
1. Panoramica
Nelle organizzazioni moderne, la quantità di dati provenienti da varie fonti è in costante aumento. Ciò spesso richiede la quarantena e la classificazione di questi dati per archiviarli e proteggerli in modo strategico, un'attività che diventerà rapidamente costosa e impossibile se rimane manuale.
In questo codelab vedremo come classificare automaticamente i dati caricati in Cloud Storage e spostarli in un bucket di archiviazione corrispondente. A questo scopo, utilizzeremo Cloud Pub/Sub, Cloud Functions, Cloud Data Loss Prevention e Cloud Storage.
Attività previste
- Crea bucket Cloud Storage da utilizzare come parte della pipeline di quarantena e classificazione.
- Crea una semplice funzione Cloud che richiama l'API DLP quando vengono caricati i file.
- Crea un argomento e una sottoscrizione Pub/Sub per ricevere una notifica al termine dell'elaborazione del file.
- Carica i file di esempio nel bucket di quarantena per richiamare una Funzione Cloud
- Utilizza l'API DLP per ispezionare e classificare i file e spostarli nel bucket appropriato.
Che cosa ti serve
- Un progetto Google Cloud con la fatturazione configurata. Se non ne hai uno, dovrai crearne uno.
2. Preparazione
In questo codelab, eseguiremo il provisioning e la gestione di diversi servizi e risorse cloud utilizzando la riga di comando tramite Cloud Shell. Il seguente comando aprirà Cloud Shell insieme all'editor di Cloud Shell e clonerà il repository del progetto complementare:
Assicurati di utilizzare il progetto corretto impostandolo con gcloud config set project [PROJECT_ID]
Abilita API
Abilita le API richieste nel progetto Google Cloud:
- API Cloud Functions: gestisce funzioni semplici fornite dall'utente eseguite in risposta agli eventi.
- API Cloud Data Loss Prevention (DLP): fornisce metodi per il rilevamento, l'analisi del rischio e l'anonimizzazione di frammenti sensibili alla privacy in testo, immagini e repository di archiviazione di Google Cloud.
- Cloud Storage: Google Cloud Storage è un servizio RESTful per l'archiviazione e l'accesso ai dati sull'infrastruttura di Google.
Autorizzazioni degli account di servizio
Un service account è un tipo speciale di account utilizzato da applicazioni e macchine virtuali per effettuare chiamate API autorizzate.
Service account predefinito di App Engine
Il service account predefinito di App Engine viene utilizzato per eseguire attività nel tuo progetto Cloud per conto delle tue app in esecuzione in App Engine. Questo service account esiste nel tuo progetto per impostazione predefinita con il ruolo Editor assegnato.
Innanzitutto, concederemo al nostro service account il ruolo Amministratore DLP necessario per amministrare i job di prevenzione della perdita di dati:
gcloud projects add-iam-policy-binding $GOOGLE_CLOUD_PROJECT \ --member serviceAccount:$GOOGLE_CLOUD_PROJECT@appspot.gserviceaccount.com \ --role roles/dlp.admin
Infine, concedi il ruolo Agente di servizio API DLP che consentirà all'account di servizio di disporre delle autorizzazioni per BigQuery, Storage, Datastore, Pub/Sub e Key Management Service:
gcloud projects add-iam-policy-binding $GOOGLE_CLOUD_PROJECT \ --member serviceAccount:$GOOGLE_CLOUD_PROJECT@appspot.gserviceaccount.com \ --role roles/dlp.serviceAgent
Account di servizio DLP
Oltre al service account App Engine, utilizzeremo anche un service account DLP. Questo service account è stato creato automaticamente quando è stata abilitata l'API DLP e inizialmente non gli è stato concesso alcun ruolo. Concediamogli il ruolo Visualizzatore:
gcloud projects add-iam-policy-binding $GOOGLE_CLOUD_PROJECT \ --member serviceAccount:service-`gcloud projects list --filter="PROJECT_ID:$GOOGLE_CLOUD_PROJECT" --format="value(PROJECT_NUMBER)"`@dlp-api.iam.gserviceaccount.com \ --role roles/viewer
3. Bucket Cloud Storage
Ora dobbiamo creare tre bucket Cloud Storage per archiviare i nostri dati:
- Bucket di quarantena: i nostri dati verranno caricati inizialmente qui.
- Bucket di dati sensibili: i dati determinati dall'API DLP come sensibili verranno spostati qui.
- Bucket di dati non sensibili: i dati determinati dall'API DLP come non sensibili verranno spostati qui
Possiamo utilizzare il comando gsutil per creare tutti e tre i bucket in un'unica operazione:
gsutil mb gs://[YOUR_QUARANTINE_BUCKET] \ gs://[YOUR_SENSITIVE_DATA_BUCKET] \ gs://[YOUR_NON_SENSITIVE_DATA_BUCKET]
Prendi nota dei nomi dei bucket che hai appena creato, ti serviranno in seguito.
4. Argomento e sottoscrizione Pub/Sub
Cloud Pub/Sub fornisce messaggistica asincrona many-to-many tra le applicazioni. Un publisher crea un messaggio e lo pubblica in un feed di messaggi chiamato argomento. Un abbonato riceverà questi messaggi tramite un abbonamento. In base a questo abbonamento, nel nostro caso, una funzione Cloud Functions sposterà i file nei rispettivi bucket dopo l'esecuzione di un job DLP.
Innanzitutto, creiamo un argomento. Ogni volta che viene aggiunto un file al nostro bucket di archiviazione in quarantena, qui viene pubblicato un messaggio. Lo chiameremo "classify-topic".
gcloud pubsub topics create classify-topic
Una sottoscrizione riceverà una notifica quando l'argomento pubblica un messaggio. Creiamo una sottoscrizione Pub/Sub denominata "classify-sub":
gcloud pubsub subscriptions create classify-sub --topic classify-topic
L'abbonamento attiverà una seconda funzione Cloud Functions che avvierà un job DLP che ispezionerà il file e lo sposterà nella posizione corretta.
5. Cloud Functions
Cloud Functions ci consente di eseguire il deployment di funzioni asincrone leggere, basate su eventi e monouso senza la necessità di gestire un server o un ambiente di runtime. Eseguiremo il deployment di due funzioni Cloud utilizzando il file main.py fornito, che si trova in dlp-cloud-functions-tutorials/gcs-dlp-classification-python/
Sostituisci variabili
Prima di poter creare le nostre funzioni, dobbiamo sostituire alcune variabili nel file main.py.
Nell'editor di Cloud Shell, modifica main.py sostituendo i valori delle variabili ID progetto e bucket nelle righe da 28 a 34 utilizzando i bucket corrispondenti creati in precedenza:
main.py
PROJECT_ID = '[PROJECT_ID_HOSTING_STAGING_BUCKET]'
"""The bucket the to-be-scanned files are uploaded to."""
STAGING_BUCKET = '[YOUR_QUARANTINE_BUCKET]'
"""The bucket to move "sensitive" files to."""
SENSITIVE_BUCKET = '[YOUR_SENSITIVE_DATA_BUCKET]'
"""The bucket to move "non sensitive" files to."""
NONSENSITIVE_BUCKET = '[YOUR_NON_SENSITIVE_DATA_BUCKET]'
Inoltre, sostituisci il valore della variabile dell'argomento Pub/Sub con l'argomento Pub/Sub creato nel passaggio precedente:
""" Pub/Sub topic to notify once the DLP job completes."""
PUB_SUB_TOPIC = 'classify-topic'
Esegui il deployment delle funzioni
In Cloud Shell, cambia directory in gcs-dlp-classification-python dove esiste il file main.py:
cd ~/cloudshell_open/dlp-cloud-functions-tutorials/gcs-dlp-classification-python
È il momento di eseguire il deployment di alcune funzioni.
Per prima cosa, esegui il deployment della funzione create_DLP_job, sostituendo [YOUR_QUARANTINE_BUCKET] con il nome del bucket corretto. Questa funzione viene attivata quando vengono caricati nuovi file nel bucket di quarantena Cloud Storage designato e crea un job DLP per ogni file caricato:
gcloud functions deploy create_DLP_job --runtime python37 \ --trigger-event google.storage.object.finalize \ --trigger-resource [YOUR_QUARANTINE_BUCKET]
Successivamente, esegui il deployment della funzione resolve_DLP, indicando il nostro argomento come trigger. Questa funzione è in ascolto della notifica Pub/Sub avviata dal successivo job DLP dalla funzione precedente. Non appena riceve la notifica Pub/Sub, preleva i risultati del job DLP e sposta il file nel bucket sensibile o non sensibile a seconda dei casi:
gcloud functions deploy resolve_DLP --runtime python37 \ --trigger-topic classify-topic
Verifica
Verifica che entrambe le nostre funzioni cloud siano state implementate correttamente con il comando gcloud functions describe:
gcloud functions describe create_DLP_job
gcloud functions describe resolve_DLP
L'output sarà ACTIVE per lo stato quando il deployment è stato eseguito correttamente.
6. Test con dati di esempio
Ora che abbiamo tutti i dati a disposizione, possiamo testare il tutto con alcuni file di esempio. In Cloud Shell, cambia la directory di lavoro attuale in sample_data:
cd ~/cloudshell_open/dlp-cloud-functions-tutorials/sample_data
I nostri file di esempio sono costituiti da file txt e csv contenenti vari dati. I file con il prefisso "sample_s" conterranno dati sensibili, mentre quelli con il prefisso "sample_n" non li conterranno. Ad esempio, sample_s20.csv contiene dati formattati in modo da sembrare numeri di previdenza sociale statunitensi:
sample_s20.csv
Name,SSN,metric 1,metric 2
Maria Johnson,284-73-5110,5,43
Tyler Parker,284-73-5110,8,17
Maria Johnson,284-73-5110,54,63
Maria Johnson,245-25-8698,53,19
Tyler Parker,475-15-8499,6,67
Maria Johnson,719-12-6560,75,83
Maria Johnson,616-69-3226,91,13
Tzvika Roberts,245-25-8698,94,61
D'altra parte, i dati in sample_n15.csv non sarebbero considerati sensibili:
sample_n15.csv
record id,metric 1,metric 2,metric 3
1,59,93,100
2,53,13,17
3,59,67,53
4,52,93,34
5,14,22,88
6,18,88,3
7,32,49,5
8,93,46,14
Per vedere come la nostra configurazione tratterà i nostri file, carichiamo tutti i file di test nella quarantena.
bucket:
gsutil -m cp * gs://[YOUR_QUARANTINE_BUCKET]
Inizialmente, i nostri file si troveranno nel bucket di quarantena in cui li abbiamo caricati. Per verificarlo, subito dopo aver caricato i file, elenca i contenuti del bucket di quarantena:
gsutil ls gs://[YOUR_QUARANTINE_BUCKET]
Per dare un'occhiata alla serie di eventi che abbiamo avviato, inizia andando alla pagina Cloud Functions:
Fai clic sul menu Azioni per la funzione create_DLP_job e seleziona Visualizza log:
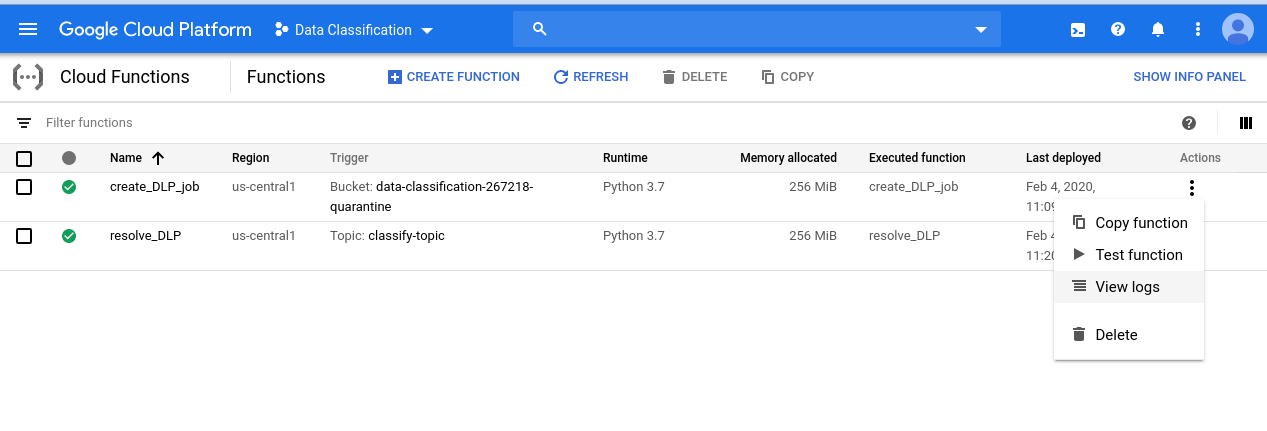
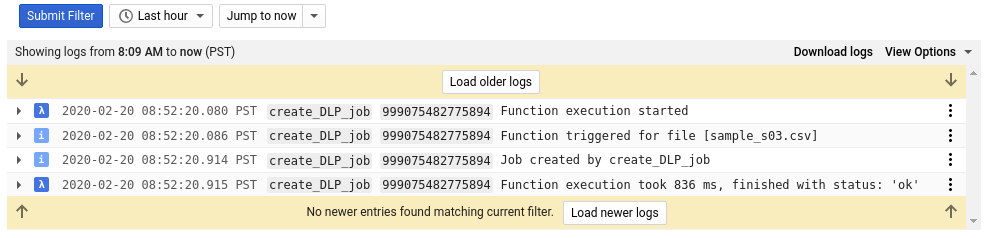
Nel log di questa funzione sono presenti almeno quattro voci per ciascuno dei nostri file che indicano:
- L'esecuzione della funzione è iniziata
- La funzione era stata attivata per un determinato file
- È stato creato un job
- L'esecuzione della funzione è terminata
Una volta completata la funzione create_DLP_job per ogni file, viene avviato un job DLP corrispondente. Vai alla pagina Job DLP per visualizzare un elenco dei job DLP in coda:
Vedrai un elenco di job in stato In attesa, In esecuzione o Completato. Ognuno di questi corrisponde a uno dei file che abbiamo caricato:
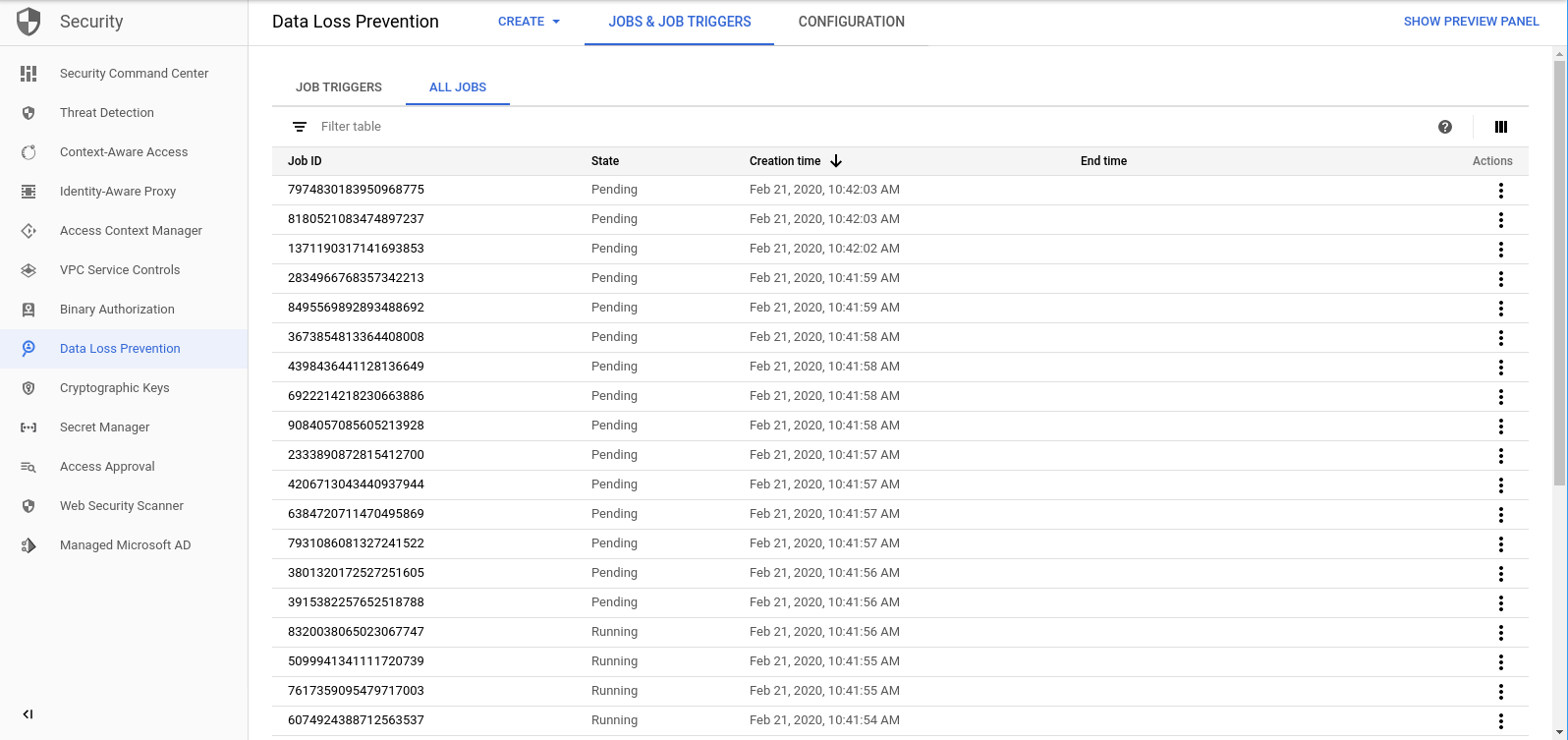
Puoi fare clic sull'ID di uno di questi job per visualizzare ulteriori dettagli.
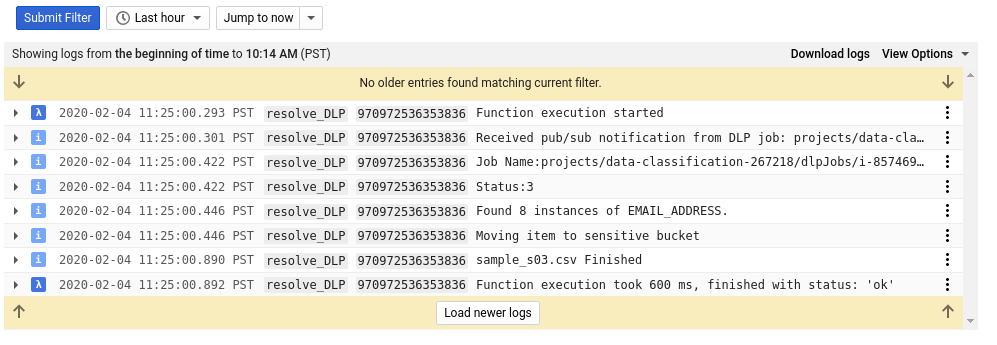
Se torni alla pagina Cloud Functions e controlli i log della funzione resolve_DLP, vedrai almeno 8 voci per ogni file, che indicano:
- L'esecuzione della funzione è iniziata
- È stata ricevuta una notifica Pub/Sub
- Il nome del job DLP corrispondente
- Un codice di stato
- Il numero di istanze di dati sensibili (se presenti)
- Il bucket in cui verrà spostato il file
- Il job DLP ha terminato l'analisi del file
- L'esecuzione della funzione è terminata
Una volta completata l'esecuzione di tutte le chiamate alla funzione resolve_DLP, controlla di nuovo i contenuti del bucket di quarantena:
gsutil ls gs://[YOUR_QUARANTINE_BUCKET]
Questa volta dovrebbe essere completamente vuoto. Se esegui lo stesso comando riportato sopra per gli altri bucket, troverai i nostri file perfettamente separati nei bucket corrispondenti.
7. Esegui la pulizia
Ora che abbiamo visto come utilizzare l'API DLP insieme a Cloud Functions per classificare i dati, puliamo il nostro progetto da tutte le risorse che abbiamo creato.
Eliminare il progetto
Se preferisci, puoi eliminare l'intero progetto. Nella console di GCP, vai alla pagina Cloud Resource Manager:
Nell'elenco dei progetti, seleziona il progetto su cui abbiamo lavorato e fai clic su Elimina. Ti verrà chiesto di digitare l'ID progetto. Inseriscilo e fai clic su Chiudi.
In alternativa, puoi eliminare l'intero progetto direttamente da Cloud Shell con gcloud:
gcloud projects delete [PROJECT_ID]
Se preferisci eliminare i diversi componenti uno alla volta, vai alla sezione successiva.
Cloud Functions
Elimina entrambe le funzioni cloud con gcloud:
gcloud functions delete -q create_DLP_job && gcloud functions delete -q resolve_DLP
Bucket di archiviazione
Rimuovi tutti i file caricati ed elimina i bucket con gsutil:
gsutil rm -r gs://[YOUR_QUARANTINE_BUCKET] \ gs://[YOUR_SENSITIVE_DATA_BUCKET] \ gs://[YOUR_NON_SENSITIVE_DATA_BUCKET]
Pub/Sub
Innanzitutto, elimina la sottoscrizione Pub/Sub con gcloud:
gcloud pubsub subscriptions delete classify-sub
Infine, elimina l'argomento Pub/Sub con gcloud:
gcloud pubsub topics delete classify-topic
8. Complimenti!
Evvai! Ce l'hai fatta! Hai imparato a utilizzare l'API DLP insieme a Cloud Functions per automatizzare la classificazione dei file.
Argomenti trattati
- Abbiamo creato bucket Cloud Storage per archiviare i nostri dati sensibili e non sensibili
- Abbiamo creato un argomento e una sottoscrizione Pub/Sub per attivare una funzione cloud
- Abbiamo creato Cloud Functions progettate per avviare un job DLP che classifica i file in base ai dati sensibili contenuti.
- Abbiamo caricato i dati di test e controllato i log Stackdriver delle nostre Cloud Functions per vedere il processo in azione.