
1. บทนำ
Cloud Spanner เป็นบริการฐานข้อมูลเชิงสัมพันธ์ที่มีการจัดการครบวงจรซึ่งปรับขนาดในแนวนอนได้ มีการกระจายทั่วโลก และมอบธุรกรรม ACID และความหมายของ SQL โดยไม่ลดทอนประสิทธิภาพและความพร้อมใช้งานสูง
GKE Autopilot เป็นโหมดการทำงานใน GKE ที่ Google จัดการการกำหนดค่าคลัสเตอร์ของคุณ ซึ่งรวมถึงโหนด การปรับขนาด ความปลอดภัย และการตั้งค่าอื่นๆ ที่กำหนดค่าไว้ล่วงหน้าเพื่อให้เป็นไปตามแนวทางปฏิบัติแนะนำ เช่น GKE Autopilot จะเปิดใช้ Workload Identity เพื่อจัดการสิทธิ์ของบริการ
เป้าหมายของแล็บนี้คือการแนะนำขั้นตอนการเชื่อมต่อบริการแบ็กเอนด์หลายรายการที่ทำงานใน GKE Autopilot กับฐานข้อมูล Cloud Spanner
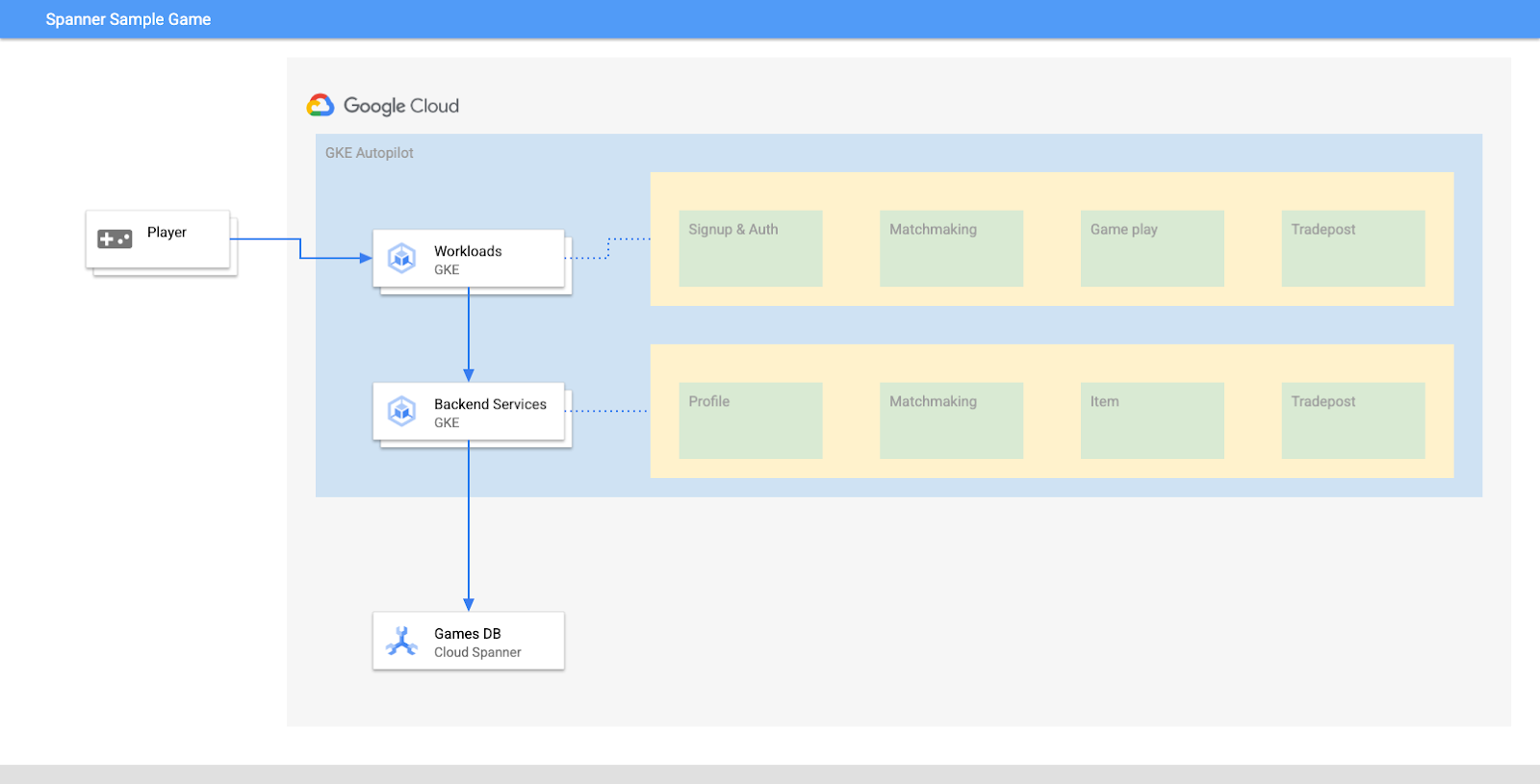
ในแล็บนี้ คุณจะได้ตั้งค่าโปรเจ็กต์และเปิดใช้ Cloud Shell ก่อน จากนั้นคุณจะทำให้โครงสร้างพื้นฐานใช้งานได้โดยใช้ Terraform
เมื่อเสร็จแล้ว คุณจะโต้ตอบกับ Cloud Build และ Cloud Deploy เพื่อทำการย้ายข้อมูลสคีมาเริ่มต้นสำหรับฐานข้อมูลเกม, ทำให้บริการแบ็กเอนด์ใช้งานได้ แล้วจึงทำให้เวิร์กโหลดใช้งานได้
บริการในโค้ดแล็บนี้เหมือนกับในโค้ดแล็บการเริ่มต้นใช้งาน Cloud Spanner สำหรับการพัฒนาเกม คุณไม่จำเป็นต้องทำตาม Codelab นั้นเพื่อให้บริการทำงานบน GKE และเชื่อมต่อกับ Spanner แต่หากสนใจรายละเอียดเพิ่มเติมเกี่ยวกับบริการเหล่านั้นที่ทำงานใน Spanner โปรดดูข้อมูล
เมื่อเวิร์กโหลดและบริการแบ็กเอนด์ทำงานอยู่ คุณจะเริ่มสร้างภาระงานและสังเกตวิธีที่บริการทำงานร่วมกันได้
สุดท้าย คุณจะล้างข้อมูลทรัพยากรที่สร้างขึ้นใน Lab นี้
สิ่งที่คุณจะสร้าง
ในส่วนหนึ่งของห้องทดลองนี้ คุณจะได้ทำสิ่งต่อไปนี้
- จัดสรรโครงสร้างพื้นฐานโดยใช้ Terraform
- สร้างสคีมาฐานข้อมูลโดยใช้กระบวนการย้ายข้อมูลสคีมาใน Cloud Build
- ติดตั้งใช้งานบริการแบ็กเอนด์ Golang ทั้ง 4 รายการที่ใช้ประโยชน์จาก Workload Identity เพื่อเชื่อมต่อกับ Cloud Spanner
- ติดตั้งใช้งานบริการเวิร์กโหลด 4 รายการที่ใช้เพื่อจำลองโหลดสำหรับบริการแบ็กเอนด์
สิ่งที่คุณจะได้เรียนรู้
- วิธีจัดสรรไปป์ไลน์ GKE Autopilot, Cloud Spanner และ Cloud Deploy โดยใช้ Terraform
- Workload Identity ช่วยให้บริการใน GKE แสดงตัวเป็นบัญชีบริการเพื่อเข้าถึงสิทธิ์ IAM ในการทำงานกับ Cloud Spanner ได้อย่างไร
- วิธีสร้างโหลดที่คล้ายกับการใช้งานจริงใน GKE และ Cloud Spanner โดยใช้ Locust.io
สิ่งที่คุณต้องมี
2. การตั้งค่าและข้อกำหนด
สร้างโปรเจ็กต์
หากยังไม่มีบัญชี Google (Gmail หรือ Google Apps) คุณต้องสร้างบัญชี ลงชื่อเข้าใช้คอนโซล Google Cloud Platform ( console.cloud.google.com) แล้วสร้างโปรเจ็กต์ใหม่
หากมีโปรเจ็กต์อยู่แล้ว ให้คลิกเมนูแบบเลื่อนลงเพื่อเลือกโปรเจ็กต์ที่ด้านซ้ายบนของคอนโซล

แล้วคลิกปุ่ม "โปรเจ็กต์ใหม่" ในกล่องโต้ตอบที่ปรากฏเพื่อสร้างโปรเจ็กต์ใหม่
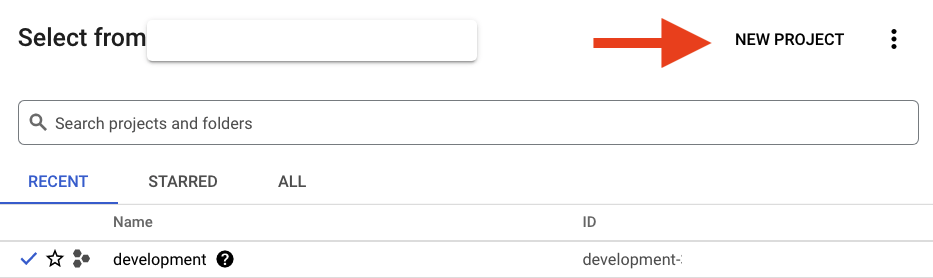
หากยังไม่มีโปรเจ็กต์ คุณจะเห็นกล่องโต้ตอบแบบนี้เพื่อสร้างโปรเจ็กต์แรก

กล่องโต้ตอบการสร้างโปรเจ็กต์ในภายหลังจะช่วยให้คุณป้อนรายละเอียดของโปรเจ็กต์ใหม่ได้
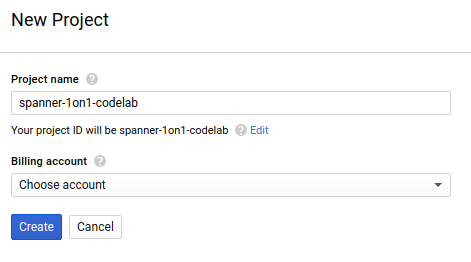
โปรดจดจำรหัสโปรเจ็กต์ ซึ่งเป็นชื่อที่ไม่ซ้ำกันในโปรเจ็กต์ Google Cloud ทั้งหมด (ชื่อด้านบนมีผู้ใช้แล้วและจะใช้ไม่ได้ ขออภัย) ซึ่งจะเรียกว่า PROJECT_ID ในภายหลังใน Codelab นี้
จากนั้น หากยังไม่ได้ดำเนินการ คุณจะต้องเปิดใช้การเรียกเก็บเงินใน Developers Console เพื่อใช้ทรัพยากร Google Cloud และเปิดใช้ Cloud Spanner API

การทำตาม Codelab นี้ไม่ควรมีค่าใช้จ่ายเกิน 2-3 ดอลลาร์ แต่ก็อาจมีค่าใช้จ่ายมากกว่านี้หากคุณตัดสินใจใช้ทรัพยากรเพิ่มเติมหรือปล่อยให้ทรัพยากรทำงานต่อไป (ดูส่วน "การล้างข้อมูล" ที่ท้ายเอกสารนี้) ดูราคาของ Google Cloud Spanner ได้ที่นี่ และดูราคาของ GKE Autopilot ได้ที่นี่
ผู้ใช้ใหม่ของ Google Cloud Platform มีสิทธิ์รับช่วงทดลองใช้ฟรีมูลค่า$300 ซึ่งจะทำให้ Codelab นี้ไม่มีค่าใช้จ่ายใดๆ
การตั้งค่า Cloud Shell
แม้ว่าคุณจะใช้งาน Google Cloud และ Spanner จากแล็ปท็อประยะไกลได้ แต่ใน Codelab นี้เราจะใช้ Google Cloud Shell ซึ่งเป็นสภาพแวดล้อมบรรทัดคำสั่งที่ทำงานในระบบคลาวด์
เครื่องเสมือนที่ใช้ Debian นี้มาพร้อมเครื่องมือพัฒนาทั้งหมดที่คุณต้องการ โดยมีไดเรกทอรีหลักแบบถาวรขนาด 5 GB และทำงานใน Google Cloud ซึ่งช่วยเพิ่มประสิทธิภาพเครือข่ายและการตรวจสอบสิทธิ์ได้อย่างมาก ซึ่งหมายความว่าคุณจะต้องมีเพียงเบราว์เซอร์เท่านั้นสำหรับโค้ดแล็บนี้ (ใช่แล้ว ใช้ได้ใน Chromebook)
- หากต้องการเปิดใช้งาน Cloud Shell จาก Cloud Console เพียงคลิกเปิดใช้งาน Cloud Shell
 (ระบบจะจัดสรรและเชื่อมต่อกับสภาพแวดล้อมในเวลาไม่กี่นาที)
(ระบบจะจัดสรรและเชื่อมต่อกับสภาพแวดล้อมในเวลาไม่กี่นาที)

เมื่อเชื่อมต่อกับ Cloud Shell แล้ว คุณควรเห็นว่าระบบได้ตรวจสอบสิทธิ์คุณแล้ว และตั้งค่าโปรเจ็กต์เป็น PROJECT_ID แล้ว
gcloud auth list
เอาต์พุตของคำสั่ง
Credentialed accounts:
- <myaccount>@<mydomain>.com (active)
gcloud config list project
เอาต์พุตของคำสั่ง
[core]
project = <PROJECT_ID>
หากไม่ได้ตั้งค่าโปรเจ็กต์ด้วยเหตุผลบางประการ ให้เรียกใช้คำสั่งต่อไปนี้
gcloud config set project <PROJECT_ID>
หากกำลังมองหา PROJECT_ID ตรวจสอบว่าคุณใช้รหัสใดในขั้นตอนการตั้งค่า หรือค้นหารหัสในแดชบอร์ด Cloud Console

นอกจากนี้ Cloud Shell ยังตั้งค่าตัวแปรสภาพแวดล้อมบางอย่างโดยค่าเริ่มต้น ซึ่งอาจมีประโยชน์เมื่อคุณเรียกใช้คำสั่งในอนาคต
echo $GOOGLE_CLOUD_PROJECT
เอาต์พุตของคำสั่ง
<PROJECT_ID>
ดาวน์โหลดรหัส
ใน Cloud Shell คุณสามารถดาวน์โหลดโค้ดสำหรับ Lab นี้ได้โดยทำดังนี้
git clone https://github.com/cloudspannerecosystem/spanner-gaming-sample.git
เอาต์พุตของคำสั่ง
Cloning into 'spanner-gaming-sample'...
*snip*
Codelab นี้อิงตามรุ่น v0.1.3 ดังนั้นโปรดตรวจสอบแท็กดังกล่าว
cd spanner-gaming-sample
git fetch --all --tags
# Check out v0.1.3 release
git checkout tags/v0.1.3 -b v0.1.3-branch
เอาต์พุตของคำสั่ง
Switched to a new branch 'v0.1.3-branch'
ตอนนี้ ให้ตั้งค่าไดเรกทอรีการทำงานปัจจุบันเป็นตัวแปรสภาพแวดล้อม DEMO_HOME ซึ่งจะช่วยให้คุณไปยังส่วนต่างๆ ของโค้ดแล็บได้ง่ายขึ้นขณะทำงาน
export DEMO_HOME=$(pwd)
สรุป
ในขั้นตอนนี้ คุณได้สร้างโปรเจ็กต์ใหม่ เปิดใช้งาน Cloud Shell และดาวน์โหลดโค้ดสำหรับแล็บนี้แล้ว
ถัดไป
จากนั้นคุณจะจัดสรรโครงสร้างพื้นฐานโดยใช้ Terraform
3. จัดสรรโครงสร้างพื้นฐาน
ภาพรวม
เมื่อโปรเจ็กต์พร้อมแล้ว ก็ถึงเวลาเปิดใช้งานโครงสร้างพื้นฐาน ซึ่งรวมถึงเครือข่าย VPC, Cloud Spanner, GKE Autopilot, Artifact Registry สำหรับจัดเก็บอิมเมจที่จะทำงานใน GKE, ไปป์ไลน์ Cloud Deploy สำหรับบริการและภาระงานแบ็กเอนด์ และสุดท้ายคือบัญชีบริการและสิทธิ์ IAM เพื่อให้ใช้บริการเหล่านั้นได้
เยอะมาก แต่โชคดีที่ Terraform ช่วยให้การตั้งค่านี้ง่ายขึ้นได้ Terraform เป็นเครื่องมือ "โครงสร้างพื้นฐานเป็นโค้ด" ที่ช่วยให้เราสามารถระบุสิ่งที่ต้องการสำหรับโปรเจ็กต์นี้ในชุดไฟล์ ".tf" ซึ่งทำให้การจัดสรรโครงสร้างพื้นฐานเป็นเรื่องง่าย
คุณไม่จำเป็นต้องคุ้นเคยกับ Terraform เพื่อทำ Codelab นี้ให้เสร็จ แต่หากต้องการดูว่าขั้นตอนถัดไปจะทำอะไร คุณสามารถดูสิ่งที่สร้างขึ้นทั้งหมดในไฟล์เหล่านี้ซึ่งอยู่ในไดเรกทอรี infrastructure
- vpc.tf
- backend_gke.tf
- spanner.tf
- artifact_registry.tf
- pipelines.tf
- iam.tf
กำหนดค่า Terraform
ใน Cloud Shell ให้เปลี่ยนเป็นไดเรกทอรี infrastructure แล้วเริ่มต้น Terraform ดังนี้
cd $DEMO_HOME/infrastructure
terraform init
เอาต์พุตของคำสั่ง
Initializing the backend...
Initializing provider plugins...
*snip*
Terraform has been successfully initialized!
You may now begin working with Terraform. Try running "terraform plan" to see
any changes that are required for your infrastructure. All Terraform commands
should now work.
If you ever set or change modules or backend configuration for Terraform,
rerun this command to reinitialize your working directory. If you forget, other
commands will detect it and remind you to do so if necessary.
จากนั้นกำหนดค่า Terraform โดยคัดลอก terraform.tfvars.sample และแก้ไขค่าโปรเจ็กต์ คุณสามารถเปลี่ยนตัวแปรอื่นๆ ได้เช่นกัน แต่มีเพียงโปรเจ็กต์เท่านั้นที่ต้องเปลี่ยนเพื่อให้ทำงานกับสภาพแวดล้อมของคุณ
cp terraform.tfvars.sample terraform.tfvars
# edit gcp_project using the project environment variable
sed -i "s/PROJECT/$GOOGLE_CLOUD_PROJECT/" terraform.tfvars
จัดสรรโครงสร้างพื้นฐาน
ถึงเวลาจัดสรรโครงสร้างพื้นฐานแล้ว
terraform apply
# review the list of things to be created
# type 'yes' when asked
เอาต์พุตของคำสั่ง
Plan: 46 to add, 0 to change, 0 to destroy.
Do you want to perform these actions?
Terraform will perform the actions described above.
Only 'yes' will be accepted to approve.
Enter a value: yes
google_project_service.project["container.googleapis.com"]: Creating...
*snip*
Apply complete! Resources: 46 added, 0 changed, 0 destroyed.
ตรวจสอบสิ่งที่สร้างขึ้น
หากต้องการยืนยันสิ่งที่สร้างขึ้น คุณต้องตรวจสอบผลิตภัณฑ์ใน Cloud Console
Cloud Spanner
ก่อนอื่น ให้ตรวจสอบ Cloud Spanner โดยไปที่เมนูแฮมเบอร์เกอร์ แล้วคลิก Spanner คุณอาจต้องคลิก "ดูผลิตภัณฑ์เพิ่มเติม" เพื่อค้นหาในรายการ
ระบบจะนำคุณไปยังรายการอินสแตนซ์ Spanner คลิกอินสแตนซ์ แล้วคุณจะเห็นฐานข้อมูล ซึ่งควรมีหน้าตาเช่นนี้

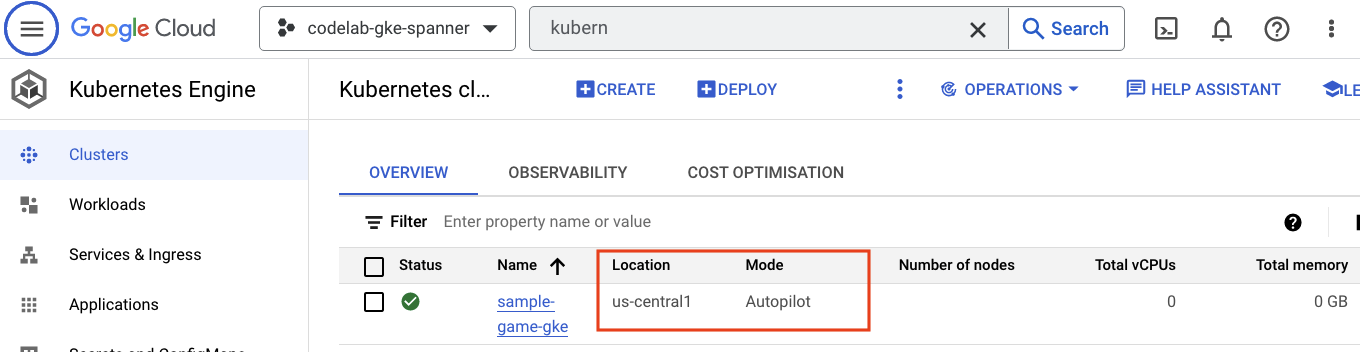
GKE Autopilot
จากนั้นลองใช้ GKE โดยไปที่เมนูแฮมเบอร์เกอร์แล้วคลิก Kubernetes Engine => Clusters คุณจะเห็นsample-games-gkeคลัสเตอร์ที่ทำงานในโหมด Autopilot ที่นี่
Artifact Registry
ตอนนี้คุณคงอยากรู้ว่าระบบจะจัดเก็บรูปภาพไว้ที่ไหน ดังนั้น ให้คลิกเมนู 3 ขีดแล้วมองหา Artifact Registry=>Repositories Artifact Registry อยู่ในส่วน CI/CD ของเมนู
คุณจะเห็นรีจิสทรี Docker ชื่อ spanner-game-images ที่นี่ ตอนนี้ส่วนนี้จะว่างเปล่า

Cloud Deploy
Cloud Deploy คือที่ที่สร้างไปป์ไลน์เพื่อให้ Cloud Build สามารถระบุขั้นตอนในการสร้างอิมเมจ แล้วทำให้ใช้งานได้กับคลัสเตอร์ GKE
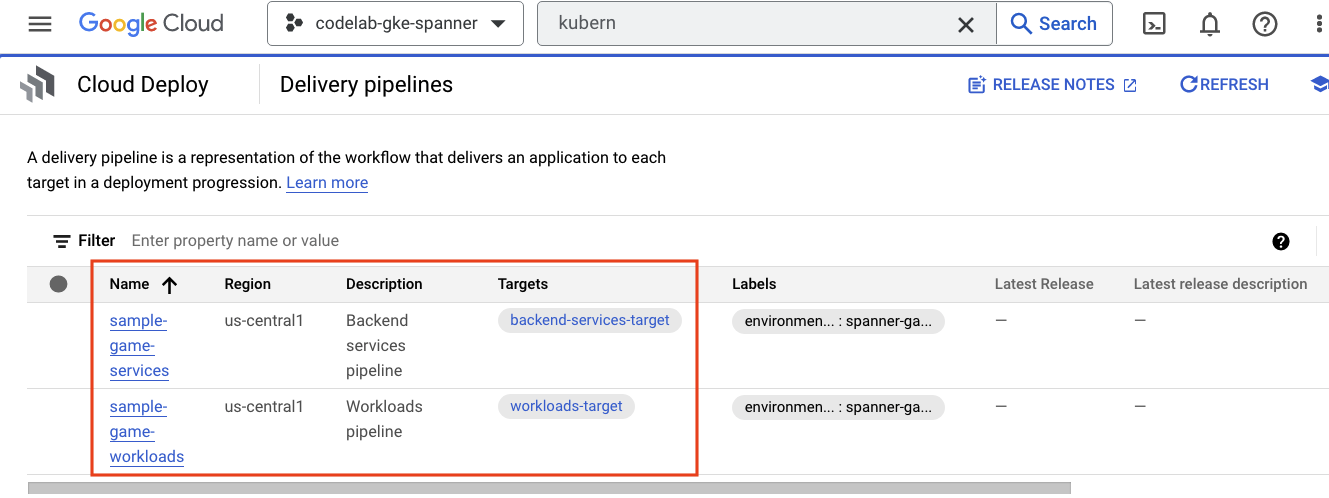
ไปที่เมนูแฮมเบอร์เกอร์แล้วค้นหา Cloud Deploy ซึ่งอยู่ในส่วน CI/CD ของเมนูด้วย
คุณจะเห็นไปป์ไลน์ 2 รายการ ได้แก่ ไปป์ไลน์สำหรับบริการแบ็กเอนด์และไปป์ไลน์สำหรับเวิร์กโหลด ทั้ง 2 รายการทำให้ใช้งานได้กับคลัสเตอร์ GKE เดียวกัน แต่ช่วยให้เราแยกการทำให้ใช้งานได้
IAM
สุดท้าย ให้ไปที่หน้า IAM ใน Cloud Console เพื่อยืนยันบัญชีบริการที่สร้างขึ้น ไปที่เมนูแฮมเบอร์เกอร์แล้วค้นหา IAM and Admin=>Service accounts ซึ่งควรมีหน้าตาเช่นนี้
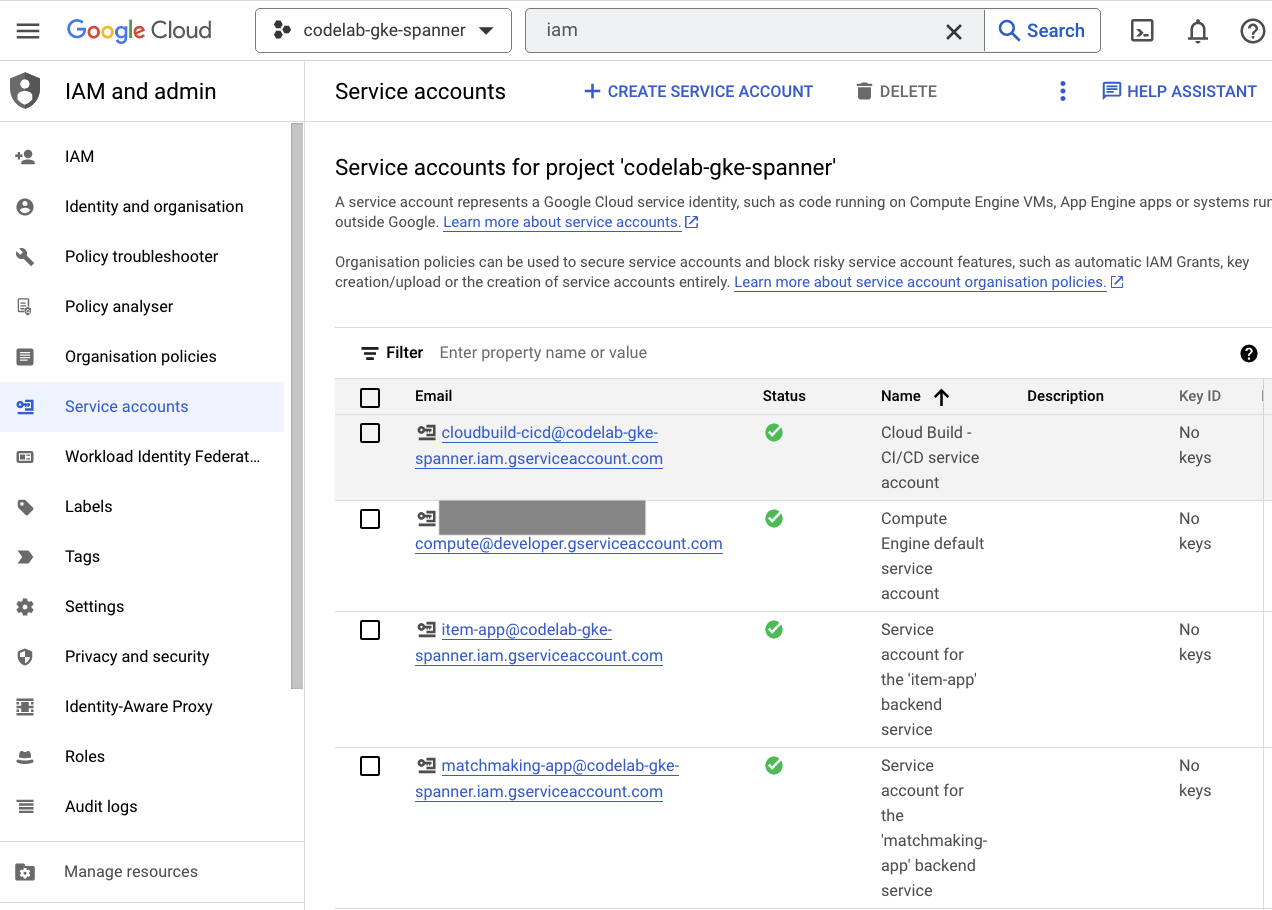
Terraform สร้างบัญชีบริการทั้งหมด 6 บัญชี ดังนี้
- บัญชีบริการคอมพิวเตอร์เริ่มต้น ซึ่งไม่ได้ใช้ในโค้ดแล็บนี้
- บัญชี cloudbuild-cicd ใช้สำหรับขั้นตอน Cloud Build และ Cloud Deploy
- บัญชี "แอป" 4 บัญชีที่บริการแบ็กเอนด์ของเราใช้เพื่อโต้ตอบกับ Cloud Spanner
จากนั้นคุณจะต้องกำหนดค่า kubectl เพื่อโต้ตอบกับคลัสเตอร์ GKE
กำหนดค่า kubectl
# Name of GKE cluster from terraform.tfvars file
export GKE_CLUSTER=sample-game-gke
# get GKE credentials
gcloud container clusters get-credentials $GKE_CLUSTER --region us-central1
# Check that no errors occur
kubectl get serviceaccounts
เอาต์พุตของคำสั่ง
#export GKE_CLUSTER=sample-game-gke
# gcloud container clusters get-credentials $GKE_CLUSTER --region us-central1
Fetching cluster endpoint and auth data.
kubeconfig entry generated for sample-game-gke.
# kubectl get serviceaccounts
NAME SECRETS AGE
default 0 37m
item-app 0 35m
matchmaking-app 0 35m
profile-app 0 35m
tradepost-app 0 35m
สรุป
เยี่ยมเลย คุณสามารถจัดสรรอินสแตนซ์ Cloud Spanner, คลัสเตอร์ GKE Autopilot ทั้งหมดใน VPC สำหรับเครือข่ายส่วนตัว
นอกจากนี้ ยังมีการสร้างไปป์ไลน์ Cloud Deploy 2 รายการสำหรับบริการแบ็กเอนด์และเวิร์กโหลด รวมถึงที่เก็บ Artifact Registry เพื่อจัดเก็บอิมเมจที่สร้างขึ้น
และสุดท้าย เราได้สร้างและกำหนดค่าบัญชีบริการให้ทำงานร่วมกับ Workload Identity เพื่อให้บริการแบ็กเอนด์ใช้ Cloud Spanner ได้
นอกจากนี้ คุณยังได้kubectlกำหนดค่าให้โต้ตอบกับคลัสเตอร์ GKE ใน Cloud Shell หลังจากที่ติดตั้งใช้งานบริการแบ็กเอนด์และเวิร์กโหลดแล้ว
ถัดไป
คุณต้องกำหนดสคีมาของฐานข้อมูลก่อนจึงจะใช้บริการได้ คุณจะตั้งค่าในขั้นตอนถัดไป
4. สร้างสคีมาฐานข้อมูล
ภาพรวม
ก่อนที่จะเรียกใช้บริการแบ็กเอนด์ คุณต้องตรวจสอบว่ามีสคีมาฐานข้อมูล
หากดูไฟล์ในไดเรกทอรี $DEMO_HOME/schema/migrations จากที่เก็บข้อมูลการสาธิต คุณจะเห็นชุดไฟล์ .sql ที่กำหนดสคีมาของเรา ซึ่งจำลองวงจรการพัฒนาที่การเปลี่ยนแปลงสคีมาจะได้รับการติดตามในที่เก็บเอง และสามารถเชื่อมโยงกับฟีเจอร์บางอย่างของแอปพลิเคชันได้
สำหรับสภาพแวดล้อมตัวอย่างนี้ wrench คือเครื่องมือที่จะใช้การย้ายข้อมูลสคีมาโดยใช้ Cloud Build
Cloud Build
ไฟล์ $DEMO_HOME/schema/cloudbuild.yaml จะอธิบายขั้นตอนที่จะดำเนินการ
serviceAccount: projects/${PROJECT_ID}/serviceAccounts/cloudbuild-cicd@${PROJECT_ID}.iam.gserviceaccount.com
steps:
- name: gcr.io/cloud-builders/curl
id: fetch-wrench
args: ['-Lo', '/workspace/wrench.tar.gz', 'https://github.com/cloudspannerecosystem/wrench/releases/download/v1.4.1/wrench-1.4.1-linux-amd64.tar.gz' ]
- name: gcr.io/cloud-builders/gcloud
id: migrate-spanner-schema
entrypoint: sh
args:
- '-xe'
- '-c'
- |
tar -xzvf wrench.tar.gz
chmod +x /workspace/wrench
# Assumes only a single spanner instance and database. Fine for this demo in a dedicated project
export SPANNER_PROJECT_ID=${PROJECT_ID}
export SPANNER_INSTANCE_ID=$(gcloud spanner instances list | tail -n1 | awk '{print $1}')
export SPANNER_DATABASE_ID=$(gcloud spanner databases list --instance=$$SPANNER_INSTANCE_ID | tail -n1 | awk '{print $1}')
if [ -d ./migrations ]; then
/workspace/wrench migrate up --directory .
else
echo "[Error] Missing migrations directory"
fi
timeout: 600s
โดยมี 2 ขั้นตอนหลักๆ ดังนี้
- ดาวน์โหลด Wrench ไปยังพื้นที่ทำงาน Cloud Build
- เรียกใช้การย้ายข้อมูลด้วยไอคอนประแจ
ต้องใช้ตัวแปรสภาพแวดล้อมของโปรเจ็กต์ อินสแตนซ์ และฐานข้อมูล Spanner เพื่อให้ Wrench เชื่อมต่อกับปลายทางการเขียนได้
Cloud Build ทำการเปลี่ยนแปลงเหล่านี้ได้เนื่องจากทำงานในฐานะcloudbuild-cicd@${PROJECT_ID}.iam.gserviceaccount.comบัญชีบริการ
serviceAccount: projects/${PROJECT_ID}/serviceAccounts/cloudbuild-cicd@${PROJECT_ID}.iam.gserviceaccount.com
และบัญชีบริการนี้มีบทบาท spanner.databaseUser ที่ Terraform เพิ่ม ซึ่งอนุญาตให้บัญชีบริการอัปเดต DDL ได้
การย้ายข้อมูลสคีมา
ขั้นตอนการย้ายข้อมูลมี 5 ขั้นตอนซึ่งดำเนินการตามไฟล์ในไดเรกทอรี $DEMO_HOME/schema/migrations ต่อไปนี้คือตัวอย่างไฟล์ 000001.sql ที่สร้างตารางและดัชนี players
CREATE TABLE players (
playerUUID STRING(36) NOT NULL,
player_name STRING(64) NOT NULL,
email STRING(MAX) NOT NULL,
password_hash BYTES(60) NOT NULL,
created TIMESTAMP,
updated TIMESTAMP,
stats JSON,
account_balance NUMERIC NOT NULL DEFAULT (0.00),
is_logged_in BOOL,
last_login TIMESTAMP,
valid_email BOOL,
current_game STRING(36)
) PRIMARY KEY (playerUUID);
CREATE UNIQUE INDEX PlayerAuthentication ON players(email) STORING(password_hash);
CREATE UNIQUE INDEX PlayerName ON players(player_name);
CREATE INDEX PlayerGame ON players(current_game);
ส่งการย้ายข้อมูลสคีมา
หากต้องการส่งบิลด์เพื่อทำการย้ายข้อมูลสคีมา ให้เปลี่ยนไปที่ไดเรกทอรี schema แล้วเรียกใช้คำสั่ง gcloud ต่อไปนี้
cd $DEMO_HOME/schema gcloud builds submit --config=cloudbuild.yaml
เอาต์พุตของคำสั่ง
Creating temporary tarball archive of 8 file(s) totalling 11.2 KiB before compression.
Uploading tarball of [.] to [gs://(project)_cloudbuild/source/(snip).tgz]
Created [https://cloudbuild.googleapis.com/v1/projects/(project)/locations/global/builds/7defe982-(snip)].
Logs are available at [ https://console.cloud.google.com/cloud-build/builds/7defe982-(snip)?project=(snip) ].
gcloud builds submit only displays logs from Cloud Storage. To view logs from Cloud Logging, run:
gcloud beta builds submit
ID: 7defe982-(snip)
CREATE_TIME: (created time)
DURATION: 3M11S
SOURCE: gs://(project)_cloudbuild/source/(snip).tgz
IMAGES: -
STATUS: SUCCESS
ในเอาต์พุตด้านบน คุณจะเห็นลิงก์ไปยังCreatedกระบวนการสร้างในระบบคลาวด์ หากคลิกที่ข้อความดังกล่าว ระบบจะนำคุณไปยังบิลด์ใน Cloud Console เพื่อให้คุณตรวจสอบความคืบหน้าของบิลด์และดูสิ่งที่บิลด์กำลังทำได้
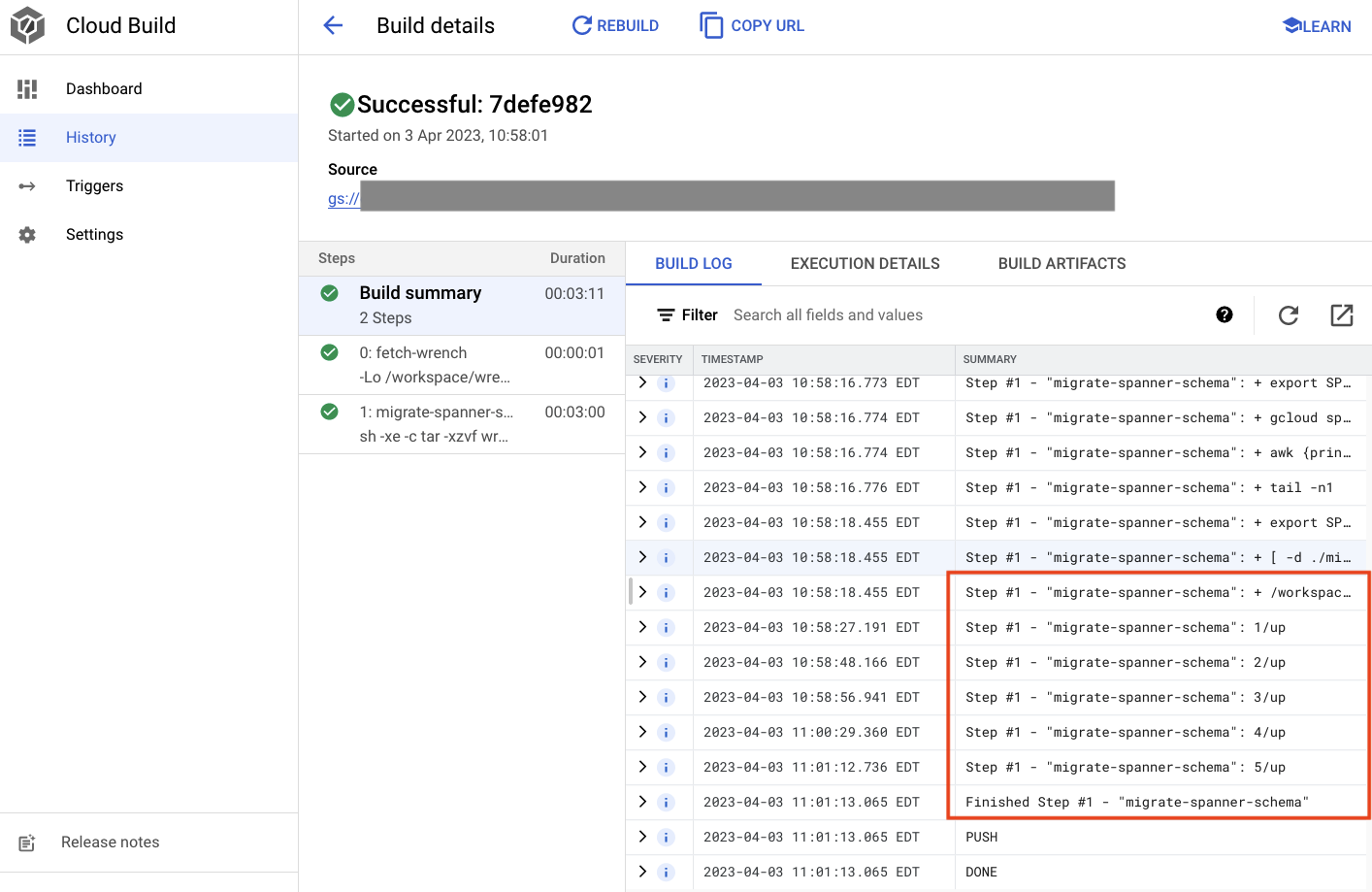
สรุป
ในขั้นตอนนี้ คุณใช้ Cloud Build เพื่อส่งการย้ายข้อมูลสคีมาครั้งแรกซึ่งใช้การดำเนินการ DDL ที่แตกต่างกัน 5 รายการ การดำเนินการเหล่านี้แสดงให้เห็นว่าเมื่อใดที่มีการเพิ่มฟีเจอร์ที่ต้องมีการเปลี่ยนแปลงสคีมาของฐานข้อมูล
ในสถานการณ์การพัฒนาปกติ คุณอาจต้องการทำการเปลี่ยนแปลงสคีมาให้เข้ากันได้แบบย้อนหลังกับแอปพลิเคชันปัจจุบันเพื่อหลีกเลี่ยงการหยุดทำงาน
สำหรับการเปลี่ยนแปลงที่เข้ากันไม่ได้กับเวอร์ชันก่อนหน้า คุณควรทำการเปลี่ยนแปลงกับแอปพลิเคชันและสคีมาเป็นระยะๆ เพื่อให้มั่นใจว่าจะไม่มีการหยุดทำงาน
ถัดไป
เมื่อมีสคีมาแล้ว ขั้นตอนถัดไปคือการติดตั้งใช้งานบริการแบ็กเอนด์
5. ติดตั้งใช้งานบริการแบ็กเอนด์
ภาพรวม
บริการแบ็กเอนด์สำหรับ Codelab นี้คือ REST API ของ Golang ซึ่งแสดงถึงบริการ 4 อย่าง ได้แก่
- โปรไฟล์: ช่วยให้ผู้เล่นลงชื่อสมัครใช้และตรวจสอบสิทธิ์เพื่อเข้าถึง "เกม" ตัวอย่างของเราได้
- การจับคู่: โต้ตอบกับข้อมูลผู้เล่นเพื่อช่วยในฟังก์ชันการจับคู่ ติดตามข้อมูลเกี่ยวกับเกมที่สร้างขึ้น และอัปเดตสถิติผู้เล่นเมื่อปิดเกม
- ไอเทม: ช่วยให้ผู้เล่นได้รับไอเทมและเงินในเกมขณะเล่นเกม
- ตลาดกลาง: ช่วยให้ผู้เล่นซื้อและขายไอเทมในตลาดกลางได้
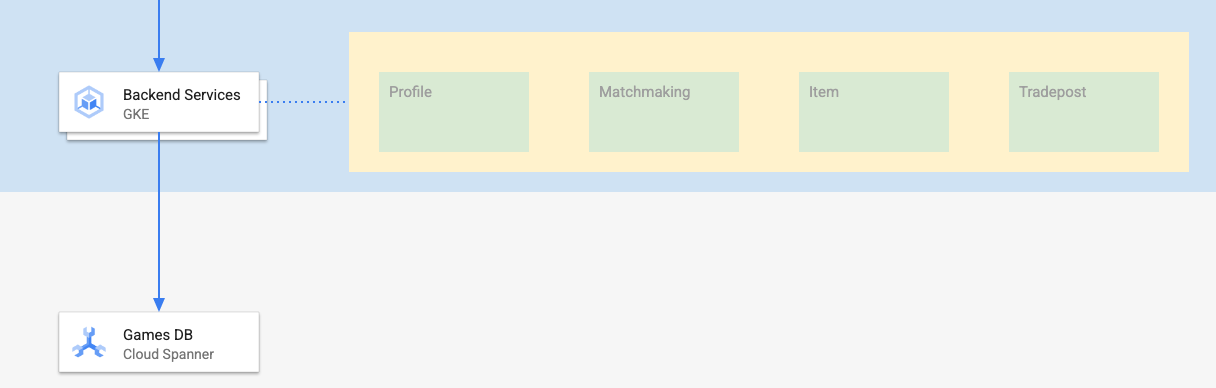
ดูข้อมูลเพิ่มเติมเกี่ยวกับบริการเหล่านี้ได้ใน Codelab Cloud Spanner Getting Started with Games Development สำหรับวัตถุประสงค์ของเรา เราต้องการให้บริการเหล่านี้ทำงานในคลัสเตอร์ GKE Autopilot
บริการเหล่านี้ต้องแก้ไขข้อมูล Spanner ได้ โดยแต่ละบริการจะมีบัญชีบริการที่สร้างขึ้นซึ่งให้บทบาท "databaseUser" แก่บริการนั้น
Workload Identity ช่วยให้บัญชีบริการ Kubernetes แสดงตัวเป็นบัญชีบริการของ Google Cloud ของบริการได้โดยทำตามขั้นตอนต่อไปนี้ใน Terraform
- สร้างทรัพยากรบัญชีบริการ Google Cloud ของบริการ (
GSA) - มอบหมายบทบาท databaseUser ให้กับบัญชีบริการนั้น
- มอบหมายบทบาท workloadIdentityUser ให้กับบัญชีบริการนั้น
- สร้างบัญชีบริการ Kubernetes (
KSA) ที่อ้างอิง GSA
แผนภาพคร่าวๆ จะมีลักษณะดังนี้

Terraform สร้างบัญชีบริการและบัญชีบริการ Kubernetes ให้คุณแล้ว และคุณสามารถตรวจสอบบัญชีบริการ Kubernetes ได้โดยใช้ kubectl ดังนี้
# kubectl get serviceaccounts
NAME SECRETS AGE
default 0 37m
item-app 0 35m
matchmaking-app 0 35m
profile-app 0 35m
tradepost-app 0 35m
การทำงานของการสร้างมีดังนี้
- Terraform สร้างไฟล์
$DEMO_HOME/backend_services/cloudbuild.yamlที่มีลักษณะดังนี้
serviceAccount: projects/${PROJECT_ID}/serviceAccounts/cloudbuild-cicd@${PROJECT_ID}.iam.gserviceaccount.com
steps:
#
# Building of images
#
- name: gcr.io/cloud-builders/docker
id: profile
args: ["build", ".", "-t", "${_PROFILE_IMAGE}"]
dir: profile
waitFor: ['-']
- name: gcr.io/cloud-builders/docker
id: matchmaking
args: ["build", ".", "-t", "${_MATCHMAKING_IMAGE}"]
dir: matchmaking
waitFor: ['-']
- name: gcr.io/cloud-builders/docker
id: item
args: ["build", ".", "-t", "${_ITEM_IMAGE}"]
dir: item
waitFor: ['-']
- name: gcr.io/cloud-builders/docker
id: tradepost
args: ["build", ".", "-t", "${_TRADEPOST_IMAGE}"]
dir: tradepost
waitFor: ['-']
#
# Deployment
#
- name: gcr.io/google.com/cloudsdktool/cloud-sdk
id: cloud-deploy-release
entrypoint: gcloud
args:
[
"deploy", "releases", "create", "${_REL_NAME}",
"--delivery-pipeline", "sample-game-services",
"--skaffold-file", "skaffold.yaml",
"--skaffold-version", "1.39",
"--images", "profile=${_PROFILE_IMAGE},matchmaking=${_MATCHMAKING_IMAGE},item=${_ITEM_IMAGE},tradepost=${_TRADEPOST_IMAGE}",
"--region", "us-central1"
]
artifacts:
images:
- ${_REGISTRY}/profile
- ${_REGISTRY}/matchmaking
- ${_REGISTRY}/item
- ${_REGISTRY}/tradepost
substitutions:
_PROFILE_IMAGE: ${_REGISTRY}/profile:${BUILD_ID}
_MATCHMAKING_IMAGE: ${_REGISTRY}/matchmaking:${BUILD_ID}
_ITEM_IMAGE: ${_REGISTRY}/item:${BUILD_ID}
_TRADEPOST_IMAGE: ${_REGISTRY}/tradepost:${BUILD_ID}
_REGISTRY: us-docker.pkg.dev/${PROJECT_ID}/spanner-game-images
_REL_NAME: rel-${BUILD_ID:0:8}
options:
dynamic_substitutions: true
machineType: E2_HIGHCPU_8
logging: CLOUD_LOGGING_ONLY
- คำสั่ง Cloud Build จะอ่านไฟล์นี้และทำตามขั้นตอนที่ระบุไว้ ก่อนอื่น ระบบจะสร้างอิมเมจบริการ จากนั้นจะเรียกใช้คำสั่ง
gcloud deploy createซึ่งจะอ่านไฟล์$DEMO_HOME/backend_services/skaffold.yamlซึ่งกำหนดตำแหน่งของไฟล์การติดตั้งใช้งานแต่ละไฟล์
apiVersion: skaffold/v2beta29
kind: Config
deploy:
kubectl:
manifests:
- spanner_config.yaml
- profile/deployment.yaml
- matchmaking/deployment.yaml
- item/deployment.yaml
- tradepost/deployment.yaml
- Cloud Deploy จะทำตามคำจำกัดความของไฟล์
deployment.yamlของแต่ละบริการ ไฟล์การติดตั้งใช้งานของบริการมีข้อมูลสำหรับการสร้างบริการ ซึ่งในกรณีนี้คือ ClusterIP ที่ทำงานบนพอร์ต 80
ประเภท "ClusterIP" จะป้องกันไม่ให้พ็อดบริการแบ็กเอนด์มี IP ภายนอก ดังนั้นเฉพาะเอนทิตีที่เชื่อมต่อกับเครือข่าย GKE ภายในได้เท่านั้นที่จะเข้าถึงบริการแบ็กเอนด์ได้ ผู้เล่นไม่ควรเข้าถึงบริการเหล่านี้โดยตรงเนื่องจากบริการเหล่านี้เข้าถึงและแก้ไขข้อมูล Spanner
apiVersion: v1
kind: Service
metadata:
name: profile
spec:
type: ClusterIP
selector:
app: profile
ports:
- port: 80
targetPort: 80
นอกจากสร้างบริการ Kubernetes แล้ว Cloud Deploy ยังสร้างการทำให้ใช้งานได้ของ Kubernetes ด้วย มาดูส่วนการติดตั้งใช้งานของprofileบริการกัน
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: profile
spec:
replicas: 2 # EDIT: Number of instances of deployment
selector:
matchLabels:
app: profile
template:
metadata:
labels:
app: profile
spec:
serviceAccountName: profile-app
containers:
- name: profile-service
image: profile
ports:
- containerPort: 80
envFrom:
- configMapRef:
name: spanner-config
env:
- name: SERVICE_HOST
value: "0.0.0.0"
- name: SERVICE_PORT
value: "80"
resources:
requests:
cpu: "1"
memory: "1Gi"
ephemeral-storage: "100Mi"
limits:
cpu: "1"
memory: "1Gi"
ephemeral-storage: "100Mi"
ส่วนบนสุดจะแสดงข้อมูลเมตาบางอย่างเกี่ยวกับบริการ ส่วนที่สำคัญที่สุดจากส่วนนี้คือการกำหนดจำนวนรีพลิก้าที่การติดตั้งใช้งานนี้จะสร้าง
replicas: 2 # EDIT: Number of instances of deployment
จากนั้นเราจะดูว่าบัญชีบริการใดควรเรียกใช้แอปและควรใช้อิมเมจใด ซึ่งจะตรงกับบัญชีบริการ Kubernetes ที่สร้างจาก Terraform และอิมเมจที่สร้างขึ้นในขั้นตอน Cloud Build
spec:
serviceAccountName: profile-app
containers:
- name: profile-service
image: profile
หลังจากนั้น เราจะระบุข้อมูลบางอย่างเกี่ยวกับตัวแปรเครือข่ายและตัวแปรสภาพแวดล้อม
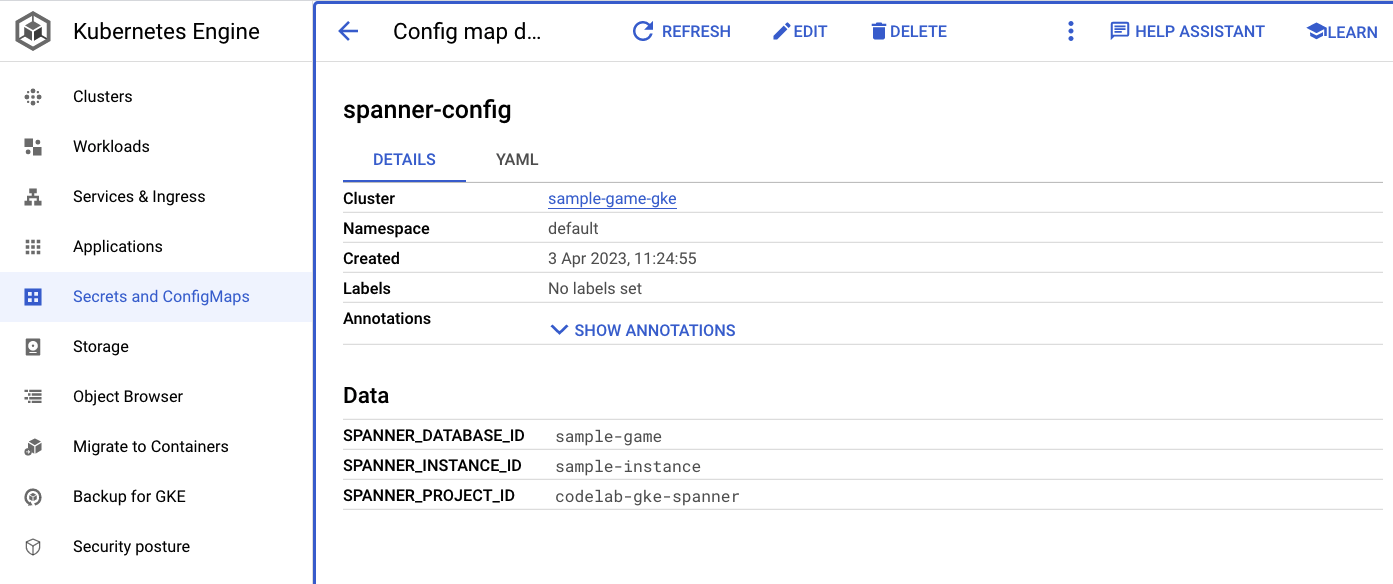
spanner_config คือ ConfigMap ของ Kubernetes ที่ระบุข้อมูลโปรเจ็กต์ อินสแตนซ์ และฐานข้อมูลที่แอปพลิเคชันต้องใช้เพื่อเชื่อมต่อกับ Spanner
apiVersion: v1
kind: ConfigMap
metadata:
name: spanner-config
data:
SPANNER_PROJECT_ID: ${project_id}
SPANNER_INSTANCE_ID: ${instance_id}
SPANNER_DATABASE_ID: ${database_id}
ports:
- containerPort: 80
envFrom:
- configMapRef:
name: spanner-config
env:
- name: SERVICE_HOST
value: "0.0.0.0"
- name: SERVICE_PORT
value: "80"
SERVICE_HOST และ SERVICE_PORT เป็นตัวแปรสภาพแวดล้อมเพิ่มเติมที่บริการต้องการเพื่อทราบว่าจะเชื่อมโยงกับที่ใด
ส่วนสุดท้ายจะบอก GKE ว่าจะอนุญาตทรัพยากรจำนวนเท่าใดสำหรับแต่ละรีพลิกาในการติดตั้งใช้งานนี้ ซึ่งเป็นสิ่งที่ GKE Autopilot ใช้ในการปรับขนาดคลัสเตอร์ตามต้องการด้วย
resources:
requests:
cpu: "1"
memory: "1Gi"
ephemeral-storage: "100Mi"
limits:
cpu: "1"
memory: "1Gi"
ephemeral-storage: "100Mi"
เมื่อมีข้อมูลนี้แล้ว ก็ถึงเวลาที่จะติดตั้งใช้งานบริการแบ็กเอนด์
ติดตั้งใช้งานบริการแบ็กเอนด์
ดังที่กล่าวไว้ การทำให้บริการแบ็กเอนด์ใช้งานได้จะใช้ Cloud Build คุณส่งคำขอสร้างได้โดยใช้บรรทัดคำสั่ง gcloud เช่นเดียวกับการย้ายข้อมูลสคีมา
cd $DEMO_HOME/backend_services gcloud builds submit --config=cloudbuild.yaml
เอาต์พุตของคำสั่ง
Creating temporary tarball archive of 66 file(s) totalling 864.6 KiB before compression.
Uploading tarball of [.] to [gs://(project)_cloudbuild/source/(snip).tgz]
Created [https://cloudbuild.googleapis.com/v1/projects/(project)/locations/global/builds/30207dd1-(snip)].
Logs are available at [ https://console.cloud.google.com/cloud-build/builds/30207dd1-(snip)?project=(snip) ].
gcloud builds submit only displays logs from Cloud Storage. To view logs from Cloud Logging, run:
gcloud beta builds submit
ID: 30207dd1-(snip)
CREATE_TIME: (created time)
DURATION: 3M17S
SOURCE: gs://(project)_cloudbuild/source/(snip).tgz
IMAGES: us-docker.pkg.dev/(project)/spanner-game-images/profile:30207dd1-(snip) (+3 more)
STATUS: SUCCESS
เอาต์พุตของการสร้างนี้จะระบุว่ามีการสร้างรูปภาพบางรูป ซึ่งแตกต่างจากเอาต์พุตของschema migration ขั้นตอน ระบบจะจัดเก็บไฟล์เหล่านั้นไว้ในที่เก็บ Artifact Registry
เอาต์พุตของgcloud build ขั้นตอนจะมีลิงก์ไปยัง Cloud Console ลองดู
เมื่อได้รับการแจ้งเตือนว่า Cloud Build ทำงานสำเร็จแล้ว ให้ไปที่ Cloud Deploy แล้วไปที่sample-game-servicesไปป์ไลน์เพื่อตรวจสอบความคืบหน้าของการติดตั้งใช้งาน

เมื่อติดตั้งใช้งานบริการแล้ว คุณจะตรวจสอบสถานะของพ็อดได้โดยไปที่ kubectl
kubectl get pods
เอาต์พุตของคำสั่ง
NAME READY STATUS RESTARTS AGE
item-6b9d5f678c-4tbk2 1/1 Running 0 83m
matchmaking-5bcf799b76-lg8zf 1/1 Running 0 80m
profile-565bbf4c65-kphdl 1/1 Running 0 83m
profile-565bbf4c65-xw74j 1/1 Running 0 83m
tradepost-68b87ccd44-gw55r 1/1 Running 0 79m
จากนั้นตรวจสอบบริการเพื่อดูว่า ClusterIP ทำงานอย่างไร
kubectl get services
เอาต์พุตของคำสั่ง
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
item ClusterIP 10.172.XXX.XXX <none> 80/TCP 84m
kubernetes ClusterIP 10.172.XXX.XXX <none> 443/TCP 137m
matchmaking ClusterIP 10.172.XXX.XXX <none> 80/TCP 84m
profile ClusterIP 10.172.XXX.XXX <none> 80/TCP 84m
tradepost ClusterIP 10.172.XXX.XXX <none> 80/TCP 84m
นอกจากนี้ คุณยังไปที่ UI ของ GKE ใน Cloud Console เพื่อดู Workloads, Services และ ConfigMaps ได้ด้วย
ภาระงาน

บริการ

ConfigMaps

สรุป
ในขั้นตอนนี้ คุณได้ติดตั้งใช้งานบริการแบ็กเอนด์ 4 รายการใน GKE Autopilot คุณสามารถเรียกใช้ขั้นตอน Cloud Build และตรวจสอบความคืบหน้าใน Cloud Deploy และใน Kubernetes ใน Cloud Console ได้
นอกจากนี้ คุณยังได้เรียนรู้วิธีที่บริการเหล่านี้ใช้ Workload Identity เพื่อแอบอ้างเป็นบัญชีบริการที่มีสิทธิ์ที่เหมาะสมในการอ่านและเขียนข้อมูลไปยังฐานข้อมูล Spanner
ขั้นตอนถัดไป
ในส่วนถัดไป คุณจะติดตั้งใช้งานเวิร์กโหลด
6. ติดตั้งใช้งานภาระงาน
ภาพรวม
เมื่อบริการแบ็กเอนด์ทำงานในคลัสเตอร์แล้ว คุณจะทำให้ภาระงานใช้งานได้

โดยจะเข้าถึงภาระงานได้จากภายนอก และมีภาระงานหนึ่งรายการสำหรับบริการแบ็กเอนด์แต่ละรายการเพื่อวัตถุประสงค์ของโค้ดแล็บนี้
ภาระงานเหล่านี้คือสคริปต์การสร้างโหลดที่อิงตาม Locust ซึ่งเลียนแบบรูปแบบการเข้าถึงจริงที่บริการตัวอย่างเหล่านี้คาดหวัง
มีไฟล์สำหรับกระบวนการ Cloud Build ดังนี้
$DEMO_HOME/workloads/cloudbuild.yaml(สร้างโดย Terraform)$DEMO_HOME/workloads/skaffold.yaml- ไฟล์
deployment.yamlสำหรับภาระงานแต่ละรายการ
ไฟล์เวิร์กโหลด deployment.yaml จะมีลักษณะแตกต่างจากไฟล์การติดตั้งใช้งานบริการแบ็กเอนด์เล็กน้อย
ตัวอย่างจาก matchmaking-workload
apiVersion: v1
kind: Service
metadata:
name: matchmaking-workload
spec:
type: LoadBalancer
selector:
app: matchmaking-workload
ports:
- port: 8089
targetPort: 8089
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: matchmaking-workload
spec:
replicas: 1 # EDIT: Number of instances of deployment
selector:
matchLabels:
app: matchmaking-workload
template:
metadata:
labels:
app: matchmaking-workload
spec:
serviceAccountName: default
containers:
- name: matchmaking-workload
image: matchmaking-workload
ports:
- containerPort: 8089
resources:
requests:
cpu: "500m"
memory: "512Mi"
ephemeral-storage: "100Mi"
limits:
cpu: "500m"
memory: "512Mi"
ephemeral-storage: "100Mi"
ส่วนบนของไฟล์จะกำหนดบริการ ในกรณีนี้ ระบบจะสร้าง LoadBalancer และเวิร์กโหลดจะทำงานบนพอร์ต 8089
LoadBalancer จะระบุ IP ภายนอกที่ใช้เชื่อมต่อกับเวิร์กโหลดได้
apiVersion: v1
kind: Service
metadata:
name: matchmaking-workload
spec:
type: LoadBalancer
selector:
app: matchmaking-workload
ports:
- port: 8089
targetPort: 8089
ส่วนบนสุดของส่วนการทำให้ใช้งานได้คือข้อมูลเมตาเกี่ยวกับเวิร์กโหลด ในกรณีนี้ ระบบจะติดตั้งใช้งานเพียงรีพลิกาดังนี้
replicas: 1
แต่ข้อกำหนดของคอนเทนเนอร์จะแตกต่างกัน ประการแรก เราใช้defaultบัญชีบริการ Kubernetes บัญชีนี้ไม่มีสิทธิ์พิเศษใดๆ เนื่องจากภาระงานไม่จำเป็นต้องเชื่อมต่อกับทรัพยากร Google Cloud ใดๆ ยกเว้นบริการแบ็กเอนด์ที่ทำงานในคลัสเตอร์ GKE
ความแตกต่างอีกอย่างคือไม่จำเป็นต้องใช้ตัวแปรสภาพแวดล้อมสำหรับภาระงานเหล่านี้ ผลลัพธ์ที่ได้คือข้อกำหนดการติดตั้งใช้งานที่สั้นลง
spec:
serviceAccountName: default
containers:
- name: matchmaking-workload
image: matchmaking-workload
ports:
- containerPort: 8089
การตั้งค่าทรัพยากรจะคล้ายกับบริการแบ็กเอนด์ โปรดทราบว่าวิธีนี้คือวิธีที่ GKE Autopilot ทราบว่าต้องใช้ทรัพยากรจำนวนเท่าใดจึงจะตอบสนองคำขอของพ็อดทั้งหมดที่ทำงานในคลัสเตอร์ได้
เริ่มทำให้ภาระงานใช้งานได้เลย
ติดตั้งใช้งานภาระงาน
คุณส่งคำขอสร้างได้โดยใช้บรรทัดคำสั่ง gcloud เช่นเดียวกับก่อนหน้านี้
cd $DEMO_HOME/workloads gcloud builds submit --config=cloudbuild.yaml
เอาต์พุตของคำสั่ง
Creating temporary tarball archive of 18 file(s) totalling 26.2 KiB before compression.
Some files were not included in the source upload.
Check the gcloud log [/tmp/tmp.4Z9EqdPo6d/logs/(snip).log] to see which files and the contents of the
default gcloudignore file used (see `$ gcloud topic gcloudignore` to learn
more).
Uploading tarball of [.] to [gs://(project)_cloudbuild/source/(snip).tgz]
Created [https://cloudbuild.googleapis.com/v1/projects/(project)/locations/global/builds/(snip)].
Logs are available at [ https://console.cloud.google.com/cloud-build/builds/0daf20f6-(snip)?project=(snip) ].
gcloud builds submit only displays logs from Cloud Storage. To view logs from Cloud Logging, run:
gcloud beta builds submit
ID: 0daf20f6-(snip)
CREATE_TIME: (created_time)
DURATION: 1M41S
SOURCE: gs://(project)_cloudbuild/source/(snip).tgz
IMAGES: us-docker.pkg.dev/(project)/spanner-game-images/profile-workload:0daf20f6-(snip) (+4 more)
STATUS: SUCCESS
อย่าลืมตรวจสอบบันทึกของ Cloud Build และไปป์ไลน์ Cloud Deploy ใน Cloud Console เพื่อตรวจสอบสถานะ สำหรับภาระงาน ไปป์ไลน์ Cloud Deploy จะมีลักษณะดังนี้ sample-game-workloads
เมื่อทำให้ใช้งานได้แล้ว ให้ตรวจสอบสถานะด้วย kubectl ใน Cloud Shell ดังนี้
kubectl get pods
เอาต์พุตของคำสั่ง
NAME READY STATUS RESTARTS AGE
game-workload-7ff44cb657-pxxq2 1/1 Running 0 12m
item-6b9d5f678c-cr29w 1/1 Running 0 9m6s
item-generator-7bb4f57cf8-5r85b 1/1 Running 0 12m
matchmaking-5bcf799b76-lg8zf 1/1 Running 0 117m
matchmaking-workload-76df69dbdf-jds9z 1/1 Running 0 12m
profile-565bbf4c65-kphdl 1/1 Running 0 121m
profile-565bbf4c65-xw74j 1/1 Running 0 121m
profile-workload-76d6db675b-kzwng 1/1 Running 0 12m
tradepost-68b87ccd44-gw55r 1/1 Running 0 116m
tradepost-workload-56c55445b5-b5822 1/1 Running 0 12m
จากนั้นตรวจสอบบริการของเวิร์กโหลดเพื่อดู LoadBalancer ในการทำงาน โดยทำดังนี้
kubectl get services
เอาต์พุตของคำสั่ง
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
game-workload LoadBalancer *snip* 35.XX.XX.XX 8089:32483/TCP 12m
item ClusterIP *snip* <none> 80/TCP 121m
item-generator LoadBalancer *snip* 34.XX.XX.XX 8089:32581/TCP 12m
kubernetes ClusterIP *snip* <none> 443/TCP 174m
matchmaking ClusterIP *snip* <none> 80/TCP 121m
matchmaking-workload LoadBalancer *snip* 34.XX.XX.XX 8089:31735/TCP 12m
profile ClusterIP *snip* <none> 80/TCP 121m
profile-workload LoadBalancer *snip* 34.XX.XX.XX 8089:32532/TCP 12m
tradepost ClusterIP *snip* <none> 80/TCP 121m
tradepost-workload LoadBalancer *snip* 34.XX.XX.XX 8089:30002/TCP 12m
สรุป
ตอนนี้คุณได้ติดตั้งใช้งานเวิร์กโหลดไปยังคลัสเตอร์ GKE แล้ว เวิร์กโหลดเหล่านี้ไม่จำเป็นต้องมีสิทธิ์ IAM เพิ่มเติม และเข้าถึงได้จากภายนอกในพอร์ต 8089 โดยใช้บริการ LoadBalancer
ขั้นตอนถัดไป
เมื่อบริการและภาระงานของแบ็กเอนด์ทำงานแล้ว ก็ถึงเวลา "เล่น" เกมแล้ว
7. เริ่มเล่นเกม
ภาพรวม
ตอนนี้บริการแบ็กเอนด์สำหรับ "เกม" ตัวอย่างของคุณทำงานอยู่ และคุณยังมีวิธีสร้าง "ผู้เล่น" ที่โต้ตอบกับบริการเหล่านั้นโดยใช้เวิร์กโหลดด้วย
เวิร์กโหลดแต่ละรายการใช้ Locust เพื่อจำลองโหลดจริงเทียบกับ API ของบริการ ในขั้นตอนนี้ คุณจะเรียกใช้ภาระงานหลายอย่างเพื่อสร้างภาระงานในคลัสเตอร์ GKE และใน Spanner รวมถึงจัดเก็บข้อมูลใน Spanner
คำอธิบายของภาระงานแต่ละอย่างมีดังนี้
- ภาระงาน
item-generatorเป็นภาระงานที่รวดเร็วในการสร้างรายการ game_items ที่ผู้เล่นจะได้รับจากการ "เล่น" เกม profile-workloadจำลองการลงชื่อสมัครใช้และเข้าสู่ระบบของผู้เล่นmatchmaking-workloadจะจำลองผู้เล่นที่เข้าคิวเพื่อรับการจับคู่กับเกมgame-workloadจำลองการที่ผู้เล่นได้รับ game_item และเงินจากการเล่นเกมtradepost-workloadจำลองการที่ผู้เล่นสามารถขายและซื้อไอเทมในตลาดกลาง
Codelab นี้จะเน้นการเรียกใช้ item-generator และ profile-workload โดยเฉพาะ
เรียกใช้เครื่องมือสร้างรายการ
item-generator ใช้ปลายทางบริการแบ็กเอนด์ item เพื่อเพิ่ม game_items ลงใน Spanner คุณต้องระบุข้อมูลเหล่านี้เพื่อให้ game-workload และ tradepost-workload ทำงานได้อย่างถูกต้อง
ขั้นตอนแรกคือการรับ IP ภายนอกของบริการ item-generator ใน Cloud Shell ให้เรียกใช้คำสั่งต่อไปนี้
# The external IP is the 4th column of the output
kubectl get services | grep item-generator | awk '{print $4}'
เอาต์พุตของคำสั่ง
{ITEMGENERATOR_EXTERNAL_IP}
ตอนนี้ให้เปิดแท็บเบราว์เซอร์ใหม่แล้วไปที่ http://{ITEMGENERATOR_EXTERNAL_IP}:8089 คุณควรเห็นหน้าเว็บดังนี้
คุณจะปล่อยให้ users และ spawn มีค่าเริ่มต้นเป็น 1 สำหรับ host ให้ป้อน http://item คลิกตัวเลือกขั้นสูง แล้วป้อน 10s สำหรับระยะเวลาการทำงาน
การกำหนดค่าควรมีลักษณะดังนี้

คลิก "เริ่มการสวอม"
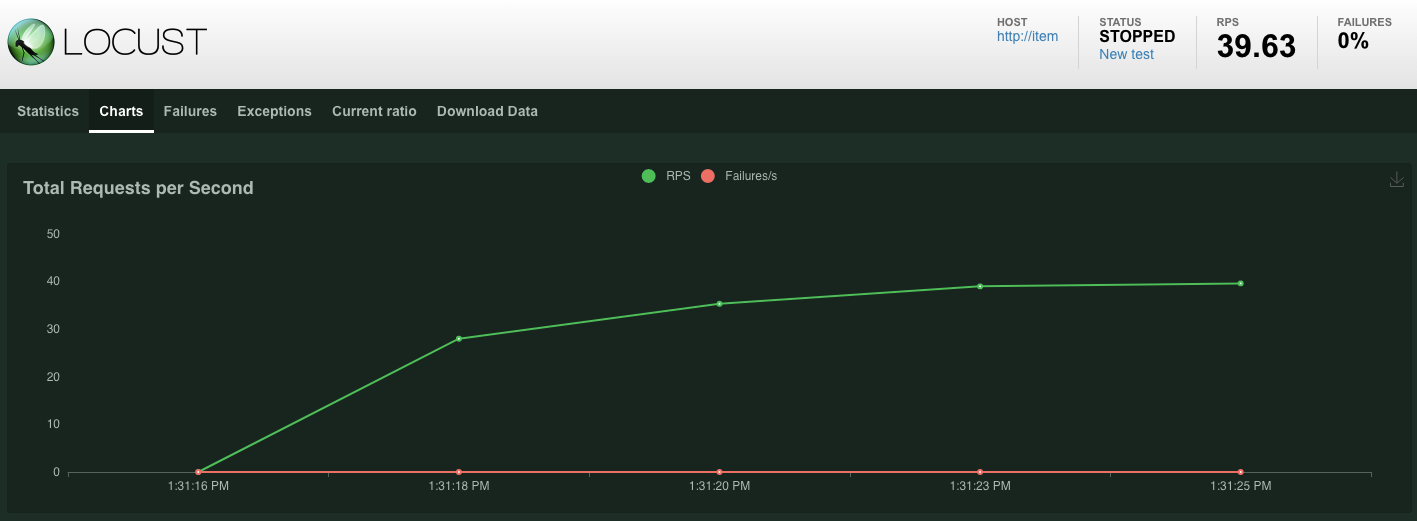
สถิติจะเริ่มแสดงสำหรับคำขอที่ออกในปลายทาง POST /items หลังจากผ่านไป 10 วินาที ระบบจะหยุดโหลด
คลิกไปที่ Charts แล้วคุณจะเห็นกราฟบางส่วนเกี่ยวกับประสิทธิภาพของคำขอเหล่านี้
ตอนนี้คุณต้องการตรวจสอบว่ามีการป้อนข้อมูลลงในฐานข้อมูล Spanner หรือไม่
โดยคลิกเมนูแฮมเบอร์เกอร์แล้วไปที่ "Spanner" จากหน้านี้ ให้ไปที่sample-instanceและsample-database จากนั้นคลิก "Query"
เราต้องการเลือกจำนวน game_items:
SELECT COUNT(*) FROM game_items;
คุณจะเห็นผลลัพธ์ที่ด้านล่าง
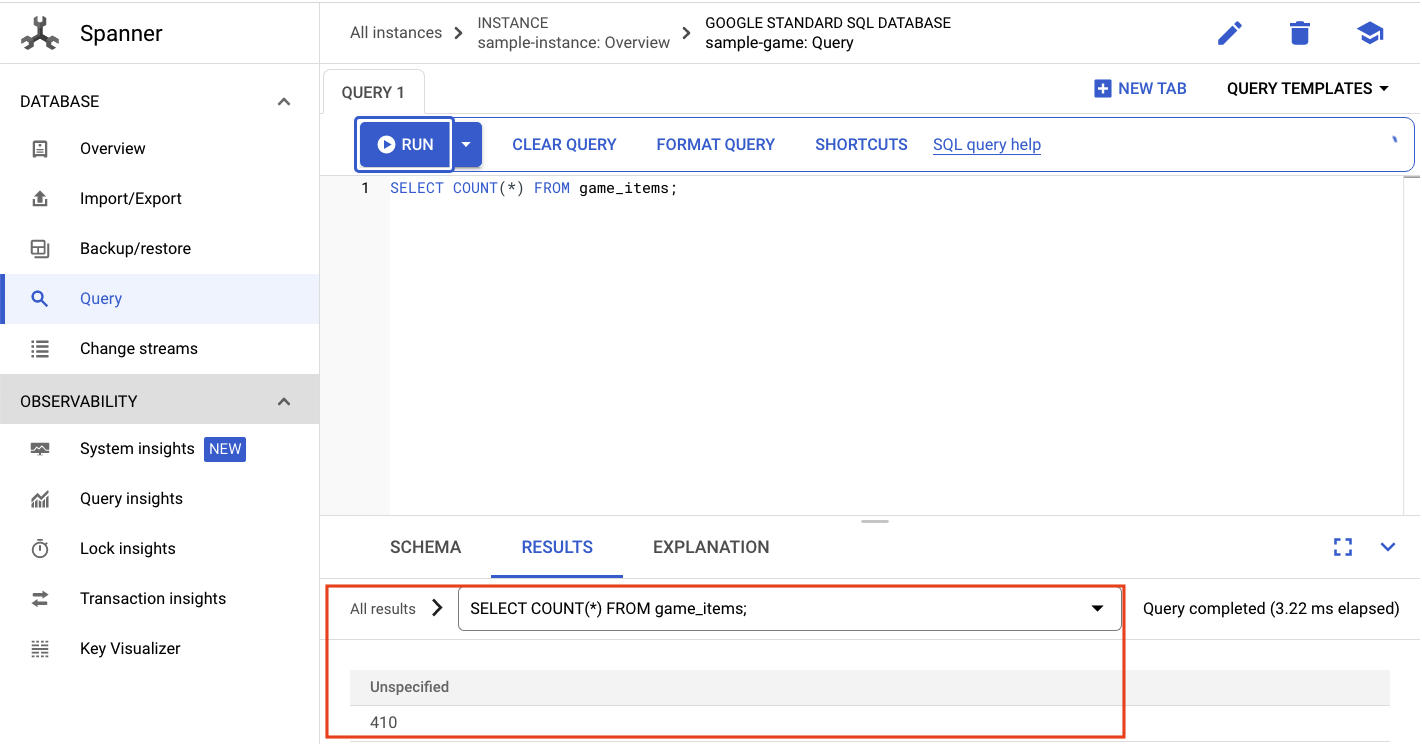
เราไม่จำเป็นต้องgame_itemsจำนวนมาก แต่ตอนนี้ผู้เล่นสามารถรับไอเทมเหล่านี้ได้แล้ว
เรียกใช้เวิร์กโหลดโปรไฟล์
เมื่อgame_itemsแล้ว ขั้นตอนถัดไปคือการให้ผู้เล่นลงชื่อสมัครใช้เพื่อเล่นเกม
profile-workload จะใช้ Locust เพื่อจำลองผู้เล่นที่สร้างบัญชี เข้าสู่ระบบ ดึงข้อมูลโปรไฟล์ และออกจากระบบ การทดสอบทั้งหมดนี้จะทดสอบปลายทางของprofileบริการแบ็กเอนด์ในปริมาณงานที่คล้ายกับการใช้งานจริงทั่วไป
หากต้องการเรียกใช้ ให้รับ profile-workloadIP ภายนอกโดยทำดังนี้
# The external IP is the 4th column of the output
kubectl get services | grep profile-workload | awk '{print $4}'
เอาต์พุตของคำสั่ง
{PROFILEWORKLOAD_EXTERNAL_IP}
ตอนนี้ให้เปิดแท็บเบราว์เซอร์ใหม่แล้วไปที่ http://{PROFILEWORKLOAD_EXTERNAL_IP}:8089 คุณควรเห็นหน้า Locust ที่คล้ายกับหน้าก่อนหน้า
ในกรณีนี้ คุณจะใช้ http://profile สำหรับโฮสต์ และคุณจะไม่ระบุรันไทม์ในตัวเลือกขั้นสูง นอกจากนี้ ให้ระบุ users เป็น 4 ซึ่งจะจำลองคำขอของผู้ใช้ 4 รายการพร้อมกัน
การทดสอบ profile-workload ควรมีลักษณะดังนี้

คลิก "เริ่มการสวอม"
เช่นเดียวกับก่อนหน้านี้ สถิติของprofileปลายทาง REST ต่างๆ จะเริ่มปรากฏขึ้น คลิกแผนภูมิเพื่อดูภาพรวมของประสิทธิภาพทั้งหมด
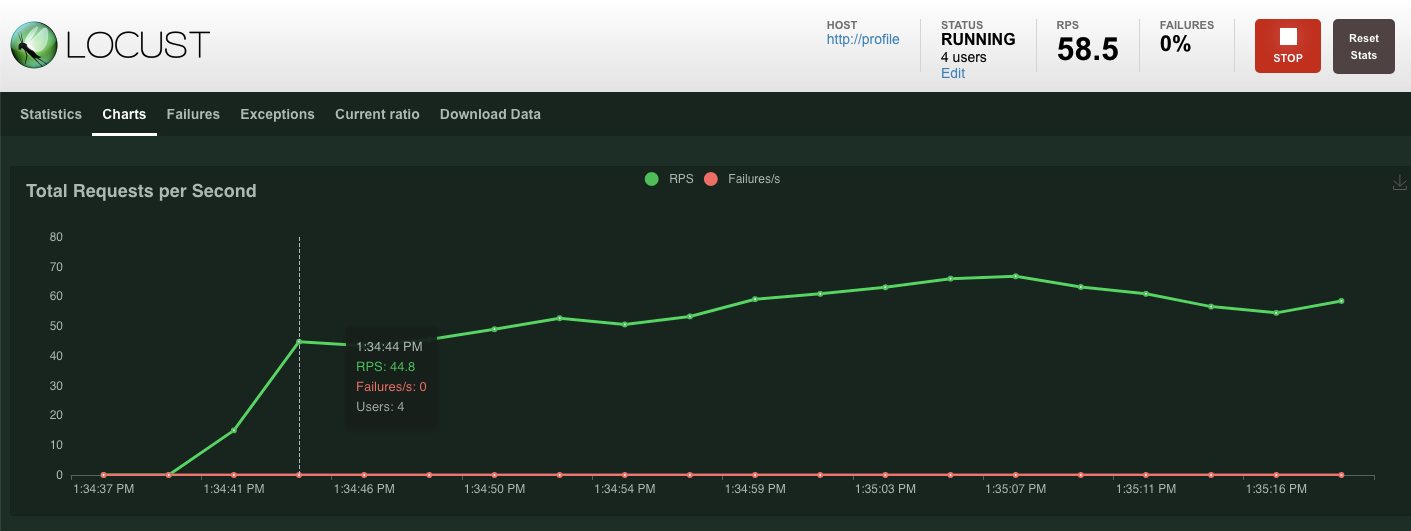
สรุป
ในขั้นตอนนี้ คุณได้สร้างgame_itemsบางรายการ จากนั้นจึงค้นหาตาราง game_items โดยใช้ UI การค้นหาของ Spanner ใน Cloud Console
นอกจากนี้ คุณยังอนุญาตให้ผู้เล่นลงชื่อสมัครใช้เกมของคุณ และดูว่า Locust สามารถสร้างภาระงานที่คล้ายกับเวอร์ชันที่ใช้งานจริงกับบริการแบ็กเอนด์ของคุณได้อย่างไร
ขั้นตอนถัดไป
หลังจากเรียกใช้เวิร์กโหลดแล้ว คุณอาจต้องการตรวจสอบลักษณะการทำงานของคลัสเตอร์ GKE และอินสแตนซ์ Spanner
8. ตรวจสอบการใช้งาน GKE และ Spanner
เมื่อบริการโปรไฟล์ทำงานแล้ว ก็ถึงเวลาใช้โอกาสนี้เพื่อดูว่าคลัสเตอร์ GKE Autopilot และ Cloud Spanner ทำงานอย่างไร
ตรวจสอบคลัสเตอร์ GKE
ไปที่คลัสเตอร์ Kubernetes โปรดทราบว่าเนื่องจากคุณได้ติดตั้งใช้งานภาระงานและบริการแล้ว ตอนนี้คลัสเตอร์จึงมีรายละเอียดเพิ่มเติมเกี่ยวกับ vCPU และหน่วยความจำทั้งหมด ข้อมูลนี้จะไม่พร้อมใช้งานเมื่อไม่มีภาระงานในคลัสเตอร์
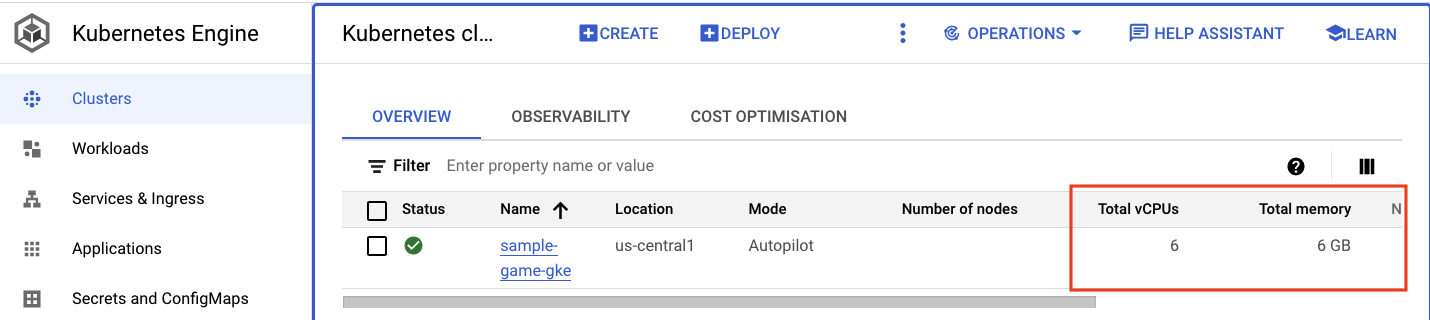
ตอนนี้ ให้คลิกคลัสเตอร์ sample-game-gke แล้วเปลี่ยนไปที่แท็บการสังเกตการณ์

default เนมสเปซ Kubernetes ควรมีการใช้งาน CPU มากกว่าเนมสเปซ kube-system เนื่องจากเวิร์กโหลดและบริการแบ็กเอนด์ของเราทำงานใน default หากยังไม่เสร็จ ให้ตรวจสอบว่า profile workload ยังทำงานอยู่ และรอสักครู่เพื่อให้แผนภูมิอัปเดต
หากต้องการดูว่าภาระงานใดใช้ทรัพยากรมากที่สุด ให้ไปที่Workloadsแดชบอร์ด
แทนที่จะไปที่เวิร์กโหลดแต่ละรายการ ให้ไปที่แท็บการสังเกตการณ์ของแดชบอร์ดโดยตรง คุณควรเห็นว่า CPU ของ profile และ profile-workload เพิ่มขึ้น

ตอนนี้ไปตรวจสอบใน Cloud Spanner
ตรวจสอบอินสแตนซ์ Cloud Spanner
หากต้องการตรวจสอบประสิทธิภาพของ Cloud Spanner ให้ไปที่ Spanner แล้วคลิกsample-instanceอินสแตนซ์และsample-gameฐานข้อมูล
จากนั้นคุณจะเห็นแท็บข้อมูลเชิงลึกของระบบในเมนูด้านซ้าย
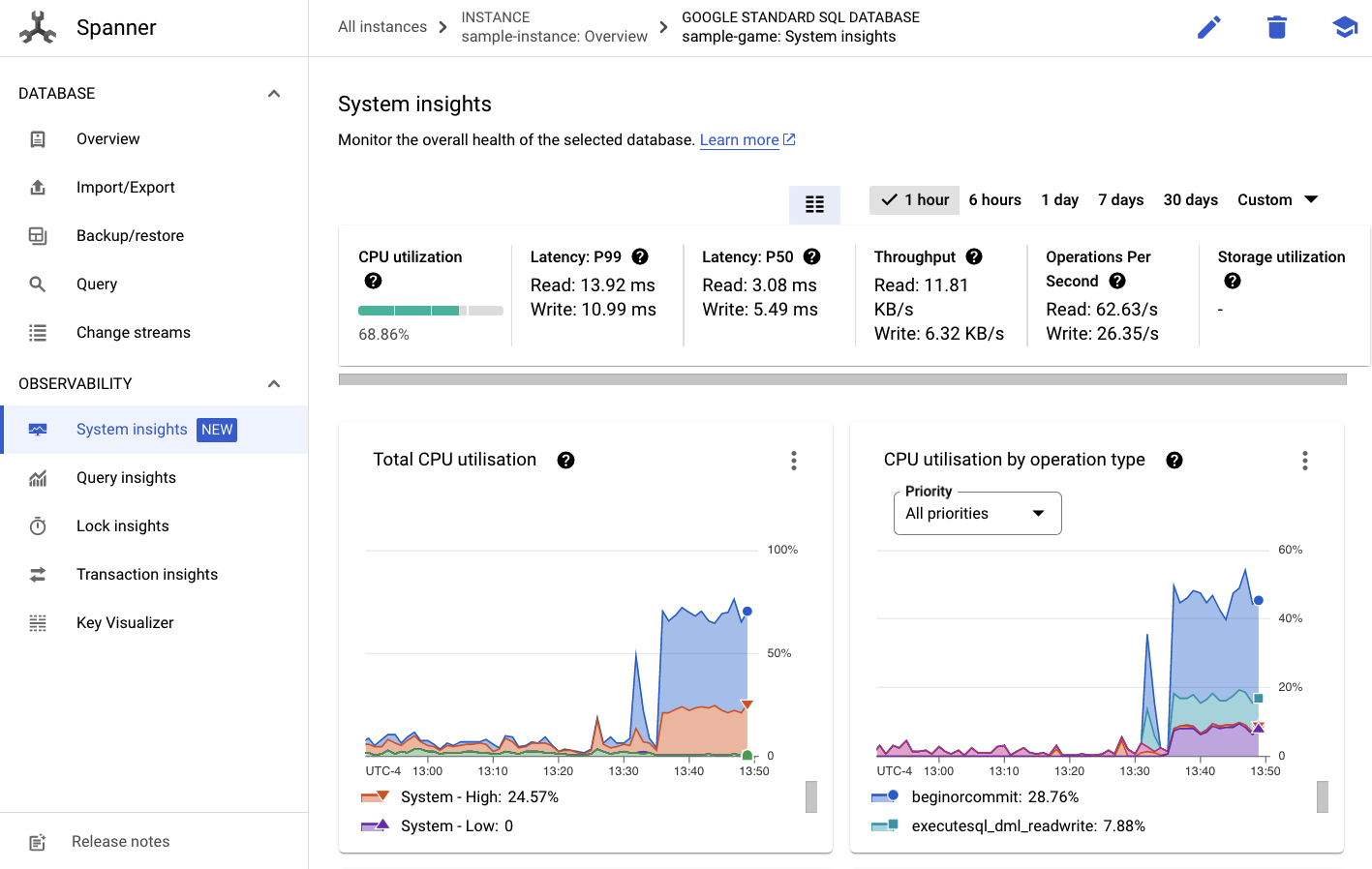
ที่นี่มีแผนภูมิมากมายที่จะช่วยให้คุณเข้าใจประสิทธิภาพทั่วไปของอินสแตนซ์ Spanner ซึ่งรวมถึง CPU utilization, transaction latency and locking และ query throughput
นอกจากข้อมูลเชิงลึกของระบบแล้ว คุณยังดูข้อมูลโดยละเอียดเพิ่มเติมเกี่ยวกับภาระงานของคําค้นหาได้โดยดูลิงก์อื่นๆ ในส่วนการสังเกตการณ์
- ข้อมูลเชิงลึกของการค้นหาช่วยระบุการค้นหาที่ใช้ทรัพยากรใน Spanner มากที่สุด
- ข้อมูลเชิงลึกเกี่ยวกับธุรกรรมและการล็อกช่วยระบุธุรกรรมที่มีเวลาในการตอบสนองสูง
- เครื่องมือแสดงภาพคีย์ช่วยให้เห็นภาพรูปแบบการเข้าถึงและช่วยติดตามฮอตสปอตในข้อมูล
สรุป
ในขั้นตอนนี้ คุณได้เรียนรู้วิธีตรวจสอบเมตริกประสิทธิภาพพื้นฐานบางอย่างสำหรับทั้ง GKE Autopilot และ Spanner
เช่น เมื่อเวิร์กโหลดโปรไฟล์ทำงาน ให้ค้นหาตาราง players เพื่อดูข้อมูลเพิ่มเติมเกี่ยวกับข้อมูลที่จัดเก็บไว้
ขั้นตอนถัดไป
จากนั้นก็ถึงเวลาทำความสะอาด
9. การล้างข้อมูล
ก่อนที่จะล้างข้อมูล คุณสามารถสำรวจเวิร์กโหลดอื่นๆ ที่ไม่ได้กล่าวถึงได้ โดยเฉพาะอย่างยิ่ง matchmaking-workload, game-workload และ tradepost-workload
เมื่อ "เล่น" เกมเสร็จแล้ว คุณก็ทำความสะอาดสนามเด็กเล่นได้ โชคดีที่การดำเนินการนี้ค่อนข้างง่าย
ก่อนอื่น หาก profile-workload ยังทำงานอยู่ในเบราว์เซอร์ ให้ไปที่ profile-workload แล้วหยุดการทำงาน
ทำเช่นเดียวกันกับภาระงานแต่ละอย่างที่คุณอาจทดสอบ
จากนั้นใน Cloud Shell ให้ไปที่โฟลเดอร์โครงสร้างพื้นฐาน คุณจะdestroyโครงสร้างพื้นฐานโดยใช้ Terraform
cd $DEMO_HOME/infrastructure
terraform destroy
# type 'yes' when asked
เอาต์พุตของคำสั่ง
Plan: 0 to add, 0 to change, 46 to destroy.
Do you really want to destroy all resources?
Terraform will destroy all your managed infrastructure, as shown above.
There is no undo. Only 'yes' will be accepted to confirm.
Enter a value: yes
*snip*
Destroy complete! Resources: 46 destroyed.
ใน Cloud Console ให้ไปที่ Spanner, Kubernetes Cluster, Artifact Registry, Cloud Deploy และ IAM เพื่อตรวจสอบว่าได้นำทรัพยากรทั้งหมดออกแล้ว
10. ยินดีด้วย
ขอแสดงความยินดี คุณได้ทำให้แอปพลิเคชัน Golang ตัวอย่างใช้งานได้ใน GKE Autopilot และเชื่อมต่อกับ Cloud Spanner โดยใช้ Workload Identity เรียบร้อยแล้ว
นอกจากนี้ โครงสร้างพื้นฐานนี้ยังตั้งค่าและนำออกได้ง่ายในลักษณะที่ทำซ้ำได้โดยใช้ Terraform
อ่านข้อมูลเพิ่มเติมเกี่ยวกับบริการ Google Cloud ที่คุณโต้ตอบด้วยใน Codelab นี้ได้ที่
ขั้นตอนต่อไปคืออะไร
ตอนนี้คุณเข้าใจพื้นฐานเกี่ยวกับวิธีที่ GKE Autopilot และ Cloud Spanner ทำงานร่วมกันแล้ว ทำไมไม่ลองก้าวไปอีกขั้นและเริ่มสร้างแอปพลิเคชันของคุณเองเพื่อทำงานกับบริการเหล่านี้