
۱. مرور کلی
این آموزش برای Tensorflow 2.2 بهروزرسانی شده است!

در این آزمایشگاه کد، شما یاد خواهید گرفت که چگونه یک شبکه عصبی بسازید و آموزش دهید که ارقام دستنویس را تشخیص دهد. در طول مسیر، همزمان با ارتقاء شبکه عصبی خود برای دستیابی به دقت ۹۹٪، ابزارهای حرفهای را که متخصصان یادگیری عمیق برای آموزش کارآمد مدلهای خود استفاده میکنند، نیز کشف خواهید کرد.
این آزمایشگاه کد از مجموعه داده MNIST استفاده میکند، مجموعهای از ۶۰،۰۰۰ رقم برچسبگذاری شده که تقریباً دو دهه است نسلهای زیادی از دانشجویان دکترا را مشغول خود کرده است. شما این مسئله را با کمتر از ۱۰۰ خط کد پایتون/TensorFlow حل خواهید کرد.
آنچه یاد خواهید گرفت
- شبکه عصبی چیست و چگونه آن را آموزش دهیم
- نحوه ساخت یک شبکه عصبی تک لایه پایه با استفاده از tf.keras
- نحوه اضافه کردن لایههای بیشتر
- نحوه تنظیم برنامه نرخ یادگیری
- نحوه ساخت شبکههای عصبی کانولوشن
- نحوه استفاده از تکنیکهای منظمسازی: حذف، نرمالسازی دستهای
- بیشبرازش چیست؟
آنچه نیاز دارید
فقط یک مرورگر. این کارگاه میتواند کاملاً با Google Colaboratory اجرا شود.
بازخورد
لطفاً اگر در این آزمایشگاه نکتهای نادرست میبینید یا فکر میکنید باید بهبود یابد، به ما اطلاع دهید. ما از طریق GitHub به بازخوردها رسیدگی میکنیم [ لینک بازخورد ].
۲. شروع سریع Google Colaboratory
این آزمایشگاه از Google Colaboratory استفاده میکند و نیازی به راهاندازی از طرف شما ندارد. میتوانید آن را از طریق یک Chromebook اجرا کنید. لطفاً فایل زیر را باز کنید و سلولها را اجرا کنید تا با دفترچههای Colab آشنا شوید.

دستورالعملهای تکمیلی در ادامه:
یک پردازنده گرافیکی (GPU) پشتیبان انتخاب کنید

در منوی Colab، Runtime > Change runtime type را انتخاب کنید و سپس GPU را انتخاب کنید. اتصال به runtime به طور خودکار در اولین اجرا اتفاق میافتد، یا میتوانید از دکمه "Connect" در گوشه بالا سمت راست استفاده کنید.
اجرای نوت بوک
با کلیک روی یک سلول و استفاده از Shift-ENTER، سلولها را یکییکی اجرا کنید. همچنین میتوانید کل نوتبوک را با Runtime > Run all اجرا کنید.
فهرست مطالب

همه دفترچهها فهرست مطالب دارند. میتوانید آن را با استفاده از فلش سیاه سمت چپ باز کنید.
سلولهای پنهان

بعضی از سلولها فقط عنوان خود را نشان میدهند. این یک ویژگی مخصوص دفترچه یادداشت Colab است. میتوانید روی آنها دوبار کلیک کنید تا کد داخلشان را ببینید، اما معمولاً خیلی جالب نیست. معمولاً از توابع پشتیبانی یا تجسمسازی میکنند. برای تعریف توابع داخلشان، هنوز باید این سلولها را اجرا کنید.
۳. آموزش یک شبکه عصبی
ابتدا یک شبکه عصبی را در حال آموزش تماشا خواهیم کرد. لطفاً دفترچه یادداشت زیر را باز کنید و تمام سلولها را مرور کنید. فعلاً به کد توجه نکنید، بعداً توضیح آن را شروع خواهیم کرد.
همانطور که دفترچه یادداشت را اجرا میکنید، روی تجسمها تمرکز کنید. برای توضیحات به زیر مراجعه کنید.
دادههای آموزشی
ما یک مجموعه داده از ارقام دستنویس داریم که برچسبگذاری شدهاند تا بدانیم هر تصویر چه چیزی را نشان میدهد، یعنی عددی بین ۰ تا ۹. در دفترچه یادداشت، گزیدهای از آن را خواهید دید:

شبکه عصبی که ما خواهیم ساخت، ارقام دستنویس را در 10 کلاس (0، ..، 9) طبقهبندی میکند. این کار را بر اساس پارامترهای داخلی انجام میدهد که برای عملکرد خوب طبقهبندی، باید مقدار صحیحی داشته باشند. این «مقدار صحیح» از طریق یک فرآیند آموزش که به یک «مجموعه داده برچسبگذاری شده» با تصاویر و پاسخهای صحیح مرتبط نیاز دارد، آموخته میشود.
چگونه بفهمیم که شبکه عصبی آموزشدیده عملکرد خوبی دارد یا خیر؟ استفاده از مجموعه دادههای آموزشی برای آزمایش شبکه تقلب محسوب میشود. شبکه قبلاً چندین بار در طول آموزش، آن مجموعه دادهها را دیده است و مطمئناً روی آن بسیار کارآمد است. ما به یک مجموعه داده برچسبگذاری شده دیگر نیاز داریم که هرگز در طول آموزش دیده نشده باشد تا عملکرد «دنیای واقعی» شبکه را ارزیابی کنیم. این مجموعه داده « مجموعه دادههای اعتبارسنجی » نامیده میشود.
آموزش
با پیشرفت آموزش، یک دسته از دادههای آموزشی در هر زمان، پارامترهای مدل داخلی بهروزرسانی میشوند و مدل در تشخیص ارقام دستنویس بهتر و بهتر میشود. میتوانید آن را در نمودار آموزش مشاهده کنید:

در سمت راست، «دقت» صرفاً درصد ارقام درست تشخیص داده شده است. این مقدار با پیشرفت آموزش افزایش مییابد که خوب است.
در سمت چپ، میتوانیم «ضریب» را ببینیم. برای هدایت آموزش، یک تابع «ضریب» تعریف میکنیم که نشان میدهد سیستم چقدر ارقام را بد تشخیص میدهد و سعی میکنیم آن را به حداقل برسانیم. چیزی که اینجا میبینید این است که با پیشرفت آموزش، میزان خطا هم در دادههای آموزش و هم در دادههای اعتبارسنجی کاهش مییابد: این خوب است. این بدان معناست که شبکه عصبی در حال یادگیری است.
محور X تعداد «دورهها» یا تکرارها را در کل مجموعه دادهها نشان میدهد.
پیشبینیها
وقتی مدل آموزش داده شد، میتوانیم از آن برای تشخیص ارقام دستنویس استفاده کنیم. تصویرسازی بعدی نشان میدهد که عملکرد آن روی چند رقم رندر شده از فونتهای محلی (خط اول) و سپس روی 10000 رقم مجموعه داده اعتبارسنجی چقدر خوب است. کلاس پیشبینیشده در زیر هر رقم ظاهر میشود و در صورت اشتباه بودن، با رنگ قرمز نمایش داده میشود.

همانطور که میبینید، این مدل اولیه خیلی خوب نیست اما هنوز برخی از ارقام را به درستی تشخیص میدهد. دقت اعتبارسنجی نهایی آن حدود ۹۰٪ است که برای مدل سادهای که با آن شروع میکنیم خیلی بد نیست، اما هنوز هم به این معنی است که ۱۰۰۰ رقم اعتبارسنجی از ۱۰۰۰۰ رقم را از دست میدهد. این خیلی بیشتر از آن چیزی است که میتواند نمایش داده شود، به همین دلیل است که به نظر میرسد همه پاسخها اشتباه هستند (قرمز).
تانسورها
دادهها در ماتریسها ذخیره میشوند. یک تصویر خاکستری ۲۸x۲۸ پیکسلی در یک ماتریس دوبعدی ۲۸x۲۸ جای میگیرد. اما برای یک تصویر رنگی، به ابعاد بیشتری نیاز داریم. در هر پیکسل ۳ مقدار رنگ وجود دارد (قرمز، سبز، آبی)، بنابراین به یک جدول سهبعدی با ابعاد [۲۸، ۲۸، ۳] نیاز خواهیم داشت. و برای ذخیره یک دسته ۱۲۸ تصویر رنگی، به یک جدول چهاربعدی با ابعاد [۱۲۸، ۲۸، ۲۸، ۳] نیاز داریم.
این جداول چندبعدی «تانسور» نامیده میشوند و فهرست ابعاد آنها «شکل» آنهاست.
۴. [اطلاعات]: شبکههای عصبی ۱۰۱
به طور خلاصه
اگر تمام اصطلاحات پررنگشده در پاراگراف بعدی را از قبل میدانید، میتوانید به تمرین بعدی بروید. اگر تازه یادگیری عمیق را شروع کردهاید، خوش آمدید و لطفاً ادامه مطلب را بخوانید.

برای مدلهایی که به صورت دنبالهای از لایهها ساخته شدهاند، Keras رابط برنامهنویسی کاربردی Sequential را ارائه میدهد. برای مثال، یک طبقهبندیکننده تصویر با استفاده از سه لایه متراکم را میتوان در Keras به صورت زیر نوشت:
model = tf.keras.Sequential([
tf.keras.layers.Flatten(input_shape=[28, 28, 1]),
tf.keras.layers.Dense(200, activation="relu"),
tf.keras.layers.Dense(60, activation="relu"),
tf.keras.layers.Dense(10, activation='softmax') # classifying into 10 classes
])
# this configures the training of the model. Keras calls it "compiling" the model.
model.compile(
optimizer='adam',
loss= 'categorical_crossentropy',
metrics=['accuracy']) # % of correct answers
# train the model
model.fit(dataset, ... )

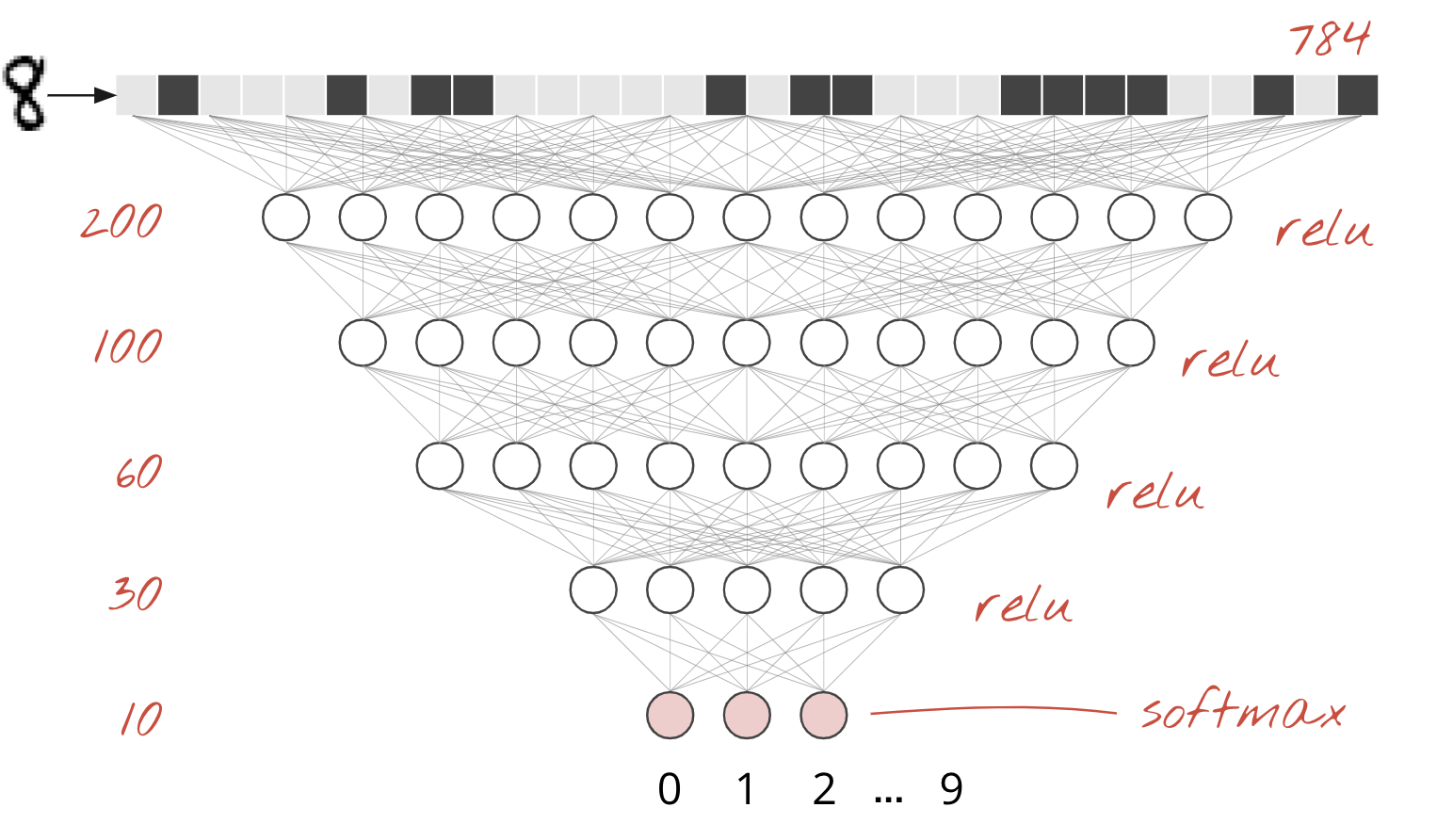
یک لایه متراکم واحد
ارقام دستنویس در مجموعه داده MNIST، تصاویر خاکستری با ابعاد ۲۸x۲۸ پیکسل هستند. سادهترین روش برای طبقهبندی آنها، استفاده از ۲۸x۲۸=۷۸۴ پیکسل به عنوان ورودی برای یک شبکه عصبی تک لایه است.

هر «نورون» در یک شبکه عصبی، مجموع وزنی تمام ورودیهای خود را محاسبه میکند، یک ثابت به نام «بایاس» به آن اضافه میکند و سپس نتیجه را از طریق یک «تابع فعالسازی» غیرخطی ارسال میکند. «وزنها» و «بایاسها» پارامترهایی هستند که از طریق آموزش تعیین میشوند. آنها در ابتدا با مقادیر تصادفی مقداردهی اولیه میشوند.
تصویر بالا یک شبکه عصبی تک لایه با ۱۰ نورون خروجی را نشان میدهد، زیرا میخواهیم ارقام را در ۱۰ کلاس (۰ تا ۹) طبقهبندی کنیم.
با ضرب ماتریسی
در اینجا نحوه نمایش یک لایه شبکه عصبی، که مجموعهای از تصاویر را پردازش میکند، با ضرب ماتریسی نشان داده شده است:

با استفاده از ستون اول وزنها در ماتریس وزنها W، مجموع وزندار تمام پیکسلهای تصویر اول را محاسبه میکنیم. این مجموع مربوط به نورون اول است. با استفاده از ستون دوم وزنها، همین کار را برای نورون دوم و به همین ترتیب تا نورون دهم انجام میدهیم. سپس میتوانیم عملیات را برای ۹۹ تصویر باقیمانده تکرار کنیم. اگر X را ماتریسی بنامیم که شامل ۱۰۰ تصویر ماست، تمام مجموعهای وزندار برای ۱۰ نورون ما که روی ۱۰۰ تصویر محاسبه شدهاند، به سادگی XW هستند، یک ضرب ماتریسی.
حالا هر نورون باید بایاس (یک ثابت) خود را اضافه کند. از آنجایی که ما 10 نورون داریم، 10 ثابت بایاس نیز داریم. این بردار 10 مقداری را b مینامیم. این بردار باید به هر خط از ماتریس محاسبه شده قبلی اضافه شود. با استفاده از کمی جادو به نام "پخش" این را با یک علامت جمع ساده مینویسیم.
در نهایت یک تابع فعالسازی، مثلاً "softmax" (که در ادامه توضیح داده شده است) را اعمال میکنیم و فرمول توصیفکننده یک شبکه عصبی تکلایه را که روی ۱۰۰ تصویر اعمال شده است، به دست میآوریم:

در کراس
با کتابخانههای شبکه عصبی سطح بالا مانند Keras، نیازی به پیادهسازی این فرمول نخواهیم داشت. با این حال، درک این نکته مهم است که یک لایه شبکه عصبی فقط مجموعهای از ضربها و جمعها است. در Keras، یک لایه متراکم به صورت زیر نوشته میشود:
tf.keras.layers.Dense(10, activation='softmax')
عمیق برو
زنجیرهسازی لایههای شبکه عصبی کار سادهای است. لایه اول مجموع وزندار پیکسلها را محاسبه میکند. لایههای بعدی مجموع وزندار خروجیهای لایههای قبلی را محاسبه میکنند.
تنها تفاوت، جدا از تعداد نورونها، انتخاب تابع فعالسازی خواهد بود.
توابع فعالسازی: relu، softmax و sigmoid
شما معمولاً از تابع فعالسازی "relu" برای همه لایهها به جز آخرین لایه استفاده میکنید. آخرین لایه، در یک طبقهبندیکننده، از فعالسازی "softmax" استفاده میکند.

باز هم، یک «نورون» مجموع وزنی تمام ورودیهای خود را محاسبه میکند، مقداری به نام «بایاس» را به آن اضافه میکند و نتیجه را از طریق تابع فعالسازی ارسال میکند.
محبوبترین تابع فعالسازی «RELU» (واحد خطی یکسو شده) نام دارد. همانطور که در نمودار بالا میبینید، این تابع بسیار ساده است.
تابع فعالسازی سنتی در شبکههای عصبی «سیگموئید» بود، اما نشان داده شده است که «رلو» تقریباً در همه جا خواص همگرایی بهتری دارد و اکنون ترجیح داده میشود.

فعالسازی Softmax برای طبقهبندی
آخرین لایه شبکه عصبی ما دارای ۱۰ نورون است زیرا میخواهیم ارقام دستنویس را در ۱۰ کلاس (۰،..۹) طبقهبندی کنیم. این شبکه باید ۱۰ عدد بین ۰ و ۱ را در خروجی ارائه دهد که نشاندهنده احتمال ۰، ۱، ۲ و غیره بودن این رقم است. برای این کار، در آخرین لایه، از یک تابع فعالسازی به نام "softmax" استفاده خواهیم کرد.
اعمال softmax روی یک بردار با در نظر گرفتن تابع نمایی هر عنصر و سپس نرمالسازی بردار انجام میشود، که معمولاً با تقسیم آن بر نرم "L1" آن (یعنی مجموع مقادیر مطلق) انجام میشود، به طوری که مجموع مقادیر نرمال شده برابر با ۱ شود و بتوان آنها را به عنوان احتمال تفسیر کرد.
خروجی آخرین لایه، قبل از فعالسازی، گاهی اوقات "logits" نامیده میشود. اگر این بردار L = [L0، L1، L2، L3، L4، L5، L6، L7، L8، L9] باشد، آنگاه:


اتلاف آنتروپی متقاطع
حالا که شبکه عصبی ما پیشبینیهایی از تصاویر ورودی تولید میکند، باید میزان دقت آنها را اندازهگیری کنیم، یعنی فاصله بین آنچه شبکه به ما میگوید و پاسخهای صحیح، که اغلب "برچسب" نامیده میشوند. به یاد داشته باشید که ما برای همه تصاویر موجود در مجموعه دادهها برچسبهای صحیح داریم.
هر فاصلهای جواب میدهد، اما برای مسائل طبقهبندی، فاصلهای که «فاصله آنتروپی متقاطع» نامیده میشود، مؤثرترین است. ما این را تابع خطا یا «زیان» مینامیم:

گرادیان نزولی
«آموزش» شبکه عصبی در واقع به معنای استفاده از تصاویر آموزشی و برچسبها برای تنظیم وزنها و بایاسها به منظور به حداقل رساندن تابع زیان آنتروپی متقاطع است. در اینجا نحوه کار آن آمده است.
آنتروپی متقاطع تابعی از وزنها، بایاسها، پیکسلهای تصویر آموزشی و کلاس شناختهشده آن است.
اگر مشتقات جزئی آنتروپی متقاطع را نسبت به تمام وزنها و تمام بایاسها محاسبه کنیم، یک "گرادیان" به دست میآوریم که برای یک تصویر، برچسب و مقدار فعلی وزنها و بایاسهای مشخص محاسبه میشود. به یاد داشته باشید که میتوانیم میلیونها وزن و بایاس داشته باشیم، بنابراین محاسبه گرادیان کار زیادی به نظر میرسد. خوشبختانه، TensorFlow این کار را برای ما انجام میدهد. خاصیت ریاضی گرادیان این است که به سمت "بالا" اشاره میکند. از آنجایی که میخواهیم به جایی برویم که آنتروپی متقاطع کم است، در جهت مخالف میرویم. وزنها و بایاسها را با کسری از گرادیان بهروزرسانی میکنیم. سپس همین کار را بارها و بارها با استفاده از دستههای بعدی تصاویر آموزشی و برچسبها، در یک حلقه آموزشی انجام میدهیم. امیدواریم که این به جایی همگرا شود که آنتروپی متقاطع حداقل باشد، اگرچه هیچ چیز تضمین نمیکند که این حداقل منحصر به فرد باشد.

مینی بچینگ و مومنتوم
شما میتوانید گرادیان خود را فقط روی یک تصویر نمونه محاسبه کنید و وزنها و بایاسها را فوراً بهروزرسانی کنید، اما انجام این کار روی یک دسته، مثلاً ۱۲۸ تصویر، گرادیانی را ارائه میدهد که محدودیتهای اعمال شده توسط تصاویر نمونه مختلف را بهتر نشان میدهد و بنابراین احتمالاً سریعتر به سمت راهحل همگرا میشود. اندازه مینی-دسته یک پارامتر قابل تنظیم است.
این تکنیک که گاهی اوقات «کاهش گرادیان تصادفی» نامیده میشود، یک مزیت عملیتر دیگر نیز دارد: کار با دستهها به معنای کار با ماتریسهای بزرگتر نیز هست و بهینهسازی این ماتریسها روی GPUها و TPUها معمولاً آسانتر است.
با این حال، همگرایی هنوز میتواند کمی آشوبناک باشد و حتی اگر بردار گرادیان همه صفر باشد، میتواند متوقف شود. آیا این بدان معناست که ما یک مینیمم پیدا کردهایم؟ نه همیشه. یک مؤلفه گرادیان میتواند روی یک مینیمم یا یک ماکزیمم صفر باشد. با یک بردار گرادیان با میلیونها عنصر، اگر همه آنها صفر باشند، احتمال اینکه هر صفر مربوط به یک مینیمم باشد و هیچ یک از آنها به یک نقطه ماکزیمم نرسد، بسیار کم است. در فضایی با ابعاد زیاد، نقاط زینی بسیار رایج هستند و ما نمیخواهیم در آنها متوقف شویم.

تصویر: یک نقطه زینی. گرادیان صفر است اما در همه جهات حداقل نیست. (منبع تصویر: ویکیمدیا: نوشته نیکوگوارو - اثر شخصی، CC BY 3.0 )
راه حل این است که مقداری مومنتوم به الگوریتم بهینهسازی اضافه کنیم تا بتواند بدون توقف از نقاط زینی عبور کند.
واژهنامه
دستهای یا مینی-دستهای : آموزش همیشه روی دستههایی از دادههای آموزشی و برچسبها انجام میشود. انجام این کار به همگرایی الگوریتم کمک میکند. بُعد «دستهای» معمولاً اولین بُعد از تانسورهای داده است. به عنوان مثال، یک تانسور شکل [100، 192، 192، 3] شامل 100 تصویر با ابعاد 192x192 پیکسل با سه مقدار در هر پیکسل (RGB) است.
تابع زیان آنتروپی متقاطع : یک تابع زیان ویژه که اغلب در طبقهبندیکنندهها استفاده میشود.
لایه متراکم : لایهای از نورونها که در آن هر نورون به تمام نورونهای لایه قبلی متصل است.
ویژگیها : ورودیهای یک شبکه عصبی گاهی اوقات «ویژگیها» نامیده میشوند. هنر تشخیص اینکه کدام بخشهای یک مجموعه داده (یا ترکیبی از بخشها) باید به یک شبکه عصبی داده شوند تا پیشبینیهای خوبی حاصل شود، «مهندسی ویژگی» نامیده میشود.
برچسبها : نام دیگری برای «کلاسها» یا پاسخهای صحیح در یک مسئله طبقهبندی نظارتشده
نرخ یادگیری : کسری از گرادیان که وزنها و بایاسها در هر تکرار حلقه آموزش بهروزرسانی میشوند.
لوجیتها : خروجیهای یک لایه از نورونها قبل از اعمال تابع فعالسازی، «لوجیت» نامیده میشوند. این اصطلاح از «تابع لجستیک» یا «تابع سیگموئید» گرفته شده است که قبلاً محبوبترین تابع فعالسازی بود. «خروجیهای نورون قبل از تابع لجستیک» به «لوجیتها» خلاصه شد.
تابع خطا (loss) : تابع خطایی که خروجیهای شبکه عصبی را با پاسخهای صحیح مقایسه میکند.
نورون : مجموع وزنی ورودیهایش را محاسبه میکند، یک بایاس اضافه میکند و نتیجه را از طریق یک تابع فعالسازی ارسال میکند.
کدگذاری وان-هات : کلاس ۳ از ۵ به صورت برداری با ۵ عنصر کدگذاری میشود که همه عناصر آن صفر هستند به جز عنصر سوم که ۱ است.
relu : واحد خطی یکسو شده. یک تابع فعالسازی محبوب برای نورونها.
سیگموئید : تابع فعالسازی دیگری که قبلاً محبوب بود و هنوز هم در موارد خاص مفید است.
softmax : یک تابع فعالسازی ویژه که روی یک بردار عمل میکند، تفاوت بین بزرگترین مؤلفه و سایر مؤلفهها را افزایش میدهد، و همچنین بردار را طوری نرمالسازی میکند که مجموع آن ۱ باشد تا بتوان آن را به عنوان برداری از احتمالات تفسیر کرد. به عنوان آخرین مرحله در طبقهبندیکنندهها استفاده میشود.
تانسور : یک "تانسور" مانند یک ماتریس است اما با تعداد دلخواهی از ابعاد. یک تانسور یک بعدی یک بردار است. یک تانسور دو بعدی یک ماتریس است. و سپس میتوانید تانسورهایی با ۳، ۴، ۵ یا بیشتر بعد داشته باشید.
۵. بیایید به سراغ کد برویم
برگردیم به دفترچه مطالعه و این بار، بیایید کد را بخوانیم.
بیایید تمام سلولهای این دفترچه یادداشت را بررسی کنیم.
سلول "پارامترها"
اندازه دسته، تعداد دورههای آموزشی و محل فایلهای داده در اینجا تعریف شده است. فایلهای داده در یک مخزن ذخیرهسازی ابری گوگل (GCS) میزبانی میشوند، به همین دلیل آدرس آنها با gs:// شروع میشود.
سلول "واردات"
تمام کتابخانههای لازم پایتون، از جمله TensorFlow و همچنین matplotlib برای مصورسازی، در اینجا وارد شدهاند.
ابزار تجسم سلولی [اجرای من]****
این سلول حاوی کد بصریسازی نه چندان جالبی است. به طور پیشفرض جمع شده است، اما میتوانید در صورت داشتن وقت، با دوبار کلیک کردن روی آن، آن را باز کرده و کد را مشاهده کنید.
سلول " tf.data.Dataset: تجزیه فایلها و آمادهسازی مجموعه دادههای آموزشی و اعتبارسنجی "
این سلول از API مربوط به tf.data.Dataset برای بارگذاری مجموعه داده MNIST از فایلهای داده استفاده کرد. لازم نیست زمان زیادی را صرف این سلول کنید. اگر به API مربوط به tf.data.Dataset علاقهمند هستید، در اینجا آموزشی وجود دارد که آن را توضیح میدهد: خطوط لوله داده با سرعت TPU . در حال حاضر، اصول اولیه عبارتند از:
تصاویر و برچسبها (پاسخهای صحیح) از مجموعه داده MNIST در رکوردهایی با طول ثابت در ۴ فایل ذخیره میشوند. این فایلها را میتوان با تابع رکورد ثابت اختصاصی بارگذاری کرد:
imagedataset = tf.data.FixedLengthRecordDataset(image_filename, 28*28, header_bytes=16)
اکنون مجموعهای از بایتهای تصویر داریم. آنها باید به تصاویر رمزگشایی شوند. ما یک تابع برای انجام این کار تعریف میکنیم. تصویر فشرده نشده است، بنابراین تابع نیازی به رمزگشایی چیزی ندارد ( decode_raw اساساً هیچ کاری انجام نمیدهد). سپس تصویر به مقادیر ممیز شناور بین ۰ و ۱ تبدیل میشود. میتوانیم آن را در اینجا به عنوان یک تصویر دوبعدی تغییر شکل دهیم، اما در واقع آن را به عنوان یک آرایه مسطح از پیکسلها با اندازه ۲۸*۲۸ نگه میداریم، زیرا این همان چیزی است که لایه متراکم اولیه ما انتظار دارد.
def read_image(tf_bytestring):
image = tf.io.decode_raw(tf_bytestring, tf.uint8)
image = tf.cast(image, tf.float32)/256.0
image = tf.reshape(image, [28*28])
return image
ما این تابع را با استفاده از .map روی مجموعه دادهها اعمال میکنیم و مجموعهای از تصاویر را به دست میآوریم:
imagedataset = imagedataset.map(read_image, num_parallel_calls=16)
ما همین نوع خواندن و رمزگشایی را برای برچسبها انجام میدهیم و تصاویر و برچسبها را با هم .zip میکنیم:
dataset = tf.data.Dataset.zip((imagedataset, labelsdataset))
اکنون یک مجموعه داده از جفتها (تصویر، برچسب) داریم. این چیزی است که مدل ما انتظار دارد. ما هنوز کاملاً آماده نیستیم که از آن در تابع آموزش استفاده کنیم:
dataset = dataset.cache()
dataset = dataset.shuffle(5000, reshuffle_each_iteration=True)
dataset = dataset.repeat()
dataset = dataset.batch(batch_size)
dataset = dataset.prefetch(tf.data.experimental.AUTOTUNE)
رابط برنامهنویسی کاربردی (API) مربوط به tf.data.Dataset تمام توابع کاربردی لازم برای تهیه مجموعه دادهها را دارد:
.cache مجموعه دادهها را در RAM ذخیره میکند. این یک مجموعه داده کوچک است، بنابراین کار خواهد کرد. .shuffle آن را با یک بافر ۵۰۰۰ عنصری ترکیب میکند. مهم است که دادههای آموزشی به خوبی ترکیب شوند. .repeat مجموعه دادهها را حلقه میکند. ما چندین بار (چندین دوره) روی آن آموزش خواهیم داد. .batch چندین تصویر و برچسب را در یک مینی-بچ جمع میکند. در نهایت، .prefetch میتواند از CPU برای آمادهسازی دسته بعدی استفاده کند در حالی که دسته فعلی در GPU آموزش داده میشود.
مجموعه دادههای اعتبارسنجی به روشی مشابه آماده میشوند. اکنون آمادهایم تا یک مدل تعریف کنیم و از این مجموعه دادهها برای آموزش آن استفاده کنیم.
سلول "مدل کراس"
تمام مدلهای ما توالیهای مستقیمی از لایهها خواهند بود، بنابراین میتوانیم از سبک tf.keras.Sequential برای ایجاد آنها استفاده کنیم. در ابتدا، در اینجا، یک لایه متراکم واحد است. این لایه 10 نورون دارد زیرا ما ارقام دستنویس را در 10 کلاس طبقهبندی میکنیم. از فعالسازی "softmax" استفاده میکند زیرا آخرین لایه در یک طبقهبندیکننده است.
یک مدل Keras همچنین باید شکل ورودیهای خود را بداند. tf.keras.layers.Input میتواند برای تعریف آن استفاده شود. در اینجا، بردارهای ورودی، بردارهای مسطح با مقادیر پیکسلی به طول 28*28 هستند.
model = tf.keras.Sequential(
[
tf.keras.layers.Input(shape=(28*28,)),
tf.keras.layers.Dense(10, activation='softmax')
])
model.compile(optimizer='sgd',
loss='categorical_crossentropy',
metrics=['accuracy'])
# print model layers
model.summary()
# utility callback that displays training curves
plot_training = PlotTraining(sample_rate=10, zoom=1)
پیکربندی مدل در Keras با استفاده از تابع model.compile انجام میشود. در اینجا ما از بهینهساز پایه 'sgd' (کاهش گرادیان تصادفی) استفاده میکنیم. یک مدل طبقهبندی به یک تابع زیان آنتروپی متقاطع نیاز دارد که در Keras 'categorical_crossentropy' نامیده میشود. در نهایت، از مدل میخواهیم معیار 'accuracy' را محاسبه کند، که درصد تصاویر طبقهبندی شده صحیح است.
Keras ابزار بسیار خوب model.summary() را ارائه میدهد که جزئیات مدلی را که ایجاد کردهاید چاپ میکند. مربی مهربان شما ابزار PlotTraining (تعریف شده در سلول "visualization utilities") را اضافه کرده است که منحنیهای آموزشی مختلفی را در طول آموزش نمایش میدهد.
سلول "آموزش و اعتبارسنجی مدل"
اینجاست که آموزش اتفاق میافتد، با فراخوانی model.fit و ارسال مجموعه دادههای آموزش و اعتبارسنجی. به طور پیشفرض، Keras در پایان هر دوره، یک دور اعتبارسنجی اجرا میکند.
model.fit(training_dataset, steps_per_epoch=steps_per_epoch, epochs=EPOCHS,
validation_data=validation_dataset, validation_steps=1,
callbacks=[plot_training])
در Keras، میتوان با استفاده از callbackها، رفتارهای سفارشی را در طول آموزش اضافه کرد. به این ترتیب، نمودار آموزشی که به صورت پویا بهروزرسانی میشود، برای این کارگاه پیادهسازی شد.
سلول "تجسم پیشبینیها"
پس از آموزش مدل، میتوانیم با فراخوانی model.predict() از آن پیشبینیهایی دریافت کنیم:
probabilities = model.predict(font_digits, steps=1)
predicted_labels = np.argmax(probabilities, axis=1)
در اینجا ما مجموعهای از ارقام چاپشده را که از فونتهای محلی رندر شدهاند، به عنوان آزمایش آماده کردهایم. به یاد داشته باشید که شبکه عصبی برداری از احتمالات 10 را از "softmax" نهایی خود برمیگرداند. برای دریافت برچسب، باید بفهمیم کدام احتمال بالاترین است. np.argmax از کتابخانه numpy این کار را انجام میدهد.
برای درک اینکه چرا پارامتر axis=1 مورد نیاز است، لطفاً به یاد داشته باشید که ما یک دسته شامل ۱۲۸ تصویر را پردازش کردهایم و بنابراین مدل ۱۲۸ بردار احتمال را برمیگرداند. شکل تانسور خروجی [۱۲۸، ۱۰] است. ما در حال محاسبه argmax در طول ۱۰ احتمال برگردانده شده برای هر تصویر هستیم، بنابراین axis=1 (محور اول ۰ است).
این مدل ساده در حال حاضر ۹۰٪ ارقام را تشخیص میدهد. بد نیست، اما اکنون این را به طور قابل توجهی بهبود خواهید بخشید.

۶. اضافه کردن لایهها

برای بهبود دقت تشخیص، لایههای بیشتری به شبکه عصبی اضافه خواهیم کرد.

ما softmax را به عنوان تابع فعالسازی در آخرین لایه نگه میداریم زیرا این تابع برای طبقهبندی بهترین عملکرد را دارد. با این حال، در لایههای میانی از کلاسیکترین تابع فعالسازی یعنی سیگموئید استفاده خواهیم کرد:
برای مثال، مدل شما میتواند به این شکل باشد (کاماها را فراموش نکنید، tf.keras.Sequential لیستی از لایههای جدا شده با کاما را میگیرد):
model = tf.keras.Sequential(
[
tf.keras.layers.Input(shape=(28*28,)),
tf.keras.layers.Dense(200, activation='sigmoid'),
tf.keras.layers.Dense(60, activation='sigmoid'),
tf.keras.layers.Dense(10, activation='softmax')
])
به «خلاصه» مدل خود نگاه کنید. اکنون حداقل 10 برابر پارامترهای بیشتری دارد. باید 10 برابر بهتر باشد! اما به دلایلی، اینطور نیست...
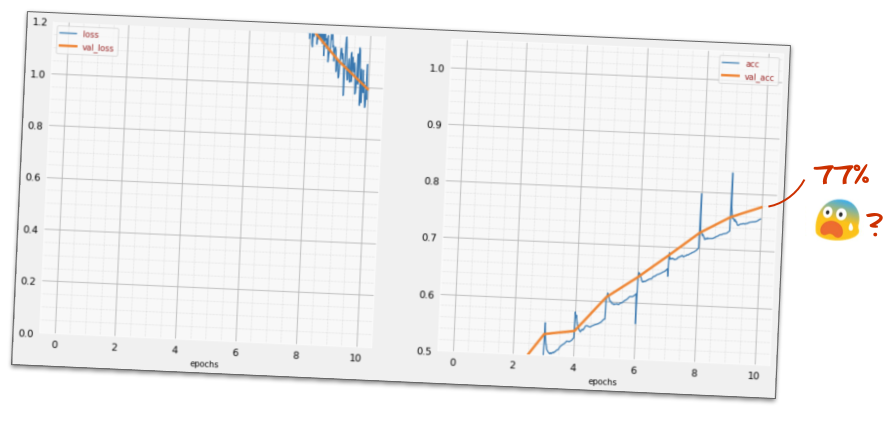
به نظر میرسد که این باخت به اوج خود رسیده است. یک جای کار میلنگد.
۷. توجه ویژه به شبکههای عمیق
شما همین الان شبکههای عصبی را تجربه کردهاید، همانطور که مردم در دهههای ۸۰ و ۹۰ آنها را طراحی میکردند. جای تعجب نیست که آنها از این ایده دست کشیدند و به اصطلاح "زمستان هوش مصنوعی" را آغاز کردند. در واقع، با اضافه شدن لایهها، شبکههای عصبی برای همگرایی با مشکلات بیشتری روبرو میشوند.
معلوم شد که شبکههای عصبی عمیق با لایههای زیاد (امروزه ۲۰، ۵۰، حتی ۱۰۰ لایه) میتوانند واقعاً خوب کار کنند، البته به شرطی که چند ترفند ریاضی آنها را همگرا کند. کشف این ترفندهای ساده یکی از دلایل رنسانس یادگیری عمیق در دهه ۲۰۱۰ است.
فعال سازی RELU

تابع فعالسازی سیگموئید در شبکههای عمیق واقعاً مشکلساز است. این تابع تمام مقادیر بین ۰ و ۱ را در هم میکوبد و وقتی این کار را بارها و بارها انجام دهید، خروجیهای نورون و گرادیانهای آنها میتواند کاملاً ناپدید شود. این موضوع به دلایل تاریخی ذکر شده است، اما شبکههای مدرن از RELU (واحد خطی یکسو شده) استفاده میکنند که به این شکل است:

از طرف دیگر، relu حداقل در سمت راست خود مشتقی برابر با ۱ دارد. با فعالسازی RELU، حتی اگر گرادیانهای ناشی از برخی نورونها بتوانند صفر باشند، همیشه نورونهای دیگری وجود خواهند داشت که گرادیان غیر صفر واضحی ارائه دهند و آموزش میتواند با سرعت خوبی ادامه یابد.
یک بهینهساز بهتر
در فضاهای با ابعاد بسیار بالا مانند اینجا - که حدود ۱۰ هزار وزن و بایاس داریم - «نقاط زینی» (saddle points) به وفور یافت میشوند. اینها نقاطی هستند که مینیمم محلی نیستند، اما در عین حال گرادیان صفر است و بهینهساز گرادیان نزولی در آنجا گیر میکند. TensorFlow مجموعهای کامل از بهینهسازهای موجود را دارد، از جمله برخی که با مقداری اینرسی کار میکنند و با خیال راحت از نقاط زینی عبور میکنند.
مقداردهی اولیه تصادفی
هنر مقداردهی اولیه بایاسهای وزنها قبل از آموزش، خود یک حوزه تحقیقاتی است و مقالات متعددی در این زمینه منتشر شده است. میتوانید نگاهی به تمام مقداردهیهای اولیه موجود در Keras در اینجا بیندازید. خوشبختانه، Keras به طور پیشفرض کار درست را انجام میدهد و از مقداردهی اولیه 'glorot_uniform' استفاده میکند که تقریباً در همه موارد بهترین است.
کاری از دست شما بر نمیآید، زیرا کراس از قبل کار درست را انجام میدهد.
نان ان ؟؟؟
فرمول آنتروپی متقاطع شامل لگاریتم است و log(0) یک عدد نیست (NaN، اگر ترجیح میدهید یک تصادف عددی باشد). آیا ورودی آنتروپی متقاطع میتواند 0 باشد؟ ورودی از softmax میآید که اساساً یک تابع نمایی است و تابع نمایی هرگز صفر نمیشود. بنابراین ما در امان هستیم!
واقعاً؟ در دنیای زیبای ریاضیات، ما در امان خواهیم بود، اما در دنیای کامپیوتر، exp(-150) که با فرمت float32 نمایش داده میشود، تا حد امکان صفر میشود و آنتروپی متقاطع از بین میرود.
خوشبختانه، در اینجا هم کاری از دست شما بر نمیآید، زیرا Keras این کار را انجام میدهد و softmax و به دنبال آن cross-entropy را به روشی بسیار دقیق محاسبه میکند تا پایداری عددی را تضمین کند و از NaN های ترسناک جلوگیری کند.
موفقیت؟

حالا باید به دقت ۹۷٪ رسیده باشید. هدف در این کارگاه رسیدن به دقتی بالاتر از ۹۹٪ است، پس ادامه میدهیم.
اگر گیر کردهاید، در این مرحله راه حل اینجاست:
۸. کاهش نرخ یادگیری
شاید بتوانیم سعی کنیم سریعتر آموزش دهیم؟ نرخ یادگیری پیشفرض در بهینهساز Adam برابر با 0.001 است. بیایید سعی کنیم آن را افزایش دهیم.
انگار تندتر رفتن کمکی نمیکند و این همه سر و صدا برای چیست؟

منحنیهای آموزش واقعاً نویز دارند و به هر دو منحنی اعتبارسنجی نگاه کنید: آنها بالا و پایین میپرند. این بدان معناست که ما خیلی سریع پیش میرویم. میتوانیم به سرعت قبلی خود برگردیم، اما راه بهتری وجود دارد.

راه حل خوب این است که سریع شروع کنید و نرخ یادگیری را به صورت نمایی کاهش دهید. در Keras، میتوانید این کار را با فراخوانی tf.keras.callbacks.LearningRateScheduler انجام دهید.
کد مفید برای کپی پیست:
# lr decay function
def lr_decay(epoch):
return 0.01 * math.pow(0.6, epoch)
# lr schedule callback
lr_decay_callback = tf.keras.callbacks.LearningRateScheduler(lr_decay, verbose=True)
# important to see what you are doing
plot_learning_rate(lr_decay, EPOCHS)
فراموش نکنید که از lr_decay_callback که ایجاد کردهاید استفاده کنید. آن را به لیست callbackها در model.fit اضافه کنید:
model.fit(..., callbacks=[plot_training, lr_decay_callback])
تأثیر این تغییر کوچک چشمگیر است. میبینید که بیشتر نویز از بین رفته و دقت آزمایش اکنون به طور پایدار بالای ۹۸٪ است.

۹. حذف، بیشبرازش
به نظر میرسد که مدل اکنون به خوبی همگرا شده است. بیایید سعی کنیم عمیقتر بررسی کنیم.
آیا کمکی میکند؟

Not really, the accuracy is still stuck at 98% and look at the validation loss. It is going up! The learning algorithm works on training data only and optimises the training loss accordingly. It never sees validation data so it is not surprising that after a while its work no longer has an effect on the validation loss which stops dropping and sometimes even bounces back up.
This does not immediately affect the real-world recognition capabilities of your model, but it will prevent you from running many iterations and is generally a sign that the training is no longer having a positive effect.

This disconnect is usually called "overfitting" and when you see it, you can try to apply a regularisation technique called "dropout". The dropout technique shoots random neurons at each training iteration.
Did it work?

Noise reappears (unsurprisingly given how dropout works). The validation loss does not seem to be creeping up anymore, but it is higher overall than without dropout. And the validation accuracy went down a bit. This is a fairly disappointing result.
It looks like dropout was not the correct solution, or maybe "overfitting" is a more complex concept and some of its causes are not amenable to a "dropout" fix?
What is "overfitting"? Overfitting happens when a neural network learns "badly", in a way that works for the training examples but not so well on real-world data. There are regularisation techniques like dropout that can force it to learn in a better way but overfitting also has deeper roots.

Basic overfitting happens when a neural network has too many degrees of freedom for the problem at hand. Imagine we have so many neurons that the network can store all of our training images in them and then recognise them by pattern matching. It would fail on real-world data completely. A neural network must be somewhat constrained so that it is forced to generalise what it learns during training.
If you have very little training data, even a small network can learn it by heart and you will see "overfitting". Generally speaking, you always need lots of data to train neural networks.
Finally, if you have done everything by the book, experimented with different sizes of network to make sure its degrees of freedom are constrained, applied dropout, and trained on lots of data you might still be stuck at a performance level that nothing seems to be able to improve. This means that your neural network, in its present shape, is not capable of extracting more information from your data, as in our case here.
Remember how we are using our images, flattened into a single vector? That was a really bad idea. Handwritten digits are made of shapes and we discarded the shape information when we flattened the pixels. However, there is a type of neural network that can take advantage of shape information: convolutional networks. Let us try them.
If you are stuck, here is the solution at this point:
10. [INFO] convolutional networks
به طور خلاصه
If all the terms in bold in the next paragraph are already known to you, you can move to the next exercise. If your are just starting out with convolutional neural networks, please read on.

Illustration: filtering an image with two successive filters made of 4x4x3=48 learnable weights each.
This is how a simple convolutional neural network looks in Keras:
model = tf.keras.Sequential([
tf.keras.layers.Reshape(input_shape=(28*28,), target_shape=(28, 28, 1)),
tf.keras.layers.Conv2D(kernel_size=3, filters=12, activation='relu'),
tf.keras.layers.Conv2D(kernel_size=6, filters=24, strides=2, activation='relu'),
tf.keras.layers.Conv2D(kernel_size=6, filters=32, strides=2, activation='relu'),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(10, activation='softmax')
])
In a layer of a convolutional network, one "neuron" does a weighted sum of the pixels just above it, across a small region of the image only. It adds a bias and feeds the sum through an activation function, just as a neuron in a regular dense layer would. This operation is then repeated across the entire image using the same weights. Remember that in dense layers, each neuron had its own weights. Here, a single "patch" of weights slides across the image in both directions (a "convolution"). The output has as many values as there are pixels in the image (some padding is necessary at the edges though). It is a filtering operation. In the illustration above, it uses a filter of 4x4x3=48 weights.
However, 48 weights will not be enough. To add more degrees of freedom, we repeat the same operation with a new set of weights. This produces a new set of filter outputs. Let's call it a "channel" of outputs by analogy with the R,G,B channels in the input image.

The two (or more) sets of weights can be summed up as one tensor by adding a new dimension. This gives us the generic shape of the weights tensor for a convolutional layer. Since the number of input and output channels are parameters, we can start stacking and chaining convolutional layers.

Illustration: a convolutional neural network transforms "cubes" of data into other "cubes" of data.
Strided convolutions, max pooling
By performing the convolutions with a stride of 2 or 3, we can also shrink the resulting data cube in its horizontal dimensions. There are two common ways of doing this:
- Strided convolution: a sliding filter as above but with a stride >1
- Max pooling: a sliding window applying the MAX operation (typically on 2x2 patches, repeated every 2 pixels)

Illustration: sliding the computing window by 3 pixels results in fewer output values. Strided convolutions or max pooling (max on a 2x2 window sliding by a stride of 2) are a way of shrinking the data cube in the horizontal dimensions.
The final layer
After the last convolutional layer, the data is in the form of a "cube". There are two ways of feeding it through the final dense layer.
The first one is to flatten the cube of data into a vector and then feed it to the softmax layer. Sometimes, you can even add a dense layer before the softmax layer. This tends to be expensive in terms of the number of weights. A dense layer at the end of a convolutional network can contain more than half the weights of the whole neural network.
Instead of using an expensive dense layer, we can also split the incoming data "cube" into as many parts as we have classes, average their values and feed these through a softmax activation function. This way of building the classification head costs 0 weights. In Keras, there is a layer for this: tf.keras.layers.GlobalAveragePooling2D() .

Jump to the next section to build a convolutional network for the problem at hand.
11. A convolutional network
Let us build a convolutional network for handwritten digit recognition. We will use three convolutional layers at the top, our traditional softmax readout layer at the bottom and connect them with one fully-connected layer:

Notice that the second and third convolutional layers have a stride of two which explains why they bring the number of output values down from 28x28 to 14x14 and then 7x7.
Let's write the Keras code.
Special attention is needed before the first convolutional layer. Indeed, it expects a 3D 'cube' of data but our dataset has so far been set up for dense layers and all the pixels of the images are flattened into a vector. We need to reshape them back into 28x28x1 images (1 channel for grayscale images):
tf.keras.layers.Reshape(input_shape=(28*28,), target_shape=(28, 28, 1))
You can use this line instead of the tf.keras.layers.Input layer you had up to now.
In Keras, the syntax for a 'relu'-activated convolutional layer is:

tf.keras.layers.Conv2D(kernel_size=3, filters=12, padding='same', activation='relu')
For a strided convolution, you would write:
tf.keras.layers.Conv2D(kernel_size=6, filters=24, padding='same', activation='relu', strides=2)
To flatten a cube of data into a vector so that it can be consumed by a dense layer:
tf.keras.layers.Flatten()
And for dense layer, the syntax has not changed:
tf.keras.layers.Dense(200, activation='relu')
Did your model break the 99% accuracy barrier? Pretty close... but look at the validation loss curve. Does this ring a bell?

Also look at the predictions. For the first time, you should see that most of the 10,000 test digits are now correctly recognized. Only about 4½ rows of misdetections remain (about 110 digits out of 10,000)

If you are stuck, here is the solution at this point:
12. Dropout again
The previous training exhibits clear signs of overfitting (and still falls short of 99% accuracy). Should we try dropout again?
How did it go this time?

It looks like dropout has worked this time. The validation loss is not creeping up anymore and the final accuracy should be way above 99%. Congratulations!
The first time we tried to apply dropout, we thought we had an overfitting problem, when in fact the problem was in the architecture of the neural network. We could not go further without convolutional layers and there is nothing dropout could do about that.
This time, it does look like overfitting was the cause of the problem and dropout actually helped. Remember, there are many things that can cause a disconnect between the training and validation loss curves, with the validation loss creeping up. Overfitting (too many degrees of freedom, used badly by the network) is only one of them. If your dataset is too small or the architecture of your neural network is not adequate, you might see a similar behavior on the loss curves, but dropout will not help.
13. Batch normalization

Finally, let's try to add batch normalization.
That's the theory, in practice, just remember a couple of rules:
Let's play by the book for now and add a batch norm layer on each neural network layer but the last. Do not add it to the last "softmax" layer. It would not be useful there.
# Modify each layer: remove the activation from the layer itself.
# Set use_bias=False since batch norm will play the role of biases.
tf.keras.layers.Conv2D(..., use_bias=False),
# Batch norm goes between the layer and its activation.
# The scale factor can be turned off for Relu activation.
tf.keras.layers.BatchNormalization(scale=False, center=True),
# Finish with the activation.
tf.keras.layers.Activation('relu'),
How is the accuracy now?

With a little bit of tweaking (BATCH_SIZE=64, learning rate decay parameter 0.666, dropout rate on dense layer 0.3) and a bit of luck, you can get to 99.5%. The learning rate and dropout adjustments were done following the "best practices" for using batch norm:
- Batch norm helps neural networks converge and usually allows you to train faster.
- Batch norm is a regularizer. You can usually decrease the amount of dropout you use, or even not use dropout at all.
The solution notebook has a 99.5% training run:
14. Train in the cloud on powerful hardware: AI Platform

You will find a cloud-ready version of the code in the mlengine folder on GitHub , along with instructions for running it on Google Cloud AI Platform . Before you can run this part, you will have to create a Google Cloud account and enable billing. The resources necessary to complete the lab should be less than a couple of dollars (assuming 1h of training time on one GPU). To prepare your account:
- Create a Google Cloud Platform project ( http://cloud.google.com/console ).
- Enable billing.
- Install the GCP command line tools ( GCP SDK here ).
- Create a Google Cloud Storage bucket (put in the region
us-central1). It will be used to stage the training code and store your trained model. - Enable the necessary APIs and request the necessary quotas (run the training command once and you should get error messages telling you what to enable).
۱۵. تبریک میگویم!
You have built your first neural network and trained it all the way to 99% accuracy. The techniques learned along the way are not specific to the MNIST dataset, actually they are widely used when working with neural networks. As a parting gift, here is the "cliff's notes" card for the lab, in cartoon version. You can use it to remember what you have learned:

مراحل بعدی
- After fully-connected and convolutional networks, you should have a look at recurrent neural networks .
- To run your training or inference in the cloud on a distributed infrastructure, Google Cloud provides AI Platform .
- Finally, we love feedback. Please tell us if you see something amiss in this lab or if you think it should be improved. We handle feedback through GitHub issues [ feedback link ].

|
|
 The author: Martin GörnerTwitter:
The author: Martin GörnerTwitter: 
All cartoon images in this lab copyright: alexpokusay / 123RF stock photos