
1. Übersicht
Diese Anleitung wurde für Tensorflow 2.2 aktualisiert.

In diesem Codelab lernen Sie, wie Sie ein neuronales Netzwerk erstellen und trainieren, das handschriftliche Ziffern erkennt. Während Sie Ihr neuronales Netzwerk verbessern, um eine Genauigkeit von 99% zu erreichen, lernen Sie auch die Tools kennen, die Deep-Learning-Experten verwenden, um ihre Modelle effizient zu trainieren.
In diesem Codelab wird das MNIST-Dataset verwendet, eine Sammlung von 60.000 beschrifteten Ziffern,die seit fast zwei Jahrzehnten Generationen von Doktoranden beschäftigt. Sie lösen das Problem mit weniger als 100 Zeilen Python-/TensorFlow-Code.
Lerninhalte
- Was ist ein neuronales Netzwerk und wie wird es trainiert?
- Einfaches einschichtiges neuronales Netzwerk mit tf.keras erstellen
- Weitere Ebenen hinzufügen
- Lernratenplan einrichten
- Convolutional Neural Networks erstellen
- Regularisierungstechniken verwenden: Dropout, Batchnormalisierung
- Was ist Überanpassung?
Voraussetzungen
Sie benötigen lediglich einen Browser. Dieser Workshop kann vollständig mit Google Colaboratory durchgeführt werden.
Feedback
Bitte teilen Sie uns mit, wenn Sie in diesem Lab etwas Ungewöhnliches feststellen oder wenn Sie der Meinung sind, dass es verbessert werden sollte. Wir bearbeiten Feedback über GitHub-Probleme [ Feedback-Link].
2. Google Colaboratory – Kurzanleitung
In diesem Lab wird Google Colaboratory verwendet. Sie müssen nichts einrichten. Sie können es auf einem Chromebook ausführen. Öffnen Sie die Datei unten und führen Sie die Zellen aus, um sich mit Colab-Notebooks vertraut zu machen.

Weitere Informationen finden Sie unten.
GPU-Backend auswählen

Wählen Sie im Colab-Menü Laufzeit > Laufzeittyp ändern und dann „GPU“ aus. Die Verbindung zur Laufzeit erfolgt bei der ersten Ausführung automatisch. Sie können aber auch die Schaltfläche „Verbinden“ rechts oben verwenden.
Notebook-Ausführung
Führen Sie die Zellen einzeln aus, indem Sie auf eine Zelle klicken und UMSCHALTTASTE + EINGABETASTE drücken. Sie können das gesamte Notebook auch mit Laufzeit > Alle ausführen ausführen.
Inhaltsverzeichnis

Alle Notebooks haben ein Inhaltsverzeichnis. Sie können sie über den schwarzen Pfeil auf der linken Seite öffnen.
Ausgeblendete Zellen

Bei einigen Zellen wird nur der Titel angezeigt. Dies ist eine Colab-spezifische Notebook-Funktion. Sie können doppelt darauf klicken, um den Code zu sehen, aber das ist in der Regel nicht sehr interessant. Sie unterstützen in der Regel Support- oder Visualisierungsfunktionen. Sie müssen diese Zellen weiterhin ausführen, damit die Funktionen darin definiert werden.
3. Neuronales Netzwerk trainieren
Zuerst sehen wir uns an, wie ein neuronales Netzwerk trainiert wird. Öffnen Sie das Notebook unten und führen Sie alle Zellen aus. Achten Sie noch nicht auf den Code. Wir werden ihn später erläutern.
Konzentrieren Sie sich bei der Ausführung des Notebooks auf die Visualisierungen. Weitere Informationen finden Sie unten.
Trainingsdaten
Wir haben ein Dataset mit handschriftlichen Ziffern, die mit Labels versehen wurden, sodass wir wissen, was jedes Bild darstellt, d.h. eine Zahl zwischen 0 und 9. Im Notebook sehen Sie einen Auszug:

Das neuronale Netzwerk, das wir erstellen, klassifiziert die handschriftlichen Ziffern in ihren 10 Klassen (0, …, 9). Dabei werden interne Parameter berücksichtigt, die einen korrekten Wert haben müssen, damit die Klassifizierung gut funktioniert. Dieser „richtige Wert“ wird durch einen Trainingsprozess ermittelt, für den ein „gelabeltes Dataset“ mit Bildern und den zugehörigen richtigen Antworten erforderlich ist.
Woher wissen wir, ob das trainierte neuronale Netzwerk gut funktioniert? Das Trainings-Dataset zum Testen des Netzwerks zu verwenden, wäre Betrug. Das Modell hat diesen Datensatz bereits mehrmals während des Trainings gesehen und ist mit Sicherheit sehr leistungsfähig. Wir benötigen ein weiteres Dataset mit Labels, das während des Trainings nicht verwendet wurde, um die „realistische“ Leistung des Netzwerks zu bewerten. Es wird als Validierungs-Dataset bezeichnet.
Schulung
Im Laufe des Trainings wird jeweils ein Batch von Trainingsdaten verarbeitet, interne Modellparameter werden aktualisiert und das Modell wird immer besser darin, die handschriftlichen Ziffern zu erkennen. Das ist im Trainingsdiagramm zu sehen:
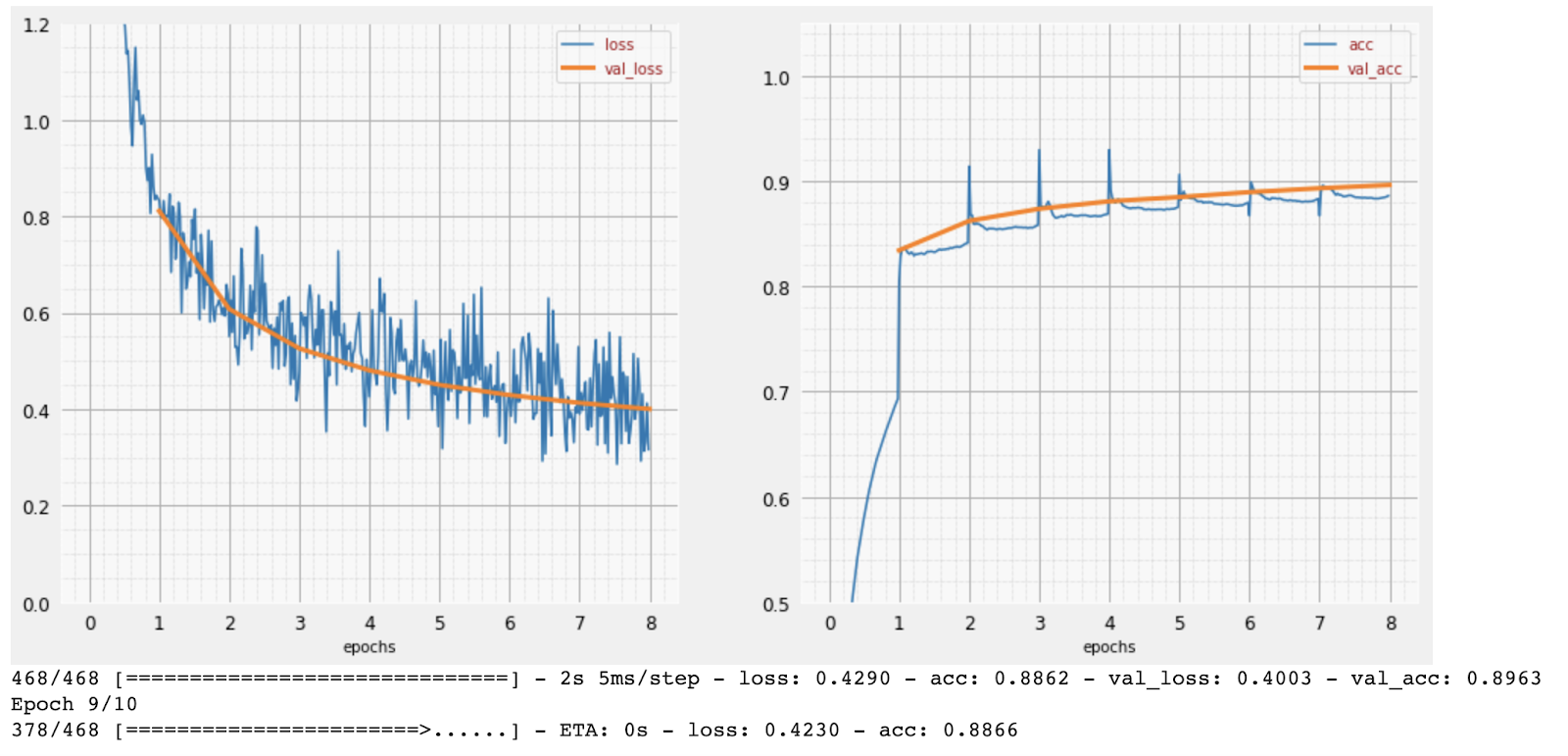
Rechts sehen Sie die „Genauigkeit“, die einfach der Prozentsatz der richtig erkannten Ziffern ist. Sie steigt im Laufe des Trainings, was gut ist.
Links sehen wir den Verlust. Um das Training voranzutreiben, definieren wir eine „Verlustfunktion“, die angibt, wie schlecht das System die Ziffern erkennt, und versuchen, sie zu minimieren. Hier sehen Sie, dass der Verlust sowohl bei den Trainings- als auch bei den Validierungsdaten mit fortschreitendem Training sinkt. Das ist gut. Das bedeutet, dass das neuronale Netzwerk lernt.
Die X-Achse stellt die Anzahl der Epochen oder Iterationen durch das gesamte Dataset dar.
Vorhersagen
Wenn das Modell trainiert ist, können wir es verwenden, um handschriftliche Ziffern zu erkennen. Die nächste Visualisierung zeigt, wie gut das Modell bei einigen Ziffern abschneidet, die mit lokalen Schriftarten gerendert wurden (erste Zeile), und dann bei den 10.000 Ziffern des Validierungs-Datasets. Die vorhergesagte Klasse wird unter jeder Ziffer angezeigt. Wenn sie falsch ist, wird sie rot dargestellt.

Wie Sie sehen, ist dieses erste Modell nicht sehr gut, erkennt aber trotzdem einige Ziffern richtig. Die endgültige Validierungsgenauigkeit liegt bei etwa 90 %. Das ist für das einfache Modell, mit dem wir beginnen, nicht schlecht. Es bedeutet aber auch, dass 1.000 der 10.000 Validierungsziffern nicht erkannt werden. Das ist viel mehr, als angezeigt werden kann. Deshalb sieht es so aus, als wären alle Antworten falsch (rot).
Tensoren
Daten werden in Matrizen gespeichert. Ein 28 × 28 Pixel großes Graustufenbild passt in eine zweidimensionale Matrix mit 28 × 28 Elementen. Für ein Farbbild benötigen wir jedoch mehr Dimensionen. Es gibt drei Farbwerte pro Pixel (Rot, Grün, Blau). Daher ist eine dreidimensionale Tabelle mit den Dimensionen [28, 28, 3] erforderlich. Um einen Batch von 128 Farbbildern zu speichern, ist eine vierdimensionale Tabelle mit den Dimensionen [128, 28, 28, 3] erforderlich.
Diese mehrdimensionalen Tabellen werden als Tensoren bezeichnet und die Liste ihrer Dimensionen ist ihre Form.
4. [INFO]: Neuronale Netzwerke – Grundlagen
Kurz zusammengefasst
Wenn Sie alle fett gedruckten Begriffe im nächsten Absatz bereits kennen, können Sie mit der nächsten Übung fortfahren. Wenn Sie gerade erst mit Deep Learning beginnen, sind Sie hier genau richtig.

Für Modelle, die als Folge von Layern erstellt wurden, bietet Keras die Sequential API. Ein Bildklassifikator mit drei dichten Layern kann in Keras so geschrieben werden:
model = tf.keras.Sequential([
tf.keras.layers.Flatten(input_shape=[28, 28, 1]),
tf.keras.layers.Dense(200, activation="relu"),
tf.keras.layers.Dense(60, activation="relu"),
tf.keras.layers.Dense(10, activation='softmax') # classifying into 10 classes
])
# this configures the training of the model. Keras calls it "compiling" the model.
model.compile(
optimizer='adam',
loss= 'categorical_crossentropy',
metrics=['accuracy']) # % of correct answers
# train the model
model.fit(dataset, ... )

Eine einzelne Dense-Ebene
Handschriftliche Ziffern im MNIST-Dataset sind 28 × 28 Pixel große Graustufenbilder. Der einfachste Ansatz für die Klassifizierung ist die Verwendung der 28 × 28=784 Pixel als Eingaben für ein einschichtiges neuronales Netzwerk.

Jedes Neuron in einem neuronalen Netzwerk berechnet eine gewichtete Summe aller seiner Eingaben, addiert eine Konstante, die als Bias bezeichnet wird, und leitet das Ergebnis dann durch eine nichtlineare Aktivierungsfunktion weiter. Die Gewichtungen und Biases sind Parameter, die durch Training bestimmt werden. Sie werden zuerst mit zufälligen Werten initialisiert.
Das Bild oben zeigt ein einschichtiges neuronales Netzwerk mit 10 Ausgabeneuronen, da wir Ziffern in 10 Klassen (0 bis 9) klassifizieren möchten.
Mit einer Matrixmultiplikation
So kann eine Ebene eines neuronalen Netzwerks, die eine Sammlung von Bildern verarbeitet, durch eine Matrixmultiplikation dargestellt werden:

Mithilfe der ersten Spalte der Gewichtsmatrix W wird die gewichtete Summe aller Pixel des ersten Bildes berechnet. Diese Summe entspricht dem ersten Neuron. Mit der zweiten Spalte der Gewichte wiederholen wir den Vorgang für das zweite Neuron und so weiter bis zum zehnten Neuron. Wir können den Vorgang dann für die restlichen 99 Bilder wiederholen. Wenn wir X als die Matrix mit unseren 100 Bildern bezeichnen, sind alle gewichteten Summen für unsere 10 Neuronen, die für 100 Bilder berechnet werden, einfach X.W, eine Matrixmultiplikation.
Jedes Neuron muss nun seinen Bias (eine Konstante) hinzufügen. Da wir 10 Neuronen haben, gibt es 10 Bias-Konstanten. Wir nennen diesen Vektor mit 10 Werten „b“. Sie muss jeder Zeile der zuvor berechneten Matrix hinzugefügt werden. Mit einer Funktion namens „Broadcasting“ können wir das mit einem einfachen Pluszeichen schreiben.
Schließlich wenden wir eine Aktivierungsfunktion an, z. B. „Softmax“ (siehe unten), und erhalten die Formel für ein einschichtiges neuronales Netzwerk, das auf 100 Bilder angewendet wird:

In Keras
Bei High-Level-Bibliotheken für neuronale Netze wie Keras müssen wir diese Formel nicht implementieren. Es ist jedoch wichtig zu verstehen, dass eine Schicht eines neuronalen Netzwerks nur eine Reihe von Multiplikationen und Additionen ist. In Keras würde eine Dense-Ebene so geschrieben werden:
tf.keras.layers.Dense(10, activation='softmax')
Tiefer einsteigen
Es ist ganz einfach, neuronale Netzwerkebenen zu verketten. In der ersten Ebene werden gewichtete Summen von Pixeln berechnet. In den nachfolgenden Schichten werden gewichtete Summen der Ausgaben der vorherigen Schichten berechnet.

Der einzige Unterschied neben der Anzahl der Neuronen ist die Wahl der Aktivierungsfunktion.
Aktivierungsfunktionen: ReLU, Softmax und Sigmoid
Normalerweise verwenden Sie die Aktivierungsfunktion „relu“ für alle Ebenen außer der letzten. In der letzten Ebene eines Klassifikators wird die Softmax-Aktivierung verwendet.

Auch hier berechnet ein „Neuron“ eine gewichtete Summe aller seiner Eingaben, addiert einen Wert namens „Bias“ und leitet das Ergebnis durch die Aktivierungsfunktion.
Die beliebteste Aktivierungsfunktion ist RELU (Rectified Linear Unit). Wie Sie im Diagramm oben sehen, ist es eine sehr einfache Funktion.
Die herkömmliche Aktivierungsfunktion in neuronalen Netzen war die Sigmoidfunktion. Es hat sich jedoch gezeigt, dass die ReLU-Funktion fast überall bessere Konvergenzeigenschaften aufweist. Sie wird daher jetzt bevorzugt.

Softmax-Aktivierung für die Klassifizierung
Die letzte Ebene unseres neuronalen Netzes hat 10 Neuronen, da wir handschriftliche Ziffern in 10 Klassen (0 bis 9) klassifizieren möchten. Es sollten 10 Zahlen zwischen 0 und 1 ausgegeben werden, die die Wahrscheinlichkeit dafür darstellen, dass diese Ziffer eine 0, eine 1, eine 2 usw. ist. Dazu verwenden wir in der letzten Ebene eine Aktivierungsfunktion namens Softmax.
Beim Anwenden von Softmax auf einen Vektor wird von jedem Element der Exponentialwert berechnet und der Vektor dann normalisiert. Dazu wird er in der Regel durch seine L1-Norm (d. h. die Summe der Absolutwerte) geteilt, sodass die normalisierten Werte in der Summe 1 ergeben und als Wahrscheinlichkeiten interpretiert werden können.
Die Ausgabe der letzten Ebene vor der Aktivierung wird manchmal als Logits bezeichnet. Wenn dieser Vektor L = [L0, L1, L2, L3, L4, L5, L6, L7, L8, L9] ist, gilt Folgendes:


Cross-Entropy Loss
Nachdem unser neuronales Netzwerk Vorhersagen aus Eingabebildern generiert, müssen wir messen, wie gut diese sind. Das heißt, wir müssen den Abstand zwischen dem, was das Netzwerk uns sagt, und den richtigen Antworten, oft als „Labels“ bezeichnet, ermitteln. Wir haben die richtigen Labels für alle Bilder im Dataset.
Jede Distanz würde funktionieren, aber für Klassifizierungsprobleme ist die sogenannte „Kreuzentropie-Distanz“ am effektivsten. Wir nennen dies unsere Fehler- oder Verlustfunktion:

Gradientenabstieg
Das „Trainieren“ des neuronalen Netzes bedeutet, dass Trainingsbilder und ‑labels verwendet werden, um Gewichte und Bias so anzupassen, dass die Cross-Entropy-Verlustfunktion minimiert wird. So funktioniert es:
Die Kreuzentropie ist eine Funktion von Gewichten, Bias, Pixeln des Trainingsbilds und seiner bekannten Klasse.
Wenn wir die partiellen Ableitungen der Kreuzentropie in Bezug auf alle Gewichte und alle Bias berechnen, erhalten wir einen „Gradienten“, der für ein bestimmtes Bild, Label und den aktuellen Wert der Gewichte und Bias berechnet wird. Da es Millionen von Gewichten und Bias geben kann, ist die Berechnung des Gradienten sehr aufwendig. Glücklicherweise übernimmt TensorFlow das für uns. Die mathematische Eigenschaft eines Gradienten ist, dass er „nach oben“ zeigt. Da wir dorthin gehen möchten, wo die Kreuzentropie niedrig ist, gehen wir in die entgegengesetzte Richtung. Wir aktualisieren Gewichte und Bias um einen Bruchteil des Gradienten. Das wiederholen wir dann immer wieder mit den nächsten Batches von Trainingsbildern und ‑Labels in einer Trainingsschleife. Im Idealfall konvergiert dies zu einem Punkt, an dem die Kreuzentropie minimal ist. Es gibt jedoch keine Garantie dafür, dass dieses Minimum eindeutig ist.

Mini-Batching und Momentum
Sie können den Gradienten für nur ein Beispielbild berechnen und die Gewichte und Bias sofort aktualisieren. Wenn Sie dies jedoch für einen Batch von z. B. 128 Bildern tun, erhalten Sie einen Gradienten, der die Einschränkungen durch verschiedene Beispielbilder besser repräsentiert und daher wahrscheinlich schneller zur Lösung konvergiert. Die Größe des Mini-Batch ist ein anpassbarer Parameter.
Diese Technik, die manchmal auch als „stochastic gradient descent“ (stochastischer Gradientenabstieg) bezeichnet wird, hat einen weiteren, pragmatischeren Vorteil: Die Arbeit mit Batches bedeutet auch die Arbeit mit größeren Matrizen, die sich in der Regel leichter auf GPUs und TPUs optimieren lassen.
Die Konvergenz kann jedoch immer noch etwas chaotisch sein und sogar stoppen, wenn der Gradientenvektor nur Nullen enthält. Bedeutet das, dass wir ein Minimum gefunden haben? Nimmt immer. Eine Gradientenkomponente kann an einem Minimum oder Maximum null sein. Bei einem Gradientenvektor mit Millionen von Elementen ist die Wahrscheinlichkeit, dass alle Nullen einem Minimum und keine einem Maximum entsprechen, ziemlich gering. In einem Raum mit vielen Dimensionen sind Sattelpunkte ziemlich häufig und wir möchten nicht an ihnen anhalten.

Abbildung: Sattelpunkt. Der Gradient ist 0, aber es handelt sich nicht in allen Richtungen um ein Minimum. (Bildnachweis: Wikimedia: Von Nicoguaro – Eigene Arbeit, CC BY 3.0)
Die Lösung besteht darin, dem Optimierungsalgorithmus etwas Schwung zu verleihen, damit er Sattelpunkte passieren kann, ohne anzuhalten.
Glossar
Batch oder Mini-Batch: Das Training erfolgt immer mit Batches von Trainingsdaten und Labels. Das hilft dem Algorithmus, zu konvergieren. Die Dimension „Batch“ ist in der Regel die erste Dimension von Datentensoren. Ein Tensor mit der Form [100, 192, 192, 3] enthält beispielsweise 100 Bilder mit 192 × 192 Pixeln und drei Werten pro Pixel (RGB).
Kreuzentropie-Verlust: Eine spezielle Verlustfunktion, die häufig in Klassifizierern verwendet wird.
Dense Layer (dichte Schicht): Eine Schicht von Neuronen, in der jedes Neuron mit allen Neuronen in der vorherigen Schicht verbunden ist.
Features: Die Eingaben eines neuronalen Netzwerks werden manchmal als „Features“ bezeichnet. Die Kunst, herauszufinden, welche Teile eines Datensatzes (oder Kombinationen von Teilen) in ein neuronales Netzwerk eingegeben werden müssen, um gute Vorhersagen zu erhalten, wird als „Feature-Engineering“ bezeichnet.
Labels: ein anderer Name für „Klassen“ oder richtige Antworten in einem überwachten Klassifizierungsproblem
Lernrate: Bruchteil des Gradienten, um den Gewichte und Bias bei jeder Iteration der Trainingsschleife aktualisiert werden.
Logits: Die Ausgaben einer Neuronen-Schicht, bevor die Aktivierungsfunktion angewendet wird, werden als „Logits“ bezeichnet. Der Begriff stammt von der „logistischen Funktion“ bzw. „Sigmoid-Funktion“, die früher die beliebteste Aktivierungsfunktion war. „Neuron outputs before logistic function“ (Neuronenausgaben vor logistischer Funktion) wurde zu „Logits“ verkürzt.
loss: Die Fehlerfunktion, mit der die Ausgaben des neuronalen Netzwerks mit den richtigen Antworten verglichen werden.
Neuron: Berechnet die gewichtete Summe seiner Eingaben, fügt einen Bias hinzu und leitet das Ergebnis durch eine Aktivierungsfunktion.
One-Hot-Codierung: Die Klasse 3 von 5 wird als Vektor mit 5 Elementen codiert, die alle null sind, mit Ausnahme des dritten Elements, das 1 ist.
relu: Rektifizierte Lineareinheit. Eine beliebte Aktivierungsfunktion für Neuronen.
sigmoid: Eine weitere Aktivierungsfunktion, die früher beliebt war und in Sonderfällen immer noch nützlich ist.
softmax: Eine spezielle Aktivierungsfunktion, die auf einen Vektor angewendet wird, den Unterschied zwischen der größten Komponente und allen anderen erhöht und den Vektor so normalisiert, dass die Summe 1 ergibt. So kann er als Vektor von Wahrscheinlichkeiten interpretiert werden. Wird als letzter Schritt in Klassifikatoren verwendet.
Tensor: Ein Tensor ist wie eine Matrix, aber mit einer beliebigen Anzahl von Dimensionen. Ein eindimensionaler Tensor ist ein Vektor. Ein 2-dimensionaler Tensor ist eine Matrix. Dann können Sie Tensoren mit 3, 4, 5 oder mehr Dimensionen haben.
5. Sehen wir uns den Code an.
Kehren wir zum Notebook zurück und lesen wir uns den Code an.
Sehen wir uns alle Zellen in diesem Notebook an.
Zelle „Parameter“
Hier werden die Batchgröße, die Anzahl der Trainingsepochen und der Speicherort der Datendateien definiert. Datendateien werden in einem Google Cloud Storage-Bucket (GCS) gehostet. Daher beginnt ihre Adresse mit gs://.
Zelle „Importe“
Hier werden alle erforderlichen Python-Bibliotheken importiert, einschließlich TensorFlow und matplotlib für Visualisierungen.
Zelle Visualisierungstools [RUN ME]****
Diese Zelle enthält uninteressanten Visualisierungscode. Sie ist standardmäßig minimiert, kann aber durch Doppelklicken geöffnet werden, wenn Sie Zeit haben, sich den Code anzusehen.
Zelle „tf.data.Dataset: parse files and prepare training and validation datasets“
In dieser Zelle wurde die tf.data.Dataset API verwendet, um das MNIST-Dataset aus den Datendateien zu laden. Es ist nicht notwendig, zu viel Zeit mit dieser Zelle zu verbringen. Wenn Sie sich für die tf.data.Dataset API interessieren, finden Sie hier ein entsprechendes Tutorial. Die Grundlagen sind derzeit:
Bilder und Labels (richtige Antworten) aus dem MNIST-Dataset werden in Datensätzen mit fester Länge in vier Dateien gespeichert. Die Dateien können mit der entsprechenden Funktion für Datensätze mit fester Länge geladen werden:
imagedataset = tf.data.FixedLengthRecordDataset(image_filename, 28*28, header_bytes=16)
Wir haben jetzt ein Dataset mit Bild-Bytes. Sie müssen in Bilder decodiert werden. Wir definieren eine Funktion dafür. Das Bild wird nicht komprimiert, sodass die Funktion nichts decodieren muss (decode_raw macht im Grunde nichts). Das Bild wird dann in Gleitkommawerte zwischen 0 und 1 umgewandelt. Wir könnten es hier als 2D-Bild umformen, aber wir behalten es als flaches Pixel-Array der Größe 28 × 28 bei, da dies von unserer ersten Dense-Schicht erwartet wird.
def read_image(tf_bytestring):
image = tf.io.decode_raw(tf_bytestring, tf.uint8)
image = tf.cast(image, tf.float32)/256.0
image = tf.reshape(image, [28*28])
return image
Wir wenden diese Funktion mit .map auf das Dataset an und erhalten ein Dataset mit Bildern:
imagedataset = imagedataset.map(read_image, num_parallel_calls=16)
Wir lesen und decodieren Labels auf dieselbe Weise und .zip Bilder und Labels zusammen:
dataset = tf.data.Dataset.zip((imagedataset, labelsdataset))
Wir haben jetzt ein Dataset mit Paaren aus Bild und Label. Das ist das, was unser Modell erwartet. Wir sind noch nicht ganz so weit, dass wir sie in der Trainingsfunktion verwenden können:
dataset = dataset.cache()
dataset = dataset.shuffle(5000, reshuffle_each_iteration=True)
dataset = dataset.repeat()
dataset = dataset.batch(batch_size)
dataset = dataset.prefetch(tf.data.experimental.AUTOTUNE)
Die tf.data.Dataset API enthält alle erforderlichen Hilfsfunktionen zum Vorbereiten von Datasets:
.cache speichert das Dataset im RAM. Da es sich um ein kleines Dataset handelt, funktioniert das. .shuffle mischt die Elemente mit einem Puffer von 5.000 Elementen. Es ist wichtig, dass die Trainingsdaten gut gemischt werden. .repeat durchläuft das Dataset. Wir werden das Modell mehrmals damit trainieren (mehrere Epochen). .batch fasst mehrere Bilder und Labels zu einem Mini-Batch zusammen. Schließlich kann .prefetch die CPU verwenden, um den nächsten Batch vorzubereiten, während der aktuelle Batch auf der GPU trainiert wird.
Das Validierungs-Dataset wird auf ähnliche Weise vorbereitet. Wir können jetzt ein Modell definieren und dieses Dataset zum Trainieren verwenden.
Zelle „Keras-Modell“
Alle unsere Modelle sind einfache Sequenzen von Layern. Wir können sie also mit dem tf.keras.Sequential-Stil erstellen. Anfangs ist es eine einzelne dichte Ebene. Sie hat 10 Neuronen, weil wir handschriftliche Ziffern in 10 Klassen klassifizieren. Sie verwendet die „Softmax“-Aktivierung, da sie die letzte Ebene in einem Klassifikator ist.
Ein Keras-Modell muss auch die Form seiner Eingaben kennen. tf.keras.layers.Input kann verwendet werden, um sie zu definieren. Hier sind Eingabevektoren flache Vektoren von Pixelwerten der Länge 28*28.
model = tf.keras.Sequential(
[
tf.keras.layers.Input(shape=(28*28,)),
tf.keras.layers.Dense(10, activation='softmax')
])
model.compile(optimizer='sgd',
loss='categorical_crossentropy',
metrics=['accuracy'])
# print model layers
model.summary()
# utility callback that displays training curves
plot_training = PlotTraining(sample_rate=10, zoom=1)
Die Konfiguration des Modells erfolgt in Keras mit der Funktion model.compile. Hier verwenden wir den einfachen Optimierer 'sgd' (Stochastic Gradient Descent). Für ein Klassifizierungsmodell ist eine Kreuzentropie-Verlustfunktion erforderlich, die in Keras als 'categorical_crossentropy' bezeichnet wird. Schließlich bitten wir das Modell, den Messwert 'accuracy' zu berechnen, der den Prozentsatz der korrekt klassifizierten Bilder angibt.
Keras bietet das sehr nützliche model.summary()-Dienstprogramm, mit dem die Details des erstellten Modells ausgegeben werden. Ihr freundlicher Kursleiter hat das Dienstprogramm PlotTraining (definiert in der Zelle „Visualisierungsdienstprogramme“) hinzugefügt, mit dem während des Trainings verschiedene Trainingskurven angezeigt werden.
Zelle „Modell trainieren und validieren“
Hier findet das Training statt. Dazu wird model.fit aufgerufen und sowohl die Trainings- als auch die Validierungs-Datasets werden übergeben. Standardmäßig führt Keras am Ende jeder Epoche eine Validierungsrunde durch.
model.fit(training_dataset, steps_per_epoch=steps_per_epoch, epochs=EPOCHS,
validation_data=validation_dataset, validation_steps=1,
callbacks=[plot_training])
In Keras ist es möglich, während des Trainings benutzerdefinierte Verhaltensweisen mithilfe von Callbacks hinzuzufügen. So wurde das dynamisch aktualisierte Trainingsdiagramm für diesen Workshop implementiert.
Zelle „Vorhersagen visualisieren“
Sobald das Modell trainiert ist, können wir Vorhersagen daraus abrufen, indem wir model.predict() aufrufen:
probabilities = model.predict(font_digits, steps=1)
predicted_labels = np.argmax(probabilities, axis=1)
Hier haben wir als Test eine Reihe von gedruckten Ziffern vorbereitet, die mit lokalen Schriftarten gerendert wurden. Das neuronale Netzwerk gibt einen Vektor mit 10 Wahrscheinlichkeiten aus seinem finalen „Softmax“ zurück. Um das Label zu erhalten, müssen wir herausfinden, welche Wahrscheinlichkeit am höchsten ist. np.argmax aus der NumPy-Bibliothek erledigt das.
Um zu verstehen, warum der Parameter axis=1 erforderlich ist, müssen Sie bedenken, dass wir einen Batch von 128 Bildern verarbeitet haben. Das Modell gibt daher 128 Wahrscheinlichkeitsvektoren zurück. Der Ausgabetensor hat die Form [128, 10]. Wir berechnen den Argmax-Wert für die 10 Wahrscheinlichkeiten, die für jedes Bild zurückgegeben werden. Daher ist axis=1 (die erste Achse ist 0).
Mit diesem einfachen Modell werden bereits 90% der Ziffern erkannt. Nicht schlecht, aber du wirst das jetzt deutlich verbessern.

6. Ebenen hinzufügen

Um die Erkennungsgenauigkeit zu verbessern, fügen wir dem neuronalen Netzwerk weitere Ebenen hinzu.

Wir behalten Softmax als Aktivierungsfunktion für die letzte Ebene bei, da sie sich am besten für die Klassifizierung eignet. Bei Zwischenschichten verwenden wir jedoch die klassischste Aktivierungsfunktion: die Sigmoid-Funktion:
Ihr Modell könnte beispielsweise so aussehen (Kommas nicht vergessen, tf.keras.Sequential akzeptiert eine durch Kommas getrennte Liste von Layern):
model = tf.keras.Sequential(
[
tf.keras.layers.Input(shape=(28*28,)),
tf.keras.layers.Dense(200, activation='sigmoid'),
tf.keras.layers.Dense(60, activation='sigmoid'),
tf.keras.layers.Dense(10, activation='softmax')
])
Sehen Sie sich die Zusammenfassung Ihres Modells an. Es hat jetzt mindestens zehnmal so viele Parameter. Es sollte 10-mal besser sein. Aber aus irgendeinem Grund ist das nicht der Fall.

Der Verlust scheint auch in die Höhe geschossen zu sein. Irgendetwas stimmt nicht.
7. Besondere Vorsicht bei Deep-Learning-Netzwerken
Sie haben gerade neuronale Netze kennengelernt, wie sie in den 1980er- und 1990er-Jahren entworfen wurden. Kein Wunder, dass sie die Idee aufgaben und den sogenannten „KI-Winter“ einläuteten. Tatsächlich wird es für neuronale Netze immer schwieriger, zu konvergieren, wenn Sie weitere Ebenen hinzufügen.
Es hat sich herausgestellt, dass tiefe neuronale Netze mit vielen Schichten (heute 20, 50 oder sogar 100) sehr gut funktionieren können, sofern einige mathematische Tricks angewendet werden, damit sie konvergieren. Die Entdeckung dieser einfachen Tricks ist einer der Gründe für die Renaissance des Deep Learning in den 2010er-Jahren.
RELU-Aktivierung

Die Sigmoid-Aktivierungsfunktion ist in Deep-Learning-Netzwerken tatsächlich ziemlich problematisch. Sie komprimiert alle Werte zwischen 0 und 1. Wenn Sie dies wiederholt tun, können Neuronenausgaben und ihre Gradienten vollständig verschwinden. Sie wurde aus historischen Gründen erwähnt, aber in modernen Netzwerken wird die ReLU-Funktion (Rectified Linear Unit) verwendet, die so aussieht:

Die ReLU-Funktion hat dagegen eine Ableitung von 1, zumindest auf der rechten Seite. Bei der RELU-Aktivierung können die Gradienten einiger Neuronen zwar null sein, aber es gibt immer andere, die einen klaren Gradienten ungleich null liefern, sodass das Training in einem guten Tempo fortgesetzt werden kann.
Ein besserer Optimizer
In sehr hochdimensionalen Räumen wie hier – wir haben etwa 10.000 Gewichte und Bias-Werte – sind „Sattelpunkte“ häufig. Das sind Punkte, die keine lokalen Minima sind, an denen der Gradient aber trotzdem null ist und der Gradient-Descent-Optimizer dort hängen bleibt. TensorFlow bietet eine Vielzahl von Optimierern, darunter einige, die mit einem gewissen Trägheitsmoment arbeiten und Sattelpunkte sicher überwinden.
Zufällige Initialisierungen
Die Initialisierung von Gewichten und Bias vor dem Training ist ein Forschungsbereich für sich, zu dem zahlreiche Publikationen veröffentlicht wurden. Eine Liste aller in Keras verfügbaren Initialisierer finden Sie hier. Glücklicherweise verwendet Keras standardmäßig den 'glorot_uniform'-Initialisierer, der in fast allen Fällen die beste Wahl ist.
Sie müssen nichts weiter tun, da Keras bereits das Richtige tut.
NaN ???
Die Formel für die Kreuzentropie enthält einen Logarithmus und log(0) ist keine Zahl (NaN, ein numerischer Fehler). Kann die Eingabe für die Kreuzentropie 0 sein? Die Eingabe stammt von Softmax, was im Wesentlichen eine Exponentialfunktion ist. Eine Exponentialfunktion ist nie null. Wir sind also sicher!
Wirklich? In der schönen Welt der Mathematik wären wir sicher, aber in der Computerwelt ist exp(-150), dargestellt im float32-Format, so gut wie NULL und die Kreuzentropie stürzt ab.
Glücklicherweise müssen Sie hier nichts tun, da Keras sich darum kümmert und Softmax gefolgt von der Kreuzentropie auf besonders sorgfältige Weise berechnet, um numerische Stabilität zu gewährleisten und die gefürchteten NaNs zu vermeiden.
Erfolgreich?

Sie sollten jetzt eine Genauigkeit von 97% erreichen. Das Ziel dieses Workshops ist es, deutlich über 99% zu kommen.
Wenn Sie nicht weiterkommen, finden Sie hier die Lösung für diesen Schritt:
8. Verringerung der Lernrate
Vielleicht können wir versuchen, schneller zu trainieren. Die Standard-Lernrate im Adam-Optimierer ist 0,001. Versuchen wir, sie zu erhöhen.
Schneller zu fahren scheint nicht viel zu bringen und was ist das für ein Lärm?

Die Trainingskurven sind sehr unregelmäßig und die Validierungskurven schwanken stark. Das bedeutet, dass wir zu schnell vorangehen. Wir könnten zu unserer vorherigen Geschwindigkeit zurückkehren, aber es gibt einen besseren Weg.

Die beste Lösung ist, schnell zu beginnen und die Lernrate exponentiell zu verringern. In Keras können Sie dazu den tf.keras.callbacks.LearningRateScheduler-Callback verwenden.
Nützlicher Code zum Kopieren und Einfügen:
# lr decay function
def lr_decay(epoch):
return 0.01 * math.pow(0.6, epoch)
# lr schedule callback
lr_decay_callback = tf.keras.callbacks.LearningRateScheduler(lr_decay, verbose=True)
# important to see what you are doing
plot_learning_rate(lr_decay, EPOCHS)
Vergessen Sie nicht, die erstellte lr_decay_callback zu verwenden. Fügen Sie sie der Liste der Rückrufe in model.fit hinzu:
model.fit(..., callbacks=[plot_training, lr_decay_callback])
Die Auswirkungen dieser kleinen Änderung sind spektakulär. Sie sehen, dass der Großteil des Rauschens verschwunden ist und die Testgenauigkeit nun dauerhaft über 98% liegt.

9. Dropout, Überanpassung
Das Modell scheint jetzt gut zu konvergieren. Versuchen wir, noch tiefer zu gehen.
Hilft das?

Nicht wirklich. Die Genauigkeit liegt immer noch bei 98% und der Validierungsverlust ist hoch. Es geht aufwärts! Der Lernalgorithmus wird nur auf Trainingsdaten angewendet und optimiert den Trainingsverlust entsprechend. Das Modell sieht nie Validierungsdaten. Es ist daher nicht verwunderlich, dass seine Arbeit nach einer Weile keine Auswirkungen mehr auf den Validierungsverlust hat, der nicht mehr sinkt und manchmal sogar wieder ansteigt.
Das hat nicht sofort Auswirkungen auf die Erkennungsfunktionen Ihres Modells in der realen Welt, aber es verhindert, dass Sie viele Iterationen durchführen können. Im Allgemeinen ist es ein Zeichen dafür, dass das Training keine positiven Auswirkungen mehr hat.

Diese Diskrepanz wird in der Regel als „Overfitting“ bezeichnet. Wenn Sie sie feststellen, können Sie versuchen, eine Regularisierungstechnik namens „Dropout“ anzuwenden. Bei der Dropout-Technik werden in jedem Trainingsdurchlauf zufällige Neuronen deaktiviert.
Hat es funktioniert?

Das Rauschen kehrt zurück (was angesichts der Funktionsweise von Dropout nicht überraschend ist). Der Validierungsverlust scheint nicht mehr zuzunehmen, ist aber insgesamt höher als ohne Dropout. Und die Validierungsgenauigkeit ist etwas gesunken. Das ist ein ziemlich enttäuschendes Ergebnis.
Offenbar war Dropout nicht die richtige Lösung. Vielleicht ist „Overfitting“ auch ein komplexeres Konzept und einige seiner Ursachen lassen sich nicht durch „Dropout“ beheben.
Was ist „Überanpassung“? Eine Überanpassung tritt auf, wenn ein neuronales Netzwerk „schlecht“ lernt, d. h. so, dass es zwar für die Trainingsbeispiele funktioniert, aber nicht so gut für Daten aus der realen Welt. Es gibt Regularisierungstechniken wie Dropout, die das Modell zu einem besseren Lernen zwingen können. Eine Überanpassung hat jedoch auch tiefere Ursachen.

Eine grundlegende Überanpassung tritt auf, wenn ein neuronales Netzwerk zu viele Freiheitsgrade für das jeweilige Problem hat. Stellen Sie sich vor, wir haben so viele Neuronen, dass das Netzwerk alle unsere Trainingsbilder darin speichern und sie dann durch Mustervergleich erkennen kann. Bei realen Daten würde es komplett scheitern. Ein neuronales Netzwerk muss in gewisser Weise eingeschränkt werden, damit es gezwungen ist, das, was es während des Trainings lernt, zu verallgemeinern.
Wenn Sie nur sehr wenige Trainingsdaten haben, kann selbst ein kleines Netzwerk diese auswendig lernen und es kommt zu einer Überanpassung. Im Allgemeinen benötigen Sie immer viele Daten, um neuronale Netzwerke zu trainieren.
Wenn Sie alles richtig gemacht, mit verschiedenen Netzwerkgrößen experimentiert, um sicherzustellen, dass die Freiheitsgrade begrenzt sind, Dropout angewendet und mit vielen Daten trainiert haben, kann es sein, dass Sie immer noch auf einem Leistungsniveau feststecken, das sich nicht verbessern lässt. Das bedeutet, dass Ihr neuronales Netzwerk in seiner aktuellen Form nicht in der Lage ist, mehr Informationen aus Ihren Daten zu extrahieren, wie in unserem Fall hier.
Erinnern Sie sich, wie wir unsere Bilder verwenden, die in einen einzelnen Vektor umgewandelt wurden? Das war eine wirklich schlechte Idee. Handschriftliche Ziffern bestehen aus Formen. Wir haben die Forminformationen verworfen, als wir die Pixel vereinfacht haben. Es gibt jedoch eine Art von neuronalem Netzwerk, das Forminformationen nutzen kann: Convolutional Networks. Probieren wir sie aus.
Wenn Sie nicht weiterkommen, finden Sie hier die Lösung für diesen Schritt:
10. [INFO] Convolutional Networks
Kurz zusammengefasst
Wenn Sie alle fett gedruckten Begriffe im nächsten Absatz bereits kennen, können Sie mit der nächsten Übung fortfahren. Wenn Sie gerade erst mit Convolutional Neural Networks beginnen, lesen Sie bitte weiter.

Abbildung: Filtern eines Bildes mit zwei aufeinanderfolgenden Filtern mit jeweils 4 × 4 × 3=48 lernbaren Gewichten.
So sieht ein einfaches Convolutional Neural Network in Keras aus:
model = tf.keras.Sequential([
tf.keras.layers.Reshape(input_shape=(28*28,), target_shape=(28, 28, 1)),
tf.keras.layers.Conv2D(kernel_size=3, filters=12, activation='relu'),
tf.keras.layers.Conv2D(kernel_size=6, filters=24, strides=2, activation='relu'),
tf.keras.layers.Conv2D(kernel_size=6, filters=32, strides=2, activation='relu'),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(10, activation='softmax')
])
In einer Schicht eines faltenden Netzwerks berechnet ein „Neuron“ eine gewichtete Summe der Pixel direkt darüber, und zwar nur in einem kleinen Bereich des Bildes. Es wird ein Bias hinzugefügt und die Summe wird durch eine Aktivierungsfunktion geleitet, genau wie bei einem Neuron in einer regulären dichten Schicht. Dieser Vorgang wird dann mit denselben Gewichten für das gesamte Bild wiederholt. In dichten Schichten hatte jedes Neuron eigene Gewichte. Hier wird ein einzelner „Patch“ von Gewichten in beide Richtungen über das Bild geschoben (eine „Faltung“). Die Ausgabe enthält so viele Werte wie das Bild Pixel hat. An den Rändern ist jedoch etwas Auffüllung erforderlich. Es handelt sich um einen Filtervorgang. Im obigen Beispiel werden 48 Gewichte verwendet (4 × 4 × 3=48).
48 Gewichte reichen jedoch nicht aus. Um weitere Freiheitsgrade hinzuzufügen, wiederholen wir denselben Vorgang mit einer neuen Gruppe von Gewichten. Dadurch wird eine neue Reihe von Filterausgaben erstellt. Wir nennen sie analog zu den R-, G- und B-Kanälen im Eingabebild einen „Kanal“ von Ausgaben.

Die beiden (oder mehr) Gewichtssätze können als ein Tensor zusammengefasst werden, indem eine neue Dimension hinzugefügt wird. Das ist die allgemeine Form des Gewichtetensors für eine Faltungsschicht. Da die Anzahl der Ein- und Ausgabekanäle Parameter sind, können wir mit dem Stapeln und Verketten von Convolutional Layers beginnen.

Abbildung: Ein Convolutional Neural Network wandelt „Datenwürfel“ in andere „Datenwürfel“ um.
Strided Convolutions, Max Pooling
Durch die Durchführung der Faltungen mit einem Stride von 2 oder 3 können wir den resultierenden Datenwürfel auch in seinen horizontalen Dimensionen verkleinern. Dafür gibt es zwei gängige Möglichkeiten:
- Strided Convolution: Ein gleitender Filter wie oben, aber mit einem Stride > 1
- Max-Pooling: Ein gleitendes Fenster, das den MAX-Vorgang anwendet (in der Regel auf 2×2-Felder, die alle 2 Pixel wiederholt werden)

Abbildung: Wenn das Berechnungsfenster um 3 Pixel verschoben wird, ergeben sich weniger Ausgabewerte. Strided Convolutions oder Max Pooling (Maximum in einem 2×2-Fenster, das mit einem Schritt von 2 verschoben wird) sind eine Möglichkeit, den Datenwürfel in den horizontalen Dimensionen zu verkleinern.
Die letzte Ebene
Nach der letzten Faltungsschicht liegen die Daten in Form eines „Würfels“ vor. Es gibt zwei Möglichkeiten, die Ausgabe durch die letzte Dense-Ebene zu leiten.
Zuerst wird der Datenwürfel in einen Vektor umgewandelt und dann in die Softmax-Schicht eingespeist. Manchmal können Sie sogar eine Dense-Ebene vor der Softmax-Ebene hinzufügen. Das ist in der Regel mit einer großen Anzahl von Gewichten verbunden. Eine dichte Schicht am Ende eines Faltungsnetzwerks kann mehr als die Hälfte der Gewichte des gesamten neuronalen Netzwerks enthalten.
Anstelle einer rechenaufwendigen dichten Schicht können wir den eingehenden Daten-„Cube“ auch in so viele Teile aufteilen, wie wir Klassen haben, ihre Werte mitteln und diese durch eine Softmax-Aktivierungsfunktion leiten. Für diese Art der Erstellung des Klassifikations-Heads sind keine Gewichte erforderlich. In Keras gibt es dafür eine Ebene: tf.keras.layers.GlobalAveragePooling2D().

Fahren Sie mit dem nächsten Abschnitt fort, um ein faltendes Netzwerk für das vorliegende Problem zu erstellen.
11. Ein Convolutional Network
Wir erstellen ein Convolutional Network für die Erkennung handschriftlicher Ziffern. Wir verwenden oben drei Convolutional Layers, unten unseren herkömmlichen Softmax-Readout-Layer und verbinden sie mit einem Fully Connected Layer:

Die zweite und dritte Faltungsschicht haben einen Stride von zwei. Dadurch wird die Anzahl der Ausgabewerte von 28 × 28 auf 14 × 14 und dann auf 7 × 7 reduziert.
Schreiben wir nun den Keras-Code.
Vor dem ersten Faltungslayer ist besondere Aufmerksamkeit erforderlich. Tatsächlich wird ein dreidimensionaler „Würfel“ mit Daten erwartet, aber unser Dataset wurde bisher für dichte Ebenen eingerichtet und alle Pixel der Bilder werden in einen Vektor umgewandelt. Wir müssen sie wieder in 28 × 28 × 1-Bilder umwandeln (1 Kanal für Graustufenbilder):
tf.keras.layers.Reshape(input_shape=(28*28,), target_shape=(28, 28, 1))
Sie können diese Zeile anstelle der bisherigen tf.keras.layers.Input-Ebene verwenden.
In Keras lautet die Syntax für eine mit „relu“ aktivierte Convolutional-Ebene so:

tf.keras.layers.Conv2D(kernel_size=3, filters=12, padding='same', activation='relu')
Für eine Convolution mit Schrittweite würden Sie Folgendes schreiben:
tf.keras.layers.Conv2D(kernel_size=6, filters=24, padding='same', activation='relu', strides=2)
So wandeln Sie einen Datenwürfel in einen Vektor um, damit er von einer Dense-Schicht verarbeitet werden kann:
tf.keras.layers.Flatten()
Für die Dense-Ebene hat sich die Syntax nicht geändert:
tf.keras.layers.Dense(200, activation='relu')
Hat Ihr Modell die 99‑%‑Marke für die Genauigkeit überschritten? Fast… Sehen Sie sich stattdessen die Kurve für den Validierungsverlust an. Kommt Ihnen das bekannt vor?

Sehen Sie sich auch die Vorhersagen an. Zum ersten Mal sollten Sie sehen, dass die meisten der 10.000 Testziffern jetzt richtig erkannt werden. Es sind nur noch etwa 4½ Zeilen mit Falscherkennungen übrig (etwa 110 Ziffern von 10.000).

Wenn Sie nicht weiterkommen, finden Sie hier die Lösung für diesen Schritt:
12. Noch einmal abbrechen
Das vorherige Training weist deutliche Anzeichen für Overfitting auf und erreicht immer noch nicht die angestrebte Accuracy von 99 %. Sollen wir es noch einmal mit Dropout versuchen?
Wie ist es dieses Mal gelaufen?

Diesmal hat das Ausblenden offenbar funktioniert. Der Validierungsverlust steigt nicht mehr an und die endgültige Genauigkeit sollte deutlich über 99 % liegen. Glückwunsch!
Als wir Dropout zum ersten Mal angewendet haben, dachten wir, wir hätten ein Overfitting-Problem. Tatsächlich lag das Problem aber in der Architektur des neuronalen Netzes. Ohne Convolutional Layers konnten wir nicht weiterkommen und Dropout konnte daran nichts ändern.
Dieses Mal scheint eine Überanpassung die Ursache des Problems gewesen zu sein und Dropout hat tatsächlich geholfen. Es gibt viele Gründe für eine Diskrepanz zwischen den Kurven für Trainings- und Validierungsverlust, bei der der Validierungsverlust steigt. Eine Überanpassung (zu viele Freiheitsgrade, die vom Netzwerk schlecht genutzt werden) ist nur einer davon. Wenn Ihr Datensatz zu klein ist oder die Architektur Ihres neuronalen Netzes nicht angemessen ist, sehen Sie möglicherweise ein ähnliches Verhalten bei den Verlustkurven, aber Dropout hilft nicht.
13. Batchnormalisierung

Zum Schluss versuchen wir, die Batch-Normalisierung hinzuzufügen.
Das ist die Theorie. In der Praxis sollten Sie sich an ein paar Regeln halten:
Wir halten uns erst einmal an die Regeln und fügen jeder Ebene des neuronalen Netzwerks mit Ausnahme der letzten eine Batch-Normalisierungsebene hinzu. Fügen Sie sie nicht der letzten „Softmax“-Schicht hinzu. Dort wäre sie nicht nützlich.
# Modify each layer: remove the activation from the layer itself.
# Set use_bias=False since batch norm will play the role of biases.
tf.keras.layers.Conv2D(..., use_bias=False),
# Batch norm goes between the layer and its activation.
# The scale factor can be turned off for Relu activation.
tf.keras.layers.BatchNormalization(scale=False, center=True),
# Finish with the activation.
tf.keras.layers.Activation('relu'),
Wie genau ist die Funktion jetzt?

Mit ein paar Anpassungen (BATCH_SIZE=64, Parameter für den Learning Rate Decay 0,666, Dropout-Rate für die Dense-Schicht 0,3) und etwas Glück können Sie 99,5 % erreichen. Die Anpassungen der Lernrate und des Dropout erfolgten gemäß den Best Practices für die Verwendung von Batchnorm:
- Die Batch-Normalisierung trägt dazu bei, dass neuronale Netze konvergieren, und ermöglicht in der Regel ein schnelleres Training.
- Die Batchnormalisierung ist ein Regularisierer. Sie können die Dropout-Rate in der Regel verringern oder sogar ganz darauf verzichten.
Das Lösungs-Notebook hat einen Trainingslauf von 99,5 %:
14. In der Cloud auf leistungsstarker Hardware trainieren: AI Platform

Eine cloudfähige Version des Codes finden Sie im Ordner „mlengine“ auf GitHub. Dort finden Sie auch eine Anleitung zum Ausführen des Codes auf der Google Cloud AI Platform. Bevor Sie diesen Teil ausführen können, müssen Sie ein Google Cloud-Konto erstellen und die Abrechnung aktivieren. Die für die Durchführung des Labs erforderlichen Ressourcen sollten weniger als ein paar Dollar kosten (bei einer Trainingszeit von einer Stunde auf einer GPU). So bereiten Sie Ihr Konto vor:
- Erstellen Sie ein Google Cloud Platform-Projekt ( http://cloud.google.com/console).
- Aktivieren Sie die Abrechnung.
- Installieren Sie die GCP-Befehlszeilentools ( GCP SDK hier).
- Erstellen Sie einen Google Cloud Storage-Bucket (in der Region
us-central1). Er wird zum Bereitstellen des Trainingscodes und zum Speichern des trainierten Modells verwendet. - Aktivieren Sie die erforderlichen APIs und fordern Sie die erforderlichen Kontingente an. Führen Sie den Trainingsbefehl einmal aus. Sie sollten dann Fehlermeldungen erhalten, in denen steht, was Sie aktivieren müssen.
15. Glückwunsch!
Sie haben Ihr erstes neuronales Netzwerk erstellt und es bis zu einer Genauigkeit von 99% trainiert. Die dabei erlernten Techniken sind nicht spezifisch für den MNIST-Datensatz, sondern werden häufig bei der Arbeit mit neuronalen Netzwerken verwendet. Als Abschiedsgeschenk erhalten Sie hier die „Cliff’s Notes“-Karte für das Lab in einer Cartoonversion. Sie können es verwenden, um sich an das Gelernte zu erinnern:

Weiteres Vorgehen
- Nach vollständig verbundenen und faltungsbasierten Netzwerken sollten Sie sich rekurrente neuronale Netze ansehen.
- Wenn Sie Ihr Training oder Ihre Inferenz in der Cloud auf einer verteilten Infrastruktur ausführen möchten, bietet Google Cloud AI Platform.
- Und schließlich freuen wir uns über Feedback. Bitte teilen Sie uns mit, wenn Sie in diesem Lab etwas Ungewöhnliches feststellen oder wenn Sie der Meinung sind, dass es verbessert werden sollte. Wir bearbeiten Feedback über GitHub-Probleme [ Feedback-Link].

|
|
 Autor: Martin GörnerTwitter:
Autor: Martin GörnerTwitter: 
Alle Cartoonbilder in diesem Lab sind urheberrechtlich geschützt: alexpokusay / 123RF stock photos