
1. Présentation
Dans les entreprises modernes, le volume de données provenant de diverses sources ne cesse d'augmenter. Cela nécessite souvent de mettre en quarantaine et de classer ces données afin de les stocker et de les protéger de manière stratégique. Cette tâche deviendra rapidement coûteuse et impossible si elle reste manuelle.
Dans cet atelier de programmation, nous allons voir comment classer automatiquement les données importées dans Cloud Storage et les déplacer vers un bucket de stockage correspondant. Pour ce faire, nous utiliserons Cloud Pub/Sub, Cloud Functions, Cloud Data Loss Prevention et Cloud Storage.
Objectifs de l'atelier
- Créez des buckets Cloud Storage dans le pipeline de zone de quarantaine et de classification.
- Créer une fonction Cloud Functions simple qui appelle l'API DLP lors de l'importation de fichiers.
- Créez un sujet et un abonnement Pub/Sub pour vous avertir lorsque le traitement du fichier est terminé.
- Importer des exemples de fichiers dans le bucket de zone de quarantaine pour appeler une fonction Cloud
- Utilisez l'API DLP pour inspecter et classifier les fichiers avant de les déplacer dans le bucket approprié.
Prérequis
- Un projet Google Cloud avec la facturation configurée. Si vous n'en avez pas, vous devrez en créer un.
2. Configuration
Tout au long de cet atelier de programmation, nous allons provisionner et gérer différentes ressources et différents services cloud à l'aide de la ligne de commande via Cloud Shell. La commande suivante ouvre Cloud Shell et l'éditeur Cloud Shell, puis clone le dépôt du projet associé :
Assurez-vous d'utiliser le bon projet en le définissant avec gcloud config set project [PROJECT_ID]
Activer les API
Activez les API requises dans votre projet Google Cloud :
- API Cloud Functions : gère les fonctions légères fournies par l'utilisateur et exécutées en réponse aux événements.
- API Cloud Data Loss Prevention (DLP) : fournit des méthodes pour détecter, analyser les risques et anonymiser les fragments de contenu confidentiels et sensibles dans le texte, les images et les dépôts de stockage Google Cloud Platform.
- Cloud Storage : Google Cloud Storage est un service RESTful permettant de stocker vos données sur l'infrastructure de Google et d'y accéder.
Autorisations des comptes de service
Un compte de service est un type de compte spécial utilisé par les applications et les machines virtuelles pour effectuer des appels d'API autorisés.
Compte de service App Engine par défaut
Le compte de service App Engine par défaut est utilisé pour exécuter des tâches dans votre projet Cloud pour le compte de vos applications exécutées dans App Engine. Ce compte de service existe par défaut dans votre projet et le rôle "Éditeur" lui est attribué.
Tout d'abord, nous allons accorder à notre compte de service le rôle d'administrateur DLP, qui est nécessaire pour gérer les jobs de protection contre la perte de données :
gcloud projects add-iam-policy-binding $GOOGLE_CLOUD_PROJECT \ --member serviceAccount:$GOOGLE_CLOUD_PROJECT@appspot.gserviceaccount.com \ --role roles/dlp.admin
Enfin, attribuez le rôle "Agent de service de l'API DLP" qui accordera au compte de service les autorisations pour BigQuery, Storage, Datastore, Pub/Sub et le service de gestion des clés :
gcloud projects add-iam-policy-binding $GOOGLE_CLOUD_PROJECT \ --member serviceAccount:$GOOGLE_CLOUD_PROJECT@appspot.gserviceaccount.com \ --role roles/dlp.serviceAgent
Compte de service DLP
En plus du compte de service App Engine, nous utiliserons également un compte de service DLP. Ce compte de service a été créé automatiquement lorsque l'API DLP a été activée. Aucun rôle ne lui est attribué au départ. Attribuons-lui le rôle de lecteur :
gcloud projects add-iam-policy-binding $GOOGLE_CLOUD_PROJECT \ --member serviceAccount:service-`gcloud projects list --filter="PROJECT_ID:$GOOGLE_CLOUD_PROJECT" --format="value(PROJECT_NUMBER)"`@dlp-api.iam.gserviceaccount.com \ --role roles/viewer
3. Buckets Cloud Storage
Nous devons maintenant créer trois buckets Cloud Storage pour stocker nos données :
- Bucket de mise en quarantaine : c'est là que vos données seront importées initialement.
- Bucket de données sensibles : les données que l'API DLP a identifiées comme sensibles seront déplacées ici.
- Bucket de données non sensibles : les données que l'API DLP a déterminées comme non sensibles seront déplacées ici.
Nous pouvons utiliser la commande gsutil pour créer nos trois buckets en une seule fois :
gsutil mb gs://[YOUR_QUARANTINE_BUCKET] \ gs://[YOUR_SENSITIVE_DATA_BUCKET] \ gs://[YOUR_NON_SENSITIVE_DATA_BUCKET]
Notez les noms des buckets que vous venez de créer. Vous en aurez besoin plus tard.
4. Sujet et abonnement Pub/Sub
Cloud Pub/Sub fournit une messagerie asynchrone de type "plusieurs à plusieurs" entre applications. Un éditeur crée un message et le publie dans un flux de messages appelé sujet. Un abonné recevra ces messages par le biais d'un abonnement. En fonction de cet abonnement, dans notre cas, une fonction Cloud déplacera les fichiers vers leurs buckets respectifs après l'exécution d'un job DLP.
Commençons par créer un sujet. Un message sera publié ici chaque fois qu'un fichier sera ajouté à notre bucket de stockage en quarantaine. Nous allons l'appeler "classify-topic".
gcloud pubsub topics create classify-topic
Un abonnement recevra une notification lorsque le sujet publiera un message. Créez un abonnement Pub/Sub nommé "classify-sub" :
gcloud pubsub subscriptions create classify-sub --topic classify-topic
Cet abonnement déclenchera une deuxième fonction Cloud qui lancera une tâche DLP pour inspecter le fichier et le déplacer vers l'emplacement approprié.
5. Cloud Functions
Cloud Functions nous permet de déployer des fonctions légères, asynchrones et à usage unique basées sur les événements, sans avoir à gérer de serveur ni d'environnement d'exécution. Nous allons déployer deux fonctions Cloud à l'aide du fichier main.py fourni, situé dans dlp-cloud-functions-tutorials/gcs-dlp-classification-python/.
Remplacer des variables
Avant de pouvoir créer nos fonctions, nous devons remplacer certaines variables dans notre fichier main.py.
Dans l'éditeur Cloud Shell, modifiez main.py en remplaçant les valeurs de l'ID de projet et des variables de bucket aux lignes 28 à 34 par les buckets correspondants créés précédemment :
main.py
PROJECT_ID = '[PROJECT_ID_HOSTING_STAGING_BUCKET]'
"""The bucket the to-be-scanned files are uploaded to."""
STAGING_BUCKET = '[YOUR_QUARANTINE_BUCKET]'
"""The bucket to move "sensitive" files to."""
SENSITIVE_BUCKET = '[YOUR_SENSITIVE_DATA_BUCKET]'
"""The bucket to move "non sensitive" files to."""
NONSENSITIVE_BUCKET = '[YOUR_NON_SENSITIVE_DATA_BUCKET]'
De plus, remplacez la valeur de la variable de sujet Pub/Sub par le sujet Pub/Sub créé à l'étape précédente :
""" Pub/Sub topic to notify once the DLP job completes."""
PUB_SUB_TOPIC = 'classify-topic'
Déployer des fonctions
Dans votre Cloud Shell, accédez au répertoire gcs-dlp-classification-python où se trouve le fichier main.py :
cd ~/cloudshell_open/dlp-cloud-functions-tutorials/gcs-dlp-classification-python
Il est temps de déployer des fonctions.
Commencez par déployer la fonction create_DLP_job en remplaçant [YOUR_QUARANTINE_BUCKET] par le nom de bucket approprié. Cette fonction se déclenche lorsque de nouveaux fichiers sont importés dans le bucket de mise en quarantaine Cloud Storage désigné et crée un job DLP pour chaque fichier importé :
gcloud functions deploy create_DLP_job --runtime python37 \ --trigger-event google.storage.object.finalize \ --trigger-resource [YOUR_QUARANTINE_BUCKET]
Ensuite, déployez la fonction resolve_DLP, en indiquant notre thème comme déclencheur. Cette fonction écoute la notification Pub/Sub lancée par le job DLP suivant à partir de la fonction ci-dessus. Dès qu'il reçoit une notification Pub/Sub, il récupère les résultats de la tâche DLP et déplace le fichier vers le bucket "sensible" ou "non sensible", selon le cas :
gcloud functions deploy resolve_DLP --runtime python37 \ --trigger-topic classify-topic
Valider
Vérifiez que les deux fonctions Cloud ont bien été déployées à l'aide de la commande gcloud functions describe :
gcloud functions describe create_DLP_job
gcloud functions describe resolve_DLP
La sortie indiquera ACTIVE pour l'état lorsque le déploiement aura réussi.
6. Tester avec des exemples de données
Maintenant que toutes les parties sont en place, nous pouvons tester le tout avec des exemples de fichiers. Dans Cloud Shell, remplacez votre répertoire de travail actuel par sample_data :
cd ~/cloudshell_open/dlp-cloud-functions-tutorials/sample_data
Nos exemples de fichiers sont des fichiers .txt et .csv contenant diverses données. Les fichiers préfixés par "sample_s" contiendront des données sensibles, tandis que ceux préfixés par "sample_n" n'en contiendront pas. Par exemple, sample_s20.csv contient des données qui ressemblent à des numéros de sécurité sociale américains :
sample_s20.csv
Name,SSN,metric 1,metric 2
Maria Johnson,284-73-5110,5,43
Tyler Parker,284-73-5110,8,17
Maria Johnson,284-73-5110,54,63
Maria Johnson,245-25-8698,53,19
Tyler Parker,475-15-8499,6,67
Maria Johnson,719-12-6560,75,83
Maria Johnson,616-69-3226,91,13
Tzvika Roberts,245-25-8698,94,61
En revanche, les données du fichier sample_n15.csv ne seraient pas considérées comme sensibles :
sample_n15.csv
record id,metric 1,metric 2,metric 3
1,59,93,100
2,53,13,17
3,59,67,53
4,52,93,34
5,14,22,88
6,18,88,3
7,32,49,5
8,93,46,14
Pour voir comment notre configuration traitera nos fichiers, importons tous nos fichiers de test dans notre zone de quarantaine.
bucket :
gsutil -m cp * gs://[YOUR_QUARANTINE_BUCKET]
Au début, nos fichiers se trouveront dans le bucket de mise en quarantaine dans lequel nous les avons importés. Pour le vérifier, listez le contenu du bucket de mise en quarantaine immédiatement après l'importation des fichiers :
gsutil ls gs://[YOUR_QUARANTINE_BUCKET]
Pour découvrir la série d'événements que nous avons lancée, commencez par accéder à la page Cloud Functions :
Cliquez sur le menu "Actions" de la fonction create_DLP_job, puis sélectionnez "Afficher les journaux" :
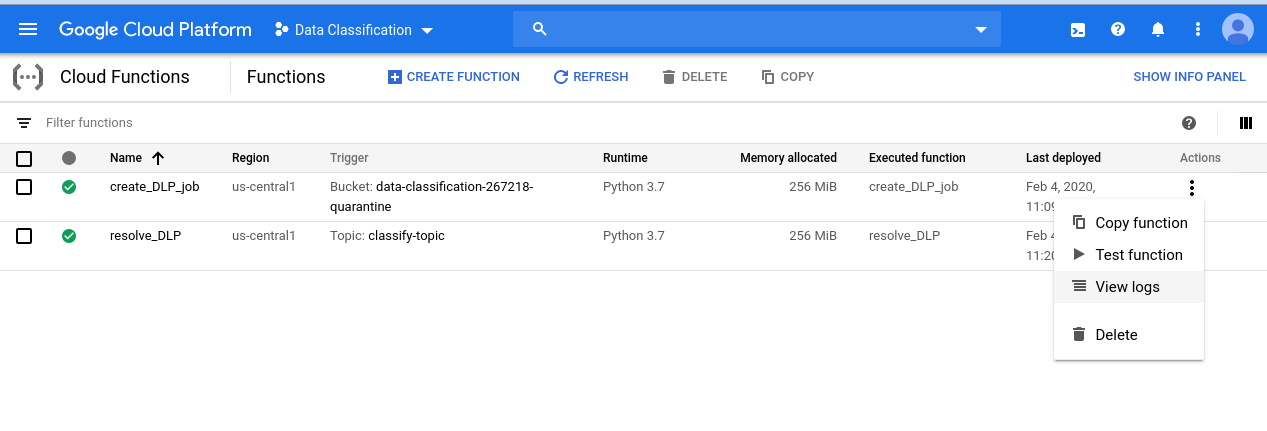
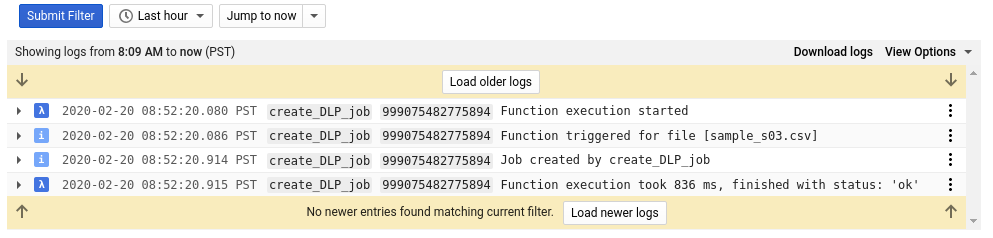
Dans le journal de cette fonction, nous voyons au moins quatre entrées pour chacun de nos fichiers, indiquant :
- L'exécution de la fonction a commencé
- La fonction a été déclenchée pour un fichier spécifique.
- Un job a été créé
- La fonction avait terminé son exécution
Une fois la fonction create_DLP_job terminée pour chaque fichier, une tâche DLP correspondante est lancée. Accédez à la page "Tâches DLP" pour afficher la liste des tâches DLP dans la file d'attente :
La liste des jobs en attente, en cours d'exécution ou terminés s'affiche. Chacun d'eux correspond à l'un des fichiers que nous avons importés :
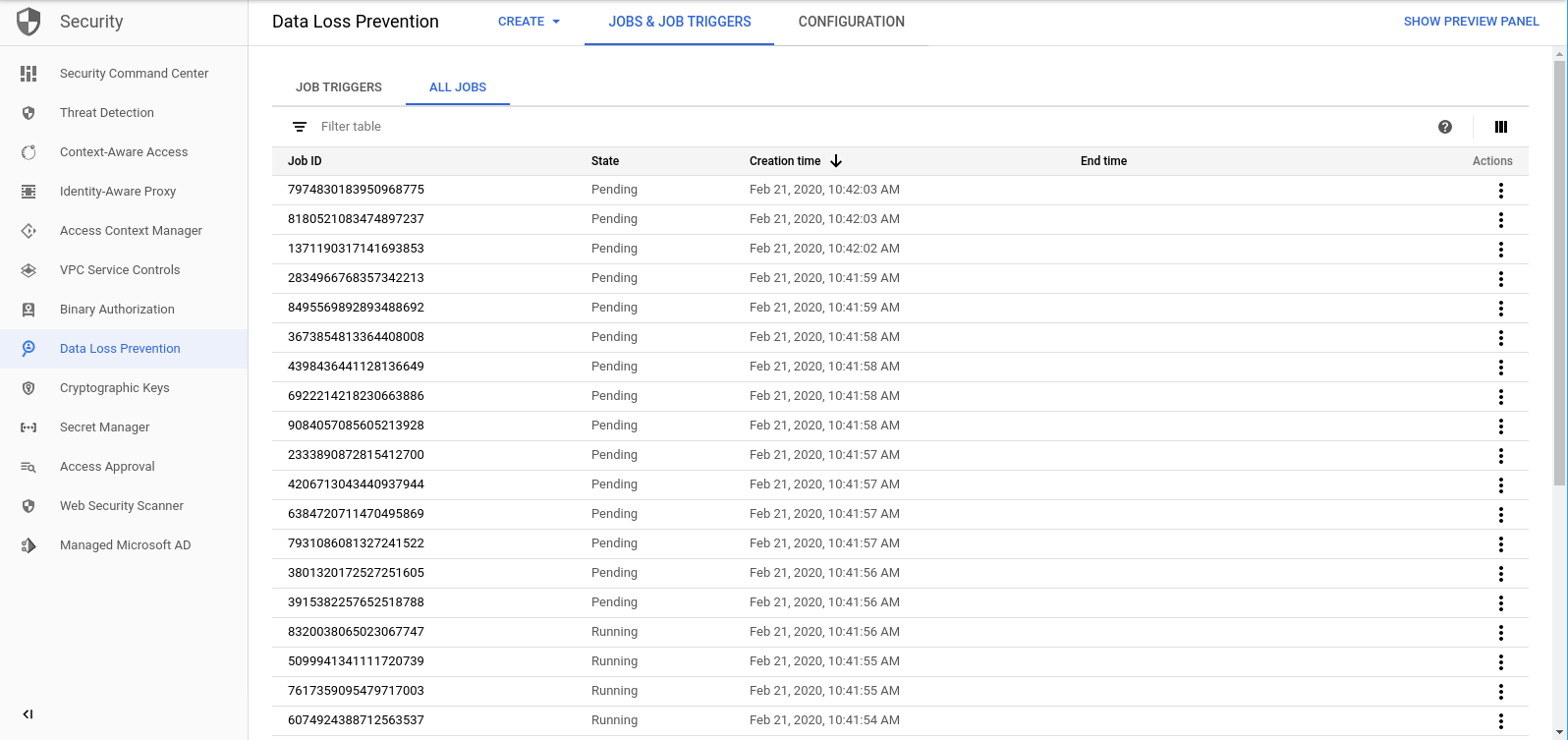
Vous pouvez cliquer sur l'ID de l'un de ces jobs pour afficher plus de détails.
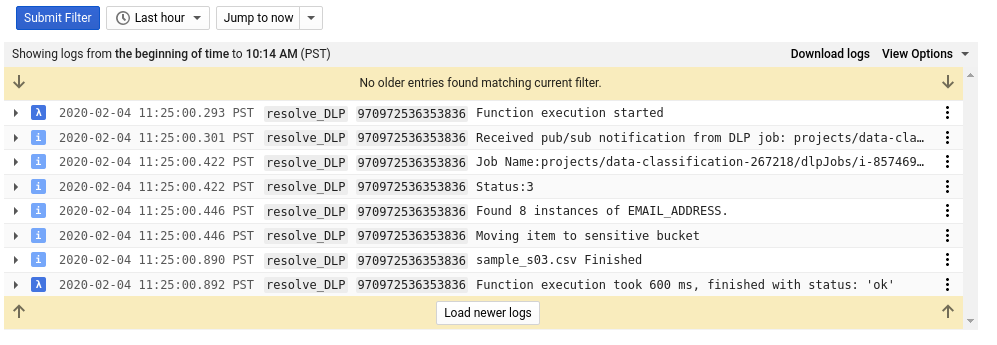
Si vous revenez à la page Cloud Functions et que vous consultez les journaux de la fonction resolve_DLP, vous verrez au moins huit entrées pour chaque fichier, indiquant :
- L'exécution de la fonction a commencé
- Une notification Pub/Sub a été reçue
- Nom du job de protection contre la perte de données correspondant
- Un code d'état
- Nombre d'occurrences de données sensibles (le cas échéant)
- Bucket vers lequel le fichier sera déplacé
- La tâche DLP a terminé d'analyser le fichier.
- La fonction avait terminé son exécution
Une fois que tous les appels à la fonction resolve_DLP ont été exécutés, vérifiez à nouveau le contenu du bucket de mise en quarantaine :
gsutil ls gs://[YOUR_QUARANTINE_BUCKET]
Cette fois, il devrait être complètement vide. Toutefois, si vous exécutez la même commande pour les autres buckets, vous constaterez que nos fichiers sont parfaitement séparés dans leurs buckets respectifs.
7. Nettoyage
Maintenant que nous avons vu comment utiliser l'API DLP avec Cloud Functions pour classer les données, nettoyons notre projet de toutes les ressources que nous avons créées.
Supprimer le projet
Si vous le souhaitez, vous pouvez supprimer l'intégralité du projet. Dans la console GCP, accédez à la page Cloud Resource Manager :
Dans la liste des projets, sélectionnez celui dans lequel vous avez travaillé, puis cliquez sur Supprimer. Vous serez alors invité à saisir l'ID du projet. Saisissez-le, puis cliquez sur Arrêter.
Vous pouvez également supprimer le projet dans son intégralité directement dans Cloud Shell avec gcloud :
gcloud projects delete [PROJECT_ID]
Si vous préférez supprimer les différents composants un par un, passez à la section suivante.
Cloud Functions
Supprimez les deux fonctions Cloud avec gcloud :
gcloud functions delete -q create_DLP_job && gcloud functions delete -q resolve_DLP
Buckets de stockage
Supprimez tous les fichiers importés et les buckets avec gsutil :
gsutil rm -r gs://[YOUR_QUARANTINE_BUCKET] \ gs://[YOUR_SENSITIVE_DATA_BUCKET] \ gs://[YOUR_NON_SENSITIVE_DATA_BUCKET]
Pub/Sub
Commencez par supprimer l'abonnement Pub/Sub avec gcloud :
gcloud pubsub subscriptions delete classify-sub
Enfin, supprimez le sujet Pub/Sub avec gcloud :
gcloud pubsub topics delete classify-topic
8. Félicitations !
Bravo ! Bravo ! Vous avez appris à utiliser l'API DLP avec Cloud Functions pour automatiser la classification des fichiers.
Points abordés
- Nous avons créé des buckets Cloud Storage pour stocker nos données sensibles et non sensibles.
- Nous avons créé un sujet et un abonnement Pub/Sub pour déclencher une fonction Cloud.
- Nous avons créé des fonctions Cloud conçues pour lancer une tâche DLP qui catégorise les fichiers en fonction des données sensibles qu'ils contiennent.
- Nous avons importé des données de test et consulté les journaux Stackdriver de nos fonctions Cloud pour voir le processus en action.