
1. Введение
Cloud Spanner — это полностью управляемый, горизонтально масштабируемый, глобально распределенный сервис реляционных баз данных, обеспечивающий ACID-транзакции и семантику SQL без ущерба для производительности и высокой доступности.
GKE Autopilot — это режим работы в GKE, в котором Google управляет конфигурацией кластера, включая узлы, масштабирование, безопасность и другие предварительно настроенные параметры, в соответствии с передовыми методами. Например, GKE Autopilot позволяет Workload Identity управлять разрешениями для служб.
Цель этой лабораторной работы — показать вам процесс подключения нескольких серверных служб, работающих на GKE Autopilot, к базе данных Cloud Spanner.

В этой лабораторной работе вы сначала настроите проект и запустите Cloud Shell. Затем вы развернете инфраструктуру с помощью Terraform.
После завершения этого этапа вы будете взаимодействовать с Cloud Build и Cloud Deploy для выполнения первоначальной миграции схемы базы данных Games, развертывания серверных служб, а затем развертывания рабочих нагрузок.
Сервисы в этом практическом занятии идентичны сервисам из практического занятия «Начало работы с разработкой игр в Cloud Spanner» . Прохождение этого практического занятия не является обязательным условием для запуска сервисов в GKE и подключения к Spanner. Но если вас интересуют более подробные сведения о специфике работы этих сервисов в Spanner, ознакомьтесь с ним.
После запуска рабочих нагрузок и серверных служб вы можете начать создавать нагрузку и наблюдать за тем, как службы взаимодействуют друг с другом.
Наконец, вам предстоит очистить ресурсы, созданные в этой лабораторной работе.
Что вы построите
В рамках этой лабораторной работы вы:
- Разверните инфраструктуру с помощью Terraform.
- Создайте схему базы данных, используя процесс миграции схемы в Cloud Build.
- Разверните четыре бэкэнд-сервиса на Golang, использующих Workload Identity для подключения к Cloud Spanner.
- Разверните четыре сервиса рабочей нагрузки, которые используются для моделирования нагрузки на серверные службы.
Что вы узнаете
- Как настроить конвейеры GKE Autopilot, Cloud Spanner и Cloud Deploy с помощью Terraform.
- Как Workload Identity позволяет службам в GKE имитировать учетные записи служб для доступа к разрешениям IAM для работы с Cloud Spanner.
- Как создать нагрузку, аналогичную производственной, на GKE и Cloud Spanner с помощью Locust.io
Что вам понадобится
2. Настройка и требования
Создать проект
Если у вас еще нет учетной записи Google (Gmail или Google Apps), вам необходимо ее создать . Войдите в консоль Google Cloud Platform ( console.cloud.google.com ) и создайте новый проект.
Если у вас уже есть проект, щелкните раскрывающееся меню выбора проекта в левом верхнем углу консоли:

и нажмите кнопку « НОВЫЙ ПРОЕКТ » в появившемся диалоговом окне, чтобы создать новый проект:

Если у вас ещё нет проекта, вы увидите диалоговое окно, подобное этому, для создания вашего первого проекта:

В появившемся диалоговом окне создания проекта вы можете ввести подробные сведения о вашем новом проекте:
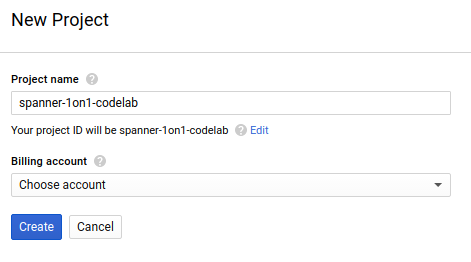
Запомните идентификатор проекта (Project ID), который является уникальным именем для всех проектов Google Cloud (указанное выше имя уже занято и вам не подойдёт, извините!). В дальнейшем в этом практическом занятии он будет обозначаться как PROJECT_ID .
Далее, если вы еще этого не сделали, вам необходимо включить оплату в консоли разработчика, чтобы использовать ресурсы Google Cloud и активировать API Cloud Spanner .

Выполнение этого практического задания не должно обойтись вам дороже нескольких долларов, но может стоить больше, если вы решите использовать больше ресурсов или оставите их запущенными (см. раздел «очистка» в конце этого документа). Информация о ценах на Google Cloud Spanner приведена здесь , а на GKE Autopilot — здесь .
Новые пользователи Google Cloud Platform могут воспользоваться бесплатной пробной версией стоимостью 300 долларов , что сделает этот практический семинар совершенно бесплатным.
Настройка Cloud Shell
Хотя Google Cloud и Spanner можно запускать удаленно с ноутбука, в этом практическом занятии мы будем использовать Google Cloud Shell — среду командной строки, работающую в облаке.
Эта виртуальная машина на базе Debian содержит все необходимые инструменты разработки. Она предоставляет постоянный домашний каталог размером 5 ГБ и работает в облаке Google, что значительно повышает производительность сети и аутентификацию. Это означает, что для выполнения этого практического задания вам понадобится только браузер (да, он работает и на Chromebook).
- Для активации Cloud Shell из консоли Cloud Console просто нажмите «Активировать Cloud Shell».
 (На подготовку и подключение к среде должно уйти всего несколько минут).
(На подготовку и подключение к среде должно уйти всего несколько минут).


После подключения к Cloud Shell вы увидите, что ваша аутентификация пройдена и проект уже настроен на ваш PROJECT_ID .
gcloud auth list
вывод команды
Credentialed accounts:
- <myaccount>@<mydomain>.com (active)
gcloud config list project
вывод команды
[core]
project = <PROJECT_ID>
Если по какой-либо причине проект не создан, просто выполните следующую команду:
gcloud config set project <PROJECT_ID>
Ищете свой PROJECT_ID ? Проверьте, какой ID вы использовали на этапах настройки, или найдите его на панели управления Cloud Console:

Cloud Shell также по умолчанию устанавливает некоторые переменные среды, которые могут быть полезны при выполнении будущих команд.
echo $GOOGLE_CLOUD_PROJECT
вывод команды
<PROJECT_ID>
Скачать код
В Cloud Shell вы можете скачать код для этой лабораторной работы:
git clone https://github.com/cloudspannerecosystem/spanner-gaming-sample.git
вывод команды
Cloning into 'spanner-gaming-sample'...
*snip*
Данный практический урок основан на версии v0.1.3 , поэтому проверьте соответствующий тег:
cd spanner-gaming-sample
git fetch --all --tags
# Check out v0.1.3 release
git checkout tags/v0.1.3 -b v0.1.3-branch
вывод команды
Switched to a new branch 'v0.1.3-branch'
Теперь установите текущий рабочий каталог в качестве переменной среды DEMO_HOME. Это упростит навигацию по мере выполнения различных частей практического задания.
export DEMO_HOME=$(pwd)
Краткое содержание
На этом шаге вы создали новый проект, активировали облачную оболочку и загрузили код для этой лабораторной работы.
Далее
Далее вы выполните развертывание инфраструктуры с помощью Terraform.
3. Обеспечение инфраструктуры
Обзор
После того, как ваш проект готов, пришло время запустить инфраструктуру. Это включает в себя сетевое подключение VPC, Cloud Spanner, GKE Autopilot, реестр артефактов для хранения образов, которые будут работать в GKE, конвейеры Cloud Deploy для бэкэнд-сервисов и рабочих нагрузок, а также, наконец, учетные записи служб и привилегии IAM для использования этих сервисов.
Это непросто. Но, к счастью, Terraform может упростить настройку. Terraform — это инструмент «инфраструктура как код», который позволяет нам указать все необходимое для этого проекта в серии файлов с расширением '.tf'. Это упрощает выделение инфраструктуры.
Знание Terraform не является обязательным условием для выполнения этого практического задания. Но если вы хотите увидеть, что происходит на следующих этапах, вы можете посмотреть, что создается в этих файлах, расположенных в каталоге infrastructure :
- vpc.tf
- backend_gke.tf
- spanner.tf
- artifact_registry.tf
- pipelines.tf
- iam.tf
Настройка Terraform
В Cloud Shell перейдите в каталог infrastructure и инициализируйте Terraform:
cd $DEMO_HOME/infrastructure
terraform init
вывод команды
Initializing the backend...
Initializing provider plugins...
*snip*
Terraform has been successfully initialized!
You may now begin working with Terraform. Try running "terraform plan" to see
any changes that are required for your infrastructure. All Terraform commands
should now work.
If you ever set or change modules or backend configuration for Terraform,
rerun this command to reinitialize your working directory. If you forget, other
commands will detect it and remind you to do so if necessary.
Далее настройте Terraform, скопировав файл terraform.tfvars.sample и изменив значение параметра project. Другие переменные также можно изменить, но для работы с вашей средой необходимо изменить только параметр project.
cp terraform.tfvars.sample terraform.tfvars
# edit gcp_project using the project environment variable
sed -i "s/PROJECT/$GOOGLE_CLOUD_PROJECT/" terraform.tfvars
Обеспечение инфраструктуры
Теперь пришло время подготовить инфраструктуру!
terraform apply
# review the list of things to be created
# type 'yes' when asked
вывод команды
Plan: 46 to add, 0 to change, 0 to destroy.
Do you want to perform these actions?
Terraform will perform the actions described above.
Only 'yes' will be accepted to approve.
Enter a value: yes
google_project_service.project["container.googleapis.com"]: Creating...
*snip*
Apply complete! Resources: 46 added, 0 changed, 0 destroyed.
Проверьте, что было создано.
Чтобы проверить, что было создано, вам нужно посмотреть товары в Cloud Console.
Облачный гальник
Для начала найдите Cloud Spanner, перейдя в меню-гамбургер и щелкнув по Spanner . Возможно, вам придется нажать «Посмотреть другие товары», чтобы найти его в списке.
Это переведет вас к списку экземпляров Spanner. Щелкните по нужному экземпляру, и вы увидите базы данных. Они должны выглядеть примерно так:

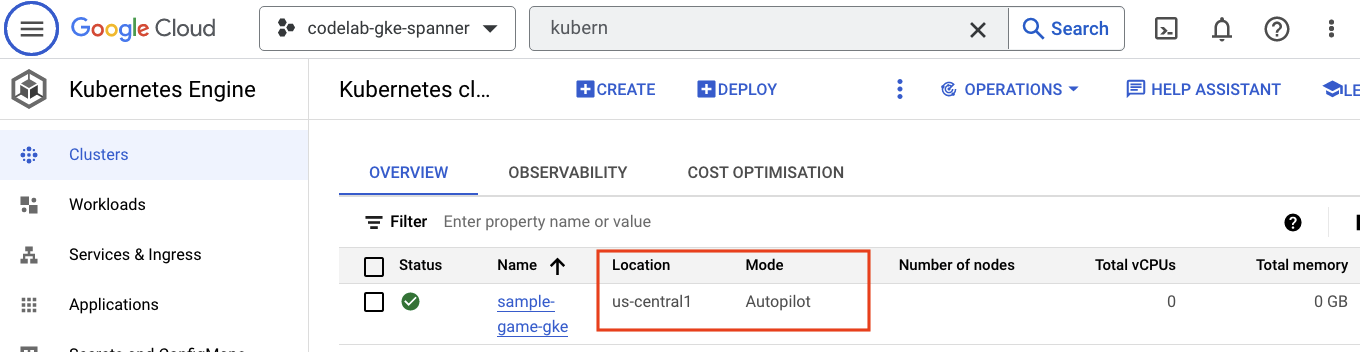
Автопилот GKE
Далее, чтобы ознакомиться с GKE, перейдите в меню-гамбургер и выберите Kubernetes Engine => Clusters . Здесь вы увидите кластер sample-games-gke , работающий в режиме Autopilot.
Реестр артефактов
Теперь вам нужно посмотреть, где будут храниться изображения. Для этого нажмите на значок меню (гамбургер) и найдите Artifact Registry=>Repositories . «Реестр артефактов» находится в разделе CI/CD этого меню.
Здесь вы увидите файл реестра Docker под названием spanner-game-images . Пока он будет пустым.

Развертывание в облаке
В Cloud Deploy были созданы конвейеры, позволяющие Cloud Build предоставлять шаги для сборки образов и их последующего развертывания в нашем кластере GKE.
Перейдите в меню-гамбургер и найдите Cloud Deploy , который также находится в разделе CI/CD этого меню.
Здесь вы увидите два конвейера: один для бэкэнд-сервисов, а другой для рабочих нагрузок. Оба развертывают образы в одном и том же кластере GKE, что позволяет разделить процессы развертывания.

Я
Наконец, проверьте страницу IAM в Cloud Console, чтобы убедиться в наличии созданных учетных записей служб. Перейдите в меню-гамбургер и найдите IAM and Admin=>Service accounts . Должно получиться примерно так:

Terraform создает в общей сложности шесть учетных записей служб:
- Учетная запись службы компьютера по умолчанию. В данном практическом задании она не используется.
- Учетная запись cloudbuild-cicd используется для этапов Cloud Build и Cloud Deploy.
- Четыре учетные записи приложений, используемые нашими внутренними сервисами для взаимодействия с Cloud Spanner.
Далее вам потребуется настроить kubectl для взаимодействия с кластером GKE.
Настройте kubectl
# Name of GKE cluster from terraform.tfvars file
export GKE_CLUSTER=sample-game-gke
# get GKE credentials
gcloud container clusters get-credentials $GKE_CLUSTER --region us-central1
# Check that no errors occur
kubectl get serviceaccounts
вывод команды
#export GKE_CLUSTER=sample-game-gke
# gcloud container clusters get-credentials $GKE_CLUSTER --region us-central1
Fetching cluster endpoint and auth data.
kubeconfig entry generated for sample-game-gke.
# kubectl get serviceaccounts
NAME SECRETS AGE
default 0 37m
item-app 0 35m
matchmaking-app 0 35m
profile-app 0 35m
tradepost-app 0 35m
Краткое содержание
Отлично! Вам удалось развернуть экземпляр Cloud Spanner и кластер GKE Autopilot в VPC для частной сети.
Кроме того, были созданы два конвейера Cloud Deploy для серверных служб и рабочих нагрузок, а также репозиторий Artifact Registry для хранения собранных образов.
И наконец, были созданы и настроены учетные записи служб для работы с Workload Identity, чтобы бэкэнд-службы могли использовать Cloud Spanner.
Также у вас настроен kubectl для взаимодействия с кластером GKE в Cloud Shell после развертывания серверных служб и рабочих нагрузок.
Далее
Прежде чем вы сможете использовать сервисы, необходимо определить схему базы данных. Вы настроите её позже.
4. Создайте схему базы данных.
Обзор
Прежде чем запускать серверные службы, необходимо убедиться, что схема базы данных настроена.
Если вы посмотрите файлы в каталоге $DEMO_HOME/schema/migrations из демонстрационного репозитория, вы увидите ряд файлов .sql , определяющих нашу схему. Это имитирует цикл разработки, в котором изменения схемы отслеживаются в самом репозитории и могут быть привязаны к определенным функциям приложений.
В данной тестовой среде инструментом для применения миграций схемы с помощью Cloud Build является Wrench .
Cloud Build
В файле $DEMO_HOME/schema/cloudbuild.yaml описывается, какие шаги будут предприняты:
serviceAccount: projects/${PROJECT_ID}/serviceAccounts/cloudbuild-cicd@${PROJECT_ID}.iam.gserviceaccount.com
steps:
- name: gcr.io/cloud-builders/curl
id: fetch-wrench
args: ['-Lo', '/workspace/wrench.tar.gz', 'https://github.com/cloudspannerecosystem/wrench/releases/download/v1.4.1/wrench-1.4.1-linux-amd64.tar.gz' ]
- name: gcr.io/cloud-builders/gcloud
id: migrate-spanner-schema
entrypoint: sh
args:
- '-xe'
- '-c'
- |
tar -xzvf wrench.tar.gz
chmod +x /workspace/wrench
# Assumes only a single spanner instance and database. Fine for this demo in a dedicated project
export SPANNER_PROJECT_ID=${PROJECT_ID}
export SPANNER_INSTANCE_ID=$(gcloud spanner instances list | tail -n1 | awk '{print $1}')
export SPANNER_DATABASE_ID=$(gcloud spanner databases list --instance=$$SPANNER_INSTANCE_ID | tail -n1 | awk '{print $1}')
if [ -d ./migrations ]; then
/workspace/wrench migrate up --directory .
else
echo "[Error] Missing migrations directory"
fi
timeout: 600s
В основном, есть два этапа:
- Загрузите гаечный ключ в рабочую область Cloud Build.
- выполнить миграцию гаечного ключа
Для подключения инструмента Wrench к точке записи необходимы переменные среды проекта, экземпляра и базы данных Spanner.
Cloud Build может вносить эти изменения, поскольку работает от имени сервисной учетной записи cloudbuild-cicd@${PROJECT_ID}.iam.gserviceaccount.com :
serviceAccount: projects/${PROJECT_ID}/serviceAccounts/cloudbuild-cicd@${PROJECT_ID}.iam.gserviceaccount.com
И этому сервисному аккаунту добавлена роль spanner.databaseUser , созданная Terraform, которая позволяет сервисному аккаунту выполнять команду updateDDL.
Миграция схем
Миграция выполняется в пять этапов в зависимости от файлов в каталоге $DEMO_HOME/schema/migrations . Вот пример файла 000001.sql , который создает таблицу players и индексы:
CREATE TABLE players (
playerUUID STRING(36) NOT NULL,
player_name STRING(64) NOT NULL,
email STRING(MAX) NOT NULL,
password_hash BYTES(60) NOT NULL,
created TIMESTAMP,
updated TIMESTAMP,
stats JSON,
account_balance NUMERIC NOT NULL DEFAULT (0.00),
is_logged_in BOOL,
last_login TIMESTAMP,
valid_email BOOL,
current_game STRING(36)
) PRIMARY KEY (playerUUID);
CREATE UNIQUE INDEX PlayerAuthentication ON players(email) STORING(password_hash);
CREATE UNIQUE INDEX PlayerName ON players(player_name);
CREATE INDEX PlayerGame ON players(current_game);
Отправьте миграцию схемы.
Чтобы отправить сборку на миграцию схемы, перейдите в каталог schema и выполните следующую команду gcloud:
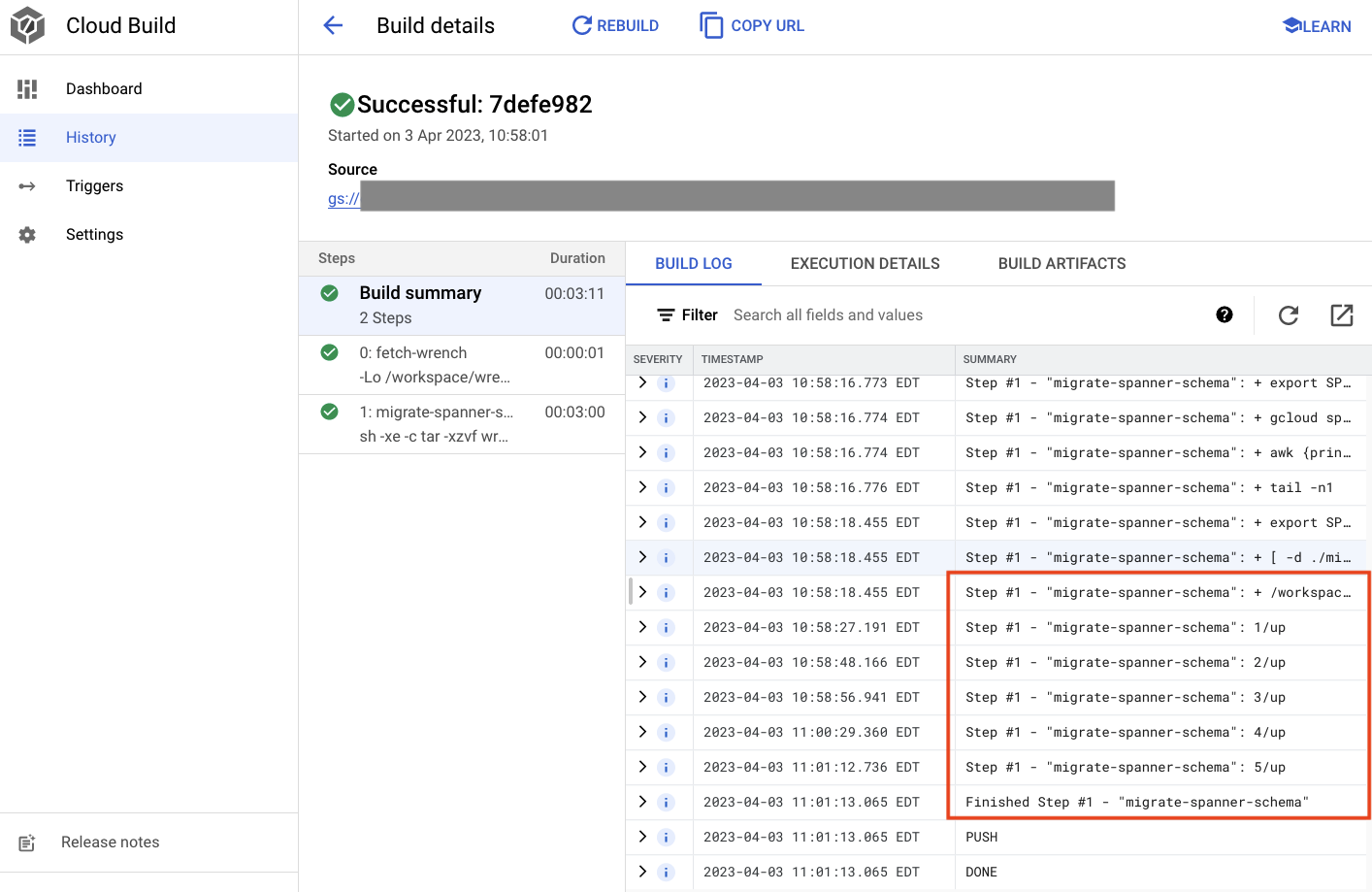
cd $DEMO_HOME/schema gcloud builds submit --config=cloudbuild.yaml
вывод команды
Creating temporary tarball archive of 8 file(s) totalling 11.2 KiB before compression.
Uploading tarball of [.] to [gs://(project)_cloudbuild/source/(snip).tgz]
Created [https://cloudbuild.googleapis.com/v1/projects/(project)/locations/global/builds/7defe982-(snip)].
Logs are available at [ https://console.cloud.google.com/cloud-build/builds/7defe982-(snip)?project=(snip) ].
gcloud builds submit only displays logs from Cloud Storage. To view logs from Cloud Logging, run:
gcloud beta builds submit
ID: 7defe982-(snip)
CREATE_TIME: (created time)
DURATION: 3M11S
SOURCE: gs://(project)_cloudbuild/source/(snip).tgz
IMAGES: -
STATUS: SUCCESS
В приведенном выше выводе вы заметите ссылку на процесс Created облачной сборки. Если вы нажмете на нее, вы перейдете к сборке в Cloud Console, где сможете отслеживать ход сборки и видеть, что происходит.
Краткое содержание
На этом этапе вы использовали Cloud Build для отправки первоначальной миграции схемы, которая включала 5 различных операций DDL. Эти операции отражают добавление функций, требующих изменения схемы базы данных.
В обычных условиях разработки желательно обеспечить обратную совместимость изменений схемы с текущим приложением, чтобы избежать сбоев.
Для изменений, несовместимых с предыдущими версиями, рекомендуется развертывать изменения в приложении и схеме поэтапно, чтобы избежать сбоев.
Далее
После создания схемы следующим шагом будет развертывание серверных служб!
5. Разверните серверные службы.
Обзор
В качестве серверной части для этой практической работы используются REST API на языке Golang, представляющие четыре различных сервиса:
- Профиль: предоставить игрокам возможность зарегистрироваться и пройти аутентификацию в нашей демонстрационной «игре».
- Подбор игроков: взаимодействие с данными игроков для помощи в функции подбора игроков, отслеживание информации о созданных играх и обновление статистики игроков после завершения игр.
- Цель: дать игрокам возможность приобретать игровые предметы и деньги в процессе игры.
- Торговая площадка: позволяет игрокам покупать и продавать предметы на торговой площадке.

Более подробную информацию об этих сервисах можно найти в практическом руководстве Cloud Spanner «Начало работы с разработкой игр» . В наших целях нам необходимо, чтобы эти сервисы работали в нашем кластере GKE Autopilot.
Эти службы должны иметь возможность изменять данные Spanner. Для этого для каждой службы создается учетная запись, которая предоставляет ей роль «databaseUser».
Функция Workload Identity позволяет учетной записи службы Kubernetes имитировать учетную запись службы Google Cloud, выполнив следующие шаги в Terraform:
- Создайте ресурс учетной записи облачной службы Google (
GSA) для данной службы. - Назначьте этой учетной записи службы роль databaseUser .
- Назначьте этой учетной записи службы роль workloadIdentityUser .
- Создайте учетную запись службы Kubernetes (
KSA), которая ссылается на GSA.
Примерная схема будет выглядеть так:

Terraform создал для вас учетные записи служб и учетные записи служб Kubernetes. Проверить учетные записи служб Kubernetes можно с помощью kubectl :
# kubectl get serviceaccounts
NAME SECRETS AGE
default 0 37m
item-app 0 35m
matchmaking-app 0 35m
profile-app 0 35m
tradepost-app 0 35m
Процесс сборки выглядит следующим образом:
- Terraform сгенерировал файл
$DEMO_HOME/backend_services/cloudbuild.yaml, который выглядит примерно так:
serviceAccount: projects/${PROJECT_ID}/serviceAccounts/cloudbuild-cicd@${PROJECT_ID}.iam.gserviceaccount.com
steps:
#
# Building of images
#
- name: gcr.io/cloud-builders/docker
id: profile
args: ["build", ".", "-t", "${_PROFILE_IMAGE}"]
dir: profile
waitFor: ['-']
- name: gcr.io/cloud-builders/docker
id: matchmaking
args: ["build", ".", "-t", "${_MATCHMAKING_IMAGE}"]
dir: matchmaking
waitFor: ['-']
- name: gcr.io/cloud-builders/docker
id: item
args: ["build", ".", "-t", "${_ITEM_IMAGE}"]
dir: item
waitFor: ['-']
- name: gcr.io/cloud-builders/docker
id: tradepost
args: ["build", ".", "-t", "${_TRADEPOST_IMAGE}"]
dir: tradepost
waitFor: ['-']
#
# Deployment
#
- name: gcr.io/google.com/cloudsdktool/cloud-sdk
id: cloud-deploy-release
entrypoint: gcloud
args:
[
"deploy", "releases", "create", "${_REL_NAME}",
"--delivery-pipeline", "sample-game-services",
"--skaffold-file", "skaffold.yaml",
"--skaffold-version", "1.39",
"--images", "profile=${_PROFILE_IMAGE},matchmaking=${_MATCHMAKING_IMAGE},item=${_ITEM_IMAGE},tradepost=${_TRADEPOST_IMAGE}",
"--region", "us-central1"
]
artifacts:
images:
- ${_REGISTRY}/profile
- ${_REGISTRY}/matchmaking
- ${_REGISTRY}/item
- ${_REGISTRY}/tradepost
substitutions:
_PROFILE_IMAGE: ${_REGISTRY}/profile:${BUILD_ID}
_MATCHMAKING_IMAGE: ${_REGISTRY}/matchmaking:${BUILD_ID}
_ITEM_IMAGE: ${_REGISTRY}/item:${BUILD_ID}
_TRADEPOST_IMAGE: ${_REGISTRY}/tradepost:${BUILD_ID}
_REGISTRY: us-docker.pkg.dev/${PROJECT_ID}/spanner-game-images
_REL_NAME: rel-${BUILD_ID:0:8}
options:
dynamic_substitutions: true
machineType: E2_HIGHCPU_8
logging: CLOUD_LOGGING_ONLY
- Команда Cloud Build считывает этот файл и выполняет указанные шаги. Сначала она создает образы сервисов. Затем она выполняет команду
gcloud deploy create. Эта команда считывает файл$DEMO_HOME/backend_services/skaffold.yaml, который определяет местоположение каждого файла развертывания:
apiVersion: skaffold/v2beta29
kind: Config
deploy:
kubectl:
manifests:
- spanner_config.yaml
- profile/deployment.yaml
- matchmaking/deployment.yaml
- item/deployment.yaml
- tradepost/deployment.yaml
- Cloud Deploy будет следовать определениям, содержащимся в файле
deployment.yamlкаждой службы. Файл развертывания службы содержит информацию для создания службы, которая в данном случае представляет собой clusterIP, работающий на порту 80.
Тип " ClusterIP" предотвращает присвоение подам бэкэнд-сервисов внешнего IP-адреса, поэтому доступ к бэкэнд-сервисам имеют только сущности, способные подключаться к внутренней сети GKE. Эти сервисы не должны быть напрямую доступны игрокам, поскольку они получают доступ к данным Spanner и изменяют их.
apiVersion: v1
kind: Service
metadata:
name: profile
spec:
type: ClusterIP
selector:
app: profile
ports:
- port: 80
targetPort: 80
Помимо создания сервиса Kubernetes, Cloud Deploy также создает развертывание Kubernetes. Давайте рассмотрим раздел развертывания сервиса profile :
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: profile
spec:
replicas: 2 # EDIT: Number of instances of deployment
selector:
matchLabels:
app: profile
template:
metadata:
labels:
app: profile
spec:
serviceAccountName: profile-app
containers:
- name: profile-service
image: profile
ports:
- containerPort: 80
envFrom:
- configMapRef:
name: spanner-config
env:
- name: SERVICE_HOST
value: "0.0.0.0"
- name: SERVICE_PORT
value: "80"
resources:
requests:
cpu: "1"
memory: "1Gi"
ephemeral-storage: "100Mi"
limits:
cpu: "1"
memory: "1Gi"
ephemeral-storage: "100Mi"
В верхней части представлены некоторые метаданные о сервисе. Наиболее важная часть — это определение количества реплик, которые будут созданы в результате этого развертывания.
replicas: 2 # EDIT: Number of instances of deployment
Далее мы видим, какая учетная запись службы должна запускать приложение и какой образ она должна использовать. Эти параметры совпадают с учетной записью службы Kubernetes, созданной с помощью Terraform, и образом, созданным на этапе Cloud Build.
spec:
serviceAccountName: profile-app
containers:
- name: profile-service
image: profile
После этого мы указываем некоторую информацию о сетевых и переменных среды.
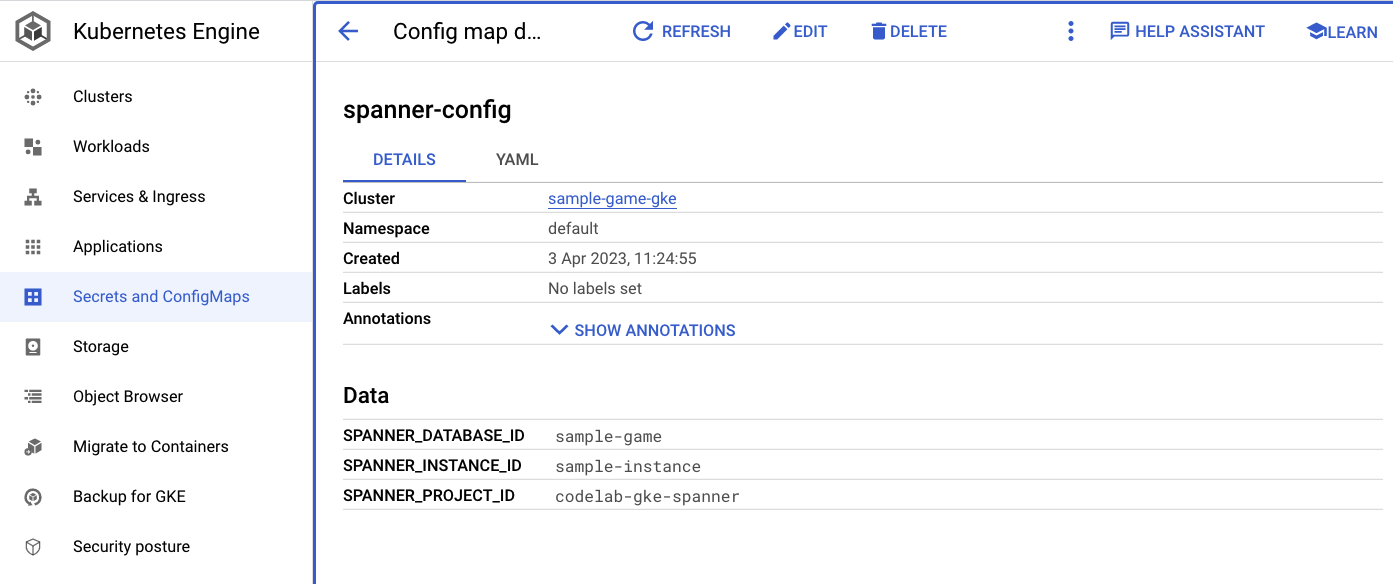
Параметр spanner_config представляет собой Kubernetes ConfigMap, который определяет информацию о проекте, экземпляре и базе данных, необходимую приложению для подключения к Spanner.
apiVersion: v1
kind: ConfigMap
metadata:
name: spanner-config
data:
SPANNER_PROJECT_ID: ${project_id}
SPANNER_INSTANCE_ID: ${instance_id}
SPANNER_DATABASE_ID: ${database_id}
ports:
- containerPort: 80
envFrom:
- configMapRef:
name: spanner-config
env:
- name: SERVICE_HOST
value: "0.0.0.0"
- name: SERVICE_PORT
value: "80"
SERVICE_HOST и SERVICE_PORT — это дополнительные переменные среды, необходимые сервису для определения места привязки.
В заключительном разделе указывается, сколько ресурсов следует выделить для каждой реплики в этом развертывании. Эти данные также используются GKE Autopilot для масштабирования кластера по мере необходимости.
resources:
requests:
cpu: "1"
memory: "1Gi"
ephemeral-storage: "100Mi"
limits:
cpu: "1"
memory: "1Gi"
ephemeral-storage: "100Mi"
Имея эту информацию, пришло время развернуть серверные службы.
Разверните серверные службы
Как уже упоминалось, развертывание серверных служб осуществляется с помощью Cloud Build. Как и в случае с миграцией схем, запрос на сборку можно отправить с помощью командной строки gcloud:
cd $DEMO_HOME/backend_services gcloud builds submit --config=cloudbuild.yaml
вывод команды
Creating temporary tarball archive of 66 file(s) totalling 864.6 KiB before compression.
Uploading tarball of [.] to [gs://(project)_cloudbuild/source/(snip).tgz]
Created [https://cloudbuild.googleapis.com/v1/projects/(project)/locations/global/builds/30207dd1-(snip)].
Logs are available at [ https://console.cloud.google.com/cloud-build/builds/30207dd1-(snip)?project=(snip) ].
gcloud builds submit only displays logs from Cloud Storage. To view logs from Cloud Logging, run:
gcloud beta builds submit
ID: 30207dd1-(snip)
CREATE_TIME: (created time)
DURATION: 3M17S
SOURCE: gs://(project)_cloudbuild/source/(snip).tgz
IMAGES: us-docker.pkg.dev/(project)/spanner-game-images/profile:30207dd1-(snip) (+3 more)
STATUS: SUCCESS
В отличие от результатов этапа schema migration , результаты этой сборки указывают на то, что были созданы некоторые образы. Они будут сохранены в вашем репозитории реестра артефактов.
В результате выполнения шага gcloud build будет ссылка на Cloud Console. Ознакомьтесь с ней.
После получения уведомления об успешном завершении развертывания от Cloud Build перейдите в Cloud Deploy, а затем в конвейер sample-game-services чтобы отслеживать ход развертывания.

После развертывания сервисов вы можете проверить статус подов с помощью kubectl :
kubectl get pods
вывод команды
NAME READY STATUS RESTARTS AGE
item-6b9d5f678c-4tbk2 1/1 Running 0 83m
matchmaking-5bcf799b76-lg8zf 1/1 Running 0 80m
profile-565bbf4c65-kphdl 1/1 Running 0 83m
profile-565bbf4c65-xw74j 1/1 Running 0 83m
tradepost-68b87ccd44-gw55r 1/1 Running 0 79m
Затем проверьте работу сервисов, чтобы увидеть ClusterIP в действии:
kubectl get services
вывод команды
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
item ClusterIP 10.172.XXX.XXX <none> 80/TCP 84m
kubernetes ClusterIP 10.172.XXX.XXX <none> 443/TCP 137m
matchmaking ClusterIP 10.172.XXX.XXX <none> 80/TCP 84m
profile ClusterIP 10.172.XXX.XXX <none> 80/TCP 84m
tradepost ClusterIP 10.172.XXX.XXX <none> 80/TCP 84m
Также вы можете перейти в пользовательский интерфейс GKE в Cloud Console, чтобы просмотреть Workloads , Services и ConfigMaps .
Рабочая нагрузка
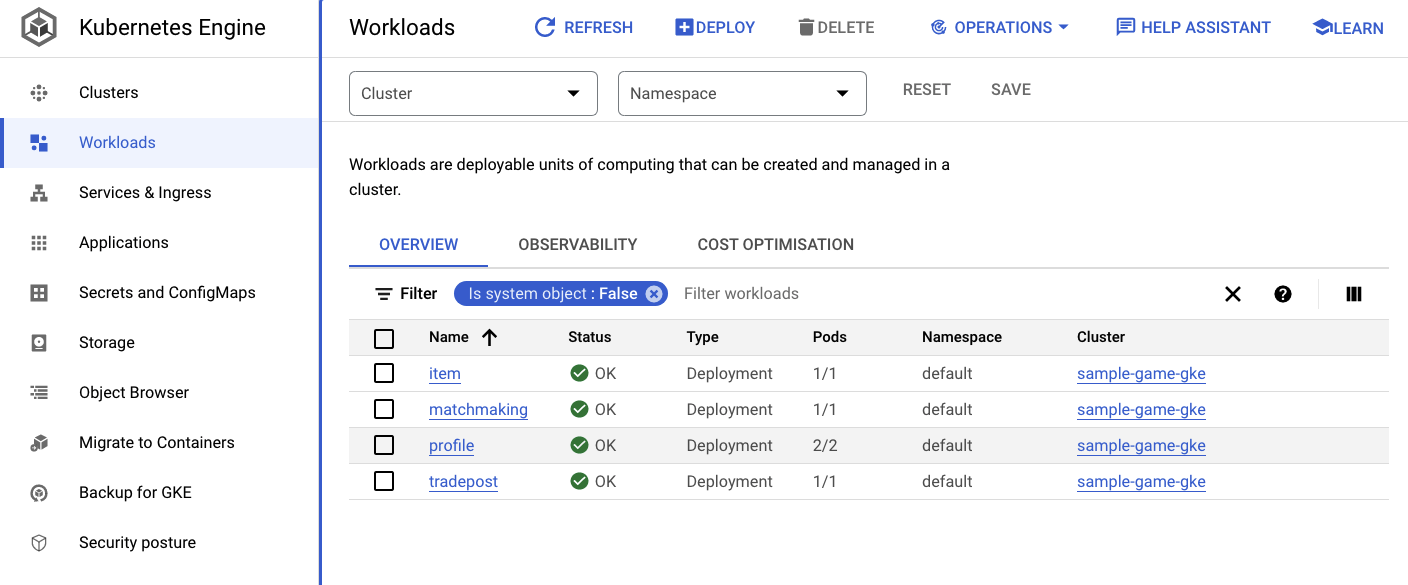
Услуги

Карты конфигурации

Краткое содержание
На этом этапе вы развернули четыре серверных сервиса в GKE Autopilot. Вы смогли запустить этап Cloud Build и проверить ход выполнения в Cloud Deploy, а также в Kubernetes в Cloud Console.
Вы также узнали, как эти службы используют Workload Identity для имитации учетной записи службы, имеющей необходимые права на чтение и запись данных в базу данных Spanner.
Следующие шаги
В следующем разделе вы развернете рабочие нагрузки.
6. Разверните рабочие нагрузки
Обзор
Теперь, когда серверные службы запущены в кластере, вы приступите к развертыванию рабочих нагрузок.

Доступ к рабочим нагрузкам осуществляется извне, и для целей данного практического занятия имеется отдельный экземпляр для каждой серверной части.
Эти рабочие нагрузки представляют собой скрипты генерации нагрузки на основе Locust , имитирующие реальные шаблоны доступа, ожидаемые от этих тестовых сервисов.
Для процесса Cloud Build имеются файлы:
-
$DEMO_HOME/workloads/cloudbuild.yaml(сгенерировано Terraform) -
$DEMO_HOME/workloads/skaffold.yaml - файл
deployment.yamlдля каждой рабочей нагрузки
Файлы deployment.yaml рабочей нагрузки немного отличаются от файлов развертывания серверной службы.
Вот пример из matchmaking-workload :
apiVersion: v1
kind: Service
metadata:
name: matchmaking-workload
spec:
type: LoadBalancer
selector:
app: matchmaking-workload
ports:
- port: 8089
targetPort: 8089
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: matchmaking-workload
spec:
replicas: 1 # EDIT: Number of instances of deployment
selector:
matchLabels:
app: matchmaking-workload
template:
metadata:
labels:
app: matchmaking-workload
spec:
serviceAccountName: default
containers:
- name: matchmaking-workload
image: matchmaking-workload
ports:
- containerPort: 8089
resources:
requests:
cpu: "500m"
memory: "512Mi"
ephemeral-storage: "100Mi"
limits:
cpu: "500m"
memory: "512Mi"
ephemeral-storage: "100Mi"
В верхней части файла определяется служба. В данном случае создается LoadBalancer , и рабочая нагрузка выполняется на порту 8089 .
Балансировщик нагрузки предоставит внешний IP-адрес, который можно использовать для подключения к рабочей нагрузке.
apiVersion: v1
kind: Service
metadata:
name: matchmaking-workload
spec:
type: LoadBalancer
selector:
app: matchmaking-workload
ports:
- port: 8089
targetPort: 8089
В верхней части раздела развертывания находятся метаданные о рабочей нагрузке. В данном случае развертывается только одна реплика:
replicas: 1
Однако спецификация контейнера отличается. Во-первых, мы используем учетную запись службы Kubernetes default . Эта учетная запись не имеет никаких особых привилегий, поскольку рабочей нагрузке не нужно подключаться к каким-либо ресурсам Google Cloud, кроме бэкэнд-сервисов, работающих в кластере GKE.
Другое отличие заключается в том, что для этих рабочих нагрузок не требуются никакие переменные среды. В результате получается более короткое описание развертывания.
spec:
serviceAccountName: default
containers:
- name: matchmaking-workload
image: matchmaking-workload
ports:
- containerPort: 8089
Настройки ресурсов аналогичны настройкам бэкэнд-сервисов. Помните, что именно так GKE Autopilot определяет, сколько ресурсов необходимо для удовлетворения запросов всех подов, работающих в кластере.
Смело развертывайте рабочие нагрузки!
Разверните рабочие нагрузки
Как и прежде, вы можете отправить запрос на сборку, используя командную строку gcloud:
cd $DEMO_HOME/workloads gcloud builds submit --config=cloudbuild.yaml
вывод команды
Creating temporary tarball archive of 18 file(s) totalling 26.2 KiB before compression.
Some files were not included in the source upload.
Check the gcloud log [/tmp/tmp.4Z9EqdPo6d/logs/(snip).log] to see which files and the contents of the
default gcloudignore file used (see `$ gcloud topic gcloudignore` to learn
more).
Uploading tarball of [.] to [gs://(project)_cloudbuild/source/(snip).tgz]
Created [https://cloudbuild.googleapis.com/v1/projects/(project)/locations/global/builds/(snip)].
Logs are available at [ https://console.cloud.google.com/cloud-build/builds/0daf20f6-(snip)?project=(snip) ].
gcloud builds submit only displays logs from Cloud Storage. To view logs from Cloud Logging, run:
gcloud beta builds submit
ID: 0daf20f6-(snip)
CREATE_TIME: (created_time)
DURATION: 1M41S
SOURCE: gs://(project)_cloudbuild/source/(snip).tgz
IMAGES: us-docker.pkg.dev/(project)/spanner-game-images/profile-workload:0daf20f6-(snip) (+4 more)
STATUS: SUCCESS
Обязательно проверьте журналы Cloud Build и конвейер Cloud Deploy в Cloud Console, чтобы узнать статус. Для рабочих нагрузок конвейер Cloud Deploy выглядит следующим образом: sample-game-workloads :
После завершения развертывания проверьте его статус с помощью kubectl в Cloud Shell:
kubectl get pods
вывод команды
NAME READY STATUS RESTARTS AGE
game-workload-7ff44cb657-pxxq2 1/1 Running 0 12m
item-6b9d5f678c-cr29w 1/1 Running 0 9m6s
item-generator-7bb4f57cf8-5r85b 1/1 Running 0 12m
matchmaking-5bcf799b76-lg8zf 1/1 Running 0 117m
matchmaking-workload-76df69dbdf-jds9z 1/1 Running 0 12m
profile-565bbf4c65-kphdl 1/1 Running 0 121m
profile-565bbf4c65-xw74j 1/1 Running 0 121m
profile-workload-76d6db675b-kzwng 1/1 Running 0 12m
tradepost-68b87ccd44-gw55r 1/1 Running 0 116m
tradepost-workload-56c55445b5-b5822 1/1 Running 0 12m
Затем проверьте службы рабочей нагрузки, чтобы увидеть балансировщик LoadBalancer в действии:
kubectl get services
вывод команды
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
game-workload LoadBalancer *snip* 35.XX.XX.XX 8089:32483/TCP 12m
item ClusterIP *snip* <none> 80/TCP 121m
item-generator LoadBalancer *snip* 34.XX.XX.XX 8089:32581/TCP 12m
kubernetes ClusterIP *snip* <none> 443/TCP 174m
matchmaking ClusterIP *snip* <none> 80/TCP 121m
matchmaking-workload LoadBalancer *snip* 34.XX.XX.XX 8089:31735/TCP 12m
profile ClusterIP *snip* <none> 80/TCP 121m
profile-workload LoadBalancer *snip* 34.XX.XX.XX 8089:32532/TCP 12m
tradepost ClusterIP *snip* <none> 80/TCP 121m
tradepost-workload LoadBalancer *snip* 34.XX.XX.XX 8089:30002/TCP 12m
Краткое содержание
Теперь вы развернули рабочие нагрузки в кластере GKE. Для этих рабочих нагрузок не требуются дополнительные разрешения IAM, и они доступны извне через порт 8089 с помощью службы LoadBalancer .
Следующие шаги
После запуска серверных служб и рабочих нагрузок пришло время « сыграть » в игру!
7. Начните играть в игру.
Обзор
Теперь серверные службы для вашей тестовой «игры» запущены, и у вас также есть возможность генерировать «игроков», взаимодействующих с этими службами, используя рабочие нагрузки.
Для имитации реальной нагрузки на API наших сервисов в каждой рабочей нагрузке используется Locust . На этом этапе вы запустите несколько рабочих нагрузок, чтобы создать нагрузку на кластер GKE и на Spanner, а также сохранить данные на Spanner.
Вот описание каждой рабочей нагрузки:
-
item-generator— это быстрая задача, которая генерирует список игровых предметов , которые игроки могут получить в процессе «игры». - Функция
profile-workloadимитирует регистрацию и вход игроков в систему. -
matchmaking-workloadигроков имитирует очередь игроков, ожидающих назначения в матчи. -
game-workloadимитирует получение игроками игровых предметов и денег в процессе игры. -
tradepost-workloadимитирует возможность игроков продавать и покупать товары на торговом посту.
В этом практическом занятии будет рассмотрен конкретный запуск item-generator и profile-workload .
Запустите генератор предметов
item-generator использует конечную точку службы бэкэнда item для добавления game_items в Spanner. Эти предметы необходимы для корректной работы game-workload и tradepost-workload .
Первый шаг — получить внешний IP-адрес сервиса item-generator . В Cloud Shell выполните следующую команду:
# The external IP is the 4th column of the output
kubectl get services | grep item-generator | awk '{print $4}'
вывод команды
{ITEMGENERATOR_EXTERNAL_IP}
Теперь откройте новую вкладку браузера и перейдите по адресу http://{ITEMGENERATOR_EXTERNAL_IP}:8089 . Вы должны увидеть страницу примерно такого вида:
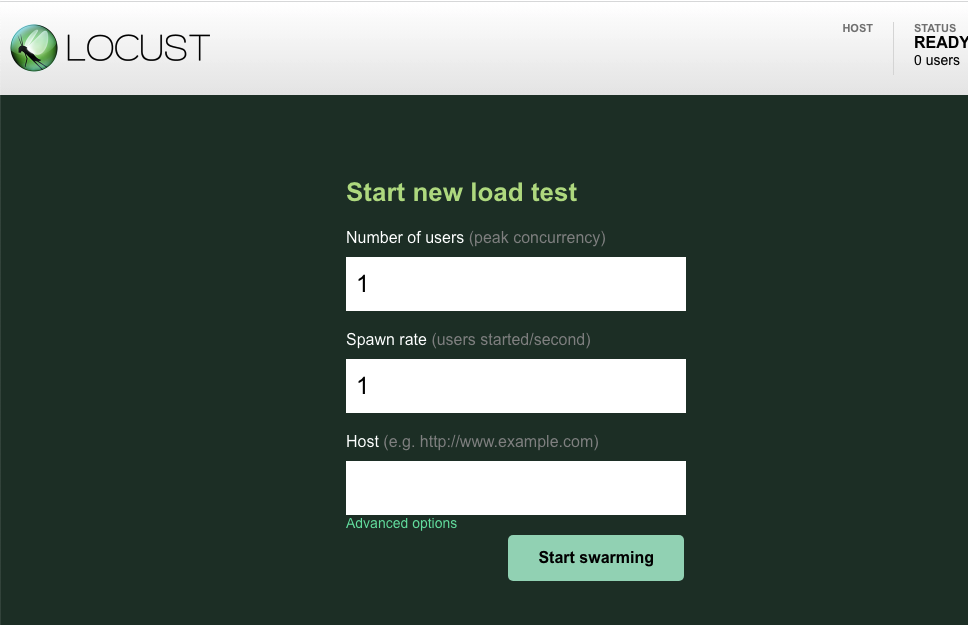
Вы оставите users и spawn в момент по умолчанию 1. В качестве host введите http://item . Нажмите на «Дополнительные параметры» и введите 10s в качестве времени выполнения.
Вот как должна выглядеть конфигурация:

Нажмите «Начать роение»!
Начнёт отображаться статистика запросов, отправляемых через конечную точку POST /items . Через 10 секунд загрузка прекратится.
Перейдите в Charts , и вы увидите графики, демонстрирующие производительность этих запросов.

Теперь вам нужно проверить, были ли данные внесены в базу данных Spanner.
Для этого щелкните по значку меню-гамбургера и перейдите к пункту «Spanner». На этой странице перейдите к sample-instance и sample-database . Затем щелкните по кнопке « Query ».
Мы хотим выбрать количество game_items :
SELECT COUNT(*) FROM game_items;
Внизу вы увидите результат.
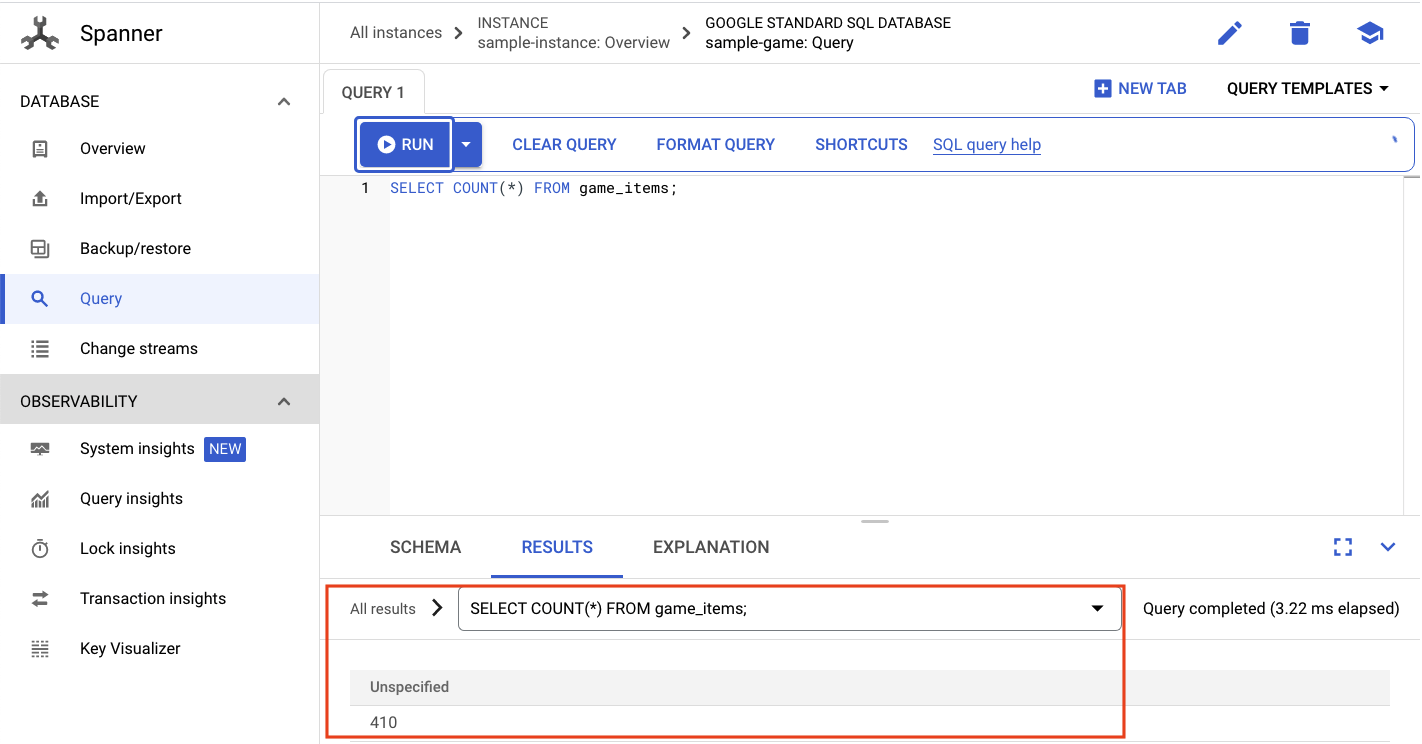
Нам не нужно было задавать много game_items . Но теперь игроки могут их получить!
Запустите profile-workload
После того, как вы заполнили переменную game_items , следующим шагом будет регистрация игроков для участия в играх.
profile-workload будет использоваться Locust для имитации создания игроками учетных записей, входа в систему, получения информации профиля и выхода из системы. Все эти действия проверяют работу конечных точек бэкэнд-сервиса profile в условиях, приближенных к производственной среде.
Для запуска этой команды получите внешний IP profile-workload :
# The external IP is the 4th column of the output
kubectl get services | grep profile-workload | awk '{print $4}'
вывод команды
{PROFILEWORKLOAD_EXTERNAL_IP}
Теперь откройте новую вкладку браузера и перейдите по адресу http://{PROFILEWORKLOAD_EXTERNAL_IP}:8089 . Вы должны увидеть страницу Locust, похожую на предыдущую.
В этом случае в качестве хоста следует использовать http://profile . В расширенных настройках указывать среду выполнения не нужно. Также укажите количество users — 4, что позволит имитировать одновременную обработку 4 запросов от одного пользователя.
Тест profile-workload должен выглядеть следующим образом:

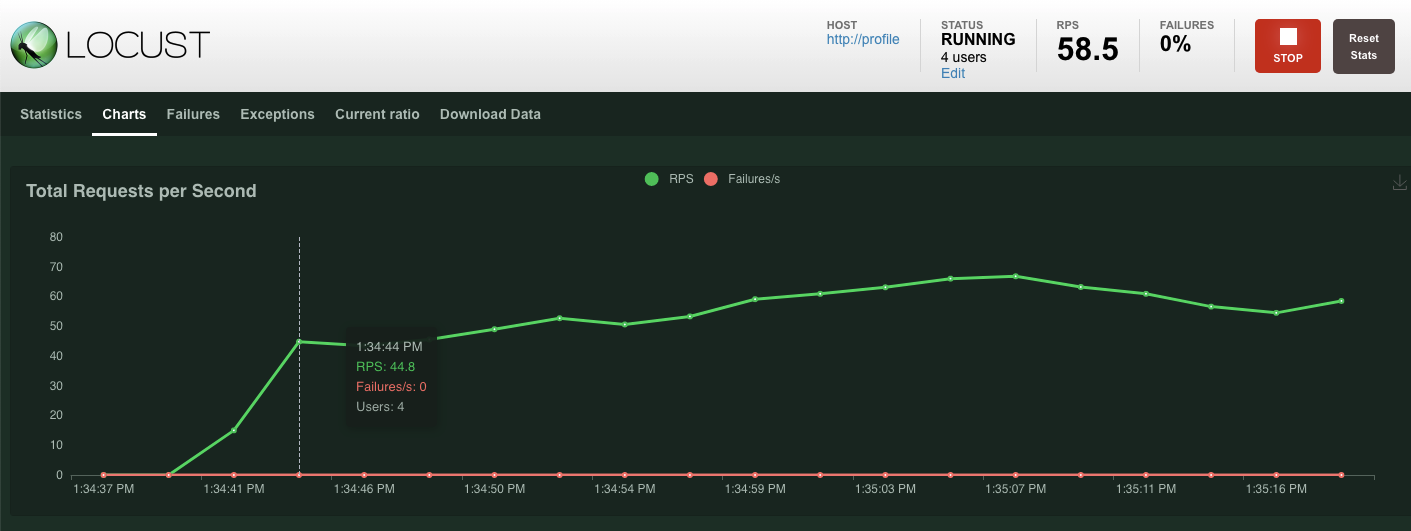
Нажмите «Начать роение»!
Как и прежде, начнут отображаться статистические данные по различным REST-конечным точкам profile . Перейдите к графикам, чтобы увидеть, насколько хорошо всё работает.
Краткое содержание
На этом шаге вы сгенерировали несколько game_items , а затем выполнили запрос к таблице game_items с помощью пользовательского интерфейса запросов Spanner в Cloud Console.
Вы также разрешили игрокам регистрироваться в вашей игре и увидели, как Locust способен создавать нагрузки, аналогичные производственным, для ваших бэкэнд-сервисов.
Следующие шаги
После запуска рабочих нагрузок вам потребуется проверить, как работают кластер GKE и экземпляр Spanner.
8. Повторите использование GKE и Spanner.
После запуска службы профилирования самое время проверить, как работает ваш кластер GKE Autopilot и Cloud Spanner.
Проверьте кластер GKE.
Перейдите в кластер Kubernetes. Обратите внимание, что после развертывания рабочих нагрузок и сервисов в кластере появились дополнительные сведения об общем количестве виртуальных процессоров и памяти. Эта информация была недоступна, когда в кластере не было рабочих нагрузок.
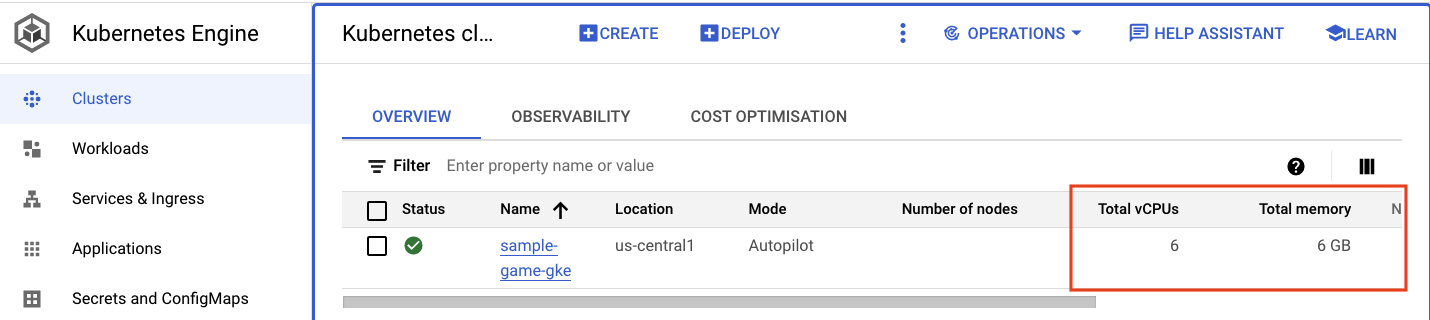
Теперь перейдите в кластер sample-game-gke и откройте вкладку «Наблюдаемость»:

Поскольку наши рабочие нагрузки и бэкэнд-сервисы работают в пространстве имен Kubernetes default default использование ЦП должно было превысить пространство имен kube-system . Если этого не произошло, убедитесь, что profile workload все еще запущена, и подождите несколько минут, пока обновятся диаграммы.
Чтобы узнать, какие рабочие нагрузки потребляют больше всего ресурсов, перейдите на панель мониторинга Workloads .
Вместо того чтобы просматривать каждую рабочую нагрузку по отдельности, перейдите сразу на вкладку «Наблюдаемость» в панели мониторинга. Вы должны увидеть, что загрузка ЦП profile и profile-workload увеличилась.

А теперь идите проверьте Cloud Spanner.
Проверьте экземпляр Cloud Spanner.
Чтобы проверить производительность Cloud Spanner, перейдите в Spanner и щелкните по экземпляру sample-instance и базе данных sample-game .
Там, в левом меню, вы увидите вкладку «Системная аналитика» :
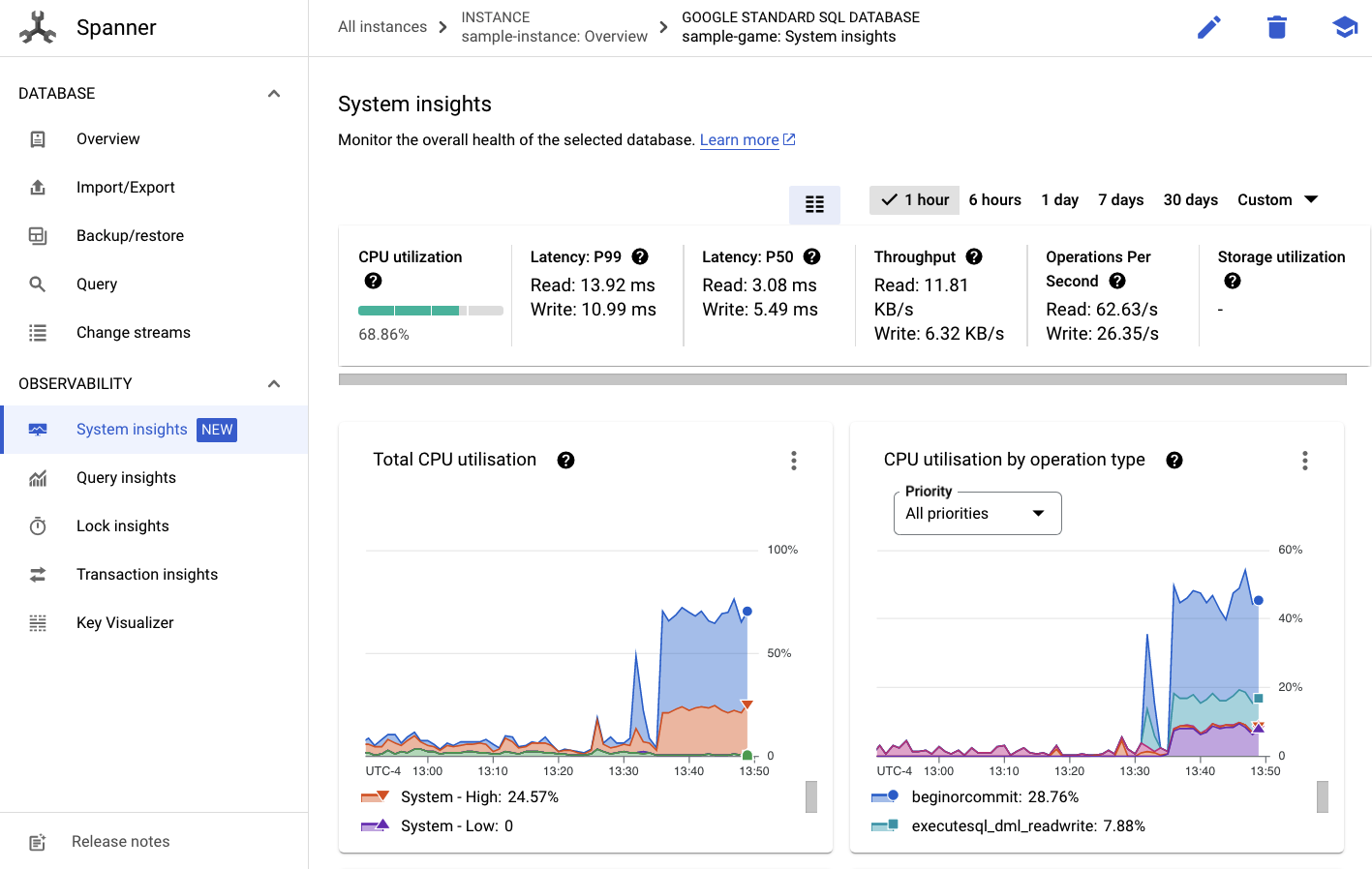
Здесь представлено множество диаграмм, которые помогут вам понять общую производительность вашего экземпляра Spanner, включая CPU utilization , transaction latency and locking , а также query throughput .
Помимо System Insights, вы можете получить более подробную информацию о нагрузке на запросы, перейдя по другим ссылкам в разделе «Наблюдаемость»:
- Функция анализа запросов помогает выявить N наиболее часто используемых запросов на платформе Spanner.
- Анализ транзакций и блокировок помогает выявлять транзакции с высокой задержкой.
- Key Visualizer помогает визуализировать шаблоны доступа и выявлять проблемные места в данных.
Краткое содержание
На этом этапе вы научились проверять некоторые основные показатели производительности как GKE Autopilot, так и Spanner.
Например, при запущенной задаче профилирования, выполните запрос к таблице игроков , чтобы получить дополнительную информацию о хранящихся там данных.
Следующие шаги
Далее, пора убираться!
9. Уборка
Прежде чем приступать к очистке, можете ознакомиться с другими задачами, которые не были рассмотрены. В частности, matchmaking-workload , game-workload и tradepost-workload .
Когда вы закончите «играть», вы можете убрать свою игровую площадку. К счастью, это довольно просто.
Во-первых, если ваша profile-workload все еще выполняется в браузере, перейдите и остановите ее:

Повторите то же самое для каждой рабочей нагрузки, которую вы, возможно, тестировали.
Затем в Cloud Shell перейдите в папку infrastructure. Вы destroy инфраструктуру с помощью Terraform:
cd $DEMO_HOME/infrastructure
terraform destroy
# type 'yes' when asked
вывод команды
Plan: 0 to add, 0 to change, 46 to destroy.
Do you really want to destroy all resources?
Terraform will destroy all your managed infrastructure, as shown above.
There is no undo. Only 'yes' will be accepted to confirm.
Enter a value: yes
*snip*
Destroy complete! Resources: 46 destroyed.
В консоли Cloud перейдите к Spanner , Kubernetes Cluster , Artifact Registry , Cloud Deploy и IAM , чтобы убедиться, что все ресурсы удалены.
10. Поздравляем!
Поздравляем, вы успешно развернули тестовые приложения на Golang в GKE Autopilot и подключили их к Cloud Spanner с помощью Workload Identity!
В качестве бонуса, эту инфраструктуру было легко и быстро создавать и удалять с помощью Terraform.
Подробнее о сервисах Google Cloud, с которыми вы взаимодействовали в этом практическом занятии, вы можете узнать здесь:
- Автопилот GKE и идентификация рабочей нагрузки
- Облачный гальник
- Реестр артефактов
- Создание и развертывание облачных решений
Что дальше?
Теперь, когда вы получили базовое представление о том, как GKE Autopilot и Cloud Spanner могут работать вместе, почему бы не сделать следующий шаг и не начать создавать собственное приложение для работы с этими сервисами?