
この Codelab について
1. 概要

Text-to-Speech API を使用すると、人間のような音声を生成できます。この API は、テキストを WAV、MP3、Ogg Opus などの音声形式に変換します。また、音声合成マークアップ言語(SSML)の入力もサポートしており、一時停止、数字、日時形式、その他の発音上の指示を指定できます。
このチュートリアルでは、Python での Text-to-Speech API の使用に焦点を当てます。
学習内容
- 環境の設定方法
- サポートされている言語を一覧表示する方法
- 利用可能な音声を一覧表示する方法
- テキストから音声を合成する方法
必要なもの
アンケート
このチュートリアルをどのように使用されますか?
Python のご利用経験はどの程度ありますか?
Google Cloud サービスの利用経験をどのように評価されますか。
2. 設定と要件
セルフペース型の環境設定
- Google Cloud Console にログインして、プロジェクトを新規作成するか、既存のプロジェクトを再利用します。Gmail アカウントも Google Workspace アカウントもまだお持ちでない場合は、アカウントを作成してください。

- プロジェクト名は、このプロジェクトの参加者に表示される名称です。Google API では使用されない文字列です。いつでも更新できます。
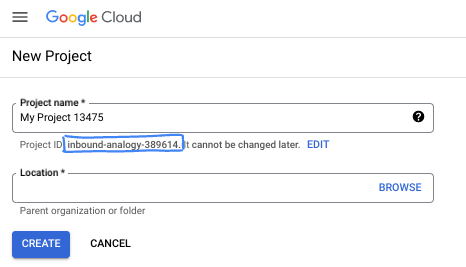
- プロジェクト ID は、すべての Google Cloud プロジェクトにおいて一意でなければならず、不変です(設定後は変更できません)。Cloud コンソールでは一意の文字列が自動生成されます。通常は、この内容を意識する必要はありません。ほとんどの Codelab では、プロジェクト ID(通常は
PROJECT_IDと識別されます)を参照する必要があります。生成された ID が好みではない場合は、ランダムに別の ID を生成できます。または、ご自身で試して、利用可能かどうかを確認することもできます。このステップ以降は変更できず、プロジェクトを通して同じ ID になります。 - なお、3 つ目の値として、一部の API が使用するプロジェクト番号があります。これら 3 つの値について詳しくは、こちらのドキュメントをご覧ください。
- 次に、Cloud のリソースや API を使用するために、Cloud コンソールで課金を有効にする必要があります。この Codelab の操作をすべて行って、費用が生じたとしても、少額です。このチュートリアルの終了後に請求が発生しないようにリソースをシャットダウンするには、作成したリソースを削除するか、プロジェクトを削除します。Google Cloud の新規ユーザーは、300 米ドル分の無料トライアル プログラムをご利用いただけます。
Cloud Shell の起動
Google Cloud はノートパソコンからリモートで操作できますが、この Codelab では Cloud 上で動作するコマンドライン環境である Cloud Shell を使用します。
Cloud Shell をアクティブにする
- Cloud Console で、[Cloud Shell をアクティブにする]
 をクリックします。
をクリックします。

Cloud Shell を初めて起動する場合は、内容を説明する中間画面が表示されます。中間画面が表示されたら、[続行] をクリックします。
Cloud Shell のプロビジョニングと接続に少し時間がかかる程度です。

この仮想マシンには、必要なすべての開発ツールが読み込まれます。5 GB の永続的なホーム ディレクトリが用意されており、Google Cloud で稼働するため、ネットワークのパフォーマンスと認証が大幅に向上しています。この Codelab での作業のほとんどはブラウザを使って行うことができます。
Cloud Shell に接続すると、認証が完了し、プロジェクトに各自のプロジェクト ID が設定されていることがわかります。
- Cloud Shell で次のコマンドを実行して、認証されたことを確認します。
gcloud auth list
コマンド出力
Credentialed Accounts
ACTIVE ACCOUNT
* <my_account>@<my_domain.com>
To set the active account, run:
$ gcloud config set account `ACCOUNT`
- Cloud Shell で次のコマンドを実行して、gcloud コマンドがプロジェクトを認識していることを確認します。
gcloud config list project
コマンド出力
[core] project = <PROJECT_ID>
上記のようになっていない場合は、次のコマンドで設定できます。
gcloud config set project <PROJECT_ID>
コマンド出力
Updated property [core/project].
3. 環境のセットアップ
Text-to-Speech API を使用する前に、Cloud Shell で次のコマンドを実行して API を有効にします。
gcloud services enable texttospeech.googleapis.com
次のように表示されます。
Operation "operations/..." finished successfully.
これで Text-to-Speech API を使用できるようになりました。
ホーム ディレクトリに移動します。
cd ~
依存関係を分離する Python 仮想環境を作成します。
virtualenv venv-texttospeech
仮想環境をアクティブにします。
source venv-texttospeech/bin/activate
IPython と Text-to-Speech API クライアント ライブラリをインストールします。
pip install ipython google-cloud-texttospeech
次のように表示されます。
... Installing collected packages: ..., ipython, google-cloud-texttospeech Successfully installed ... google-cloud-texttospeech-2.16.3 ...
これで Text-to-Speech API クライアント ライブラリを使用できるようになりました。
次の手順では、前のステップでインストールした IPython というインタラクティブな Python インタープリタを使用します。Cloud Shell で ipython を実行してセッションを開始します。
ipython
次のように表示されます。
Python 3.9.2 (default, Feb 28 2021, 17:03:44) Type 'copyright', 'credits' or 'license' for more information IPython 8.18.1 -- An enhanced Interactive Python. Type '?' for help. In [1]:
最初のリクエストを行い、サポートされている言語の一覧を取得する準備が整いました...
4. サポートされている言語を一覧表示する
このセクションでは、サポートされているすべての言語の一覧を取得します。
次のコードを IPython セッションにコピーします。
from typing import Sequence
import google.cloud.texttospeech as tts
def unique_languages_from_voices(voices: Sequence[tts.Voice]):
language_set = set()
for voice in voices:
for language_code in voice.language_codes:
language_set.add(language_code)
return language_set
def list_languages():
client = tts.TextToSpeechClient()
response = client.list_voices()
languages = unique_languages_from_voices(response.voices)
print(f" Languages: {len(languages)} ".center(60, "-"))
for i, language in enumerate(sorted(languages)):
print(f"{language:>10}", end="\n" if i % 5 == 4 else "")
コードを読み、list_voices クライアント ライブラリのメソッドを使用して、サポートされている言語のリストを作成する方法を見てみましょう。
関数を呼び出す
list_languages()
次の(またはより大きい)リストが表示されます。
---------------------- Languages: 58 -----------------------
af-ZA am-ET ar-XA bg-BG bn-IN
ca-ES cmn-CN cmn-TW cs-CZ da-DK
de-DE el-GR en-AU en-GB en-IN
en-US es-ES es-US eu-ES fi-FI
fil-PH fr-CA fr-FR gl-ES gu-IN
he-IL hi-IN hu-HU id-ID is-IS
it-IT ja-JP kn-IN ko-KR lt-LT
lv-LV ml-IN mr-IN ms-MY nb-NO
nl-BE nl-NL pa-IN pl-PL pt-BR
pt-PT ro-RO ru-RU sk-SK sr-RS
sv-SE ta-IN te-IN th-TH tr-TR
uk-UA vi-VN yue-HK
このリストには、以下を含む 58 の言語と言語変種が表示されます。
- 中国語、台湾語、標準中国語、
- 英語(オーストラリア、イギリス、インド、アメリカ)
- フランス語
- ブラジルおよびポルトガルからのポルトガル語です。
このリストは固定されているわけではなく、新しい音声が登場するにつれて増えていきます。
概要
このステップでは、サポートされている言語の一覧を取得しました。
5. 利用可能な音声を一覧表示する
このセクションでは、さまざまな言語で利用できる音声の一覧を示します。
次のコードを IPython セッションにコピーします。
import google.cloud.texttospeech as tts
def list_voices(language_code=None):
client = tts.TextToSpeechClient()
response = client.list_voices(language_code=language_code)
voices = sorted(response.voices, key=lambda voice: voice.name)
print(f" Voices: {len(voices)} ".center(60, "-"))
for voice in voices:
languages = ", ".join(voice.language_codes)
name = voice.name
gender = tts.SsmlVoiceGender(voice.ssml_gender).name
rate = voice.natural_sample_rate_hertz
print(f"{languages:<8} | {name:<24} | {gender:<8} | {rate:,} Hz")
コードを読み、クライアント ライブラリのメソッド list_voices(language_code) を使用して、特定の言語で利用可能な音声を一覧表示する方法を確認します。
次に、利用可能なドイツ語の音声のリストを取得します。
list_voices("de")
次のように表示されます。
------------------------ Voices: 20 ------------------------ de-DE | de-DE-Neural2-A | FEMALE | 24,000 Hz de-DE | de-DE-Neural2-B | MALE | 24,000 Hz ... de-DE | de-DE-Standard-A | FEMALE | 24,000 Hz de-DE | de-DE-Standard-B | MALE | 24,000 Hz ... de-DE | de-DE-Studio-B | MALE | 24,000 Hz de-DE | de-DE-Studio-C | FEMALE | 24,000 Hz de-DE | de-DE-Wavenet-A | FEMALE | 24,000 Hz de-DE | de-DE-Wavenet-B | MALE | 24,000 Hz ...
複数の女性音声と男性音声のほか、標準の WaveNet、Neural2、Studio 音声を使用できます。
- 標準音声は信号処理アルゴリズムで生成されます。
- WaveNet、Neural2、Studio 音声は、機械学習モデルによって合成された高品質の音声で、より自然に聞こえます。
では、利用可能な英語の音声のリストを取得します。
list_voices("en")
次のように表示されます。
------------------------ Voices: 90 ------------------------ en-AU | en-AU-Neural2-A | FEMALE | 24,000 Hz ... en-AU | en-AU-Wavenet-A | FEMALE | 24,000 Hz ... en-GB | en-GB-Neural2-A | FEMALE | 24,000 Hz ... en-GB | en-GB-Wavenet-A | FEMALE | 24,000 Hz ... en-IN | en-IN-Standard-A | FEMALE | 24,000 Hz ... en-IN | en-IN-Wavenet-A | FEMALE | 24,000 Hz ... en-US | en-US-Neural2-A | MALE | 24,000 Hz ... en-US | en-US-News-K | FEMALE | 24,000 Hz ... en-US | en-US-Standard-A | MALE | 24,000 Hz ... en-US | en-US-Studio-M | MALE | 24,000 Hz ... en-US | en-US-Wavenet-A | MALE | 24,000 Hz ...
性別や質に応じて複数の音声を選択できるほか、オーストラリア英語、英国英語、インド英語、アメリカ英語など、複数のアクセントを使用できます。
使用する言語と言語変種(またはすべて)で利用可能な音声のリストを作成します。
list_voices("fr")
list_voices("pt")
list_voices()
概要
このステップでは、使用可能な音声を一覧表示しました。詳しくは、サポートされている音声と言語をご覧ください。
6. テキストから音声を合成する
Text-to-Speech API を使用して、文字列を音声データに変換できます。音声合成の出力は、独自の音声の選択や、出力のピッチ、音量、発話速度、サンプルレートの調節など、さまざまな方法で構成できます。
次のコードを IPython セッションにコピーします。
import google.cloud.texttospeech as tts
def text_to_wav(voice_name: str, text: str):
language_code = "-".join(voice_name.split("-")[:2])
text_input = tts.SynthesisInput(text=text)
voice_params = tts.VoiceSelectionParams(
language_code=language_code, name=voice_name
)
audio_config = tts.AudioConfig(audio_encoding=tts.AudioEncoding.LINEAR16)
client = tts.TextToSpeechClient()
response = client.synthesize_speech(
input=text_input,
voice=voice_params,
audio_config=audio_config,
)
filename = f"{voice_name}.wav"
with open(filename, "wb") as out:
out.write(response.audio_content)
print(f'Generated speech saved to "{filename}"')
コードを読み、synthesize_speech クライアント ライブラリ メソッドを使用して音声データを生成し、wav ファイルとして保存する方法を確認します。
次に、いくつかの異なるアクセントで文を生成してみましょう。
text_to_wav("en-AU-Neural2-A", "What is the temperature in Sydney?")
text_to_wav("en-GB-Neural2-B", "What is the temperature in London?")
text_to_wav("en-IN-Wavenet-C", "What is the temperature in Delhi?")
text_to_wav("en-US-Studio-O", "What is the temperature in New York?")
text_to_wav("fr-FR-Neural2-A", "Quelle est la température à Paris ?")
text_to_wav("fr-CA-Neural2-B", "Quelle est la température à Montréal ?")
次のように表示されます。
Generated speech saved to "en-AU-Neural2-A.wav" Generated speech saved to "en-GB-Neural2-B.wav" Generated speech saved to "en-IN-Wavenet-C.wav" Generated speech saved to "en-US-Studio-O.wav" Generated speech saved to "fr-FR-Neural2-A.wav" Generated speech saved to "fr-CA-Neural2-B.wav"
生成されたすべてのファイルを一度にダウンロードするには、Python 環境から次の Cloud Shell コマンドを使用します。
!cloudshell download *.wav
検証すると、ブラウザでファイルがダウンロードされます。
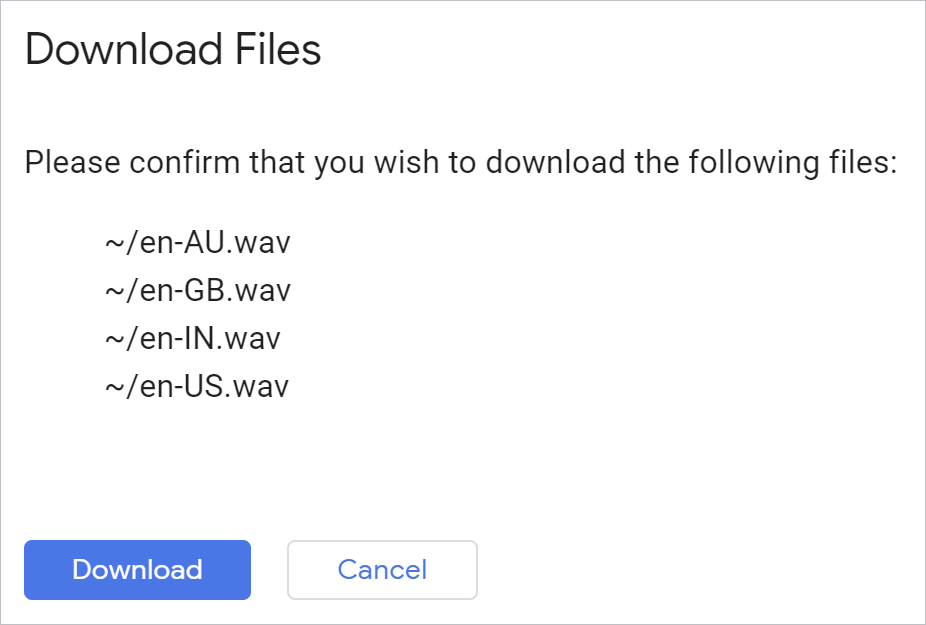
各ファイルを開いて結果を確認します。
概要
このステップでは、Text-to-Speech API を使用して文を音声 wav ファイルに変換できました。詳しくは、音声ファイルの作成をご覧ください。
7. お疲れさまでした
Python で Text-to-Speech API を使用して、人間のような音声を生成する方法を学びました。
クリーンアップ
Cloud Shell から開発環境をクリーンアップするには:
- IPython セッションをまだ開いている場合は、シェルに戻ります(
exit)。 - Python 仮想環境の使用を停止します:
deactivate - 仮想環境フォルダ
cd ~ ; rm -rf ./venv-texttospeechを削除します
Cloud Shell から Google Cloud プロジェクトを削除するには:
- 現在のプロジェクト ID
PROJECT_ID=$(gcloud config get-value core/project)を取得します。 - 削除するプロジェクトが
echo $PROJECT_IDであることを確認します。 - プロジェクトを削除します。
gcloud projects delete $PROJECT_ID
詳細
- ブラウザでデモをテストする: https://cloud.google.com/text-to-speech
- Text-to-Speech のドキュメント: https://cloud.google.com/text-to-speech/docs
- Google Cloud 上の Python: https://cloud.google.com/python
- Python 用の Cloud クライアント ライブラリ: https://github.com/googleapis/google-cloud-python
ライセンス
この作業はクリエイティブ・コモンズの表示 2.0 汎用ライセンスにより使用許諾されています。