
1. Обзор

API Video Intelligence позволяет использовать технологию анализа видео от Google в ваших приложениях.
В этой лабораторной работе вы сосредоточитесь на использовании API Video Intelligence с Python.
Что вы узнаете
- Как настроить свою среду
- Как настроить Python
- Как обнаружить смену ракурса съемки
- Как обнаружить метки
- Как обнаружить контент откровенного характера
- Как расшифровать речь
- Как обнаружить и отследить текст
- Как обнаруживать и отслеживать объекты
- Как обнаруживать и отслеживать логотипы
Что вам понадобится
Опрос
Как вы будете использовать этот учебный материал?
Как бы вы оценили свой опыт работы с Python?
Как бы вы оценили свой опыт использования сервисов Google Cloud?
2. Настройка и требования
Настройка среды для самостоятельного обучения
- Войдите в консоль Google Cloud и создайте новый проект или используйте существующий. Если у вас еще нет учетной записи Gmail или Google Workspace, вам необходимо ее создать .


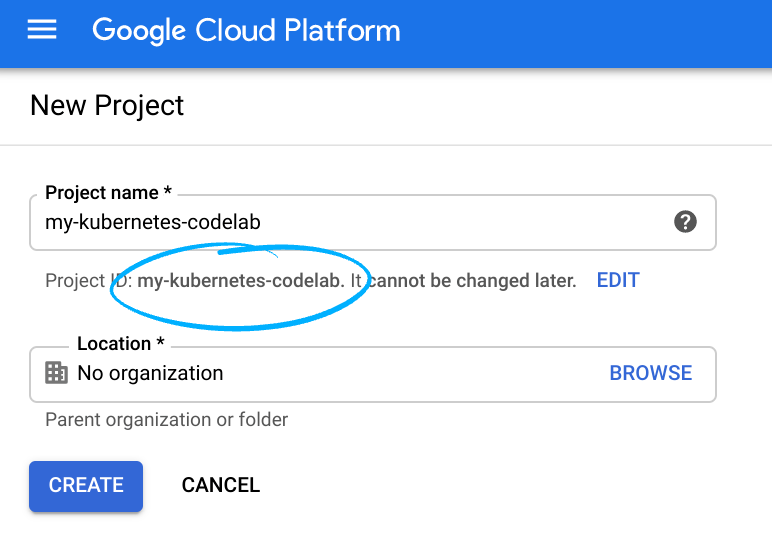
- Название проекта — это отображаемое имя участников данного проекта. Это строка символов, не используемая API Google. Вы всегда можете его изменить.
- Идентификатор проекта уникален для всех проектов Google Cloud и является неизменяемым (его нельзя изменить после установки). Консоль Cloud автоматически генерирует уникальную строку; обычно вам неважно, какая она. В большинстве практических заданий вам потребуется указать идентификатор вашего проекта (обычно обозначается как
PROJECT_ID). Если сгенерированный идентификатор вас не устраивает, вы можете сгенерировать другой случайный идентификатор. В качестве альтернативы вы можете попробовать свой собственный и посмотреть, доступен ли он. После этого шага его нельзя изменить, и он сохраняется на протяжении всего проекта. - К вашему сведению, существует третье значение — номер проекта , которое используется некоторыми API. Подробнее обо всех трех значениях можно узнать в документации .
- Далее вам потребуется включить оплату в консоли Cloud для использования ресурсов/API Cloud. Выполнение этого практического задания не потребует больших затрат, если вообще потребует. Чтобы отключить ресурсы и избежать дополнительных расходов после завершения этого урока, вы можете удалить созданные ресурсы или удалить проект. Новые пользователи Google Cloud имеют право на бесплатную пробную версию стоимостью 300 долларов США .
Запустить Cloud Shell
Хотя Google Cloud можно управлять удаленно с ноутбука, в этом практическом занятии вы будете использовать Cloud Shell — среду командной строки, работающую в облаке.
Активировать Cloud Shell
- В консоли Cloud нажмите «Активировать Cloud Shell» .
 .
.

Если вы запускаете Cloud Shell впервые, вам будет показан промежуточный экран с описанием его возможностей. Если вам был показан промежуточный экран, нажмите «Продолжить» .

Подготовка и подключение к Cloud Shell займут всего несколько минут.

Эта виртуальная машина оснащена всеми необходимыми инструментами разработки. Она предоставляет постоянный домашний каталог объемом 5 ГБ и работает в облаке Google, что значительно повышает производительность сети и аутентификацию. Большая часть, если не вся, ваша работа в этом практическом задании может быть выполнена с помощью браузера.
После подключения к Cloud Shell вы увидите, что прошли аутентификацию и что проект настроен на ваш идентификатор проекта.
- Выполните следующую команду в Cloud Shell, чтобы подтвердить свою аутентификацию:
gcloud auth list
вывод команды
Credentialed Accounts
ACTIVE ACCOUNT
* <my_account>@<my_domain.com>
To set the active account, run:
$ gcloud config set account `ACCOUNT`
- Выполните следующую команду в Cloud Shell, чтобы убедиться, что команда gcloud знает о вашем проекте:
gcloud config list project
вывод команды
[core] project = <PROJECT_ID>
Если это не так, вы можете установить это с помощью следующей команды:
gcloud config set project <PROJECT_ID>
вывод команды
Updated property [core/project].
3. Настройка среды
Прежде чем начать использовать API Video Intelligence, выполните следующую команду в Cloud Shell, чтобы включить API:
gcloud services enable videointelligence.googleapis.com
Вы должны увидеть что-то подобное:
Operation "operations/..." finished successfully.
Теперь вы можете использовать API видеоаналитики!
Перейдите в свою домашнюю директорию:
cd ~
Создайте виртуальное окружение Python для изоляции зависимостей:
virtualenv venv-videointel
Активируйте виртуальную среду:
source venv-videointel/bin/activate
Установите IPython и клиентскую библиотеку Video Intelligence API:
pip install ipython google-cloud-videointelligence
Вы должны увидеть что-то подобное:
... Installing collected packages: ..., ipython, google-cloud-videointelligence Successfully installed ... google-cloud-videointelligence-2.11.0 ...
Теперь вы готовы использовать клиентскую библиотеку Video Intelligence API!
На следующих шагах вы будете использовать интерактивный интерпретатор Python под названием IPython , который вы установили на предыдущем шаге. Чтобы начать сессию, запустите ipython в Cloud Shell:
ipython
Вы должны увидеть что-то подобное:
Python 3.9.2 (default, Feb 28 2021, 17:03:44) Type 'copyright', 'credits' or 'license' for more information IPython 8.12.0 -- An enhanced Interactive Python. Type '?' for help. In [1]:
4. Пример видео
Вы можете использовать API Video Intelligence для аннотирования видео, хранящихся в облачном хранилище или предоставленных в виде байтов данных.
На следующих шагах вы будете использовать пример видео, хранящийся в облачном хранилище. Вы можете просмотреть видео в своем браузере .

На старт, внимание, марш!
5. Обнаружение изменений в выстреле.
Вы можете использовать API Video Intelligence для обнаружения смены кадров в видео. Кадр — это сегмент видео, последовательность кадров, обладающих визуальной непрерывностью.
Скопируйте следующий код в свою сессию IPython:
from typing import cast
from google.cloud import videointelligence_v1 as vi
def detect_shot_changes(video_uri: str) -> vi.VideoAnnotationResults:
video_client = vi.VideoIntelligenceServiceClient()
features = [vi.Feature.SHOT_CHANGE_DETECTION]
request = vi.AnnotateVideoRequest(input_uri=video_uri, features=features)
print(f'Processing video: "{video_uri}"...')
operation = video_client.annotate_video(request)
# Wait for operation to complete
response = cast(vi.AnnotateVideoResponse, operation.result())
# A single video is processed
results = response.annotation_results[0]
return results
Уделите немного времени изучению кода и посмотрите, как он использует метод клиентской библиотеки annotate_video с параметром SHOT_CHANGE_DETECTION для анализа видео и обнаружения смены кадров.
Вызовите функцию для анализа видео:
video_uri = "gs://cloud-samples-data/video/JaneGoodall.mp4"
results = detect_shot_changes(video_uri)
Дождитесь обработки видео:
Processing video: "gs://cloud-samples-data/video/JaneGoodall.mp4"...
Добавьте эту функцию для вывода видеокадров:
def print_video_shots(results: vi.VideoAnnotationResults):
shots = results.shot_annotations
print(f" Video shots: {len(shots)} ".center(40, "-"))
for i, shot in enumerate(shots):
t1 = shot.start_time_offset.total_seconds()
t2 = shot.end_time_offset.total_seconds()
print(f"{i+1:>3} | {t1:7.3f} | {t2:7.3f}")
Вызовите функцию:
print_video_shots(results)
Вы должны увидеть что-то подобное:
----------- Video shots: 34 ------------ 1 | 0.000 | 12.880 2 | 12.920 | 21.680 3 | 21.720 | 27.880 ... 32 | 135.160 | 138.320 33 | 138.360 | 146.200 34 | 146.240 | 162.520
Если вырезать средний кадр из каждого фрагмента и расположить их в виде сплошной полосы кадров, можно создать визуальное резюме видео:

Краткое содержание
На этом этапе вы смогли выполнить обнаружение смены кадров в видео с помощью API Video Intelligence. Подробнее об обнаружении смены кадров можно прочитать здесь.
6. Обнаружение меток
Вы можете использовать API Video Intelligence для обнаружения меток в видео. Метки описывают видео на основе его визуального содержимого.
Скопируйте следующий код в свою сессию IPython:
from datetime import timedelta
from typing import Optional, Sequence, cast
from google.cloud import videointelligence_v1 as vi
def detect_labels(
video_uri: str,
mode: vi.LabelDetectionMode,
segments: Optional[Sequence[vi.VideoSegment]] = None,
) -> vi.VideoAnnotationResults:
video_client = vi.VideoIntelligenceServiceClient()
features = [vi.Feature.LABEL_DETECTION]
config = vi.LabelDetectionConfig(label_detection_mode=mode)
context = vi.VideoContext(segments=segments, label_detection_config=config)
request = vi.AnnotateVideoRequest(
input_uri=video_uri,
features=features,
video_context=context,
)
print(f'Processing video "{video_uri}"...')
operation = video_client.annotate_video(request)
# Wait for operation to complete
response = cast(vi.AnnotateVideoResponse, operation.result())
# A single video is processed
results = response.annotation_results[0]
return results
Уделите немного времени изучению кода и посмотрите, как он использует метод клиентской библиотеки annotate_video с параметром LABEL_DETECTION для анализа видео и обнаружения меток.
Вызовите функцию для анализа первых 37 секунд видео:
video_uri = "gs://cloud-samples-data/video/JaneGoodall.mp4"
mode = vi.LabelDetectionMode.SHOT_MODE
segment = vi.VideoSegment(
start_time_offset=timedelta(seconds=0),
end_time_offset=timedelta(seconds=37),
)
results = detect_labels(video_uri, mode, [segment])
Дождитесь обработки видео:
Processing video: "gs://cloud-samples-data/video/JaneGoodall.mp4"...
Добавьте эту функцию для вывода меток на уровне видео:
def print_video_labels(results: vi.VideoAnnotationResults):
labels = sorted_by_first_segment_confidence(results.segment_label_annotations)
print(f" Video labels: {len(labels)} ".center(80, "-"))
for label in labels:
categories = category_entities_to_str(label.category_entities)
for segment in label.segments:
confidence = segment.confidence
t1 = segment.segment.start_time_offset.total_seconds()
t2 = segment.segment.end_time_offset.total_seconds()
print(
f"{confidence:4.0%}",
f"{t1:7.3f}",
f"{t2:7.3f}",
f"{label.entity.description}{categories}",
sep=" | ",
)
def sorted_by_first_segment_confidence(
labels: Sequence[vi.LabelAnnotation],
) -> Sequence[vi.LabelAnnotation]:
def first_segment_confidence(label: vi.LabelAnnotation) -> float:
return label.segments[0].confidence
return sorted(labels, key=first_segment_confidence, reverse=True)
def category_entities_to_str(category_entities: Sequence[vi.Entity]) -> str:
if not category_entities:
return ""
entities = ", ".join([e.description for e in category_entities])
return f" ({entities})"
Вызовите функцию:
print_video_labels(results)
Вы должны увидеть что-то подобное:
------------------------------- Video labels: 10 ------------------------------- 96% | 0.000 | 36.960 | nature 74% | 0.000 | 36.960 | vegetation 59% | 0.000 | 36.960 | tree (plant) 56% | 0.000 | 36.960 | forest (geographical feature) 49% | 0.000 | 36.960 | leaf (plant) 43% | 0.000 | 36.960 | flora (plant) 38% | 0.000 | 36.960 | nature reserve (geographical feature) 38% | 0.000 | 36.960 | woodland (forest) 35% | 0.000 | 36.960 | water resources (water) 32% | 0.000 | 36.960 | sunlight (light)
Благодаря этим пояснениям к видео, вы можете понять, что начало ролика посвящено преимущественно природе и растительности.
Добавьте эту функцию для вывода меток на уровне кадра:
def print_shot_labels(results: vi.VideoAnnotationResults):
labels = sorted_by_first_segment_start_and_confidence(
results.shot_label_annotations
)
print(f" Shot labels: {len(labels)} ".center(80, "-"))
for label in labels:
categories = category_entities_to_str(label.category_entities)
print(f"{label.entity.description}{categories}")
for segment in label.segments:
confidence = segment.confidence
t1 = segment.segment.start_time_offset.total_seconds()
t2 = segment.segment.end_time_offset.total_seconds()
print(f"{confidence:4.0%} | {t1:7.3f} | {t2:7.3f}")
def sorted_by_first_segment_start_and_confidence(
labels: Sequence[vi.LabelAnnotation],
) -> Sequence[vi.LabelAnnotation]:
def first_segment_start_and_confidence(label: vi.LabelAnnotation):
first_segment = label.segments[0]
ms = first_segment.segment.start_time_offset.total_seconds()
return (ms, -first_segment.confidence)
return sorted(labels, key=first_segment_start_and_confidence)
Вызовите функцию:
print_shot_labels(results)
Вы должны увидеть что-то подобное:
------------------------------- Shot labels: 29 -------------------------------- planet (astronomical object) 83% | 0.000 | 12.880 earth (planet) 53% | 0.000 | 12.880 water resources (water) 43% | 0.000 | 12.880 aerial photography (photography) 43% | 0.000 | 12.880 vegetation 32% | 0.000 | 12.880 92% | 12.920 | 21.680 83% | 21.720 | 27.880 77% | 27.920 | 31.800 76% | 31.840 | 34.720 ... butterfly (insect, animal) 84% | 34.760 | 36.960 ...
Благодаря этим обозначениям на уровне кадров, вы можете понять, что видео начинается с кадра планеты (вероятно, Земли), что на кадре 34.760-36.960s видна бабочка...
Краткое содержание
На этом этапе вы смогли выполнить обнаружение меток на видео с помощью API Video Intelligence. Подробнее об обнаружении меток можно прочитать здесь.
7. Выявление контента откровенного характера
Вы можете использовать API Video Intelligence для обнаружения контента откровенного характера в видео. Контент откровенного характера — это контент для взрослых, как правило, неприемлемый для лиц младше 18 лет, и включает, помимо прочего, обнаженность, сексуальные действия и порнографию. Обнаружение выполняется только на основе покадровых визуальных сигналов (аудио не используется). Ответ включает значения вероятности в диапазоне от VERY_UNLIKELY до VERY_LIKELY .
Скопируйте следующий код в свою сессию IPython:
from datetime import timedelta
from typing import Optional, Sequence, cast
from google.cloud import videointelligence_v1 as vi
def detect_explicit_content(
video_uri: str,
segments: Optional[Sequence[vi.VideoSegment]] = None,
) -> vi.VideoAnnotationResults:
video_client = vi.VideoIntelligenceServiceClient()
features = [vi.Feature.EXPLICIT_CONTENT_DETECTION]
context = vi.VideoContext(segments=segments)
request = vi.AnnotateVideoRequest(
input_uri=video_uri,
features=features,
video_context=context,
)
print(f'Processing video "{video_uri}"...')
operation = video_client.annotate_video(request)
# Wait for operation to complete
response = cast(vi.AnnotateVideoResponse, operation.result())
# A single video is processed
results = response.annotation_results[0]
return results
Уделите немного времени изучению кода и посмотрите, как он использует метод клиентской библиотеки annotate_video с параметром EXPLICIT_CONTENT_DETECTION для анализа видео и обнаружения контента откровенного характера.
Вызовите функцию для анализа первых 10 секунд видео:
video_uri = "gs://cloud-samples-data/video/JaneGoodall.mp4"
segment = vi.VideoSegment(
start_time_offset=timedelta(seconds=0),
end_time_offset=timedelta(seconds=10),
)
results = detect_explicit_content(video_uri, [segment])
Дождитесь обработки видео:
Processing video: "gs://cloud-samples-data/video/JaneGoodall.mp4"...
Добавьте эту функцию для вывода различных значений вероятности:
def print_explicit_content(results: vi.VideoAnnotationResults):
from collections import Counter
frames = results.explicit_annotation.frames
likelihood_counts = Counter([f.pornography_likelihood for f in frames])
print(f" Explicit content frames: {len(frames)} ".center(40, "-"))
for likelihood in vi.Likelihood:
print(f"{likelihood.name:<22}: {likelihood_counts[likelihood]:>3}")
Вызовите функцию:
print_explicit_content(results)
Вы должны увидеть что-то подобное:
----- Explicit content frames: 10 ------ LIKELIHOOD_UNSPECIFIED: 0 VERY_UNLIKELY : 10 UNLIKELY : 0 POSSIBLE : 0 LIKELY : 0 VERY_LIKELY : 0
Добавьте эту функцию для вывода сведений о кадре:
def print_frames(results: vi.VideoAnnotationResults, likelihood: vi.Likelihood):
frames = results.explicit_annotation.frames
frames = [f for f in frames if f.pornography_likelihood == likelihood]
print(f" {likelihood.name} frames: {len(frames)} ".center(40, "-"))
for frame in frames:
print(frame.time_offset)
Вызовите функцию:
print_frames(results, vi.Likelihood.VERY_UNLIKELY)
Вы должны увидеть что-то подобное:
------- VERY_UNLIKELY frames: 10 ------- 0:00:00.365992 0:00:01.279206 0:00:02.268336 0:00:03.289253 0:00:04.400163 0:00:05.291547 0:00:06.449558 0:00:07.452751 0:00:08.577405 0:00:09.554514
Краткое содержание
На этом этапе вы смогли выполнить обнаружение контента откровенного характера в видео с помощью API Video Intelligence. Подробнее об обнаружении контента откровенного характера можно прочитать здесь.
8. Расшифровка речи
Вы можете использовать API Video Intelligence для преобразования речи из видео в текст.
Скопируйте следующий код в свою сессию IPython:
from datetime import timedelta
from typing import Optional, Sequence, cast
from google.cloud import videointelligence_v1 as vi
def transcribe_speech(
video_uri: str,
language_code: str,
segments: Optional[Sequence[vi.VideoSegment]] = None,
) -> vi.VideoAnnotationResults:
video_client = vi.VideoIntelligenceServiceClient()
features = [vi.Feature.SPEECH_TRANSCRIPTION]
config = vi.SpeechTranscriptionConfig(
language_code=language_code,
enable_automatic_punctuation=True,
)
context = vi.VideoContext(
segments=segments,
speech_transcription_config=config,
)
request = vi.AnnotateVideoRequest(
input_uri=video_uri,
features=features,
video_context=context,
)
print(f'Processing video "{video_uri}"...')
operation = video_client.annotate_video(request)
# Wait for operation to complete
response = cast(vi.AnnotateVideoResponse, operation.result())
# A single video is processed
results = response.annotation_results[0]
return results
Уделите немного времени изучению кода и посмотрите, как он использует метод клиентской библиотеки annotate_video с параметром SPEECH_TRANSCRIPTION для анализа видео и расшифровки речи.
Вызовите функцию для анализа видео с 55 по 80 секунду:
video_uri = "gs://cloud-samples-data/video/JaneGoodall.mp4"
language_code = "en-GB"
segment = vi.VideoSegment(
start_time_offset=timedelta(seconds=55),
end_time_offset=timedelta(seconds=80),
)
results = transcribe_speech(video_uri, language_code, [segment])
Дождитесь обработки видео:
Processing video: "gs://cloud-samples-data/video/JaneGoodall.mp4"...
Добавьте эту функцию для вывода расшифрованной речи:
def print_video_speech(results: vi.VideoAnnotationResults, min_confidence: float = 0.8):
def keep_transcription(transcription: vi.SpeechTranscription) -> bool:
return min_confidence <= transcription.alternatives[0].confidence
transcriptions = results.speech_transcriptions
transcriptions = [t for t in transcriptions if keep_transcription(t)]
print(f" Speech transcriptions: {len(transcriptions)} ".center(80, "-"))
for transcription in transcriptions:
first_alternative = transcription.alternatives[0]
confidence = first_alternative.confidence
transcript = first_alternative.transcript
print(f" {confidence:4.0%} | {transcript.strip()}")
Вызовите функцию:
print_video_speech(results)
Вы должны увидеть что-то подобное:
--------------------------- Speech transcriptions: 2 --------------------------- 91% | I was keenly aware of secret movements in the trees. 92% | I looked into his large and lustrous eyes. They seem somehow to express his entire personality.
Добавьте эту функцию для вывода списка обнаруженных слов и их временных меток:
def print_word_timestamps(
results: vi.VideoAnnotationResults,
min_confidence: float = 0.8,
):
def keep_transcription(transcription: vi.SpeechTranscription) -> bool:
return min_confidence <= transcription.alternatives[0].confidence
transcriptions = results.speech_transcriptions
transcriptions = [t for t in transcriptions if keep_transcription(t)]
print(" Word timestamps ".center(80, "-"))
for transcription in transcriptions:
first_alternative = transcription.alternatives[0]
confidence = first_alternative.confidence
for word in first_alternative.words:
t1 = word.start_time.total_seconds()
t2 = word.end_time.total_seconds()
word = word.word
print(f"{confidence:4.0%} | {t1:7.3f} | {t2:7.3f} | {word}")
Вызовите функцию:
print_word_timestamps(results)
Вы должны увидеть что-то подобное:
------------------------------- Word timestamps -------------------------------- 93% | 55.000 | 55.700 | I 93% | 55.700 | 55.900 | was 93% | 55.900 | 56.300 | keenly 93% | 56.300 | 56.700 | aware 93% | 56.700 | 56.900 | of ... 94% | 76.900 | 77.400 | express 94% | 77.400 | 77.600 | his 94% | 77.600 | 78.200 | entire 94% | 78.200 | 78.500 | personality.
Краткое содержание
На этом этапе вы смогли выполнить транскрипцию речи из видео с помощью API Video Intelligence. Подробнее о транскрипции аудио можно прочитать здесь.
9. Обнаружение и отслеживание текста
Вы можете использовать API Video Intelligence для обнаружения и отслеживания текста в видео.
Скопируйте следующий код в свою сессию IPython:
from datetime import timedelta
from typing import Optional, Sequence, cast
from google.cloud import videointelligence_v1 as vi
def detect_text(
video_uri: str,
language_hints: Optional[Sequence[str]] = None,
segments: Optional[Sequence[vi.VideoSegment]] = None,
) -> vi.VideoAnnotationResults:
video_client = vi.VideoIntelligenceServiceClient()
features = [vi.Feature.TEXT_DETECTION]
config = vi.TextDetectionConfig(
language_hints=language_hints,
)
context = vi.VideoContext(
segments=segments,
text_detection_config=config,
)
request = vi.AnnotateVideoRequest(
input_uri=video_uri,
features=features,
video_context=context,
)
print(f'Processing video "{video_uri}"...')
operation = video_client.annotate_video(request)
# Wait for operation to complete
response = cast(vi.AnnotateVideoResponse, operation.result())
# A single video is processed
results = response.annotation_results[0]
return results
Уделите немного времени изучению кода и посмотрите, как он использует метод клиентской библиотеки annotate_video с параметром TEXT_DETECTION для анализа видео и обнаружения текста.
Вызовите функцию для анализа видео с 13 по 27 секунду:
video_uri = "gs://cloud-samples-data/video/JaneGoodall.mp4"
segment = vi.VideoSegment(
start_time_offset=timedelta(seconds=13),
end_time_offset=timedelta(seconds=27),
)
results = detect_text(video_uri, segments=[segment])
Дождитесь обработки видео:
Processing video: "gs://cloud-samples-data/video/JaneGoodall.mp4"...
Добавьте эту функцию для вывода обнаруженного текста:
def print_video_text(results: vi.VideoAnnotationResults, min_frames: int = 15):
annotations = sorted_by_first_segment_end(results.text_annotations)
print(" Detected text ".center(80, "-"))
for annotation in annotations:
for text_segment in annotation.segments:
frames = len(text_segment.frames)
if frames < min_frames:
continue
text = annotation.text
confidence = text_segment.confidence
start = text_segment.segment.start_time_offset
seconds = segment_seconds(text_segment.segment)
print(text)
print(f" {confidence:4.0%} | {start} + {seconds:.1f}s | {frames} fr.")
def sorted_by_first_segment_end(
annotations: Sequence[vi.TextAnnotation],
) -> Sequence[vi.TextAnnotation]:
def first_segment_end(annotation: vi.TextAnnotation) -> int:
return annotation.segments[0].segment.end_time_offset.total_seconds()
return sorted(annotations, key=first_segment_end)
def segment_seconds(segment: vi.VideoSegment) -> float:
t1 = segment.start_time_offset.total_seconds()
t2 = segment.end_time_offset.total_seconds()
return t2 - t1
Вызовите функцию:
print_video_text(results)
Вы должны увидеть что-то подобное:
-------------------------------- Detected text --------------------------------- GOMBE NATIONAL PARK 99% | 0:00:15.760000 + 1.7s | 15 fr. TANZANIA 100% | 0:00:15.760000 + 4.8s | 39 fr. With words and narration by 100% | 0:00:23.200000 + 3.6s | 31 fr. Jane Goodall 99% | 0:00:23.080000 + 3.8s | 33 fr.
Добавьте эту функцию для вывода списка обнаруженных текстовых фреймов и ограничивающих рамок:
def print_text_frames(results: vi.VideoAnnotationResults, contained_text: str):
# Vertex order: top-left, top-right, bottom-right, bottom-left
def box_top_left(box: vi.NormalizedBoundingPoly) -> str:
tl = box.vertices[0]
return f"({tl.x:.5f}, {tl.y:.5f})"
def box_bottom_right(box: vi.NormalizedBoundingPoly) -> str:
br = box.vertices[2]
return f"({br.x:.5f}, {br.y:.5f})"
annotations = results.text_annotations
annotations = [a for a in annotations if contained_text in a.text]
for annotation in annotations:
print(f" {annotation.text} ".center(80, "-"))
for text_segment in annotation.segments:
for frame in text_segment.frames:
frame_ms = frame.time_offset.total_seconds()
box = frame.rotated_bounding_box
print(
f"{frame_ms:>7.3f}",
box_top_left(box),
box_bottom_right(box),
sep=" | ",
)
Вызовите функцию, чтобы проверить, в каких кадрах отображается имя диктора:
contained_text = "Goodall"
print_text_frames(results, contained_text)
Вы должны увидеть что-то подобное:
--------------------------------- Jane Goodall --------------------------------- 23.080 | (0.39922, 0.49861) | (0.62752, 0.55888) 23.200 | (0.38750, 0.49028) | (0.62692, 0.56306) ... 26.800 | (0.36016, 0.49583) | (0.61094, 0.56048) 26.920 | (0.45859, 0.49583) | (0.60365, 0.56174)
Если нарисовать ограничивающие рамки поверх соответствующих кадров, получится вот это:

Краткое содержание
На этом этапе вы смогли выполнить обнаружение и отслеживание текста на видео с помощью API Video Intelligence. Подробнее об обнаружении и отслеживании текста можно прочитать здесь.
10. Обнаружение и отслеживание объектов
Вы можете использовать API Video Intelligence для обнаружения и отслеживания объектов в видео.
Скопируйте следующий код в свою сессию IPython:
from datetime import timedelta
from typing import Optional, Sequence, cast
from google.cloud import videointelligence_v1 as vi
def track_objects(
video_uri: str, segments: Optional[Sequence[vi.VideoSegment]] = None
) -> vi.VideoAnnotationResults:
video_client = vi.VideoIntelligenceServiceClient()
features = [vi.Feature.OBJECT_TRACKING]
context = vi.VideoContext(segments=segments)
request = vi.AnnotateVideoRequest(
input_uri=video_uri,
features=features,
video_context=context,
)
print(f'Processing video "{video_uri}"...')
operation = video_client.annotate_video(request)
# Wait for operation to complete
response = cast(vi.AnnotateVideoResponse, operation.result())
# A single video is processed
results = response.annotation_results[0]
return results
Уделите немного времени изучению кода и посмотрите, как он использует метод клиентской библиотеки annotate_video с параметром OBJECT_TRACKING для анализа видео и обнаружения объектов.
Вызовите функцию для анализа видео с 98 по 112 секунду:
video_uri = "gs://cloud-samples-data/video/JaneGoodall.mp4"
segment = vi.VideoSegment(
start_time_offset=timedelta(seconds=98),
end_time_offset=timedelta(seconds=112),
)
results = track_objects(video_uri, [segment])
Дождитесь обработки видео:
Processing video: "gs://cloud-samples-data/video/JaneGoodall.mp4"...
Добавьте эту функцию для вывода списка обнаруженных объектов:
def print_detected_objects(
results: vi.VideoAnnotationResults,
min_confidence: float = 0.7,
):
annotations = results.object_annotations
annotations = [a for a in annotations if min_confidence <= a.confidence]
print(
f" Detected objects: {len(annotations)}"
f" ({min_confidence:.0%} <= confidence) ".center(80, "-")
)
for annotation in annotations:
entity = annotation.entity
description = entity.description
entity_id = entity.entity_id
confidence = annotation.confidence
t1 = annotation.segment.start_time_offset.total_seconds()
t2 = annotation.segment.end_time_offset.total_seconds()
frames = len(annotation.frames)
print(
f"{description:<22}",
f"{entity_id:<10}",
f"{confidence:4.0%}",
f"{t1:>7.3f}",
f"{t2:>7.3f}",
f"{frames:>2} fr.",
sep=" | ",
)
Вызовите функцию:
print_detected_objects(results)
Вы должны увидеть что-то подобное:
------------------- Detected objects: 3 (70% <= confidence) -------------------- insect | /m/03vt0 | 87% | 98.840 | 101.720 | 25 fr. insect | /m/03vt0 | 71% | 108.440 | 111.080 | 23 fr. butterfly | /m/0cyf8 | 91% | 111.200 | 111.920 | 7 fr.
Добавьте эту функцию для вывода списка обнаруженных рамок объектов и ограничивающих прямоугольников:
def print_object_frames(
results: vi.VideoAnnotationResults,
entity_id: str,
min_confidence: float = 0.7,
):
def keep_annotation(annotation: vi.ObjectTrackingAnnotation) -> bool:
return (
annotation.entity.entity_id == entity_id
and min_confidence <= annotation.confidence
)
annotations = results.object_annotations
annotations = [a for a in annotations if keep_annotation(a)]
for annotation in annotations:
description = annotation.entity.description
confidence = annotation.confidence
print(
f" {description},"
f" confidence: {confidence:.0%},"
f" frames: {len(annotation.frames)} ".center(80, "-")
)
for frame in annotation.frames:
t = frame.time_offset.total_seconds()
box = frame.normalized_bounding_box
print(
f"{t:>7.3f}",
f"({box.left:.5f}, {box.top:.5f})",
f"({box.right:.5f}, {box.bottom:.5f})",
sep=" | ",
)
Вызовите функцию, указав идентификатор сущности для насекомых:
insect_entity_id = "/m/03vt0"
print_object_frames(results, insect_entity_id)
Вы должны увидеть что-то подобное:
--------------------- insect, confidence: 87%, frames: 25 ---------------------- 98.840 | (0.49327, 0.19617) | (0.69905, 0.69633) 98.960 | (0.49559, 0.19308) | (0.70631, 0.69671) ... 101.600 | (0.46668, 0.19776) | (0.76619, 0.69371) 101.720 | (0.46805, 0.20053) | (0.76447, 0.68703) --------------------- insect, confidence: 71%, frames: 23 ---------------------- 108.440 | (0.47343, 0.10694) | (0.63821, 0.98332) 108.560 | (0.46960, 0.10206) | (0.63033, 0.98285) ... 110.960 | (0.49466, 0.05102) | (0.65941, 0.99357) 111.080 | (0.49572, 0.04728) | (0.65762, 0.99868)
Если нарисовать ограничивающие рамки поверх соответствующих кадров, получится вот это:


Краткое содержание
На этом этапе вы смогли выполнить обнаружение и отслеживание объектов на видео с помощью API Video Intelligence. Подробнее об обнаружении и отслеживании объектов можно прочитать здесь.
11. Обнаружение и отслеживание логотипов.
С помощью API Video Intelligence можно обнаруживать и отслеживать логотипы в видео. Можно обнаружить более 100 000 брендов и логотипов.
Скопируйте следующий код в свою сессию IPython:
from datetime import timedelta
from typing import Optional, Sequence, cast
from google.cloud import videointelligence_v1 as vi
def detect_logos(
video_uri: str, segments: Optional[Sequence[vi.VideoSegment]] = None
) -> vi.VideoAnnotationResults:
video_client = vi.VideoIntelligenceServiceClient()
features = [vi.Feature.LOGO_RECOGNITION]
context = vi.VideoContext(segments=segments)
request = vi.AnnotateVideoRequest(
input_uri=video_uri,
features=features,
video_context=context,
)
print(f'Processing video "{video_uri}"...')
operation = video_client.annotate_video(request)
# Wait for operation to complete
response = cast(vi.AnnotateVideoResponse, operation.result())
# A single video is processed
results = response.annotation_results[0]
return results
Уделите немного времени изучению кода и посмотрите, как он использует метод клиентской библиотеки annotate_video с параметром LOGO_RECOGNITION для анализа видео и обнаружения логотипов.
Вызовите функцию для анализа предпоследней последовательности видео:
video_uri = "gs://cloud-samples-data/video/JaneGoodall.mp4"
segment = vi.VideoSegment(
start_time_offset=timedelta(seconds=146),
end_time_offset=timedelta(seconds=156),
)
results = detect_logos(video_uri, [segment])
Дождитесь обработки видео:
Processing video: "gs://cloud-samples-data/video/JaneGoodall.mp4"...
Добавьте эту функцию для вывода списка обнаруженных логотипов:
def print_detected_logos(results: vi.VideoAnnotationResults):
annotations = results.logo_recognition_annotations
print(f" Detected logos: {len(annotations)} ".center(80, "-"))
for annotation in annotations:
entity = annotation.entity
entity_id = entity.entity_id
description = entity.description
for track in annotation.tracks:
confidence = track.confidence
t1 = track.segment.start_time_offset.total_seconds()
t2 = track.segment.end_time_offset.total_seconds()
logo_frames = len(track.timestamped_objects)
print(
f"{confidence:4.0%}",
f"{t1:>7.3f}",
f"{t2:>7.3f}",
f"{logo_frames:>3} fr.",
f"{entity_id:<15}",
f"{description}",
sep=" | ",
)
Вызовите функцию:
print_detected_logos(results)
Вы должны увидеть что-то подобное:
------------------------------ Detected logos: 1 ------------------------------- 92% | 150.680 | 155.720 | 43 fr. | /m/055t58 | Google Maps
Добавьте эту функцию для вывода списка обнаруженных рамок логотипа и ограничивающих прямоугольников:
def print_logo_frames(results: vi.VideoAnnotationResults, entity_id: str):
def keep_annotation(annotation: vi.LogoRecognitionAnnotation) -> bool:
return annotation.entity.entity_id == entity_id
annotations = results.logo_recognition_annotations
annotations = [a for a in annotations if keep_annotation(a)]
for annotation in annotations:
description = annotation.entity.description
for track in annotation.tracks:
confidence = track.confidence
print(
f" {description},"
f" confidence: {confidence:.0%},"
f" frames: {len(track.timestamped_objects)} ".center(80, "-")
)
for timestamped_object in track.timestamped_objects:
t = timestamped_object.time_offset.total_seconds()
box = timestamped_object.normalized_bounding_box
print(
f"{t:>7.3f}",
f"({box.left:.5f}, {box.top:.5f})",
f"({box.right:.5f}, {box.bottom:.5f})",
sep=" | ",
)
Вызовите функцию, используя идентификатор объекта с логотипом Google Maps:
maps_entity_id = "/m/055t58"
print_logo_frames(results, maps_entity_id)
Вы должны увидеть что-то подобное:
------------------- Google Maps, confidence: 92%, frames: 43 ------------------- 150.680 | (0.42024, 0.28633) | (0.58192, 0.64220) 150.800 | (0.41713, 0.27822) | (0.58318, 0.63556) ... 155.600 | (0.41775, 0.27701) | (0.58372, 0.63986) 155.720 | (0.41688, 0.28005) | (0.58335, 0.63954)
Если нарисовать ограничивающие рамки поверх соответствующих кадров, получится вот это:

Краткое содержание
На этом этапе вы смогли выполнить обнаружение и отслеживание логотипов на видео с помощью API Video Intelligence. Подробнее об обнаружении и отслеживании логотипов можно прочитать здесь.
12. Выявление множественных признаков
Вот пример запроса, который позволит получить всю необходимую информацию сразу:
from google.cloud import videointelligence_v1 as vi
video_client = vi.VideoIntelligenceServiceClient()
video_uri = "gs://..."
features = [
vi.Feature.SHOT_CHANGE_DETECTION,
vi.Feature.LABEL_DETECTION,
vi.Feature.EXPLICIT_CONTENT_DETECTION,
vi.Feature.SPEECH_TRANSCRIPTION,
vi.Feature.TEXT_DETECTION,
vi.Feature.OBJECT_TRACKING,
vi.Feature.LOGO_RECOGNITION,
vi.Feature.FACE_DETECTION, # NEW
vi.Feature.PERSON_DETECTION, # NEW
]
context = vi.VideoContext(
segments=...,
shot_change_detection_config=...,
label_detection_config=...,
explicit_content_detection_config=...,
speech_transcription_config=...,
text_detection_config=...,
object_tracking_config=...,
face_detection_config=..., # NEW
person_detection_config=..., # NEW
)
request = vi.AnnotateVideoRequest(
input_uri=video_uri,
features=features,
video_context=context,
)
# video_client.annotate_video(request)
13. Поздравляем!
Вы научились использовать API Video Intelligence с помощью Python!
Уборка
Для очистки среды разработки используйте Cloud Shell:
- Если вы всё ещё находитесь в сессии IPython, вернитесь в командную оболочку:
exit - Прекратите использование виртуальной среды Python:
deactivate - Удалите папку виртуального окружения:
cd ~ ; rm -rf ./venv-videointel
Чтобы удалить свой проект Google Cloud, используйте Cloud Shell:
- Получите текущий идентификатор проекта:
PROJECT_ID=$(gcloud config get-value core/project) - Убедитесь, что это именно тот проект, который вы хотите удалить:
echo $PROJECT_ID - Удалите проект:
gcloud projects delete $PROJECT_ID
Узнать больше
- Протестируйте демоверсию в своем браузере: https://zackakil.github.io/video-intelligence-api-visualiser
- Документация по системе Video Intelligence: https://cloud.google.com/video-intelligence/docs
- Функции бета-версии: https://cloud.google.com/video-intelligence/docs/beta
- Python в Google Cloud: https://cloud.google.com/python
- Клиентские библиотеки для облачных сервисов на Python: https://github.com/googleapis/google-cloud-python
Лицензия
Данная работа распространяется под лицензией Creative Commons Attribution 2.0 Generic.