
1. Introduzione

Panoramica
I servizi Cloud Run sono adatti ai container che vengono eseguiti a tempo indeterminato in ascolto di richieste HTTP, mentre i job Cloud Run sono più adatti ai container che vengono eseguiti fino al completamento (attualmente fino a 24 ore) e non gestiscono le richieste. Ad esempio, l'elaborazione di record da un database, l'elaborazione di un elenco di file da un bucket Cloud Storage o un'operazione a lunga esecuzione, come il calcolo di Pi greco, funzionerebbe bene se implementata come job Cloud Run.
I job non hanno la possibilità di gestire le richieste o rimanere in ascolto su una porta. Ciò significa che, a differenza dei servizi Cloud Run, i job non devono includere un server web. I container dei job devono invece uscire al termine.
Nei job Cloud Run, puoi eseguire più copie del container in parallelo specificando un numero di attività. Ogni attività rappresenta una copia in esecuzione del contenitore. L'utilizzo di più attività è utile se ogni attività può elaborare in modo indipendente un sottoinsieme dei dati. Ad esempio, l'elaborazione di 10.000 record da Cloud SQL o 10.000 file da Cloud Storage potrebbe essere eseguita più rapidamente con 10 attività che elaborano 1000 record o file ciascuna in parallelo.
L'utilizzo dei job Cloud Run è un processo in due fasi:
- Crea un job:questo include tutta la configurazione necessaria per eseguire il job, ad esempio l'immagine container, la regione e le variabili di ambiente.
- Esegui il job:viene creata una nuova esecuzione del job. Se vuoi, configura il job in modo che venga eseguito in base a una pianificazione utilizzando Cloud Scheduler.
In questo codelab, esplorerai innanzitutto un'applicazione Node.js per acquisire screenshot di pagine web e archiviarli in Cloud Storage. Quindi, crei un'immagine container per l'applicazione, la esegui sui job Cloud Run, aggiorni il job per elaborare più pagine web ed esegui il job in base a una pianificazione con Cloud Scheduler.
Obiettivi didattici
- Come utilizzare un'app per acquisire screenshot di pagine web.
- Come creare un'immagine container per l'applicazione.
- Come creare un job Cloud Run per l'applicazione.
- Come eseguire l'applicazione come job Cloud Run.
- Come aggiornare il job.
- Come pianificare il job con Cloud Scheduler.
2. Configurazione e requisiti
Configurazione dell'ambiente autonomo
- Accedi alla console Google Cloud e crea un nuovo progetto o riutilizzane uno esistente. Se non hai ancora un account Gmail o Google Workspace, devi crearne uno.



- Il nome del progetto è il nome visualizzato per i partecipanti a questo progetto. È una stringa di caratteri non utilizzata dalle API di Google. Puoi sempre aggiornarlo.
- L'ID progetto è univoco in tutti i progetti Google Cloud ed è immutabile (non può essere modificato dopo l'impostazione). La console Cloud genera automaticamente una stringa univoca, di solito non ti interessa di cosa si tratta. Nella maggior parte dei codelab, dovrai fare riferimento all'ID progetto (in genere identificato come
PROJECT_ID). Se l'ID generato non ti piace, puoi generarne un altro casuale. In alternativa, puoi provare a crearne uno e vedere se è disponibile. Non può essere modificato dopo questo passaggio e rimane per tutta la durata del progetto. - Per tua informazione, esiste un terzo valore, un numero di progetto, utilizzato da alcune API. Scopri di più su tutti e tre questi valori nella documentazione.
- Successivamente, devi abilitare la fatturazione in Cloud Console per utilizzare le risorse/API Cloud. Completare questo codelab non costa molto, se non nulla. Per arrestare le risorse ed evitare addebiti oltre a quelli previsti in questo tutorial, puoi eliminare le risorse che hai creato o il progetto. I nuovi utenti di Google Cloud possono beneficiare del programma prova senza costi di 300$.
Avvia Cloud Shell
Sebbene Google Cloud possa essere gestito da remoto dal tuo laptop, in questo codelab utilizzerai Google Cloud Shell, un ambiente a riga di comando in esecuzione nel cloud.
Nella console Google Cloud, fai clic sull'icona di Cloud Shell nella barra degli strumenti in alto a destra:
Bastano pochi istanti per eseguire il provisioning e connettersi all'ambiente. Al termine, dovresti vedere un risultato simile a questo:

Questa macchina virtuale è caricata con tutti gli strumenti per sviluppatori di cui avrai bisogno. Offre una home directory permanente da 5 GB e viene eseguita su Google Cloud, migliorando notevolmente le prestazioni e l'autenticazione della rete. Tutto il lavoro in questo codelab può essere svolto all'interno di un browser. Non devi installare nulla.
Configura gcloud
In Cloud Shell, imposta l'ID progetto e la regione in cui vuoi eseguire il deployment del job Cloud Run. Salvali come variabili PROJECT_ID e REGION. In futuro potrai scegliere una regione tra le località di Cloud Run.
PROJECT_ID=[YOUR-PROJECT-ID] REGION=us-central1 gcloud config set core/project $PROJECT_ID
Abilita API
Attiva tutti i servizi necessari:
gcloud services enable \ artifactregistry.googleapis.com \ cloudbuild.googleapis.com \ run.googleapis.com
3. Ottieni il codice
Per prima cosa, esplori un'applicazione Node.js per acquisire screenshot di pagine web e archiviarli in Cloud Storage. In un secondo momento, crei un'immagine container per l'applicazione e la esegui come job su Cloud Run.
Da Cloud Shell, esegui questo comando per clonare il codice dell'applicazione da questo repository:
git clone https://github.com/GoogleCloudPlatform/jobs-demos.git
Vai alla directory contenente l'applicazione:
cd jobs-demos/screenshot
Dovresti vedere questo layout del file:
screenshot | ├── Dockerfile ├── README.md ├── screenshot.js ├── package.json
Ecco una breve descrizione di ogni file:
screenshot.jscontiene il codice Node.js per l'applicazione.package.jsondefinisce le dipendenze della libreria.Dockerfiledefinisce l'immagine container.
4. Esplora il codice
Per esplorare il codice, utilizza l'editor di testo integrato facendo clic sul pulsante Open Editor nella parte superiore della finestra di Cloud Shell.
Ecco una breve spiegazione di ogni file.
screenshot.js
screenshot.js aggiunge prima Puppeteer e Cloud Storage come dipendenze. Puppeteer è una libreria Node.js che utilizzi per acquisire screenshot di pagine web:
const puppeteer = require('puppeteer');
const {Storage} = require('@google-cloud/storage');
Esiste una funzione initBrowser per inizializzare Puppeteer e una funzione takeScreenshot per acquisire screenshot di un determinato URL:
async function initBrowser() {
console.log('Initializing browser');
return await puppeteer.launch();
}
async function takeScreenshot(browser, url) {
const page = await browser.newPage();
console.log(`Navigating to ${url}`);
await page.goto(url);
console.log(`Taking a screenshot of ${url}`);
return await page.screenshot({
fullPage: true
});
}
Successivamente, c'è una funzione per ottenere o creare un bucket Cloud Storage e un'altra per caricare lo screenshot di una pagina web in un bucket:
async function createStorageBucketIfMissing(storage, bucketName) {
console.log(`Checking for Cloud Storage bucket '${bucketName}' and creating if not found`);
const bucket = storage.bucket(bucketName);
const [exists] = await bucket.exists();
if (exists) {
// Bucket exists, nothing to do here
return bucket;
}
// Create bucket
const [createdBucket] = await storage.createBucket(bucketName);
console.log(`Created Cloud Storage bucket '${createdBucket.name}'`);
return createdBucket;
}
async function uploadImage(bucket, taskIndex, imageBuffer) {
// Create filename using the current time and task index
const date = new Date();
date.setMinutes(date.getMinutes() - date.getTimezoneOffset());
const filename = `${date.toISOString()}-task${taskIndex}.png`;
console.log(`Uploading screenshot as '${filename}'`)
await bucket.file(filename).save(imageBuffer);
}
Infine, la funzione main è l'entry point:
async function main(urls) {
console.log(`Passed in urls: ${urls}`);
const taskIndex = process.env.CLOUD_RUN_TASK_INDEX || 0;
const url = urls[taskIndex];
if (!url) {
throw new Error(`No url found for task ${taskIndex}. Ensure at least ${parseInt(taskIndex, 10) + 1} url(s) have been specified as command args.`);
}
const bucketName = process.env.BUCKET_NAME;
if (!bucketName) {
throw new Error('No bucket name specified. Set the BUCKET_NAME env var to specify which Cloud Storage bucket the screenshot will be uploaded to.');
}
const browser = await initBrowser();
const imageBuffer = await takeScreenshot(browser, url).catch(async err => {
// Make sure to close the browser if we hit an error.
await browser.close();
throw err;
});
await browser.close();
console.log('Initializing Cloud Storage client')
const storage = new Storage();
const bucket = await createStorageBucketIfMissing(storage, bucketName);
await uploadImage(bucket, taskIndex, imageBuffer);
console.log('Upload complete!');
}
main(process.argv.slice(2)).catch(err => {
console.error(JSON.stringify({severity: 'ERROR', message: err.message}));
process.exit(1);
});
Tieni presente quanto segue in merito al metodo main:
- Gli URL vengono passati come argomenti.
- Il nome del bucket viene passato come variabile di ambiente
BUCKET_NAMEdefinita dall'utente. Il nome del bucket deve essere univoco a livello globale in tutto Google Cloud. - Una variabile di ambiente
CLOUD_RUN_TASK_INDEXviene passata dai job Cloud Run. I job Cloud Run possono eseguire più copie dell'applicazione come attività uniche.CLOUD_RUN_TASK_INDEXrappresenta l'indice dell'attività in esecuzione. Il valore predefinito è zero quando il codice viene eseguito al di fuori dei job Cloud Run. Quando l'applicazione viene eseguita come più attività, ogni attività/container recupera l'URL di cui è responsabile, acquisisce uno screenshot e salva l'immagine nel bucket.
package.json
Il file package.json definisce l'applicazione e specifica le dipendenze per Cloud Storage e Puppeteer:
{
"name": "screenshot",
"version": "1.0.0",
"description": "Create a job to capture screenshots",
"main": "screenshot.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"author": "Google LLC",
"license": "Apache-2.0",
"dependencies": {
"@google-cloud/storage": "^5.18.2",
"puppeteer": "^13.5.1"
}
}
Dockerfile
Dockerfile definisce l'immagine container per l'applicazione con tutte le librerie e le dipendenze richieste:
FROM ghcr.io/puppeteer/puppeteer:16.1.0 COPY package*.json ./ RUN npm ci --omit=dev COPY . . ENTRYPOINT ["node", "screenshot.js"]
5. Esegui il deployment di un job
Prima di creare un job, devi creare un service account che utilizzerai per eseguirlo.
gcloud iam service-accounts create screenshot-sa --display-name="Screenshot app service account"
Concedi il ruolo storage.admin al service account, in modo che possa essere utilizzato per creare bucket e oggetti.
gcloud projects add-iam-policy-binding $PROJECT_ID \ --role roles/storage.admin \ --member serviceAccount:screenshot-sa@$PROJECT_ID.iam.gserviceaccount.com
Ora puoi eseguire il deployment di un job Cloud Run che include la configurazione necessaria per eseguire il job.
gcloud beta run jobs deploy screenshot \ --source=. \ --args="https://example.com" \ --args="https://cloud.google.com" \ --tasks=2 \ --task-timeout=5m \ --region=$REGION \ --set-env-vars=BUCKET_NAME=screenshot-$PROJECT_ID-$RANDOM \ --service-account=screenshot-sa@$PROJECT_ID.iam.gserviceaccount.com
Utilizza il deployment basato sull'origine e crea un job Cloud Run senza eseguirlo.
Nota come le pagine web vengono trasmesse come argomenti. Il nome del bucket in cui salvare gli screenshot viene passato come variabile di ambiente.
Puoi eseguire più copie del contenitore in parallelo specificando un numero di attività da eseguire con il flag --tasks. Ogni attività rappresenta una copia in esecuzione del contenitore. L'utilizzo di più attività è utile se ogni attività può elaborare in modo indipendente un sottoinsieme dei dati. Per facilitare questa operazione, ogni attività è a conoscenza del proprio indice, che viene memorizzato nella variabile di ambiente CLOUD_RUN_TASK_INDEX. Il tuo codice è responsabile della determinazione di quale attività gestisce quale sottoinsieme di dati. Nota --tasks=2 in questo esempio. In questo modo, vengono eseguiti due container per i due URL che vogliamo elaborare.
Ogni attività può essere eseguita per un massimo di 24 ore. Puoi ridurre questo timeout utilizzando il flag --task-timeout, come abbiamo fatto in questo esempio. Tutte le attività devono avere esito positivo affinché il job venga completato correttamente. Per impostazione predefinita, le attività non riuscite non vengono riprovate. Puoi configurare i tentativi per le attività non riuscite. Se un'attività supera il numero di tentativi, l'intero job non riesce.
Per impostazione predefinita, il job verrà eseguito con il maggior numero possibile di attività in parallelo. Sarà uguale al numero di attività per il job, fino a un massimo di 100. Potresti voler impostare un parallelismo inferiore per i job che accedono a un backend con scalabilità limitata. Ad esempio, un database che supporta un numero limitato di connessioni attive. Puoi ridurre il parallelismo con il flag --parallelism.
6. Esegui un job
Prima di eseguire il job, elencalo per verificare che sia stato creato:
gcloud run jobs list ✔ JOB: screenshot REGION: us-central LAST RUN AT: CREATED: 2022-02-22 12:20:50 UTC
Esegui il job con il seguente comando:
gcloud run jobs execute screenshot --region=$REGION
Viene eseguito il job. Puoi elencare le esecuzioni attuali e passate:
gcloud run jobs executions list --job screenshot --region=$REGION ... JOB: screenshot EXECUTION: screenshot-znkmm REGION: $REGION RUNNING: 1 COMPLETE: 1 / 2 CREATED: 2022-02-22 12:40:42 UTC
Descrivi l'esecuzione. Dovresti vedere il segno di spunta verde e il messaggio tasks completed successfully:
gcloud run jobs executions describe screenshot-znkmm --region=$REGION ✔ Execution screenshot-znkmm in region $REGION 2 tasks completed successfully Image: $REGION-docker.pkg.dev/$PROJECT_ID/containers/screenshot at 311b20d9... Tasks: 2 Args: https://example.com https://cloud.google.com Memory: 1Gi CPU: 1000m Task Timeout: 3600s Parallelism: 2 Service account: 11111111-compute@developer.gserviceaccount.com Env vars: BUCKET_NAME screenshot-$PROJECT_ID-$RANDOM
Puoi anche controllare la pagina dei job Cloud Run di Cloud Console per visualizzare lo stato:

Se controlli il bucket Cloud Storage, dovresti vedere i due file di screenshot creati:

A volte potrebbe essere necessario interrompere un'esecuzione prima che venga completata, ad esempio perché ti sei reso conto che devi eseguire il job con parametri diversi o perché c'è un errore nel codice e non vuoi utilizzare tempo di calcolo non necessario.
Per interrompere l'esecuzione di un job, devi eliminarla:
gcloud run jobs executions delete screenshot-znkmm --region=$REGION
7. Aggiornare un job
Le nuove versioni del container non vengono selezionate automaticamente dai job Cloud Run nella successiva esecuzione. Se modifichi il codice del job, devi ricompilare il container e aggiornare il job. L'utilizzo di immagini con tag ti aiuterà a identificare la versione dell'immagine attualmente in uso.
Allo stesso modo, devi aggiornare il job se vuoi aggiornare alcune variabili di configurazione. Le esecuzioni successive del job utilizzeranno il nuovo contenitore e le nuove impostazioni di configurazione.
Aggiorna il job e modifica le pagine di cui l'app acquisisce screenshot nel flag --args. Aggiorna anche il flag --tasks in modo che rifletta il numero di pagine.
gcloud run jobs update screenshot \ --args="https://www.pinterest.com" \ --args="https://www.apartmenttherapy.com" \ --args="https://www.google.com" \ --region=$REGION \ --tasks=3
Esegui di nuovo il job. Passa questo tempo nel flag --wait per attendere il completamento delle esecuzioni:
gcloud run jobs execute screenshot --region=$REGION --wait
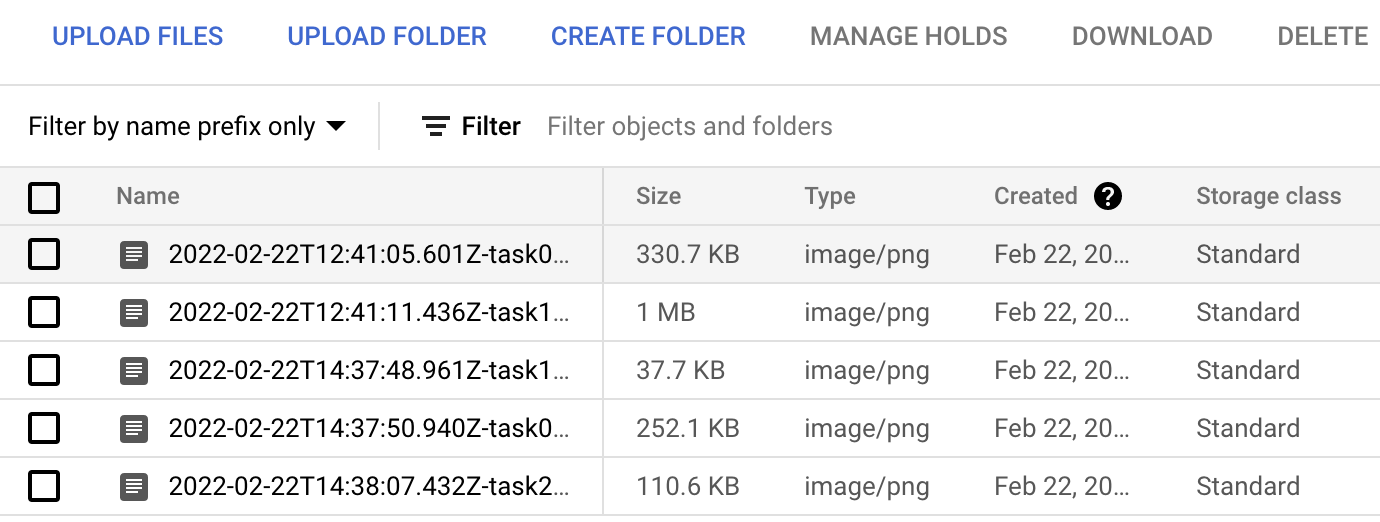
Dopo alcuni secondi, dovresti vedere altri tre screenshot aggiunti al bucket:
8. Pianificare un job
Finora, esegui i job manualmente. In uno scenario reale, probabilmente vuoi eseguire i job in risposta a un evento o in base a una pianificazione. Vediamo come eseguire il job di acquisizione degli screenshot in base a una pianificazione utilizzando Cloud Scheduler.
Innanzitutto, assicurati che l'API Cloud Scheduler sia abilitata:
gcloud services enable cloudscheduler.googleapis.com
Vai alla pagina dei dettagli dei job Cloud Run e fai clic sulla sezione Triggers:

Seleziona il pulsante Add Scheduler Trigger:

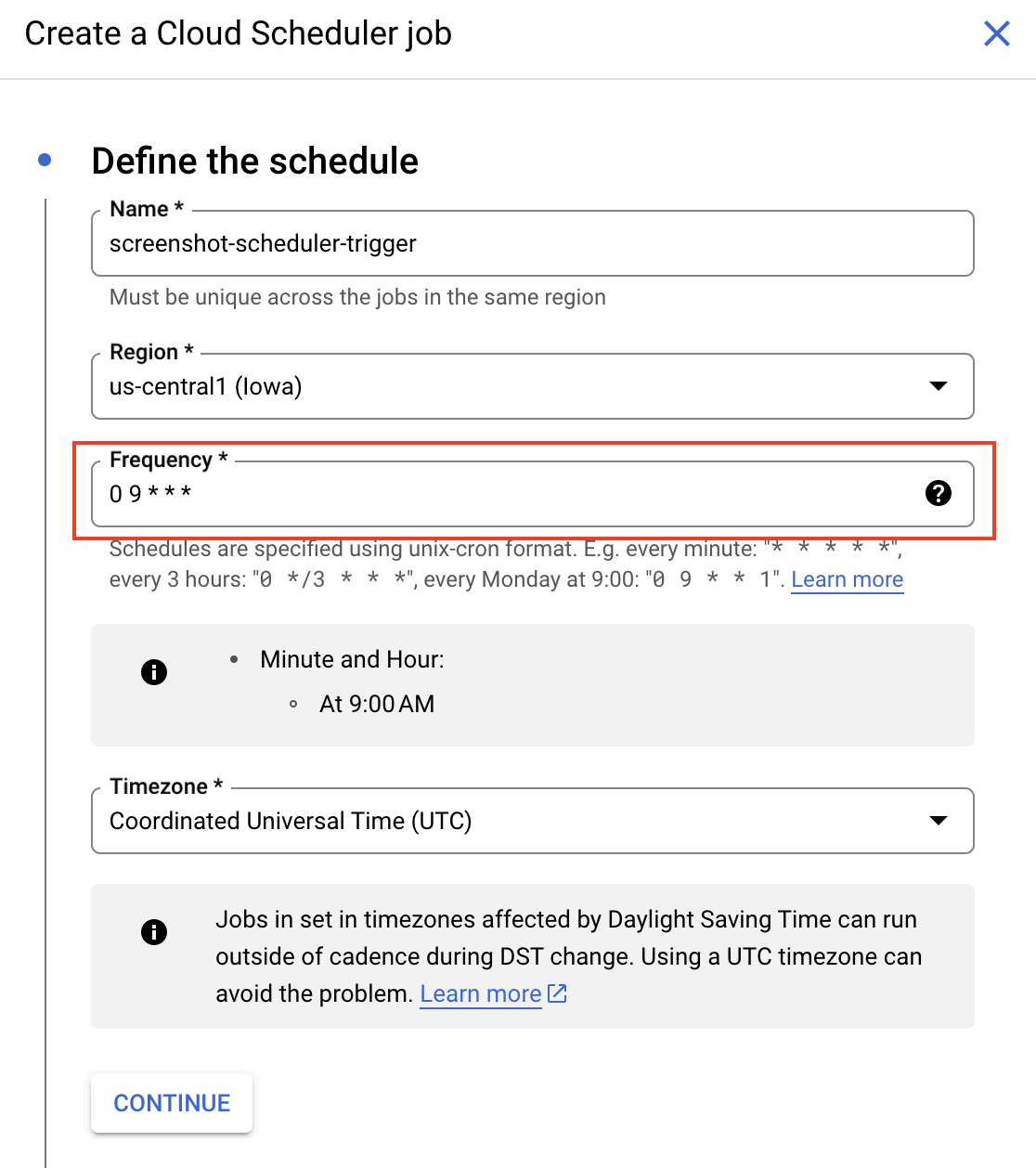
A destra si apre un riquadro. Crea un job di pianificazione da eseguire ogni giorno alle 9:00 con questa configurazione e seleziona Continue:
Nella pagina successiva, seleziona il service account predefinito di Compute e seleziona Create:

Ora dovresti vedere un nuovo attivatore Cloud Scheduler creato:

Fai clic su View Details per andare alla pagina Cloud Scheduler.
Puoi aspettare le 9:00 per l'attivazione di Cloud Scheduler oppure puoi attivarlo manualmente selezionando Force Run:

Dopo alcuni secondi, dovresti vedere l'esecuzione del job Cloud Scheduler riuscita:
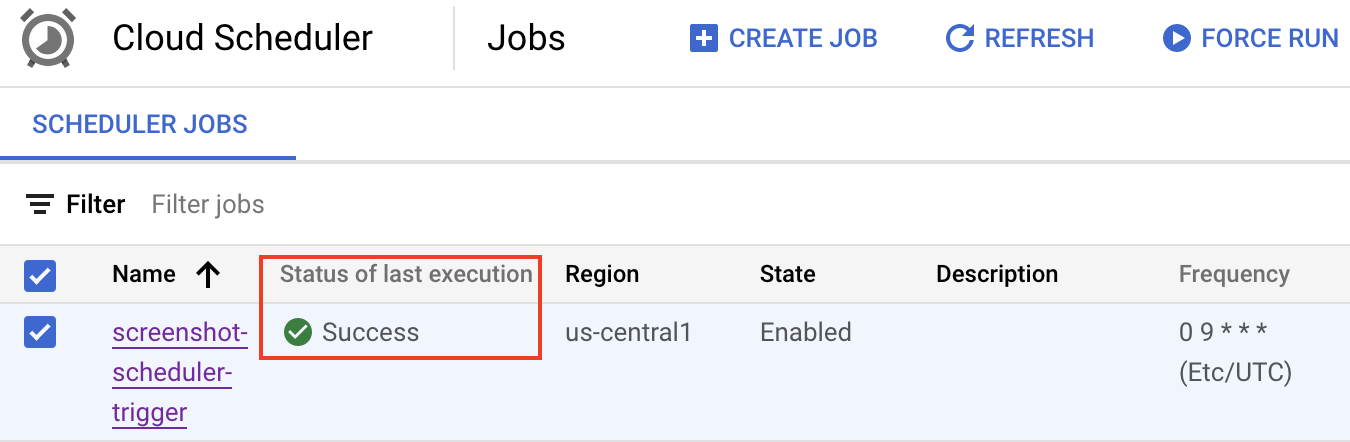
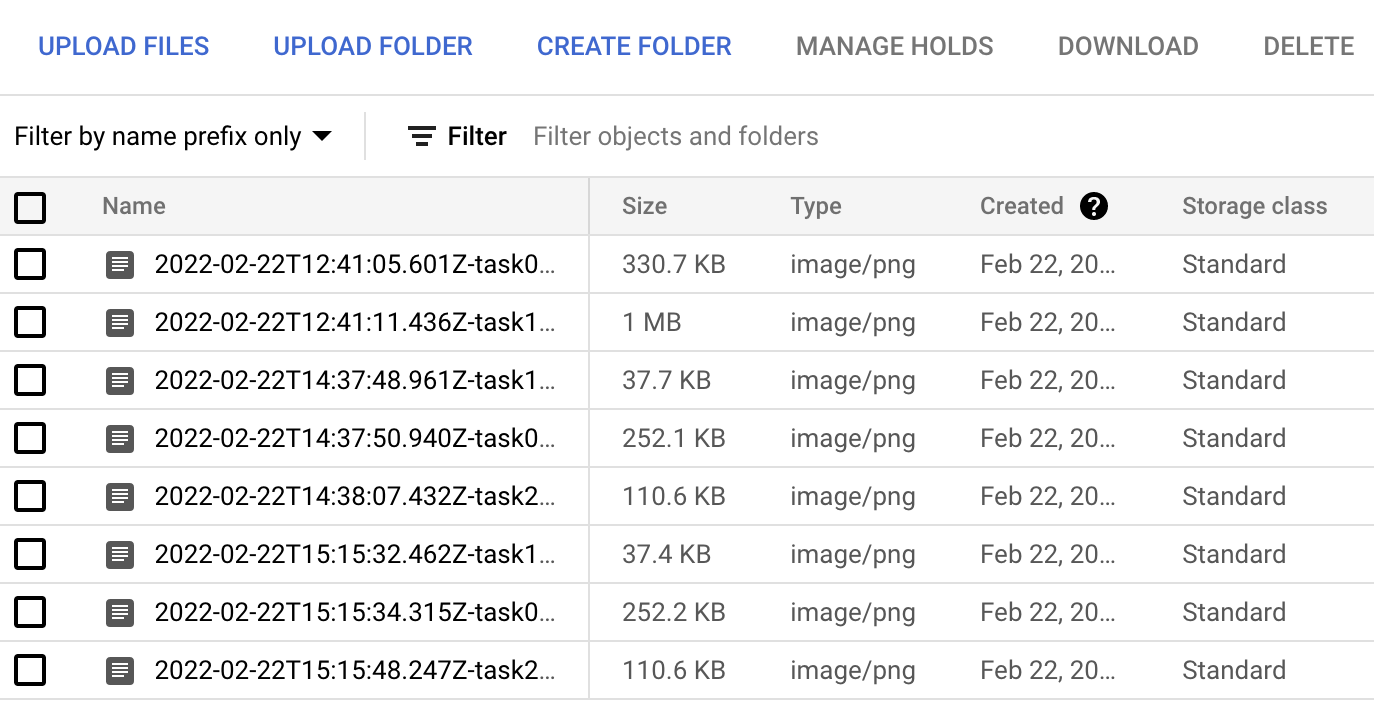
Dovresti anche vedere altri tre screenshot aggiunti dalla chiamata da Cloud Scheduler:
9. Complimenti
Congratulazioni, hai completato il codelab.
Pulizia (facoltativa)
Per evitare addebiti, è consigliabile eseguire la pulizia delle risorse.
Se non hai bisogno del progetto, puoi semplicemente eliminarlo:
gcloud projects delete $PROJECT_ID
Se hai bisogno del progetto, puoi eliminare le risorse singolarmente.
Elimina il codice sorgente:
rm -rf ~/jobs-demos/
Elimina il repository Artifact Registry:
gcloud artifacts repositories delete containers --location=$REGION
Elimina il account di servizio:
gcloud iam service-accounts delete screenshot-sa@$PROJECT_ID.iam.gserviceaccount.com
Elimina il job Cloud Run:
gcloud run jobs delete screenshot --region=$REGION
Elimina il job Cloud Scheduler:
gcloud scheduler jobs delete screenshot-scheduler-trigger --location=$REGION
Elimina il bucket Cloud Storage:
gcloud storage rm --recursive gs://screenshot-$PROJECT_ID
Argomenti trattati
- Come utilizzare un'app per acquisire screenshot di pagine web.
- Come creare un'immagine container per l'applicazione.
- Come creare un job Cloud Run per l'applicazione.
- Come eseguire l'applicazione come job Cloud Run.
- Come aggiornare il job.
- Come pianificare il job con Cloud Scheduler.