
Sobre este codelab
1. Visão geral

A API Text-to-Speech permite que os desenvolvedores gerem falas semelhantes às humanas. A API converte texto em formatos de áudio, como WAV, MP3 ou Ogg Opus. Ele também é compatível com entradas de Linguagem de marcação de síntese de fala (SSML, na sigla em inglês) para especificar pausas, números, formatação de data e hora e outras instruções de pronúncia.
Neste tutorial, você vai usar a API Text-to-Speech com o Python.
O que você vai aprender
- Como configurar o ambiente
- Como listar os idiomas compatíveis
- Como listar as vozes disponíveis
- Como sintetizar áudio a partir de texto
O que é necessário
Pesquisa
Como você vai usar este tutorial?
Como você classificaria sua experiência com Python?
Como você classificaria sua experiência com os serviços do Google Cloud?
2. Configuração e requisitos
Configuração de ambiente autoguiada
- Faça login no Console do Google Cloud e crie um novo projeto ou reutilize um existente. Crie uma conta do Gmail ou do Google Workspace, se ainda não tiver uma.

- O Nome do projeto é o nome de exibição para os participantes do projeto. É uma string de caracteres não usada pelas APIs do Google e pode ser atualizada quando você quiser.
- O ID do projeto precisa ser exclusivo em todos os projetos do Google Cloud e não pode ser mudado após a definição. O console do Cloud gera automaticamente uma string exclusiva. Em geral, não importa o que seja. Na maioria dos codelabs, é necessário fazer referência ao ID do projeto, normalmente identificado como
PROJECT_ID. Se você não gostar do ID gerado, crie outro aleatório. Se preferir, teste o seu e confira se ele está disponível. Ele não pode ser mudado após essa etapa e permanece durante o projeto. - Para sua informação, há um terceiro valor, um Número do projeto, que algumas APIs usam. Saiba mais sobre esses três valores na documentação.
- Em seguida, ative o faturamento no console do Cloud para usar os recursos/APIs do Cloud. A execução deste codelab não vai ser muito cara, se tiver algum custo. Para encerrar os recursos e evitar cobranças além deste tutorial, exclua os recursos criados ou exclua o projeto. Novos usuários do Google Cloud estão qualificados para o programa de US$ 300 de avaliação sem custos.
Inicie o Cloud Shell
Embora o Google Cloud possa ser operado remotamente em um laptop, neste codelab você vai usar o Cloud Shell, um ambiente de linha de comando executado no Cloud.
Ativar o Cloud Shell
- No Console do Cloud, clique em Ativar o Cloud Shell
 .
.

Se você estiver iniciando o Cloud Shell pela primeira vez, verá uma tela intermediária com a descrição dele. Se aparecer uma tela intermediária, clique em Continuar.
Leva apenas alguns instantes para provisionar e se conectar ao Cloud Shell.

Essa máquina virtual tem todas as ferramentas de desenvolvimento necessárias. Ela oferece um diretório principal persistente de 5 GB, além de ser executada no Google Cloud. Isso aprimora o desempenho e a autenticação da rede. Grande parte do trabalho neste codelab, se não todo, pode ser feito em um navegador.
Depois de se conectar ao Cloud Shell, você verá sua autenticação e o projeto estará configurado com o ID do seu projeto.
- Execute o seguinte comando no Cloud Shell para confirmar se a conta está autenticada:
gcloud auth list
Resposta ao comando
Credentialed Accounts
ACTIVE ACCOUNT
* <my_account>@<my_domain.com>
To set the active account, run:
$ gcloud config set account `ACCOUNT`
- Execute o seguinte comando no Cloud Shell para confirmar que o comando gcloud sabe sobre seu projeto:
gcloud config list project
Resposta ao comando
[core] project = <PROJECT_ID>
Se o projeto não estiver configurado, configure-o usando este comando:
gcloud config set project <PROJECT_ID>
Resposta ao comando
Updated property [core/project].
3. Configuração do ambiente
Antes de começar a usar a API Text-to-Speech, execute o seguinte comando no Cloud Shell para ativá-la:
gcloud services enable texttospeech.googleapis.com
Você verá algo como:
Operation "operations/..." finished successfully.
Agora, você pode usar a API Text-to-Speech!
Navegue até seu diretório principal:
cd ~
Crie um ambiente virtual de Python para isolar as dependências:
virtualenv venv-texttospeech
Ative o ambiente virtual:
source venv-texttospeech/bin/activate
Instale o IPython e a biblioteca de cliente da API Text-to-Speech:
pip install ipython google-cloud-texttospeech
Você verá algo como:
... Installing collected packages: ..., ipython, google-cloud-texttospeech Successfully installed ... google-cloud-texttospeech-2.16.3 ...
Agora, você já pode usar a biblioteca de cliente da API Text-to-Speech.
Nas próximas etapas, você vai usar um interpretador de Python interativo chamado IPython, que foi instalado na etapa anterior. Inicie uma sessão executando ipython no Cloud Shell:
ipython
Você verá algo como:
Python 3.9.2 (default, Feb 28 2021, 17:03:44) Type 'copyright', 'credits' or 'license' for more information IPython 8.18.1 -- An enhanced Interactive Python. Type '?' for help. In [1]:
Você já pode fazer sua primeira solicitação e listar os idiomas compatíveis...
4. Lista de idiomas compatíveis
Nesta seção, você vai encontrar a lista de todos os idiomas compatíveis.
Copie o código a seguir na sessão do IPython:
from typing import Sequence
import google.cloud.texttospeech as tts
def unique_languages_from_voices(voices: Sequence[tts.Voice]):
language_set = set()
for voice in voices:
for language_code in voice.language_codes:
language_set.add(language_code)
return language_set
def list_languages():
client = tts.TextToSpeechClient()
response = client.list_voices()
languages = unique_languages_from_voices(response.voices)
print(f" Languages: {len(languages)} ".center(60, "-"))
for i, language in enumerate(sorted(languages)):
print(f"{language:>10}", end="\n" if i % 5 == 4 else "")
Estude o código e confira como ele usa o método da biblioteca de cliente list_voices para criar a lista de linguagens com suporte.
Como chamar a função:
list_languages()
Você vai receber a seguinte lista (ou uma lista maior):
---------------------- Languages: 58 -----------------------
af-ZA am-ET ar-XA bg-BG bn-IN
ca-ES cmn-CN cmn-TW cs-CZ da-DK
de-DE el-GR en-AU en-GB en-IN
en-US es-ES es-US eu-ES fi-FI
fil-PH fr-CA fr-FR gl-ES gu-IN
he-IL hi-IN hu-HU id-ID is-IS
it-IT ja-JP kn-IN ko-KR lt-LT
lv-LV ml-IN mr-IN ms-MY nb-NO
nl-BE nl-NL pa-IN pl-PL pt-BR
pt-PT ro-RO ru-RU sk-SK sr-RS
sv-SE ta-IN te-IN th-TH tr-TR
uk-UA vi-VN yue-HK
A lista mostra 58 idiomas e variantes, como:
- chinês e mandarim taiwanês,
- inglês australiano, britânico, indiano e americano,
- francês do Canadá e da França,
- Português do Brasil e de Portugal.
Essa lista não é fixa e aumenta conforme novas vozes são disponibilizadas.
Resumo
Nesta etapa, você pode listar os idiomas disponíveis.
5. Listar vozes disponíveis
Nesta seção, você vai receber a lista de vozes disponíveis em diferentes idiomas.
Copie o código a seguir na sessão do IPython:
import google.cloud.texttospeech as tts
def list_voices(language_code=None):
client = tts.TextToSpeechClient()
response = client.list_voices(language_code=language_code)
voices = sorted(response.voices, key=lambda voice: voice.name)
print(f" Voices: {len(voices)} ".center(60, "-"))
for voice in voices:
languages = ", ".join(voice.language_codes)
name = voice.name
gender = tts.SsmlVoiceGender(voice.ssml_gender).name
rate = voice.natural_sample_rate_hertz
print(f"{languages:<8} | {name:<24} | {gender:<8} | {rate:,} Hz")
Reserve um tempo para estudar o código e ver como ele usa o método da biblioteca de cliente list_voices(language_code) para listar vozes disponíveis em um determinado idioma.
Confira a lista de vozes disponíveis em alemão:
list_voices("de")
Você verá algo como:
------------------------ Voices: 20 ------------------------ de-DE | de-DE-Neural2-A | FEMALE | 24,000 Hz de-DE | de-DE-Neural2-B | MALE | 24,000 Hz ... de-DE | de-DE-Standard-A | FEMALE | 24,000 Hz de-DE | de-DE-Standard-B | MALE | 24,000 Hz ... de-DE | de-DE-Studio-B | MALE | 24,000 Hz de-DE | de-DE-Studio-C | FEMALE | 24,000 Hz de-DE | de-DE-Wavenet-A | FEMALE | 24,000 Hz de-DE | de-DE-Wavenet-B | MALE | 24,000 Hz ...
Várias vozes femininas e masculinas estão disponíveis, bem como vozes padrão, WaveNet, Neural2 e Studio:
- As vozes padrão são geradas por algoritmos de processamento de sinal.
- As vozes WaveNet, Neural2 e Studio são de maior qualidade sintetizadas por modelos de aprendizado de máquina e soam mais naturais.
Veja a lista de vozes disponíveis em inglês:
list_voices("en")
O resultado será parecido com este:
------------------------ Voices: 90 ------------------------ en-AU | en-AU-Neural2-A | FEMALE | 24,000 Hz ... en-AU | en-AU-Wavenet-A | FEMALE | 24,000 Hz ... en-GB | en-GB-Neural2-A | FEMALE | 24,000 Hz ... en-GB | en-GB-Wavenet-A | FEMALE | 24,000 Hz ... en-IN | en-IN-Standard-A | FEMALE | 24,000 Hz ... en-IN | en-IN-Wavenet-A | FEMALE | 24,000 Hz ... en-US | en-US-Neural2-A | MALE | 24,000 Hz ... en-US | en-US-News-K | FEMALE | 24,000 Hz ... en-US | en-US-Standard-A | MALE | 24,000 Hz ... en-US | en-US-Studio-M | MALE | 24,000 Hz ... en-US | en-US-Wavenet-A | MALE | 24,000 Hz ...
Além de uma seleção de várias vozes em diferentes gêneros e qualidades, vários sotaques estão disponíveis: inglês australiano, britânico, indiano e americano.
Liste as vozes disponíveis para seus idiomas e variantes preferidos (ou para todos eles):
list_voices("fr")
list_voices("pt")
list_voices()
Resumo
Esta etapa permitiu que você listasse as vozes disponíveis. Leia mais sobre as vozes e idiomas compatíveis.
6. Sintetizar áudio de texto
Use a API Text-to-Speech para converter uma string em dados de áudio. Você pode configurar a saída da síntese de fala de várias maneiras, incluindo selecionando uma voz exclusiva ou modulando o tom, o volume, a velocidade de fala e a taxa de amostragem da saída.
Copie o código a seguir na sessão do IPython:
import google.cloud.texttospeech as tts
def text_to_wav(voice_name: str, text: str):
language_code = "-".join(voice_name.split("-")[:2])
text_input = tts.SynthesisInput(text=text)
voice_params = tts.VoiceSelectionParams(
language_code=language_code, name=voice_name
)
audio_config = tts.AudioConfig(audio_encoding=tts.AudioEncoding.LINEAR16)
client = tts.TextToSpeechClient()
response = client.synthesize_speech(
input=text_input,
voice=voice_params,
audio_config=audio_config,
)
filename = f"{voice_name}.wav"
with open(filename, "wb") as out:
out.write(response.audio_content)
print(f'Generated speech saved to "{filename}"')
Estude o código e confira como ele usa o método da biblioteca de cliente synthesize_speech para gerar os dados de áudio e salvá-los como um arquivo wav.
Agora, gere frases com alguns sotaques diferentes:
text_to_wav("en-AU-Neural2-A", "What is the temperature in Sydney?")
text_to_wav("en-GB-Neural2-B", "What is the temperature in London?")
text_to_wav("en-IN-Wavenet-C", "What is the temperature in Delhi?")
text_to_wav("en-US-Studio-O", "What is the temperature in New York?")
text_to_wav("fr-FR-Neural2-A", "Quelle est la température à Paris ?")
text_to_wav("fr-CA-Neural2-B", "Quelle est la température à Montréal ?")
Você verá algo como:
Generated speech saved to "en-AU-Neural2-A.wav" Generated speech saved to "en-GB-Neural2-B.wav" Generated speech saved to "en-IN-Wavenet-C.wav" Generated speech saved to "en-US-Studio-O.wav" Generated speech saved to "fr-FR-Neural2-A.wav" Generated speech saved to "fr-CA-Neural2-B.wav"
Para fazer o download de todos os arquivos gerados de uma só vez, use este comando do Cloud Shell no ambiente Python:
!cloudshell download *.wav
Valide e seu navegador fará o download dos arquivos:
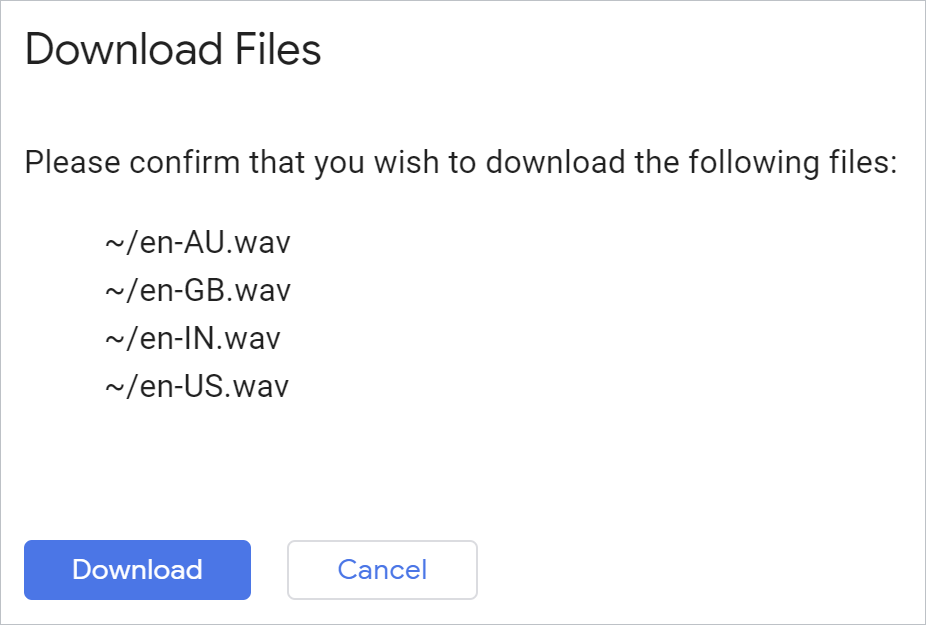
Abra cada arquivo e ouça o resultado.
Resumo
Nesta etapa, você conseguiu usar a API Text-to-Speech para converter frases em arquivos wav de áudio. Leia mais sobre como criar arquivos de áudio de voz.
7. Parabéns!
Você aprendeu a usar a API Text-to-Speech com Python para gerar falas semelhantes às humanas.
Limpar
Para limpar seu ambiente de desenvolvimento, faça o seguinte no Cloud Shell:
- Se você ainda estiver na sessão do IPython, volte para o shell:
exit - Pare de usar o ambiente virtual do Python:
deactivate - Exclua a pasta do ambiente virtual:
cd ~ ; rm -rf ./venv-texttospeech
Para excluir seu projeto do Google Cloud usando o Cloud Shell:
- Recupere seu ID do projeto atual:
PROJECT_ID=$(gcloud config get-value core/project) - Verifique se este é o projeto que você quer excluir:
echo $PROJECT_ID - Exclua o projeto:
gcloud projects delete $PROJECT_ID
Saiba mais
- Teste a demonstração no navegador: https://cloud.google.com/text-to-speech
- Documentação da Text-to-Speech: https://cloud.google.com/text-to-speech/docs
- Python no Google Cloud: https://cloud.google.com/python
- Bibliotecas de cliente do Cloud para Python: https://github.com/googleapis/google-cloud-python
Licença
Este conteúdo está sob a licença Atribuição 2.0 Genérica da Creative Commons.