
1. Introdução

Visão geral
Os serviços do Cloud Run são ideais para contêineres que são executados indefinidamente e recebem solicitações HTTP, enquanto os jobs do Cloud Run são mais adequados para contêineres executados até serem concluídos (atualmente até 24 horas) e que não atendem a solicitações. Por exemplo, o processamento de registros de um banco de dados, o processamento de uma lista de arquivos de um bucket do Cloud Storage ou uma operação de longa duração, como calcular o valor de Pi, funcionam bem se implementados como um job do Cloud Run.
Os jobs não podem atender a solicitações ou fazer detecções em uma porta. Isso significa que, ao contrário dos serviços do Cloud Run, os jobs não devem incluir um servidor da Web. Em vez disso, os contêineres de jobs são encerrados quando terminam a função deles.
Nos jobs do Cloud Run, é possível executar várias cópias do contêiner em paralelo especificando várias tarefas. Cada tarefa representa uma cópia em execução do contêiner. É útil usar várias tarefas se cada uma delas puder processar independentemente um subconjunto dos dados. Por exemplo, o processamento de 10.000 registros do Cloud SQL ou de 10.000 arquivos do Cloud Storage pode ser feito mais rapidamente com 10 tarefas processando 1.000 registros ou arquivos, cada uma em paralelo.
Usar jobs do Cloud Run é um processo de duas etapas:
- Criar um job:isso encapsula toda a configuração necessária para executar o job, como a imagem de contêiner, a região e as variáveis de ambiente.
- Executar o job:isso cria uma nova execução do job. Como opção, configure o job para ser executado em uma programação usando o Cloud Scheduler.
Neste codelab, você primeiro vai explorar um aplicativo Node.js para fazer capturas de tela de páginas da Web e armazená-las no Cloud Storage. Em seguida, crie uma imagem de contêiner para o aplicativo, execute-a em jobs do Cloud Run, atualize o job para processar mais páginas da Web e execute o job em uma programação com o Cloud Scheduler.
O que você vai aprender
- Como usar um app para fazer capturas de tela de páginas da Web.
- Como criar uma imagem de contêiner para o aplicativo.
- Como criar um job do Cloud Run para o aplicativo.
- Como executar o aplicativo como um job do Cloud Run.
- Como atualizar o job.
- Como programar o job com o Cloud Scheduler.
2. Configuração e requisitos
Configuração de ambiente personalizada
- Faça login no Console do Google Cloud e crie um novo projeto ou reutilize um existente. Crie uma conta do Gmail ou do Google Workspace, se ainda não tiver uma.


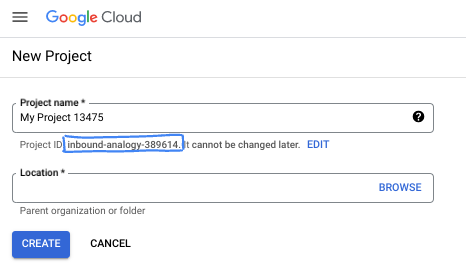
- O Nome do projeto é o nome de exibição para os participantes do projeto. É uma string de caracteres não usada pelas APIs do Google e pode ser atualizada quando você quiser.
- O ID do projeto precisa ser exclusivo em todos os projetos do Google Cloud e não pode ser mudado após a definição. O console do Cloud gera automaticamente uma string exclusiva. Em geral, não importa o que seja. Na maioria dos codelabs, é necessário fazer referência ao ID do projeto, normalmente identificado como
PROJECT_ID. Se você não gostar do ID gerado, crie outro aleatório. Se preferir, teste o seu e confira se ele está disponível. Ele não pode ser mudado após essa etapa e permanece durante o projeto. - Para sua informação, há um terceiro valor, um Número do projeto, que algumas APIs usam. Saiba mais sobre esses três valores na documentação.
- Em seguida, ative o faturamento no console do Cloud para usar os recursos/APIs do Cloud. A execução deste codelab não vai ser muito cara, se tiver algum custo. Para encerrar os recursos e evitar cobranças além deste tutorial, exclua os recursos criados ou exclua o projeto. Novos usuários do Google Cloud estão qualificados para o programa de US$ 300 de avaliação sem custos.
Iniciar o Cloud Shell
Embora o Google Cloud e o Spanner possam ser operados remotamente do seu laptop, neste codelab usaremos o Google Cloud Shell, um ambiente de linha de comando executado no Cloud.
No Console do Google Cloud, clique no ícone do Cloud Shell na barra de ferramentas superior à direita:
O provisionamento e a conexão com o ambiente levarão apenas alguns instantes para serem concluídos: Quando o processamento for concluído, você verá algo como:

Essa máquina virtual contém todas as ferramentas de desenvolvimento necessárias. Ela oferece um diretório principal persistente de 5 GB, além de ser executada no Google Cloud. Isso aprimora o desempenho e a autenticação da rede. Neste codelab, todo o trabalho pode ser feito com um navegador. Você não precisa instalar nada.
Configurar a gcloud
No Cloud Shell, defina o ID do projeto e a região para implantar o job do Cloud Run. Salve-as como variáveis PROJECT_ID e REGION. No futuro, será possível escolher uma região em um dos locais do Cloud Run.
PROJECT_ID=[YOUR-PROJECT-ID] REGION=us-central1 gcloud config set core/project $PROJECT_ID
Ativar APIs
Ative todos os serviços necessários:
gcloud services enable \ artifactregistry.googleapis.com \ cloudbuild.googleapis.com \ run.googleapis.com
3. Buscar o código
Primeiro, você vai explorar um aplicativo Node.js para fazer capturas de tela de páginas da Web e armazená-las no Cloud Storage. Mais tarde, você vai criar uma imagem de contêiner para o aplicativo e executá-la como um job no Cloud Run.
No Cloud Shell, execute o seguinte comando para clonar o código do aplicativo deste repositório:
git clone https://github.com/GoogleCloudPlatform/jobs-demos.git
Acesse o diretório que contém o aplicativo:
cd jobs-demos/screenshot
Você verá este layout de arquivo:
screenshot | ├── Dockerfile ├── README.md ├── screenshot.js ├── package.json
Veja uma breve descrição de cada página:
screenshot.jscontém o código Node.js do aplicativo.package.jsondefine as dependências da biblioteca.Dockerfiledefine a imagem do contêiner.
4. Explorar o código
Para explorar o código, use o editor de texto integrado clicando no botão Open Editor na parte superior da janela do Cloud Shell.

Veja uma breve explicação de cada arquivo.
screenshot.js
screenshot.js primeiro adiciona o Puppeteer e o Cloud Storage como dependências O Puppeteer é uma biblioteca do Node.js que você usa para fazer capturas de tela de páginas da Web:
const puppeteer = require('puppeteer');
const {Storage} = require('@google-cloud/storage');
Há uma função initBrowser para inicializar o Puppeteer e uma função takeScreenshot para fazer capturas de tela de um determinado URL:
async function initBrowser() {
console.log('Initializing browser');
return await puppeteer.launch();
}
async function takeScreenshot(browser, url) {
const page = await browser.newPage();
console.log(`Navigating to ${url}`);
await page.goto(url);
console.log(`Taking a screenshot of ${url}`);
return await page.screenshot({
fullPage: true
});
}
Em seguida, há uma função para acessar ou criar um bucket do Cloud Storage e outra para fazer upload da captura de tela de uma página da Web para um bucket:
async function createStorageBucketIfMissing(storage, bucketName) {
console.log(`Checking for Cloud Storage bucket '${bucketName}' and creating if not found`);
const bucket = storage.bucket(bucketName);
const [exists] = await bucket.exists();
if (exists) {
// Bucket exists, nothing to do here
return bucket;
}
// Create bucket
const [createdBucket] = await storage.createBucket(bucketName);
console.log(`Created Cloud Storage bucket '${createdBucket.name}'`);
return createdBucket;
}
async function uploadImage(bucket, taskIndex, imageBuffer) {
// Create filename using the current time and task index
const date = new Date();
date.setMinutes(date.getMinutes() - date.getTimezoneOffset());
const filename = `${date.toISOString()}-task${taskIndex}.png`;
console.log(`Uploading screenshot as '${filename}'`)
await bucket.file(filename).save(imageBuffer);
}
Por fim, a função main é o ponto de entrada:
async function main(urls) {
console.log(`Passed in urls: ${urls}`);
const taskIndex = process.env.CLOUD_RUN_TASK_INDEX || 0;
const url = urls[taskIndex];
if (!url) {
throw new Error(`No url found for task ${taskIndex}. Ensure at least ${parseInt(taskIndex, 10) + 1} url(s) have been specified as command args.`);
}
const bucketName = process.env.BUCKET_NAME;
if (!bucketName) {
throw new Error('No bucket name specified. Set the BUCKET_NAME env var to specify which Cloud Storage bucket the screenshot will be uploaded to.');
}
const browser = await initBrowser();
const imageBuffer = await takeScreenshot(browser, url).catch(async err => {
// Make sure to close the browser if we hit an error.
await browser.close();
throw err;
});
await browser.close();
console.log('Initializing Cloud Storage client')
const storage = new Storage();
const bucket = await createStorageBucketIfMissing(storage, bucketName);
await uploadImage(bucket, taskIndex, imageBuffer);
console.log('Upload complete!');
}
main(process.argv.slice(2)).catch(err => {
console.error(JSON.stringify({severity: 'ERROR', message: err.message}));
process.exit(1);
});
Observe o seguinte sobre o método main:
- Os URLs são transmitidos como argumentos.
- O nome do bucket é transmitido como a variável de ambiente
BUCKET_NAMEdefinida pelo usuário. O nome do bucket precisa ser globalmente exclusivo em todo o Google Cloud. - Uma variável de ambiente
CLOUD_RUN_TASK_INDEXé transmitida pelos jobs do Cloud Run. Os jobs do Cloud Run podem executar várias cópias do aplicativo como tarefas únicas.CLOUD_RUN_TASK_INDEXrepresenta o índice da tarefa em execução. O padrão é zero quando o código é executado fora dos jobs do Cloud Run. Quando o aplicativo é executado como várias tarefas, cada tarefa/contêiner escolhe o URL pelo qual é responsável, faz uma captura de tela e salva a imagem no bucket.
package.json
O arquivo package.json define o aplicativo e especifica as dependências do Cloud Storage e do Puppeteer:
{
"name": "screenshot",
"version": "1.0.0",
"description": "Create a job to capture screenshots",
"main": "screenshot.js",
"scripts": {
"test": "echo \"Error: no test specified\" && exit 1"
},
"author": "Google LLC",
"license": "Apache-2.0",
"dependencies": {
"@google-cloud/storage": "^5.18.2",
"puppeteer": "^13.5.1"
}
}
Dockerfile
O Dockerfile define a imagem do contêiner para o aplicativo com todas as bibliotecas e dependências necessárias:
FROM ghcr.io/puppeteer/puppeteer:16.1.0 COPY package*.json ./ RUN npm ci --omit=dev COPY . . ENTRYPOINT ["node", "screenshot.js"]
5. Implantar um job
Antes de criar um job, você precisa criar uma conta de serviço para executar esse job.
gcloud iam service-accounts create screenshot-sa --display-name="Screenshot app service account"
Atribua o papel storage.admin à conta de serviço para que ela possa ser usada para criar buckets e objetos.
gcloud projects add-iam-policy-binding $PROJECT_ID \ --role roles/storage.admin \ --member serviceAccount:screenshot-sa@$PROJECT_ID.iam.gserviceaccount.com
Agora está tudo pronto para você implantar um job do Cloud Run que inclui a configuração necessária para executá-lo.
gcloud beta run jobs deploy screenshot \ --source=. \ --args="https://example.com" \ --args="https://cloud.google.com" \ --tasks=2 \ --task-timeout=5m \ --region=$REGION \ --set-env-vars=BUCKET_NAME=screenshot-$PROJECT_ID-$RANDOM \ --service-account=screenshot-sa@$PROJECT_ID.iam.gserviceaccount.com
Isso usa a implantação baseada em origem e cria um job do Cloud Run sem executá-lo.
Observe como as páginas da Web são transmitidas como argumentos. O nome do bucket para salvar as capturas de tela é transmitido como uma variável de ambiente.
É possível executar várias cópias do seu contêiner em paralelo especificando várias tarefas a serem executadas com a sinalização --tasks. Cada tarefa representa uma cópia em execução do contêiner. É útil usar várias tarefas se cada uma delas puder processar independentemente um subconjunto dos dados. Para facilitar esse processo, cada tarefa reconhece o índice, que é armazenado na variável de ambiente CLOUD_RUN_TASK_INDEX. Seu código é responsável por determinar qual tarefa processa qual subconjunto dos dados. Observe o --tasks=2 neste exemplo. Isso garante que dois contêineres sejam executados para os dois URLs que queremos processar.
Cada tarefa pode ser executada por até 24 horas. É possível diminuir esse tempo limite usando a sinalização --task-timeout, como fizemos neste exemplo. Todas as tarefas precisam ser concluídas corretamente para que o job seja concluído. Por padrão, os jobs com falha não serão executados novamente. É possível configurar novas tentativas quando elas falharem. Se alguma tarefa exceder o número de novas tentativas, todo o job falhará.
Por padrão, o job será executado com o maior número possível de tarefas em paralelo. Isso será igual ao número de tarefas do seu job, até um máximo de 100. É recomendável definir um paralelismo mais baixo para jobs que acessam um back-end com escalonabilidade limitada. Por exemplo, um banco de dados que suporta um número limitado de conexões ativas. É possível reduzir o paralelismo com a sinalização --parallelism.
6. Executar um job
Antes de executar o job, liste-o para ver se ele foi criado:
gcloud run jobs list ✔ JOB: screenshot REGION: us-central LAST RUN AT: CREATED: 2022-02-22 12:20:50 UTC
Execute o job com o seguinte comando:
gcloud run jobs execute screenshot --region=$REGION
Isso executa o job. É possível listar as execuções atuais e antigas:
gcloud run jobs executions list --job screenshot --region=$REGION ... JOB: screenshot EXECUTION: screenshot-znkmm REGION: $REGION RUNNING: 1 COMPLETE: 1 / 2 CREATED: 2022-02-22 12:40:42 UTC
Descreva a execução. Você vai ver a marca de seleção verde e a mensagem tasks completed successfully:
gcloud run jobs executions describe screenshot-znkmm --region=$REGION ✔ Execution screenshot-znkmm in region $REGION 2 tasks completed successfully Image: $REGION-docker.pkg.dev/$PROJECT_ID/containers/screenshot at 311b20d9... Tasks: 2 Args: https://example.com https://cloud.google.com Memory: 1Gi CPU: 1000m Task Timeout: 3600s Parallelism: 2 Service account: 11111111-compute@developer.gserviceaccount.com Env vars: BUCKET_NAME screenshot-$PROJECT_ID-$RANDOM
Você também pode verificar a página "Jobs do Cloud Run" no Console do Cloud para ver o status:

Se você verificar o bucket do Cloud Storage, pode ver os dois arquivos de captura de tela criados:

Às vezes, pode ser necessário interromper uma execução antes que ela seja concluída, talvez porque você percebeu que precisa executar o job com parâmetros diferentes ou que há um erro no código e que não quer usar um tempo de computação desnecessário.
Para interromper a execução do job, é necessário excluí-la:
gcloud run jobs executions delete screenshot-znkmm --region=$REGION
7. Atualizar uma vaga
As novas versões do contêiner não são selecionadas automaticamente por jobs do Cloud Run na próxima execução. Se você alterar o código do job, será necessário recriar o contêiner e atualizar o job. O uso de imagens marcadas ajuda a identificar qual versão da imagem está sendo usada no momento.
Da mesma maneira, também é preciso atualizar o job se você quiser atualizar alguma das variáveis de configuração. As execuções subsequentes do job usarão as novas definições de contêiner e configurações.
Atualize o job e mude as páginas em que o app faz capturas de tela na sinalização --args. Atualize também a sinalização --tasks para refletir o número de páginas.
gcloud run jobs update screenshot \ --args="https://www.pinterest.com" \ --args="https://www.apartmenttherapy.com" \ --args="https://www.google.com" \ --region=$REGION \ --tasks=3
Execute o job novamente. Esse tempo é transmitido na sinalização --wait para aguardar a conclusão das execuções:
gcloud run jobs execute screenshot --region=$REGION --wait
Após alguns segundos, mais três capturas de tela serão adicionadas ao bucket:

8. Programar um job
Até agora, você está executando jobs manualmente. Em um cenário real, você provavelmente quer executar jobs em resposta a um evento ou a uma programação. Vamos ver como executar o job de captura de tela em uma programação usando o Cloud Scheduler.
Primeiro, verifique se a API Cloud Scheduler está ativada:
gcloud services enable cloudscheduler.googleapis.com
Acesse a página de detalhes dos jobs do Cloud Run e clique na seção Triggers:
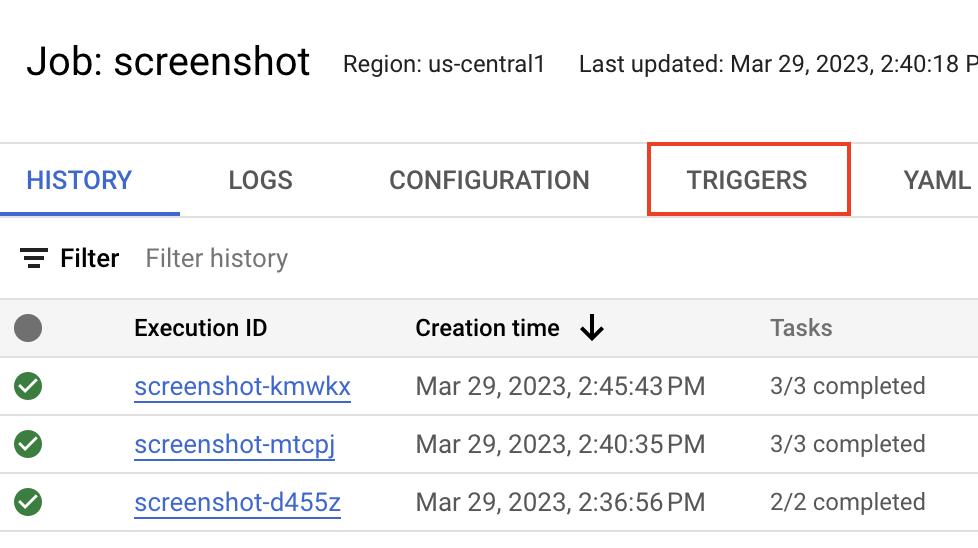
Selecione o botão Add Scheduler Trigger:

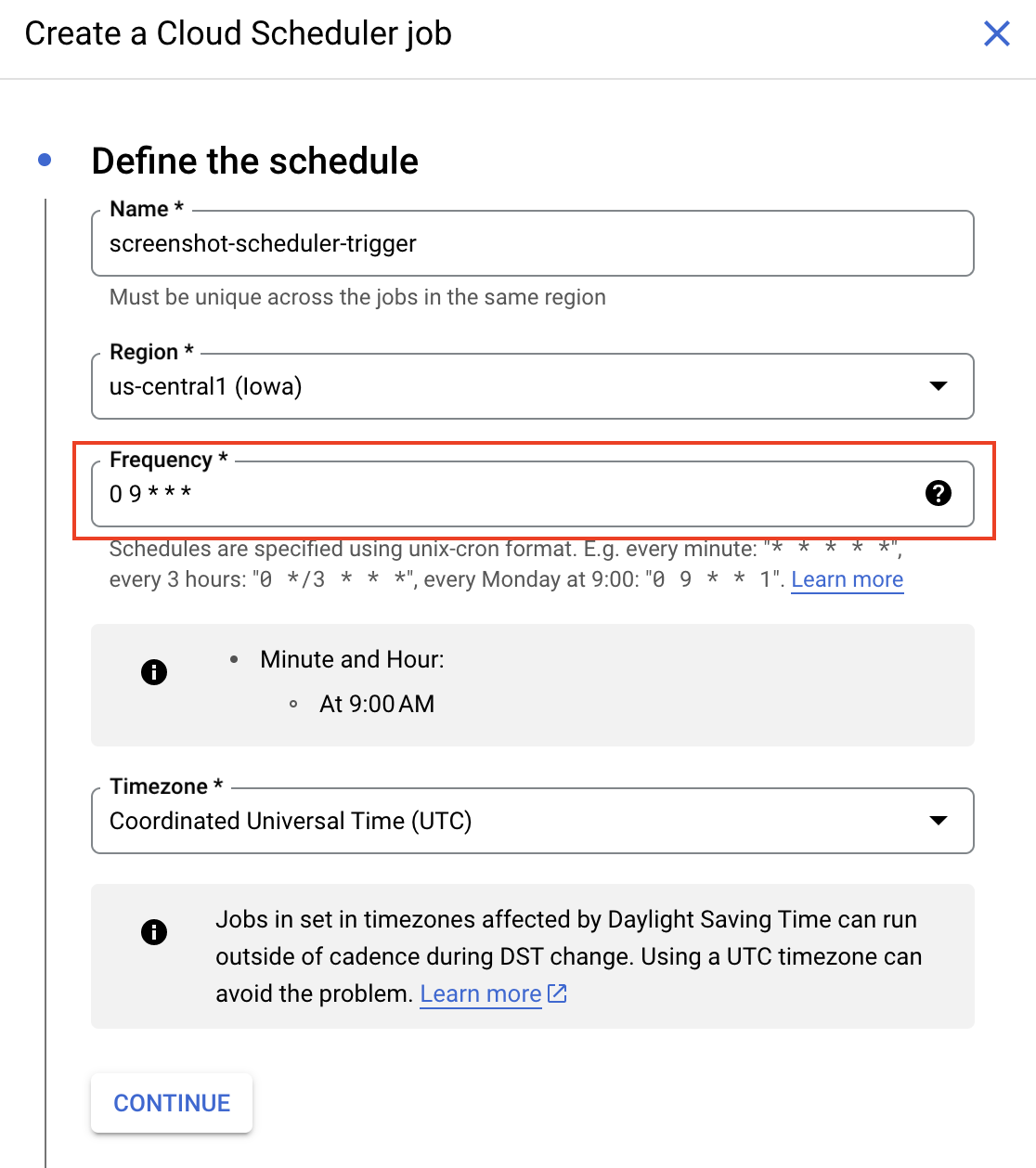
Um painel é aberto à direita. Crie um job do Scheduler para ser executado todos os dias às 9h com essa configuração e selecione Continue:
Na próxima página, selecione a conta de serviço padrão do Compute e clique em Create:

Agora você vai ver um novo gatilho do Cloud Scheduler criado:

Clique em View Details para acessar a página do Cloud Scheduler.
Você pode esperar até as 9h para que o programador seja ativado ou acionar manualmente o Cloud Scheduler selecionando Force Run:

Após alguns segundos, o job do Cloud Scheduler será executado com sucesso:
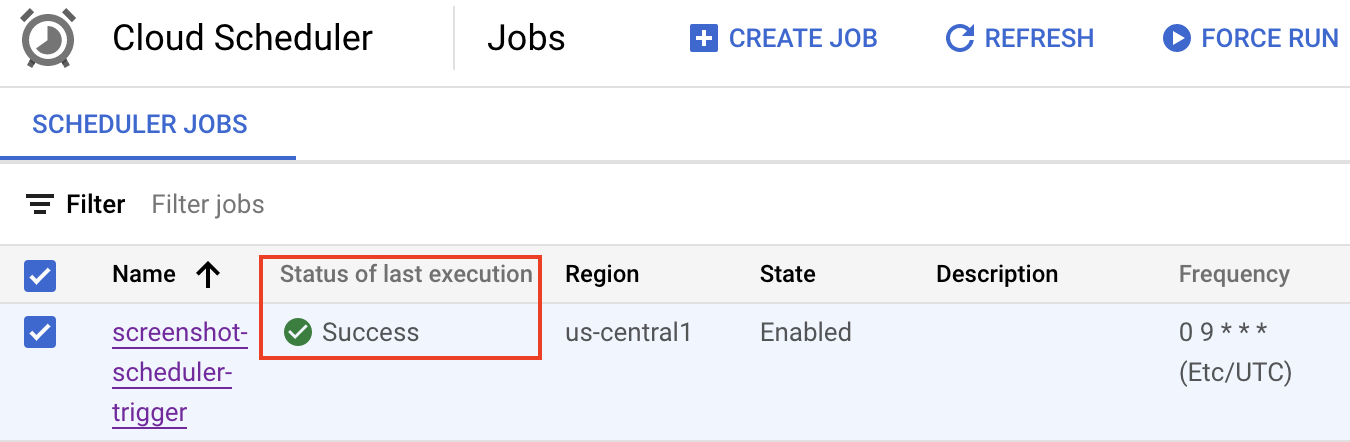
Você também vai ver mais três capturas de tela adicionadas pela chamada do Cloud Scheduler:

9. Parabéns
Parabéns, você concluiu o codelab.
Limpeza (opcional)
Para evitar cobranças, é uma boa ideia limpar os recursos.
Se você não precisar do projeto, basta excluí-lo:
gcloud projects delete $PROJECT_ID
Se você precisar do projeto, exclua os recursos individualmente.
Exclua o código-fonte:
rm -rf ~/jobs-demos/
Exclua o repositório do Artifact Registry:
gcloud artifacts repositories delete containers --location=$REGION
Exclua a conta de serviço:
gcloud iam service-accounts delete screenshot-sa@$PROJECT_ID.iam.gserviceaccount.com
Exclua o job do Cloud Run:
gcloud run jobs delete screenshot --region=$REGION
Exclua o job do Cloud Scheduler:
gcloud scheduler jobs delete screenshot-scheduler-trigger --location=$REGION
Exclua o bucket do Cloud Storage:
gcloud storage rm --recursive gs://screenshot-$PROJECT_ID
O que aprendemos
- Como usar um app para fazer capturas de tela de páginas da Web.
- Como criar uma imagem de contêiner para o aplicativo.
- Como criar um job do Cloud Run para o aplicativo.
- Como executar o aplicativo como um job do Cloud Run.
- Como atualizar o job.
- Como programar o job com o Cloud Scheduler.