
1. 概览

借助 Text-to-Speech API,开发者可以生成类人语音。该 API 可将文本转换为音频格式,例如 WAV、MP3 或 Ogg Opus。它还支持语音合成标记语言 (SSML) 输入,用于指定停顿、数字、日期和时间格式以及其他发音指令。
在本教程中,您将重点学习将 Text-to-Speech API 与 Python 搭配使用。
学习内容
- 如何设置环境
- 如何列出支持的语言
- 如何列出可用的语音
- 如何从文本合成音频
所需条件
调查问卷
您将如何使用本教程?
您如何评价使用 Python 的体验?
您如何评价自己在 Google Cloud 服务方面的经验水平?
<ph type="x-smartling-placeholder">2. 设置和要求
自定进度的环境设置
- 登录 Google Cloud 控制台,然后创建一个新项目或重复使用现有项目。如果您还没有 Gmail 或 Google Workspace 账号,则必须创建一个。

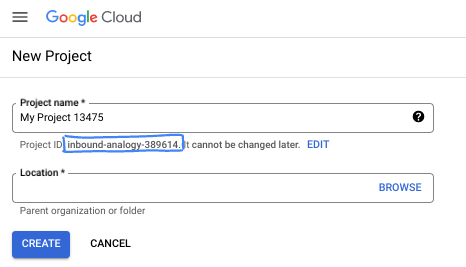
- 项目名称是此项目参与者的显示名称。它是 Google API 尚未使用的字符串。您可以随时对其进行更新。
- 项目 ID 在所有 Google Cloud 项目中是唯一的,并且是不可变的(一经设置便无法更改)。Cloud 控制台会自动生成一个唯一字符串;通常情况下,您无需关注该字符串。在大多数 Codelab 中,您都需要引用项目 ID(通常用
PROJECT_ID标识)。如果您不喜欢生成的 ID,可以再随机生成一个 ID。或者,您也可以尝试自己的项目 ID,看看是否可用。完成此步骤后便无法更改该 ID,并且此 ID 在项目期间会一直保留。 - 此外,还有第三个值,即部分 API 使用的项目编号,供您参考。如需详细了解所有这三个值,请参阅文档。
- 接下来,您需要在 Cloud 控制台中启用结算功能,以便使用 Cloud 资源/API。运行此 Codelab 应该不会产生太多的费用(如果有的话)。若要关闭资源以避免产生超出本教程范围的结算费用,您可以删除自己创建的资源或删除项目。Google Cloud 新用户符合参与 300 美元免费试用计划的条件。
启动 Cloud Shell
虽然 Google Cloud 可以通过笔记本电脑远程操作,但在此 Codelab 中,您将使用 Cloud Shell,这是一个在云端运行的命令行环境。
激活 Cloud Shell
- 在 Cloud Console 中,点击激活 Cloud Shell
 。
。

如果这是您第一次启动 Cloud Shell,系统会显示一个中间屏幕,说明它是什么。如果您看到中间屏幕,请点击继续。
预配和连接到 Cloud Shell 只需花几分钟时间。

这个虚拟机装有所需的所有开发工具。它提供了一个持久的 5 GB 主目录,并在 Google Cloud 中运行,大大增强了网络性能和身份验证功能。您在此 Codelab 中的大部分(即使不是全部)工作都可以通过浏览器完成。
在连接到 Cloud Shell 后,您应该会看到自己已通过身份验证,并且相关项目已设为您的项目 ID。
- 在 Cloud Shell 中运行以下命令以确认您已通过身份验证:
gcloud auth list
命令输出
Credentialed Accounts
ACTIVE ACCOUNT
* <my_account>@<my_domain.com>
To set the active account, run:
$ gcloud config set account `ACCOUNT`
- 在 Cloud Shell 中运行以下命令,以确认 gcloud 命令了解您的项目:
gcloud config list project
命令输出
[core] project = <PROJECT_ID>
如果不是上述结果,您可以使用以下命令进行设置:
gcloud config set project <PROJECT_ID>
命令输出
Updated property [core/project].
3. 环境设置
在开始使用 Text-to-Speech API 之前,请在 Cloud Shell 中运行以下命令以启用该 API:
gcloud services enable texttospeech.googleapis.com
您应该会看到与以下类似的内容:
Operation "operations/..." finished successfully.
现在,您可以使用 Text-to-Speech API 了!
导航到您的主目录:
cd ~
创建一个 Python 虚拟环境来隔离依赖项:
virtualenv venv-texttospeech
激活此虚拟环境:
source venv-texttospeech/bin/activate
安装 IPython 和 Text-to-Speech API 客户端库:
pip install ipython google-cloud-texttospeech
您应该会看到与以下类似的内容:
... Installing collected packages: ..., ipython, google-cloud-texttospeech Successfully installed ... google-cloud-texttospeech-2.16.3 ...
现在,您可以使用 Text-to-Speech API 客户端库了!
在接下来的步骤中,您将使用在上一步中安装的名为 IPython 的交互式 Python 解释器。在 Cloud Shell 中运行 ipython 来启动会话:
ipython
您应该会看到与以下类似的内容:
Python 3.9.2 (default, Feb 28 2021, 17:03:44) Type 'copyright', 'credits' or 'license' for more information IPython 8.18.1 -- An enhanced Interactive Python. Type '?' for help. In [1]:
您可以发出第一个请求并列出支持的语言...
4. 列出支持的语言
在本部分中,您将获得所有受支持语言的列表。
将以下代码复制到您的 IPython 会话中:
from typing import Sequence
import google.cloud.texttospeech as tts
def unique_languages_from_voices(voices: Sequence[tts.Voice]):
language_set = set()
for voice in voices:
for language_code in voice.language_codes:
language_set.add(language_code)
return language_set
def list_languages():
client = tts.TextToSpeechClient()
response = client.list_voices()
languages = unique_languages_from_voices(response.voices)
print(f" Languages: {len(languages)} ".center(60, "-"))
for i, language in enumerate(sorted(languages)):
print(f"{language:>10}", end="\n" if i % 5 == 4 else "")
请花点时间研究一下代码,看看它如何使用 list_voices 客户端库方法来构建受支持语言的列表。
调用函数:
list_languages()
您应该会看到以下(或更大的)列表:
---------------------- Languages: 58 -----------------------
af-ZA am-ET ar-XA bg-BG bn-IN
ca-ES cmn-CN cmn-TW cs-CZ da-DK
de-DE el-GR en-AU en-GB en-IN
en-US es-ES es-US eu-ES fi-FI
fil-PH fr-CA fr-FR gl-ES gu-IN
he-IL hi-IN hu-HU id-ID is-IS
it-IT ja-JP kn-IN ko-KR lt-LT
lv-LV ml-IN mr-IN ms-MY nb-NO
nl-BE nl-NL pa-IN pl-PL pt-BR
pt-PT ro-RO ru-RU sk-SK sr-RS
sv-SE ta-IN te-IN th-TH tr-TR
uk-UA vi-VN yue-HK
该列表显示了 58 种语言和语言变体,例如:
- 中文和台湾普通话
- 澳大利亚、英国、印度和美式英语
- 来自加拿大和法国的法语
- 葡萄牙语来自巴西和葡萄牙。
此列表并非固定的,而是会随着新的语音的出现而不断增加。
摘要
通过此步骤,您可以列出支持的语言。
5. 列出可用的语音
在本部分中,您将获得不同语言的语音列表。
将以下代码复制到您的 IPython 会话中:
import google.cloud.texttospeech as tts
def list_voices(language_code=None):
client = tts.TextToSpeechClient()
response = client.list_voices(language_code=language_code)
voices = sorted(response.voices, key=lambda voice: voice.name)
print(f" Voices: {len(voices)} ".center(60, "-"))
for voice in voices:
languages = ", ".join(voice.language_codes)
name = voice.name
gender = tts.SsmlVoiceGender(voice.ssml_gender).name
rate = voice.natural_sample_rate_hertz
print(f"{languages:<8} | {name:<24} | {gender:<8} | {rate:,} Hz")
请花点时间研究一下代码,看看它如何使用客户端库方法 list_voices(language_code) 列出适用于给定语言的语音。
现在,您可以获取可用的德语语音列表:
list_voices("de")
您应该会看到与以下类似的内容:
------------------------ Voices: 20 ------------------------ de-DE | de-DE-Neural2-A | FEMALE | 24,000 Hz de-DE | de-DE-Neural2-B | MALE | 24,000 Hz ... de-DE | de-DE-Standard-A | FEMALE | 24,000 Hz de-DE | de-DE-Standard-B | MALE | 24,000 Hz ... de-DE | de-DE-Studio-B | MALE | 24,000 Hz de-DE | de-DE-Studio-C | FEMALE | 24,000 Hz de-DE | de-DE-Wavenet-A | FEMALE | 24,000 Hz de-DE | de-DE-Wavenet-B | MALE | 24,000 Hz ...
提供多种女性语音和男性语音,以及标准语音、WaveNet、Neural2 和 Studio 语音:
- 标准语音由信号处理算法生成。
- WaveNet、Neural2 和 Studio 语音是由机器学习模型合成的更优质语音,听起来更自然。
现在,您可以获取可用的英语语音列表:
list_voices("en")
您应该会看到如下内容:
------------------------ Voices: 90 ------------------------ en-AU | en-AU-Neural2-A | FEMALE | 24,000 Hz ... en-AU | en-AU-Wavenet-A | FEMALE | 24,000 Hz ... en-GB | en-GB-Neural2-A | FEMALE | 24,000 Hz ... en-GB | en-GB-Wavenet-A | FEMALE | 24,000 Hz ... en-IN | en-IN-Standard-A | FEMALE | 24,000 Hz ... en-IN | en-IN-Wavenet-A | FEMALE | 24,000 Hz ... en-US | en-US-Neural2-A | MALE | 24,000 Hz ... en-US | en-US-News-K | FEMALE | 24,000 Hz ... en-US | en-US-Standard-A | MALE | 24,000 Hz ... en-US | en-US-Studio-M | MALE | 24,000 Hz ... en-US | en-US-Wavenet-A | MALE | 24,000 Hz ...
除了多种不同性别和品质的语音可供选择,还提供多种口音:澳大利亚、英国、印度和美式英语。
请花点时间列出您首选语言和语言变体(或所有语言变体)的可用语音:
list_voices("fr")
list_voices("pt")
list_voices()
摘要
在此步骤中,您可以列出可用的语音。您可以详细了解支持的语音和语言。
6. 将文字合成为音频
您可以使用 Text-to-Speech API 将字符串转换为音频数据。您可以通过多种方式配置语音合成的输出,包括选择独特的语音或调制输出的音高、音量、语速和采样率。
将以下代码复制到您的 IPython 会话中:
import google.cloud.texttospeech as tts
def text_to_wav(voice_name: str, text: str):
language_code = "-".join(voice_name.split("-")[:2])
text_input = tts.SynthesisInput(text=text)
voice_params = tts.VoiceSelectionParams(
language_code=language_code, name=voice_name
)
audio_config = tts.AudioConfig(audio_encoding=tts.AudioEncoding.LINEAR16)
client = tts.TextToSpeechClient()
response = client.synthesize_speech(
input=text_input,
voice=voice_params,
audio_config=audio_config,
)
filename = f"{voice_name}.wav"
with open(filename, "wb") as out:
out.write(response.audio_content)
print(f'Generated speech saved to "{filename}"')
请花点时间研究一下代码,看看它如何使用 synthesize_speech 客户端库方法生成音频数据并将其另存为 wav 文件。
现在,生成具有几种不同口音的句子:
text_to_wav("en-AU-Neural2-A", "What is the temperature in Sydney?")
text_to_wav("en-GB-Neural2-B", "What is the temperature in London?")
text_to_wav("en-IN-Wavenet-C", "What is the temperature in Delhi?")
text_to_wav("en-US-Studio-O", "What is the temperature in New York?")
text_to_wav("fr-FR-Neural2-A", "Quelle est la température à Paris ?")
text_to_wav("fr-CA-Neural2-B", "Quelle est la température à Montréal ?")
您应该会看到与以下类似的内容:
Generated speech saved to "en-AU-Neural2-A.wav" Generated speech saved to "en-GB-Neural2-B.wav" Generated speech saved to "en-IN-Wavenet-C.wav" Generated speech saved to "en-US-Studio-O.wav" Generated speech saved to "fr-FR-Neural2-A.wav" Generated speech saved to "fr-CA-Neural2-B.wav"
如需一次性下载生成的所有文件,您可以在 Python 环境中使用以下 Cloud Shell 命令:
!cloudshell download *.wav
验证并确保浏览器会下载文件:
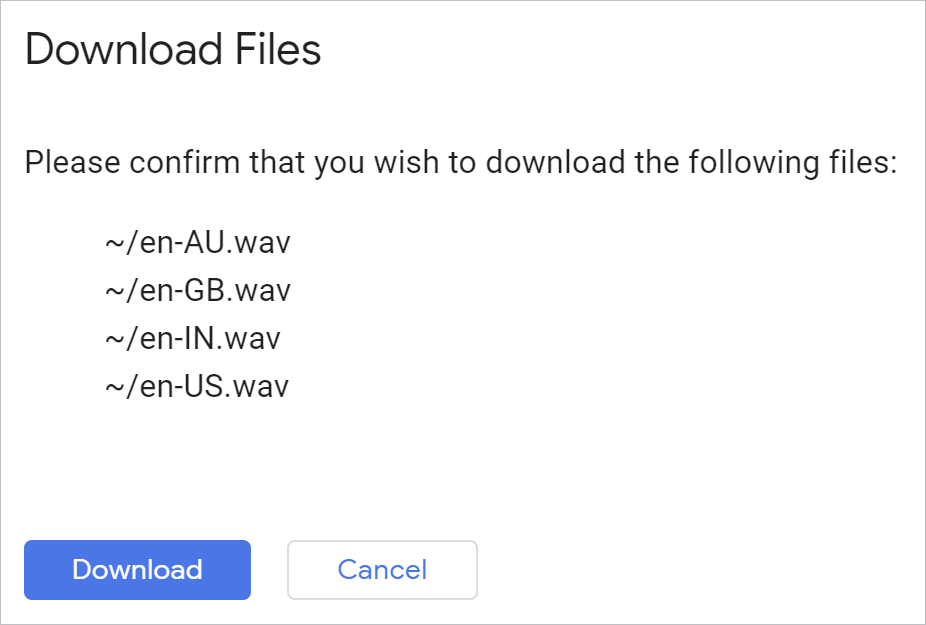
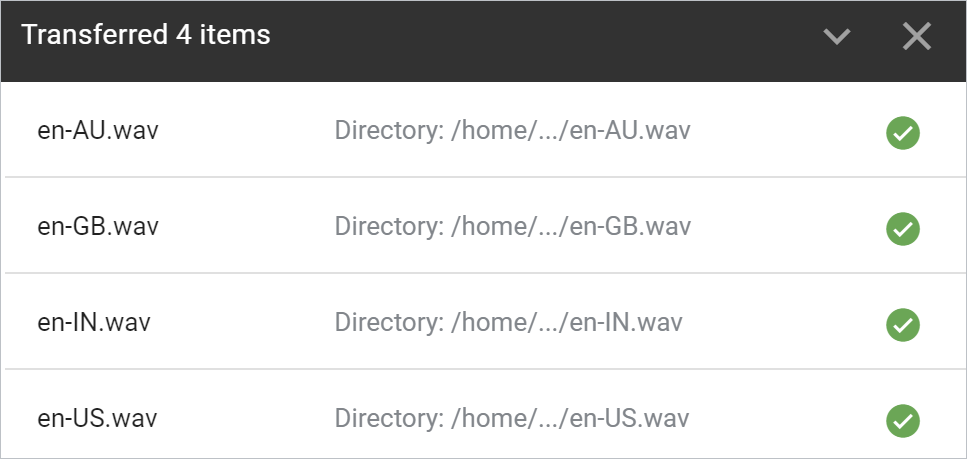
打开每个文件并听取结果。
摘要
在此步骤中,您可以使用 Text-to-Speech API 将句子转换为音频 wav 文件。详细了解如何创建语音音频文件。
7. 恭喜!
您已了解如何使用 Python 和 Text-to-Speech API 生成类人语音!
清理
如需在 Cloud Shell 中清理开发环境,请执行以下操作:
- 如果您仍处于 IPython 会话,请返回到 shell:
exit - 停止使用 Python 虚拟环境:
deactivate - 删除虚拟环境文件夹:
cd ~ ; rm -rf ./venv-texttospeech
如需从 Cloud Shell 中删除 Google Cloud 项目,请执行以下操作:
- 检索当前项目 ID:
PROJECT_ID=$(gcloud config get-value core/project) - 确保这是您要删除的项目:
echo $PROJECT_ID - 删除项目:
gcloud projects delete $PROJECT_ID
了解详情
- 在浏览器中测试演示版:https://cloud.google.com/text-to-speech
- 文字转语音文档:https://cloud.google.com/text-to-speech/docs
- Google Cloud 上的 Python:https://cloud.google.com/python
- Python 版 Cloud 客户端库:https://github.com/googleapis/google-cloud-python
许可
此作品已获得 Creative Commons Attribution 2.0 通用许可授权。