
1. 總覽
本教學課程已更新,適用於 Tensorflow 2.2!

在本程式碼研究室中,您將學習如何建構及訓練可辨識手寫數字的類神經網路。在將類神經網路的準確率提升至 99% 的過程中,您也會瞭解深層學習專業人員用來有效訓練模型的工具。
本程式碼研究室使用 MNIST 資料集,這個資料集包含 60,000 個標示的數字,近二十年來讓許多博士生忙得不可開交。您將使用不到 100 行的 Python / TensorFlow 程式碼解決問題。
課程內容
- 什麼是類神經網路?如何訓練?
- 如何使用 tf.keras 建構基本單層類神經網路
- 如何新增更多圖層
- 如何設定學習率時間表
- 如何建構卷積類神經網路
- 如何使用正規化技術:丟棄、批次正規化
- 什麼是過度配適
軟硬體需求
只要有瀏覽器即可。本研討會可完全在 Google Colaboratory 中執行。
意見回饋
如果您在本實驗室中發現任何錯誤,或認為有需要改進之處,請告訴我們。我們會透過 GitHub 問題處理意見回饋 [意見回饋連結]。
2. Google Colaboratory 快速入門
本實驗室使用 Google Colaboratory,您無須進行任何設定。您可以在 Chromebook 上執行這項工具。請開啟下方檔案並執行儲存格,熟悉 Colab 筆記本。

其他操作說明如下:
選取 GPU 後端

在 Colab 選單中,依序選取「執行階段」>「變更執行階段類型」,然後選取「GPU」。首次執行時,系統會自動連線至執行階段,您也可以使用右上角的「連線」按鈕。
筆記本執行
按一下儲存格並使用 Shift-ENTER,即可一次執行一個儲存格。您也可以依序選取「執行階段」>「全部執行」,執行整個筆記本。
Table of contents

所有筆記本都有目錄。你可以使用左側的黑色箭頭開啟這個選單。
隱藏的儲存格

部分儲存格只會顯示標題,這是 Colab 專屬的筆記本功能。你可以按兩下查看其中的程式碼,但通常不會很有趣。通常是支援或視覺化函式。您仍需執行這些儲存格,才能定義其中的函式。
3. 訓練類神經網路
我們會先觀看類神經網路的訓練過程,請開啟下方的筆記本,並執行所有儲存格。請先不要理會程式碼,我們稍後會開始說明。
執行筆記本時,請著重於視覺化內容。詳情請參閱下文。
訓練資料
我們有一個手寫數字資料集,其中已加上標籤,因此我們知道每張圖片代表的內容,也就是介於 0 到 9 之間的數字。筆記本中會顯示摘要:

我們將建構的類神經網路會將手寫數字分類到 10 個類別 (0、...、9)。這項功能會根據內部參數進行分類,這些參數必須有正確的值,分類功能才能正常運作。這項「正確值」是透過訓練程序學習而來,需要包含圖片和相關正確答案的「標籤資料集」。
我們如何判斷訓練好的類神經網路是否運作良好?使用訓練資料集測試網路是作弊行為。模型在訓練期間已多次看過該資料集,因此在該資料集上的表現肯定非常出色。我們需要另一個加上標籤的資料集 (訓練期間從未見過),才能評估網路的「實際」成效。這就是所謂的「驗證資料集」
訓練
隨著訓練進度,模型會一次處理一批訓練資料,更新內部模型參數,並越來越擅長辨識手寫數字。您可以在訓練圖表中看到這點:

右側的「準確度」只是正確辨識的數字百分比。隨著訓練進行,準確率會提高,這是好事。
左側顯示的是「損失」。為推動訓練,我們將定義「損失」函式,代表系統辨識數字的錯誤程度,並嘗試將損失降至最低。您會看到訓練和驗證資料的損失隨著訓練進行而下降,這是好現象。這表示類神經網路正在學習。
X 軸代表「週期」數,也就是整個資料集的疊代次數。
預測
模型訓練完成後,即可用來辨識手寫數字。下一個視覺化內容顯示從本機字型算繪幾個數字時的效能 (第一行),以及驗證資料集中的 10,000 個數字。每個數字下方都會顯示預測類別,如果預測錯誤,就會以紅色顯示。

如您所見,這個初始模型並不算好,但仍可正確辨識部分數字。最終驗證準確率約為 90%,以我們開始使用的簡化模型來說,這個結果還算不錯,但這仍表示在 10, 000 個驗證數字中,有 1,000 個數字未正確辨識。這遠遠超出可顯示的數量,因此看起來所有答案都是錯誤的 (紅色)。
張量
資料會儲存在矩陣中。28x28 像素的灰階圖片適合 28x28 的二維矩陣。但如果是彩色圖片,我們需要更多維度。每個像素有 3 個顏色值 (紅、綠、藍),因此需要維度為 [28, 28, 3] 的三維表格。如要儲存 128 張彩色圖片,則需要四維表格,維度為 [128, 28, 28, 3]。
這些多維度表格稱為「張量」,而維度清單則稱為「形狀」。
4. [INFO]: neural networks 101
簡介
如果下一段粗體字詞你都瞭解,即可進行下一個練習。如果你才剛開始接觸深度學習,歡迎閱讀下文。

如要以層序列建構模型,Keras 提供 Sequential API。舉例來說,使用三個密集層的圖片分類器可以 Keras 撰寫,如下所示:
model = tf.keras.Sequential([
tf.keras.layers.Flatten(input_shape=[28, 28, 1]),
tf.keras.layers.Dense(200, activation="relu"),
tf.keras.layers.Dense(60, activation="relu"),
tf.keras.layers.Dense(10, activation='softmax') # classifying into 10 classes
])
# this configures the training of the model. Keras calls it "compiling" the model.
model.compile(
optimizer='adam',
loss= 'categorical_crossentropy',
metrics=['accuracy']) # % of correct answers
# train the model
model.fit(dataset, ... )

單一密集層
MNIST 資料集中的手寫數字是 28x28 像素的灰階圖片。如要分類這些圖片,最簡單的方法是將 28x28=784 像素做為單層類神經網路的輸入。

類神經網路中的每個「神經元」都會計算所有輸入的加權總和,加入稱為「偏差」的常數,然後透過某個非線性「活化函數」饋送結果。「權重」和「偏誤」是透過訓練決定的參數。一開始會以隨機值初始化。
上圖代表一個具有 10 個輸出神經元的單層類神經網路,因為我們要將數字分類為 10 個類別 (0 到 9)。
使用矩陣乘法
以下是類神經網路層處理一系列圖片時,可透過矩陣乘法表示的方式:

使用權重矩陣 W 中的第一欄權重,計算第一張圖片所有像素的加權總和。這個總和對應至第一個神經元。使用第二欄權重,對第二個神經元執行相同操作,依此類推,直到第 10 個神經元為止。接著,我們就能對其餘 99 張圖片重複這項作業。如果我們將包含 100 張圖片的矩陣稱為 X,則在 100 張圖片上計算的 10 個神經元所有加權總和,就只是 X.W,也就是矩陣乘法。
現在每個神經元都必須加入偏差值 (常數)。由於我們有 10 個神經元,因此有 10 個偏差常數。我們將這個 10 個值的向量稱為 b。必須加到先前計算的矩陣每一行。我們會使用稱為「廣播」的魔法,以簡單的加號編寫這項功能。
最後,我們套用活化函數,例如「softmax」(說明如下),並取得描述 1 層類神經網路的公式,套用至 100 張圖片:

在 Keras 中
使用 Keras 等高階神經網路程式庫時,我們不需要實作這個公式。不過,請務必瞭解類神經網路層只是一堆乘法和加法。在 Keras 中,密集層會寫成:
tf.keras.layers.Dense(10, activation='softmax')
深入瞭解
串連類神經網路層非常簡單。第一層會計算像素的加權總和。後續層會計算前一層輸出的加權總和。

除了神經元數量,唯一的差異就是活化函數的選擇。
啟動函式:relu、softmax 和 sigmoid
通常,您會為最後一層以外的所有層使用「relu」活化函式。在分類器中,最後一層會使用「softmax」啟動。

同樣地,「神經元」會計算所有輸入的加權總和,加上稱為「偏差」的值,然後透過啟動函式饋送結果。
最熱門的啟動函式稱為「RELU」,是線性整流單元 (Rectified Linear Unit) 的縮寫。如上圖所示,這項函式非常簡單。
神經網路中的傳統啟動函式是「sigmoid」,但「relu」幾乎在所有地方都展現出較佳的收斂特性,因此現在是首選函式。

用於分類的 Softmax 啟動
類神經網路的最後一層有 10 個神經元,因為我們要將手寫數字分類為 10 個類別 (0 到 9)。輸出結果應為 10 個介於 0 到 1 之間的數字,分別代表這個數字是 0、1、2 等的機率。為此,我們會在最後一層使用名為「softmax」的啟動函式。
對向量套用 Softmax 函數時,會先計算每個元素的指數,然後將向量正規化,通常是除以「L1」範數 (即絕對值總和),使正規化值加總為 1,並可解讀為機率。
啟動前的最後一層輸出有時稱為「logits」。如果這個向量是 L = [L0, L1, L2, L3, L4, L5, L6, L7, L8, L9],則:


交叉熵損失
現在類神經網路會根據輸入圖片產生預測結果,我們需要測量預測結果的準確度,也就是網路提供的結果與正確答案 (通常稱為「標籤」) 之間的距離。請注意,資料集中的所有圖片都有正確標籤。
任何距離都適用,但對於分類問題,所謂的「交叉熵距離」最有效。我們將此稱為誤差或「損失」函式:

梯度下降
「訓練」類神經網路實際上是指使用訓練圖片和標籤調整權重和偏誤,盡量減少交叉熵損失函式。運作方式如下:
交叉熵是權重、偏差、訓練圖片的像素及其已知類別的函式。
如果我們計算相對於所有權重和所有偏差的交叉熵偏導數,就會得到「梯度」,這是針對特定圖片、標籤,以及權重和偏差的現值計算而得。請注意,我們可能有數百萬個權重和偏差,因此計算梯度聽起來像是大量的工作。幸好,TensorFlow 會為我們執行這項作業。漸層的數學特性是「向上」指向。由於我們希望交叉熵較低,因此要朝相反方向移動。我們會根據梯度的一小部分更新權重和偏差值。接著,我們會在訓練迴圈中,使用下一批訓練圖片和標籤,重複執行相同的操作。希望這會收斂到交叉熵最小的地方,但無法保證這個最小值是唯一的。
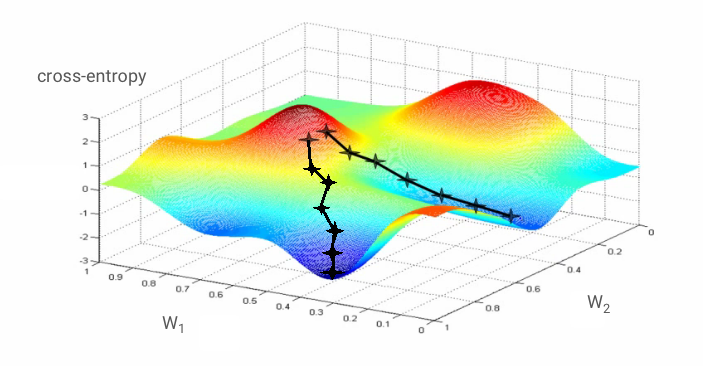
迷你批次和動量
您可以在單一範例圖片上計算梯度,並立即更新權重和偏差,但如果對一批 (例如 128 張) 圖片執行這項操作,得出的梯度就能更準確地呈現不同範例圖片施加的限制,因此更有可能更快收斂至解決方案。迷你批次的大小是可調整的參數。
這項技術有時稱為「隨機梯度下降」,還有另一項更實用的優點:處理批次資料也表示要處理較大的矩陣,而這類矩陣通常更容易在 GPU 和 TPU 上進行最佳化。
不過,收斂過程可能還是有點混亂,如果梯度向量全為零,甚至可能會停止。這是否表示我們已找到最小值?不一定。梯度分量在最小值或最大值時可為零。如果梯度向量有數百萬個元素,且全為零,則每個零都對應到最小值,且沒有任何一個對應到最大值的機率相當小。在多維空間中,鞍點相當常見,我們不希望停留在鞍點。

插圖:鞍點。梯度為 0,但並非所有方向的最小值。(圖片出處: Wikimedia:作者 Nicoguaro - Own work,CC BY 3.0)
解決方法是為最佳化演算法增加一些動能,讓演算法能順利通過鞍點,不會停滯不前。
詞彙
批次或迷你批次:訓練一律會對批次的訓練資料和標籤執行。這麼做有助於演算法收斂。「批次」維度通常是資料張量的第一個維度。舉例來說,形狀為 [100, 192, 192, 3] 的張量包含 100 張 192x192 像素的圖片,每個像素有三個值 (RGB)。
交叉熵損失:分類器常用的特殊損失函式。
密集層:神經元層,其中每個神經元都會連結至前一層的所有神經元。
特徵:神經網路的輸入內容有時稱為「特徵」。找出要將資料集中的哪些部分 (或部分組合) 輸入類神經網路,才能獲得準確預測結果,這門技術稱為「特徵工程」。
標籤:監督式分類問題中的「類別」或正確答案的別名
學習率:在訓練迴圈的每次疊代中,權重和偏差值更新的梯度比例。
logit:套用啟動函式前,神經元層的輸出內容稱為「logit」。這個詞彙源自「邏輯函數」,又稱「S 函數」,這是最常用的活化函數。「Neuron outputs before logistic function」縮短為「logits」。
損失:比較類神經網路輸出內容與正確答案的錯誤函式
神經元:計算輸入內容的加權總和、加入偏差,並透過啟動函式提供結果。
One-hot 編碼:5 個類別中的第 3 個類別會編碼為 5 個元素的向量,除了第 3 個元素是 1 以外,其餘都是零。
relu:線性整流函數。神經元的熱門啟動函式。
sigmoid:另一種曾廣受歡迎的啟動函式,在特殊情況下仍有用處。
softmax:一種特殊啟用函式,可作用於向量、增加最大分量與所有其他分量之間的差異,並將向量正規化為總和為 1,因此可解讀為機率向量。用做分類器的最後一個步驟。
張量:「張量」類似於矩陣,但維度數量任意。1 維張量是向量。2 維張量是矩陣。然後,您就可以使用 3、4、5 個以上的維度張量。
5. 讓我們直接進入程式碼
返回研究筆記本,這次我們來讀取程式碼。
讓我們逐一瞭解這個筆記本中的所有儲存格。
「參數」儲存格
在此定義批次大小、訓練週期數和資料檔案位置。資料檔案託管在 Google Cloud Storage (GCS) bucket 中,因此地址開頭為 gs://
「匯入」儲存格
這裡會匯入所有必要的 Python 程式庫,包括 TensorFlow 和用於視覺化的 matplotlib。
儲存格「visualization utilities [RUN ME]****」
這個儲存格包含不有趣的視覺化程式碼。這項功能預設為收合,但您可以開啟並查看程式碼 (只要有時間,按兩下即可)。
儲存格「tf.data.Dataset:剖析檔案並準備訓練和驗證資料集」
這個儲存格使用 tf.data.Dataset API,從資料檔案載入 MNIST 資料集。這個儲存格不必花太多時間。如果您對 tf.data.Dataset API 有興趣,請參閱這篇教學文章:TPU 高速資料管道。目前的基本概念如下:
MNIST 資料集的圖片和標籤 (正確答案) 會以固定長度的記錄儲存在 4 個檔案中。您可以使用專用的固定記錄函式載入檔案:
imagedataset = tf.data.FixedLengthRecordDataset(image_filename, 28*28, header_bytes=16)
現在我們有圖像位元組的資料集。必須解碼為圖片。我們定義一個函式來執行這項操作。圖片不會經過壓縮,因此函式不需要解碼任何內容 (decode_raw 基本上不會執行任何動作)。然後轉換為介於 0 和 1 之間的浮點值。我們可以在這裡將其重塑為 2D 圖片,但實際上,我們會將其保留為大小為 28*28 的像素平面陣列,因為這是初始密集層預期的結果。
def read_image(tf_bytestring):
image = tf.io.decode_raw(tf_bytestring, tf.uint8)
image = tf.cast(image, tf.float32)/256.0
image = tf.reshape(image, [28*28])
return image
我們使用 .map 將這個函式套用至資料集,並取得圖片資料集:
imagedataset = imagedataset.map(read_image, num_parallel_calls=16)
我們也會對標籤進行類似的讀取和解碼,並將圖片和標籤 .zip 在一起:
dataset = tf.data.Dataset.zip((imagedataset, labelsdataset))
現在我們有成對的資料集 (圖片、標籤)。這是模型預期的格式。我們還沒準備好在訓練函式中使用這項功能:
dataset = dataset.cache()
dataset = dataset.shuffle(5000, reshuffle_each_iteration=True)
dataset = dataset.repeat()
dataset = dataset.batch(batch_size)
dataset = dataset.prefetch(tf.data.experimental.AUTOTUNE)
tf.data.Dataset API 具備準備資料集所需的所有實用函式:
.cache 會將資料集快取到 RAM 中。這是小型資料集,因此可以運作。.shuffle 會以 5000 個元素的緩衝區隨機排序。請務必充分隨機排序訓練資料。.repeat 迴圈會將資料集。我們會多次訓練模型 (多個訓練週期)。.batch 會將多張圖片和標籤合併成一個迷你批次。最後,.prefetch 可以使用 CPU 準備下一批資料,同時在 GPU 上訓練目前批次的資料。
驗證資料集的準備方式類似。我們現在可以定義模型,並使用這個資料集訓練模型。
「Keras 模型」儲存格
我們所有的模型都會是層的直接序列,因此可以使用 tf.keras.Sequential 樣式建立模型。一開始,這裡是單一密集層。由於我們要將手寫數字分類為 10 個類別,因此有 10 個神經元。由於這是分類器的最後一層,因此會使用「softmax」啟用。
Keras 模型也需要知道輸入內容的形狀。您可以使用 tf.keras.layers.Input 定義車程。在這裡,輸入向量是長度為 28*28 的像素值平坦向量。
model = tf.keras.Sequential(
[
tf.keras.layers.Input(shape=(28*28,)),
tf.keras.layers.Dense(10, activation='softmax')
])
model.compile(optimizer='sgd',
loss='categorical_crossentropy',
metrics=['accuracy'])
# print model layers
model.summary()
# utility callback that displays training curves
plot_training = PlotTraining(sample_rate=10, zoom=1)
您可以使用 Keras 中的 model.compile 函式設定模型。這裡我們使用基本最佳化工具 'sgd' (隨機梯度下降)。分類模型需要交叉熵損失函式,在 Keras 中稱為 'categorical_crossentropy'。最後,我們要求模型計算 'accuracy' 指標,也就是正確分類的圖片百分比。
Keras 提供非常實用的 model.summary() 公用程式,可列印您建立的模型詳細資料。親切的指導老師已新增 PlotTraining 公用程式 (定義於「視覺化公用程式」儲存格中),訓練期間會顯示各種訓練曲線。
「訓練及驗證模型」儲存格
呼叫 model.fit 並傳遞訓練和驗證資料集,即可在此處進行訓練。根據預設,Keras 會在每個訓練週期結束時執行一輪驗證。
model.fit(training_dataset, steps_per_epoch=steps_per_epoch, epochs=EPOCHS,
validation_data=validation_dataset, validation_steps=1,
callbacks=[plot_training])
在 Keras 中,您可以使用回呼在訓練期間新增自訂行為。本講習課程就是這樣實作動態更新的訓練圖。
「Visualize predictions」(預測結果視覺化) 儲存格
模型訓練完成後,我們就能呼叫 model.predict() 取得預測結果:
probabilities = model.predict(font_digits, steps=1)
predicted_labels = np.argmax(probabilities, axis=1)
我們已準備好一組從本機字型算繪的印刷數字,做為測試。請注意,類神經網路會從最終的「softmax」傳回 10 個機率的向量。如要取得標籤,我們必須找出機率最高的標籤。np.argmax 程式庫中的 numpy 即可完成這項作業。
如要瞭解為何需要 axis=1 參數,請記住我們已處理一批 128 張圖片,因此模型會傳回 128 個機率向量。輸出張量的形狀為 [128, 10]。我們會計算每張圖片傳回的 10 個機率值中的 argmax,因此 axis=1 (第一個軸為 0)。
這個簡單模型已可辨識 90% 的數字。不算太差,但現在可以大幅改善。

6. 新增圖層

為提升辨識準確度,我們會在類神經網路中新增更多層。

我們在最後一層保留 Softmax 做為啟動函式,因為這是最適合分類的函式。不過,在中間層,我們會使用最經典的啟動函式:S 函數:
舉例來說,您的模型可能如下所示 (別忘了加上逗號,tf.keras.Sequential 會採用以逗號分隔的圖層清單):
model = tf.keras.Sequential(
[
tf.keras.layers.Input(shape=(28*28,)),
tf.keras.layers.Dense(200, activation='sigmoid'),
tf.keras.layers.Dense(60, activation='sigmoid'),
tf.keras.layers.Dense(10, activation='softmax')
])
查看模型的「摘要」。現在的參數數量至少是先前的 10 倍。應該要好 10 倍!但不知道為什麼,

損失似乎也大幅增加。出了點問題。
7. 深層網路的特別注意事項
您剛才體驗了 80 年代和 90 年代設計的類神經網路。難怪他們會放棄這個想法,迎來所謂的「AI 冬天」。事實上,隨著層數增加,類神經網路會越來越難收斂。
事實證明,只要提供一些數學上的小技巧,讓多層 (現今可達 20、50 甚至 100 層) 的深層類神經網路收斂,就能獲得非常好的效果。這些簡單技巧的發現,是 2010 年代深度學習復興的原因之一。
啟用 RELU

在深層網路中,Sigmoid 啟動函式其實相當有問題。這會壓縮 0 到 1 之間的所有值,如果重複執行這項操作,神經元輸出內容及其梯度可能會完全消失。這是基於歷史因素而提及,但現代網路使用 RELU (線性整流函數),如下所示:

另一方面,relu 的導數至少在右側為 1。使用 RELU 啟動函式時,即使某些神經元的梯度可能為零,其他神經元仍會提供明確的非零梯度,訓練作業也能以良好的速度繼續進行。
更優質的最佳化工具
在像這裡這樣的高維度空間中 (我們有大約 1 萬個權重和偏差),「鞍點」很常見。這些點並非局部最小值,但梯度仍為零,梯度下降最佳化工具會停滯在這些點。TensorFlow 提供各種最佳化工具,包括可處理慣性量的工具,安全地通過鞍點。
隨機初始化
訓練前初始化權重偏差的藝術本身就是一個研究領域,有許多相關論文發表。如要查看 Keras 中所有可用的初始值設定器,請按這裡。幸好,Keras 預設會採用正確做法,並使用 'glorot_uniform' 初始化子,這幾乎是所有情況下的最佳做法。
Keras 會自動執行正確操作,因此您不必採取任何行動。
NaN ???
交叉熵公式包含對數,而 log(0) 不是數字 (NaN,如果您喜歡,也可以說是數值崩潰)。交叉熵的輸入值可以為 0 嗎?輸入內容來自 softmax,而 softmax 本質上是指數,指數永遠不會是零。因此我們很安全!
真的嗎?在美麗的數學世界中,我們很安全,但在電腦世界中,以 float32 格式表示的 exp(-150) 幾乎為零,交叉熵會崩潰。
所幸,您也不必在此採取任何行動,因為 Keras 會特別謹慎地處理這項作業,計算 Softmax 函數和交叉熵,確保數值穩定性,並避免出現 NaN。
成功?

現在準確率應可達到 97%。本研討會的目標是大幅提高至 99% 以上,因此請繼續。
如果遇到困難,請按照下列步驟操作:
8. 學習率衰減
或許我們可以嘗試加快訓練速度?Adam 最佳化工具的預設學習率為 0.001。我們試著增加。
加快速度似乎沒有太大幫助,而且這些噪音是怎麼回事?

訓練曲線非常雜亂,且驗證曲線會上下跳動。這表示我們走得太快。我們可以恢復先前的速度,但有更好的方法。

好的解決方案是快速開始,然後以指數方式衰減學習率。在 Keras 中,您可以使用 tf.keras.callbacks.LearningRateScheduler 回呼執行這項操作。
可複製貼上的實用程式碼:
# lr decay function
def lr_decay(epoch):
return 0.01 * math.pow(0.6, epoch)
# lr schedule callback
lr_decay_callback = tf.keras.callbacks.LearningRateScheduler(lr_decay, verbose=True)
# important to see what you are doing
plot_learning_rate(lr_decay, EPOCHS)
別忘了使用您建立的 lr_decay_callback。將其新增至 model.fit 中的回呼清單:
model.fit(..., callbacks=[plot_training, lr_decay_callback])
這項小小的變更帶來了驚人的影響。您會發現大部分的雜訊都已消除,且測試準確度現在持續高於 98%。

9. Dropout、過度配適
模型現在似乎會順利收斂。讓我們再深入一點。
這是否有幫助?

並非如此,準確率仍停留在 98%,而且驗證損失也未減少。即將上架!學習演算法只會處理訓練資料,並據此最佳化訓練損失。模型從未看過驗證資料,因此一段時間後,模型的工作不再影響驗證損失,損失停止下降,有時甚至會回升,這並不令人意外。
這不會立即影響模型的實際辨識能力,但會導致您無法執行多次疊代,而且通常表示訓練不再有正面效果。

這種脫節現象通常稱為「過度擬合」,如果發現這種情況,可以嘗試套用稱為「Dropout」的正則化技術。在每次訓練疊代中,Dropout 技術會隨機射出神經元。
最終成效

雜訊會再次出現 (這並不令人意外,因為這是捨棄運作方式)。驗證損失似乎不再增加,但整體而言,仍高於沒有 Dropout 的情況。驗證準確度也稍微下降。這個結果相當令人失望。
看來 Dropout 並非正確的解決方案,或許「過度擬合」是更複雜的概念,而 Dropout 無法解決部分原因?
什麼是「過度擬合」?如果類神經網路「學得不好」,也就是說,雖然能處理訓練樣本,但無法有效處理實際資料,就會發生過度配適的情況。有許多正則化技術 (例如 Dropout) 可強制模型以更優異的方式學習,但過度配適也有更深層的原因。

如果類神經網路針對當前問題的自由度過高,就會發生基本過度訓練。假設我們有許多神經元,網路可以將所有訓練圖片儲存在神經元中,然後透過模式比對辨識圖片。如果使用實際資料,模型會完全失敗。類神經網路必須受到某種程度的限制,才能在訓練期間被迫概括所學內容。
如果訓練資料很少,即使是小型網路也能記住這些資料,這時就會發生「過度擬合」現象。一般來說,訓練類神經網路需要大量資料。
最後,如果您已按照規定完成所有步驟、嘗試使用不同大小的網路來確保自由度受到限制、套用 Dropout,並訓練大量資料,但成效仍停滯不前,似乎無法改善,這表示以目前的形狀來說,神經網路無法從資料中擷取更多資訊,就像我們這裡的情況一樣。
還記得我們如何使用圖片,並將其攤平成單一向量嗎?這真是個糟糕的主意。手寫數字是由形狀組成,而我們在將像素平面化時捨棄了形狀資訊。不過,有一種類神經網路可以運用形狀資訊,那就是卷積網路。讓我們試試看。
如果遇到困難,請按照下列步驟操作:
10. [INFO] convolutional networks
簡介
如果下一段粗體字詞你都瞭解,即可進行下一個練習。如果您剛開始接觸卷積類神經網路,請繼續閱讀。

插圖:使用兩個連續的濾鏡篩選圖片,每個濾鏡由 4x4x3=48 個可學習權重組成。
以下是 Keras 中簡易卷積類神經網路的樣貌:
model = tf.keras.Sequential([
tf.keras.layers.Reshape(input_shape=(28*28,), target_shape=(28, 28, 1)),
tf.keras.layers.Conv2D(kernel_size=3, filters=12, activation='relu'),
tf.keras.layers.Conv2D(kernel_size=6, filters=24, strides=2, activation='relu'),
tf.keras.layers.Conv2D(kernel_size=6, filters=32, strides=2, activation='relu'),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(10, activation='softmax')
])
在卷積網路的層中,一個「神經元」只會對上方一小塊圖像區域的像素進行加權總和。它會新增偏差值,並透過啟動函式饋送總和,就像一般密集層中的神經元一樣。然後使用相同權重,在整張圖片上重複執行這項作業。請注意,在密集層中,每個神經元都有自己的權重。在此,單一「權重修補程式」會以兩個方向滑過圖片 (即「捲積」)。輸出值數量與圖片中的像素數量相同 (但邊緣需要一些邊框間距)。這是篩選作業。在上圖中,它使用 4x4x3=48 個權重的篩選器。
不過,48 個權重並不夠。如要增加自由度,請使用一組新的權重重複相同作業。系統會產生一組新的篩選器輸出內容。以輸入圖片中的 R、G、B 通道類比,我們將輸出內容稱為「通道」。

這兩組 (或更多組) 權重可以透過新增維度加總為一個張量。這會提供卷積層權重張量的通用形狀。由於輸入和輸出管道的數量是參數,我們可以開始堆疊和串連捲積層。

插圖:卷積類神經網路將資料「立方體」轉換為其他資料「立方體」。
步進卷積、最大池化
以 2 或 3 的步幅執行捲積時,我們也可以縮減結果資料方塊的水平維度。常見做法有兩種:
- 步進式捲積:滑動篩選器,但步進 >1
- 最大集區化:套用 MAX 作業的滑動視窗 (通常在 2x2 修補程式上,每 2 像素重複一次)

插圖:將運算視窗滑動 3 像素,輸出值就會減少。步幅式捲積或最大集區化 (在以步幅 2 滑動的 2x2 視窗上取最大值) 是縮減水平維度資料立方體的方法。
最後一層
最後一個捲積層之後,資料會以「立方體」的形式呈現。有兩種方法可將其饋入最終稠密層。
第一種方法是將資料方塊攤平成向量,然後提供給 Softmax 層。有時,您甚至可以在 Softmax 層之前新增密集層。就權重數量而言,這往往很昂貴。卷積網路結尾的密集層可能包含整個類神經網路一半以上的權重。
我們也可以將傳入的資料「立方體」分割成與類別數量相同的多個部分,然後計算這些部分的平均值,並透過 softmax 啟動函式饋送這些值,而不必使用昂貴的密集層。以這種方式建構分類標題的權重為 0。在 Keras 中,有一個專門用於此用途的層:tf.keras.layers.GlobalAveragePooling2D()。

請前往下一節,為目前的問題建構卷積網路。
11. 卷積網路
讓我們建構手寫數字辨識的卷積網路。我們會在頂端使用三個卷積層,在底部使用傳統的 Softmax 讀出層,並以一個全連接層連結兩者:

請注意,第二和第三個捲積層的步幅為 2,這說明瞭為何輸出值的數量會從 28x28 降至 14x14,然後再降至 7x7。
現在來編寫 Keras 程式碼。
在第一個捲積層之前,需要特別注意。事實上,它預期會收到 3D「立方體」資料,但我們的資料集目前是為密集層設定,且圖片的所有像素都會扁平化為向量。我們需要將這些圖片重新塑造成 28x28x1 的圖片 (灰階圖片為 1 個管道):
tf.keras.layers.Reshape(input_shape=(28*28,), target_shape=(28, 28, 1))
您可以改用這行程式碼,取代目前使用的 tf.keras.layers.Input 層。
在 Keras 中,以「relu」啟用的捲積層語法如下:

tf.keras.layers.Conv2D(kernel_size=3, filters=12, padding='same', activation='relu')
如果是步幅式捲積,您會編寫:
tf.keras.layers.Conv2D(kernel_size=6, filters=24, padding='same', activation='relu', strides=2)
如要將資料方塊攤平成向量,以便密集層使用,請執行下列操作:
tf.keras.layers.Flatten()
密集層的語法維持不變:
tf.keras.layers.Dense(200, activation='relu')
您的模型是否突破了 99% 的準確率障礙?差不多了... 但請查看驗證損失曲線。您是否有印象呢?

同時查看預測結果。您應該會看到系統首次正確辨識出大部分的 10,000 個測試數字。只剩下約 4½ 列的誤檢測結果 (約 10,000 個數字中有 110 個)

如果遇到困難,請按照下列步驟操作:
12. 再次退出
先前的訓練顯示明顯的過度擬合跡象 (且準確率仍未達到 99%)。要再次嘗試中途退出嗎?
這次如何?

這次 dropout 似乎已正常運作。驗證損失不再增加,最終準確率應遠高於 99%。恭喜!
我們第一次嘗試套用 Dropout 時,以為是過度擬合問題,但事實上問題出在神經網路的架構。如果沒有卷積層,我們就無法進一步發展,而 Dropout 無法解決這個問題。
這次看來過度訓練確實是問題的原因,而 Dropout 確實有幫助。請注意,訓練和驗證損失曲線之間可能出現許多不一致的情況,導致驗證損失逐漸增加。過度擬合 (自由度過高,網路使用不當) 只是其中之一。如果資料集太小或神經網路架構不夠完善,您可能會在損失曲線中看到類似行為,但 Dropout 無濟於事。
13. 批次正規化

最後,我們來嘗試加入批次正規化。
以上是理論,實際操作時,請記住以下幾條規則:
現在先按照規定,在每個類神經網路層 (最後一層除外) 上新增批次正規化層。請勿將其新增至最後一個「softmax」層。在這種情況下,這項功能就沒有用處。
# Modify each layer: remove the activation from the layer itself.
# Set use_bias=False since batch norm will play the role of biases.
tf.keras.layers.Conv2D(..., use_bias=False),
# Batch norm goes between the layer and its activation.
# The scale factor can be turned off for Relu activation.
tf.keras.layers.BatchNormalization(scale=False, center=True),
# Finish with the activation.
tf.keras.layers.Activation('relu'),
現在的準確度如何?

只要稍做調整 (BATCH_SIZE=64、學習率衰減參數 0.666、密集層的 Dropout 率 0.3),再加上一點運氣,就能達到 99.5%。我們遵循使用批次正規化的「最佳做法」,調整了學習率和 Dropout:
- 批次正規化可協助類神經網路收斂,通常也能加快訓練速度。
- 批次正規化是正規化器。通常可以減少使用的 Dropout 量,甚至完全不使用 Dropout。
解決方案筆記本的訓練執行率為 99.5%:
14. 在雲端使用強大硬體訓練:AI Platform

您可以在 GitHub 上的 mlengine 資料夾中找到適用於雲端的程式碼版本,以及在 Google Cloud AI Platform 上執行的操作說明。您必須先建立 Google Cloud 帳戶並啟用計費功能,才能執行這部分。完成實驗所需的資源應不到幾美元 (假設在一個 GPU 上訓練 1 小時)。如要準備帳戶,請按照下列步驟操作:
- 建立 Google Cloud Platform 專案 ( http://cloud.google.com/console)。
- 啟用計費功能。
- 安裝 GCP 指令列工具 ( GCP SDK)。
- 建立 Google Cloud Storage 值區 (放在
us-central1區域中)。這個值區會用於暫存訓練程式碼,並儲存訓練好的模型。 - 啟用必要的 API 並要求必要的配額 (執行一次訓練指令,您應該會收到錯誤訊息,指出要啟用哪些項目)。
15. 恭喜!
您已建構第一個類神經網路,並訓練至準確率達 99%。您在過程中學到的技術並非 MNIST 資料集專用,而是廣泛用於類神經網路。這是實驗室的「重點摘要」卡片,以卡通形式呈現,做為送別禮物。你可以使用這項功能記住學到的內容:

後續步驟
- 在全連通和卷積網路之後,您應該看看循環類神經網路。
- 如要在雲端分散式基礎架構上執行訓練或推論作業,請使用 Google Cloud 提供的 AI Platform。
- 最後,我們非常重視意見回饋。如果您在本實驗室中發現任何錯誤,或認為有需要改進之處,請告訴我們。我們會透過 GitHub 問題處理意見回饋 [意見回饋連結]。

|
|
 作者:Martin GörnerTwitter:
作者:Martin GörnerTwitter:
本實驗室中的所有卡通圖片版權:alexpokusay / 123RF 圖庫相片