
1. Présentation

L'API Text-to-Speech permet aux développeurs de générer un discours semblable à celui d'un humain. L'API convertit le texte dans des formats audio tels que WAV, MP3 ou Ogg Opus. Il est également compatible avec les entrées en langage de balisage de synthèse vocale (SSML) permettant de spécifier des pauses, des nombres, la mise en forme de la date et de l'heure, ainsi que d'autres instructions de prononciation.
Dans ce tutoriel, vous allez vous concentrer sur l'utilisation de l'API Text-to-Speech avec Python.
Points abordés
- Configurer votre environnement
- Lister les langues disponibles
- Afficher les voix disponibles
- Comment synthétiser des contenus audio à partir de texte
Prérequis
Enquête
Comment allez-vous utiliser ce tutoriel ?
Quel est votre niveau d'expérience avec Python ?
Comment évalueriez-vous votre expérience des services Google Cloud ?
<ph type="x-smartling-placeholder">2. Préparation
Configuration de l'environnement au rythme de chacun
- Connectez-vous à la console Google Cloud, puis créez un projet ou réutilisez un projet existant. Si vous n'avez pas encore de compte Gmail ou Google Workspace, vous devez en créer un.

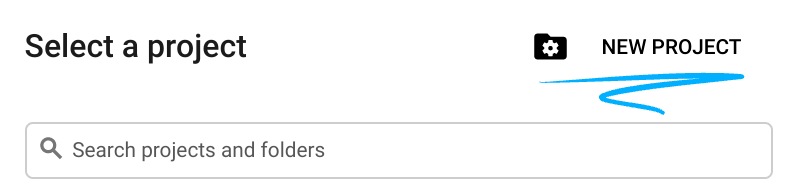
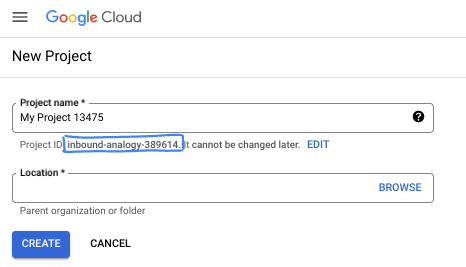
- Le nom du projet est le nom à afficher pour les participants au projet. Il s'agit d'une chaîne de caractères non utilisée par les API Google. Vous pourrez toujours le modifier.
- L'ID du projet est unique parmi tous les projets Google Cloud et non modifiable une fois défini. La console Cloud génère automatiquement une chaîne unique (en général, vous n'y accordez d'importance particulière). Dans la plupart des ateliers de programmation, vous devrez indiquer l'ID de votre projet (généralement identifié par
PROJECT_ID). Si l'ID généré ne vous convient pas, vous pouvez en générer un autre de manière aléatoire. Vous pouvez également en spécifier un et voir s'il est disponible. Après cette étape, l'ID n'est plus modifiable et restera donc le même pour toute la durée du projet. - Pour information, il existe une troisième valeur (le numéro de projet) que certaines API utilisent. Pour en savoir plus sur ces trois valeurs, consultez la documentation.
- Vous devez ensuite activer la facturation dans la console Cloud pour utiliser les ressources/API Cloud. L'exécution de cet atelier de programmation est très peu coûteuse, voire sans frais. Pour désactiver les ressources et éviter ainsi que des frais ne vous soient facturés après ce tutoriel, vous pouvez supprimer le projet ou les ressources que vous avez créées. Les nouveaux utilisateurs de Google Cloud peuvent participer au programme d'essai sans frais pour bénéficier d'un crédit de 300 $.
Démarrer Cloud Shell
Bien que Google Cloud puisse être utilisé à distance depuis votre ordinateur portable, vous allez utiliser Cloud Shell dans cet atelier de programmation, un environnement de ligne de commande exécuté dans le cloud.
Activer Cloud Shell
- Dans Cloud Console, cliquez sur Activer Cloud Shell
 .
.

Si vous démarrez Cloud Shell pour la première fois, un écran intermédiaire vous explique de quoi il s'agit. Si un écran intermédiaire s'est affiché, cliquez sur Continuer.

Le provisionnement et la connexion à Cloud Shell ne devraient pas prendre plus de quelques minutes.

Cette machine virtuelle contient tous les outils de développement nécessaires. Elle comprend un répertoire d'accueil persistant de 5 Go et s'exécute dans Google Cloud, ce qui améliore considérablement les performances du réseau et l'authentification. Une grande partie, voire la totalité, de votre travail dans cet atelier de programmation peut être effectué dans un navigateur.
Une fois connecté à Cloud Shell, vous êtes authentifié et le projet est défini sur votre ID de projet.
- Exécutez la commande suivante dans Cloud Shell pour vérifier que vous êtes authentifié :
gcloud auth list
Résultat de la commande
Credentialed Accounts
ACTIVE ACCOUNT
* <my_account>@<my_domain.com>
To set the active account, run:
$ gcloud config set account `ACCOUNT`
- Exécutez la commande suivante dans Cloud Shell pour vérifier que la commande gcloud connaît votre projet:
gcloud config list project
Résultat de la commande
[core] project = <PROJECT_ID>
Si vous obtenez un résultat différent, exécutez cette commande :
gcloud config set project <PROJECT_ID>
Résultat de la commande
Updated property [core/project].
3. Cofiguration de l'environnement
Avant de pouvoir utiliser l'API Text-to-Speech, vous devez l'activer en exécutant la commande suivante dans Cloud Shell:
gcloud services enable texttospeech.googleapis.com
L'écran qui s'affiche devrait ressembler à ce qui suit :
Operation "operations/..." finished successfully.
Vous pouvez maintenant utiliser l'API Text-to-Speech.
Accédez à votre répertoire d'accueil:
cd ~
Créez un environnement virtuel Python pour isoler les dépendances:
virtualenv venv-texttospeech
Activez l'environnement virtuel :
source venv-texttospeech/bin/activate
Installez IPython et la bibliothèque cliente de l'API Text-to-Speech:
pip install ipython google-cloud-texttospeech
L'écran qui s'affiche devrait ressembler à ce qui suit :
... Installing collected packages: ..., ipython, google-cloud-texttospeech Successfully installed ... google-cloud-texttospeech-2.16.3 ...
Vous êtes maintenant prêt à utiliser la bibliothèque cliente de l'API Text-to-Speech.
Dans les étapes suivantes, vous allez utiliser un interpréteur Python interactif appelé IPython, que vous avez installé à l'étape précédente. Démarrez une session en exécutant ipython dans Cloud Shell:
ipython
L'écran qui s'affiche devrait ressembler à ce qui suit :
Python 3.9.2 (default, Feb 28 2021, 17:03:44) Type 'copyright', 'credits' or 'license' for more information IPython 8.18.1 -- An enhanced Interactive Python. Type '?' for help. In [1]:
Vous êtes prêt à envoyer votre première requête et à lister les langues prises en charge...
4. Répertorier les langues disponibles
Dans cette section, vous obtiendrez la liste de toutes les langues prises en charge.
Copiez le code suivant dans votre session IPython:
from typing import Sequence
import google.cloud.texttospeech as tts
def unique_languages_from_voices(voices: Sequence[tts.Voice]):
language_set = set()
for voice in voices:
for language_code in voice.language_codes:
language_set.add(language_code)
return language_set
def list_languages():
client = tts.TextToSpeechClient()
response = client.list_voices()
languages = unique_languages_from_voices(response.voices)
print(f" Languages: {len(languages)} ".center(60, "-"))
for i, language in enumerate(sorted(languages)):
print(f"{language:>10}", end="\n" if i % 5 == 4 else "")
Prenez quelques instants pour étudier le code et découvrir comment il utilise la méthode de la bibliothèque cliente list_voices pour créer la liste des langages compatibles.
Appelez la fonction :
list_languages()
Vous devriez obtenir la liste suivante (ou une liste plus longue) :
---------------------- Languages: 58 -----------------------
af-ZA am-ET ar-XA bg-BG bn-IN
ca-ES cmn-CN cmn-TW cs-CZ da-DK
de-DE el-GR en-AU en-GB en-IN
en-US es-ES es-US eu-ES fi-FI
fil-PH fr-CA fr-FR gl-ES gu-IN
he-IL hi-IN hu-HU id-ID is-IS
it-IT ja-JP kn-IN ko-KR lt-LT
lv-LV ml-IN mr-IN ms-MY nb-NO
nl-BE nl-NL pa-IN pl-PL pt-BR
pt-PT ro-RO ru-RU sk-SK sr-RS
sv-SE ta-IN te-IN th-TH tr-TR
uk-UA vi-VN yue-HK
La liste comprend 58 langues et variantes, par exemple:
- chinois et mandarin taïwanais,
- l'anglais australien, britannique, indien et américain,
- le français du Canada et de France,
- Portugais du Brésil et du Portugal.
Cette liste n'est pas fixe et s'allonge à mesure que de nouvelles voix sont disponibles.
Résumé
Cette étape vous a permis de lister les langues disponibles.
5. Répertorier les voix disponibles
Dans cette section, vous trouverez la liste des voix disponibles dans différentes langues.
Copiez le code suivant dans votre session IPython:
import google.cloud.texttospeech as tts
def list_voices(language_code=None):
client = tts.TextToSpeechClient()
response = client.list_voices(language_code=language_code)
voices = sorted(response.voices, key=lambda voice: voice.name)
print(f" Voices: {len(voices)} ".center(60, "-"))
for voice in voices:
languages = ", ".join(voice.language_codes)
name = voice.name
gender = tts.SsmlVoiceGender(voice.ssml_gender).name
rate = voice.natural_sample_rate_hertz
print(f"{languages:<8} | {name:<24} | {gender:<8} | {rate:,} Hz")
Prenez quelques instants pour étudier le code et découvrir comment il utilise la méthode list_voices(language_code) de la bibliothèque cliente afin de répertorier les voix disponibles pour un langage donné.
Maintenant, obtenez la liste des voix allemandes disponibles:
list_voices("de")
L'écran qui s'affiche devrait ressembler à ce qui suit :
------------------------ Voices: 20 ------------------------ de-DE | de-DE-Neural2-A | FEMALE | 24,000 Hz de-DE | de-DE-Neural2-B | MALE | 24,000 Hz ... de-DE | de-DE-Standard-A | FEMALE | 24,000 Hz de-DE | de-DE-Standard-B | MALE | 24,000 Hz ... de-DE | de-DE-Studio-B | MALE | 24,000 Hz de-DE | de-DE-Studio-C | FEMALE | 24,000 Hz de-DE | de-DE-Wavenet-A | FEMALE | 24,000 Hz de-DE | de-DE-Wavenet-B | MALE | 24,000 Hz ...
Plusieurs voix féminines et masculines sont disponibles, ainsi que des voix standards, WaveNet, Neural2 et Studio:
- Les voix standards sont générées par des algorithmes de traitement du signal.
- Les voix WaveNet, Neural2 et Studio sont des voix de meilleure qualité, synthétisées par des modèles de machine learning et semblent plus naturelles.
Maintenant, obtenez la liste des voix anglaises disponibles:
list_voices("en")
Vous devriez obtenir un résultat semblable à celui-ci:
------------------------ Voices: 90 ------------------------ en-AU | en-AU-Neural2-A | FEMALE | 24,000 Hz ... en-AU | en-AU-Wavenet-A | FEMALE | 24,000 Hz ... en-GB | en-GB-Neural2-A | FEMALE | 24,000 Hz ... en-GB | en-GB-Wavenet-A | FEMALE | 24,000 Hz ... en-IN | en-IN-Standard-A | FEMALE | 24,000 Hz ... en-IN | en-IN-Wavenet-A | FEMALE | 24,000 Hz ... en-US | en-US-Neural2-A | MALE | 24,000 Hz ... en-US | en-US-News-K | FEMALE | 24,000 Hz ... en-US | en-US-Standard-A | MALE | 24,000 Hz ... en-US | en-US-Studio-M | MALE | 24,000 Hz ... en-US | en-US-Wavenet-A | MALE | 24,000 Hz ...
En plus d'une sélection de plusieurs voix de sexes et de qualités différents, plusieurs accents sont disponibles: anglais américain, australien, britannique et indien.
Prenez quelques instants pour lister les voix disponibles dans vos langues et variantes préférées (ou même toutes):
list_voices("fr")
list_voices("pt")
list_voices()
Résumé
Cette étape vous a permis d'obtenir la liste des voix disponibles. En savoir plus sur les voix et langues compatibles
6. Synthétiser des contenus audio à partir de texte
Vous pouvez utiliser l'API Text-to-Speech pour convertir une chaîne en données audio. Vous pouvez configurer la sortie de la synthèse vocale de différentes manières, par exemple en sélectionnant une voix unique ou en modulant la tonalité, le volume, la vitesse d'élocution et le taux d'échantillonnage de la sortie.
Copiez le code suivant dans votre session IPython:
import google.cloud.texttospeech as tts
def text_to_wav(voice_name: str, text: str):
language_code = "-".join(voice_name.split("-")[:2])
text_input = tts.SynthesisInput(text=text)
voice_params = tts.VoiceSelectionParams(
language_code=language_code, name=voice_name
)
audio_config = tts.AudioConfig(audio_encoding=tts.AudioEncoding.LINEAR16)
client = tts.TextToSpeechClient()
response = client.synthesize_speech(
input=text_input,
voice=voice_params,
audio_config=audio_config,
)
filename = f"{voice_name}.wav"
with open(filename, "wb") as out:
out.write(response.audio_content)
print(f'Generated speech saved to "{filename}"')
Prenez quelques instants pour étudier le code et découvrir comment il utilise la méthode de la bibliothèque cliente synthesize_speech pour générer les données audio et les enregistrer en tant que fichier wav.
Maintenant, générez des phrases avec quelques accents différents:
text_to_wav("en-AU-Neural2-A", "What is the temperature in Sydney?")
text_to_wav("en-GB-Neural2-B", "What is the temperature in London?")
text_to_wav("en-IN-Wavenet-C", "What is the temperature in Delhi?")
text_to_wav("en-US-Studio-O", "What is the temperature in New York?")
text_to_wav("fr-FR-Neural2-A", "Quelle est la température à Paris ?")
text_to_wav("fr-CA-Neural2-B", "Quelle est la température à Montréal ?")
L'écran qui s'affiche devrait ressembler à ce qui suit :
Generated speech saved to "en-AU-Neural2-A.wav" Generated speech saved to "en-GB-Neural2-B.wav" Generated speech saved to "en-IN-Wavenet-C.wav" Generated speech saved to "en-US-Studio-O.wav" Generated speech saved to "fr-FR-Neural2-A.wav" Generated speech saved to "fr-CA-Neural2-B.wav"
Pour télécharger tous les fichiers générés en même temps, vous pouvez utiliser la commande Cloud Shell suivante depuis votre environnement Python:
!cloudshell download *.wav
Validez les fichiers pour que votre navigateur les télécharge:
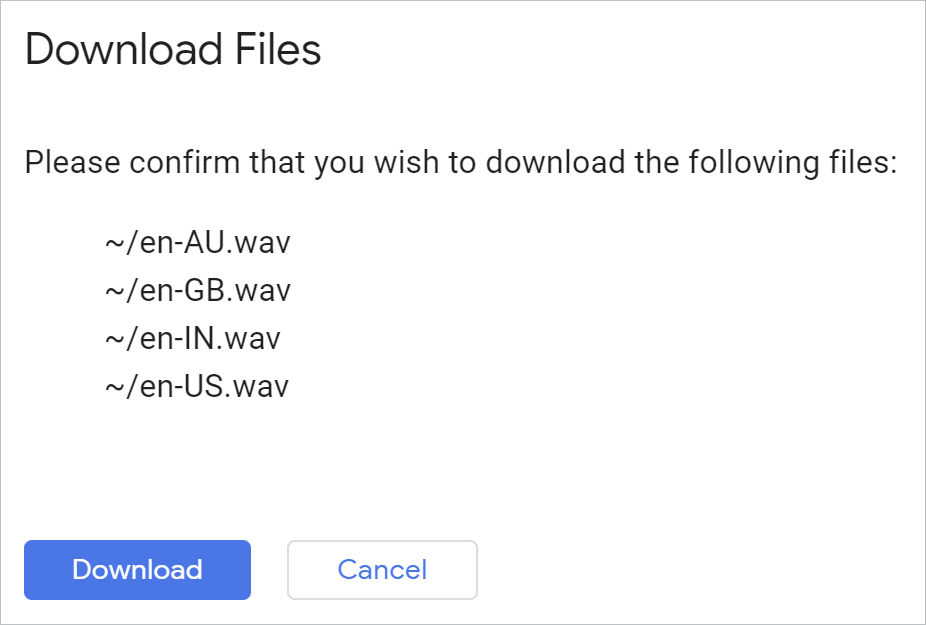
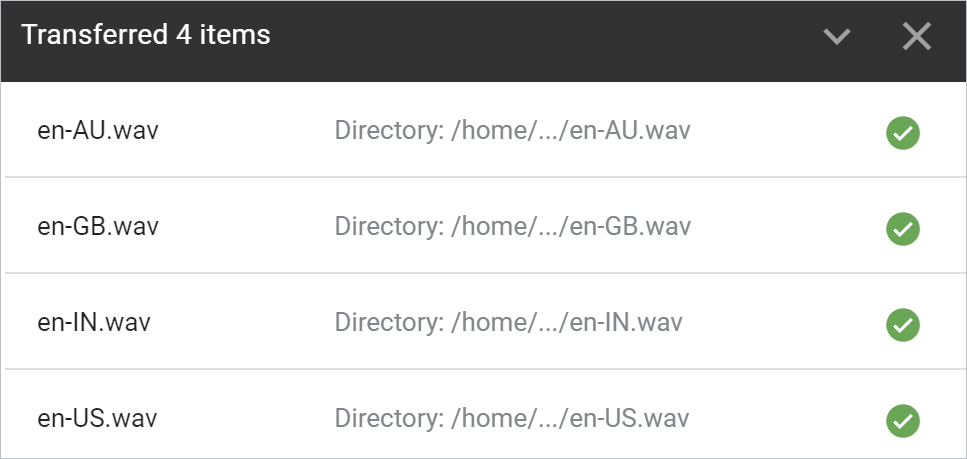
Ouvrez chaque fichier et écoutez le résultat.
Résumé
Au cours de cette étape, vous avez pu utiliser l'API Text-to-Speech pour convertir des phrases en fichiers wav audio. En savoir plus sur la création de fichiers audio vocaux
7. Félicitations !
Vous avez appris à générer un discours semblable à celui d'un humain à l'aide de l'API Text-to-Speech avec Python.
Effectuer un nettoyage
Pour nettoyer votre environnement de développement à partir de Cloud Shell:
- Si vous êtes toujours dans votre session IPython, revenez au shell:
exit - Cessez d'utiliser l'environnement virtuel Python:
deactivate - Supprimez le dossier d'environnement virtuel:
cd ~ ; rm -rf ./venv-texttospeech.
Pour supprimer votre projet Google Cloud à partir de Cloud Shell, procédez comme suit:
- Récupérez l'ID de votre projet actuel:
PROJECT_ID=$(gcloud config get-value core/project) - Assurez-vous qu'il s'agit bien du projet que vous souhaitez supprimer:
echo $PROJECT_ID - Supprimez le projet:
gcloud projects delete $PROJECT_ID
En savoir plus
- Testez la démonstration dans votre navigateur: https://cloud.google.com/text-to-speech
- Documentation Text-to-Speech: https://cloud.google.com/text-to-speech/docs
- Python sur Google Cloud: https://cloud.google.com/python
- Bibliothèques clientes Cloud pour Python: https://github.com/googleapis/google-cloud-python
Licence
Ce document est publié sous une licence Creative Commons Attribution 2.0 Generic.