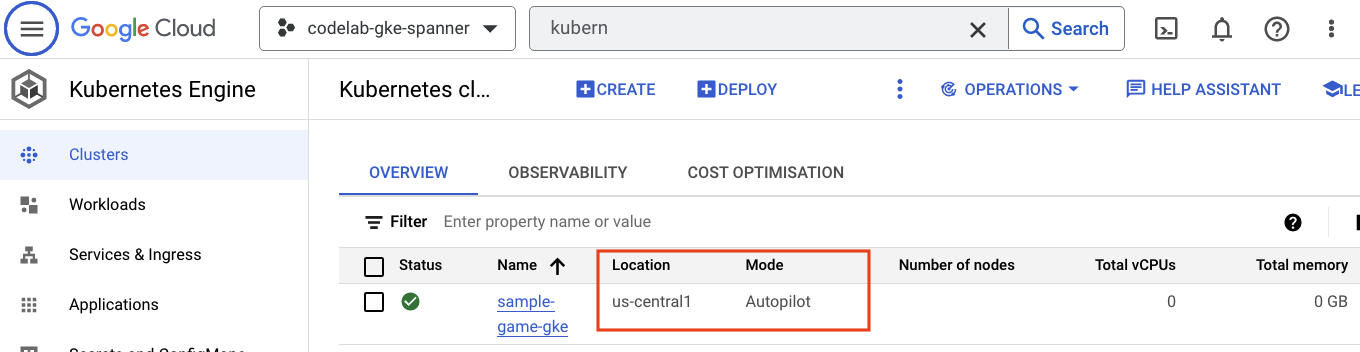
Autopilot w GKE
Następnie sprawdź GKE. W tym celu otwórz menu z 3 kreskami i kliknij Kubernetes Engine => Clusters. Zobaczysz tu klaster sample-games-gke działający w trybie Autopilota.
Artifact Registry
Teraz sprawdź, gdzie będą przechowywane obrazy. Kliknij menu z 3 kreskami i znajdź Artifact Registry=>Repositories. Artifact Registry znajduje się w sekcji CI/CD w menu.
Zobaczysz tu rejestr Dockera o nazwie spanner-game-images. Na razie to pole będzie puste.

Cloud Deploy
W Cloud Deploy utworzyliśmy potoki, dzięki którym Cloud Build może wykonywać czynności związane z tworzeniem obrazów, a następnie wdrażać je w naszym klastrze GKE.
Otwórz menu z 3 paskami i znajdź ikonę Cloud Deploy, która znajduje się też w sekcji CI/CD menu.
Zobaczysz tu 2 potoki: jeden dla usług backendu, a drugi dla zbiorów zadań. Oba wdrażają obrazy w tym samym klastrze GKE, ale umożliwia to rozdzielenie wdrożeń.

Uprawnienia
Na koniec otwórz stronę IAM w Cloud Console, aby sprawdzić utworzone konta usługi. Otwórz menu i znajdź IAM and Admin=>Service accounts. Powinna wyglądać mniej więcej tak:
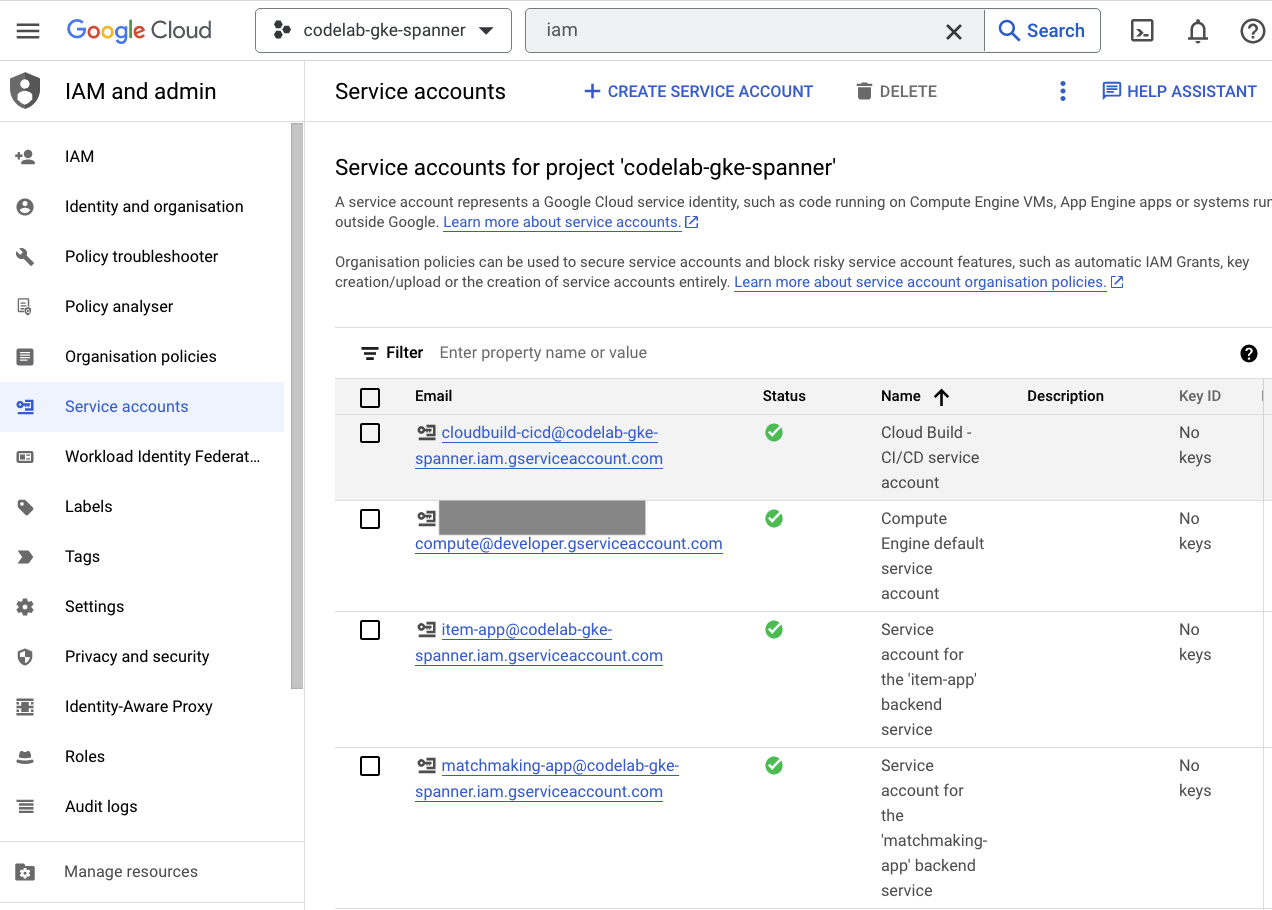
Terraform tworzy łącznie 6 kont usługi:
- Domyślne konto usługi Compute. W tym laboratorium nie jest on używany.
- Konto cloudbuild-cicd jest używane w krokach Cloud Build i Cloud Deploy.
- 4 konta „aplikacji”, które są używane przez nasze usługi backendu do interakcji z Cloud Spanner.
Następnie skonfiguruj kubectl do interakcji z klastrem GKE.
Konfigurowanie narzędzia kubectl
# Name of GKE cluster from terraform.tfvars file
export GKE_CLUSTER=sample-game-gke
# get GKE credentials
gcloud container clusters get-credentials $GKE_CLUSTER --region us-central1
# Check that no errors occur
kubectl get serviceaccounts
Wynik polecenia
#export GKE_CLUSTER=sample-game-gke
# gcloud container clusters get-credentials $GKE_CLUSTER --region us-central1
Fetching cluster endpoint and auth data.
kubeconfig entry generated for sample-game-gke.
# kubectl get serviceaccounts
NAME SECRETS AGE
default 0 37m
item-app 0 35m
matchmaking-app 0 35m
profile-app 0 35m
tradepost-app 0 35m
Podsumowanie
Świetnie. Udało Ci się utworzyć instancję Cloud Spanner i klaster GKE Autopilot w sieci VPC na potrzeby sieci prywatnej.
Utworzono też 2 potoki Cloud Deploy dla usług backendu i zbiorów zadań oraz repozytorium Artifact Registry do przechowywania utworzonych obrazów.
Na koniec utworzono konta usługi i skonfigurowano je do współpracy z Workload Identity, aby usługi backendu mogły korzystać z Cloud Spanner.
Masz też skonfigurowane narzędzie kubectl do interakcji z klastrem GKE w Cloud Shell po wdrożeniu usług backendu i zadań.
Następny
Zanim zaczniesz korzystać z usług, musisz zdefiniować schemat bazy danych. Skonfigurujesz to w następnym kroku.
4. Tworzenie schematu bazy danych
Przegląd
Zanim uruchomisz usługi backendu, musisz się upewnić, że schemat bazy danych jest na miejscu.
Jeśli przejrzysz pliki w katalogu $DEMO_HOME/schema/migrations w repozytorium demonstracyjnym, zobaczysz serię plików .sql, które definiują nasz schemat. Naśladuje to cykl programowania, w którym zmiany schematu są śledzone w samym repozytorium i mogą być powiązane z określonymi funkcjami aplikacji.
W tym przykładowym środowisku narzędzie wrench będzie stosować migracje schematu za pomocą Cloud Build.
Cloud Build
Plik $DEMO_HOME/schema/cloudbuild.yaml opisuje, jakie działania zostaną podjęte:
serviceAccount: projects/${PROJECT_ID}/serviceAccounts/cloudbuild-cicd@${PROJECT_ID}.iam.gserviceaccount.com
steps:
- name: gcr.io/cloud-builders/curl
id: fetch-wrench
args: ['-Lo', '/workspace/wrench.tar.gz', 'https://github.com/cloudspannerecosystem/wrench/releases/download/v1.4.1/wrench-1.4.1-linux-amd64.tar.gz' ]
- name: gcr.io/cloud-builders/gcloud
id: migrate-spanner-schema
entrypoint: sh
args:
- '-xe'
- '-c'
- |
tar -xzvf wrench.tar.gz
chmod +x /workspace/wrench
# Assumes only a single spanner instance and database. Fine for this demo in a dedicated project
export SPANNER_PROJECT_ID=${PROJECT_ID}
export SPANNER_INSTANCE_ID=$(gcloud spanner instances list | tail -n1 | awk '{print $1}')
export SPANNER_DATABASE_ID=$(gcloud spanner databases list --instance=$$SPANNER_INSTANCE_ID | tail -n1 | awk '{print $1}')
if [ -d ./migrations ]; then
/workspace/wrench migrate up --directory .
else
echo "[Error] Missing migrations directory"
fi
timeout: 600s
W zasadzie są 2 kroki:
- pobieranie klucza do obszaru roboczego Cloud Build;
- przeprowadzić migrację klucza;
Zmienne środowiskowe projektu, instancji i bazy danych Spannera są potrzebne, aby narzędzie wrench mogło połączyć się z punktem końcowym zapisu.
Usługa Cloud Build może wprowadzać te zmiany, ponieważ działa jako konto usługi cloudbuild-cicd@${PROJECT_ID}.iam.gserviceaccount.com:
serviceAccount: projects/${PROJECT_ID}/serviceAccounts/cloudbuild-cicd@${PROJECT_ID}.iam.gserviceaccount.com
To konto usługi ma rolę spanner.databaseUser dodaną przez Terraform, która umożliwia mu aktualizowanie DDL.
Migracje schematu
Na podstawie plików w katalogu $DEMO_HOME/schema/migrations wykonywanych jest 5 etapów migracji. Oto przykład pliku 000001.sql, który tworzy tabelę players i indeksy:
CREATE TABLE players (
playerUUID STRING(36) NOT NULL,
player_name STRING(64) NOT NULL,
email STRING(MAX) NOT NULL,
password_hash BYTES(60) NOT NULL,
created TIMESTAMP,
updated TIMESTAMP,
stats JSON,
account_balance NUMERIC NOT NULL DEFAULT (0.00),
is_logged_in BOOL,
last_login TIMESTAMP,
valid_email BOOL,
current_game STRING(36)
) PRIMARY KEY (playerUUID);
CREATE UNIQUE INDEX PlayerAuthentication ON players(email) STORING(password_hash);
CREATE UNIQUE INDEX PlayerName ON players(player_name);
CREATE INDEX PlayerGame ON players(current_game);
Przesyłanie migracji schematu
Aby przesłać kompilację w celu przeprowadzenia migracji schematu, przejdź do katalogu schema i uruchom to polecenie gcloud:
cd $DEMO_HOME/schema gcloud builds submit --config=cloudbuild.yaml
Wynik polecenia
Creating temporary tarball archive of 8 file(s) totalling 11.2 KiB before compression.
Uploading tarball of [.] to [gs://(project)_cloudbuild/source/(snip).tgz]
Created [https://cloudbuild.googleapis.com/v1/projects/(project)/locations/global/builds/7defe982-(snip)].
Logs are available at [ https://console.cloud.google.com/cloud-build/builds/7defe982-(snip)?project=(snip) ].
gcloud builds submit only displays logs from Cloud Storage. To view logs from Cloud Logging, run:
gcloud beta builds submit
ID: 7defe982-(snip)
CREATE_TIME: (created time)
DURATION: 3M11S
SOURCE: gs://(project)_cloudbuild/source/(snip).tgz
IMAGES: -
STATUS: SUCCESS
W danych wyjściowych powyżej zobaczysz link do Createdprocesu kompilacji w chmurze. Jeśli klikniesz ten link, przejdziesz do kompilacji w konsoli Cloud, gdzie możesz monitorować postępy kompilacji i sprawdzać, co się dzieje.

Podsumowanie
W tym kroku użyto Cloud Build do przesłania początkowej migracji schematu, która zastosowała 5 różnych operacji DDL. Te operacje reprezentują momenty, w których dodano funkcje wymagające zmian w schemacie bazy danych.
W normalnym scenariuszu programowania zmiany schematu powinny być zgodne wstecznie z bieżącą aplikacją, aby uniknąć przerw w działaniu.
W przypadku zmian, które nie są wstecznie kompatybilne, warto wdrażać zmiany w aplikacji i schemacie etapami, aby uniknąć przerw w działaniu.
Następny
Po utworzeniu schematu następnym krokiem jest wdrożenie usług backendu.
5. Wdrażanie usług backendu
Przegląd
Usługi backendu w tym laboratorium to interfejsy API REST w języku Go, które reprezentują 4 różne usługi:
- Profil: umożliwia graczom rejestrację i uwierzytelnianie w naszej przykładowej „grze”.
- Dobieranie graczy: interakcja z danymi graczy w celu ułatwienia funkcji dobierania graczy, śledzenia informacji o utworzonych grach i aktualizowania statystyk graczy po zamknięciu gier.
- Przedmiot: umożliwia graczom zdobywanie przedmiotów i pieniędzy w grze.
- Punkt handlowy: umożliwia graczom kupowanie i sprzedawanie przedmiotów w punkcie handlowym.

Więcej informacji o tych usługach znajdziesz w samouczku Cloud Spanner – pierwsze kroki w zakresie tworzenia gier. W naszym przypadku chcemy, aby te usługi działały w klastrze GKE w trybie Autopilota.
Te usługi muszą mieć możliwość modyfikowania danych Spanner. W tym celu każda usługa ma utworzone konto usługi, które przyznaje jej rolę „databaseUser”.
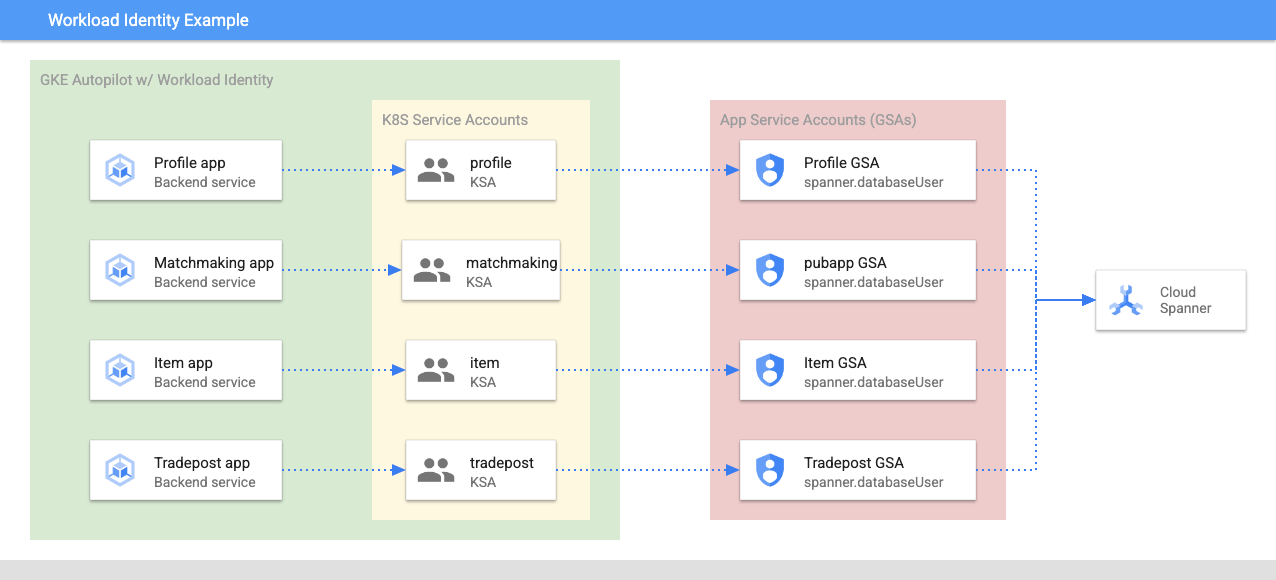
Workload Identity umożliwia kontu usługi Kubernetes przyjmowanie tożsamości konta usługi Google Cloud w usługach, wykonując te czynności w Terraform:
- Utwórz zasób konta usługi Google Cloud (
GSA) usługi. - Przypisz do tego konta usługi rolę databaseUser.
- Przypisz do tego konta usługi rolę workloadIdentityUser.
- Utwórz konto usługi Kubernetes (
KSA), które odwołuje się do konta usługi Google.
Schemat może wyglądać tak:
Terraform utworzył konta usługi i konta usługi Kubernetes. Konta usługi Kubernetes możesz sprawdzić za pomocą polecenia kubectl:
# kubectl get serviceaccounts
NAME SECRETS AGE
default 0 37m
item-app 0 35m
matchmaking-app 0 35m
profile-app 0 35m
tradepost-app 0 35m
Proces kompilacji wygląda tak:
- Terraform wygenerował plik
$DEMO_HOME/backend_services/cloudbuild.yaml, który wygląda mniej więcej tak:
serviceAccount: projects/${PROJECT_ID}/serviceAccounts/cloudbuild-cicd@${PROJECT_ID}.iam.gserviceaccount.com
steps:
#
# Building of images
#
- name: gcr.io/cloud-builders/docker
id: profile
args: ["build", ".", "-t", "${_PROFILE_IMAGE}"]
dir: profile
waitFor: ['-']
- name: gcr.io/cloud-builders/docker
id: matchmaking
args: ["build", ".", "-t", "${_MATCHMAKING_IMAGE}"]
dir: matchmaking
waitFor: ['-']
- name: gcr.io/cloud-builders/docker
id: item
args: ["build", ".", "-t", "${_ITEM_IMAGE}"]
dir: item
waitFor: ['-']
- name: gcr.io/cloud-builders/docker
id: tradepost
args: ["build", ".", "-t", "${_TRADEPOST_IMAGE}"]
dir: tradepost
waitFor: ['-']
#
# Deployment
#
- name: gcr.io/google.com/cloudsdktool/cloud-sdk
id: cloud-deploy-release
entrypoint: gcloud
args:
[
"deploy", "releases", "create", "${_REL_NAME}",
"--delivery-pipeline", "sample-game-services",
"--skaffold-file", "skaffold.yaml",
"--skaffold-version", "1.39",
"--images", "profile=${_PROFILE_IMAGE},matchmaking=${_MATCHMAKING_IMAGE},item=${_ITEM_IMAGE},tradepost=${_TRADEPOST_IMAGE}",
"--region", "us-central1"
]
artifacts:
images:
- ${_REGISTRY}/profile
- ${_REGISTRY}/matchmaking
- ${_REGISTRY}/item
- ${_REGISTRY}/tradepost
substitutions:
_PROFILE_IMAGE: ${_REGISTRY}/profile:${BUILD_ID}
_MATCHMAKING_IMAGE: ${_REGISTRY}/matchmaking:${BUILD_ID}
_ITEM_IMAGE: ${_REGISTRY}/item:${BUILD_ID}
_TRADEPOST_IMAGE: ${_REGISTRY}/tradepost:${BUILD_ID}
_REGISTRY: us-docker.pkg.dev/${PROJECT_ID}/spanner-game-images
_REL_NAME: rel-${BUILD_ID:0:8}
options:
dynamic_substitutions: true
machineType: E2_HIGHCPU_8
logging: CLOUD_LOGGING_ONLY
- Polecenie Cloud Build odczytuje ten plik i wykonuje wymienione w nim czynności. Najpierw tworzy obrazy usług. Następnie wykonuje polecenie
gcloud deploy create. Odczytuje plik$DEMO_HOME/backend_services/skaffold.yaml, który określa, gdzie znajduje się każdy plik wdrożenia:
apiVersion: skaffold/v2beta29
kind: Config
deploy:
kubectl:
manifests:
- spanner_config.yaml
- profile/deployment.yaml
- matchmaking/deployment.yaml
- item/deployment.yaml
- tradepost/deployment.yaml
- Cloud Deploy będzie postępować zgodnie z definicjami w pliku
deployment.yamlkażdej usługi. Plik wdrożenia usługi zawiera informacje o tworzeniu usługi, która w tym przypadku jest adresem IP klastra działającym na porcie 80.
Typ „ClusterIP” uniemożliwia uzyskanie zewnętrznego adresu IP przez pody usługi backendu, dzięki czemu tylko podmioty, które mogą łączyć się z wewnętrzną siecią GKE, mają dostęp do usług backendu. Te usługi nie powinny być bezpośrednio dostępne dla graczy, ponieważ mają dostęp do danych Spannera i je modyfikują.
apiVersion: v1
kind: Service
metadata:
name: profile
spec:
type: ClusterIP
selector:
app: profile
ports:
- port: 80
targetPort: 80
Oprócz utworzenia usługi Kubernetes Cloud Deploy tworzy też wdrożenie Kubernetes. Przyjrzyjmy się sekcji wdrożenia usługi profile:
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: profile
spec:
replicas: 2 # EDIT: Number of instances of deployment
selector:
matchLabels:
app: profile
template:
metadata:
labels:
app: profile
spec:
serviceAccountName: profile-app
containers:
- name: profile-service
image: profile
ports:
- containerPort: 80
envFrom:
- configMapRef:
name: spanner-config
env:
- name: SERVICE_HOST
value: "0.0.0.0"
- name: SERVICE_PORT
value: "80"
resources:
requests:
cpu: "1"
memory: "1Gi"
ephemeral-storage: "100Mi"
limits:
cpu: "1"
memory: "1Gi"
ephemeral-storage: "100Mi"
W górnej części znajdują się metadane usługi. Najważniejszym elementem jest określenie, ile replik zostanie utworzonych w ramach tego wdrożenia.
replicas: 2 # EDIT: Number of instances of deployment
Następnie sprawdzamy, które konto usługi powinno uruchamiać aplikację i którego obrazu powinno używać. Są one zgodne z kontem usługi Kubernetes utworzonym za pomocą Terraform i obrazem utworzonym na etapie Cloud Build.
spec:
serviceAccountName: profile-app
containers:
- name: profile-service
image: profile
Następnie podajemy informacje o sieci i zmiennych środowiskowych.
spanner_config to obiekt Kubernetes ConfigMap, który określa informacje o projekcie, instancji i bazie danych potrzebne aplikacji do połączenia się z usługą Spanner.
apiVersion: v1
kind: ConfigMap
metadata:
name: spanner-config
data:
SPANNER_PROJECT_ID: ${project_id}
SPANNER_INSTANCE_ID: ${instance_id}
SPANNER_DATABASE_ID: ${database_id}
ports:
- containerPort: 80
envFrom:
- configMapRef:
name: spanner-config
env:
- name: SERVICE_HOST
value: "0.0.0.0"
- name: SERVICE_PORT
value: "80"
Zmienne SERVICE_HOST i SERVICE_PORT to dodatkowe zmienne środowiskowe, których usługa potrzebuje, aby wiedzieć, gdzie się powiązać.
Ostatnia sekcja informuje GKE, ile zasobów ma być dostępne dla każdej repliki w tym wdrożeniu. Jest to również mechanizm, którego GKE Autopilot używa do skalowania klastra w razie potrzeby.
resources:
requests:
cpu: "1"
memory: "1Gi"
ephemeral-storage: "100Mi"
limits:
cpu: "1"
memory: "1Gi"
ephemeral-storage: "100Mi"
Mając te informacje, możesz wdrożyć usługi backendu.
Wdrażanie usług backendu
Jak już wspomnieliśmy, do wdrażania usług backendu używana jest usługa Cloud Build. Podobnie jak w przypadku migracji schematu, możesz przesłać prośbę o utworzenie kompilacji za pomocą wiersza poleceń gcloud:
cd $DEMO_HOME/backend_services gcloud builds submit --config=cloudbuild.yaml
Wynik polecenia
Creating temporary tarball archive of 66 file(s) totalling 864.6 KiB before compression.
Uploading tarball of [.] to [gs://(project)_cloudbuild/source/(snip).tgz]
Created [https://cloudbuild.googleapis.com/v1/projects/(project)/locations/global/builds/30207dd1-(snip)].
Logs are available at [ https://console.cloud.google.com/cloud-build/builds/30207dd1-(snip)?project=(snip) ].
gcloud builds submit only displays logs from Cloud Storage. To view logs from Cloud Logging, run:
gcloud beta builds submit
ID: 30207dd1-(snip)
CREATE_TIME: (created time)
DURATION: 3M17S
SOURCE: gs://(project)_cloudbuild/source/(snip).tgz
IMAGES: us-docker.pkg.dev/(project)/spanner-game-images/profile:30207dd1-(snip) (+3 more)
STATUS: SUCCESS
W przeciwieństwie do wyniku kroku schema migration, wynik tej kompilacji wskazuje, że utworzono niektóre obrazy. Będą one przechowywane w repozytorium Artifact Registry.
Wynik kroku gcloud build będzie zawierać link do Cloud Console. Spójrz na nie.
Gdy otrzymasz powiadomienie o sukcesie z Cloud Build, przejdź do Cloud Deploy, a następnie do potoku sample-game-services, aby monitorować postęp wdrażania.

Po wdrożeniu usług możesz sprawdzić stan zasobników, wpisując kubectl:
kubectl get pods
Wynik polecenia
NAME READY STATUS RESTARTS AGE
item-6b9d5f678c-4tbk2 1/1 Running 0 83m
matchmaking-5bcf799b76-lg8zf 1/1 Running 0 80m
profile-565bbf4c65-kphdl 1/1 Running 0 83m
profile-565bbf4c65-xw74j 1/1 Running 0 83m
tradepost-68b87ccd44-gw55r 1/1 Running 0 79m
Następnie sprawdź usługi, aby zobaczyć ClusterIP w działaniu:
kubectl get services
Wynik polecenia
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
item ClusterIP 10.172.XXX.XXX <none> 80/TCP 84m
kubernetes ClusterIP 10.172.XXX.XXX <none> 443/TCP 137m
matchmaking ClusterIP 10.172.XXX.XXX <none> 80/TCP 84m
profile ClusterIP 10.172.XXX.XXX <none> 80/TCP 84m
tradepost ClusterIP 10.172.XXX.XXX <none> 80/TCP 84m
Możesz też przejść do interfejsu GKE w konsoli Cloud, aby zobaczyć Workloads, Services i ConfigMaps.
Zadania
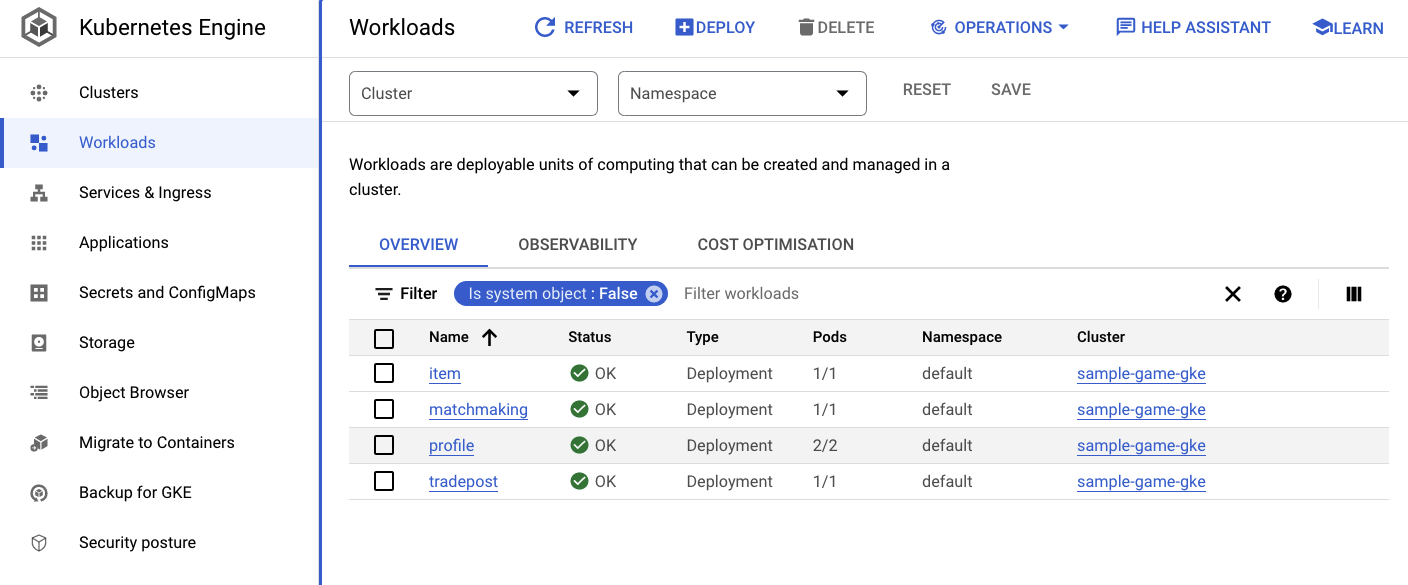
Usługi
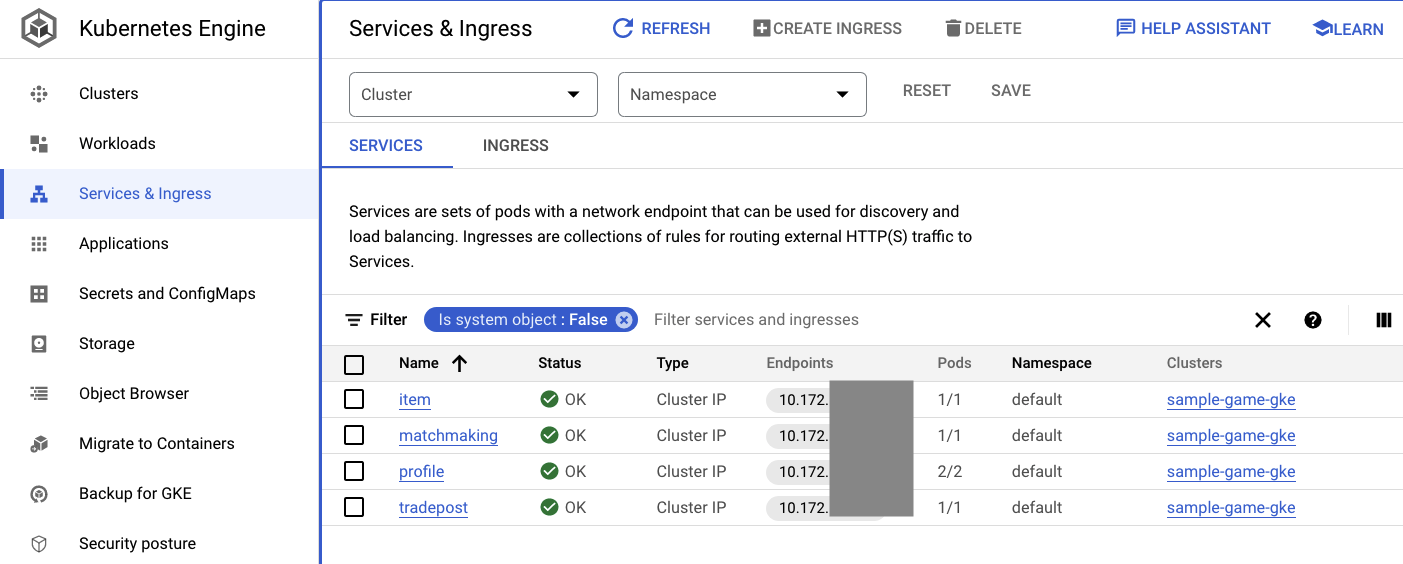
Pliki ConfigMap


Podsumowanie
W tym kroku wdrożono 4 usługi backendu w GKE Autopilot. Udało Ci się uruchomić krok Cloud Build i sprawdzić postęp w Cloud Deploy i Kubernetes w Cloud Console.
Dowiedzieliśmy się też, jak te usługi wykorzystują Workload Identity do podszywania się pod konto usługi, które ma odpowiednie uprawnienia do odczytywania i zapisywania danych w bazie danych Spanner.
Następne kroki
W następnej sekcji wdrożysz zbiory zadań.
6. Wdrażanie zbiorów zadań
Przegląd
Teraz, gdy usługi backendu działają w klastrze, możesz wdrożyć zbiory zadań.

Obciążenia są dostępne z zewnątrz i w tym ćwiczeniu jest po jednym obciążeniu dla każdej usługi backendu.
Są to skrypty generowania obciążenia oparte na Locust, które naśladują rzeczywiste wzorce dostępu oczekiwane przez te przykładowe usługi.
W procesie Cloud Build są używane te pliki:
$DEMO_HOME/workloads/cloudbuild.yaml(wygenerowany przez Terraform)$DEMO_HOME/workloads/skaffold.yamldeployment.yamlplik dla każdego rodzaju zbioru zadań,
Pliki deployment.yaml obciążenia różnią się nieco od plików wdrożenia usługi backendu.
Oto przykład z matchmaking-workload:
apiVersion: v1
kind: Service
metadata:
name: matchmaking-workload
spec:
type: LoadBalancer
selector:
app: matchmaking-workload
ports:
- port: 8089
targetPort: 8089
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: matchmaking-workload
spec:
replicas: 1 # EDIT: Number of instances of deployment
selector:
matchLabels:
app: matchmaking-workload
template:
metadata:
labels:
app: matchmaking-workload
spec:
serviceAccountName: default
containers:
- name: matchmaking-workload
image: matchmaking-workload
ports:
- containerPort: 8089
resources:
requests:
cpu: "500m"
memory: "512Mi"
ephemeral-storage: "100Mi"
limits:
cpu: "500m"
memory: "512Mi"
ephemeral-storage: "100Mi"
Górna część pliku definiuje usługę. W tym przypadku tworzony jest LoadBalancer, a zadanie jest uruchamiane na porcie 8089.
System równoważenia obciążenia udostępni zewnętrzny adres IP, który można wykorzystać do połączenia z zadaniem.
apiVersion: v1
kind: Service
metadata:
name: matchmaking-workload
spec:
type: LoadBalancer
selector:
app: matchmaking-workload
ports:
- port: 8089
targetPort: 8089
U góry sekcji wdrożenia znajdują się metadane zbioru zadań. W tym przypadku wdrażana jest tylko jedna replika:
replicas: 1
Specyfikacja kontenera jest jednak inna. Po pierwsze, używamy default konta usługi Kubernetes. To konto nie ma żadnych specjalnych uprawnień, ponieważ zadanie nie musi łączyć się z żadnymi zasobami Google Cloud z wyjątkiem usług backendu działających w klastrze GKE.
Kolejna różnica polega na tym, że te zbiory zadań nie wymagają zmiennych środowiskowych. W rezultacie specyfikacja wdrożenia jest krótsza.
spec:
serviceAccountName: default
containers:
- name: matchmaking-workload
image: matchmaking-workload
ports:
- containerPort: 8089
Ustawienia zasobów są podobne do ustawień usług backendu. Pamiętaj, że w ten sposób GKE Autopilot określa, ile zasobów jest potrzebnych do spełnienia żądań wszystkich podów działających w klastrze.
Wdróż zbiory zadań.
Wdrażanie zbiorów zadań
Podobnie jak wcześniej możesz przesłać żądanie kompilacji za pomocą wiersza poleceń gcloud:
cd $DEMO_HOME/workloads gcloud builds submit --config=cloudbuild.yaml
Wynik polecenia
Creating temporary tarball archive of 18 file(s) totalling 26.2 KiB before compression.
Some files were not included in the source upload.
Check the gcloud log [/tmp/tmp.4Z9EqdPo6d/logs/(snip).log] to see which files and the contents of the
default gcloudignore file used (see `$ gcloud topic gcloudignore` to learn
more).
Uploading tarball of [.] to [gs://(project)_cloudbuild/source/(snip).tgz]
Created [https://cloudbuild.googleapis.com/v1/projects/(project)/locations/global/builds/(snip)].
Logs are available at [ https://console.cloud.google.com/cloud-build/builds/0daf20f6-(snip)?project=(snip) ].
gcloud builds submit only displays logs from Cloud Storage. To view logs from Cloud Logging, run:
gcloud beta builds submit
ID: 0daf20f6-(snip)
CREATE_TIME: (created_time)
DURATION: 1M41S
SOURCE: gs://(project)_cloudbuild/source/(snip).tgz
IMAGES: us-docker.pkg.dev/(project)/spanner-game-images/profile-workload:0daf20f6-(snip) (+4 more)
STATUS: SUCCESS
Aby sprawdzić stan, przejrzyj dzienniki Cloud Build i potok Cloud Deploy w Cloud Console. W przypadku zbiorów zadań potok Cloud Deploy to sample-game-workloads:
Po zakończeniu wdrażania sprawdź stan za pomocą polecenia kubectl w Cloud Shell:
kubectl get pods
Wynik polecenia
NAME READY STATUS RESTARTS AGE
game-workload-7ff44cb657-pxxq2 1/1 Running 0 12m
item-6b9d5f678c-cr29w 1/1 Running 0 9m6s
item-generator-7bb4f57cf8-5r85b 1/1 Running 0 12m
matchmaking-5bcf799b76-lg8zf 1/1 Running 0 117m
matchmaking-workload-76df69dbdf-jds9z 1/1 Running 0 12m
profile-565bbf4c65-kphdl 1/1 Running 0 121m
profile-565bbf4c65-xw74j 1/1 Running 0 121m
profile-workload-76d6db675b-kzwng 1/1 Running 0 12m
tradepost-68b87ccd44-gw55r 1/1 Running 0 116m
tradepost-workload-56c55445b5-b5822 1/1 Running 0 12m
Następnie sprawdź usługi zadania, aby zobaczyć działanie LoadBalancer:
kubectl get services
Wynik polecenia
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
game-workload LoadBalancer *snip* 35.XX.XX.XX 8089:32483/TCP 12m
item ClusterIP *snip* <none> 80/TCP 121m
item-generator LoadBalancer *snip* 34.XX.XX.XX 8089:32581/TCP 12m
kubernetes ClusterIP *snip* <none> 443/TCP 174m
matchmaking ClusterIP *snip* <none> 80/TCP 121m
matchmaking-workload LoadBalancer *snip* 34.XX.XX.XX 8089:31735/TCP 12m
profile ClusterIP *snip* <none> 80/TCP 121m
profile-workload LoadBalancer *snip* 34.XX.XX.XX 8089:32532/TCP 12m
tradepost ClusterIP *snip* <none> 80/TCP 121m
tradepost-workload LoadBalancer *snip* 34.XX.XX.XX 8089:30002/TCP 12m
Podsumowanie
Zbiory zadań zostały wdrożone w klastrze GKE. Te obciążenia nie wymagają dodatkowych uprawnień IAM i są dostępne zewnętrznie na porcie 8089 za pomocą usługi LoadBalancer.
Następne kroki
Gdy usługi backendu i obciążenia są uruchomione, możesz zacząć „grać”.
7. Rozpocznij grę
Przegląd
Usługi backendu dla przykładowej „gry” są już uruchomione, a Ty masz też możliwość generowania „graczy” wchodzących w interakcje z tymi usługami za pomocą obciążeń.
Każdy zbiór zadań używa narzędzia Locust do symulowania rzeczywistego obciążenia interfejsów API naszych usług. W tym kroku uruchomisz kilka obciążeń, aby wygenerować obciążenie w klastrze GKE i w Spannerze, a także zapisać dane w Spannerze.
Oto opis każdego rodzaju zadań:
- Zadanie
item-generatorto szybkie zadanie, które generuje listę game_items, które gracze mogą zdobyć podczas „grania” w nią. profile-workloadsymuluje rejestrację i logowanie graczy.- Ikona
matchmaking-workloadsymuluje graczy czekających w kolejce na przypisanie do gier. -
game-workloadsymuluje zdobywanie przez graczy elementów w grze i pieniędzy podczas rozgrywki. -
tradepost-workloadsymuluje możliwość sprzedaży i kupowania przedmiotów na targu.
W tym laboratorium skupimy się na uruchamianiu item-generator i profile-workload.
Uruchom generator elementów
item-generator używa punktu końcowego usługi backendu item, aby dodać game_items do Spannera. Te elementy są wymagane do prawidłowego działania usług game-workload i tradepost-workload.
Pierwszym krokiem jest uzyskanie zewnętrznego adresu IP usługi item-generator. W Cloud Shell uruchom to polecenie:
# The external IP is the 4th column of the output
kubectl get services | grep item-generator | awk '{print $4}'
Wynik polecenia
{ITEMGENERATOR_EXTERNAL_IP}
Teraz otwórz nową kartę przeglądarki i przejdź do adresu http://{ITEMGENERATOR_EXTERNAL_IP}:8089. Powinna pojawić się strona podobna do tej:

Wartości users i spawn pozostaw domyślne, czyli 1. W polu host wpisz http://item. Kliknij opcje zaawansowane i wpisz 10s jako czas trwania.
Konfiguracja powinna wyglądać tak:

Kliknij „Start swarming” (Rozpocznij rojenie).
Statystyki zaczną się pojawiać w przypadku żądań wysyłanych do punktu końcowego POST /items. Po 10 sekundach ładowanie zostanie przerwane.
Kliknij Charts, aby zobaczyć wykresy skuteczności tych żądań.
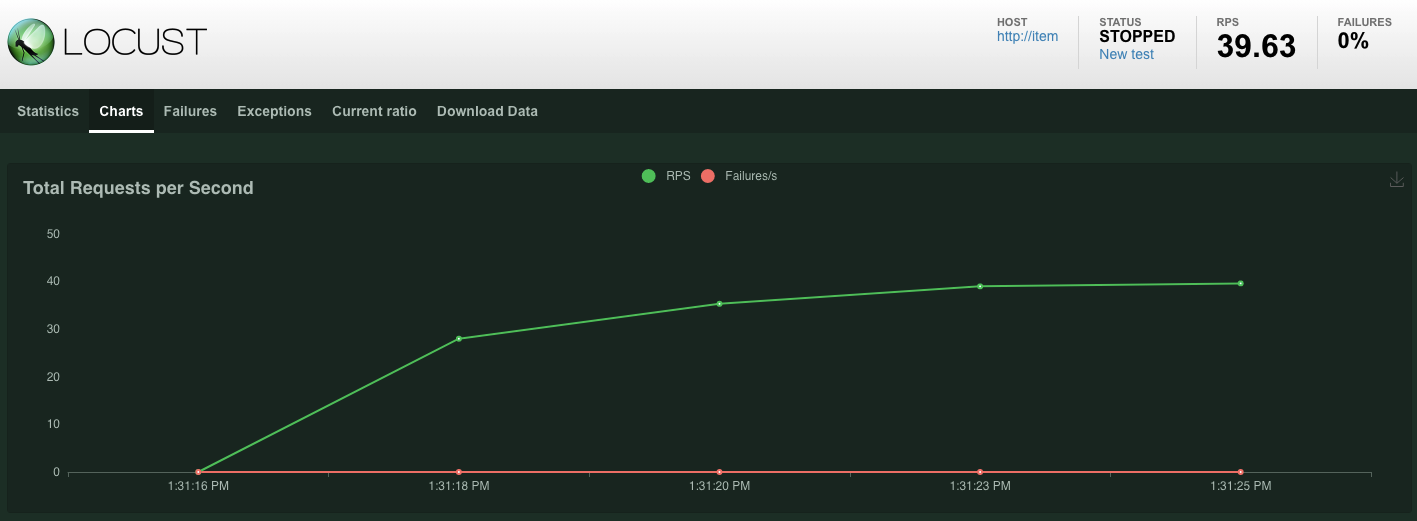
Teraz chcesz sprawdzić, czy dane zostały wprowadzone do bazy danych Spanner.
Aby to zrobić, kliknij menu z 3 kreskami i przejdź do „Spanner”. Na tej stronie przejdź do sekcji sample-instance i sample-database. Następnie kliknij „Query”.
Chcemy wybrać liczbę game_items:
SELECT COUNT(*) FROM game_items;
U dołu zobaczysz wynik.
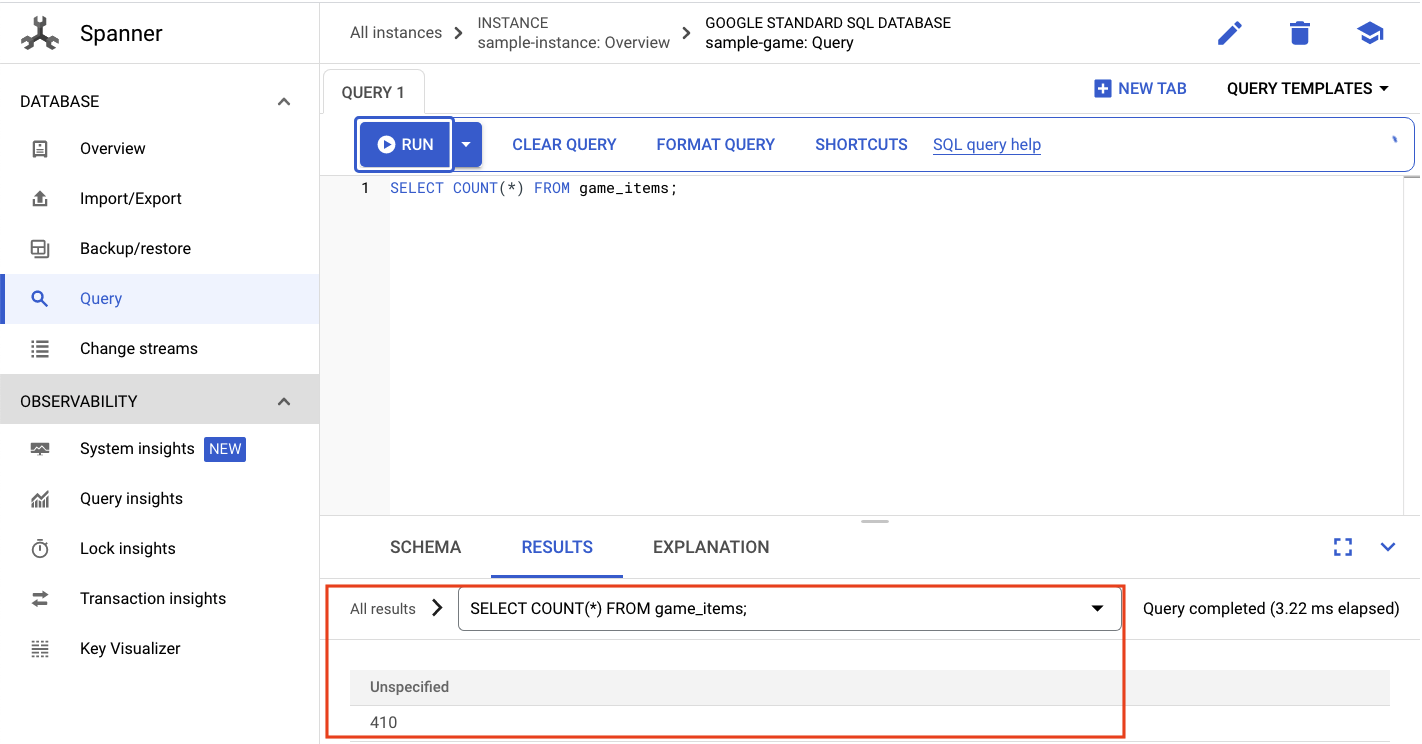
Nie potrzebujemy wielu game_items. Teraz jednak gracze mogą je zdobyć.
Uruchamianie profilu zadania
Po game_items kolejnym krokiem jest zarejestrowanie graczy, aby mogli grać w gry.
profile-workload będzie używać Locust do symulowania graczy tworzących konta, logujących się, pobierających informacje o profilu i wylogowujących się. Wszystkie te testy sprawdzają punkty końcowe usługi backendu profile w typowym obciążeniu podobnym do produkcyjnego.
Aby to zrobić, uzyskaj zewnętrzny adres IP profile-workload:
# The external IP is the 4th column of the output
kubectl get services | grep profile-workload | awk '{print $4}'
Wynik polecenia
{PROFILEWORKLOAD_EXTERNAL_IP}
Teraz otwórz nową kartę przeglądarki i przejdź do adresu http://{PROFILEWORKLOAD_EXTERNAL_IP}:8089. Powinna się wyświetlić strona Locust podobna do poprzedniej.
W tym przypadku użyjesz http://profile w przypadku hosta. W opcjach zaawansowanych nie określisz czasu działania. Określ też wartość users na 4, co spowoduje symulację 4 żądań użytkowników jednocześnie.
Test profile-workload powinien wyglądać tak:

Kliknij „Start swarming” (Rozpocznij rojenie).
Podobnie jak wcześniej zaczną się pojawiać statystyki dotyczące różnych profile punktów końcowych REST. Kliknij wykresy, aby zobaczyć, jak wszystko działa.

Podsumowanie
W tym kroku wygenerowano kilka game_items, a następnie wykonano zapytanie na tabeli game_items za pomocą interfejsu zapytań Spanner w konsoli Cloud.
Umożliwiłeś też graczom rejestrację w grze i sprawdziłeś, jak Locust tworzy obciążenia podobne do produkcyjnych w usługach backendu.
Następne kroki
Po uruchomieniu zbiorów zadań warto sprawdzić, jak działają klaster GKE i instancja Spanner.
8. Sprawdzanie wykorzystania GKE i Spannera
Po uruchomieniu usługi profilu możesz sprawdzić, jak działają klaster Autopilot GKE i Cloud Spanner.
Sprawdzanie klastra GKE
Otwórz klaster Kubernetes. Zwróć uwagę, że po wdrożeniu zbiorów zadań i usług w klastrze pojawiły się szczegóły dotyczące łącznej liczby procesorów wirtualnych i pamięci. Te informacje nie były dostępne, gdy w klastrze nie było żadnych zadań.

Teraz kliknij klaster sample-game-gke i przejdź na kartę dostrzegalności:

Przestrzeń nazw Kubernetes default powinna przekroczyć przestrzeń nazw kube-system pod względem wykorzystania procesora, ponieważ nasze zadania i usługi backendu działają w przestrzeni nazw default. Jeśli nie, sprawdź, czy profile workload nadal działa, i poczekaj kilka minut, aż wykresy się zaktualizują.
Aby sprawdzić, które zadania zużywają najwięcej zasobów, otwórz panel Workloads.
Zamiast przechodzić do poszczególnych zadań, przejdź bezpośrednio do karty Obserwacja na panelu. Powinno być widać, że wykorzystanie procesora profile i profile-workload wzrosło.

Teraz sprawdź Cloud Spanner.
Sprawdź instancję Cloud Spanner
Aby sprawdzić wydajność Cloud Spanner, otwórz Spanner i kliknij sample-instance instancję oraz sample-game bazę danych.
W menu po lewej stronie zobaczysz kartę Statystyki systemu:

Znajdziesz tu wiele wykresów, które pomogą Ci zrozumieć ogólną wydajność instancji Spanner, w tym wykresy CPU utilization, transaction latency and locking i query throughput.
Oprócz informacji o systemie możesz uzyskać bardziej szczegółowe informacje o obciążeniu zapytań, korzystając z innych linków w sekcji Dostrzegalność:
- Statystyki zapytań pomagają identyfikować N najpopularniejszych zapytań wykorzystujących zasoby w usłudze Spanner.
- Statystyki Transakcja i blokada pomagają identyfikować transakcje o dużych opóźnieniach.
- Key Visualizer pomaga wizualizować wzorce dostępu i wykrywać w danych obszary o dużej aktywności.
Podsumowanie
W tym kroku dowiedzieliśmy się, jak sprawdzić podstawowe wskaźniki wydajności Autopilota GKE i Spannera.
Na przykład podczas działania profilu zadania wykonaj zapytanie do tabeli players, aby uzyskać więcej informacji o przechowywanych w niej danych.
Następne kroki
Następnie czas na zwolnienie miejsca!
9. Czyszczę dane
Przed rozpoczęciem czyszczenia możesz zapoznać się z innymi zbiorami zadań, które nie zostały omówione. W szczególności matchmaking-workload, game-workload i tradepost-workload.
Gdy skończysz „grać”, możesz zwalniać miejsce. Na szczęście jest to dość proste.
Jeśli profile-workload jest nadal uruchomiony w przeglądarce, zatrzymaj go:

Zrób to samo w przypadku każdego przetestowanego zadania.
Następnie w Cloud Shell przejdź do folderu infrastruktury. destroy infrastrukturę za pomocą Terraform:
cd $DEMO_HOME/infrastructure
terraform destroy
# type 'yes' when asked
Wynik polecenia
Plan: 0 to add, 0 to change, 46 to destroy.
Do you really want to destroy all resources?
Terraform will destroy all your managed infrastructure, as shown above.
There is no undo. Only 'yes' will be accepted to confirm.
Enter a value: yes
*snip*
Destroy complete! Resources: 46 destroyed.
W konsoli Cloud otwórz kolejno Spanner, Kubernetes Cluster, Artifact Registry, Cloud Deploy i IAM, aby sprawdzić, czy wszystkie zasoby zostały usunięte.
10. Gratulacje!
Gratulacje, udało Ci się wdrożyć przykładowe aplikacje w języku Go w GKE Autopilot i połączyć je z Cloud Spanner przy użyciu Workload Identity.
Dodatkowo tę infrastrukturę można było łatwo skonfigurować i usunąć w powtarzalny sposób za pomocą Terraform.
Więcej informacji o usługach Google Cloud, z których korzystasz w tym samouczku, znajdziesz w tych artykułach:
Co dalej?
Teraz gdy masz już podstawowe informacje o tym, jak mogą współpracować GKE Autopilot i Cloud Spanner, możesz przejść do następnego etapu i zacząć tworzyć własną aplikację, która będzie korzystać z tych usług.